Bayesian Estimation of Geometric Morphometric Landmarks for Simultaneous Localization of Multiple Anatomies in Cardiac CT Images


1
School of Computer Science, Kyungil University, Gyeongsan 38428, Korea
2
CONNECT-AI R&D Center, Yonsei University College of Medicine, Seoul 03722,Korea
3
Division of Cardiology Department of Internal Medicine, Yonsei University College of Medicine, Seoul 03722, Korea
*
Author to whom correspondence should be addressed.
Entropy 2021, 23(1), 64; https://doi.org/10.3390/e23010064
Submission received: 6 November 2020
/
Revised: 18 December 2020
/
Accepted: 27 December 2020
/
Published: 2 January 2021
(This article belongs to the Special Issue Bayesian Inference and Computation)
Abstract
:We propose a robust method to simultaneously localize multiple objects in cardiac computed tomography angiography (CTA) images. The relative prior distributions of the multiple objects in the three-dimensional (3D) space can be obtained through integrating the geometric morphological relationship of each target object to some reference objects. In cardiac CTA images, the cross-sections of ascending and descending aorta can play the role of the reference objects. We employed the maximum a posteriori (MAP) estimator that utilizes anatomic prior knowledge to address this problem of localizing multiple objects. We propose a new feature for each pixel using the relative distances, which can define any objects that have unclear boundaries. Our experimental results targeting four pulmonary veins (PVs) and the left atrial appendage (LAA) in cardiac CTA images demonstrate the robustness of the proposed method. The method could also be extended to localize other multiple objects in different applications.
1. Introduction
As a type of arrhythmia, atrial fibrillation (AF) is a powerful risk factor for stroke, independently increasing risk fivefold in all age ranges. Radio frequency (RF) energy, a procedure that is used in many clinical methods and studies [1,2,3] to treat arrhythmia, is applied around the pulmonary veins (PVs) using a catheter to block sources of ectopic foci. This minimally invasive arrhythmia procedure is performed by matching the anatomical landmarks manually annotated in the pre-scanned three-dimensional (3D) computed tomography angiography (CTA) image with the rough points obtained in the real-time electrophysiology (EP) catheterization and form the atrial shape [4]. However, since it is time-consuming to designate the 3D landmark manually, an automatic method for localization of the target objects is needed to reduce the time required and improve the accuracy of the procedure.
The left atrial appendage (LAA) is known as one of the major locations of cardiac thrombus formation. LAA occlusion devices are used to prevent stroke in AF patients [5], and accurate measurement of the LAA diameter is important for determining the appropriate device sizes. However, as LAA can have a variety of sizes and shapes, it is challenging to describe its anatomic structure. Localization of the LAA is a prerequisite for automatically finding a longitudinal view of the LAA, where the operator can define the size of the device. Furthermore, in fluid simulations based on the left atrium for predicting patient-specific blood patterns or planning LAA intervention, precise manual annotation of in- and out-lets such as four PVs and LAA is essential [6].
A benchmark for a number of left atrium (LA) segmentation algorithms was reported [7,8]. Because of variations in the intensities and shapes of the PVs, the LAA, and other anatomical structures surrounding the LA, many different approaches have been proposed for segmenting 3D medical images. Purely data-driven methods using region growing and graph cut as well as more advanced methods using prior knowledge were proposed in [9,10]. Region growing based approaches need a manual placement of the seed point inside the LA. There are atlas-based approaches, which use deformable registration to propagate an atlas to the images [11,12,13]. In addition, multi-atlas based approaches have been introduced [14,15,16]. Qiao et al. proposed a multi-atlas registration method based on the contrast probability map [15]. Nuñes-Garcia et al. utilized rank similarity of different atrial shapes for multi-atlas segmentation [16]. Recently, deep convolutional neural network (CNN)-based methods for LA segmentation have been proposed [17,18,19,20]. CNN automatically extracts features and outperforms traditional methods. They show higher accuracies on LA segmentation tasks and may be used for quantification or the prerequisite process of LA landmark detection. Recently, other approaches were introduced using CNN to find landmarks [21,22]. An initialized position is updated by regression and classification using small patches [21]. In addition, multi-scale deep reinforcement learning successfully finds anatomical landmarks [23], which reduces computational complexity by policy-based searches. However, sometimes the multi-atlas or the labeled images are often difficult to locate or generate, especially in clinical image datasets.
In morphometrics, the anatomical landmark positions can be analyzed using various statistical techniques independently of size, position, and orientation so that the only variables being observed are based on morphology. Various applications based on geometric morphometrics are also introduced [24,25,26,27]. A fully automatic method is introduced [28] for simultaneously localizing two target clinical regions in CTA images using pair-wise estimation based on their geometric relationships. Similarly, coronary arteries are also identified successfully using the geometric estimation [29].
In this paper, we propose a fully automated method for the localization of multiple target regions using relative geometric priors from reference objects, which improves the geometric method. The proposed method can automatically localize a total of five anatomical objects in cardiac CT, which are needed for arrhythmia procedures as well as for assisting an image-guiding LAA occlusion procedure. The main targets are left superior pulmonary vein (LSPV), left inferior pulmonary vein (LIPV), right superior pulmonary vein (RSPV), right inferior pulmonary vein (RIPV), and LAA. As reference objects, the ascending aorta (AA) and descending aorta (DA) are considered for geometric estimation. The target and reference objects in CTA images are shown in Figure 1. In summary, we provide three main contributions:
- We proposed an adaptive model for estimating patient-specific image parameters.
- We designed a Bayesian formulation utilizing the relative geometric prior distribution to solve the LA landmark detection problem.
- We estimated and provided the relative prior distributions between five anatomies (LSPV, RSPV, LIPV, LSPV, LAA) and AA and DA based on distance measures.
We organize the rest of this paper as follows. We describe a Bayesian formulation that comprises the entire process of our method in Section 2, and the details are described in Section 2.1, Section 2.2 and Section 2.3. Experimental results are presented in Section 3. Finally, the discussion and conclusion are drawn in Section 4.
2. Materials and Methods
The proposed method simultaneously estimates multiple objects on the basis of anatomic and geometric features. Our target objects are four PVs and LAA. As these have variable shapes and locations, it is difficult to automatically localize the target objects if each object is considered separately. However, by considering geometric information from the aorta as a robust reference, robust detection of the PVs and LAA is possible. The overall workflow was divided into three parts, as shown in Figure 2. CTA images were observed to have a large variation in intensity distribution. Hence, adaptive image parameters needed to be estimated before the next processes Figure 2a. The image parameters were utilized for the two localization processes both for reference and target objects Figure 2b,c.
We can obtain the geometric prior distributions of the five targets by estimating the AA and DA together to derive the geometric information in terms of angle and distance. We can estimate AA, DA, PVs, and LAA automatically by using the corresponding geometric information as the prior distribution.
After pre-processing, we assume the set of objects , where m is the number of target objects, and n is the number of reference objects. Note that is either a voxel or a discrete region depending on the pre-processing method. Our goal is to find objects among N candidates. Here we assume that m target objects are conditionally independent of the reference objects. Then, for a given image I, we have the following Bayesian formula:
where is treated as a constant since I is given data. If we set the probability of the reference objects as , then we have
Putting Equation (1) into Equation (1), we now have
The probabilities of both target and reference objects are simultaneously modeled by Equation (3). However, we separately consider target- and reference-associated terms for reducing computational complexity. Thus, we first identify the reference objects by
where is the log-likelihood, . After the reference objects are detected, the probability associated with the reference objects, is assumed to be a uniform distribution. Thus, the multiple target objects are finally estimated by the equation
In Section 2.2 and Section 2.3, we analyze each component in detail.
2.1. Estimation of Image-Specific Parameters
The PVs, LAAs, AA, and DA all have the common feature that they belong to contrast-enhanced regions. However, since contrast density may vary from case to case, as shown in Figure 3, we propose a method to adaptively determine thresholds by automatically separating foreground and background values using the unsupervised manner from the input images.
First, we analyze the histogram of input images after thresholding by 0 HU. Then, is divided into the foreground set ( ) and the background set () by applying k-means clustering () with the within-cluster sum-of-squares (WCSS) optimization function.
Let and be the average and standard deviation, respectively, of the set . Likewise, let and be the average and standard deviation, respectively, of the set . Then, the input image is thresholded to generate candidates for the reference and targets, and the resulting mask is generated as follows:
where and . The estimated values will also be used for the target value of the likelihood function in Section 2.3.
2.2. Localization of Reference Objects
The ascending and descending aorta (AA and DA) have the relatively distinct features of large, thick, stem-like shapes and the appearance of two large circles in the axial plane. For this reason, AA and DA are selected as reference objects (). The locations of AA and DA can be robustly identified by the method in [28], which exploits the ratios of the eigenvalues, as their shape is relatively close to circular in the axial view. To find the eigenvalues, first, the resulting mask in Equation (4) is labeled as multiple discrete regions using connected-component analysis (CCA):
Then, we consider the covariance matrix for each :
where . Let be the eigenvalues of and let . Then, the ideal value of if the object is near circular. The joint log-likelihood for the two most isotropic components is formulated as
where is the variance of the eigenvalue ratio for AA and DA. The log-likelihood measures the deviation of the two components from the isotropy for both AA and DA.
The prior term with two references is denoted as . With the discrete candidates in Equation (5), the geometric features of the aorta in the axial images are described in terms of the distance and the angle between the ascending and descending aorta (Figure 4):
This prior term is interpreted as the two learned prior distributions with regard to the angles and distances. Let be the vector from the centroid of to the centroid of , and let be its norm. The variable is the angle between the x-axis and . Let and be the mean angle and distance, where the distance and angle variations can be evaluated as the ratios and , respectively. The two independent variables are converted into the prior probabilities as
The ratios and are a perfect match to our model. Recall the reference estimator in Equation (2); two reference objects are found by maximizing the following equation:
The object pair and , which maximize Equation (10), is assumed to be AA and DA. We now have two robust cylinder-like objects that cover the entire range of the CTA volume as patient-specific references, as shown in Figure 5.
2.3. Localization of Multiple Target Objects
Although the deviation of the geometric relationships between the clinical positions from the average is small, the variation in the size of the whole heart can be very large, for example between adults and children. In addition, the angle at which the heart is placed may be slightly different in different cases. To minimize this variance, we used a prior distribution created by sampling the distance ratios between each clinically named location and the references, similarly to the flexible prior distribution illustrated. This can fit most human heart shapes if the reference positions are correctly posed (such as by using the robust reference identification method introduced in Section 2.2).
Unlike the reference objects, the boundaries of the target objects are generally not clear. Hence, it may not be possible to have discrete components that were used in the technique for identifying the reference objects. Instead, we propose a new feature for each pixel using the relative distances.
Let and be the coordinates of the centroids of and , respectively. We define three distances by
As we have the prior distributions of the relative distances between all target objects, we denote and to be the average distance between the i-th object and the j-th object, and its variance, respectively.
Then, we propose a target similarity measure for each target as follows:
The target similarity measure is computed for every 2D slice. Our estimated parameter for reference is 81.6 mm. Table 1 shows our estimated parameter values from the distance measurement samples by Equation (11), which can be referred for Equation (12).
Given a robust reference, a relative distance distribution is determined in order to localize the target object, as shown in Figure 6c. Additionally, the elements of are separately analyzed, and Figure 7 shows why distance distributions from both references are needed to localize an object. However, since the intersection of each distribution forming the 2D ring shape appears in two places, it still does not uniquely specify a single position. Therefore, we combine it with the directional information shown in Figure 4a to obtain the final distribution. The behavior of in Equation (12) is also analyzed to show that the target object can be localized without depending on the rotation and scale by using the geometric prior distribution, which changes dynamically according to changes in the position of the reference, as shown in Figure 8.
In order to simultaneously localize multiple targets in 3D, we compute for each 2D slice, and we finally obtain the following 3D mask by thresholding the resultant measure:
where the element is a grouped sample set specified by Equation (13), which is visualized, for example, in Figure 9c.
A common fact that the target objects exist in the contrast region is considered in the likelihood function for the targets, which is formulated as
where is the mean intensity of all voxels in . The image-specific parameters, and , for Equation (14), can be calculated by the adaptive method given in Section 2.1. The higher probabilities are mapped on the contrast regions by computing the likelihood as shown in Figure 6b.
Then, the positions of the target objects with unclear boundaries can be specified by the posterior probability in Figure 6d.
Subsequently, we formulate the probability of the target objects as follows:
where is the distance between and , and and are its average and variance, respectively, for Equation (15). The geometry of the relationships among the components is similar to a complete graph. The goal of our method is to find a geometry that fits our prior probabilities.
3. Experimental Results
We have performed a number of experiments to demonstrate the robustness of our system and the quantitative results for the five target objects.
3.1. Data Set
The proposed method was applied on a total of 60 CTA images. Besides thirty-two public datasets, Rotterdam Challenge images [30,31], which are well focused on hearts, were acquired on the CT scanners from various vendors. We additionally selected twenty-eight cases with variations in the field of views, contrast injection timings, artifacts, and morphology from Severance Hospital, Republic of Korea. Each CTA image was reconstructed to 512 × 512 × [272, 433] voxels with an isotropic voxel size between (0.26 mm × 0.26 mm × 0.26 mm) and (0.48 mm × 0.48 mm × 0.48 mm ). Ground truth sets for 60 CTA cases were manually labeled by a medical expert. We have each labeled target region (four PVs and LAA).
3.2. Parameters
We fixed parameters for Equation (9) as mm, , , and . The parameters were referred from the previous investigation on aortic localization [28], which were measured from CTA images from eight patients in the Rotterdam Challenge training set [30,31]. and are the parameters normalized by and , which play the roles of the internal weighting parameters that can be adjusted so that the larger the difference from the mean values (, ), the greater the penalty. Despite the limited amount of data, the estimated average values can be converged quite closely to the actual values. For example, the average arch width (notated as ) has been reported as 82 mm, which is a value obtained from 234 patient cases in a clinical study [32].
3.3. Analysis of Geometric Prior Distribution
Given the robust reference objects, a geometric prior distribution was determined to localize a target object. Figure 7 shows why two reference objects are needed to localize a target position. The elements of are separately analyzed, and each 2D ring-shaped distribution is drawn in Figure 7a,b based on and . For the experiment, the learned parameters, which are provided in Table 1, are referred for localizing the five target objects based on AA and DA.
Figure 8 shows that the geometric prior distributions were rotation- and scale-invariant. A target object can be localized regardless of rotation and scale using the geometric prior distribution that flexibly changes according to the change of the positions of the reference objects, as shown in Figure 8a,b. However, since the joint distributions have two local peaks, it still can not specify a unique target position. Hence, we used directional information described in Figure 8c together for a unique position.
3.4. Quantitative Comparison with Other Methods
Table 2 presents the results of localization of the five targets, a quantitative comparison of the proposed method with the result given by a workstation (Vitrea, by Vital Images [33]). We used the following measures to evaluate the robustness:
- TPR, true positive rate ();
- TP, true positive; TP:=;
- FN, false negative; FN:=;
where X and Y can be the outputs by one of methods and ground truth, respectively. In terms of a detection rate, TPR is computed to compare the robustness, as shown in Table 2. Even though the experiments were done without any user interaction or parameter changes, the reference objects, AA and DA, were detected 100% of the time in our dataset.
Table 2 presents the results for PVs and LAA localizations. The quantitative comparison of our method with the output given by the CT EP planning function of a workstation (Vitrea, by Vital Images [33]) is shown. The success rate was measured with a prepared ground truth set corresponding to 60 images in the dataset we tested.
Our proposed method required 7.34 s total computation time using an i7 3.50-GHz 32-GB PC. Most of the time was consumed in the processing the object preparation. Vitrea required about 10–20 s computation time, depending on CTA images, using dual Xeon E5-2690 2.90 GHz 128-GB HP workstation. Vitrea does not provide a description of the detailed methodology for the detection of LA and its landmarks, but it seems to always conduct LA segmentation first, and then the landmark detection process is done based on the LA segment. On the other hand, the proposed method did not need a segmentation process for LA, rather it could directly detect LA landmarks, which seems to make a difference in computation time.
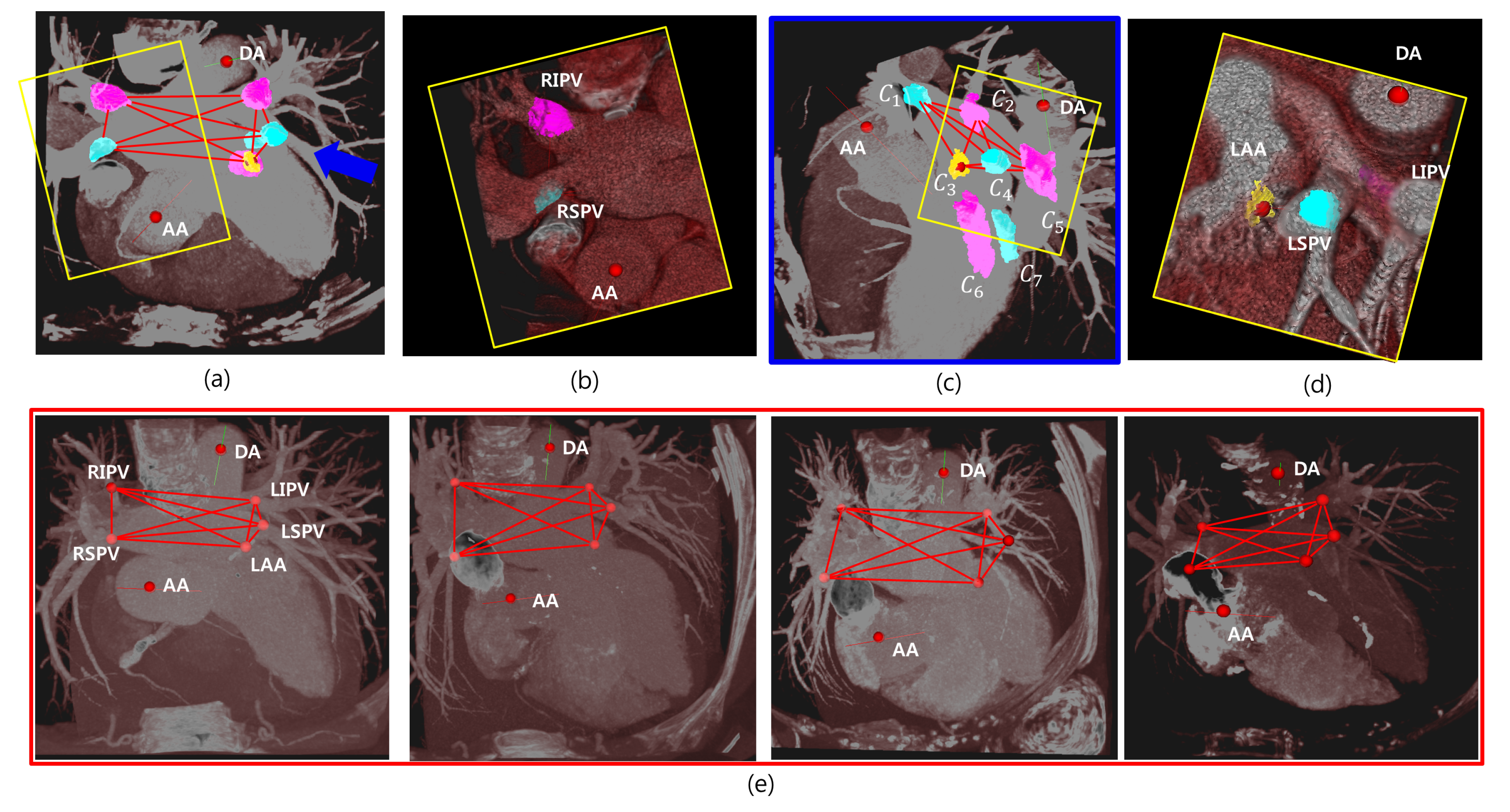
Figure 9 shows some examples, some target candidates, and their estimated geometries, where maximum probability is visualized with maximum intensity projection (MIP), in the axial view in Figure 9a and a magnified view in the yellow box in Figure 9b. It shows the candidates on the target regions, RIPV and RSPV. All the candidates in Equation (13) are visualized in Figure 9c from a view slightly rotated to the blue arrow in Figure 9a. Figure 9d shows a magnified view of the yellow box in Figure 9c. In this example, the five objects connected to each other with red edges are the estimated 3D target objects among seven candidate objects by Equation (15), and , and are RSPV, RIPV, LAA, LSPV, and LIPV, respectively. Figure 9e demonstrates that the results were detected with maximum probabilities from several cases. We find such geometries form a complete graph, and its vertices are our target objects.
4. Discussion and Conclusions
In this paper, we proposed a Bayesian framework to localize five target objects (four PVs and LAA) in LA based on the two reference objects (AA and DA) by designing a Bayesian formulation that utilizes geometric prior distributions. The proposed method is based on the important prior knowledge that there are geometrical relationships among the cardiac anatomies and that follow Gaussian distributions. Multiple target objects whose structures are complex can be robustly localized. For successful localization of the multiple objects, first, we propose an adaptive model for estimating patient-specific image parameters using an unsupervised manner, which can be generally utilized for the preprocessing of other methods. We also designed a Bayesian formulation comprising the relative geometric prior distribution to solve the LA landmark detection problem. We investigated and provided the geometric prior distributions between five anatomies (LSPV, RSPV, LIPV, LSPV, and LAA) and AA and DA based on distance measures. As a result, the average detection rates were 1.0, 0.97, 0.91, 1.0, and 0.94 for localizing LSPV, LIPV, LAA, RIPV, and RSPV, respectively. The proposed method required a total of 7.34 s computation time.
The geometric prior distributions can be easily integrated into other methods. In addition, the proposed method can be easily applied to other applications since it can specify all positions in the cardiac CT image based on two robust reference objects. For example, policy-based localization methods [23,34,35] using deep reinforcement learning, which are the new approaches in the literature, are very fast compared to other approaches that require an extensive search. However, in order to track a target object from a random location in CT images, the direction toward the target location is sequentially searched using only local boxed information. For this reason, sometimes it fails to converge to the target location. Such a problem may occur because the agent cannot use the context of the global heart structure. Initializing the start position of the agent using the proposed method can help to minimize the failure case.
A limitation of the proposed method may arise when the reference or target anatomic parts are abnormally positioned. Cardiac malposition is very rarely reported, but the position of the heart can be reversed, or parts may be missing as in cases of situs inversus, asplenia, or polysplenia. However, we will include case-specific distributions in our database, which is supposed to solve these problems.
In future work, we plan to approximate the likelihood function using a convolutional neural network to obtain a more robust posterior probability in order to improve the robustness of the proposed method, and the geometric prior distribution will be combined with a policy-based method to minimize the failure rate of target object localization in further research. In addition, we aim to apply the proposed method to automatically analyze the morphology of LAA, select device sizes for the LAA procedure, and automate the detection of the landing zone. For LA fluid simulations, we also plan to generate simulation-ready LA geometries by automatically localizing the inlets and outlets of blood flow.
Author Contributions
Bayesian modeling, B.J.; visualization and analysis S.J.; writing—review and editing, H.S.; supervision, H.-J.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Korea Medical Device Development Fund grant funded by the Korea government (the Ministry of Science and ICT, the Ministry of Trade, Industry and Energy, the Ministry of Health & Welfare, Republic of Korea, the Ministry of Food and Drug Safety) (Project Number: 202016B02) and supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (1345322865).
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Oral, H.; Scharf, C.; Chugh, A.; Hall, B.; Cheung, P.; Good, E.; Veerareddy, S.; Pelosi, F.; Morady, F. Catheter ablation for paroxysmal atrial fibrillation. Circulation 2003, 108, 2355–2360. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weerasooriya, R.; Khairy, P.; Litalien, J.; Macle, L.; Hocini, M.; Sacher, F.; Lellouche, N.; Knecht, S.; Wright, M.; Nault, I.; et al. Catheter ablation for atrial fibrillation. J. Am. Coll. Cardiol. 2011, 57, 160–166. [Google Scholar] [CrossRef] [PubMed]
- Verma, A.; Jiang, C.Y.; Betts, T.R.; Chen, J.; Deisenhofer, I.; Mantovan, R.; Macle, L.; Morillo, C.A.; Haverkamp, W.; Weerasooriya, R.; et al. Approaches to catheter ablation for persistent atrial fibrillation. N. Engl. J. Med. 2015, 372, 1812–1822. [Google Scholar] [CrossRef] [PubMed]
- Kistler, P.M.; Earley, M.J.; Harris, S.; Abrams, D.; Ellis, S.; Sporton, S.C.; Schilling, R.J. Validation of Three-Dimensional Cardiac Image Integration: Use of Integrated CT Image into Electroanatomic Mapping System to Perform Catheter Ablation of Atrial Fibrillation. J. Cardiovasc. Electrophysiol. 2006, 17, 341–348. [Google Scholar] [CrossRef] [PubMed]
- Ostermayer, S.H.; Reisman, M.; Kramer, P.H.; Matthews, R.V.; Gray, W.A.; Block, P.C.; Omran, H.; Bartorelli, A.L.; Della Bella, P.; Di Mario, C.; et al. Percutaneous left atrial appendage transcatheter occlusion (PLAATO system) to prevent stroke in high-risk patients with non-rheumatic atrial fibrillation: Results from the international multi-center feasibility trials. J. Am. Coll. Cardiol. 2005, 46, 9–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jia, D.; Jeon, B.; Park, H.B.; Chang, H.J.; Zhang, L.T. Image-Based Flow Simulations of Pre-and Post-left Atrial Appendage Closure in the Left Atrium. Cardiovasc. Eng. Technol. 2019, 10, 225–241. [Google Scholar] [CrossRef] [PubMed]
- Tobon-Gomez, C.; Geers, A.J.; Peters, J.; Weese, J.; Pinto, K.; Karim, R.; Ammar, M.; Daoudi, A.; Margeta, J.; Sandoval, Z.; et al. Benchmark for algorithms segmenting the left atrium from 3D CT and MRI datasets. IEEE Trans. Med. Imaging 2015, 34, 1460–1473. [Google Scholar] [CrossRef]
- Xiong, Z.; Xia, Q.; Hu, Z.; Huang, N.; Bian, C.; Zheng, Y.; Vesal, S.; Ravikumar, N.; Maier, A.; Yang, X.; et al. A global benchmark of algorithms for segmenting the left atrium from late gadolinium-enhanced cardiac magnetic resonance imaging. Med. Image Anal. 2020, 67, 101832. [Google Scholar] [CrossRef]
- Karim, R.; Mohiaddin, R.; Rueckert, D. Left atrium segmentation for atrial fibrillation ablation. In Medical Imaging; International Society for Optics and Photonics: Washington, DC, USA, 2008. [Google Scholar]
- Lombaert, H.; Sun, Y.; Grady, L.; Xu, C. A multilevel banded graph cuts method for fast image segmentation. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 1, pp. 259–265. [Google Scholar]
- Depa, M.; Sabuncu, M.R.; Holmvang, G.; Nezafat, R.; Schmidt, E.J.; Golland, P. Robust atlas-based segmentation of highly variable anatomy: Left atrium segmentation. In International Workshop on Statistical Atlases and Computational Models of the Heart; Springer: Berlin/Heidelberg, Germany, 2010; pp. 85–94. [Google Scholar]
- Zhuang, X.; Rhode, K.S.; Razavi, R.S.; Hawkes, D.J.; Ourselin, S. A registration-based propagation framework for automatic whole heart segmentation of cardiac MRI. IEEE Trans. Med. Imaging 2010, 29, 1612–1625. [Google Scholar] [CrossRef] [Green Version]
- Tao, Q.; Shahzad, R.; Ipek, E.G.; Berendsen, F.F.; Nazarian, S.; van der Geest, R.J. Fully automated segmentation of left atrium and pulmonary veins in late gadolinium enhanced MRI. J. Cardiovasc. Magn. Reson. 2016, 18, O84. [Google Scholar] [CrossRef] [Green Version]
- Zuluaga, M.A.; Cardoso, M.J.; Modat, M.; Ourselin, S. Multi-atlas propagation whole heart segmentation from MRI and CTA using a local normalised correlation coefficient criterion. In Proceedings of the International Conference on Functional Imaging and Modeling of the Heart, Bordeaux, France, 6–8 June 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 174–181. [Google Scholar]
- Qiao, M.; Wang, Y.; van der Geest, R.J.; Tao, Q. Fully automated left atrium cavity segmentation from 3D GE-MRI by multi-atlas selection and registration. In Proceedings of the International Workshop on Statistical Atlases and Computational Models of the Heart, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 230–236. [Google Scholar]
- Nuñez-Garcia, M.; Zhuang, X.; Sanroma, G.; Li, L.; Xu, L.; Butakoff, C.; Camara, O. Left atrial segmentation combining multi-atlas whole heart labeling and shape-based atlas selection. In International Workshop on Statistical Atlases and Computational Models of the Heart; Springer: Berlin/Heidelberg, Germany, 2018; pp. 302–310. [Google Scholar]
- Mortazi, A.; Karim, R.; Rhode, K.; Burt, J.; Bagci, U. CardiacNET: Segmentation of left atrium and proximal pulmonary veins from MRI using multi-view CNN. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 11–13 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 377–385. [Google Scholar]
- Liao, H.; Tang, Y.; Funka-Lea, G.; Luo, J.; Zhou, S.K. More knowledge is better: Cross-modality volume completion and 3D+ 2D segmentation for intracardiac echocardiography contouring. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 535–543. [Google Scholar]
- Zhang, X.; Noga, M.; Martin, D.G.; Punithakumar, K. Fully automated left atrium segmentation from anatomical cine long-axis MRI sequences using deep convolutional neural network with unscented Kalman filter. Med. Image Anal. 2020, 68, 101916. [Google Scholar] [CrossRef] [PubMed]
- Borra, D.; Andalò, A.; Paci, M.; Fabbri, C.; Corsi, C. A fully automated left atrium segmentation approach from late gadolinium enhanced magnetic resonance imaging based on a convolutional neural network. Quant. Imaging Med. Surg. 2020, 10, 1894. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Alansary, A.; Cerrolaza, J.J.; Khanal, B.; Sinclair, M.; Matthew, J.; Gupta, C.; Knight, C.; Kainz, B.; Rueckert, D. Fast multiple landmark localisation using a patch-based iterative network. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 563–571. [Google Scholar]
- Oktay, O.; Bai, W.; Guerrero, R.; Rajchl, M.; de Marvao, A.; O’Regan, D.P.; Cook, S.A.; Heinrich, M.P.; Glocker, B.; Rueckert, D.; et al. Stratified Decision Forests for Accurate Anatomical Landmark Localization in Cardiac Images. IEEE Trans. Med. Imaging 2017, 36, 332–342. [Google Scholar] [CrossRef] [PubMed]
- Ghesu, F.C.; Georgescu, B.; Zheng, Y.; Grbic, S.; Maier, A.; Hornegger, J.; Comaniciu, D. Multi-scale deep reinforcement learning for real-time 3D-landmark detection in CT scans. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 176–189. [Google Scholar] [CrossRef] [PubMed]
- Seidlitz, J.; Váša, F.; Shinn, M.; Romero-Garcia, R.; Whitaker, K.J.; Vértes, P.E.; Wagstyl, K.; Reardon, P.K.; Clasen, L.; Liu, S.; et al. Morphometric similarity networks detect microscale cortical organization and predict inter-individual cognitive variation. Neuron 2018, 97, 231–247. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Daboul, A.; Ivanovska, T.; Bülow, R.; Biffar, R.; Cardini, A. Procrustes-based geometric morphometrics on MRI images: An example of inter-operator bias in 3D landmarks and its impact on big datasets. PLoS ONE 2018, 13, e0197675. [Google Scholar] [CrossRef] [Green Version]
- Moriconi, S.; Zuluaga, M.A.; Jäger, H.R.; Nachev, P.; Ourselin, S.; Cardoso, M.J. Elastic registration of geodesic vascular graphs. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 810–818. [Google Scholar]
- Devine, J.; Aponte, J.D.; Katz, D.C.; Liu, W.; Vercio, L.D.L.; Forkert, N.D.; Marcucio, R.; Percival, C.J.; Hallgrímsson, B. A Registration and Deep Learning Approach to Automated Landmark Detection for Geometric Morphometrics. Evol. Biol. 2020, 47, 246–259. [Google Scholar] [CrossRef]
- Jeon, B.; Hong, Y.; Han, D.; Jang, Y.; Jung, S.; Hong, Y.; Ha, S.; Shim, H.; Chang, H.J. Maximum a posteriori estimation method for aorta localization and coronary seed identification. Pattern Recognit. 2017, 68, 222–232. [Google Scholar] [CrossRef]
- Jeon, B.; Jang, Y.; Shim, H.; Chang, H.J. Identification of coronary arteries in CT images by Bayesian analysis of geometric relations among anatomical landmarks. Pattern Recognit. 2019, 96, 106958. [Google Scholar] [CrossRef]
- Rotterdam Dataset. Available online: http://coronary.bigr.nl/centerlines/ (accessed on 30 December 2020).
- Schaap, M.; Metz, C.; van Walsum, T.; van der Giessen, A.; Weustink, A.; Mollet, N.; Bauer, C.; Bogunovi, H.; Castro, C.; Deng, X.; et al. Standardized Evaluation Methodology and Reference Database for Evaluating Coronary Artery Centerline Extraction Algorithms. Med. Image Anal. 2009, 13, 701–714. [Google Scholar] [CrossRef] [Green Version]
- Alhafez, B.A.; Ocazionez, D.; Sohrabi, S.; Sandhu, H.; Estrera, A.; Safi, H.J.; Evangelista, A.; Hurtado, L.D.S.; Guala, A.; Prakash, S.K.; et al. Aortic arch tortuosity, a novel biomarker for thoracic aortic disease, is increased in adults with bicuspid aortic valve. Int. J. Cardiol. 2019, 284, 84–89. [Google Scholar] [CrossRef] [PubMed]
- Vital. Available online: https://www.vitalimages.com/ (accessed on 30 December 2020).
- Alansary, A.; Oktay, O.; Li, Y.; Le Folgoc, L.; Hou, B.; Vaillant, G.; Kamnitsas, K.; Vlontzos, A.; Glocker, B.; Kainz, B.; et al. Evaluating reinforcement learning agents for anatomical landmark detection. Med. Image Anal. 2019, 53, 156–164. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Al, W.A.; Yun, I.D. Partial policy-based reinforcement learning for anatomical landmark localization in 3d medical images. IEEE Trans. Med. Imaging 2019, 39, 1245–1255. [Google Scholar] [CrossRef] [PubMed] [Green Version]
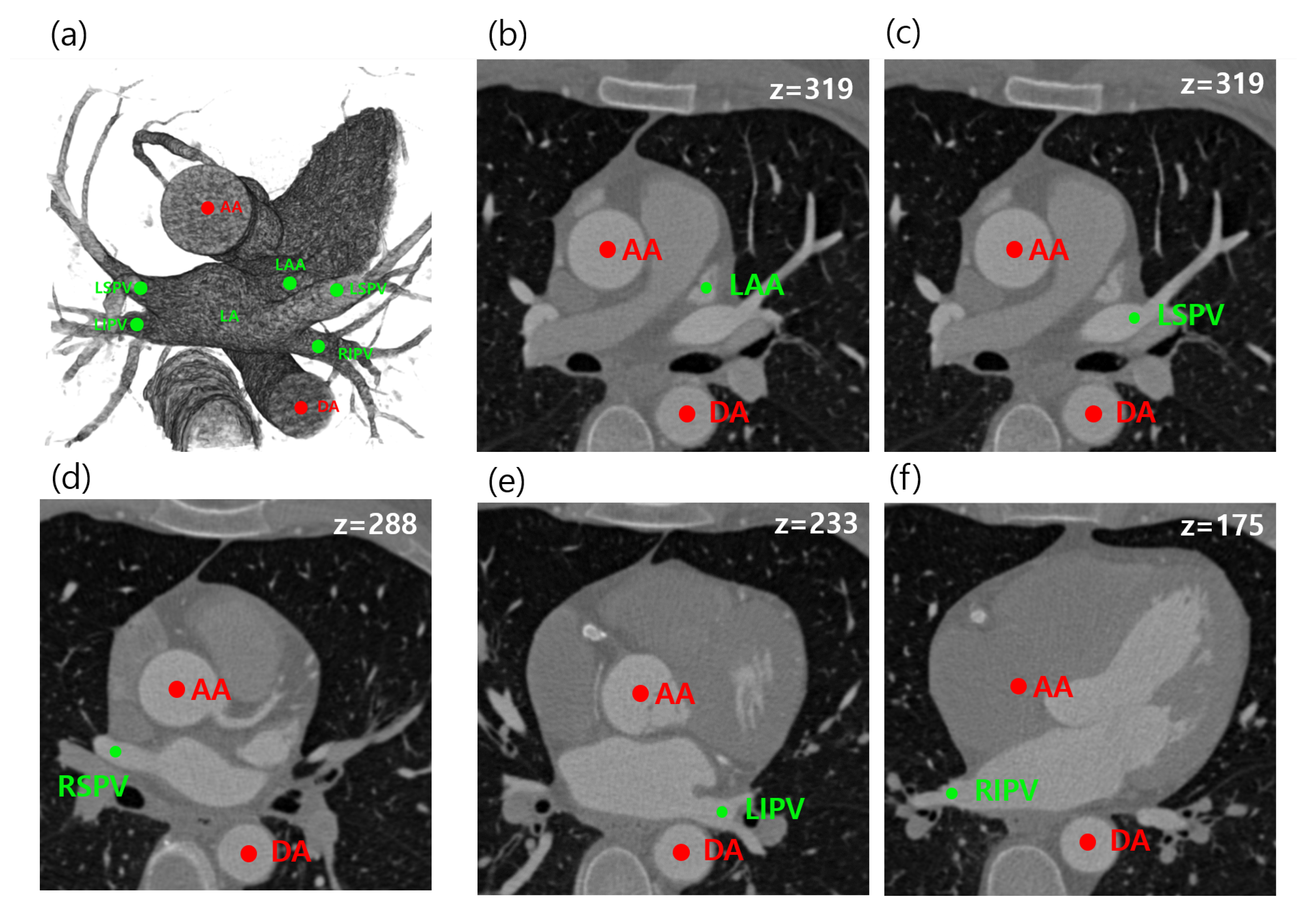
Figure 1.
Relationships of five target (green) and two reference (red) objects in computed tomography angiography (CTA) images are illustrated. All the left atrial landmarks are visualized in 3D volume rendering (a), and each target object and the reference objects (AA and DA) are separately visualized at a specific 2D slice of z (b–f). LSPV, left superior pulmonary vein; LIPV, left inferior pulmonary vein; RSPV, right superior pulmonary vein; RIPV, right inferior pulmonary vein; LAA, left atrial appendage; CTA, computed tomography angiography.
Figure 1.
Relationships of five target (green) and two reference (red) objects in computed tomography angiography (CTA) images are illustrated. All the left atrial landmarks are visualized in 3D volume rendering (a), and each target object and the reference objects (AA and DA) are separately visualized at a specific 2D slice of z (b–f). LSPV, left superior pulmonary vein; LIPV, left inferior pulmonary vein; RSPV, right superior pulmonary vein; RIPV, right inferior pulmonary vein; LAA, left atrial appendage; CTA, computed tomography angiography.

Figure 2.
Workflow of the proposed method: image-specific parameters are estimated for the adaptation of various CTA images with different intensity distributions (a). Then, the ascending aorta (AA) and descending aorta (DA) are used to localize other anatomies, including four PVs, and LAA (b,c). PVs, pulmonary artery; LAA, left atrial appendage.
Figure 2.
Workflow of the proposed method: image-specific parameters are estimated for the adaptation of various CTA images with different intensity distributions (a). Then, the ascending aorta (AA) and descending aorta (DA) are used to localize other anatomies, including four PVs, and LAA (b,c). PVs, pulmonary artery; LAA, left atrial appendage.

Figure 3.
Various intensity histograms showing how the image can be parsed. The mean intensity of contrast regions () and the mean intensity of non-contrast regions () are adaptively estimated using k-means clustering. Foreground () and background () indicate the contrast regions and non-contrast regions, respectively. The display window level and width for the images in this figure are fixed to 60 and 700 HU, respectively, for visualization.
Figure 3.
Various intensity histograms showing how the image can be parsed. The mean intensity of contrast regions () and the mean intensity of non-contrast regions () are adaptively estimated using k-means clustering. Foreground () and background () indicate the contrast regions and non-contrast regions, respectively. The display window level and width for the images in this figure are fixed to 60 and 700 HU, respectively, for visualization.

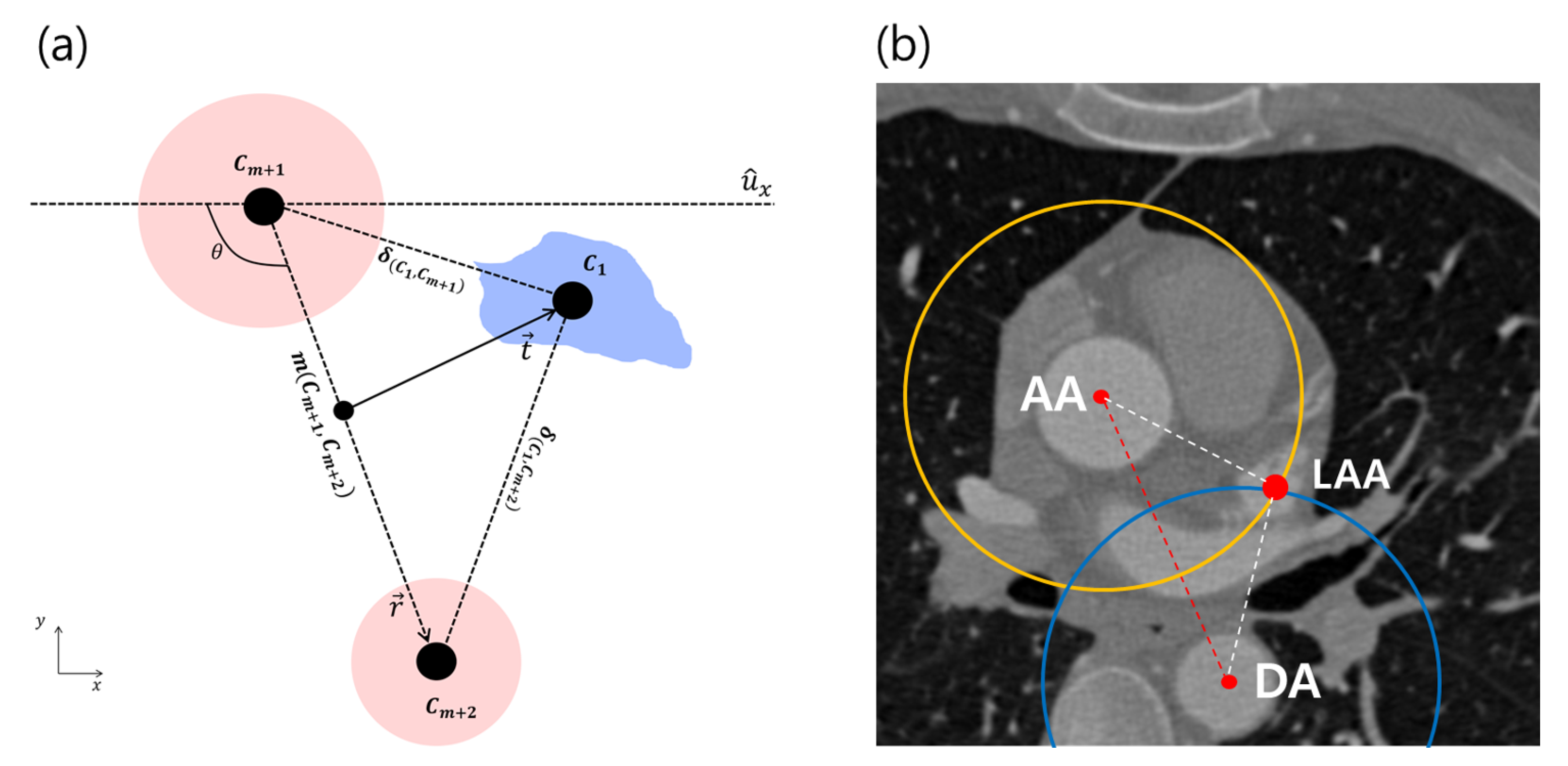
Figure 4.
A geometric model for AA and DA () and a target (). (a) The distance and angle between and are sampled to obtain a prior distribution for reference, where is the vector between the two references. m is the mean point between the two references, and is the direction of the target , which would be used to specify a single solution. is the distance between and . (b) The simplified geometry is overlaid on a CTA image with an example of = LAA. More details about the intersection of two circles whose centroids are AA and DA are described in Section 3.3. AA, ascending aorta; DA, descending aorta; LAA, left atrial appendage.
Figure 4.
A geometric model for AA and DA () and a target (). (a) The distance and angle between and are sampled to obtain a prior distribution for reference, where is the vector between the two references. m is the mean point between the two references, and is the direction of the target , which would be used to specify a single solution. is the distance between and . (b) The simplified geometry is overlaid on a CTA image with an example of = LAA. More details about the intersection of two circles whose centroids are AA and DA are described in Section 3.3. AA, ascending aorta; DA, descending aorta; LAA, left atrial appendage.

Figure 5.
The detected references are visualized both in 2D and 3D (a,b). Each cylinder-like object is approximated to a vector to cover the entire range of volume (c). AA, ascending aorta; DA, descending aorta.
Figure 5.
The detected references are visualized both in 2D and 3D (a,b). Each cylinder-like object is approximated to a vector to cover the entire range of volume (c). AA, ascending aorta; DA, descending aorta.

Figure 6.
Example of a process for specifying a target object LAA in axial images; (a) original image; (b) likelihood, ; (c) prior ; (d) posterior, ; LAA, left atrial appendage.
Figure 6.
Example of a process for specifying a target object LAA in axial images; (a) original image; (b) likelihood, ; (c) prior ; (d) posterior, ; LAA, left atrial appendage.

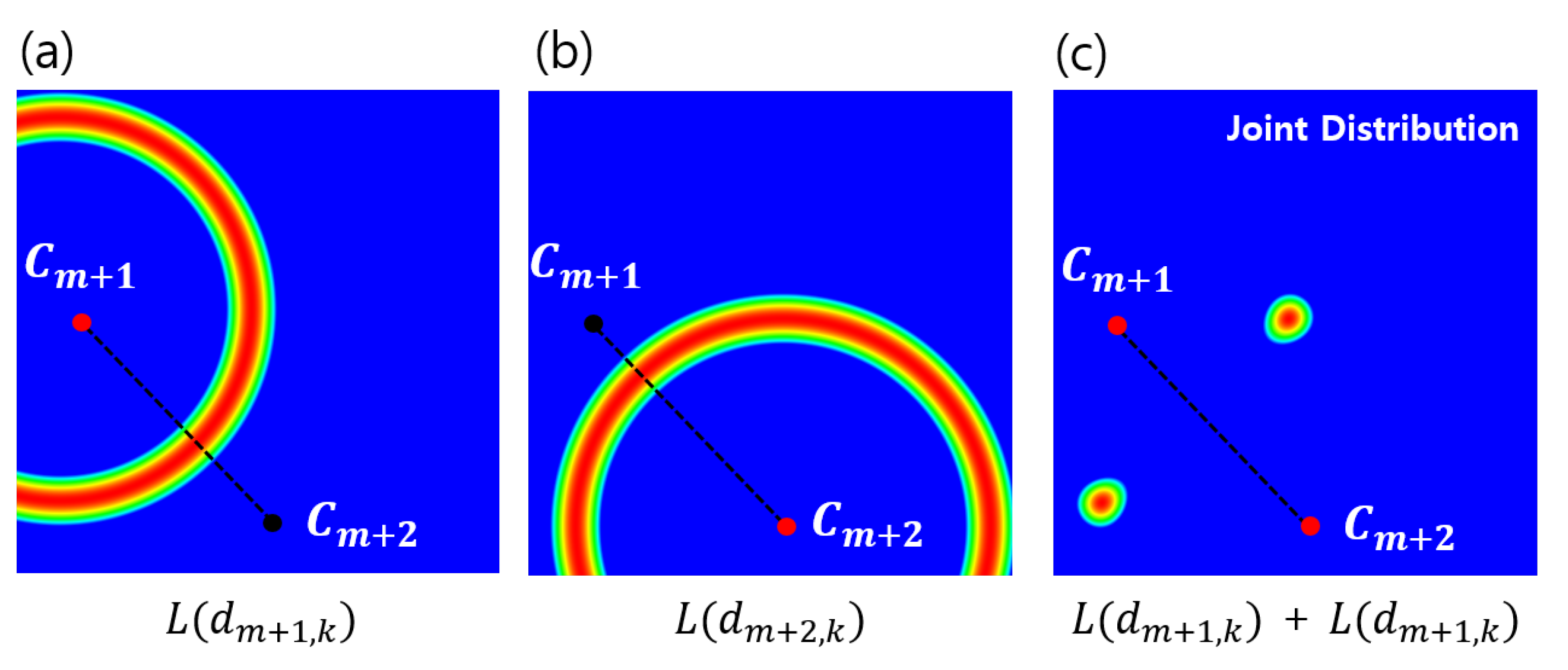
Figure 7.
Visualization of geometric prior distributions: the distance-based PDFs based on two reference locations, (a) and (b). While each ring-shaped PDF is not able to identify a unique location, the joint PDF (c) can simply designate a target location; PDF, probability density function.
Figure 7.
Visualization of geometric prior distributions: the distance-based PDFs based on two reference locations, (a) and (b). While each ring-shaped PDF is not able to identify a unique location, the joint PDF (c) can simply designate a target location; PDF, probability density function.

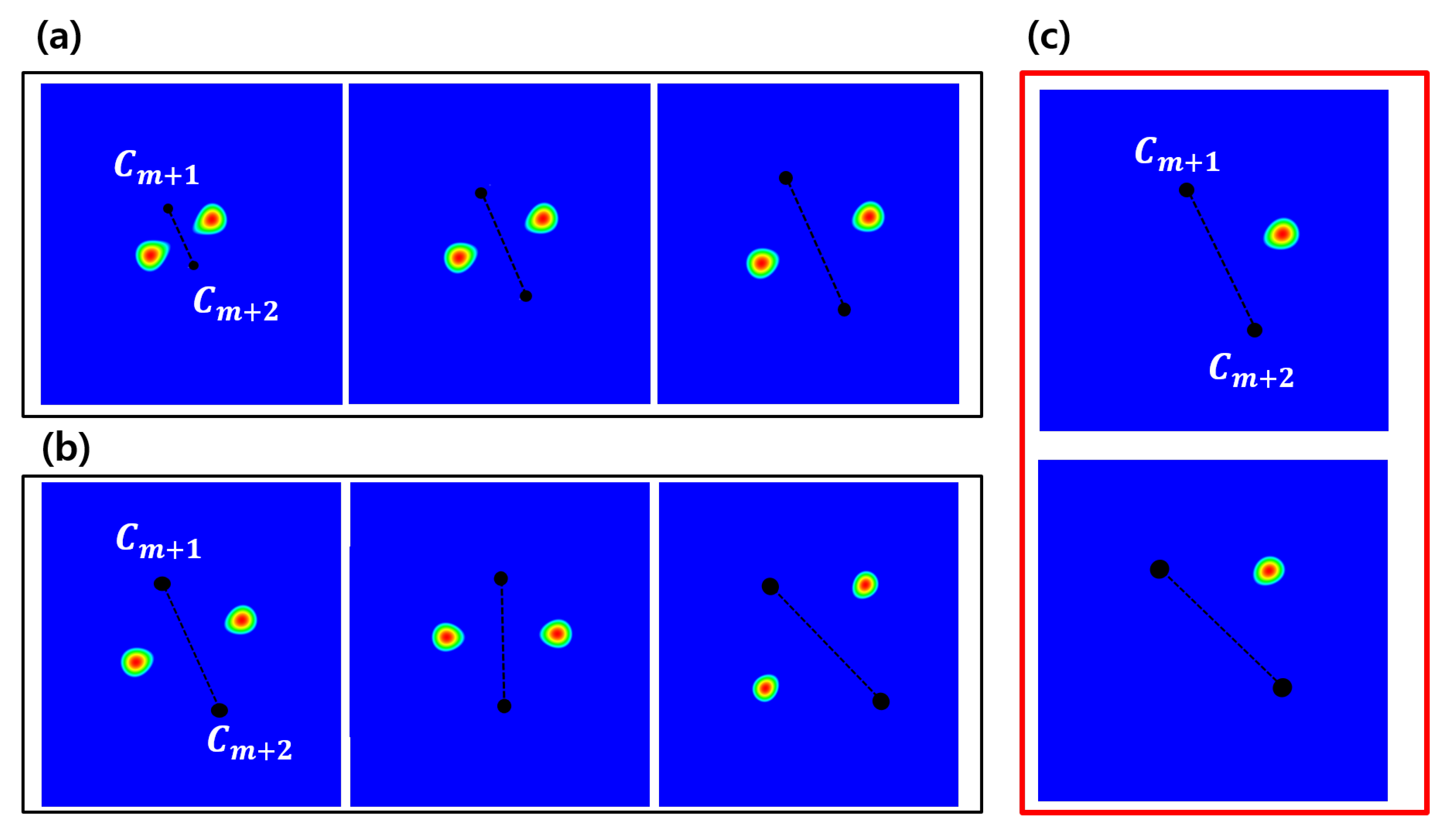
Figure 8.
Flexibility of prior distributions are shown in terms of (a) scale and (b) rotation by varying distance and angle of reference . (c) Prior distribution defined by two distance samples may give two peaks, one for the correct target and the other on the opposite side. The distribution on the unwanted opposing side is removed simply by using the direction .
Figure 8.
Flexibility of prior distributions are shown in terms of (a) scale and (b) rotation by varying distance and angle of reference . (c) Prior distribution defined by two distance samples may give two peaks, one for the correct target and the other on the opposite side. The distribution on the unwanted opposing side is removed simply by using the direction .

Figure 9.
Results and visualizations of the candidates and their estimation. (a) Five anatomies are visualized. (b) The magnified view of RIPV and RSPV. (c) The rotated view of the results. Some candidate objects are co-visualized. Simple level comparison enables one to select the correct objects. (d) The magnified views of LSPV, LIPV, and LAA. (e) The results of four example cases. LSPV, left superior pulmonary vein; LIPV, left inferior pulmonary vein; RSPV, right superior pulmonary vein; RIPV, right inferior pulmonary vein; LAA, left atrial appendage.
Figure 9.
Results and visualizations of the candidates and their estimation. (a) Five anatomies are visualized. (b) The magnified view of RIPV and RSPV. (c) The rotated view of the results. Some candidate objects are co-visualized. Simple level comparison enables one to select the correct objects. (d) The magnified views of LSPV, LIPV, and LAA. (e) The results of four example cases. LSPV, left superior pulmonary vein; LIPV, left inferior pulmonary vein; RSPV, right superior pulmonary vein; RIPV, right inferior pulmonary vein; LAA, left atrial appendage.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Estimated distances between reference and target objects as optimal internal parameters for localization of four pulmonary veins and the left atrial appendage.
Table 1.
Estimated distances between reference and target objects as optimal internal parameters for localization of four pulmonary veins and the left atrial appendage.
| Reference | LSPV (mm) | LIPV (mm) | RSPV (mm) | RIPV (mm) | LAA (mm) |
|---|---|---|---|---|---|
| AA | 65.71 2.95 | 80.09 6.04 | 44.16 3.55 | 63.74 8.71 | 49.23 3.02 |
| DA | 46.54 7.31 | 26.22 4.38 | 82.15 9.62 | 63.31 8.66 | 65.37 10.77 |
: average distance, : deviation where , . LSPV, left superior pulmonary vein; LIPV, left inferior pulmonary vein; RSPV, right superior pulmonary vein; RIPV, right inferior pulmonary vein; LAA, left atrial appendage.
Table 2.
Quantitative comparison for the detection rate of the five target locations from 60 CTA images, where TPR is the measurement.
Table 2.
Quantitative comparison for the detection rate of the five target locations from 60 CTA images, where TPR is the measurement.
| Method | LSPV | LIPV | LAA | RIPV | RSPV | Average |
|---|---|---|---|---|---|---|
| Proposed (Public [31]) | 1.0 | 1.0 | 0.93 | 1.0 | 0.96 | 0.98 |
| Proposed (Selected) | 1.0 | 0.94 | 0.88 | 1.0 | 0.92 | 0.95 |
| Vitrea (Public [31]) | 0.94 | 0.97 | - | 0.97 | 0.81 | 0.92 |
| Vitrea (Selected) | 0.93 | 0.89 | - | 0.96 | 0.82 | 0.90 |
Note that LAA could not be directly compared since Vitrea does not provide an automatic LAA detection function. TPR, true positive rate ; LSPV, left superior pulmonary vein; LIPV, left inferior pulmonary vein; RSPV, right superior pulmonary vein; RIPV, right inferior pulmonary vein; LAA, left atrial appendage.
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Jeon, B.; Jung, S.; Shim, H.; Chang, H.-J. Bayesian Estimation of Geometric Morphometric Landmarks for Simultaneous Localization of Multiple Anatomies in Cardiac CT Images. Entropy 2021, 23, 64. https://doi.org/10.3390/e23010064
AMA Style
Jeon B, Jung S, Shim H, Chang H-J. Bayesian Estimation of Geometric Morphometric Landmarks for Simultaneous Localization of Multiple Anatomies in Cardiac CT Images. Entropy. 2021; 23(1):64. https://doi.org/10.3390/e23010064
Chicago/Turabian StyleJeon, Byunghwan, Sunghee Jung, Hackjoon Shim, and Hyuk-Jae Chang. 2021. "Bayesian Estimation of Geometric Morphometric Landmarks for Simultaneous Localization of Multiple Anatomies in Cardiac CT Images" Entropy 23, no. 1: 64. https://doi.org/10.3390/e23010064
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.