1. Introduction
The high prevalence and mortality rates of persons with chronic diseases, such as chronic kidney disease (CKD) [
1], are real-world public health problems. The world health organization (WHO) estimated that chronic diseases would cause 60 percent of the deaths reported in 2005, 80 percent in low-income and lower-middle-income countries, increasing to 66.7 percent in 2020 [
2]. According to the WHO health statistics 2019 [
3], people who live in low-income and lower-middle-income countries have a higher probability of dying prematurely from known chronic diseases such as diabetes mellitus (DM). Estimates reveal that in 2045, about 628.6 million people will have DM, with 79% of them living in low-income and lower-middle-income countries [
4].
For CKD’s specific case, the early prediction and monitoring of this disease and its risk factors reduce the CKD progression and prevent adverse events, such as sudden development of diabetic nephropathy. Thus, this study considers CKD early prediction and monitoring focusing on a dataset from people who live in Brazil, a continental-size developing country. Developing countries stand for low- and middle-income regions, while developed countries are high-income regions, such as the USA [
5]. Developing countries suffer from increased mortality rates caused by chronic diseases, e.g., CKD, arterial hypertension (AH), and DM [
6]. AH and DM are two of the most common CKD risk factors. People with type 1 or type 2 DM are at high risk of developing diabetic nephropathy [
7], while severe AH cases may increase kidney damage. For example, in 2019, about 10 percent of the adult Brazilian population was aware of having kidney damage, while about 70 percent remained undiagnosed [
8].
The CKD is characterized by permanent damage, reducing the kidneys’ excretory function, measured using glomerular filtration [
9]. However, the diagnosis usually occurs during more advanced stages because it is asymptomatic, postponing the application of countermeasures, decreasing people’s quality of life, and possibly leading to lethal kidney damage. For example, in 2010, about 500–650 people per million of the Brazilian population faced dialysis and kidney transplantation [
10]. This number has grown, warning governments about the relevance of the CKD early prediction. In 2016, according to the Brazilian chronic dialysis survey, the number of patients under dialysis was 122,825.00, increasing this number by 31,000.00 in the last five years [
11]. In 2017, the prevalence and incidence rates of patients under dialysis were 610 and 194 per million [
12]. The incidence continued to be high in 2018 (133,464.00) [
13]. Estimates also indicate that, in 2030, about 4 million patients will be under dialysis worldwide [
14].
The high prevalence and incidence of dialysis and kidney transplantation increase public health costs. Therefore, CKD has an expressive impact on the health economics perspective [
15]. For instance, the Brazilian Ministry of Health reported that transplantation and its procedures spent about 720 million reais in 2008 and 1.3 billion in 2015 [
16]. According to the Brazilian Ministry of Health, in 2020, the Brazilian government spent more than 1.4 billion reais for hemodialysis procedures. The costs and the high rates of persons waiting for transplantation suggest the increased public spending on kidney diseases. Preventing CKD has a relevant role in reducing mortality rates and public health costs [
17]. The CKD early prediction is even more challenging for people who live in remote and hard-to-reach settings because of either lack of or precarious primary care. CKD early prediction is relevant to improve CKD screening and reduce public health costs.
In this study, we address four problems. The first problem is size limitation, in which training models using small datasets can result in skewed performance estimates [
18]. The second problem is the imbalance problem [
19], in which models may underperform in minority classes, producing misleading results [
20]. The third problem is the choice of the algorithm to address imbalanced and limited-size datasets. The fourth problem is the early prediction of CKD using risk levels (low risk, moderate risk, high risk, and very high risk) and a reduced number of biomarkers. CKD datasets with risk level evaluation are very scarce and of limited size. The majority of available datasets are composed of binary classes. The analyses based on risk levels enable patients to have more detailed explanations about the evaluation results. In the medical area, the availability of imbalanced and limited-size datasets is common. Although the usage of limited-size datasets may be questioned, it is already evidenced that such datasets can be relevant for the medical area [
21].
Our study relies on data from medical records of Brazilians to provide classification models to assist in the early prediction of CKD in developing countries. We performed comparisons between machine learning (ML) models, considering ensemble and non-ensemble approaches. This work complements the results presented in our previous study [
5], where a comparative analysis was performed with the following ML techniques: decision tree (DT), random forest (RF), naive Bayes, support vector machine (SVM), multilayer perceptron, and k-nearest neighbor (KNN). In such a previous study, DT and RF presented the highest performances. However, in our previous experiments, we did not apply automated oversampling techniques.
Notwithstanding, in the current study, we used the same Brazilian CKD dataset to enable the implementation and validation of the models: DT, RF, and multi-class AdaBoosted DTs. We conduct further experiments to improve the state-of-the-art by presenting an approach based on oversampling techniques. We applied the overall local accuracy (OLA) and local class accuracy (LCA) methods for dynamic classifier selection (DCS). We used the k-nearest oracles-union (KNORA-U), k-nearest oracles- eliminate (KNORA-E), and META-DES methods for dynamic ensemble selection (DES). We used such methods due to their usual high performance with imbalanced and limited size datasets [
22]. The definitions of frequently used acronyms are presented in
Table 1.
For the implemented ensemble models, we prioritized the attributes of the dataset by applying the multi-class feature selection framework proposed by Pineda-Bautista et al. [
23], including class binarization and balancing with the synthetic minority oversampling technique (SMOTE), evaluated with the receiver operating characteristic (ROC) curve and precision-recall curve (PRC) areas.
To address problems related to imbalanced and limited-size datasets, it is relevant to carry out data oversampling by rebalancing the classes before training the ML models [
24,
25]. We conducted experiments by oversampling the data from the medical records of Brazilian patients and comparing methods for resampling the data. We also used dynamic selection methods for further addressing such problems.
Besides, to deploy our approach, we developed a decision support system (DSS) to embed the ML model with the highest performance. In this article, the development of a DSS was relevant to discuss a clinical practice context, showing how our approach can be reused in a real-world scenario.
This work provides insights for developers of medical systems to assist in the early prediction of CKD to reduce the impacts of the late diagnosis, mainly in low-income and hard-to-reach locations, when using imbalanced and limited-size datasets. The main contributions of this work are: (1) the presentation of an approach for data oversampling (i.e., a combination of manual augmentation with automated augmentation); (2) the comparison of data oversampling techniques; (3) the comparison of validation methods; and (4) the comparison of ML models to assist the CKD early prediction in developing countries using imbalanced and limited size datasets. Therefore, one of the main technical novelties of this article relates to the presentation and evaluation of our oversampling approach that combines manual augmentation and automated augmentation.
2. Preliminaries
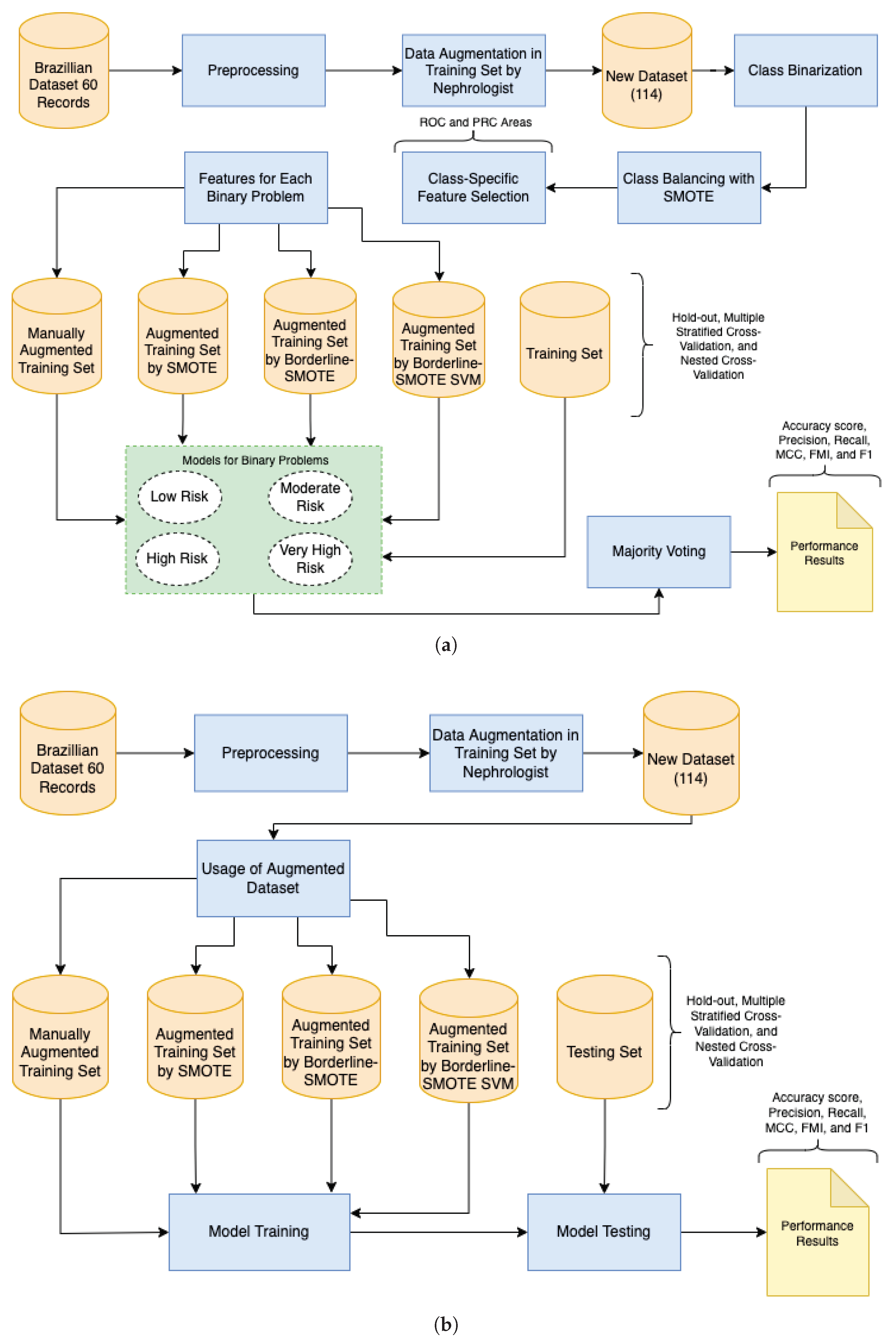
The research methodology of this study consists of data preprocessing, model implementation, validation methods, data augmentation, and multi-class classification metrics (
Figure 1). Firstly, we preprocessed the Brazilian CKD dataset (i.e., binarization of attributes) and translated it to English.
We implemented ensemble (
Figure 1a) and non-ensemble (
Figure 1b) models using the algorithms DT, RF, and multi-class AdaBoosted DTs. We also selected the DCS (OLA and LCA) and DES (KNORA-U, KNORA-E, and META-DES) methods. We used the default configuration with a pool of classifiers of 10 decision trees. We chose this configuration because decision tree-based algorithms usually present high performance in imbalanced datasets. We implemented the ensemble models based on the framework proposed by Pineda-Bautista et al. [
23].
We applied three ensemble and non-ensemble models validation methods: hold-out validation, multiple stratified CV, and nested CV. We used these methods to investigate whether they satisfactorily control overfitting caused due to the limited size of our dataset [
26]. We applied the multiple stratified CV and nested CV with 10 folds and five repetitions. For the hold-out method, we split our dataset into 70% for training and 30% for testing. Thus, we conducted data augmentation only for the training set to ensure that the test set contained only real data. Our approach combines the data oversampling using: (1) manual augmentation, validated by an experienced nephrologist, and (2) automated augmentation (experimenting with the SMOTE, Borderline-SMOTE, and Borderline-SMOTE SVM).
Hence, we applied the following multi-class classification metrics: precision, accuracy score, recall, weighted F-score (F1), macro F1, Matthew’s correlation coefficient (MCC), Fowlkes-Mallows (FMI), ROC, and PRC. We used the python scikit-learn library [
27] to implement the models and to apply the validation methods and metrics. For dynamic selection techniques, we used the DESlib library [
22].
Figure 1.
(
a) Research steps based on the framework proposed by Pineda-Bautista et al. [
23]: data preprocessing, model implementation, validation methods, data augmentation, and multi-class classification metrics. (
b) Research steps based on simple approach: data preprocessing, model implementation, validation methods, data augmentation, and multi-class classification metrics.
Figure 1.
(
a) Research steps based on the framework proposed by Pineda-Bautista et al. [
23]: data preprocessing, model implementation, validation methods, data augmentation, and multi-class classification metrics. (
b) Research steps based on simple approach: data preprocessing, model implementation, validation methods, data augmentation, and multi-class classification metrics.
2.1. Data Collection and Preprocessing
In a previous study [
28], we collected medical data (60 real-world medical records) from physical medical records of adult subjects (age ≥ 18) under the treatment of University Hospital Prof. Alberto Antunes of the UFAL, Brazil. The data collection from medical records maintained in a non-electronic format at the hospital was approved by the Brazilian ethics committee of UFAL and conducted between 2015 and 2016. The dataset comprises 16 subjects with no kidney damage, 14 subjects diagnosed only with CKD, and 30 subjects diagnosed with CKD, AH, and/or DM. In general, the sample included subjects with ages between 18 and 79 years; approximately 94.5% of the subjects were diagnosed with AH, and 58.82% were diagnosed with DM (
Table 2). With over 30 years of experience in CKD treatment and diagnosis in Brazil, a nephrologist labeled the risk classifications based on the KDIGO guideline [
29]. The dataset with 60 medical records from the real world was classified into four risk classes: low risk (30 records), moderate risk (11 records), high risk (16 records), and very high risk (3 records).
We primarily selected dataset features based on medical guidelines. Specifically, the KDIGO guideline [
29], the national institute for health and care excellence guideline [
30], and the KDOQI guideline [
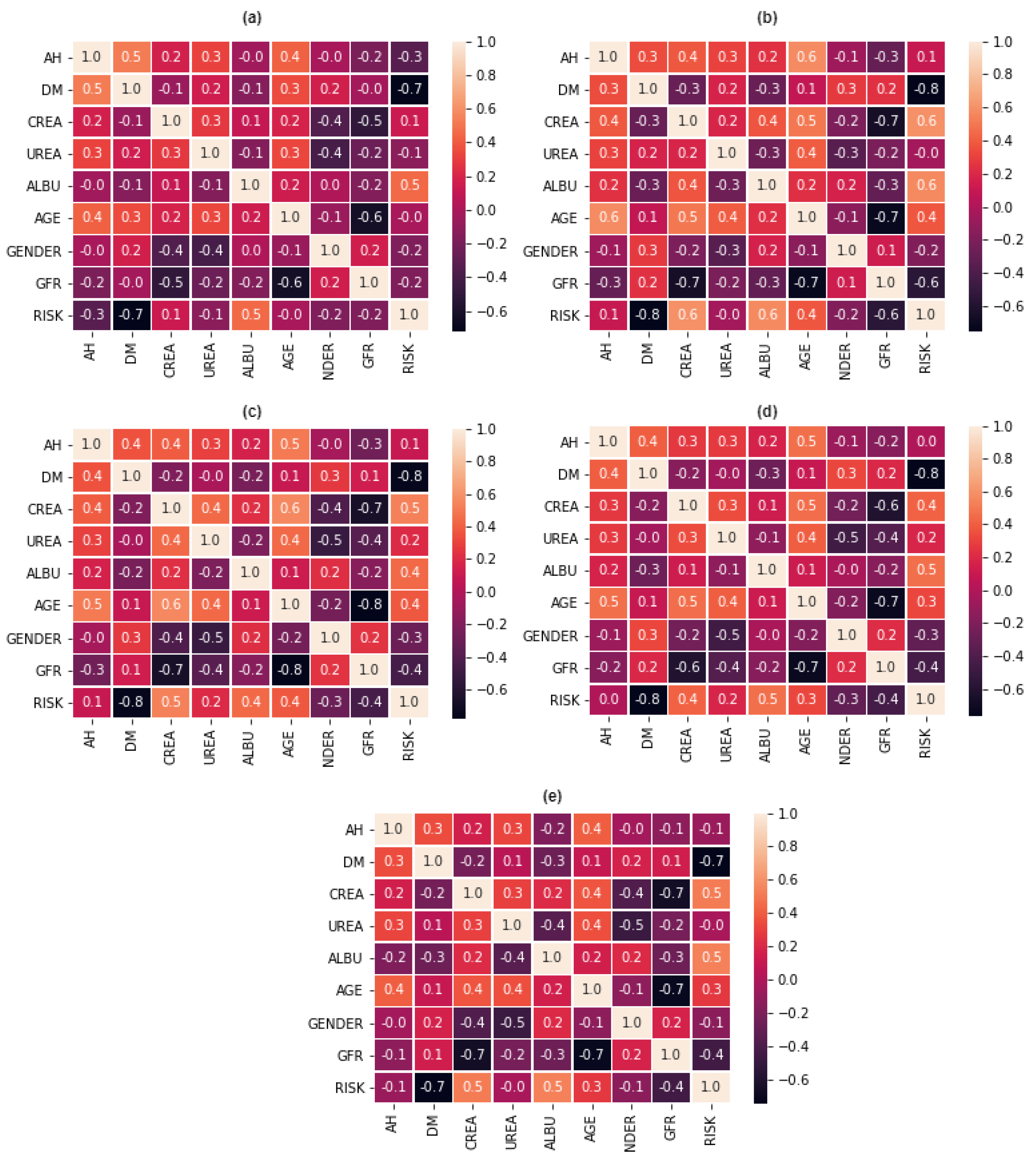
31]. Besides, we interviewed a set of Brazilian nephrologists to confirm the relevance of the features in Brazil’s context. The final set of CKD features focusing on Brazilian communities included AH, DM, creatinine, urea, albuminuria, age, gender, and glomerular filtration rate (GFR). The dataset did not contain duplicated and missing values. We only translated the dataset to English and converted the gender of subjects from string to a binary representation to enable the DT algorithm’s usage.
2.2. Manual Augmentation
In our previous study [
5], only for the training set, we manually augmented the dataset to decrease the impacts of using a small number of instances, including more than 54 records, by duplicating real-world medical records and carefully modifying the features, i.e., increasing each CKD biomarker by 0.5. We selected the constant 0.5 with no other purpose than to differentiate the instances and maintain the new one with the correct label. The perturbation of the data did not result in unacceptable ranges of values and incorrect labeling. An experienced nephrologist verified the augmented data’s validity by analyzing each record regarding the correct risk classification (i.e., low, moderate, high, or very high risk). As stated above, the experienced nephrologist also evaluated the 60 real-world medical records. The preprocessed original dataset (60 records) and augmented dataset (54 records) are freely available in our public repository [
32]. As an experienced nephrologist evaluated the new 54 records, all training and testing are conducted using more than 100 records (an acceptable number of instances for a small dataset). In this article, we propose the usage of such a manual step, along with automated augmentation (e.g., SMOTE), to address extremely small and imbalanced datasets.
2.3. Automated Augmentation
In the current study, based on the Python imbalanced-learn library [
33], we conducted the automated data augmentation using the SMOTE, Borderline-SMOTE, and Borderline-SMOTE SVM. The SMOTE is one of the most used oversampling techniques and consists of oversampling the minority class by generating synthetic data through feature space. The method draws a line between the k-neighbors closest to the minority class and creates a synthetic sample at one point along that line [
34]. Borderline-SMOTE is a widely used variation of SMOTE and consists of selecting samples from the minority class wrongly classified using the KNN classifier [
35]. Finally, Borderline-SMOTE SVM uses the SVM classifier to identify erroneously classified samples in the decision limit [
36]. In our implementation, due to a limited amount of data from the minority class, we use k = 3 to create a new synthetic sample.
2.4. Multi-Class Feature Selection
As stated, we conducted manual data augmentation to improve the original dataset. Besides, we binarized the translated, preprocessed, and manually augmented dataset to enable the multi-class feature selection for implementing ensemble models. The multi-class feature selection included an additional data augmentation using SMOTE to balance each binary problem (low risk, moderate risk, high risk, and very high risk). We solve each binary problem with feature selection based on the framework proposed by Pineda-Bautista et al. [
23]. The framework considers multi-class feature selection using class binarization and balancing. Thus, we applied the one-against-all class strategy and the SMOTE. Our main objective with the multi-class feature selection is to verify the importance of features and improve the ML ensemble models’ implementation. We used the ROC and PRC areas to conduct evaluations during the multi-class feature selection. Although ROC and PRC areas are typically used in binary classification, it is possible to extend them to evaluate multi-class classification problems using the one-against-all class strategy, as is the case of our multi-class feature selection. This enabled the definition of an ensemble model to solve our original multi-class problem by voting, trained based on the feature selection results for each binary problem.
2.5. Hold-Out Validation
We applied the hold-out method by splitting the original dataset into 70% for training and 30% for testing. For the manual augmentation, a dataset with 54 records, used in our previous study [
5], was added to the training set composed of the original data, resulting in 96 records: low risk (51 records), moderate risk (18 records), high risk (24 records), and very high risk (3 records). We used the dataset generated by the manual augmentation for the automated augmentation and applied the SMOTE, Borderline-SMOTE, and Borderline-SMOTE SVM. The resampling using the SMOTE and Borderline-SMOTE resulted in 204 records, in which each class contained 51 records. The usage of Borderline-SMOTE SVM resulted in 181 records: low risk (51 records), moderate risk (51 records), high risk (51 records), and very high risk (28 records). The test sets, for all approaches, contained 18 records: low risk (7 records), moderate risk (1 record), high risk (8 records), and very high risk (2 records). The test set only contains non-augmented data. Thus, we only conducted data augmentation for the training set to ensure that the test set contained real data. We conducted comparisons using the following datasets: Only Manual Augmentation, Manual Augmentation + Augmentation with SMOTE, Manual Augmentation + Augmentation with Borderline-SMOTE, and Manual Augmentation + Augmentation with Borderline-SMOTE SVM.
2.6. Multiple Stratified Cross-Validation and Nested Cross-Validation
For the multiple stratified CV and nested CV methods, we split the original dataset into 10-folds, resulting in 54 records for training and 6 for testing. For the manual augmentation, we included 54 records in each of the 10-folds, in which each fold contained 108 data for training and 6 for testing. Training folds from 1 to 6 contained: low risk (55 records), moderate risk (18 records), high risk (30 records), and very high risk (5 records). The 7th-fold contained: low risk (55 records), moderate risk (17 records), high risk (31 records), and very high risk (5 records). From the 8th to 10th folds: low risk (55 records), moderate risk (18 records), high risk (31 records), and very high risk (4 records). We used the dataset generated by the manual augmentation for the automated augmentation and applied the SMOTE, Borderline-SMOTE, and Borderline-SMOTE SVM. The resampling using SMOTE and Borderline-SMOTE resulted in 220 records, in which all folds contained 55 records for each class. The Borderline-SMOTE SVM resulted in training folds, from 1st to 7th, with 196 records: low risk (55 records), moderate risk (55 records), high risk (55 records), and very high risk (31 records). Besides, from the 8th to 10th folds, it resulted in 195 records: low risk (55 records), moderate risk (55 records), high risk (55 records), and very high risk (30 records).
Besides investigating whether such methods satisfactorily control overfitting for our dataset (by comparison), in this article, the evaluation results are relevant to increase confidence in the ML model embedded in our developed DSS (
Section 5—clinical context scenario). Therefore, they enabled us to evaluate the quality of our approach.
2.7. Algorithms
We experimented with supervised learning and the DT, RF, and multi-class AdaBoosted DTs classification models. We also apply methods for DCS (OLA and LCA) and methods for DES (KNORA-U, KNORA-E, and META-DES).
A DT uses the divide-and-conquer technique to solve classification and regression problems. It is an acyclic graph where each node is a division node or leaf node. The rules are based on information gain, which uses the concept of entropy to measure the randomness of a discrete random variable A (with domain
) [
37]. Entropy is used to calculate the difficulty of predicting the target attribute, where the entropy of A can be calculated by:
where,
is the probability of observing each value
. In the literature, DT has performed well with imbalanced datasets. Different algorithms generate the DT, such as ID3, C4.5, C5.0, and CART. The Scikit-learn library uses the CART algorithm.
The RF algorithm is used to combine DTs, generating several random trees. The algorithm assists modelers in preventing overfitting, being more robust when compared to a DT. It uses the Gini impurity criterion to conduct the feature selection, in which the following equation [
38] guides the split of a node:
where
is the relative frequency of class
j [
33].
The multi-class AdaBoosted DTs algorithm creates a set of classifiers that contribute to the classification of test samples through weighted voting. With each new iteration, the weight of the training samples is changed considering the error of the set of classifiers previously implemented [
37]. A multi-class AdaBoosted DTs performs the combination of predictions from all DTs in the set for multi-class problems.
Finally, a dynamic selection technique measures the performance level of each classifier in a classifier pool. If a classifier pool is not defined, a BaggingClassifier generates a pool containing 10 DTs. For the DCS method, the classifier that has achieved the highest performance level when classifying the samples in the test set is selected [
22]. For the DES method, a set of classifiers that provide a minimum performance level is selected.
2.8. Classification Metrics
We computed the performance of the classification models using the python scikit-learn library [
39] and the following metrics: precision, accuracy score, recall, balanced F score, MCC, ROC, and PRC. Precision represents the classifier’s ability of not label a sample incorrectly and is given by the equation:
where,
represents the true positives and
represents the false positives. The accuracy score calculates the total performance of the model using the equation:
where,
represents the value that the model classified the sample,
represents the real value of the sample,
n is the total number of samples, and
is the indicator function [
27].
The recall corresponds to the hit rate in the positive class and is given by
where,
represents the false negatives. The balanced
F-score or
F measure is a weighted average between precision and recall:
The
MCC is used to assess the quality of ratings and is highly recommended for imbalanced data [
40], given by the following equation:
where,
represents the true negative. Besides, the
FMI is used to measure the similarity between two clusters, the measure varies between 0 and 1, where a high value indicates a good similarity [
41].
FMI is defined as the geometric mean between precision and recall, given by the equation:
The ROC calculates the probability estimates that a sample belongs to a specific class [
42]. For multi-class problems, ROC uses two approaches: one-vs-one and one-vs-rest. Finally, the PRC is a widely used metric for imbalanced datasets that provides a clear visualization of the performance of a classifier [
43].
5. Clinical Practice Context
Using eHealth and mHealth systems to aid in the treatment and identification of chronic diseases can be one way to reduce high mortality rates through monitoring chronic diseases such as CKD. This situation refers to using information and technologies intelligently and effectively to guide those whom public health systems will eventually assist. Early computer-aided identification of CKD can help people living in the countryside and environments with difficult access to primary care. In addition, mobile health apps (i.e., mHealth), which generate personal health records (PHR), can be used to reduce issues (i.e., store a patient’s complete medical history with diagnosis, administered medications, plans for treatment, vaccination dates, allergies) related to primary health care in remote locations.
Therefore, the presented classification models can be used to develop eHealth and mHealth systems that assist patients, clinicians, and the government in monitoring CKD and its risk factors. Using the Brazilian CKD dataset, we recommend applying the DT model with data resampled with the SMOTE technique to develop a DSS. The DT model achieved high performance, and it is considered a white box analysis approach with a straightforward interpretation of results. Interpreting the results helps doctors understand how the model achieved a specific risk rating, increasing these professionals’ confidence in the results.
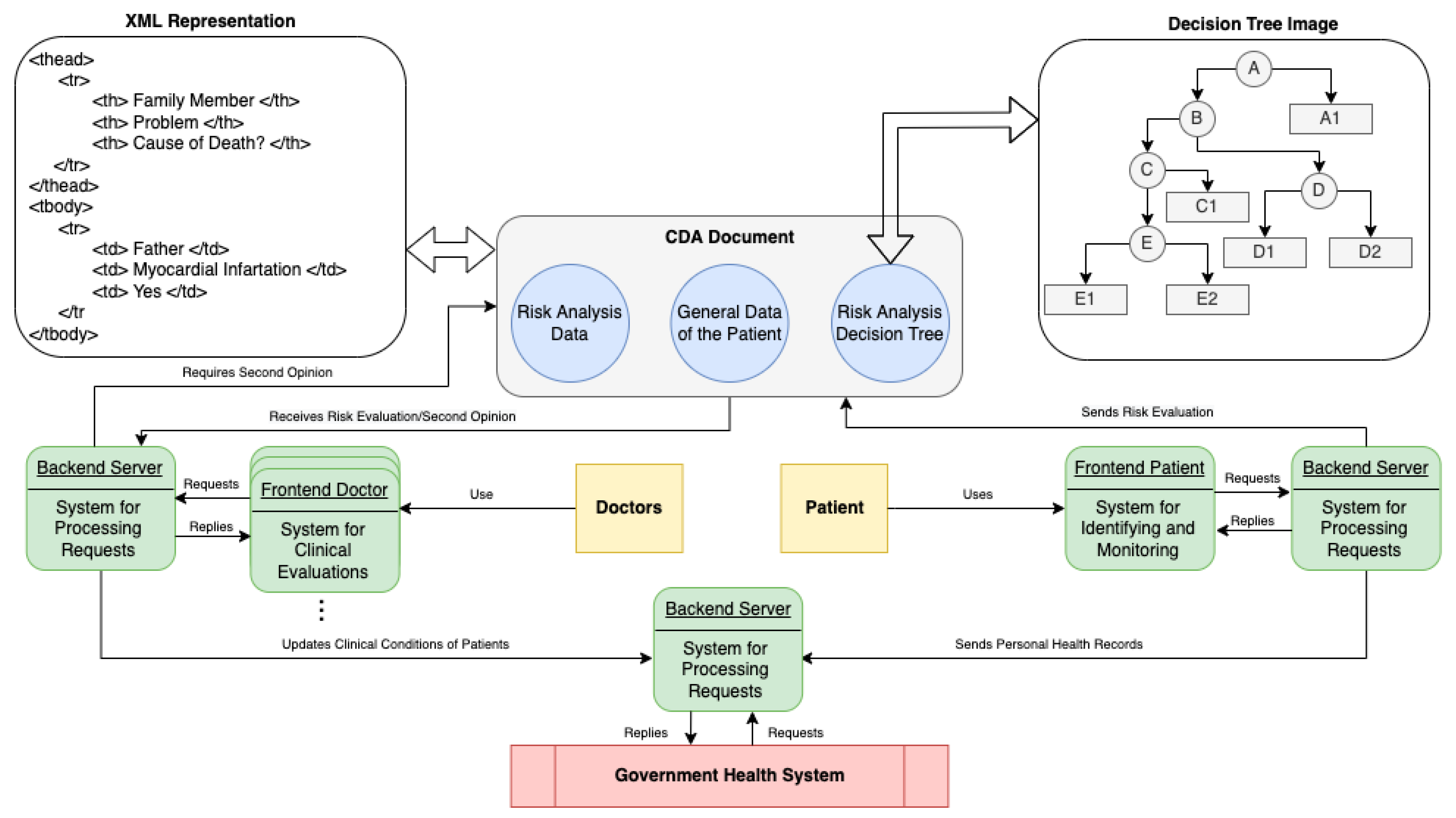
The ML model can be the basis for developing a DSS to identify and monitor CKD in Brazilian communities, where the interaction between three actors is proposed: doctor, patient, and public health system (
Figure 5). The system used by patients is presented as a web-based system divided into front-end and back-end, which contains PHR and CKD risk assessment functionality. The risk assessment is performed after inputting the results of exams, where the classification of risk of CKD is based on the DT model. After the user’s clinical evaluation, the system can send a clinical document, structured from the HL7 clinical document architecture (CDA) to the doctor responsible for monitoring the patient. The HL7 CDA document is an XML file that contains the risk analysis data, a risk analysis DT, and the PHR.
The medical system receives the CDA document to confirm the risk assessment by analyzing the classification, the DT, and the PHR data. In an uncertain diagnosis, the doctor can send the CDA document to other doctors for a second opinion. The patient and medical subsystems use web services provided by the Server subsystem to update the PHR of patients as part of the medical records available at a healthcare facility. We provide a more detailed explanation of this type of system for CKD and related technologies in our previous publication [
28].
Therefore, we implemented a web-based application considering the system used by patients, as an improvement of the results presented in [
28]. The back-end of such subsystem was implemented using the Java programming language and web services. The subsystem comprises the following main features: access control, management of ingested drugs, management of allergies, management of examinations, monitoring of hypertension and DM, execution of risk analysis, generation and sharing CDA documents, and analysis of the emergency. In contrast, the front-end of the subsystem is implemented using HTML 5, Bootstrap, JavaScript, and Vue.js. For the graphical user interface (GUI) for recording a new CKD test result (the main inputs for the risk assessment model), the user can also upload an XML file containing the test results to present a large number of manual inputs. Once the patient provides the current test results, the main GUI of the subsystem is updated, showing the test results available for the risk assessment.
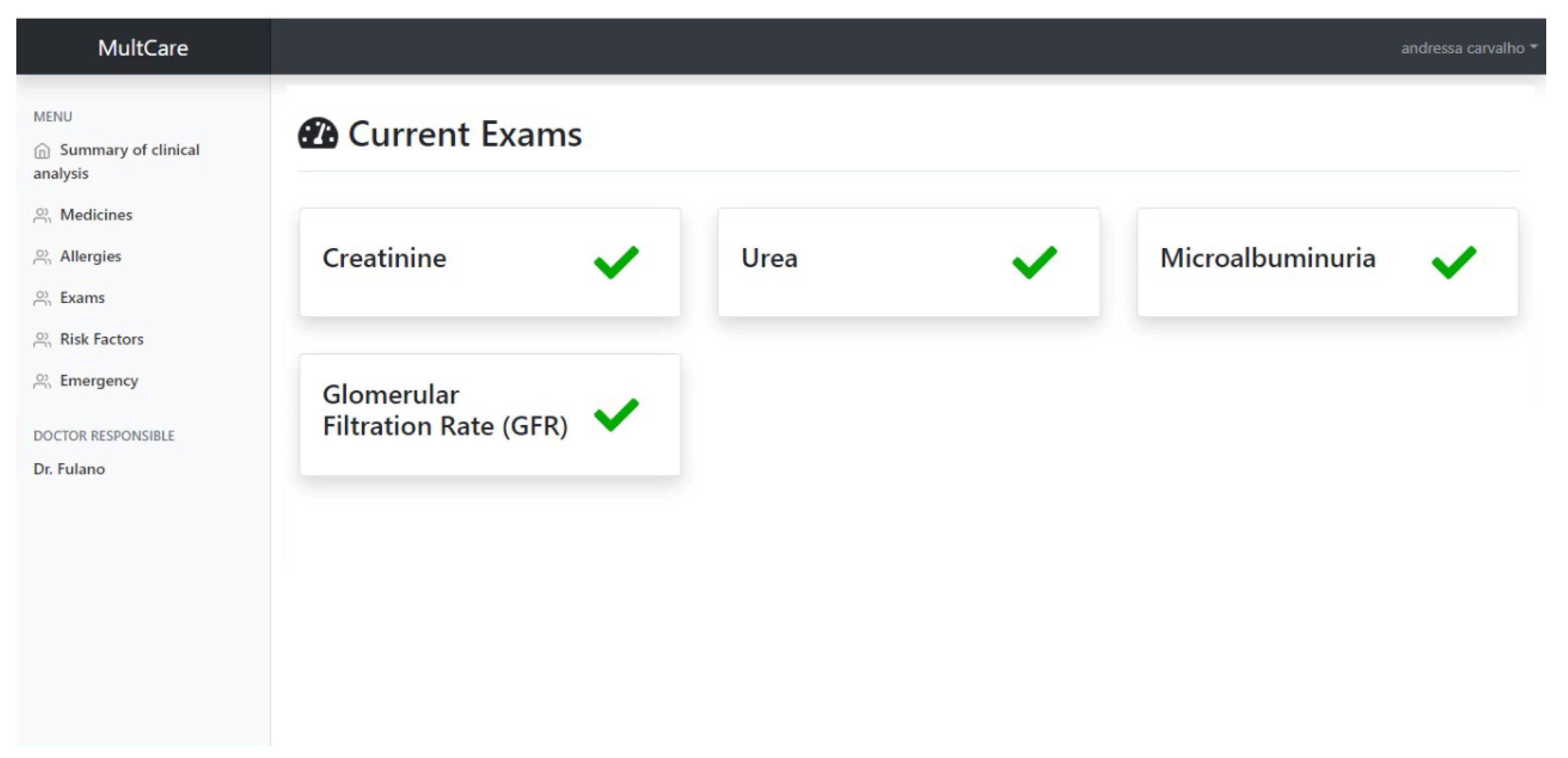
Figure 6 illustrates the main GUI of the patient sub-system, describing the creatinine, urea, albuminuria, and GFR (i.e., the main attributes used by the risk assessment model). This study reduces the number of required test results to conduct the CKD risk analysis from 5 to 4 compared to the previously published research [
16]. This is critical for low-income populations using the sub-system because a very large number of biomarkers increases costs, that usually cannot be afforded by such people. Indeed, a reduced number of biomarkers can include more users for this type of DSS that would be possibly excluded due to their limited financial resources. The sub-system provides a new CKD risk analysis when the patient inputs all CKD attributes.
During the CKD risk analysis (conducted when all tests are available), and based on the presence/absence of DM, presence/absence of hypertension, age, and gender, the J48 decision tree algorithm classifies the patient’s situation considering four classes: low risk, moderate risk, high risk, and very high risk. In case of moderate risk, high risk, or very high risk, the sub-system packages the classification results as a CDA document, along with the decision tree graphic and general data of the patient. The sub-system alerts the physician responsible for the patient and sends the complete CDA document (i.e., the main output of the DSS) for further clinical analysis. In the case of low risk, the sub-system only records the risk analysis results to keep track of the patient’s clinical situation. It does not send the physician alert, automating the risk analysis and sharing. This illustrates an example of scenario that shows how the definition of risk levels can provide more details on the patients’ clinical conditions.
Results presented in this article justify the usage of the DT algorithm and attributes (i.e., presence/absence of DM, presence/absence of AH, creatinine, urea, albuminuria, age, gender, and GFR) to conduct risk analyses in developing countries. The physician responsible for the healthcare of a specific patient can, remotely, access the CDA document by a medical sub-system, re-evaluate or confirm the risk analysis (i.e., preliminary diagnosis) provided by the patient sub-system, and share the data with other physicians to get second opinions. If the physician confirms the preliminary diagnosis, the patient can continue using the patient sub-system to prevent the CKD progression, including the monitoring of risk factors (DM and AH), CKD stage, and risk level.
We also implemented the medical and server sub-systems using web technologies based on
Figure 5. However, the description of such sub-systems is not in the scope of this article.
6. Discussion
During CKD monitoring, based on the non-ensemble DT model with data resampled with manual augmentation + SMOTE, assuming the previous DM evaluation, the user only needs to perform two blood tests: creatinine and urea periodically. Albuminuria is measured using a urine test, while GFR can be calculated using the Cockcroft-Gault equation. The reduced number of exams is relevant for developing countries like Brazil due to the high poverty levels.
From the misclassified instances identified when testing the non-ensemble DT model, with data resampled with manual augmentation + SMOTE, the model disagreed with the experienced nephrologist, declaring very high risk rather than high risk (only one individual). However, the model did not lead to any critical underestimation of individuals’ at-risk status (e.g., low risk rather than moderate risk). This situation would be a critical issue because the patient is usually referred to a nephrologist at moderate or high risk. Misleading classifications are less harmful to the patient as they still result in the patient being referred for evaluation, even if the risk is overestimated.
Along with using a reduced number of features and the absence of critical underestimations, another advantage of the DT model is the direct interpretation of results. A more straightforward interpretation of the CKD risk analysis by nephrologists and primary care doctors who need to perform additional tests to confirm a patient’s clinical status is critical to reusing the model in real-world situations. The tree generated by the DT model encompasses each CKD biomarker considered and the related classification. A doctor follows the decisions to interpret the logic of classification. Of the 8 CKD features, only 5 were used by the non-ensemble DT model with data resampled with manual augmentation + SMOTE, to classify the risk (i.e., creatinine, gender, HA, urea, and albuminuria), requiring one blood test and one urine test when DM has already been evaluated, at the cost of one misclassified instance.
However, one of the main limitations of this study is the usage of the gridSearchCV tool to find the best parameters for each algorithm. We faced processing limitations, mainly for the ensemble models, because the parameter search was conducted for each ML model. The usage of gridSearchCV with 5 folds for the DT model is one example of such a situation. We handled 960 candidates, resulting in 4800 adjustments. However, when using the META-DES model, we handle 8640 candidates, resulting in 43,200 adjustments for the ensemble model, presenting a higher processing cost to adjust the parameters.
Besides, the reduced amount of manually augmented instances may also be considered a limitation. For example, the number of instances for the very high risk class in the test set is too reduced, which can have a negative impact on the performance evaluation for such class. The nested CV assisted us in reducing this limitation. We did not provide more augmented data because it is a time-consuming task for the nephrologist. However, given that one of the main purposes of this study is to address limited size datasets, the manual augmentation provided by the nephrologist was enough to conduct the experiments.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}