 Yuda Munarko1*
Yuda Munarko1* Dewan M. Sarwar1
Dewan M. Sarwar1 Anand Rampadarath1Koray Atalag1
Anand Rampadarath1Koray Atalag1 John H. Gennari2Maxwell L. Neal3
John H. Gennari2Maxwell L. Neal3 David P. Nickerson1
David P. Nickerson1- 1Auckland Bioengineering Institute, University of Auckland, Auckland, New Zealand
- 2Department of Biomedical Informatics and Medical Education, University of Washington, Seattle, WA, United States
- 3Center for Global Infectious Disease Research, Seattle Children's Research Institute, Seattle, WA, United States
Semantic annotation is a crucial step to assure reusability and reproducibility of biosimulation models in biology and physiology. For this purpose, the COmputational Modeling in BIology NEtwork (COMBINE) community recommends the use of the Resource Description Framework (RDF). This grounding in RDF provides the flexibility to enable searching for entities within models (e.g., variables, equations, or entire models) by utilizing the RDF query language SPARQL. However, the rigidity and complexity of the SPARQL syntax and the nature of the tree-like structure of semantic annotations, are challenging for users. Therefore, we propose NLIMED, an interface that converts natural language queries into SPARQL. We use this interface to query and discover model entities from repositories of biosimulation models. NLIMED works with the Physiome Model Repository (PMR) and the BioModels database and potentially other repositories annotated using RDF. Natural language queries are first “chunked” into phrases and annotated against ontology classes and predicates utilizing different natural language processing tools. Then, the ontology classes and predicates are composed as SPARQL and finally ranked using our SPARQL Composer and our indexing system. We demonstrate that NLIMED's approach for chunking and annotating queries is more effective than the NCBO Annotator for identifying relevant ontology classes in natural language queries.Comparison of NLIMED's behavior against historical query records in the PMR shows that it can adapt appropriately to queries associated with well-annotated models.
1. Introduction
The Resource Description Framework (RDF) is a standard data model from the semantic web community that is used in semantically annotated biosimulation models such as those formatted in CellML (Cuellar et al., 2003) and Systems Biology Markup Language (SBML) (Hucka et al., 2003) in the Physiome Repository Model (PMR) (Yu et al., 2011) and BioModels Database (Chelliah et al., 2015). These RDF-annotated models can then be discovered by their model entities, such as variables, components, mathematical formula, reactions, compartments, species, and events. Leveraging these semantic annotations when searching the model repositories improves the discoverability of relevant models, thus supporting communities in biology and physiology by guiding modelers to potential starting points for reuse.
The use of RDF in the semantic annotation of biosimulation models has been formalized as the recommended technology by the Computational Modeling in BIology NEtwork (COMBINE) community (Neal et al., 2019). Furthermore, the community encourages standardized model annotation to ensure interoperability and sharing between modelers using different platforms (Gennari et al., 2021; Welsh et al., 2021). The standard uses composite annotations (Gennari et al., 2011) for more expressive and consistent model annotation. Composite annotations are logical statements linking multiple knowledge resource terms, enabling modelers to precisely define model elements in a structured manner. Methods such as those presented here are able to make use of that structure to go beyond the raw RDF triples with which a model may be annotated.
Because these semantic annotations are encoded with RDF, we can leverage the SPARQL Query Language for RDF, a standard query language, to retrieve information from RDF data. SPARQL is a well-defined and high-performance query language, well-suited for triple (subject, predicate, and object) searches over RDF graphs (Pérez et al., 2009). Thus, it is possible to search for entities related to queries such as “the formula for potassium transport across the apical plasma membrane” to compose a new model. In the biosimulation model, the entities might be annotated compositely by several ontology classes to accurately represent the underlying biological knowledge inherent to the model. Moreover, the ontology classes can be connected by a series of predicates and objects, creating a tree structure. Therefore, writing SPARQL becomes complicated because knowledge about the ontology classes and tree structure related to the model is critical, requiring expert users to be able to create SPARQL queries that suit their information needs. Thus, the availability of a tool or interface to assist an ordinary user in composing SPARQL using a natural language based query is required.
Several studies answering this challenge have been carried out by developing a graphical user interface (GUI) that provides assistance when building SPARQL for a query. Arenas et al. (2016) and Ferré (2014) have created a textual-based GUI using faceted queries where the user can select one or multiple facets and then specify its coverage. For an easier use of SPARQL features, Ferré (2014) complemented their work with natural language verbalism and readability. Another textual-based GUI was SPARQL Query-Builder which generated the WHERE clause based on ontology classes and attributes (Vcelak et al., 2018). Visual-based GUIs such as SparqlBlocks (Ceriani and Bottoni, 2017) and ViziQuer (Čerāns et al., 2019) provided different user experiences by minimizing typing activity. SparqlBlocks implemented block-based programming so the user can quickly drag and drop subjects, predicates, objects, and SPARQL features, while ViziQuer presented a Unified Modeling Language (UML) style interface targeting general IT expert and non-IT users. The advantage of a GUI lies in the ability to create a complex SPARQL query, accommodating various features, however, understanding the RDF data structure and SPARQL logic is still required in all of these examples.
Other studies have addressed this challenge by proposing a converter from query to SPARQL. Using Natural Language Processing (NLP), Hamon et al. (2014) developed POMELO (PathOlogies, MEdicaments, aLimentatiOn), a tool that enriches a query with linguistic and semantic features and then abstracts and constructs SPARQL. A similar approach is used by Yahya et al. (2012) and Xu et al. (2014) who have developed tools that identify the subject, predicate, and object associated with a query and eventually generate SPARQL. Marginean (2014) proposed a different approach using manually generated rules and showed that it performs better than POMELO for biomedical data (QALD-4) (Unger et al., 2014); however, this approach is brittle and does not work for newer or more complex queries. Another approach is SimplePARQL (Djebali and Raimbault, 2015) which is a pseudo-SPARQL query language where the query is made in SPARQL form, but the structure, especially the WHERE clause, is in textual form. With SimplePARQL, SPARQL can be more expressive, and multiple SPARQL queries are created based on the available templates. The query to SPARQL converter offers a seamless interface that allows the user to provide keywords and get results directly. These queries to the SPARQL converter are the most similar to Natural Language Interface for Model Entity Discovery (NLIMED); however, they are less suitable for exploring RDF in biosimulation models that use composite annotations. We differentiate our work by applying different approaches for ontology class identification and SPARQL generation. In addition, our work accommodates complex RDF annotations that are not just a set of triples but rather a tree structure with different depths where the leaves are either ontology classes or literals.
In the biosimulation model communities, to the best of our knowledge, the only study of a query to SPARQL conversion is based on semantic queries with a web interface aimed at finding model entities related to epithelial transport (Sarwar et al., 2019b). This interface was utilized by the Epithelial Modelling Platform (EMP), a visual web tool for creating new epithelial transport models based on existing models (Sarwar et al., 2019a). However, for more general discoveries involving several repositories with various biosimulation models, this interface requires a significant modification.
In this manuscript, we introduce NLIMED, a natural language interface for searching semantically annotated model entities from biosimulation model repositories. In order to translate queries into SPARQL, there are two stages. (1) The terms in the query must be identified as ontology classes. This task is similar to named entity recognition, and could be done by off-the-shelf tools like the NCBO annotator (Jonquet et al., 2010). (2) The now-annotated query can be used to generate an SPARQL query. As an alternative to NCBO Annotator, we apply off-the-shelf NLP tools such as Stanford CoreNLP (Manning et al., 2014) and Stanza (Zhang et al., 2020) to “chunk” a query into phrases and then link the phrases to ontology classes using our proposed similarity measure. We first examine entities' semantic annotation patterns in a repository involving the detected ontology classes to generate SPARQL. For all patterns that have the detected ontology classes, the SPARQL are generated.
We evaluated NLIMED on all CellML models within the PMR that are annotated with RDF. We show that the NLIMED approach for detecting ontology classes in NLQ is more effective than the NCBO Annotator based on precision, recall, and F-measure statistics with margins above 0.13. In addition to the PMR, we have performed preliminary testing of NLIMED with the BioModels database indexing models encoded in the SBML format. This testing supports our belief that NLIMED can be implemented and adapted for different biosimulation model repositories and modelling formats, and that it is possible to create a generic model entity discovery tool. Also, comparing the behavior of NLIMED against historical records of actual queries and results in the PMR shows that NLIMED can perform appropriately on well-annotated biosimulation models. Currently, we have implemented NLIMED in the Epithelial Modeling Platform and Model Annotation and Discovery web tools (Sarwar et al., 2019a) to optimize user experiences when searching for model entities. We provide our implementation and experiment setup at https://github.com/napakalas/NLIMED.
2. Materials and Methods
Our interface consists of two primary modules, the NLQ Annotator and the SPARQL Generator (Figure 1). Both modules are based on data collected from the PMR (Yu et al., 2011), BioModels (Chelliah et al., 2015), and BioPortal (Whetzel et al., 2011). We utilize natural language parsers provided by Stanford CoreNLP (Manning et al., 2014) and Benepar (Kitaev and Klein, 2018) contained in NLTK (Bird et al., 2009), and named entity recognition for biomedical and clinical data by Stanza (Zhang et al., 2020).
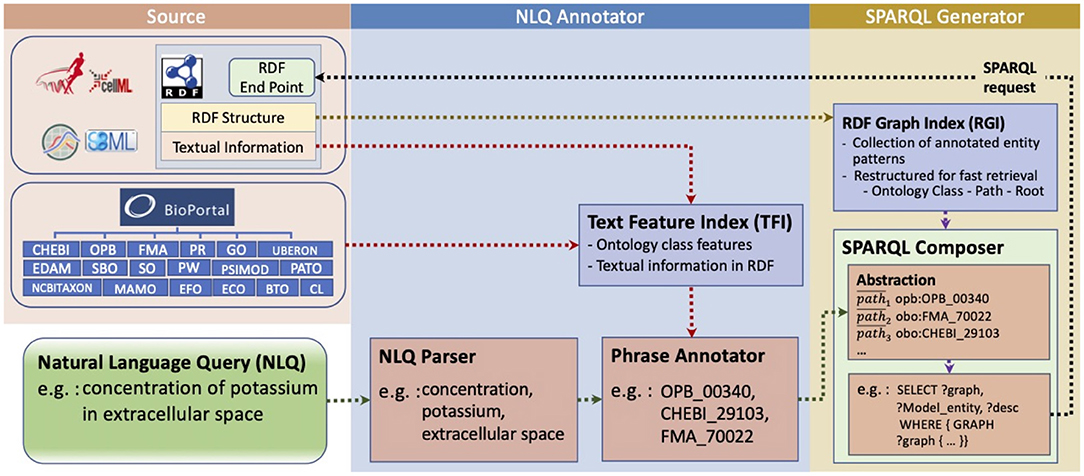
Figure 1. NLIMED workflow. We first create a Text Feature Index (TFI) and an RDF Graph Index (RGI) based on data available in the PMR, BioModels database, and ontology dictionaries. The natural language query is initially annotated into ontology classes in the NLQ Annotator module and then translated into SPARQL in the SPARQL Generator module.
2.1. The Physiome Model Repository, BioModels, and BioPortal
The PMR contains more than 800 CellML biosimulation models in which around 25% have been annotated with RDF. Within these annotated models, there are 4,671 model entities annotated described using ontology classes, textual data, and other attributes such as author name, doi, and journal title. Figure 2 is an example of well-annotated entities and shows how this example entity is expressed in RDF, and thus can be viewed as a tree structure, where the leaves are ontology terms. There are 3,472 distinct leaves, 29,755 paths between roots and leaves, and 529 distinct ontology leaves in the models contained in the PMR.
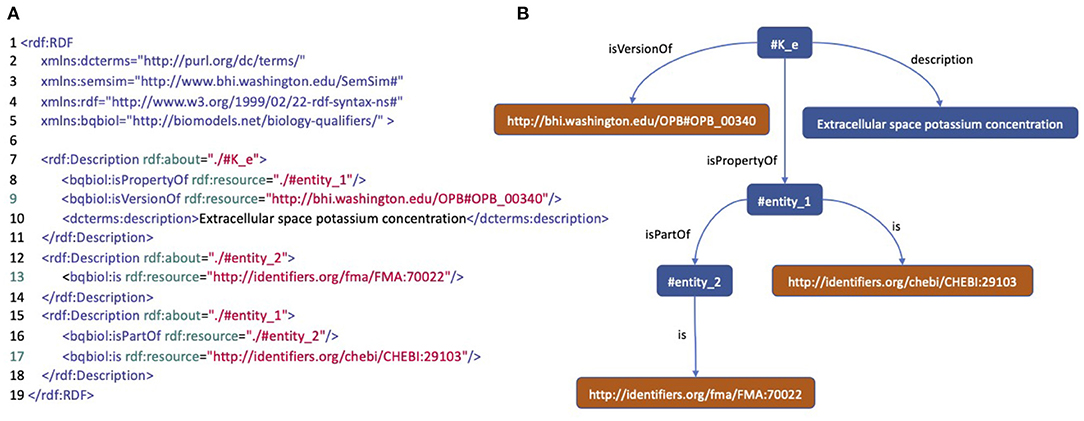
Figure 2. An annotation of a model entity of concentration of potassium in extracellular space. (A) An RDF/XML code describing the model entity. (B) A tree structure representing the RDF code describing the model entity.
The BioModels database has a larger biosimulation model collection consisting of 2,287 SBML files of which 1,039 have been manually annotated. Similar to CellML, model entities are represented as a tree structure but are usually annotated with a simpler format consisting of a single triple linking an entity, a predicate, and an ontology class. Overall, the BioModels database has 13,957 model entities, 46,431 paths connecting roots and leaves, and 2,419 ontology classes.
We utilize BioPortal (Whetzel et al., 2011) to get ontology dictionaries covering ontology classes found in the PMR and most of the ontology classes found in BioModels. In total there are 18 ontology dictionaries collected (Figure 1), of which the most commonly found in the PMR are Gene Ontology (GO), Ontology of Physics for Biology (OPB), Foundational Model of Anatomy (FMA), and Chemical Entities of Biological Interest (ChEBI). Moreover, BioPortal provides the NCBO Annotator tool (Jonquet et al., 2010), which is used as the gold standard to measure NLIMED's performance. The NCBO Annotator can identify ontology classes in a text based on three features: textual metadata, the number of other ontology classes referring to the ontology class, and the number of classes in the same ontology.
2.2. Selecting Features of Ontology Classes to Associate With Query Phrases
Each ontology class collected from BioPortal is described by a set of features such as preferred label, synonym, definition, is_a, parents, regex, and comment. These features, then, are used to compute the degree of association of a phrase to an ontology class. However, some features do not have attributes useful to calculate the degree of association, for example, created_by, comment, and creation_date are aimed to record the class development history, and obsolete, is_obsolete, and obsolete_since are used to show the class status. Some other features are also limited for specific ontologies, such as regex, part_of, example, and Wikipedia, while the last two features tend to consist of a very long text and bias calculations. Therefore, we chose features that can textually represent concepts in the ontology class and are highly related to the user query, i.e., preferred label, synonym, definition, and parent label (Table 1). In addition, many entities in the PMR and BioModel repositories come with textual descriptions that complement the RDF annotations, so we include them as an additional feature.
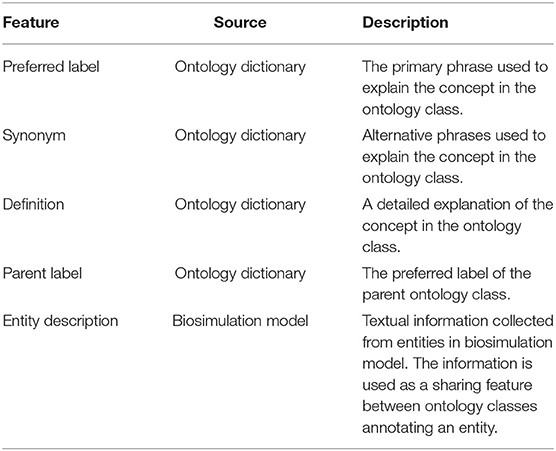
Table 1. Features representing an ontology class used by the Phrase Annotator to calculate the degree of association of a phrase to the ontology class.
2.3. Natural Language Query (NLQ) Annotator
The NLQ Annotator is a module for identifying ontology classes with their predicates in an NLQ. It works by chunking the query into candidate phrases using the NLQ Parser, then calculating the degree of association between candidate phrases and ontology classes using the Phrase Annotator (Figure 1). However, calculating the degree of association for all candidate phrases to all ontology classes is inefficient; here, we filter only the likely relevant ontology classes using the Text Feature Index (TFI). The TFI holds a vector space model (Salton et al., 1975) describing ontology classes and adapts an inverted index concept (Harman et al., 1992) to manage features and their relationship to ontology classes. To chunk the query, we investigated the effectiveness of using three NLP tools, CoreNLP (Manning et al., 2014), Benepar (Kitaev and Klein, 2018), and Stanza (Zhang et al., 2020). Stanza differs from the other two in that it functions as a Named Entity Recognition (NER) tool to identify biomedical and clinical entities directly. In contrast, others are parsers that are only used to identify phrases. For simplicity, each approach will be referred to as a parser.
The use of parsers (Figure 3, left side) initially identifies all possible noun phrases, fragments, and sentences as candidate phrases. For example, the NLQ of “concentration of potassium in extracellular space” is chunked to cp1: “concentration of potassium in extracellular space,” cp2: “concentration of potassium,” cp3: “concentration,” cp4: “potassium,” cp5: “extracellular space,” and cp6: “space” by CoreNLP. The more interesting phrases are those with the highest degree of association to an ontology class while having the most extended terms without overlap while fully covering the NLQ. For the example NLQ, cp3: “concentration,” cp4: “potassium,” and cp5: “extracellular space” are selected, while the other phrases are considered as irrelevant and removed.
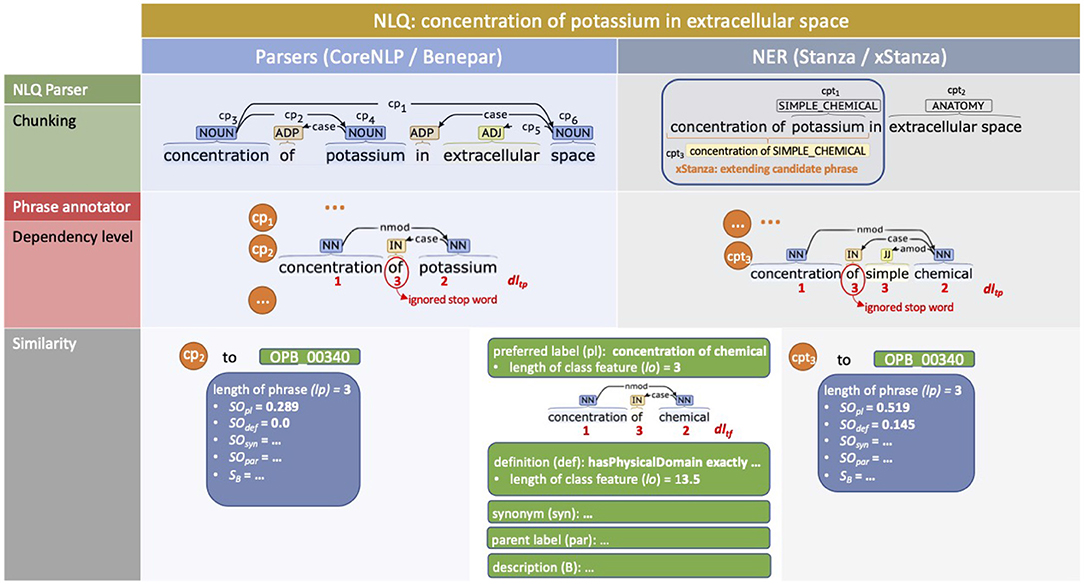
Figure 3. Example NLQ annotation including chunking, dependency level recognition, and similarity calculation for “concentration of potassium in extracellular space.” The left side presents the use of parsers (CoreNLP and Benepar) while the right side presents the use of NER (Stanza and xStanza).
The implementation of NER (Figure 3, right side) makes it possible to identify candidate phrases along with entity types. This allows evaluation of the phrase's context and the identification of additional candidate phrases and related predicates, which are used as extra variables for SPARQL ranking. We utilize three biomedical datasets, AnatEM (Pyysalo and Ananiadou, 2014), BioNLP13CG (Pyysalo et al., 2015), JNLPBA and one clinical dataset (Kim et al., 2003), i2b2 (Uzuner et al., 2011), covering most required entity types including anatomy, chemical, protein, gene, DNA, RNA, cell line, cell type, organ, tissue, amino acid, problem, test, and treatment. Considering the example NLQ; initially we get phrase:entity-type pairs such as cpt1: “potassium—SIMPLE_CHEMICAL” and cpt2: “extracellular space—ANATOMY.” Then the contexts related to each cpt are identified, for example the cpt1 context phrase is “concentration of simple chemical.” The context phrase has a higher degree of association with an ontology class rather than a predicate, and so it is selected as an additional phrase cpt3.
The degree of association between a candidate phrase and an ontology class is the addition of similarity values of the candidate phrase to each feature in the ontology class. Since candidate phrases and features derived from ontology dictionaries are generally short, the similarity is simply the proportion of overlapping terms in candidate phrase P and feature F normalized by the number of terms in feature F [Equation (1)].
However, longer candidate phrases tend to have high similarity value when the feature text is shorter. For example, cp1: “concentration of potassium in extracellular space” and cp5: “extracellular space” have the same similarity values when compared to FMA_70022's preferred label feature, “extracellular space;” but intuitively cp5 should be higher. Therefore, we add the number of terms in the candidate phrase P to the normaliser but prevent the excessive similarity value decrease of a longer candidate phrase with [Equation (2)]. Assuming that candidate phrases are always short, we can set the appearance of a term t in the candidate phrase to 1, so Equation (2) can be reduced to Equation (3).
So far all terms in the candidate phrase get the same weight, while based on the level of dependence, different terms ideally have different weights. For example, “potassium” in cp2: “concentration of potassium” should have lower weight than in cp4: “potassium,” because in cp2 “potassium” is not the main term and a noun modifier of “concentration,” while in cp4 “potassium” is the main term. Considering that the universal dependencies of the candidate phrase can be constructed as a tree structure, we use the depth of a node plus 1 as the dependency level of a term, so a lower dependency level contributes more to the similarity value. In Figure 3, we can see the example of dependency level determination of cp2: “concentration of potassium” to 1, 3, 2, and cpt3: “concentration of simple chemical” to 1, 3, 3, and 2. However, when the dependency level of a term in the candidate phrase dltp differs from that in the ontology class feature dltf, the highest value is chosen. Thus, we introduce the dependency level of a term into Equation (3) so that it becomes Equation (4), where max(dltp, dltf) selects the highest dependency level.
Next, |F|.ln(max(k1, |F|+k1−max(dltp, dltf))) calculates the contribution of the dependency level to the feature's similarity value, where k1 is an empirical variable with minimum value of 2. Here, we ensure that a term with a lower dependency level higher than k1 still has a contribution. Then, this contribution is normalized with ln((|F|+k2)!) where k2 is an empirical variable with minimal value of 1. For our experiment, k1 and k2 were set to 2 and 1, respectively.
With the dependency level, less specific terms have a higher contribution than more specific terms. It should be noted that the terms in the candidate phrases and ontology classes are generally short, so the least specific terms are usually the primary descriptors. We found that higher contribution of more specific terms lead to overfitting resulting in a performance decrease. For example, when comparing “concentration of simple chemical” to OPB_00340 “concentration of chemical,” if we put more contribution on more specific terms, “chemical” and “simple,” the phrase will be identified as SBO_0000247 “simple chemical” rather than OPB_00340. Here, the least specific term “concentration” represents the ontology class better than “simple” and “chemical.” Another example is comparing FMA_84669 “basolateral plasma membrane” and GO_0090652 “basolateral cytoplasm” to a phrase containing “basolateral;” the phrase will be associated with both classes since “basolateral” is used in a limited number of classes. The additional “plasma membrane” or “cytoplasm” will specifically direct the phrases to one of the ontology classes.
For the description feature extracted from the biosimulation model, we use a different similarity calculation because the number of terms in this feature is usually larger than for the other features [Equation (5)]. The similarity value is the proportion of overlapping phrases in the candidate phrase and the description feature normalized by the smoothing length of the candidate phrase (1+ln(|P|)) and the smoothing of the total number of terms in the entity descriptions appearing with the ontology class (1+ln(1+tea)). We assume that the more an ontology class is used to annotate entities, the more important that ontology class is. So we multiply by (1+ln(1+teo)), which represents the number of entities annotated by the ontology class.
Finally, the degree of association between the candidate phrase and the ontology class is the sum of similarities between the candidate phrase against all features, including preferred label (pl), synonym (syn), definition (def), parent label (par), and description (desc) [see Equation(6)].
We believe that features such as preferred label and synonym are more critical than others; for example, in FMA_70022, pl=“extracellular space” and syn=“intercellular space” represent the class better than par =“interstitial space,” so the weights of pl and syn are naturally higher than the others. Therefore, we apply multiple weighting scenarios (Ogilvie et al., 2003; Robertson et al., 2004), so we have multipliers α, β, γ, δ, and θ for pl, syn, def, par, and desc, respectively. The multipliers are decided empirically to obtain the best performance and will vary based on the training data. At this point, a candidate phrase may relate to multiple ontology classes with various degrees of associations. To get the final phrase, we remove ontology classes with a degree of association lower than a particular threshold value t, resulting in candidate phrases with zero or more ontology classes. Hence, the final phrases have at least one association with an ontology class. The SPARQL Generator will use these final phrases with their corresponding ontology classes to derive SPARQL patterns and compile them into SPARQL. If NLQ Annotator uses NER, then predicates are obtained to make SPARQL more specific and ranking more accurate.
2.4. SPARQL Generator
With the NLQ Annotator result consisting of phrases and their associated ontology classes and predicates, our SPARQL Generator generates SPARQL utilizing the RDF Graph Index (RGI) and SPARQL Composer. RGI is an indexing system used to represent entities' semantic annotation patterns in biosimulation models, where SPARQL Composer is a compiler that locates SPARQL elements in RGI, then constructs and ranks SPARQL.
RGI stores all existing semantic annotation patterns in the repository. For example, the annotated entity in Figure 2 has a pattern consisting of the entities “#K_e” as root described by the ontology classes OPB_00340, FMA_70022, and CHEBI_29103. Between the root and the ontology class, some predicates make up the path. With the ontology classes as the RGI input, we can get the annotation pattern; and then construct SPARQL. This pattern search is done using the indexing system in RGI, which can search for predicate and root sets based on ontology classes (see Supplementary Figure S1 for the RGI creation process).
Each phrase selected by the NLQ Annotator can be associated with multiple ontology classes. For example, in the query we have used throughout this paper, cp3: “concentration,” cp4: “potassium,” and cp5: “extracellular space” are associated with : (OPB_00340, OPB_00592), : (CHEBI_29103, CHEBI_26216), and : (FMA_70022, FMA_17555), respectively (Figure 4A). The SPARQL Composer initially searches for the available , , and combinations in the RDF Graph by leveraging the RGI's ontology class to root index. Of the eight combinations, only two have patterns, ac1: (OPB_00340, FMA_70022, CHEBI_29103) and ac2: (OPB_00592, FMA_70022, CHEBI_29103) (Figure 4B). The other six possibilities have no matching results in the repositories, and thus, they are discarded. Then, each ac is searched for the relationship pattern between its ontology class and root using the RGI ontology class and root to the path. In Figure 4C, we show that ac1 and ac2 have one and three relationship patterns, respectively. Next, these patterns are compiled into SPARQL and ranked by summing the degree of phrase association to the ontology class (Figure 4D). Additionally, when using xStanza, the predicate context of a phrase is also used in the ranking. In our example, if the NLQ has predicate terms such as “as sink participant,” this can be used to calculate the ranking more accurately.
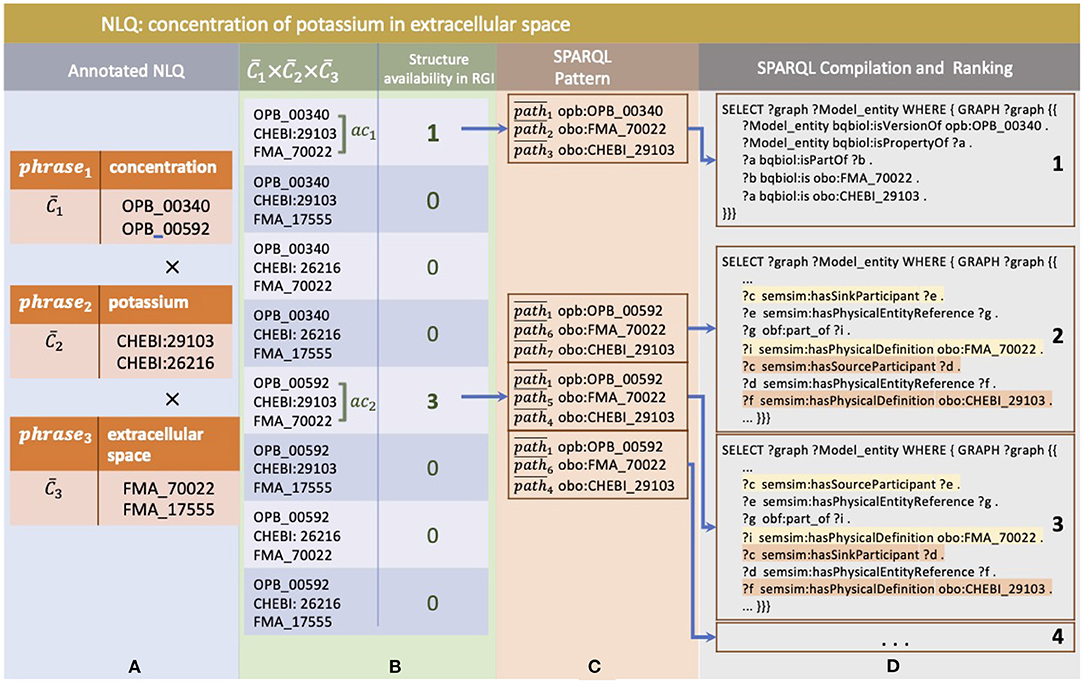
Figure 4. The example of SPARQL generation in SPARQL Composer where (A) phrases and ontology classes as NLQ Annotator result, (B) are combined and checked for their availability in RGI, (C) then are related to available entity annotation patterns, (D) and finally are compiled to SPARQL and ranked.
Since NLIMED is developed based on the structure of composite annotation of biosimulation models in the repositories, it stores information regarding ontology classes, entities, and their connecting paths. Therefore, it is also possible to discover entities based on the identified ontology classes and paths without constructing SPARQL and send a request to an SPARQL endpoint. However, the non-SPARQL approach will fail to find entities in the new RDF annotated models added to repositories. The COMBINE recommendation to standardize the composite annotation makes it possible to get the new entities using the generated SPARQL. Moreover, although not mandatory, regular update of the NLIMED indexes (TFI and RGI) is beneficial for recording the overall RDF annotation structure and improving performance.
3. Experiments and results
We performed experiments to measure the performance of our NLQ Annotator in detecting NLQ-related phrases and ontology classes, and to examine NLIMED's behavior toward historical query records in the PMR. For the first experiment, we prepared a test dataset examined by experts consisting of 52 NLQ and their associated ontology classes with differing complexity, having 1−14 terms and 1−4 phrases (Supplementary Table S1). In the second experiment, we collected query-result pairs of from search sessions in the PMR query logs. We obtained 110 pairs by selecting those whose results were models annotated against ontology classes (Supplementary Table S2). An entity identified by NLIMED was considered a relevant result if a model in these pairs contains the entity.
While the preferred label feature is available in all ontology classes, other features may not be present. These empty features may lead to lower degrees of association between a phrase and an ontology class; therefore, adding the preferred label to other features can provide a fairer result. We found that this addition (WPL), along with the use of dependency level to calculate similarity, works well with NLIMED. Furthermore, we varied the measurement on four parsers, i.e., CoreNLP, Benepar, Stanza, xStanza (Stanza with context identification). If a phrase was associated with more than one ontology class, the class with the highest degree of association was selected. We also examined different feature modifications and dependency level implementations more closely. Detailed results are presented in Supplementary Figure S2.
3.1. NLQ Annotator Performance
The NLQ Annotator performance was measured by calculating precision, recall, and F-measure. Precision is the proportion of correctly identified ontology classes among the number of detected ontology classes, while recall is the proportion of correctly identified classes among the number of ontology classes that count as correct classes. F-measure is the harmonization of precision and recall obtained by dividing the multiplication of precision and recall by the addition of precision and recall and then multiplying by two. As the gold standard, parsing using the NCBO Annotator is fixed on seven ontologies primarily found in the PMR and prioritized the most prolonged-phrase, resulting in a precision of 0.542 and recall of 0.504.
Table 2 shows experimental results where our approach outperforms the NCBO Annotator. CoreNLP can chunk better than other approaches; moreover, with context identification, xStanza outperforms Stanza by adding new ontology classes, placing this approach second after CoreNLP in recall and F-measure. Furthermore, xStanza provides the ability to detect predicates useful to rank and compose SPARQL. The use of dependency levels and WPL (the distribution of preferred label to other features) can increase the overall performance (see Supplementary Figure S2 with higher AuCPR). Here, dependency levels can improve similarity measurement by giving higher weight to the more critical term. At the same time, WPL can overcome the empty feature problem and balance the participation of each feature by distributing the preferred label, as the essential feature, to other features. As a reference, our most reliable configuration is WPL, using dependency level, CoreNLP with multipliers α = 3.0, β = 3.0, γ = 0.0, δ = 0.0, and θ = 0.38. The complete configurations are available in Supplementary Table S3.
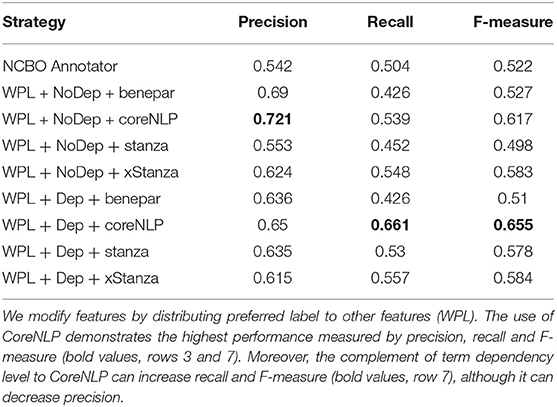
Table 2. The performance of NLIMED to annotate NLQ on a test dataset containing 52 NLQs.
Considering the NLQ complexity, Figures 5A,B present the F-measure for different NLQ lengths. All parsers generally work better than the NCBO Annotator, where CoreNLP is consistently superior to other parsers, and xStanza follows. The analysis based on the number of phrases shows that xStanza is best for one phrase NLQ while CoreNLP is best for the longer NLQ (Figure 5A). The higher performance of CoreNLP is mainly due to its better ability to chunk NLQ, while xStanza's performance depends on the datasets used to identify named entities. For example, the NLQ “luminal antiporter activity” ideally comprises the two phrases “luminal” and “transporter activity” correctly identified by CoreNLP. In contrast, xStanza identifies “luminal” (entity: multi-network structure) or “luminal antiporter activity” (entity: problem). Since the implementation of Stanza avoids any overlapping, “luminal” with the higher degree of association to an ontology class is selected while “luminal antiporter activity” is discarded. The analysis based on the number of terms shows a similar pattern as the analysis based on the number of phrases (Figure 5B), although xStanza is best for two-term NLQ. In general, the high performance of NLIMED on short NLQ shows that the Equation (6) used to calculate the degree of association between a phrase and an ontology class is working well. Hence, NLIMED performance is available to be improved by implementing a better chunker.
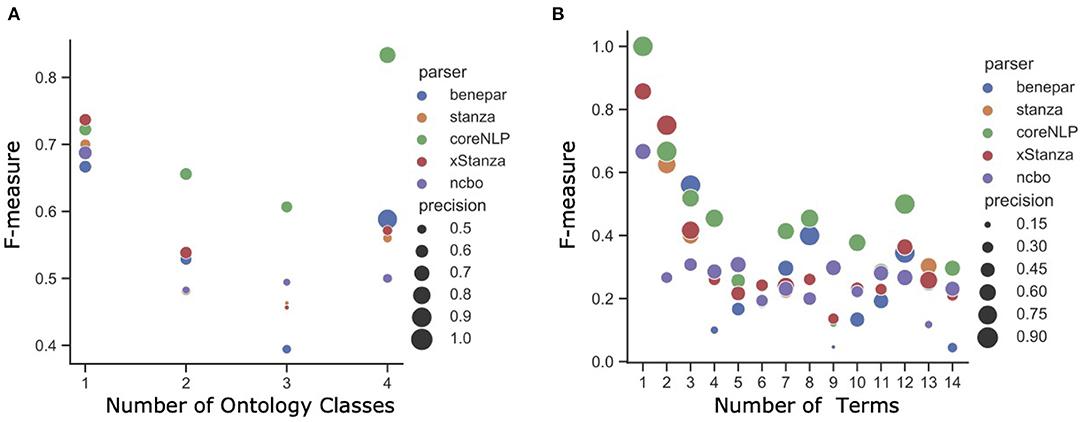
Figure 5. The analysis of NLIMED performance over different number of terms and phrases in NLQ (A) F-measure based on the number of terms in NLQ. (B) F-measure based on the number of phrases in NLQ.
Considering the role of features, the preferred label is the essential feature, and its use with the synonym feature using WPL and CoreNLP could reach higher performance (Supplementary Figure S2A, row 2, column 3). The importance of other features is presented in Supplementary Figure S3 where synonym and description contribute positively for the higher AuCPR.
3.2. NLIMED Behavior for Historical Query Records in the PMR
The data used in this experiment has the characteristic that the terms in the ontology classes describing a model are rarely found in the query. It is natural since the available PMR search tools are intended to find biosimulation models rather than entities; therefore, queries tend to use common terms in model descriptions such as author, year, and publication title rather than specific terms in ontology classes. Consequently, NLIMED's ability to find relevant results based on the provided queries is relatively low. We divided query-result pairs into three groups based on the number of terms that appear together in the query and the results ontology classes divided by the number of terms in the ontology classes. Those groups are G1:“proportion=0,” G2:“0 < proportion < = 0.5,” and G3:“0.5 < proportion < = 1.0.” The experiment was conducted using the best multipliers combination stated at Subsection 3.1 and two additional combinations of α, β, γ, δ, and θ as (3.0, 3.0, 0.5, 0.5, 0.5) and (3.0, 3.0, 1.0, 1.0, 1.0). Using mAP@10 (Mean Average Precision at 10) as a performance measurement, in Supplementary Figure S5, the mAP@10 value continuously increases from G1 to G3. The increase is as expected that a query containing terms in the result's ontology classes is an advanced query that can find models more precisely. Moreover, in G1, NLIMED can still retrieve a small number of relevant results due to using the entity's description as a feature.
Contradicting the finding in 3.1, Benepar outperformed other parsers in terms of retrieval, raising F-measure around 0.7 for G3. It seems that Benepar benefits from the relatively higher precision (shown by bigger circles in Figures 5A,B), so it can suppress false positives while the number of retrievals is limited. The low performance of CoreNLP and Stanza is probably due to their better ability to identify terms related to ontology classes so that in the chunking process, many common terms are discarded from the query. These common terms help find models that are more general than entities. Meanwhile, the additional ontology classes and predicates by xStanza seem unrelated to the query's intent, so relevant models found using Stanza have a lower ranking.
4. Discussion
4.1. NLQ to SPARQL Evaluation
We have shown that NLIMED can translate NLQ to SPARQL and find entities annotated to ontology classes. The degree of association equation proposed in the NLQ Annotator combined with the corresponding parser outperformed the NCBO Annotator in terms of associating NLQ with ontology classes. NLIMED performance varies based on the number of terms or the number of phrases in the query (Figure 5), so for future study, it is necessary to consider this query length factor. Next, we discuss NLIMED based on the length and the type of NLQ.
4.1.1. Short NLQ (1–2 Phrases)
Most queries have terms that can be annotated correctly, such as “chloride,” “cardiac myocyte,” “apical plasma membrane,” “left ventricular wall,” and “flux of potassium.” The use of a different parser has its own character on the annotation result; for example, “flux of potassium” is chunked to “flux” and “potassium” by CoreNLP but to “flux of simple chemical” and “potassium” by xStanza, although they are annotated to the same ontology classes, OPB_00593 and CHEBI_29103, respectively. For the same NLQ, Stanza skips the “flux” related phrase because of the lack of a named entity dataset related to the Ontology of Physics for Biology. The use of the NCBO Annotator has a similar issue to Stanza by ignoring some phrases that have a low degree of association to ontology classes. Thus, using information from the annotated entities such as textual description as an additional feature in NLIMED may improve performance.
Nevertheless, recognizing phrases not linked by prepositions is quite challenging, for example, noticing that “potassium flux” is similar to “flux of potassium.” CoreNLP and Benepar consider it a single phrase that is conceptually correct but does not match the intent of the NLQ, while Stanza only considers the “potassium” term. Extending Stanza, xStanza extracts the context around “potassium” as an additional phrase and successfully associates it as an ontology class. Further, xStanza also identifies additional ontology classes and predicates so that it can construct more specific SPARQL.
4.1.2. Long NLQ (3–4 Phrases)
NLQ Annotator's performance, especially using CoreNLP, is better than NCBO Annotator for NLQ with three and four phrases. Long NLQ are generally well-structured so that determining phrases and ontology classes can be relatively accurate. However, possible drawbacks can occur when there are a lack or excess of identified NLQ phrases. The lack of phrases might not be critical as they only lead to the more general SPARQL, whereas in reality, entities are rarely annotated against more than three ontology classes, so the lack of one ontology class can still generate quite specific SPARQL. On the other hand, the excess of phrases is a critical problem that leads to more specific SPARQL causing NLIMED to miss entities. To overcome this problem, NLIMED implements a filtering threshold based on the degree of association between the phrase and the ontology class.
4.1.3. Question Type NLQ
A question type NLQ such as “give me models containing a glucose transporter” usually consists of supporting phrases that are not related to ontology concepts and some relevant phrases which are the core of the NLQ. While Benepar and CoreNLP cannot differentiate accurately, Stanza and xStanza can extract the relevant phrases only as long as the phrase is associated with the available named entity. For the example, Stanza and xStanza can identify “glucose transporter” only, but Benepar and CoreNLP identify an additional phrase “give me models.” Nevertheless, for our purposes, since “give me models” contains “models” term which is frequent in biosimulation models, we may consider terms in this phrase as stop words and ignore the phrase. Alternatively, to prevent the same problem, we may apply an inverse document frequency threshold to determine whether to ignore a candidate phrase or not. However, in the future, we may use these non-biological phrases containing terms such as “model,” “variable,” and “constant” to identify the type of entity to present more accurate results.
4.2. NLIMED Embedded Within Other Tools
Currently, NLIMED is working over CellML models in the PMR (Yu et al., 2011) and SBML models in BioModels (Chelliah et al., 2015), and has been implemented in EMP (Sarwar et al., 2019a) as an additional interface for discovering model entities. We are confident that NLIMED may also be developed for use with different repositories, e.g., ChEMBL (Gaulton et al., 2012) and BioSamples (Barrett et al., 2012), since they contain models richly annotated with the RDF utilizing ontologies. NLIMED has potential to be applied to EMP-like tools such as the Cardiac Electrophysiology Web Lab (Cooper et al., 2016), eSolv (de Boer et al., 2017), and SemGen (Neal et al., 2018). Present annotation tools, e.g., SemGen (Neal et al., 2018), OpenCOR (Garny and Hunter, 2015), and Saint (Lister et al., 2009), which can provide ontology class suggestions based on available ontology databases may take advantage of NLIMED. Following the COMBINE recommendation about standardization of biosimulation model annotation (Neal et al., 2019), this work can be directed to provide a comprehensive search interface to discover model entities from various biosimulation model repositories.
4.3. Limitations and Future Directions
There are several limitations of NLIMED, some of which will direct our future work. While NLIMED can identify phrases in NLQ and then classify them into ontology classes, we have not yet explored the lexical-semantics such as synonymy and hyponymy. Consequently, NLIMED cannot detect perfectly the similarity of queries “the role of potassium within the cytosol” and “the regulation of K+ in liquid medium contained within a cell,” and the specificity of query “sodium across epithelial cell” to “sodium across basolateral plasma membrane” and “sodium across apical plasma membrane.” We believe that the lexical-semantic in NLQ is closely related to the model entity's tree structure and the dependency between ontology classes.
Currently, NLIMED calculates ranking for all generated SPARQL but not yet for the model entities returned from SPARQL queries. Ranking model entities is quite tricky because all entities retrieved using the same SPARQL have the same ranking and are associated with the same ontology classes, so they do not have differentiation properties. However, the use of the text in the original publication related to the model entities might be helpful, so it may be possible to implement term-weighting strategies such as BM25 (Robertson and Walker, 1994). Furthermore, other entities that surround an entity may also be used to supplement the ranking.
5. Conclusion
We demonstrated NLIMED, an interface for translating NLQ into SPARQL that consists of NLQ Annotator and SPARQL Generator modules, for model entity discovery. The NLQ Annotator can identify ontology classes in NLQ utilizing features extracted from ontologies (preferred label, synonym, definition, and parent label) and biosimulation models' RDF (description). The ontology class identification performance is relatively high, reaching AuCPR of 0.690 when using the CoreNLP parser and term dependency level. We also showed that NLIMED could handle a wide range of NLQ types containing one or many terms with one or many phrases. Our SPARQL Generator uses the RDF graphs as indexes into the repositories, and then can generate all possible SPARQL queries (those that have results) based on the provided ontology classes. NLIMED has been implemented in EMP for model entity searching and could potentially be applied as a generic search interface for exploring model entities from numerous biosimulation model repositories, e.g., PMR and BioModels. Further, we are interested in exploring lexical-semantics such as synonymy, hyponymy, and hypernymy by exploring hierarchies in ontology, entity composite annotation patterns, and co-occurrence of terms in query collections. Thus, we can recognize and take advantage of the similarity of terms such as “K+” and potassium and the specificity of terms such as “epithelial cells” to the “basolateral and apical plasma membranes.” By allowing users to easily perform sophisticated search queries over model repositories, we believe that NLIMED will be a valuable model-discovery tool for the biosimulation model community.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
YM, KA, and DN contributed to the conception and design of the study. YM implemented NLIMED, performed the analyses, and wrote the first draft of the manuscript. DS embedded NLIMED in an external project. YM, AR, and DN wrote sections of the manuscript. All authors contributed to the testing, evaluation of NLIMED, manuscript revision, read, and approved submitted version.
Funding
YM and DN were supported by an Aotearoa Fellowship to DN. AR, JG, MN, and DN were supported by the Center for Reproducible Biomedical Modeling P41 EB023912/EB/NIBIB NIH HHS/United States. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors acknowledge financial support by the Aotearoa Foundation and Auckland Bioengineering Institute.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fphys.2022.820683/full#supplementary-material
References
Arenas, M., Cuenca Grau, B., Kharlamov, E., Marciuška, Š., and Zheleznyakov, D. (2016). Faceted search over RDF-based knowledge graphs. J. Web Semantics 37–38, 55–74. doi: 10.1016/j.websem.2015.12.002
Barrett, T., Clark, K., Gevorgyan, R., Gorelenkov, V., Gribov, E., Karsch-Mizrachi, I., et al. (2012). BioProject and BioSample databases at NCBI: facilitating capture and organization of metadata. Nucl. Acids Res. 40, D57–D63. doi: 10.1093/nar/gkr1163
Bird, S., Klein, E., and Loper, E. (2009). Natural Language Processing With Python, 1st Edn. Sebastopol, CA: O'Reilly Media, Inc.
Čerāns, K., Šostaks, A., Bojārs, U., Bārzdiņš, J., Ovčiņņikova, J., Lāce, L., et al. (2019). ViziQuer: a visual notation for RDF data analysis queries. in Metadata and Semantic Research, Communications in Computer and Information Science, eds E. Garoufallou, F. Sartori, R. Siatri, and M. Zervas (Cham: Springer International Publishing), 50–62.
Ceriani, M., and Bottoni, P. (2017). SparqlBlocks: using blocks to design structured linked data queries. J. Vis. Lang. Sentient Syst. 3, 1–21. doi: 10.18293/VLSS2017-006
Chelliah, V., Juty, N., Ajmera, I., Ali, R., Dumousseau, M., Glont, M., et al. (2015). BioModels: ten-year anniversary. Nucl. Acids Res. 43, D542–548. doi: 10.1093/nar/gku1181
Cooper, J., Scharm, M., and Mirams, G. R. (2016). The cardiac electrophysiology web lab. Biophys. J. 110, 292–300. doi: 10.1016/j.bpj.2015.12.012
Cuellar, A. A., Lloyd, C. M., Nielsen, P. F., Bullivant, D. P., Nickerson, D. P., and Hunter, P. J. (2003). An Overview of CellML 1.1, a biological model description language. Simulation 79, 740–747. doi: 10.1177/0037549703040939
de Boer, T. P., van der Werf, S., Hennekam, B., Nickerson, D. P., Garny, A., Gerbrands, M., et al. (2017). eSolv, a CellML-based simulation front-end for online teaching. Adv. Physiol. Educ. 41, 425–427. doi: 10.1152/advan.00127.2016
Djebali, S., and Raimbault, T. (2015). SimplePARQL: a new approach using keywords over SPARQL to query the web of data. in Proceedings of the 11th International Conference on Semantic Systems, SEMANTICS '15 (New York, NY: ACM), 188–191
Ferré, S. (2014). “Sparklis: A SPARQL endpoint explorer for expressive question answering,” in ISWC Posters and Demonstrations Track.
Garny, A., and Hunter, P. J. (2015). OpenCOR: a modular and interoperable approach to computational biology. Front. Physiol. 6:26. doi: 10.3389/fphys.2015.00026
Gaulton, A., Bellis, L. J., Bento, A. P., Chambers, J., Davies, M., Hersey, A., et al. (2012). ChEMBL: a large-scale bioactivity database for drug discovery. Nucl. Acids Res. 40, D1100–D1107. doi: 10.1093/nar/gkr777
Gennari, J. H., König, M., Misirli, G., Neal, M. L., Nickerson, D. P., and Waltemath, D. (2021). OMEX metadata specification (version 1.2). J. Integrat. Bioinf. 18:20210020. doi: 10.1515/jib-2021-0020
Gennari, J. H., Neal, M. L., Galdzicki, M., and Cook, D. L. (2011). Multiple ontologies in action: composite annotations for biosimulation models. J. Biomed. Inf. 44, 146–154. doi: 10.1016/j.jbi.2010.06.007
Hamon, T., Grabar, N., Mougin, F., and Thiessard, F. (2014). Description of the POMELO system for the task 2 of QALD-2014. in CLEF (Sheffield).
Harman, D., Baeza-Yates, R., Fox, E., and Lee, W. (1992). “Inverted files,” in Information Retrieval: Data Structures and Algorithms (New York, NY: Prentice-Hall), 28–43.
Hucka, M., Finney, A., Sauro, H. M., Bolouri, H., Doyle, J. C., Kitano, H., et al. (2003). The systems biology markup language (SBML): A medium for representation and exchange of biochemical network models. Bioinformatics 19, 524–531. doi: 10.1093/bioinformatics/btg015
Jonquet, C., Musen, M. A., and Shah, N. H. (2010). Building a biomedical ontology recommender web service. J. Biomed. Semantics 1:S1. doi: 10.1186/2041-1480-1-S1-S1
Kim, J.-D., Ohta, T., Tateisi, Y., and Tsujii, J. (2003). GENIA corpus—a semantically annotated corpus for bio-textmining. Bioinformatics 19, i180–i182. doi: 10.1093/bioinformatics/btg1023
Kitaev, N., and Klein, D. (2018). Constituency parsing with a self-attentive encoder. arXiv:1805.01052 [cs].
Lister, A. L., Pocock, M., Taschuk, M., and Wipat, A. (2009). Saint: a lightweight integration environment for model annotation. Bioinformatics (Oxford, England) 25, 3026–3027. doi: 10.1093/bioinformatics/btp523
Manning, C., Surdeanu, M., Bauer, J., Finkel, J., Bethard, S., and McClosky, D. (2014). The stanford CoreNLP natural language processing toolkit. in Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations (Baltimore, MD: Association for Computational Linguistics), 55–60.
Marginean, A. (2014). GFMed: question answering over biomedical linked data with grammatical framework. in CLEF (Sheffield).
Neal, M. L., König, M., Nickerson, D., Mısırlı, G., Kalbasi, R., Dräger, A., et al. (2019). Harmonizing semantic annotations for computational models in biology. Briefings Bioinf. 20, 540–550. doi: 10.1093/bib/bby087
Neal, M. L., Thompson, C. T., Kim, K. G., James, R. C., Cook, D. L., Carlson, B. E., et al. (2018). SemGen: a tool for semantics-based annotation and composition of biosimulation models. Bioinformatics 35, 1600–1602. doi: 10.1093/bioinformatics/bty829
Ogilvie, P., Callan, J., and Callan, J. (2003). Combining Document Representations for Known-item Search. in Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval, SIGIR '03 (New York, NY: ACM), 143–150.
Pérez, J., Arenas, M., and Gutierrez, C. (2009). Semantics and Complexity of SPARQL. ACM Trans. Database Syst. 34, 1–45. doi: 10.1145/1567274.1567278
Pyysalo, S., and Ananiadou, S. (2014). Anatomical entity mention recognition at literature scale. Bioinformatics 30, 868–875. doi: 10.1093/bioinformatics/btt580
Pyysalo, S., Ohta, T., Rak, R., Rowley, A., Chun, H.-W., Jung, S.-J., et al. (2015). Overview of the cancer genetics and pathway curation tasks of BioNLP shared task 2013. BMC Bioinf. 16:S2. doi: 10.1186/1471-2105-16-S10-S2
Robertson, S., Zaragoza, H., and Taylor, M. (2004). Simple BM25 extension to multiple weighted fields. in Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management, CIKM '04 (New York, NY: ACM), 42–49.
Robertson, S. E., and Walker, S. (1994). Some simple effective approximations to the 2-Poisson model for probabilistic weighted retrieval. in SIGIR '94, eds B. W. Croft, and C. J. van Rijsbergen (London: Springer), 232–241.
Salton, G., Wong, A., and Yang, C. S. (1975). A vector space model for automatic indexing. Commun. ACM 18, 613–620.
Sarwar, D. M., Atalag, K., Hunter, P. J., and Nickerson, D. P. (2019a). Epithelial modelling platform: a tool for investigating hypothesis through discovery and assembly of computational models of epithelial transport. FASEB J. 33, 862.11–862.11. doi: 10.1096/fasebj.2019.33.1supplement.862.11
Sarwar, D. M., Kalbasi, R., Gennari, J. H., Carlson, B. E., Neal, M. L., de Bono, B., et al. (2019b). Model annotation and discovery with the Physiome Model Repository. BMC Bioinf. 20, 457. doi: 10.1186/s12859-019-2987-y
Unger, C., Forascu, C., Lopez, V., Ngomo, A.-C. N., Cabrio, E., Cimiano, P., et al. (2014). Question answering over linked data (QALD-4). in Working Notes for CLEF 2014 Conference (Sheffield).
Uzuner, Ö., South, B. R., Shen, S., and DuVall, S. L. (2011). 2010 i2b2/VA challenge on concepts, assertions, and relations in clinical text. J. Am. Med. Inf. Assoc. 18, 552–556. doi: 10.1136/amiajnl-2011-000203
Vcelak, P., Kryl, M., and Kleckova, J. (2018). SPARQL query-builder for medical temporal data. in 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI) (Beijing), 1–9.
Welsh, C., Nickerson, D. P., Rampadarath, A., Neal, M. L., Sauro, H. M., and Gennari, J. H. (2021). libOmexMeta: enabling semantic annotation of models to support FAIR principles. Bioinformatics 37, 4898–4900. doi: 10.1093/bioinformatics/btab445
Whetzel, P. L., Noy, N. F., Shah, N. H., Alexander, P. R., Nyulas, C., Tudorache, T., et al. (2011). BioPortal: enhanced functionality via new Web services from the national center for biomedical ontology to access and use ontologies in software applications. Nucl. Acids Res. 39, W541–W545. doi: 10.1093/nar/gkr469
Xu, K., Zhang, S., Feng, Y., and Zhao, D. (2014). Answering natural language questions via phrasal semantic parsing. in Natural Language Processing and Chinese Computing, Communications in Computer and Information Science, eds C. Zong, J.-Y. Nie, D. Zhao, and Y. Feng (Berlin: Springer), 333–344.
Yahya, M., Berberich, K., Elbassuoni, S., Ramanath, M., Tresp, V., and Weikum, G. (2012). Natural language questions for the web of data. in Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, EMNLP-CoNLL '12 (Stroudsburg: Association for Computational Linguistics), 379–390.
Yu, T., Lloyd, C. M., Nickerson, D. P., Cooling, M. T., Miller, A. K., Garny, A., et al. (2011). The physiome model repository 2. Bioinformatics 27, 743–744. doi: 10.1093/bioinformatics/btq723
Keywords: semantic annotation, ontology class, physiome model repository, BioModels, NLP, SPARQL, information retrieval
Citation: Munarko Y, Sarwar DM, Rampadarath A, Atalag K, Gennari JH, Neal ML and Nickerson DP (2022) NLIMED: Natural Language Interface for Model Entity Discovery in Biosimulation Model Repositories. Front. Physiol. 13:820683. doi: 10.3389/fphys.2022.820683
Received: 23 November 2021; Accepted: 31 January 2022;
Published: 24 February 2022.
Edited by:
Raimond L. Winslow, Johns Hopkins University, United StatesReviewed by:
Steve McKeever, Uppsala University, SwedenJames Alastair McLaughlin, European Bioinformatics Institute (EMBL-EBI), United Kingdom
Copyright © 2022 Munarko, Sarwar, Rampadarath, Atalag, Gennari, Neal and Nickerson. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yuda Munarko, ymun794@aucklanduni.ac.nz