
Exploring Natural Language Processing in Construction and Integration with Building Information Modeling: A Scientometric Analysis

 , , and
, , and
Abstract
:1. Introduction
1.1. European Union Digitalization Strategy
1.2. Document-Based and Model-Based Approaches
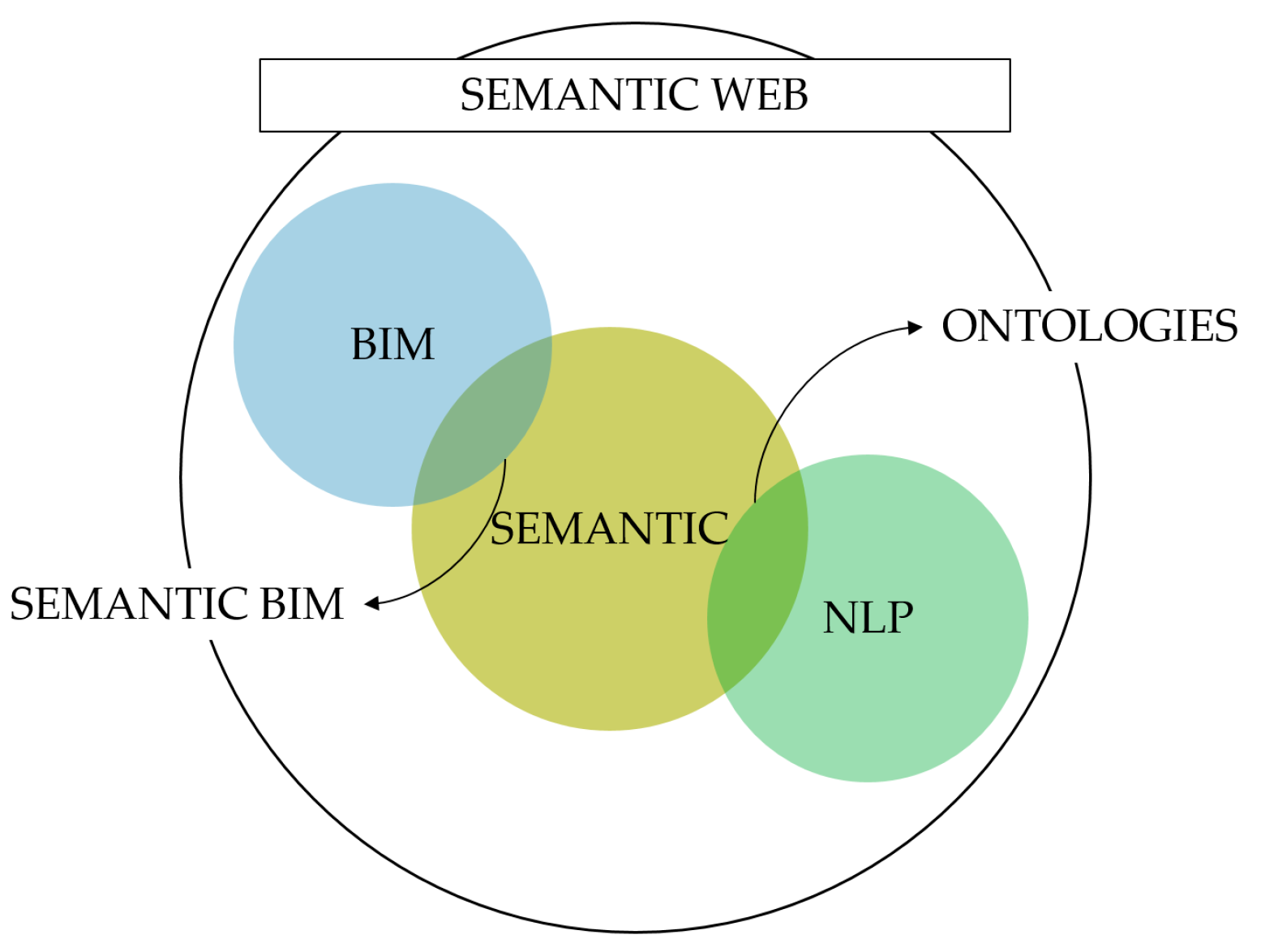
1.3. Seizing the Full Potential of Digitalization: Pairing BIM with NLP Technology
1.4. Goal Setting and Article Structure
2. Natural Language Processing Overview and Evolution
2.1. Linguistic and Natural Language Processing: Definition and Application Areas
- Natural Language Understanding (NLU);
- Natural Language Generation (NLG);
- Speech or Voice Recognition;
- Machine Translation (MT);
- Automatic Text Summarization (ATS);
- Spelling Correction and Grammar Checking;
- Information Retrieval and Extraction (IR and IE);
- Question Answering Systems or Dialogue Agents (i.e., chatbot);
- Deep analysis of texts or spoken language for topic, sentiment, or other psychological attributes.
2.2. NLP History and Evolution: From Rule-Based to Pre-Trained Models
- Rule-based systems: systems based on complex sets of manual written rules.
- ○
- Pros: the system has a high level of interpretability;
- ○
- Cons: it is not accurate and flexible. A rule-based system is too deterministic to manage noisy and ambiguous text data since human language is per se prone to error and incomplete.
- Statistical inference systems: systems based on statistical models.
- ○
- Pros: statistical NLP affords rapid prototyping, the model is semi-automatically constructed from linguistically annotated resources, for that reason they are cheaper than rule-based systems [33];
- ○
- Cons: statistical systems are robust systems which means that an output is always produced regardless of the quality of the input, consequently these systems require a more careful analysis of the quality of the input [34].
- Deep learning approach: systems based on deep learning algorithm and neural network.
- ○
- Pros: they can efficiently manage the sparsity and non-structuring of learning data, respecting the complexity, articulation, and multidimensionality of human language, furthermore, they can solve most non-trivial NLP problems;
- ○
- Cons: low explainability of the models since there is no way to investigate and explain the structure of the net after the training task. The phenomenon is called black-box effect [35]. Moreover, one of the biggest issues of the deep learning approach is the shortage of training data, since they require a huge amount of data to be trained [36].
2.3. Latest Developments: Contextual Pre-Trained Models, the Transformers Mechanism
- BERT (Bidirectional Encoder Representations from Transformers);
- ULMFiT (Universal Language Model Fine-Tuning);
- OpenAI’s GPT-2 and GPT-3 (Generative Pre-Trained Transformer).
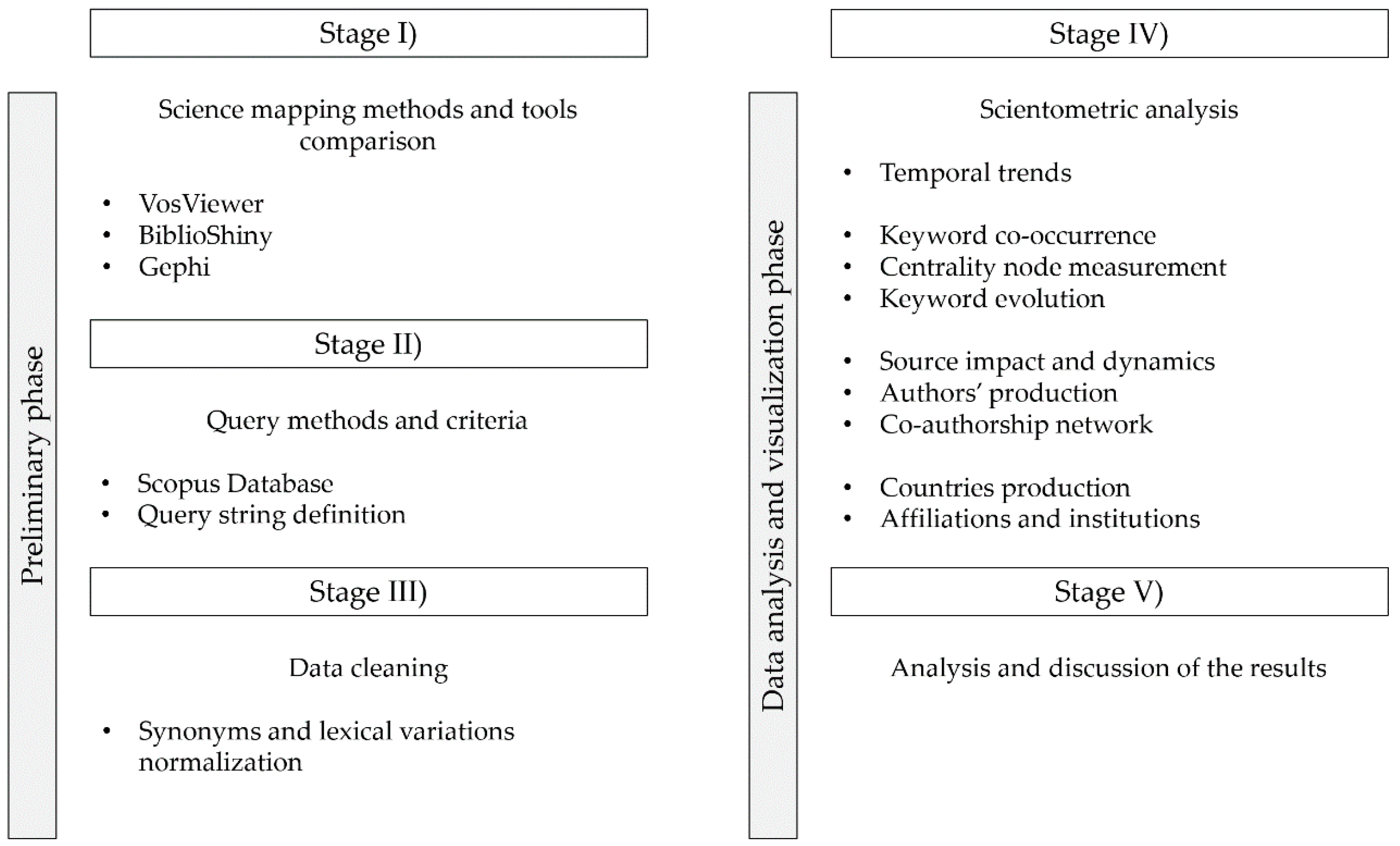
3. Methodology
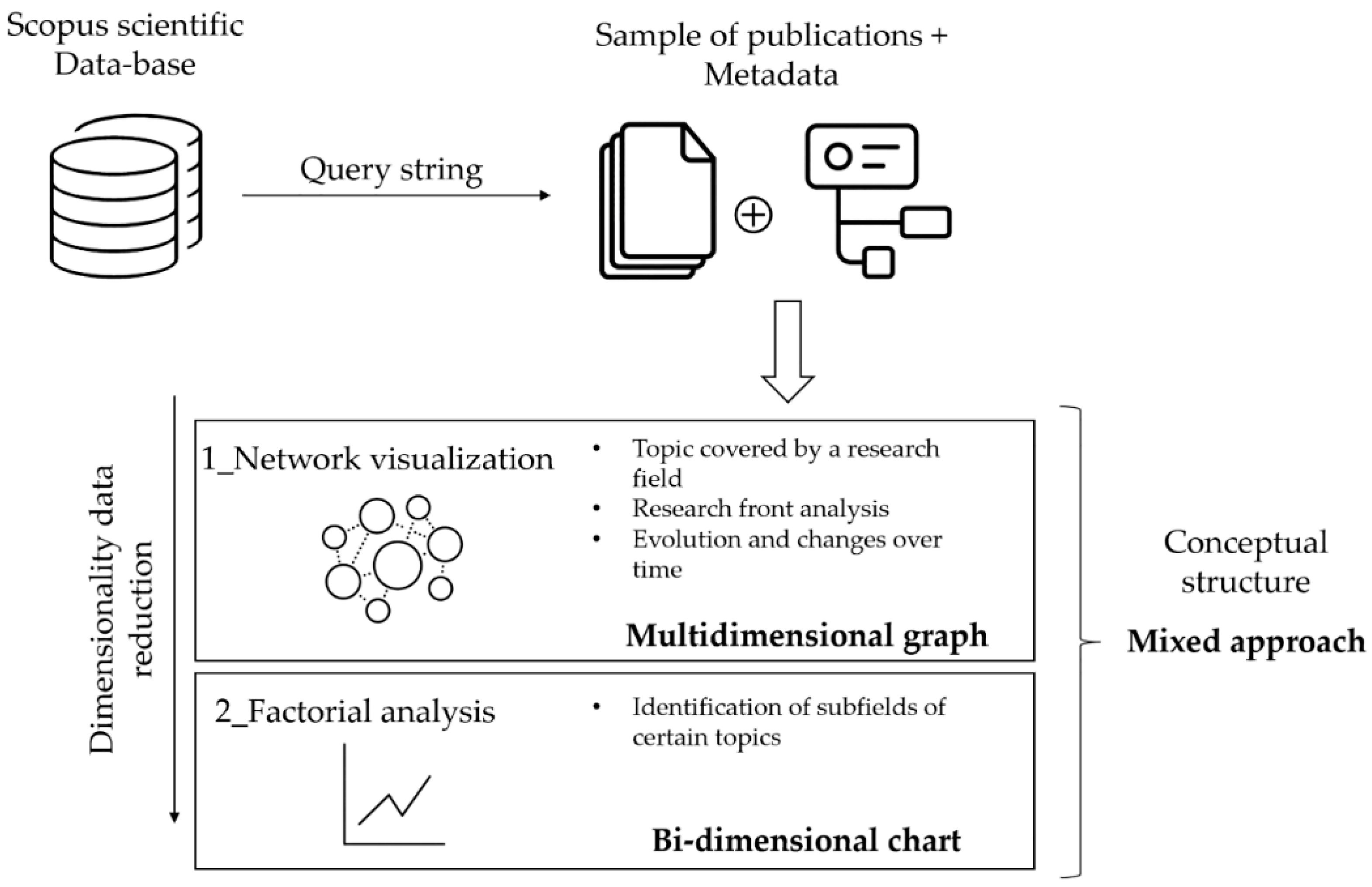
3.1. Science Mapping Methods and Tools Selection
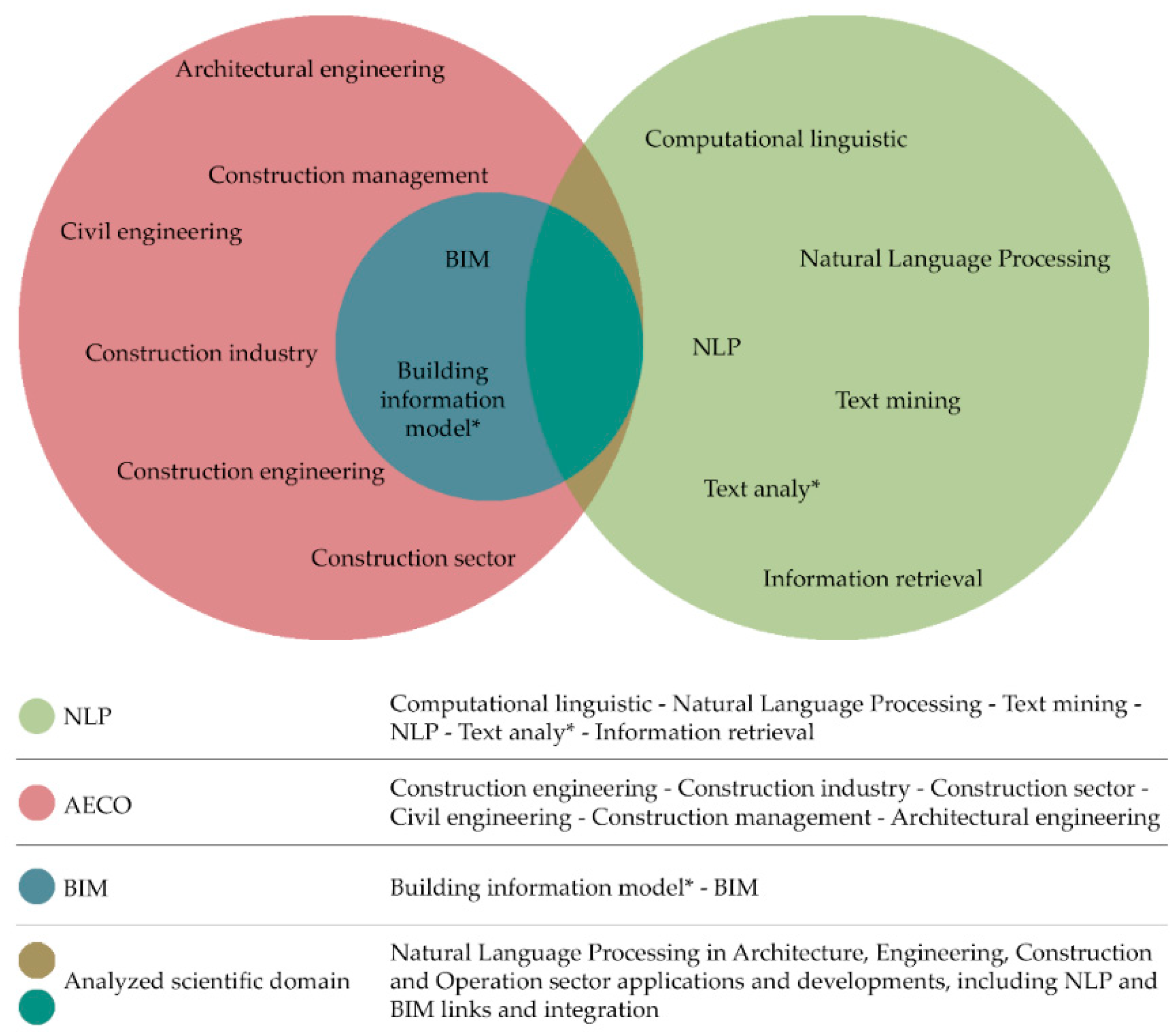
3.2. Query Methods and Criteria
- (“Civil engineering” OR “Construction engineering” OR “Architectural engineering” OR “Construction industry” OR “Construction management” OR “Construction sector” OR “BIM” OR “Building information model*”) AND (“Natural Language Processing” OR “NLP” OR “Text mining” OR “Computational linguistic” OR “Information retrieval” OR “Text analy*”).
3.3. Data Cleaning
4. Results and Discussion
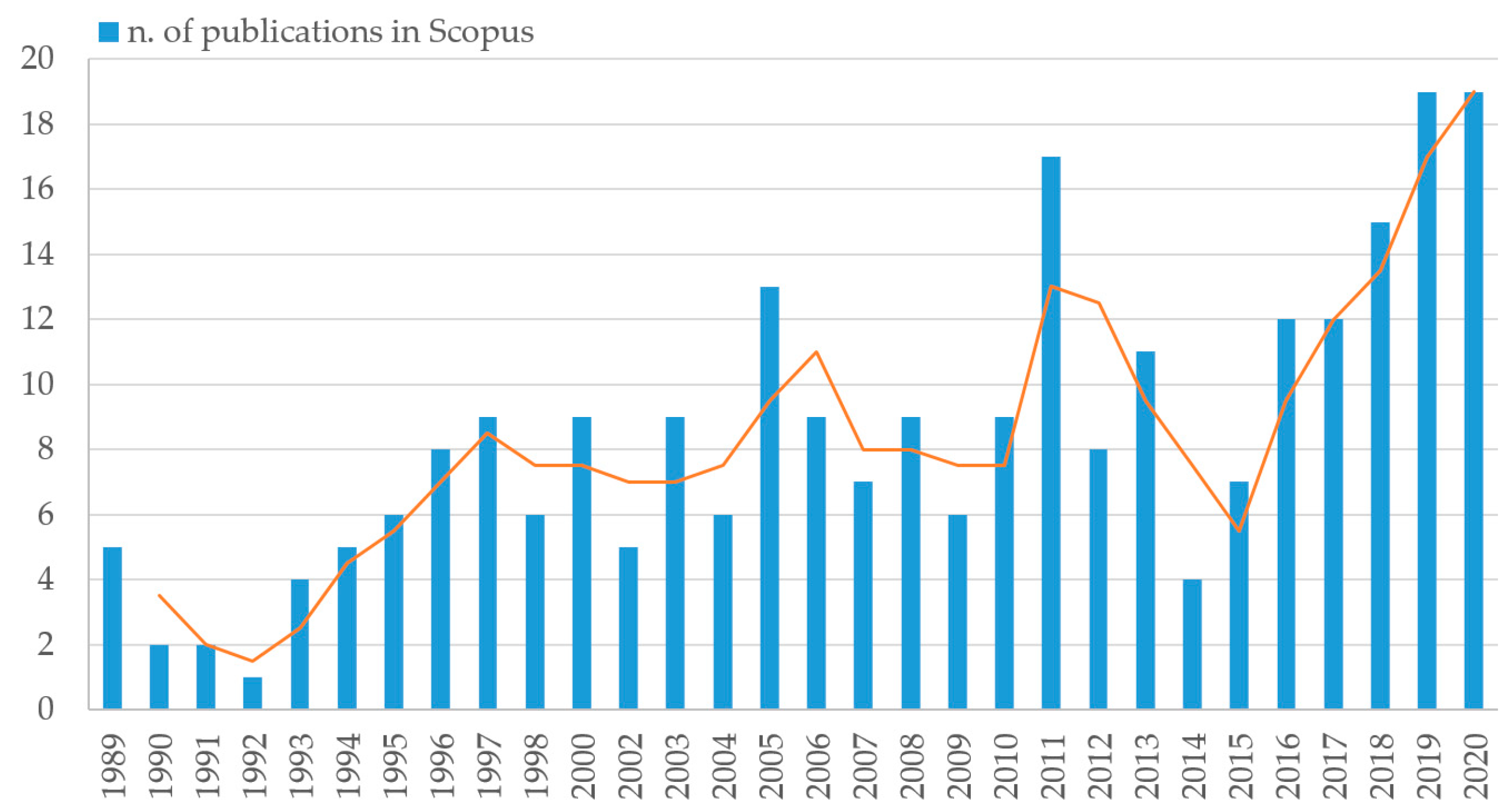
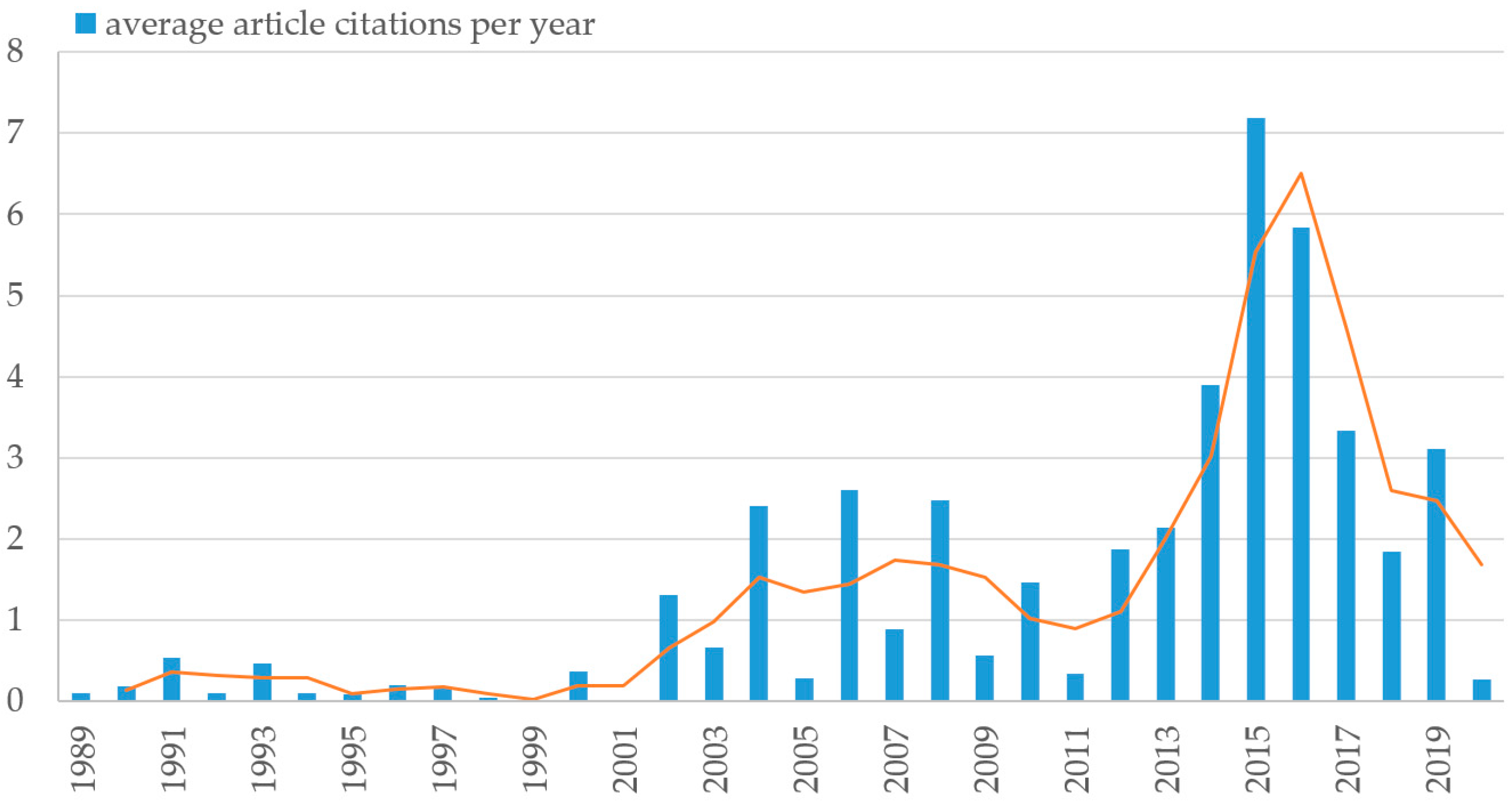
4.1. Temporal Trends
4.1.1. First Application and Annual Scientific Production Trend
4.1.2. Average Citation per Year Trend
4.2. Conceptual Structure Analysis: Key Research Patterns, Affinity, and Links
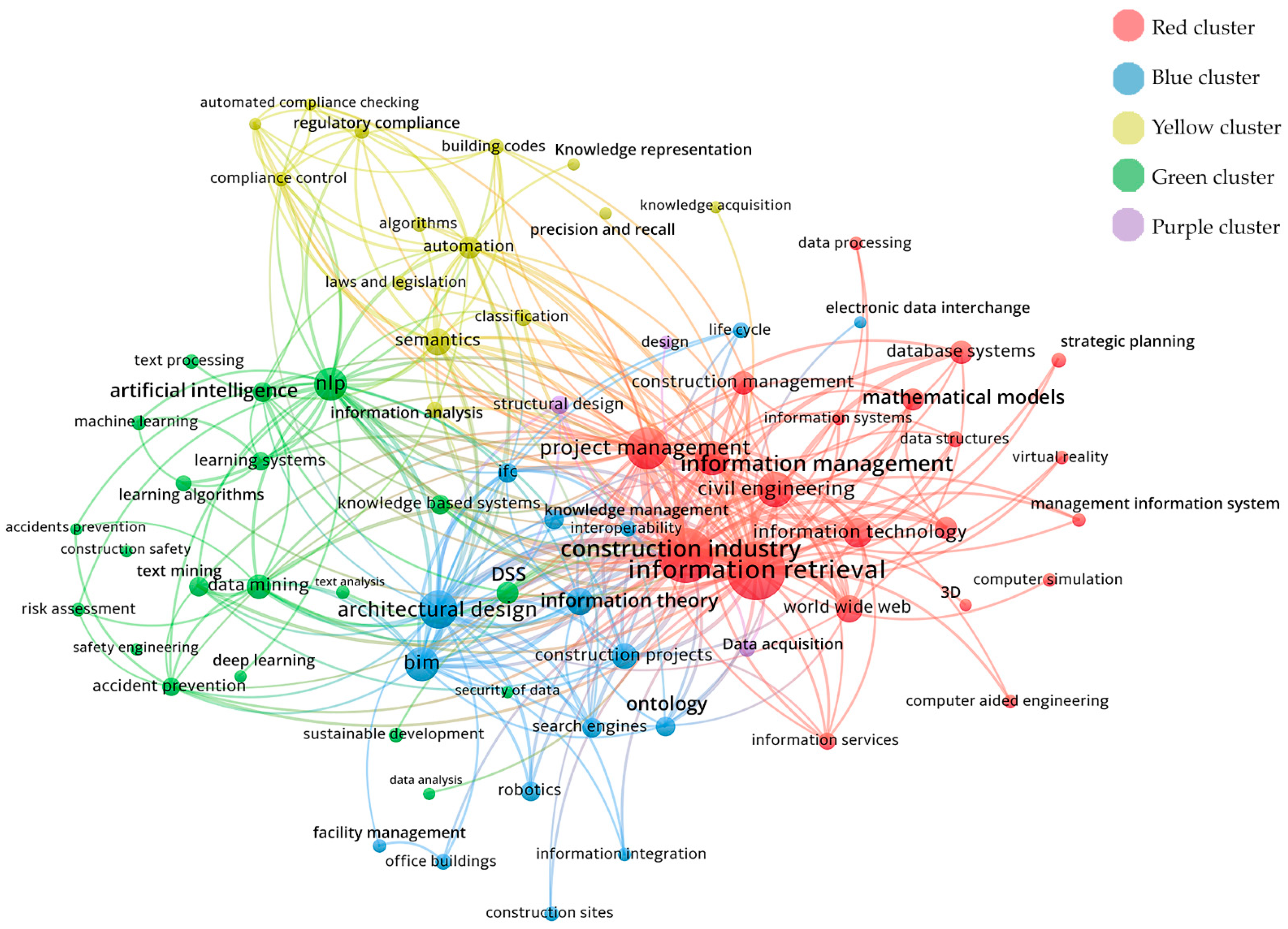
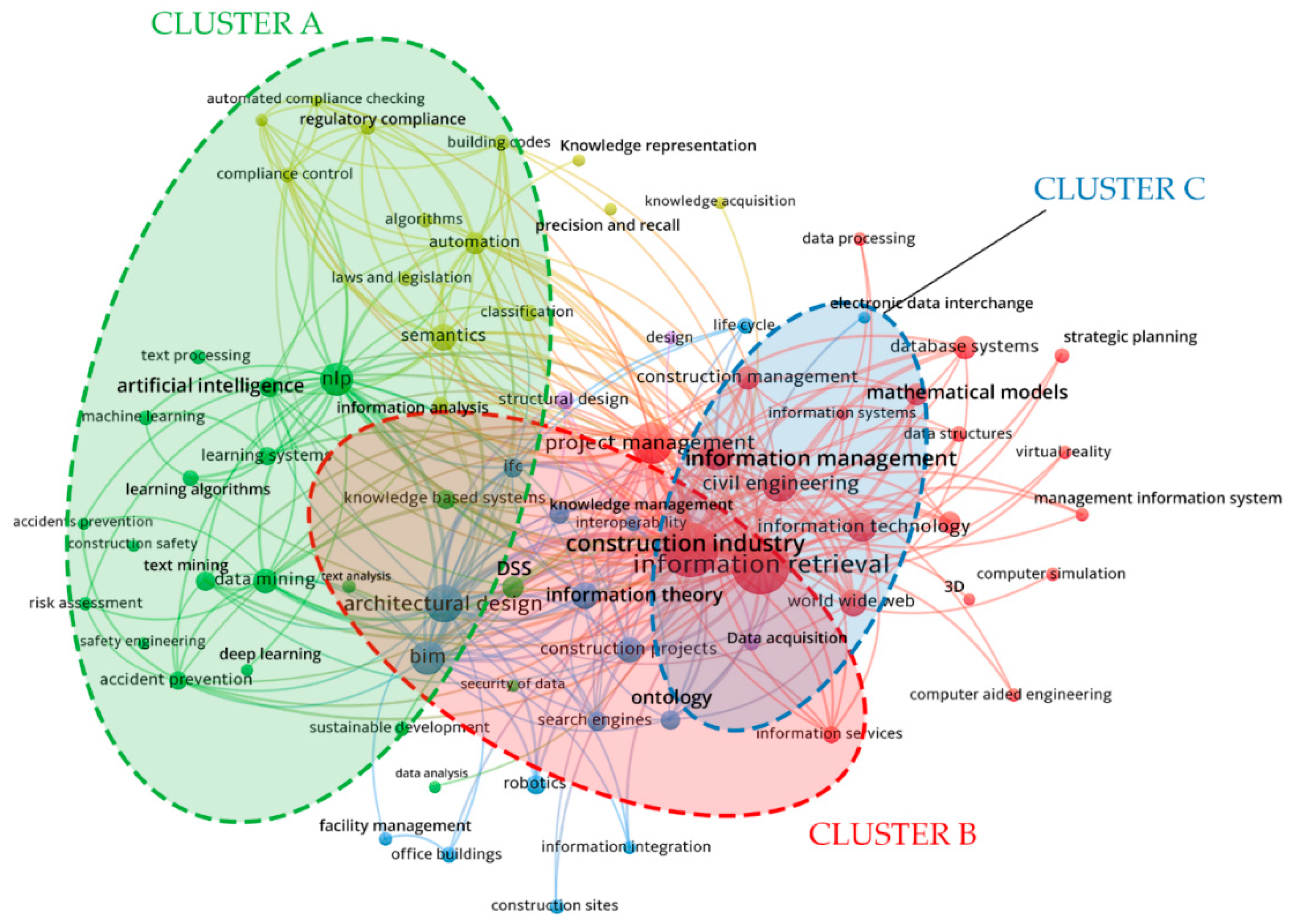
4.2.1. Co-Occurrence Keywords Network Maps
- Analysis type: co-occurrence, the relatedness of items (keywords) is determined based on the number documents in which they occur together;
- Unit of analysis: authors’ keywords;
- Counting methods: full counting methods, meaning that each co-occurrence link has the same weight;
- Threshold: the minimum number of occurrences of a keyword is 6; from the set of 1936 initial keywords 74 meet the threshold and they are graphically visualized.
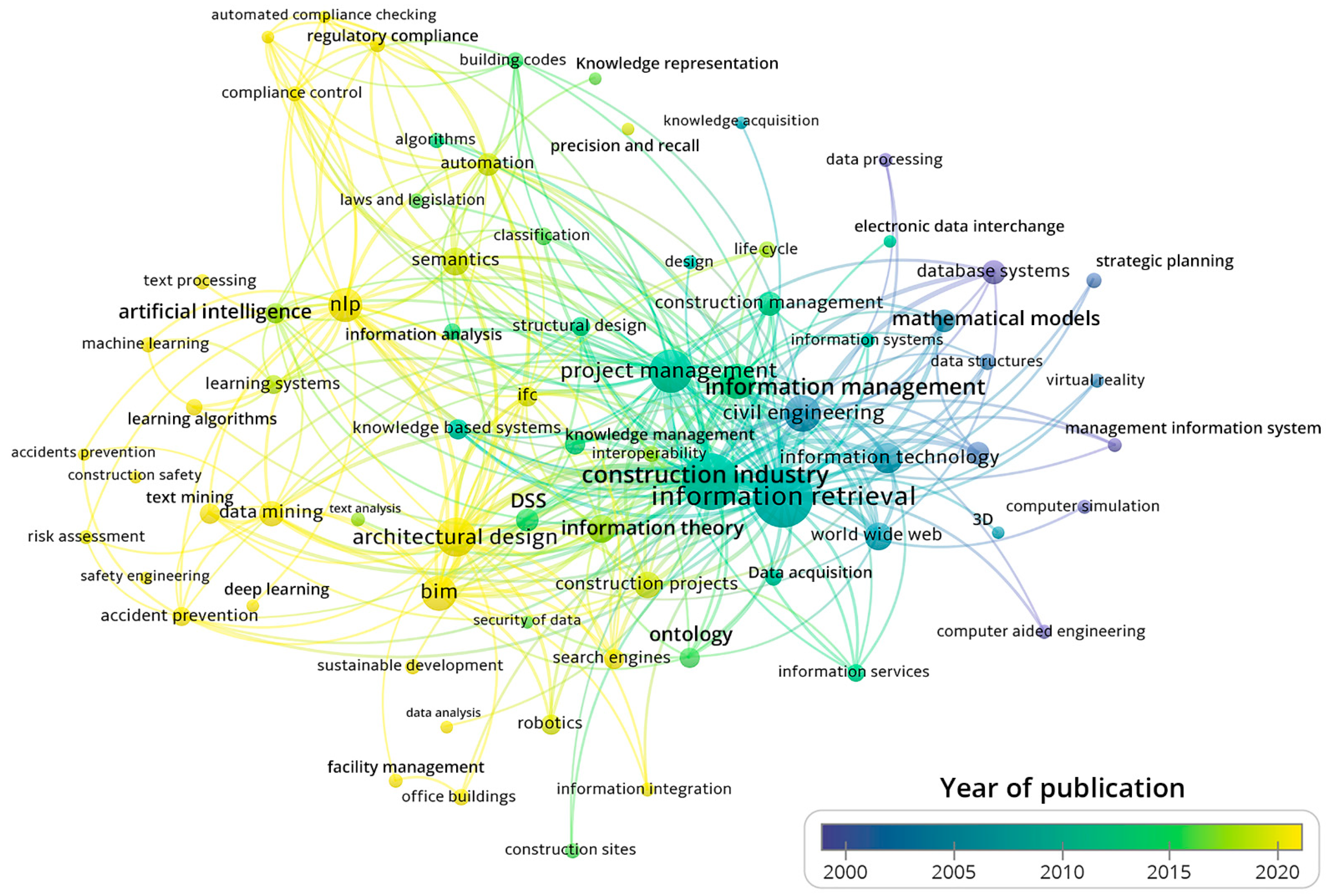
4.2.2. Co-Occurrence Keywords Temporal Overlay Network Maps
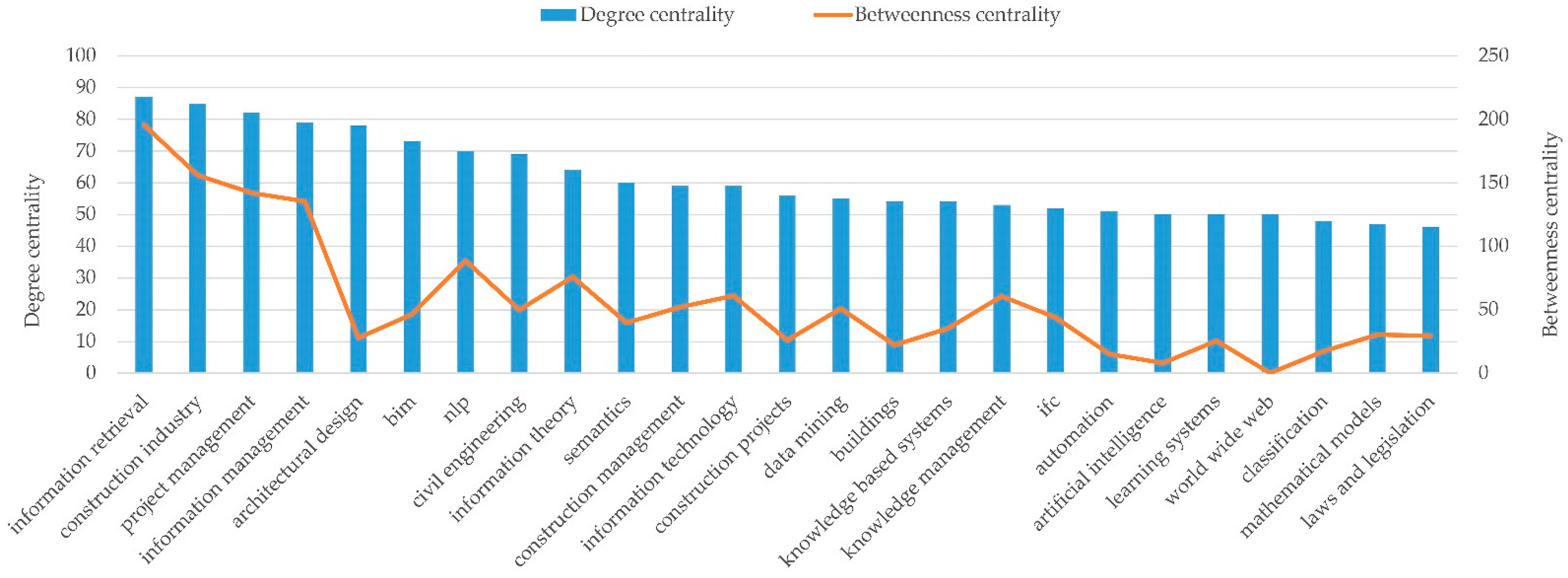
4.2.3. Centrality Node Measurement
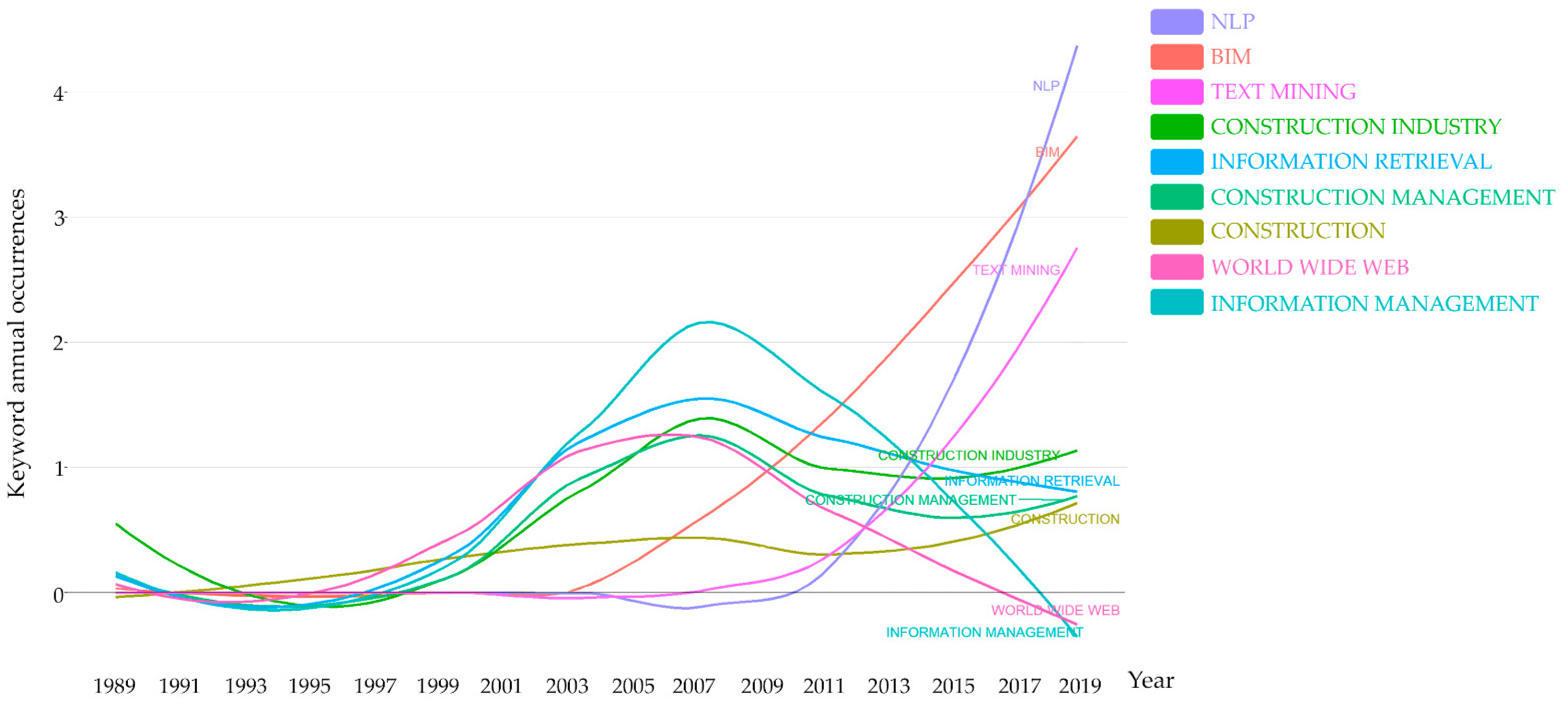
4.2.4. Keywords Evolution (1989–2020)
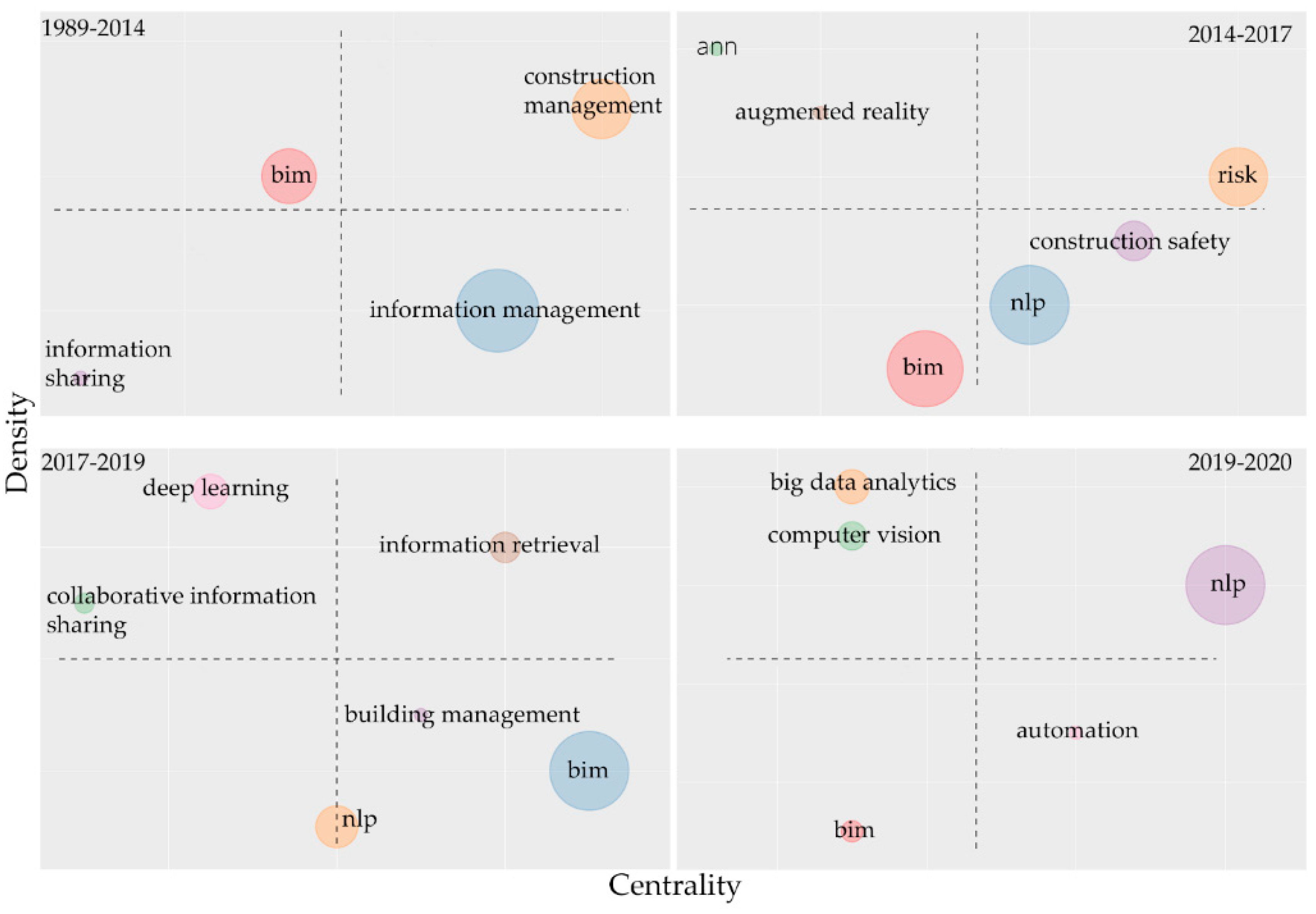
4.3. Factorial Approach and Thematic Map: From Network Graph to Bivariate Map
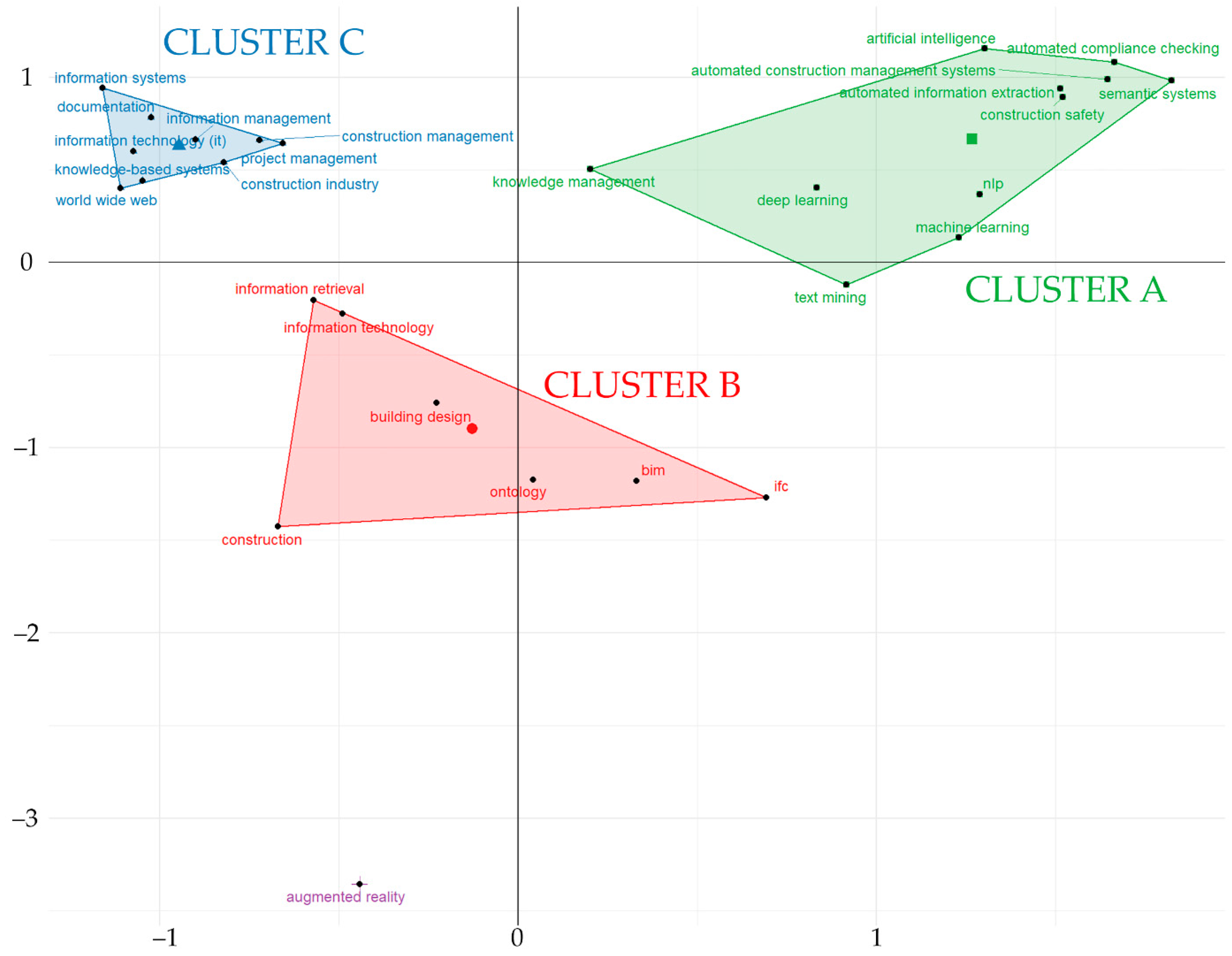
4.3.1. Correspondence Analysis and Clustering: Map of Words
4.3.2. Thematic Map Analysis
- Upper left quadrant: highly developed but isolated themes, very specialized themes with few connections with other topics;
- Upper right quadrant: motor-themes, themes with high density and high centrality values, they are well developed and are core elements of the structure of the research field;
- Lower left quadrant: emerging or declining themes, themes with low density and low centrality values, they are weakly developed and currently marginal;
- Lower right quadrant: transversal and general, basic themes, and themes important to the research field which are nonetheless not developed;
- First time-slice (1989–2014);
- Second time-slice (2014–2017);
- Third time-slice (2017–2019);
- Fourth time-slice (2019–2020).
4.4. Source Impact and Dynamics
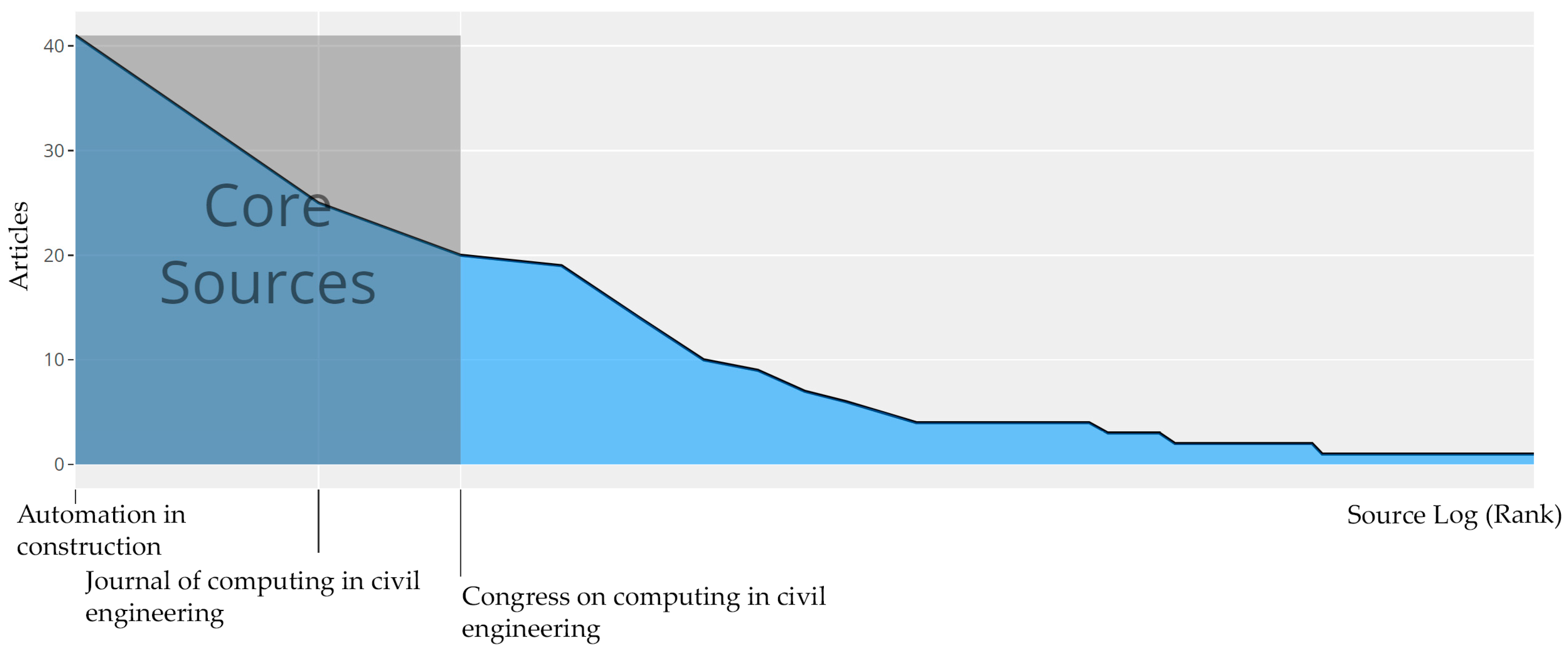
4.4.1. Source Ranking and Impact: The Bradford’s Law
4.4.2. Source Impacts: H-Index, G-Index, and M-Index
- H-index, or Hirsch-index, is an author’s or journals’ number of published items (i.e., articles), each of which has been cited in others papers at least a number of times (h) [114];
- G-index, introduced in 2006 is: “an improvement of H-index to measure the global citation performance of a set of articles. If this set is ranked in decreasing order of the number of citations that they received, the G-index is the (unique) largest number such that the top g articles received (together) at least g2 citations” [115];
- M-index is equal to H-index/n, where n is the number of years since the first published paper of the source [114].
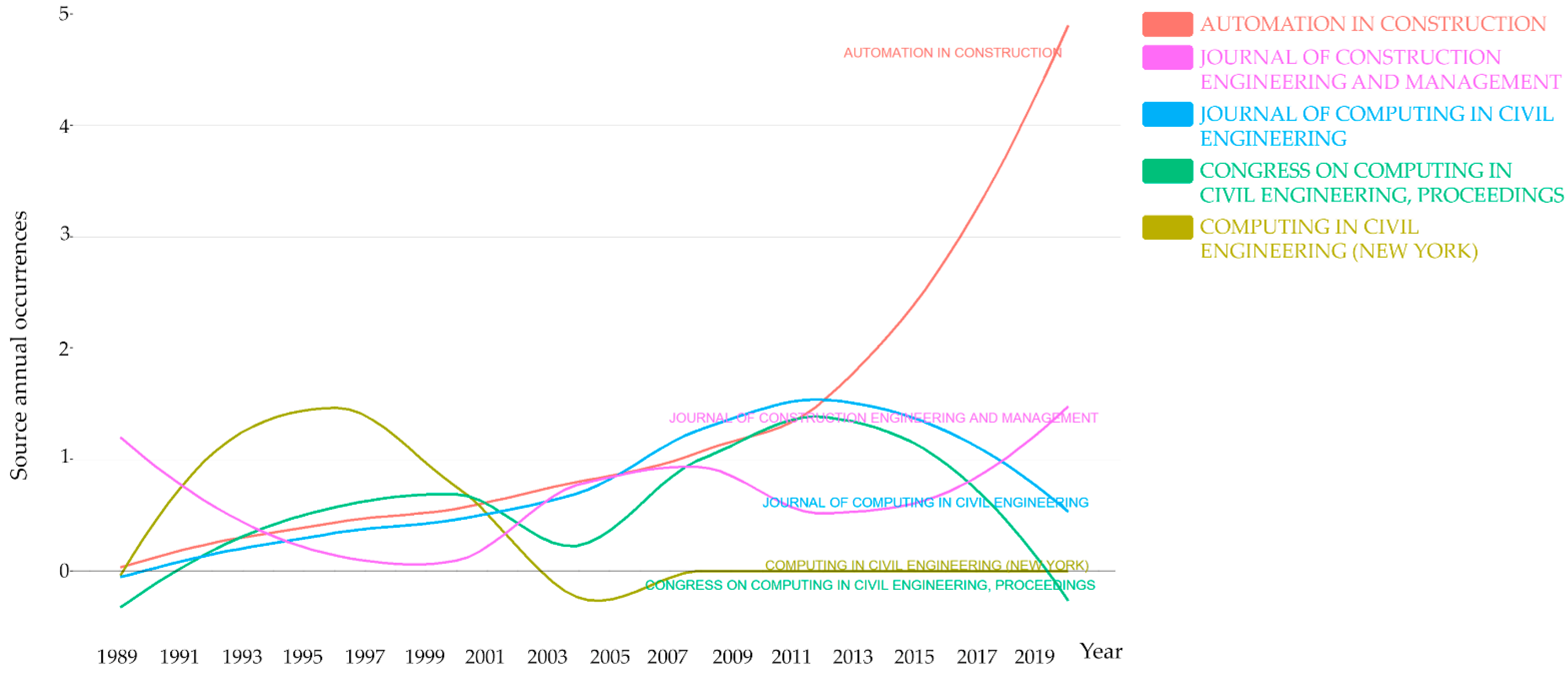
4.4.3. Source Evolution and Dynamics
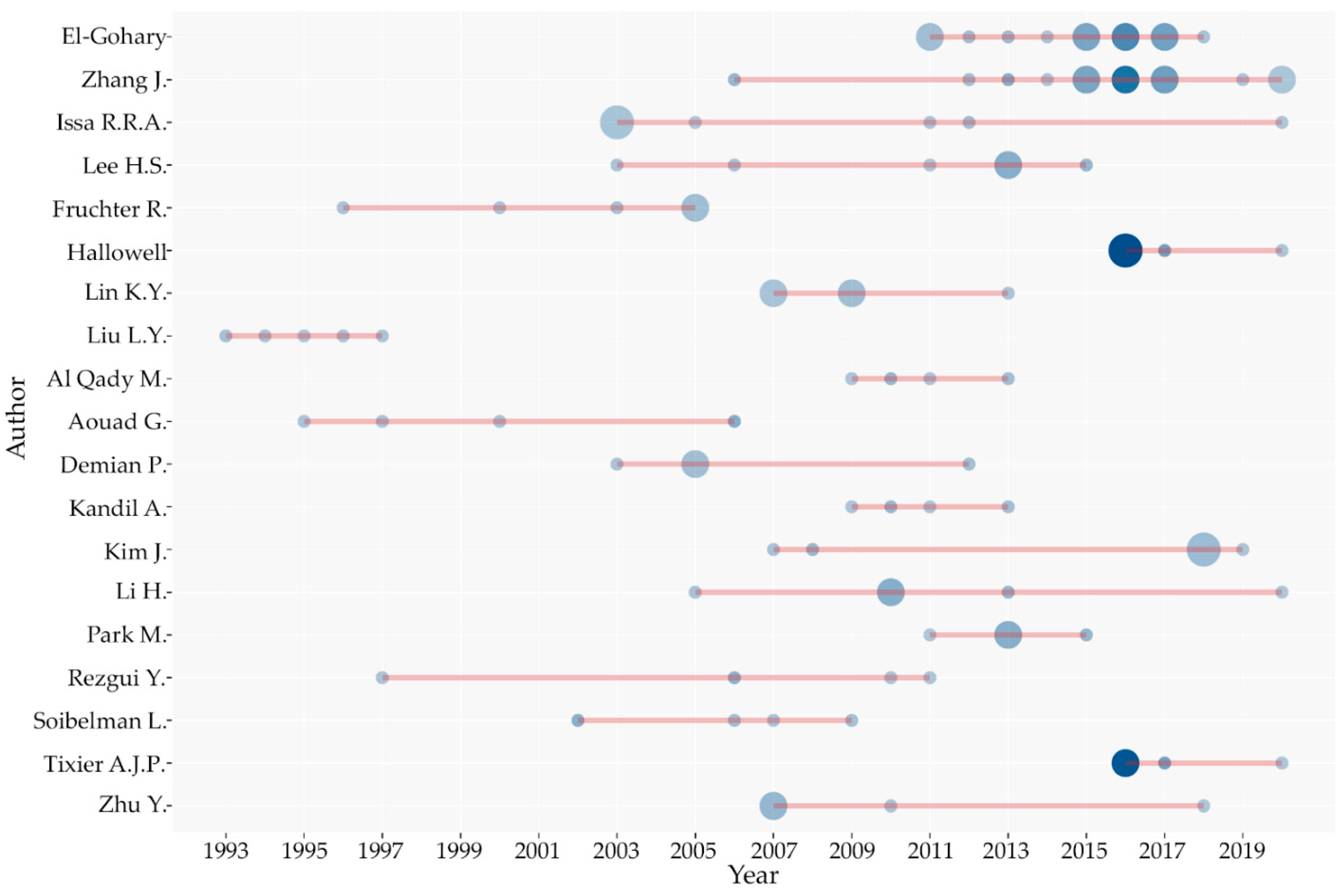
4.5. Author Production over Time
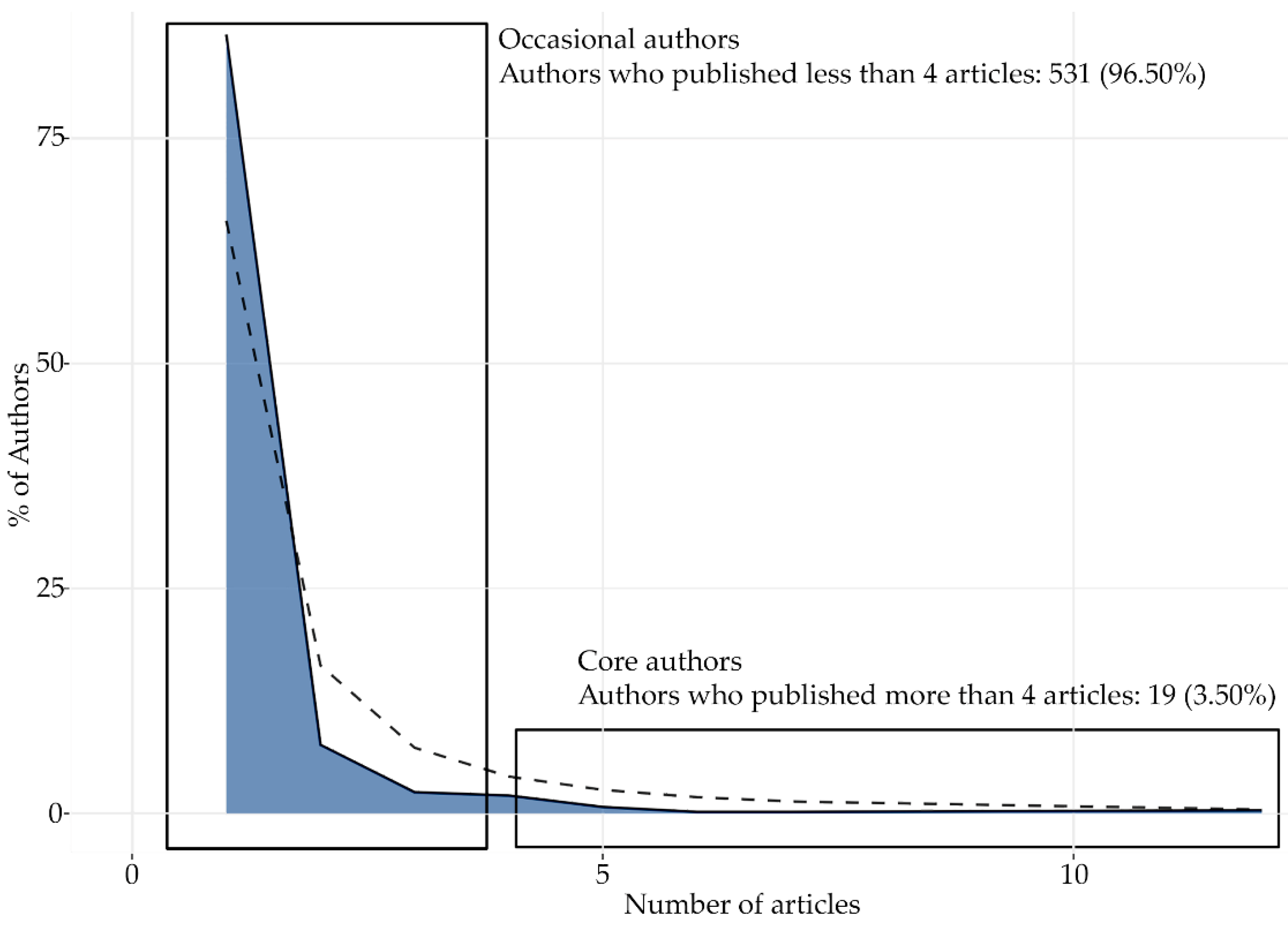
4.5.1. Top-Authors’ Productivity: Lotka’s Law (1993–2020)
4.5.2. Top-Authors’ Production (1993–2020)
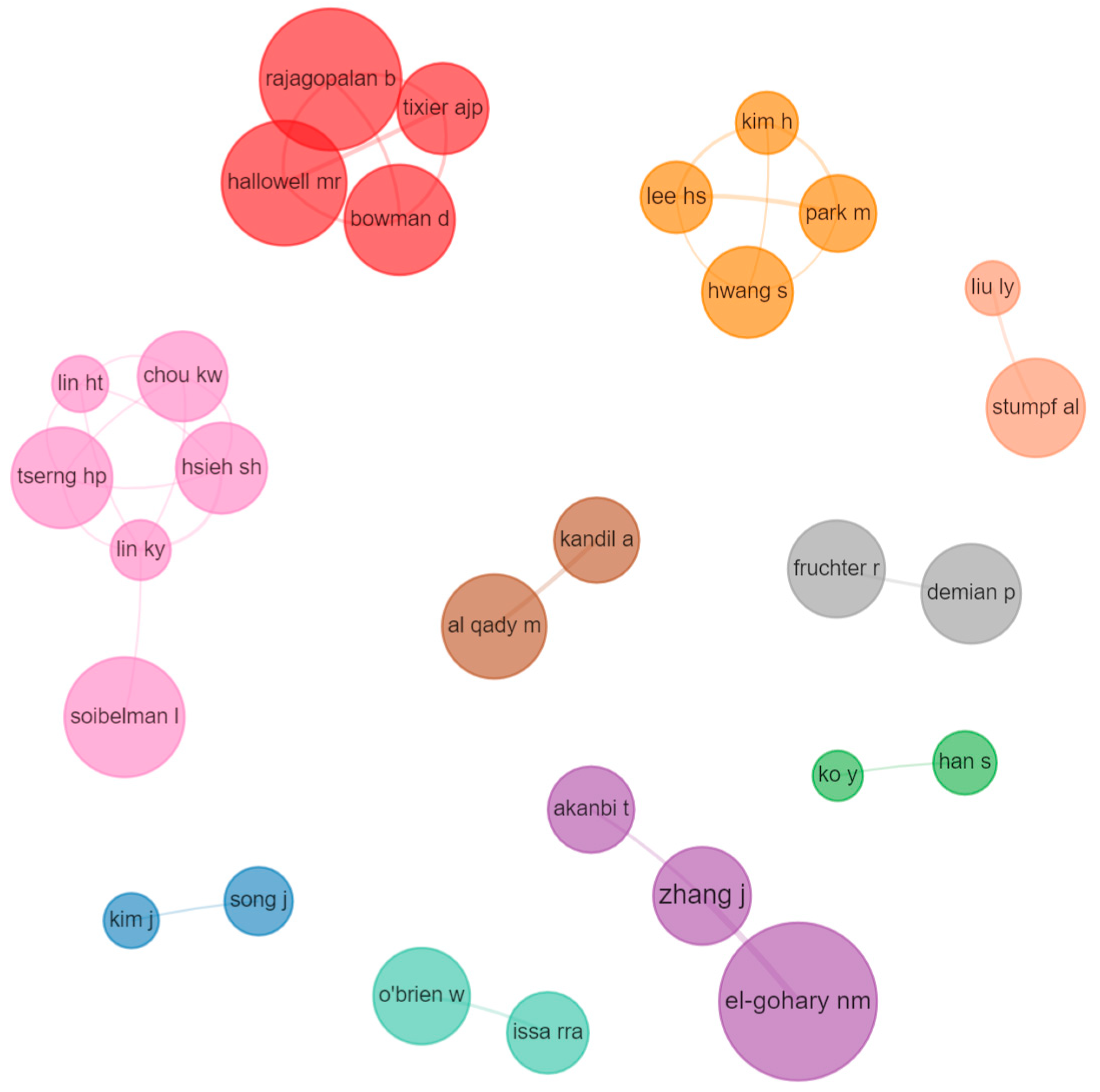
4.5.3. Authors Collaboration: Co-Authorship Network
4.6. Social and Geographical Analysis
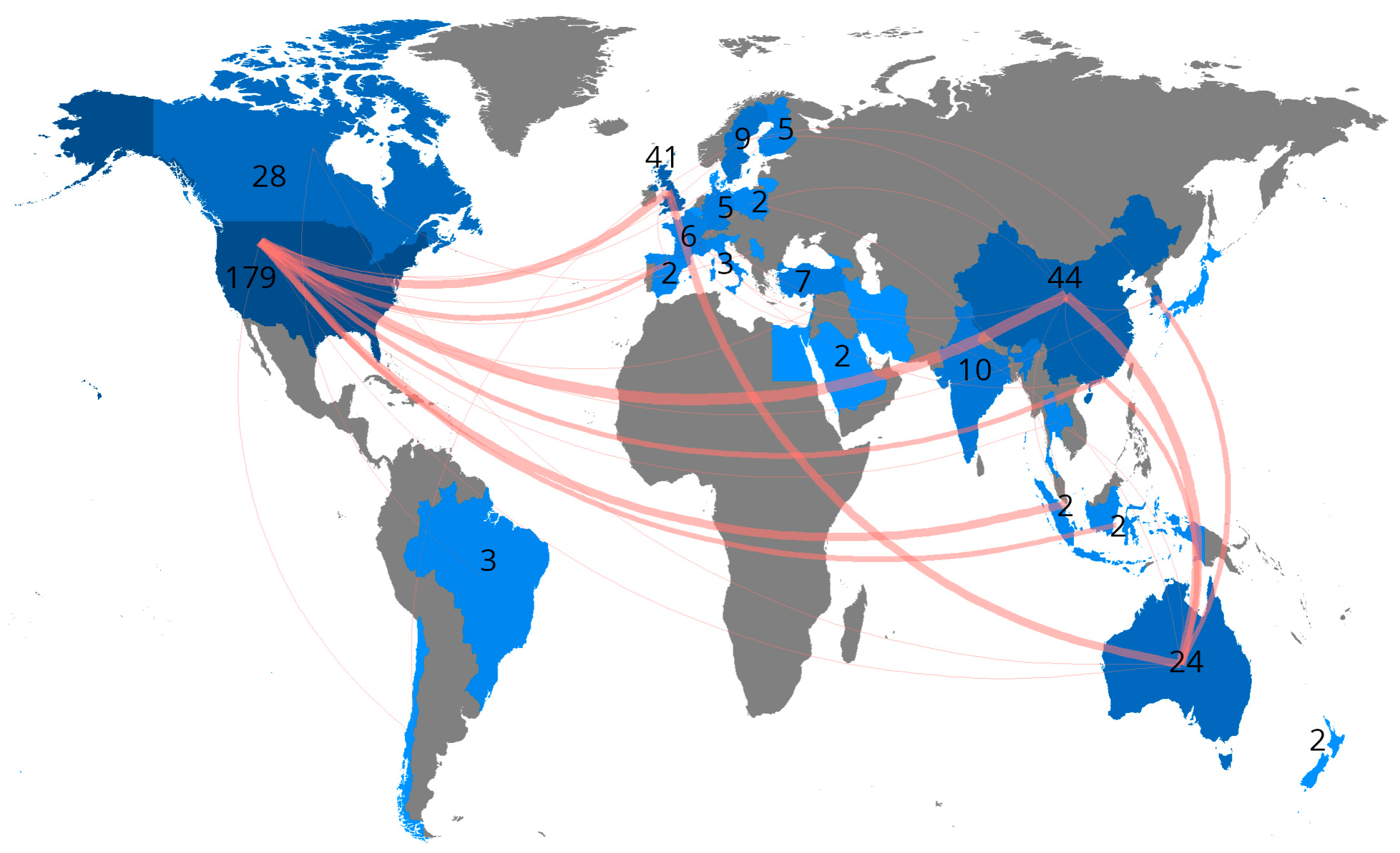
4.6.1. Countries Scientific Production and Collaboration Intensity
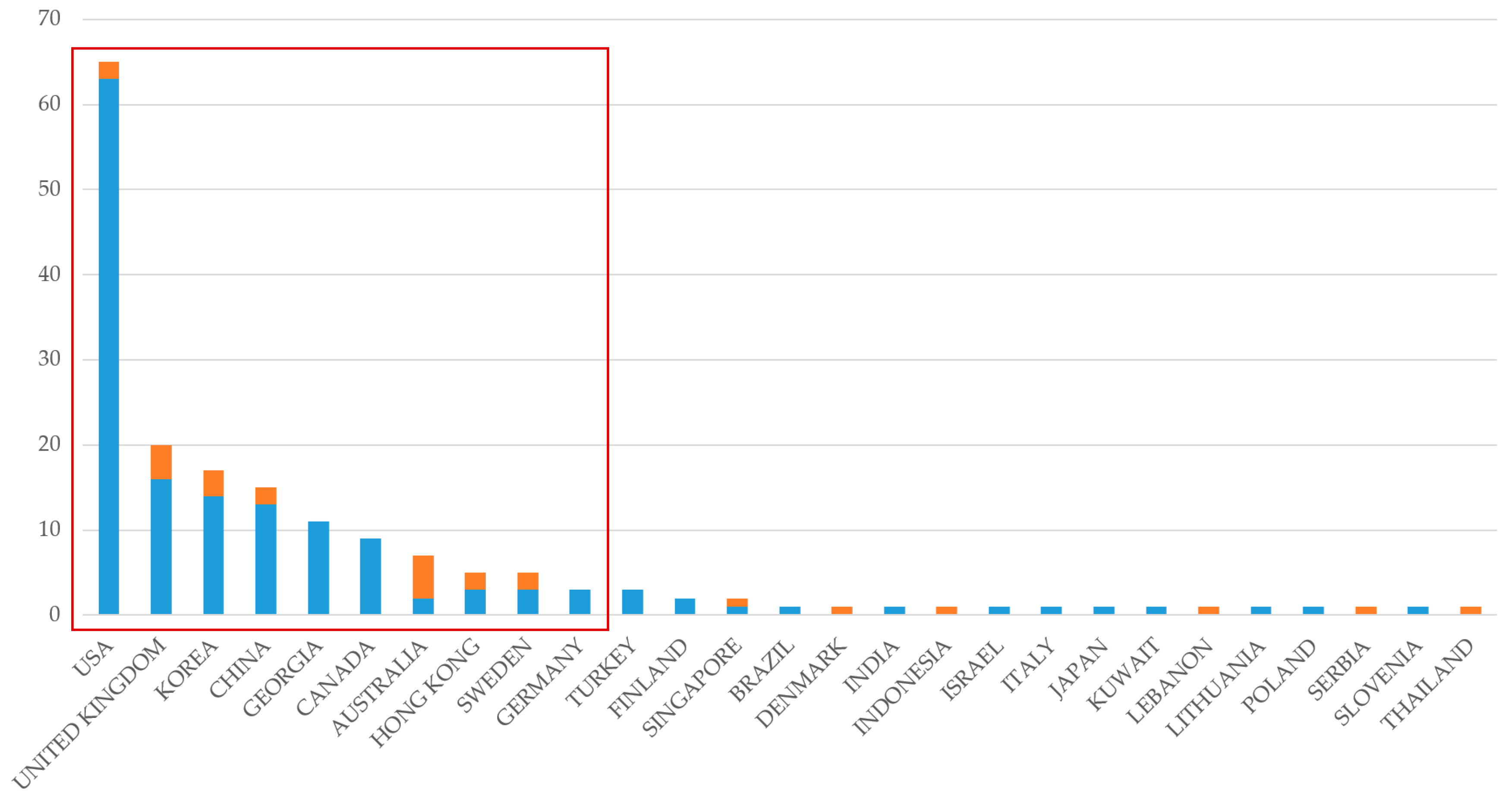
4.6.2. Most Relevant Affiliations and Institutions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Conflicts of Interest
References
- European Comission. Supporting Digitalisation of the Construction Sector and SMEs: Including Building Information Modelling; European Comission: Brussels, Belgium, 2019. [Google Scholar]
- World Economic Forum. Shaping the Future of Construction a Breakthrough in Mindset and Technology; World Economic Forum: Cologny, Switzerland, 2016. [Google Scholar]
- Abanda, F.H.; Mzyece, D.; Oti, A.H.; Manjia, M.B. A study of the potential of cloud/mobile bim for the management of construction projects. Appl. Syst. Innov. 2018, 1, 9. [Google Scholar] [CrossRef] [Green Version]
- Ullah, K.; Lill, I.; Witt, E. An overview of BIM adoption in the construction industry: Benefits and barriers. In Proceedings of the 10th Nordic Conference, Tallinn, Estonia, 7–8 May 2019; Emerald Publishing Limited: Tallin, Estonia, 2019; Volume 2, pp. 297–303. [Google Scholar]
- International Organization for Standardization. ISO 19650-1:2018—Organization and Digitization of Information about Buildings and Civil Engineering Works, Including Building Information Modelling (BIM)—Information Management Using Building Information Modelling; International Organization for Standardization: Geneve, Switzerland, 2021. [Google Scholar]
- Rezgui, Y.; Cooper, G.; Marir, F.; Vakola, M.; Tracey, A. Advanced Document Management Solutions for the Construction Industry: The Condor Approach. In Proceedings of the Life-Cycle of Construction IT Innovations—Technology Transfer from Research to Practice, Stockholm, Sweden, 3–5 June 1998; Bjork, B.C., Jagbecj, A., Eds.; Royal Institute of Technology: Stockholm, Sweden, 1998; pp. 1–11. [Google Scholar]
- Haimes, R. Document Interface. Interactions 1994, 1, 15–18. [Google Scholar] [CrossRef]
- Opitz, F.; Windisch, R.; Scherer, R.J. Integration of document- and model-based building information for project management support. Procedia Eng. 2014, 85, 403–411. [Google Scholar] [CrossRef] [Green Version]
- Rezgui, Y.; Zarli, A. Paving the Way to the Vision of Digital Construction: A Strategic Roadmap. J. Constr. Eng. Manag. 2006, 132, 767–776. [Google Scholar] [CrossRef]
- Wang, C.C.; Plume, J.; Jim, P. A Review on Document and Information Management in the Construction Industry: From Paper-based Documents to BIM-based Approach. In Proceedings of the 2012 International Conference on Construction and Real Estate Management, Kansas City, MO, USA, 1–2 October 2012; pp. 369–373. [Google Scholar]
- Moon, S.; Shin, Y.; Hwang, B.-G.; Chi, S. Document Management System Using Text Mining for Information Acquisition of International Construction. KSCE J. Civ. Eng. 2018, 22, 4791–4798. [Google Scholar] [CrossRef]
- Zhu, Y.; Raja, R.A.I.; Cox, R.F. Web-Based Construction Document Processing Via Malleable Frame. J. Comput. Civ. Eng. 2001, 15, 157–169. [Google Scholar] [CrossRef]
- Hala, N.; Mahmoud, E.J.; Melanie, P. Transforming the AEC Industry: A Model-Centric Approach. In Creative Construction e-Conference; Skibniewski, M.J., Hajdu, M., Eds.; Budapest University of Technology and Economics: Budapest, Hungary, 2020; pp. 13–18. [Google Scholar]
- Mich, L. NL-OOPS: From natural language to object oriented requirements using the natural language processing system LOLITA. Nat. Lang. Eng. 1996, 2, 161–187. [Google Scholar] [CrossRef]
- Sacks, R.; Girolami, M.; Brilakis, I. Building Information Modelling, Artificial Intelligence and Construction Tech. Dev. Built Environ. 2020, 4, 1–9. [Google Scholar] [CrossRef]
- Lenci, A.; Montemagni, S.; Pirelli, V. Testo e Computer. Elementi di Linguistica Computazionale; Carocci Editore@Aulamagna: Rome, Italy, 2005. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Di Giuda, G.M.; Locatelli, M.; Schievano, M.; Pellegrini, L.; Pattini, G.; Giana, P.E.; Seghezzi, E. Natural Language Processing for Information and Project Management. In Digital Transformation of the Design, Construction and Management Processes of the Built Environment; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 95–102. ISBN 9783030335700. [Google Scholar]
- Briscoe, T. Introduction to Linguistics for Natural Language Processing, 4th ed.; Cambridge University: Cambridge, UK, 2013. [Google Scholar]
- Schubert, L. Computational Linguistics. In The Stanford Encyclopedia of Philosophy; Zalta, E.N., Ed.; Metaphysics Research Lab, Stanford University: Stanford, CA, USA, 2020. [Google Scholar]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural Language Processing: State of The Art, Current Trends and Challenges. arXiv 2018, arXiv:1708.05148. [Google Scholar]
- Church, K.W.; Rau, L.F. Commercial Applications of Natural Language Processing. Commun. ACM 1995, 38, 71–79. [Google Scholar] [CrossRef]
- Singh, S. Natural Language Processing for Information Extraction. arXiv 2018, arXiv:1807.02383. [Google Scholar]
- Kaur, N.; Pushe, V.; Kaur, R. Natural Language Processing Interface for Synonym. Int. J. Comput. Sci. Mob. Comput. 2014, 3, 638–642. [Google Scholar]
- Vijayarani, S.; Ilamathi, J.; Nithya, S. Preprocessing Techniques for Text Mining—An Overview. Int. J. Comput. Sci. Commun. Netw. 2015, 5, 7–16. [Google Scholar]
- Chomsky, N. Syntactic Structures; The Hague, Mouton: New York, NY, USA, 1957; ISBN1 9027933855. ISBN2 9789027933850. [Google Scholar]
- Weizenbaum, J. ELIZA—A Computer Program for the Study of Natural Language Communication between Man and Machine. Commun. ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Sparck, J.K. Natural Language Processing: A Historical Review. In Current Issues in Computational Linguistics: In Honour of Don Walker. Linguistica Computazionale; Zampolli, A., Calzolari, N., Palmer, M., Eds.; Springer: Dordrecht, The Netherlands, 1994; Volume 9, pp. 3–16. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A Neural Probabilistic Language Model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Guresen, E.; Kayakutlu, G. Definition of Artificial Neural Networks with comparison to other networks. Procedia Comput. Sci. 2011, 3, 426–433. [Google Scholar] [CrossRef] [Green Version]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall: Hoboken, NJ, USA, 1999. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Callison-Burch, C.; Osborne, M. Statistical Natural Language Processing. In A Handbook for Language Engineers; Farghaly, A., Ed.; CSLI Publications: Stanford, CA, USA, 2003; pp. 1–31. ISBN 1575863952. [Google Scholar]
- Junqua, J.-C.; Van Noord, G. Chapter 1. In Robustness in Language and Speech Technology; Junqua, J.-C., van Noord, G., Eds.; Springer: Dordrecht, The Netherlands, 2001; pp. 1–7. ISBN 978-94-015-9719-7. [Google Scholar]
- Paliwal, M.; Kumar, U.A. Assessing the contribution of variables in feed forward neural network. Appl. Soft Comput. J. 2011, 11, 3690–3696. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Nagda, K.; Mukherjee, A.; Shah, M.; Mulchandani, P.; Kurup, L. Ascent of Pre-Trained State-of-the-Art Language Models. In Advanced Computing Technologies and Applications. Algorithms for Intelligent Systems; Vasudevan, H., Michalas, A., Shekokar, N., Narvekar, M., Eds.; Springer: Singapore, 2020; pp. 269–280. ISBN 978-981-15-3242-9. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Malte, A.; Ratadiya, P. Evolution of Transfer Learning in Natural Language Processing. arXiv 2019, arXiv:1910.07370. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 2227–2237. [Google Scholar]
- Chen, C. Science Mapping: A Systematic Review of the Literature. J. Data Inf. Sci. 2017, 2, 1–40. [Google Scholar] [CrossRef] [Green Version]
- Chen, C. Visualising semantic spaces and author co-citation networks in digital libraries. Inf. Process. Manag. 1999, 35, 401–420. [Google Scholar] [CrossRef] [Green Version]
- Small, H. Co-citation in the scientific literature: A new measure of the relationship between two documents. J. Am. Soc. Inf. Sci. 1973, 24, 265–269. [Google Scholar] [CrossRef]
- Herman, I.; Melançon, G.; Marshall, M.S. Graph visualization and navigation in information visualization: A survey. IEEE Trans. Vis. Comput. Graph. 2000, 6, 24–43. [Google Scholar] [CrossRef] [Green Version]
- Morris, S.A.; Yen, G.; Asnake, B. Time line visualization of research fronts. J. Am. Soc. Inf. Sci. Technol. 2003, 54, 413–422. [Google Scholar] [CrossRef]
- Garfield, E. Citation indexes for science. Science 1955, 122, 108–111. [Google Scholar] [CrossRef] [PubMed]
- Bankar, R.S.; Lihitkar, S.R. Science Mapping and Visualization Tools Used for Bibliometric and Scientometric Studies: A Comparative Study. J. Adv. Libr. Sci. 2019, 6, 382–394. [Google Scholar] [CrossRef]
- Moral-Muñoz, J.A.; Herrera-Viedma, E.; Santisteban-Espejo, A.; Cobo, M.J. Software tools for conducting bibliometric analysis in science: An up-to-date review. Prof. Inf. 2020, 29, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Aria, M.; Cuccurullo, C. bibliometrix: An R-tool for comprehensive science mapping analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Van Eck, N.J.; Waltman, L. Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics 2010, 84, 523–538. [Google Scholar] [CrossRef] [Green Version]
- Pouris, A.; Pouris, A. Scientometrics of a pandemic: HIV/AIDS research in South Africa and the World. Scientometrics 2011, 86, 541–552. [Google Scholar] [CrossRef]
- Song, J.; Zhang, H.; Dong, W. A review of emerging trends in global PPP research: Analysis and visualization. Scientometrics 2016, 107, 1111–1147. [Google Scholar] [CrossRef]
- Zhao, X. A scientometric review of global BIM research: Analysis and visualization. Autom. Constr. 2017, 37–47. [Google Scholar] [CrossRef]
- Zhao, X.; Zuo, J.; Wu, G.; Huang, C. A bibliometric review of green building research 2000–2016. Archit. Sci. Rev. 2019, 62, 74–88. [Google Scholar] [CrossRef]
- Meho, L.I.; Rogers, Y. Citation counting, citation ranking, and h-index of human-computer interaction researchers: A comparison of scopus and web of science. J. Am. Soc. Inf. Sci. Technol. 2008, 59, 1711–1726. [Google Scholar] [CrossRef] [Green Version]
- Archambault, É.; Campbell, D.; Gingras, Y.; Larivière, V. Comparing bibliometric statistics obtained from the web of science and Scopus. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 1320–1326. [Google Scholar] [CrossRef]
- Yin, X.; Liu, H.; Chen, Y.; Al-Hussein, M. Building information modelling for off-site construction: Review and future directions. Autom. Constr. 2019, 101, 72–91. [Google Scholar] [CrossRef]
- Mongeon, P.; Paul-Hus, A. The journal coverage of Web of Science and Scopus: A comparative analysis. Scientometrics 2016, 106, 213–228. [Google Scholar] [CrossRef]
- Locatelli, M.; Seghezzi, E.; Di Giuda, G.M. Exploring BIM and NLP applications: A scientometric approach. In Proceedings of the International Structural Engineering and Construction, Interdisciplinary Civil and Construction Engineering Projects; El Baradei, S.A., Abodonya, A., Singh, A., Yazdani, S., Eds.; ISEC Press: Fargo, ND, USA, 2021; Volume 8, pp. 1–6. [Google Scholar]
- Akram, R.; Thaheem, M.J.; Nasir, A.R.; Ali, T.H.; Khan, S. Exploring the role of building information modeling in construction safety through science mapping. Saf. Sci. 2019, 120, 456–470. [Google Scholar] [CrossRef]
- Zhong, B.; Wu, H.; Li, H.; Sepasgozar, S.; Luo, H.; He, L. A scientometric analysis and critical review of construction related ontology research. Autom. Constr. 2019, 101, 17–31. [Google Scholar] [CrossRef]
- Darko, A.; Chan, A.P.C.; Adabre, M.A.; Edwards, D.J.; Hosseini, M.R.; Ameyaw, E.E. Artificial intelligence in the AEC industry: Scientometric analysis and visualization of research activities. Autom. Constr. 2020, 112. [Google Scholar] [CrossRef]
- Hao, T.; Chen, X.; Li, G.; Yan, J. A bibliometric analysis of natural language processing in medical research. Soft Comput. 2018, 22, 7875–7892. [Google Scholar] [CrossRef]
- Logcher, R.D.; Wang, M.; Chen, F.H. Knowledge Processing for Construction Management Data Base. J. Constr. Eng. Manag. 1989, 115, 196–211. [Google Scholar] [CrossRef] [Green Version]
- Bilal, M.; Oyedele, L.O.; Qadir, J.; Munir, K.; Ajayi, S.O.; Akinade, O.O.; Owolabi, H.A.; Alaka, H.A.; Pasha, M. Big Data in the construction industry: A review of present status, opportunities, and future trends. Adv. Eng. Inform. 2016, 30, 500–521. [Google Scholar] [CrossRef]
- Randall, J.H. Conceptual Structure. In Linking: The Geometry of Argument Structure; Springer: Dordrecht, The Netherlands, 2010; pp. 11–34. ISBN 978-1-4020-8308-2. [Google Scholar]
- Li, M.; Chu, Y. Explore the research front of a specific research theme based on a novel technique of enhanced co-word analysis. J. Inf. Sci. 2017, 43, 725–741. [Google Scholar] [CrossRef]
- Nishisato, S. Correspondence Analysis and Dual Scaling. In Encyclopedia of Social Measurement; Elsevier Inc.: Amsterdam, The Netherlands, 2004; pp. 531–536. ISBN 9780123693983. [Google Scholar]
- Van Eck, N.J.; Waltman, L. Text Mining and Visualization Using VOSviewer 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1–5. [Google Scholar]
- Kroeger, P. Analyzing Grammar: An Introduction; Cambridge University Press: Cambridge, UK, 2005; ISBN 978-0-521-01653-7. [Google Scholar]
- Van Eck, N.J.; Waltman, L. Visualizing bibliometric networks. In Measuring Scholarly Impact; Springer: Cham, Switzerland, 2014; pp. 285–320. ISBN 9783319103778. [Google Scholar]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Karshenas, S.; Niknam, M. Ontology-Based Building Information Modeling. Comput. Civ. Eng. 2013, 2013, 476–483. [Google Scholar]
- Beetz, J.; van Leeuwen, J.P.; de Vries, B. An Ontology Web Language Notation of the Industry Foundation Classes. In Proceedings of the 22nd CIB W78 Conference on Information Technology in Construction, Dresden, Germany, 19–21 July 2005; pp. 193–198. [Google Scholar]
- Abanda, F.H.; Tah, J.H.M.; Keivani, R. Trends in built environment Semantic Web applications: Where are we today? Expert Syst. Appl. 2013, 40, 5563–5577. [Google Scholar] [CrossRef]
- Cheng, J.; Law, K.H. Using process specification language for project information exchange. In Proceedings of the 3rd International Conference on Concurrent Engineering in Construction, Dublin, Ireland, 24–25 September 2002. [Google Scholar]
- Staub-French, S.; Fischer, M.; Kunz, J.; Paulson, B. An Ontology for Relating Features with Activities to Calculate Costs. J. Comput. Civ. Eng. 2003, 17, 243–254. [Google Scholar] [CrossRef]
- Gu, T.; Wang, X.H.; Zhang, D.Q. An ontology-based context model in intelligent environments. In Proceedings of the Communication Networks and Distributed Systems Modeling and Simulation Conference, San Diego, CA, USA, 18–24 January 2004. [Google Scholar]
- Schevers, H.; Drogemuller, R. Converting industry foundation classes to the Web ontology language. In Proceedings of the Proceedings of the 1st international conference on semantics, knowledge and grid, Washington, DC, USA, 27–29 November 2005. [Google Scholar]
- Lima, C.; El-Diraby, T.; Fiès, B.; Zarli, A.; Ferneley, E. The e-COGNOS project: Current status and future directions of an ontology-enabled IT solution infrastructure supporting knowledge management in construction. In Proceedings of the Construction Research Congress, Honolulu, HI, USA, 19–1 March 2003; pp. 1–8. [Google Scholar]
- Yang, Q.Z.; Zhang, Y. Semantic interoperability in building design: Methods and tools. CAD Comput. Aided Des. 2006, 38, 1099–1112. [Google Scholar] [CrossRef]
- Schevers, H.; Mitchell, J.; Akhurst, P.; Marchant, D.; Bull, S.; McDonald, K.; Drogemuller, R.; Linning, C. Towards digital facility modelling for Sydney Opera House using IFC and semantic web technology. Electron. J. Inf. Technol. Constr. 2007, 12, 347–362. [Google Scholar]
- Mauher, M.; Vanja, S. Municipal asset and property management system for the web collaborative environment. In Proceedings of the 31st International Convention on Information and Communication Technology, Electronics and Microelectronics: DE\&ISS\&miproBIS\&LG\&SP., Opatija, Croatia, 26–30 May 2008; p. 200. [Google Scholar]
- Aksamija, A.; Grobler, F. Architectural Ontology: Development of Machine-Readable Representations for Building Design Drivers. In Proceedings of the Computing in Civil Engineering; American Society of Civil Engineers (ASCE), Pittsburgh, PA, USA, 24–27 July 2007; pp. 168–175. [Google Scholar]
- García, L.E.R. Ontological CAD data interoperability framework. In Proceedings of the 4th International Conference on Advances in Semantic Processing, Florence, Italy, 25–30 October 2010. [Google Scholar]
- Yurchyshyna, A.; Faron-Zucker, C.; Le Thanh, N.; Zarli, A. Knowledge capitalisation and organisation for conformance checking model in construction. Int. J. Knowl. Eng. Soft Data Paradig. 2010, 2, 15–32. [Google Scholar] [CrossRef]
- Kumar, V.; Tomic, S.; Pellegrini, T.; Fensel, A.V.; Mayrhofer, R. User created machine-readable policies for energy efficiency in smart homes. In Proceedings of the Ubicomp 2010 Workshop: Ubiquitous Computing for Sustainable Energy (UCSE), Copenhagen, Denmark, 26–29 September 2010. [Google Scholar]
- International Organization for Standardization. ISO 16739-1:2018 Industry Foundation Classes (IFC) for Data Sharing in the Construction and Facility Management Industries—Part 1: Data Schema; ISO: Geneve, Switzerland, 2018. [Google Scholar]
- Simeone, D.; Cursi, S. The role of semantic enrichment in Building Information Modelling. TEMA 2016, 2, 1–30. [Google Scholar]
- Zou, Y.; Kiviniemi, A.; Jones, S.W. Retrieving similar cases for construction project risk management using Natural Language Processing techniques. Autom. Constr. 2017, 80, 66–76. [Google Scholar] [CrossRef]
- Marzouk, M.; Enaba, M. Text analytics to analyze and monitor construction project contract and correspondence. Autom. Constr. 2019, 98, 265–274. [Google Scholar] [CrossRef]
- Lee, J.; Yi, J.-S.; Son, J. Development of Automatic-Extraction Model of Poisonous Clauses in International Construction Contracts Using Rule-Based NLP. J. Comput. Civ. Eng. 2019, 33, 04019003. [Google Scholar] [CrossRef]
- Tixier, A.J.P.; Hallowell, M.R.; Rajagopalan, B.; Bowman, D. Construction Safety Clash Detection: Identifying Safety Incompatibilities among Fundamental Attributes using Data Mining. Autom. Constr. 2017, 74, 39–54. [Google Scholar] [CrossRef] [Green Version]
- Baker, H.; Hallowell, M.R.; Tixier, A.J.P. AI-based prediction of independent construction safety outcomes from universal attributes. Autom. Constr. 2020, 118, 103146. [Google Scholar] [CrossRef]
- Kim, T.; Chi, S. Accident Case Retrieval and Analyses: Using Natural Language Processing in the Construction Industry. J. Constr. Eng. Manag. 2019, 145, 1–13. [Google Scholar] [CrossRef]
- Pan, J.; Anumba, C.J.; Ren, Z. Potential application of the semantic web in construction. In Proceedings of the 20th Annual ARCOM Conference; Khosrowshahi, F., Ed.; Association of Researchers in Construction Management: Edinburgh, UK, 2004; Volume 2, pp. 923–932. [Google Scholar]
- Kuck, G. Tim Berners-Lee’s Semantic Web. SA J. Inf. Manag. 2004, 6. [Google Scholar] [CrossRef] [Green Version]
- Pauwels, P.; Zhang, S.; Lee, Y.-C.C. Semantic web technologies in AEC industry: A literature overview. Autom. Constr. 2017, 8, 55. [Google Scholar] [CrossRef]
- Prell, C. Social Network Analysis: History, Theory and Methodology; Sage: Los Angeles, CA, USA, 2012; ISBN 1412947146. [Google Scholar]
- Hosseini, M.R.; Martek, I.; Zavadskas, E.K.; Aibinu, A.A.; Arashpour, M.; Chileshe, N. Critical evaluation of off-site construction research: A Scientometric analysis. Autom. Constr. 2018, 87, 235–247. [Google Scholar] [CrossRef]
- Freeman, L.C. A Set of Measures of Centrality Based on Betweenness. Sociometry 1977, 40, 35–41. [Google Scholar] [CrossRef]
- Cuccurullo, C.; Aria, M.; Sarto, F. Foundations and trends in performance management. A twenty-five years bibliometric analysis in business and public administration domains. Scientometrics 2016, 108, 595–611. [Google Scholar] [CrossRef]
- Lee, J.; Yi, J.-S. Predicting Project’s Uncertainty Risk in the Bidding Process by Integrating Unstructured Text Data and Structured Numerical Data Using Text Mining. Appl. Sci. 2017, 7, 1141. [Google Scholar] [CrossRef] [Green Version]
- Salama, D.M.; El-Gohary, N.M. Semantic Text Classification for Supporting Automated Compliance Checking in Construction. J. Comput. Civ. Eng. 2016, 30. [Google Scholar] [CrossRef]
- Song, J.; Kim, J.; Lee, J.-K. NLP and Deep Learning-based Analysis of Building Regulations to Support Automated Rule Checking System. In Proceedings of the 35th International Symposium on Automation and Robotics in Construction (ISARC), Berlin, Germany, 20–25 July 2018; Curran Associates: New York, NY, USA, 2018. [Google Scholar]
- Zhang, F.; Fleyeh, H.; Wang, X.; Lu, M. Construction site accident analysis using text mining and natural language processing techniques. Autom. Constr. 2019, 99, 238–248. [Google Scholar] [CrossRef]
- Cobo, M.J.; López-Herrera, A.G.; Herrera-Viedma, E.; Herrera, F. An approach for detecting, quantifying, and visualizing the evolution of a research field: A practical application to the Fuzzy Sets Theory field. J. Informetr. 2011, 5, 146–166. [Google Scholar] [CrossRef]
- Callon, M.; Courtial, J.; Laville, F. Co-word analysis as a tool for describing the network of interactions between basic and technological research: The case of polymer chemsitry. Scientometrics 1991, 22, 155–205. [Google Scholar] [CrossRef]
- Courtial, J.P. A coword analysis of scientometrics. Scientometrics 1994, 31, 251–260. [Google Scholar] [CrossRef]
- Qin, H. Knowledge Discovery Through Co-Word Analysis. Libr. Trends 1999, 48, 133–159. [Google Scholar]
- Bradford, S. Sources of information on specific subject. Engineering 1934, 137, 85–86. [Google Scholar]
- Venable, G.T.; Shepherd, B.A.; Loftis, C.M.; McClatchy, S.G.; Roberts, M.L.; Fillinger, M.E.; Tansey, J.B.; Klimo, P. Bradford’s law: Identification of the core journals for neurosurgery and its subspecialties. J. Neurosurg. 2016, 124, 569–579. [Google Scholar] [CrossRef] [Green Version]
- Hjørland, B.; Nicolaisen, J. Bradford’s law of scattering: Am-biguities in the concept of “subject”. In Information Context: Nature, Impact, and Role; Crestani, F., Ruthven, I., Eds.; Springer: Berlin, Germany, 2005; pp. 96–106. [Google Scholar]
- Hirsch, J.E. An index to quantify an individual’s scientific research output. Proc. Natl. Acad. Sci. USA 2005, 102, 16569–16572. [Google Scholar] [CrossRef] [Green Version]
- Egghe, L. Theory and practise of the g-index. Scientometrics 2006, 69, 131–152. [Google Scholar] [CrossRef]
- Pao, M.L. Lotka’s law: A testing procedure. Inf. Process. Manag. 1985, 21, 305–320. [Google Scholar] [CrossRef]
- Qiu, J.; Zhao, R.; Yang, S.; Dong, K. Informetrics: Theory, Methods and Applications; Springer: Berlin/Heidelberg, Germany, 2017; ISBN 9789811040320. [Google Scholar]
- Ioannou, P.G.; Liu, L.Y. Advanced Construction Technology System—ACTS. J. Constr. Eng. Manag. 1993, 119, 288–306. [Google Scholar] [CrossRef] [Green Version]
- Xiaorui, X.; Jiansong, Z. Building Codes Part-of-Speech Tagging Performance Improvement by Error-Driven Transformational Rules. J. Comput. Civ. Eng. 2020, 34, 4020035. [Google Scholar] [CrossRef]
- Sangyun, S.; Chankyu, L.; Issa, R.R. Framework for Automatic Speech Recognition-Based Building Information Retrieval from BIM Software. Constr. Res. Congr. 2020, 2020, 992–1000. [Google Scholar]
- Baker, H.; Hallowell, M.R.; Tixier, A.J.P. Automatically Learning Construction Injury Precursors from Text. Autom. Constr. 2019, 118, 103145. [Google Scholar] [CrossRef]
- Mo, Y.; Zhao, D.; Du, J.; Syal, M.; Aziz, A.; Li, H. Automated staff assignment for building maintenance using natural language processing. Autom. Constr. 2020, 113, 103150. [Google Scholar] [CrossRef]
- Peters, H.P.F.; Van Raan, A.F. Structuring scientific activities by co-author analysis—An exercise on a university faculty level. Scientometrics 1991, 20, 235–255. [Google Scholar] [CrossRef]
- Leng, S.; Hu, Z.-Z.; Luo, Z.; Zhang, J.-P.; Lin, J.-R. Automatic MEP knowledge acquisition based on documents and Natural Language Processing. In Proceedings of the 36th International Conference of CIB W78, Newcastle-upon-Tyne, UK, 18–20 September 2019; pp. 800–809. [Google Scholar]
- Rasmussen, M.H.; Lefrançois, M.; Pauwels, P.; Hviid, C.A.; Karlshøj, J. Managing interrelated project information in AEC Knowledge Graphs. Autom. Constr. 2019, 108, 102956. [Google Scholar] [CrossRef]
- Santos, R.; Costa, A.A.; Grilo, A. Bibliometric analysis and review of Building Information Modelling literature published between 2005 and 2015. Autom. Constr. 2017, 80, 118–136. [Google Scholar] [CrossRef]
- Isikdag, U.; Aouad, G.; Underwood, J.; Wu, S. Building information models: A review on storage and exchange mechanisms. In Proceedings of the International Conference on IT for Construction CIBW78, Maribor, Slovenia, 27–29 June 2007; pp. 135–143. [Google Scholar]
- Deshpande, A.; Azhar, S.; Amireddy, S. A framework for a BIM-based knowledge management system. Procedia Eng. 2014, 85, 113–122. [Google Scholar] [CrossRef] [Green Version]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tool Comparison Matrix | Science Mapping Tool | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Bibexcel | BiblioShiny | BiblioMaps | CiteSpace | CitNetExplorer | SciMAT | Sci Tool | VosViewer | Gephi | ||
| Network analysis | Thematic | yes | yes | yes | yes | yes | yes | yes | yes | |
| Author | yes | yes | yes | yes | yes | yes | yes | yes | ||
| Reference | yes | yes | yes | yes | yes | yes | yes | yes | yes | |
| Other | yes | yes | yes | yes | yes | yes | yes | yes | ||
| Geospatial | yes | yes | yes | yes | yes | |||||
| Other analysis | Burst detection | yes | yes | yes | ||||||
| Spectrogram | yes | |||||||||
| Map visualization | Network | yes | yes | yes | yes | yes | yes | yes | ||
| Geospatial | yes | yes | yes | yes | ||||||
| Temporal | yes | yes | yes | |||||||
| Cluster | yes | yes | yes | |||||||
| Evolution | yes | yes | ||||||||
| Overlay | yes | yes | yes | yes | ||||||
| Density | yes | yes | yes | yes | ||||||
| Tree ring | yes | yes | yes | |||||||
| Other | yes | yes | yes | |||||||
| Topic | Synonyms | Normalized Term |
|---|---|---|
| Building Information Modeling | building information model-bim | bim |
| bim | ||
| building information model | ||
| building information modeling | ||
| building information modeling (bim) | ||
| building information modelling | ||
| Industry Foundation Classes | industry foundation classes (ifc) | ifc |
| industry foundation classes—ifc | ||
| industry foundation classes | ||
| Natural Language Processing | computational linguistics | nlp |
| natural language processing | ||
| natural language processing systems | ||
| nlp systems | ||
| Construction sector | constructions sectors | construction industry |
| construction | ||
| constructions | ||
| construction sector |
| Main Information about the Data Set | |
|---|---|
| Timespan | 1989:2020 |
| Sources | 64 |
| Documents | 254 |
| Average years from publication | 11.4 |
| Average citations per documents | 12.77 |
| Average citations per year per doc | 1.662 |
| References | 6169 |
| Document types | |
| Article | 141 |
| Conference paper | 113 |
| Document contents | |
| Indexed keywords | 1725 |
| Author’s keywords | 473 |
| Authors | |
| Authors | 551 |
| Author appearances | 700 |
| Authors of single-authored documents | 31 |
| Authors of multi-authored documents | 520 |
| Authors collaboration | |
| Single-authored documents | 33 |
| Documents per Author | 0.461 |
| Authors per Document | 2.17 |
| Co-Authors per Documents | 2.76 |
| Collaboration Index | 2.35 |
| Color Cluster | Main Cluster Topic | Keywords | Less Recent Publication | Average Publication Year | Most Recent Publication |
|---|---|---|---|---|---|
| Red | Construction and Information Management | 21 | 1998 | 2004 | 2010 |
| Blue | BIM, Design, Ontology and IFC (Interoperability format and Knowledge Management) | 16 | 2009 | 2013 | 2016 |
| Yellow | Semantic technology and Automated Compliance Checking | 14 | 2005 | 2012 | 2017 |
| Green | NLP tools and application in AECO | 20 | 2008 | 2015 | 2019 |
| Keywords | Degree Centrality | Betweenness Centrality |
|---|---|---|
| information retrieval | 87 | 196 |
| construction industry | 85 | 156 |
| project management | 82 | 142 |
| information management | 79 | 135 |
| architectural design | 78 | 28 |
| bim | 73 | 46 |
| nlp | 70 | 89 |
| civil engineering | 69 | 50 |
| information theory | 64 | 76 |
| semantics | 60 | 40 |
| construction management | 59 | 52 |
| information technology | 59 | 61 |
| construction projects | 56 | 26 |
| data mining | 55 | 51 |
| buildings | 54 | 22 |
| knowledge based systems | 54 | 35 |
| knowledge management | 53 | 61 |
| ifc | 52 | 44 |
| automation | 51 | 15 |
| artificial intelligence | 50 | 8 |
| learning systems | 50 | 26 |
| world wide web | 50 | 0 |
| classification | 48 | 17 |
| mathematical models | 47 | 30 |
| laws and legislation | 46 | 29 |
| Topic | Brief Description and Main Goal | Reference |
|---|---|---|
| Risk management | NLP based system to analyze the uncertainty of the bidding documents: predicting risks during the bidding process of construction projects. | [103] |
| Automated Compliance Checking | Semantic machine learning-based text classification algorithm for classifying clauses and sub-clauses: enhancing Automated Compliance Checking (ACC). | [104] |
| NLP and deep learning-based approach, converting human-readable building regulations to computer-readable format: supporting Automated Rule Checking activity. | [105] | |
| Construction safety | NLP techniques performed on construction accident report databases: improving efficiency and performance of risk mitigation Case Base Reasoning (CBR) method. | [90] |
| Text mining and NLP to analyze construction site accident: preventing reoccurrence of similar accidents enhancing scientific risk control plans. | [106] |
| Source | Journal Articles | Conference Papers |
|---|---|---|
| Automation in Construction | 41 | - |
| Journal of Computing in Civil Engineering | 25 | - |
| Congress on Computing in Civil Engineering | - | 20 |
| Journal of Construction Engineering and Management | 19 | - |
| Computing in Civil Engineering (New York) | - | 14 |
| Computing in Civil and Building Engineering | - | 10 |
| Canadian Society for Civil Engineering- Annual Conference | - | 9 |
| Journal of Management in Engineering | 7 | - |
| Engineering, Construction and Architectural Management | 6 | - |
| ASCE Construction Congress | - | 5 |
| Computer-Aided Civil And Infrastructure Engineering | 4 | - |
| Construction Innovation | 4 | - |
| Electronic Journal of Information Technology in Construction | 4 | - |
| ISARC-International Symposium On Automation And Robotics in Construction | - | 4 |
| Journal of Civil Engineering and Management | 4 | - |
| Journal of Information Technology in Construction | 4 | - |
| ASCE International Conference on Computing in Civil Engineering | - | 4 |
| Towards a Vision for Information Technology in Civil Engineering | - | 4 |
| Architectural Engineering and Design Management | 3 | - |
| Civil Engineering Systems | 3 | |
| Total | 124 | 70 |
| Source: Journal or Conference Proceedings | H-Index | G-Index | M-Index | Number of Documents | Total Citations | Years of Publications |
|---|---|---|---|---|---|---|
| Automation in Construction | 21 | 35 | 0.78 | 41 | 1227 | 1994 |
| Journal of Computing in Civil Engineering | 14 | 25 | 0.54 | 25 | 633 | 1995 |
| Congress on Computing in Civil Engineering | 6 | 9 | 0.26 | 20 | 93 | 1998 |
| Journal of Construction Engineering and Management | 11 | 19 | 0.34 | 19 | 465 | 1989 |
| Computing in Civil Engineering (New York) | 4 | 5 | 0.15 | 14 | 37 | 1994 |
| Computing in Civil and Building Engineering | 4 | 6 | 0.14 | 10 | 38 | 1993 |
| Canadian Society for Civil Engineering- Annual Conference | 1 | 1 | 0.06 | 9 | 4 | 2003 |
| Journal of Management in Engineering | 6 | 7 | 0.19 | 7 | 137 | 1990 |
| Engineering, Construction and Architectural Management | 2 | 6 | 0.13 | 6 | 91 | 2006 |
| ASCE Construction Congress | 2 | 3 | 0.08 | 5 | 11 | 1995 |
| Computer-Aided Civil And Infrastructure Engineering | 4 | 4 | 0.21 | 4 | 70 | 2002 |
| Construction Innovation | 3 | 4 | 0.17 | 4 | 29 | 2003 |
| Electronic Journal of Information Technology in Construction | 3 | 4 | 0.17 | 4 | 114 | 2003 |
| ISARC-International Symposium On Automation And Robotics in Construction | 1 | 1 | 0.33 | 4 | 3 | 2018 |
| Journal of Civil Engineering and Management | 3 | 4 | 0.16 | 4 | 62 | 2002 |
| Journal of Information Technology in Construction | 2 | 4 | 0.25 | 4 | 23 | 2013 |
| ASCE International Conference on Computing in Civil Engineering | 1 | 1 | 0.06 | 4 | 2 | 2005 |
| Towards a Vision for Information Technology in Civil Engineering | 3 | 4 | 0.17 | 4 | 17 | 2003 |
| Architectural Engineering and Design Management | 2 | 3 | 0.67 | 3 | 12 | 2018 |
| Civil Engineering Systems | 1 | 1 | 0.03 | 3 | 3 | 1989 |
| Affiliation | Country | Articles |
|---|---|---|
| University of Illinois At Urbana-Champaign | USA | 17 |
| University of Florida | USA | 9 |
| Purdue University | USA | 8 |
| University of Colorado At Boulder | USA | 8 |
| Concordia University | Canada | 7 |
| Stanford University | USA | 7 |
| Florida International University | USA | 5 |
| Georgia Institute of Technology | USA | 5 |
| National Taiwan University | Taiwan | 5 |
| University Of Toronto | Canada | 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Locatelli, M.; Seghezzi, E.; Pellegrini, L.; Tagliabue, L.C.; Di Giuda, G.M. Exploring Natural Language Processing in Construction and Integration with Building Information Modeling: A Scientometric Analysis. Buildings 2021, 11, 583. https://doi.org/10.3390/buildings11120583
Locatelli M, Seghezzi E, Pellegrini L, Tagliabue LC, Di Giuda GM. Exploring Natural Language Processing in Construction and Integration with Building Information Modeling: A Scientometric Analysis. Buildings. 2021; 11(12):583. https://doi.org/10.3390/buildings11120583
Chicago/Turabian StyleLocatelli, Mirko, Elena Seghezzi, Laura Pellegrini, Lavinia Chiara Tagliabue, and Giuseppe Martino Di Giuda. 2021. "Exploring Natural Language Processing in Construction and Integration with Building Information Modeling: A Scientometric Analysis" Buildings 11, no. 12: 583. https://doi.org/10.3390/buildings11120583