1. Introduction
Experts in the field of rice can determine and identify the cultivars by their experience and evaluating geometric properties (dimensions, and the convexity of the seeds), color and texture specificities (the darkening or lightening, roughness, and fineness of seeds), and the way of putting seeds together in a mass. These experimental methods are time-consuming and need experts. It should be noted that the mental and physical conditions of the experts affect the results of the analysis, and human errors caused by fatigue are involved in these methods. Therefore, evaluation and design a new method to identify cultivars in a short time and the development of an automatic system through new advanced technology without involving human interference are necessary. The image processing method plays an important role in the automatic system. Various researchers employed these methods to diagnosis rice disease [
1,
2], measure the number of broken seeds [
3], visual inspection of the quality of various seeds, such as rice [
4,
5,
6], evaluation of rice seed germination [
7], and the identification of various cultivars of rice [
8,
9,
10,
11,
12].
Yang et al. [
13,
14] developed a research on the classification of various samples of rice from different geographic areas using laser-induced breakdown spectroscopy. In this research, the classification was carried out using a support vector machine (SVM) method. Finally, the results showed a higher than 98% classification. The accuracy of this method is acceptable, but since the method is based on spectral data, the cost of setup for extract spectral data to identify various samples of rice is higher than the method based on visible image processing. The cost of developing a portable device for this method is prohibitive. This research was based on spectroscopy. Kuo et al. [
5] identified rice seeds by image analysis and sparse-representation-based classification (SRC) and evaluated various rice cultivars. The results indicated that the method had an 89.1% ability to identify various rice cultivars. The accuracy of this method is low, so it is unreliable in the field when identifying various cultivars. Anami et al. [
15] evaluated the behavioral co-occurrence HSI (hue, saturation, intensity) color characteristics to identify the cultivar form of a rough mass. The results demonstrated that the accuracy of multilayer neural network classification was more than 92%. Chaugule [
16] evaluated the color and shape characteristics to classify four paddy cultivars. The results showed that the highest classification accuracy of 90.9% was obtained using color attributes. In addition, the highest classification accuracy of the specificities was 93.6%. In the segmentation of the cultivars, the highest accuracy of 98%was obtained using a combination of color and shape specificities. In this study, only four paddy cultivars were studied. The number of cultivars is low for proving the performance of the proposed method. Kambo and Yerpude [
17] classified common Basmati rice using PCA and employed a digital camera to capture an image of the seeds and transpose it onto a black background. They developed algorithms in MATLAB 2016a (MathWorks, Inc.) to extract morphologic specificities of each seed, including area, long axis length, small axle length, distance from the center, and circumference. Two effective components in cultivars’ segmentation were selected using PCA, and k-nearest neighbors were employed to classify cultivars. The accuracy of Classic, Rozana, and Mini cultivars were respectively obtained to be 80%, 75%, and 80%. Therefore, the categorization of cultivars was performed with a mean accuracy of 79%. The accuracy of this method is low. Therefore, a system based on it would not deliver high performance in the identification of different varieties of rice.
As described above, many studies have been conducted on rice, and various methods have been employed. Because of the high consumption of rice worldwide and its variety, research into methods for the identification and classification of different varieties of indigenous rice cultivars is necessary. Therefore, in the present study, 13 indigenous rice cultivars of Iran, including Tencc (10cc), Alikazemi, Asgari, Binam, Domsiyah, Dorfak, Gohar, Hasani, Hashemi, Kadoos, Khazar, Khazaregarm, Lenjan, were classified using integrated image processing and an artificial neural network (ANN).
The highlights and novelties of the present research are listed below:
- -
Using more rice varieties in the form of white rice, brown rice, and paddy compared to other research work.
- -
Selecting the effective color, morphological, and textural features of the rice varieties’ images using principal component analysis (PCA).
- -
Classification of the rice varieties in the form of white rice, brown rice, and paddy with backpropagation- artificial neural network (ANN) and linear discriminant analysis (DA).
2. Materials and Methods
2.1. Providing Samples
Based on reviewing different references, available information, and asking experts, 13 common rice cultivars, Tencc (10cc), Alikazemi, Asgari, Binam, Domsiyah, Dorfak, Gohar, Hasani, Hashemi, Kadoos, Khazar, Khazaregarm, Lenjan, were identified in Iran. Various samples of rice cultivars were obtained from the Iranian Rice Research Institute. The samples were paddy, and about one to two kilograms were prepared from each cultivar.
2.2. Samples Preparation
To prepare white rice, the following process was performed on paddy: winnowing, drying, cleaning, peeling, bleaching, and brightening. After the rice moisture was dropped to the optimum level, it was cleaned, and then its skin was removed by a peeling machine to obtain brown rice. After harvesting rice moisture varied between 18% and 26% on a wet basis. The initial drying was performed in the field. In doing so, the harvested crop remained in the field for 24 h to 72 h. After reducing the moisture content to a range of 15% to 17% of a wet basis, the crop was transferred to the depot. This amount of moisture is high for converting paddy to white one; therefore, its moisture content was reduced until the standard level. The suitable drying temperature and final paddy moisture were effective in the reduction of the size of the microscopic cracks, decreasing the number of cracked grains, and reducing the fracture percentage resulting from these cracks in the next steps. Based on the view of Iran rice research institute’s experts, 45 °C was used to reduce the moisture. Paddy was placed into a small rectangular-shaped sieve with small openings, after the name of cultivars were attached to the sieves. They were placed in the dryer for about 20 h. The seeds moisture was checked during the drying process several times, until the moisture content samples reached a 10% wet basis. Then, all samples were transferred into plastic bags to prevent interaction with ambient moisture. Due to the limitations in the capacity of the peeling machine, 150 gr-paddy of each cultivar was placed in the laboratory for about 5 min to equalize their temperature with ambient temperature. This was done to minimize the damage caused by thermal stresses. In the next step, the bleaching of brown rice of each cultivar was performed. After finishing the mentioned process in the Rice Research Institute, paddy, brown rice, and white rice of all cultivars were transferred to the Laboratory of Physical and Mechanical Properties at the University of Mohaghegh Ardabili. After removing possible waste materials and separating broken grains, all samples were poured into small plastic containers.
2.3. Imaging of Samples
2.3.1. Hardware System
To take the image of paddy, brown rice, and white rice, the imaging system at the Laboratory of Physical and Mechanical Properties at the University of Mohaghegh Ardabili was employed. The system used in this study included a steel hemisphere compartment, a lightening system, and a digital camera. The proper lightening of a scene before photographing is one of the effective factors in visual image quality and, consequently, obtaining accurate data and results. The combination of the placement of light sources as well as the ability of the spherical chamber to properly reflect the light beams will result in uniformity of light throughout the compartment and thus minimize the presence of shadows in the images. Therefore, a 30 cm diameter ring of white LED lamps and four fluorescent lamps placed 90 degrees apart were positioned in the upper half of the compartment. A digital camera (DFK 23GM021, CMOS, 120 f/s, Imaging Source GmbH, Maisach, Germany) was mounted perpendicular to the background with the lens approximately 30 cm from the samples in the upper part of the compartment. The images were directly transferred from the camera to a computer (processor Intel Core i3 CFI, 330M at 2.13 GHz, 4 GB of RAM-4GB, and Windows 10) programmed with MATLAB 2016a software.
Figure 1 shows the imaging compartment. Considering good diffraction of samples’ color with black color, A 30 × 20 cm sheet of black paper was mounted on a flat surface to contrast the diffraction of the samples’ color and minimize distortions. To ensure the equality of lightning, all images were taken one hour after the light source was switched on when the light source had reached optimal propagation and was in a steady state. Seeds were distributed randomly, and were completely separated from each other.
2.3.2. The Number of Samples for Imaging
To take images, 20 seeds scattered with a plastic straw in a 4 × 5 dimension on a background. In each repetition, for each cultivar and form, former seeds were removed, and new ones were used. JPG images with dimensions of 3872 × 2592 pixels were used. For the 13 rice cultivars in 3 forms, rough, brown, and white, with 5 images for each form, a total of 180 images were obtained, and 3600 seeds were used (20 seeds per image).
2.3.3. Segmentation
Segmentation is a process of dividing the image into its constituent regions or identifying the object in an image. The segmentation level depends on the problem that should be solved. It means that segmentation will be stopped when considered objects of regions are identified. Segmentation is one of the important tasks in image processing. The accuracy of segmentation determines the success or failure of final computer analysis. Therefore, the accuracy of this process is of central importance [
18].
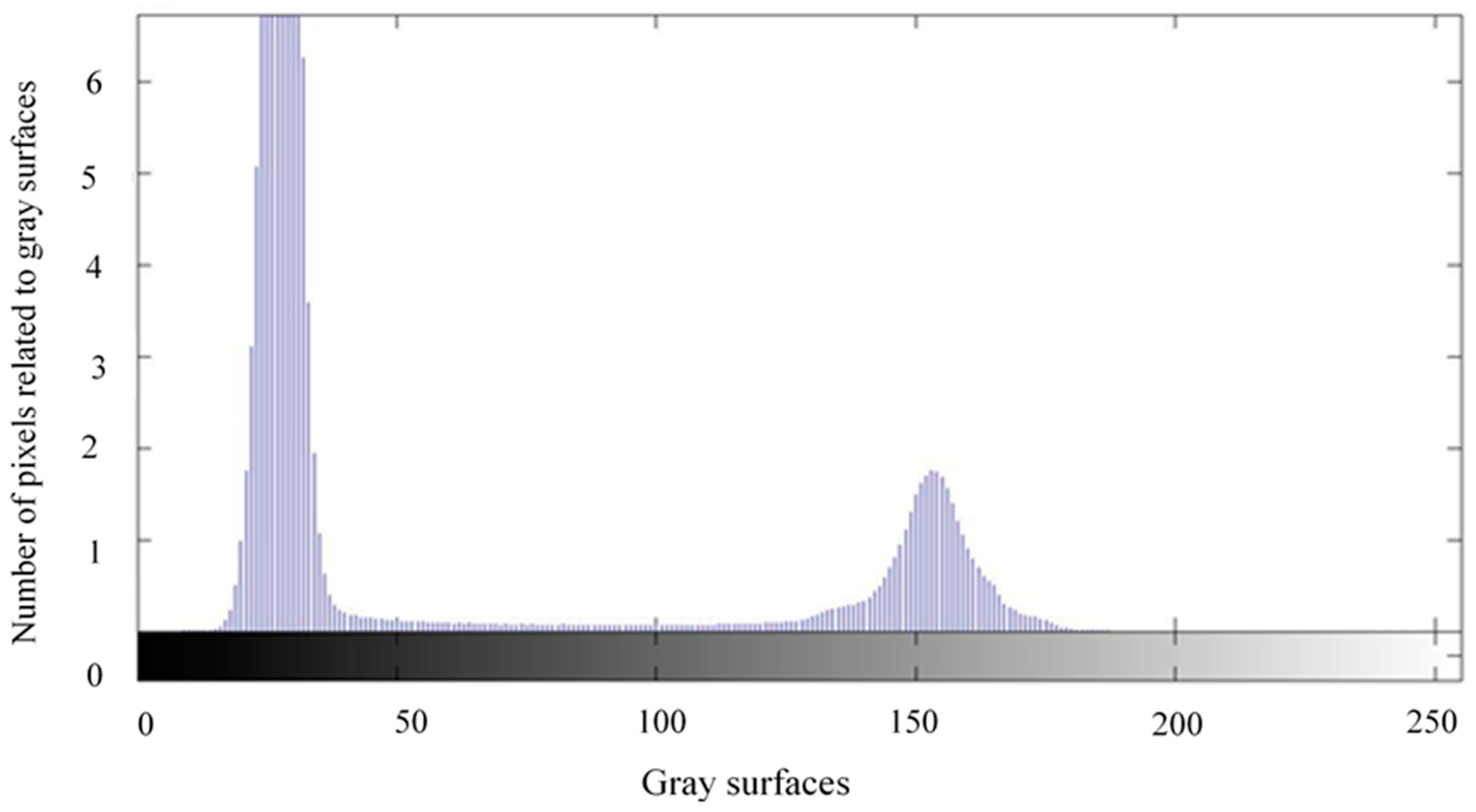
Figure 2 shows the intensity histogram of a taken image so that seeds pixels and background were divided into domain groups. The peaks in the right and left sides are related to rice seeds and background pixels, respectively. As seen, the peaks are far from each other, which ensures high-accuracy segmentation. The various steps of applying a threshold to segment the rice samples from the background are as follows:
Otsu’s method: it is an automatic thresholding method that produces a threshold value considering the image histogram. In this step, after thresholding, the image converts to a binary one with only black and white pixels.
Elimination of objects with less than 100 pixels: due to the noise related to rice powder on the background, objects with less than 100 pixels were removed. This threshold was selected after the evaluation of images of rough, brown, and white rice.
After the elimination of the aforementioned objects and producing a new binary image, some background-colored cavities were observed on the seeds. This issue can occur due to the unsuitable light reflection, especially on the edges. These very small black spots were observed, especially in rough and brown rice. To fill the cavities, the “imfill” order of the MATLAB software was run.
2.3.4. Extraction Characteristics of Samples
Color Features
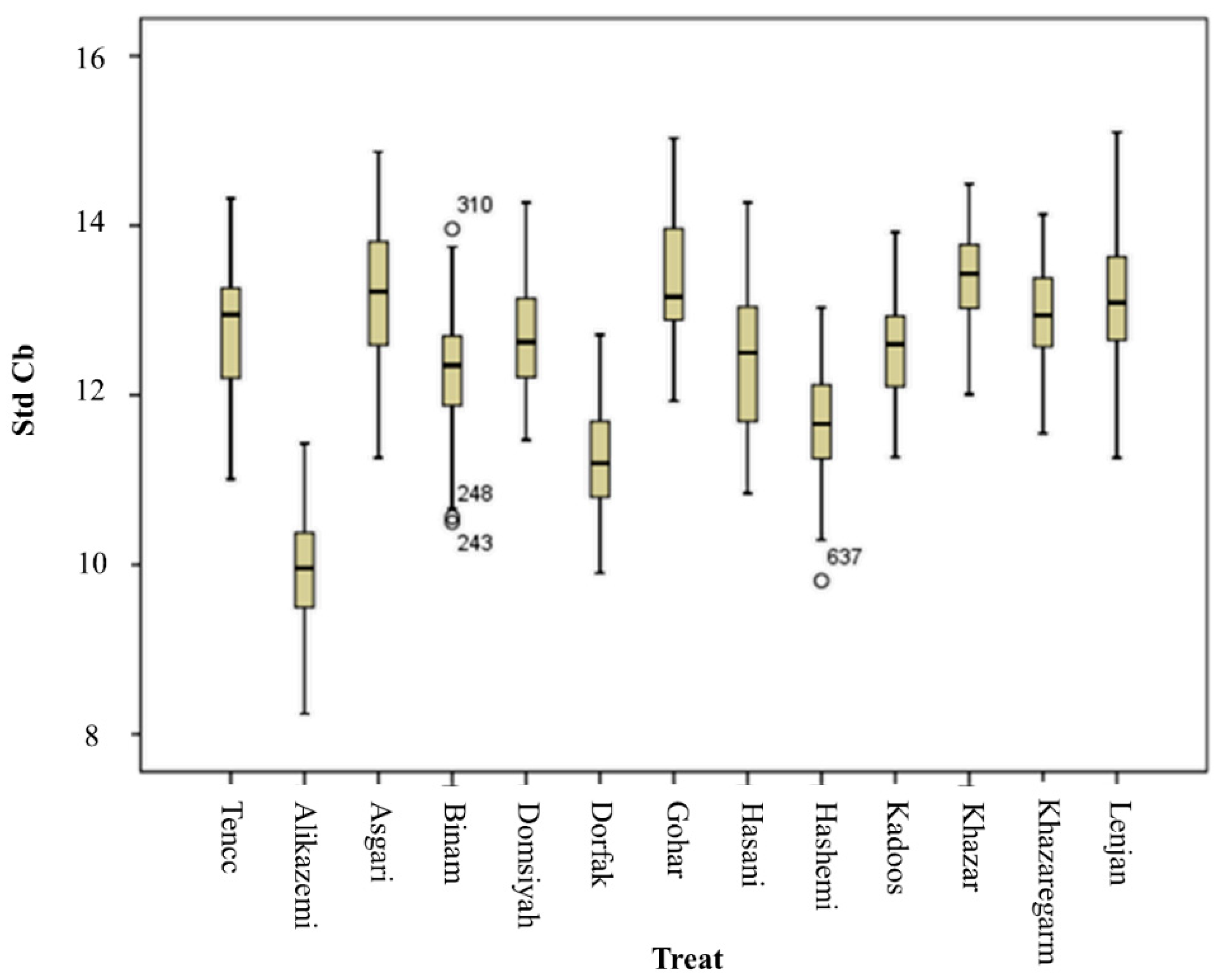
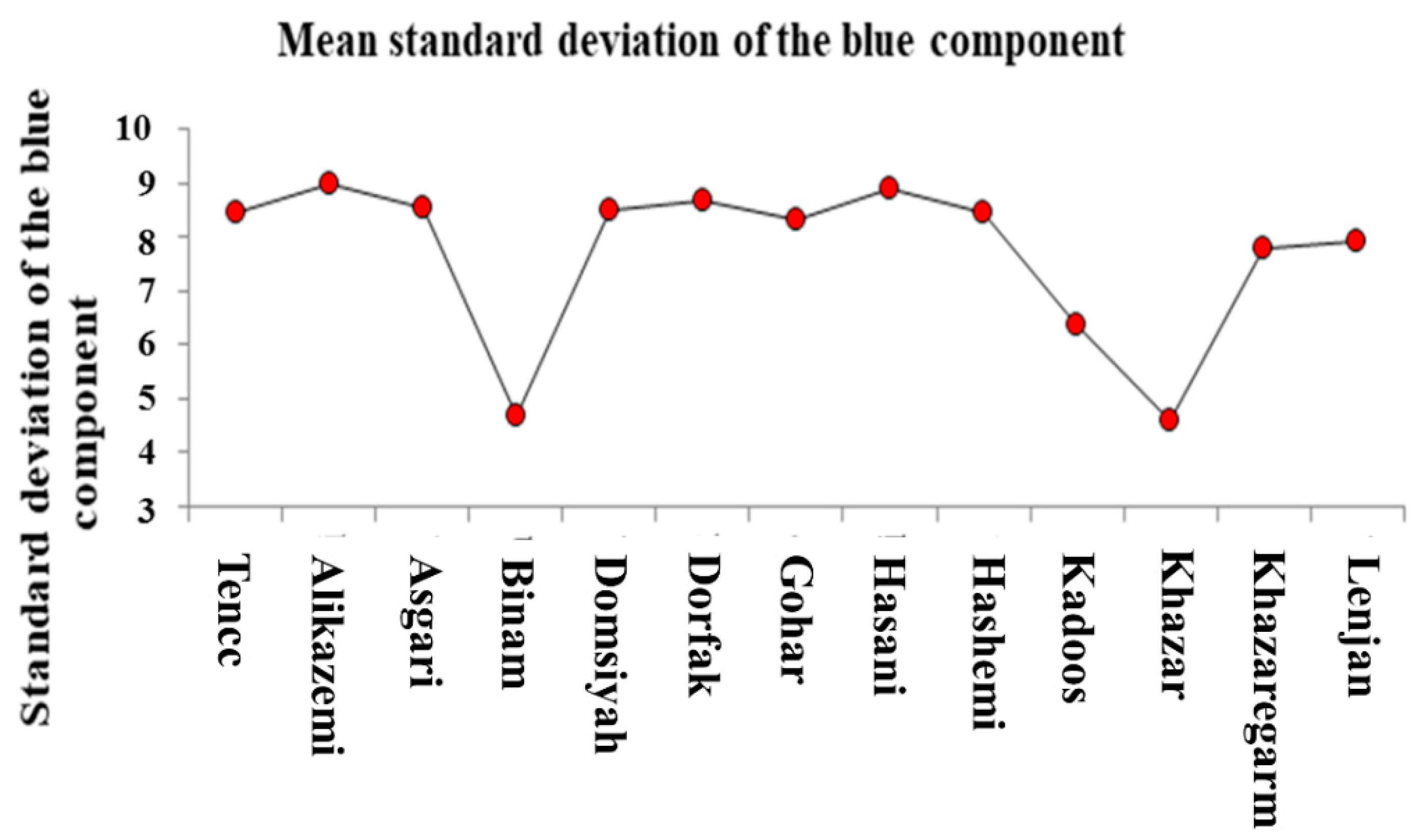
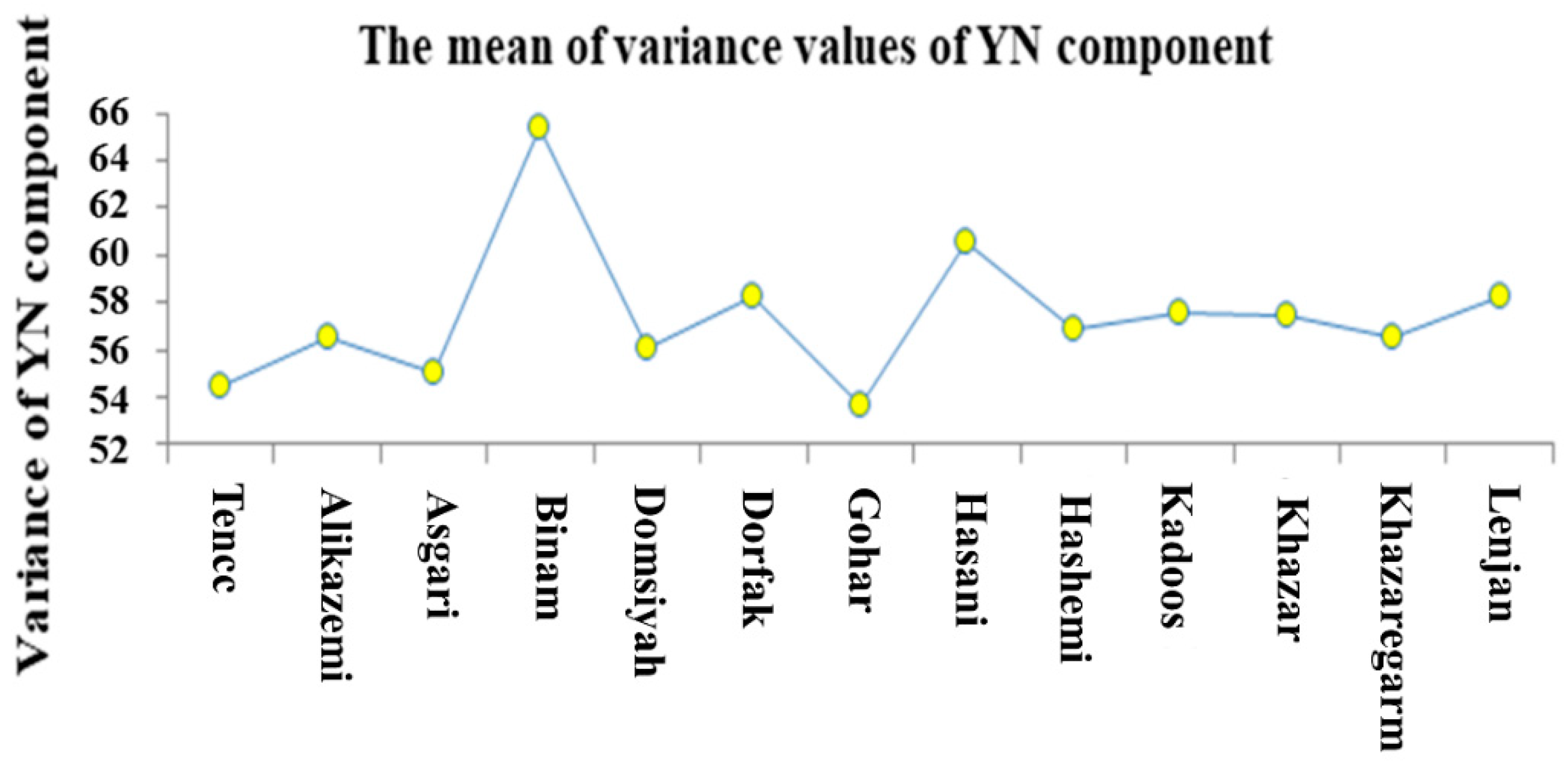
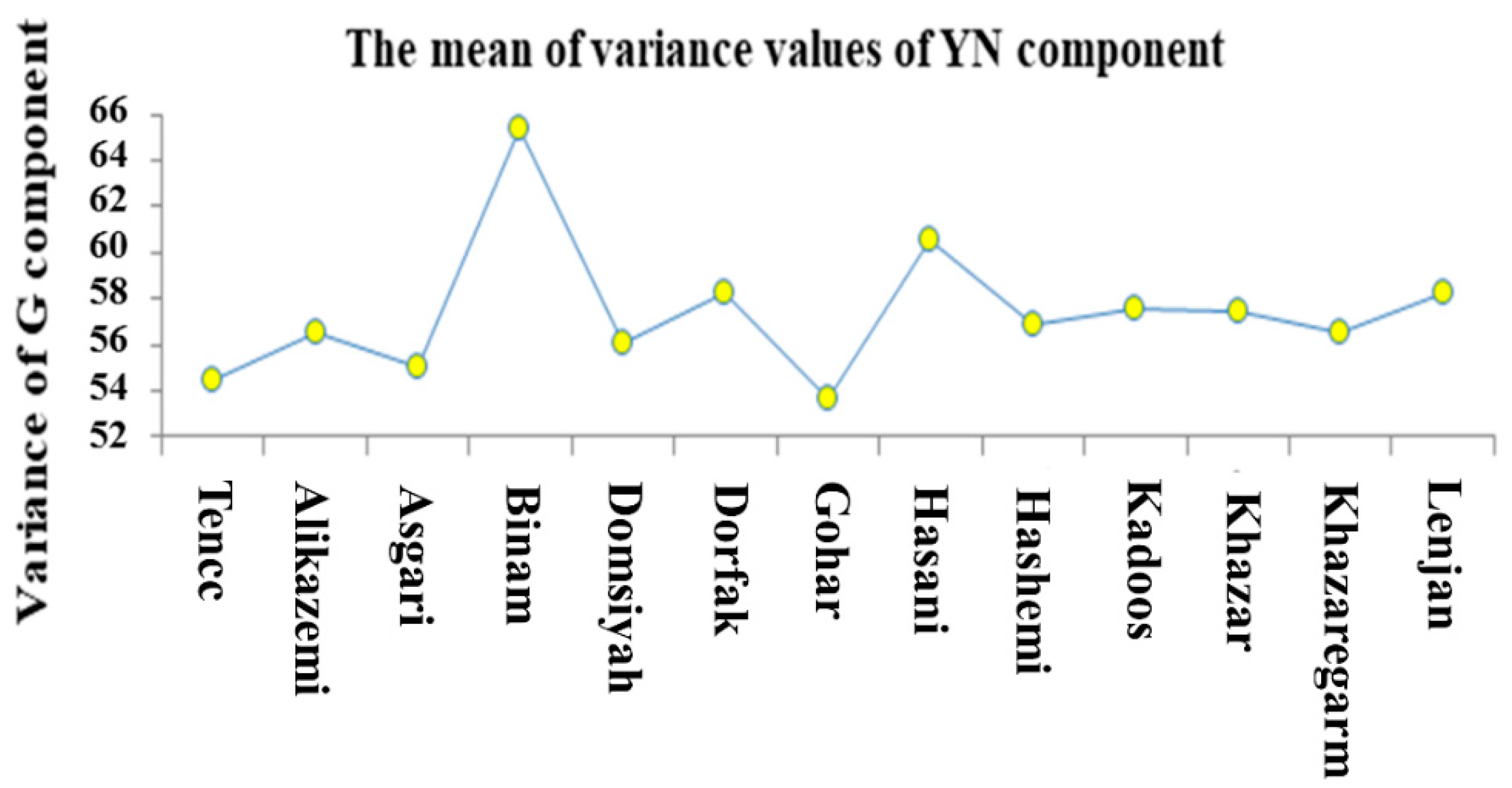
Several color models are available to extract the color attributes, which are defined and used as international standards. The aim of the color model is to facilitate the determination of color attributes in a standard form. In fact, a color model is a coordinate system specification, in which each color is expressed by just one point. To extract the color characteristics of each rice seed in an image, a code was written in MATLAB software to calculate the mean, mean square, variance, and standard deviation of the color component values of pixels of each seed per image. Five color models of RGB (Red, Green, and Blue), YIQ, YCbCr, HSV, and HIS were used to extract color attributes. Finally, given the existence of three color components in each model, the color attribute of 4 × 5 × 3 = 60 was extracted.
Table 1 shows the extractive characteristics of this form. There is a high chance of having effective inputs after using the PCA method when the features are extracted from each image.
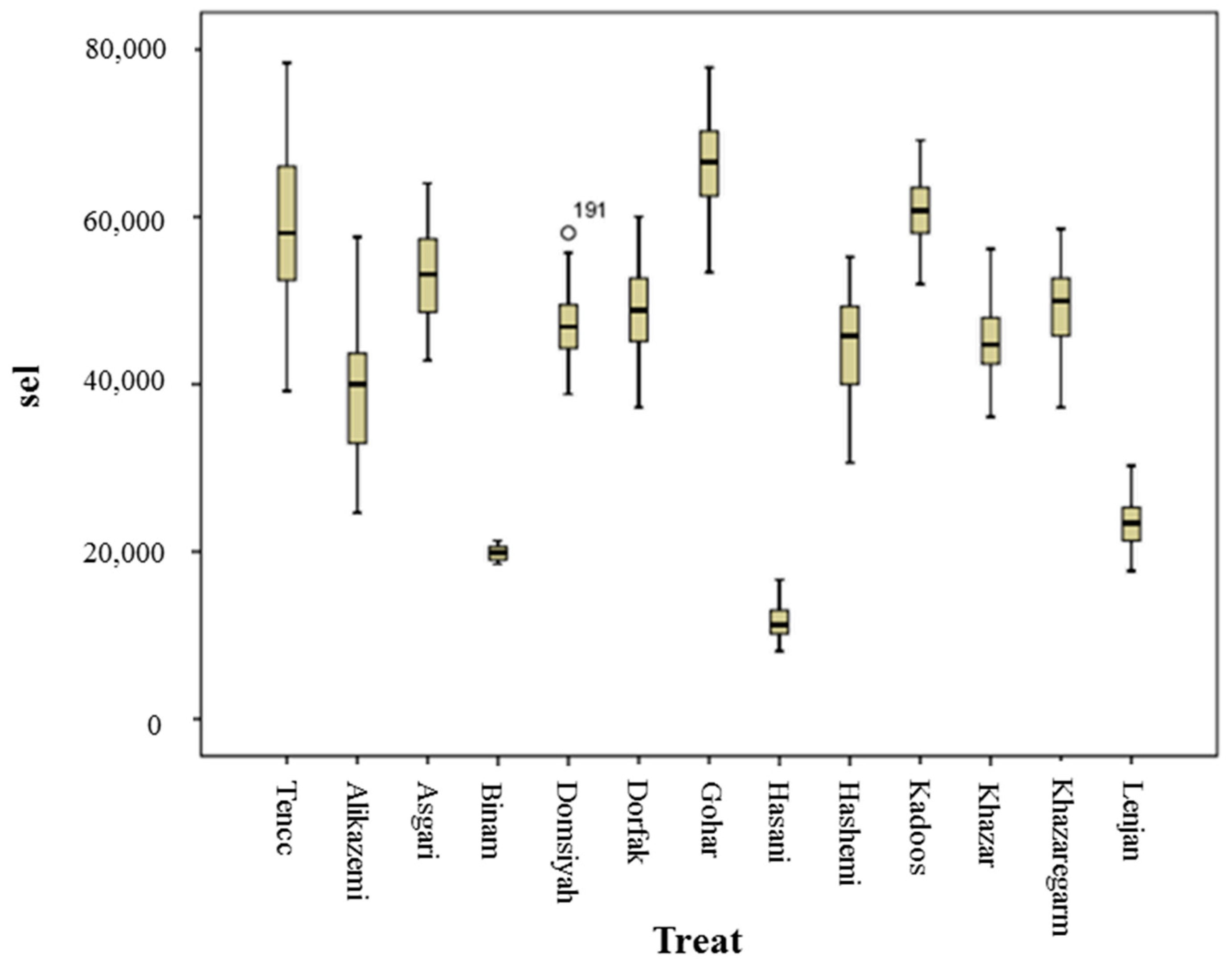
Morphological Characteristics
Morphology can be defined as a theory for analyzing spatial structures. The aim of this scientific field is to analyze the shape of objects. Therefore, this scientific branch is a powerful method for analyzing images. Morphological image processing is a set of nonlinear operators that is related to the shape and characteristics of an image [
19,
20].
Table 2 shows the extracted morphological characteristics of rice samples. To extract each feature, at first, each seed was identified based on a MATLAB code, then these features were extracted from each seed. The code of all these features exists in MATLAB software.
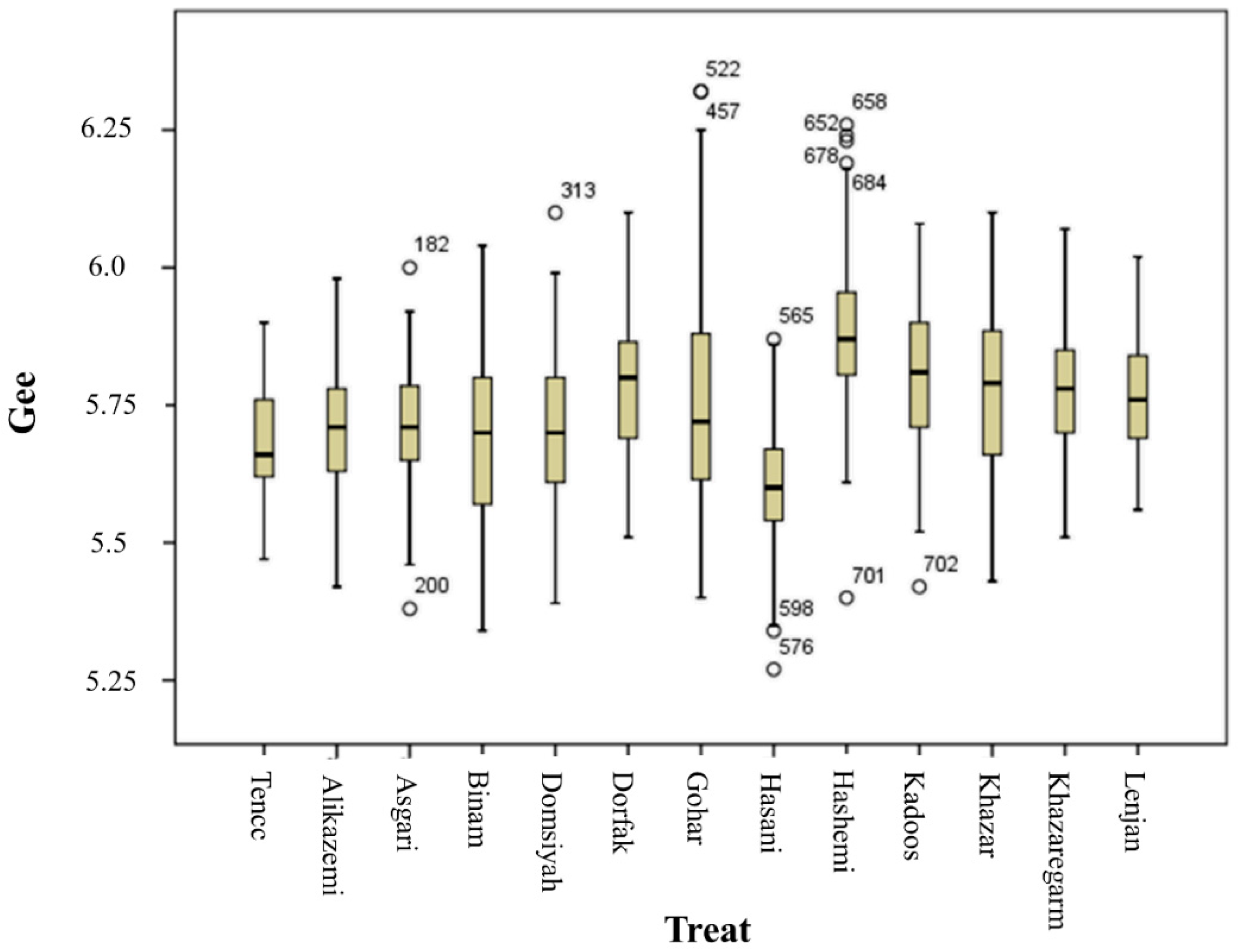
Texture Characteristics
An important method for describing a region is to quantify its texture content. Although there is no formal definition for texture, the intuitive character of this descriptor provides some properties such as smooth, coarse, and orderly [
21]. The three main methods used in image processing to describe the texture of a region are statistical methods, structural methods, and spectral methods. The statistical methods characterize the texture properties as smooth, coarse, fine, etc. Structural methods deal with the layout of basic image operations, such as texture descriptions based on parallel lines with regular spacing. Spectral methods are based on the properties of the Fourier spectrum and are used to determine the photocurrent capability by identifying high and narrow peaks in the image spectrum [
22].
Table 3 shows the extracted texture properties for each rice seed. Finally, 92 color, morphology, and texture characteristics were extracted from each seed.
Table 3 shows the extracted texture features for each seed where L is the number of levels,
zi a random variable of intensity values,
p(
zi) is the histogram of intensity level values in one region, m is the mean intensity value over that region of the image,
σ is Standard deviation.
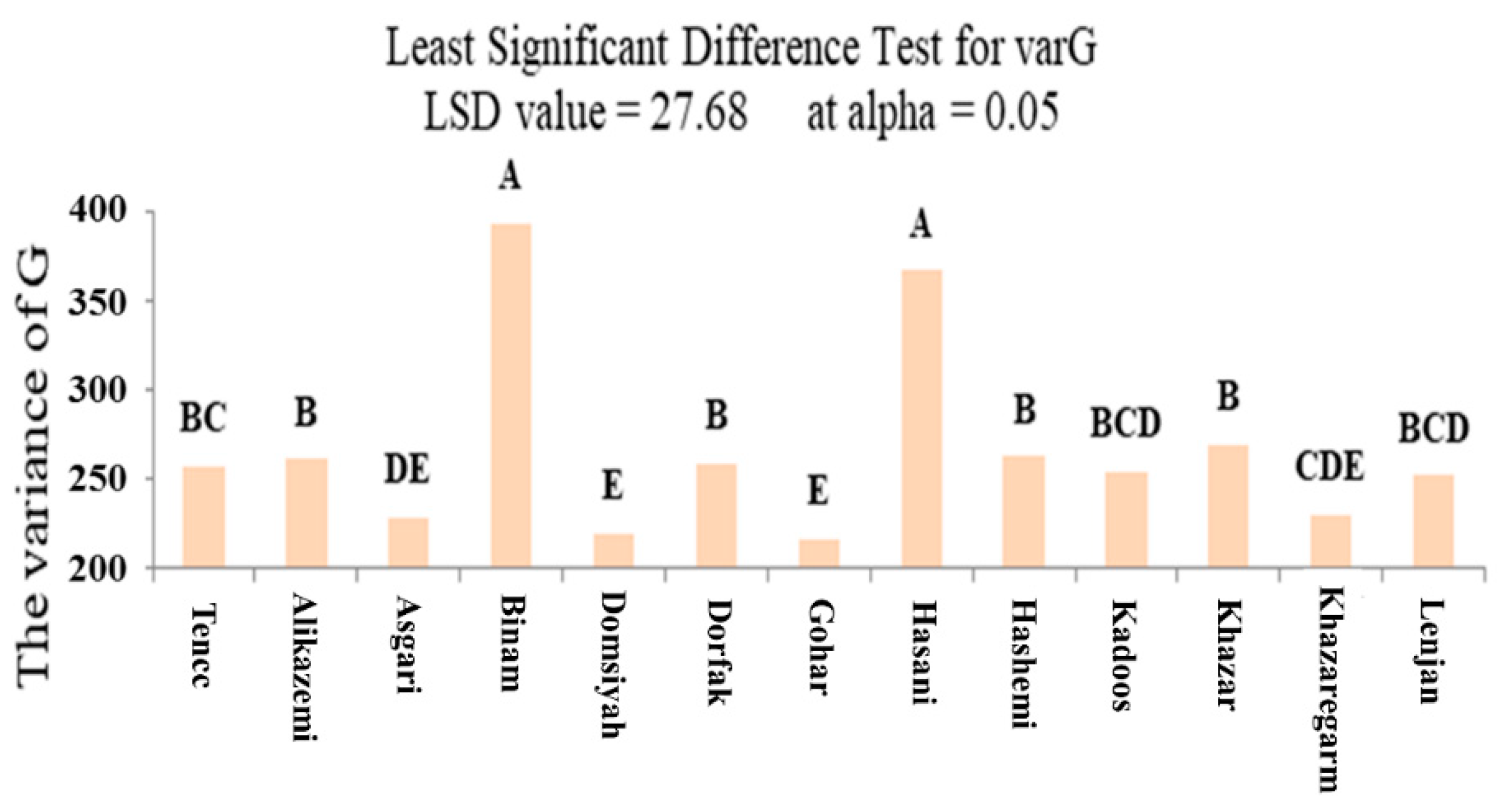
2.4. ANOVA
By extracting values for all parameters and completing the analysis of images, data were transferred to Microsoft Excel software (Microsoft Corporation) and categorized. To measure the probability of significance, the differences between cultivars mean in various parameters were analyzed using ANOVA by MSTATC software (Michigan State Univ., MI, USA).
2.5. Analyzing Principal Components
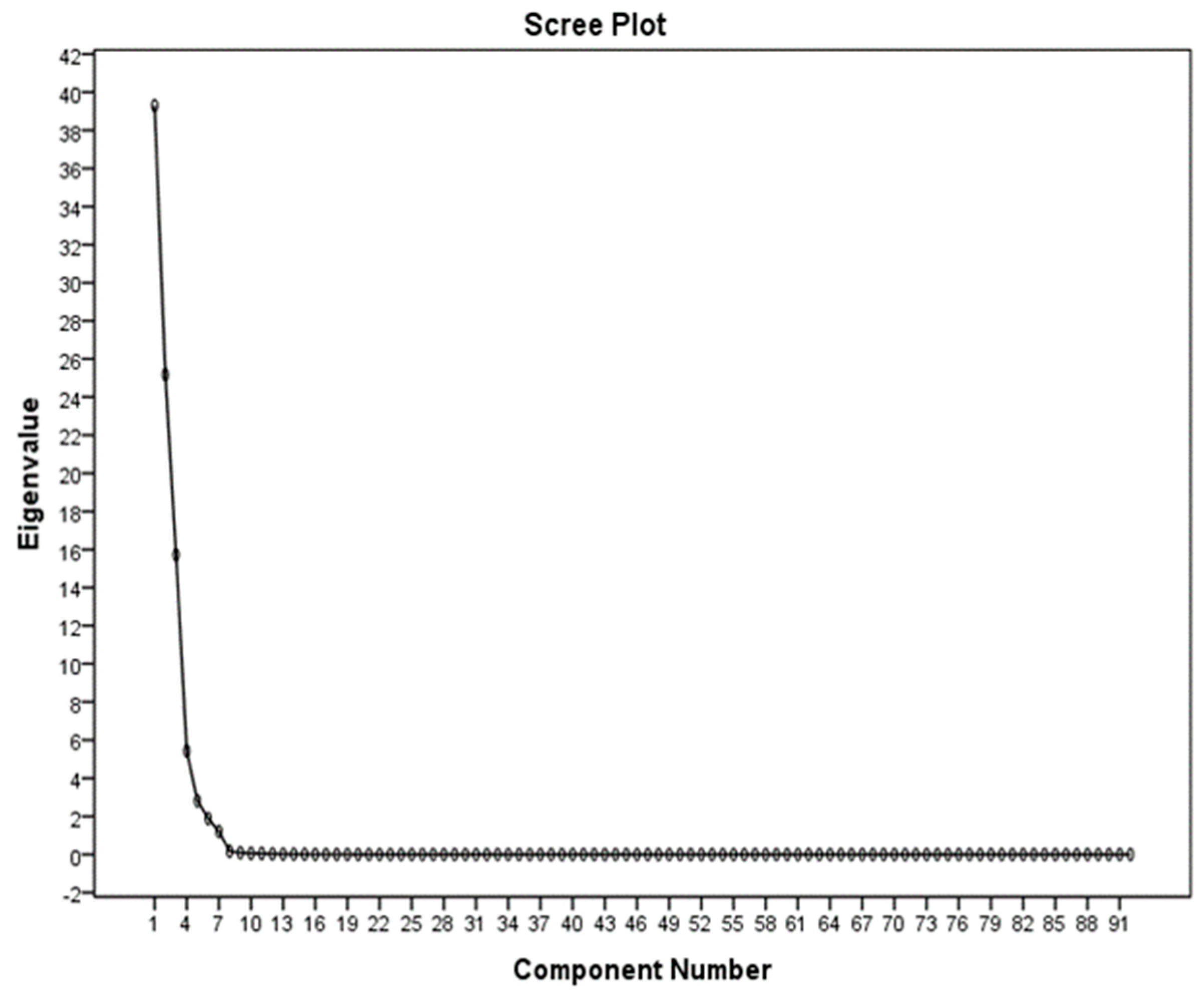
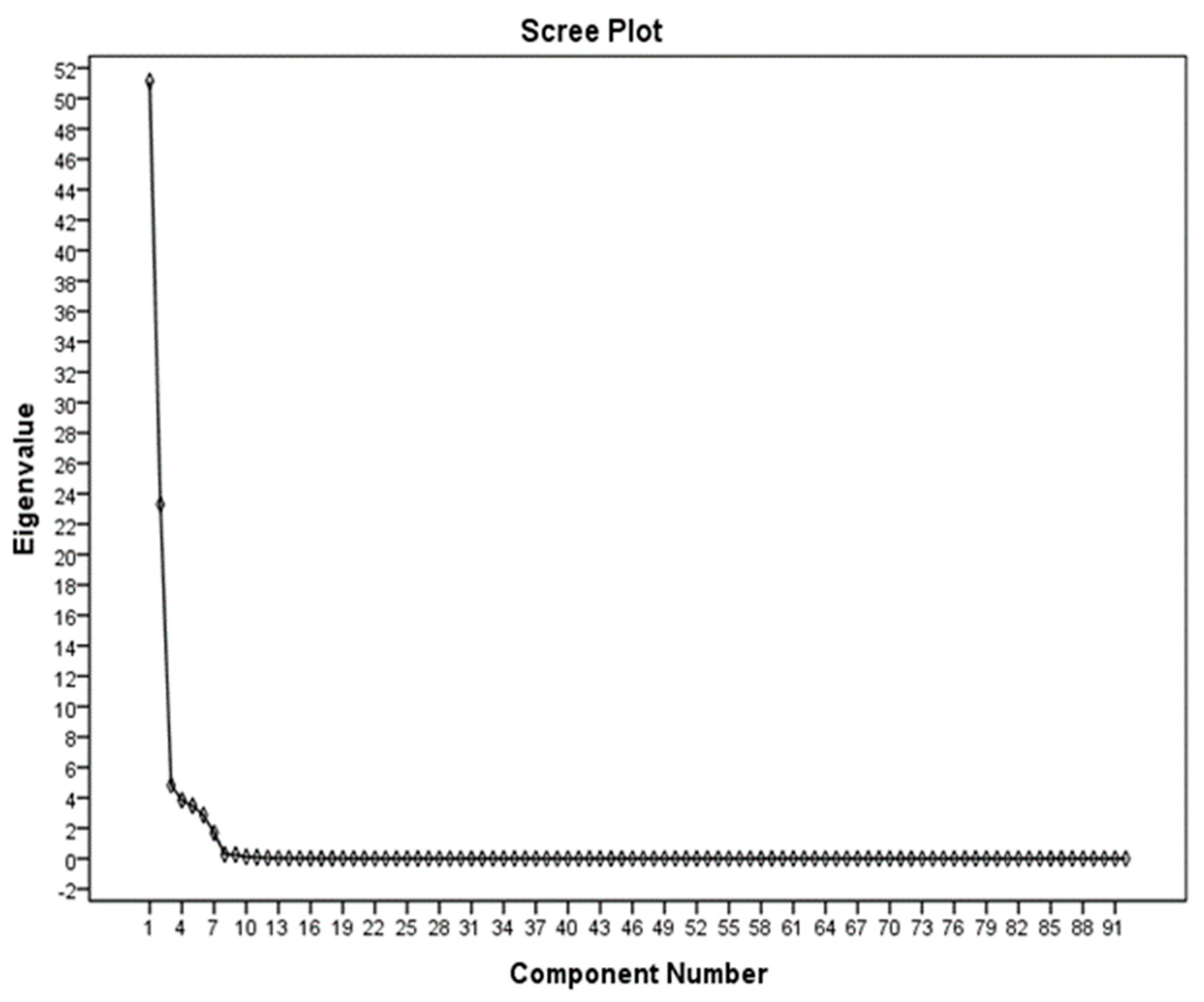
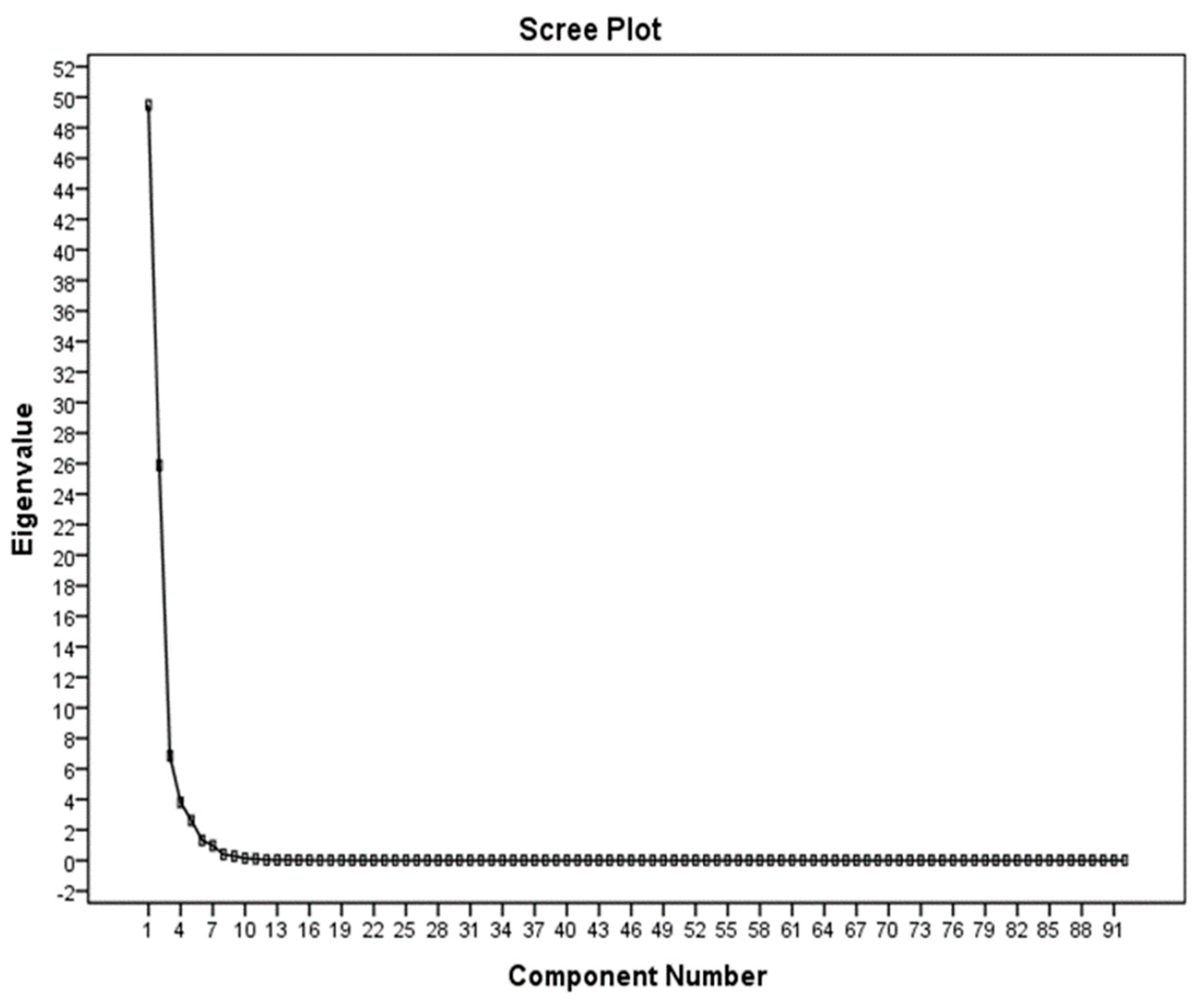
Sometimes a high amount of data is collected for variables related to society or sample. Since there exist numerous binary relationships between variables, the distribution matrix will be very large. Graphic representation of data is also unlikely to help because, for the 12 variables, more than 200 three-dimensional dispersion charts should be studied. Therefore, for a comprehensive interpretation of the data, it is necessary to reduce the number of variables and provide a linear combination of data, so that each linear combination is related to one of the parameters. The PCA method is a conversion in vector space, which is employed to reduce the dimensions of the data set [
7]. For a set of data, the PCA of the system’s axles is determined by the principal directions of the variance. If the changes in a set of data are created by some natural properties or by accidental laboratory errors, we expect normal data distribution. But if changes in a dataset are created by other factors, then we can identify the most effective parameters by the PCA from the parameters involved [
23]. In this study, SPSS software (IBM, Armonk, NY, USA) was used to perform PCA.
2.6. Classification
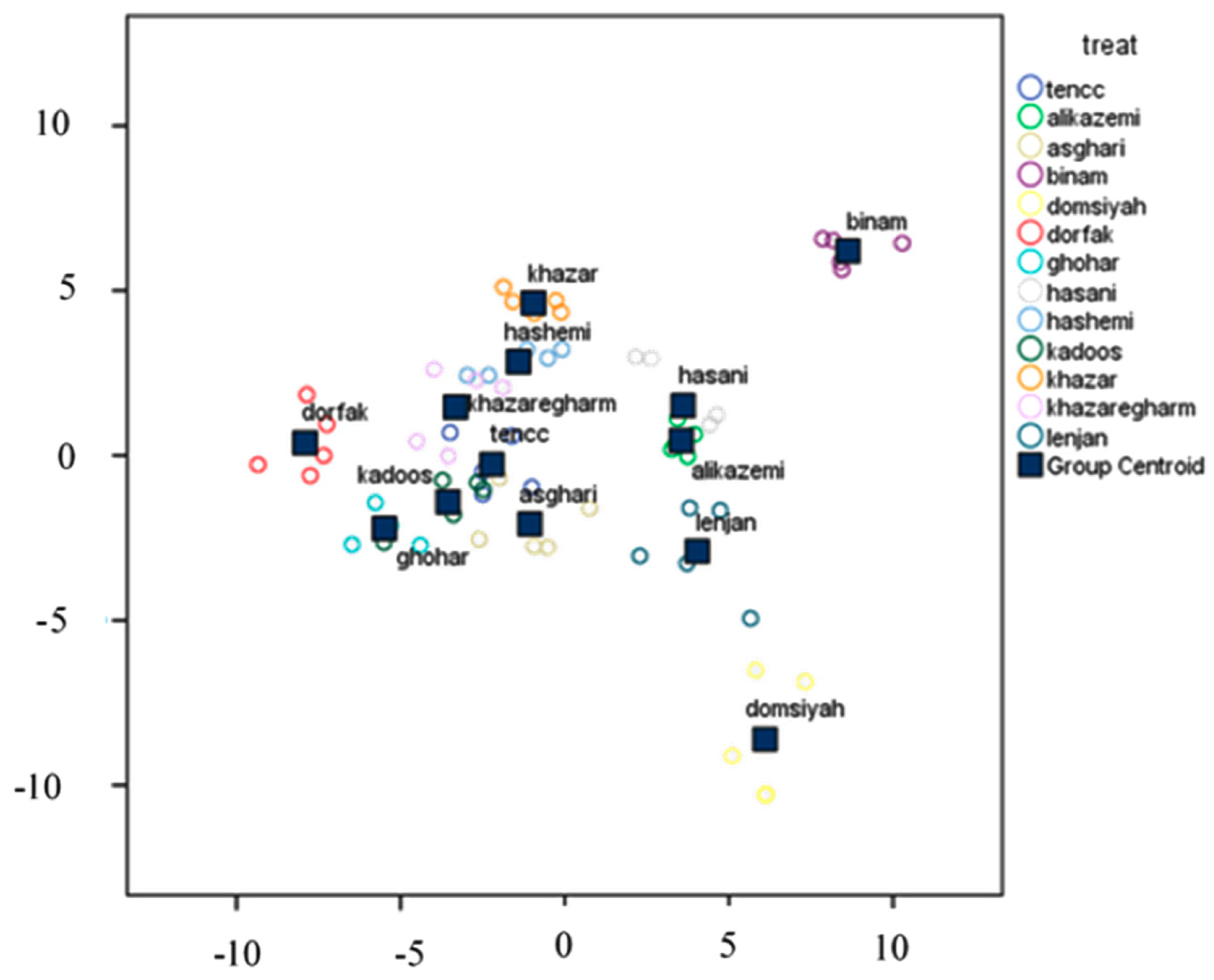
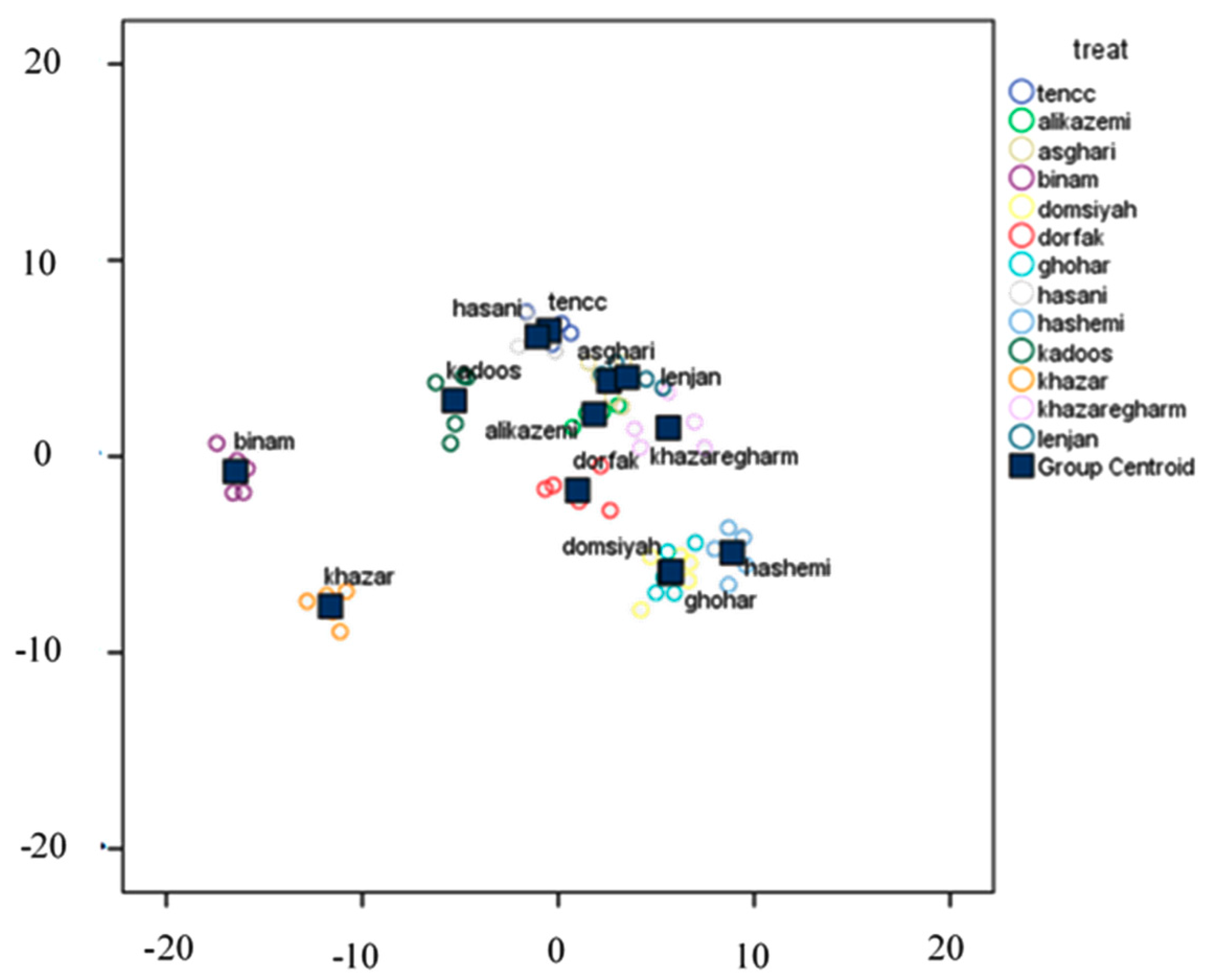
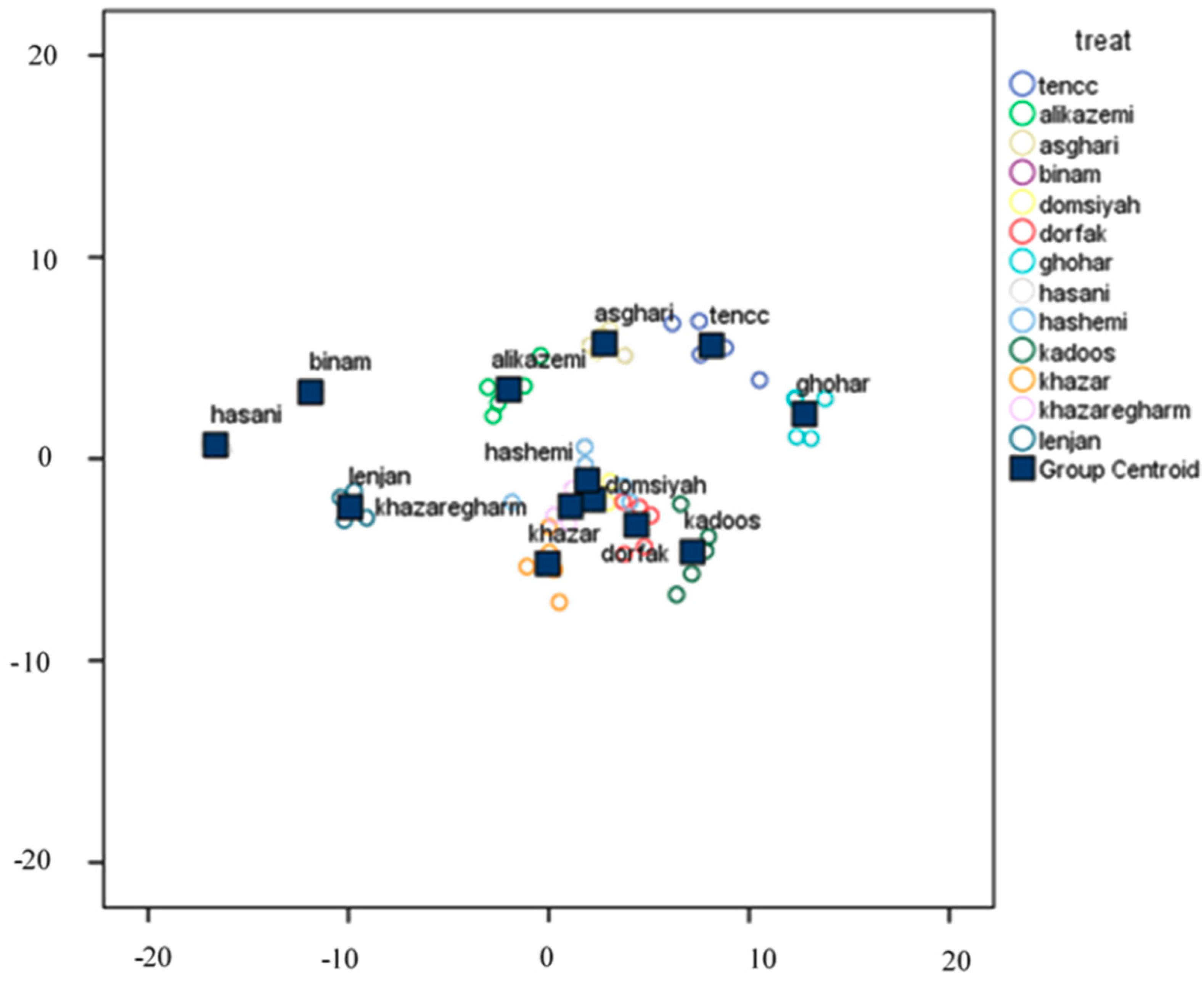
2.6.1. Discriminant Analysis (DA)
Discriminant analysis (DA) is an approach to divide independent variables into separated groups. In fact, this method is used to determine an equation whereby an property of the member society can be input, and the belonging group can be predicted [
7,
24]. The aim of DA is a classification of data into homogeneous groups (less similarity between observations of various groups). Therefore, we need to have good samples from each group to obtain a powerful discriminant function. SPSS software was used to perform DA.
2.6.2. Back-Propagation Artificial Neural Network
A neural network consists of a large number of simple processor components called neuron, unit, cell, or node. Each neuron is connected to other neurons by joints or edges that each has its own weight. These weights represent the information used by the network to solve the problem. A neuron can send only one signal at any given time, although this signal can be sent to several other neurons [
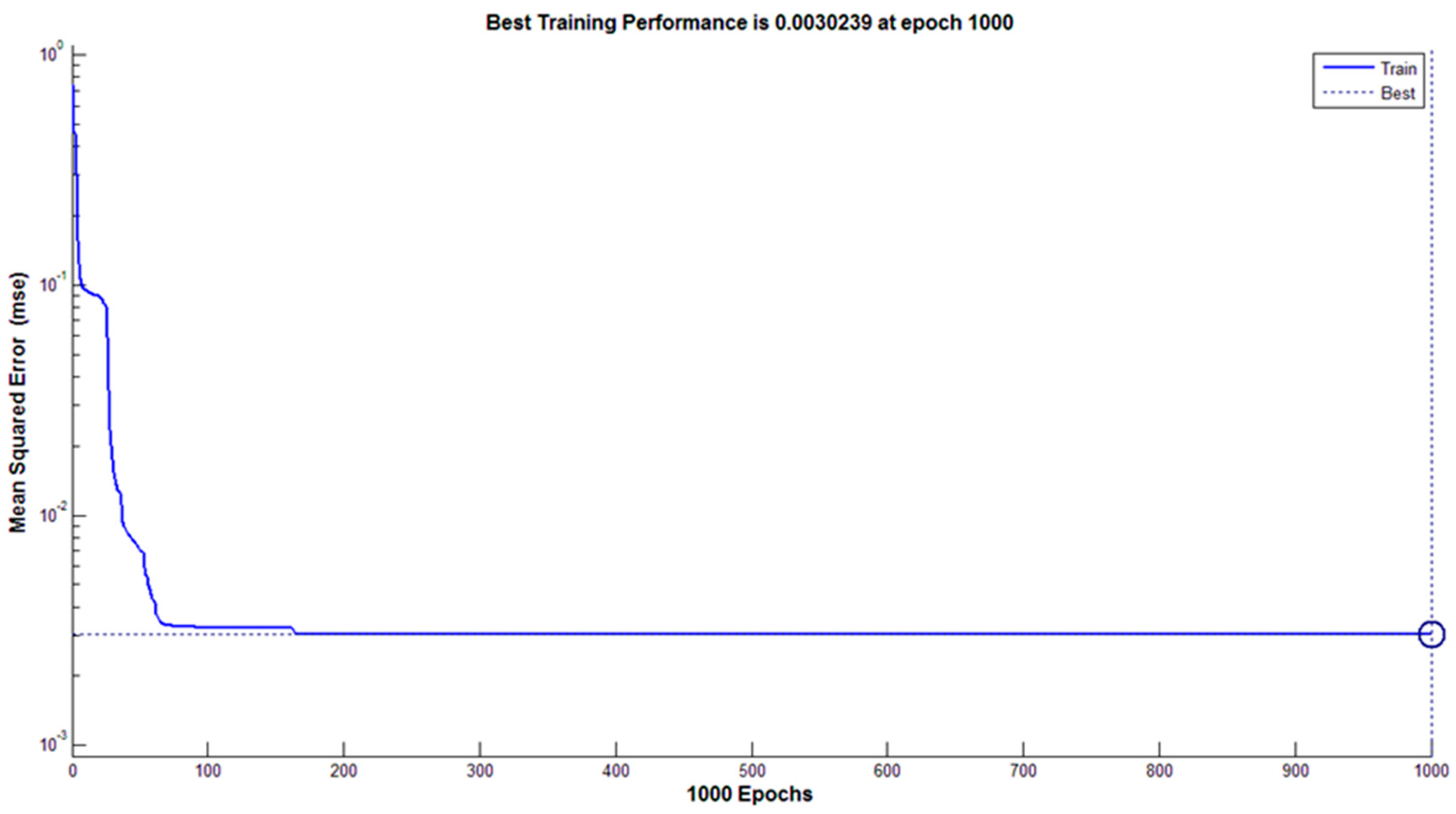
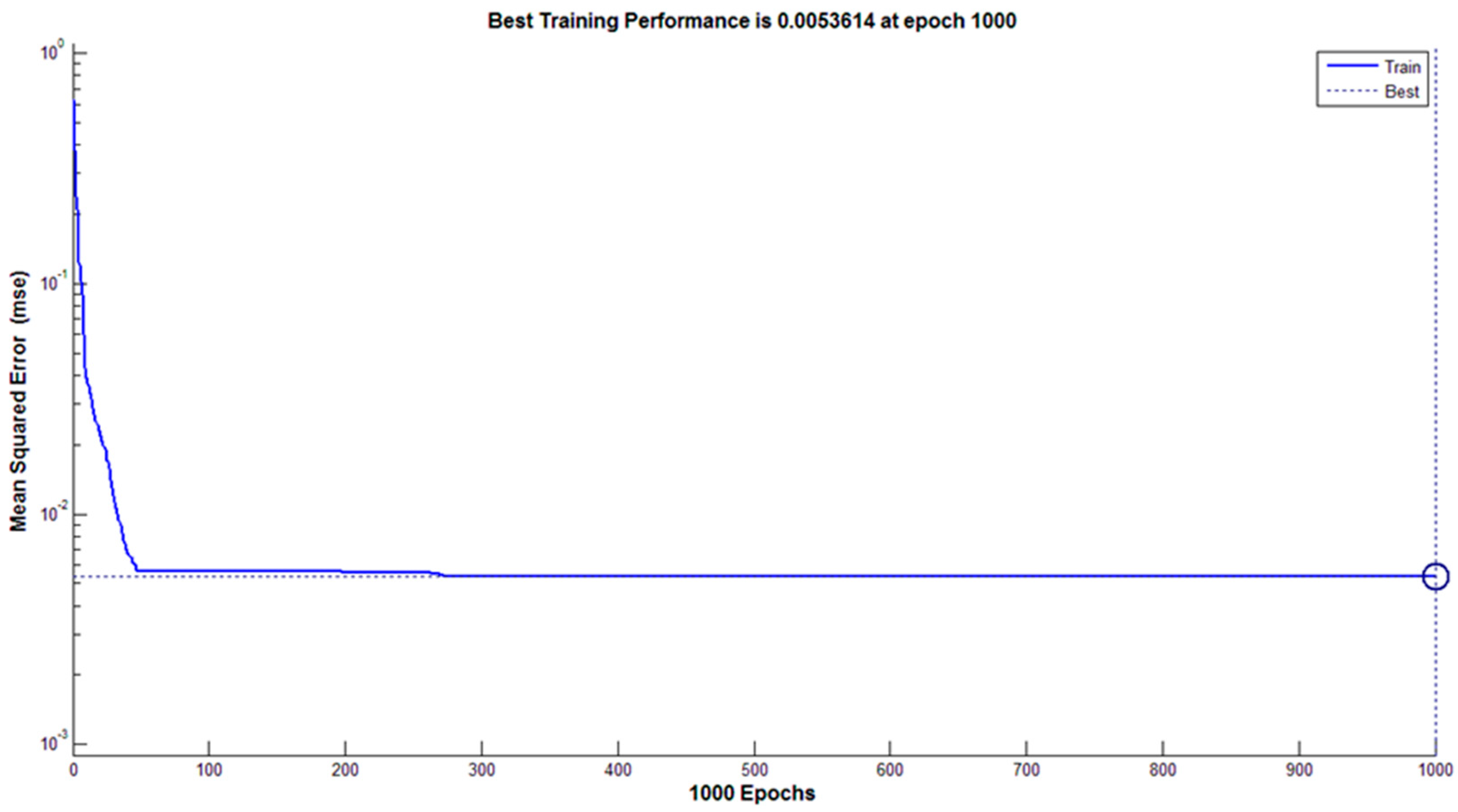
25]. In this research, we used a back-propagation artificial neural network to identify and categorize 13 rice cultivars in three forms of rough, brown, and white rice. We developed code in MATLAB, and the network architecture was defined in this program. The number of input layer neurons was equal to the number of characteristics used for the separation of rice cultivars, and the number of output layer neurons was equal to the number of under-examined cultivars. The number of hidden layers in the neural network, as well as the number of neurons in each hidden layer, was determined by the trial and error method, which is the most important decision in the neural network configuration. This method plays an important role in the capability of the network in the classification of cultivars and learning time. After performing the trial and error method several times, a network with two hidden layers was used for the present study. The optimal numbers of neurons for first and second hidden layers were 20 and 10 neurons, respectively. The activation function of the first and second hidden layers was a sigmoid tangent, and the activation function of the output layer was considered to be a sigmoid logarithm. In addition, 70% of the data was used for network training and network validation, and 30% for network testing. The Levenberg–Marquardt algorithm was used to train the network. The maximum number of training courses was considered to be 1000 periods, and the mean square error (MSE) of classified data was used to evaluate the network performance.
2.7. Criteria for Performance Evaluation of Classifiers
Sensitivity, specificity, and accuracy are the three main characteristics in the classifier analysis. The sensitivity is a fraction of a well-ordered sample, while specificity is a fraction of the relevant sample categorized by the system, and the accuracy is the total classification rate of classifiers. These three criteria are expressed using Equations (1)–(3).
where TR is the number of correctly classified samples in each class. TN is the number of samples on the main diameter of the conjugation matrix minus the number of samples that are correctly classed in the class. The FN is defined as the sum of the horizontal samples minus the number of samples that are correctly classified in the class. Finally, FP is the sum of the vertical samples of the class under consideration, minus the number of samples that are correctly categorized in the class [
26]. The lowest values of sensitivity, specificity, and accuracy are 0, and the highest of these values is 100. Observe that sensitivity of 100% means that no sample of a given class was incorrectly classified in another one. A specificity of 100% means that no sample of other classes was incorrectly classified in the class of interest. An accuracy of 100% appears when any sample of the intended class is correctly classified, and no sample of other classes is assigned to the intended class incorrectly [
11]. This parameter work based on the number of samples that classify in different classes.
4. Conclusions
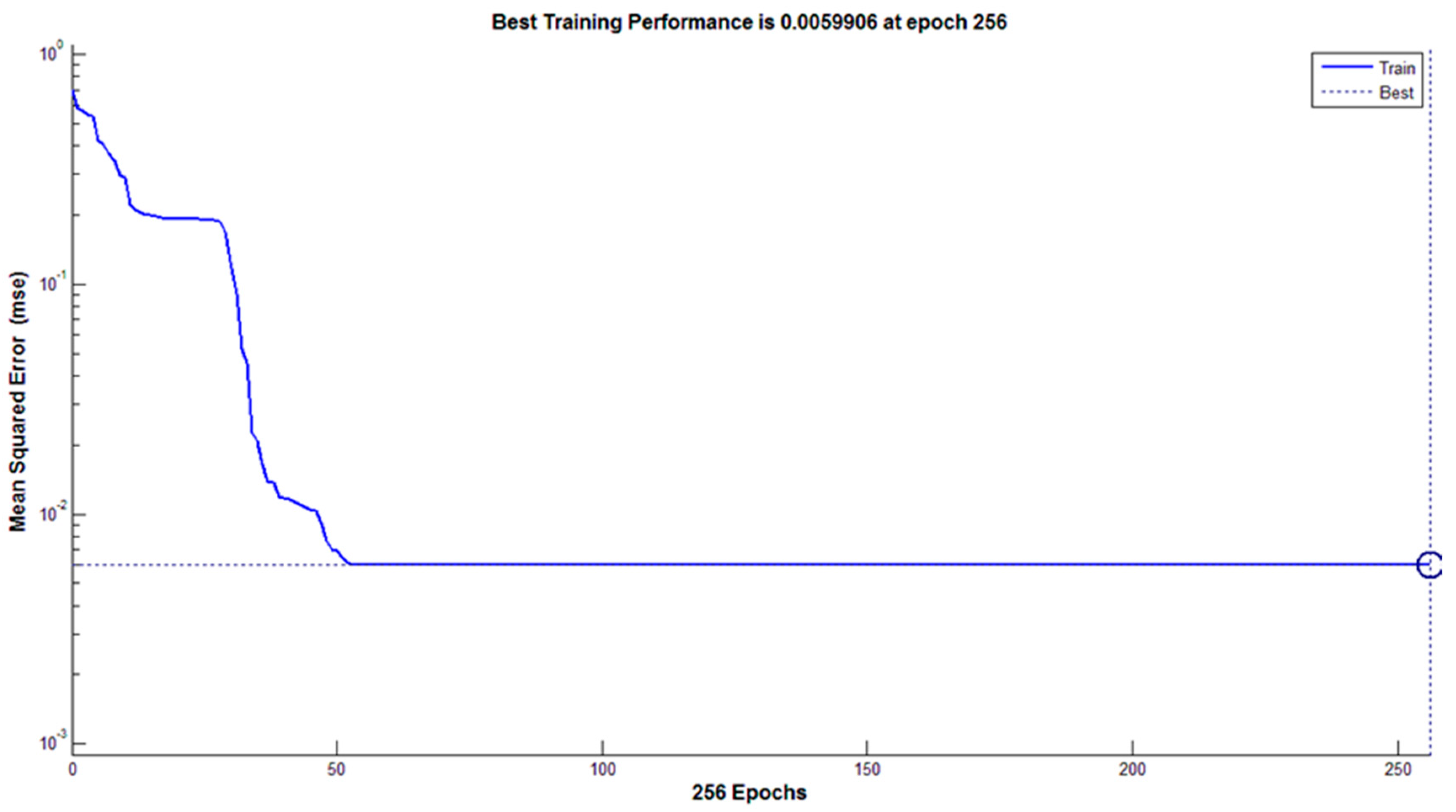
In the present study, a combined method of image processing and ANN method was used to identify and classify 13 common rice cultivars in Iran in three forms of paddy, brown, and white rice. The results showed that the highest classification accuracy obtained by the DA method was less than 90%. This is a linear method, and obtained values indicated the nonlinear relationship between the various rice cultivars of the present study in terms of different attributes, such as color, texture, and morphology. It should be noted that to achieve a higher separation rate, a nonlinear classifier, such as an artificial neural network, is required. The results of the neural network method in identifying and classifying rice cultivars in the white form indicated that the neural network was able to minimize the error by 256 repetitions and identify and categorize the cultivars with a precision of 100%. Fewer repetitions to the default setup of the network, which was 1000 repetitions, showed a suitable learning rate and coverage of network toward the subject (the correct classification of cultivars). Due to the ANN classifier being a nonlinear method, it is able to separate similar cultivars, while DA was unable to separate samples. For example, one can name Kadoos in brown rice, Domsiyah and Gohar in paddy, and Hashemi and Khazargarm in white rice, but the other cannot. The most important advantage of the suggested method is high-accuracy classification, high-speed classification, the possibility of use in cell phones by creating a small file to record video, and the capability of classifying most of the rice cultivars in Iran because it can classify indigenous 13 cultivars. As the accuracy of the method in identifying different varieties of rice in natural conditions is high, it would be possible to develop an application for mobile use to identify different varieties of rice.

 ,
, 






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}