A Cloud-Based Framework for Large-Scale Log Mining through Apache Spark and Elasticsearch

 , , ,
, , ,
Abstract
:1. Introduction
2. Related Work
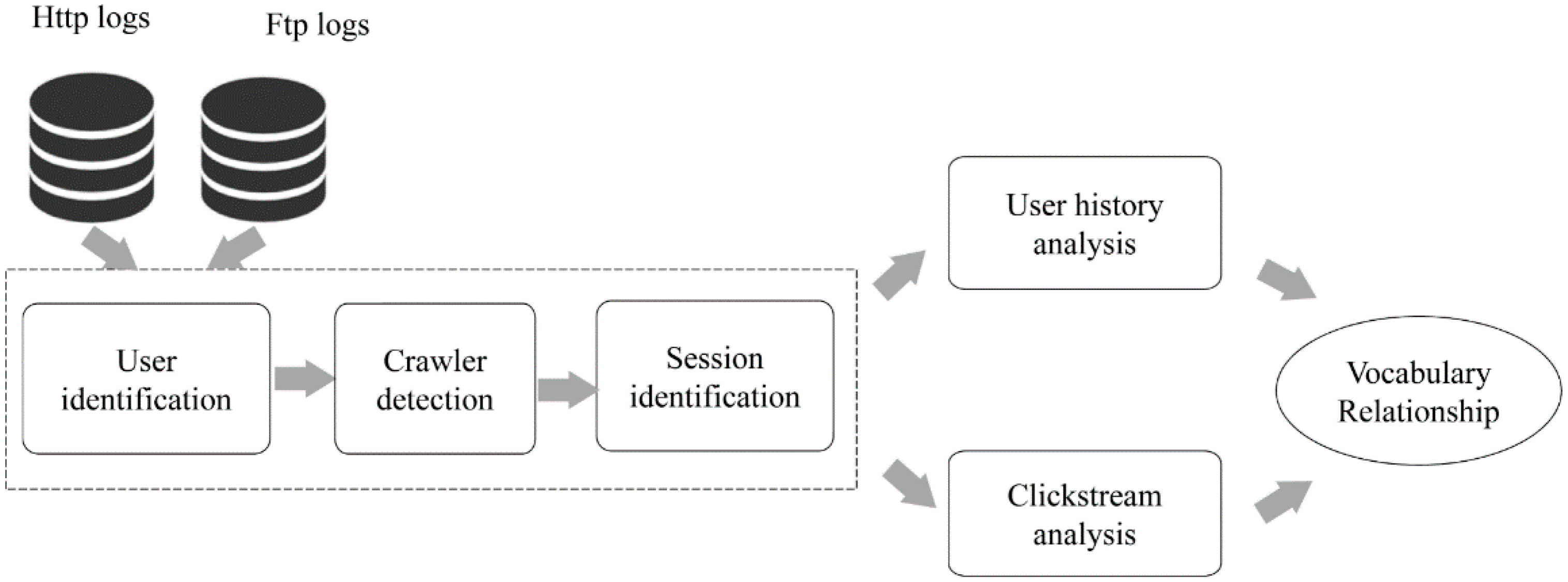
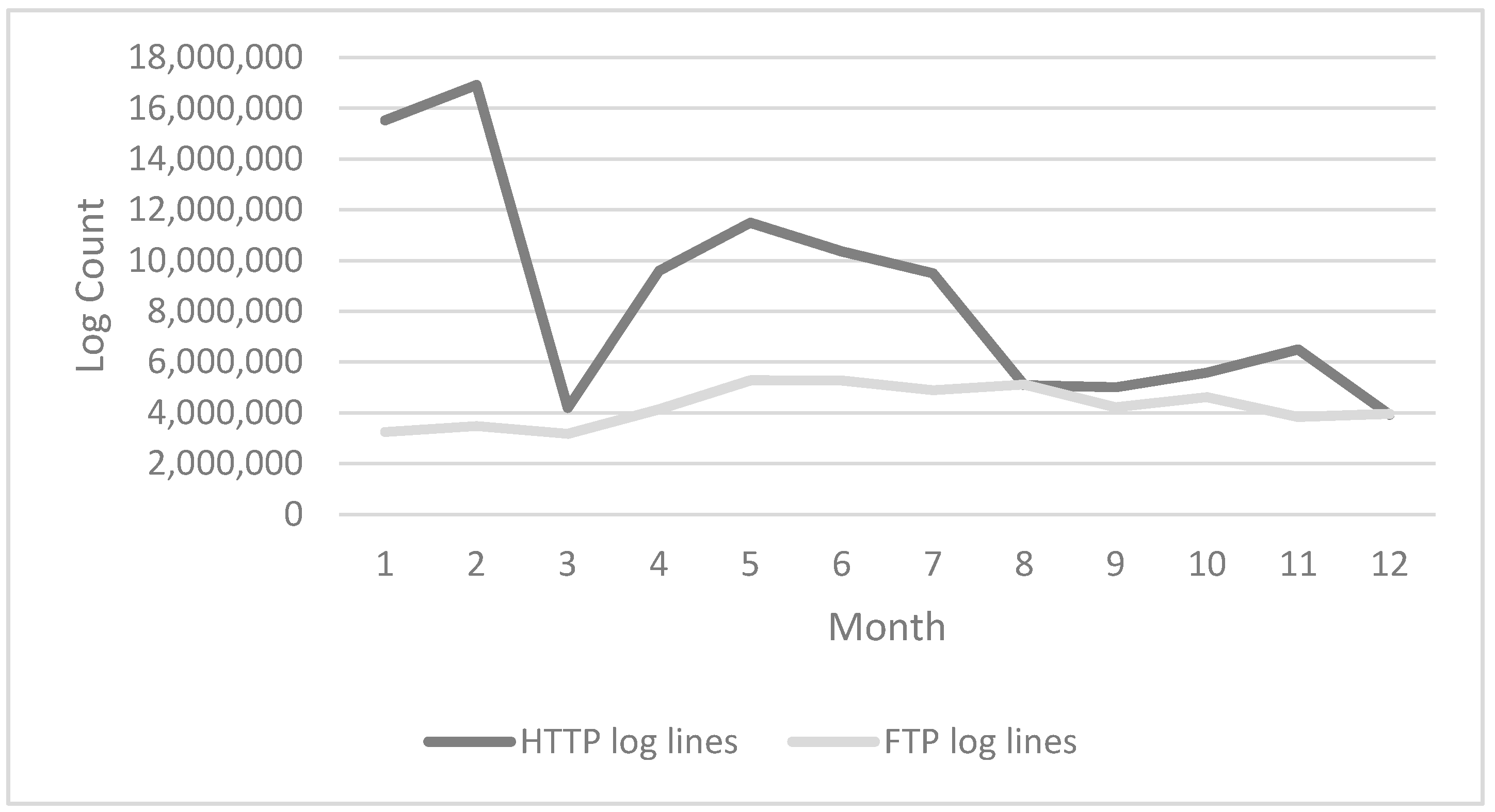
3. Data
4. Methodology
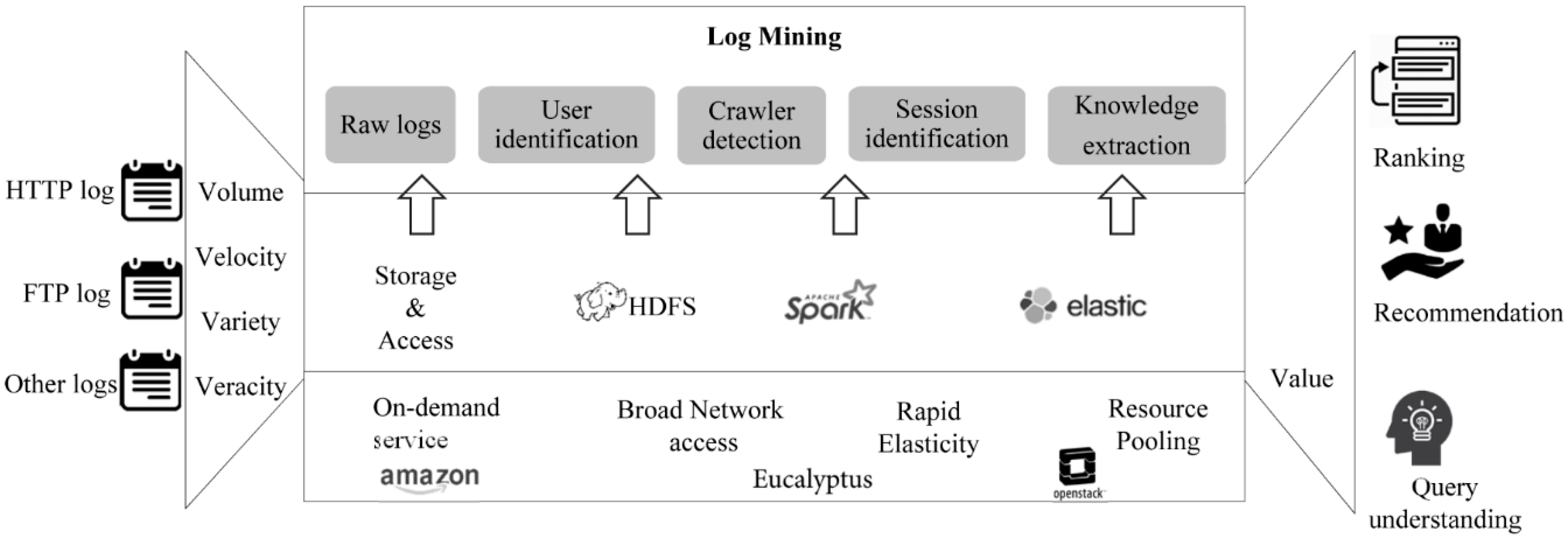
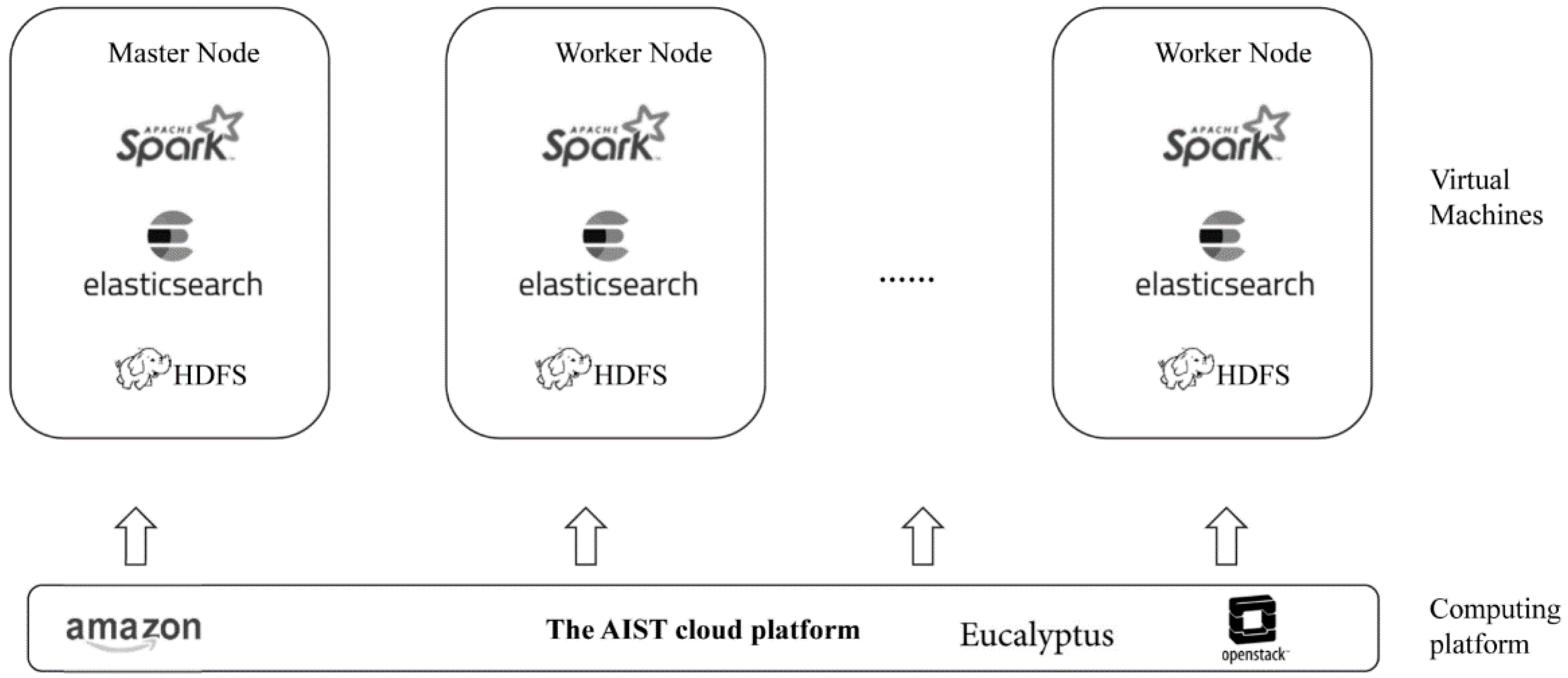
4.1. Proposed Framework Architecture for Log Mining
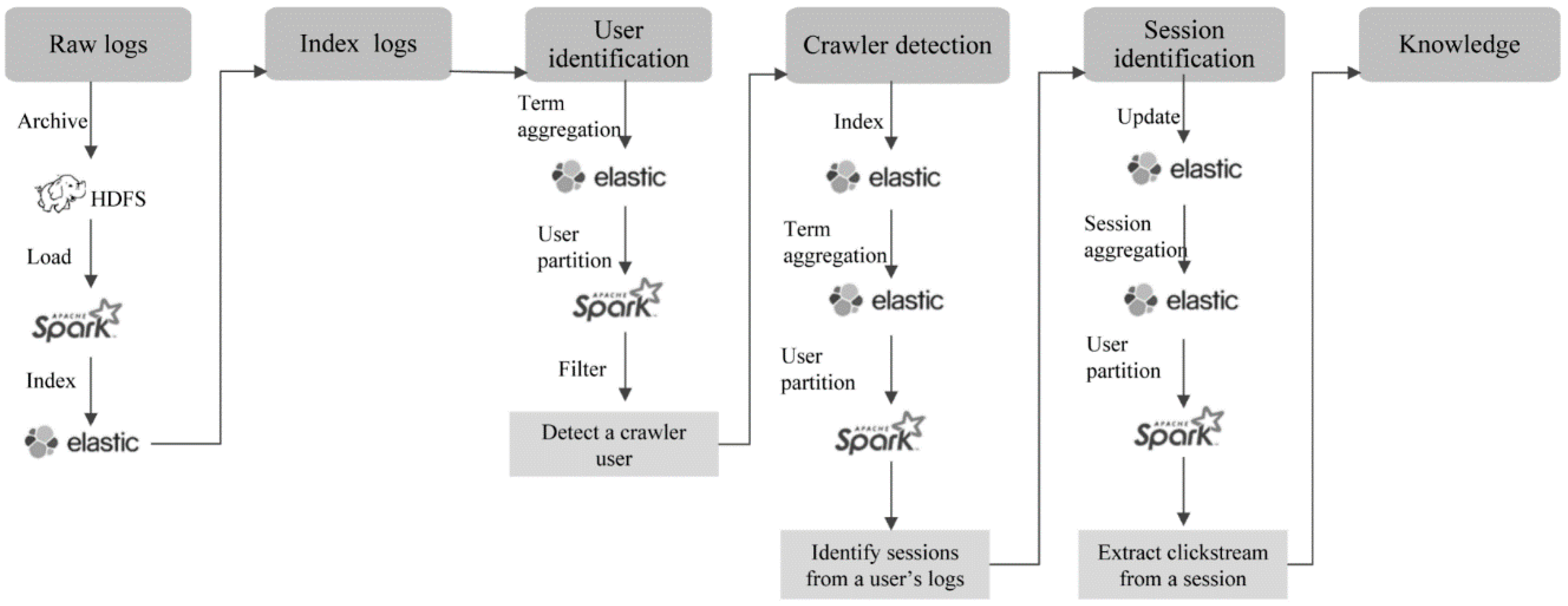
4.2. Information Flow
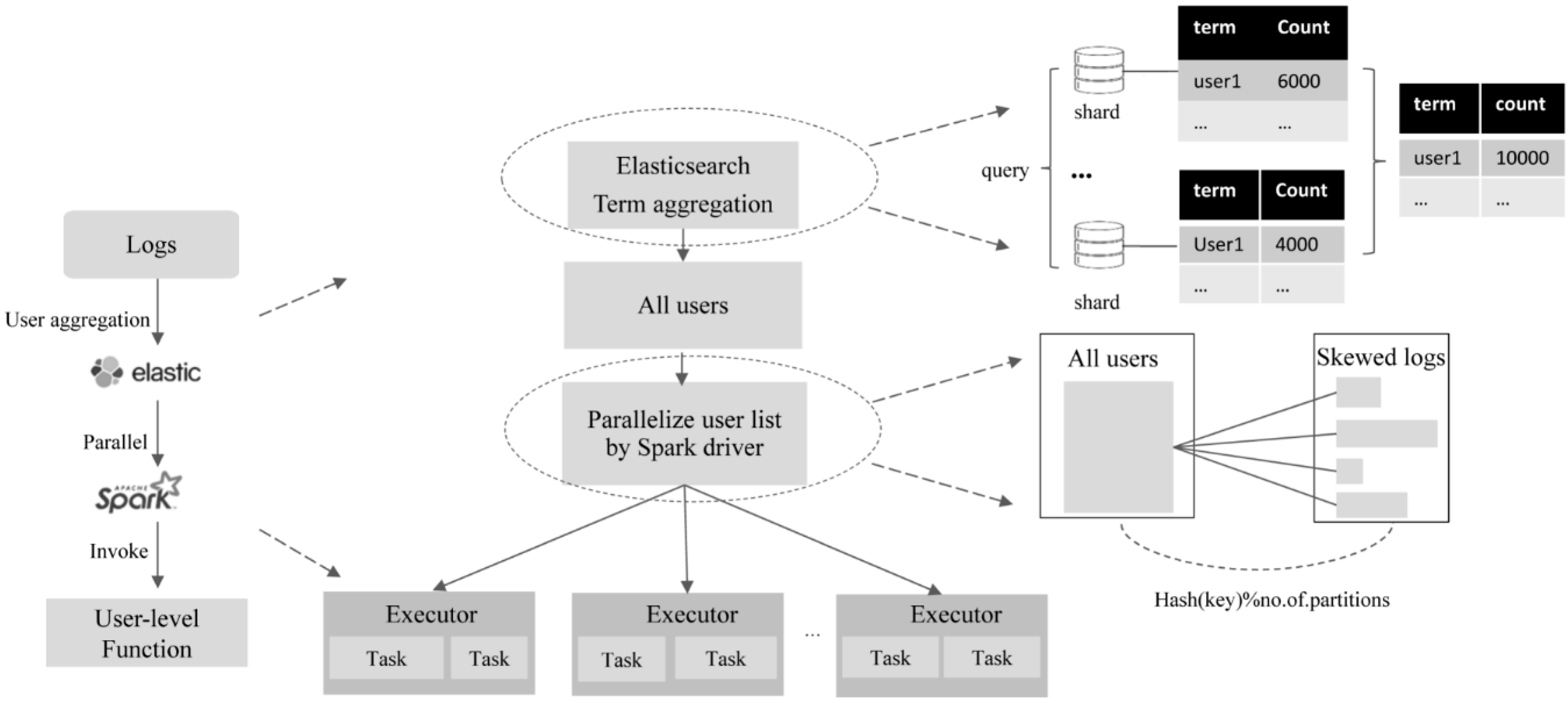
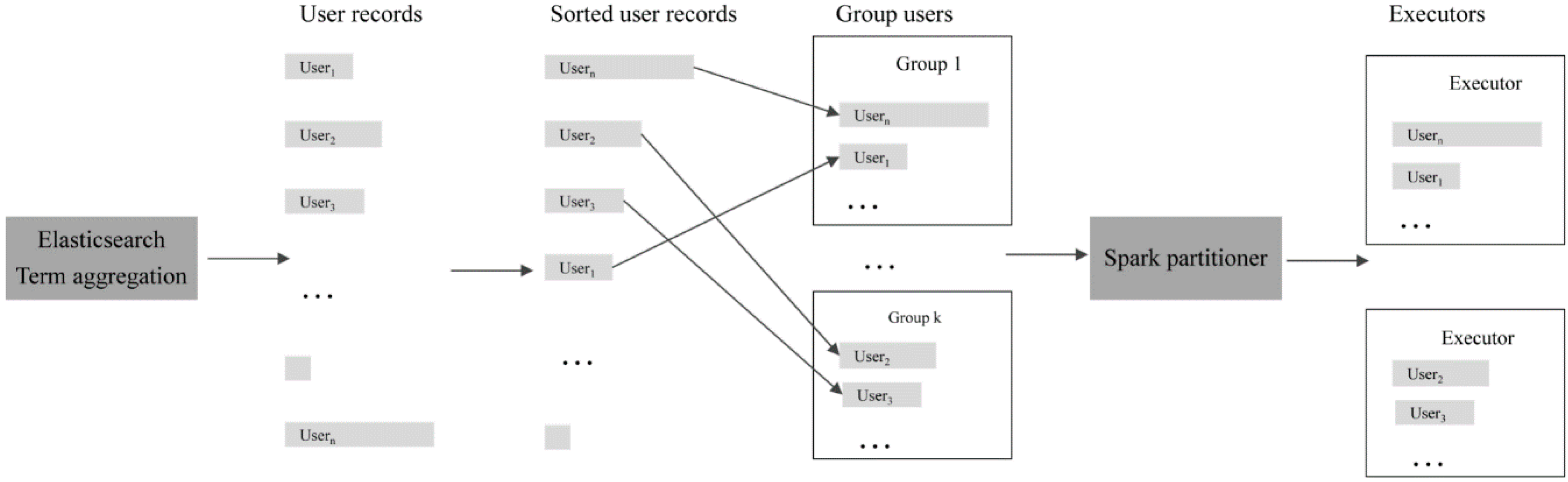
4.3. Log Partitioner
- Calculate log records for each user. A user map stores the user and the corresponding log count as (user1, log_count1), (user2, log_count2), …, (userk, log_countk). The calculation module is implemented with the Elasticsearch term aggregation API and the performance depends on the cluster configuration and unique IPs in the log. Generally, the runtime increases linearly with the increment of log number; thus, the time complexity is approximately O(n).
- Sort the user map by the log number in descending order. The higher a user is ranked in the map, the more frequently the user uses the website. The time complexity of the map sort operation is O(nlog2n)).
- Split users into k groups using the greedy algorithm [28]. The top k users in the sorted user map are assigned to k groups in series. For the rest, each user is assigned to the group with minimal logs until all users are assigned to the k groups. A user group map stores the split strategy in the format of (useri, group1), (userj, group1), …, (userk, groupn). Note that the greedy algorithm yields local optimum group strategy. The dynamic planning solutions can be adopted to split users too. In addition, to maximize the usage of all computation resources, k is suggested to be equal to or be multiples of the total number of Central Processing Unit (CPU) cores managed by Spark. The greedy algorithm is straightforward, and the time complexity is linear (O(n)).
- Load all users into Spark and distribute user data across Spark tasks with a customized partitioner. The partitioner receives the user map and partition number as input and assigns each user to a partition using the corresponding group identifier instead of the hash value of the user IP. As a result, the logs are nearly evenly distributed across all partitions, which prevents significant slow tasks and improves the log-mining performance.
5. Experiments
6. Result and Evaluation
6.1. Comparison of the HashPartitioner and the LogPartitioner
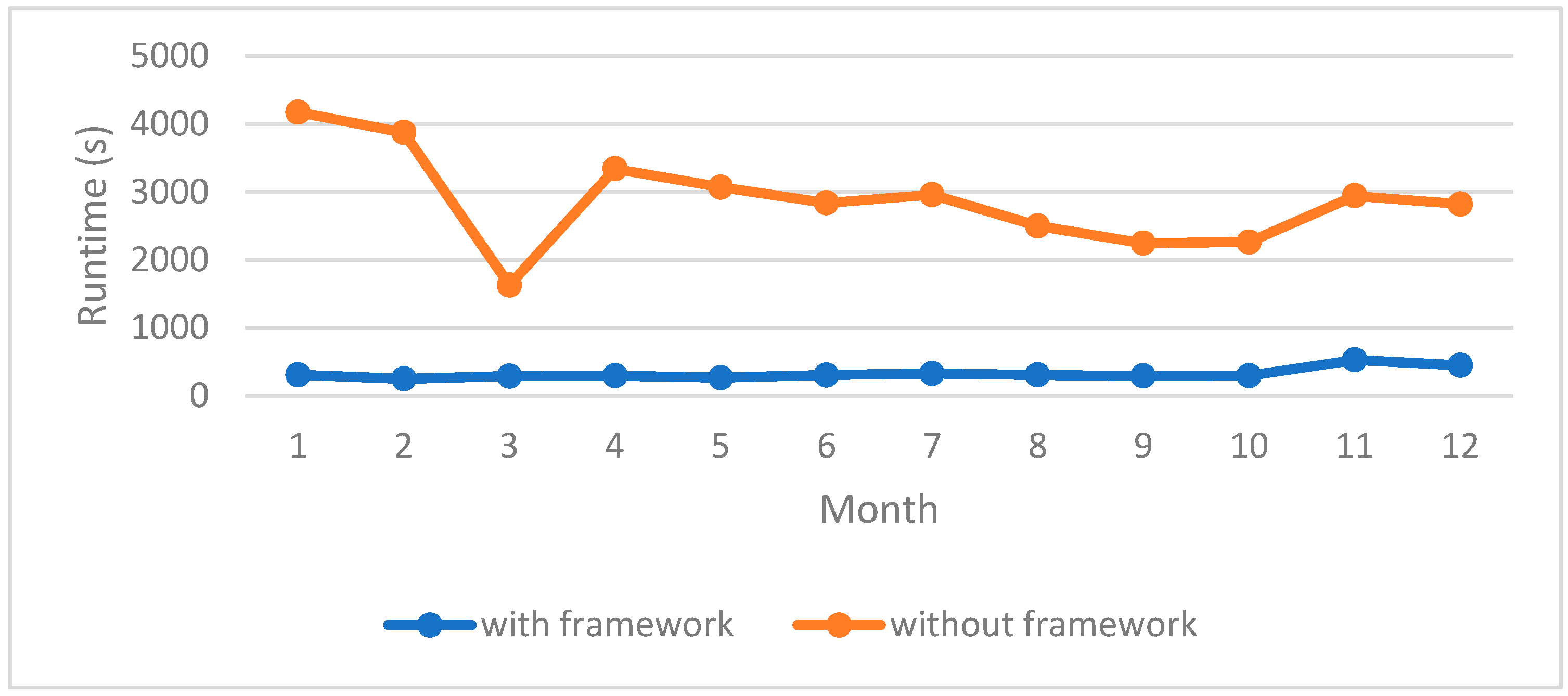
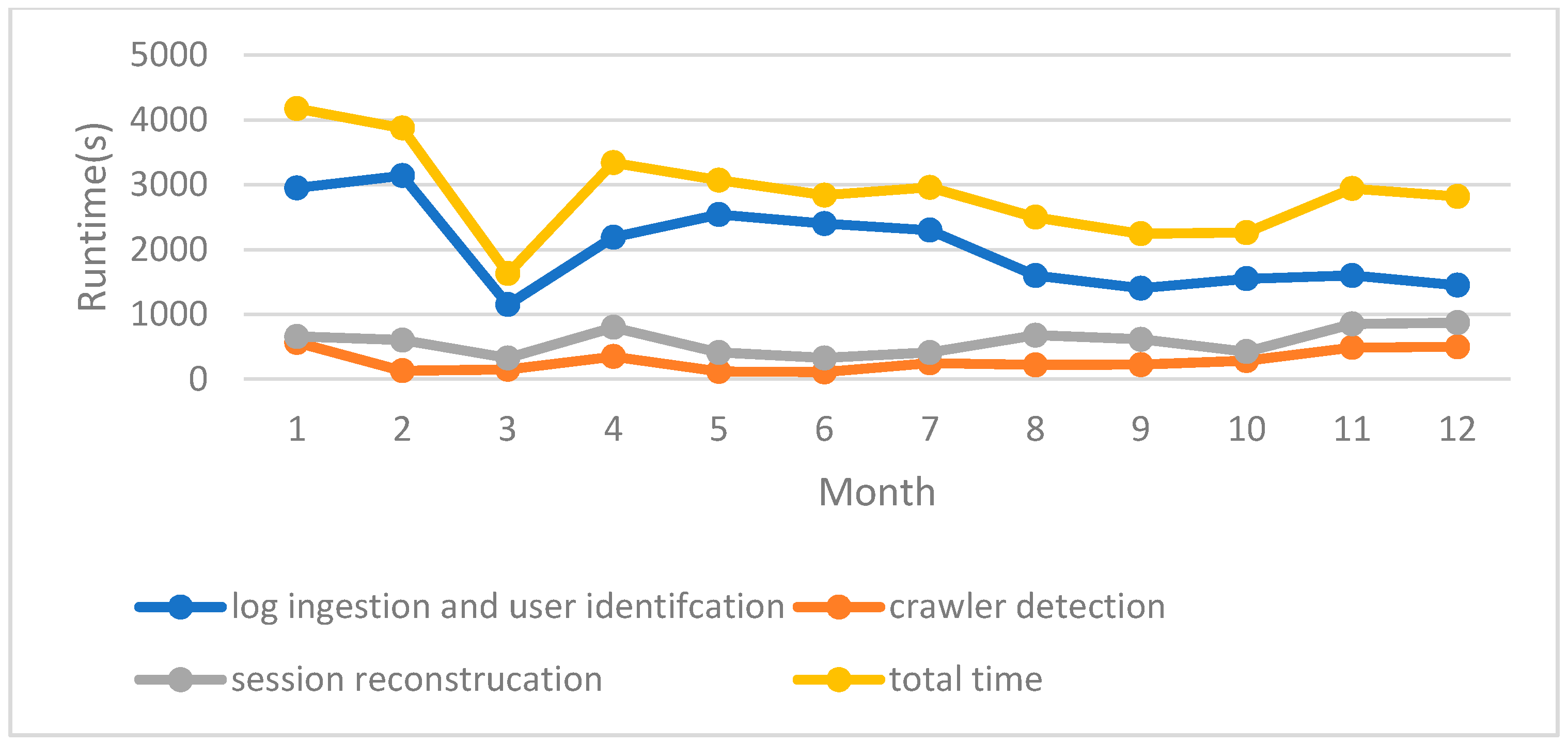
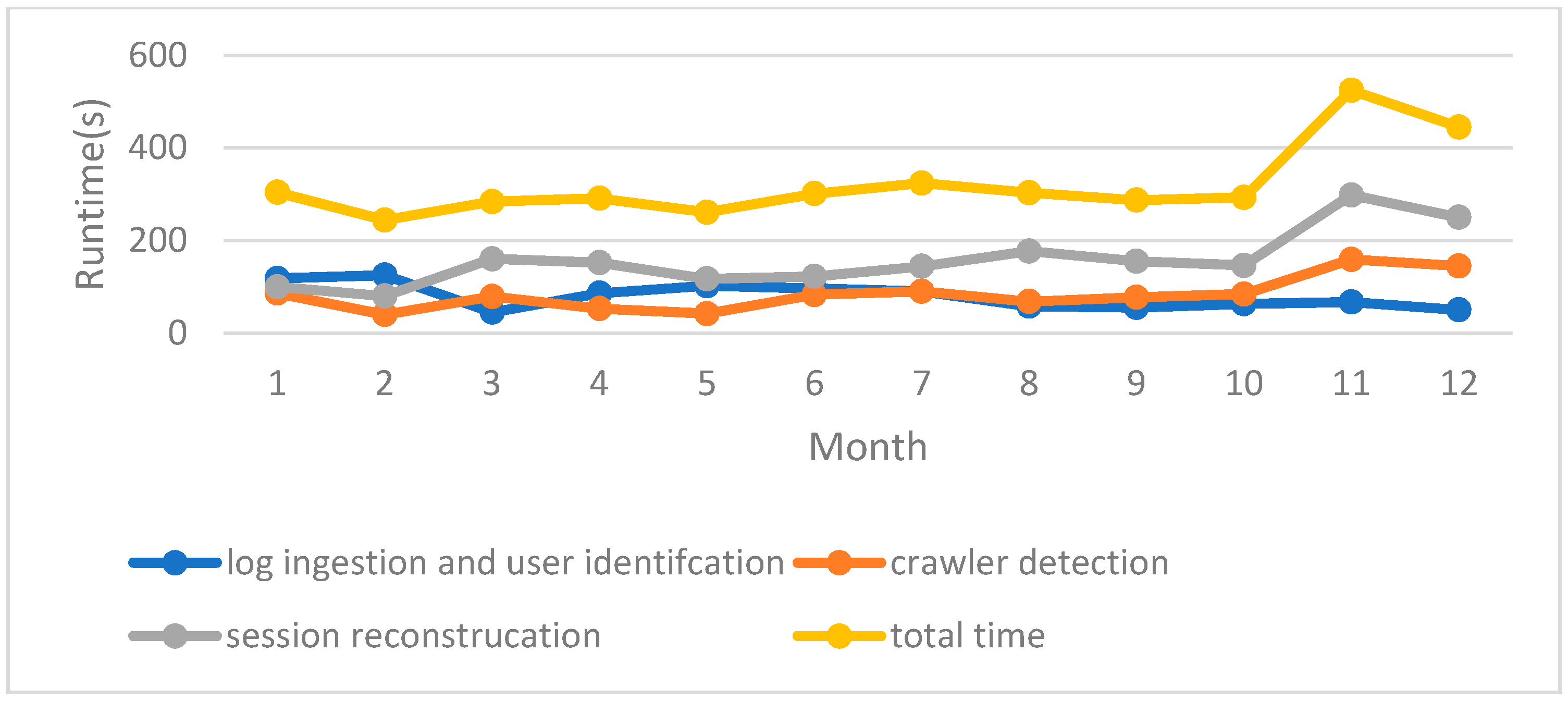
6.2. Comparison of Performance with and without the Framework
6.3. Scalability of the Proposed Framework
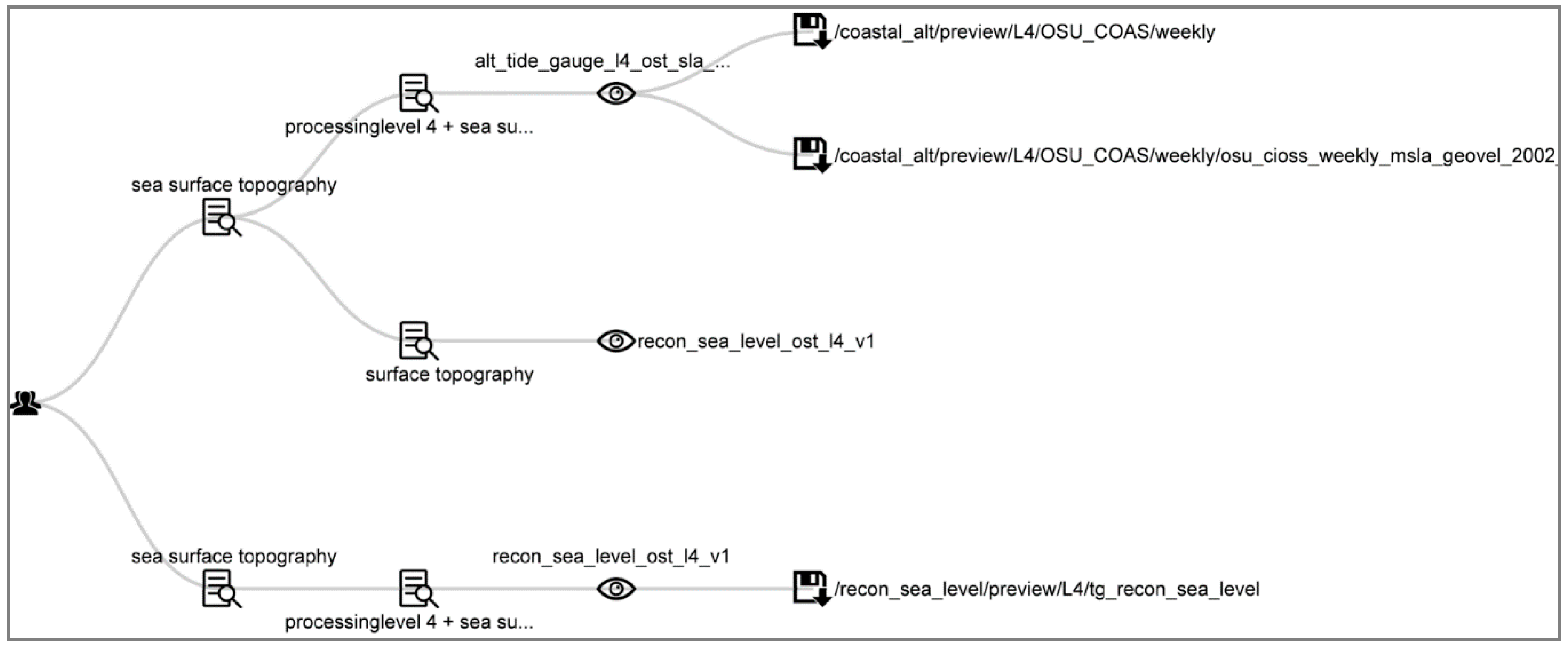
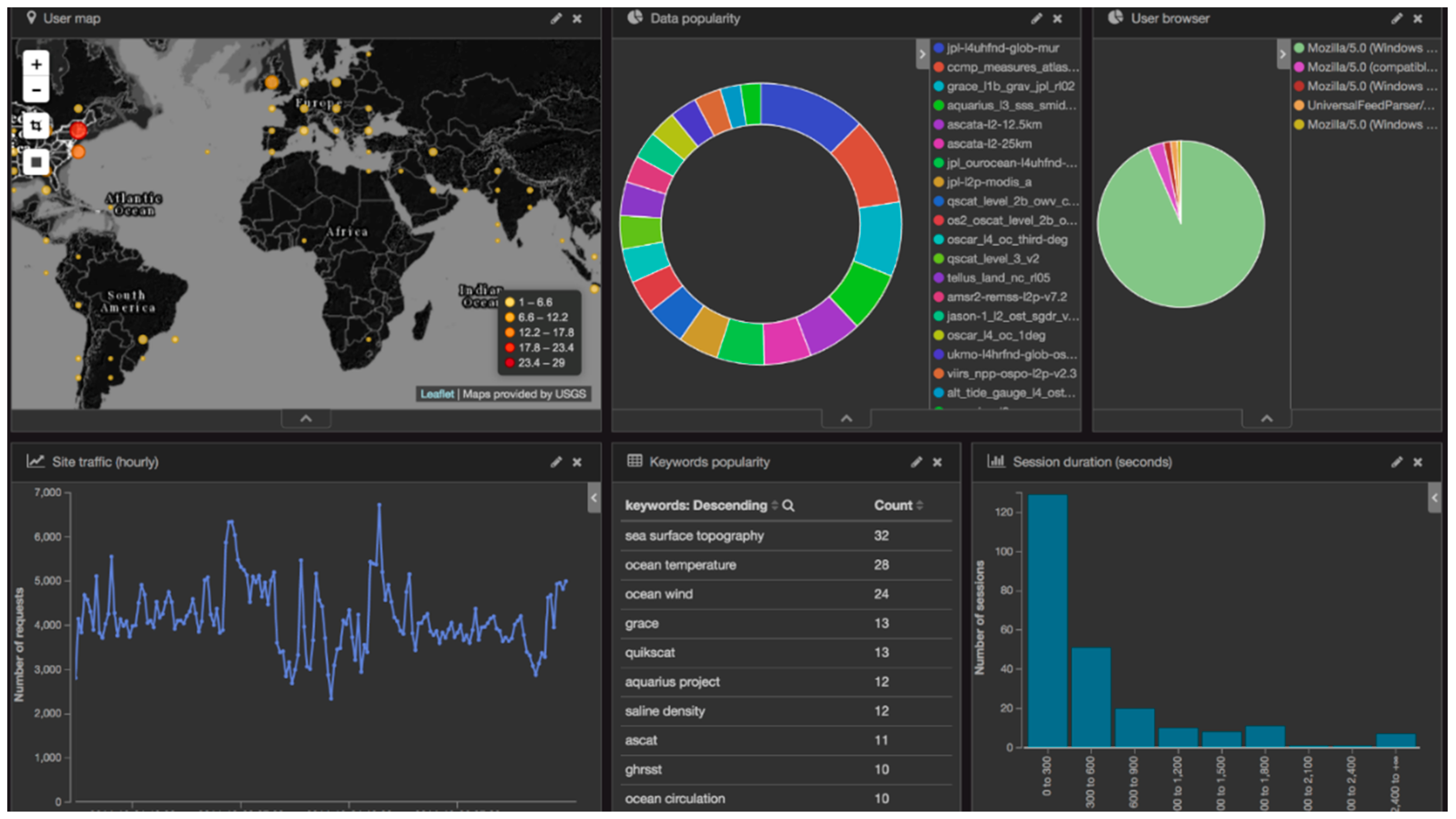
6.4. Sample Mining Results
7. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gui, Z.; Yang, C.; Xia, J.; Liu, K.; Xu, C.; Li, J.; Lostritto, P. A performance, semantic and service quality-enhanced distributed search engine for improving geospatial resource discovery. Int. J. Geogr. Inf. Sci. 2013, 27, 1109–1132. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, Y.; Yang, C.; Hu, F.; Armstrong, E.M.; Huang, T.; Moroni, D.; McGibbney, L.J.; Greguska, F.; Finch, C.J. A Smart Web-Based Geospatial Data Discovery System with Oceanographic Data as an Example. ISPRS Int. J. Geo-Inf. 2018, 7, 62. [Google Scholar] [CrossRef]
- Srivastava, J.; Cooley, R.; Deshpande, M.; Tan, P.-N. Web usage mining: Discovery and applications of usage patterns from web data. ACM Sigkdd Explor. Newslett. 2000, 1, 12–23. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, Y.; Yang, C.; Armstrong, E.M.; Huang, T.; Moroni, D. Reconstructing sessions from data discovery and access logs to build a semantic knowledge base for improving data discovery. ISPRS Int. J. Geo-Inf. 2016, 5, 54. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, Y.; Yang, C.; Liu, K.; Armstrong, E.M.; Huang, T.; Moroni, D.F.; Finch, C.J. A comprehensive methodology for discovering semantic relationships among geospatial vocabularies using oceanographic data discovery as an example. Int. J. Geogr. Inf. Sci. 2017, 31, 2310–2328. [Google Scholar] [CrossRef]
- Joachims, T. Optimizing search engines using clickthrough data. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 133–142. [Google Scholar]
- Gan, Q.; Attenberg, J.; Markowetz, A.; Suel, T. Analysis of geographic queries in a search engine log. In Proceedings of the First International Workshop on Location and the Web, New York, NY, USA, 22 April 2008; pp. 49–56. [Google Scholar]
- Jiang, Y.; Li, Y.; Yang, C.; Hu, F.; Armstrong, E.M.; Huang, T.; Moroni, D.; McGibbney, L.J.; Finch, C.J. Towards intelligent geospatial data discovery: A machine learning framework for search ranking. Int. J. Dig. Earth 2018, 11, 956–971. [Google Scholar] [CrossRef]
- Frignani, M.; Auld, J.; Mohammadian, A.; Williams, C.; Nelson, P. Urban travel route and activity choice survey: Internet-based prompted-recall activity travel survey using global positioning system data. Trans. Res. Record J. Trans. Res. Board 2010, 2183, 19–28. [Google Scholar] [CrossRef]
- Mei, Q.; Liu, C.; Su, H.; Zhai, C. A probabilistic approach to spatiotemporal theme pattern mining on weblogs. In Proceedings of the 15th International Conference on World Wide Web, Scotland, UK, 23–26 May 2006; pp. 533–542. [Google Scholar]
- Kaur, N.; Aggarwal, H. A novel semantically-time-referrer based approach of web usage mining for improved sessionization in pre-processing of web log. Int. J. Adv. comput. Sci. Appl. 2017, 8. [Google Scholar] [CrossRef]
- Dell, R.F.; Roman, P.E.; Velasquez, J.D. Web user session reconstruction using integer programming. In Proceedings of the 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Washington, DC, USA, 9–12 December 2008; Volume 1, pp. 385–388. [Google Scholar]
- Yang, C.; Yu, M.; Hu, Y.; Jiang, Y.; Li, Y. Utilizing cloud computing to address big geospatial data challenges. Comput. Environ. Urban Syst. 2017, 61, 120–128. [Google Scholar] [CrossRef]
- Yang, C.; Huang, Q.; Li, Z.; Liu, K.; Hu, F. Big Data and cloud computing: Innovation opportunities and challenges. Int. J. Dig. Earth 2017, 10, 13–53. [Google Scholar] [CrossRef]
- Mavridis, I.; Karatza, H. Performance evaluation of cloud-based log file analysis with Apache Hadoop and Apache Spark. J. Syst. Softw. 2017, 125, 133–151. [Google Scholar] [CrossRef]
- Lin, X.; Wang, P.; Wu, B. Log analysis in cloud computing environment with Hadoop and Spark. In Proceedings of the 2013 5th IEEE International Conference on Broadband Network & Multimedia Technology (IC-BNMT), Guilin, China, 17–19 November; pp. 273–276.
- Therdphapiyanak, J.; Piromsopa, K. Applying Hadoop for log analysis toward distributed IDS. In Proceedings of the 7th International Conference on Ubiquitous Information Management and Communication, Kota Kinabalu, Malaysia, 17–19 January 2013; p. 3. [Google Scholar]
- Chhajed, S. Learning ELK Stack; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Prakash, T.; Kakkar, M.; Patel, K. Geo-identification of web users through logs using ELK stack. In Proceedings of the 2016 6th International Conference Cloud System and Big Data Engineering (Confluence), Noida, India, 14–15 January 2016; pp. 606–610. [Google Scholar]
- Bagnasco, S.; Berzano, D.; Guarise, A.; Lusso, S.; Masera, M.; Vallero, S. Monitoring of IaaS and scientific applications on the Cloud using the Elasticsearch ecosystem. Proc. J. Phys. 2015, 608, 012016. [Google Scholar] [CrossRef] [Green Version]
- Mehta, S.; Kothuri, P.; Garcia, D.L. Anomaly Detection for Network Connection Logs. arXiv, 2018; arXiv:1812.01941. [Google Scholar]
- Li, Y.; Jiang, Y.; Hu, F.; Yang, C.; Armstrong; Huang, T.; Moroni, D.; Fench, C. Leveraging cloud computing to speedup user access log mining. In Proceedings of the OCEANS 2016 MTS/IEEE Monterey, Monterey, CA, USA, 19–23 September 2016. [Google Scholar]
- Apache. Apache HTTP Server Version 2.4. Available online: http://httpd.apache.org/docs/current/logs.html#combined (accessed on 1 January 2016).
- Cornillon, P.; Gallagher, J.; Sgouros, T. OPeNDAP: Accessing data in a distributed, heterogeneous environment. Data Sci. J. 2003, 2, 164–174. [Google Scholar] [CrossRef]
- Fox, A.; Griffith, R.; Joseph, A.; Katz, R.; Konwinski, A.; Lee, G.; Patterson, D.; Rabkin, A.; Stoica, I. Above the clouds: A berkeley view of cloud computing. UCB/EECS 2009, 28, 2009. [Google Scholar]
- Sefraoui, O.; Aissaoui, M.; Eleuldj, M. OpenStack: Toward an open-source solution for cloud computing. Int. J. Comput. Appl. 2012, 55, 38–42. [Google Scholar] [CrossRef]
- Dixit, B. Elasticsearch Essentials; Packt Publishing Ltd.: Birmingham, UK, 2016. [Google Scholar]
- Edmonds, J. Matroids and the greedy algorithm. Math. Programm. 1971, 1, 127–136. [Google Scholar] [CrossRef]
- Meng, X.; Bradley, J.; Yavuz, B.; Sparks, E.; Venkataraman, S.; Liu, D.; Freeman, J.; Tsai, D.; Amde, M.; Owen, S. Mllib: Machine learning in apache spark. J. Mach. Learn. Res. 2016, 17, 1235–1241. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Log-Mining Steps/Processing Time | Index Log and User Identification | Crawler Detection | Session Identification | Total Time |
|---|---|---|---|---|
| With Elasticsearch (s) | 3140 | 130 | 603 | 3873 |
| Cluster with the HashPartitioner (s) | 152 | 108 | 329 | 589 |
| Cluster with the LogPartitioner (s) | 152 | 54 | 104 | 310 |
| Experiment No. | No. of Workers | No. of Executors | No. of Cores | No. of Partitions | Time Cost | Session Number |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 2 | 120 | 2056 | 1073 |
| 2 | 2 | 2 | 4 | 120 | 1055 | 1073 |
| 3 | 3 | 3 | 12 | 120 | 386 | 1073 |
| 4 | 4 | 4 | 16 | 112 | 317 | 1073 |
| 5 | 5 | 5 | 20 | 120 | 281 | 1073 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Jiang, Y.; Gu, J.; Lu, M.; Yu, M.; Armstrong, E.M.; Huang, T.; Moroni, D.; McGibbney, L.J.; Frank, G.; et al. A Cloud-Based Framework for Large-Scale Log Mining through Apache Spark and Elasticsearch. Appl. Sci. 2019, 9, 1114. https://doi.org/10.3390/app9061114
Li Y, Jiang Y, Gu J, Lu M, Yu M, Armstrong EM, Huang T, Moroni D, McGibbney LJ, Frank G, et al. A Cloud-Based Framework for Large-Scale Log Mining through Apache Spark and Elasticsearch. Applied Sciences. 2019; 9(6):1114. https://doi.org/10.3390/app9061114
Chicago/Turabian StyleLi, Yun, Yongyao Jiang, Juan Gu, Mingyue Lu, Manzhu Yu, Edward M. Armstrong, Thomas Huang, David Moroni, Lewis J. McGibbney, Greguska Frank, and et al. 2019. "A Cloud-Based Framework for Large-Scale Log Mining through Apache Spark and Elasticsearch" Applied Sciences 9, no. 6: 1114. https://doi.org/10.3390/app9061114