Reduction of Markov Chains Using a Value-of-Information-Based Approach



1
Advanced Signal Processing and Automated Target Recognition Branch, US Naval Surface Warfare Center—Panama City Division, Panama City, FL 32407, USA
2
Department of Electrical and Computer Engineering, University of Florida, Gainesville, FL 32611, USA
3
Department of Biomedical Engineering, University of Florida, Gainesville, FL 32611, USA
4
Computational NeuroEngineering Laboratory (CNEL), University of Florida, Gainesville, FL 32611, USA
*
Author to whom correspondence should be addressed.
Entropy 2019, 21(4), 349; https://doi.org/10.3390/e21040349
Submission received: 18 February 2019
/
Revised: 24 March 2019
/
Accepted: 25 March 2019
/
Published: 30 March 2019
(This article belongs to the Special Issue Information Theoretic Learning and Kernel Methods)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:In this paper, we propose an approach to obtain reduced-order models of Markov chains. Our approach is composed of two information-theoretic processes. The first is a means of comparing pairs of stationary chains on different state spaces, which is done via the negative, modified Kullback–Leibler divergence defined on a model joint space. Model reduction is achieved by solving a value-of-information criterion with respect to this divergence. Optimizing the criterion leads to a probabilistic partitioning of the states in the high-order Markov chain. A single free parameter that emerges through the optimization process dictates both the partition uncertainty and the number of state groups. We provide a data-driven means of choosing the ‘optimal’ value of this free parameter, which sidesteps needing to a priori know the number of state groups in an arbitrary chain.
1. Introduction
Markov models have seen a widespread adoption in a variety of disciplines. Part of their appeal is that the application and simulation of such models is rather efficient, provided that the corresponding state space has a small to moderate size. Dealing with large state spaces is often troublesome, in comparison, as it may not be possible to adequately simulate the underlying models. Such large-scale spaces are frequently encountered in reinforcement learning, for instance [1,2,3,4,5].
A means of rendering the simulation of large-scale models tractable is crucial for many applications. One way of doing this is to reduce the overall size of the Markov-chain state space by aggregation [6]. Aggregation entails either explicitly or implicitly defining and utilizing a function to partition nodes in the probability transition graph associated with the large-scale chain. Groups of nodes, which are related by the their inter-state transition probabilities and have strong interactions, are combined and treated as a single aggregated node in a new graph. This results in a lower-order chain with a reduced state space. A stochastic matrix for the lower-order chain is then specified, which describes the transitions from one super-state to another. This stochastic matrix should roughly mimic the dynamics of the original chain despite the potential loss in information incurred from the state combination.
There are a variety of methods for aggregating Markov chains, as we discuss shortly. In this paper, we develop and analyze a novel approach for aggregating Markov chains, which is composed of two information-theoretic processes [7]. The first process entails quantifying the dissimilarity of nodes in the original and reduced-order probability transition graphs, despite the difference in state space sizes. The second process involves iteratively partitioning similar nodes without explicit knowledge of the number of groups.
For the first process, we adopt the reasonable view that nodes in a pair of chains are dissimilar if their associated rows of the stochastic matrix are sufficiently distinct. We employ an information-theoretic measure, the negative, modified Kullback–Leibler divergence [8], , to gauge distinctiveness and hence identify candidate nodes in the original chain for aggregation. Here, and are stochastic matrices associated with two Markov chains, while is the stationary distribution associated with the first chain. This divergence assesses the overlap between probability distributions. It coincides with the Donsker–Varadhan rate function appearing in the large-deviations theory of Markov chains [9,10] and measures the ‘distance’ between two Markov chains defined on the same discrete state space.
In the aggregation process that we consider, a reduced-order stochastic matrix is constructed on a discrete state space of a different size than that of the stochastic matrix associated with the original chain. To facilitate assessing the negative, modified Kullback–Leibler divergence between the original and reduced-order models, we construct a so-called joint model that incorporates details from both models. This model encodes the salient properties of the lower-order transition matrix. Its corresponding stochastic matrix , is of the proper dimensionality to compare against rows of the original transition matrix; will be specified by , where is a partition matrix. A byproduct of using this joint model is that we can sidestep considering all possible liftings of the reduced-order models to the original space by averaging their dynamics according to a given distribution [11,12]. Our approach therefore avoids having to solve an additional optimization problem, which is a boon when aggregating chains with large state spaces.
The problem of finding an aggregated Markov chain that captures much of the dynamics in the original chain can be posed as a cost function that uses the above divergence. For the second process, we consider the use of an information-theoretic criterion known as the value of information [13,14,15] to efficiently segment the probability transition graph. It proves a partition matrix as the optimal solution of minimizing with respect to , where is a marginal probability and is a hyperparameter. This criterion is a constrained, modified free-energy difference that describes the maximum benefit associated with a given quantity of information in order to minimize average losses [16,17]. It is an optimal, non-linear conversion between information, , in the Shannon sense [18], and either costs or utilities, , in the sense of von Neumann and Morgenstern [19].
In the context of aggregating Markov chains, the value of information describes the change in the distortion between the high-order and low-order transition models that occurs from potentially modifying the number of state groups and elements of those groups. The number of groups is implicitly determined by the bounded information that a given row of the original chain’s transition matrix shares with a corresponding row of the reduced-order chain’s transition matrix. Low information bounds lead to small numbers of groups with many states per group. A potentially good qualitative partitioning is often observed in such cases, as the reduced-order chain is parsimonious. Higher information bounds can lead to large numbers of groups with fewer states per group. The partitioning of the original chain can be over-complete, as related states may be unnecessarily split to yield a lower free energy.
Directly optimizing the value of information via a gradient-based approach yields a pair of updates that are iterated in an alternating manner. The first update, , revises the marginal probability. The second update makes use of the marginal probability to adjust the partition matrix using a modified Gibbs distribution , where the division is element-wise. The stochastic matrix associated with the joint model is also changed as a part of the second update equation.
The second update relies on the hyperparameter , which captures the effect of the information bound. Increasing from some base value yields a hierarchy of partitions. Each element of this hierarchy corresponds to a partition with an increasing information bound amount and hence a potentially increasing number of state groups. Finer-scale group structure in the transition matrix is captured as rises. After some value, however, there are diminishing returns on the quality of the aggregation results. Determining the “optimal” value, in a completely data-driven fashion, is hence crucial. To find such values for arbitrary Markov chains, we apply perturbation theory. In particular, we calculate the underestimation error of the information constraint in the value of information that occurs when considering finite-state chains. We then augment the value-of-information criterion by subtracting out this overestimation. Finally, we determine a lower bound for that minimizes the underestimation error. The corresponding aggregation process empirically avoids fitting more to the noise than the structure in the stochastic matrix of the high-order model.
As a part of our treatment of the value of information, we furnish convergence and convergence-rate proofs to demonstrate the optimality of the criterion for the aggregation problem.
The remainder of this paper is organized as follows. We begin, in Section 2, with a survey of aggregation techniques for Markov chains. Our approach is given in Section 3. In Section 3.1, we introduce our notation and some fundamental concepts for binary-partition-based aggregation. In Section 3.1.1, we introduce the concept of a joint model so that the differently sized transition matrices of the original and reduced-order chains can be compared. We outline, in Section 3.1.2, how this joint model facilitates the formulation of an minimum-dissimilarity aggregation optimization problem. Properties of this problem are analyzed for general divergence measures. At the end of Section 3.1.2, we discuss practical issues associated with this initial optimization problem, which motivates the use of the value of information. We show, in Section 3.2.1 and Section 3.2.2, how this information-theoretic criterion can be applied to probabilistically partition transition matrices. We also cover how the criterion can be efficiently solved, how to construct the reduced-order transition matrices after partitioning, and how to bound the free parameter that emerges from optimizing this information-theoretic criterion. Lastly, in Section 3.2.3, we furnish a bound on the expected criterion performance. In Section 4, we assess the empirical capabilities of the value of information for Markov chain aggregation. We begin by covering our experimental protocols in Section 4.1. In Section 4.2, we present our simulation results for series of synthetic datasets. We first assess the performance of our value-of-information-based reduction for multiplier values that are either manually selected or chosen in a perturbation-theoretic manner. We also comment on the convergence properties. The appropriateness of the Shannon information constraint over an entropy constraint is additionally investigated in these Sections. Discussions of these results are given at the end of this Section. We summarize these findings in the broader context of our theoretical results in Section 5. Additionally, we outline directions for future research. Appendix A contains all of our proofs.
2. Literature Review
A variety of Markov model aggregation techniques have been proposed over the years. Some of the earliest work exploited the strong–weak interaction structure of nearly completely decomposable Markov chains to obtain reduced-order approximations [20,21]. Both uncontrolled [22,23] and controlled Markov chains [24,25,26] have been extensively studied in the literature.
The aggregation of nearly completely decomposable Markov chains has been investigated by Courtois [27] and other researchers [28,29,30]. Courtois developed an aggregation procedure that yields an approximation of the steady-state probability distribution with respect to a parameter that represents the weak interaction between state groups. This process was later augmented to provide more accurate approximations [31]. It was also combined with various iterative schemes, like the Gauss–Seidel method, to improve the speed of convergence [32,33,34,35]. Years later, Phillips and Kokotovic presented a singular perturbation interpretation of Courtois’ aggregation approach [36]. They developed a similarity transformation that converts the system into a singularly perturbed form, whose slow model coincides with the aggregated matrix found by Courtois’ approach. The use of singular perturbation has also been considered by other researchers [37,38,39].
There are additional approaches that have been developed. A few are worth noting here, as they resemble our contributions in various ways [11,12,40,41,42,43]. For example, Deng and Huang [41] used the Kullback–Leibler divergence as a cost function to obtain a low-rank approximation of the original transition matrix via nuclear-norm regularization. This preserved the cardinality of the state space. Here, we employ the negative, modified Kullback–Leibler divergence as a means of measuring the change in the original and modified chains. We, however, consider a modified chain that is of a reduced order, not the same order. This change should provide more tangible benefits for the simulation of large-scale systems.
Another scheme that is related to ours is that of Vidyasagar [43]. Vidyasagar investigated an information-theoretic metric, the variation of information, between distributions on sets with different cardinalities. Actually computing the metric that he proposed turns out to be computationally intractable for large-scale systems, though. He therefore considered an efficient greedy approximation for finding an upper bound of the distance and studied its use for optimal order reduction. He demonstrated that the optimal reduced-order distribution of a set of a particular cardinality is obtained by projecting the original distribution. That is, the reduced-order distribution should have maximal entropy. This condition is equivalent to requiring that the partition function induces the minimum information loss. In our work, the metric that we consider is tractable for different-cardinality sets. The partitioning process is not, however, which motivates the use of the value of information for efficiently finding approximate partitions. An advantage of using the value of information is that it directly minimizes the information loss, as it relies on a Shannon information constraint that quantifies the mutual dependence of the high-order and low-order chain states.
In [11,12,40], Deng et al. and Geiger et al. developed two-step, information-theoretic approaches for Markov chain aggregation. In the first step, the optimal model reduction problem is solved on the reduced space defined by a fixed partition function. In the second step, Deng et al. [11,40] select an optimal partition function according to a non-convex relaxation of the bi-partition problem, while Geiger et al. [12] find an approximate partition using the information-bottleneck method. In both works, the distortion between the original and reduced-order models was assessed via Kullback–Leibler divergence. The authors defined an optimization-based lifting procedure so that both chains would have the same cardinality. The lifting employed by Geiger et al. incorporates one-step transition probabilities of the original chain, which minimizes information loss. They obtained a tight bound for lumpable chains. This lifting employed by Deng et al. was based only on the stationary distribution of the original chain, which maximizes the redundancy of the aggregated Markov chain. Here, we consider the formation of a joint model based on a similar approach to Deng et al.: we form a probabilistically weighted average of the entries from the original stochastic matrix. However, our formulation of this joint model occurs in a more natural manner; see Definitions 4 and 7 for the details.
In [11,40], Deng et al. note that their optimization problem for partitioning state space of the Markov chains is both non-linear and non-convex. Instead of attempting to solve this problem for a general number of state groups, they focused on addressing the simpler bi-partition problem. In contrast, our formulation of the state-partition process using the value of information is convex. For the case of discrete state spaces, we derive expectation-maximization-like updates for efficiently uncovering partitions with arbitrary numbers of groups; see Proposition 1. These updates converge at a linear rate; we refer to Propositions 2 and 3 for details about the iterative error decrease and appeal to the Picard-iteration theory of Zangwill to establish convergence.
There are other topical differences between these approaches. For example, Geiger et al. [12], through the use of the information bottleneck, attempt to compress the original-model states into reduced-model states, in a lossy way, while keeping as much information about the original transition probabilities as possible. Optimizing the value of information achieves a similar effect, albeit in a different manner. It limits the information lost during quantization by both bounding the divergence between the original and reduced-order models and simultaneously maximizing the mutual dependence between the states in both models. Despite this similar effect, the value of information has practical advantages. We prove that the dynamical system underlying the partitioning process undergoes phase changes, for certain values of the criterion’s single free-parameter, where a new state-group emerges in the reduced-order model. Between critical values of the free parameter, no phase changes occur, which implies that only a finite number of distinct values must be considered; refer to Proposition 3 for the details. For the information bottleneck, investigators would have to sweep over many parameter values, often far more than we consider, and repeatedly solve the aggregation problem. Using an information-bottleneck scheme can hence be computationally prohibitive for large-scale Markov chains.
We further enhance the practicality of the value of information by deriving an expression for the “optimal” free-parameter value; see Proposition 4 the details. This value performs a second-order minimization of the estimation error associated with the Shannon-information term in the value of information. Empirically, using this value causes the partitioning process to fit more to the structure of well-defined state groups in the original model than outlier states. It also tends to yield parsimonious partitions that quantize the state space neither too much nor to little.
Our motivation for considering the value of information arose from our use of this criterion in reinforcement learning. We have previously applied this criterion, in [13,14,15], for resolving the exploration-exploitation dilemma in Markov-decision-process-based reinforcement learning. In our experiments on a variety of complicated application domains, we found that the value of information would consistently outperform existing search heuristics. We originally attributed this improved learning rate solely to a systematic partitioning of the state space. That is, groups of states would be partitioned, according to their action-value function magnitude, and assigned the same action. The problem of determining an action that works well for an entire group of related states is easier than doing the same for each state individually. However, it is our hypothesis that there is an aggregation of the Markov chains underlying the Markov decision processes. The aggregation theory developed in this paper represents a necessary first step to showing that the criterion can perform reinforcement learning on a simpler Markov decision process whose dynamics roughly mirror those of the original problem.
We are not the first to consider the aggregation of Markov chains that appear in Markov-decision-process-based reinforcement learning, though [1,2,3,4,5]. Aldhaheri and Khalil [2] focused on the optimal control of nearly completely decomposable Markov chains. They adapted Howard’s policy-iteration algorithm to work on an aggregated model. They showed that they could provide optimal control that minimizes the average cost over an infinite horizon. Sun et al. [4] employed time aggregation to reduce the state space for complicated Markov decision processes. They divided the original process into segments, by certain states, to form an embedded Markov decision process. Value iteration is then executed on this lower-order model. In [5], Jia provided a polynomial-time means of aggregating states of a Markov decision process when the optimal value function is known. For approximate value functions, he showed how to apply ordinal optimization to uncover a good state reduction with a high probability of being the correct aggregation. A commonality of these works is that they are model-based: they assume that the transition probabilities are explicitly known. Our previous work [14,15], however, focused on model-free learning, where these probabilities are not available a priori. Model reduction should therefore occur implicitly during the exploration process if the concepts we develop as part of our aggregation theory extend to Markov decision processes.
3. Methodology
Our approach for aggregating Markov chains can be described as follows. Given a stochastic matrix of transition probabilities between states, we seek to partition this matrix to produce a reduced-size matrix which we refer to as an aggregated stochastic matrix. The aggregated stochastic matrix has an equivalent graph-based interpretation, as it characterizes the edge weights of an undirected graph. The vertices in this matrix correspond to states of a reduced-order chain. There is a one-to-many mapping of a vertex from the aggregated stochastic matrix to the vertices of the original transition-matrix graph for the high-order chain. Edges of the aggregated stochastic matrix codify the transition probability between pairs of states in the low-order model.
There are many possible aggregated stochastic matrices that can be formed for a given Markov chain. We would like to find a matrix that yields the least total distortion for some measure, particularly the negative, modified Kullback–Leibler divergence, since it is viewed as a measure of change between Markov chains with many beneficial properties [8]. Due to the different sizes of the original transition matrix and the aggregated stochastic matrix, though, directly applying this divergence is not possible. While we could re-define the Kullback–Leibler divergence for probability vectors with different cardinalities, we have opted to instead transform the aggregated stochastic matrices so that they are of the same size as the original transition matrix. We specify how to construct a so-called joint model that encodes all of the dynamics of the reduced-order chain. We provide a straightforward objective function for constructing a binary partition of the original transition matrix to uncover the optimal aggregated stochastic matrix.
The objective function that we specify leads to another issue: finding the optimal aggregated stochastic matrix is not trivial due to the binary-valuedness of the one-to-many mappings. It can quickly become computationally intractable as the size of the state space rises. To make our aggregation approach more computationally efficient, we relax the binary assumption by considering an alternate objective function, which is based on the value of information. Optimization of the value of information yields a probabilistic partitioning process for finding the aggregated stochastic matrix in a subspace. A single parameter associated with this function dictates both the uniformity of the probabilistic partitions and the number of state groups that emerge. In the limit of the parameter value, the solution of the value of information approaches the global solutions of the original objective function. A hierarchy of possible partitions, each with a different number of groups, is produced for other parameter values; these are approximate solutions of the binary-partition-based objective function.
Much of our notation for the theory that follows is summarized in Nomenclature at the end of the paper.
3.1. Aggregating Markov Chains
3.1.1. Preliminaries
For our approach, we consider a first-order, homogeneous Markov chain defined on a finite state space. Our analyses of such chains focus on graph-based transition abstractions.
Definition 1.
The transition model of a first-order, homogeneous Markov chain is a weighted, directed graph given by the three-tuple with the following elements
- (i)
- A set of n vertices representing the states of the Markov chain.
- (ii)
- A set of edge connections between reachable states in the Markov chain.
- (iii)
- A stochastic transition matrix . Here, represents the non-negative transition probability between states i and j. We impose the constraint that the probability of experiencing a state transition is independent of time.
The subscripts on the vertices and edges represent the dependence on the matrix Π.
Throughout, we assume that all Markov chains are irreducible and aperiodic. As a consequence, there is a unique invariant probability distribution associated with the chain such that . We will sometimes write this distribution as to denote to which matrix the distribution is associated.
We are interested in comparing pairs of Markov chains. A means to do this is by considering given rows of the stochastic transition matrix. We represent the ith row of by . is a probability vector describing the chance of transitioning from state to any possible next states. We assume that if and only if there is no directed edge from state to state and hence no chance of transitioning between the corresponding states. Note that it does not make sense to quantify the distortion between columns of the stochastic matrices, since they are not guaranteed to be state-transition probabilities.
If a pair of transition models for different Markov chains, and , have the same number of states, then they can be compared according to a measure acting on and . Here, we take this measure to be the negative, modified Kullback–Leibler divergence; the theory that follows is applicable to many general divergence measures, though.
Definition 2.
Let and be transition models of two Markov chains over n states. The negative, modified relative entropy, or negative, modified Kullback–Leibler divergence, between a given set of states for these two chains is a function given by , where γ is the invariant probability distribution associated with . The divergence rate is finite provided that Π is absolutely continuous with respect to Φ.
The modified Kullback–Leibler divergence that we consider includes a term for the stationary distribution of the Markov chain, which is not present in the standard definition of the Kullback–Leibler divergence. This is the relative entropy between two time-invariant Markov sources, as defined by Rached et al. [8], which admits a closed-form expression. Note that much like in the standard definition of Kullback–Leibler divergence, division by zero can occur for this modified divergence. This event is largely avoided for our problem, though, since the density in the subspace should be broader than that in the original space.
Since we are considering the problem of chain aggregation, the state spaces will be different. One chain will have n states while another will have m states, with . The dimensionalities of given rows in the corresponding transition matrices will hence not be equivalent, which precludes a direct comparison using conventional measures.
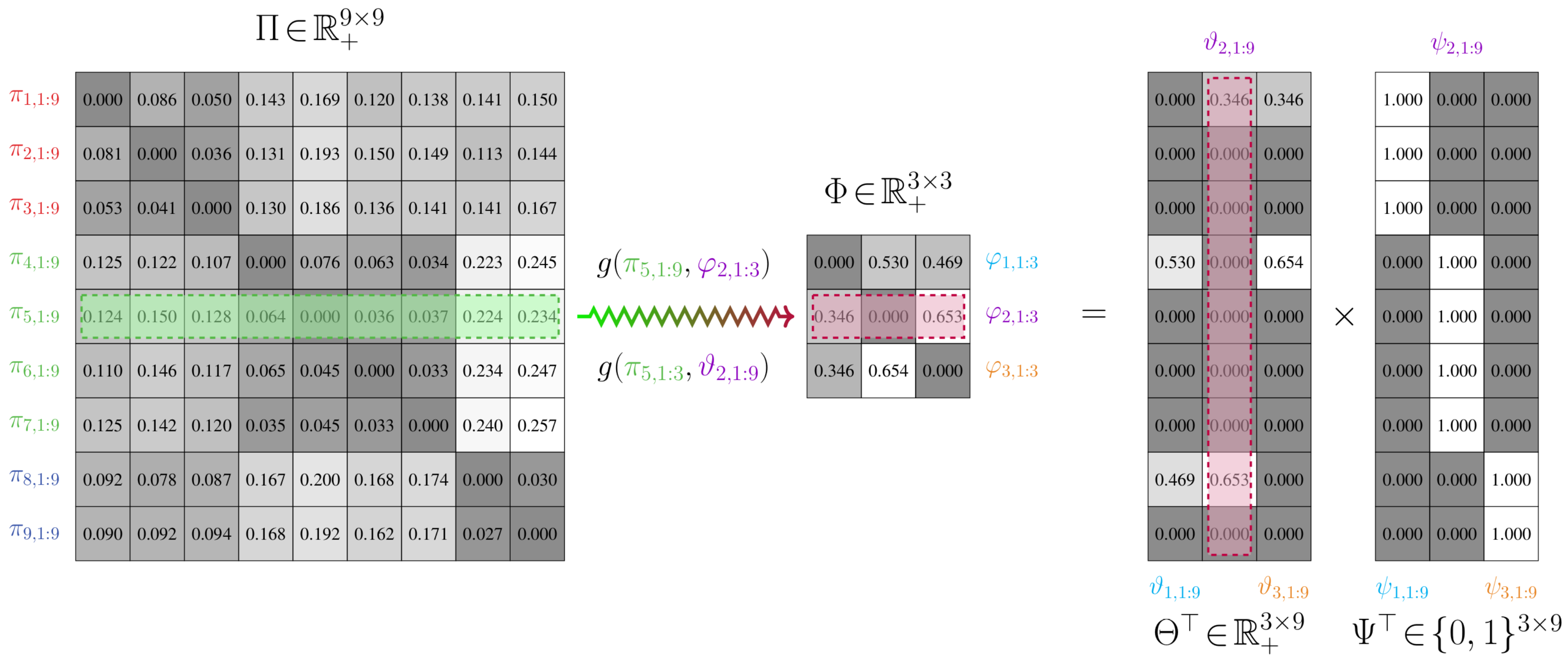
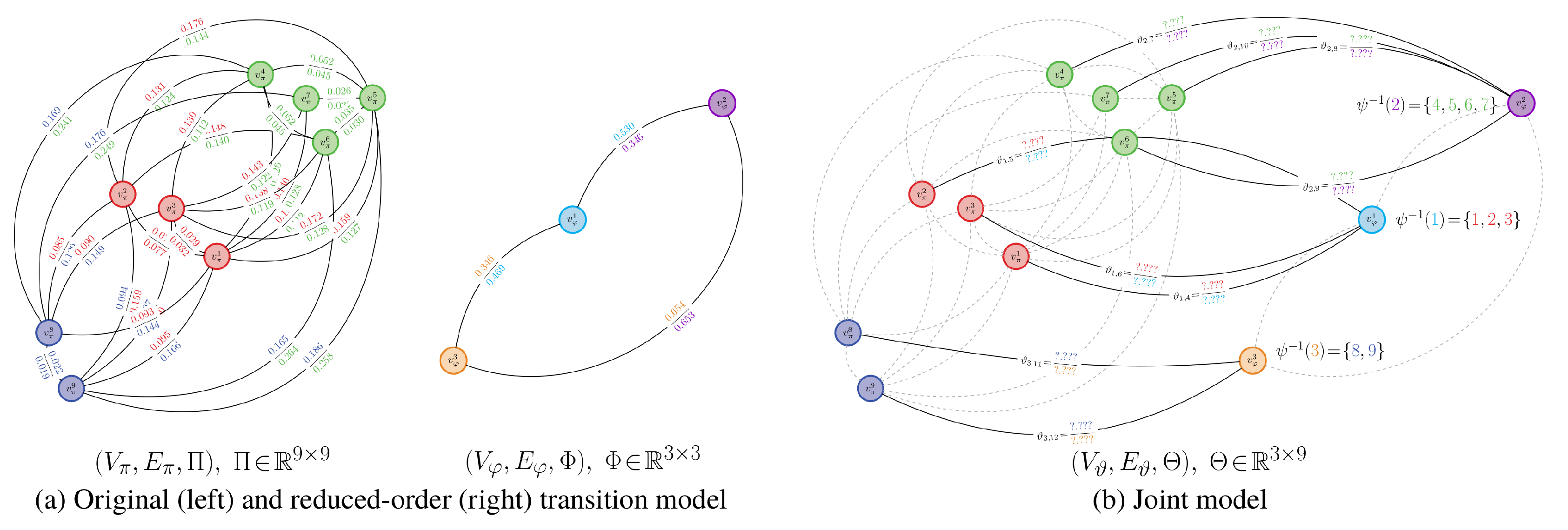
To facilitate the application of measures to and when they have different discrete state spaces, we consider construction of a joint model . This joint model defines a joint state space composed of and . It consequently possesses a weighting matrix with the same number of columns as , which is outlined in Definition 4 and illustrated in Figure 1.
The joint model relies on the specification of a binary partition function , which is given in Definition 3. This function provides a one-to-many mapping between states in and and hence can be seen as a means of delineating which states of the original chain should be combined.
Definition 3.
Let and be transition models of two Markov chains over n and m states, respectively. A binary partition function ψ is a surjective mapping between two state index sets, and , such that is a partition of . That is, is not empty, , and , for . It can be seen that a partition of a state index set induces a binary partition matrix , where if and if . Thus, , where is the ith unit vector. The set of all binary partition matrices is .
Definition 4.
Let and be transition models of two Markov chains over n and m states, respectively, where . is a joint model, with states, that is defined by
- (i)
- A vertex set , which is the union of all state vertices in and . For simplicity, we assume that the vertex set for the intermediate transition model is indexed such that the first m nodes are from and the remaining n nodes are from .
- (ii)
- An edge set , which are one-to-many mappings from the states in the original transition model to the reduced-order transition model .
- (iii)
- A weighting matrix Θ, which is such that , . The partition function ψ provides a relationship between the stochastic matrices Φ and Θ of and , respectively. This is given by , or, rather, , where .
An illustration of the joint model relative to the other models is provided in Figure 2.
3.1.2. Partitioning Process and State Aggregation
For any given transition model , we would like to find, by way of the joint model , another transition model with fewer states that resembles the dynamics encoded by . We therefore seek a with a weighting matrix that has the least total distortion with respect to the transition matrix of for some partition. In what follows, we specify how to find .
Before we can define the notion of least total distortion, we must first specify the concept of the total distortion of with respect to .
Definition 5.
Let , , and be transition models of two Markov chains over n and m states and the joint model over states, respectively. The total distortion between Π and Θ and hence Π and Φ is
for some unit-sum weights . We can take these weights to be the invariant distribution of the original Markov chain, i.e., . For this objective function, we have the constraint that must be a member of the set of all joint models for and .
It can be seen from Definition 5 that the total distortion is over the set of all possible binary partitions. We, however, seek the best binary partition. Best, in this context, means that it would yield an with the least total distortion to . It hence would lead to a lower-order model that most resembles according to the chosen measure g.
Definition 6.
Let and be transition models of two Markov chains over n and m states, respectively. The accumulation matrix for that achieves the least total distortion to Π of , according to , is given by
Here, is the total distortion.
At least one minimizer exists for both assessing total distortion and least total distortion. This is because both are continuous functions operating on closed and bounded sets and hence, according to the Weierstrass extreme value theorem, obtain both a maximum and minimum on those sets.
From Definition 5, we can now specify the optimization problem of aggregating a Markov chain described. This problem can be solved in a two-step process. The first step entails finding the optimal partition that leads to the least total distortion between the original chain and , as described by . The second step involves constructing the corresponding low-order transition matrix from and .
Definition 7.
Let and be transition models of two Markov chains over n and m states, respectively. The optimal reduced-order transition model with respect to the original model can be found as follows
- (i)
- Optimal partitioning: Find a binary partition matrix Ψ that leads to the least total distortion between the models and . As well, find the corresponding weighting matrix Θ that satisfiesSolving this problem partitions the n vertices of the relational matrix into m groups.
- (ii)
- Transition matrix construction: Obtain the transition matrix for from the following expression: using the optimal weights Θ and the binary partition matrix Ψ from step (i).
It is important to notice for the first step in Definition 7 that there is no efficient way to find a with least total distortion to . This is due to the binary nature of the partitions, which leads to a problem with an NP-hard computational complexity. For practical problems, which may contain thousands or even millions of states, this aggregation procedure will not be tractable. A more efficient alternative is therefore required.
3.2. Approximately Aggregating Markov Chains
3.2.1. Preliminaries
A straightforward way to make the aggregation problem more efficient is by approximating the least total distortion optimization given in Definition 6. This can be effectuated by relaxing the constraint that the state–state assignments specified by the partition matrix are binary. Instead, each state from the high-order chain can have a chance to map to states in the low-order chain. Such changes lead to the notion of a probabilistic partition matrix.
Definition 8.
Let and be transition models of two Markov chains over n and m states, respectively. A probabilistic partition function ψ is a surjective mapping between two state index sets, and , such that is a partition of , which has a given probabilistic chance of occurring. That is, is not empty and where , with the real-valued responses being non-negative and summing to one. The probabilistic partition of a state index set induces a probabilistic partition matrix , where if occurs with probability ζ. The set of all probabilistic partition matrices for the two chains specified above is given by .
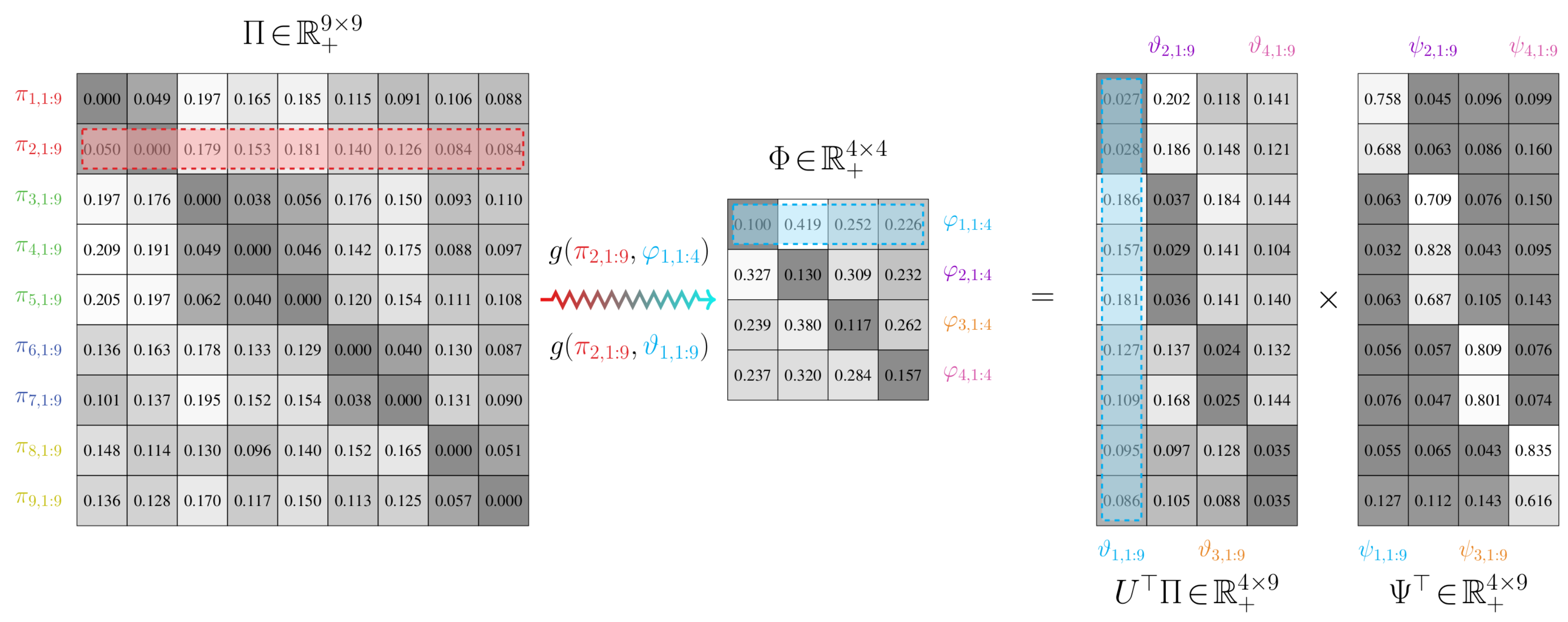
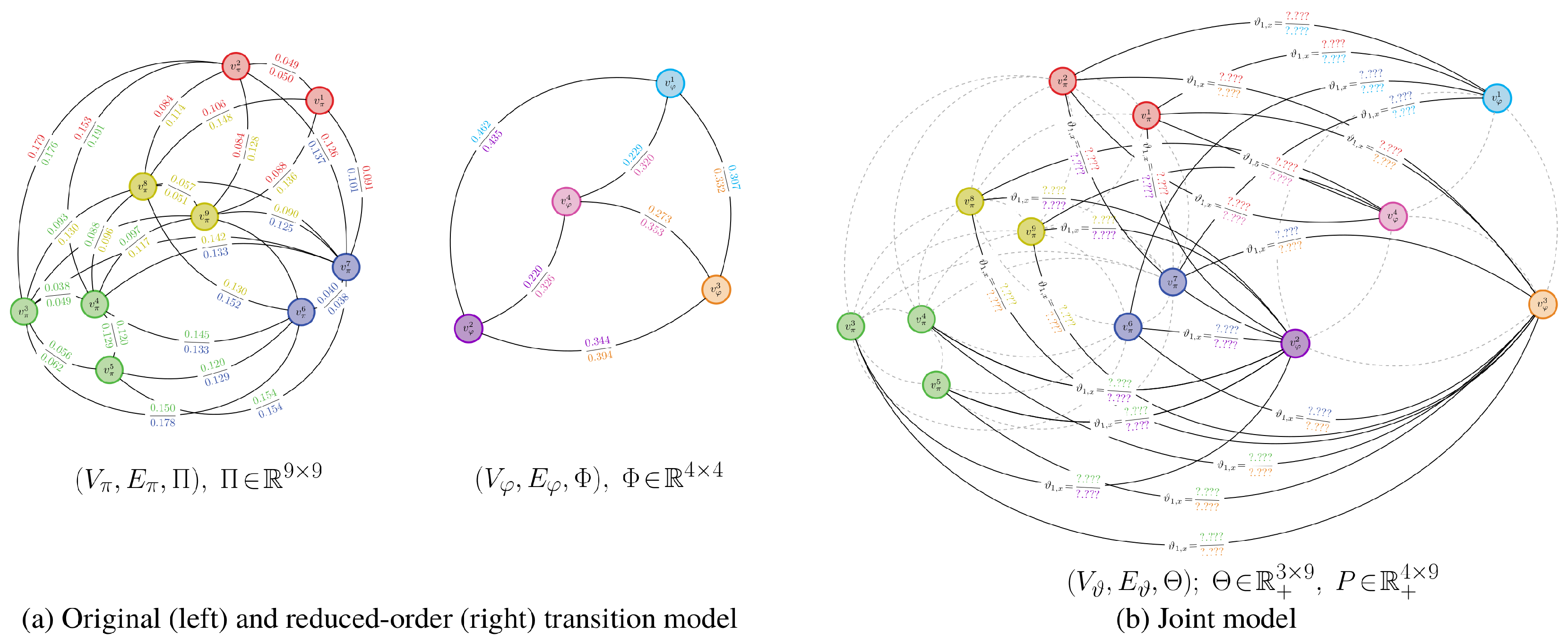
An example of a probabilistic partitioning is given in Figure 3. Here and in Figure 4, is a matrix where , ; the proof to Proposition 4 explains how this matrix arises when finding a probabilistic partition.
As before, we will partition and compare the dynamics for pairs of chains according to rows of the corresponding stochastic transition matrices. We will, therefore, still encounter issues when trying to compare transition models and with differing state spaces. We again consider the construction of a joint model to avoid this issue. The only difference between this joint model and the one defined for binary-valued partitions is that the weighting matrix has a different form. The connectivity of the joint-space graph can hence be different.
Definition 9.
Let and be transition models of two Markov chains over n and m states, respectively, where . is a joint model, with states, that is defined by
- (i)
- A vertex set , which is the union of all state vertices in and .
- (ii)
- An edge set , which are one-to-many mappings from the states in the original transition model to the reduced-order transition model .
- (iii)
- A weighting matrix . The partition function ψ provides a relationship between the stochastic matrices Φ and Θ of and , respectively. This is given by , or, rather, , where is the probabilistic partition matrix.
3.2.2. Partitioning Process and State Aggregation
For any transition model , we, again, would like to find a joint model that facilitates the construction of another transition model . should have fewer states than while still possessing similar intra-group transition dynamics. Since we are now considering probabilistic partitions, we instead seek a with the least expected distortion to to ensure that the dynamics of largely match those of . Definition 5 is hence modified as follows.
Definition 10.
Let , , and be transition models of two Markov chains over n and m states and the joint model over states, respectively. The least expected distortion between Π and Θ and hence Π and Φ is
There are few constraints on the probabilistic partitions in Definition 10, which can make finding viable solutions difficult. To address this issue, we impose that the partitions should minimize the information loss associated with the state quantization process. That is, the mutual dependence between states in the high-order and low-order chains should be maximized with respect to a supplied upper bound. Simultaneously, the least expected distortion, for this supplied bound, should be achieved.
Aggregating Markov chains in this fashion can be done via a two-step process similar to Definition 7.
Definition 11.
Let and be transition models of two Markov chains over n and m states, respectively. The optimal reduced-order transition model with respect to the original model can be found as follows:
- (i)
- Optimal partitioning: Find a probabilistic partition matrix Ψ that leads to the least expected distortion between the models and . As well, find the corresponding weighting matrix Θ that satisfiesfor some positive value of r; r has an upper bound of . The variables α, γ, and ψ all have probabilistic interpretations: and correspond to marginal probabilities of states and , while is the conditional probability of state mapping to state .
- (ii)
- Transition matrix construction: Obtain the transition matrix for from the following expression: using the optimal weights Θ and the probabilistic partition matrix Ψ from step (i).
The optimization problem presented in Definition 11 trades off between the minimum expected distortion and the information contained by the states in the low-order chain about those in the original, high-order chain after partitioning. It is hence describing the value of quantizing the high-order model by a certain amount [16,17]; this is the value of information formulated for Markov chains, which is, itself, an analogue of rate-distortion theory [18]. Coarsely quantizing , as dictated by the parameter r, leads to a parsimonious low-order stochastic matrix that may not greatly resemble the dynamics of . Finely quantizing , again determined by r, yields a that is similar to the high-order model’s transition matrix yet may contain many redundant details.
In the value of information, the role of the Shannon information term is to impose a certain level of randomness, or uncertainty, in the partition matrix to ensure that the entries can be non-binary. A similar effect could be achieved by considering a Shannon entropy constraint on the partition matrix . However, a Shannon entropy constraint is rather non-restrictive on the entries of the partition matrix: it is a projection of Shannon information that introduces ambiguities. There is hence the potential that a given row could be a duplicate of another, thereby over-inflating the number of states in the reduced-order chain and leading to a poor aggregation. We have found, empirically, that Shannon mutual information does not share this defect, except when all states have a uniform chance of being grouped together in every group. This is because we are bounding the informational overlap between the original and aggregated states. Coincident partitions often violate this bound. In the Shannon-entropy case, however, we are only bounding the uncertainty on the entries of the partition, so there is no direct constraint between the original and aggregated states.
Definitions 8, 9 and 11 provide a means of approximating the computationally intractable aggregation process outlined in Section 3.1 Actually solving the constrained optimization problem in Definition 11 can be efficiently performed in a few ways. Here, we opt to optimize the Lagrangian. This provides an expectation-maximization-like procedure for specifying the probabilistic partitions .
Proposition 1.
For a transition model over n states and a joint model and states, the Lagrangian of the relevant terms for the minimization problem given in Definition 11 is , or, rather,
Here, is a Lagrange multiplier that emerges from the Shannon mutual information constraint in the value of information. Probabilistic partitions , which are local solutions of , can be found by the following expectation-maximization-based alternating updates
which are iterated until convergence.
Proposition 2 shows that the alternating optimization updates in Proposition 3 yield monotonic decreases in the modified free-energy associated with the value of information. Global convergence to solutions can therefore be obtained. Proposition 3 bounds the approximation error as a function of the number of alternating-optimization iterations. Linear-speed convergence to solutions is hence obtained, which coincides with the interpretation of the updates as an expectation-maximization-type algorithm.
Proposition 2.
Let and be transition models of two Markov chains over n and m states, respectively, where . If is an optimal probabilistic partition and an optimal marginal probability vector, then, for the updates in Proposition 1, we have that:
- (i)
- The approximation error is non-negative
- (ii)
- The modified free energy monotonically decreases across all iterations k.
- (iii)
- For any , we have the following bound for the sum of approximation errors
In both (i) and (ii), is the Lagrangian.
Proposition 3.
Let and be transition models of two Markov chains over n and m states, respectively, where . If is an optimal probabilistic partition and an optimal marginal probability vector, then, the approximation error
falls off as a function of the inverse of the iteration count k. Here, the constant factor of the error bound is a Kullback–Leibler divergence between the initial partition matrix and the global-best partition matrix .
As shown in Proposition 1, a Lagrange multiplier is introduced to account for the mutual information constraint. The effects of are as follows. As tends to zero, minimizing the Lagrangian is approximately the same as minimizing the negative Shannon information. The information loss associated with the quantization process takes precedence, albeit at the expense of a potentially poor reconstruction. In this case, there are few state clusters defined by the partition; that is, there are few rows in . Every state in the high-order transition model has an almost uniform chance to map to each state in the low-order model . The alternating updates from Proposition 1 yield a global minimizer of the value of information, which follows from the convexity of the dual criterion and the Picard-iteration theory of Zangwill [44].
As is increased, the probabilistic partitions become more binary. Higher probabilities are therefore assigned for a state in to map to either a small set of states or a single state in . This is because the effects of the Shannon information term are increasingly ignored in favor of achieving the minimum expected distortion. The value-of-information problem given in Definition 11 therefore approaches the binary aggregation problem from Definition 7. An increasing number of clusters are formed by the partition matrix, which increases the number of rows in the weighting matrix and hence . When tends to infinity, we obtain a completely binary partition matrix. We hence recover the least total distortion function given in Definition 6. This binary partition can contain as many clusters as states in the high-order model ; that is, no aggregation may be performed, so is typically equal to .
The number of state clusters in the high-order chain, or, rather, the number of distinct rows of the weight matrix , does not increase continuously as a function of . Instead, it increases only for certain critical values of where a bifurcation occurs in the underlying gradient flow of the Lagrangian. Critical values of can be explicitly determined when using the negative, modified Kullback–Leibler divergence by looking at the second derivative of the Lagrangian at .
Proposition 4.
Let and be transition models of two Markov chains over n and m states, respectively, where . Let , where is the joint model. The following hold
- (i)
- The transition matrix Φ of a low-order Markov chain over states m is given by , where . Here, for the probabilistic partition matrix found using the updates in Proposition 1.
- (ii)
- Suppose that we have a low-order chain over m states with a transition matrix Φ and weight matrix Θ given by (i). For some , suppose , the matrix Θ for that value of , satisfies the following inequality . Here, is a matrix such that and . A critical value , occurs whenever the minimum eigenvalue of the matrixis zero. The number of rows in Θ and columns in Ψ needs to be increased for .
Proposition 4 illustrates a major advantage of the value-of-information cost function for partitioning Markov chains: the number of states in a low-order model does not need to be manually specified. It is dictated implicitly by the value of the Lagrange multiplier that captures the effects of favoring information retainment over achieving a minimal expected distortion. This automatic increase in the number of state groups is depicted in Figure 5.
Choosing a good value for is crucial for practical problems. There are a variety of ways to do this. One such approach entails applying perturbation theory to obtain an upper bound on . More specifically, it is known that measurements of Shannon mutual information are always, on average, improperly estimated when considering finite samples [45]. That is, for finitely sized state spaces, the probability distributions that comprise the mutual information expression are approximating, thereby leading to errors that propagate into the aggregation process. Our approach therefore entails modeling this perturbation error and removing it from the value of information. This leads to a modified criterion for which a value of can be determined that minimizes the estimation error and better fits to the structure of the transition matrix. Such values typically correspond to the beginning of an asymptotic region of the original value-of-information expression where favoring a minimum expected distortion over information loss leads to negligible improvements.
Proposition 5.
Let and be transition models of two Markov chains over n and m states, respectively, where . is a joint model, with states. The systematic underestimation of the information cost of the Shannon mutual information term in Definition 11 can be second-order minimized by solving the following optimization problem
where .
This corrected version of the value of information has a rescaled slope compared to the original, where a lower bound on the rescaling is given by .
3.2.3. Partitioning Process and State Aggregation
The preceding theory outlines how Markov chains can be aggregated by trading off between expected distortion and expected relative entropy. We have shown that global-optimal solutions can be uncovered. However, we have not bounded the aggregation quality of those solutions for arbitrary problems; such bounds are important for understanding how our approach will behave in general.
Toward this end, we quantify the relationship between stationary distributions of the original and reduced-order stochastic matrix for nearly-completely-decomposable systems. Many practical examples of Markov chains are typically nearly-completely-decomposable: groups of states possess similar transition dynamics where the chance to jump between states within the group is higher than states outside of the group.
Definition 12.
The transition model of a first-order, homogeneous, nearly-completely-decomposable Markov chain is a weighted, directed graph given by the three-tuple with
- (i)
- A set of n vertices representing the states of the Markov chain.
- (ii)
- A set of edge connections between reachable states in the Markov chain.
- (iii)
- A stochastic transition matrix . Here, represents the non-negative transition probability between states i and j. We impose the constraint that the probability of experiencing a state transition is independent of time. Moreover, for a block-diagonal matrix with zeros along the diagonal, we have that . Here, is a completely-decomposable stochastic matrix with m indecomposable sub-matrix blocks of order .Since Π and are both stochastic, the matrix must satisfy the equality constraint , for blocks and . That is, they must obey . Additionally, the maximum degree of coupling between sub-systems and , given by the perturbation factor ε, must obey .
Proposition 6.
Let be a transition model of a Markov chain with n states, where is nearly completely decomposable into m Markov sub-chains.
- (i)
- The associated low-order stochastic matrix found by solving the value of information is given by , where represent state indices associated with block i, while represents a state index into block j. The variable denotes the invariant-distribution probability of state p in block i of Π.
- (ii)
- Suppose that is approximated by the entries of the first left-eigenvector for block i of . We then have thatwhere the first term is the invariant distribution of the low-order matrix , under the simplifying assumption, and is the probabilistic partition matrix found by solving the value of information.
Proposition 6 elucidates the behavior of the value-of-information aggregation results: a reduced Markov chain will have similar long-run dynamics as a projected version of the original Markov chain. This result is made possible by the work of Simon and Ando [20]. They proved that, for nearly-completely-decomposable chains, there are two types of dynamics that influence the stationary distribution: short and long term. In the short term, each completely-decomposable block evolves almost independently towards a local equilibrium, as if the system was completely decomposable. In the long run, the entire aggregated chain moves toward the steady state defined by the first left-eigenvalue of the original stochastic matrix. The equilibrium states attained for each block of the original stochastic matrix are approximately the same as those for the short-run dynamics.
More specifically, the local-equilibrium states for the short-term dynamics may be closely approximated by the steady-state vectors of the sub-systems for the completely decomposable stochastic matrix . The macro-transition probability between blocks and of remains, in the long term, more or less constant in time and is approximately equal to . Hence, the elements of the steady-state probability vector , where , are so-called macro-variables that yield good approximations to the steady-state probabilities of being in any one state of block . The so-called micro-variables are good approximations to the steady-state probabilities of being in any particular state p of block i. That is, as we showed in the previous section, both the macro- and micro-variables have an -norm error that is a square of the perturbation factor compared to those for the original stochastic matrix. The aggregated chain will thus possess similar long-term dynamics as the original.
4. Simulations
In the previous section, we provided an information-theoretic criterion, the value of information, for quantifying the effects of quantizing stochastic matrices associated with Markov chains. We also provided a first-order approach for optimizing this criterion, which provides a mechanism for simultaneously partitioning and aggregating chain states. In this section, we assess the empirical performance of this criterion. The aims of our simulations are multi-fold. First, we ascertain how well the value of information reduces the complexity of Markov chains when they possess either simple or complex state-transition dynamics. We also discuss various facets of the criterion within the context of these results. We then gauge how well the results for the “optimal” free-parameter value, as predicted via perturbation theory, align with the ground truth. We also illustrate that using Shannon mutual information, versus Shannon entropy, as a constraint for the expected-distortion objective function, avoids returning coincident partitions.
4.1. Simulation Protocols
For each of the examples that follow, we adopted the following simulation protocols for value-of-information-based aggregation. We initialized the aggregation process with a partition matrix of all ones, , signifying that each state belongs to a single group. This is the global optimal solution of Markov chain aggregation for both the binary- and probabilistic-partition cases. For the latter case, it coincides with a parameter value of zero for the value of information. We then found the subsequent critical values of and increased the column count of the partition matrix . We determined which state group would be further split and modified both the new column and an existing column of to randomly allocate the appropriate states. This initialization process bootstraps the quantization for the new cluster and typically achieves convergence in only a few iterations. It also permits the value of information to reliably track the global minimizer for the binary-partition aggregation problem case as increases.
For certain problems, a priori specifying a fixed amount of partition updates may not permit finding a steady-state solution. We therefore run the alternating updates until no entries of the partition matrix change across two iterations.
4.2. Simulation Results and Analyses
4.2.1. Value-of-Information Aggregation
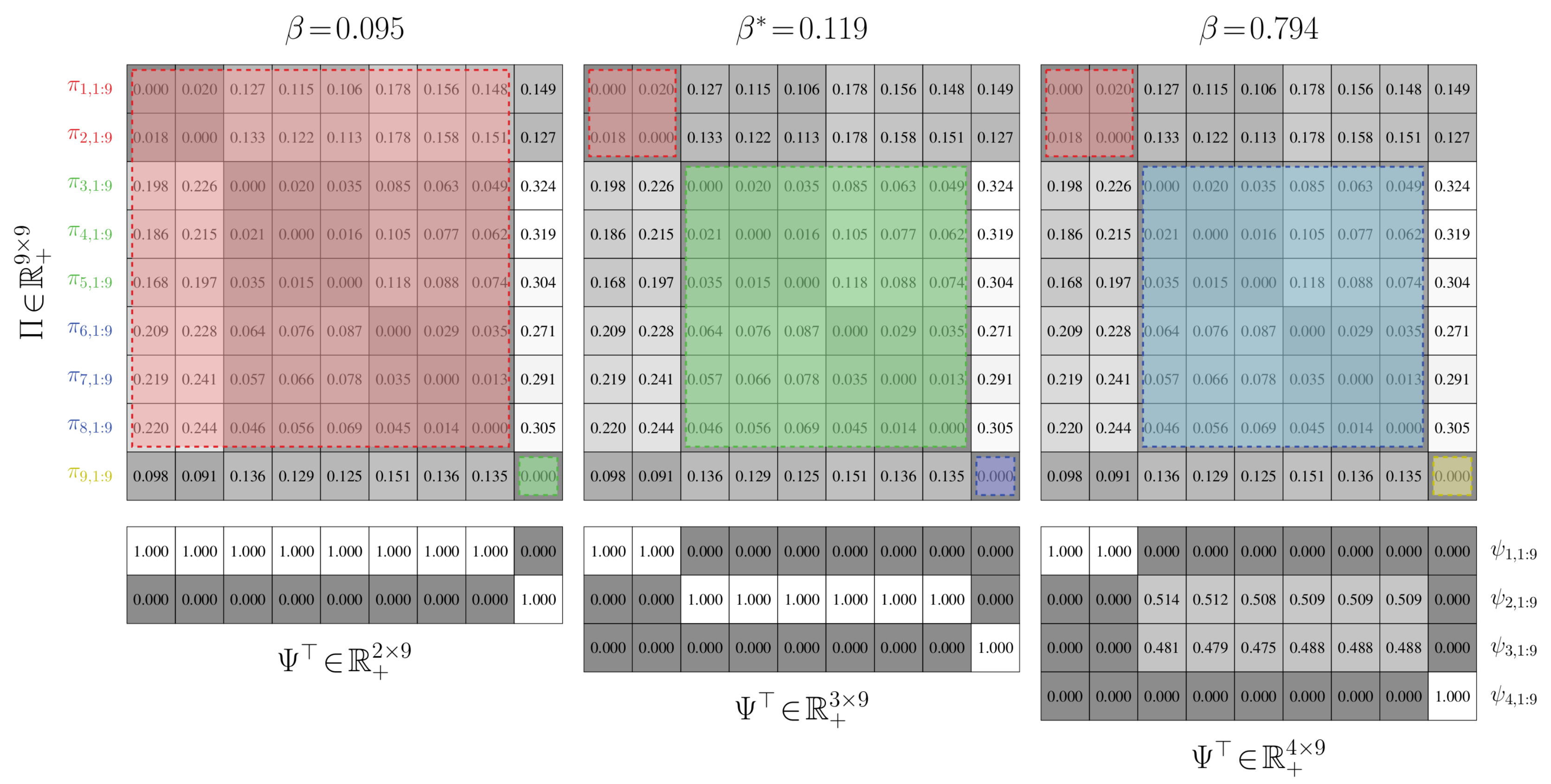
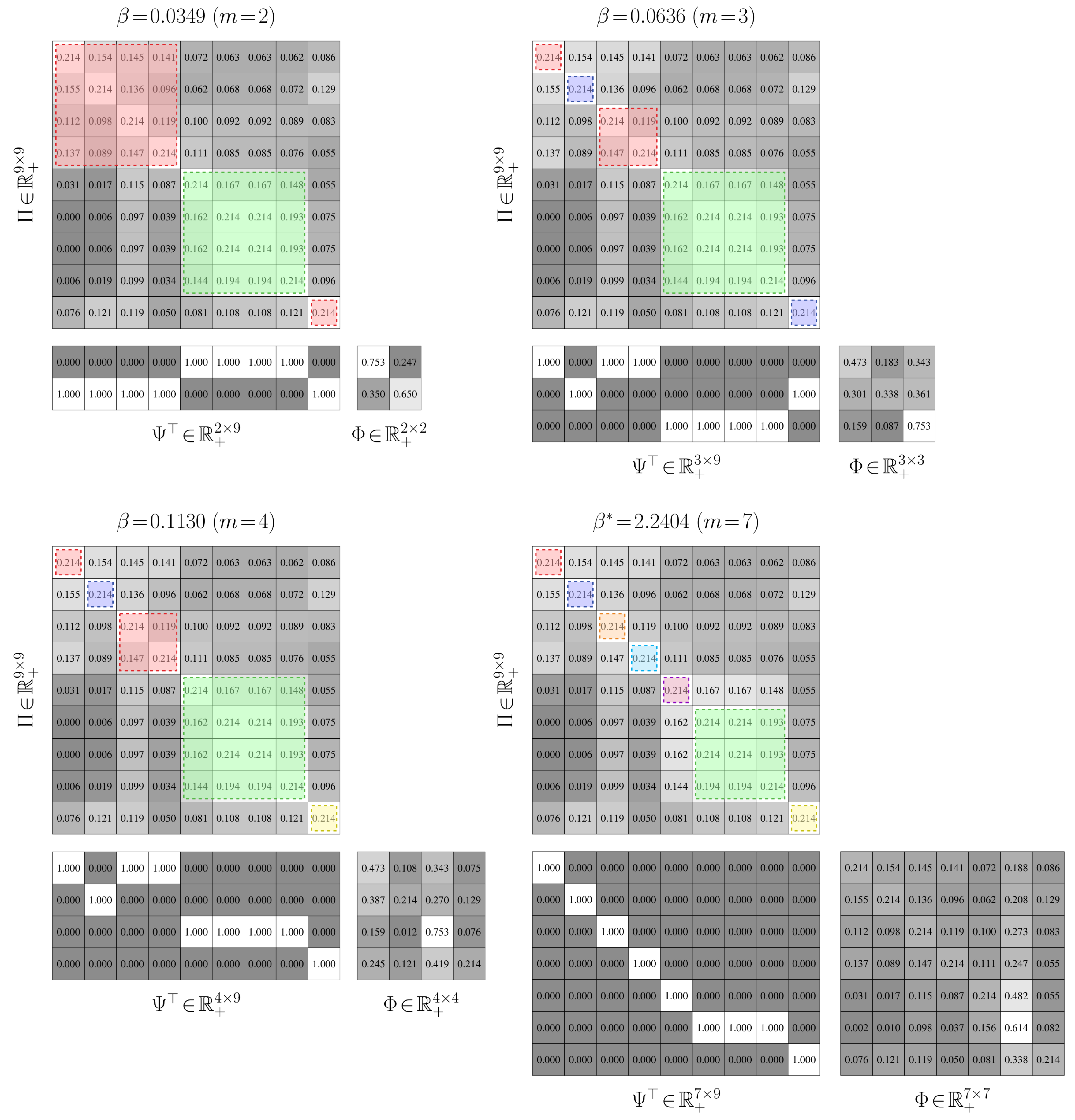
Aggregation Performance. We establish the performance of value-of-information aggregation through two examples. The first, shown in Figure 6, corresponds to a Markov chain with nine states and four state groups with strong intra-group interactions and weak inter-group interactions. This is a relatively simple aggregation problem. The second example, presented in Figure 7, is of a nine-state Markov chain with a single dominant state group and six outlying states with near-equal transition probabilities. This is a more challenging problem than the first, as the outlying states cannot be reliably combined without adversely impacting the mutual dependence. In both cases, the transition probabilities were randomly generated through knowledge of a limit distribution .
In Figure 6 and Figure 7, we provide partitions and aggregated Markov chains for four critical values of the free parameter . The “optimal” value of , as predicted by our perturbation-theory formulation of the value of information, leads to four and seven state groups for the first and second examples, respectively. The associated partitions align with an inspection of the dynamics of the stochastic matrix: the partitions separate states that are more likely to transition to each other from those that are not. The ”optimal” aggregated stochastic matrix encodes this behavior well. The remaining aggregated chains do too for their respective partitions, as they all mimic the interaction dynamics of the original chain for the given state groups. However, those partitions for “non-optimal” s either over- or under-quantize the chain states, which is illustrated by the plot of expected distortion versus the critical values of ; these plots are given in Figure 8. That is, for critical s before the “optimal” value, there is a steep drop in the distortion, while the remaining s only yield modest decreases. The “optimal” value of for both examples, in contrast, lies at the “knee” of this curve, which is where the expected-distortion minimization, , is roughly balanced against the competing objective of state-mutual-dependence maximization with respect to some bound, .
For both examples, we aggregated at critical values of where the number of state groups increases. We also considered non-critical values of between two phase changes; a thousand Monte Carlo trials were conducted for random s. For each of these trials, the partitions produced between two related critical values were virtually identical, up to a permutation of the rows. Only minute, arithmetic-error-attributed differences were encountered. Such results illustrate the validity of our theory: only a finite number of critical values for need to be used for reducing finite-cardinality stochastic matrices.
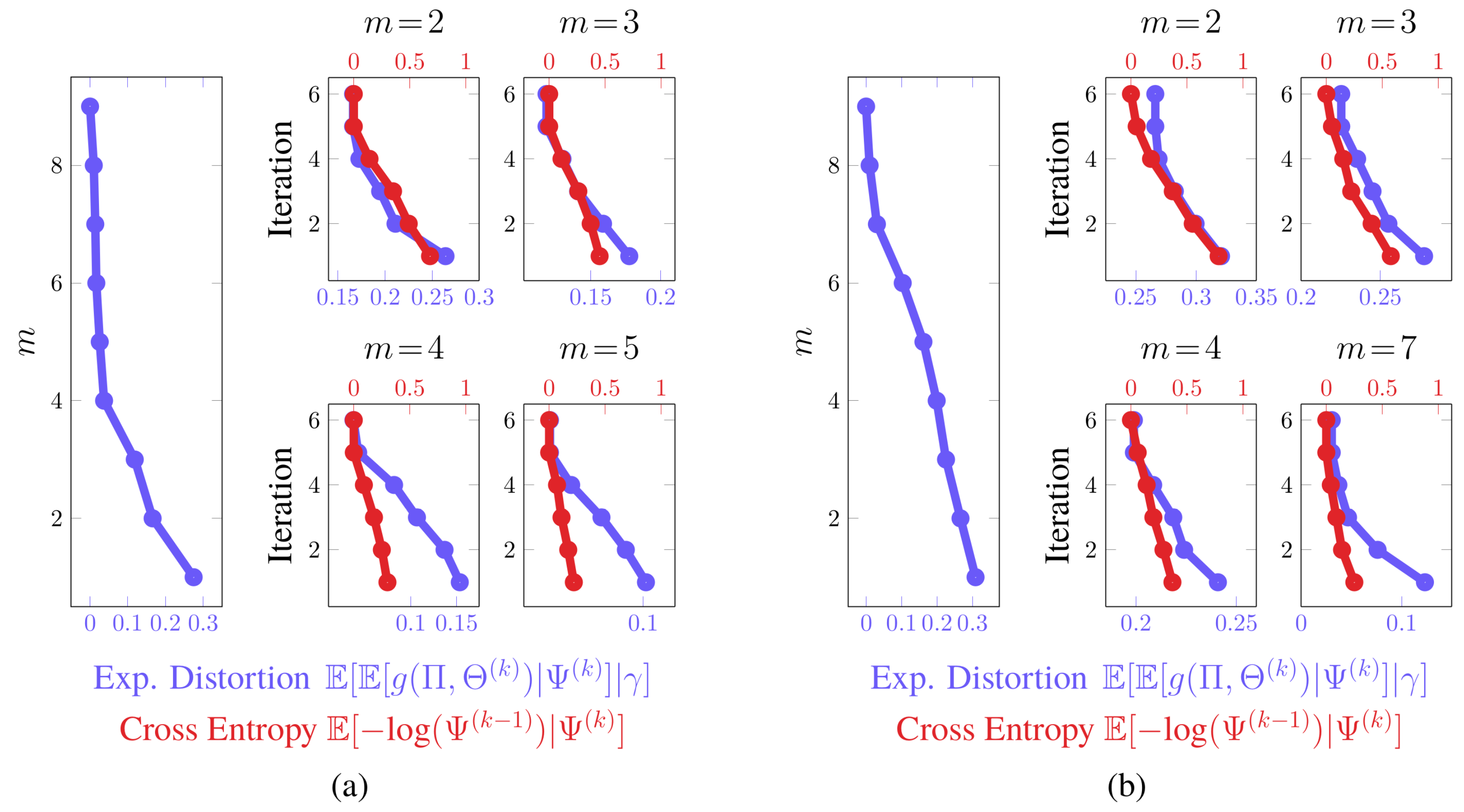
Convergence. In Figure 8, we furnished plots of the decrease in the expected distortion, across each iteration . This provides a means of gauging the per-iteration solution improvement and hence convergence. We also provided plots of the partition matrix cross-entropy for consecutive iterations, . The partition cross-entropy is a bounded measure of change between consecutive partitions and captures how greatly the partition changed across a single update. Taken together, they offer alternate views of the aggregation improvement during intermediate stages of the dynamics reduction process. In either example, the average of these quantities across the Monte Carlo trials exhibits a nearly-linear decrease in their respective quantities before plateauing, regardless of the critical value of . This finding suggests rapid convergence to the global solution, which was anticipated from our convergence analysis. That is, due to how we initialize the partitions, we are roughly ensuring that they are in close proximity to the next global optima , up to a permutation of the rows. The term in the approximation error bound dominates over the term in this situation and hence few changes in are needed.
To assess the convergence stability of the aggregation process, we performed a thousand Monte Carlo trials on both examples. In only a very small fraction of the trials did the partitions deviate from those presented in Figure 6 and Figure 7 by more than a simple permutation. Such occurrences were largely due to a degenerate initialization of a new partition column whereby no states would be associated with that new state group. Imposing a constraint that a new group must contain at least a single state fixed this issue and led to consistent partitions being produced. The expectation-maximization-based procedure for solving the value of information was then able to discover global optima well in just a few iterations; the optima often were binary partitions like those presented in Figure 6 and Figure 7.
Avoiding coincident Partitions. The results for the preceding examples indicate that the Shannon-information constraint, , has the potential to yield non-coincident partitions. We now demonstrate using two additional Markov chains that using a Shannon-entropy penalty, , is more likely to return partitions with duplicated rows. This unnecessarily inflates the state-group cardinality, leading to aggregations with redundant details.
Both of these examples are for Markov chains with nine states. The first example, shown in the top left-hand corner of Figure 9, contains three state groups with a high chance to both jump to states in different groups and jump to states within a group. Moreover, many of the rows in the matrix are the same. We anticipate that coincident partitions will easily materialize due to these properties. The second example is given in the bottom left-hand corner of Figure 9. It contains two state groups with weakly interacting intra-group dynamics and strong inter-group dynamics. Each group has highly distinct transition probabilities. We hence expect that returning coincident partitions will be more difficult than in the first case. As before, the transition probabilities for each matrix were randomly generated through knowledge of a limit distribution.
Partitions for nine state groups are presented in Figure 9. The partitions in the middle column of Figure 9 are the results for the Shannon-mutual-information constraint, while those in right column are for the Shannon-entropy constraint. The Shannon-mutual-information case quantizes the data in the manner we would expect for both examples: each state is, more or less, assigned to its own group so that the original stochastic matrix is exactly recovered. There are hence no degenerate clusters. For the Shannon-entropy case, three coincident clusters formed for the first problem and this value of . Two states from the first state group were incorrectly viewed as being equivalent. Two states from the second group and three states from the third group were also improperly treated, leading to further coincident partitions. Four degenerate clusters thus emerged and the original stochastic matrix could not be recovered; the Kullback–Leibler distortion for this value of and other s illustrates this. For the second problem, every state in the second state group was considered equal. Seven degenerate groups were thus created, leading to a stochastic matrix with a very different invariant distribution and hence longer-term dynamics than the original.
For these examples, we considered the same number of groups as states to highlight the severity of the coincident partition issue when using an uncertainty constraint. Coincident clusters were also observed when the group count was below the number of states.
4.2.2. Value-of-Information Aggregation Discussions
We have illustrated that the value-of-information criterion provides an effective mechanism for dynamics reduction of Markov chains for these examples. Consistently stable partitions of the transition probabilities are produced by optimizing this criterion. Such partitions induce reduced-order chains that do not have duplicate state groups and are often parsimonious representations. We have additionally demonstrated that only a finite number of free-parameter values need to be considered for this purpose, the “optimal” value of which can be discerned in a data-driven fashion.
Aggregation Performance: Binary Partitions. In the previous section, we relaxed the binary-valued constraint on the partition matrices to avoid exactly solving a potentially computationally intractable problem. However, our aggregation results for the first two examples indicate that either binary or nearly-binary partition matrices may still be returned when solving the value of information. The reason for this is the interplay between the expected distortion and the Shannon-mutual-information constraint: while the latter does not explicitly preclude their formation, the former naturally favors binary partitions.
More specifically, non-binary partitions will always have less Shannon mutual information than binary partitions. This is because the conditional entropy of the states in the original and aggregated chains increases more quickly than the marginal entropy, which is due to the additional uncertainty in the non-binary partitions. Hence, for a given upper bound on the Shannon information, if a binary partition can be formed for that bound, then a corresponding non-binary one can also be formed. The minimization of the distortion term, however, impedes the formation of non-binary partitions. In the binary case, provided that the partition reflects the underlying structure of the transitions, only related probability vectors will be compared to each other. Vastly different rows and columns of the stochastic and joint stochastic matrices will not factor into the expected distortion, since the state-assignment probability will be zero if the partition encodes well the underlying transition structure. Making highly non-binary state-group assignments can raise the expected distortion: the Kullback–Leibler divergence between two, possibly very distinct, probability vectors may be multiplied by a non-zero state-assignment probability.
This behavior contrasts with the use of a conditional Shannon entropy equality constraint on the entries of the partition matrix. Such a constraint directly imposes that the partition matrix should have a given amount of uncertainty, potentially at the expense of a worse distortion. Non-binary partitions hence can be more readily constructed.
Aggregation Performance: “Optimal” State Group Count. We considered a perturbation-theoretic approach for determining the ‘optimal’ number of state groups. The approach operates on the assumption that, for finitely sized stochastic matrices, there is an error in estimating the marginal distribution of the original states. This poor estimate leads to a systematic error in evaluating the Shannon-information term, which we quantified in a second-order sense. In the case of binary partitions, a second-order correction of this error introduces a penalty in the value of information for using more aggregated state groups than can be resolved for a particular finitely sized state space. Values for the free parameter were returned that, for our examples, aligned well with a balance between the expected distortion of the aggregation and the mutual dependence between states in the original and aggregated chains.
As shown in our experiments, the value of information monotonically decreases for an increasing number of state groups. The second-order-corrected version shares this trait, as it is a slope-rescaled version of the original value of information. Ideally, we would like to further transform this slope-scaled value-of-information curve so that it possesses an extremum where both terms of the objective function are balanced. This would lend further credence to the notion that such a free parameter value, and hence the number of state groups, for any stochastic matrix is “optimal”. In our upcoming work, we will demonstrate how to perform this transformation. We will show that the value of information can be written, in some cases, as a variational problem involving two Shannon-mutual-information terms. Applying the same perturbation-theoretic arguments to this version of the value of information reveals that the corrected criterion is monotonically increasing up to a certain point, after which it is monotonically non-increasing and often is strictly decreasing. This inflexion point corresponds to the ‘optimal’ parameter value determined here. This value minimizes the mutual dependence between the original and aggregated states while simultaneously retraining as much information about the original transition dynamics as possible.
5. Conclusions
In this paper, we have provided a novel, two-part information-theoretic approach for aggregating Markov chains. The first part of our approach is aimed at assessing the distortion between original-and reduced-order chains according to the negative, modified Kullback–Leibler divergence between rows of their corresponding stochastic matrices. The discrete nature of the graphs precludes the direct comparison of the transition probabilities according to this divergence, which motivated our construction of a joint transition model. This joint model encodes all of the information of the reduced-order Markov chain and is of the proper size to compare against the original Markov chain. The second part of our approach addresses how to combine states in the original chain, according to the chosen divergence, by solving a value-of-information criterion. This criterion aggregates states together if doing so reduces the total expected distortion between the low- and high-order chains and simultaneously maximizes the bounded mutual dependence between states in the high- and low-order chains. It thus attempts to find a low-order Markov chain that most resembles the global and local transition structure of the original, high-order Markov chain.
The value of information provides a principled and optimal trade-off between the quality of the aggregation, as measured by the total expected distortion, and the complexity of it, as measured by the state mutual dependence according to Shannon mutual information. The complexity constraint has dual roles. The first is that it explicitly dictates the number of states in the low-order chain. We proved that changing the value of a variable associated with this constraint causes the aggregation process to undergo phase transitions where new groupings emerge by splitting an existing state cluster. The second role of the constraint is that it relaxes the condition that the partition matrices must be strictly binary. This relaxation permits the formulation of an efficient procedure for approximately solving the aggregation problem. While the same effect could be achieved with a Shannon entropy constraint, it has the tendency to yield coincident partitions. This over-inflates the number of states in the reduced-order model.
We applied our approach to a series of Markov chains. Our simulation results showed that our value-of-information scheme achieved equal or better performance compared to a range of different aggregation techniques. A practical advantage of our methodology is that we have derived a data-driven expression for the “optimal” value for a parameter associated with the state mutual dependence constraint. This expression was based upon correcting the underestimation of the Shannon information term for finitely sized stochastic matrices. Employing this expression fits the partitions more to the structure of the data than to the noise, ensuring that it tends not to over-cluster states in the original chain. It also frees investigators from having to supply the number of state groups. Many existing aggregation approaches rely on the manual specification of the state-group count, in contrast; a reasonable number of state groups may not be immediately evident for certain problems, which complicates their effective application.
As we noted at the beginning of the paper, our emphasis is on understanding the effects of the value of information when it is applied to resolve the exploration–exploitation dilemma in reinforcement learning. In particular, we seek to address the question of whether the value of information is implicitly aggregating the Markov chains underlying the Markov decision process during exploration. Toward this end, our next step will be to show that hidden Markov models can be reduced in a value-of-information-based manner. Much like our work here, this will entail defining a joint model that allows for comparisons between pairs of hidden Markov models with different state spaces. We will need to construct the joint model so that it is Markovian, which will ensure that the theory in this paper applies with few modifications. Following this, for the Markov-decision-process case, we will need to show that a lumpable partition of the state space can be defined by the value of information, where the partition is bounded by the state-transition and cost effects. States in the same partition will then be viewed as a single state in a reduced-order, aggregated Markov chain. An aggregated Markov decision process with average cost on the aggregated Markov chain can then be obtained. As a part of this effort, we will also quantify the local-neighborhood performance difference between this aggregated Markov decision process and the optimal one.
Author Contributions
Conceptualization, J.C.P.; Investigation, I.J.S.; Methodology, I.J.S. and J.C.P.; Writing—original draft, I.J.S. and J.C.P.
Funding
The work of the authors was funded by grants N00014-15-1-2013 (Jason Stack), N00014-14-1-0542 (Marc Steinberg), and N00014-19-WX-00636 (Marc Steinberg) from the US Office of Naval Research. The first author was additionally supported by in-house laboratory independent research (ILIR) grant N00014-19-WX-00687 (Frank Crosby) from the US Office of Naval Research, a University of Florida Research Fellowship, a University of Florida Robert C. Pittman Research Fellowship, and an ASEE Naval Research Enterprise Fellowship.
Acknowledgments
The authors would like to thank Sean P. Meyn at the University of Florida for his suggestion to use the value of information for aggregating Markov chains.
Conflicts of Interest
The authors declare no conflict of interest.
Nomenclature
| Weighted, directed graph associated with a stochastic matrix | |
| Vertex set for ; represents the n states of the original Markov chain, with the ith state denoted by | |
| Edge set for ; represents the reachability between states of the original Markov chain | |
| A stochastic matrix of size for the original Markov chain; the i-jth entry of this matrix is denoted by | |
| The ith row of ; describes the chance to transition from state i to all other states in the original chain | |
| Weighted, directed graph associated with a stochastic matrix | |
| Vertex set for ; represents the m states of the reduced-order Markov chain, with the jth state denoted by | |
| Edge set for ; represents the reachability between states of the reduced-order Markov chain | |
| A stochastic matrix of size for the reduced-order Markov chain; the i–jth entry of this matrix is denoted by | |
| The jth row of ; describes the chance to transition from state j to all other states in the reduced-order chain | |
| The unique invariant distribution associated with the original Markov chain; the ith entry is denoted by and describes the probability of being in state | |
| g | A divergence measure; written either as , when comparing the entirety of to , or , when comparing rows and of the stochastic matrices |
| A partition function | |
| A partition matrix; the i–jth entry of this matrix is denoted by and represents the conditional probability between states and | |
| Weighted, directed graph associated with a stochastic matrix | |
| Vertex set for ; represents the states of the original Markov chain, with the kth state denoted by | |
| Edge set for ; represents the reachability between states of the original Markov chain | |
| A stochastic matrix of size ; the j–kth entry of this matrix is denoted by | |
| U | A matrix of size ; the i–jth entry of this matrix is denoted by |
| e | A unit vector; the ith unit vector is denoted by |
| q | The total distortion; written as for the weighted, directed graphs and |
| The marginal probability; the jth entry, describes the probability of being in state | |
| r | A non-negative value for the Shannon-mutual-information bound |
| F | The value of information |
| The corresponding hyperparameter associated with r | |
| , | The initial and critical values of |
| Q | An offset matrix; the j–ith entry of this matrix is denoted by |
| An offset amount | |
| C | An offset matrix; the p–kth entry of this matrix is denoted by |
Appendix A
Proposition A1.
For a transition model over n states and a joint model and states, the Lagrangian of the relevant terms for the minimization problem given in Definition 11 is , or, rather,
Here, is a Lagrange multiplier that emerges from the Shannon mutual information constraint in the value of information. Probabilistic partitions , which are local solutions of , can be found by the following expectation-maximization-based alternating updates
which are iterated until convergence.
Proof.
We can convert the constrained value-of-information into an unconstrained problem using the theory of Lagrange multipliers. There are five different constraints for which we need to account,
The first constraint corresponds to the Shannon mutual information term. The remaining constraints ensure that entries from and correspond to valid probabilities.
We can derive the update for the probabilistic partition matrix by differentiating the Lagrangian and setting it to zero
Solving for yields , where and have been selected such that and , respectively. It is apparent that the update for the marginal probabilities is encoded in this update for .
We now can show that the update for the marginal probabilities is optimal. For a fixed probabilistic partition matrix , the following inequality
holds with equality if and only if . This result is a consequence of applying the divergence inequality to . That is,
where equality to zero is only obtained if and only if . This implies that, for a fixed , the update for globally solves the problem , establishing its optimality.
We now demonstrate that the probabilistic partition update is optimal. For a fixed marginal probability vector , the following inequality
holds with equality if and only if . This follows from showing that
Here, we used the divergence inequality in the second-to-last step. As well, we have that the last step can be written as , where the right-hand side is the desired expression. Substituting the update for in the original inequality leads to equivalency. Hence, for a fixed , the update for globally solves . ☐
Proposition A2.
Let and be transition models of two Markov chains over n and m states, respectively, where . If is an optimal probabilistic partition and an optimal marginal probability vector, then, for the updates in Proposition A1, we have that:
- (i)
- The approximation error is non-negative
- (ii)
- The modified free energy monotonically decreases across all iterations k.
- (iii)
- For any , we have the following bound for the sum of approximation errors
Here, is the Lagrangian.
Proof.
Parts (i) and (ii) follow immediately from Proposition 3.1. For part (iii), we have the following equality expressions for iterations k and of the expectation-maximization updates
We obtain that the last term in the last inequality expression is non-negative, since, from part (i), we have that . We thus have that.
Since , it can be seen that . We hence recover the following inequality
which holds for any Summing up this inequality up to K, we have that
Since , we get the desired inequality. ☐
Proposition A3.
Let and be transition models of two Markov chains over n and m states, respectively, where . If is an optimal probabilistic partition and an optimal marginal probability vector, then, the approximation error
falls off as a function of the inverse of the iteration count k. Here, the constant factor of the error bound is a Kullback–Leibler divergence between the initial partition matrix and the global-best partition matrix .
Proof.
From Propositions A2 (ii) and A2 (iii), we get that
The desired inequality follows after dividing both sides by k and substituting the bound obtained in Proposition 3.2(iii) on the right-hand side of the inequality. ☐
Proposition A4.
Let and be transition models of two Markov chains over n and m states, respectively, where . Let , where is the joint model. The following hold:
- (i)
- The transition matrix Φ of a low-order Markov chain over states m is given by , where . Here, for the probabilistic partition matrix found using the updates in Proposition A1.
- (ii)
- Suppose that we have a low-order chain over m states with a transition matrix Φ and weight matrix Θ given by (i). For some , suppose , the matrix Θ for that value of , satisfies the following inequality . Here, is a matrix such that and . A critical value , occurs whenever the minimum eigenvalue of the matrixis zero. The number of rows in Θ and columns in Ψ needs to be increased once .
Proof.
For part (i), we first substitute the partition matrix update into the Lagrangian . After some simplification and when ignoring irrelevant terms, we find that
Setting this expression to zero and solving, we arrive at . Due to the conditions that , we have , where . It is apparent that the entries of are non-negative. As well, every entry in is a convex combination of a column in . Therefore, is a probabilistic transition matrix.
For part (ii), the second variation of at the optimal weighting matrix is given by
Here, we have used the fact that is continuous and strictly positive for . We have also used the spectral theorem [46] to obtain a lower bound on the lowest eigenvalue for a self-adjoint operator. Equality to zero, , can thus only be obtained for if and only if
At such a point , a bifurcation in occurs, for a finite perturbation term Q, and the minimum is no longer stable. That is, there is a bifurcation on a solution branch that is fixed by the algebraic group of all permutations on symbols, , which follows from the equivariant branching lemma and the Smoller–Wasserman theorem; this bifurcation is symmetry breaking. The equivariant branching lemma gives explicit bifurcating directions of the m branching solutions, each of which has symmetry . The branches are hence associated with a and of different cardinalities m. ☐
Proposition A5.
Let and be transition models of two Markov chains over n and m states, respectively, where . is a joint model, with states. The systematic underestimation of the information cost of the Shannon mutual information term in Definition 11 can be second-order minimized by solving the following optimization problem
where .
Proof.
Let us assume that we approximate the marginal distribution by , where is the true marginal, with zero average over all possible realizations. There is hence an underestimation of the Shannon mutual information , which can be found by taking the multi-order Taylor expansion about ,
For the last and second-to-last steps, we considered only the second-order Taylor series expansion term. For the last step, we used the following equality , which is bounded below by . Here, is the joint distribution of the random variables. It can be seen that the Shannon mutual information term is underestimated by bits. The bound on the second-order Taylor expansion hence has a rescaled slope.
Plugging the augmented Shannon information term into the value of information Lagrangian, in place of the original Shannon mutual information constraint, and solving yields following update for ,
where z is a normalization factor that ensures the entries of are probabilities. Considering only the second-order terms from the Taylor expansion and using leads to a second-order minimization of the underestimation of information. ☐
Proposition A6.
Let be a transition model of a Markov chain with n states, where is nearly completely decomposable into m Markov sub-chains.
- (i)
- The associated low-order stochastic matrix found by solving the value of information is given by , where represent state indices associated with block i, while represents a state index into block j. The variable denotes the invariant-distribution probability of state p in block i of Π.
- (ii)
- Suppose that is approximated by the entries of the first left-eigenvector for block i of . We then have thatwhere the first term is the invariant distribution of the low-order matrix , under the simplifying assumption, and is the probabilistic partition matrix found by solving the value of information.
Proof.
For part (i), we note that the aggregated stochastic matrix for nearly-completely decomposable chains, obtained via and , satisfies the implicit equation
In what follows, we want to assess the form of the aggregated stochastic matrix when it contains m state groups. However, dictates the number of state groups in a manner that is dependent on the original stochastic matrix . We therefore simply consider what happens when is infinite and note that the same expression for can be obtained for finite s. In the former case, we have that
where is the indicator function. Due to the nearly-completely decomposable structure of the Markov chain, . Hence,
Part (ii) follows from the work of Courtois [21]. ☐
References
- Arruda, E.F.; Fragoso, M.D. Standard dynamic programming applied to time aggregated Markov decision processes. In Proceedings of the IEEE Conference on Decision and Control (CDC), Shanghai, China, 15–18 December 2009; pp. 2576–2580. [Google Scholar] [CrossRef]
- Aldhaheri, R.W.; Khalil, H.K. Aggregation of the policy iteration method for nearly completely decomposable Markov chains. IEEE Trans. Autom. Control 1991, 36, 178–187. [Google Scholar] [CrossRef]
- Ren, Z.; Krogh, B.H. Markov decision processes with fractional costs. IEEE Trans. Autom. Control 2005, 50, 646–650. [Google Scholar] [CrossRef]
- Sun, T.; Zhao, Q.; Luh, P.B. Incremental value iteration for time-aggregated Markov decision processes. IEEE Trans. Autom. Control 2007, 52, 2177–2182. [Google Scholar] [CrossRef]
- Jia, Q.S. On state aggregation to approximate complex value functions in large-scale Markov decision processes. IEEE Trans. Autom. Control 2011, 56, 333–334. [Google Scholar] [CrossRef]
- Aoki, M. Some approximation methods for estimation and control of large scale systems. IEEE Trans. Autom. Control 1978, 23, 173–182. [Google Scholar] [CrossRef]
- Príncipe, J.C. Information Theoretic Learning; Springer-Verlag: New York, NY, USA, 2010. [Google Scholar]
- Rached, Z.; Alajaji, F.; Campbell, L.L. The Kullback-Leibler divergence rate between Markov sources. IEEE Trans. Inf. Theory 2004, 50, 917–921. [Google Scholar] [CrossRef]
- Donsker, M.D.; Varadhan, S.R.S. Asymptotic evaluation of certain Markov process expectations for large time I. Commun. Pure Appl. Math. 1975, 28, 1–47. [Google Scholar] [CrossRef]
- Donsker, M.D.; Varadhan, S.R.S. Asymptotic evaluation of certain Markov process expectations for large time II. Commun. Pure Appl. Math. 1975, 28, 279–301. [Google Scholar] [CrossRef]
- Deng, K.; Mehta, P.G.; Meyn, S.P. Optimal Kullback-Leibler aggregation via spectral theory of Markov chains. IEEE Trans. Autom. Control 2011, 56, 2793–2808. [Google Scholar] [CrossRef]
- Geiger, B.C.; Petrov, T.; Kubin, G.; Koeppl, H. Optimal Kullback-Leibler aggregation via inforamtion bottleneck. IEEE Trans. Autom. Control 2015, 60, 1010–1022. [Google Scholar] [CrossRef]
- Sledge, I.J.; Príncipe, J.C. An analysis of the value of information when exploring stochastic, discrete multi-armed bandits. Entropy 2018, 20, 155. [Google Scholar] [CrossRef]
- Sledge, I.J.; Príncipe, J.C. Analysis of agent expertise in Ms. Pac-Man using value-of-information-based policies. IEEE Trans. Comput. Intell. Artif. Intell. Games 2018. [Google Scholar] [CrossRef]
- Sledge, I.J.; Emigh, M.S.; Príncipe, J.C. Guided policy exploration for Markov decision processes using an uncertainty-based value-of-information criterion. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2080–2098. [Google Scholar] [CrossRef]
- Stratonovich, R.L. On value of information. Izv. USSR Acad. Sci. Technical Cybern. 1965, 5, 3–12. [Google Scholar]
- Stratonovich, R.L.; Grishanin, B.A. Value of information when an estimated random variable is hidden. Izv. USSR Acad. Sci. Technical Cybern. 1966, 6, 3–15. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley and Sons: New York, NY, USA, 2006. [Google Scholar]
- Von Neumann, J.; Morgenstern, O. Theory of Games and Economic Behavior; Princeton University Press: Princeton, NJ, USA, 1953. [Google Scholar]
- Simon, H.A.; Ando, A. Aggregation of variables in dynamic systems. Econometrica 1961, 29, 111–138. [Google Scholar] [CrossRef]
- Courtois, P.J. Error analysis in nearly-completely decomposable stochastic systems. Econometrica 1975, 43, 691–709. [Google Scholar] [CrossRef]
- Pervozvanskii, A.A.; Smirnov, I.N. Stationary-state evaluation for a complex system with slowly varying couplings. Kibernetika 1974, 3, 45–51. [Google Scholar] [CrossRef]
- Gaitsgori, V.G.; Pervozvanskii, A.A. Aggregation of states in a Markov chain with weak interaction. Kibernetika 1975, 4, 91–98. [Google Scholar] [CrossRef]
- Teneketzis, D.; Javid, S.H.; Sridhar, B. Control of weakly-coupled Markov chains. In Proceedings of the IEEE Conference on Decision and Control (CDC), Albuquerque, NM, USA, 10–12 December 1980; pp. 137–142. [Google Scholar] [CrossRef]
- Delebecque, F.; Quadrat, J.P. Optimal control of Markov chains admitting strong and weak interactions. Automatica 1981, 17, 281–296. [Google Scholar] [CrossRef]
- Zhang, Q.; Yin, G.; Boukas, E.K. Controlled Markov chains with weak and strong interactions. J. Optim. Theory Appl. 1997, 94, 169–194. [Google Scholar] [CrossRef]
- Courtois, P.J. Decomposability, Instabilities, and Saturation in Multiprogramming Systems; Academic Press: New York, NY, USA, 1977. [Google Scholar]
- Aldhaheri, R.W.; Khalil, H.K. Aggregation and optimal control of nearly completely decomposable Markov chains. In Proceedings of the IEEE Conference on Decision and Control (CDC), Tampa, FL, USA, 13–15 December 1989; pp. 1277–1282. [Google Scholar] [CrossRef]
- Kotsalis, G.; Dahleh, M. Model reduction of irreducible Markov chains. In Proceedings of the IEEE Conference on Decision and Control (CDC), Maui, HI, USA, 9–12 December 2003; pp. 5727–5728. [Google Scholar] [CrossRef]
- Dey, S. Reduced-complexity filtering for partially observed nearly completely decomposable Markov chains. IEEE Trans. Signal Process. 2000, 48, 3334–3344. [Google Scholar] [CrossRef]
- Vantilborgh, H. Aggregation with an error of O(ϵ2). J. ACM 1985, 32, 162–190. [Google Scholar] [CrossRef]
- Cao, W.L.; Stewart, W.J. Iterative aggregation/disaggregation techniques for nearly uncoupled Markov chains. J. ACM 1985, 32, 702–719. [Google Scholar] [CrossRef]
- Koury, J.R.; McAllister, D.F.; Stewart, W.J. Iterative methods for computing stationary distributions of nearly completely decomposable Markov chains. SIAM J. Algebraic Discrete Methods 1984, 5, 164–186. [Google Scholar] [CrossRef]
- Barker, G.P.; Piemmons, R.J. Convergent iterations for computing stationary distributions of Markov chains. SIAM J. Algebraic Discrete Methods 1986, 7, 390–398. [Google Scholar] [CrossRef]
- Dayar, T.; Stewart, W.J. On the effects of using the Grassman-Taksar-Heyman method in iterative aggregation-disaggregation. SIAM J. Sci. Comput. 1996, 17, 287–303. [Google Scholar] [CrossRef]
- Phillips, R.; Kokotovic, P. A singular perturbation approach to modeling and control of Markov chains. IEEE Trans. Autom. Control 1981, 26, 1087–1094. [Google Scholar] [CrossRef]
- Peponides, G.; Kokotovic, P. Weak connections, time scales, and aggregation of nonlinear systems. IEEE Trans. Autom. Control 1983, 28, 729–735. [Google Scholar] [CrossRef]
- Chow, J.; Kokotovic, P. Time scale modeling of sparse dynamic networks. IEEE Trans. Autom. Control 1985, 30, 714–722. [Google Scholar] [CrossRef]
- Filar, J.A.; Gaitsgory, V.; Haurie, A.B. Control of singularly perturbed hybrid stochastic systems. IEEE Trans. Autom. Control 2001, 46, 179–180. [Google Scholar] [CrossRef]
- Deng, K.; Sun, Y.; Mehta, P.G.; Meyn, S.P. An information-theoretic framework to aggregate a Markov chain. In Proceedings of the American Control Conference (ACC), St. Louis, MO, USA, 10–12 June 2009; pp. 731–736. [Google Scholar] [CrossRef]
- Deng, K.; Huang, D. Model reduction of Markov chains via low-rank approximation. In Proceedings of the American Control Conference (ACC), Montreal, QC, Canada, 27–29 June 2012; pp. 2651–2656. [Google Scholar] [CrossRef]
- Vidyasagar, M. Reduced-order modeling of Markov and hidden Markov processes via aggregation. In Proceedings of the IEEE Conference on Decision and Control (CDC), Atlanta, GA, USA, 15–17 December 2010; pp. 1810–1815. [Google Scholar] [CrossRef]
- Vidyasagar, M. A metric between probability distributions on finite sets of different cardinalities and applications to order reduction. IEEE Trans. Autom. Control 2012, 57, 2464–2477. [Google Scholar] [CrossRef]
- Zangwill, W.I. Nonlinear Programming: A Unified Approach; Prentice-Hall: Upper Saddle River, NJ, USA, 1969. [Google Scholar]
- Treves, A.; Panzeri, S. The upward bias in meausres of information derived from limited data samples. Neural Comput. 1995, 7, 399–407. [Google Scholar] [CrossRef]
- Kato, T. Perturbation Theory for Linear Operators; Springer-Verlag: New York, NY, USA, 1966. [Google Scholar]
Figure 1.
Depiction of the comparison process for exact, binary aggregation of a nine-state Markov chain. The transition matrix associated with the low-order, three-state Markov chain cannot be directly compared to the transition matrix of the high-order, nine-state chain for general measures g. For example, we may want to compare the fifth row of , , which is highlighted in green, with the second row of , : , which is highlighted in purple. To facilitate this comparison, we consider a joint model whose accumulation matrix is of the proper size for comparison against . when multiplied with the binary partition matrix equals the low-order transition matrix . It can be seen that the accumulation matrix of the joint model encodes all of the dynamics of . This relationship ensures that is actually comparing the dynamics of and . has been automatically padded with zero entries, by way of the exact aggregation process developed in Section 3.1, to ensure that it is of the same size as . For this example, only the first, fourth, and eighth entries of any row in are relevant for the comparison of the entries in . Such entries lead to the maximal preservation of the information between and when using the negative, modified Kullback–Leibler divergence for g.
Figure 1.
Depiction of the comparison process for exact, binary aggregation of a nine-state Markov chain. The transition matrix associated with the low-order, three-state Markov chain cannot be directly compared to the transition matrix of the high-order, nine-state chain for general measures g. For example, we may want to compare the fifth row of , , which is highlighted in green, with the second row of , : , which is highlighted in purple. To facilitate this comparison, we consider a joint model whose accumulation matrix is of the proper size for comparison against . when multiplied with the binary partition matrix equals the low-order transition matrix . It can be seen that the accumulation matrix of the joint model encodes all of the dynamics of . This relationship ensures that is actually comparing the dynamics of and . has been automatically padded with zero entries, by way of the exact aggregation process developed in Section 3.1, to ensure that it is of the same size as . For this example, only the first, fourth, and eighth entries of any row in are relevant for the comparison of the entries in . Such entries lead to the maximal preservation of the information between and when using the negative, modified Kullback–Leibler divergence for g.

Figure 2.
Depictions of the various models when using binary-valued partitions for the transition matrices in Figure 1. In (a), we show the transition model for a high-order, nine-state Markov chain (right) and its low-order, three-state transition model representation (left) after the aggregation process. The numbers along the edges represent the probabilities of transitioning to and from pairs of states. In (b), we show the joint model. The vertices of the joint model represent states in both the high-order and low-order chains. The edges between state pairs in both the high- and low-order chains, which are depicted using dashed lines, are removed. In the joint model, edges are inserted to connect states in the high-order chain with those in the low-order chain, thereby providing the state aggregation. Note that the edge weights in the joint model are unknown a priori and must be uncovered.
Figure 2.
Depictions of the various models when using binary-valued partitions for the transition matrices in Figure 1. In (a), we show the transition model for a high-order, nine-state Markov chain (right) and its low-order, three-state transition model representation (left) after the aggregation process. The numbers along the edges represent the probabilities of transitioning to and from pairs of states. In (b), we show the joint model. The vertices of the joint model represent states in both the high-order and low-order chains. The edges between state pairs in both the high- and low-order chains, which are depicted using dashed lines, are removed. In the joint model, edges are inserted to connect states in the high-order chain with those in the low-order chain, thereby providing the state aggregation. Note that the edge weights in the joint model are unknown a priori and must be uncovered.

Figure 3.
Depiction of the comparison process for approximate, probabilistic aggregation of a nine-state Markov chain. Here, we want to compare the second row of the high-order transition matrix with the first row of a potential low-order stochastic matrix . We show the transition matrix associated with a nine-state Markov chain on the left; four state clusters are visible along the main diagonal. The corresponding low-order transition matrix for a four-state chain is given in the right. As before, comparisons between and occur by comparing rows of with rows of . can be found via the joint model weight matrix and the probabilistic partition : , where , . The least expect-ed distortion between the high-order and low-order transition matrices is determined by way of and . When performing exact aggregation, the dynamics of are directly encoded in . is only used to determine which columns of can be ignored. For approximate aggregation, the dynamics of are split between and . This is because each state in the high-order model can have the chance to map to multiple states in the low-order model.
Figure 3.
Depiction of the comparison process for approximate, probabilistic aggregation of a nine-state Markov chain. Here, we want to compare the second row of the high-order transition matrix with the first row of a potential low-order stochastic matrix . We show the transition matrix associated with a nine-state Markov chain on the left; four state clusters are visible along the main diagonal. The corresponding low-order transition matrix for a four-state chain is given in the right. As before, comparisons between and occur by comparing rows of with rows of . can be found via the joint model weight matrix and the probabilistic partition : , where , . The least expect-ed distortion between the high-order and low-order transition matrices is determined by way of and . When performing exact aggregation, the dynamics of are directly encoded in . is only used to determine which columns of can be ignored. For approximate aggregation, the dynamics of are split between and . This is because each state in the high-order model can have the chance to map to multiple states in the low-order model.

Figure 4.
Depictions of the various models for the transition matrices in Figure 3 when using probabilistic partitions. In (a), we show the transition model for a high-order, nine-state Markov chain (right) and its low-order, four-state transition model representation (left) after the approximate aggregation process; In (b), we show the joint model defined by and a relatively low value of for this example. As before, eacht edge in both chains is removed and mappings between states in the two chains are established. For probabilistic partitions, each state in the high-order chain has the chance to map to more than one state in the low-order chain. This contrasts with the binary-valued partition case, where each state in the high-order chain could only be associated with a single state in the low-order chain.
Figure 4.
Depictions of the various models for the transition matrices in Figure 3 when using probabilistic partitions. In (a), we show the transition model for a high-order, nine-state Markov chain (right) and its low-order, four-state transition model representation (left) after the approximate aggregation process; In (b), we show the joint model defined by and a relatively low value of for this example. As before, eacht edge in both chains is removed and mappings between states in the two chains are established. For probabilistic partitions, each state in the high-order chain has the chance to map to more than one state in the low-order chain. This contrasts with the binary-valued partition case, where each state in the high-order chain could only be associated with a single state in the low-order chain.

Figure 5.
An illustration of the phase change property when the Lagrange multiplier is increased above three critical values. For , all of the states in the original chain are grouped together. As is slightly increased beyond this upper threshold, a new state group emerges, as we highlight on the left-hand side of the figure. For any , only two state groups are formed. As is increased to and , three and four state groups are formed, respectively; these results are shown in the middle and right-hand side of the figure. The “optimal” value of , predicted by our perturbation-theory results, is close to . This yields a parsimonious aggregation where the state-groups are compact and well separated. For , the original chain is over-partitioned: near-coincident clusters are defined in . The value of information hence starts to fit more to the noise in the state transitions than to the well-defined state groupings as is increased beyond the next critical point after the ‘optimal’ value.
Figure 5.
An illustration of the phase change property when the Lagrange multiplier is increased above three critical values. For , all of the states in the original chain are grouped together. As is slightly increased beyond this upper threshold, a new state group emerges, as we highlight on the left-hand side of the figure. For any , only two state groups are formed. As is increased to and , three and four state groups are formed, respectively; these results are shown in the middle and right-hand side of the figure. The “optimal” value of , predicted by our perturbation-theory results, is close to . This yields a parsimonious aggregation where the state-groups are compact and well separated. For , the original chain is over-partitioned: near-coincident clusters are defined in . The value of information hence starts to fit more to the noise in the state transitions than to the well-defined state groupings as is increased beyond the next critical point after the ‘optimal’ value.

Figure 6.
Value-of-information-based aggregation for a 9-state Markov chain with four discernible state groups. We show the original stochastic matrix with the partitions overlaid for four critical values of . We also show the resulting aggregation , which, in each case, approximately mimics the dynamics of the original stochastic matrix.
Figure 6.
Value-of-information-based aggregation for a 9-state Markov chain with four discernible state groups. We show the original stochastic matrix with the partitions overlaid for four critical values of . We also show the resulting aggregation , which, in each case, approximately mimics the dynamics of the original stochastic matrix.

Figure 7.
Value-of-information-based aggregation for a 9-state Markov chain with one discernible state group and six outlying states. We show the original stochastic matrix with the partitions overlaid for four critical values of . We also show the resulting aggregation , which, in each case, approximately mimics the dynamics of the original stochastic matrix.
Figure 7.
Value-of-information-based aggregation for a 9-state Markov chain with one discernible state group and six outlying states. We show the original stochastic matrix with the partitions overlaid for four critical values of . We also show the resulting aggregation , which, in each case, approximately mimics the dynamics of the original stochastic matrix.

Figure 8.
Expected distortion (blue curves) and cross-entropy (red curves) plots for the aggregation results in Figure 6, shown in (a), and Figure 7, shown in (b). For both (a,b), the large, left-most plot shows the expected distortion as a function of the number of state groups m after convergence has been achieved. The “knee” of the plot in (a) is given for , while for (b) it is at . These “knee” regions correspond to the “optimal” number of state groups as returned by our perturbation-theoretic criterion. They indicate where there are diminishing returns for including more aggregated state groups. The smaller four plots in (a,b) highlight the change in the expected distortion and cross-entropy as a function of the number of alternating-update iterations. These plots highlight a rapid stabilization of the update process.
Figure 8.
Expected distortion (blue curves) and cross-entropy (red curves) plots for the aggregation results in Figure 6, shown in (a), and Figure 7, shown in (b). For both (a,b), the large, left-most plot shows the expected distortion as a function of the number of state groups m after convergence has been achieved. The “knee” of the plot in (a) is given for , while for (b) it is at . These “knee” regions correspond to the “optimal” number of state groups as returned by our perturbation-theoretic criterion. They indicate where there are diminishing returns for including more aggregated state groups. The smaller four plots in (a,b) highlight the change in the expected distortion and cross-entropy as a function of the number of alternating-update iterations. These plots highlight a rapid stabilization of the update process.

Figure 9.
Value-of-information-based aggregation for a 9-state Markov chain with three discernible state groups (top row) and two discernible state groups (bottom row). The left-most column shows the original stochastic matrices . The middle column gives the partitions found when using a Shannon mutual information constraint for the expected-distortion objective function. The right-most column gives the partitions found when using a Shannon entropy constraint for the expected-distortion objective function. When using Shannon entropy, several columns of the partition matrix are duplicated for high values of , leading to an incorrect aggregation of states.
Figure 9.
Value-of-information-based aggregation for a 9-state Markov chain with three discernible state groups (top row) and two discernible state groups (bottom row). The left-most column shows the original stochastic matrices . The middle column gives the partitions found when using a Shannon mutual information constraint for the expected-distortion objective function. The right-most column gives the partitions found when using a Shannon entropy constraint for the expected-distortion objective function. When using Shannon entropy, several columns of the partition matrix are duplicated for high values of , leading to an incorrect aggregation of states.

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Sledge, I.J.; Príncipe, J.C. Reduction of Markov Chains Using a Value-of-Information-Based Approach. Entropy 2019, 21, 349. https://doi.org/10.3390/e21040349
AMA Style
Sledge IJ, Príncipe JC. Reduction of Markov Chains Using a Value-of-Information-Based Approach. Entropy. 2019; 21(4):349. https://doi.org/10.3390/e21040349
Chicago/Turabian StyleSledge, Isaac J., and José C. Príncipe. 2019. "Reduction of Markov Chains Using a Value-of-Information-Based Approach" Entropy 21, no. 4: 349. https://doi.org/10.3390/e21040349
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.