1. Introduction
Oil palm (Elaeis guineensis) is a palm species that has been extensively planted in Southeast Asia, primarily in Indonesia and Malaysia, to fulfil the global demand for vegetable oil due to the increasing population, income, and growing biofuel market. In Malaysia, oil palm is the main commodity crop that has significantly contributed to the country’s economic development and stability. Furthermore, the increasing exports of palm-based products such as palm oil, palm kernel oil, palm kernel cake and palm-based oleochemicals maintain Malaysia as the second-largest exporter in the world.
Nevertheless, in Southeast Asia, oil palm has been affected by basal stem rot (BSR) disease caused by white-rot fungus identified as
Ganoderma boninense (
G. boninense). BSR is a soil-borne disease that once infected only mature trees; however, the study by Sanderson [
1] reported that seedlings are also susceptible to the infection whereby the symptoms appear earlier and more severe.
G. boninense cultivates through uninjured roots and produces enzymes that could degrade the woody tissues, cellulose, lignin layers, and xylem, causing a major disruption in water and nutrients distribution to the top part of the palm [
2,
3,
4]. In brief, the earliest symptoms in oil palm seedlings can be detected by the appearance of fungal mass, followed by yellowing and necrosis of older leaves [
5]. In severe cases, the infection could cause stunted growth, especially in height, girth and frond count due to the inability to perform photosynthesis. However, the appearance of fungal mass is difficult to examine by naked eyes and can often be overlooked because it may present or may not present before or after the yellowing of leaves [
6,
7].
Consequently, Malaysia has reported annual losses of up to RM 1.5 billion due to this disease, making BSR the most economically devastating disease in oil palm plantations. Based on the BSR incident rate, the total area affected in 2020 was estimated to be 443,440 hectares, equivalent to 65.6 million oil palms, which is worrying if preventive measures are not implemented [
8]. According to Idris et al. [
7],
G. boninense infection could cause 80% of the affected trees to die and 25% to 40% yield losses. However, the trees with less than 20% infection can still be treated [
9]. Therefore, it is crucial to detect the BSR disease at an early stage to ensure sufficient time for proper treatments, which hence prevent the disease from spreading.
Laboratory-based methods are considered reliable for early detection of
G. boninense. However, these methods involve stem collections that may cause injuries to trees that lead to destruction. Meanwhile, sensor-based methods for BSR detection are widely studied, but these methods are time-consuming and impractical for large-scale plantations. Hyperspectral imaging provides a solution by its ability to cover large areas in a single imaging session. This device has been employed by Helmi and Mohanad [
10], Shafri and Hamdan [
11], Shafri et al. [
12], Izzuddin et al. [
13], and Izzuddin et al. [
14] to detect BSR disease in oil palm plantations. These studies used hyperspectral reflectance data to calculate vegetation indices and optimize spectral indices to differentiate between different healthiness levels of oil palm trees. Shafri et al. [
12] developed the best approach, which used a combination of red (610.5 nm) and NIR (738 nm) bands to formulate optimized spectral indices. As a result, the ratio of red and NIR bands and the normalized difference vegetation index a (NDVIa) had an overall accuracy of 86%. Based on this research, it can be concluded that hyperspectral imaging is an excellent tool for detecting BSR disease in oil palms.
Machine learning techniques have been applied widely in many fields, such as speech recognition [
15,
16] and remote sensing land cover detection [
17,
18]. In recent years, the agricultural field has also started to take advantage of machine learning capability. For example, in crop yield estimation [
19], disease detection [
20], weed detection [
21], crop quality [
22], species recognition [
23], animal welfare [
24], livestock production [
25], water management [
26] and soil management [
27].
Further, machine learning application in
G. boninense detection in mature oil palms was started by Lelong et al. [
28] in North Sumatra, Indonesia. Leaves reflectance was collected using a Unispec spectroradiometer (PP Systems, Amesbury, MA, USA) that covers from 310–1130 nm. However, only reflectance spectra from 450–1000 nm were included and smoothed using the Savitzky–Golay method prior to the development of the partial least square discriminant analysis (PLS-DA) classification model. The PLS-DA yielded a classification accuracy of 94% in classifying healthy trees and trees with different levels of
G. boninense infection. Next, Liaghat et al. [
29] carried out early detection of
G. boninense in 15 years old oil palm trees. Reflectance spectra were taken from frond number 17 of healthy (T0), mild (T1), medium (T2), and severely (T3) infected trees using an ASD field spectroradiometer (Analytical Spectral Devices Inc., Boulder, CO, USA). The infections were confirmed using a polymerase chain reaction (PCR) test. The reflectance spectra were then smoothed and transformed into the first and second derivatives spectra using the Savitzky–Golay method. It can be observed that NIR reflectance was significantly reduced as the disease severity increased. The data were reduced using principal component analysis (PCA). Naïve Bayes classification model predicted the diseased trees with 96% accuracy using raw reflectance spectra, while kNN yielded 97% using the first and second derivative data.
Meanwhile, Liaghat et al. [
30] collected the absorbance data of T0, T1, T2 and T3 infected oil palms using a Fourier transform infrared spectroscopy (FT-IR) spectrometer (Thermo Fisher Scientific Inc., Waltham, MA, USA). The data were obtained from frond number 17 and transformed into the first and second derivatives using the Savitzky–Golay method after baseline correction and normalization. The dimensionality of the data was reduced using PCA before classification models were developed based on the best principal components to classify the different levels of
G. boninense infections. The result showed that the linear discriminant analysis (LDA) model showed the highest overall classification accuracy of 92% when using the raw absorbance dataset. In addition, Ahmadi et al. [
31] acquired the reflectance spectra of frond number 9 and 17 of 12 years old oil palm trees using GER 1500 handheld spectrometer (Geophysical and Environmental Research Corporation, Millbrook, NY, USA). The study focused on the early detection of BSR; thus, the reflectance spectra were obtained only from T0 and T1 infected trees. The artificial neural network (ANN) was applied to discriminate between the T0 and T1 using raw, first and second derivative spectra. The raw reflectance spectra between 550 and 556 nm produced 100% classification accuracy for T1, while the first derivative reflectance has yielded 100% accuracy for T1 and 83% accuracy for T0.
Furthermore, Khaled et al. [
32] utilized dielectric spectroscopy to obtain impedance, capacitance, dielectric constant and dissipation factor to detect
G. boninense in oil palm plantation. The dielectric properties of T0, T1, T2 and T3 diseased trees were reduced using PCA and classified using LDA, quadratic discriminant analysis (QDA), kNN and naïve Bayes. The QDA attained the highest accuracy of 81%, and impedance was the best parameter to assess severity levels of
G. boninense. Next, Husin et al. [
33] conducted a study to discriminate the healthiness levels of mature
G. boninense infected oil palms using a FARO laser scanner (Faro Technologies Inc., Lake Mary, FL, USA). Five features were extracted from the data, i.e., C200 (crown slice at 200 cm from the top), C850 (crown slice at 850 cm from the top), crown area (number of pixels inside the crown), frond angle, and frond number. Then, the data were reduced using PCA to increase its interpretability. Kernel naïve Bayes, medium Gaussian support vector machine (SVM), and ensemble subspace discriminant achieved the highest accuracies when using PC1 and PC2, PC1 and PC3, and PC1, PC2, and PC3. The best model for the classification was kernel naïve Bayes with 85% accuracy and a kappa value of 0.80.
For oil palm seedlings, Shafri et al. [
34] acquired reflectance spectra of healthy and
G. boninense infected seedlings obtained using APOGEE spectroradiometer (Apogee Instruments Inc., Logan, UT, USA) in three healthiness levels, i.e., healthy, mildly infected, and severely infected. The seedlings were inoculated with
G. boninense inoculum at four months old. Reflectance spectra of leaves 1 and 2 were collected after six months of inoculation when disease symptoms appeared for severely infected seedlings. The data were denoised and transformed into the first derivative. The significant bands were identified using a one-way analysis of variance (ANOVA) and were inputted into a maximum likelihood algorithm. The result yielded 82% accuracy with a kappa value of 0.73.
The exploration of hyperspectral imaging and machine learning for
G. boninense detection at the seedlings stage was first undertaken by Azmi et al. [
35]. The result achieved over 93% classification accuracy in discriminating healthy and asymptomatic
G. boninense infected seedlings. However, the limitation of this study was the use of SVM kernel methods such as linear, Gaussian radial basis function (RBF), and polynomial algorithms. On the other hand, this study demonstrated that the combination of reflectance of frond 1 and frond 2 is feasible for early detection of
G. boninense infection in oil palm seedlings even before the physical symptoms appear, obviating the need for complex pre-processing to distinguish between those fronds. Additionally, Khairunniza-Bejo et al. [
36] utilized a single band of 934 nm to discriminate between healthy and
G. boninense-infected oil palm seedlings and discovered the best model to be a linear SVM with a 94.8% accuracy and 0.95 area under the curve. A summary of machine learning application to classify
G. boninense infection in oil palm seedlings and mature trees are presented in
Table 1. Different sensors and machine learning models were used to achieve various degrees of classification accuracies. However, studies that utilized hyperspectral reflectance data are limited. Therefore, further study is needed to scrutinize hyperspectral imaging capabilities and machine learning techniques other than SVM to detect
G. boninense in oil palm seedlings.
4. Discussion
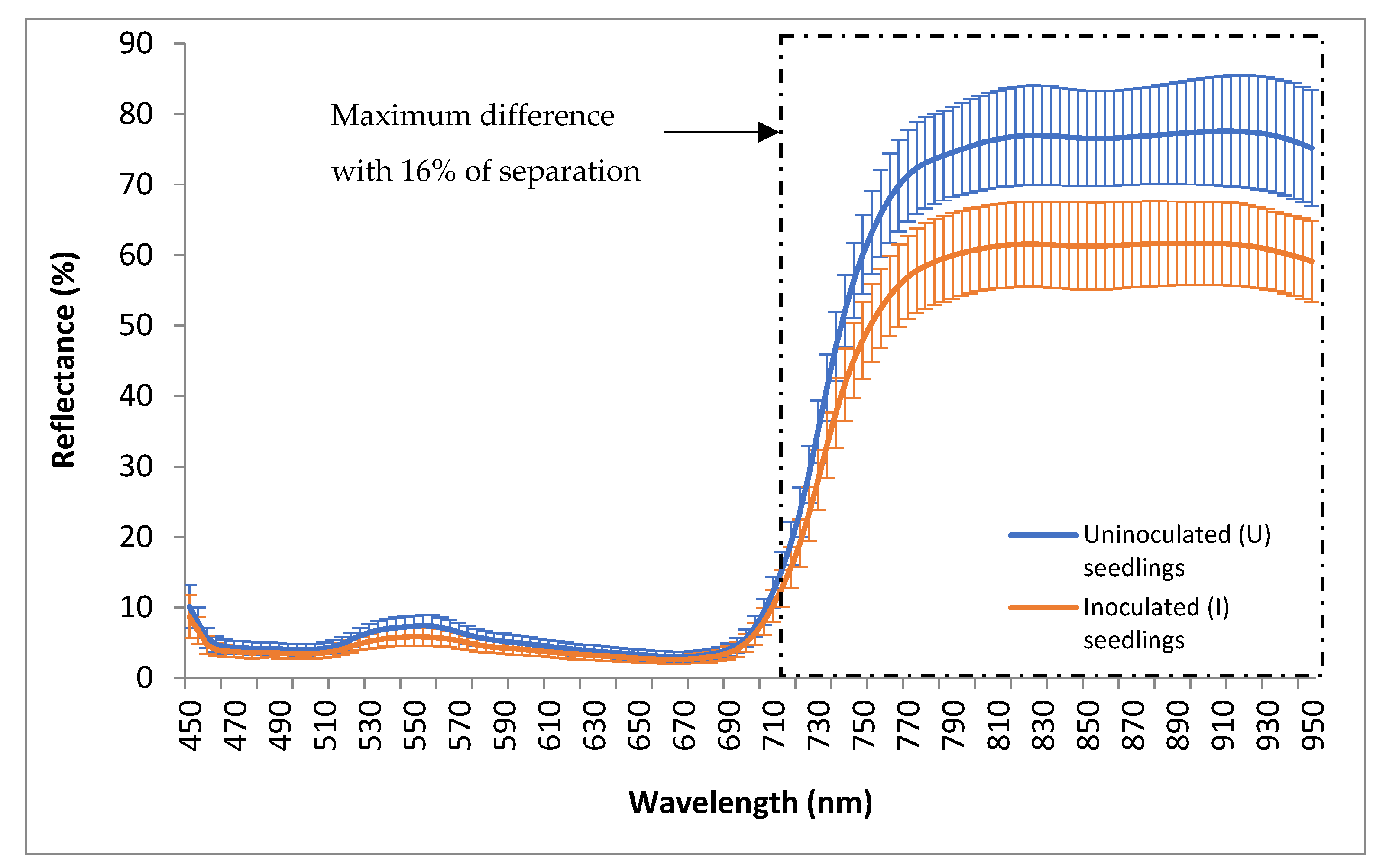
In this study, it should be noted that the low reflectance of the I seedlings in the NIR spectrum was typical for diseased plants that demonstrated the damaged leaf’s internal structure, which consequently causes water stress in the plants. Furthermore, changes in the NIR reflectance during a stress period were more evident than changes in the visible reflectance since NIR could penetrate deeper through the internal leaf structure than visible wavelengths [
29]. This finding agreed with [
46], where healthy citrus and asymptomatic huanglongbing infected leaves showed significant differences in the NIR spectrum. Undoubtedly, in a nutshell, healthy leaves reflect higher NIR reflectance than infected leaves even before the development of physical symptoms.
Conversely, the U seedlings provide a slightly higher reflectance in the visible spectrum than the I seedlings. This pattern was contrary to the spectral signature of healthy plants examined by other researchers who agreed that healthy plants normally have lower reflectance than a diseased plant in the visible range, especially in green (520 to 560 nm) due to the higher level of chlorophyll in the leaves. However, in this study, the pattern shown was identical to the study carried out by [
34], where the healthy seedlings developed higher reflectance than infected seedlings in the green wavelengths. As each plant has a specific spectral signature [
47], this pattern may be a unique spectral signature for oil palm seedlings.
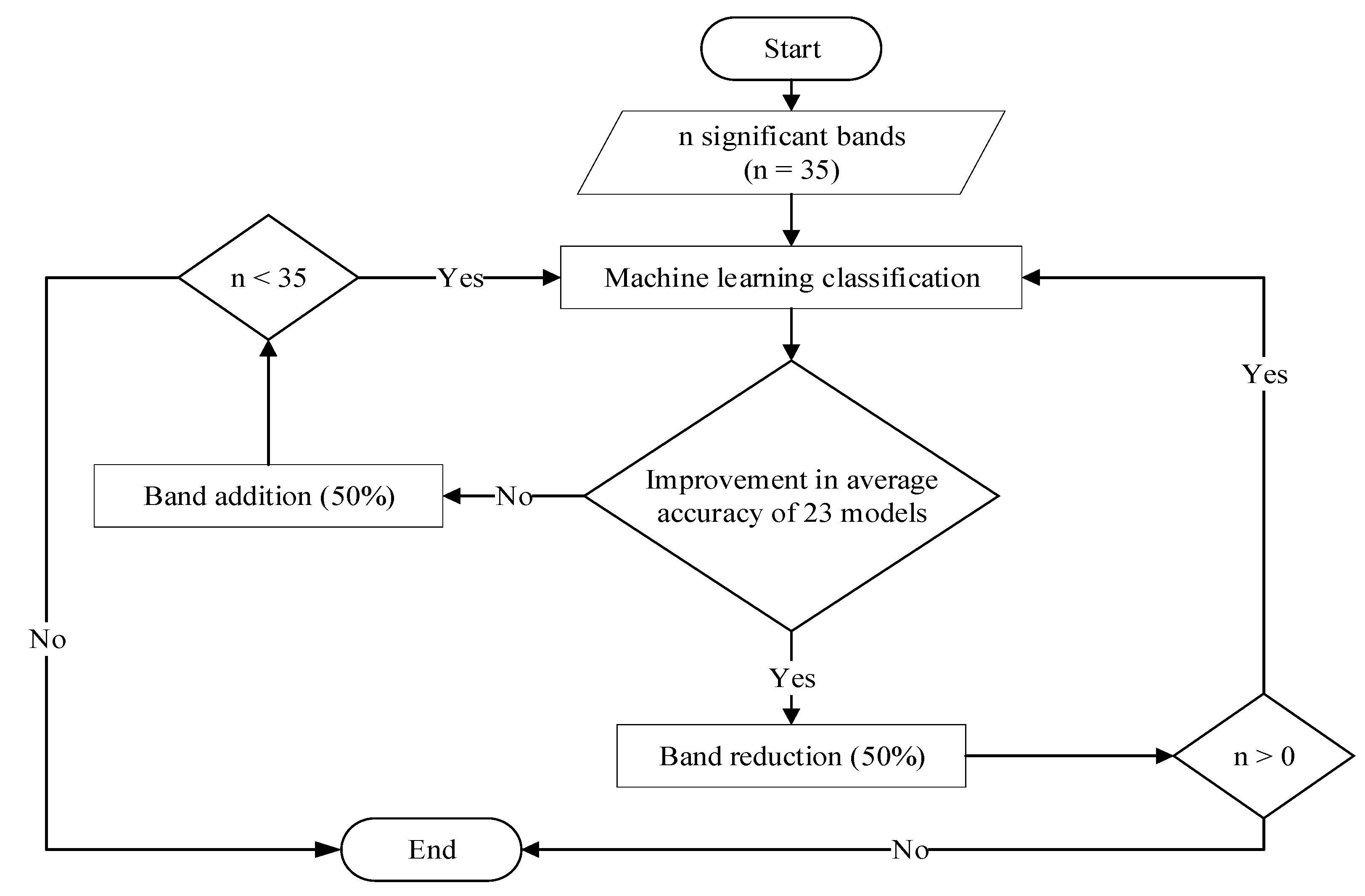
According to [
48], a higher number of input parameters in machine learning had resulted in higher accuracy models; however, this finding contrasted with linear discriminant, quadratic discriminant, and subspace kNN models, which produced higher accuracy at a lower number of bands, e.g., 9 bands. In addition, linear SVM has maintained a nearly consistent accuracy of ±95% at 35, 18, 14 and 11 bands despite the reduced number of bands that reflect its insensitivity towards bands optimization. The differences in classification accuracy were due to different characteristics and sensitivities of specific classifiers towards the optimization of parameters [
33]. For example, bagged trees only achieved the highest classification accuracy of 94.49% when 35 bands were used, whereas quadratic SVM achieved the highest classification accuracy when 11 bands were used.
Additionally, it was noted that there were minor discrepancies in the percentage classification accuracy and F-score. This is because classification accuracy is only concerned with the total number of correct predictions ( and ), whereas F-scores balance precision and sensitivity by assigning equal weight to each. Accuracy alone is insufficient as a performance metric for issues involving unequal classification; for example, in this case, U is 279 and I is 360. The key reason for this is that the amount of data of I overwhelmed the amount of data of U, which means that even unskilled models can achieve high classification accuracy, depending on the severity of the class imbalance.
However, the results showed that most SVM-based models achieved a higher F-score than the other models. The linear kernel provided the optimal hyperplane to separate the data points of U and I, followed by the fine and medium gaussian kernels. Additionally, kNN algorithms were also determined as the best classifier based on the classification accuracy obtained, with medium, cubic, and weighted kNN models outperforming other kNN models. Thus, it is revealed that medium distinctions between classes with 10 number of neighbors are more suitable, while one neighbor is too fine, and 100 neighbors are too coarse. On the other hand, the less accuracy from discriminant analysis indicates that the U and I data does not fit with the Gaussian distributions. Furthermore, both classes also do not fit well with the sigmoid function, as indicated by logistic regression results.
Coarse Gaussian SVM is a Gaussian radial basis function (RBF) that was used to improve SVM classification when the data were not linearly separable. The kernel approach enables SVM to find a hyperplane in the kernel space, enabling non-linear separation within the feature space to be viable. The best kernel width is determined by balancing underfitting and overfitting loss. In the remote sensing field, SVM is particularly appealing for managing limited training data effectively and having higher classification accuracy than the conventional classification [
49]. The basic principle that benefits SVM compared to conventional classification is the structural risk minimization learning process. SVM minimizes the classification error on unseen data without making prior assumptions about the probability distribution of data [
50]. In contrast, conventional classification, such as maximum likelihood, usually assumes that data distribution is a priority.
In recent studies, SVM was frequently used to classify healthily and
G. boninense infected oil palm with high accuracy of 100% [
35], 94.8% [
36], 91% [
51], and 89% [
32], which confirmed the suitability of SVM classifiers in oil palm disease classification. Furthermore, machine learning classification models typically produced better results compared to conventional classification models, such in the study conducted by Shafri et al. [
34] that produced a net accuracy of 82% and kappa coefficient of 0.73 using maximum likelihood to classify multiple severities of
G. boninense infection in oil palm seedlings. Furthermore, this finding was not only consistent with previous research conducted for BSR disease in mature oil palm trees, but also with other diseases such as identifying cotton canopy infected with
Verticillium wilt, apple scab disease caused by
Venturia inaequalis, and corn kernels infected with fungi.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}