Analysis of Blind Reconstruction of BCH Codes



Department of Electronics and Computer Engineering, Hanyang University, Seoul 04763, Korea
*
Author to whom correspondence should be addressed.
Entropy 2020, 22(11), 1256; https://doi.org/10.3390/e22111256
Submission received: 16 October 2020
/
Revised: 2 November 2020
/
Accepted: 4 November 2020
/
Published: 5 November 2020
(This article belongs to the Section Information Theory, Probability and Statistics)
{kind=link}
{kind=link}
Abstract
:In this paper, the theoretical lower-bound on the success probability of blind reconstruction of Bose–Chaudhuri–Hocquenghem (BCH) codes is derived. In particular, the blind reconstruction method of BCH codes based on the consecutive roots of generator polynomials is mainly analyzed because this method shows the best blind reconstruction performance. In order to derive a performance lower-bound, the theoretical analysis of BCH codes on the aspects of blind reconstruction is performed. Furthermore, the analysis results can be applied not only to the binary BCH codes but also to the non-binary BCH codes including Reed–Solomon (RS) codes. By comparing the derived lower-bound with the simulation results, it is confirmed that the success probability of the blind reconstruction of BCH codes based on the consecutive roots of generator polynomials is well bounded by the proposed lower-bound.
1. Introduction
In order to achieve reliable information transmission through noisy communication channels, the use of error-correcting codes (ECCs) in data-stream is indispensable [1]. By sharing the parameters of ECCs between the transmitter and the receiver, the errors occurred by communication channels can be detected or corrected at the receiver in a cooperative way. However, in a non-cooperative context, it is necessary to decode received (or intercepted) data without the knowledge of parameters of the used ECC. In other words, a blind reconstruction of the parameters of the used ECC should be performed by the receiver.
A blind reconstruction of ECCs has been studied in various ways [2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19]. The blind reconstruction schemes of linear block codes are studied in [2,3,4,5,6,7,8,9], the blind reconstruction schemes of Bose–Chaudhuri–Hocquenghem (BCH) codes are studied in [10,11,12,13,14,15], and the blind reconstruction schemes of convolutional codes are studied in [16,17,18,19]. Most of the blind reconstruction schemes of ECCs take the dual code approach to reconstruct the dual code space of the used code by using the received codewords. Valembois [2] proposed a detection and recognition algorithm for binary linear codes by using the dual code property and Cluzeau [3] proposed a blind reconstruction method based on iterative decoding techniques by using the dual code property. Moreover, most of the blind detection methods of BCH codes are also based on the dual code approach. By using the properties of BCH codes, their parity-check matrices can be constructed through applying Galois field Fourier transform (GFFT) on the received codewords and many of the blind reconstruction methods of BCH codes are based on GFFT [10,11,12,13,14,15]. In the same manner, most of the blind reconstruction methods of convolutional codes are also based on the dual code approach [16,17,18,19]. To reconstruct the generator polynomial or generator matrix of convolutional code, its dual code is recognized preferentially.
An analysis of the blind reconstruction of cyclic codes over binary erasure channel (BEC) is performed in [20]. Note that for BEC, the number and the locations of error bits in the received data-stream are known to the receiver. By using this property of BEC, a blind reconstruction scheme of binary cyclic codes is proposed and a lower-bound on the detection probability of this scheme is analyzed in [20]. However, many blind reconstruction schemes consider the binary symmetric channel (BSC) where the number and the locations of error bits in the received data-stream are not unavailable. Therefore, the analysis in [20] is not directly applicable to the blind reconstruction schemes considering the BSC.
In this paper, the blind reconstruction of BCH codes over q-ary symmetric channel is mainly considered because BCH codes are a most widely used class of cyclic codes, especially in communication and storage systems and q-ary symmetric channel is a general form of BSC. Especially, the method in [15] shows the best blind reconstruction performance among the existing blind reconstruction methods of BCH codes, but the theoretical analysis of this method has not been performed yet. Therefore, by analyzing the properties of BCH codes on the aspects of blind reconstruction, a lower-bound on the success probability of the blind reconstruction method in [15] is derived. More specifically, the distribution of GFFT values of the received codewords is analyzed and the blind reconstruction method is formulated by using the conjugacy classes. By comparing the derived lower-bound with the simulation results, it is confirmed that the success probability of the blind reconstruction is well lower-bounded. Furthermore, the analysis of BCH codes on the aspects of blind reconstruction may lay a foundation for an analysis of other blind reconstruction methods of BCH codes based on GFFT.
In Section 2, definitions and properties of BCH codes and GFFT are briefly explained. In Section 3, the theoretic analysis of the properties of BCH codes on the aspects of blind reconstruction is performed. In Section 4, the blind reconstruction method in [15] is explained, and a lower-bound on the success probability of this blind reconstruction method is derived. The simulation results confirm that the success probability of the blind reconstruction method is well-bounded by the derived lower-bound. In Section 5, conclusions are provided.
2. BCH Codes and Galois Field Fourier Transform
In this section, the BCH codes and the Galois field Fourier transform (GFFT) are briefly described.
2.1. BCH Codes
BCH codes is a class of linear block codes for forward error correction. Let denote the Galois field (or finite field) of q elements and let denote the BCH code with length n and dimension k over . Note that the dimension k is the same as the length of random message which also implies the number of codewords. Then, the generator polynomial of is defined as follows:
where denotes the least common multiple function, is a primitive n-th root of unity in , is a minimal polynomial of over , b is an arbitrary positive integer smaller than n, and d is a designed distance. Note that m is the smallest integer such that n divides . By the definition of generator polynomial , , , ⋯, are the roots of , i.e., . Let be the set of the exponents of all roots of as follows:
A message can be expressed in polynomial form as and in vector form as , where for . A codeword of can be expressed in polynomial form as and in vector form as , where for . Then, can be obtained as follows:
Since a codeword has as a factor, all roots of are also roots of , i.e., for all . In this paper, the q-ary symmetric channel with error probability is considered. Channel error can be expressed in polynomial form as and in vector form as , where for . Note that by the definition of q-ary symmetric channel, and for and where . Then, a received codeword at the receiver is expressed in polynomial form as
or in vector form as follows:
Throughout the paper, the polynomial form and the vector form will be used interchangeably.
If there is no error (i.e., ), for all because . However, if , we may have for some because it can be for some .
2.2. Conjugacy Classes and Cyclotomic Cosets
Let denote a conjugacy class of . Then, consists of and its conjugates , , , ⋯. Note that the conjugacy classes of the elements in the same conjugacy class are the same. The minimal polynomial of over , , can be obtained by using the conjugacy classes as follows:
The degree of is equal to , where is the cardinality of a set S. Note that since has all the elements in as its roots, in (1) has all the elements in , , ⋯, as its roots. Let denote the null spectrum of the which has the generator polynomial in (1). Then is obtained as follows:
in (2) is also expressed as the set of the exponents of the elements in such as . Then, the complement of , denoted by , is obtained as follows:
It is clear that where .
2.3. Galois Field Fourier Transform
The roots of a received codeword can also be obtained by performing the Galois field Fourier transform (GFFT) on . The GFFT of , denoted as , can be expressed in polynomial form as follows:
where for . It is also expressed in vector form as follows:
The GFFT matrix is defined as follows:
Then, the GFFT of is simply obtained by . By the definition of in (1), .
The GFFT of , denoted as , can be expressed in polynomial form as follows:
where for . The vector form of is expressed as follows:
By using in (11), the GFFT of is simply obtained by . In the error-free case (i.e., ), . However, if , we may have for some .
3. Theoretical Analysis of BCH Codes on the Aspects of Blind Reconstruction
3.1. GFFT of a Single Symbol Error
In this subsection, the GFFT values of a single symbol error is investigated. Let denote the Hamming weight of a vector , i.e., is the number of non-zero elements in . Note that a single symbol error satisfies .
Lemma 1.
If a received codeword of contains a single symbol error, then
Proof.
Let for some and . Since the GFFT value of with respect to is for all and for , for . □
Lemma 1 shows that if contains a single symbol error, any root of cannot be a root of . In the next subsection, the distribution of GFFT values of is analyzed.
3.2. GFFT of Codewords
Let denote the set of the GFFT values taken by all the codewords of for as follows:
Suppose that the minimal polynomial of a primitive n-th root of unity over has a degree where . Then, any can be expressed by a linear combination of as follows:
where for . Moreover, based on (18), any can be expressed in vector form, denoted as , as follows:
Note that is a row vector. Let be a matrix with , , ⋯, as its rows, and denote the rank of over .
Lemma 2.
Suppose that a message is generated uniformly at random, a codeword of is encoded by as in (3), and . Then, it is satisfied that
Proof.
First of all, for any , it is always true that due to the definition of . Therefore, and for any .
Second, in order to prove (21), let denote a matrix having all the codewords of as its rows. Then, the GFFT values of codewords can be expressed in vector form as follows:
where is a matrix with the vector forms of all GFFT values of codewords with respect to as its rows. Note that the rank of is k because all the rows of are the codewords of , and the rank of is by the definition. The matrix can be decomposed as where has all the elements of as its rows and is the generator matrix of . Note that the rank of , , is equal to . Since the size of is and , . The j-th row of is expressed as where is the j-th row of , . Since for and , are linearly independent, and , it is clear that is equal to . Therefore, the rank of is also equal to , which implies that there are distinct rows in and for any .
Lastly, in order to show (22), let be all distinct codewords such that for given i and . Also, let be all distinct codewords such that for the same i and . These relations can be expressed in matrix multiplication as follows:
where is the -st column of in (11). In order to show , it is enough to show . Without loss of generality, suppose that . From (24), we can obtain
Note that vectors are all distinct. By adding to each row of the first matrix in LHS of (26), we obtain
Note that vectors are still all distinct and they are valid codewords. According to (27), the number of codewords which have y as the GFFT value with respect to is , which is a contradiction to the assumption and hence . Therefore, if GFFT is performed on all the codewords of with respect to , all the elements of occur uniformly at random for the random message , which implies for any . □
By Lemma 2, it is clear that for and for takes a value from uniformly at random. In the next subsection, the distribution of GFFT values of is analyzed.
3.3. GFFT of Received Codewords
Consider a received codeword having a single symbol error, i.e., with . Let be the set of all GFFT values of a single symbol error with respect to as follows:
By using Lemma 2, the distribution of GFFT values of with a single symbol error is analyzed as follows.
Corollary 1.
Suppose that a message is generated uniformly at random, a codeword of is encoded by as (3), is a single symbol error, and . Then, it is satisfied that
Proof.
By Lemma 2, if , it is clear that for , which means that contains all the linear combinations of , , ⋯, over . Therefore, contains for any and (29) holds. □
Let be the set of all GFFT values of with a single symbol error with respect to as follows:
Lemma 3.
Suppose that a message is generated uniformly at random, a codeword of is encoded by as (3), is a single symbol error, and . Then, it is satisfied that
Proof.
Based on (30), can be expressed as follows:
As shown in Corollary 1, if is a single symbol error and , for any i∈. Therefore, is equal to for any .
The probability in (32) is derived as follows:
for and . The equality (a) holds by Lemma 2. □
Lemma 3 assumes , however, in practice, multiple errors also occur. If , Lemma 1 does not hold because can be 0 for some even though . Note that , , is equal to the undetectable error probability of the BCH code which has as its null spectrum.
Lemma 4.
Suppose that a message is generated uniformly at random, a codeword of is encoded by as (3), is generated by q-ary symmetric channel with error probability ϵ, and . Then, it is satisfied that
Proof.
For , contains all the linear combinations of , , ⋯, over . Since the error is not a single symbol error anymore, is defined as follows:
also contains all the linear combinations of , , ⋯, over and hence for any because .
The probability in (36) is derived as follows:
for and . □
As you can see from Lemmas 3 and 4, the conclusions (31) and (32) and (35) and (36) are the same. It implies that if the encoded message is generated uniformly at random, the GFFT of with respect to takes a value in uniformly at random regardless of the distribution of for . By Lemma 4, the probability that has as its root for is . Based on Lemma 4, the performance of blind reconstruction method of BCH codes [15] is analyzed in the next section.
4. Analysis of Blind Reconstruction Method of BCH Codes
4.1. Blind Reconstruction Method of BCH Codes
In this subsection, the blind reconstruction method of BCH codes based on consecutive roots of generator polynomials [15] is described. In order to perform this method, it is assumed that the codeword synchronization is perfectly done and the code length n is known to the receiver. Suppose that M codewords are received. The j-th received codeword is expressed in polynomial form as and in vector form as for . Let denote the set of pairs consisting of the length l of the consecutive roots and the starting value s of these consecutive roots of defined as follows:
where . For example, if is received, then the GFFT of is , and therefore . Note that and of the elements in . By using (39), for , the maximum length of consecutive roots (MLCR) and the corresponding starting value of consecutive roots (SVCR) are obtained as follows:
Let denote the set of for as follows:
The blind reconstruction method of BCH codes in [15] has two-stage processes.
- First stage: The most frequent in is selected and called a reference SVCR (R-SVCR), denoted as .
- Second stage: The most frequent among the pairs having in is selected and called a reference MLCR (R-MLCR), denoted as .
By setting and in (1), the generator polynomial of the used BCH code is reconstructed.
4.2. Performance Analysis of Blind Reconstruction Method of BCH Codes
In this subsection, the performance of blind reconstruction method in [15] is analyzed. Suppose that is used and M codewords are received. The generator polynomial is set as in (1) with and . In order to succeed in blind reconstruction of this BCH code, and should be correctly determined as and . Define the sets of received codewords, , , , and as follows:
Note that . In order to succeed in the first stage of the blind reconstruction method, the following relation should be satisfied,
The relation (46) can be simplified as in the following Lemma 5.
Lemma 5.
If the following inequality is satisfied, then the first stage of the blind reconstruction of BCH codes in [15] always succeeds,
and the success probability of the first stage is lower-bounded as
Proof.
In order to succeed in the first stage of the blind reconstruction method in [15], the relation (46) should be satisfied. The LHS in (46) satisfies the following inequalities,
The first inequality (a) is derived by using , and the second inequality (b) is trivial. The RHS in (46) satisfies the following inequality,
The first equality (a) in (50) is derived by using for all . The second inequality (b) is derived by using . The third equality (c) is derived by using for all .
If the first stage succeeds, in order for the second stage to succeed, the following relation should be satisfied,
The relation (51) can be simplified as in the following Lemma 6.
Lemma 6.
If , holds and the following inequality is satisfied, then the second stage of the blind reconstruction of BCH codes in [15] always succeeds,
and the success probability of the second stage is lower-bounded as
where, for better readability, the given condition that , is omitted in the probability.
Proof.
Since for any , holds for as follows:
The inequality (a) in (54) is derived by using . The inequality (b) is derived by using for and . The inequality (c) is derived by using . Therefore, it remains to prove that our assumption implies for .
If the j-th received codeword is error-free (i.e., ), then for all because always holds. Therefore, for , and then, the relation (51) can be simplified as for . Since it is always satisfied that , if for , the second stage succeeds. Furthermore, since for , if is satisfied, then the second stage also succeeds. Note that the LHS in (51) satisfies that . Therefore, if is satisfied, then the second stage always succeeds.
The lower-bound on the success probability of the second stage is derived as follows:
Note that, for better readability, the given condition that , is omitted in the probability. □
By Lemmas 5 and 6, if and , then the blind reconstruction method of BCH code in [15] always succeeds. Moreover, the success probability of the blind reconstruction method of BCH code in [15] is lower-bounded, as in the following Theorem 1.
Theorem 1.
Suppose that randomly generated M codewords of , which uses the generator polynomial as in (1) with and , are received after passing through q-ary symmetric channel with error probability ϵ. Then, the success probability of the blind reconstruction method of BCH codes in [15], denoted as , is lower-bounded as follows:
where , , , and is the undetectable error probability of BCH code having as its null spectrum.
Proof.
By Lemmas 5 and 6, if and , then the blind reconstruction of BCH codes in [15] always succeeds. In order to calculate the probability that and , the probabilities that , , and should be calculated, respectively.
If the j-th received codeword is error-free or has an undetectable error, it is always true that . Furthermore, if for , it is also true that , where . Then, is derived as follows:
where is the undetectable error probability of BCH code having as its null spectrum. In the equality (a) in (57), for occurs uniformly at random because the message is generated uniformly at random. Therefore, the event that for any and the event that for any are independent and hence the equality (a) holds. The equality (b) is derived by using and Lemma 4.
The probability that for is calculated by using Lemma 4 as follows:
For better readability, is omitted in the probability.
Let be and be . If is greater than for any and also greater than for any , it is also satisfied that for any . It is because if there exists such that , it is true that due to for any . Furthermore, if there exists such that , then it is also true that due to for any . Then, the condition for the success of the first stage of blind reconstruction method is simplified as follows:
Moreover, for is simplified as follows:
The equality (a) is derived by using (58) and (b) is derived by using and . Furthermore, for , is also simplified as follows:
The equality (a) is derived by using and
The probability that is the same as the undetectable error probability of a BCH code having as its null spectrum as follows:
If for , then the second stage of the blind reconstruction method succeeds. Therefore, for .
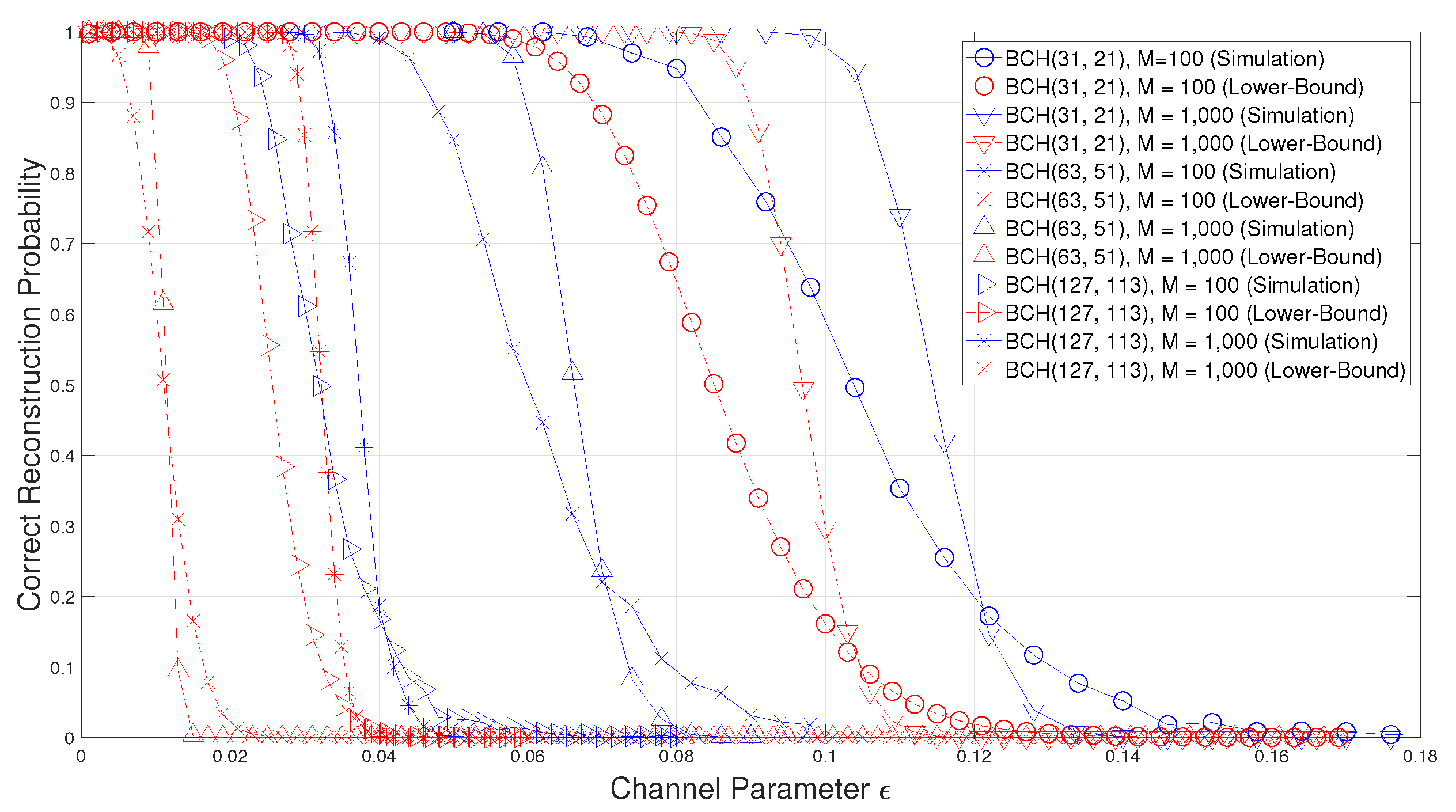
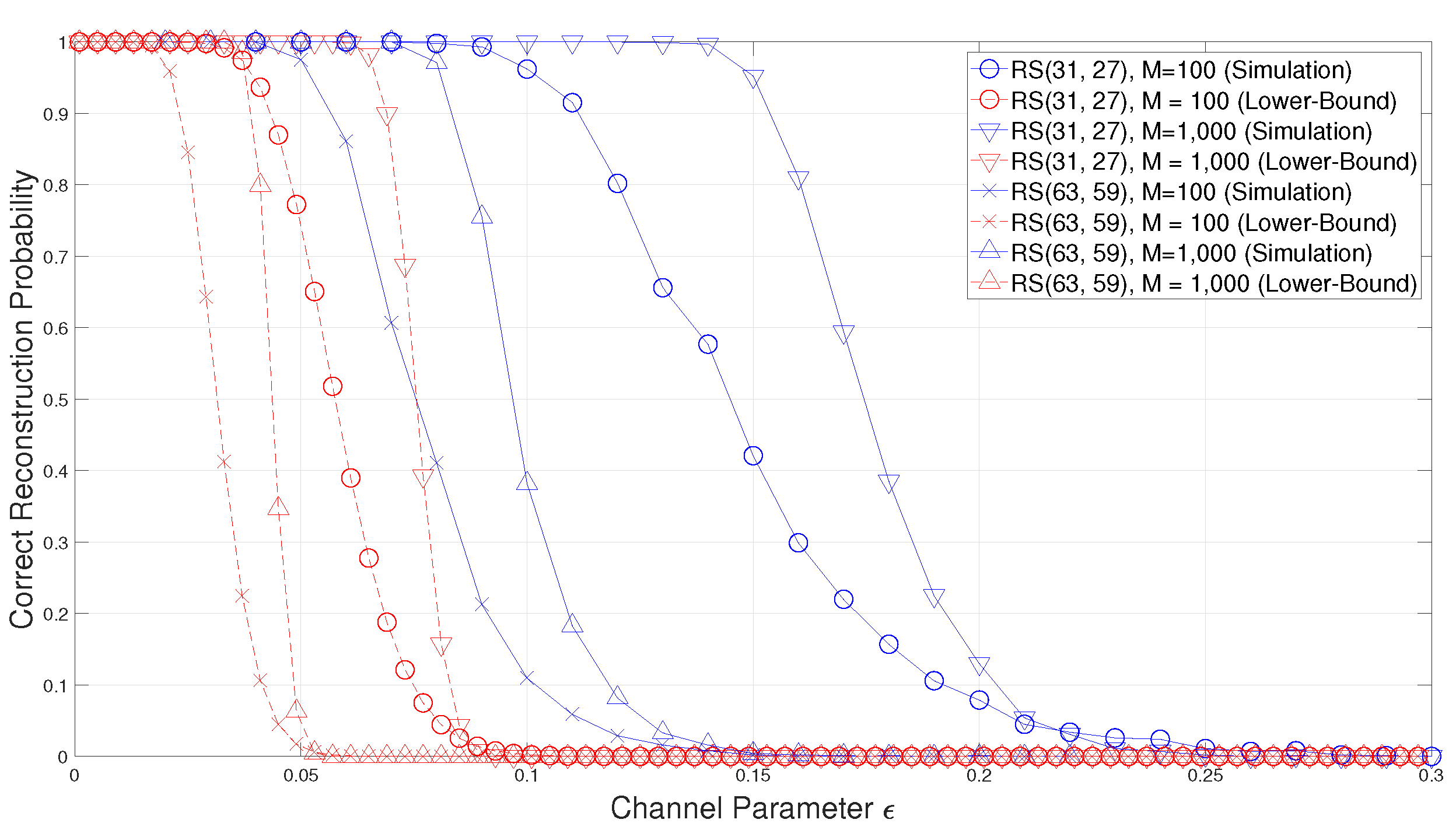
In Theorem 1, a lower-bound on the success probability of the blind reconstruction method of BCH codes in [15] is obtained. In order to confirm the validity of this lower-bound, simulations are performed by using the following BCH codes.
- , , : These are binary BCH codes having as their null spectrum.
- , : These are Reed–Solomon (RS) codes having as their null spectrum.
As you can see from Figure 1, the success probability of the blind reconstruction of binary BCH codes is well bounded by the lower-bound in (56). However, for , the gap between the simulation result and the lower-bound is larger than the others because has a cyclotomic coset of cardinality 2, while all the cyclotomic cosets of and have the cardinality 5 and 7, respectively. In (56), if a cyclotomic coset has small cardinality, becomes bigger and then, becomes smaller. Therefore, the lower-bounds of the blind reconstruction performance of and is much tighter than .
As you can see from Figure 2, the success probability of the blind reconstruction of RS codes is also well bounded by the lower-bound in (56). Moreover, as the code length increase, the proposed lower-bound of RS codes becomes tighter and therefore this lower-bound can be a good estimation of blind reconstruction performance for practical RS codes. Furthermore, since the proposed lower-bound can estimate the blind reconstruction performance without the extensive simulation, the proposed lower-bound is suitable for practical use.
5. Conclusions
The blind reconstruction method of BCH codes in [15] shows the best performance, but the theoretical analysis of this method has not been performed. In this paper, by analyzing the properties of BCH codes on the aspects of blind reconstruction, a lower-bound on the success probability of the blind reconstruction method in [15] is derived. Especially, the distribution of GFFT values of the received codewords are analyzed and the blind reconstruction method is formalized based on the conjugacy classes. Furthermore, the analysis results can be applied not only to the binary BCH codes, but also to the non-binary BCH codes, including RS codes. By comparing the derived lower-bound with the simulation results, it is confirmed that the success probability of the blind reconstruction is well bounded by the proposed lower-bound.
Author Contributions
S.K. and D.-J.S. developed the main idea, conducted simulations and wrote the manuscript. S.K. played a leading role in the analysis and simulation and D.-J.S. played a leading role in fixing research direction and procedures. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the research fund of Signal Intelligence Research Center supervised by Defense Acquisition Program Administration and Agency for Defense Development of Korea.
Conflicts of Interest
The authors declare no conflict of interest. The founding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
References
- Wicker, S. Error control coding for digital communication systems In Error Control Systems for Digital Communication and Storage; Prentice-Hall: Englewood Cliffs, NJ, USA, 1995; pp. 1–16. [Google Scholar]
- Valembois, A. Detection and recognition of a binary linear code. Discret. Appl. Math. 2001, 111, 199–218. [Google Scholar] [CrossRef]
- Cluzeau, M. Block code reconstruction using iterative decoding techniques. In Proceedings of the 2006 IEEE International Symposium on Information Theory (ISIT 2006), Seattle, DC, USA, 9–14 July 2006; pp. 2269–2273. [Google Scholar]
- Burel, G.; Gautier, R. Blind estimation of encoder and interleaver characteristics in a non cooperative context. In Proceedings of the IASTED International Conference on Communications, Internet and Information Technology (CIIT 2003), Scottsdale, AZ, USA, 17–19 November 2003. [Google Scholar]
- Moosavi, R.; Larsson, E. Fast blind recognition of channel codes. IEEE Trans. Commun. 2014, 62, 1393–1405. [Google Scholar] [CrossRef] [Green Version]
- Chabot, C. Recognition of a code in a noisy environment. In Proceedings of the 2007 IEEE International Symposium on Information Theory (ISIT 2007), Nice, France, 24–29 June 2007; pp. 2211–2215. [Google Scholar]
- Yardi, A.; Kumar, A.; Vijayakumaran, S. Channel-code detection by a third-party receiver via the likelihood ratio test. In Proceedings of the 2014 IEEE International Symposium on Information Theory (ISIT 2014), Honolulu, HI, USA, 24 June–4 July 2014; pp. 1051–1055. [Google Scholar]
- Yardi, A.; Vijayakumaran, S.; Kumar, A. Blind reconstruction of binary cyclic codes. In Proceedings of the 20th European Wireless Conference, Barcelona, Spain, 14–16 May 2014; pp. 849–854. [Google Scholar]
- Yardi, A.; Vijayakumaran, S.; Kumar, A. Blind reconstruction of binary cyclic codes from unsynchronized bitstream. IEEE Trans. Commun. 2016, 64, 2693–2706. [Google Scholar] [CrossRef]
- Wu, G.; Zhang, B.; Wen, X.; Guo, D. Blind recognition of BCH code based on Galois field Fourier transform. In Proceedings of the 2015 International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 15–17 October 2015; pp. 1–4. [Google Scholar]
- Wang, J.; Yue, Y.; Yao, J. Statistical recognition method of binary BCH code. Commun. Netw. 2011, 3, 17–22. [Google Scholar] [CrossRef] [Green Version]
- Jing, Z.; Zhiping, H. Blind recognition of binary BCH codes for cognitive radios. Math. Probl. Eng. 2016, 2016, 1–6. [Google Scholar]
- Lee, H.; Park, C.; Lee, J.; Song, Y. Reconstruction of BCH codes using probability compensation. In Proceedings of the 18th Asia-Pacific Conference on Communications (APCC), Jeju, Korea, 15–17 October 2012; pp. 591–594. [Google Scholar]
- Li, C.; Zhang, T.; Lin, Y. Blind recognition of RS codes based on Galois field columns Gaussian elimination. In Proceedings of the 7th International Congress on Image and Signal Processing, Dalian, China, 14–16 October 2014; pp. 836–841. [Google Scholar]
- Jo, D.; Kwon, S.; Shin, D. Blind reconstruction of BCH codes based on consecutive roots of generator polynomials. IEEE Commun. Lett. 2018, 22, 894–897. [Google Scholar] [CrossRef]
- Filiol, E. Reconstruction of convolutional encoders over GF(q). In IMA International Conference on Cryptography and Coding; Springer: Berlin/Heidelberg, Germany, 1997; Volume 1355, pp. 101–109. [Google Scholar] [CrossRef]
- Lu, P.; Li, S.; Luo, X.; Zou, Y. Blind recognition of punctured convolutional codes. In Proceedings of the 2004 International Symposium on Information Theory (ISIT 2004), Chicago, IL, USA, 27 June–2 July 2004; p. 457. [Google Scholar]
- Barbier, J. Reconstruction of turbo-code encoder. In Digital Wireless Communications VII and Space Communication Technologies; International Society for Optics and Photonics: Bellingham, WA, USA, 2005; pp. 463–473. [Google Scholar]
- Marazin, M.; Gautier, R.; Burel, G. Blind recovery of k/n rate convolutional encoders in a noisy environment. EURASIP J. Wirel. Commun. Netw. 2011, 2011, 1–9. [Google Scholar] [CrossRef]
- Yardi, A. Blind reconstruction of binary cyclic codes over binary erasure channel. In Proceedings of the 2018 International Symposium on Information Theory and Its Applications (ISITA), Singapore, 28–31 October 2018; pp. 301–305. [Google Scholar]
Figure 1.
Comparison of the correct reconstruction probability with the proposed lower-bound for binary Bose–Chaudhuri–Hocquenghem (BCH) codes.
Figure 1.
Comparison of the correct reconstruction probability with the proposed lower-bound for binary Bose–Chaudhuri–Hocquenghem (BCH) codes.

Figure 2.
Comparison of the correct reconstruction probability with the proposed lower-bound for Reed–Solomon (RS) codes.
Figure 2.
Comparison of the correct reconstruction probability with the proposed lower-bound for Reed–Solomon (RS) codes.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Kwon, S.; Shin, D.-J. Analysis of Blind Reconstruction of BCH Codes. Entropy 2020, 22, 1256. https://doi.org/10.3390/e22111256
AMA Style
Kwon S, Shin D-J. Analysis of Blind Reconstruction of BCH Codes. Entropy. 2020; 22(11):1256. https://doi.org/10.3390/e22111256
Chicago/Turabian StyleKwon, Soonhee, and Dong-Joon Shin. 2020. "Analysis of Blind Reconstruction of BCH Codes" Entropy 22, no. 11: 1256. https://doi.org/10.3390/e22111256
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.