Using a Motion Sensor to Categorize Nonspecific Low Back Pain Patients: A Machine Learning Approach

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
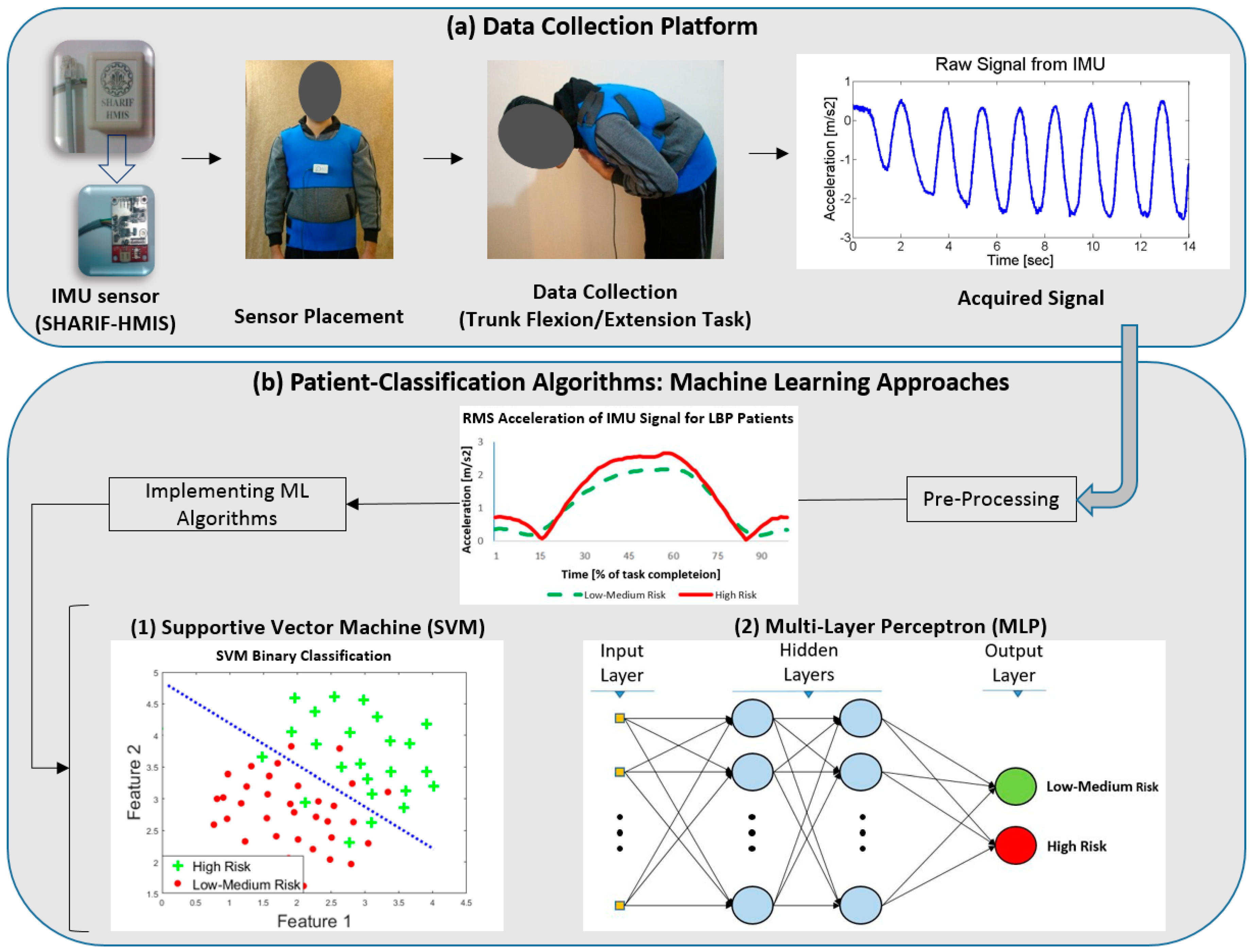
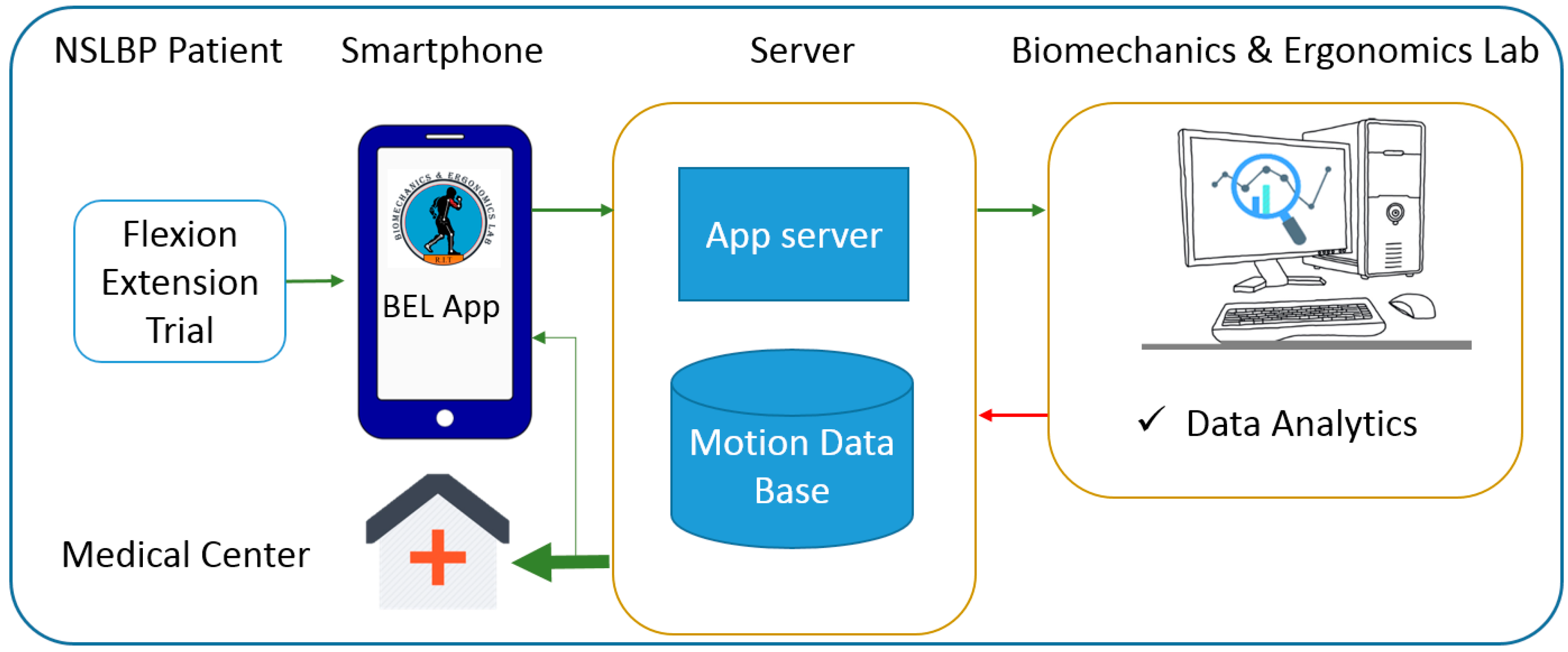
2.2. Experimental Design
2.3. Data Processing
2.3.1. Data Preparation
2.3.2. Feature Selection
- Full signal features including angular velocity, linear acceleration and angular acceleration in three directions of X, Y and Z. This feature set resulted in 900 features.
- Sixteen significant statistical features from the variables in the full signal, as they are described in Table 2. For example, frequency at maximum power indicates the frequency associated to the maximum power in spectral analysis of the signal and median frequency estimates the median normalized frequency of the power spectrum of the signal. It is noteworthy that these 16 scales were calculated for each of the variable (angular velocity, linear acceleration and angular acceleration) in each direction (X, Y and Z). Hence, each feature vector has the length of 144 (16 × 3 × 3).
- Balance analysis features that were extracted from the COP data for the whole duration of the experiment. These four measures obtained from the force platform placed underneath the participants’ feet, namely, the COP range of displacement in both x and y directions, the COP path length during the motion, and the ellipse area of the COP’s amplitude which was area of the motion ellipse, which captured 95% of the COP data [47]. These features enabled the algorithm to consider balance factors as a part of the discriminating protocol.
- Subjective features included HADS and TSK questionnaire.
2.4. Classification Approaches
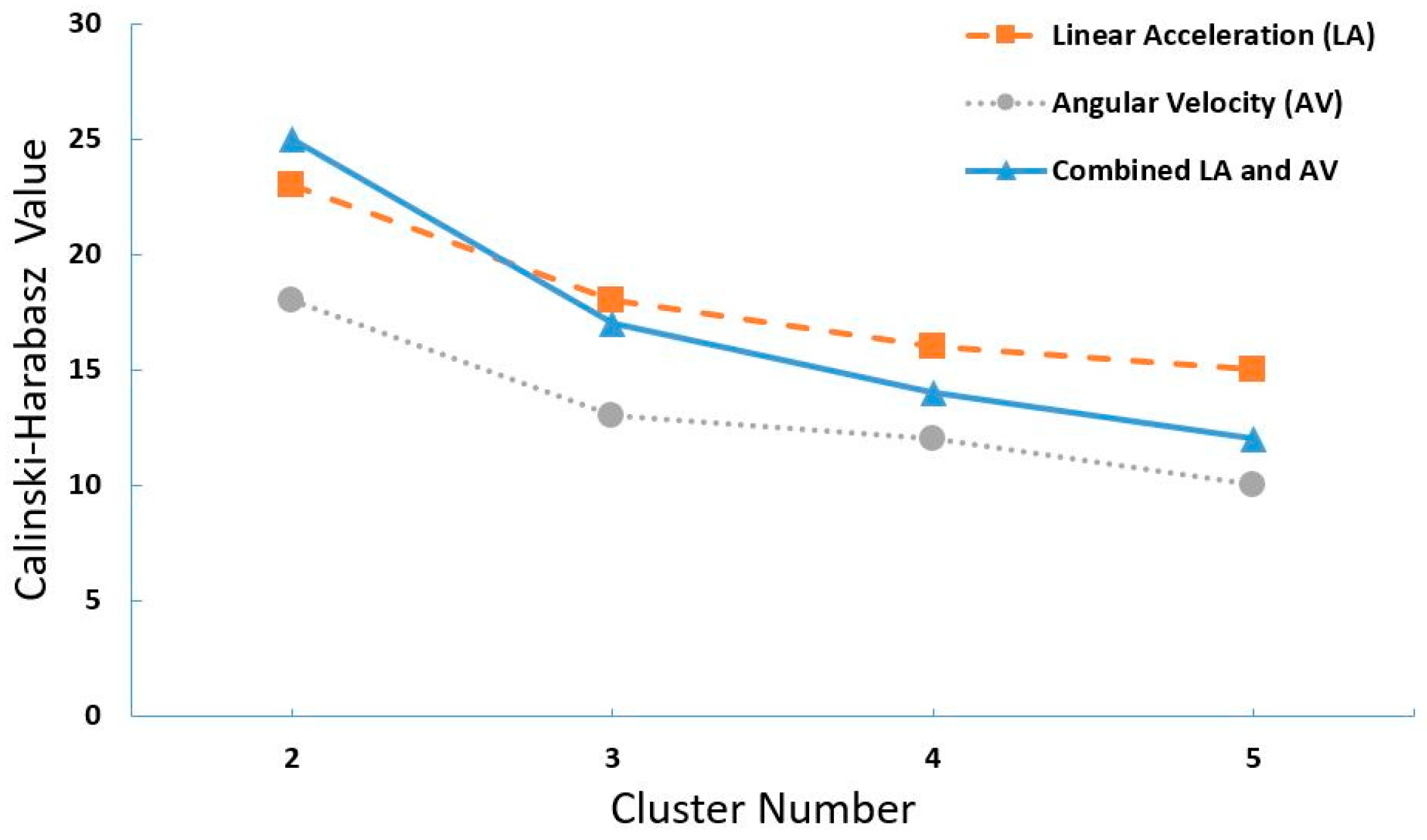
2.4.1. K-Means
2.4.2. Support Vector Machine (SVM)
2.4.3. Neural Network
2.5. Performance Evaluation
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Woolf, A.D.; Pfleger, B. Burden of major musculoskeletal conditions. Bull. World Health Organ. 2003, 81, 646–656. [Google Scholar]
- Vos, T.; Flaxman, A.D.; Naghavi, M.; Lozano, R.; Michaud, C.; Ezzati, M.; Shibuya, K.; Salomon, J.A.; Abdalla, S.; Aboyans, V. Years lived with disability (YLDs) for 1160 sequelae of 289 diseases and injuries 1990–2010: A systematic analysis for the Global Burden of Disease Study 2010. Lancet 2012, 380, 2163–2196. [Google Scholar] [CrossRef]
- Costa-Black, K.M.; Loisel, P.; Anema, J.R.; Pransky, G. Back pain and work. Best Pract. Res. Clin. Rheumatol. 2010, 24, 227–240. [Google Scholar] [CrossRef] [PubMed]
- Wheeler, S.G.; Wipf, J.E.; Staiger, T.O.; Deyo, R.A.; Jarvik, J.G. Evaluation of Low Back Pain in Adults; UpToDate: Waltham, MA, USA, 2016; Volume 27. [Google Scholar]
- WHO Scientific Group on the Burden of Musculoskeletal Conditions at the Start of the New Millennium. The burden of musculoskeletal conditions at the start of the new millennium. World Health Organ. Tech. Rep. Ser. 2003, 919, 1–218. [Google Scholar]
- Finley, C.R.; Chan, D.S.; Garrison, S.; Korownyk, C.; Kolber, M.R.; Campbell, S.; Eurich, D.T.; Lindblad, A.J.; Vandermeer, B.; Allan, G.M. What are the most common conditions in primary care?: Systematic review. Can. Fam. Phys. 2018, 64, 832–840. [Google Scholar]
- Koes, B.; Van Tulder, M.; Thomas, S. Diagnosis and treatment of low back pain. BMJ 2006, 332, 1430–1434. [Google Scholar] [CrossRef] [Green Version]
- Foster, N.E.; Hill, J.C.; Hay, E.M. Subgrouping patients with low back pain in primary care: Are we getting any better at it? Man. Ther. 2011, 16, 3–8. [Google Scholar] [CrossRef]
- van der Windt, D.; Hay, E.; Jellema, P.; Main, C. Psychosocial interventions for low back pain in primary care: Lessons learned from recent trials. Spine 2008, 33, 81–89. [Google Scholar] [CrossRef]
- Koes, B.W.; van Tulder, M.; Lin, C.-W.C.; Macedo, L.G.; McAuley, J.; Maher, C. An updated overview of clinical guidelines for the management of non-specific low back pain in primary care. Eur. Spine J. 2010, 19, 2075–2094. [Google Scholar] [CrossRef] [Green Version]
- Jellema, P.; van der Windt, D.A.; van der Horst, H.E.; Twisk, J.W.; Stalman, W.A.; Bouter, L.M. Should treatment of (sub) acute low back pain be aimed at psychosocial prognostic factors? Cluster randomised clinical trial in general practice. BMJ 2005, 331, 84. [Google Scholar] [CrossRef] [Green Version]
- Hill, J.C.; Dunn, K.M.; Lewis, M.; Mullis, R.; Main, C.J.; Foster, N.E.; Hay, E.M. A primary care back pain screening tool: Identifying patient subgroups for initial treatment. Arthritis Care Res.: Off. J. Am. Coll. Rheumatol. 2008, 59, 632–641. [Google Scholar] [CrossRef] [PubMed]
- Dunn, K.M.; Croft, P.R. Classification of low back pain in primary care: Using “bothersomeness” to identify the most severe cases. Spine 2005, 30, 1887–1892. [Google Scholar] [CrossRef] [PubMed]
- O’sullivan, P. Clinical instability of the lumbar spine: Its pathological basis, diagnosis and conservative management. Grieve’s Mod. Man. Ther.: Vertebr. Column 2004, 313. [Google Scholar]
- Dankaerts, W.; O’sullivan, P.; Straker, L.; Burnett, A.; Skouen, J. The inter-examiner reliability of a classification method for non-specific chronic low back pain patients with motor control impairment. Man. Ther. 2006, 11, 28–39. [Google Scholar] [CrossRef] [PubMed]
- Hay, E.M.; Dunn, K.M.; Hill, J.C.; Lewis, M.; Mason, E.E.; Konstantinou, K.; Sowden, G.; Somerville, S.; Vohora, K.; Whitehurst, D. A randomised clinical trial of subgrouping and targeted treatment for low back pain compared with best current care. The STarT Back Trial Study Protocol. BMC Musculoskelet. Disord. 2008, 9, 58. [Google Scholar] [CrossRef] [Green Version]
- Beneciuk, J.M.; Bishop, M.D.; Fritz, J.M.; Robinson, M.E.; Asal, N.R.; Nisenzon, A.N.; George, S.Z. The STarT back screening tool and individual psychological measures: Evaluation of prognostic capabilities for low back pain clinical outcomes in outpatient physical therapy settings. Phys. Ther. 2013, 93, 321–333. [Google Scholar] [CrossRef]
- Hill, J.C.; Whitehurst, D.G.; Lewis, M.; Bryan, S.; Dunn, K.M.; Foster, N.E.; Konstantinou, K.; Main, C.J.; Mason, E.; Somerville, S. Comparison of stratified primary care management for low back pain with current best practice (STarT Back): A randomised controlled trial. Lancet 2011, 378, 1560–1571. [Google Scholar] [CrossRef] [Green Version]
- Main, C.; Sowden, G.; Hill, J.; Watson, P.; Hay, E. Integrating physical and psychological approaches to treatment in low back pain: The development and content of the STarT Back trial’s ‘high-risk’intervention (StarT Back; ISRCTN 37113406). Physiotherapy 2012, 98, 110–116. [Google Scholar] [CrossRef]
- Keele, K. Keele University. STarT Back. Available online: https://www.keele.ac.uk/sbst/startbacktool/ (accessed on 21 October 2015).
- Moons, K.G.; Altman, D.G.; Vergouwe, Y.; Royston, P. Prognosis and prognostic research: Application and impact of prognostic models in clinical practice. BMJ 2009, 338, b606. [Google Scholar] [CrossRef]
- Ashouri, S.; Abedi, M.; Abdollahi, M.; Dehghan Manshadi, F.; Parnianpour, M.; Khalaf, K. A novel approach to spinal 3-D kinematic assessment using inertial sensors: Towards effective quantitative evaluation of low back pain in clinical settings. Comput. Biol. Med. 2017, 89, 144–149. [Google Scholar] [CrossRef]
- Papi, E.; Bull, A.M.; McGregor, A.H. Is there evidence to use kinematic/kinetic measures clinically in low back pain patients? A systematic review. Clin. Biomech. 2018, 55, 53–64. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Al-Eisa, E.; Egan, D.; Deluzio, K.; Wassersug, R. Effects of pelvic asymmetry and low back pain on trunk kinematics during sitting: A comparison with standing. Spine 2006, 31, E135–E143. [Google Scholar] [CrossRef]
- Christe, G.; Redhead, L.; Legrand, T.; Jolles, B.M.; Favre, J. Multi-segment analysis of spinal kinematics during sit-to-stand in patients with chronic low back pain. J. Biomech. 2016, 49, 2060–2067. [Google Scholar] [CrossRef] [PubMed]
- Laird, R.A.; Gilbert, J.; Kent, P.; Keating, J.L. Comparing lumbo-pelvic kinematics in people with and without back pain: A systematic review and meta-analysis. BMC Musculoskelet. Disord. 2014, 15, 229. [Google Scholar] [CrossRef] [PubMed]
- Keefe, F.J.; Hill, R.W. An objective approach to quantifying pain behavior and gait patterns in low back pain patients. Pain 1985, 21, 153–161. [Google Scholar] [CrossRef]
- Givon, U.; Zeilig, G.; Achiron, A. Gait analysis in multiple sclerosis: Characterization of temporal–spatial parameters using GAITRite functional ambulation system. Gait Posture 2009, 29, 138–142. [Google Scholar] [CrossRef]
- Blin, O.; Ferrandez, A.-M.; Serratrice, G. Quantitative analysis of gait in Parkinson patients: Increased variability of stride length. J. Neurol. Sci. 1990, 98, 91–97. [Google Scholar] [CrossRef]
- Bejek, Z.; Paróczai, R.; Illyés, Á.; Kiss, R.M. The influence of walking speed on gait parameters in healthy people and in patients with osteoarthritis. Knee Surg. Sports Traumatol. Arthrosc. 2006, 14, 612–622. [Google Scholar] [CrossRef]
- van Schooten, K.S.; Pijnappels, M.; Rispens, S.M.; Elders, P.J.; Lips, P.; van Dieën, J.H. Ambulatory fall-risk assessment: Amount and quality of daily-life gait predict falls in older adults. J. Gerontol. A Biol. Sci. Med. Sci. 2015, 70, 608–615. [Google Scholar] [CrossRef] [Green Version]
- Varatharajan, R.; Manogaran, G.; Priyan, M.; Sundarasekar, R. Wearable sensor devices for early detection of Alzheimer disease using dynamic time warping algorithm. Clust. Comput. 2017, 21, 1–10. [Google Scholar] [CrossRef]
- Marras, W.S.; Lavender, S.A.; Leurgans, S.E.; Rajulu, S.L.; Allread, W.G.; Fathallah, F.A.; Ferguson, S.A. The role of dynamic three-dimensional trunk motion in occupationally-related low back disorders. The effects of workplace factors, trunk position, and trunk motion characteristics on risk of injury. Spine 1993, 18, 617–628. [Google Scholar] [CrossRef] [PubMed]
- Marras, W.S.; Parnianpour, M.; Ferguson, S.A.; Kim, J.Y.; Crowell, R.R.; Bose, S.; Simon, S.R. The classification of anatomic- and symptom-based low back disorders using motion measure models. Spine 1995, 20, 2531–2546. [Google Scholar] [CrossRef] [PubMed]
- Ferguson, S.A.; Marras, W.S.; Burr, D.L. Differences among outcome measures in occupational low back pain. J. Occup. Rehabil. 2005, 15, 329–341. [Google Scholar] [CrossRef] [PubMed]
- Ferguson, S.A.; Marras, W.S.; Burr, D.L.; Woods, S.; Mendel, E.; Gupta, P. Quantification of a meaningful change in low back functional impairment. Spine 2009, 34, 2060–2065. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marras, W.S.; Lewis, K.E.; Ferguson, S.A.; Parnianpour, M. Impairment magnification during dynamic trunk motions. Spine 2000, 25, 587–595. [Google Scholar] [CrossRef]
- Sarig Bahat, H.; Weiss, P.L.; Laufer, Y. The effect of neck pain on cervical kinematics, as assessed in a virtual environment. Arch. Phys. Med. Rehabil. 2010, 91, 1884–1890. [Google Scholar] [CrossRef]
- Davoudi, M.; Shokouhyan, S.M.; Abedi, M.; Meftahi, N.; Rahimi, A.; Rashedi, E.; Hoviattalab, M.; Narimani, R.; Parnianpour, M.; Khalaf, K. A Practical Sensor-Based Methodology for the Quantitative Assessment and Classification of Chronic Non Specific Low Back Patients (NSLBP) in Clinical Settings. Sensors 2020, 20, 2902. [Google Scholar] [CrossRef]
- Waddell, G. An approach to backache. Br. J. Hosp. Med. 1982, 28, 187. [Google Scholar] [CrossRef]
- Langley, G.; Sheppeard, H. The visual analogue scale: Its use in pain measurement. Rheumatol. Int. 1985, 5, 145–148. [Google Scholar] [CrossRef]
- Ogon, M.; Krismer, M.; Söllner, W.; Kantner-Rumplmair, W.; Lampe, A. Chronic low back pain measurement with visual analogue scales in different settings. Pain 1996, 64, 425–428. [Google Scholar] [CrossRef]
- Abedi, M.; Manshadi, F.D.; Zavieh, M.K.; Ashouri, S.; Azimi, H.; Parnanpour, M. A reliability study of the new sensors for movement analysis (SHARIF–HMIS). J. Bodyw. Mov. Ther. 2016, 20, 341–345. [Google Scholar] [CrossRef] [PubMed]
- Zigmond, A.S.; Snaith, R.P. The hospital anxiety and depression scale. Acta Psychiatr. Scand. 1983, 67, 361–370. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kori, S. Kinisophobia: A new view of chronic pain behavior. Pain Manag. 1990, 35–43. [Google Scholar]
- Abedi, M.; Manshadi, F.D.; Khalkhali, M.; Mousavi, S.J.; Baghban, A.A.; Montazeri, A.; Parnianpour, M. Translation and validation of the Persian version of the STarT Back Screening Tool in patients with nonspecific low back pain. Man. Ther. 2015, 20, 850–854. [Google Scholar] [CrossRef]
- Pau, M.; Coghe, G.; Corona, F.; Leban, B.; Marrosu, M.G.; Cocco, E. Effectiveness and limitations of unsupervised home-based balance rehabilitation with Nintendo Wii in people with multiple sclerosis. BioMed Res. Int. 2015, 2015. [Google Scholar] [CrossRef] [Green Version]
- Halilaj, E.; Rajagopal, A.; Fiterau, M.; Hicks, J.L.; Hastie, T.J.; Delp, S.L. Machine learning in human movement biomechanics: Best practices, common pitfalls, and new opportunities. J. Biomech. 2018. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat.-Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Conforti, I.; Mileti, I.; Del Prete, Z.; Palermo, E. Measuring Biomechanical Risk in Lifting Load Tasks Through Wearable System and Machine-Learning Approach. Sensors 2020, 20, 1557. [Google Scholar] [CrossRef] [Green Version]
- Taborri, J.; Palermo, E.; Rossi, S. Automatic detection of faults in race walking: A comparative analysis of machine-learning algorithms fed with inertial sensor data. Sensors 2019, 19, 1461. [Google Scholar] [CrossRef] [Green Version]
- Doheny, E.P.; Walsh, C.; Foran, T.; Greene, B.R.; Fan, C.W.; Cunningham, C.; Kenny, R.A. Falls classification using tri-axial accelerometers during the five-times-sit-to-stand test. Gait Posture 2013, 38, 1021–1025. [Google Scholar] [CrossRef]
- Greene, B.R.; McGrath, D.; Walsh, L.; Doheny, E.P.; McKeown, D.; Garattini, C.; Cunningham, C.; Crosby, L.; Caulfield, B.; Kenny, R.A. Quantitative falls risk estimation through multi-sensor assessment of standing balance. Physiol. Meas. 2012, 33, 2049. [Google Scholar] [CrossRef] [PubMed]
- Greene, B.R.; Redmond, S.J.; Caulfield, B. Fall Risk Assessment Through Automatic Combination of Clinical Fall Risk Factors and Body-Worn Sensor Data. IEEE J. Biomed. Health Inform. 2017, 21, 725–731. [Google Scholar] [CrossRef] [PubMed]
- Howcroft, J.; Kofman, J.; Lemaire, E.D. Feature selection for elderly faller classification based on wearable sensors. J. Neuroeng. Rehabil. 2017, 14, 47. [Google Scholar] [CrossRef] [PubMed]
- Jiang, W.; Yin, Z. Human activity recognition using wearable sensors by deep convolutional neural networks. In 23rd ACM International Conference on Multimedia; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1307–1310. [Google Scholar]
- Ordóñez, F.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [Green Version]
- Patuwo, E.; Hu, M.Y.; Hung, M.S. Two-group classification using neural networks. Decis. Sci. 1993, 24, 825–845. [Google Scholar] [CrossRef]
- Poushter, J. Smartphone ownership and internet usage continues to climb in emerging economies. Pew Res. Center 2016, 22, 1–44. [Google Scholar]
- Karvekar, S.; Abdollahi, M.; Rashedi, E. A data-driven model to identify fatigue level based on the motion data from a smartphone. In Proceedings of the 2019 IEEE Western New York Image and Signal Processing Workshop (WNYISPW), Rochester, NY, USA, 4 October 2019; pp. 1–5. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Low-Risk | Medium-Risk | High-Risk | p-Value (ANOVA) | |
|---|---|---|---|---|
| Age (year) | 43.8 (8.2) | 43.4 (5.6) | 43.6 (7.3) | 0.98 |
| Height (cm) | 172.4 (8.3) | 173.7 (6.7) | 171.5 (6.9) | 0.47 |
| Weight (kg) | 80.3 (12.5) | 80.5 (12) | 77.5 (13.3) | 0.6 |
| BMI (kg/m2) | 26.9 (3) | 26.7 (3.8) | 26.2 (3.4) | 0.74 |
| Feature | Source | Description |
|---|---|---|
| Full Signal (FS) | IMU Sensor | Linear/angular acceleration and angular velocity in X, Y, and Z directions (all time-scaled to have 100 data points) |
| Sixteen Significant Features from variables in FS (FT16) | IMU Sensor | Max, min, range, mean, quartiles, interquartile range (IQR), IQR divided by median, standard deviation, kurtosis, skewness, entropy, power, frequency at maximum power, and median frequency of the signal |
| Balance Analysis (Wii) | Balance Board | From COP data; x and y range (balance board’s axes), path length, and area of the ellipse which could capture 95% percent of the data |
| Subjective Features (ADT) | Questionnaires | Participants filled out HADS and TSK questionnaires |
| Low vs. Medium-High | Medium vs. Low-High | High vs Low-Medium | ||
|---|---|---|---|---|
| SVM | Accuracy | 46.3 (6.3) | 45.5 (6.8) | 75.4 (4.2) |
| Sensitivity | 45.0 (10) | 59.7 (7.5) | 72.5 (3.8) | |
| Specificity | 47.6 (8.6) | 31.4 (7.2) | 78.2 (5.3) | |
| F1-score | 45.6 (12.1) | 52.3 (10.4) | 74.6 (14.4) | |
| G-index | 0.76 (0.19) | 0.8 (0.15) | 0.35 (0.09) | |
| MLP | Accuracy | 51.2 (4.8) | 45.4 (6.3) | 61.8 (5.7) |
| Sensitivity | 42.8 (8.7) | 44.8 (8.9) | 66.2 (7.1) | |
| Specificity | 59.6 (7.2) | 46.1 (7.6) | 57.5 (7.3) | |
| F1-score | 46.7 (12.7) | 45.1 (11.6) | 63.7 (10.8) | |
| G-index | 0.7 (0.16) | 0.77 (0.17) | 0.54 (0.14) |
| FS | FT16 | Wii | ADT | FS + FT16 | FS + Wii | FS + ADT | FT16 + Wii | FT16 + ADT | Wii + ADT | FS + FT16 + Wii | FS + FT16 + ADT | FS + Wii + ADT | FT16 + Wii + ADT | ALL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | 75.4 (4.2) | 66.9 (5.4) | 39.5 (8.3) | 54.8 (6.8) | 63.5 (5.6) | 65.2 (6.6) | 66.6 (6.3) | 58.9 (5.1) | 52.7 (7.4) | 46.8 (4.8) | 64.8 (5.5) | 66.8 (6.2) | 64.2 (4.9) | 54.9 (6.2) | 59.3 (5.4) |
| Sensitivity | 72.5 (3.8) | 58.3 (5.1) | 40.4 (8.8) | 55.7 (6.9) | 65.8 (5.5) | 61.6 (7.9) | 67.4 (8.7) | 52.1 (5.5) | 42.5 (8.6) | 48.2 (5.3) | 58 (4.9) | 68.4 (6.7) | 64 (6.1) | 44.7 (7.7) | 61.5 (4.8) |
| Specificity | 78.2 (5.3) | 75.7 (6.5) | 38.6 (9.8) | 53.9 (7.3) | 61.2 (7.3) | 68.7 (5.5) | 65.7 (7.7) | 63.6 (8.9) | 62.8 (8.5) | 45.3 (6.9) | 71.6 (6.4) | 65.1 (7.4) | 64.4 (5.5) | 65.1 (7.6) | 65.4 (6.7) |
| F1-score | 74.6 (14.4) | 63.9 (13.1) | 40.0 (11.5) | 55.2 (13.5) | 64.3 (14.6) | 63.9 (14.9) | 66.8 (15.9) | 55.3 (16.6) | 47.3 (17.3) | 47.5 (19.6) | 62.2 (11.7) | 67.3 (14.4) | 64.1 (15.4) | 49.8 (14.4) | 62.7 (12.3) |
| G-index | 0.35 (0.09) | 0.48 (0.12) | 0.86 (0.19) | 0.64 (0.14) | 0.52 (0.13) | 0.50 (0.13) | 0.47 (0.16) | 0.60 (0.14) | 0.68 (0.17) | 0.75 (0.12) | 0.51 (0.11) | 0.47 (0.14) | 0.51 (0.12) | 0.65 (0.15) | 0.52 (0.12) |
| Low vs Medium-High | Medium vs Low-High | High vs Low-Medium | |||||||
|---|---|---|---|---|---|---|---|---|---|
| L | MH | p-Value (t-Test) | M | LH | p-Value(t-Test) | H | LM | p-Value(t-Test) | |
| Age [year] | 43.7 (8.2) | 43.5 (6.3) | 0.86 | 43.4 (5.6) | 43.7 (7.7) | 0.84 | 43.6 (7.3) | 43.6 (6.8) | 0.97 |
| Height [cm] | 172.4 (8.3) | 172.8 (6.8) | 0.75 | 173.7 (6.7) | 171.9 (7.6) | 0.24 | 171.5 (6.9) | 173.1 (7.4) | 0.34 |
| Weight[kg] | 80.3 (12.5) | 79.2 (12.6) | 0.71 | 80.5 (12) | 79.2 (13) | 0.56 | 77.5 (13.3) | 80.5 (12.3) | 0.31 |
| BMI [kg/m2] | 26.9 (3) | 26.5 (3.6) | 0.56 | 26.7 (3.8) | 26.6 (3.2) | 0.91 | 26.2 (3.4) | 26.8 (3.5) | 0.48 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdollahi, M.; Ashouri, S.; Abedi, M.; Azadeh-Fard, N.; Parnianpour, M.; Khalaf, K.; Rashedi, E. Using a Motion Sensor to Categorize Nonspecific Low Back Pain Patients: A Machine Learning Approach. Sensors 2020, 20, 3600. https://doi.org/10.3390/s20123600
Abdollahi M, Ashouri S, Abedi M, Azadeh-Fard N, Parnianpour M, Khalaf K, Rashedi E. Using a Motion Sensor to Categorize Nonspecific Low Back Pain Patients: A Machine Learning Approach. Sensors. 2020; 20(12):3600. https://doi.org/10.3390/s20123600
Chicago/Turabian StyleAbdollahi, Masoud, Sajad Ashouri, Mohsen Abedi, Nasibeh Azadeh-Fard, Mohamad Parnianpour, Kinda Khalaf, and Ehsan Rashedi. 2020. "Using a Motion Sensor to Categorize Nonspecific Low Back Pain Patients: A Machine Learning Approach" Sensors 20, no. 12: 3600. https://doi.org/10.3390/s20123600