Quantitative Analysis of Gas Phase IR Spectra Based on Extreme Learning Machine Regression Model


Abstract
:1. Introduction
2. Background Knowledge
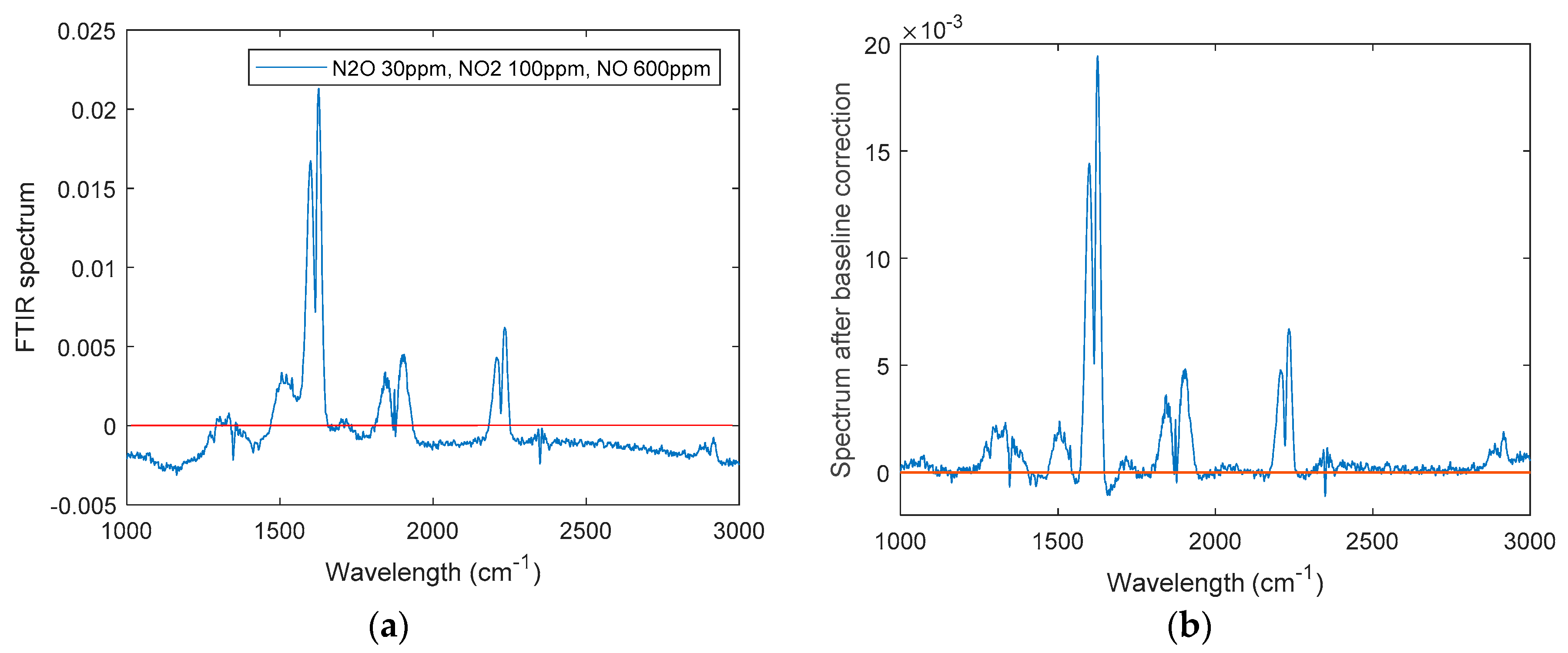
2.1. Data Pre-Processing
2.2. Regression Analysis
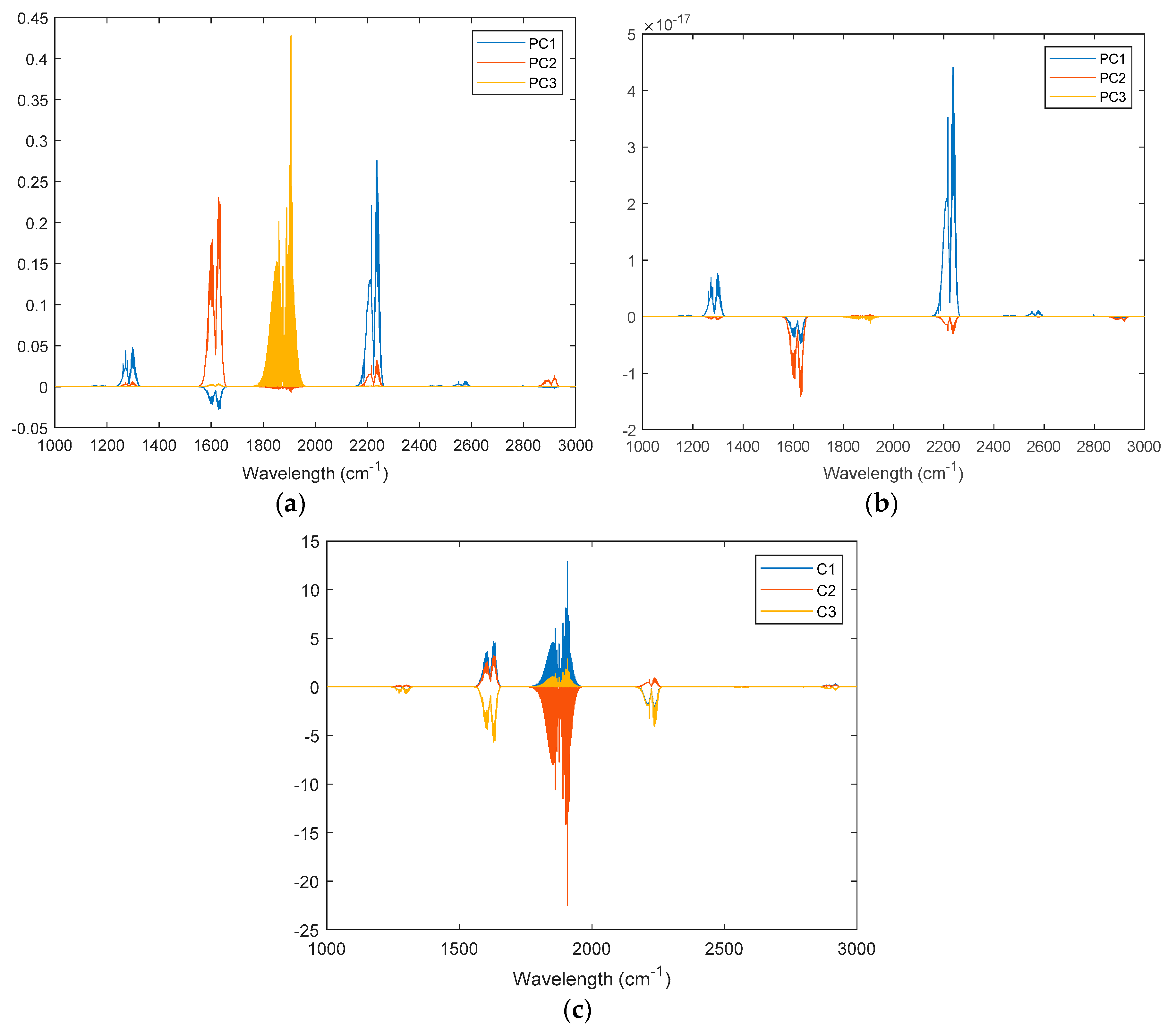
2.2.1. PCR
2.2.2. PLSR
2.3. Evaluation Metrics
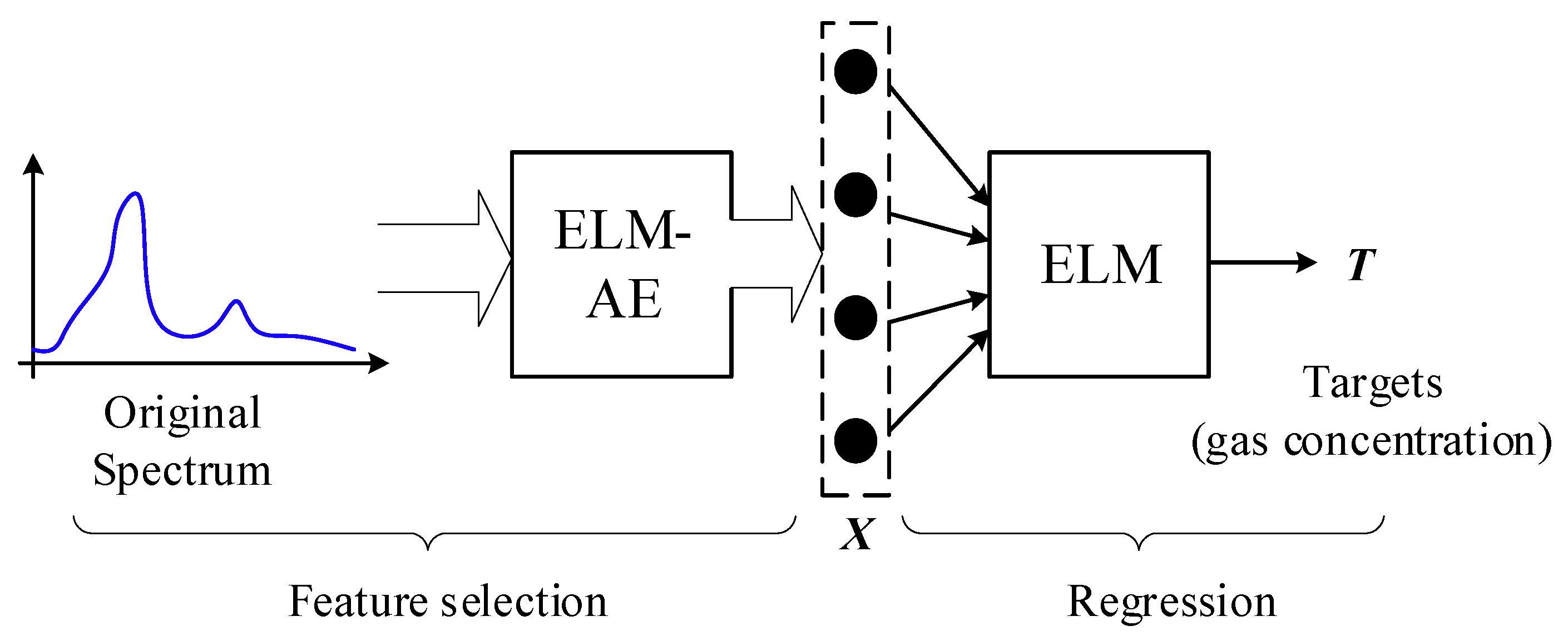
3. ELM-AE-Based Regression Model (ELM-AE-R)
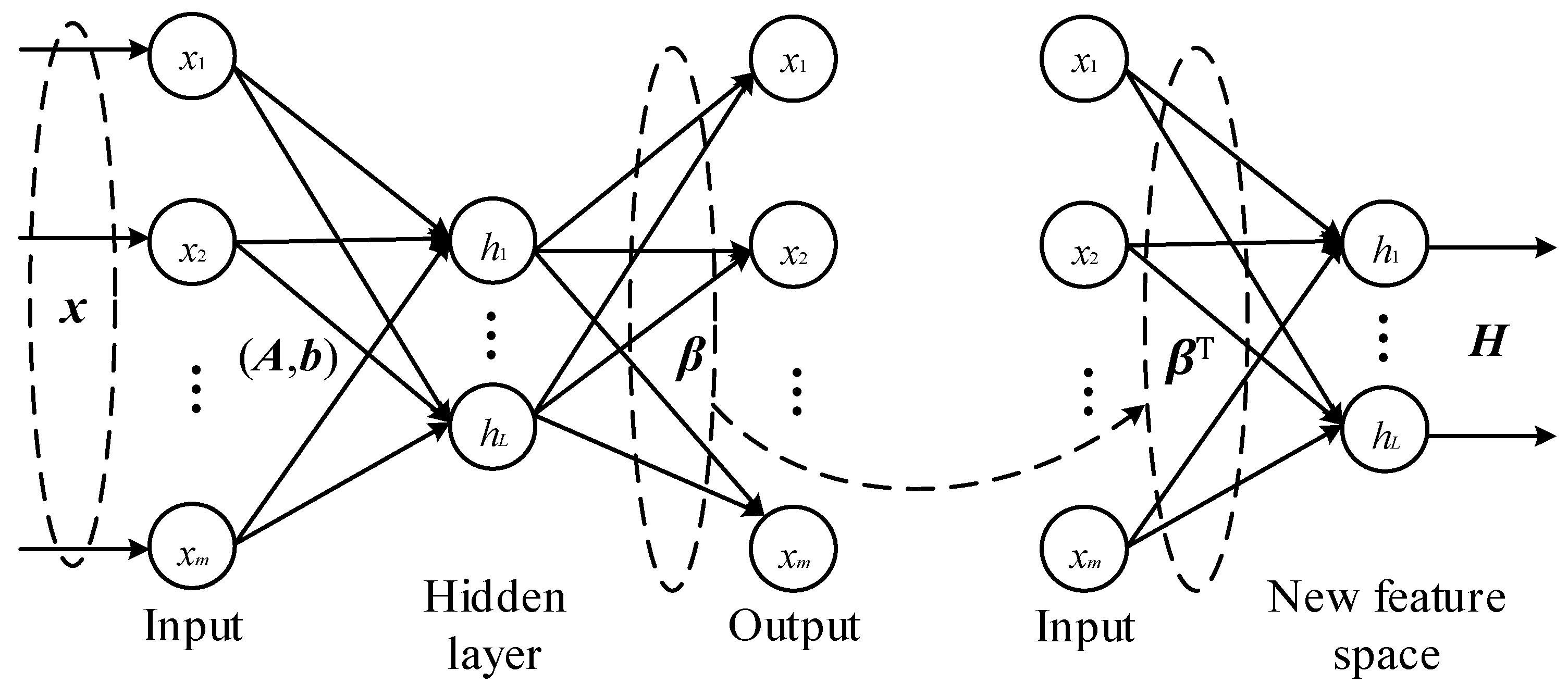
3.1. ELM Architecture
- (1)
- With randomly generated weights in the input layer, ELM shows excellent generalization performance, and lends itself to real-world application scenarios.
- (2)
- Compared with conventional neural networks whose parameters, e.g., learning rate, learning epochs, and local minima are tuned iteratively, ELM fixes the input weights to obtain extremely fast learning speed.
- (3)
- ELM can be easily implemented to achieve both the smallest training error and the smallest norm of weights.
3.2. ELM-AE
3.3. ELM-AE-R for Quantitative Analysis of IR Spectra
4. Experiments
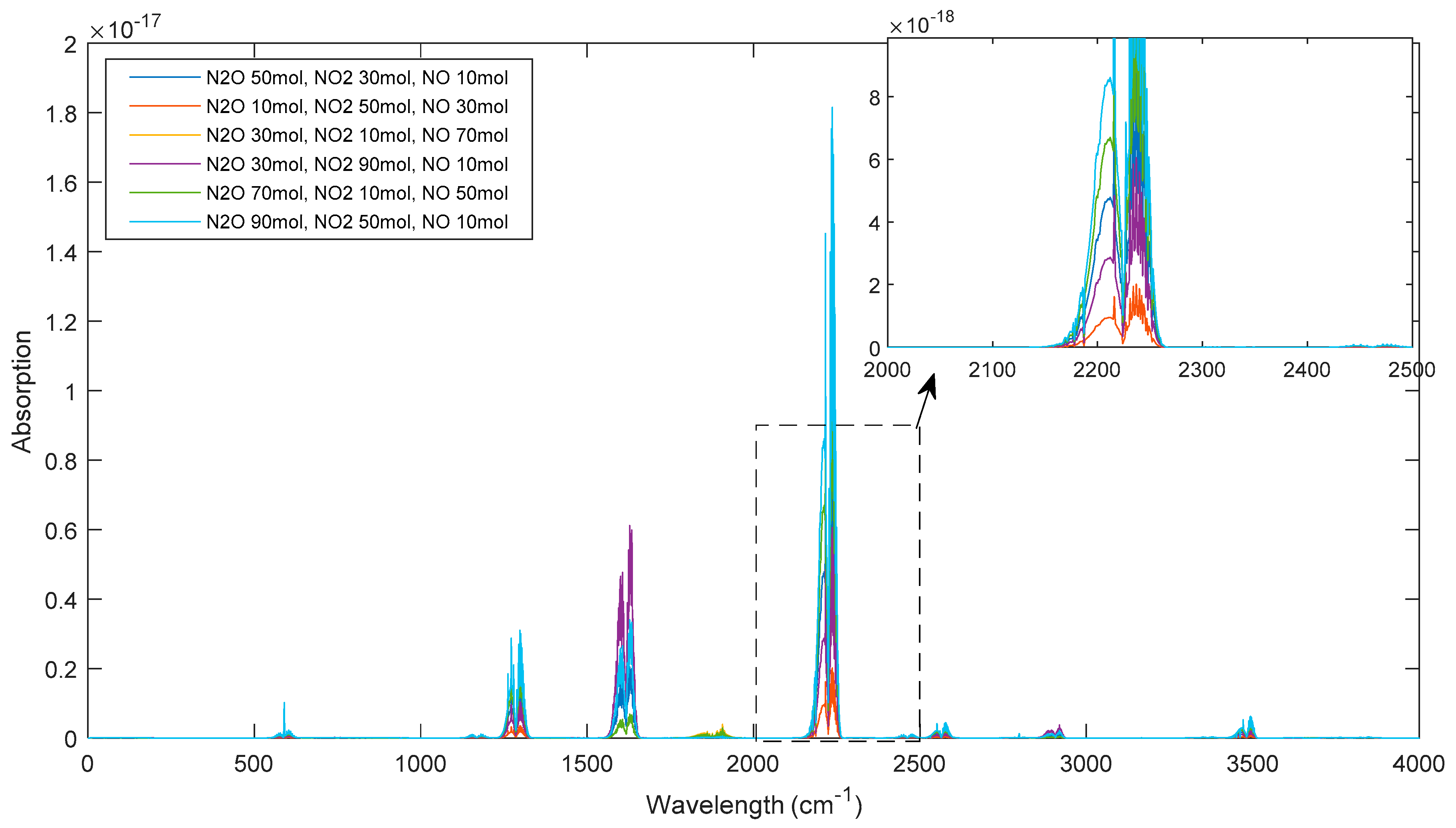
4.1. Generation of Simulated Data
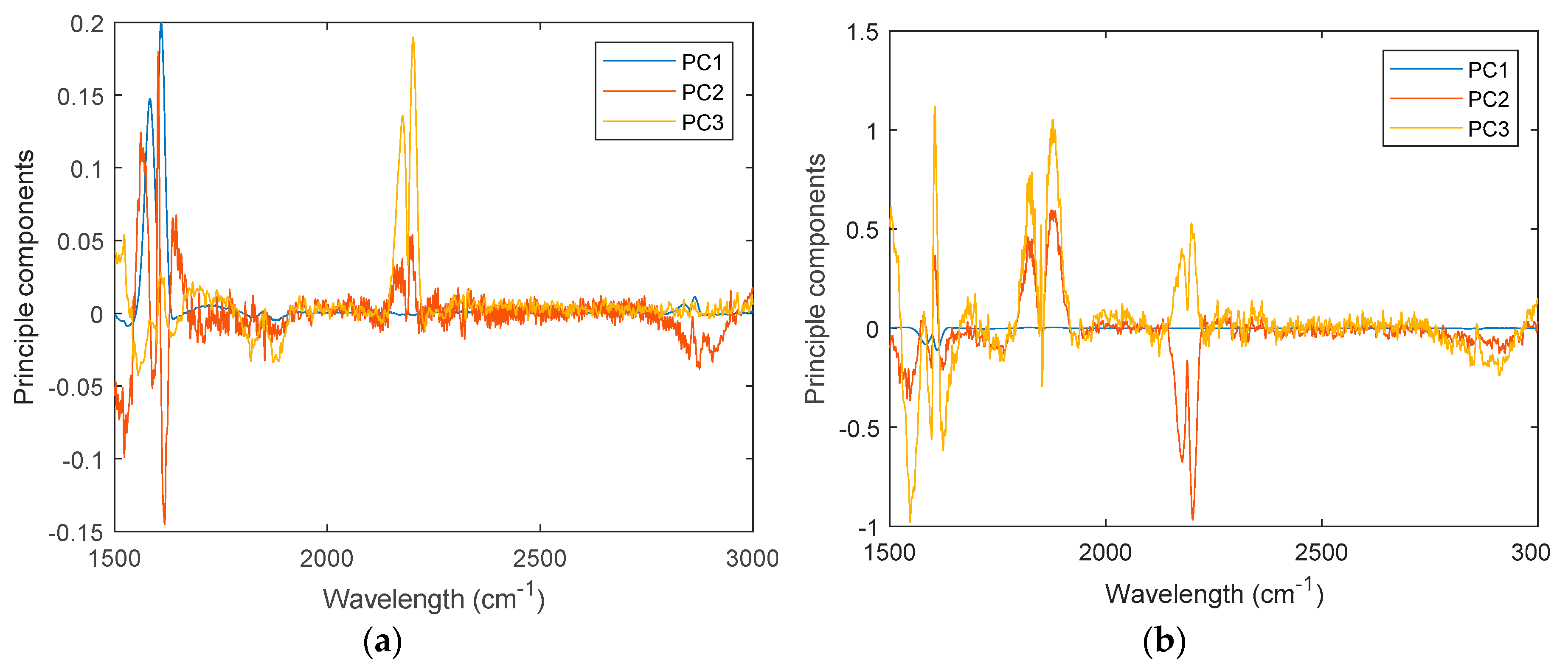
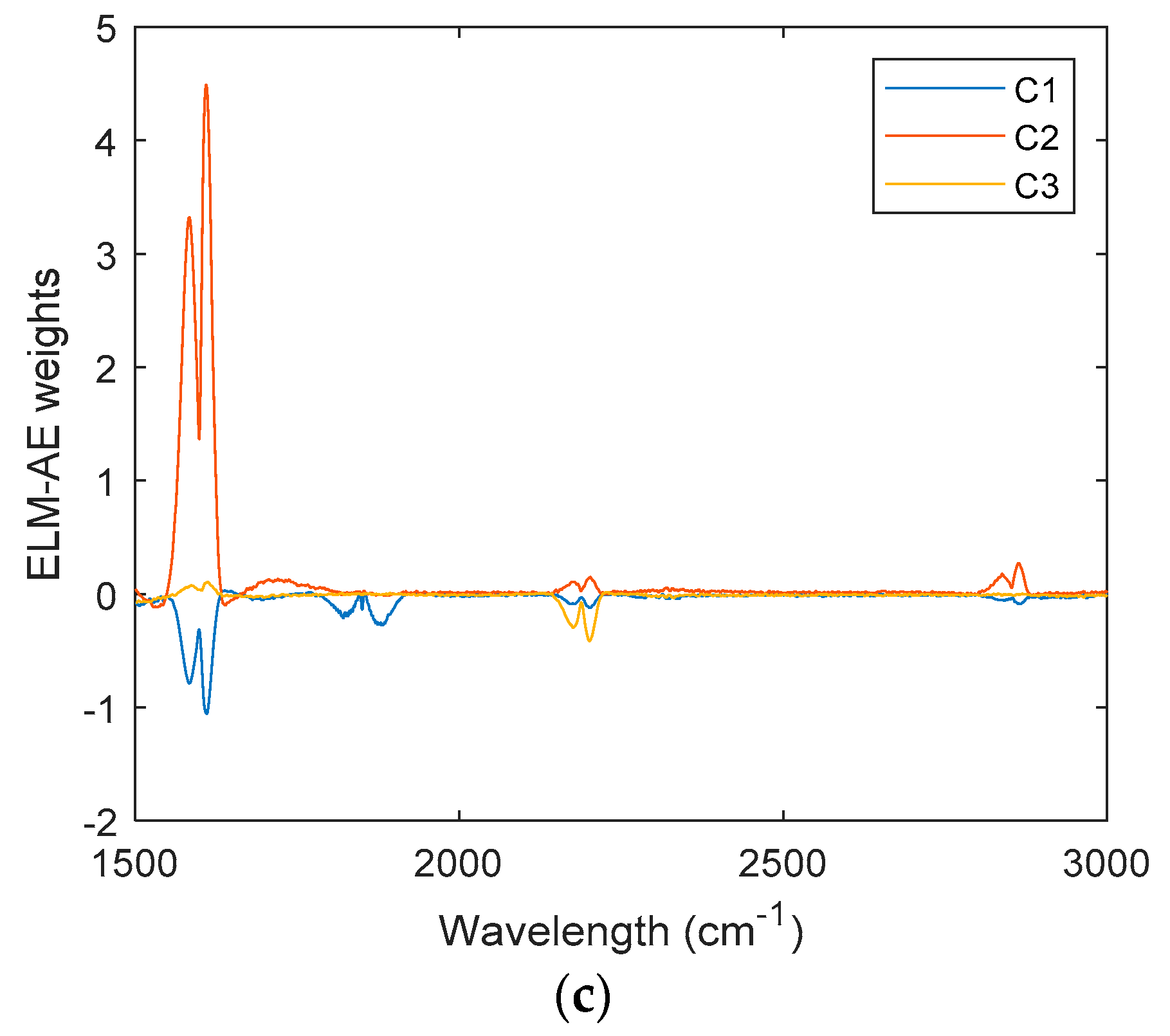
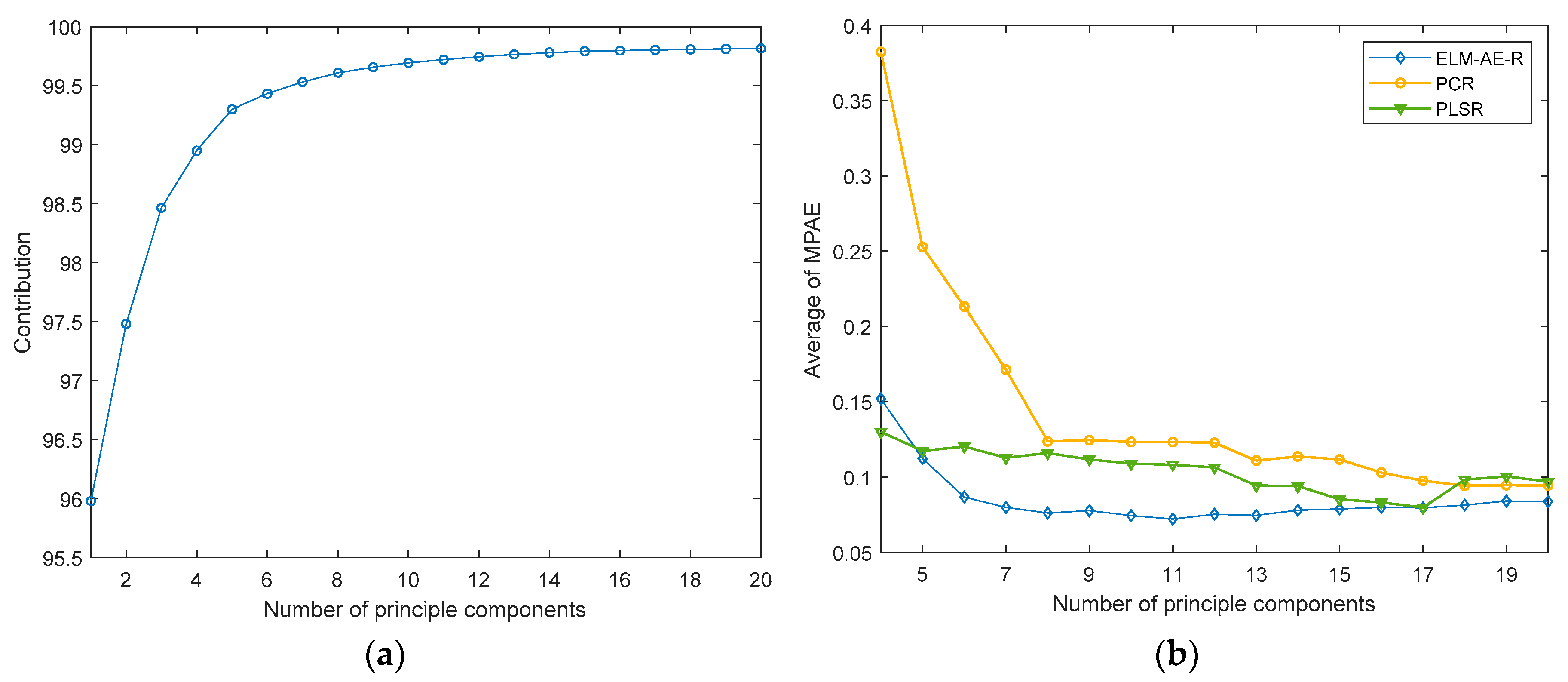
4.2. Analysis on Simulated Data
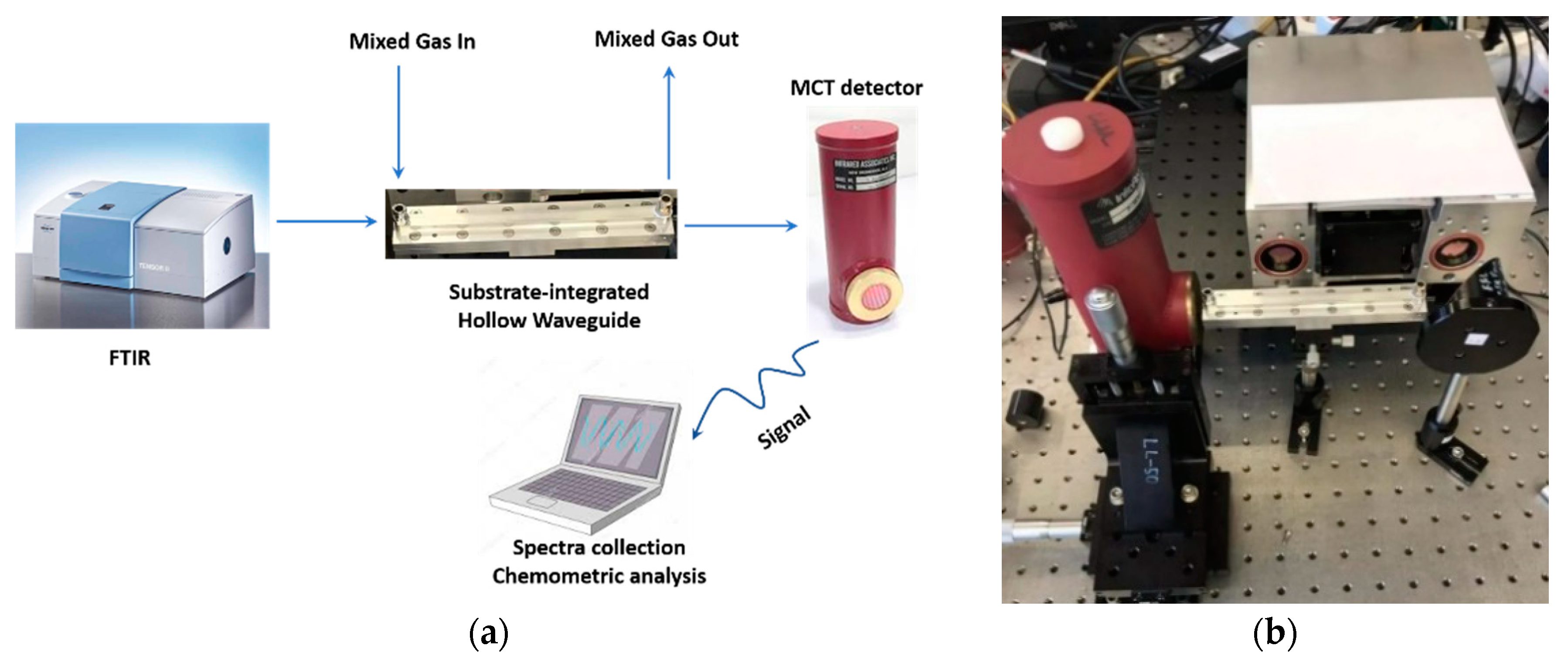
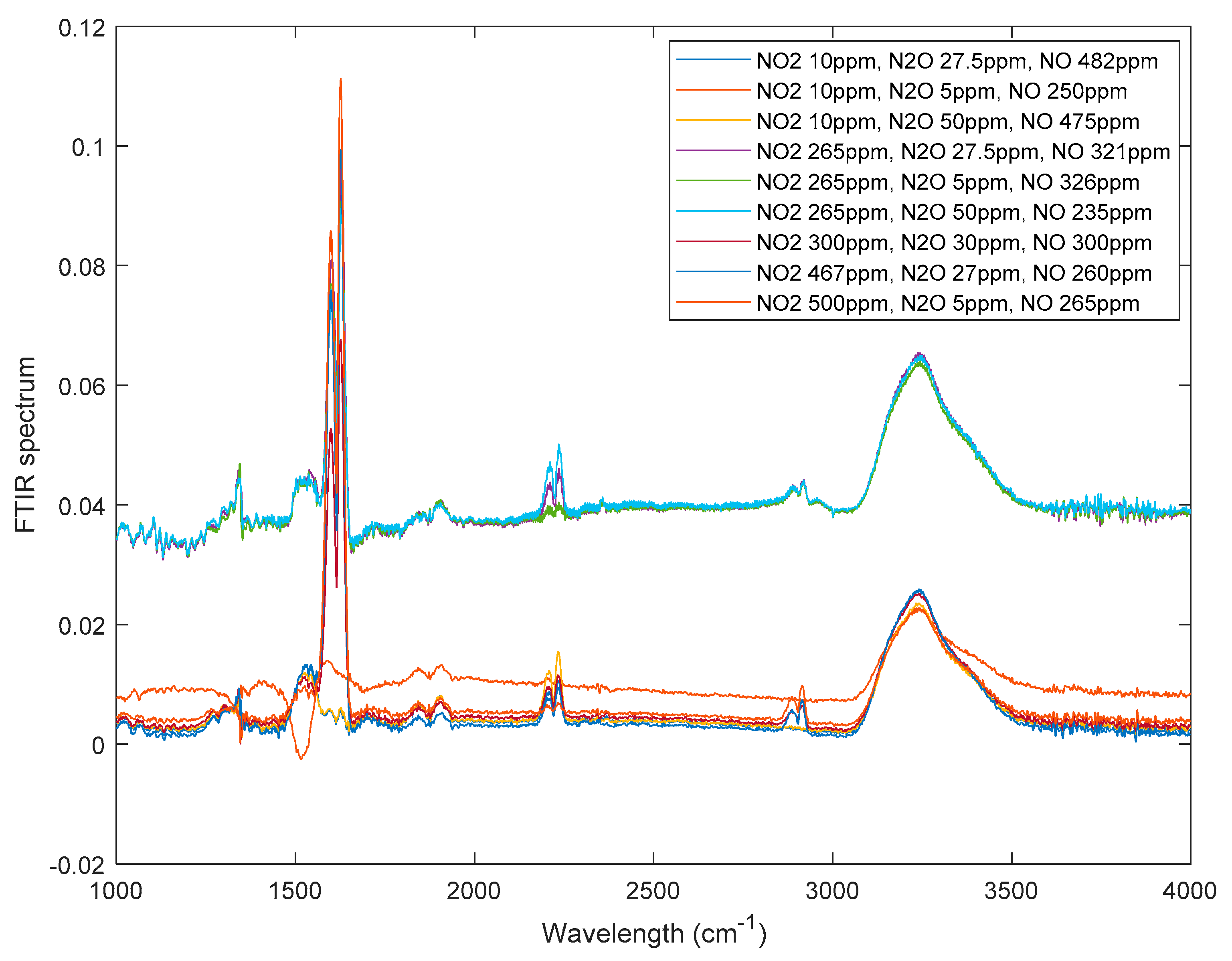
4.3. Actual Spectra Collection and Processing
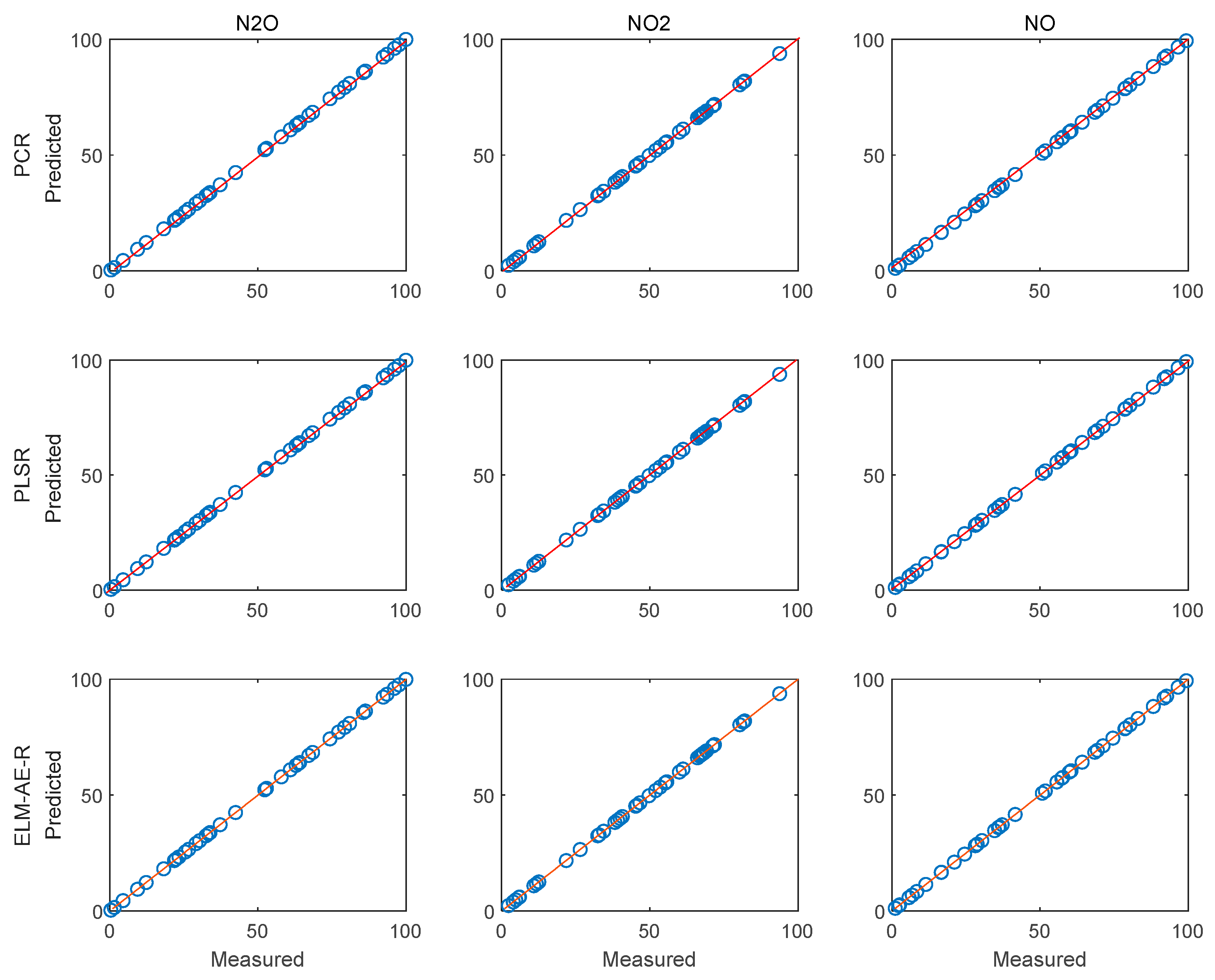
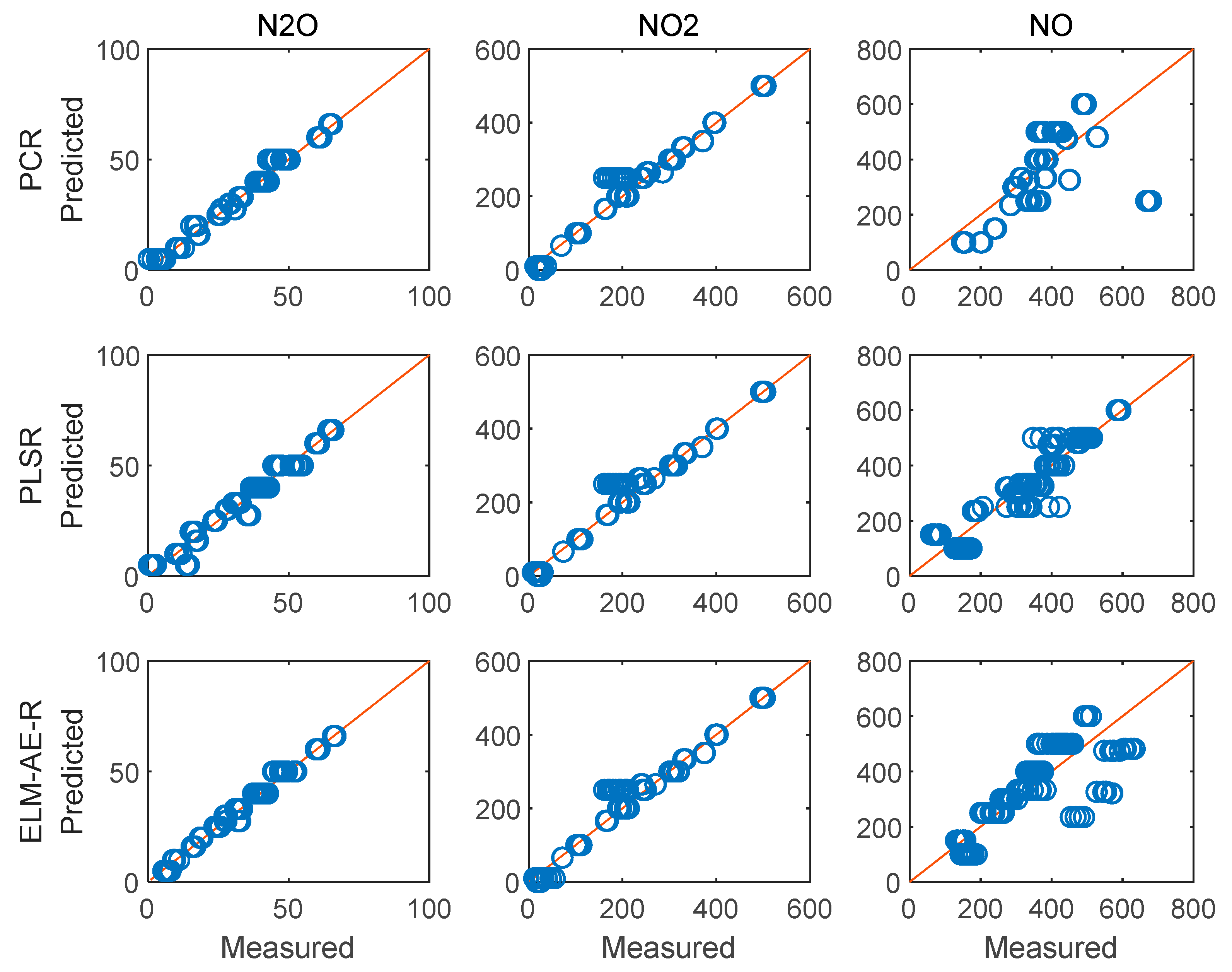
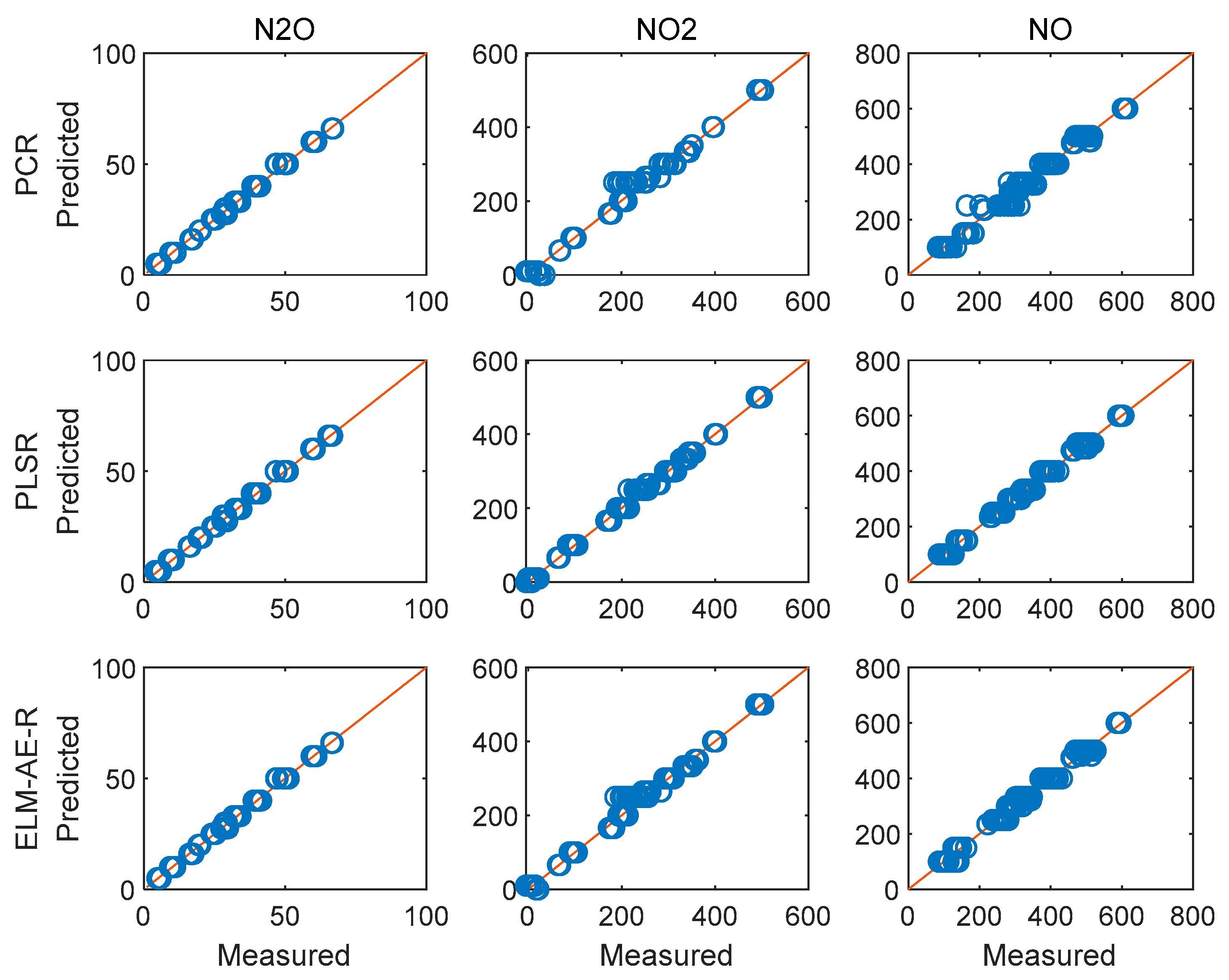
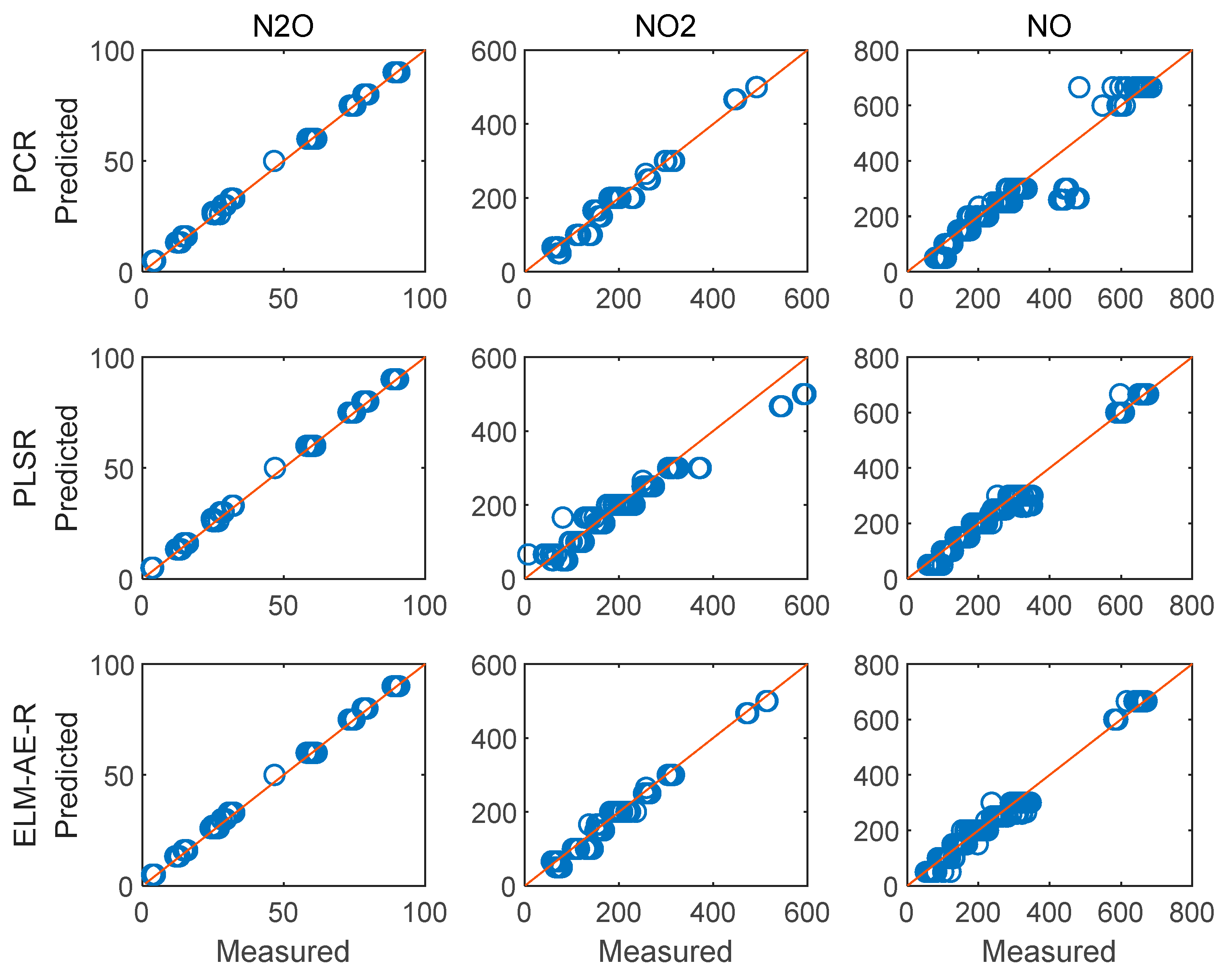
4.4. Regression Analysis and Concentration Prediction of Measurd Spectra
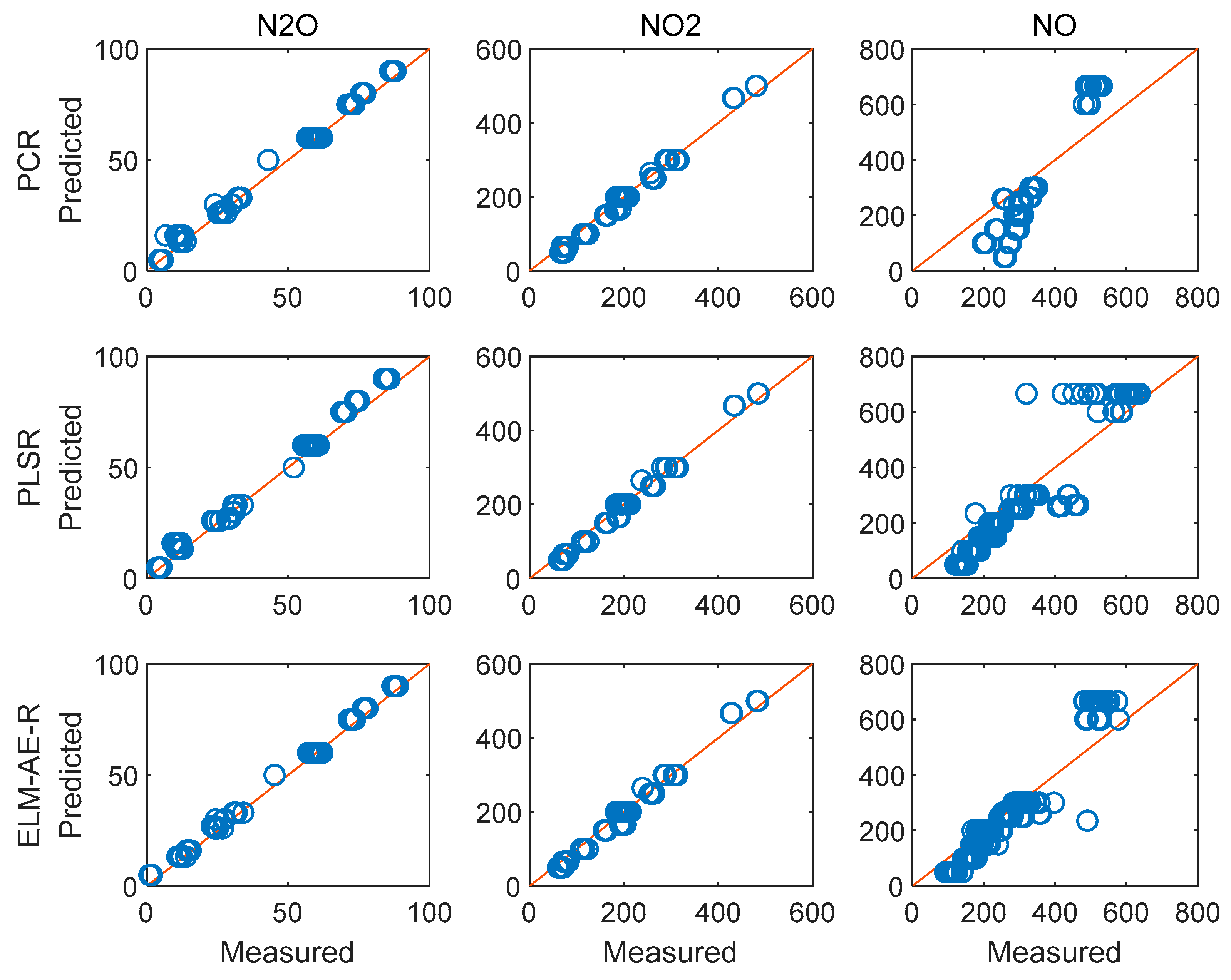
4.5. Improvement Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sun, Y.F.; Liu, S.B.; Meng, F.L.; Liu, J.Y.; Jin, Z.; Kong, L.T.; Liu, J.H. Metal oxide nanostructures and their gas sensing properties: A review. Sensors 2012, 12, 2610–2631. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, X.; Cheng, S.; Liu, H.; Hu, S.; Zhang, D.; Ning, H. A survey on gas sensing technology. Sensors 2012, 12, 9635–9665. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haas, J.; Mizaikoff, B. Advances in mid-infrared spectroscopy for chemical analysis. Annu. Rev. Anal. Chem. 2016, 9, 45–68. [Google Scholar] [CrossRef] [PubMed]
- Liana, D.D.; Raguse, B.; Gooding, J.J.; Chow, E. Recent advances in paper-based sensors. Sensors 2012, 12, 11505–11526. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tedford, C.E.; DeLapp, S.; Jacques, S.; Anders, J. Quantitative analysis of transcranial and intraparenchymal light penetration in human cadaver brain tissue. Lasers Surg. Med. 2015, 47, 312–322. [Google Scholar] [CrossRef] [PubMed]
- Fonollosa, J.; Rodríguez-Luján, I.; Trincavelli, M.; Vergara, A.; Huerta, R. Chemical discrimination in turbulent gas mixtures with mox sensors validated by gas chromatography-mass spectrometry. Sensors 2014, 14, 19336–19353. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eranna, G. Metal Oxide Nanostructures as Gas Sensing Devices; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Bernardoni, F.; Halsey, H.M.; Hartman, R.; Nowak, T.; Regalado, E.L. Generic gas chromatography flame ionization detection method using hydrogen as the carrier gas for the analysis of solvents in pharmaceuticals. J. Pharm. Biomed. Anal. 2019, 165, 366–373. [Google Scholar] [CrossRef]
- Rodriguez-Saona, L.E.; Giusti, M.M.; Shotts, M. Advances in infrared spectroscopy for food authenticity testing. In Advances in Food Authenticity Testing; Woodhead Publishing: Sawston, UK; Cambridge, UK, 2016; pp. 71–116. [Google Scholar]
- Haghi, R.K.; Yang, J.; Tohidi, B. Fourier Transform Near-Infrared (FTNIR) Spectroscopy and Partial Least-Squares (PLS) Algorithm for Monitoring Compositional Changes in Hydrocarbon Gases under In Situ Pressure. Energy Fuels 2017, 31, 10245–10259. [Google Scholar] [CrossRef]
- Via, B.; Zhou, C.; Acquah, G.; Jiang, W.; Eckhardt, L. Near infrared spectroscopy calibration for wood chemistry: Which chemometric technique is best for prediction and interpretation. Sensors 2014, 14, 13532–13547. [Google Scholar] [CrossRef] [Green Version]
- Lakowicz, J.R. Topics in Fluorescence Spectroscopy: Probe Design and Chemical Sensing; Springer Science and Business Media: Berlin/Heidelberg, Germany, 1994; Volume 4. [Google Scholar]
- Swinehart, D.F. The beer-lambert law. J. Chem. Educ. 1962, 39, 333. [Google Scholar] [CrossRef]
- Ayyalasomayajula, K.K.; Yu-Yueh, F.; Singh, J.P.; McIntyre, D.L.; Jain, J. Application of laser-induced breakdown spectroscopy for total carbon quantification in soil samples. Appl. Opt. 2012, 51, B149–B154. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.B.; Yao, M.Y.; Liu, M.H.; Lin, Y.Z.; Li, W.B.; Zheng, M.L.; Zhou, H.M. Quantitative Analysis of Laser Induced Breakdown Spectroscopy of Pb in Navel Orange Based on Multivariate Calibration. Acta Phys. Sin. 2014, 63, 104213. [Google Scholar]
- Cama-Moncunill, R.; Casado-Gavalda, M.P.; Cama-Moncunill, X.; Markiewicz-Keszycka, M.; Dixit, Y.; Cullen, P.J.; Sullivan, C. Quantification of trace metals in infant formula premixes using laser-induced breakdown spectroscopy. Spectrochim. Acta Part B At. Spectrosc. 2017, 135, 6–14. [Google Scholar] [CrossRef]
- Nicolodelli, G.; Romano, R.A.; Senesi, G.S.; Cabral, J.; Watanabe, A.; Telli, S.; Milori, D.M. Evaluation of Nitrogen Fertilization in Sugarcane Leaves Using Laser-Induced Breakdown Spectroscopy (LIBS) Coupled with Principal Component Analysis (PCA). In Proceedings of the Latin America Optics and Photonics Conference, Lima, Peru, 12–15 November 2018. [Google Scholar]
- Wang, H.; Peng, J.; Xie, C.; Bao, Y.; He, Y. Fruit quality evaluation using spectroscopy technology: A review. Sensors 2015, 15, 11889–11927. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ye, Q.; Spencer, P. Analyses of material-tissue interfaces by Fourier transform infrared, Raman spectroscopy, and chemometrics. In Material-Tissue Interfacial Phenomena; Woodhead Publishing: Sawston, UK; Cambridge, UK, 2017; pp. 231–251. [Google Scholar]
- Mahesh, S.; Jayas, D.S.; Paliwal, J.; White, N.D.G. Comparison of partial least squares regression (PLSR) and principal components regression (PCR) methods for protein and hardness predictions using the near-infrared (NIR) hyperspectral images of bulk samples of Canadian wheat. Food Bioprocess Technol. 2015, 8, 31–40. [Google Scholar] [CrossRef]
- Singh, M.; Sarkar, A. Comparative Study of the PLSR and PCR Methods in Laser-Induced Breakdown Spectroscopic Analysis. J. Appl. Spectrosc. 2018, 85, 962–970. [Google Scholar] [CrossRef]
- Niu, G.; Shi, Q.; Yuan, X.; Wang, J.; Wang, X.; Duan, Y. Combination of support vector regression (SVR) and microwave plasma atomic emission spectrometry (MWP-AES) for quantitative elemental analysis in solid samples using the continuous direct solid sampling (CDSS) technique. J. Anal. At. Spectrom. 2018, 33, 1954–1961. [Google Scholar] [CrossRef]
- Moncayo, S.; Manzoor, S.; Rosales, J.D.; Anzano, J.; Caceres, J.O. Qualitative and quantitative analysis of milk for the detection of adulteration by Laser Induced Breakdown Spectroscopy (LIBS). Food Chem. 2017, 232, 322–328. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B 2011, 42, 513–529. [Google Scholar] [CrossRef] [Green Version]
- Ouyang, T.; He, Y.; Huang, H. Monitoring Wind Turbines’ Unhealthy Status: A Data-Driven Approach. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 3, 163–172. [Google Scholar] [CrossRef]
- Kasun, L.L.C.; Yang, Y.; Huang, G.B.; Zhang, Z. Dimension reduction with extreme learning machine. IEEE Trans. Image Process. 2016, 25, 3906–3918. [Google Scholar] [CrossRef] [PubMed]
- Torrione, P.; Collins, L.M.; Morton, K.D., Jr. Multivariate analysis, chemometrics, and machine learning in laser spectroscopy. In Laser Spectroscopy for Sensing; Woodhead Publishing: Sawston, UK; Cambridge, UK, 2014; pp. 125–164. [Google Scholar]
- Li, Z.; Deen, M.J.; Kumar, S.; Selvaganapathy, P.R. Raman spectroscopy for in-line water quality monitoring—Instrumentation and potential. Sensors 2014, 14, 17275–17303. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Biagetti, G.; Crippa, P.; Falaschetti, L.; Orcioni, S.; Turchetti, C. Multivariate direction scoring for dimensionality reduction in classification problems. In Proceedings of the International Conference on Intelligent Decision Technologies, Puerto de la Cruz, Spain, 15–17 June 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 413–423. [Google Scholar]
- Gianfelici, F.; Biagetti, G.; Crippa, P.; Turchetti, C. A novel KLT algorithm optimized for small signal sets. In Proceedings of the (ICASSP’05) IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 23 March 2005. [Google Scholar]
- Haney, R.; Siddiqui, N.; Andress, J.; Fergus, J.; Overfelt, R.; Prorok, B. Principal Component Analysis (PCA) Application to FTIR Spectroscopy Data of CO/CO2 Contaminants of Air. In Proceedings of the 41st International Conference on Environmental Systems, Portland, OR, USA, 17–21 July 2011; p. 5091. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Kasun, L.L.C.; Zhou, H.; Huang, G.B.; Vong, C.M. Representational learning with extreme learning machine for big data. IEEE Intell. Syst. 2013, 28, 31–34. [Google Scholar]
- High-Resolution Spectral Modeling. Available online: https://www.spectralcalc.com/spectral_browser/db_data.php (accessed on 20 November 2019).
- Tütüncü, E.; Nägele, M.; Fuchs, P.; Fischer, M.; Mizaikoff, B. iHWG-ICL: Methane sensing with substrate-integrated hollow waveguides directly coupled to interband cascade lasers. ACS Sens. 2016, 1, 847–851. [Google Scholar] [CrossRef]
- Wilk, A.; Carter, J.C.; Chrisp, M.; Manuel, A.M.; Mirkarimi, P.; Alameda, J.B.; Mizaikoff, B. Substrate-integrated hollow waveguides: A new level of integration in mid-infrared gas sensing. Anal. Chem. 2013, 85, 11205–11210. [Google Scholar] [CrossRef]
- Da Silveira Petruci, J.F.; Fortes, P.R.; Kokoric, V.; Wilk, A.; Raimundo, I.M.; Cardoso, A.A.; Mizaikoff, B. Monitoring of hydrogen sulfide via substrate-integrated hollow waveguide mid-infrared sensors in real-time. Analyst 2014, 139, 198–203. [Google Scholar] [CrossRef]
- Jackson, M.; Mantsch, H.H. The use and misuse of FTIR spectroscopy in the determination of protein structure. Crit. Rev. Biochem. Mol. Boil. 1995, 30, 95–120. [Google Scholar] [CrossRef]
- Eilers, P.H.C.; Boelens, H.F.M. Baseline Correction with Asymmetric Least Squares Smoothing. Leiden Univ. Med. Centre Rep. 2005, 1, 5. [Google Scholar]
- Ouyang, T.; Zha, X.; Qin, L.; He, Y.; Tang, Z. Prediction of wind power ramp events based on residual correction. Renew. Energy 2019, 136, 781–792. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NO/mol | NO2/mol | N2O/mol | |
|---|---|---|---|
| 1 | 10 | 30 | 50 |
| 2 | 10 | 50 | 30 |
| 3 | 30 | 10 | 50 |
| 4 | 30 | 50 | 10 |
| 5 | 50 | 10 | 30 |
| 6 | 50 | 30 | 10 |
| ⋮ | ⋮ | ⋮ | ⋮ |
| Training Data | RMSE | R2 | ||||
| N2O | NO2 | NO | N2O | NO2 | NO | |
| PCR | 2.2417 | 17.6933 | 99.5121 | 0.9716 | 0.9819 | 0.5335 |
| PLSR | 3.2259 | 18.0488 | 44.0656 | 0.9413 | 0.9812 | 0.9085 |
| ELM-AE-R | 1.7082 | 18.5939 | 89.4675 | 0.9835 | 0.9801 | 0.6229 |
| Testing Data | RMSE | R2 | ||||
| N2O | NO2 | NO | N2O | NO2 | NO | |
| PCR | 2.2966 | 14.3814 | 121.2787 | 0.9900 | 0.9823 | 0.6129 |
| PLSR | 3.2336 | 14.3355 | 86.3352 | 0.9803 | 0.9824 | 0.8038 |
| ELM-AE-R | 1.8801 | 14.5293 | 74.5609 | 0.9933 | 0.9819 | 0.8537 |
| ELM-AE-R vs. PCR | ELM-AE-R vs. PLSR | |||
|---|---|---|---|---|
| Training | Testing | Training | Testing | |
| RMSE | 9.60% | 18.54% | −19.67% | 18.05% |
| R2 | 3.32% | 8.12% | −8.15% | 2.08% |
| Training Data | RMSE | R2 | ||||
| N2O | NO2 | NO | N2O | NO2 | NO | |
| PCR | 0.7841 | 12.9753 | 18.1921 | 0.9965 | 0.9903 | 0.9844 |
| PLSR | 0.8372 | 7.95820 | 12.3824 | 0.9960 | 0.9963 | 0.9912 |
| ELM-AE-R | 0.8000 | 10.2871 | 13.3505 | 0.9964 | 0.9950 | 0.9916 |
| Testing Data | RMSE | R2 | ||||
| N2O | NO2 | NO | N2O | NO2 | NO | |
| PCR | 0.8533 | 19.3015 | 59.1022 | 0.9986 | 0.9681 | 0.9081 |
| PLSR | 0.9415 | 31.0466 | 24.8107 | 0.9983 | 0.9176 | 0.9838 |
| ELM-AE-R | 0.9529 | 16.5519 | 23.1046 | 0.9983 | 0.9766 | 0.9860 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouyang, T.; Wang, C.; Yu, Z.; Stach, R.; Mizaikoff, B.; Liedberg, B.; Huang, G.-B.; Wang, Q.-J. Quantitative Analysis of Gas Phase IR Spectra Based on Extreme Learning Machine Regression Model. Sensors 2019, 19, 5535. https://doi.org/10.3390/s19245535
Ouyang T, Wang C, Yu Z, Stach R, Mizaikoff B, Liedberg B, Huang G-B, Wang Q-J. Quantitative Analysis of Gas Phase IR Spectra Based on Extreme Learning Machine Regression Model. Sensors. 2019; 19(24):5535. https://doi.org/10.3390/s19245535
Chicago/Turabian StyleOuyang, Tinghui, Chongwu Wang, Zhangjun Yu, Robert Stach, Boris Mizaikoff, Bo Liedberg, Guang-Bin Huang, and Qi-Jie Wang. 2019. "Quantitative Analysis of Gas Phase IR Spectra Based on Extreme Learning Machine Regression Model" Sensors 19, no. 24: 5535. https://doi.org/10.3390/s19245535