Gaze as a Window to the Process of Novel Adjective Mapping

1
Department of Psychology, University of Houston, Houston, TX 77204, USA
2
Department of Psychology, The Ohio State University, Columbus, OH 43210, USA
*
Author to whom correspondence should be addressed.
Languages 2019, 4(2), 33; https://doi.org/10.3390/languages4020033
Submission received: 19 October 2018
/
Revised: 27 April 2019
/
Accepted: 20 May 2019
/
Published: 3 June 2019
(This article belongs to the Special Issue Embodied Cognition and Language: Theoretical and Empirical Perspectives)
Abstract
:This study evaluated two explanations for how learning of novel adjectives is facilitated when all the objects are from the same category (e.g., exemplar and testing objects are all CUPS) and the object category is a known to the children. One explanation (the category knowledge account) focuses on early knowledge of syntax–meaning correspondence, and another (the attentional account) focuses on the role of repeated perceptual properties. The first account presumes implicit understanding that all the objects belong to the same category, and the second account presumes only that redundant perceptual experiences minimize distraction from irrelevant features and thus guide children’s attention directly to the correct item. The present study tests the two accounts by documenting moment-to-moment attention allocation (e.g., looking at experimenter’s face, exemplar object, target object) during a novel adjective learning task with 50 3-year-olds. The results suggest that children’s attention was guided directly to the correct item during the adjective mapping and that such direct attention allocation to the correct item predicted children’s adjective mapping performance. Results are discussed in relation to their implication for children’s active looking as the determinant of process for mapping new words to their meanings.
1. Introduction
Relative to their acquisition of common nouns, children learn adjectives slowly (Gasser and Smith 1998; Gentner 1982; Imai and Gentner 1997; Mintz and Gleitman 2002). This difficulty has prompted a number of studies that investigate supporting factors and the contexts in which adjectives can be successfully mapped to object properties. In these studies, experimenters present children with a novel object property attached to an exemplar item (e.g., small bumps made out of glue bits covering a bottle), label the property (“this is a stoof one”), and then ask the children to extend that label to other instances (Figure 1). Many of those studies documented the benefit of learning adjective-to-property mappings when the mappings are first made within the same basic-level category. For example, children were able to successfully learn when pairing a novel adjective with a novel property of a bottle and testing the child with other bottles having the target property and other novel properties (Klibanoff and Waxman 2000; Waxman and Klibanoff 2000).
One potential process for using same-category objects in adjective learning capitalizes on early knowledge of syntax–meaning correspondence in adjective mapping (Waxman and Kosowski 1990; Hall et al. 1993; Mintz 2005). We call this “the category knowledge account”. Within this framework, the novel label “stoof” is interpreted as an adjective after recognition that all the objects are from the same basic category. An alternative account, “the attentional account”, focuses on the role of perceptual similarities in directing attention right to the most similar object (Colunga and Smith 2005; Regier 2005; Smith et al. 1997), which is typically the correct choice for novel adjective learning (Figure 1). According to this account, the same-category advantage occurs at the initial response stage. Though these accounts both reflect the important contribution of early language knowledge and attentional processing in word learning, they propose a difference in mechanism that has not been demonstrated empirically.
Given that objects in the same category tend to have similar perceptual properties and are potentially learned through similar learning processes, testing these explanatory accounts directly can be challenging (for a review, Twomey et al. 2013). To address the issue, the present study documents moment-to-moment visual attention allocation (e.g., looking at experimenter’s face, exemplar object, target object) by fitting a head-mounted eye-tracker to each child during the typical novel adjective learning task. The study aims to determine whether knowing that all the objects are from the same category is important, i.e., whether the child tends to look at the presented objects equally, starting with any of the objects; or if perceptual overlap directs attention preferentially to the target object, i.e., if similarity of object shape cues attention directly to the target object during adjective mapping. Investigating different gaze behaviors that underlie task performance may reveal processes in lexical learning that may be hidden from traditional measures of task performance (i.e., accuracy, speed) and vocabulary. We first briefly review the literature on the role of nouns and category in children’s adjective learning and then consider the possible processes in this learning.
To learn about adjective meanings such as color, texture, and size, children must first learn about context–object categories. A number of studies report evidence of early formation of basic-level object categories (Eimas and Quinn 1994; Landau et al. 1998) and evidence that young children learn many nouns before they know many adjectives (Dromi 1996; Gasser and Smith 1998; Gentner 1982; Jackson-Maldonado et al. 1993; Nelson 1973; Sandhofer and Smith 2007). In particular, children tend to map novel adjectives to the corresponding properties within a common noun category, and they have more difficulty when the noun category is not a basic-level category (Baldwin and Markman 1989; Hall et al. 1993; Hutchinson 1984; Klibanoff and Waxman 2000; Waxman and Kosowski 1990; Waxman and Kosowski 1990). Further, a number of studies document the importance of accessibility of the noun category. For example, young children are more likely to successfully map a novel adjective to the correct property when the object is known to them (Clark 1997; Golinkoff et al. 1994; Hall et al. 1993; Mintz 2005; Smith and Heise 1992) and when the object’s name is explicitly mentioned (Mintz and Gleitman 2002), as in the sentence frame of “the stoof cup” rather in “the stoof one”.
The category knowledge account for the role of object category proposes that children develop an assumption that adjectives refer to property-based comparisons among the set of familiar basic level object categories (natural level category), such as dog, as opposite to animal and poodle (Gelman and Markman 1986; Waxman and Kosowski 1990; Klibanoff and Waxman 2000; Waxman and Booth 2003; Waxman and Klibanoff 2000). Accordingly, adjectives are most readily interpreted within the context of the basic level category that they modify (Dixon 1982; Gasser and Smith 1998; Gelman and Markman 1986; Medin and Shoben 1988; Waxman and Kosowski 1990). Indeed, categorization is essential for cognition in that it organizes information and aids memory for efficient learning. Category learning is robust and has been demonstrated even by young infants (e.g., Eimas and Quinn 1994). In this framework, one may expect children to have a specific expectation for adjectives in relation to the formed object category. Thus, initial attention should be guided to any object, and allocated across all the testing objects—to establish object comparisons within the same basic category.
An alternative account proposes that an object set selected from the same basic category supports perceptual redundancy, which makes the target property (i.e., the property named by the adjective) salient—perceptually and computationally—and thus directs attention. For example, previous studies concerning perceptual comparison and binding make it clear that, when perceptual differences vary along a single dimension, people can identify a specified property more readily than when multiple dimensions are involved (e.g., Klibanoff and Waxman 2000; Kemler 1983; Smith 1984, 1993; Gentner and Markman 1994; Goldstone and Medin 1994; Aslin and Smith 1988; Shipley and Kuhn 1983). The idea that objects from the same category often share both conceptual and perceptual commonalities is not a novel one; in fact, it underlies earlier proposals about the relevancy of competition and contrast in early word learning (Klibanoff and Waxman 2000; Mandler and Hall 2002; Mandler 2000; Eimas and Quinn 1994; Yoshida and Hanania 2013). However, the idea of commonalities also fits what is known about how attention is flexibly cued by past learning (Kruschke 1996, 2009; Chun and Jiang 1998; Darby et al. 2014; Burling and Yoshida 2016) and how the learned attentional shifts can reduce memory interference and improve word learning (Merriman 1999; Smith et al. 2002; Smith 2005; Yoshida and Smith 2005, Yoshida and Burling 2012).
For example, learning that similarly shaped objects tend to have the same name helps young children—as young as 17-month-olds—to attend to the object’s shape when the object is labeled by a novel name (Smith et al. 2002; Landau et al. 1998). This learned attention is strengthened as the child encounters more of such instances—same shaped objects having the same name—and the additional experience propels word learning further (Smith et al. 2002). A number of models of word learning point to the direct effect of learned associations on attention (Elman 1993; Plunkett and Marchman 1991). Further, direct evidence of a relation between successful attention to target properties and performance on an attentional control task has been previously noted (Yoshida et al. 2011). However, how attention reflects immediate task context during novel adjective learning has not been documented.
In the experiment reported here, we recorded eye fixation as an index of “looking” during novel adjective mapping to identify the processes underlying the ability to learn to use novel adjectives. To ensure the previously reported basic category advantage, we tested children’s adjective extension within and beyond the basic level category constraint (the “same” versus “different” condition as a between-subjects variable). The working hypothesis regarding the gaze information is that, if knowing that objects are from the same category is important (category knowledge account), then successful adjective learning will depend on attention being guided to any object at first and distributed among presented objects (exemplar, target object, and two distractor objects). Thus, a distributed looking pattern should predict children’s accuracy. By contrast, if perceptual repetition guides attention, then children’s looking will be guided directly to the target object (e.g., above chance), and the initial gaze shifts to the target object should better predict a child’s accuracy.
Study
The goal of this study was to understand how showing objects from the same basic category facilitates children’s learning of novel adjectives attached to familiar objects. We first replicated the advantage of using the same category objects during the novel adjective mapping task (Gelman and Markman 1986; Klibanoff and Waxman 2000; Waxman and Booth 2003). In this task, children were shown an exemplar object (e.g., a bumpy object) and then asked to choose among (1) a target test object (e.g., another bumpy object); (2) a distractor test object (e.g., a rough-surfaced object); and (3) another distractor test object (e.g., a smooth object). Half of the children were presented with novel adjectives in the Same Category condition (exemplar, target test object, and other test objects are all from the same basic category); the remaining children participated in the Different Category condition, in which they were presented with an exemplar object (a bumpy mouse, followed by three test objects differing from the exemplar object category (bumpy penguin, rough-surfaced penguin, and smooth penguin). Children were expected to select the target test object (correct choice) more often in the Same Category condition than in the Different Category condition. This will set up the foundation critical for the present study in which we test how the different performances are predicted by the key attentional patterns. If sensitivity to the category membership of objects underlies the benefit (category knowledge account), then children’s attention should be directed to any object initially and distributed among presented test objects. This might be especially true in the Same Category condition, where successful novel adjective mapping is expected, and success is predicted by this type of distributed looking pattern. By contrast, if perceptual repetition guides attention directly to the target object (attentional account), then initial gaze shifts to the target object would be more apparent, and this type of looking pattern should better predict a child’s accuracy.
2. Materials and Methods
2.1. Subjects
Fifty 3- to 4-year-old children (18 male and 32 female) participated. All the participants came from English-only speaking families with a mean age of 45.7 months (range 36.20–54.80, SD = 5.3). The ethnic background of parents included Caucasian (50%), African American (10%), Hispanic (28%), and Asian (12%). Children were recruited from communities in Houston, TX, USA. Children were randomly assigned to one of two conditions: The Same Category condition and the Different Category condition. Parents were asked to fill out social economic status (SES) queries taken from the MacArthur Network on SES and Health (MacArthur and MacArthur 2013). This allows assessment of the role of SES on children’s cognitive task performance and academic achievement (e.g., Smith et al. 1997; Bradley and Corwyn 2002; Davis-Kean 2005; Biedinger 2011). The key section used for the current study concerns family income (see Table 1). The median family income of children who participated in the present study was $66,500, which falls within the middle SES range ($61,372 to $77,713) for the US (Fontenot et al. 2018). We found no significant group difference (Same Category condition vs. Different Category condition) in these SES measures, t(37) = −0.130, p = 0.897.
2.2. Procedure
All subjects gave their informed consent for inclusion before they participated in the study. The study was conducted in accordance with the Declaration of Helsinki, and the protocol was approved by the Institutional Review Board (IRB) of the University of Houston 07148-02. The child and parent were taken to a room containing a small table, chairs, a set of adjective task objects, and the video-capturing devices. The small chair for the child was located so that the child and experimenter could sit face to face with the table between them, and another chair was placed behind the child for the parent to sit on during the experiment. The small 75 cm × 50 cm table had a shelf on which the exemplar object was displayed without being occluded by other test objects. A wall-mounted camera at a distance of 2.5 m captured the task scene in a third-person view (TPV: See Figure 2A, right). A head-mounted eye tracking system was used to capture the child’s first-person view (FPV: See Figure 2B, right) and his or her point-of-regard (Franchak et al. 2011).
Correspondence between eye images and egocentric FPV images was achieved using a manual calibration procedure consisting of a board measuring 60 cm × 40 cm that displayed nine spatially distributed stickers. We calibrated gaze direction during the beginning and end of each experiment by pointing to each sticker to attract the child’s attention to a particular point in the image space. After calibration, an experimenter initiated recording on all video capturing devices and started the adjective task experiment. The entire experiment, including setup time (e.g., instruction, calibration), took approximately 30 min.
2.3. Adjective Task
All children participated in one of two conditions, the Same Category condition or the Different Category condition, for the novel adjective task. Both conditions included two phases: A familiarization phase that provided the child with the basic rule of the task; and a test phase, which measured children’s ability to extend a newly introduced label (e.g., stoof) to another object having the same novel property (e.g., small bumps made out of glue bits covering the object). For each child, we randomly used 6 novel adjectives from 10 novel adjective labels selected from previous studies: blickish, dax, equish, faunish, fepp, kekish, pradish, stoof, wugg, and zav (e.g., Klibanoff and Waxman 2000; Waxman and Klibanoff 2000). The appropriate properties were realized on the target objects by covering the surface with small raised bumps, small colored spots, or a textured ribbon, or by cutting small round holes through the object. The toy objects were approximately 10 cm × 10 cm × 10 cm and consisted of typical representations of six object categories: Balls, bottles, cars, penguins, seals, and toothbrushes. In the familiarization phase, the child was presented a set of familiar objects (e.g., hat, pig, spoon, apple, and elephant), and the experimenter presented a duplicate of each object in a random order and asked the child to pick the identical object from the set by saying, “See these, can you get me the hat?”. This was repeated up for four trials, and all the participants provided at least three consecutive correct responses. The test phase, which consisted of four trials, immediately followed the familiarization phase. The mean proportion of the correct responses on test trials was recorded as the measure of accuracy.
For each test trial, the child was shown an exemplar object that was a member of an early learned noun category1 (e.g., penguin), of a specific color (e.g., orange) with the to-be-tested property (e.g., small bumps covering the penguin) and was told, “This is a stoof penguin.” This labeled exemplar remained on the table. The child was then shown three new penguins (Same Category condition), immediately followed by a query “Can you get me the stoof penguin?” (See Figure 3A). Experimenter was trained to hold the three test objects in the way that their hands largely occlude the objects and quickly bring them to the table to prevent children to have clear view of each object and the category information during the transition. For the Different Category condition, a different exemplar (e.g., mouse) was used (See Figure 3B). The child’s score was the number of target test objects selected. All the test objects in both conditions were of the same color, which was different from the color of the exemplar. A target test object had the same target property as the exemplar (e.g., bumpy), but distractor test objects did not (e.g., one was rough and another was shiny instead). There were six trials with which six properties and corresponding adjectives were tested (see Appendix A). The six trials were randomly ordered for each participant, and the location in which the target test object appeared was also equally distributed according to a chi-square test comparing the relationship between the target test object and its location (left position, middle position, or right position), X2 (2, N = 1013) = 3.492, p = 0.174.
The purpose of having the two conditions is two-fold. The first purpose is to ensure that the design replicates the advantage of having all objects come from the same basic category before trying to determine the mechanism underlying the advantage. The second purpose is to evaluate the process. For this purpose, gaze patterns during the task are the behaviors of concern. The purpose does not depend on revealing an accuracy difference between conditions but on a process difference, which would be reflected in patterns of eye movements. If a particular gaze pattern is exclusive to the Same Category condition, this would serve to characterize the advantageous “looking” associated with the processing of objects/noun categories of the same basic category. It is important to note that the only difference between the two conditions is in the test phase. Figure 3 shows one of the eight stimulus sets used in the Same Category condition and in the Different Category condition.
Video Processing and Annotation of Looking Behavior
Mapping the eye position to the first-person view (FPV) image coordinates was completed offline using the Yarbus software, which also superimposed a circular graphic (representing the infant’s focal area of attention) onto the estimated gaze position coordinates (Franchak et al. 2011). The exported video with superimposed eye tracking information had a resolution of 640 × 480 pixels, corresponding to a 42.2° vertical and 54.4° horizontal angle. The final TPV and FPV images were synchronized at 30 frames per second and imported into the Datavyu coding software (datavyu.org, Datavyu Team 2014) for analysis by humans.
A child’s “looking” was determined according to the gaze position estimated from the eye tracker. We specifically computed the frequency of direct looking by annotating the object (target test object, one distractor test object, or the other distractor object) to which children’s attention was directly shifted after the presentation of test objects. If the child’s initial attention was shifted to the experimenter’s face, the saccade following such attention was annotated as a direct look (Birch et al. 2010). To validate the duration of looks, we annotated the onset and offset of each gaze shift for each of the specific items (target test object, distractor test objects) and coded the frequency. We excluded optical artifacts such as unrealistic eye movements due to eye-tracker movement or slippage through recalibration and saccades (<33 ms) to focus on gaze behaviors relevant to information processing (Kooiker et al. 2016). Two research assistants were thoroughly trained in the laboratory to annotate these variables. Reliability was measured by fully recoding four of the participants at random and checking interrater reliability between independent coders. The interrater reliability calculated using Krippendorf’s alpha was 0.982, indicating a high level of reliability (Krippendorf 2004).
2.4. Analytic Approach
To replicate the expected advantage of using objects from the same basic category, we compared the mean proportion of correct adjective mappings between the conditions. We then addressed the key question of the underlying mechanism by counting the frequency of direct gaze shifts to the target test object and determining whether direct attention to target a test object predicts the accuracy of adjective mapping. To further characterize a child’s looking behavior during the novel adjective mapping, we compared the duration of looking at the exemplar, the experimenter’s face, the target object, and the distractor objects. The last analysis was planned to reveal the type of information children are gathering during the task.
3. Results
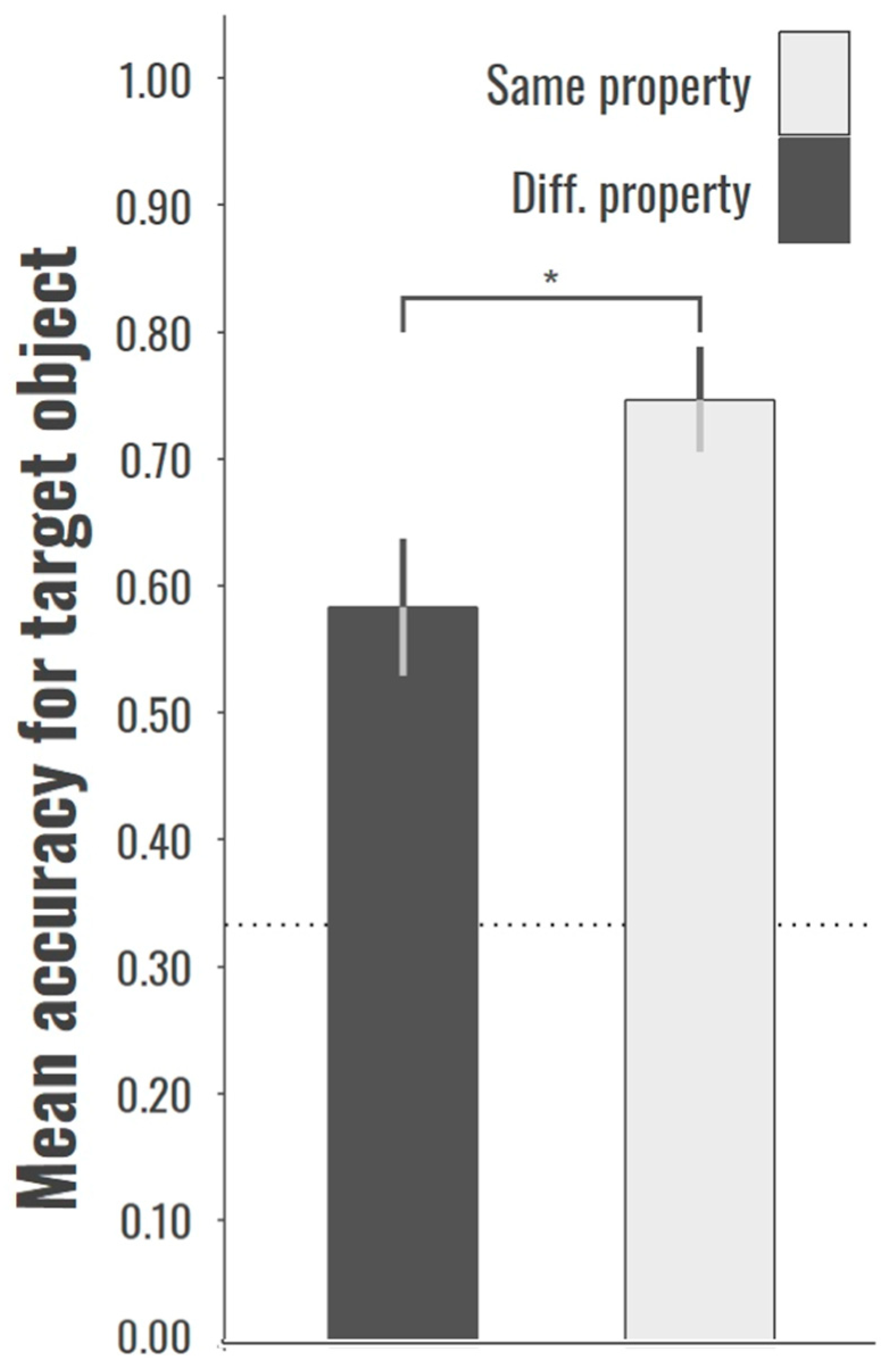
Before addressing the key question, the question of the underlying mechanism, we considered children’s performance accuracy to ensure that the study replicates previous findings of an advantage of using objects from the same basic category, relative to objects from different basic categories. There was a significant difference in the mean proportion of correct responses between the Same Category and Different Category conditions, t(38) = 2.43, p < 0.05. Children in the Same Condition outperformed children in the Different Condition. The mean proportion of correct responses was above chance (at 0.33) for both the Same and Different Conditions, t(26) = 8.89, p < 0.01, and t(22) = 4.80, p < 0.01, respectively (See Figure 4). There was no age-related performance difference for either the Same Category, F(1, 25) = 4.11, p = 0.053, R2 = 0.141 or the Different Category condition, F(1, 21) = 0.711, p = 0.390, R2 = 0.035.
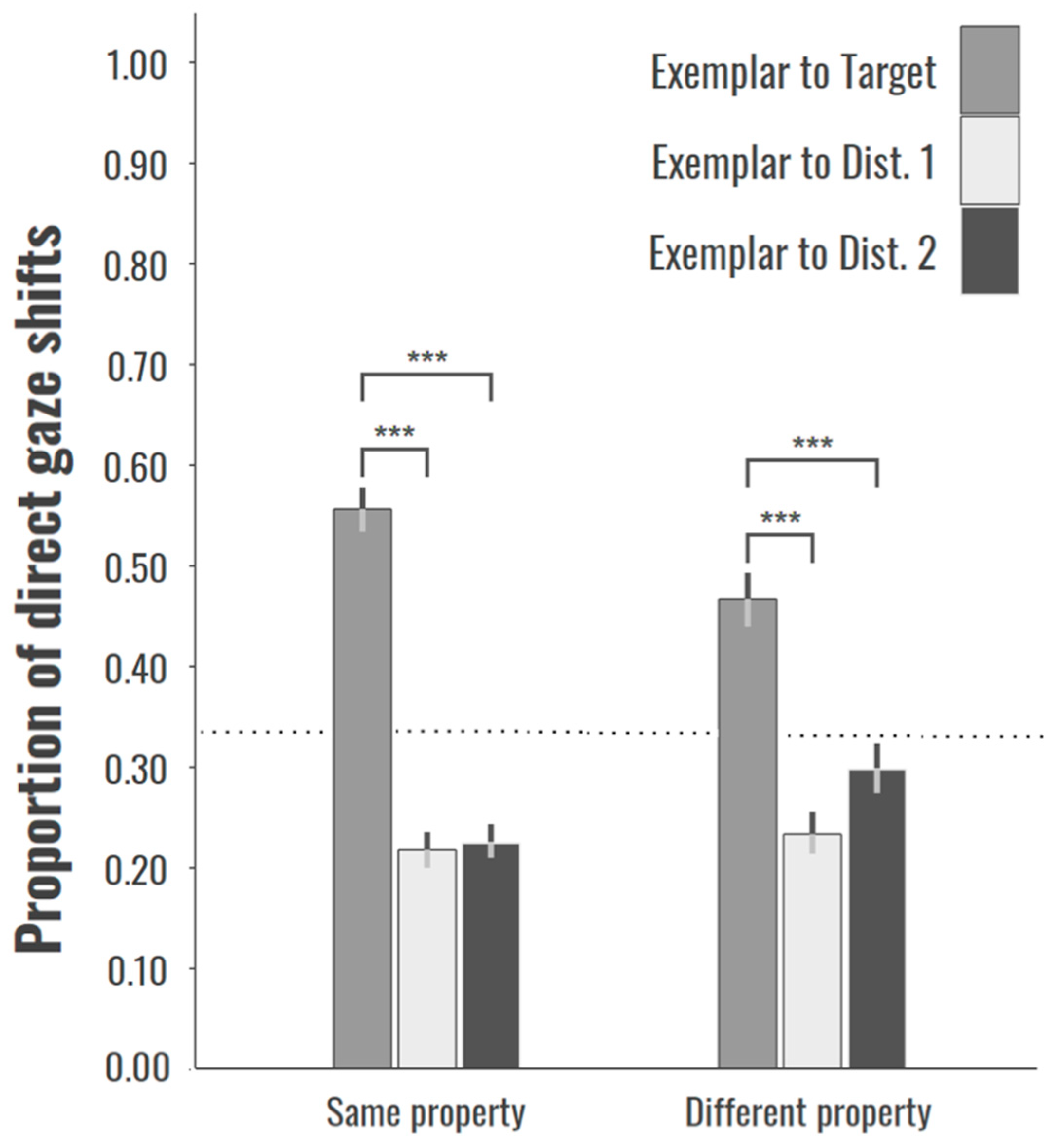
Next, we compared the frequency of directly looking at the target test object and at each of the distractor objects. For the Same Category, direct looks at the target object were more frequent than at either distractor object, t(26) = 11.97, p < 0.001, and t(26) = 12.07, p < 0.001, respectively, and also for the Different Category conditions, t(20) = 6.95, p < 0.001, and t(20) = 4.65, p < 0.001, respectively. Irrespective of condition, direct looking at the target test object dominated the children’s looking behavior—significantly above chance levels (0.33) for the Same, t(26) = 5.56, p < 0.001, and Different conditions, t(22) = 4.903, p < 0.001 (Figure 5). However, regression analysis indicated that frequency of child’s direct attention at the target test object predicted mean proportion of correct adjective mappings only for the Same Condition, F(6, 26) = 2.70, p < 0.05, R2 = 0.49. No comparable relationship was obtained for children in the Different Condition, F(6, 22) = 1.51, p = 0.76 (see Figure 5).
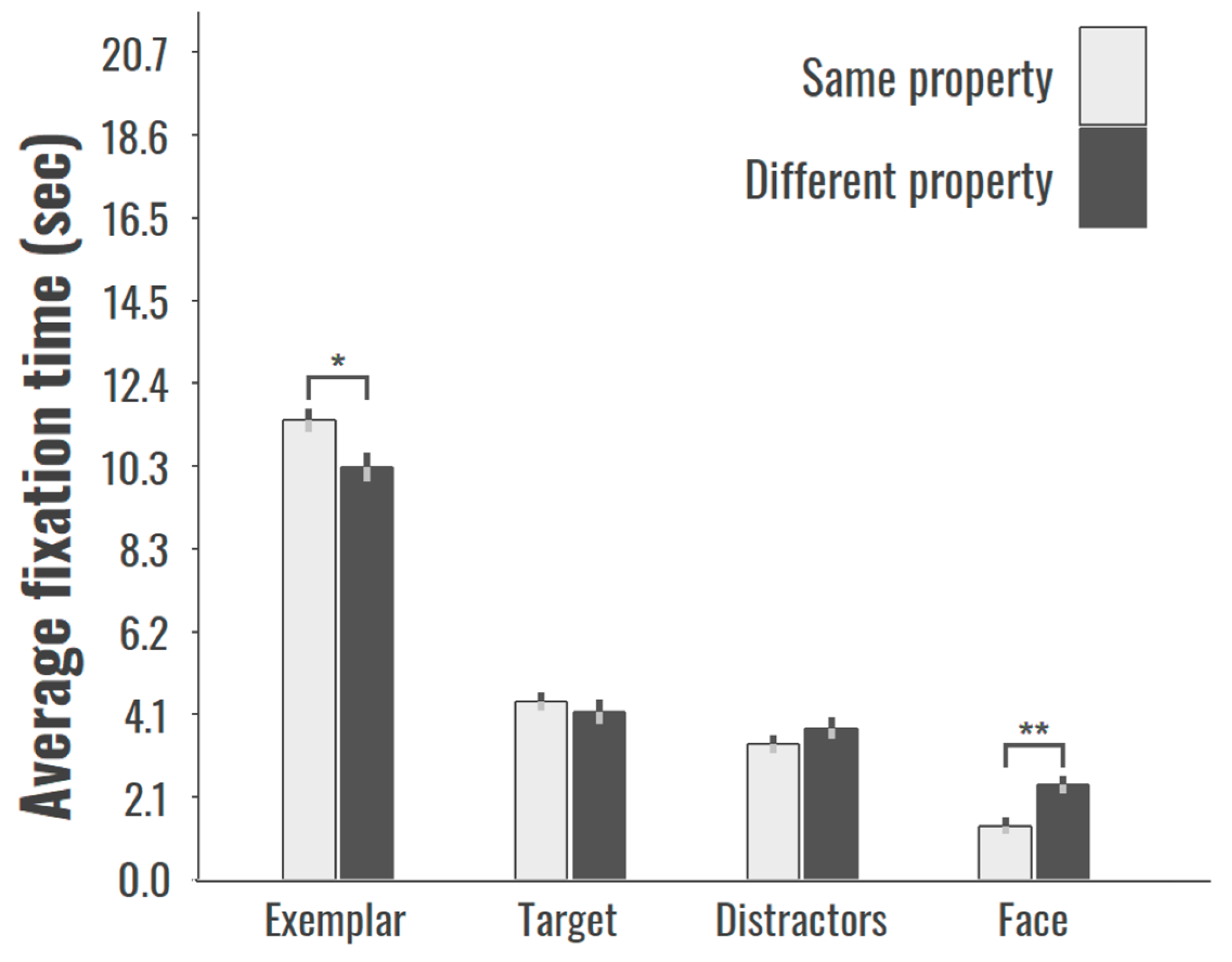
We also compared the two conditions with respect to the mean duration of looking at the exemplar, the experimenter’s face, the target object, and the distractor test objects. There was no effect of condition for the duration of looking at the target object, t(48) = −0.22, p = 0.83, or the distractor, t(48) = −1.56, p = 0.13, but children in the Same Category condition spent more time looking at exemplar, t(39.7) = 2.51, p < 0.05, and less time looking at the experimenter’s face, t(42.7) = 3.24, p < 0.01 (See Figure 6).
4. General Discussion
The present study sought to elucidate the basis of the previously reported advantage of using the same category of objects during the novel adjective mapping task (e.g., Klibanoff and Waxman 2000; Waxman and Klibanoff 2000). Past accounts regarding the relation between object category and children’s extension of novel adjectives vary in terms of the potential underlying processes. One focuses on category knowledge and thus presupposes children’s recognition of object category membership. Another account proposes that attention is guided directly by perceptual characteristics of within-category objects. Since objects in the same category tend to have similar perceptual properties, the confound makes it difficult to tease these accounts apart. The present study used children’s looking behaviors to shed light on our understanding of the processes responsible for the advantage of using same-category objects in novel adjective mapping. Our findings replicate the advantage and suggest the direct role of perceptual arrangement in guiding attention and predicting the successful mapping.
One unexpected finding is that although direct looking for the Different Category condition was not predictive of novel word learning performance, direct looking at the target test object proved to be the dominant initial response in both conditions. One possibility is that the redundancy between test object and distractors is sufficient to facilitate moving attention immediately to the target test object (which has a distinctive feature) but not sufficient to enhance performance. There is an unclear relation between direct looking and actual performance, yet the significant difference between conditions in children’s duration of gaze at the experimenter’s face—children looked the experimenter’s face longer in the Different Category condition—seems to reflect the greater ambiguity in the Different Category situation (Nappa et al. 2009). This is an interesting possibility because it suggests that multilevel processes support word learning. Future work needs to address the extent to which attention predicts performance not only in the scanning of available response choices but at different phases of the task that have been neglected in previous studies.
Cued Attention—Word or Perceptual Redundancy?
The present study was motivated by assumptions regarding the role of category knowledge (Gelman and Markman 1986; Waxman and Kosowski 1990; Klibanoff and Waxman 2000; Waxman and Booth 2003; Waxman and Klibanoff 2000) and the computational power of statistical learning that guides attention (Hayhoe and Ballard 2005; Henderson and Ferreira 2004; Desimone and Duncan 1995; Fecteau and Munoz 2006; Wolfe et al. 2007; Fisher and Aslin 2002; Turk-Browne et al. 2005). The results support the latter assumption, viz. cued attention. Rapid deployment of attention depends on past experience and past learning in various task contexts (Brockmole et al. 2006; Chun and Jiang 1998; Henderson and Hollingworth 1999; Neider and Zelinsky 2006; Torralba et al. 2006; Dahan and Tanenhaus 2005; Huettig and Altmann 2007). A large amount of literature suggests that the natural statistics of the learning context (e.g., speech and scenes) effectively direct attention: Words that are consistently associated with a visual referent in those scenes rapidly direct attention to visual experiences (Bergelson and Swingley 2012; Tincoff and Jusczyk 2012; Borovsky et al. 2012; Griffin and Bock 2000). In this framework, the present study further documented the potential power of newly obtained experiences (viewing a novel property paired with a novel label) in directing attention.
One clear limitation of the current paradigm is its inability to pinpoint the aspect of the child’s experience that guides attention. It could be that mere visual redundancy (a newly exposed object property reappearing in a similar perceptual arrangement) creates memory-guided attention (e.g., Chun and Jiang 1998), or the simple redundancy may create a saliency-based “pop-out” effect (Krummenacher et al. 2001), which may require the least learning. Or the learned association between the newly heard word and the target property, which now appears in a similar perceptual arrangement, could guide attention in a manner similar to language-mediated attention (e.g., Borovsky et al. 2012; Griffin and Bock 2000; Vales and Smith 2015).
Accordingly, though these putative cuing effects (with the possible exception of the pop-out like effect) are clearly organized by co-occurrences and predictive control of attention, and all the effects are supported by a perceptually similar context (the Same category condition), one nevertheless may argue that the processes by which these cues direct attention can be different. If perceptual similarity alone plays the role in guiding attention, then mere exposure to an exemplar object (even without the naming of objects) would guide attention to the target test object. In this case, the nonlinguistic attentional process supports the advantage of within-category objects for novel adjective mapping. This conjecture demands further studies that focus on how nonlinguistic general processes support the use of same objects in novel adjective mapping and contribute to language development (Darby et al. 2014; Yoshida and Burling 2012). Simple processes, including “pop-out” effect and perceptual redundancy, may be available to younger learners in word-learning contexts. Then, when children have acquired better working memory—and can effectively generate representations of recently learned words—novel adjective learning extends beyond perceptual learning. Repeated visual exposure to a set of objects can promote attention to “typical” objects in a cluttered context with many potential meanings that might be more likely to get named. On the other hand, if words (“stoof”)—by their predictive regularities to the relevant portions of visual scenes—guide attention to a recently associated property (in a similar context such as shape), then linking words to relevant perceptual experiences will help young learners to attend to the right information for learning (Lupyan and Spivey 2010). Then the naming of the object strengthens (and/or maintains) activation of the corresponding representation, and the process is enhanced further by a perceptually similar task context.
Recent studies have shown that three-year-old children are faster to find objects in cluttered scenes if they are cued with the object name than if they are cued with the object picture (Vales and Smith 2015). This suggests the potential role of interaction between words and visual working memory representations in directing attention. Even outside of laboratory tasks, and especially in classrooms, much learning requires linking linguistic and visual information. Thus, pulling apart these respective influences on attention is essential to understanding how children learn from nonlinguistic perceptual experiences and how linguistic experiences support learning of language beyond the early stages of word learning. The potential role of these processes in early language development itself is an important new area for research.
In summary, the present study identified the object (target test object, one distractor test object, or the other distractor object) to which children’s attention was directly shifted, thus determining whether the attention is initially moved directly to the target test object or distributed equally to the three test objects in front of the child. The primary objective was to explain the advantage of using same category objects for children’s novel adjective learning. The tracking of direct looking behavior during the novel adjective learning task is an innovative way to obtain detailed information regarding the processes underlying word mapping in a relatively naturalistic interactive task context. The potential role of looking behaviors during the word-learning task itself is an important new area for research. The present results contribute specifically by showing how direct looking to the target object is prevalent when within-category objects are used and predictive of successful mapping when the target object belongs to the same category as the exemplar. The findings suggest a mechanistic premise about why within-category objects may be so important to adjective learning.
Author Contributions
Conceptualization, H.Y.; Data curation, H.Y.; Formal analysis, H.Y., A.P. and J.B.; Funding acquisition, H.Y.; Investigation, H.Y.; Methodology, H.Y.; Project administration, H.Y.; Software, A.P. and J.B.; Validation, H.Y., A.P. and J.B.; Visualization, H.Y. and J.B.; Writing—original draft, H.Y. and A.P.; Writing—review & editing, H.Y., A.P. and J.B.
Funding
Data collection was supported in part by a National Institutes of Health grant (R01 HD058620) and the University of Houston Small Grant Program.
Acknowledgments
We thank the parents and children in Houston community, who supported the research and participated in the study and thank the Cognitive Development Lab for collection of the data and coding data.
Conflicts of Interest
The authors declare no conflict of interest. The funding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Appendix A
The entire stimulus set used in the study (test objects are identical across the Same and Different conditions, thus not repeated).

References
- Aslin, Richard N., and Linda B. Smith. 1988. Perceptual Development. Annual Review of Psychology 39: 435–73. [Google Scholar] [CrossRef] [PubMed]
- Baldwin, Dare. A., and Ellen M. Markman. 1989. Establishing word-object relations: A first step. Child Development 60: 381–98. [Google Scholar] [CrossRef] [PubMed]
- Bergelson, Elika, and Daniel Swingley. 2012. At 6–9 months, human infants know the meanings of many common nouns. Proceedings of the National Academy of Sciences of the United States of America 109: 3253–58. [Google Scholar] [CrossRef] [PubMed]
- Biedinger, Nicole. 2011. The influence of education and home environment on the cognitive outcomes of preschool children in Germany. Child Development Research 2011: 916303. [Google Scholar] [CrossRef]
- Birch, S. A., Nazanin Akmal, and Kristen L. Frampton. 2010. Two-year-old are vigilant of others’ non-verbal cues to credibility. Developmental Science 13: 363–69. [Google Scholar] [CrossRef]
- Borovsky, Arielle, Jeffrey L. Elman, and Anne Fernald. 2012. Knowing a lot for one’s age: Vocabulary skill and not age is associated with anticipatory incremental sentence interpretation in children and adults. Journal of Experimental Child Psychology 112: 417–36. [Google Scholar] [CrossRef]
- Bradley, Robert H., and Robert F. Corwyn. 2002. Socioeconomic status and child development. Annual Review of Psychology 53: 371–99. [Google Scholar] [CrossRef]
- Brockmole, James R., Monica S. Castelhano, and John M. Henderson. 2006. Contextual cueing in naturalistic scenes: Global and local contexts. Journal of Experimental Psychology: Learning, Memory, and Cognition 32: 699–706. [Google Scholar] [CrossRef]
- Burling, Joseph, and Hanako Yoshida. 2016. Highlighting in Early Childhood: Learning Biases through Attentional Shifting. Cognitive Science 41: 96–119. [Google Scholar] [CrossRef]
- Chun, Marvin M., and Yuhong Jiang. 1998. Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology 36: 28–71. [Google Scholar] [CrossRef]
- Clark, A. 1997. Being There: Putting Mind, Body, and World Together Again. Cambridge: The MIT Press. [Google Scholar]
- Colunga, Eliana, and Linda B. Smith. 2005. From the lexicon to expectations about kinds: A role for associative learning. Psychological Review 112: 347–82. [Google Scholar] [CrossRef] [PubMed]
- Dahan, Delphine, and Michael K. Tanenhaus. 2005. Looking at the rope when looking for the snake: Conceptually mediated eye movements during spoken-word recognition. Psychonomic Bulletin & Review 12: 453–59. [Google Scholar]
- Darby, Kevin, Joseph Burling, and Hanako Yoshida. 2014. The role of search speed in contextual cueing of children’s attention. Cognitive Development 29: 17–29. [Google Scholar] [CrossRef]
- Davis-Kean, Pamela E. 2005. The influence of parent education and family income on child achievement: The indirect role of parental expectations and the home environment. Journal of Family Psychology: Journal of the Division of Family Psychology of the American Psychological Association 19: 294–304. [Google Scholar] [CrossRef]
- Desimone, Robert, and John Duncan. 1995. Neural mechanisms of selective visual attention. Annual Review of Neuroscience 18: 193–222. [Google Scholar] [CrossRef] [PubMed]
- Dixon, Robert M. W. 1982. ‘Where Have All the Adjectives Gone?’ and Other Essays in Semantics and Syntax. Berlin: Mouton de Gruyter. [Google Scholar]
- Dromi, Esther. 1996. Early Lexical Development. San Diego: Singular Publishing Group. [Google Scholar]
- Eimas, Peter D., and Paul C. Quinn. 1994. Studies on the formation of perceptually based basic-level categories in young infants. Child Development 65: 903–17. [Google Scholar] [CrossRef] [PubMed]
- Elman, Jeffrey L. 1993. Learning and development in neural networks: The importance of starting small. Cognition 48: 71. [Google Scholar] [CrossRef]
- Fecteau, Jillian H., and Douglas P. Munoz. 2006. Salience, relevance, and firing: A priority map for target selection. Trends in Cognitive Sciences 10: 382–90. [Google Scholar] [CrossRef]
- Fenson, Larry, Philip S. Dale, J. Steven Reznick, Elizabeth Bates, Donna J. Thal, and Stephen J. Pethick. 1994. Variability in early communicative development. Monographs of the Society for Research in Child Development 59: 85. [Google Scholar] [CrossRef]
- Fisher, József, and Richard N. Aslin. 2002. Statistical learning of new visual feature combinations by infants. Proceedings of the National Academy of Sciences USA 99: 15822–26. [Google Scholar] [CrossRef]
- Fontenot, Kayla, Jessica Semega, and Melissa Kollar. 2018. Census Bureau, Current Population Reports. In Income and Poverty in the United States: 2017; Washington: U.S. Government Printing Office, pp. 60–263. [Google Scholar]
- Franchak, John M., Kari S. Kretch, Kasey C. Soska, and Karen E. Adolph. 2011. Head-mounted eye tracking: A new method to describe infant looking. Child Development 82: 1738–50. [Google Scholar] [CrossRef] [PubMed]
- Gasser, Michael, and Linda B. Smith. 1998. Learning nouns and adjectives: A connectionist account. Language and Cognitive Processes 13: 269–306. [Google Scholar] [CrossRef]
- Gelman, Susan A., and Ellen M. Markman. 1986. Categories and induction in young children. Cognition 23: 183–209. [Google Scholar] [CrossRef] [Green Version]
- Gentner, Dedre. 1982. Why nouns are learned before verbs: Linguistic relativity vs. natural partitioning. In Language Development. Language, Thought and Culture. Hillsdale: Erlbaum, vol. 2, pp. 301–34. [Google Scholar]
- Gentner, Dedre, and Arthur B. Markman. 1994. Structural alignment in comparison: No difference without similarity. Psychological Science 5: 152–58. [Google Scholar] [CrossRef]
- Goldstone, R. L., and Douglas L. Medin. 1994. Time course of comparison. Journal of Experimental Psychology: Learning Memory and Cognition 20: 29–50. [Google Scholar] [CrossRef]
- Golinkoff, Roberta Michnick, Carolyn B. Mervis, and Hirsh-K. Pasek. 1994. Early object labels: The case for a developmental lexical principles framework. Journal of Child Language 21: 125–55. [Google Scholar] [CrossRef]
- Griffin, Zenzi M., and Kathryn Bock. 2000. What the eyes say about speaking. Psychological Science 11: 274–79. [Google Scholar] [CrossRef] [PubMed]
- Hall, D. Geoffrey, Sandra R. Waxman, and Wendy M. Hurwitz. 1993. How two- and four-year-old children interpret adjectives and count nouns. Child Development 64: 1651–64. [Google Scholar] [CrossRef]
- Hayhoe, Mary, and Dana Ballard. 2005. Eye movements in natural behavior. Trends in Cognitive Sciences 9: 188–94. [Google Scholar] [CrossRef]
- Henderson, John M., and Fernanda Ferreira. 2004. Scene Perception for Psycholinguists: The Interface of Language, Vision, and Action: Eye Movements and the Visual World. New York: Psychology Press, pp. 1–58. [Google Scholar]
- Henderson, John, and Andrew Hollingworth. 1999. High-level scene perception. Annual Review of Psychology 50: 243–71. [Google Scholar] [CrossRef]
- Huettig, Falk, and Gerry T. M. Altmann. 2007. Visual-shape competition during language-mediated attention is based on lexical input and not modulated by contextual appropriateness. Visual Cognition 15: 985–1018. [Google Scholar] [CrossRef] [Green Version]
- Hutchinson, Jean E. 1984. Constraints on Children’s Implicit Hypotheses about Word Meanings. Ph.D. dissertation, Stanford University, Stanford, CA, USA. [Google Scholar]
- Imai, Mutsumi, and Dedre Gentner. 1997. A cross-linguistic study of early word meaning: Universal ontology and linguistic influence. Cognition 62: 169–200. [Google Scholar] [CrossRef]
- Jackson-Maldonado, Donna, D. Thal, Virginia Marchman, Elizabeth Bates, and Vera Gutierrez-Clellen. 1993. Early lexical development in Spanish-speaking infants and toddlers. Journal of Child Language 20: 523–49. [Google Scholar] [CrossRef] [PubMed]
- Kemler, Deborah G. 1983. Exploring and reexploring issues of integrality, perceptual sensitivity, and dimensional salience. Journal of Experimental Child Psychology 36: 365. [Google Scholar] [CrossRef]
- Klibanoff, Raquel S., and Sandra R. Waxman. 2000. Basic level object categories support the acquisition of novel adjectives: Evidence from preschool-aged children. Child Development 71: 649–59. [Google Scholar] [CrossRef]
- Kooiker, Marlou J., Johan J. Pel, Sanny P. van der Steen-Kant, and Johannes van der Steen. 2016. A Method to Quantify Visual Information Processing in Children Using Eye Tracking. Journal of Visualized Experiments JoVE 113: 54031. [Google Scholar] [CrossRef] [PubMed]
- Krippendorf, K. 2004. Reliability in Content Analysis—Some Common Misconceptions and Recommendations. Human Communication Research 30: 411–33. [Google Scholar] [CrossRef]
- Krummenacher, Joseph, Hermann J. Muller, and Dieter Heller. 2001. Visual search for dimensionally redundant pop-out targets: Evidence for parallel-coactive processing of dimensions. Perception & Psychophysics 63: 901–17. [Google Scholar]
- Kruschke, John K. 1996. Base rates in category learning. Journal of Experimental Psychology: Learning, Memory and Cognition 22: 3–26. [Google Scholar] [CrossRef]
- Kruschke, John K. 2009. Highlighting: A canonical experiment. The Psychology of Learning and Motivation 51: 153–85. [Google Scholar]
- Landau, Barbara, Linda Smith, and Susan Jones. 1998. Object shape, object function, and object name. Journal of Memory and Language 38: 1. [Google Scholar] [CrossRef]
- Lupyan, Gary, and Michael J. Spivey. 2010. Making the invisible visible: Verbal but not visual cues enhance visual detection. PLoS ONE 5: e11452. [Google Scholar] [CrossRef]
- MacArthur, J. D., and C. T. MacArthur. 2013. MacArthur Foundation Research Network on Socioeconomic Status and Health. Available online: http://www.macses.ucsf.edu (accessed on 24 May 2019).
- Mandler, Jean M. 2000. Perceptual and conceptual processes in infancy. Journal of Cognition and Development 1: 3–36. [Google Scholar] [CrossRef]
- Mandler, Katherine, and D. Geoffery Hall. 2002. Comparison, basic-level categories, and the teaching of adjectives. Journal of Child Language 29: 923–37. [Google Scholar]
- Medin, Douglas L., and Edward J. Shoben. 1988. Context and structure in conceptual combination. Cognitive Psychology 20: 158–90. [Google Scholar] [CrossRef]
- Merriman, William E. 1999. Competition, Attention, and Young Children’s Lexical Processing: The Emergence of Language. Mahwah: Lawrence Erlbaum Associates Publishers, pp. 331–58. [Google Scholar]
- Mintz, Toben. 2005. Linguistic and conceptual influences on adjective acquisition in 24- and 36-month-olds. Developmental Psychology 41: 17–29. [Google Scholar] [CrossRef]
- Mintz, Toben H., and Lila R. Gleitman. 2002. Adjectives really do modify nouns: The incremental and restricted nature of early adjective acquisition. Cognition 84: 267–93. [Google Scholar] [CrossRef]
- Nappa, Rebecca, Allison Wessell, Katherine McEldoon, Lila Gleitman, and John Trueswell. 2009. Use of speaker’s gaze and syntax in verb learning. Language Learning and Development 5: 203–34. [Google Scholar] [CrossRef]
- Neider, Mark B., and Gregory J. Zelinsky. 2006. Scene context guides eye movements during visual search. Vision Research 46: 614–21. [Google Scholar] [CrossRef]
- Nelson, Katherine. 1973. Structure and strategy in learning to talk. Monographs of the Society for Research in Child Development 38: 1–135. [Google Scholar] [CrossRef]
- Plunkett, Kim, and Virginia Marchman. 1991. U-shaped learning and frequency effects in a multi-layered perception: Implications for child language acquisition. Cognition 38: 43–102. [Google Scholar] [CrossRef]
- Quinn, J. G. 1994. Towards a clarification of spatial processing. The Quarterly Journal of Experimental Psychology, Section A 47: 465–80. [Google Scholar] [CrossRef]
- Regier, Terry. 2005. The emergence of words: Attentional learning in form and meaning. Cognitive Science 29: 819–65. [Google Scholar] [CrossRef]
- Sandhofer, Catherine, and Linda B. Smith. 2007. Learning adjectives in the real world: How learning nouns impedes learning adjectives. Language Learning and Development 3: 233–67. [Google Scholar] [CrossRef]
- Shipley, Elizabeth F., and Ivy F. Kuhn. 1983. A constraint on comparisons: Equally detailed alternatives. Journal of Experimental Child Psychology 35: 195–222. [Google Scholar] [CrossRef]
- Smith, Linda B. 1984. Young children’s understanding of attributes and dimensions: A comparison of conceptual and linguistic measures. Child Development 55: 363–80. [Google Scholar] [CrossRef] [PubMed]
- Smith, Linda. 1993. The concept of same. In Advances in Child Development and Behavior. Edited by H. Reese. San Diego: Academic Press, pp. 215–52. [Google Scholar]
- Smith, Linda B. 2005. Cognition as a dynamic system: Principles from embodiment. Developmental Review; Development as Self-Organization: New Approaches to the Psychology and Neurobiology of Development 25: 278–98. [Google Scholar] [CrossRef]
- Smith, Linda, and Diana Heise. 1992. Perceptual similarity and conceptual structure. In Percepts, Concepts and Categories. Edited by B. Burns. Amsterdam: Elsevier Science Publishers B. V., pp. 233–72. [Google Scholar]
- Smith, Linda B., Michael Gasser, and Catherine M. Sandhofer. 1997. Learning to talk about the properties of objects: A network model of the development of dimensions. In Perceptual Learning, The Psychology of Learning and Motivation 36. San Diego: Academic Press, pp. 219–55. [Google Scholar]
- Smith, Linda B., Susan S. Jones, Barbara Landau, Lisa Gershkoff-Stowe, and Larissa Samuelson. 2002. Object name learning provides on-the-job training for attention. Psychological Science 13: 13–19. [Google Scholar] [CrossRef] [PubMed]
- Tincoff, Ruth, and Peter W. Jusczyk. 2012. Six-month-olds comprehend words that refer to parts of the body. Infancy 17: 432–44. [Google Scholar] [CrossRef]
- Torralba, Antonio, Aude Oliva, Monica S. Castelhano, and John M. Henderson. 2006. Contextual guidance of eye movements and attention in real-world scenes: The role of global features in object search. Psychological Review 113: 766–86. [Google Scholar] [CrossRef]
- Turk-Browne, Nicholas B., Justin Junge, and Brian J. Scholl. 2005. The automaticity of visual statistical learning. Journal of Experimental Psychology: Learning, Memory, and Cognition 34: 399–407. [Google Scholar] [CrossRef] [PubMed]
- Twomey, Katherine E., Jessica S. Horst, and Anthony F. Morse. 2013. An embodied model of young children’s categorization and word learning. In Theoretical and Computational Models of Word Learning: Trends in Psychology and Artificial Intelligence. Hershey: IGI Globa, pp. 172–96. [Google Scholar]
- Vales, Catarina, and Linda B. Smith. 2015. Words, shape, visual search and visual working memory in 3-year-old children. Developmental Science 18: 65–79. [Google Scholar] [CrossRef] [PubMed]
- Waxman, Sandra, and Amy Booth. 2003. The origins and evolution of links between word learning and conceptual organization. Developmental Science 6: 128–35. [Google Scholar] [CrossRef]
- Waxman, Sandra R., and Raquel S. Klibanoff. 2000. The role of comparison in the extension of novel adjectives. Developmental Psychology 36: 571–81. [Google Scholar] [CrossRef] [PubMed]
- Waxman, Sandra R., and Toby D. Kosowski. 1990. Nouns mark category relations: Toddlers’ and preschoolers’ word-learning biases. Child Development 61: 1461–73. [Google Scholar] [CrossRef] [PubMed]
- Wolfe, Jeremy M., Todd S. Horowitz, and Kristin O. Michod. 2007. Is visual attention required for robust picture memory? Vision Research 47: 955–64. [Google Scholar] [CrossRef] [PubMed]
- Yoshida, Hanako, and Joseph M. Burling. 2012. Highlighting: A mechanism relevant for word learning. Frontiers in Psychology 3: 1–12. [Google Scholar] [CrossRef] [PubMed]
- Yoshida, Hanako, and Rima Hanania. 2013. If it’s red, it’s not vap: How competition among words may benefit early word learning. First Language 33: 3–19. [Google Scholar] [CrossRef] [PubMed]
- Yoshida, Hanako, and Linda B. Smith. 2005. Linguistic cues enhance the learning of perceptual cues. Psychological Sciences 16: 90–95. [Google Scholar] [CrossRef]
- Yoshida, Hanako, Duc N. Tran, Viridiana Benitez, and Megumi Kuwabara. 2011. Inhibition and adjective learning in bilingual and monolingual children. Frontiers in Psychology 2: 210. [Google Scholar] [CrossRef]
| 1. | Noun object categories were selected from the MacArthur Communicative Developmental Inventory (MCDI) toddler form (Fenson et al. 1994). |
Figure 1.
Typical stimuli arrangement used in novel adjective learning task consisting of exemplar object and testing objects, including target test object (correct choice) and distractor test objects.
Figure 1.
Typical stimuli arrangement used in novel adjective learning task consisting of exemplar object and testing objects, including target test object (correct choice) and distractor test objects.

Figure 2.
First-person view (FPV) was recorded by having the child wear a head-mounted eye tracking headset. A room view (third person view: TPV) was recorded by a wall-mounted camera in the testing room. Videos from these cameras were joined and synchronized with child eye tracking coordinates superimposed over the FPV image (pink/purple circles indicating the point of focus).
Figure 2.
First-person view (FPV) was recorded by having the child wear a head-mounted eye tracking headset. A room view (third person view: TPV) was recorded by a wall-mounted camera in the testing room. Videos from these cameras were joined and synchronized with child eye tracking coordinates superimposed over the FPV image (pink/purple circles indicating the point of focus).

Figure 3.
One of the six stimulus sets used in the Same category condition (A, left) and in the Different category condition (B, right).
Figure 3.
One of the six stimulus sets used in the Same category condition (A, left) and in the Different category condition (B, right).

Figure 4.
Mean accuracy for selecting the correct target object with the property that is the same as the exemplar object. Bootstrapped standard errors are shown as vertical lines, and the horizontal dotted line is chance performance at 0.33, and * indicates the significant difference.
Figure 4.
Mean accuracy for selecting the correct target object with the property that is the same as the exemplar object. Bootstrapped standard errors are shown as vertical lines, and the horizontal dotted line is chance performance at 0.33, and * indicates the significant difference.

Figure 5.
Mean proportion of frequencies of direct gaze shifts to the target or distractor objects from the exemplar object. Bootstrapped standard errors are shown as vertical lines, and the horizontal dotted line is chance performance at 0.33.
Figure 5.
Mean proportion of frequencies of direct gaze shifts to the target or distractor objects from the exemplar object. Bootstrapped standard errors are shown as vertical lines, and the horizontal dotted line is chance performance at 0.33.

Figure 6.
Mean duration of looking at the exemplar, the experimenter’s face, the target object, and the distractor test objects for the Same and Different conditions. Bootstrapped standard errors are shown as vertical lines.
Figure 6.
Mean duration of looking at the exemplar, the experimenter’s face, the target object, and the distractor test objects for the Same and Different conditions. Bootstrapped standard errors are shown as vertical lines.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Participants’ information.
| Condition | Same | Different |
|---|---|---|
| Mean Age (months) | 44.40 (SD 5.06) | 46.99 (4.00) |
| Highest Education Earned | 6.12 (SD 0.90) | 5.93 (SD 1.10) |
| Mean Income | $64,708 (SD 30,539) | $66,000 (SD 29,472) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Yoshida, H.; Patel, A.; Burling, J. Gaze as a Window to the Process of Novel Adjective Mapping. Languages 2019, 4, 33. https://doi.org/10.3390/languages4020033
AMA Style
Yoshida H, Patel A, Burling J. Gaze as a Window to the Process of Novel Adjective Mapping. Languages. 2019; 4(2):33. https://doi.org/10.3390/languages4020033
Chicago/Turabian StyleYoshida, Hanako, Aakash Patel, and Joseph Burling. 2019. "Gaze as a Window to the Process of Novel Adjective Mapping" Languages 4, no. 2: 33. https://doi.org/10.3390/languages4020033