Automatic Salient Object Extraction Based on Locally Adaptive Thresholding to Generate Tactile Graphics

 ,
,  ,
,
Abstract
:1. Introduction
- Salient object extraction based on locally adaptive triple thresholding using an integral image.
- We combined the GrabCuts algorithm with the generated four-region seeds to refine the segmentation results.
- One of the applications of salient object extraction is detected outer boundary, and inner edges of the salient object were illustrated on tactile graphics to facilitate the learning process of visually impaired.
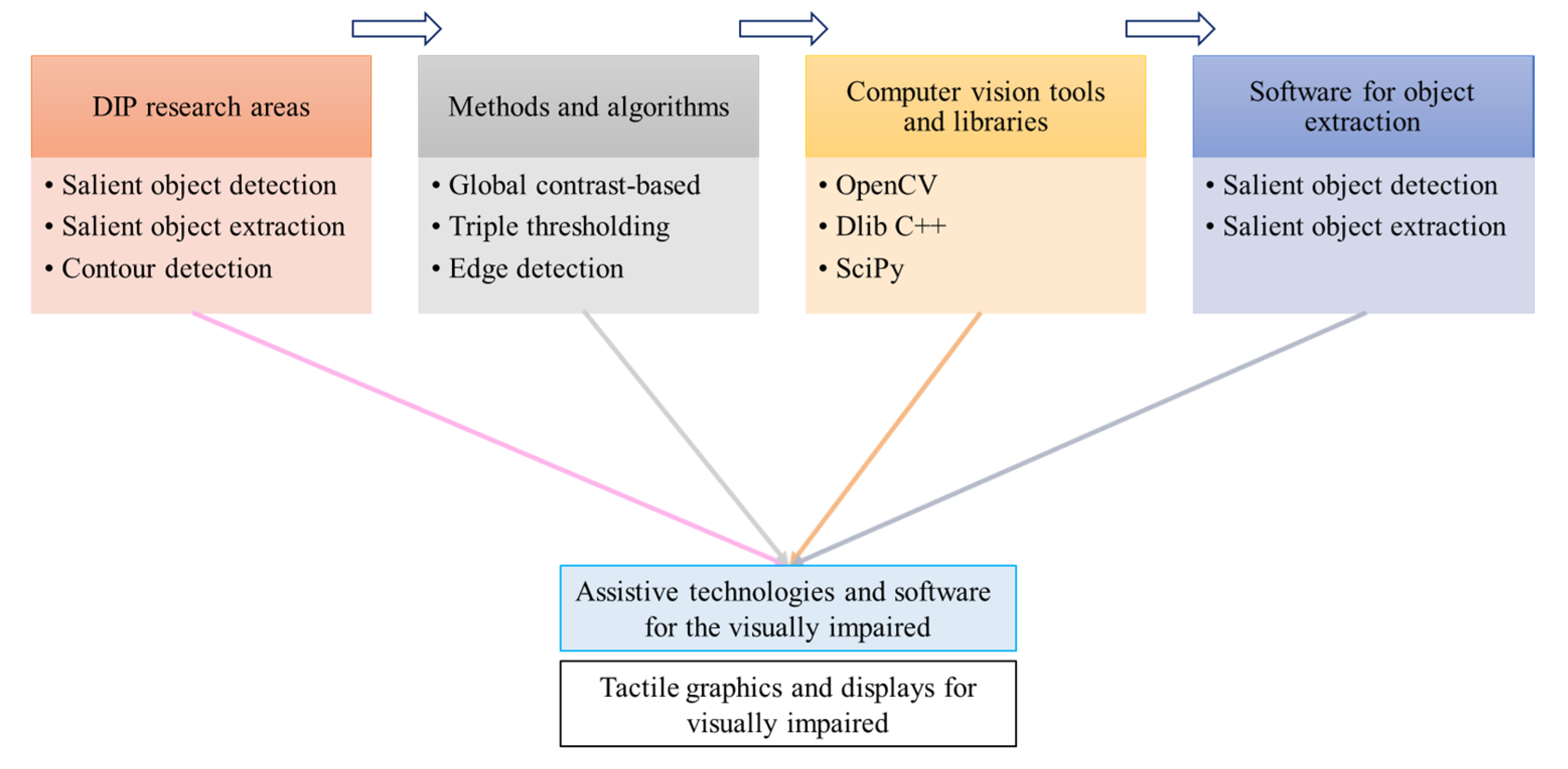
2. Related Works
3. Proposed Method
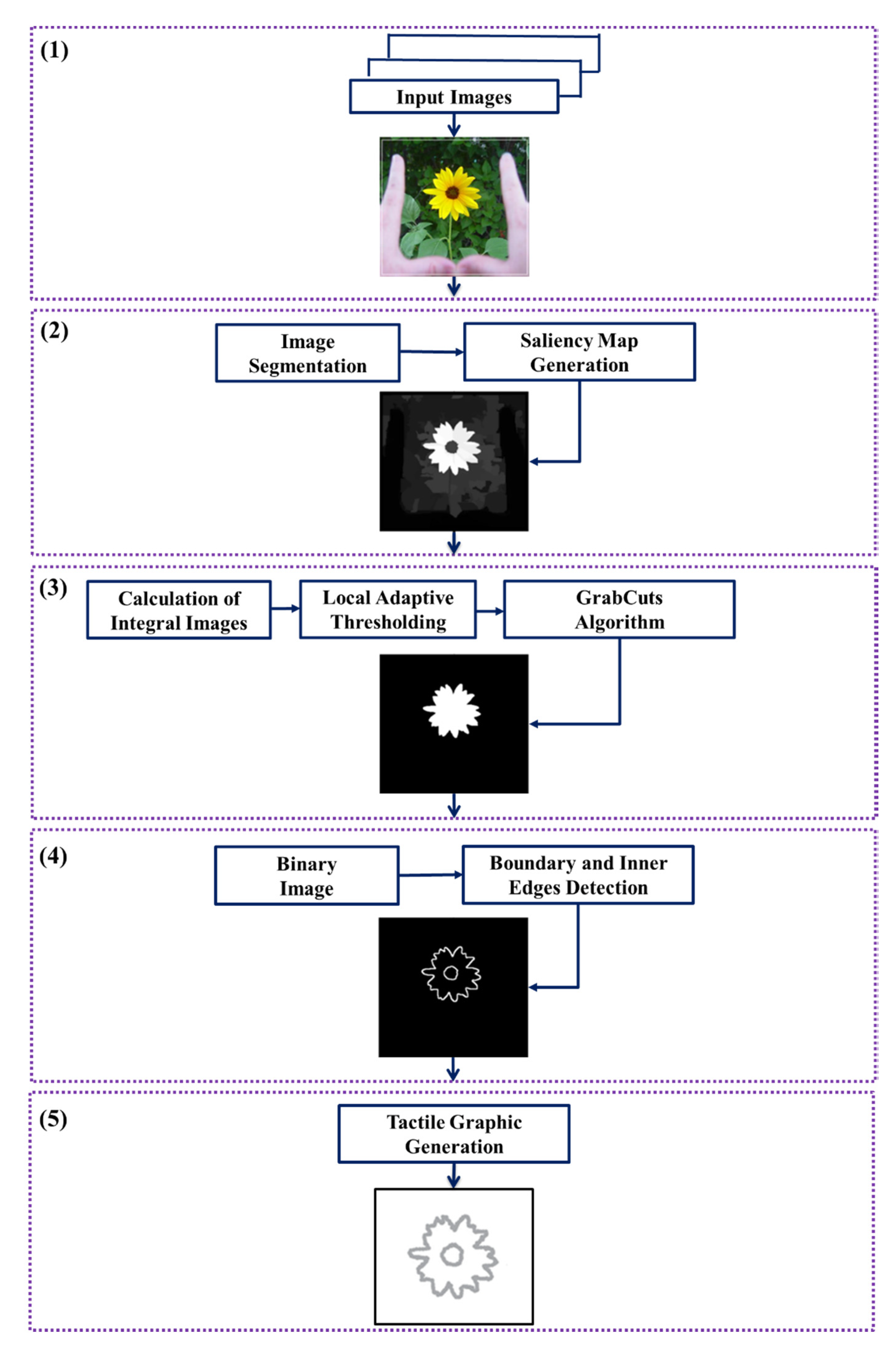
3.1. Overview
3.2. Saliency Cuts Using Local Adaptive Thresholding
3.2.1. Local Adaptive and Global Thresholding
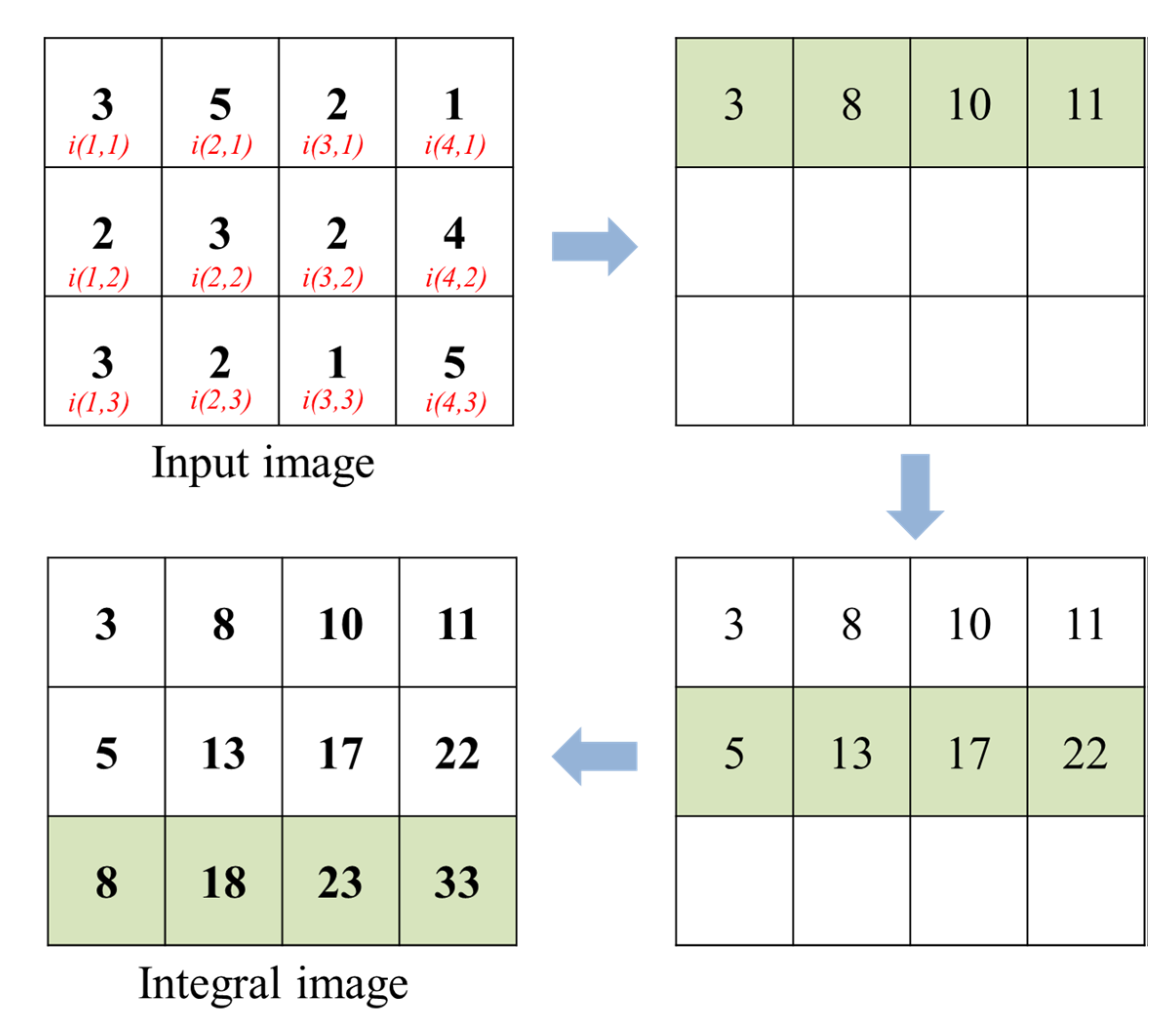
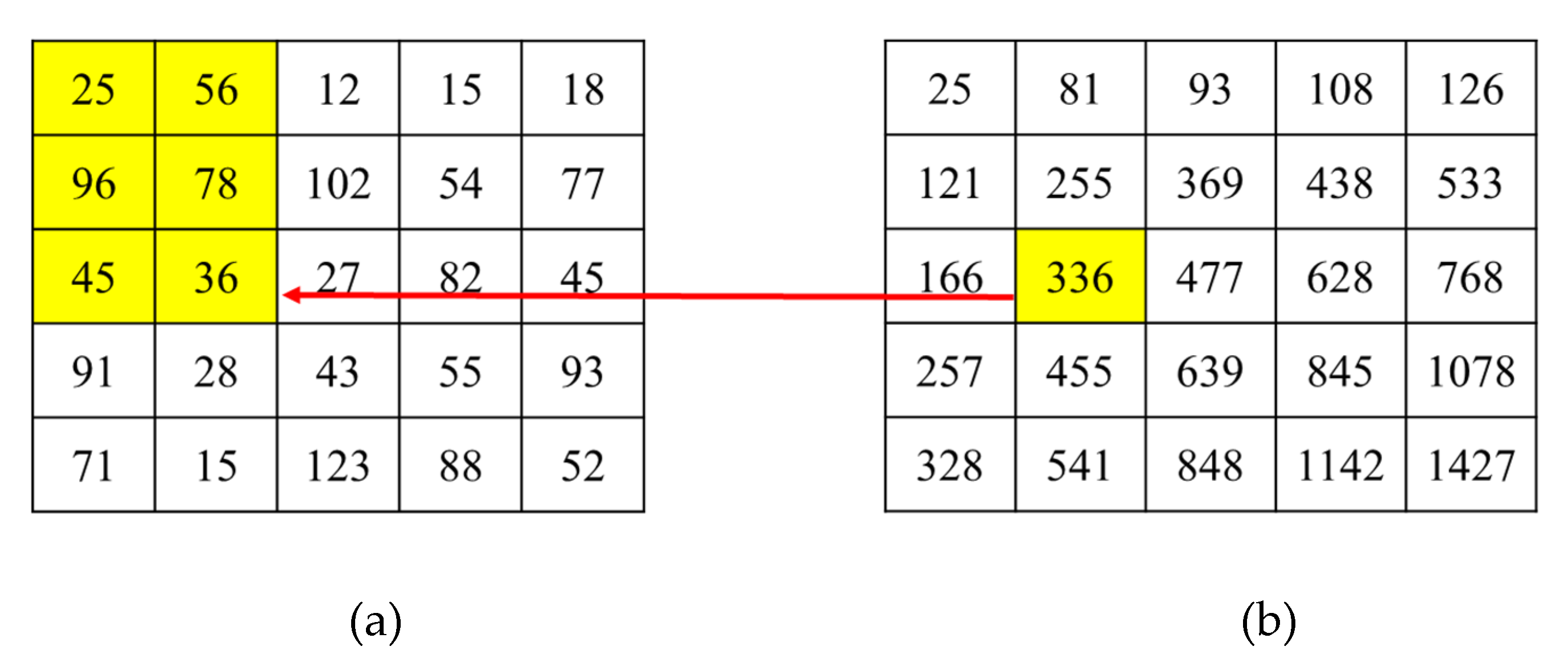
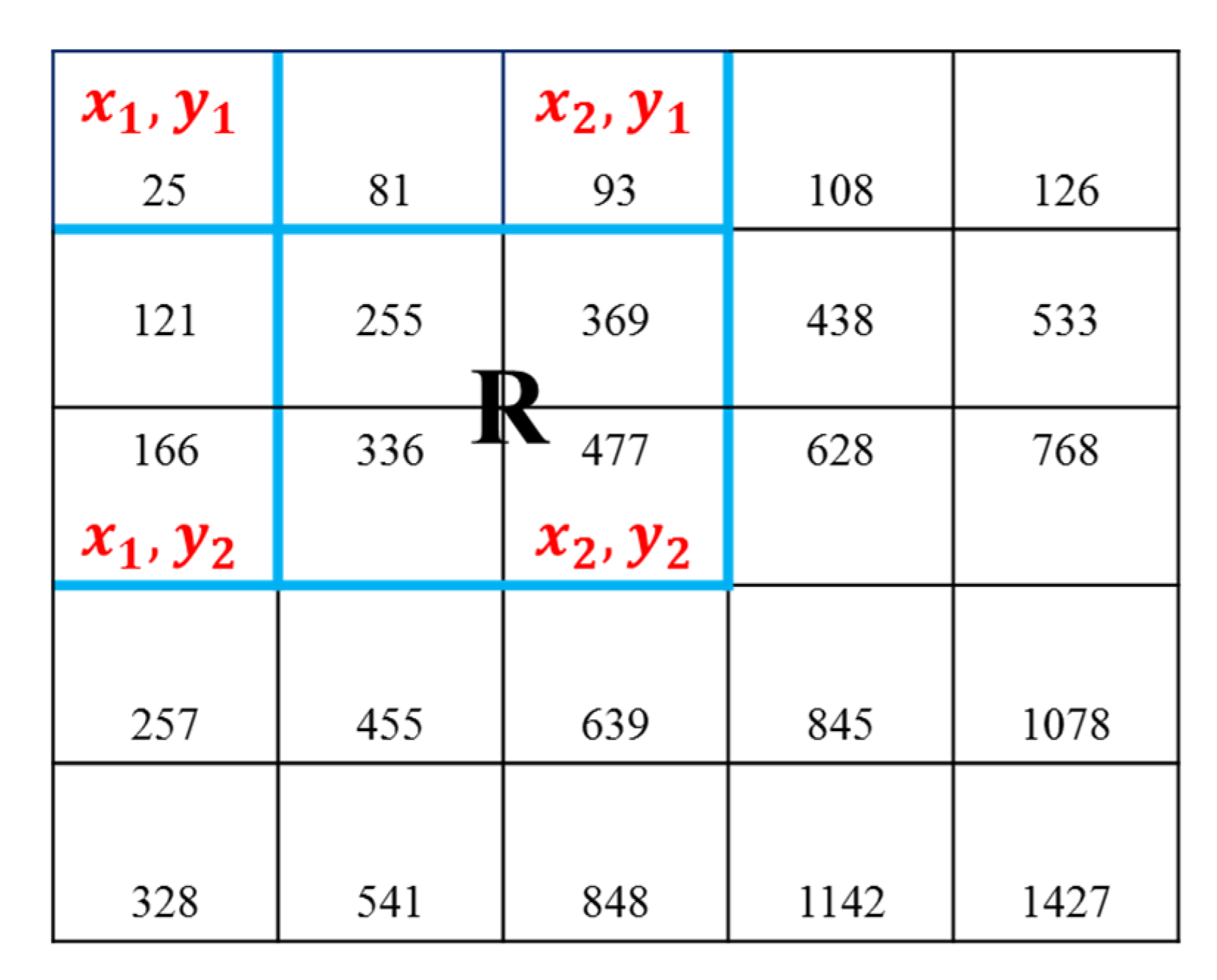
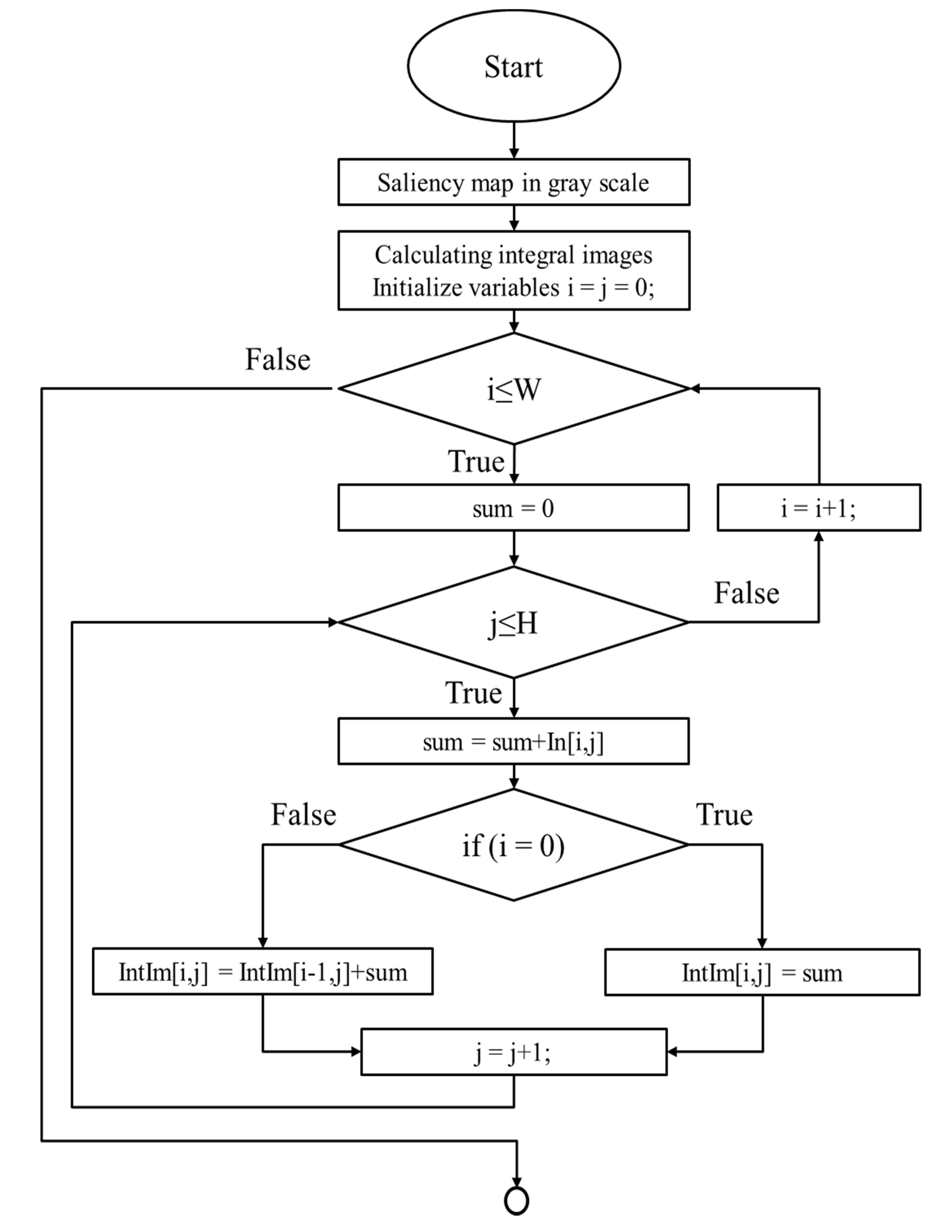
3.2.2. Integral Images
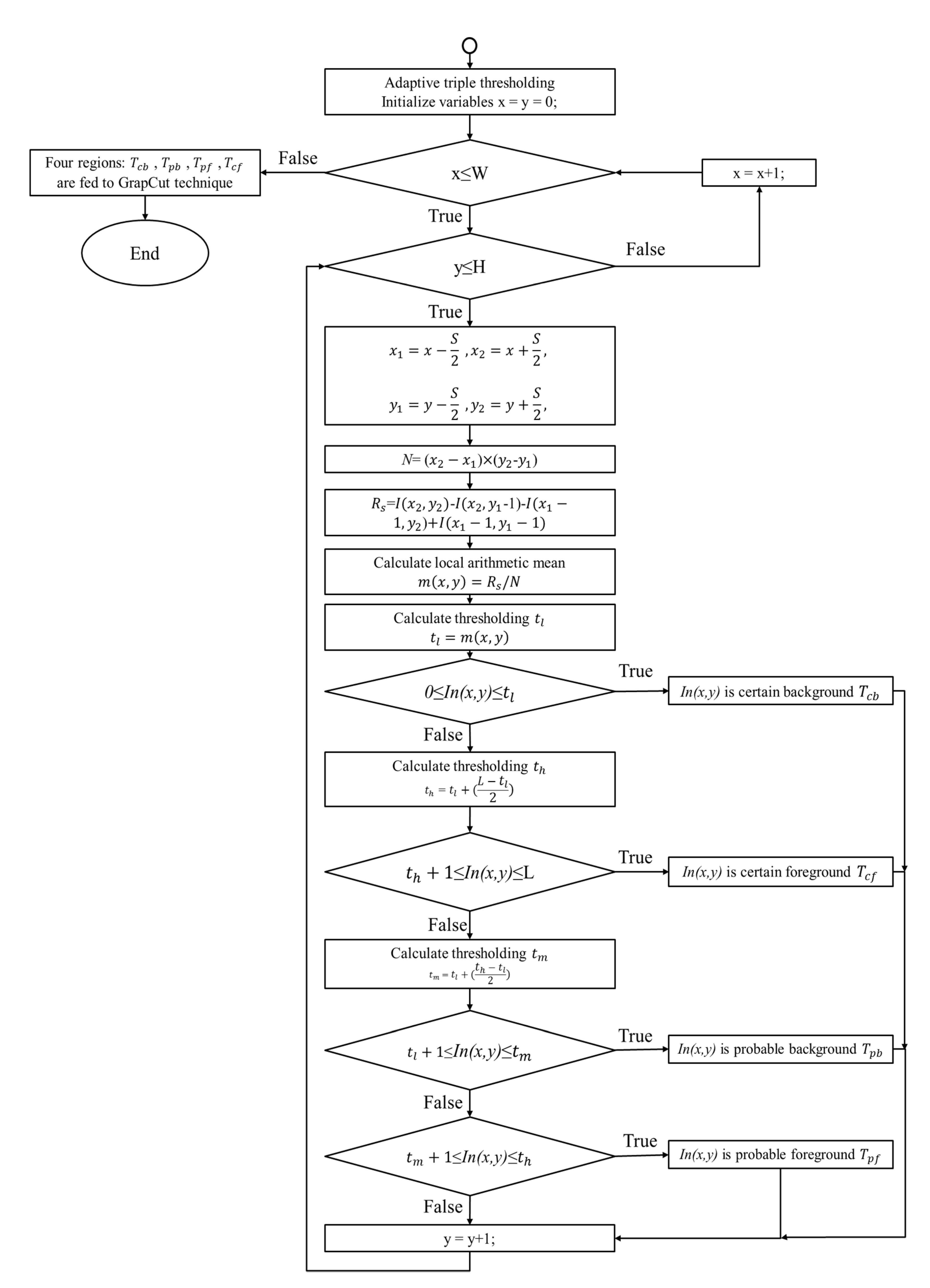
3.2.3. Local Adaptive Triple Thresholding
3.2.4. GrabCuts with Auto-Generated Seeds
3.2.5. Boundary and Inner Edge Detection
4. Experiment Results and Analysis
4.1. Qualitative Evaluation
4.2. Quantitative Evaluation
4.3. Subjective Evaluation
4.4. Runtime Analysis
4.5. Implementation at the School for Visually Impaired
5. Limitations
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A


References
- Rahtu, E.; Kannala, J.; Salo, M.; Heikkila, J. Segmenting Salient Objects from Images and Videos. In Proceedings of the 11th European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010. [Google Scholar]
- Guo, C.; Zhang, L. A Novel Multiresolution Spatiotemporal Saliency Detection Model and Its Applications in Image and Video Compression. IEEE Trans. Image Process. 2010, 19, 185–198. [Google Scholar] [PubMed]
- Setlur, V.; Lechner, T.; Nienhaus, M.; Gooch, B. Retargeting Images and Video for Preserving Information Saliency. IEEE Comput. Graph. Appl. 2017, 27, 80–88. [Google Scholar] [CrossRef] [PubMed]
- Fang, Y.; Chen, Z.; Lin, W.; Lin, C.-W. Saliency Detection in the Compressed Domain for Adaptive Image Retargeting. IEEE Trans. Image Process. 2012, 21, 3888–3901. [Google Scholar] [CrossRef]
- Khamdamov, U.; Zaynidinov, H. Parallel Algorithms for Bitmap Image Processing Based on Daubechies Wavelets. In Proceedings of the 2018 10th International Conference on Communication Software and Networks (ICCSN), Chengdu, China, 6–9 July 2018; pp. 537–541. [Google Scholar]
- Gao, Y.; Shi, M.; Tao, D.; Xu, C. Database Saliency for Fast Image Retrieval. IEEE Trans. Multimed. 2015, 17, 359–369. [Google Scholar] [CrossRef]
- Wei, X.; Tao, Z.; Zhang, C.; Cao, X. Structured Saliency Fusion Based on Dempster–Shafer Theory. IEEE Signal Process. Lett. 2015, 22, 1345–1349. [Google Scholar] [CrossRef]
- Donoser, M.; Urschler, M.; Hirzer, M.; Bischof, H. Saliency Driven Total Variation Segmentation. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Rutishauser, U.; Walther, D.; Koch, C.; Perona, P. Is bottom-up attention useful for object recognition? In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Ren, Z.; Gao, S.; Chia, L.-T.; Tsang, I.W.-H. Region-Based Saliency Detection and Its Application in Object Recognition. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 769–779. [Google Scholar] [CrossRef]
- Mukhiddinov, M.; Akmuradov, B.; Djuraev, O. Robust Text Recognition for Uzbek Language in Natural Scene Images. In Proceedings of the 2019 International Conference on Information Science and Communications Technologies (ICISCT), Tashkent, Uzbekistan, 4–6 November 2019; pp. 1–5. [Google Scholar]
- Sharma, G.; Jurie, F.; Schmid, C. Discriminative Spatial Saliency for Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Ma, Z.; Qing, L.; Miao, J.; Chen, X. Advertisement evaluation using visual saliency based on foveated image. In Proceedings of the IEEE Conference on Multimedia and Expo, New York, NY, USA, 28 June–3 July 2009. [Google Scholar]
- Ghariba, B.; Shehata, M.S.; McGuire, P. Visual Saliency Prediction Based on Deep Learning. Information 2019, 10, 257. [Google Scholar] [CrossRef] [Green Version]
- Yoon, H.; Kim, B.-H.; Mukhriddin, M.; Cho, J. Salient Region Extraction based on Global Contrast Enhancement and Saliency Cut for Image Information Recognition of the Visually Impaired. TIIS 2018, 12, 2287–2312. [Google Scholar]
- Li, S.; Ju, R.; Ren, T.; Wu, G. Saliency Cut based on adabtive triple thresholding. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015. [Google Scholar]
- Cheng, M.-M.; Zhang, G.-X.; Mitra, N.J.; Huang, X.; Hu, S.-M. Global contrast based salient region detection. TPAMI 2015, 37, 409–416. [Google Scholar] [CrossRef] [Green Version]
- Fu, Y.; Cheng, J.; Li, Z.; Lu, H. Saliency cuts: An automatic approach to object segmentation. In Proceedings of the 2008 19th International Conference on Pattern Recognition (ICPR), Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Singh, O.I.; Sinam, T.; James, O.; Singh, T.R. Local Contrast and Mean based Thresholding technique in Image Binarization. Int. J. Comput. Appl. 2012, 51, 6. [Google Scholar]
- Rother, C.; Kolmogorov, V.; Blake, A. “GrabCut”: Interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Shi, J.; Yan, Q.; Xu, L.; Jia, J. Hierarchical Image Saliency Detection on Extended CSSD. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 717–729. [Google Scholar] [CrossRef] [PubMed]
- Felzenszwalb, P.; Huttenlocher, D. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef] [Green Version]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Susstrunk, S. SLIC Superpixels; EPFL Technical Report No. 149300; EPFL: Lausanne, Switzerland, June 2010. [Google Scholar]
- Zhou, Q. Object-based attention: Saliency detection using contrast via background prototypes. Electron. Lett. 2014, 50, 997–999. [Google Scholar] [CrossRef]
- Zhou, Q.; Chen, J.; Ren, S.; Zhou, Y.; Chen, J.; Liu, W. On Contrast Combinations for Visual Saliency Detection. In Proceedings of the 2013 IEEE International Conference on Image Processing (ICIP), Melbourne, Australia, 15–18 September 2013. [Google Scholar]
- Han, J.; Zhang, D.; Hu, X.; Guo, L.; Ren, J.; Wu, F. Background Prior-Based Salient Object Detection via Deep Reconstruction Residual. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1309–1321. [Google Scholar]
- Lee, G.; Tai, Y.-W.; Kim, J. Deep saliency with encoded low level distance map and high level features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 660–668. [Google Scholar]
- Li, G.; Yu, Y. Visual Saliency Based on Multiscale Deep Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Liu, N.; Han, J. DHSNet: Deep Hierarchical Saliency Network for Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yuan, Y.; Li, C.; Kim, J.; Cai, W.; Feng, D.D. Dense and Sparse Labelling with Multi-Dimensional Features for Saliency Detection. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 1130–1143. [Google Scholar] [CrossRef]
- Li, G.; Yu, Y. Deep Contrast Learning for Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Mehrani, P.; Veksler, O. Saliency segmentation based on learning and graph cut refinement. In Proceedings of the British Machine Vision Conference, Aberystwyth, UK, 31 August–3 September 2010; pp. 1–12. [Google Scholar]
- Ko, B.C.; Nam, J.-Y. Automatic Object-of-Interest segmentation from natural images. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006. [Google Scholar]
- Jiang, H.; Wang, J.; Yuan, Z.; Liu, T.; Zheng, N. Automatic Salient Object Segmentation based on Context and Shape Prior. In Proceedings of the British Machine Vision Conference, University of Dundee, Dundee, UK, 29 August–2 September 2011; pp. 110.1–110.12. [Google Scholar]
- Aytekin, Ç.; Ozan, E.C.; Kiranyaz, S.; Gabbouj, M. Visual Saliency by Extended Quantum Cuts. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015. [Google Scholar]
- Winn, J.; Jojic, N. LOCUS: Learning Object Classes with Unsupervised Segmentation. In Proceedings of the 10th IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005. [Google Scholar]
- Shi, J.; Malik, J. Normalized Cuts and Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Peng, J.; Shen, J.; Jia, Y. Saliency Cut in Stereo Images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Grady, L. Random Walks for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1768–1783. [Google Scholar] [CrossRef] [Green Version]
- Chew, S.E.; Cahill, N.D. Semi-Supervised Normalized Cuts for Image Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Han, J.; Ngan, K.N.; Li, M.; Zhang, H.-J. Unsupervised Extraction of Visual Attention objects in Color Images. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 141–145. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. TSMC 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Wellner, P.D. Adaptive Thresholding for the DigitalDesk; Rank Xerox Ltd.: Cambridge, UK, 1993. [Google Scholar]
- Sauvola, J.; Pietikainen, M. Adaptive document image binarization. Pattern Recognit. 2000, 33, 225–236. [Google Scholar] [CrossRef] [Green Version]
- Bradley, D.; Roth, G. Adaptive thresholding using the integral image. J. Graph. Tools 2007, 12, 13–21. [Google Scholar] [CrossRef]
- Peuwnuan, K.; Woraratpanya, K.; Pasupa, K. Modified Adaptive Thresholding using integral image. In Proceedings of the 13th International Joint Conference on Computer Science and Softare Engineering, Khon Kaen, Thailand, 13–15 July 2016. [Google Scholar]
- Benny, D.; Soumya, K.R. New Local Adaptive Thresholding and Dynamic Self-Organizing Feature Map Techniques for Handwritten Character Recognizer. In Proceedings of the International Conference on Circuit, Power and Computing Technologies, Nagercoil, India, 19–20 March 2015. [Google Scholar]
- Biswas, B.; Bhattacharya, U.; Chaudhuri, B.B. A Global-to-Local Approach to Binarization of Degraded Document Images. In Proceedings of the 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014. [Google Scholar]
- Takagi, N.; Chen, J. A Broken Line Classification Method of Mathematical Graphs for Automating Translation into Scalable Vector Graphic. In Proceedings of the IEEE 43rd International Symposium on Multiple-Valued Logic, Toyama, Japan, 22–24 May 2013. [Google Scholar]
- Jungil, J.; Hongchan, Y.; Hyelim, L.; Jinsoo, C. Graphic haptic electronic board-based education assistive technology system for blind people. In Proceedings of the 2015 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 9–12 January 2015. [Google Scholar]
- Chen, J.; Takagi, N. A Pattern Recognition Method for Automating Tactile Graphics Translation from Hand-drawn Maps. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013. [Google Scholar]
- Takagi, N.; Chen, J. Character string extraction from scene images by eliminating non-character elements. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, San Diego, CA, USA, 5–8 October 2014. [Google Scholar]
- Meng, Y.; Zhang, Z.; Yin, H.; Ma, T. Automatic detection of particle size distribution by image analysis based on local adaptive canny edge detection and modified circular Hough transform. Micron 2018, 106, 34–41. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
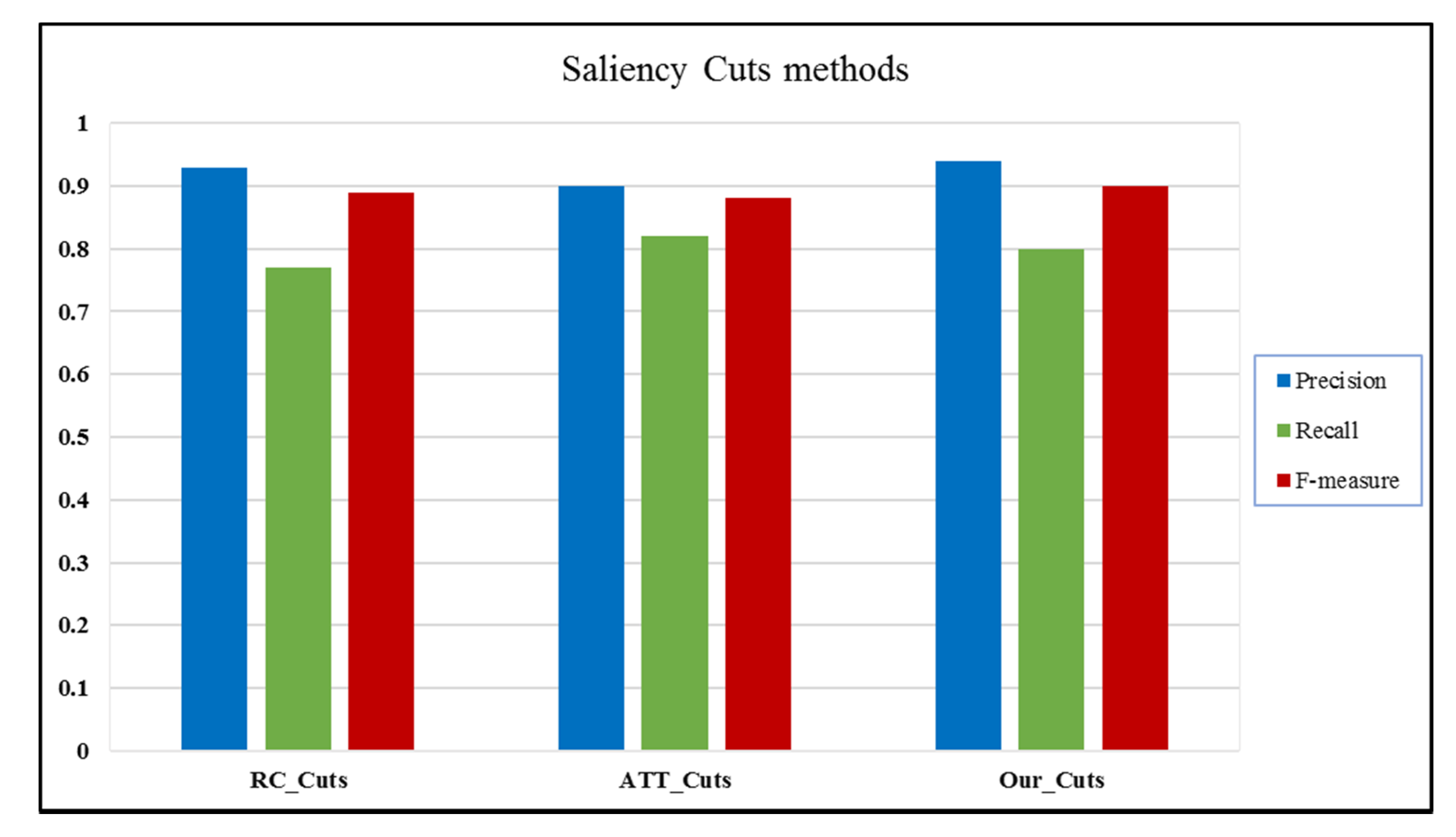
| Methods | RC_Cuts [17] | ATT_Cuts [16] | Proposed Method |
|---|---|---|---|
| Precision | 0.93 | 0.90 | 0.94 |
| Recall | 0.77 | 0.82 | 0.80 |
| F-measure | 0.89 | 0.88 | 0.90 |
| Methods | Foreground Extraction Accuracy | Clear Edge of Objects | Multiple Objects Detection | Noise Introduced | False Object Detection | Average |
|---|---|---|---|---|---|---|
| RC_Cuts | 4 | 5 | 3 | 3 | 3 | 3.6 |
| ATT_Cuts | 4 | 5 | 4 | 4 | 4 | 4.2 |
| Proposed method | 5 | 5 | 5 | 4 | 4 | 4.6 |
| The Comparison of Processing Time | |||
|---|---|---|---|
| Method | RC_Cuts [17] | ATT_Cuts [16] | Proposed Method |
| Times (s) | 1.24 | 1.86 | 1.33 |
| Code Type | C++ | C++ | C++ |
| Blind Students | Correct Identification | Incorrect Identification | ||
|---|---|---|---|---|
| Percentage % | Number of Images | Percentage % | Number of Images | |
| Student 1 | 72.5% | 14.5/20 | 27.5% | 5.5/20 |
| Student 2 | 75% | 15/20 | 25% | 5/20 |
| Student 3 | 67.5% | 13.5/20 | 32.5% | 6.5/20 |
| Student 4 | 77.5% | 15.5/20 | 22.5% | 4.5/20 |
| Student 5 | 72.5% | 14.5/20 | 27.5% | 5.5/20 |
| Student 6 | 75% | 15/20 | 25% | 5/20 |
| Student 7 | 80% | 16/20 | 20% | 4/20 |
| Student 8 | 77.5% | 15.5/20 | 22.5% | 4.5/20 |
| Student 9 | 75% | 15/20 | 25% | 5/20 |
| Student 10 | 70% | 14/20 | 30% | 6/20 |
| Student 11 | 77.5% | 15.5/20 | 22.5% | 4.5/20 |
| Student 12 | 70% | 14/20 | 30% | 6/20 |
| Student 13 | 75% | 15/20 | 25% | 5/20 |
| Student 14 | 70% | 14/20 | 30% | 6/20 |
| Overall | 74% | 26% | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdusalomov, A.; Mukhiddinov, M.; Djuraev, O.; Khamdamov, U.; Whangbo, T.K. Automatic Salient Object Extraction Based on Locally Adaptive Thresholding to Generate Tactile Graphics. Appl. Sci. 2020, 10, 3350. https://doi.org/10.3390/app10103350
Abdusalomov A, Mukhiddinov M, Djuraev O, Khamdamov U, Whangbo TK. Automatic Salient Object Extraction Based on Locally Adaptive Thresholding to Generate Tactile Graphics. Applied Sciences. 2020; 10(10):3350. https://doi.org/10.3390/app10103350
Chicago/Turabian StyleAbdusalomov, Akmalbek, Mukhriddin Mukhiddinov, Oybek Djuraev, Utkir Khamdamov, and Taeg Keun Whangbo. 2020. "Automatic Salient Object Extraction Based on Locally Adaptive Thresholding to Generate Tactile Graphics" Applied Sciences 10, no. 10: 3350. https://doi.org/10.3390/app10103350