Shallow Landslide Susceptibility Mapping: A Comparison between Logistic Model Tree, Logistic Regression, Naïve Bayes Tree, Artificial Neural Network, and Support Vector Machine Algorithms

 , ,
, ,  ,
,  ,
,  ,
, 
 , , , ,
, , , ,
Abstract
:1. Introduction
2. Description of the Study Area
3. Data Preparation
3.1. Landslide Inventory Map
3.2. Landslide Conditioning Factors
3.2.1. Slope Angle
3.2.2. Slope Aspect
3.2.3. Elevation
3.2.4. Curvature
3.2.5. Plan Curvature
3.2.6. Profile Curvature
3.2.7. Slope Length
3.2.8. Rainfall
3.2.9. Annual Solar Radiation
3.2.10. Stream Power Index
3.2.11. Topographic Wetness Index
3.2.12. Distance to Rivers
3.2.13. River Density
3.2.14. Lithology
3.2.15. Distance to Faults
3.2.16. Fault Density
3.2.17. Land Use
3.2.18. NDVI
3.2.19. Distance to Roads
3.2.20. Road Density
4. Methods
4.1. Naïve Bayes Tree
4.2. Logistic Regression
4.3. Logistic Model Tree
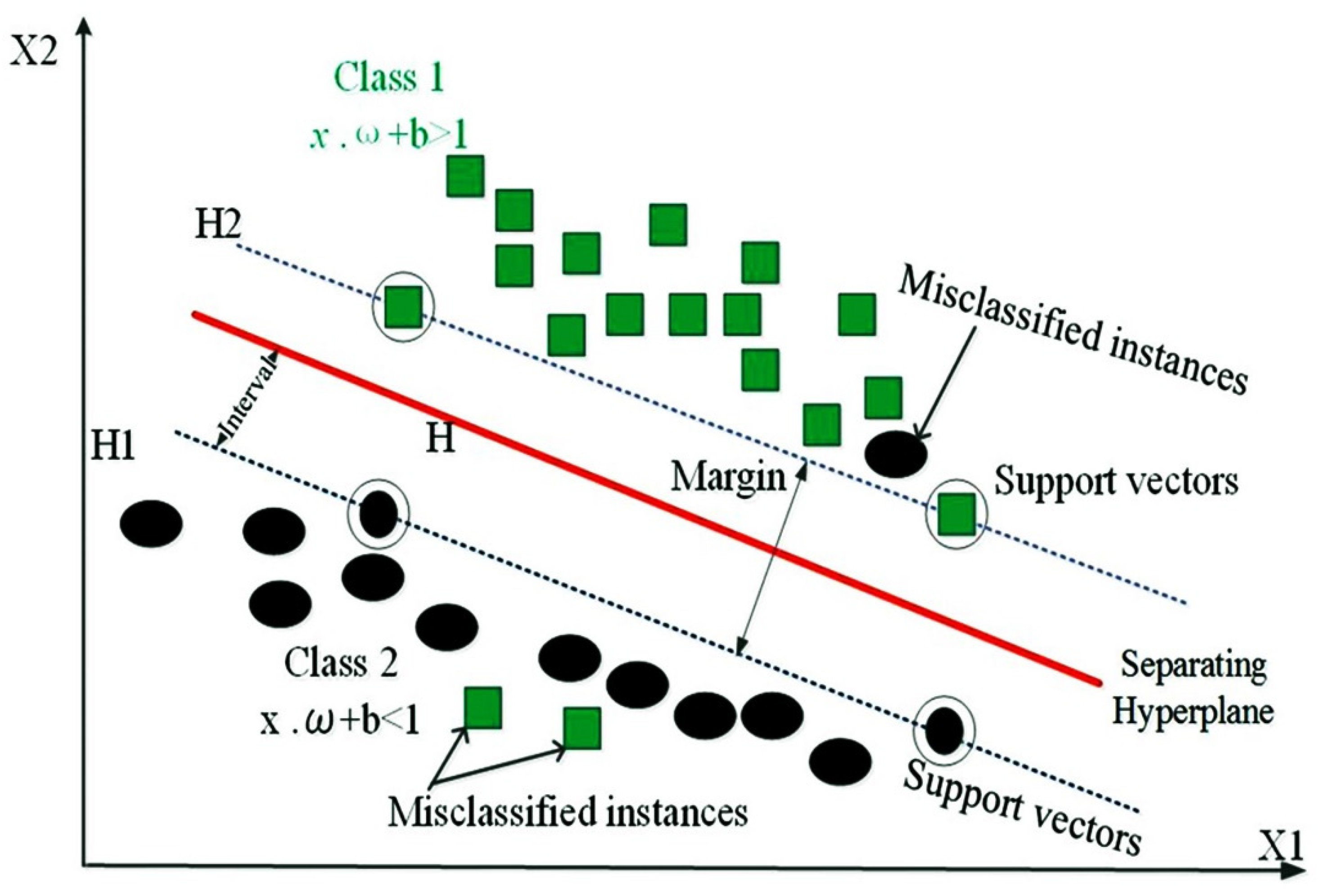
4.4. Support Vector Machine
4.5. Artificial Neutral Network
4.6. Model Comparison and Validation
4.6.1. Statistical Metrics
4.6.2. ROC Curve and AUC Metric
4.6.3. Friedman and Wilcoxon Sign Rank Statistical Tests
4.7. Factor Selection Using One-R Attribute Evaluation Technique
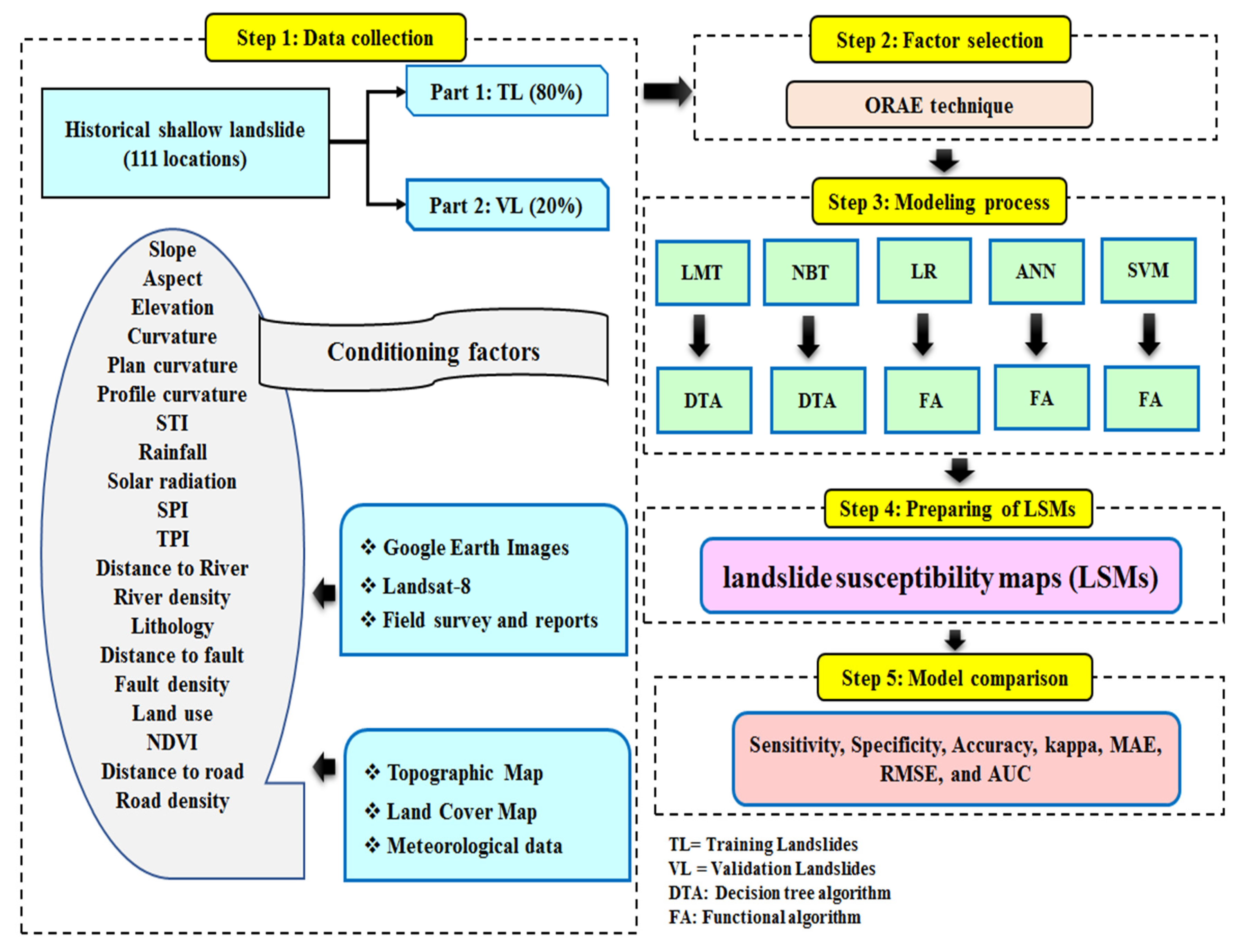
4.8. Summary of the Methodology Used in This Study
5. Results and Analysis
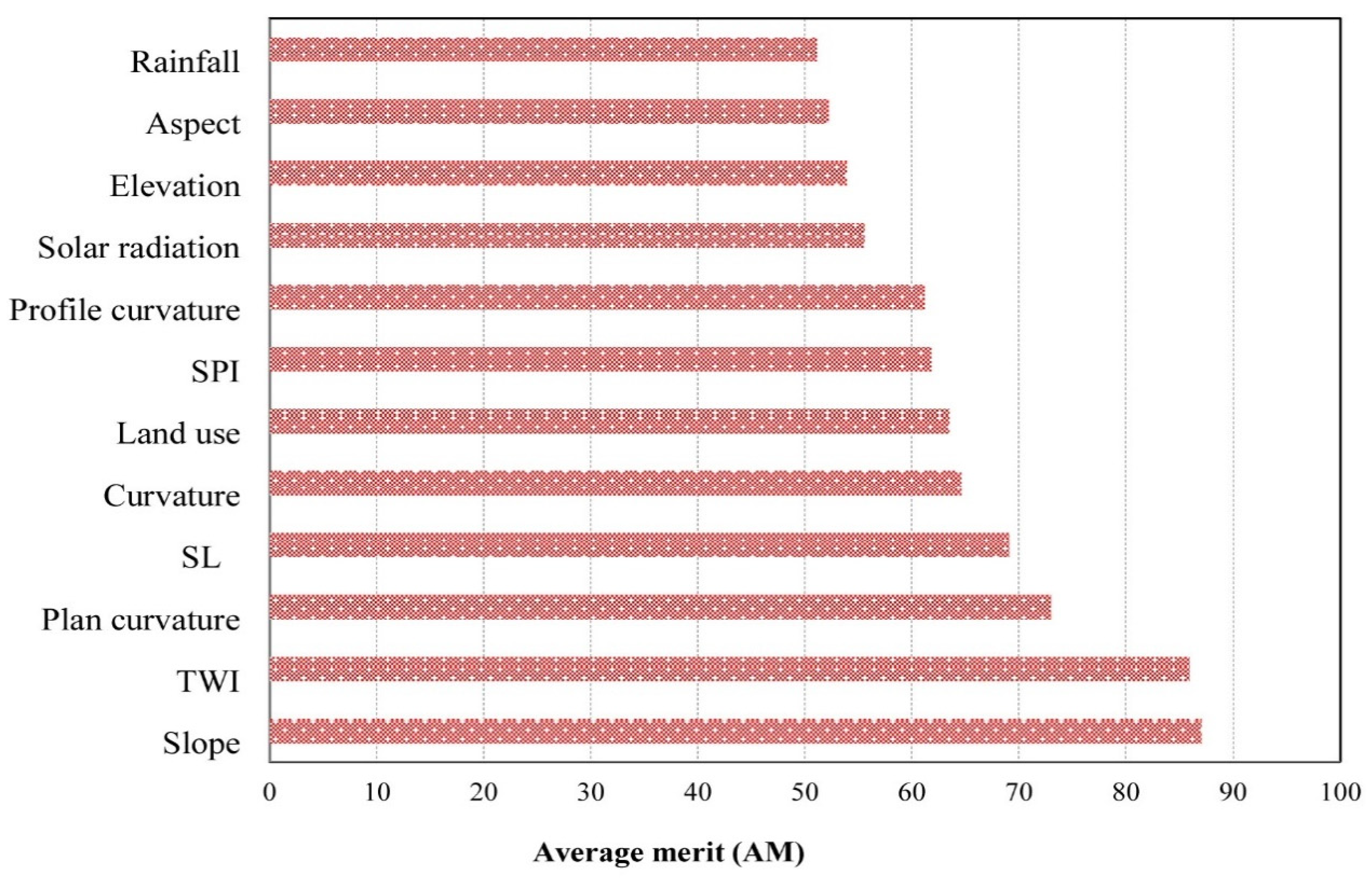
5.1. Most Important Landslide Conditioning Factors
5.2. Model Performance and Analysis
5.3. Development of Landslide Susceptibility Maps
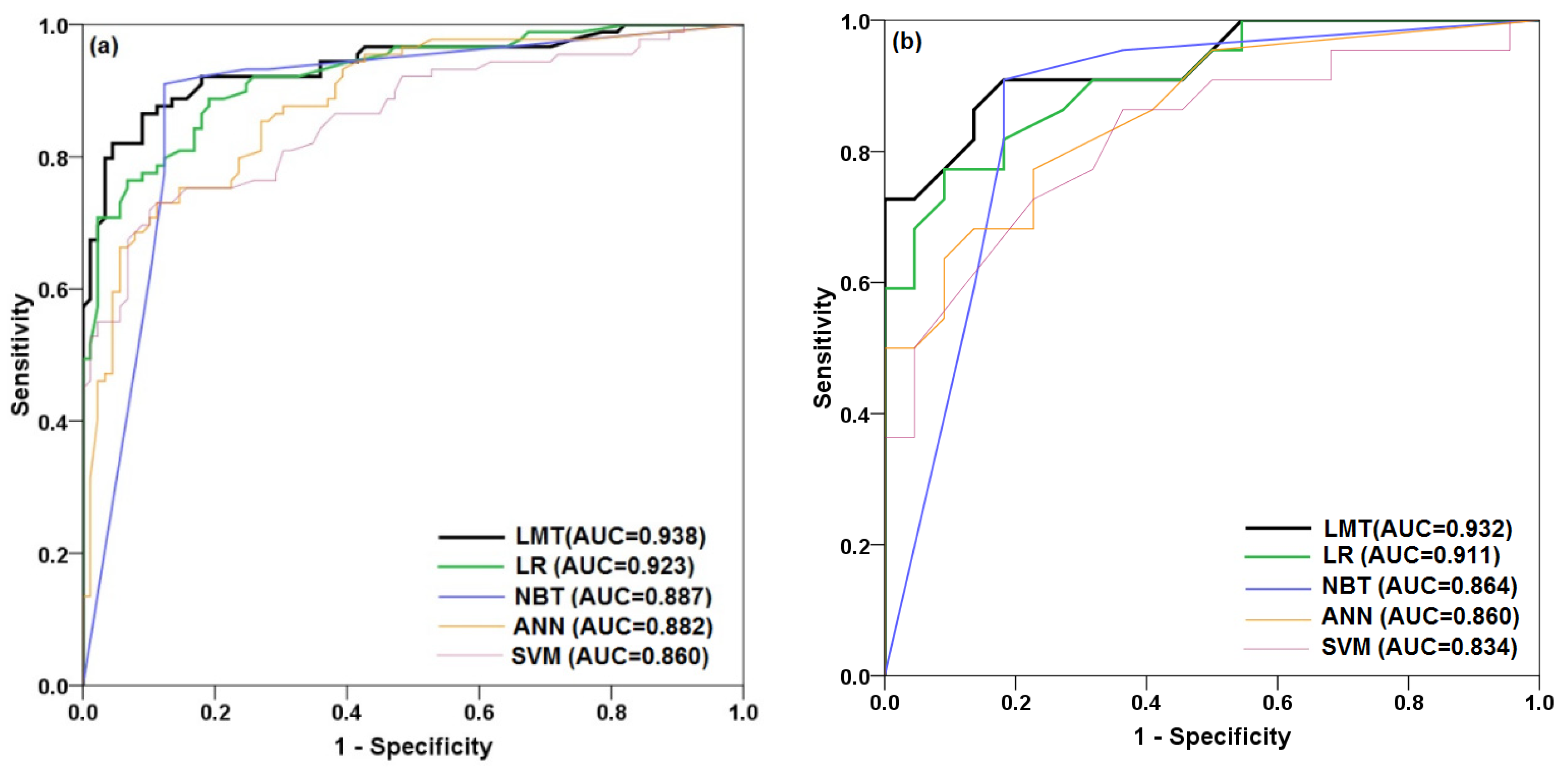
5.4. Model Comparison and Validation
5.4.1. ROC Curve
5.4.2. Wilcoxon Sign Rank Test
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Klose, M.; Maurischat, P.; Damm, B. Landslide impacts in Germany: A historical and socioeconomic perspective. Landslides 2016, 13, 183–199. [Google Scholar] [CrossRef]
- Dilley, M.; Chen, R.S.; Deichmann, U.; Lerner-Lam, A.L.; Arnold, M. Natural Disaster Hotspots: A Global Risk Analysis; The World Bank: Washington, DC, USA, 2005. [Google Scholar]
- Gariano, S.L.; Sarkar, R.; Dikshit, A.; Dorji, K.; Brunetti, M.T.; Peruccacci, S.; Melillo, M. Automatic calculation of rainfall thresholds for landslide occurrence in Chukha Dzongkhag, Bhutan. Bull. Eng. Geol. Environ. 2019, 78, 4325–4332. [Google Scholar] [CrossRef]
- Dikshit, A.; Sarkar, R.; Pradhan, B.; Acharya, S.; Dorji, K. Estimating rainfall thresholds for landslide occurrence in the Bhutan Himalayas. Water 2019, 11, 1616. [Google Scholar] [CrossRef] [Green Version]
- Froude, M.J.; Petley, D. Global fatal landslide occurrence from 2004 to 2016. Nat. Hazards Earth Syst. Sci. 2018, 18, 2161–2181. [Google Scholar] [CrossRef] [Green Version]
- Cruden, D. A suggested method for a landslide summary. Bull. Int. Assoc. Eng. Geol. -Bull. De L’association Int. De Géologie De L’ingénieur 1991, 43, 101–110. [Google Scholar]
- Farrokhnia, A.; Pirasteh, S.; Pradhan, B.; Pourkermani, M.; Arian, M. A recent scenario of mass wasting and its impact on the transportation in Alborz Mountains, Iran using geo-information technology. Arab. J. Geosci. 2011, 4, 1337–1349. [Google Scholar] [CrossRef]
- Ayazi, M.H.; Pirasteh, S.; Arvin, A.; Pradhan, B.; Nikouravan, B.; Mansor, S. Disasters and risk reduction in groundwater: Zagros mountain southwest Iran using geoinformatics techniques. Disaster Adv. 2010, 3, 51–57. [Google Scholar]
- Safari, H.O.; Pirasteh, S.; Pradhan, B. Upliftment estimation of the Zagros transverse fault in Iran using geoinformatics technology. Remote Sens. 2009, 1, 1240–1256. [Google Scholar] [CrossRef] [Green Version]
- Akbarimehr, M.; Motagh, M.; Haghshenas-Haghighi, M. Slope stability assessment of the Sarcheshmeh landslide, northeast Iran, investigated using INSAR and GPS observations. Remote Sens. 2013, 5, 3681–3700. [Google Scholar] [CrossRef] [Green Version]
- Talaei, R.; Samadov, S. Quantitative landslide risk analysis in the Hashtchin area (NW-Iran). Eur. J. Environ. Civ. Eng. 2018, 22, 883–909. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Merghadi, A.; Shirzadi, A.; Nguyen, H.; Hussain, Y.; Avtar, R.; Chen, Y.; Pham, B.T.; Yamagishi, H. Different sampling strategies for predicting landslide susceptibilities are deemed less consequential with deep learning. Sci. Total Environ. 2020, 720, 137–153. [Google Scholar] [CrossRef]
- Pham, B.T.; Jaafari, A.; Prakash, I.; Bui, D.T. A novel hybrid intelligent model of support vector machines and the MultiBoost ensemble for landslide susceptibility modeling. Bull. Eng. Geol. Environ. 2019, 78, 2865–2886. [Google Scholar] [CrossRef]
- Brabb, E.E. Innovative approaches to landslide hazard and risk mapping. In Proceedings of the International Landslide Symposium Proceedings, Toronto, ON, Canada, 23–31 August 1985; pp. 17–22. [Google Scholar]
- Guzzetti, F.; Reichenbach, P.; Cardinali, M.; Galli, M.; Ardizzone, F. Probabilistic landslide hazard assessment at the basin scale. Geomorphology 2005, 72, 272–299. [Google Scholar] [CrossRef]
- Dikshit, A.; Sarkar, R.; Pradhan, B.; Jena, R.; Drukpa, D.; Alamri, A.M. Temporal probability assessment and its use in landslide susceptibility mapping for eastern Bhutan. Water 2020, 12, 267. [Google Scholar] [CrossRef] [Green Version]
- Shirzadi, A.; Bui, D.T.; Pham, B.T.; Solaimani, K.; Chapi, K.; Kavian, A.; Shahabi, H.; Revhaug, I. Shallow landslide susceptibility assessment using a novel hybrid intelligence approach. Environ. Earth Sci. 2017, 76, 60. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I.; Singh, S.K.; Shirzadi, A.; Shahabi, H.; Bui, D.T. Landslide susceptibility modeling using reduced error pruning trees and different ensemble techniques: Hybrid machine learning approaches. Catena 2019, 175, 203–218. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Yansari, Z.T.; Panagos, P.; Pradhan, B. Analysis and evaluation of landslide susceptibility: A review on articles published during 2005–2016 (periods of 2005–2012 and 2013–2016). Arab. J. Geosci. 2018, 11, 193. [Google Scholar] [CrossRef]
- Bai, S.-B.; Wang, J.; Lü, G.-N.; Zhou, P.-G.; Hou, S.-S.; Xu, S.-N. Gis-based logistic regression for landslide susceptibility mapping of the zhongxian segment in the three gorges area, China. Geomorphology 2010, 115, 23–31. [Google Scholar] [CrossRef]
- Atkinsson, P.; Massari, R. Generalized linear modeling of susceptibility to landsliding in the central Appennines, Italy. Comput. Geosci. 1998, 24, 373–385. [Google Scholar] [CrossRef]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar]
- Wang, Y.; Hong, H.; Chen, W.; Li, S.; Panahi, M.; Khosravi, K.; Shirzadi, A.; Shahabi, H.; Panahi, S.; Costache, R. Flood susceptibility mapping in Dingnan county (China) using adaptive neuro-fuzzy inference system with biogeography based optimization and imperialistic competitive algorithm. J. Environ. Manag. 2019, 247, 712–729. [Google Scholar] [CrossRef] [PubMed]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamowski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.-B.; Gróf, G.; Ho, H.L. A comparative assessment of flood susceptibility modeling using multi-criteria decision-making analysis and machine learning methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Chen, W.; Hong, H.; Li, S.; Shahabi, H.; Wang, Y.; Wang, X.; Ahmad, B.B. Flood susceptibility modelling using novel hybrid approach of reduced-error pruning trees with bagging and random subspace ensembles. J. Hydrol. 2019, 575, 864–873. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shirzadi, A.; Chapi, K.; Shahabi, H.; Pradhan, B.; Pham, B.T.; Singh, V.P.; Chen, W.; Khosravi, K.; Bin Ahmad, B. A hybrid computational intelligence approach to groundwater spring potential mapping. Water 2019, 11, 2013. [Google Scholar] [CrossRef] [Green Version]
- Bui, D.T.; Panahi, M.; Shahabi, H.; Singh, V.P.; Shirzadi, A.; Chapi, K.; Khosravi, K.; Chen, W.; Panahi, S.; Li, S. Novel hybrid evolutionary algorithms for spatial prediction of floods. Sci. Rep. 2018, 8, 15364. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Khosravi, K.; Li, S.; Shahabi, H.; Panahi, M.; Singh, V.; Chapi, K.; Shirzadi, A.; Panahi, S.; Chen, W. New hybrids of ANFIS with several optimization algorithms for flood susceptibility modeling. Water 2018, 10, 1210. [Google Scholar] [CrossRef] [Green Version]
- Shafizadeh-Moghadam, H.; Valavi, R.; Shahabi, H.; Chapi, K.; Shirzadi, A. Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J. Environ. Manag. 2018, 217, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Bui, D.T.; Pham, B.T.; Khosravi, K. A novel hybrid artificial intelligence approach for flood susceptibility assessment. Environ. Model. Softw. 2017, 95, 229–245. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Xue, W.; Shahabi, H.; Li, S.; Hong, H.; Wang, X.; Bian, H.; Zhang, S.; Pradhan, B. Modeling flood susceptibility using data-driven approaches of naïve bayes tree, alternating decision tree, and random forest methods. Sci. Total Environ. 2020, 701, 134979. [Google Scholar] [CrossRef]
- Shahabi, H.; Shirzadi, A.; Ghaderi, K.; Omidvar, E.; Al-Ansari, N.; Clague, J.J.; Geertsema, M.; Khosravi, K.; Amini, A.; Bahrami, S. Flood detection and susceptibility mapping using Sentinel-1 remote sensing data and a machine learning approach: Hybrid intelligence of bagging ensemble based on k-nearest neighbor classifier. Remote Sens. 2020, 12, 266. [Google Scholar] [CrossRef] [Green Version]
- Khosravi, K.; Melesse, A.M.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Hong, H. Flood susceptibility mapping at ningdu catchment, china using bivariate and data mining techniques. In Extreme Hydrology and Climate Variability; Elsevier: Amsterdam, The Netherlands, 2019; pp. 419–434. [Google Scholar]
- Jaafari, A.; Termeh, S.V.R.; Bui, D.T. Genetic and firefly metaheuristic algorithms for an optimized neuro-fuzzy prediction modeling of wildfire probability. J. Environ. Manag. 2019, 243, 358–369. [Google Scholar] [CrossRef] [PubMed]
- Hong, H.; Jaafari, A.; Zenner, E.K. Predicting spatial patterns of wildfire susceptibility in the huichang county, china: An integrated model to analysis of landscape indicators. Ecol. Indic. 2019, 101, 878–891. [Google Scholar] [CrossRef]
- Rahmati, O.; Panahi, M.; Ghiasi, S.S.; Deo, R.C.; Tiefenbacher, J.P.; Pradhan, B.; Jahani, A.; Goshtasb, H.; Kornejady, A.; Shahabi, H. Hybridized neural fuzzy ensembles for dust source modeling and prediction. Atmos. Environ. 2020, 224, 117320. [Google Scholar] [CrossRef]
- Taheri, K.; Shahabi, H.; Chapi, K.; Shirzadi, A.; Gutiérrez, F.; Khosravi, K. Sinkhole susceptibility mapping: A comparison between bayes-based machine learning algorithms. Land Degrad. Dev. 2019, 30, 730–745. [Google Scholar] [CrossRef]
- Roodposhti, M.S.; Safarrad, T.; Shahabi, H. Drought sensitivity mapping using two one-class support vector machine algorithms. Atmos. Res. 2017, 193, 73–82. [Google Scholar] [CrossRef]
- Choubin, B.; Soleimani, F.; Pirnia, A.; Sajedi-Hosseini, F.; Alilou, H.; Rahmati, O.; Melesse, A.M.; Singh, V.P.; Shahabi, H. Effects of drought on vegetative cover changes: Investigating spatiotemporal patterns. In Extreme Hydrology and Climate Variability; Elsevier: Amsterdam, The Netherlands, 2019; pp. 213–222. [Google Scholar]
- Lee, S.; Panahi, M.; Pourghasemi, H.R.; Shahabi, H.; Alizadeh, M.; Shirzadi, A.; Khosravi, K.; Melesse, A.M.; Yekrangnia, M.; Rezaie, F. Sevucas: A novel gis-based machine learning software for seismic vulnerability assessment. Appl. Sci. 2019, 9, 3495. [Google Scholar] [CrossRef] [Green Version]
- Alizadeh, M.; Alizadeh, E.; Asadollahpour Kotenaee, S.; Shahabi, H.; Beiranvand Pour, A.; Panahi, M.; Bin Ahmad, B.; Saro, L. Social vulnerability assessment using artificial neural network (ANN) model for earthquake hazard in Tabriz City, Iran. Sustainability 2018, 10, 3376. [Google Scholar] [CrossRef] [Green Version]
- Azareh, A.; Rahmati, O.; Rafiei-Sardooi, E.; Sankey, J.B.; Lee, S.; Shahabi, H.; Ahmad, B.B. Modelling gully-erosion susceptibility in a semi-arid region, Iran: Investigation of applicability of certainty factor and maximum entropy models. Sci. Total Environ. 2019, 655, 684–696. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Chapi, K.; Omidavr, E.; Pham, B.T.; Talebpour Asl, D.; Khaledian, H.; Pradhan, B.; Panahi, M. A novel ensemble artificial intelligence approach for gully erosion mapping in a semi-arid watershed (Iran). Sensors 2019, 19, 2444. [Google Scholar] [CrossRef] [Green Version]
- Nhu, V.-H.; Janizadeh, S.; Avand, M.; Chen, W.; Farzin, M.; Omidvar, E.; Shirzadi, A.; Shahabi, H.; Clague, J.J.; Jaafari, A. Gis-based gully erosion susceptibility mapping: A comparison of computational ensemble data mining models. Appl. Sci. 2020, 10, 2039. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Pradhan, B.; Chen, W.; Khosravi, K.; Panahi, M.; Bin Ahmad, B.; Saro, L. Land subsidence susceptibility mapping in south Korea using machine learning algorithms. Sensors 2018, 18, 2464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rahmati, O.; Samadi, M.; Shahabi, H.; Azareh, A.; Rafiei-Sardooi, E.; Alilou, H.; Melesse, A.M.; Pradhan, B.; Chapi, K.; Shirzadi, A. Swpt: An automated gis-based tool for prioritization of sub-watersheds based on morphometric and topo-hydrological factors. Geosci. Front. 2019, 10, 2167–2175. [Google Scholar] [CrossRef]
- Rahmati, O.; Choubin, B.; Fathabadi, A.; Coulon, F.; Soltani, E.; Shahabi, H.; Mollaefar, E.; Tiefenbacher, J.; Cipullo, S.; Ahmad, B.B. Predicting uncertainty of machine learning models for modelling nitrate pollution of groundwater using quantile regression and uneec methods. Sci. Total Environ. 2019, 688, 855–866. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Pradhan, B.; Li, S.; Shahabi, H.; Rizeei, H.M.; Hou, E.; Wang, S. Novel hybrid integration approach of bagging-based fisher’s linear discriminant function for groundwater potential analysis. Nat. Resour. Res. 2019, 28, 1239–1258. [Google Scholar] [CrossRef] [Green Version]
- Miraki, S.; Zanganeh, S.H.; Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Pham, B.T. Mapping groundwater potential using a novel hybrid intelligence approach. Water Resour. Manag. 2019, 33, 281–302. [Google Scholar] [CrossRef]
- Rahmati, O.; Naghibi, S.A.; Shahabi, H.; Bui, D.T.; Pradhan, B.; Azareh, A.; Rafiei-Sardooi, E.; Samani, A.N.; Melesse, A.M. Groundwater spring potential modelling: Comprising the capability and robustness of three different modeling approaches. J. Hydrol. 2018, 565, 248–261. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Tsangaratos, P.; Shahabi, H.; Ilia, I.; Xue, W.; Bian, H. Groundwater spring potential mapping using artificial intelligence approach based on kernel logistic regression, random forest, and alternating decision tree models. Appl. Sci. 2020, 10, 425. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Alizadeh, M.; Chen, W.; Mohammadi, A.; Ahmad, B.; Panahi, M.; Hong, H. Landslide detection and susceptibility mapping by AIRSAR data using support vector machine and index of entropy models in Cameron Highlands, Malaysia. Remote Sens. 2018, 10, 1527. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Peng, J.; Hong, H.; Shahabi, H.; Pradhan, B.; Liu, J.; Zhu, A.-X.; Pei, X.; Duan, Z. Landslide susceptibility modelling using GIS-based machine learning techniques for Chongren county, Jiangxi province, China. Sci. Total Environ. 2018, 626, 1121–1135. [Google Scholar] [CrossRef]
- Pham, B.T.; Shirzadi, A.; Shahabi, H.; Omidvar, E.; Singh, S.K.; Sahana, M.; Asl, D.T.; Ahmad, B.B.; Quoc, N.K.; Lee, S. Landslide susceptibility assessment by novel hybrid machine learning algorithms. Sustainability 2019, 11, 4386. [Google Scholar] [CrossRef] [Green Version]
- Pham, B.T.; Prakash, I.; Dou, J.; Singh, S.K.; Trinh, P.T.; Tran, H.T.; Le, T.M.; Van Phong, T.; Khoi, D.K.; Shirzadi, A. A novel hybrid approach of landslide susceptibility modelling using rotation forest ensemble and different base classifiers. Geocarto Int. 2019, 1–25. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Shirzadi, A.; Hong, H.; Akgun, A.; Tian, Y.; Liu, J.; Zhu, A.-X.; Li, S. Novel hybrid artificial intelligence approach of bivariate statistical-methods-based kernel logistic regression classifier for landslide susceptibility modeling. Bull. Eng. Geol. Environ. 2019, 78, 4397–4419. [Google Scholar] [CrossRef]
- He, Q.; Shahabi, H.; Shirzadi, A.; Li, S.; Chen, W.; Wang, N.; Chai, H.; Bian, H.; Ma, J.; Chen, Y. Landslide spatial modelling using novel bivariate statistical based naïve bayes, RBF classifier, and RBF network machine learning algorithms. Sci. Total Environ. 2019, 663, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Jaafari, A.; Panahi, M.; Pham, B.T.; Shahabi, H.; Bui, D.T.; Rezaie, F.; Lee, S. Meta optimization of an adaptive neuro-fuzzy inference system with grey wolf optimizer and biogeography-based optimization algorithms for spatial prediction of landslide susceptibility. Catena 2019, 175, 430–445. [Google Scholar] [CrossRef]
- Hong, H.; Shahabi, H.; Shirzadi, A.; Chen, W.; Chapi, K.; Ahmad, B.B.; Roodposhti, M.S.; Hesar, A.Y.; Tian, Y.; Bui, D.T. Landslide susceptibility assessment at the Wuning area, China: A comparison between multi-criteria decision making, bivariate statistical and machine learning methods. Nat. Hazards 2019, 96, 173–212. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Minaei, M.; Shahabi, H.; Hagenauer, J. Big data in geohazard; pattern mining and large scale analysis of landslides in Iran. Earth Sci. Inform. 2019, 12, 1–17. [Google Scholar] [CrossRef]
- Nguyen, V.V.; Pham, B.T.; Vu, B.T.; Prakash, I.; Jha, S.; Shahabi, H.; Shirzadi, A.; Ba, D.N.; Kumar, R.; Chatterjee, J.M. Hybrid machine learning approaches for landslide susceptibility modeling. Forests 2019, 10, 157. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, P.T.; Tuyen, T.T.; Shirzadi, A.; Pham, B.T.; Shahabi, H.; Omidvar, E.; Amini, A.; Entezami, H.; Prakash, I.; Phong, T.V. Development of a novel hybrid intelligence approach for landslide spatial prediction. Appl. Sci. 2019, 9, 2824. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Shahabi, H.; Omidvar, E.; Shirzadi, A.; Geertsema, M.; Clague, J.J.; Khosravi, K.; Pradhan, B.; Pham, B.T.; Chapi, K. Shallow landslide prediction using a novel hybrid functional machine learning algorithm. Remote Sens. 2019, 11, 931. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Geertsema, M.; Omidvar, E.; Clague, J.J.; Thai Pham, B.; Dou, J.; Talebpour Asl, D.; Bin Ahmad, B. New ensemble models for shallow landslide susceptibility modeling in a semi-arid watershed. Forests 2019, 10, 743. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Zhao, X.; Shahabi, H.; Shirzadi, A.; Khosravi, K.; Chai, H.; Zhang, S.; Zhang, L.; Ma, J.; Chen, Y. Spatial prediction of landslide susceptibility by combining evidential belief function, logistic regression and logistic model tree. Geocarto Int. 2019, 34, 1177–1201. [Google Scholar] [CrossRef]
- Shirzadi, A.; Solaimani, K.; Roshan, M.H.; Kavian, A.; Chapi, K.; Shahabi, H.; Keesstra, S.; Ahmad, B.B.; Bui, D.T. Uncertainties of prediction accuracy in shallow landslide modeling: Sample size and raster resolution. Catena 2019, 178, 172–188. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Hoang, N.-D.; Pham, B.; Bui, Q.-T.; Tran, C.-T.; Panahi, M.; Bin Ahamd, B. A novel integrated approach of relevance vector machine optimized by imperialist competitive algorithm for spatial modeling of shallow landslides. Remote Sens. 2018, 10, 1538. [Google Scholar] [CrossRef] [Green Version]
- Shirzadi, A.; Soliamani, K.; Habibnejhad, M.; Kavian, A.; Chapi, K.; Shahabi, H.; Chen, W.; Khosravi, K.; Thai Pham, B.; Pradhan, B. Novel gis based machine learning algorithms for shallow landslide susceptibility mapping. Sensors 2018, 18, 3777. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Zhang, S.; Khosravi, K.; Shirzadi, A.; Chapi, K.; Pham, B.; Zhang, T.; Zhang, L.; Chai, H. Landslide susceptibility modeling based on gis and novel bagging-based kernel logistic regression. Appl. Sci. 2018, 8, 2540. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Han, L.; Chen, W.; Shahabi, H. Hybrid integration approach of entropy with logistic regression and support vector machine for landslide susceptibility modeling. Entropy 2018, 20, 884. [Google Scholar] [CrossRef] [Green Version]
- Abedini, M.; Ghasemian, B.; Shirzadi, A.; Shahabi, H.; Chapi, K.; Pham, B.T.; Bin Ahmad, B.; Tien Bui, D. A novel hybrid approach of bayesian logistic regression and its ensembles for landslide susceptibility assessment. Geocarto Int. 2018, 34, 1427–1457. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Peng, J.; Shahabi, H.; Hong, H.; Bui, D.T.; Duan, Z.; Li, S.; Zhu, A.-X. Gis-based landslide susceptibility evaluation using a novel hybrid integration approach of bivariate statistical based random forest method. Catena 2018, 164, 135–149. [Google Scholar] [CrossRef]
- Chen, W.; Shirzadi, A.; Shahabi, H.; Ahmad, B.B.; Zhang, S.; Hong, H.; Zhang, N. A novel hybrid artificial intelligence approach based on the rotation forest ensemble and naïve bayes tree classifiers for a landslide susceptibility assessment in Langao County, China. Geomat. Nat. Hazards Risk 2017, 8, 1955–1977. [Google Scholar] [CrossRef] [Green Version]
- Hong, H.; Liu, J.; Zhu, A.-X.; Shahabi, H.; Pham, B.T.; Chen, W.; Pradhan, B.; Bui, D.T. A novel hybrid integration model using support vector machines and random subspace for weather-triggered landslide susceptibility assessment in the Wuning area (China). Environ. Earth Sci. 2017, 76, 652. [Google Scholar] [CrossRef]
- Shadman Roodposhti, M.; Aryal, J.; Shahabi, H.; Safarrad, T. Fuzzy shannon entropy: A hybrid GIS-based landslide susceptibility mapping method. Entropy 2016, 18, 343. [Google Scholar] [CrossRef]
- Shahabi, H.; Hashim, M.; Ahmad, B.B. Remote sensing and gis-based landslide susceptibility mapping using frequency ratio, logistic regression, and fuzzy logic methods at the central Zab basin, Iran. Environ. Earth Sci. 2015, 73, 8647–8668. [Google Scholar] [CrossRef]
- Shahabi, H.; Khezri, S.; Ahmad, B.B.; Hashim, M. Landslide susceptibility mapping at central Zab basin, Iran: A comparison between analytical hierarchy process, frequency ratio and logistic regression models. Catena 2014, 115, 55–70. [Google Scholar] [CrossRef]
- Abedini, M.; Ghasemian, B.; Shirzadi, A.; Bui, D.T. A comparative study of support vector machine and logistic model tree classifiers for shallow landslide susceptibility modeling. Environ. Earth Sci. 2019, 78, 560. [Google Scholar] [CrossRef]
- Jaafari, A. Lidar-supported prediction of slope failures using an integrated ensemble weights-of-evidence and analytical hierarchy process. Environ. Earth Sci. 2018, 77, 42. [Google Scholar] [CrossRef]
- Mousavi, S.Z.; Kavian, A.; Soleimani, K.; Mousavi, S.R.; Shirzadi, A. Gis-based spatial prediction of landslide susceptibility using logistic regression model. Geomat. Nat. Hazards Risk 2011, 2, 33–50. [Google Scholar] [CrossRef]
- Shirzadi, A.; Saro, L.; Joo, O.H.; Chapi, K. A gis-based logistic regression model in rock-fall susceptibility mapping along a mountainous road: Salavat Abad case study, Kurdistan, Iran. Nat. Hazards 2012, 64, 1639–1656. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Sun, Z.; Han, J. Landslide susceptibility modeling using integrated ensemble weights of evidence with logistic regression and random forest models. Appl. Sci. 2019, 9, 171. [Google Scholar] [CrossRef] [Green Version]
- Shirzadi, A.; Shahabi, H.; Chapi, K.; Bui, D.T.; Pham, B.T.; Shahedi, K.; Ahmad, B.B. A comparative study between popular statistical and machine learning methods for simulating volume of landslides. Catena 2017, 157, 213–226. [Google Scholar] [CrossRef]
- Dou, J.; Yamagishi, H.; Zhu, Z.; Yunus, A.P.; Chen, C.W. Txt-tool 1.081-6.1 a comparative study of the binary logistic regression (BLR) and artificial neural network (ANN) models for GIS-based spatial predicting landslides at a regional scale. In Landslide Dynamics: Isdr-icl Landslide Interactive Teaching Tools; Springer: Berlin, Germany, 2018; pp. 139–151. [Google Scholar]
- Pham, B.T.; Shirzadi, A.; Bui, D.T.; Prakash, I.; Dholakia, M. A hybrid machine learning ensemble approach based on a radial basis function neural network and rotation forest for landslide susceptibility modeling: A case study in the Himalayan area, India. Int. J. Sediment Res. 2018, 33, 157–170. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Shirzadi, A.; Li, T.; Guo, C.; Hong, H.; Li, W.; Pan, D.; Hui, J.; Ma, M. A novel ensemble approach of bivariate statistical-based logistic model tree classifier for landslide susceptibility assessment. Geocarto Int. 2018, 33, 1398–1420. [Google Scholar] [CrossRef]
- Bui, D.T.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O.B. Spatial prediction of landslide hazards in hoa binh province (Vietnam): A comparative assessment of the efficacy of evidential belief functions and fuzzy logic models. Catena 2012, 96, 28–40. [Google Scholar]
- Zhu, A.-X.; Wang, R.; Qiao, J.; Qin, C.-Z.; Chen, Y.; Liu, J.; Du, F.; Lin, Y.; Zhu, T. An expert knowledge-based approach to landslide susceptibility mapping using GIS and fuzzy logic. Geomorphology 2014, 214, 128–138. [Google Scholar] [CrossRef]
- Kalantar, B.; Pradhan, B.; Naghibi, S.A.; Motevalli, A.; Mansor, S. Assessment of the effects of training data selection on the landslide susceptibility mapping: A comparison between support vector machine (SVM), logistic regression (LR) and artificial neural networks (ANN). Geomat. Nat. Hazards Risk 2018, 9, 49–69. [Google Scholar] [CrossRef]
- Huang, Y.; Zhao, L. Review on landslide susceptibility mapping using support vector machines. Catena 2018, 165, 520–529. [Google Scholar] [CrossRef]
- Chen, W.; Panahi, M.; Tsangaratos, P.; Shahabi, H.; Ilia, I.; Panahi, S.; Li, S.; Jaafari, A.; Ahmad, B.B. Applying population-based evolutionary algorithms and a neuro-fuzzy system for modeling landslide susceptibility. Catena 2019, 172, 212–231. [Google Scholar] [CrossRef]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at Haraz watershed, northern Iran. Sci. Total Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Tien Bui, D.; Sahana, M.; Chen, C.-W.; Zhu, Z.; Wang, W.; Pham, B.T. Evaluating gis-based multiple statistical models and data mining for earthquake and rainfall-induced landslide susceptibility using the LIDAR DEM. Remote Sens. 2019, 11, 638. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Hong, H.; Panahi, M.; Shahabi, H.; Wang, Y.; Shirzadi, A.; Pirasteh, S.; Alesheikh, A.A.; Khosravi, K.; Panahi, S. Spatial prediction of landslide susceptibility using GIS-based data mining techniques of anfis with whale optimization algorithm (WOA) and grey wolf optimizer (GWO). Appl. Sci. 2019, 9, 3755. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Moayedi, H.; Gör, M.; Jaafari, A.; Foong, L.K. Predicting slope stability failure through machine learning paradigms. ISPRS Int. J. Geo-Inf. 2019, 8, 395. [Google Scholar]
- Bui, D.T.; Ho, T.C.; Pradhan, B.; Pham, B.T.; Nhu, V.H.; Revhaug, I. GIS-based modeling of rainfall-induced landslides using data mining-based functional trees classifier with AdaBoost, Bagging, and MultiBoost ensemble frameworks. Environ. Earth Sci. 2016, 75, 1101. [Google Scholar]
- Pham, B.T.; Prakash, I.; Bui, D.T. Spatial prediction of landslides using a hybrid machine learning approach based on random subspace and classification and regression trees. Geomorphology 2018, 303, 256–270. [Google Scholar] [CrossRef]
- Nhu, V.H.; Rahmati, O.; Falah, F.; Shojaei, S.; Al-Ansari, N.; Shahabi, H.; Shirzadi, A.; Górski, K.; Nguyen, H.; Ahmad, B.B. Mapping of Groundwater Spring Potential in Karst Aquifer System Using Novel Ensemble Bivariate and Multivariate Models. Water 2020, 12, 985. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Xie, X.; Peng, J.; Wang, J.; Duan, Z.; Hong, H. Gis-based landslide susceptibility modelling: A comparative assessment of kernel logistic regression, naïve-bayes tree, and alternating decision tree models. Geomat. Nat. Hazards Risk 2017, 8, 950–973. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Zhang, S.; Li, R.; Shahabi, H. Performance evaluation of the GIS-based data mining techniques of best-first decision tree, random forest, and naïve bayes tree for landslide susceptibility modeling. Sci. Total Environ. 2018, 644, 1006–1018. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.; Prakash, I.; Dholakia, M. Evaluation of predictive ability of support vector machines and naive bayes trees methods for spatial prediction of landslides in Uttarakhand state (India) using GIS. J Geomat. 2016, 10, 71–79. [Google Scholar]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.-J.; Guo, M.; Sawada, K.; Lin, J.; Zhang, J. A comparative study of landslide susceptibility maps using logistic regression, frequency ratio, decision tree, weights of evidence and artificial neural network. Geosci. J. 2016, 20, 117–136. [Google Scholar] [CrossRef]
- Colkesen, I.; Kavzoglu, T. The use of logistic model tree (LMT) for pixel-and object-based classifications using high-resolution worldview-2 imagery. Geocarto Int. 2017, 32, 71–86. [Google Scholar] [CrossRef]
- Tien Bui, D.; Ho, T.; Revhaug, I.; Pradhan, B.; Nguyen, D. Landslide susceptibility mapping along the national road 32 of Vietnam using GIS-based j48 decision tree classifier and its ensembles. In Cartography from Pole to Pole; Springer: Berlin/Heidelberg, Germany, 2014; pp. 303–317. [Google Scholar]
- Galli, M.; Ardizzone, F.; Cardinali, M.; Guzzetti, F.; Reichenbach, P. Comparing landslide inventory maps. Geomorphology 2008, 94, 268–289. [Google Scholar] [CrossRef]
- Dehnavi, A.; Aghdam, I.N.; Pradhan, B.; Varzandeh, M.H.M. A new hybrid model using step-wise weight assessment ratio analysis (SWARA) technique and adaptive neuro-fuzzy inference system (ANFIS) for regional landslide hazard assessment in Iran. Catena 2015, 135, 122–148. [Google Scholar] [CrossRef]
- Nefeslioglu, H.A.; Duman, T.Y.; Durmaz, S. Landslide susceptibility mapping for a part of tectonic Kelkit valley (eastern black sea region of Turkey). Geomorphology 2008, 94, 401–418. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Sahin, E.K.; Colkesen, I. An assessment of multivariate and bivariate approaches in landslide susceptibility mapping: A case study of Duzkoy district. Nat. Hazards 2015, 76, 471–496. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Pourghasemi, H.R.; Indra, P.; Dholakia, M. Landslide susceptibility assesssment in the uttarakhand area (India) using GIS: A comparison study of prediction capability of naïve bayes, multilayer perceptron neural networks, and functional trees methods. Theor. Appl. Climatol. 2017, 128, 255–273. [Google Scholar] [CrossRef]
- Pham, B.T.; Pradhan, B.; Bui, D.T.; Prakash, I.; Dholakia, M. A comparative study of different machine learning methods for landslide susceptibility assessment: A case study of Uttarakhand area (India). Environ. Model. Softw. 2016, 84, 240–250. [Google Scholar] [CrossRef]
- Gorsevski, P.V.; Jankowski, P. An optimized solution of multi-criteria evaluation analysis of landslide susceptibility using fuzzy sets and kalman filter. Comput. Geosci. 2010, 36, 1005–1020. [Google Scholar] [CrossRef]
- Yilmaz, I. Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: A case study from kat landslides (Tokat—Turkey). Comput. Geosci. 2009, 35, 1125–1138. [Google Scholar] [CrossRef]
- Ercanoglu, M.; Gokceoglu, C. Assessment of landslide susceptibility for a landslide-prone area (north of Yenice, NW Turkey) by fuzzy approach. Environ. Geol. 2002, 41, 720–730. [Google Scholar]
- Oh, H.-J.; Pradhan, B. Application of a neuro-fuzzy model to landslide-susceptibility mapping for shallow landslides in a tropical hilly area. Comput. Geosci. 2011, 37, 1264–1276. [Google Scholar] [CrossRef]
- Mitchell, J.; Bubenzer, G. Soil loss estimation. In Soil Erosion; Kirkby, M.J., Morgan, R.P.C., Eds.; John Wiley and Sons: Brisbane, Australia, 1980; pp. 17–61. [Google Scholar]
- Pourghasemi, H.R.; Pradhan, B.; Gokceoglu, C. Application of fuzzy logic and analytical hierarchy process (ahp) to landslide susceptibility mapping at Haraz watershed, Iran. Nat. Hazards 2012, 63, 965–996. [Google Scholar] [CrossRef]
- Moore, I.D.; Wilson, J.P. Length-slope factors for the revised universal soil loss equation: Simplified method of estimation. J. Soil Water Conserv. 1992, 47, 423–428. [Google Scholar]
- Park, S.; Choi, C.; Kim, B.; Kim, J. Landslide susceptibility mapping using frequency ratio, analytic hierarchy process, logistic regression, and artificial neural network methods at the Inje area, Korea. Environ. Earth Sci. 2013, 68, 1443–1464. [Google Scholar] [CrossRef]
- Chowdhury, R.; Flentje, P.; Bhattacharya, G. Geotechnics in the twenty-first century, uncertainties and other challenges: With particular reference to landslide hazard and risk assessment. In Proceedings of the International Symposium on Engineering under Uncertainty: Safety Assessment and Management (ISEUSAM-2012); Springer: Berlin/Heidelberg, Germany, 2013; pp. 27–53. [Google Scholar]
- Nampak, H.; Pradhan, B.; Manap, M.A. Application of gis based data driven evidential belief function model to predict groundwater potential zonation. J. Hydrol. 2014, 513, 283–300. [Google Scholar] [CrossRef]
- Barlow, J.; Martin, Y.; Franklin, S. Detecting translational landslide scars using segmentation of landsat ETM+ and DEM data in the northern cascade mountains, British Columbia. Can. J. Remote Sens. 2003, 29, 510–517. [Google Scholar] [CrossRef]
- Yang, W.; Wang, M.; Shi, P. Using modis ndvi time series to identify geographic patterns of landslides in vegetated regions. IEEE Geosci. Remote Sens. Lett. 2012, 10, 707–710. [Google Scholar] [CrossRef]
- Demir, G.; Aytekin, M.; Akgun, A. Landslide susceptibility mapping by frequency ratio and logistic regression methods: An example from niksar–resadiye (Tokat, Turkey). Arab. J. Geosci. 2015, 8, 1801–1812. [Google Scholar] [CrossRef]
- Wang, G.; Lei, X.; Chen, W.; Shahabi, H.; Shirzadi, A. Hybrid computational intelligence methods for landslide susceptibility mapping. Symmetry 2020, 12, 325. [Google Scholar] [CrossRef] [Green Version]
- Kohavi, R. Scaling up the accuracy of naive-bayes classifiers: A decision-tree hybrid. In KDD’96: Proceedings of the Second International Conference on Knowledge Discovery and Data Mining; AAAI Press: Palo Alto, CA, USA, 1996; pp. 202–207. [Google Scholar]
- Luger, G.F. Artificial Intelligence: Structures and Strategies for Complex Problem Solving; Pearson Education: London, UK, 2005. [Google Scholar]
- Shahabi, H.; Ahmad, B.; Khezri, S. Evaluation and comparison of bivariate and multivariate statistical methods for landslide susceptibility mapping (case study: Zab basin). Arab. J. Geosci. 2013, 6, 3885–3907. [Google Scholar] [CrossRef]
- Shirzadi, A.; Chapi, K.; Shahabi, H.; Solaimani, K.; Kavian, A.; Ahmad, B.B. Rock fall susceptibility assessment along a mountainous road: An evaluation of bivariate statistic, analytical hierarchy process and frequency ratio. Environ. Earth Sci. 2017, 76, 152. [Google Scholar] [CrossRef]
- Quinlan, J. C4. 5: Programs for Machine Learning. Morgan Kaufmann, San Francisco; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993. [Google Scholar]
- Landwehr, N.; Hall, M.; Frank, E. Logistic model trees. Mach. Learn. 2005, 59, 161–205. [Google Scholar] [CrossRef] [Green Version]
- Lim, T.-S.; Loh, W.-Y.; Shih, Y.-S. A comparison of prediction accuracy, complexity, and training time of thirty-three old and new classification algorithms. Mach. Learn. 2000, 40, 203–228. [Google Scholar] [CrossRef]
- Doetsch, P.; Buck, C.; Golik, P.; Hoppe, N.; Kramp, M.; Laudenberg, J.; Oberdörfer, C.; Steingrube, P.; Forster, J.; Mauser, A. Logistic model trees with auc split criterion for the kdd cup 2009 small challenge. In Proceedings of the 2009 International Conference on KDD-Cup 2009-Volume 7; JMLR.org: Brookline, MA, USA, 2009; pp. 77–88. [Google Scholar]
- Vapnik, V.N. Adaptive and learning systems for signal processing communications, and control. In Statistical Learning Theory; Wiley: Chichester, UK, 1998. [Google Scholar]
- Tien Bui, D.; Pradhan, B.; Lofman, O.; Revhaug, I. Landslide susceptibility assessment in Vietnam using support vector machines, decision tree, and naive bayes models. Math. Probl. Eng. 2012, 2012, 974638. [Google Scholar] [CrossRef] [Green Version]
- Dou, J.; Bui, D.T.; Yunus, A.P.; Jia, K.; Song, X.; Revhaug, I.; Xia, H.; Zhu, Z. Optimization of causative factors for landslide susceptibility evaluation using remote sensing and GIS data in parts of Niigata, Japan. PLoS ONE 2015, 10, e0133262. [Google Scholar] [CrossRef] [Green Version]
- Svozil, D.; Kvasnicka, V.; Pospichal, J. Introduction to multi-layer feed-forward neural networks. Chemom. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- Pradhan, B. Landslide susceptibility mapping of a catchment area using frequency ratio, fuzzy logic and multivariate logistic regression approaches. J. Indian Soc. Remote Sens. 2010, 38, 301–320. [Google Scholar] [CrossRef]
- Dou, J.; Yamagishi, H.; Pourghasemi, H.R.; Yunus, A.P.; Song, X.; Xu, Y.; Zhu, Z. An integrated artificial neural network model for the landslide susceptibility assessment of Osado island, Japan. Nat. Hazards 2015, 78, 1749–1776. [Google Scholar] [CrossRef]
- Were, K.; Bui, D.T.; Dick, Ø.B.; Singh, B.R. A comparative assessment of support vector regression, artificial neural networks, and random forests for predicting and mapping soil organic carbon stocks across an afromontane landscape. Ecol. Indic. 2015, 52, 394–403. [Google Scholar] [CrossRef]
- Dao, D.V.; Trinh, S.H.; Ly, H.-B.; Pham, B.T. Prediction of compressive strength of geopolymer concrete using entirely steel slag aggregates: Novel hybrid artificial intelligence approaches. Appl. Sci. 2019, 9, 1113. [Google Scholar] [CrossRef] [Green Version]
- Dao, D.V.; Ly, H.-B.; Trinh, S.H.; Le, T.-T.; Pham, B.T. Artificial intelligence approaches for prediction of compressive strength of geopolymer concrete. Materials 2019, 12, 983. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ly, H.-B.; Monteiro, E.; Le, T.-T.; Le, V.M.; Dal, M.; Regnier, G.; Pham, B.T. Prediction and sensitivity analysis of bubble dissolution time in 3d selective laser sintering using ensemble decision trees. Materials 2019, 12, 1544. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pham, B.T.; Nguyen, M.D.; Bui, K.-T.T.; Prakash, I.; Chapi, K.; Bui, D.T. A novel artificial intelligence approach based on multi-layer perceptron neural network and biogeography-based optimization for predicting coefficient of consolidation of soil. Catena 2019, 173, 302–311. [Google Scholar] [CrossRef]
- Pham, B.T. A novel classifier based on composite hyper-cubes on iterated random projections for assessment of landslide susceptibility. J. Geol. Soc. India 2018, 91, 355–362. [Google Scholar] [CrossRef]
- Bui, D.T.; Tsangaratos, P.; Ngo, P.-T.T.; Pham, T.D.; Pham, B.T. Flash flood susceptibility modeling using an optimized fuzzy rule based feature selection technique and tree based ensemble methods. Sci. Total Environ. 2019, 668, 1038–1054. [Google Scholar] [CrossRef] [PubMed]
- Pham, B.T.; Prakash, I. Evaluation and comparison of logitboost ensemble, fisher’s linear discriminant analysis, logistic regression and support vector machines methods for landslide susceptibility mapping. Geocarto Int. 2017, 1–18. [Google Scholar] [CrossRef]
- Van Dao, D.; Jaafari, A.; Bayat, M.; Mafi-Gholami, D.; Qi, C.; Moayedi, H.; Van Phong, T.; Ly, H.B.; Le, T.T.; Trinh, P.T.; et al. A spatially explicit deep learning neural network model for the prediction of landslide susceptibility. Catena 2020, 188, 104451. [Google Scholar]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.-W.; Khosravi, K.; Yang, Y.; Pham, B.T. Assessment of advanced random forest and decision tree algorithms for modeling rainfall-induced landslide susceptibility in the Izu-oshima volcanic island, Japan. Sci. Total Environ. 2019, 662, 332–346. [Google Scholar] [CrossRef]
- Zimmerman, D.W.; Zumbo, B.D. Relative power of the wilcoxon test, the friedman test, and repeated-measures anova on ranks. J. Exp. Educ. 1993, 62, 75–86. [Google Scholar] [CrossRef]
- Benavoli, A.; Corani, G.; Mangili, F.; Zaffalon, M.; Ruggeri, F. A bayesian wilcoxon signed-rank test based on the dirichlet process. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1026–1034. [Google Scholar]
- Pham, B.T.; Bui, D.T.; Prakash, I.; Dholakia, M. Rotation forest fuzzy rule-based classifier ensemble for spatial prediction of landslides using GIS. Nat. Hazards 2016, 83, 97–127. [Google Scholar] [CrossRef]
- Vasu, N.N.; Lee, S.-R. A hybrid feature selection algorithm integrating an extreme learning machine for landslide susceptibility modeling of mt. Woomyeon, south Korea. Geomorphology 2016, 263, 50–70. [Google Scholar] [CrossRef]
- Lee, C.; Lee, G.G. Information gain and divergence-based feature selection for machine learning-based text categorization. Inf. Process. Manag. 2006, 42, 155–165. [Google Scholar] [CrossRef]
- Mao, K.Z. Orthogonal forward selection and backward elimination algorithms for feature subset selection. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2004, 34, 629–634. [Google Scholar] [CrossRef]
- Yildirim, P. Filter based feature selection methods for prediction of risks in hepatitis disease. Int. J. Mach. Learn. Comput. 2015, 5, 258. [Google Scholar] [CrossRef] [Green Version]
- Gariano, S.L.; Guzzetti, F. Landslides in a changing climate. Earth-Sci. Rev. 2016, 162, 227–252. [Google Scholar] [CrossRef] [Green Version]
- Jaafari, A.; Zenner, E.K.; Panahi, M.; Shahabi, H. Hybrid artificial intelligence models based on a neuro-fuzzy system and metaheuristic optimization algorithms for spatial prediction of wildfire probability. Agric. For. Meteorol. 2019, 266–267, 198–207. [Google Scholar] [CrossRef]
- Akgun, A.; Sezer, E.A.; Nefeslioglu, H.A.; Gokceoglu, C.; Pradhan, B. An easy-to-use matlab program (Mamland) for the assessment of landslide susceptibility using a mamdani fuzzy algorithm. Comput. Geosci. 2012, 38, 23–34. [Google Scholar] [CrossRef]
- Nasiri, V.; Darvishsefat, A.A.; Rafiee, R.; Shirvany, A.; Hemat, M.A. Land use change modeling through an integrated multi-layer perceptron neural network and Markov chain analysis (case study: Arasbaran region, Iran). J. For. Res. 2019, 30, 943–957. [Google Scholar] [CrossRef]
- Zhao, X.; Chen, W. GIS-based evaluation of landslide susceptibility models using certainty factors and functional trees-based ensemble techniques. Appl. Sci. 2020, 10, 16. [Google Scholar] [CrossRef] [Green Version]
- Mohammadi, A.; Shahabi, H.; Bin Ahmad, B. Integration of insartechnique, google earth images and extensive field survey for landslide inventory in a part of Cameron highlands, Pahang, Malaysia. Appl. Ecol. Environ. Res. 2019, 16, 8075–8091. [Google Scholar] [CrossRef]
- Nhu, V.H.; Shirzadi, A.; Shahabi, H.; Chen, W.; Clague, J.J.; Geertsema, M.; Jaafari, A.; Avand, M.; Miraki, S.; Asl, D.T.; et al. Shallow Landslide Susceptibility Mapping by Random Forest Base Classifier and its Ensembles in a Semi-Arid Region of Iran. Forests 2020, 11, 421. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.; Min, K. Statistical analysis of landslide susceptibility at Yongin, Korea. Environ. Geol. 2001, 40, 1095–1113. [Google Scholar] [CrossRef]
- Yilmaz, I. Comparison of landslide susceptibility mapping methodologies for koyulhisar, turkey: Conditional probability, logistic regression, artificial neural networks, and support vector machine. Environ. Earth Sci. 2010, 61, 821–836. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | LMT | NBT | LR | ANN | SVM | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| T * | V * | T | V | T | V | T | V | T | V | |
| True positive | 78 | 19 | 77 | 18 | 80 | 19 | 76 | 16 | 77 | 18 |
| True negative | 81 | 19 | 83 | 20 | 81 | 19 | 73 | 17 | 83 | 20 |
| False positive | 11 | 3 | 12 | 4 | 9 | 3 | 13 | 6 | 12 | 4 |
| False negative | 8 | 3 | 6 | 2 | 8 | 3 | 16 | 5 | 6 | 2 |
| Sensitivity (%) | 0.907 | 0.864 | 0.928 | 0.900 | 0.909 | 0.864 | 0.826 | 0.762 | 0.928 | 0.900 |
| Specificity (%) | 0.880 | 0.864 | 0.874 | 0.833 | 0.900 | 0.864 | 0.849 | 0.739 | 0.874 | 0.833 |
| Accuracy (%) | 0.893 | 0.864 | 0.899 | 0.864 | 0.904 | 0.864 | 0.837 | 0.750 | 0.899 | 0.864 |
| MAE | 0.207 | 0.216 | 0.225 | 0.225 | 0.213 | 0.216 | 0.241 | 0.235 | 0.223 | 0.246 |
| RMSE | 0.304 | 0.313 | 0.319 | 0.341 | 0.311 | 0.314 | 0.349 | 0.358 | 0.318 | 0.369 |
| AUC | 0.944 | 0.936 | 0.918 | 0.874 | 0.939 | 0.936 | 0.911 | 0.871 | 0.899 | 0.864 |
| No. | Landslide Model | Mean Rank | χ2 | p-Value |
|---|---|---|---|---|
| 1 | LMT | 2.80 | 557.912 | 0.000 |
| 2 | LR | 2.93 | ||
| 3 | NBT | 2.88 | ||
| 4 | ANN | 3.07 | ||
| 5 | SVM | 2.32 |
| No. | Pairwise Comparison | Number of Positive Differences | Number of Negative Differences | z-Value | p-Value | Significance |
|---|---|---|---|---|---|---|
| 1 | LMT vs. LR | 60 | 50 | −1.536 | 0.125 | No |
| 2 | LMT vs. NBT | 83 | 27 | −5.590 | 0.000 | Yes |
| 3 | LMT vs. ANN | 62 | 46 | −0.878 | 0.080 | Yes |
| 4 | LMT vs. SVM | 36 | 74 | −3.677 | 0.000 | Yes |
| 5 | LR vs. NBT | 82 | 29 | −5.589 | 0.000 | Yes |
| 6 | LR vs. ANN | 61 | 49 | −0.605 | 0.015 | Yes |
| 7 | LR vs. SVM | 35 | 75 | −4.081 | 0.000 | Yes |
| 8 | NBT vs. ANN | 36 | 73 | −3.958 | 0.000 | Yes |
| 9 | NBT vs. SVM | 30 | 80 | −5.711 | 0.000 | Yes |
| 10 | ANN vs. SVM | 43 | 67 | −3.140 | 0.002 | Yes |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nhu, V.-H.; Shirzadi, A.; Shahabi, H.; Singh, S.K.; Al-Ansari, N.; Clague, J.J.; Jaafari, A.; Chen, W.; Miraki, S.; Dou, J.; et al. Shallow Landslide Susceptibility Mapping: A Comparison between Logistic Model Tree, Logistic Regression, Naïve Bayes Tree, Artificial Neural Network, and Support Vector Machine Algorithms. Int. J. Environ. Res. Public Health 2020, 17, 2749. https://doi.org/10.3390/ijerph17082749
Nhu V-H, Shirzadi A, Shahabi H, Singh SK, Al-Ansari N, Clague JJ, Jaafari A, Chen W, Miraki S, Dou J, et al. Shallow Landslide Susceptibility Mapping: A Comparison between Logistic Model Tree, Logistic Regression, Naïve Bayes Tree, Artificial Neural Network, and Support Vector Machine Algorithms. International Journal of Environmental Research and Public Health. 2020; 17(8):2749. https://doi.org/10.3390/ijerph17082749
Chicago/Turabian StyleNhu, Viet-Ha, Ataollah Shirzadi, Himan Shahabi, Sushant K. Singh, Nadhir Al-Ansari, John J. Clague, Abolfazl Jaafari, Wei Chen, Shaghayegh Miraki, Jie Dou, and et al. 2020. "Shallow Landslide Susceptibility Mapping: A Comparison between Logistic Model Tree, Logistic Regression, Naïve Bayes Tree, Artificial Neural Network, and Support Vector Machine Algorithms" International Journal of Environmental Research and Public Health 17, no. 8: 2749. https://doi.org/10.3390/ijerph17082749