Hybrid Learning of Hand-Crafted and Deep-Activated Features Using Particle Swarm Optimization and Optimized Support Vector Machine for Tuberculosis Screening



Abstract
:1. Introduction
- First, instead of using all extracted features as input, we selected the important features prior to classification. This is the first attempt to use the PSO feature selection algorithm for automated TB detection. By selecting the important features prior to classification, we reduced the noisy and irrelevant features, reduced processing times, and enhanced the prediction performance.
- Second, we optimized an SVM classifier using a Bayesian algorithm.
- Third, we compared the classifications from hand-crafted and deep-activated features using the optimized SVM classifier.
- Fourth, we combined the selected hand-crafted and deep-activated features to generalize the feature set in extensive experiments. To our knowledge, this is the first approach to predict TB using a hybrid feature set which contained a combination of selected handcrafted and deep-activated features. By using the hybrid feature set, we enhanced the prediction performance compared to individual methods and state-of-the-art.
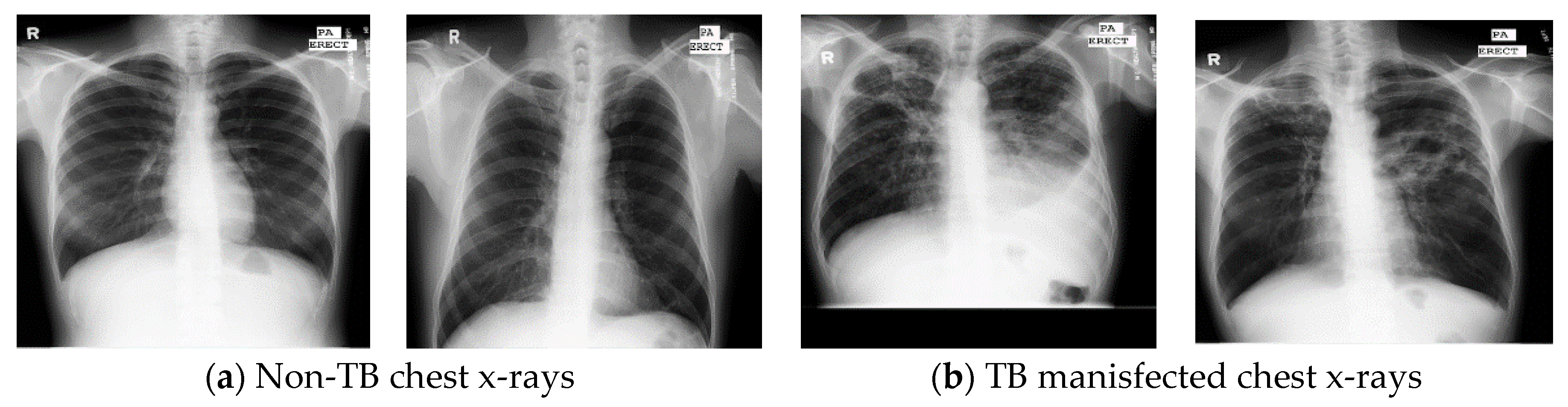
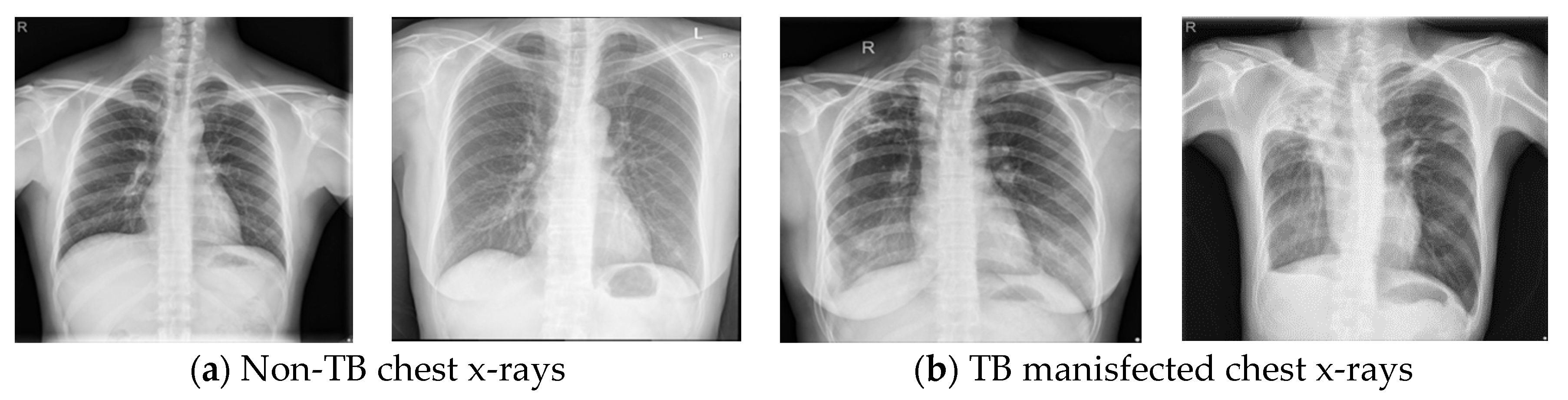
2. Dataset Description
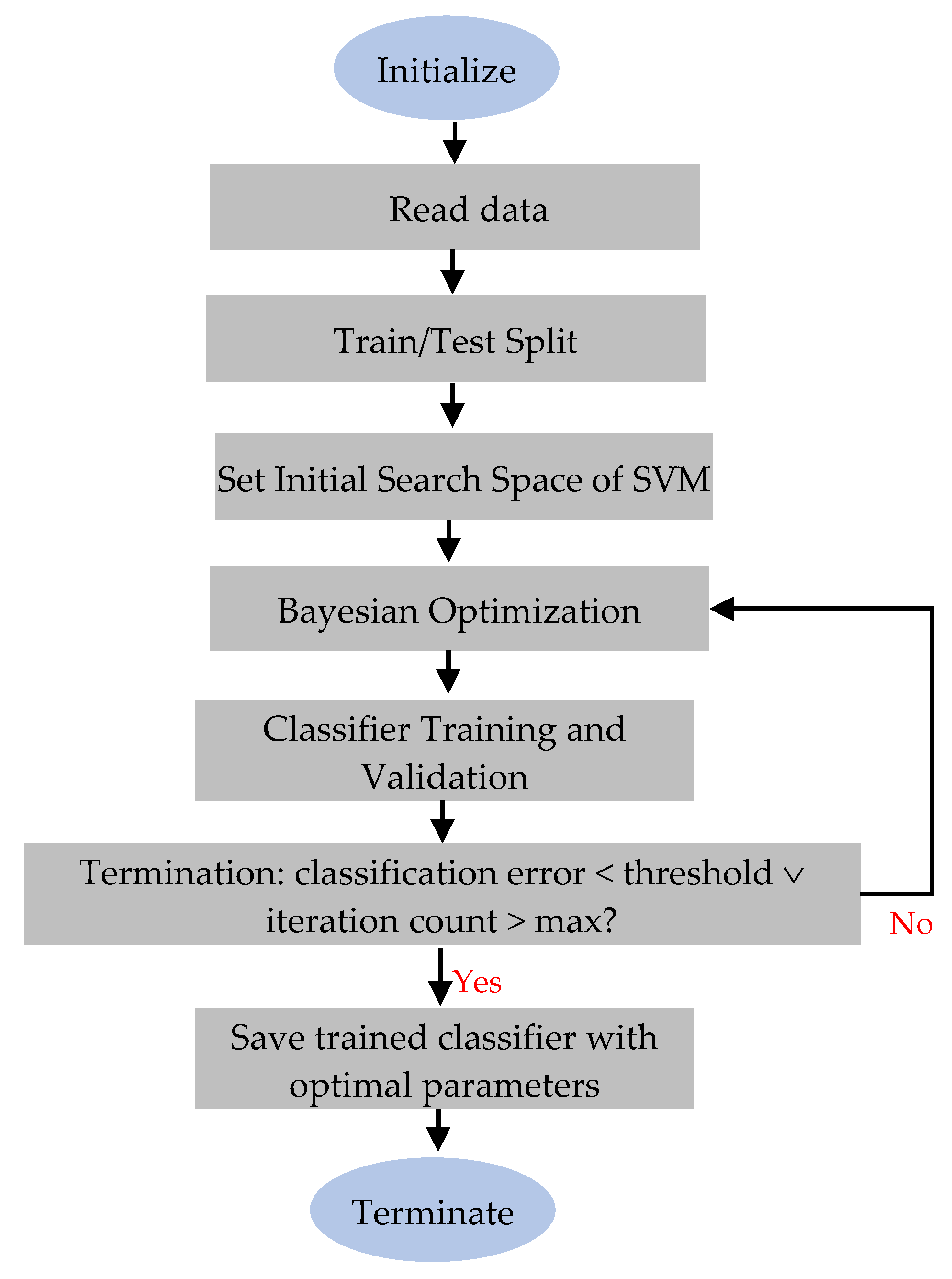
3. Methodology
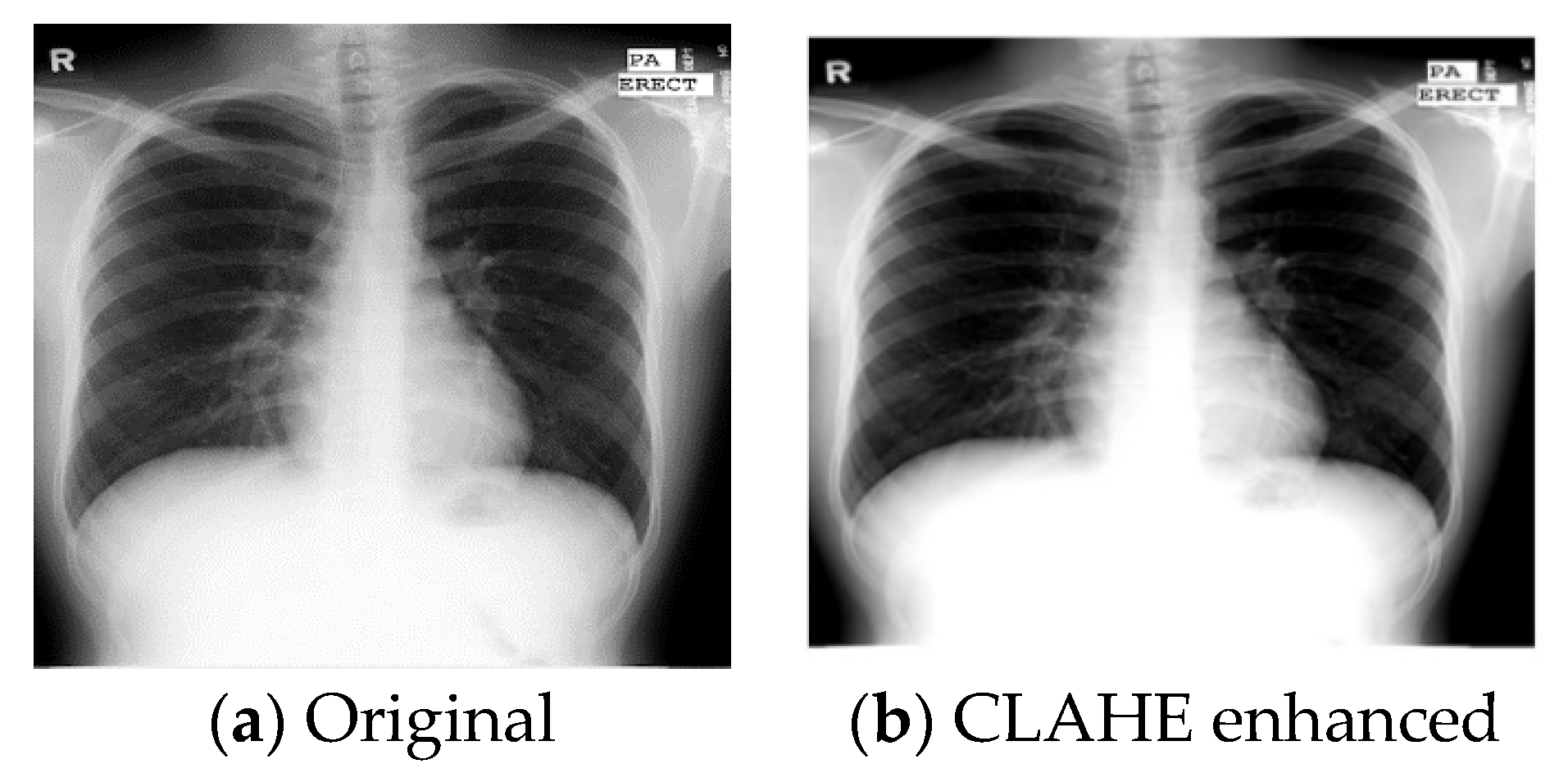
3.1. Preprocessing
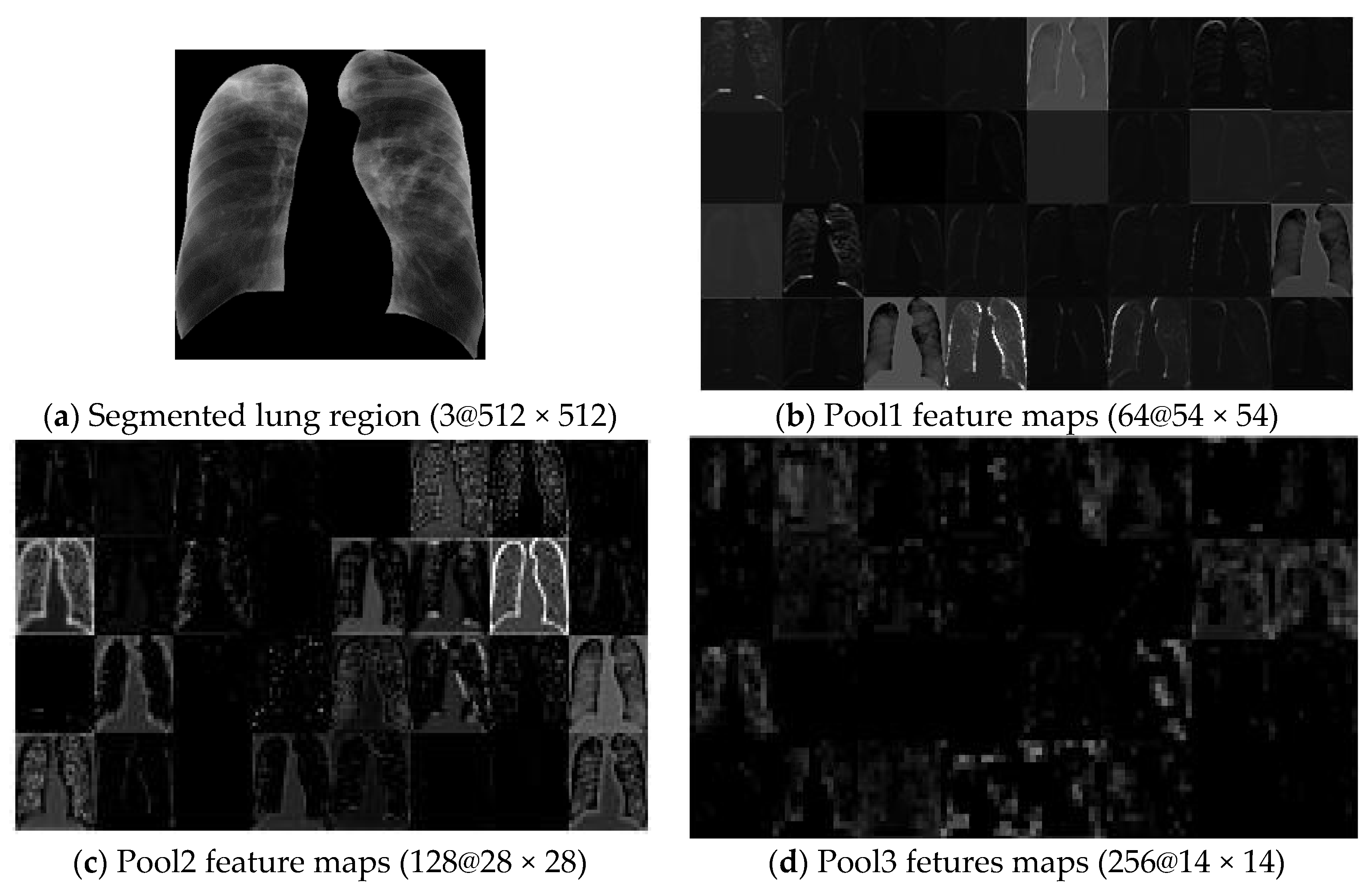
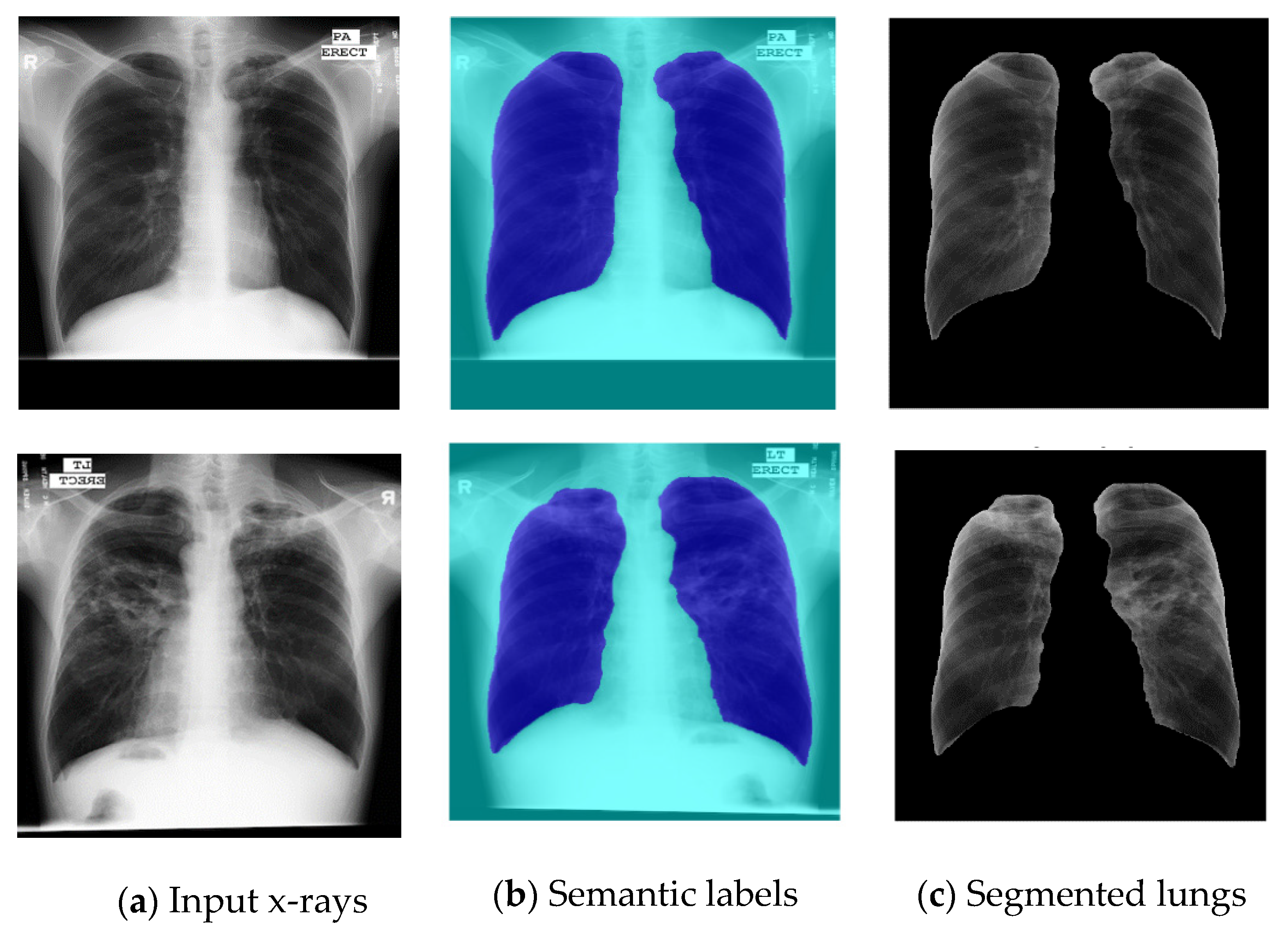
3.2. Lung Segmentation
3.3. Feature Extraction
3.3.1. Hand-Crafted Features
- Statistical textural features: Statistical textural features result from the quantitative analysis of the pixel intensities in the grayscale image using different arrangements. Intensity histograms, first-order statistical textures, gray-level co-occurrence matrices (GLCM) and gray-level run-length matrices (GLRLM) are used as the feature descriptors to extract the statistical textural features. We extracted eight first-order statistical features [33], a total of 88 GLCM features, which encoded 22 different features in four directions [34], and a total of 44 GLRLM features which encoded 11 different features in four directions [35], for a total of 140 textural features.
- Local binary pattern (LBP) features: An LBP is a texture histogram that describes a texture based on differences between central pixels and its neighbors. LBP produces a binary pattern using a threshold value for the central pixel with its neighborhood. A neighbor is 1, when it is greater than or equal to the central pixel, and 0 when it is less. Then the frequency of binary patterns is determined as a histogram of the representative number of binary patterns found in the image [36]. With an 8-pixel neighborhood, 256 features are obtained.
- GIST features: GIST is a feature descriptor that proceeds image filtering to develop a low-level feature set including intensity, color, motion, and orientation based on the information of the gradients, orientations, and scales of the image [37]. GIST captures these features toward identifying the salient image locations that significantly differ from those of the neighbors [14]. First, GIST convolves a given input image with 32 Gabor filters at four different scales and eight different orientations to generate a total of 32 feature maps. Each of these feature maps was then splatted into 16 sub-regions with a 4 × 4 square grid and the feature values within each sub-region were averaged. The averaged values from the 16 sub-regions were concatenated for the 32 different feature maps, resulting in a total of 512 GIST descriptors for a given image.
- Histogram of oriented gradients (HOG) Features: A HOG descriptor, introduced by Dalal and Triggs [38], counts gradient orientation occurrences in localized image regions. HOG measures the first-order image gradient pooled in overlapping orientation bins, and gives a compressed and encoded version of an image. It first computes gradients, creating cell histograms, and generating and normalizing the descriptor blocks. Given an image, HOG first fragments the image into to small-connected regions called cells. Following this, it computes the gradient orientations over each cell and plots a histogram of these orientations, giving the probability for a gradient with a specific orientation in a given path. The adjacent connected cells are grouped into small blocks. The features are extracted over small blocks, in a repetitive fashion, to preserve information about local structures, and the block-wise features are finally integrated into a feature vector. We used the cell size of [16 × 16] pixels, number of bins 3, and 4 × 4 cells in each block. A total of 10,800 HOG features were extracted.
- Pyramid histogram of oriented gradients (PHOG) features: Bosch et al.’s PHOG descriptor [39], represents an image by its spatial layout and local shape. First, PHOG tiles the image into sub-regions, at multiple pyramid-style resolutions, and in each sub-region, the histogram of orientation gradients is applied as a local shape descriptor using the distribution of edge directions. We extracted a total of 168 PHOG features from each image.
- Bag of visual words features: BoVW is a technique adapted from information theory to computer vision applications [40]. Contrary to text, images do not contain words, so, this method creates a bag of features extracted from the images across the classes, using a custom feature descriptor, and constructs a visual vocabulary. First, speeded-up robust features (SURF) [41] are used as feature descriptors to detect interesting key points. Then, k-means clustering [42] is used to generate a visual vocabulary by reducing the dimensions of the features. The center of each cluster refers to a feature or visual word. We extracted 500 BoVW features, using 500 clusters.
3.3.2. Deep-Activated Features from Pre-trained CNNs
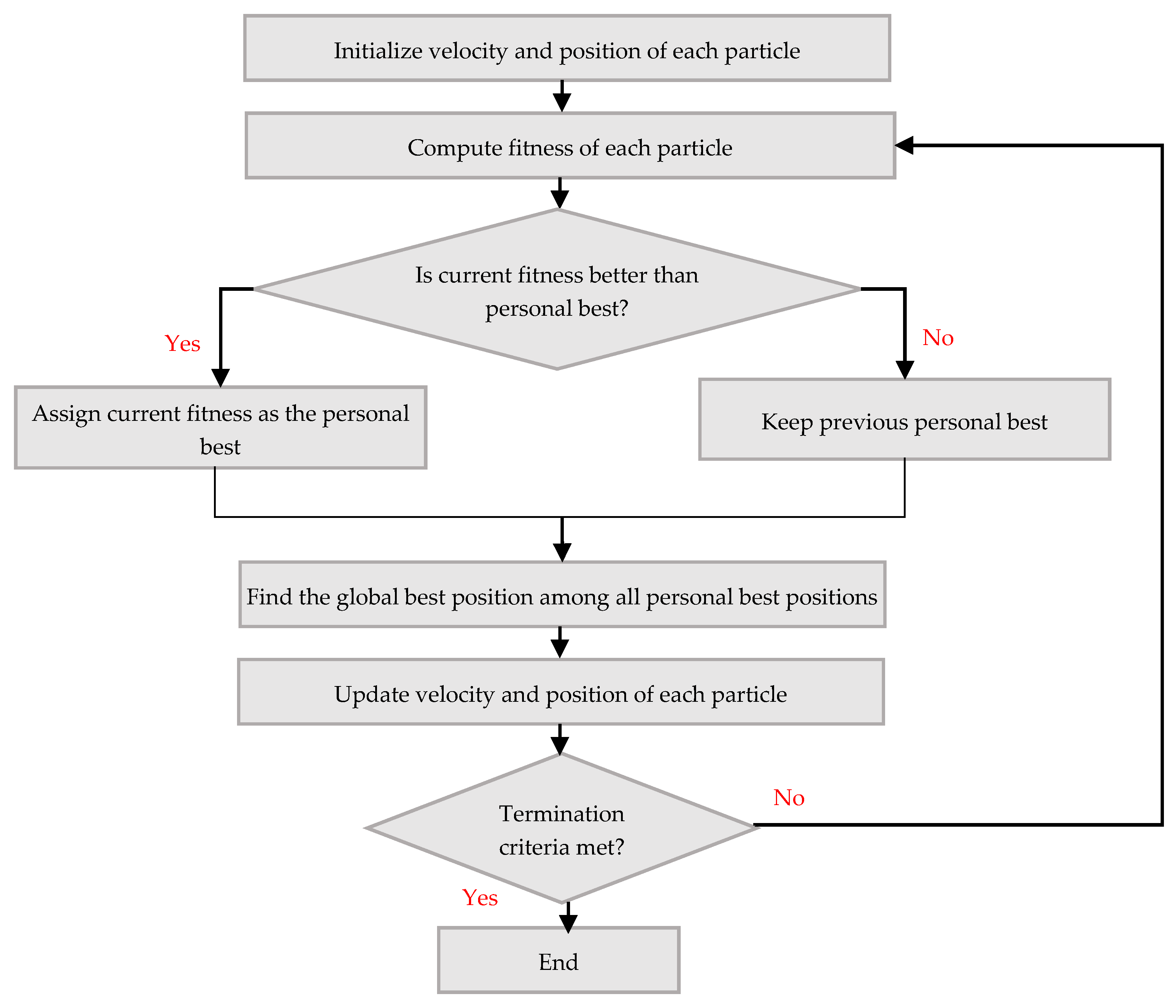
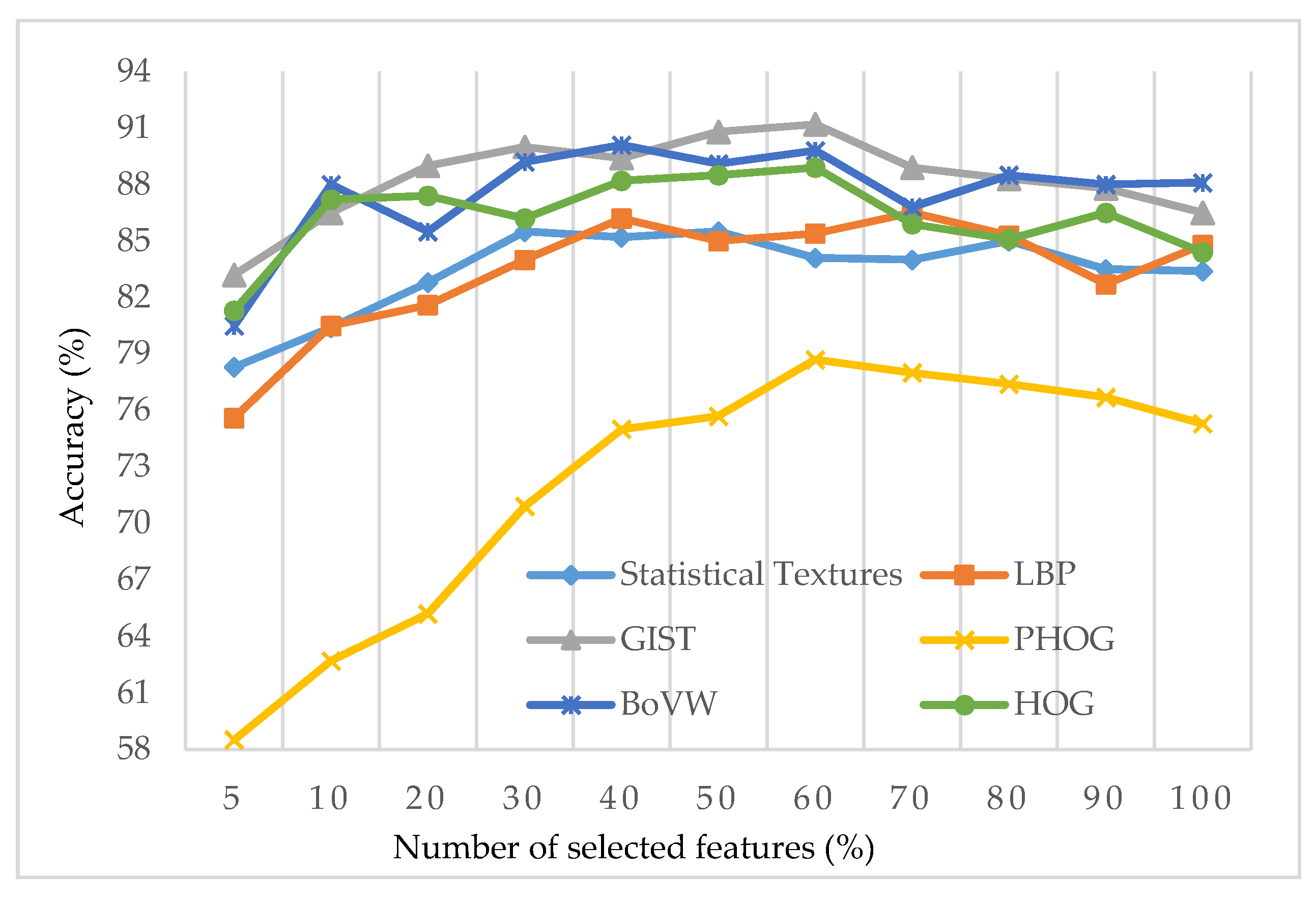
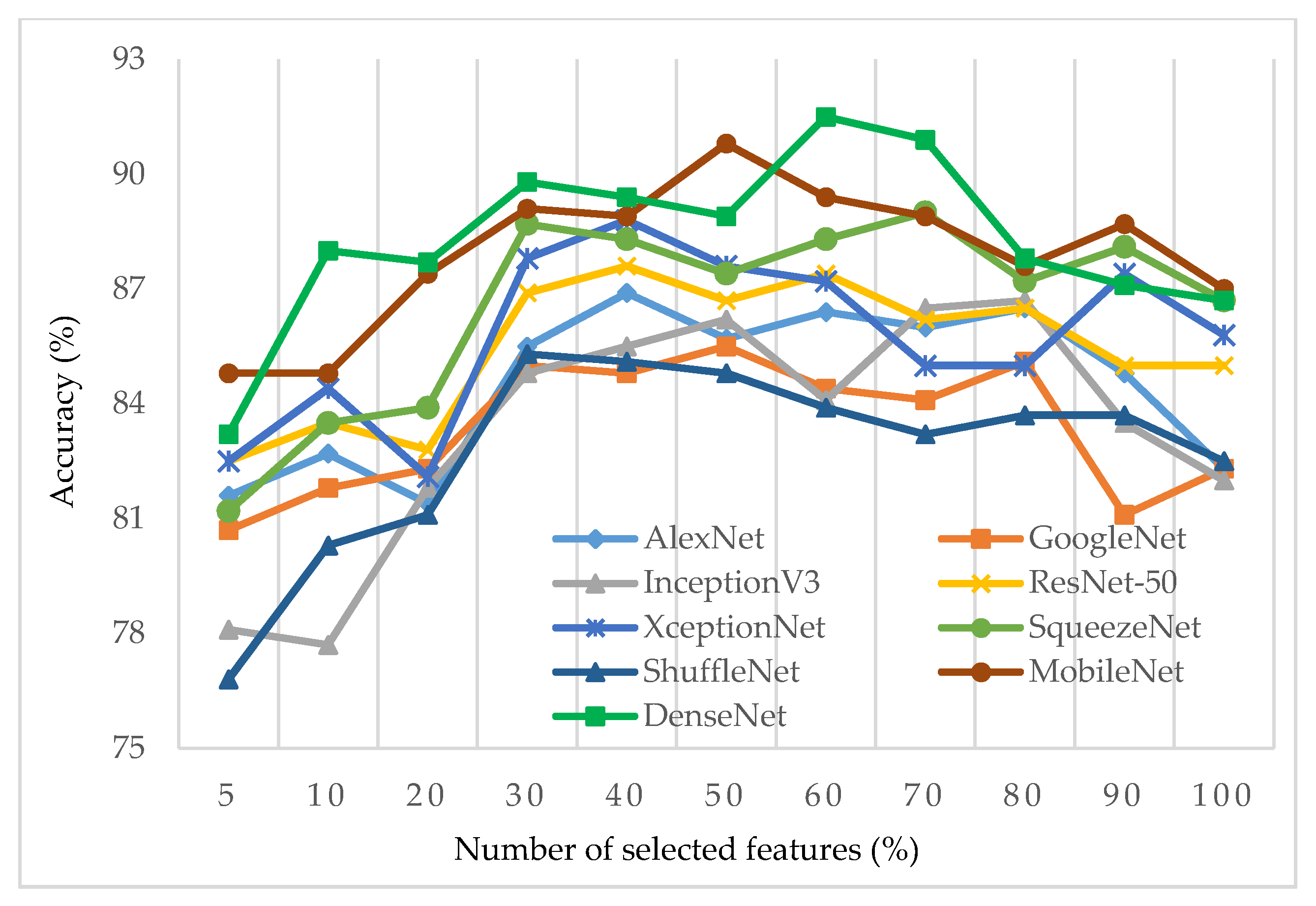
3.4. Feature Selection
| Algorithm 1. Pseudo Code 1: PSO based feature selection algorithm |
| Input: TrainingData, Population, MaximumIteration, ObjectiveFunction |
| Begin:Randomly intialize position and velocity of particle . in the population Set Iteration Counter, t ← 0 |
| Repeat |
| Compute fitness for each particle using ObjectiveFunction If fitness of > If fitnest of > Gbest Gbest ← |
| Begin |
| Update the velocity and postiion using Equations (3) and (4), respectively |
| End |
| Set t ← t+1 |
| Until terminal criteria met finalSet ← finalSet U save(particles) |
| End |
3.5. Classification
| Linear | |
| Gaussian radial basis | |
| Quadratic polynomial | |
| Cubic polynomial |
3.6. Evaluation Metrics
- TruePositive (TP) refers to the number of TB cases correctly classified as TB.
- TrueNegative (TN) refers to the number of normal cases correctly classified as normal.
- FalsePositive (FP) represents the number of normal cases incorrectly classified as TB.
- FalseNegative (FN) denotes the number of TB cases missed by our method.
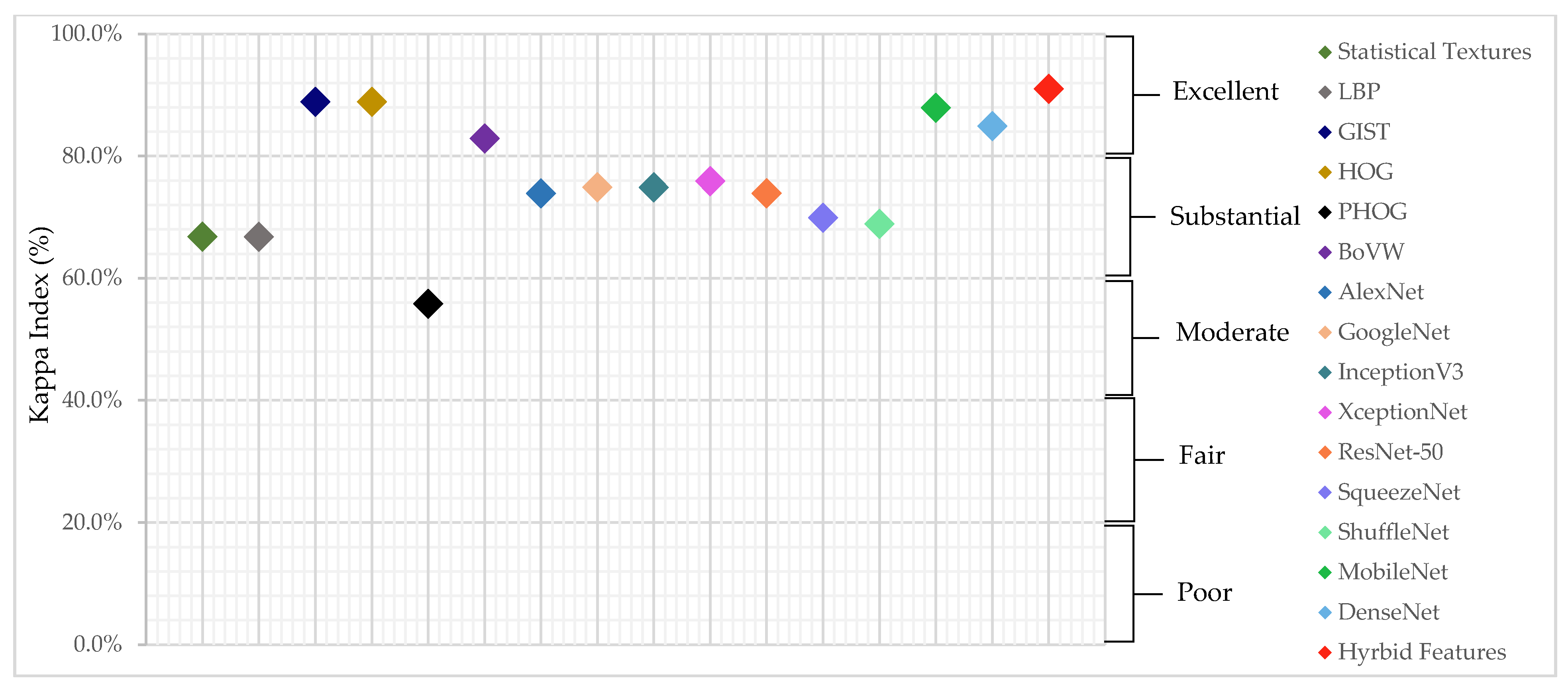
4. Experimental Results and Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization. Global Tuberculosis Report 2019. Available online: https://www.who.int/tb/publications/global_report/en/ (accessed on 25 February 2020).
- Suleiman, K.; Lessem, E. AN ACTIVIST’S. GUIDE TO “Tuberculosis Diagnostic Tools”; Treatment Action Group: New York, NY, USA, 2017. [Google Scholar]
- Qin, C.; Yao, D.; Shi, Y.; Song, Z. Computer-aided detection in chest radiography based on artificial intelligence: A survey. Biomed. Eng. Online 2018, 17, 113. [Google Scholar] [CrossRef] [Green Version]
- Van Ginneken, B.; Katsuragawa, S.; Romeny, B.M.T.H.; Doi, K.; Viergever, M.A. Automatic detection of abnormalities in chest radiographs using local texture analysis. IEEE Trans. Med. Imaging 2002, 21, 139–149. [Google Scholar] [CrossRef]
- Hogeweg, L.; Mol, C.; de Jong, P.A.; Dawson, R.; Ayles, H.; van Ginneken, B. Fusion of local and global detection systems to detect tuberculosis in chest radiographs. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention 2010, Beijing, China, 20–24 September 2010; Springer: Berlin/Heidelberg, Germany; pp. 650–657. [Google Scholar]
- Tan, J.H.; Acharya, U.R.; Tan, C.; Abraham, K.T.; Lim, C.M. Computer-assisted diagnosis of tuberculosis: A first order statistical approach to chest radiograph. J. Med. Syst. 2012, 36, 2751–2759. [Google Scholar] [CrossRef] [PubMed]
- Jaeger, S.; Karargyris, A.; Candemir, S.; Folio, L.; Siegelman, J.; Callaghan, F.; Xue, Z.; Palaniappan, K.; Singh, R.K.; Antani, S.; et al. Automatic tuberculosis screening using chest radiographs. IEEE Trans. Med. Imaging 2013, 33, 233–245. [Google Scholar] [CrossRef] [PubMed]
- Vajda, S.; Karargyris, A.; Jaeger, S.; Santosh, K.C.; Candemir, S.; Xue, Z.; Antani, S.; Thoma, G. Feature selection for automatic tuberculosis screening in frontal chest radiographs. J. Med. Syst. 2018, 42, 146. [Google Scholar] [CrossRef] [PubMed]
- Karargyris, A.; Siegelman, J.; Tzortzis, D.; Jaeger, S.; Candemir, S.; Xue, Z.; Santosh, K.C.; Vajda, S.; Antani, S.; Folio, L.; et al. Combination of texture and shape features to detect pulmonary abnormalities in digital chest X-rays. Int. J. Comput. Assist. Radiol. Surg. 2016, 11, 99–106. [Google Scholar] [CrossRef] [PubMed]
- Jemal, A. Lung Tuberculosis Detection Model in Thorax Radiography. Master’s Thesis, Department of Computing, Adama Science and Technology University, Adama, Ethiopia, 2019. [Google Scholar]
- Santosh, K.C.; Antani, S. Automated chest X-ray screening: Can lung region symmetry help detect pulmonary abnormalities? IEEE Trans. Med. Imaging 2017, 37, 1168–1177. [Google Scholar] [CrossRef]
- Melendez, J.; Van Ginneken, B.; Maduskar, P.; Philipsen, R.H.; Reither, K.; Breuninger, M.; Adetifa, I.M.; Maane, R.; Ayles, H.; Sánchez, C.I. A novel multiple-instance learning-based approach to computer-aided detection of tuberculosis on chest x-rays. IEEE Trans. Med. Imaging 2014, 34, 179–192. [Google Scholar] [CrossRef]
- Melendez, J.; Sánchez, C.I.; Philipsen, R.H.; Maduskar, P.; Dawson, R.; Theron, G.; Dheda, K.; Van Ginneken, B. An automated tuberculosis screening strategy combining X-ray-based computer-aided detection and clinical information. Sci. Rep. 2016, 6, 25265. [Google Scholar] [CrossRef]
- Chauhan, A.; Chauhan, D.; Rout, C. Role of GIST and PHOG features in computer-aided diagnosis of tuberculosis without segmentation. PLoS ONE 2014, 9, e112980. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Rajpurkar, P.; Irvin, J.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.; Lungren, M.P.; et al. Radiologist-level pneumonia detection on chest x-rays with deep learning. arXiv 2017, arXiv:1711.05225. [Google Scholar]
- Pasa, F.; Golkov, V.; Pfeiffer, F.; Cremers, D.; Pfeiffer, D. Efficient deep network architectures for fast chest x-ray tuberculosis screening and visualization. Sci. Rep. 2019, 9, 6268. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hwang, S.; Kim, H.; Jeong, J.; Kim, H. A Novel Approach for Tuberculosis Screening Based on Deep Convolutional Neural Networks. In Proceedings of the SPIE—The International Society for Optical Engineering, Medical Imaging 2016: Computer-Aided Diagnosis, San Diego, CA, USA, 28 February–3 March 2016; Volume 9785, p. 97852W. [Google Scholar]
- Islam, M.T.; Aowal, M.A.; Minhaz, A.T.; Ashraf, K. Abnormality Detection and Localization in Chest X-Rays using Deep Convolutional Neural Networks. arXiv 2017, arXiv:1705.09850. [Google Scholar]
- Lakhani, P.; Sundaram, B. Deep learning at chest radiography: Automated classification of pulmonary tuberculosis by using convolutional neural networks. Radiology 2017, 284, 574–582. [Google Scholar] [CrossRef]
- Lopes, U.K.; Valiati, J.F. Pre-trained convolutional neural networks as feature extractors for tuberculosis detection. Comput. Biol. Med. 2017, 89, 135–143. [Google Scholar] [CrossRef]
- Rajaraman, S.; Cemir, S.; Xue, Z.; Alderson, P.; Thoma, G.; Antani, S. A Novel Stacked Model Ensemble for Improved TB Detection in Chest Radiographs. In Medical Imaging: Artificial Intelligence, Image Recognition, and Machine Learning Techniques; CRC Press: Boca Raton, FL, USA, 2019; pp. 1–26. [Google Scholar]
- Jaeger, S.; Candemir, S.; Antani, S.; Wáng, Y.X.J.; Lu, P.X.; Thoma, G. Two public chest x-ray datasets for computer-aided screening of pulmonary diseases. Quant. Imaging Med. Surg. 2014, 4, 475–477. [Google Scholar]
- Zuiderveld, K. Contrast limited adaptive histogram equalization. In Graphics Gems IV; Academic Press Professional Inc.: Cambridge, MA, USA, 1994; pp. 474–485. [Google Scholar]
- Gordienko, Y.; Gang, P.; Hui, J.; Zeng, W.; Kochura, Y.; Alienin, O.; Rokovyi, O.; Stirenko, S. Deep learning with lung segmentation and bone shadow exclusion techniques for chest X-ray analysis of lung cancer. In International Conference on Theory and Applications of Fuzzy Systems and Soft Computing; Springer: New York, NY, USA, 2018; pp. 638–647. [Google Scholar]
- Win, K.Y.; Maneerat, N.; Hamamoto, K.; Syna, S. A cascade of encoder-decoder with atrous separable convolution and ensemble deep convolutional neural networks for Tuberculosis detection. IEEE Access 2020. under review. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. arXiv 2015, arXiv:1511.0051. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the ECCV: European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Soille, P. Morphological Image Analysis: Principles and Applications; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Srinivasan, G.N.; Shobha, G. Statistical texture analysis. Int. J. Comput. Inf. Eng. 2008, 36, 1264–1269. [Google Scholar]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural features for image classi cation. IEEE Trans. Syst. Man Cybern. 1973, 3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Dasarathy, B.V.; Holder, E.B. Image characterizations based on joint gray level-run length distributions. Pattern Recognit. Lett. 1991, 12, 497–502. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution Gray Scale and Rotation Invariant Texture Classification with Local Binary Patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Grigorescu, S.E.; Petkov, N.; Kruizinga, P. Comparison of texture features based on Gabor filters. IEEE Trans. Image Process. 2002, 11, 1160–1167. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dalal, N.; Triggs, W. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition CVPR05, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Bosch, A.; Zisserman, A.; Munoz, X. Representing shape with a spatial pyramid kernel. In Proceedings of the 6th ACM international conference on Image and video retrieval, Amsterdam, The Netherlands, 9–11 July 2007; pp. 401–408. [Google Scholar]
- Csurka, G.; Dance, C.R.; Fan, L.; Willamowski, J.; Bray, C. Visual Categorization with Bags of Keypoints. In Workshop on Statistical Learning in Computer Vision, ECCV, Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1–22. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. Comput. Vis. Image Underst. (CVIU) 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948, 1995. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar]
- Christianini, N.; Shawe-Taylor, J.C. An. Introduction to Support. Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. arXiv 2012, arXiv:1206.2944. [Google Scholar]
- Rosenfield, G.H.; Fitzpatrick-Lins, K. A coefficient of agreement as a measure of thematic classification accuracy. Photogramm. Eng. Remote Sens. 1986, 52, 223–227. [Google Scholar]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 174, 159–174. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Descriptors | Features | Number of Features | |
|---|---|---|---|
| Hand-crafted features | Statistical Textures | First order statistics, GLCM, GLRLM | 140 |
| LBP | Texture histogram | 256 | |
| HOG | Occurrences of oriented gradients | 10,800 | |
| PHOG | Occurences of oriented gradients at each pyramid resolution level | 168 | |
| GIST | Information of the gradients, orientations, and scales of the image | 512 | |
| BoVW | Image features as ‘words’ | 500 | |
| Deep CNNs’ Features | Alex | Deep-activated features | 1000 |
| GoogLeNet | Deep-activated features | 1000 | |
| InceptionV3 | Deep-activated features | 1000 | |
| XceptionNet | Deep-activated features | 1000 | |
| ResNet-50 | Deep-activated features | 1000 | |
| SqueezeNet | Deep-activated features | 1000 | |
| ShuffleNet | Deep-activated features | 1000 | |
| MobileNet | Deep-activated features | 1000 | |
| DenseNet | Deep-activated features | 1000 | |
| Kappa Index | Quality |
|---|---|
| <0 | Poor |
| 0–20 | Slight |
| 21–40 | Fair |
| 41–60 | Moderate |
| 61–80 | Substantial |
| 81–100 | Excellent |
| Feature Sets | Penalty Term (C) | Kernel Functions | Kernel Scale | |
|---|---|---|---|---|
| Hand-crafted features | Statistical Textures | 8.58 × 100 | Linear | N/A |
| LBP | 9.24 × 10−3 | Linear | N/A | |
| HOG | 8.28 × 102 | Gaussian | 8.21 × 102 | |
| GIST | 9.96 × 102 | Gaussian | 3.10 × 101 | |
| PHOG | 2.58 × 100 | Gaussian | 3.37 × 101 | |
| BoVW | 3.64 × 10−3 | Linear | N/A | |
| Deep-activated features | AlexNet | 9.87 × 102 | Gaussian | 6.08 × 102 |
| GoogLeNet | 5.51 × 10−2 | Linear | N/A | |
| InceptionV3 | 1.77 × 10−2 | Linear | N/A | |
| XceptionNet | 1.01 × 10−3 | Linear | NaN | |
| ResNet-50 | 9.98 × 102 | Gaussian | 9.91 × 102 | |
| SqueezeNet | 2.02 × 10−2 | Linear | N/A | |
| ShuffleNet | 1.00 × 10−3 | Linear | N/A | |
| MobileNet | 3.05 × 102 | Gaussian | 3.01 × 101 | |
| DenseNet | 5.60 × 102 | Gaussian | 7.32 × 102 | |
| Features | F1 (%) | Accuracy (%) | AUC (%) |
|---|---|---|---|
| Statistical Textures | 81.8 | 80.5 | 87.9 |
| LBP | 79.2 | 73.2 | 86.2 |
| GIST | 90.9 | 90.2 | 93.1 |
| HOG | 93.3 | 92.7 | 100.0 |
| PHOG | 75.6 | 73.2 | 83.6 |
| BoVW | 91.3 | 90.2 | 99.8 |
| AlexNet | 76.9 | 70.7 | 85.7 |
| GoogLeNet | 88.9 | 87.8 | 91.9 |
| InceptionV3 | 83.7 | 82.9 | 89.0 |
| XceptionNet | 85.7 | 82.9 | 91.0 |
| ResNet-50 | 81.8 | 80.5 | 88.8 |
| SqueezeNet | 81.6 | 78.0 | 79.5 |
| ShuffleNet | 83.3 | 80.5 | 84.0 |
| MobileNet | 90.9 | 90.2 | 93.1 |
| DenseNet | 93.3 | 92.7 | 99.5 |
| Hybrid features (GIST+HOG+BoVW+MobileNet+DenseNet) | 93.3 | 92.7 | 99.5 |
| Features | F1 (%) | Accuracy (%) | AUC (%) |
|---|---|---|---|
| Statistical Textures | 83.1 | 83.4 | 91.0 |
| LBP | 83.4 | 83.4 | 90.7 |
| GIST | 94.4 | 94.5 | 98.6 |
| HOG | 94.5 | 94.5 | 96.7 |
| PHOG | 78.8 | 77.9 | 85.9 |
| BoVW | 91.5 | 91.5 | 95.7 |
| AlexNet | 86.6 | 86.9 | 94.0 |
| GoogLeNet | 87.3 | 87.4 | 93.3 |
| InceptionV3 | 87.3 | 87.4 | 94.1 |
| XceptionNet | 88.0 | 87.9 | 94.4 |
| ResNet-50 | 85.7 | 85.9 | 94.0 |
| SqueezeNet | 85.0 | 84.9 | 90.1 |
| ShuffleNet | 84.7 | 84.4 | 88.9 |
| MobileNet | 93.9 | 94.0 | 98.6 |
| DenseNet | 92.5 | 92.5 | 97.8 |
| Hybrid features (GIST+HOG+BoVW+MobileNet+DenseNet) | 95.4 | 95.5 | 99.5 |
| Authors | Methods Used | MC | Shenzhen | ||
|---|---|---|---|---|---|
| Accuracy | AUC | Accuracy | AUC | ||
| Jaeger et al. [7] |
| 78.3% | 86.9% | 84.0% | 90.0% |
| Vajda et al. [8] |
| 78.3% | 76.0% | 95.6% | 99.0% |
| Karargyris et al. [9] |
| NA | NA | NA | 93.4% |
| Jemal [10] |
| 68.1% | 71.0% | 83.4% | 91.0% |
| Santosh et al. [11] |
| 83.0% | 90.0% | 91.0% | 96.0% |
| Pasa et al. [17] |
| 79.0% | 81.1% | 84.4% | 90.0% |
| Hwang et al. [18] |
| 67.4% | 88.4% | 83.7% | 92.6% |
| Islam et al. [19] |
| NA | NA | NA | 94% |
| Lopes et al. [21] |
| 82.6% | 92.6% | 84.7% | 92.6% |
| Rajaraman et al. [22] |
| 87.5% | 98.6% | 95.9% | 99.4% |
| Our method |
| 92.7% | 99.5% | 95.5% | 99.5% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Win, K.Y.; Maneerat, N.; Hamamoto, K.; Sreng, S. Hybrid Learning of Hand-Crafted and Deep-Activated Features Using Particle Swarm Optimization and Optimized Support Vector Machine for Tuberculosis Screening. Appl. Sci. 2020, 10, 5749. https://doi.org/10.3390/app10175749
Win KY, Maneerat N, Hamamoto K, Sreng S. Hybrid Learning of Hand-Crafted and Deep-Activated Features Using Particle Swarm Optimization and Optimized Support Vector Machine for Tuberculosis Screening. Applied Sciences. 2020; 10(17):5749. https://doi.org/10.3390/app10175749
Chicago/Turabian StyleWin, Khin Yadanar, Noppadol Maneerat, Kazuhiko Hamamoto, and Syna Sreng. 2020. "Hybrid Learning of Hand-Crafted and Deep-Activated Features Using Particle Swarm Optimization and Optimized Support Vector Machine for Tuberculosis Screening" Applied Sciences 10, no. 17: 5749. https://doi.org/10.3390/app10175749