1. Introduction
Fertilization is one of the essential links in agricultural production, and it is a necessary means to supplement soil nutrients and improve crop yield and quality [
1]. About 30–50% of crop yield increases with commercial fertilizers [
2]. Studies have shown that China’s chemical fertilizer use in the past was at the highest level among major countries worldwide, and the intensity of use is increasing yearly [
3,
4]. Meanwhile, the phenomenon of excessive fertilization and unreasonable fertilization structures still exists in China [
5]. However, there is no simple linear relationship between the amount of fertilizer applied and the derived economic benefits of crop planting. The unreasonable use of fertilizers not only increases the cost of agricultural production [
6] but also leads to inconsistent nutrient supply and crop nutrient demand, making it challenging to increase crop yields [
7,
8] and even causing reductions in crop yield [
9,
10]. In addition, improper fertilization will also cause a large amount of fertilizer to be lost to the external environment, aggravating agricultural non-point source pollution [
7,
11], reducing soil fertility [
12], and becoming detrimental to the sustainable improvement of land productivity [
1]. Therefore, establishing a scientific fertilization decision system is essential for improving agricultural production efficiency.
Soil testing and formula fertilization (STFF) is one of the essential technologies for the scientific and rational use of chemical fertilizers [
13]. It is based on soil nutrient measurements and comprehensively considers soil nutrient supply capacity, crop fertilizer requirements, target yields, and fertilizer benefits [
14] to determine the configuration of fertilizer types, nutrient element proportions, and amounts to meet the growing needs of crops [
15,
16,
17]. It usually uses measured values of organic matter, hydrolyzable nitrogen, available phosphorus, and available potassium to characterize soil nutrient status [
18,
19] and N, P
2O
5, and K
2O to characterize fertilization amounts [
20,
21]. At the same time, STFF can also effectively reduce fertilization intensity [
22]. The technology also considers the original nutrient content of soil and its relationship with the difference between crop fertilizer requirements, which improves soil physical and chemical properties, increases soil microbial population activity, and reduces fertilizer loss [
16,
23,
24,
25]. Over the past years, there have been many studies utilizing STFF to formulate fertilization strategies. For example, Yang et al. [
26] constructed a fertilizer effect regression equation with the seedling quality index (QI) as the main parameter based on the optimal regression design method. Guo et al. [
27] established a recommended fertilization index system for N, P, and K fertilizers for spring maize by using the fertilizer effect function method and the nutrient abundance index method. However, traditional STFF is usually based on the principles of the “minimum nutrient law” [
28] and the “law of diminishing returns” [
29] to establish the regression equation and fit the optimal amount of fertilization. It is essentially a regression analysis model based on the assumption that there is a uniform, stable linear relationship between the predictor and independent variables. However, in China, where small-scale farm management is still the primary mode of agricultural production activity [
8], individual differences in the agricultural production activities of different farmers lead to significant heterogeneity in the nutrient status of the fields, which means that a unified and precise formula cannot express the relationship between crop yield and fertilization amount on different fields. Therefore, it is difficult to implement the traditional STFF in large-scale regions [
30,
31]. Consequently, it is of paramount importance to develop an innovative fertilization decision model to improve the efficiency and accuracy of STFF, which can also simplify the technical process and reduce the difficulty of technology promotion and application [
32].
To solve the above problems, some researchers have introduced artificial intelligence models in STFF, which provide feasible ideas for improving agronomic measures. Thanks to the reduction in data acquisition costs and the increase in computing power, artificial intelligence algorithms, such as machine learning and reinforcement learning, have shown their advantages in processing large-scale data [
33]. They compensate for the shortcomings of traditional mathematical models in solving complex nonlinear problems and play a more and more important role in agricultural production, such as crop identification, pest monitoring, and yield estimation [
34,
35]. Escalante et al. [
36] used remote sensing images of barley to establish deep convolutional neural networks and predict the nitrogen content in barley. Wu et al. [
37] successfully optimized nitrogen management in maize by combining reinforcement learning and crop simulations. Gautron et al. [
38] constructed a crop simulator using reinforcement learning to help improve the fertilization efficiency of different crops. Siedliska et al. [
39] used random forest, BP neural networks, and other machine learning models to predict the application level of phosphorus fertilizer in different growth stages of crops. Applying artificial intelligence algorithms to the fertilization decision process can effectively improve the accuracy and universality of fertilization schemes. However, most of these studies focus on monitoring and predicting crop growth and soil nutrients using artificial intelligence methods without further attention on the relationship between fertilization management and crop yield. Therefore, this study conducted field sampling and lab measurements in Wudalianchi City, located in Heilongjiang Province, China, to establish a dataset and construct a fertilization decision model based on machine learning and swarm intelligent search algorithms. The purpose of this study is to (1) comprehensively use multiple machine learning algorithms to construct models for maize, rice, and soybean to improve the method of building a regression relationship between the fertilizer application rates and crop yield based on soil nutrients, fertilizations, and observed yield data; (2) evaluate the performance of different ML models for yield prediction; and, most importantly, (3) establish a fertilization decision model and provide references for the basic fertilizer application based on coupling the swarm intelligence algorithm and the selected ML model.
The remainder of the paper is structured as follows.
Section 2 introduces an overview of the study area, the data collection procedure, and the basic theories and procedures of the yield prediction model and fertilization decision model.
Section 3 analyzes the current soil nutrients, fertilization, and crop yields of the study area and evaluates the performance of different yield prediction models and the fertilization decision model.
Section 4 discusses the rationality of recommended fertilization strategies, the comparison between the models in this study and others, and the improvement over the traditional STFF model. In
Section 5, we summarize the superiority, insufficiency, and future improvements of this study.
4. Discussion
The Northeast region, including Heilongjiang, is one of the essential grain-producing areas in China. Many researchers have conducted quantitative research on the appropriate amount of fertilization for the main crops in this region. Wu et al. [
61] proposed that the recommended N, P
2O
5, and K
2O application rates for maize were 150–188 kg ha
−1, 75–97 kg ha
−1, and 57–60 kg ha
−1, respectively. Wu et al. [
53] also indicated that the suitable N, P
2O
5, and K
2O application rates for rice were 116–156 kg ha
−1, 64–70 kg ha
−1, and 45–59 kg ha
−1, respectively. Based on field experiments, Ji et al. [
54] found that the optimal N, P
2O
5, and K
2O application rates for maize in Heilongjiang were 176–180 kg ha
−1, 65–70 kg ha
−1, and 75–90 kg ha
−1, respectively. The experimental study by Kong et al. [
55] showed that the optimal N application rate for rice in Heilongjiang was 112.3–150 kg ha
−1, while the optimal P
2O
5 and K
2O application rates were 46.7–63.1 kg ha
−1 and 38.3–57.5 kg ha
−1, respectively. Sun et al. [
19] carried out soil testing and formula fertilization experiments and believed that the optimal N application rate for soybeans in the medium soil fertility area of Heilongjiang was 28.4–36.3 kg ha
−1, and the optimal P
2O
5 and K
2O application rates were 38.9–47.7 kg ha
−1 and 43.2–51.2 kg ha
−1, respectively.
Based on the ratio of base fertilizer and topdressing fertilizer recommended in previous studies [
19,
53,
61], the recommended fertilization formula ranges of the FDM for the 100 selected fields are shown in
Table 11. The recommended application ranges of N, P
2O
5, and K
2O for maize were 133.5–240.0 kg ha
−1, 63.0–91.5 kg ha
−1, and 46.5–112.5 kg ha
−1, respectively. The recommended fertilizer rates for rice and soybean were 111.0–162.0 kg ha
−1, 37.5–79.5 kg ha
−1, 46.5–79.5 kg ha
−1, and 37.5–57.0 kg ha
−1, 55.5–105.0 kg ha
−1, and 46.5–73.5 kg ha
−1, respectively. Therefore, the recommended fertilization amount of the FDM constructed in this study was consistent with the previous research for maize, rice, and soybean in Heilongjiang. Meanwhile, we also found that the recommended fertilization range of the FDM was generally wider than in the previous studies. The main reason was that the FDM provides personalized fertilization plans based on the original soil fertility of different fields. The recommended fertilization rate will be much higher or lower than the average level in areas with significantly low or high soil fertility. Therefore, the FDM constructed in this study can provide stable and high-yield fertilization formulas based on the soil’s physicochemical properties in different fields, especially in the base fertilizer application stage. However, further and more detailed exploration is required for the fertilization management plan for the whole process of the crop growth period.
Compared with the traditional STFF, the FDM proposed in this study has the advantage of eliminating tedious field fertilization experiments and quickly and easily offering crop fertilization formulas. It is because the traditional STFF, whether the nutrient balance method or the fertilizer effect method, requires field trials during the entire growth period of crops, which is time-consuming and lacks universality. For example, Tong et al. [
62] tried to explore the optimal nitrogen, phosphorus, and potassium fertilization ratios for maize in Heilongjiang with the fertilizer effect method. However, it took 129 days to set up the experiments with 14 treatments and 5 repetitions in a 700 m
2 maize field. Li et al. [
42] constructed the STFF model of broccoli based on effective functions of P, N, and K for broccoli yield, which needed a one-month field experiment with eleven fertilization treatments with three repetitions in thirty-three plots. Different from the above studies, to construct the FDM, all we need are historical soil nutrient parameters, fertilization rates, and yield data, which are becoming more and more convenient to obtain thanks to the development of modern agricultural management systems. On the premise of ensuring accuracy, the use of artificial intelligence methods to construct the model saves a lot of manpower and material resources and improves the efficiency of formula fertilization. Traditional statistical methods and data processing techniques have been unable to meet the needs of agricultural production for efficient extraction of valuable information from field data during the rapid development of agricultural digitalization [
63]. Machine learning methods, on the other hand, can directly use experience and follow specific learning rules to train data to mine complex nonlinear relationships between input variables such as agricultural environment, management measures, crop phenotypes, and predictor variables to accurately and conveniently solve problems such as crop yield forecasting, soil management, and other agricultural practical issues [
33,
64]. However, with the advantages come some new challenges compared with traditional STFF. For example, to build an STFF model with good performance and robustness based on artificial intelligence methods, a large amount of crop data from many diverse environments and management scenarios is required. Additionally, a lot of effort must put into data preprocessing to improve the quality of the data and make sure the dataset is representative.
Some researchers have also tried to use ML models to recommend crop fertilization rates and construct the response relationship between soil parameters, weather, and other factors and fertilization rates. ML is a reasonable method for constructing a regression relationship between a list of variables and the target value with tabular data, and may even be better than deep learning (DL) [
48]. However, some of them were relatively complex and difficult to apply in practice. For example, Bean et al. [
65] built a N fertilizer rate recommendation model using a large number of parameters that need to be adjusted and included many variables that are difficult to obtain, which cannot take into account accuracy and achievability together and lacks operability in actual agricultural management. Additionally, few studies have considered all three major fertilizers (N, P
2O
5, and K
2O) in the fertilization optimizations; most of them focused on one optimum fertilizer rate, ignoring the effects of different fertilizer combinations on crop growth [
66,
67]. In contrast, the FDM constructed in this study only considers the environmental factors most directly related to the fertilization process and is based on soil nutrients to give the fertilization formula for all three major crops of maize, rice, and soybean, which have greater practicality. The recommended ratio of N, P, and K is also provided to increase the crop yield. In addition, the recommended fertilization rates of other studies cannot fully account for the spatial variability of different fields and only give an average fertilizer formula [
18]. However, fertilizer requirements for crops could vary with the change in physical position because of the spatial diversity of the original nutrients in the soil. Moreover, the FDM constructed in this study also considers the temporal and spatial differences in crop fertilizer demands and can provide specific fertilization formulas according to the crop types and soil nutrient content of different fields. This strategy has been proven by Rotundo et al. [
68] to be efficient and valuable.
Finding the optimal fertilization rate parameters based on the CSA is another crucial point in constructing the FDM. As a recognized meta-heuristic algorithm, the CSA can effectively solve various optimization problems. The most significant advantage of the CSA is that it better balances accuracy and achievability, and the search strategy combining a local search and global search ensures that the algorithm has excellent performance and only needs to configure a small number of parameters to deal with complex multi-objective problems [
69]; thus, it is widely used in optimization problems in image processing, medical, data mining, power energy, engineering design, and other fields [
70]. The combination of the CSA and ML is an effective method to improve the efficiency of solving optimization problems. When using ML to predict complex nonlinear problems, the CSA can optimize the hyperparameters that need to be manually set in the ML process and improve the efficiency and accuracy of the simulation.
The CSA-SVM (support vector machine) model constructed by Zhang et al. [
71] is a typical representation of this application in short-term electrical load forecasting; he used the CSA to optimize the two primary hyperparameters of the SVM model with different forecasting strategies to improve the prediction accuracy of the SVM. Guo et al. [
72] introduced the CSA into the optimization process of the number of decision trees and nodes in RF and applied it to the parameter prediction of geotechnical engineering, significantly reducing the prediction error. To obtain fertilization strategies, previous studies [
19,
73,
74] usually divided soil nutrients into different levels based on relative crop yields manually before constructing the fertilizer response equation, and then retrieved suitable fertilization according to the optimal yield of different soil nutrient levels. The procedures for soil nutrient level division were relatively rough and subjective, and the regression equation for fertilization and crop yields had poor accuracy. In this study, the combination of the CSA and ML is used, that is, after building a crop yield prediction model based on ERT, in the case of known field soil nutrient parameters as part of the input, with the maximum yield as the optimization goal, the CSA is used to search for the best N, P
2O
5, and K
2O fertilizer application range. Compared to traditional STFF models, the FDM driven by the CSA could automatically seek the fertilization strategy that matches the soil nutrients to maximize crop yield, which is more convenient and accurate.
5. Conclusions
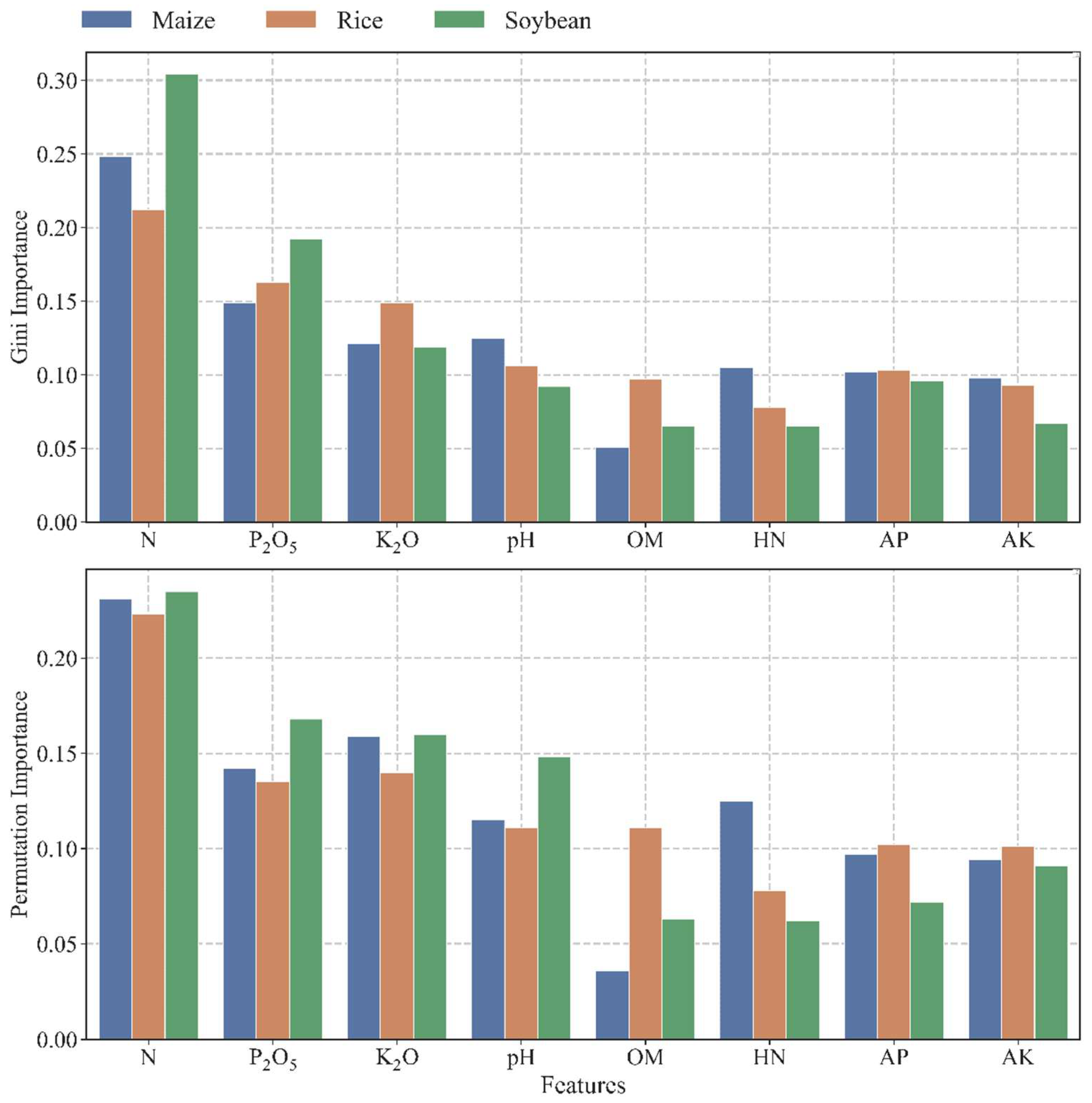
In this study, three machine learning models, including RF, ERT, and XGBoost, were used to predict the yield of maize, rice, and soybean with fertilization and soil nutrient characteristics. The results indicated that the ERT model with soil pH, OM, HN, AP, AK, and the fertilizers N, P2O5, and K2O as inputs could obtain the highest accuracy of crop yield predictions. The R2 and RRMSE of maize, rice, and soybean were 0.749, 0.775, 0.744, and 0.086, 0.051, and 0.078, respectively. In addition, the three most important variables were the application rates of N, P2O5, and K2O.
After that, this study also coupled the CSA with ERT to establish the fertilization decision model (FDM) using the amounts of N, P2O5, and K2O as independent variables to obtain the highest predicted yields of maize, rice, and soybean, respectively. The field survey data in Wudalianchi, Heilongjiang province, China, indicated that the proposed FDM could increase the yield of maize, rice, and soybean by 23.9%, 13.3%, and 20.3% compared with the average yield value in 2021. The FDM established in this study balanced accuracy and practicality and constructed a complex nonlinear relationship between fertilization and crop yields based on artificial intelligence algorithms with soil characteristics, which are relatively readily available environmental factors. It can provide a more convenient and efficient solution for large-scale regional fertilization management. Furthermore, on the premise of collecting sufficient historical crop data, the modeling process of this study can be reproduced in other regions. Fertilization decision models with different soil characteristics and crops can be easily established, which indicates a great potential for promotion.
As this is our first attempt at applying artificial intelligence algorithms to crop fertilization management, the quantity and time span of the collected crop data were limited, and the performance of the YPM remains to be improved. Since the main purpose of this paper was to explore a more effective way to construct the regression relationship between the fertilizer application rate and crop yield to replace the old methods in traditional STFF research, we did not take other environmental factors or economic benefits into consideration. In the future, by expanding the size of the model dataset and introducing more elements affecting crop growth, such as weather and terrain, the robustness and universality of the model will be improved. Additionally, more efforts should be put into the data preprocessing with the expansion of the data scale, such as data cleaning (filling in the missing values, wiping off the abnormal data, and smoothing the noise), feature dimension reduction and feature crosses, and data conversion (standardization and discretization). Moreover, deep learning models with a superior ability in data processing (e.g., LSTM, transformer) and multi-objective optimization involving economic benefits and crop yields could be used to build the FDM to improve the accuracy of fertilization decisions.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}