
Group Theory of Syntactical Freedom in DNA Transcription and Genome Decoding
by
 , , , , and
, , , , and
Michel Planat
1,*,† ,
,
Marcelo M. Amaral
2,† ,
,
Fang Fang
2,†,
David Chester
2,†,
Raymond Aschheim
2,† and
Klee Irwin
2,† 1
Institut FEMTO-ST CNRS UMR 6174, Université de Bourgogne-Franche-Comté, F-25044 Besançon, France
2
Quantum Gravity Research, Los Angeles, CA 90290, USA
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Curr. Issues Mol. Biol. 2022, 44(4), 1417-1433; https://doi.org/10.3390/cimb44040095
Submission received: 21 February 2022
/
Revised: 19 March 2022
/
Accepted: 20 March 2022
/
Published: 22 March 2022
(This article belongs to the Special Issue Next-Generation Sequencing (NGS) Technique and Personalized Medicine)
Abstract
:Transcription factors (TFs) are proteins that recognize specific DNA fragments in order to decode the genome and ensure its optimal functioning. TFs work at the local and global scales by specifying cell type, cell growth and death, cell migration, organization and timely tasks. We investigate the structure of DNA-binding motifs with the theory of finitely generated groups. The DNA ‘word’ in the binding domain—the motif—may be seen as the generator of a finitely generated group on four letters, the bases A, T, G and C. It is shown that, most of the time, the DNA-binding motifs have subgroup structures close to free groups of rank three or less, a property that we call ‘syntactical freedom’. Such a property is associated with the aperiodicity of the motif when it is seen as a substitution sequence. Examples are provided for the major families of TFs, such as leucine zipper factors, zinc finger factors, homeo-domain factors, etc. We also discuss the exceptions to the existence of such DNA syntactical rules and their functional roles. This includes the TATA box in the promoter region of some genes, the single-nucleotide markers (SNP) and the motifs of some genes of ubiquitous roles in transcription and regulation.
1. Introduction
In his recent paper, Klee Irwin writes “Reality would be non-deterministic, not because it is random, but because it is a code—a finite set of irreducible symbols and syntactical rules. 0ur definition of information is meaning conveyed by symbolism. And expressions of code or language are strings of symbols allowed by syntax—ordering rules with syntactical freedom.” [1].
Our last papers focused on the relevance of free groups in the encoding of the secondary structure of proteins [2] and in the encoding of tonal music and poetry [3].
In this present contribution, the concept of syntactical freedom is associated with that of a free group in the encoding of strings of symbols—the motifs of DNA transcription. It is shown for the first time that most transcription factors, but not all, have motifs where the DNA letters in the motif form a finitely generated group whose structure is close to a free group. The exceptions rely either on a specific functional role of the DNA sequence under investigation or a potential dysfunction in the transcription of the gene, resulting in disease.
A few definitions in the domain of genetics that we use in the paper are as follows:
Sequence motif An amino-acid sequence pattern that is related to a biological function or a gene. The motif is sometimes called a ‘consensus sequence’.
DNA-binding domain A folded protein domain that contains a structural motif that recognizes double- or single-stranded DNA.
Transcription factor A sequence-specific DNA-binding factor, or transcription factor, is a protein that controls the rate of transcription of a gene from DNA to messenger RNA by binding to a specific DNA sequence. There are approximately 1600 binding domains in the human genome that function as transcription factors. Classes of DNA-binding domains of transcription factors also exist. The most common are zinc-coordinating DNA-binding domains, helix-loop-helix or helix-turn-helix motifs, basic leucine zipper domains and homeobox domains (playing critical roles in the regulation of development). A classification of human transcription factors and their structural motifs is in References [4,5,6].
Exon A part of a gene that encodes a part of the mature RNA produced by that gene after removing all introns (the non-coding regions of RNA transcript) by RNA splicing.
Promoter A sequence of DNA in which proteins initiate the transcription of a single RNA from the DNA downstream of it. The TATA box is a sequence found in the core promoter region of some genes in archaea and eukaryotes.
Zinc finger A small protein structural motif containing one or more zinc ions in order to stabilize the protein fold.
Protein isoform A set of highly similar proteins may originate from a single gene. This process is regulated by the alternative splicing of mRNA. In this process, particular exons of a gene may be included within or excluded from the final, processed messenger RNA (mRNA) produced from that gene. Alternative splicing and the multi-exonic genes are a common feature in eukaryotes.
2. Materials and Methods
2.1. Finitely Generated Groups
In the domain of algebra, a group is a set equipped with an operation between every pair of elements of the set that is associative, has an identity element, and every element has an inverse. The elements of a group may be numbers or other structures.
One familiar group is the set of relative integers, together with the addition as the group law. Notice that has infinite elements. The addition in is commutative, not a general property for other groups.
The groups under consideration in this paper have elements that are words on four letters A, T, G and C—the bases in DNA—and the group law is the product. In the context of transcription factors (TFs), a motif fully describes the group. For example, taking only two letters/bases A and T and a relation/motif rel(A,T) = TATA, the group is of the finitely generated type and the mathematical notation is , in which the motif equals the identity element I. Infinite elements exist in . The group is non-commutative and contains a wealth of symmetries. One useful method for investigating them consists of two important concepts.
The first one is the concept of a free group on two generators with no explicit relation (but not forgetting the relations following from the axioms of a group: ). The second concept is that of a conjugacy class of subgroups. Two elements a and b belong to the same class if they are conjugate, meaning that a and belong to the same class for every .
The finitely generated group with the relation rel(A,T) = TATA may be characterized by the number of conjugacy classes at each index ] with the sequence . A signature of the group is also shared by the group of ‘dessins d’enfants’ in [7]—which the reader may consult for an introduction to the field of finitely generated groups and the related graphs, topology and geometry.
2.2. Free Groups and Their Conjugacy Classes
Let be the free group on r generators. Following a theorem derived by Hall in 1949 [8], the number of subgroups of index d in is
leading to the number Isoc of connected d-fold coverings of a graph X (i.e., the number of conjugacy classes of subgroups in the fundamental group of X) is as follows [9] (Theorem 3.2, p. 84),
where denotes the number-theoretic Möbius function.
We are interested in the cardinality sequence (card seq) of conjugacy classes for subgroups of a finitely generated group with a relation (rel) given by the sequence motif. Most of the time, the DNA motif in the transcription factor is close to that of a free group , with being the number of distinct bases involved in the motif. However, the finitely generated group , or , or (where the are taken in the four bases A, T, G, C and rel is the motif) is not the free group , or , or . The closeness of to can be checked in the finite range of indices of the card seq.
2.3. Content of the Paper
The structure of the TATA box in the core promoter region of many eukaryotes is not close to that of a free group. Remarkably, the card seq of for the TATA box is close to that of the Hecke group [10]. The case corresponds to the modular group , which is the fundamental group of the trefoil knot manifold . The Hecke group , with , is the discrete group generated by , , where with , , , , etc. In Section 3.1, it is shown that the card seq for motifs in the standard TATA box corresponds to or and that, in the case of a Gilbert’s syndrome, it is only approximate or corresponds to , .
In the same section, we investigate single-nucleotide polymorphisms (SNPs) of some genes. In the case of SNP markers involving 3 bases, the fit of the card seq to that of the free group is obtained, or not. The fit of the card seq of the selected SNP to that of is well correlated to a lower risk of disease.
In Section 3.4, we analyze the binding domains and the card seq associated with motifs of the immediately early genes Fos, EGR1 and Myc. In such cases, the card seq of the group , taken with the relation as the motif, is that of a free group (in the finite range of indices). Most of the time, the motif of a transcription factor for a gene leads to the card seq of a . This statement follows from an almost exhaustive investigation of transcription factors found in the databases defined in References [4,6].
However, it is also important to investigate the transcription factors with a group structure away from a free group. This is done in Section 3.5 with the claim that the lack of syntactical freedom (i.e., that the card seq of the gene is not that of a free group) is a marker of potential dysfunction of the gene through mutations or isoforms.
In Section 4, we show that group theoretical freedom correlates to the aperiodicity of motifs when the latter are seen as substitution sequences.
In the Conclusions, we offer some roads of progress in the connection of group theory to genetics.
3. Results
3.1. The TATA Box, the Hecke Groups and More
The TATA box (also called the Goldberg–Hogness box) is a DNA sequence located in the core promoter region of genes in many eukaryotes, as well in archaea [11]. The TATA box is a non-coding sequence whose name comes from the fact that it contains a consensus sequence with repeating T and A base pairs [12,13]. The TATA box is a component of eukaryotic promoters in which it initiates the transcription of TATA-containing genes. The TATA box binds to the TATA-binding protein (TBP) and some other transcription factors. TBP binds to the minor groove of the TATA box via a region of antiparallel sheets in the protein.
The regulation of gene transcription by transcription factors depends on the gene and is governed by the RNA polymerase II (PolII) transcription complex. In the core promoter of a typical PolII, they are key elements such as a TATA box.
Mutations such as insertions, deletions and point mutations to this consensus sequence can result in phenotypic changes. These changes can then be related to diseases such as gastric cancer, blindness, immunosuppression, Gilbert’s syndrome, etc. [12].
3.2. Gilbert’s Syndrome
Gilbert’s syndrome is a genetic polymorphism associated with the gene UGTIA1, a phase II drug-metabolizing enzyme, which is essential in the metabolism of bilirubin and other drugs. The core promoter in UGTIA1 contains a TATA box located at position −28 with respect to the transcriptional start site [14]. A polymorphism with AT(TA)TAA (with l = 5 … 8) is common in all ethnic populations with l = 6 as the major allele. Minor alleles with have less UGTIA1 transcription efficiency, leading to Gilbert’s syndrome, neonatal jaundice and toxicity in cancer chemotherapy [14].
In Table 2, we look at the finitely generated groups , where rel is the consensus sequence in the TATA box. The first two rows are for a standard TATA box. For this case, the group is found to have the same cardinality structure of cc of subgroups as the group (the modular group) or the Hecke group . Rows 3 and 4 are for the TATA box in the core promoter of the UGTIA1 gene for normal subjects, while rows 7 and 8 are for subjects with a Gilbert’s syndrome. In the former case, the group has a cardinality structure of cc of subgroups corresponding to the Hecke groups and , while in the latter case, the cardinality structure of cc of subgroups fits that of the Hecke groups and only up to index 8. Thus, we find that Gilbert’s syndrome is associated with an imperfect fit of the group G to a Hecke group.
3.3. Single Nucleotide Polymorphism
The canonical form of TBP-binding sites, the TATA box, is the best-studied regulatory element among human gene promoters. Tables identifying single-nucleotide polymorphisms (SNPs) in the (gene-dependent) TATA box have been collected in Reference [15].
At present, there are approximately stored SNP markers that have been identified in the human genome and approximately potentially possible markers. Most of them are neutral and do not affect health in any way. Markers in protein-coding regions of genes may damage proteins but are uncorrectable by treatment or lifestyle changes. However, a large number of the variants that have been identified are located in non-protein-coding regions and are presumed to affect gene expression regulation [16]. Regulatory SNPs in the TATA regions have biomedical usefulness and are correctable by medication and/or lifestyle. Ref. [15] collects 126 known SNP markers in 7 tables. We made use of these tables to compute the finitely generated group whose relation (rel) is the marker; see Table 3. For simplicity, we only took SNP markers built from 3 bases (and the exceptional SNP marker with 2 bases). We made the cardinality sequence of cc of subgroups (card seq) explicit. The computed closeness of the finitely generated group to the free group correlates to a lower risk of illness. On the contrary, markers leading to a card seq away from that of indicate a potential higher risk of illness. The symbol * corresponds to the only two-base SNP marker in the table. In this case, the card seq is the same as the sequence for the fundamental group of 3-manifold . The latter manifold is the smallest volume closed 3-manifold and is non orientable [17].
As a way of example, we take SNP markers in the first section of Table 3 that correspond to potential tumors in reproductive organs. Five of them show a card seq away from that of the free group , and they also correspond to a potential higher risk of disease. The last two markers in the same section, whose card seq is close to that of , are expected to produce a lower risk of breast cancer. Similar conclusions are valid for the SNP markers in other sections of Table 3.
3.4. A Few DNA/Protein Complexes and Their Transcription Factors
As mentioned in the Introduction, most transcription factors have a binding domain whose finitely generated group has a subgroup signature equal to that of a free group of rank r, with corresponding to distinct letters. An almost exhaustive search has been performed by using the catalogs found in [4,6]. We first give details of our calculations for a few immediate early genes. Then, in Section 3.5, most found counterexamples are summarized.
3.4.1. Immediate Early Genes and Their Motifs
Immediate early genes (IEGs) are genes that are activated transiently and rapidly in response to a wide variety of cellular stimuli. They represent a standing response mechanism that is activated at the transcription level in the first round of response to stimuli, before any new proteins are synthesized. The earliest known and best characterized include c-fos, c-myc and c-jun, genes that were found to be homologous to retroviral oncogenes. IEGs are well known as early regulators of cell growth and differentiation signals. However, other findings suggest roles for IEGs in many other cellular processes as ‘gateways to genomic response’. Many IEG products are natural transcription factors or other DNA-binding proteins. Important classes of IEG products include secreted proteins, cytoskeletal proteins and receptor subunits.
Some IEGs such as ZNF268 and Arc have been implicated in learning, memory and long-term potentiation. Neuronal IEGs are used prevalently as a marker to track brain activities in the context of memory formation and the development of psychiatric disorders [18].
The group structure of the motifs of some IEGs in the Fos, EGR and Myc classes is summarized in Table 4.
3.4.2. The DNA-Binding Domain Fos
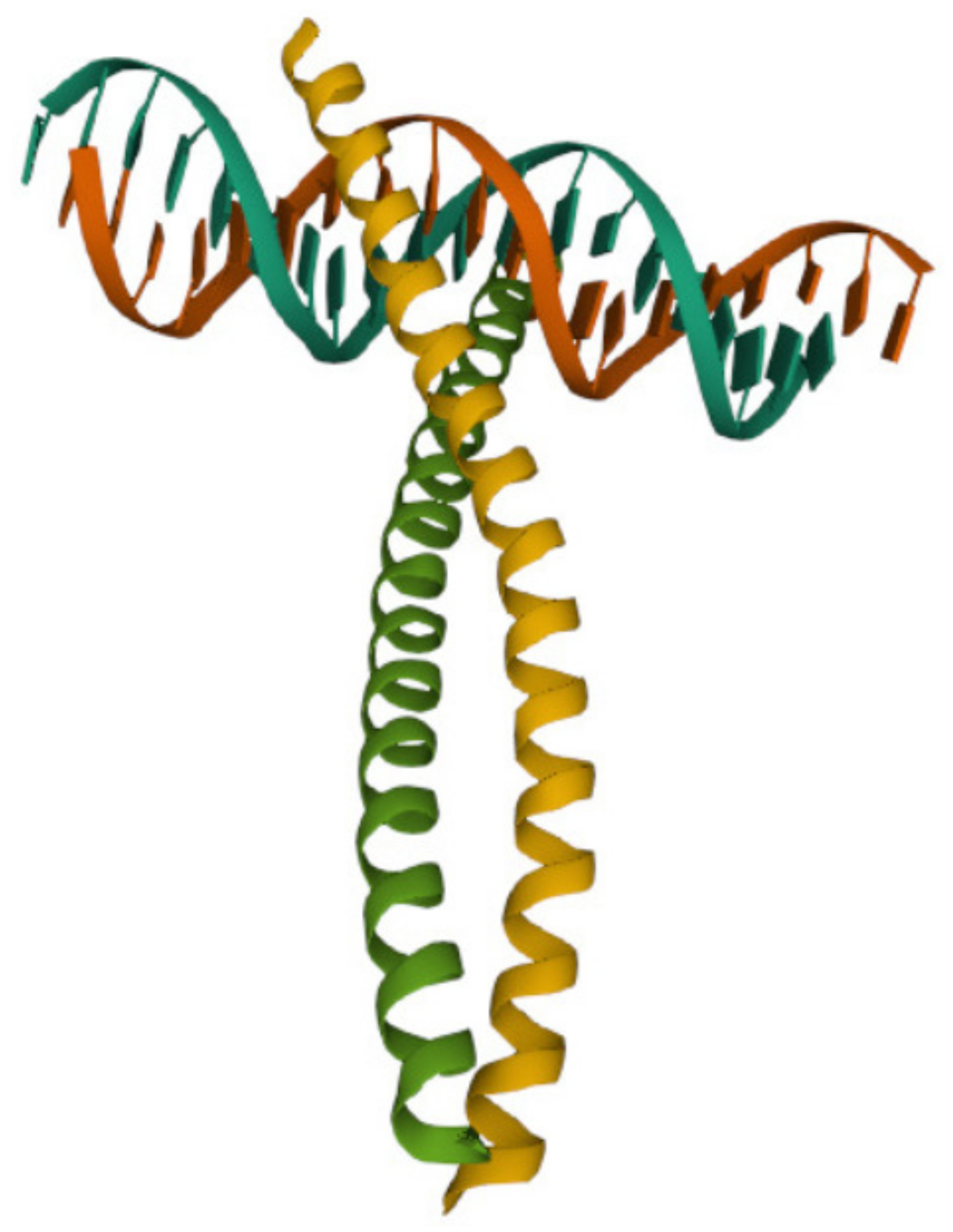
The Fos family (as well as the Jun family) are eukaryotic transcription factors that heterodimerize to form complexes binding elements such as 5-TGAGTCA-3 DNA elements [19]. The X-ray crystal structure was determined and the bZIP region (with 62 aa) of the c-Fos protein bound to DNA is available in the protein data bank as PDB: 1FOS. The protein secondary structure of this subunit of c-Fos protein consists of two alpha helices, as shown in Figure 1.
Let us consider the group on 4 letters with the relation . The card seq of up to index 6 is that of the free group of rank 3. One can use the coset enumeration (with the Todd–Coxeter procedure) to check that, up to index 6, the permutation groups organizing the cosets in the cc of groups and are the same. This shows that both groups are close, at least in the finite range of subgroups. However, and are not the same group. Incidentally, the group , with the joint relations of and , is close to the free group on two generators in the sense that the cardinality sequence of the cc of subgroups is that of , up to the higher index 9 that we could reach in our calculations.
Similarly, the finitely generated groups , where the relation is with the whole DNA chains rel = AATGGATGAGTCATAGGAGA (1FOS) or rel = TTCTCCTATGACTCATCCAT (1FOS_2) involved in the DNA/protein Fos complex (PDB:1F0S), have the same card seq as up to index 6.
3.4.3. The DNA-Binding Domain EGR1
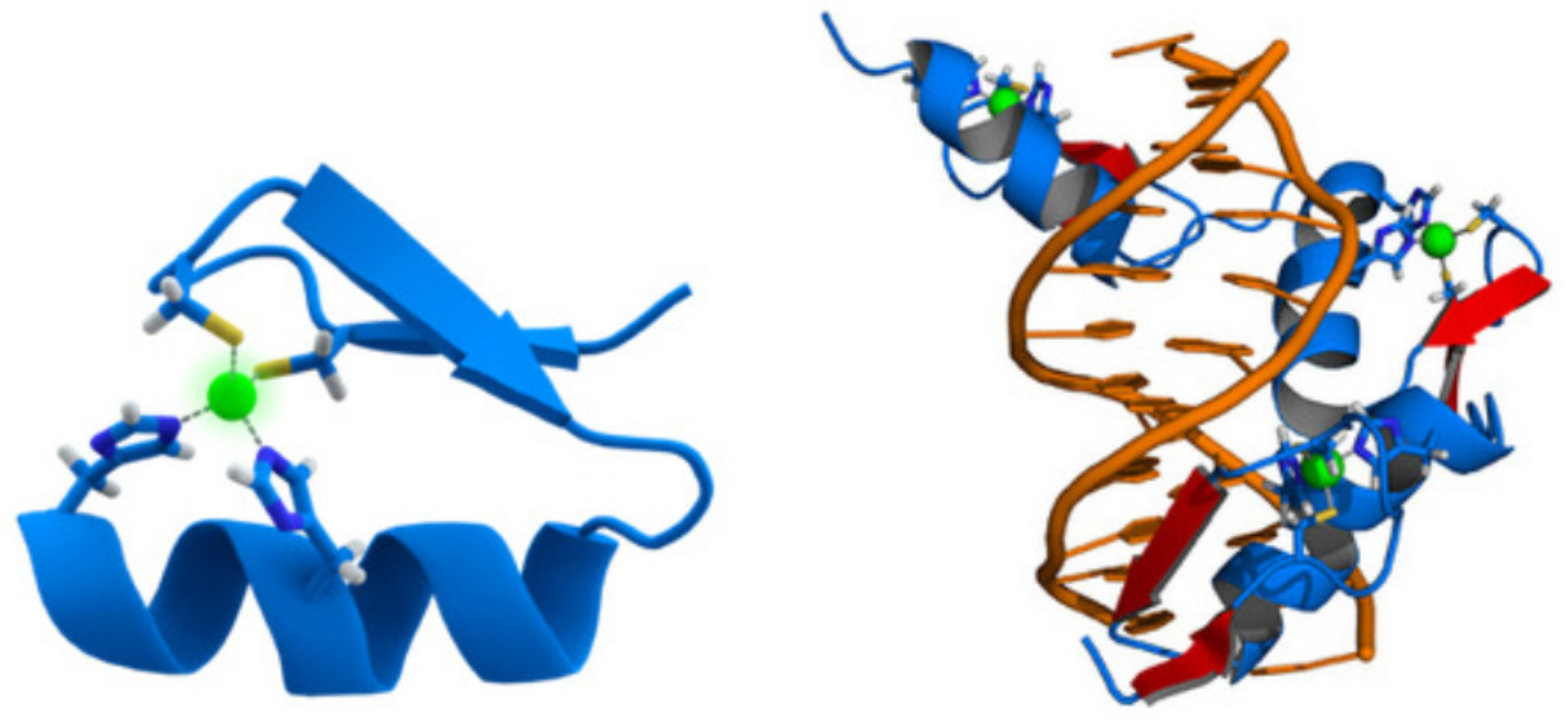
The DNA-binding domain EGR1 (for early growth response protein 1) is a mammalian transcription factor also called ZNF268 (the zinc finger protein 268). This is because the protein encoded by the EGR1 gene has the CysHis-like fold structure of a zinc finger, as shown in Figure 2. It binds to the motif -bind- [20], with bind = GCG(T/G)GGGCG.
The protein in the DNA-binding domain EGR1 is a nuclear protein and functions as a transcriptional regulator. The products of the target genes that it activates are required for differentiation and mitogenesis. When located in the brain, it has an essential role in memory formation and in brain neuron epigenetic reprogramming. An X-ray crystal structure is available in the protein data bank as PDB: 4R2A. In such a EGR1 DNA-binding domain, the DNA chains are rel = AGCGTGGGCGT and rel = TACGCCCACGC.
As for the Fos domain above, let us consider the group on 4 letters with the relation bind or . The card seq of up to index 6 is similar to that of the free group of rank 3. One can use the coset enumeration (with the Todd–Coxeter procedure) to check that, up to index 6, the permutation groups organizing the cosets in the cc of subgroups of and are the same. This shows that both groups are close, at least in the finite range of subgroups. However, and are not the same group. Again, the groups built from the joint relations of and are of rank 2, but the cardinality structure of cc of subgroups is not that of .
The group , with the joint relations of and , is close to the free group on two generators in the sense that the card seq is that of , up to the higher index 9 that we could reach in our calculations.
The early growth response protein 1 contains the chain of amino acids
GPLGS ERPYACPVESCDRRFSRSDELTRHIRIHTG QKPFQCRICMRNFSRSDHLTTHIRTHTG EKPFACDICGRKFARSDERKRHTKIHLR QKD.
The central portion of the protein contains aa decomposed into 3 zinc fingers with the following secondary structure (letter H is for the -helix segment, letter E is for the -sheet segment and letter C is for the random coil segment)
CCCEECCCCCCCCEECHHHHHHHHHHHHHH CCCEECCCCCCEECHHHHHHHHHHHHHH CCCEECCCCCCEECHHHHHHHHHHHHHC
Taking the former 3-letter chain as the relation of a finitely generated group on 3 letters (and rank 2), we get the cardinality sequence for the cc of its subgroups as , which fits the cardinality sequence of cc of subgroups of the free group only up to the index 4.
3.4.4. The DNA-Binding Domain Myc
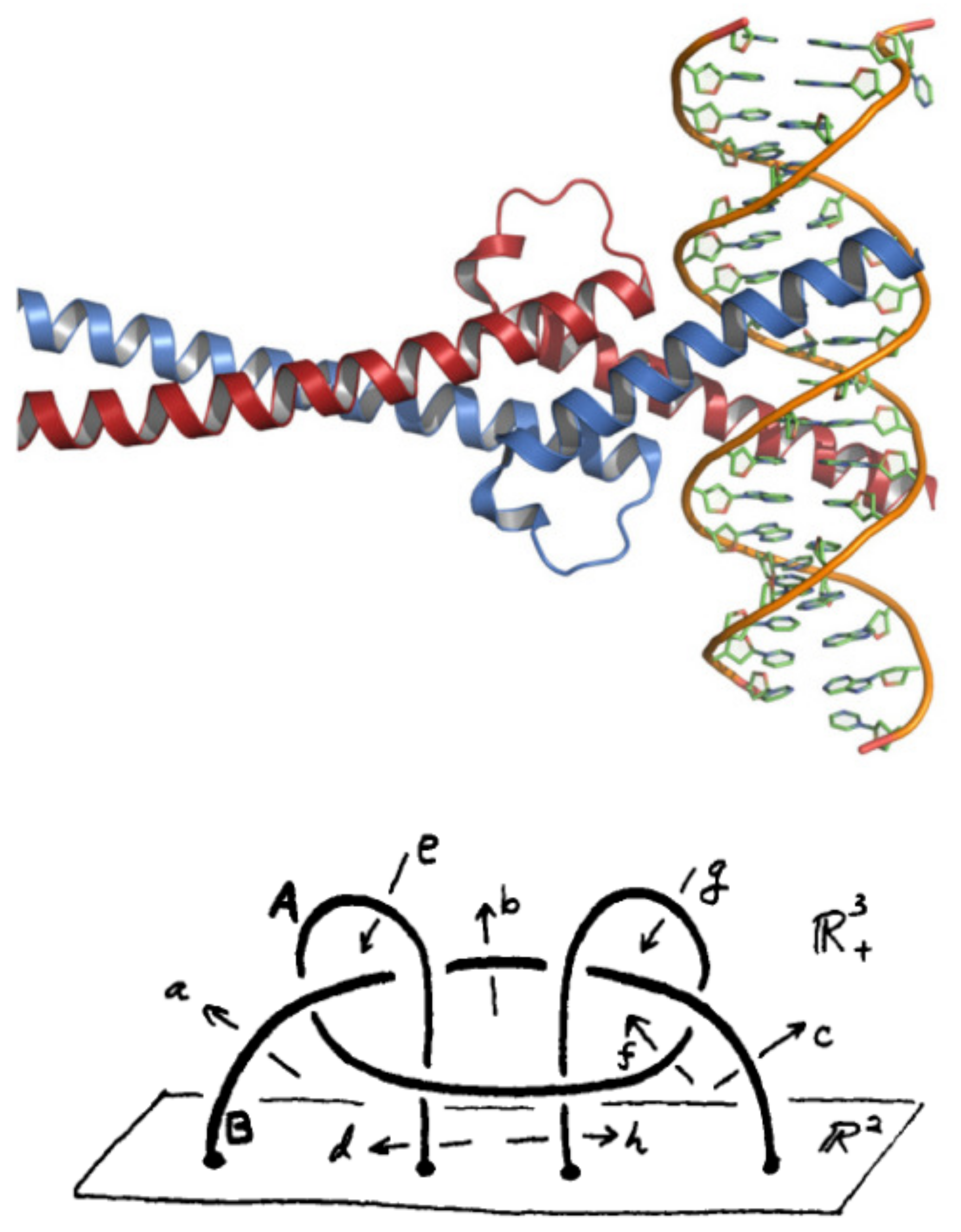
Myc proto-oncogene is a transcription factor encoding a nuclear phosphoprotein that plays a role in cell cycle progression, apoptosis and cellular transformation [21]. The protein contains a basic helix-loop-helix zipper (bHLHZ) structural motif. The encoded protein forms a heterodimer with the related transcription factor Max, as shown in Figure 3. Amplification of this gene is frequently observed in numerous human cancers. Translocations involving this gene are associated with Burkitt lymphoma and multiple myeloma in human patients.
The bHLHZ domain of Myc-Max binds to the common DNA (palindromic) target 5-CACGTG-3. In the protein data bank, the reference of the complex is PDB: 1NKP. The whole DNA chain is
Let us consider the group on 4 letters with the relation . The conjugacy classes of up to index 6 have card seq equal to that of the free group of rank 3. Again, one can use the coset enumeration (with the Todd–Coxeter procedure) to check that, up to index 6, the permutation groups organizing the cosets in the cc of groups and are the same. This shows that both groups are close, at least in the finite range of subgroups. However, and are not the same group. The group , with the joint relations of and , is close to the group defined in Figure 3 (Down). The group is the fundamental group of the union of two links A and B, which are not splittable. The proof is in Refs. [22] and ([23] p. 90) and follows from the fact that is not a free group. The group is close to in the sense that the cardinality sequence of the cc of subgroups is that of , up to the higher index 9 that we could reach in our calculations.
The non-closeness of to and the fact that is not free are distinguishing features of the Myc domain. It is tempting to associate such features with a potential abnormal replication.
3.5. Genes Whose Transcription Factors Have a Group Structure Away from a Free Group
We analyzed the group structure of motifs for some transcription factors that do not lead to free groups. This is shown in Table 5. A short account of the function or dysfunction of the corresponding genes is given in Table 6. It is observed that several transcription factors whose group structure is away from a free group have the same card seq. We conjecture that it is indicative of a related 3-dimensional structure of the corresponding domain, although these families do not fit the standard classification [6].
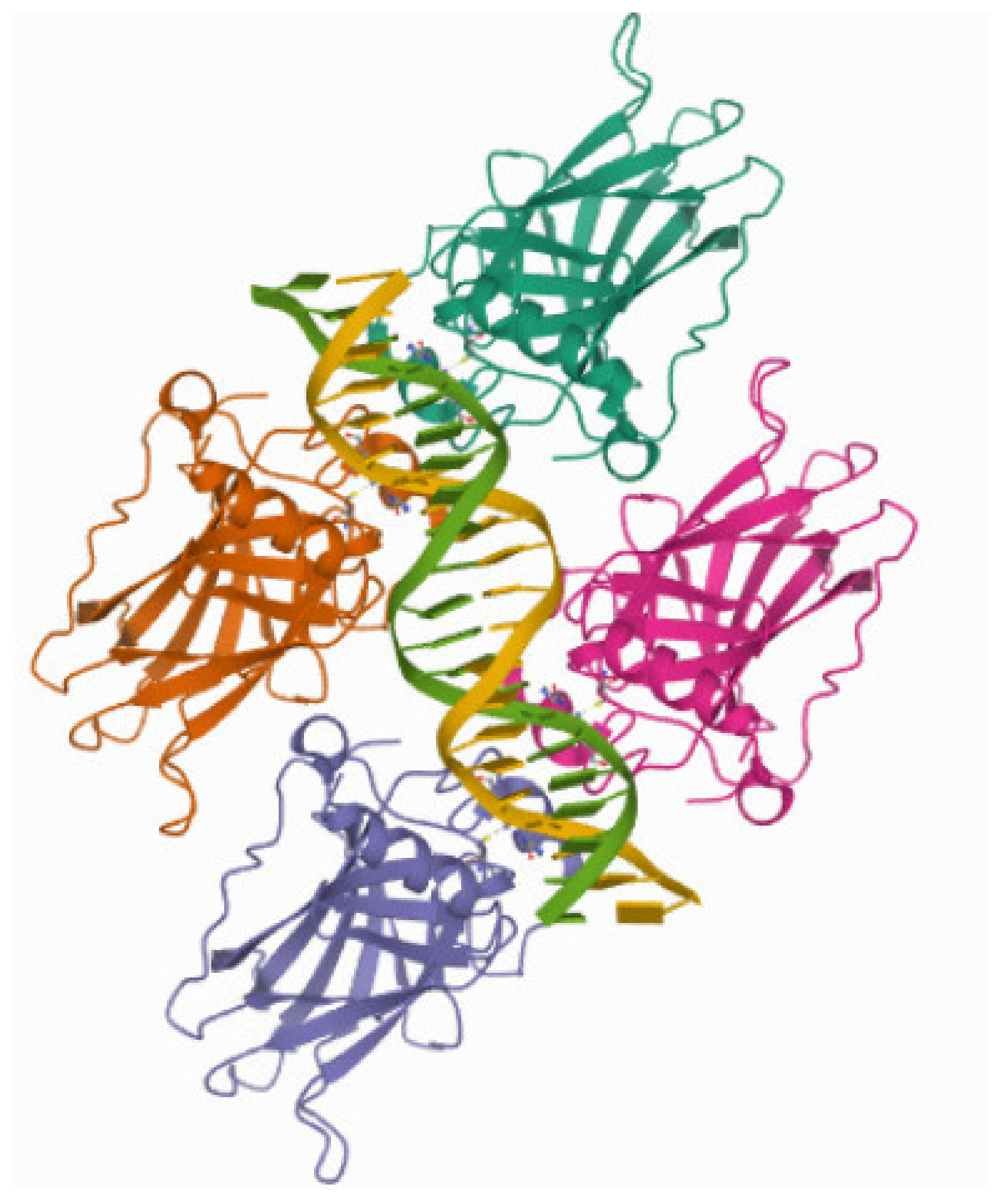
The DNA-Binding Domain of p53
Tumor protein p53 (also called tumor suppressor p53) has been called the guardian of the genome. The main reason behind this status is the critical role that p53 plays in preventing cancer development. p53’s role in tumor suppression is due to its ability to induce the apoptosis, cell cycle arrest and senescence of pre-cancerous cells. However, it also regulates other genes involved in metabolism.
According to [25], a motif for p53 is the DNA sequence CACATGTCCA. In our Table 5, the attached card seq in the finite range of indices is that of a group . However, there are motifs leading to a card seq associated with the free group or with other non-free groups that are not of type . This may be due to the fact that p53 has many isoforms to fill its role.
4. Discussion
According to Reference [1], aperiodicity is the correlate of syntactical freedom of ordering rules. How can we check this statement in the realm of transcription factors?
First, we introduce the concept of a general substitution rule in the context of free groups. A general substitution rule on a finite alphabet on r letters is an endomorphism of the corresponding free group [28] (Definition 4.1). The endomorphism property means the two relations and , for any .
A special role is played by the subgroup of automorphisms of . We introduce the map from to the Abelian group in order to investigate the substitution rule with the tools of matrix algebra.
The map induces a homomorphism . Under M, maps to the general linear group of matrices with integer entries . Given , there is a unique mapping that makes the map diagram commutative [28] (p. 68). The substitution matrix of may be specified by its elements at row i and column j as follows
We will apply this approach to binding motifs of transcription factors. The binding motif rel in the finitely presented group is split into appropriate segments so that with the substitution rules , , , .
We are interested in the sequence of finitely generated groups
whose card seq is the same at each step l and equal to the card seq of the free group (in the finite range of indices that it is possible to check with the computer).
Under these conditions, we will see that (group) syntactical freedom correlates to the aperiodicity of sequences.
4.1. Aperiodicity of Substitutions
There is no definitive classification of aperiodic order, the intermediate between crystalline order and strong disorder, but in the context of substitution rules, some criteria can be found. We need a few definitions.
A non-negative matrix is one whose entries are non-negative numbers. A positive matrix M (denoted ) has at least one positive entry. A strictly positive matrix (denoted ) has all positive entries. An irreducible matrix is one for which there exists a non-negative integer k with for each pair . A primitive matrix M is one such that is a strictly positive matrix for some k.
A Perron–Frobenius (PF for short) eigenvector v of an irreducible non-negative matrix is the only one whose entries are positive: . The corresponding eigenvalue is called the PF eigenvalue.
We will use the following criterion [28] (Corollary 4.3). A primitive substitution rule of substitution matrix with an irrational PF-eigenvalue is aperiodic.
A well-studied primitive substitution rule is the Fibonacci rule of substitution matrix and PF eigenvalue equal to the golden ratio [28] (Example 4.6). As expected, the irrationality of corresponds to the aperiodicity of the Fibonacci sequence.
The sequence of Fibonacci words is as follows:
The words have lengths equal to the Fibonacci numbers
It is straightforward to check that all finitely generated groups whose relations have a card seq whose elements are 1’s, as for the card seq of the free group . The Fibonacci sequence is our first example where group syntactical freedom correlates to aperiodicity.
We will now provide examples taken for transcription factors involving 2, 3 or 4 letters.
4.1.1. A Two-Letter Sequence for the Transcription Factor of Gene DBX in Drosophila Melanogaster
Let us consider the motif rel = TTTATTA for the gene DBX in drosophila melanogaster (fruit flies) [6] (MA0174.1). The roles of the DBX gene include neuronal specification and differentiation.
We split rel into two segments so that with the substitution maps , to produce the substitution sequence
The substitution matrix for this sequence is ; it is a primitive matrix of PF eigenvalue so that the sequence associated with the DBX factor is aperiodic.
Similarly to the Fibonacci generator rules, all finitely generated groups whose relations are have a card seq whose elements are 1’s as for the card seq of the free group .
The sequence for the DBX transcription factor is our second example where group syntactical freedom correlates to aperiodicity.
4.1.2. A Three-Letter Sequence for the Transcription Factor of Gene EGR1
The transcription factor of gene EGR1 was investigated in Section 3.4.1. The selected motif is rel = GCGTGGGCG. We split rel into two segments so that with the substitution maps , , to produce the substitution sequence:
The substitution matrix for this sequence is ; it is a primitive matrix (since ) whose eigenvalues follow from the vanishing of the polynomial . There are three real irrational roots , a,d . The PF eigenvalue is with an eigenvector of (positive) entries .
It follows that the selected sequence for the EGR1 gene is aperiodic.
All finitely generated groups whose relations are GGCG, have a card seq whose elements are those of the free group .
The sequence for the EGR1 transcription factor is our third example where group syntactical freedom correlates to aperiodicity.
4.1.3. A Four-Letter Sequence for the Transcription Factor of the Fos Gene
The transcription factor of gene Fos was investigated in Section 3.4.1. The selected motif is rel = TGAGTCA.
We split rel into two segments so that with the substitution maps , , , , to produce the substitution sequence
The substitution matrix for this sequence is . It is a primitive matrix () whose eigenvalues follow from the vanishing of the polynomial . There are two real eigenvalues and , as well as two complex conjugate eigenvalues .
The PF eigenvalue is with an eigenvector of (positive) entries 0.40211, 0.20861 ).
It follows that the selected sequence for the Fos gene is aperiodic.
All the finitely generated groups whose relations are:
which is the card seq of the free group .
The sequence for the Fos transcription factor is our fourth example where group syntactical freedom correlates to aperiodicity.
5. Conclusions
We made use of group theory for investigating transcription factors in genetics. Finite group theory plays a major role in the attempts to model the genetic code; see [29,30] and other references therein. Finitely generated groups (whose cardinality is infinite) are necessary to deal with the secondary structures of proteins [2]. It was already noted that many structures for the protein secondary codes tend to be close to free groups. The card seq for such codes is model-dependent. In the map from amino acids to proteins, the transcription factors play a critical role. The study of the group theoretical structure of TFs has been our goal in the present paper. The DNA motifs that serve as a relation for the corresponding groups are, in general, short sequences with around 10 amino acids. Taking random sequences instead of the gene-specific DNA sequences in TFs also leads to a majority of cases where the card seq of fp is close to a free group and less frequent cases where the card seq is away. However, motifs in TFs are codes with a particular meaning—the specific gene function or dysfunction. In this sense, we found it appropriate to use the concept of ‘syntactical freedom’ to qualify most TFs and to associate the lack of syntactical freedom with a potential source of illness. In our context, syntactical freedom means free groups and aperiodicity.
Potentially, there are many potential applications of our group theoretical method of TFs for characterizing genes with problematic mutations, such as cancer and Alzheimer’s disease. More work will be performed in the future.
Author Contributions
Conceptualization, M.P., F.F. and K.I.; methodology, M.P., D.C. and R.A.; software, M.P.; validation, R.A., F.F., D.C. and M.M.A.; formal analysis, M.P. and M.M.A.; investigation, M.P., D.C., F.F. and M.M.A.; writing—original draft preparation, M.P.; writing—review and editing, M.P.; visualization, F.F. and R.A.; supervision, M.P. and K.I.; project administration, K.I.; funding acquisition, K.I. All authors have read and agreed to the published version of the manuscript.
Funding
Funding was obtained from Quantum Gravity Research in Los Angeles, CA, USA.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Computational data are available from the authors.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Irwin, K. The code-theoretic axiom; the third ontology. Rep. Adv. Phys. Sci. 2019, 3, 39. [Google Scholar] [CrossRef]
- Planat, M.; Aschheim, R.; Amaral, M.M.; Fang, F.; Irwin, K. Quantum information in the protein codes, 3-manifolds and the Kummer surface. Symmetry 2020, 13, 1146. [Google Scholar] [CrossRef]
- Planat, M.; Aschheim, R.; Amaral, M.M.; Fang, F.; Irwin, K. Graph coverings for investigating non local structures in protein, music and poems. Science 2021, 3, 39. [Google Scholar] [CrossRef]
- Lambert, S.A.; Jolma, A.; Campitelli, L.F.; Das, P.K.; Yin, Y.; Albu, M.; Chen, X.; Talpale, J.; Hughes, T.R.; Weirauch, M.T. The human transcription factors. Cell 2018, 172, 650–665. Available online: http://www.edgar-wingender.de/huTF_classification.html (accessed on 1 September 2021).
- Wingender, E.; Schoeps, T.; Dönitz, J. TFClass: An expandable hierarchical classification of human transcription factors. Nucleic Acids Res. 2013, T1, D165–D170. [Google Scholar] [CrossRef] [PubMed]
- Sandelin, A.; Alkema, W.; Engström, P.; Wasserman, W.W.; Lenhard, B. JASPAR: An open-access database for eukaryotic transcription factor binding profiles. Nucleic Acids Res. 2004, 32, D91–D94. Available online: https://jaspar.genereg.net/ (accessed on 1 September 2021). [CrossRef] [Green Version]
- Planat, M.; Giorgetti, A.; Holweck, F. Saniga, M. Quantum contextual finite geometries from dessins d’enfants. Int. J. Geom. Meth. Mod. Phys. 2015, 12, 1550067. [Google Scholar] [CrossRef] [Green Version]
- Hall, M., Jr. Subgroups of finite index in free groups. Can. J. Math. 1949, 1, 187–190. [Google Scholar] [CrossRef]
- Kwak, J.H.; Nedela, R. Graphs and their coverings. Lect. Notes Ser. 2007, 17, 118. [Google Scholar]
- The Modular Group. Available online: https://en.wikipedia.org/wiki/Modular_group (accessed on 1 October 2021).
- Suzuki, Y.; Tsunoda, T.; Sese, J.; Taira, H.; Mizushima-Sugano, J.; Hata, H.; Ota, T.; Isogai, T.; Tanaka, T.; Nakamura, Y.; et al. Identification and characterization of the potential promoter regions of 1031 kinds of human genes. Genome Res. 2001, 11, 677–684. [Google Scholar] [CrossRef]
- TATA Box. Available online: https://en.wikipedia.org/wiki/TATA_box (accessed on 1 September 2021).
- Wang, Y.; Jensen, R.C.; Stumph, W.E. Role of TATA box sequence and orientation in determining RNA polymerase II/III transcription specificity. Nucleic Acids Res. 1996, 24, 3100–3106. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Buckley, D.; Wang, S.; Klaassen, C.D.; Zhong, X.B. Phenobarbital-Responsive Enhancer Module of the UGT1A1. Drug Metab. Disp. 2009, 37, 1978–1986. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chadaeva, I.V.; Ponomarenko, P.M.; Rasskazov, D.A.; Sharypova, E.B.; Kashina, E.V.; Zhechev, D.A.; Drachkova, I.A.; Arkova, O.V.; Savinkova, L.K.; Ponomarenko, M.P.; et al. Candidate SNP markers of reproductive potential are predicted by a significant change in the affinity of TATA-binding protein for human gene promoters. BMC Genom. 2018, 19, 16–38. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zerbino, D.R.; Wilder, S.P.; Johnson, N.; Juettemann, T.; Flicek, P.R. The ensembl Regulatory Build. Genome Biol. 2015, 16, 56. [Google Scholar] [CrossRef] [Green Version]
- Hodgson, C.D.; Weeks, J.R. Symmetries, Isometries and length spectra of closed hyperbolic three-manifolds. Exp. Math. 1994, 3, 261–274. [Google Scholar] [CrossRef]
- Gallo, F.T.; Katche, C.; Morici, J.F.; Medina, J.H.; Weisstaub, N.V. Immediate early genes, memory and psychiatric disorders: Focus on c-Fos, Egr1 and Arc. Front. Behav. Neurosci. 1998, 12, 79. [Google Scholar] [CrossRef] [PubMed]
- Glover, J.N.; Harrison, S.C. Crystal structure of the heterodimeric bZIP transcription factor c-Fos-c-Jun bound to DNA. Nature 1995, 373, 257–261. [Google Scholar] [CrossRef]
- Hashimoto, H.; Olanrewaju, Y.; Zheng, Y.; Wilson, G.G.; Zhang, X.; Cheng, X. Wilms tumor protein recognizes 5-carboxylcytosine within a specific DNA sequence. Genes Dev. 2019, 28, 2304–2313. [Google Scholar] [CrossRef] [Green Version]
- Nair, S.K.; Burley, S.K. X-ray structures of Myc-Max and Mad-Max recognizing DNA: Molecular bases of regulation by proto-oncogenic transcription factors. Cell 2003, 112, 193–205. [Google Scholar] [CrossRef] [Green Version]
- Zeeman, E.C. Linking spheres. Abh. Math. Sem. Univ. Hamburg 1960, 24, 149–153. [Google Scholar] [CrossRef]
- Rolfsen, D. Knots and Links; AMS Chelsea Publishing: Providence, RI, USA, 2000. [Google Scholar]
- Schaeffer, L.N.; Huchet-Dymanus, M.; Changeux, J.P. Implication of a multisubunit Ets-related transcription factor in synaptic expression of the nicotinic acetylcholine receptor. EMBO J. 1998, 17, 3078–3090. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Grimm, S.A.; Bushel, P.R.; Li, J.; Li, Y.; Bennett, B.D.; Lavender, C.A.; Ward, J.M.; Fargo, D.C.; Anderson, C.W.; et al. Revealing a human p53 universe. Nucl. Acids Res. 2018, 46, 8153–8167. [Google Scholar] [CrossRef] [Green Version]
- Nakamivhi, N.; Yoneda, Y. Transcription factors and drugs in the brain. Jpn J. Pharmacol. 2002, 89, 337–348. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Zhang, X.; Dantas Machado, A.C.; Ding, Y.; Chen, Z.; Qin, P.Z.; Rohs, R.; Chen, L. Structure of p53 binding to the BAX response element reveals DNA unwinding and compression to accommodate base-pair insertion. Nucleic Acids Res. 2013, 41, 8368–8376. [Google Scholar] [CrossRef] [PubMed]
- Baake, M.; Grimm, U. Aperiodic Order, Volume I: A Mathematical Invitation; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Planat, M.; Aschheim, R.; Amaral, M.M.; Fang, F.; Irwin, K. Complete quantum information in the DNA genetic code. Symmetry 2020, 12, 1993. [Google Scholar] [CrossRef]
- Planat, M.; Chester, D.; Aschheim, R.; Amaral, M.M.; Fang, F.; Irwin, K. Finite groups for the Kummer surface: The genetic code and quantum gravity. Quantum Rep. 2021, 3, 68–79. [Google Scholar] [CrossRef]
- Grandy, J.K. The three neurogenetic phases of human consciousness. J. Conscious Evol. 2018, 9, 24. [Google Scholar]
- Changeux, J.P. Allosteric receptors: From electric organ to cognition. Annu. Rev. Pharmacol. 2010, 50, 1–38. [Google Scholar] [CrossRef] [PubMed]
- Feinberg, T.E.; Mallatt, J. The evolutionary and genetic origin of consciousness in the Cambrian Period over 500 million years ago. Front. Psychol. 2013, 4, 667. [Google Scholar] [CrossRef] [Green Version]
- Amaral, M.M.; Fang, F.; Hammock, D.; Irwin, K. Geometric state sum models from quasicrystals. Foundations 2021, 1, 155–168. [Google Scholar] [CrossRef]
- Amaral, M.M.; Fang, F.; Aschheim, R.; Irwin, K. On the Emergence of Space Time and Matter from Model Sets. Preprint 2021, 2021110359. [Google Scholar] [CrossRef]
Figure 1.
The DNA-binding domain of the immediate early gene Fos. The name in the protein data bank is 1FOS.
Figure 1.
The DNA-binding domain of the immediate early gene Fos. The name in the protein data bank is 1FOS.

Figure 2.
(Left) Cartoon representation of the CysHis zinc finger motif, consisting of an -helix and an antiparallel -sheet. The zinc ion (green) is coordinated by two histidine residues and two cysteine residues. (Right) Cartoon representation of the protein ZNF268 (blue) containing three zinc fingers in complex with DNA (orange). The coordinating amino acid residues and zinc ions (green) are highlighted. The name of the DNA-binding domain in the protein data bank is 4R2A.
Figure 2.
(Left) Cartoon representation of the CysHis zinc finger motif, consisting of an -helix and an antiparallel -sheet. The zinc ion (green) is coordinated by two histidine residues and two cysteine residues. (Right) Cartoon representation of the protein ZNF268 (blue) containing three zinc fingers in complex with DNA (orange). The coordinating amino acid residues and zinc ions (green) are highlighted. The name of the DNA-binding domain in the protein data bank is 4R2A.

Figure 3.
(Up) Crystal structure of Myc and Max in complex with DNA. (Down) The link (which is supposed to control the binding domain Myc) is attached to the plane in the half-space . It is not splittable. This can be proven by checking that the fundamental group is not free [22] and ([23] p. 90). One gets , where (.,.) means the group theoretical commutator. The cardinality sequence of cc of subgroups of is .
Figure 3.
(Up) Crystal structure of Myc and Max in complex with DNA. (Down) The link (which is supposed to control the binding domain Myc) is attached to the plane in the half-space . It is not splittable. This can be proven by checking that the fundamental group is not free [22] and ([23] p. 90). One gets , where (.,.) means the group theoretical commutator. The cardinality sequence of cc of subgroups of is .

Figure 4.
Crystal structure of p53 binding domain. The reference number in the protein data bank is 4HJE.
Figure 4.
Crystal structure of p53 binding domain. The reference number in the protein data bank is 4HJE.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| r | d = 1 | d = 2 | d = 3 | d = 4 | d = 5 | d = 6 | d = 7 |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 2 | 1 | 3 | 7 | 26 | 97 | 624 | 4163 |
| 3 | 1 | 7 | 41 | 604 | 13,753 | 504,243 | 24,824,785 |
| 4 | 1 | 15 | 235 | 14,120 | 1,712,845 | 371,515,454 | 127,635,996,839 |
| 5 | 1 | 31 | 1361 | 334,576 | 207,009,649 | 268,530,771,271 | 644,969,015,852,641 |
Table 2.
Group structure of a TATA box. Column 1 is for the selected consensus sequence (rows 4 to 6 are for the TATA box in the core promoter of UGTIA1 gene). Column 2 is for the cardinality sequence (card seq) of conjugacy classes (cc) of subgroups in the finitely generated group whose relation (rel) is the consensus sequence (cons seq). Column 3 identifies the Hecke group , which is close to the group under consideration (based on its card seq of subgroups). Column 4 refers to some references in the literature. Bold digits feature the fit to a Hecke group.
Table 2.
Group structure of a TATA box. Column 1 is for the selected consensus sequence (rows 4 to 6 are for the TATA box in the core promoter of UGTIA1 gene). Column 2 is for the cardinality sequence (card seq) of conjugacy classes (cc) of subgroups in the finitely generated group whose relation (rel) is the consensus sequence (cons seq). Column 3 identifies the Hecke group , which is close to the group under consideration (based on its card seq of subgroups). Column 4 refers to some references in the literature. Bold digits feature the fit to a Hecke group.
| Rel: Cons Seq | Card Struct of cc of Subgroups | Group | Literature |
|---|---|---|---|
| TATAAAA | [6] (MA0108.1) | ||
| TATAAAAA | [13] | ||
| A(TA)TAA | [14] | ||
| A(TA)TAA | . | ||
| A(TA)TAA | . | ||
| A(TA)TAA | . |
Table 3.
Group analysis of a few known and candidate SNP markers (taken from [15]) Column 1 is for the selected gene. Column 2 is for the SNP marker. Column 3 is for the card seq for the finitely generated group whose relation (rel) is the marker. Column 4 is for the reference paper and the letter indicates the heuristic confidence level of the candidate SNP marker (in alphabetical order from the best (A) to the worst (E)). The computed closeness of the finitely generated group to the free group , most of time, correlates to a lower risk of illness, as described in [15]. The symbol * corresponds to the only two-base SNP marker in the table. The card seq is the same as the sequence for the fundamental group of 3-manifold . The latter manifold is the smallest volume closed 3-manifold and is non-orientable [17].
Table 3.
Group analysis of a few known and candidate SNP markers (taken from [15]) Column 1 is for the selected gene. Column 2 is for the SNP marker. Column 3 is for the card seq for the finitely generated group whose relation (rel) is the marker. Column 4 is for the reference paper and the letter indicates the heuristic confidence level of the candidate SNP marker (in alphabetical order from the best (A) to the worst (E)). The computed closeness of the finitely generated group to the free group , most of time, correlates to a lower risk of illness, as described in [15]. The symbol * corresponds to the only two-base SNP marker in the table. The card seq is the same as the sequence for the fundamental group of 3-manifold . The latter manifold is the smallest volume closed 3-manifold and is non-orientable [17].
| Gene | Rel: Marker | Card Seq of cc of Subgroups | Literature |
|---|---|---|---|
| ESR2 | TTAAAAGGAA | Table 1 in [15], B | |
| HSD17B1 | AGCCCAGAGC | ., A | |
| . | CAAGCCCAGA | ., A | |
| PGR | AAAGGAGCCG | ., A | |
| GSTM3 | GGGTATAAAG | ., E | |
| . | CCCCTCCCGC | ., C | |
| . | CCCTCCCGCT | . | ., C |
| IL1B | AAAACAGCGA | Table 2 in [15], A | |
| CYP2A6 | AAAGGCAAC | ., A | |
| DHFR | GGGACGAGGG | ., A | |
| . | GGACGAGGGG | . | ., A |
| LEP | GGGGCGGGA | Table 3 in [15], C | |
| GCG | TGCGCCTTGG | ., B | |
| GH1 | TATAAAAAGG | ] | ., E |
| . | GTATAAAAAG | . | ., D |
| . | GGTATAAAAA | . | ., E |
| . | AGGGCCCACA | ., A | |
| . | AAAGGGCCCC | ., A | |
| . | AAAGGGCCA | . | ., A |
| NOS2 | TCTTGGCTGC | Table 4 in [15], A | |
| TPI1 | ATATAAGTGG | ., B | |
| GJA5 | TATTAAACAC | ., E | |
| HBD | AAAAGGCAGG | Table 5 in [15], A | |
| F2 | AACCCAGAGG | ., A | |
| F8 | GGAAGAGGGA | * | Table 6 in [15], A |
| F3 | GCGCGGGGCA | ., A | |
| F11 | TTTTTAGTAA | . | ., D |
| . | TTTTTAGTAA | ., A | |
| . | AAGGAAATTT | ., A | |
| AR | GTGGAAGATT | Table 7 in [15], A | |
| . | CCACGACCCG | ., D | |
| MTHFR | TCCCTCCCA | ., A | |
| DMNT1 | TGTGTGGCCCG | . | ., A |
| . | GTGTGTGCCC | . | ., A |
| . | GACGAGCCCA | ., A | |
| NR5A1 | ACAAGAGAAA | ., A | |
| . | GGTGTGAGAG | ., A |
Table 4.
Group structure of motifs for transcription factors of immediately early genes Fos, EGR and Myc. Most of the time, the card seq of the group defined with the relation/motif is the free group (for a 3 letter motif) or (for a 4 letter motif). There are two exceptions for the EGR1 gene, depending on the selected motif, where the card seq corresponds to the modular group or the Baumslag–Solitar group , which is the fundamental group of the Klein bottle. The card seq for is in Table 2. The card seq for is .
Table 4.
Group structure of motifs for transcription factors of immediately early genes Fos, EGR and Myc. Most of the time, the card seq of the group defined with the relation/motif is the free group (for a 3 letter motif) or (for a 4 letter motif). There are two exceptions for the EGR1 gene, depending on the selected motif, where the card seq corresponds to the modular group or the Baumslag–Solitar group , which is the fundamental group of the Klein bottle. The card seq for is in Table 2. The card seq for is .
| Gene | Rel: Motif | Card Seq | Literature |
|---|---|---|---|
| Fos | TGAGTCA | [19] | |
| . | TGACTCA | [6], MA MA0099.2 | |
| EGR1 | GCGTGGGCG | [6], MA0162.1 | |
| . | CCGCCCCCG | ., MA0162.2 | |
| . | CCGCCCCCGC | ., . | |
| . | ACGCCCACGCA | ., MA0162.3 | |
| . | GGCCCACGC | . | ., MA0162.4 |
| EGR2 | CCGCCCACGC | . | ., MA0472.1 |
| . | ACGCCCACGCA | . | ., MA0472.2 |
| EGR3,EGR4 | ACGCCCACGCA | . | ., [ MA0732.1, MA0733.1] |
| Myc | CACGTG | [19] | |
| . | CGCACGTGGT | . | [6], MA0147.1 |
| . | CCCACGTGCTT | . | ., MA0147.2 |
| . | CCACGTGC | . | ., MA0147.3 |
| Mycn, Max::Myc, etc | GACCACGTGGT, etc. | . | ., [MA0104.1, etc.] |
Table 5.
Group structure of motifs for some transcription factors that are not leading to free groups. The card seq for is ; for it is . The card seq for is already in Figure 3 as . The card seq for is ]; for , it is ; for , it is ; for , it is . The card seq for is . The index i in refers to the rank of the group under examination. The three sections are for motifs on 2, 3 and 4 letters, respectively.
Table 5.
Group structure of motifs for some transcription factors that are not leading to free groups. The card seq for is ; for it is . The card seq for is already in Figure 3 as . The card seq for is ]; for , it is ; for , it is ; for , it is . The card seq for is . The index i in refers to the rank of the group under examination. The three sections are for motifs on 2, 3 and 4 letters, respectively.
| Gene | Rel: Motif | Card Seq | Literature |
|---|---|---|---|
| NKX6-2 | TAATTAA | [6], [MA0675.1, MA0675.2] | |
| HoxA1, HoxA2 | TAATTA | [6], [MA1495.1, MA0900.1] | |
| POU6F1, Vax | . | . | ., [MAO628.1, MA0722.1] |
| RUNX1 | TGTGGT | . | ., MA0511.1 |
| RUNX1 | TGTGGTT | [6], MA0002.2 | |
| EHF | CCTTCCTC | . | ., MA0598.1 |
| POU6F1 | TAATGAG | [6] MA1549.1 | |
| PITX2 | TAATCCC | . | ., [MA1547.1, MA1547.2] |
| ELK4 | CTTCCGG | . | ., MA0076.2 |
| OTX2, Dmbx1 | GGATTA | [6], [MA0712.2, MA0883.1] | |
| PitX1, PitX2, PitX3, OTX1 | TAATCC | . | .,[MA0682.1, MA0711.1] |
| N-box | TTCCGG | . | [24] |
| p53 | CACATGTCCA | [25] | |
| GZF1 | TGCGCGTCTATA | . | [4] |
| NF-kappa-B | GGGAATTTCC | . | [6], [MA0107.1, MA1911.1] |
| STAT1 | TTTCCCGGAA | . | ., MA0137.2 |
| . | TTCCAGGAA | . | ., MA0137.3 |
| STAT4 | TTCCAGGAAA | . | ., MA0518.1 |
| FOSL1::Jun | ATGACGTCAT | [6], MA1129.1 | |
| USF2 | GTCATGTGACC | . | . , MA0626.1 |
| PAX1 | CGTCACGCATGA | . | . , MA0779.1 |
| STAT2 | TTCCAGGAAG | . | . , MA0144.1 |
| FOS | GATGACGTCATCA | [6], MA1951.1 | |
| MAFA, MAFF,MAFK | TGCTGAGTCAGCA | . | ., [MA1521.1, MA0495.2, MA0946.2] |
| CREB | TGACGTCA | [6], [MA0018.2, MA018.3] | |
| USF2 | GGTCACGTGACC | . | ., MA0526.4 |
| SMAD3, SMAD5 | GTCTAGAC | . | ., [MA0795.1, MA1557.1], [26] |
Table 6.
A short account of the function or dysfunction (through mutations or isoforms) of genes associated with transcription factors and sections in Table 5.
Table 6.
A short account of the function or dysfunction (through mutations or isoforms) of genes associated with transcription factors and sections in Table 5.
| Gene | Type | Function | Dysfunction |
|---|---|---|---|
| NKX6-2 | homeobox | central nervous system, pancreas | spastic ataxia |
| HoxA1 | homeobox | embryonic devt of face and heart | autism |
| HoxA2 | . | . | cleft palate |
| Pou6F1 | . | neuroendocrine system | clear cell adenocarcinoma |
| Vax | . | forebrain development | craniofacial malform. |
| RunX1 | Runt-related | cell differentiation, pain neurons | myeloid leukemia |
| EHF | homeobox | epithelial expression | carcinogenesis, asthma |
| PitX2 | . | eye, tooth, abdominal organs | Axenfeld–Rieger syndrome |
| ELK4 | Ets-related | serum response for c-Fos | |
| OTX1,OTX2 | homeobox | brain and sensory organ devt | medulloblastomas |
| Dmbx1 | . | . | farsightedness and strabismus |
| PitX1 | . | organ devt, left–right asymmetry | autism, club foot |
| PitX3 | . | lens formation in eye | congenital cataracts |
| N-box | Ets-related | synaptic expression | drug sensitivity |
| p53 | p53 domain | ‘Guardian of the genome’ | cancers |
| GZF1 | Zinc fingers | protein coding | short stature, myopia |
| NF-kappa-B | . | DNA transcription, cytokines | apoptosis |
| STAT1 | Stat family | signal activator of transcription | immunodeficiency 31 |
| STAT4 | Stat family | signal activator of transcription | rheumatoid arthritis |
| FOSL1::Jun | leucine zipper | cellular proliferation | marker of cancer |
| USF2 | helix-loop-helix | transcription activator | |
| PAX1 | paired box | fetal development | Klippel–Feil syndrome |
| FOS | leucine zipper | cellular proliferation | cancers |
| Maf | . | pancreatic development | congenital cerulean cataract |
| CREB | bZIP | neuronal plasticity | Alzheimer’s disease |
| USF2 | helix-loop-helix | transcription activator | |
| SMAD | homeo domain | cell development and growth | Alzheimer’s disease |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Planat, M.; Amaral, M.M.; Fang, F.; Chester, D.; Aschheim, R.; Irwin, K. Group Theory of Syntactical Freedom in DNA Transcription and Genome Decoding. Curr. Issues Mol. Biol. 2022, 44, 1417-1433. https://doi.org/10.3390/cimb44040095
AMA Style
Planat M, Amaral MM, Fang F, Chester D, Aschheim R, Irwin K. Group Theory of Syntactical Freedom in DNA Transcription and Genome Decoding. Current Issues in Molecular Biology. 2022; 44(4):1417-1433. https://doi.org/10.3390/cimb44040095
Chicago/Turabian StylePlanat, Michel, Marcelo M. Amaral, Fang Fang, David Chester, Raymond Aschheim, and Klee Irwin. 2022. "Group Theory of Syntactical Freedom in DNA Transcription and Genome Decoding" Current Issues in Molecular Biology 44, no. 4: 1417-1433. https://doi.org/10.3390/cimb44040095