
Effects of Noise and Serial Position on Free Recall of Spoken Words and Pupil Dilation during Encoding in Normal-Hearing Adults

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Equipment and Test Materials
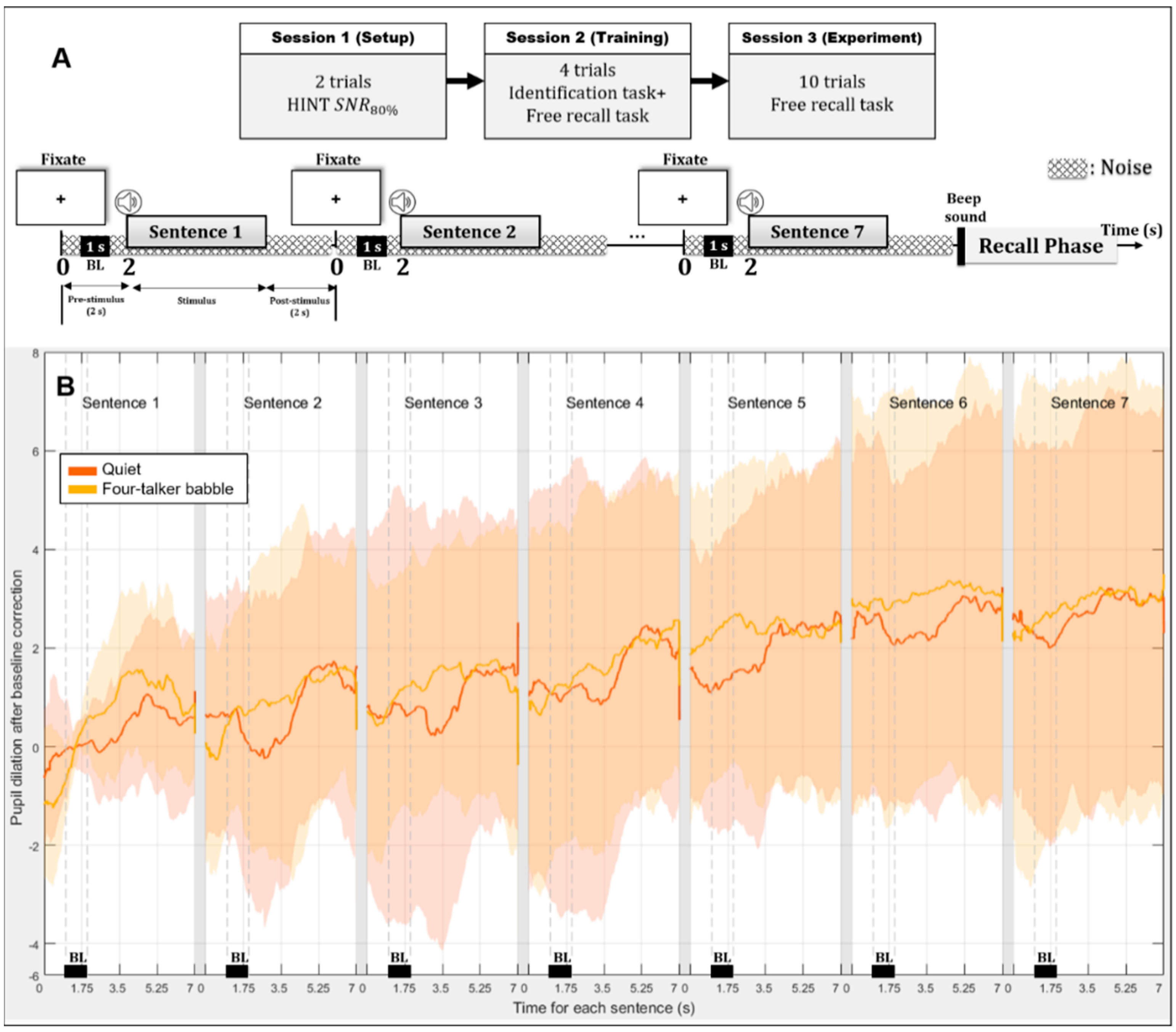
2.3. Procedure
2.4. Reading Span Test
2.5. Pupil Diameter Recording and Data Analysis
2.6. Statistical Analyses
3. Results
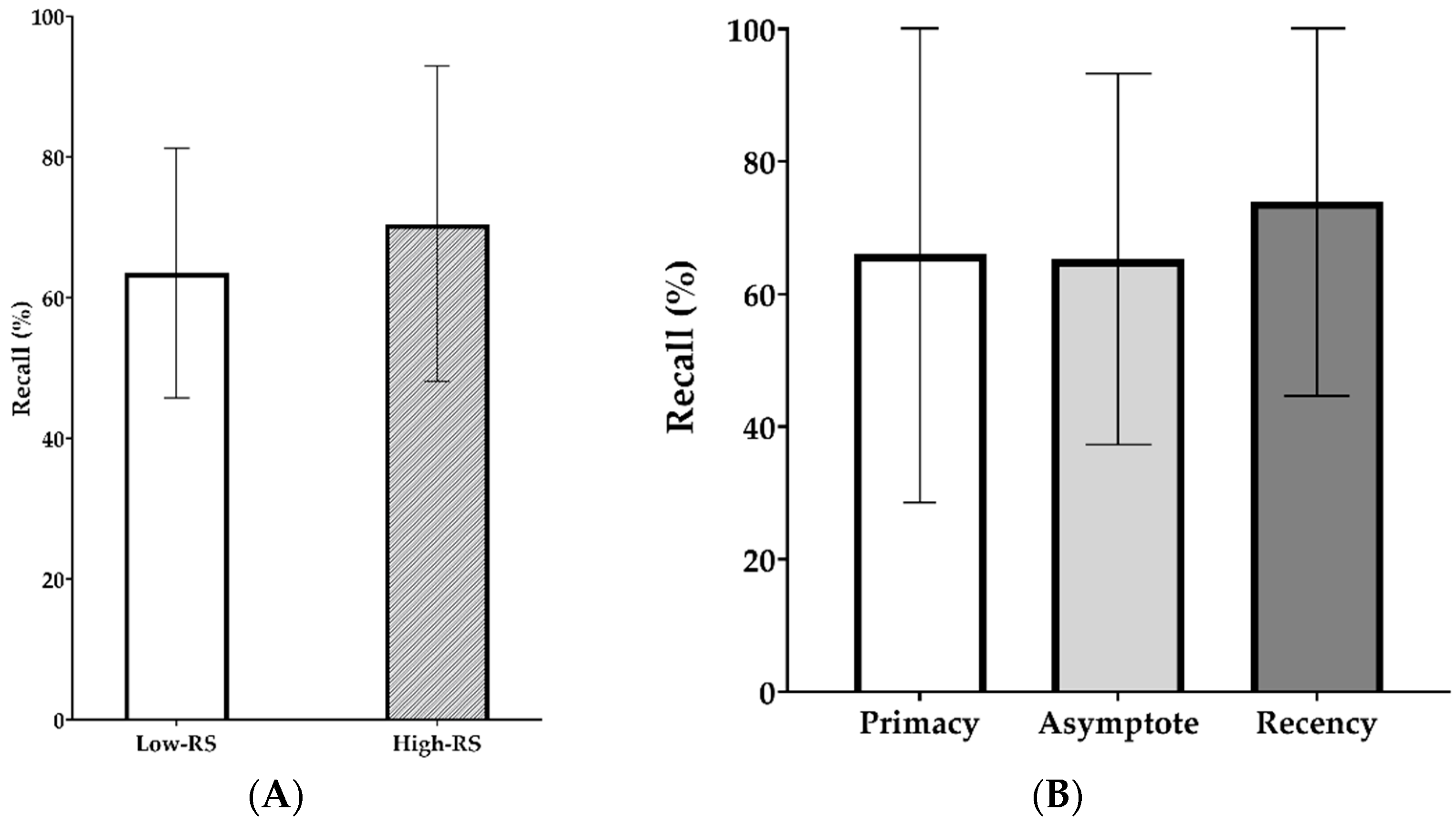
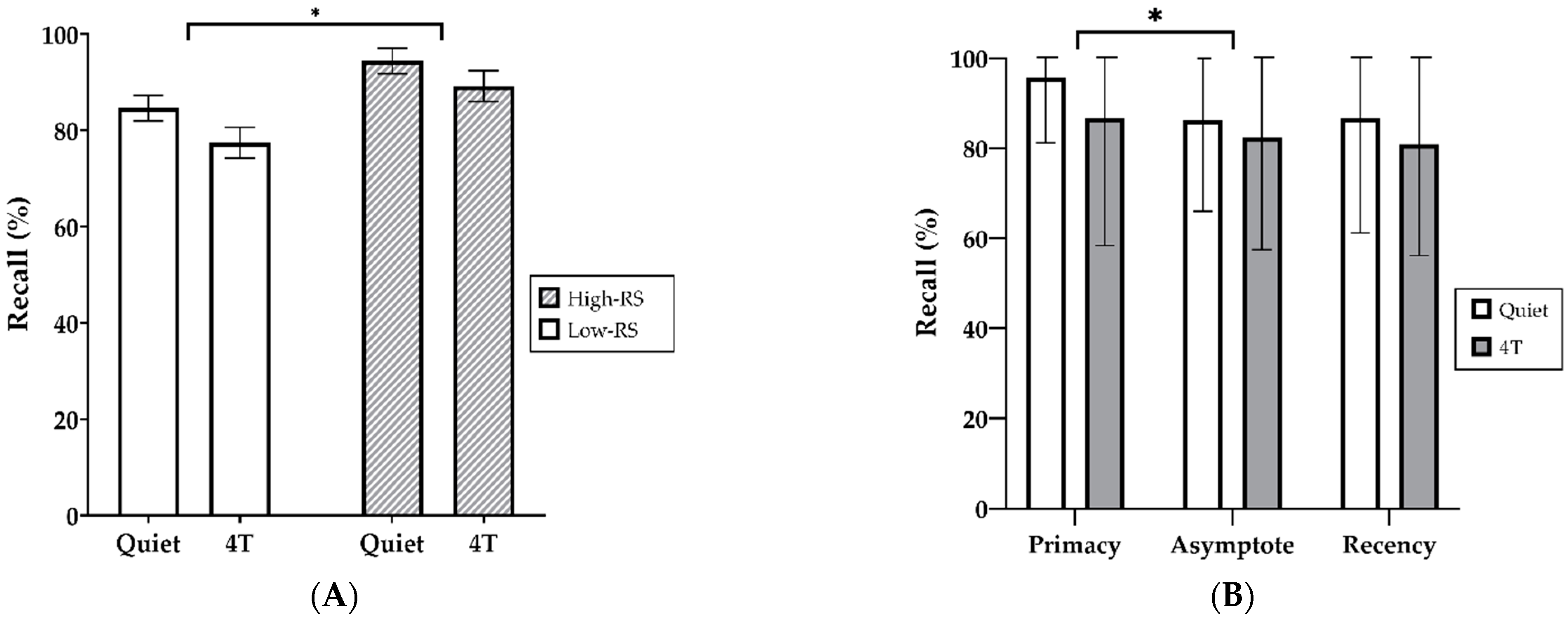
3.1. Free Recall of Spoken Words in Stationary Noise
3.2. Free Recall of Spoken Words in Quiet Condition versus Four-Talker Babble Noise
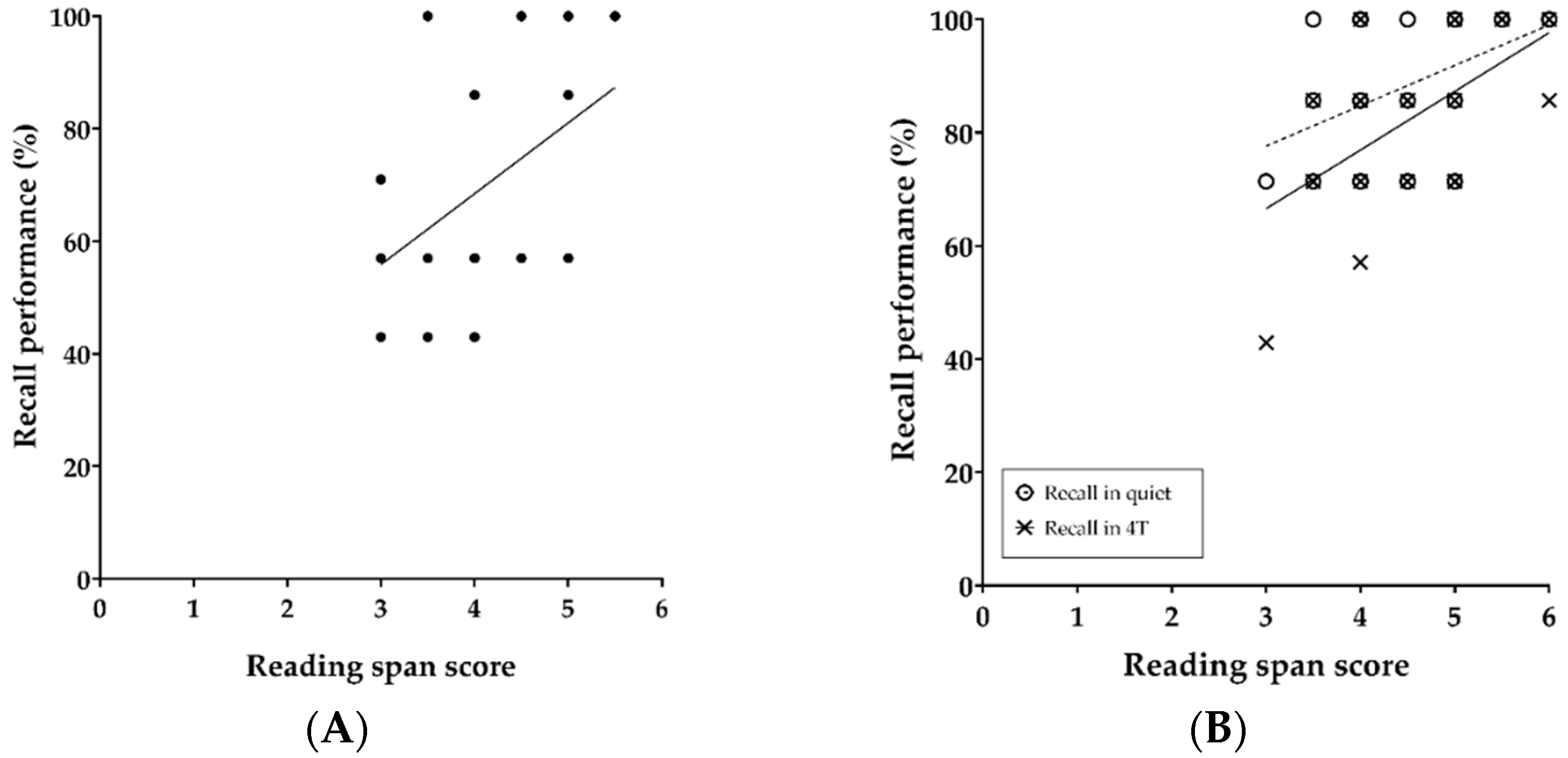
3.3. Correlation between Free Recall and RS Scores
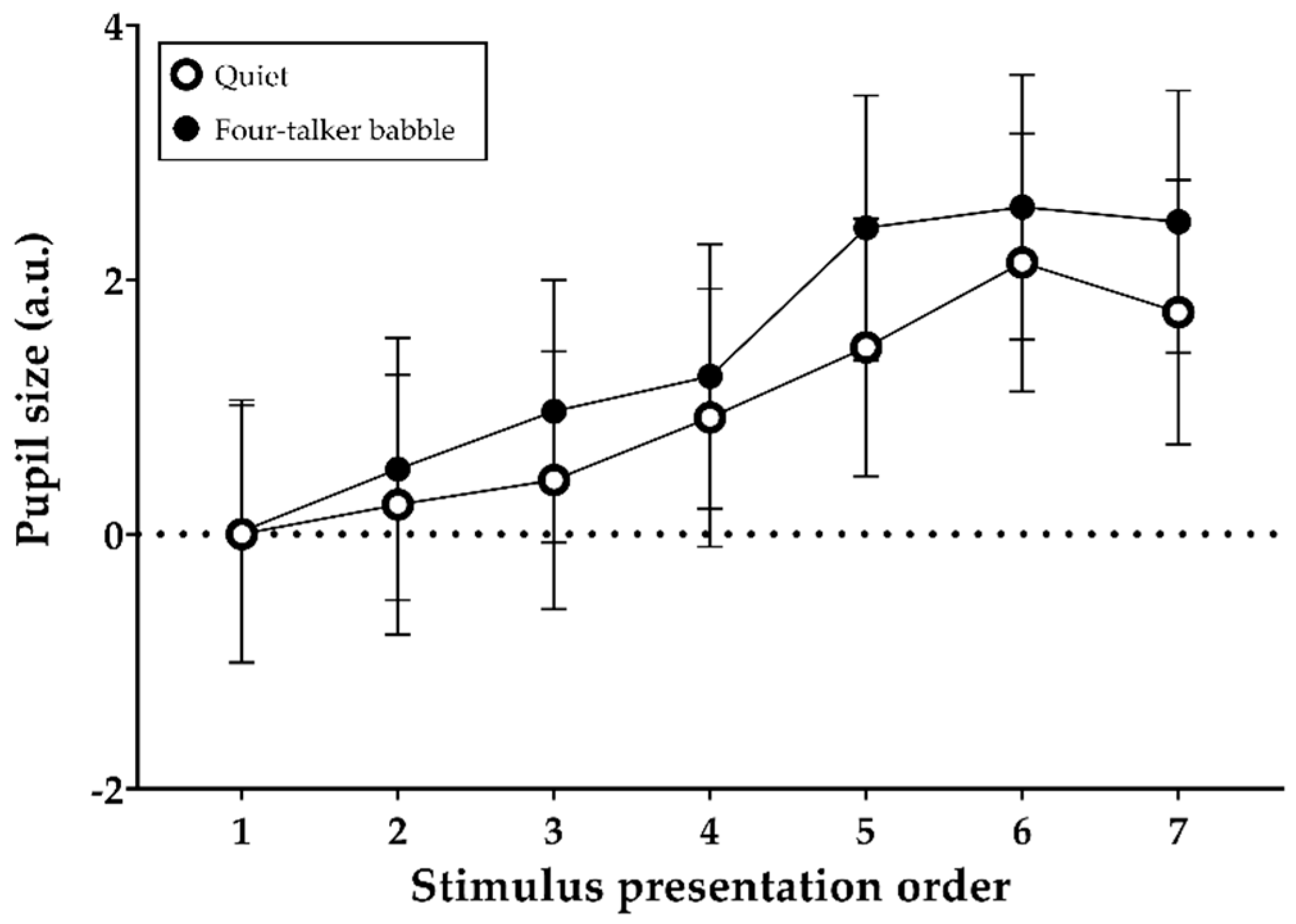
3.4. Sentence Baselines Relative to the Initial-Sentence Baseline during Encoding
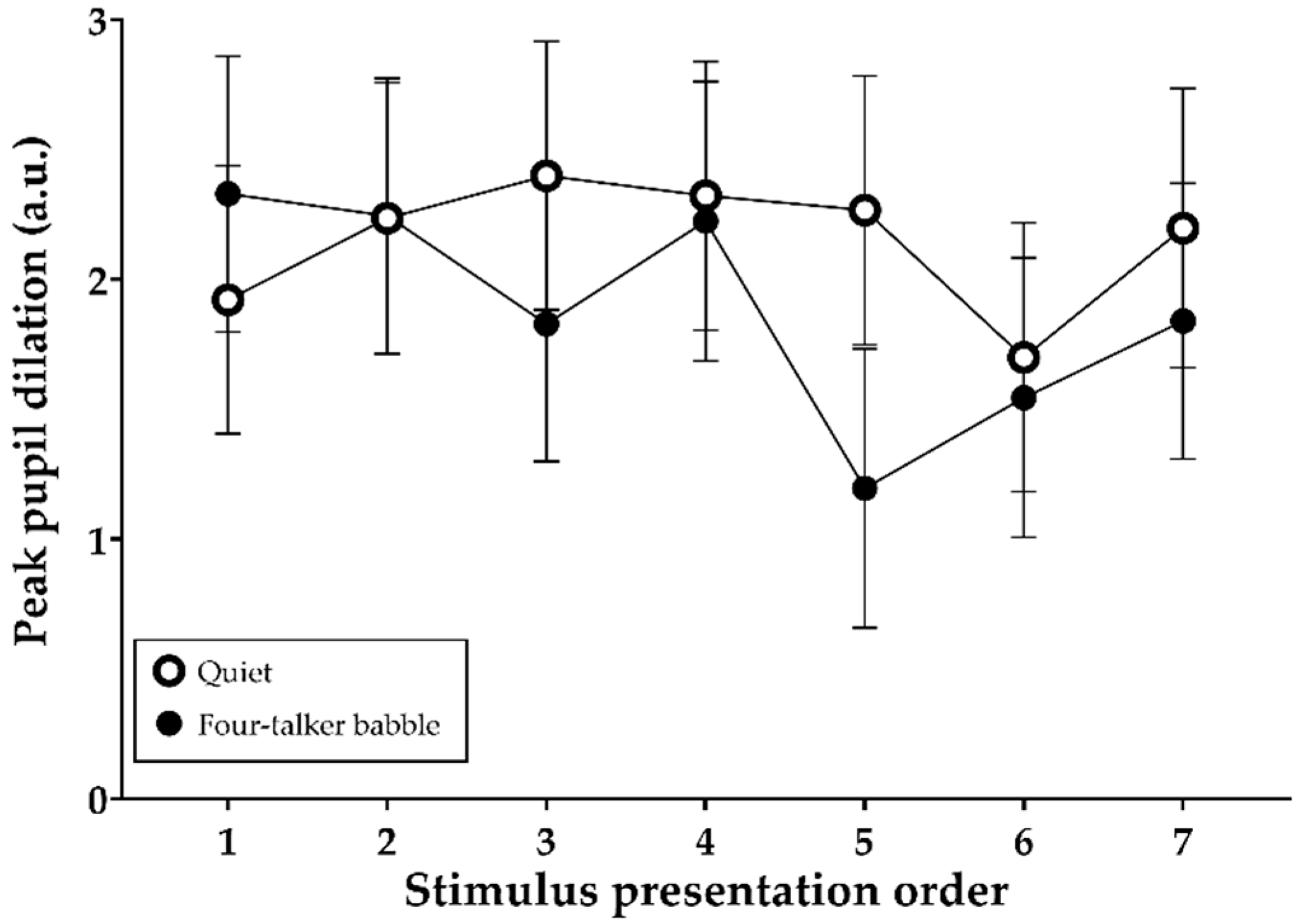
3.5. Peak Pupil Dilations during Stimulus Presentation
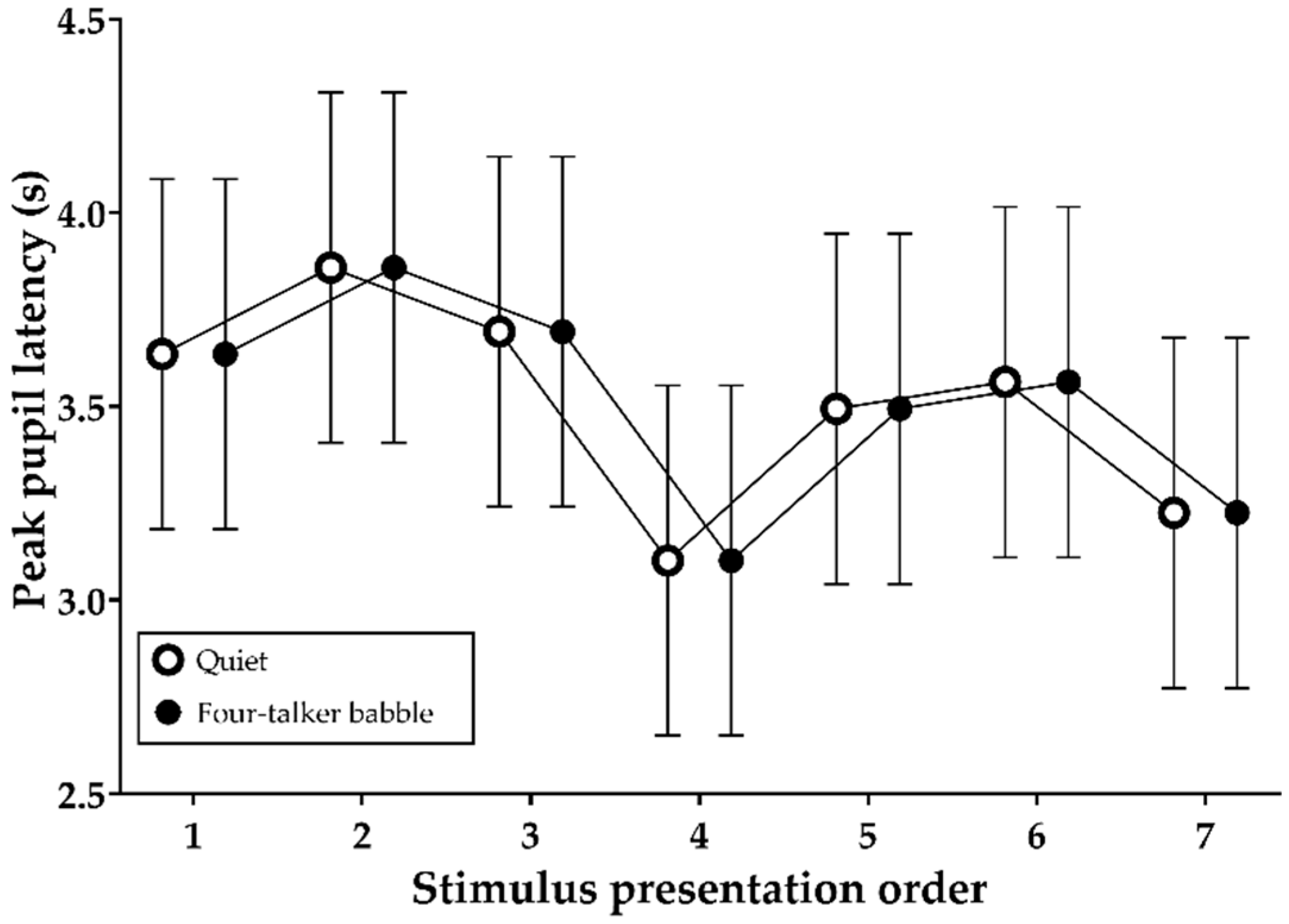
3.6. Peak Pupil Latencies during Stimulus Presentation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ma, W.J.; Husain, M.; Bays, P.M. Changing concepts of working memory. Nat. Neurosci. 2014, 17, 347–356. [Google Scholar] [CrossRef] [PubMed]
- Baddeley, A. Working memory. Science 1992, 255, 556–559. [Google Scholar] [CrossRef] [PubMed]
- Baddeley, A. Working memory and language: An overview. J Commun. Disord. 2003, 36, 189–208. [Google Scholar] [CrossRef]
- Edwards, B. The future of hearing aid technology. Trends Amplif. 2007, 11, 31–45. [Google Scholar] [CrossRef] [PubMed]
- Ronnberg, J.; Lunner, T.; Zekveld, A.; Sorqvist, P.; Danielsson, H.; Lyxell, B.; Dahlstrom, O.; Signoret, C.; Stenfelt, S.; Pichora-Fuller, M.K.; et al. The Ease of Language Understanding (ELU) model: Theoretical, empirical, and clinical advances. Front. Syst. Neurosci. 2013, 7, 31. [Google Scholar] [CrossRef] [Green Version]
- Ronnberg, J.; Rudner, M.; Foo, C.; Lunner, T. Cognition counts: A working memory system for ease of language understanding (ELU). Int. J. Audiol. 2008, 47 (Suppl. 2), S99–S105. [Google Scholar] [CrossRef]
- Pichora-Fuller, M.K.; Kramer, S.E.; Eckert, M.A.; Edwards, B.; Hornsby, B.W.; Humes, L.E.; Lemke, U.; Lunner, T.; Matthen, M.; Mackersie, C.L.; et al. Hearing Impairment and Cognitive Energy: The Framework for Understanding Effortful Listening (FUEL). Ear Hear. 2016, 37 (Suppl. 1), 5S–27S. [Google Scholar] [CrossRef] [PubMed]
- Pichora-Fuller, M.K. How Social Psychological Factors May Modulate Auditory and Cognitive Functioning During Listening. Ear Hear. 2016, 37, 92s–100s. [Google Scholar] [CrossRef]
- Wendt, D.; Hietkamp, R.K.; Lunner, T. Impact of Noise and Noise Reduction on Processing Effort: A Pupillometry Study. Ear Hear. 2017, 38, 690–700. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- DiGiovanni, J.J.; Riffle, T.L.; Nagaraj, N.K.; DiGiovanni, J.J.; Riffle, T.L.; Nagaraj, N.K. Attention-Controlled Working Memory Measures to Assess Listening Effort. Clin. Arch. Commun. Disord. 2017, 2, 163–177. [Google Scholar] [CrossRef]
- Lunner, T.; Rudner, M.; Rosenbom, T.; Agren, J.; Ng, E.H.N. Using Speech Recall in Hearing Aid Fitting and Outcome Evaluation Under Ecological Test Conditions. Ear Hear. 2016, 37, 145s–154s. [Google Scholar] [CrossRef]
- Sarampalis, A.; Kalluri, S.; Edwards, B.; Hafter, E. Objective Measures of Listening Effort: Effects of Background Noise and Noise Reduction. J. Speech Lang. Hear. Res. 2009, 52, 1230–1240. [Google Scholar] [CrossRef]
- Ng, E.H.; Rudner, M.; Lunner, T.; Pedersen, M.S.; Ronnberg, J. Effects of noise and working memory capacity on memory processing of speech for hearing-aid users. Int. J. Audiol. 2013, 52, 433–441. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Daneman, M.; Carpenter, P.A. Individual-Differences in Working Memory and Reading. J. Verbal Learn. Verbal Behav. 1980, 19, 450–466. [Google Scholar] [CrossRef]
- Murdock, B.B. A Theory for the Storage and Retrieval of Item and Associative Information. Psychol. Rev. 1982, 89, 609–626. [Google Scholar] [CrossRef]
- Bilger, R.C.; Nuetzel, J.M.; Rabinowitz, W.M.; Rzeczkowski, C. Standardization of a Test of Speech-Perception in Noise. J. Speech Hear. Res. 1984, 27, 32–48. [Google Scholar] [CrossRef]
- Kramer, S.E.; Kapteyn, T.S.; Festen, J.M.; Kuik, D.J. Assessing aspects of auditory handicap by means of pupil dilatation. Audiology 1997, 36, 155–164. [Google Scholar] [CrossRef] [PubMed]
- Zekveld, A.A.; Kramer, S.E.; Festen, J.M. Pupil Response as an Indication of Effortful Listening: The Influence of Sentence Intelligibility. Ear Hear. 2010, 31, 480–490. [Google Scholar] [CrossRef] [PubMed]
- van der Wel, P.; van Steenbergen, H. Pupil dilation as an index of effort in cognitive control tasks: A review. Psychon. Bull. Rev. 2018, 25, 2005–2015. [Google Scholar] [CrossRef]
- Kahneman, D. Attention and Effort; Prentice-Hall: Englewood Cliffs, NJ, USA, 1973; 246p. [Google Scholar]
- Reilly, J.; Kelly, A.; Kim, S.H.; Jett, S.; Zuckerman, B. The human task-evoked pupillary response function is linear: Implications for baseline response scaling in pupillometry. Behav. Res. Methods 2019, 51, 865–878. [Google Scholar] [CrossRef] [Green Version]
- Ayasse, N.D.; Wingfield, A. Anticipatory Baseline Pupil Diameter Is Sensitive to Differences in Hearing Thresholds. Front. Psychol. 2020, 10, 2947. [Google Scholar] [CrossRef] [PubMed]
- Siegle, G.J.; Ichikawa, N.; Steinhauer, S. Blink before and after you think: Blinks occur prior to and following cognitive load indexed by pupillary responses. Psychophysiology 2008, 45, 679–687. [Google Scholar] [CrossRef]
- Lee, J.Y.; Lee, D.W.; Cho, S.J.; Na, D.L.; Jeon, H.J.; Kim, S.K.; Lee, Y.R.; Youn, J.H.; Kwon, M.; Lee, J.H.; et al. Brief screening for mild cognitive impairment in elderly outpatient clinic: Validation of the Korean version of the Montreal Cognitive Assessment. J. Geriatr. Psychiatry Neurol. 2008, 21, 104–110. [Google Scholar] [CrossRef] [PubMed]
- Moon, S.K.; Mun, H.A.; Jung, H.K.; Soli, S.D.; Lee, J.H.; Park, K. Development of Sentences for Korean Hearing in Noise Test (KHINT). Korean J. Otorhinolaryngol. Head Neck Surg. 2005, 48, 724–728. [Google Scholar]
- Yeon, J. The Korean language: Structure, use and context. Bull. Sch. Orient. Afr. Stud. 2008, 71, 158–159. [Google Scholar] [CrossRef] [Green Version]
- Levitt, H. Transformed up-down methods in psychoacoustics. J. Acoust. Soc. Am. 1971, 49 (Suppl. 2), 467–477. [Google Scholar] [CrossRef]
- Winn, M.B.; Wendt, D.; Koelewijn, T.; Kuchinsky, S.E. Best Practices and Advice for Using Pupillometry to Measure Listening Effort: An Introduction for Those Who Want to Get Started. Trends Hear. 2018, 22, 2331216518800869. [Google Scholar] [CrossRef]
- Lee, B.-T. Individual Differences in Language Understanding Processing Depending on Working Memory Capacity; Seoul National University Graduate School: Seoul, Korea, 1995. [Google Scholar]
- Kret, M.E.; Sjak-Shie, E.E. Preprocessing pupil size data: Guidelines and code. Behav. Res. Methods 2019, 51, 1336–1342. [Google Scholar] [CrossRef] [PubMed]
- Noguchi, K.; Gel, Y.R.; Brunner, E.; Konietschke, F. nparLD: An R Software Package for the Nonparametric Analysis of Longitudinal Data in Factorial Experiments. J. Stat. Softw. 2012, 50, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Brunner, E.; Domhof, S.; Langer, F. Nonparametric Analysis of Longitudinal Data in Factorial Experiments; Probability and Statistics; John Wiley & Sons: New York, NY, USA, 2002. [Google Scholar]
- Rudner, M.; Lunner, T. Cognitive spare capacity and speech communication: A narrative overview. BioMed Res. Int. 2014, 2014, 869726. [Google Scholar] [CrossRef] [PubMed]
- Ohlenforst, B.; Zekveld, A.A.; Jansma, E.P.; Wang, Y.; Naylor, G.; Lorens, A.; Lunner, T.; Kramer, S.E. Effects of Hearing Impairment and Hearing Aid Amplification on Listening Effort: A Systematic Review. Ear Hear. 2017, 38, 267–281. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ohlenforst, B.; Zekveld, A.A.; Lunner, T.; Wendt, D.; Naylor, G.; Wang, Y.; Versfeld, N.J.; Kramer, S.E. Impact of stimulus-related factors and hearing impairment on listening effort as indicated by pupil dilation. Hear. Res. 2017, 351, 68–79. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Naylor, G.; Kramer, S.E.; Zekveld, A.A.; Wendt, D.; Ohlenforst, B.; Lunner, T. Relations Between Self-Reported Daily-Life Fatigue, Hearing Status, and Pupil Dilation During a Speech Perception in Noise Task. Ear Hear. 2018, 39, 573–582. [Google Scholar] [CrossRef] [PubMed] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | First Experiment (N = 25) | Second Experiment (N = 34) |
|---|---|---|
| Mean ± SD | Mean ± SD | |
| Age | 28 ± 7.6 | 28.4 ± 5.5 |
| Sex | ||
| Female | 22 (88%) | 18 (53%) |
| Male | 3 (12%) | 16 (47%) |
| Hearing threshold (dB HL) | 6 ± 3.3 | 3 ± 4.3 |
| RS score | 4 ± 0.7 | 4 ± 0.1 |
| MoCA-K | ||
| Total score | 28 ± 0.3 | 29 ± 1.7 |
| Delayed recall | 3.8 ± 1.14 | 4 ± 1.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koo, M.; Jeon, J.; Moon, H.; Suh, M.; Lee, J.; Oh, S.; Park, M. Effects of Noise and Serial Position on Free Recall of Spoken Words and Pupil Dilation during Encoding in Normal-Hearing Adults. Brain Sci. 2021, 11, 277. https://doi.org/10.3390/brainsci11020277
Koo M, Jeon J, Moon H, Suh M, Lee J, Oh S, Park M. Effects of Noise and Serial Position on Free Recall of Spoken Words and Pupil Dilation during Encoding in Normal-Hearing Adults. Brain Sciences. 2021; 11(2):277. https://doi.org/10.3390/brainsci11020277
Chicago/Turabian StyleKoo, Miseung, Jihui Jeon, Hwayoung Moon, Myungwhan Suh, Junho Lee, Seungha Oh, and Mookyun Park. 2021. "Effects of Noise and Serial Position on Free Recall of Spoken Words and Pupil Dilation during Encoding in Normal-Hearing Adults" Brain Sciences 11, no. 2: 277. https://doi.org/10.3390/brainsci11020277