The human milk proteome and allergy of mother and child: Exploring associations with protein abundances and protein network connectivity
 Pieter M. Dekker1,2
Pieter M. Dekker1,2 Meghan B. Azad3,4
Meghan B. Azad3,4 Sjef Boeren2
Sjef Boeren2 Piushkumar J. Mandhane5
Piushkumar J. Mandhane5 Theo J. Moraes6
Theo J. Moraes6 Elinor Simons3,4
Elinor Simons3,4 Padmaja Subbarao6,7
Padmaja Subbarao6,7 Stuart E. Turvey8
Stuart E. Turvey8 Edoardo Saccenti9
Edoardo Saccenti9 Kasper A. Hettinga1*
Kasper A. Hettinga1*- 1Food Quality and Design Group, Wageningen University and Research, Wageningen, Netherlands
- 2Laboratory of Biochemistry, Wageningen University and Research, Wageningen, Netherlands
- 3Department of Pediatrics and Child Health, University of Manitoba, Winnipeg, MB, Canada
- 4Manitoba Interdisciplinary Lactation Centre (MILC), Children’s Hospital Research Institute of Manitoba, Winnipeg, MB, Canada
- 5Department of Pediatrics, University of Alberta, Edmonton, AB, Canada
- 6Division of Respiratory Medicine, Department of Pediatrics, Hospital for Sick Children, University of Toronto, Toronto, ON, Canada
- 7Department of Physiology, University of Toronto, Toronto, ON, Canada
- 8Department of Pediatrics, University of British Columbia, Vancouver, BC, Canada
- 9Laboratory of Systems and Synthetic Biology, Wageningen University and Research, Wageningen, Netherlands
A corrigendum on
The human milk proteome and allergy of mother and child: exploring associations with protein abundances and protein network connectivity
by Dekker PM, Azad MB, Boeren S, Mandhane PJ, Moraes TJ, Simons E, Subbarao P, Turvey SE, Saccenti E and Hettinga KA (2022) Front. Immunol. 13:977470. doi: 10.3389/fimmu.2022.977470
In the published article, there was an error. The data processing was carried out without setting the fixed propionamide modification for cysteines.
In the sample preparation carried out in our study, proteins were reduced and alkylated before tryptic digestion and analysis. This resulted in the modification of the cysteine residues within the sequence. After the nontargeted analysis, this modification should have been taken into account in the settings of the data processing in order to correctly identify all tryptic peptides. The error was that this modification was not set in the software, which resulted in false negative identification of peptides with cysteine residues. Consequently, the identification of proteins was only based on tryptic peptides with unmodified cysteines in their sequence, and proteins rich in cysteines were therefore also identified less.
After discovering this error, we reprocessed the raw data, setting the fixed modification in the data processing software. Although this reprocessing resulted in increased identification of cysteine-rich proteins and, consequently, in differences in numbers, tables, figures, and supplementary material, the discussion and conclusions of the article remain the same.
Text Corrections
Corrections have been made to Materials and methods, Statistical methods, Missing data. This sentence previously stated:
In practice this resulted in a minimum of 66 and a median of 215 valid values.
The corrected sentence appears below:
In practice this resulted in a minimum of 49 and a median of 209 valid values.
Corrections have been made to Materials and methods, Statistical methods, Principal component analysis. This sentence previously stated:
For unsupervised data exploration, Principal Component Analysis (PCA) (40) was applied on the 300 × 647 data matrix (samples × proteins), using the FactoMineR package for R (41).
The corrected sentence appears below:
For unsupervised data exploration, Principal Component Analysis (PCA) (40) was applied on the 300 × 687 data matrix (samples × proteins), using the FactoMineR package for R (41).
Corrections have been made to Materials and methods, Statistical methods, Network inference and analysis - Covariance simultaneous component analysis (COVSCA). This sentence previously stated:
This fit was chosen as the best compromise between goodness of fit (68%) and the complexity of the COVSCA model (rank and number of the prototypical matrices).
The corrected sentence appears below:
This fit was chosen as the best compromise between goodness of fit (74%) and the complexity of the COVSCA model (rank and number of the prototypical matrices).
Corrections have been made to Results, paragraph one. This paragraph previously stated:
Proteomic analysis of all samples led to a total of 1629 identified proteins before filtering on missing values. After filtering these proteins on the requirement of being identified ≥ 25 times in at least one of the four mother-child allergy groups, 647 proteins remained for further data analysis. In this filtered dataset, the number of identified proteins per sample ranged between 256 and 586 (median = 458). The major milk proteins α-lactalbumin, albumin, lactoferrin, β-casein, and αs1-casein, were in all analyzed samples among the 15 most abundant proteins. A complete overview of the 647 identified proteins can be found in Supplementary Table 1.
The corrected paragraph appears below:
Proteomic analysis of all samples led to a total of 1690 identified proteins before filtering on missing values. After filtering these proteins on the requirement of being identified ≥ 25 times in at least one of the four mother-child allergy groups, 687 proteins remained for further data analysis. In this filtered dataset, the number of identified proteins per sample ranged between 242 and 636 (median = 480). The major milk proteins α-lactalbumin, albumin, lactoferrin, β-casein, and αs1-casein, were in all analyzed samples among the 15 most abundant proteins. A complete overview of the 687 identified proteins can be found in Supplementary Table 1.
Corrections have been made to Results, Univariate analysis. This section previously stated:
Differences in protein abundance between the different mother-child allergy groups were assessed with Kruskal-Wallis tests. After correction for multiple hypothesis testing, no significant differences were found among the four groups (Table 1). Kruskal-Wallis outcomes with uncorrected p < 0.05 were further assessed with Dunn’s post-hoc tests and subsequent correction for multiple testing, which resulted in 23 proteins that showed a difference between the groups with corrected p < 0.05 (Table 1). Most of these differences (n = 15) were found between the non-allergic group (M-C-) and the group where only the child ultimately developed an allergy (M-C+). Proteins that differed between these groups were primarily Ig chains (11 out of 15) and were mostly higher in abundance in the group where the mother was non-allergic and the child developed an allergy (Figure 3). Additionally, 4 of these Igs show also a higher abundance in milk from allergic mothers with children who did not develop an allergy. Further investigation of all identified Ig proteins showed that the mean abundance of these proteins is generally lower in the groups where mother, child or both are allergic, when compared to the non-allergic group (Figure 4). This effect is clearest in the comparison of the group where only the child developed an allergy with the group where both mother and child are nonallergic. Out of 81 Ig proteins, 75 have a mean abundance that is higher in the group where the child developed an allergy.
TABLE 1
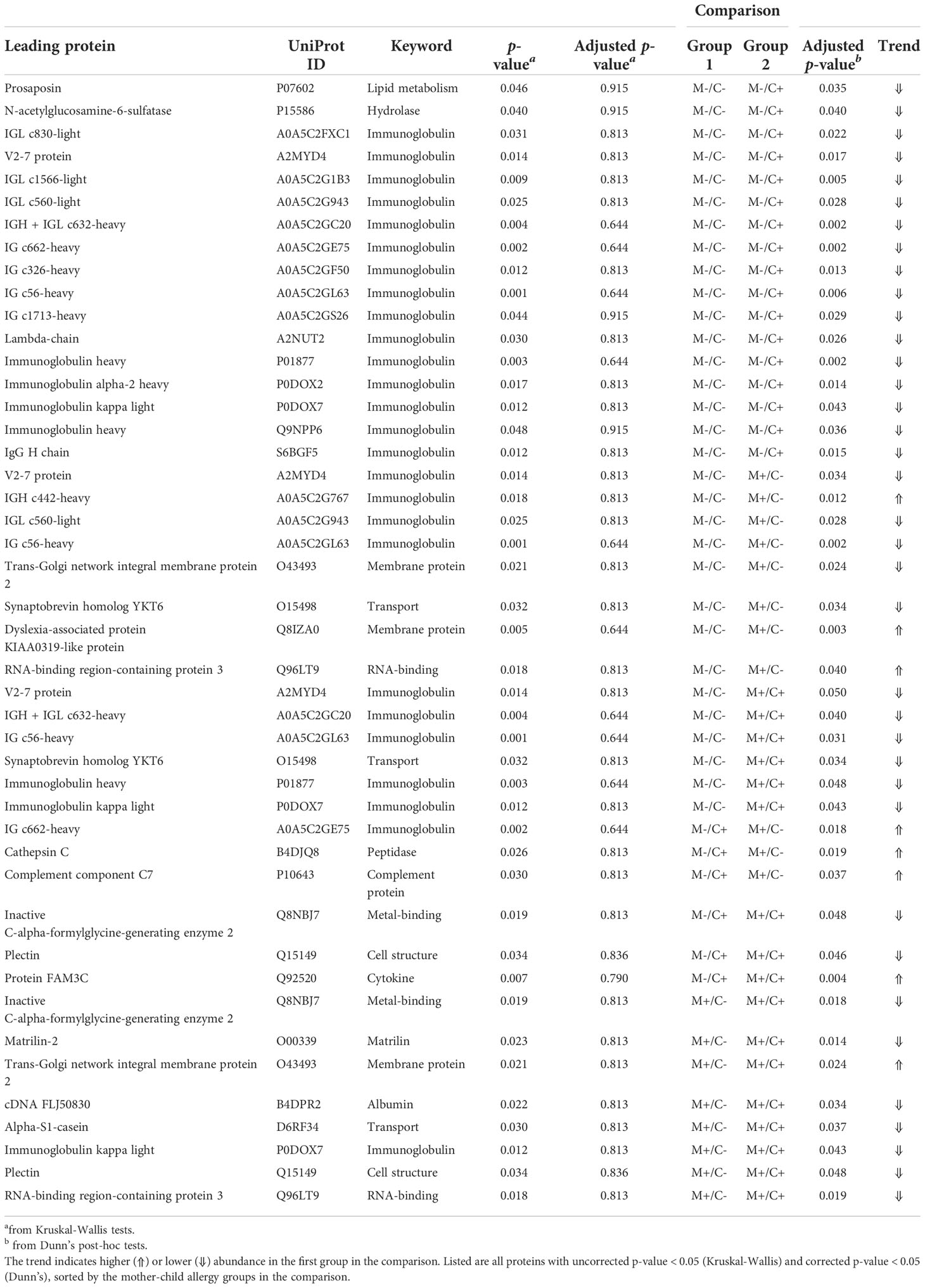
Table 1 Results of univariate analysis (Kruskal-Wallis) with subsequent post-hoc test (Dunn’s) for the comparison of protein abundance in milk from allergic (M+) and non-allergic (M-) mothers, with children who developed an allergy (C+) and did not develop an allergy (C-) in the CHILD Cohort Study.
FIGURE 3
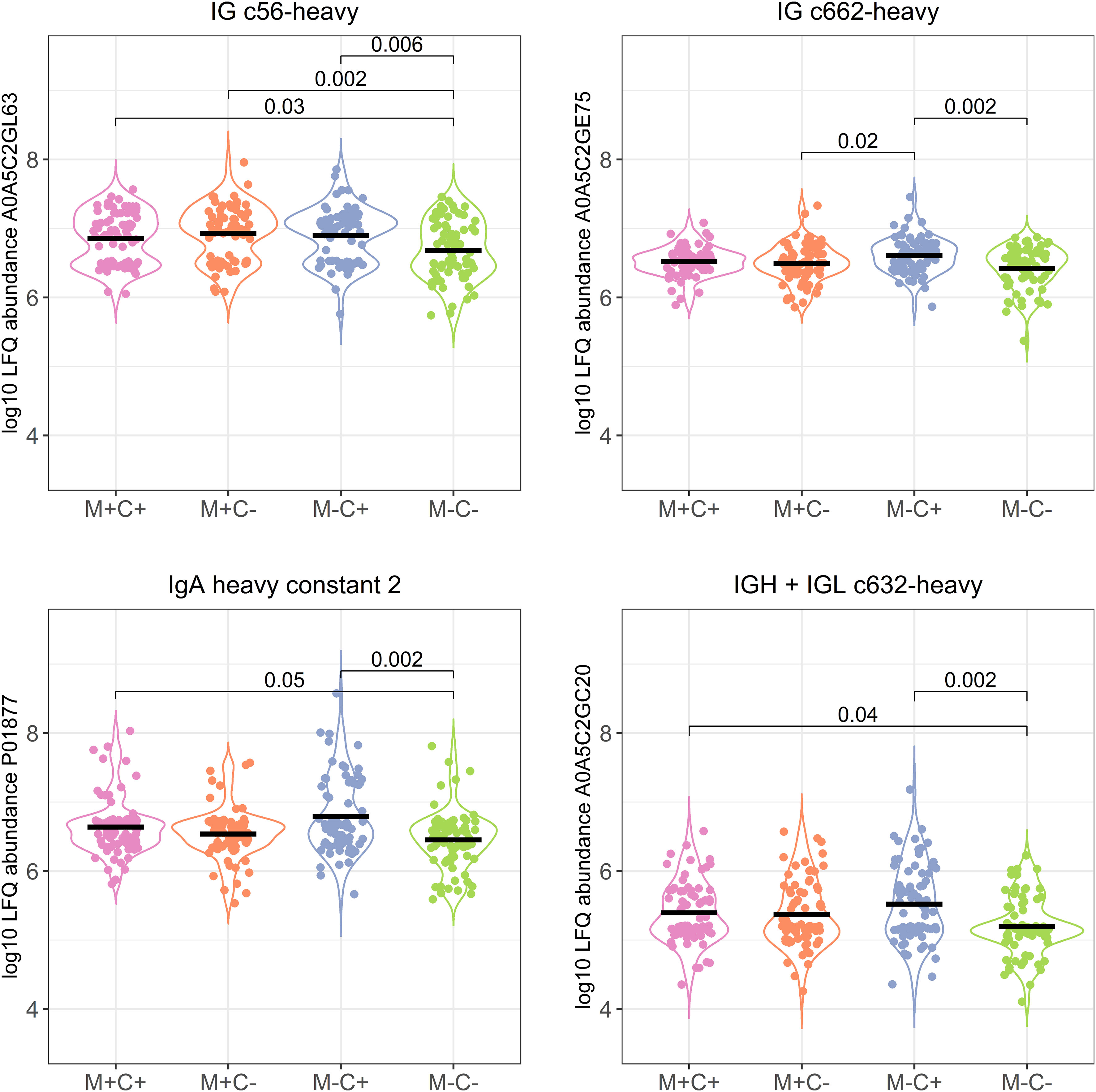
Figure 3 Violin plots visualizing the differences in abundance of the 4 most significantly different immunoglobulin (Ig) chains between the different allergy status groups from the CHILD Cohort Study. Differences between groups are indicated with p-values from Dunn’s post-hoc tests, and means of each group are shown with black, horizontal lines. In the labeling of the groups, M indicates mother, C indicates child, + indicates allergy, and - indicates no allergy.
FIGURE 4
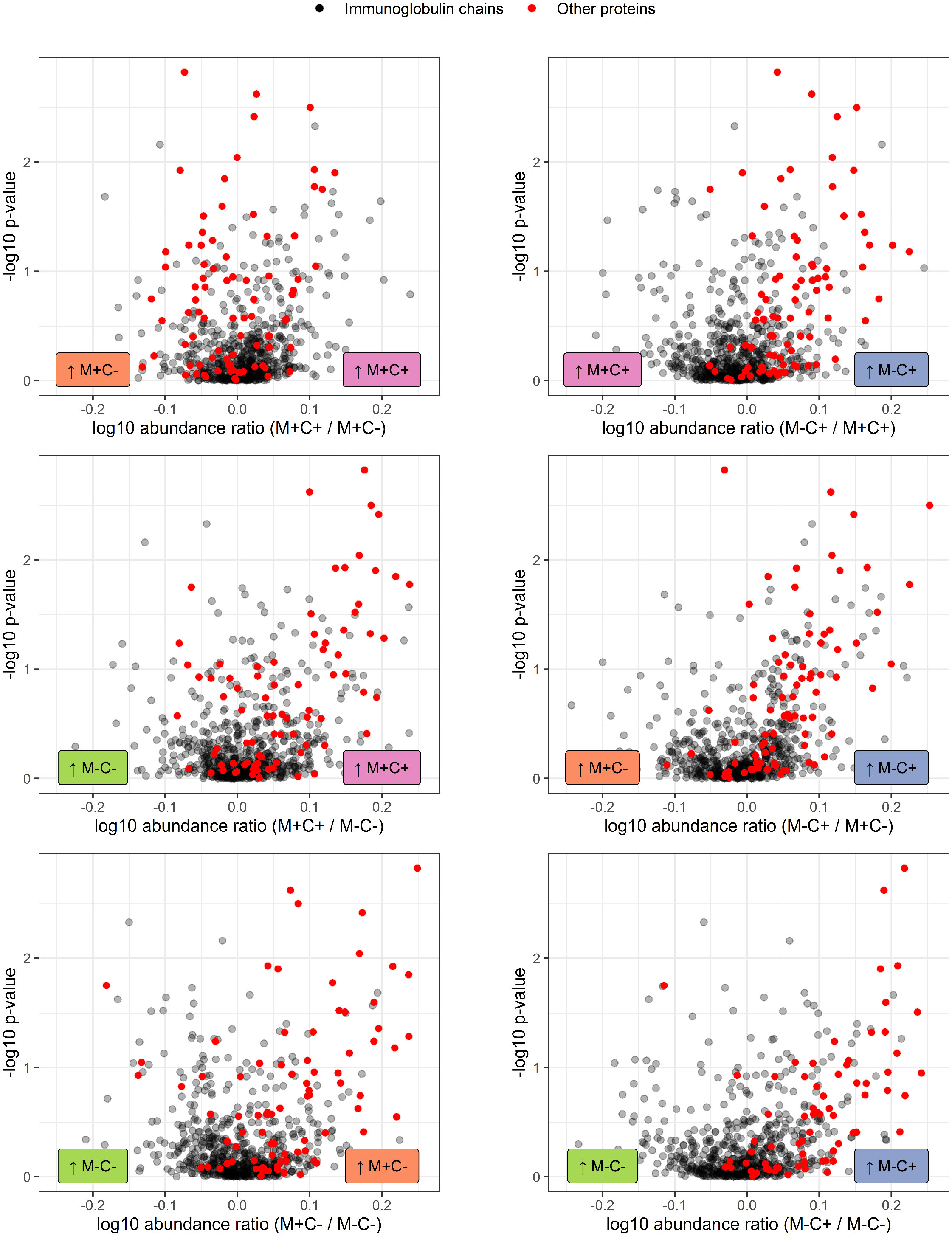
Figure 4 Volcano plots visualizing the trend in immunoglobulin abundances in milk from different mother-child allergy status groups from the CHILD Cohort Study. Each data point represents one protein, with on the x-axes the ratio of the means of the log10 transformed label-free quantification (LFQ). Immunoglobulin-related proteins are represented by red and other proteins with grey dots. Colored labels on left and right side of x = 0 indicate in which mother-child allergy status group the mean abundance of the respective proteins is higher. In the labeling of the groups, M indicates mother, C indicates child, + indicates allergy, and - indicates no allergy. A trend can be observed that most immunoglobulin-related proteins are higher in abundance in the group where the mother is non-allergic and the child ultimately develops an allergy.
The corrected section appears below:
Differences in protein abundance between the different mother-child allergy groups were assessed with Kruskal-Wallis tests. After correction for multiple hypothesis testing, no significant differences were found among the four groups (Table 1). Kruskal-Wallis outcomes with uncorrected p < 0.05 were further assessed with Dunn’s post-hoc tests and subsequent correction for multiple testing, which resulted in 30 proteins that showed a difference between the groups with corrected p < 0.05 (Table 1). Most of these differences (n = 17) were found between the non-allergic group (M-C-) and the group where only the child ultimately developed an allergy (M-C+). Proteins that differed between these groups were primarily Ig chains (15 out of 17) and were mostly higher in abundance in the group where the mother was non-allergic and the child developed an allergy (Figure 3). Additionally, 3 of these Igs show also a higher abundance in milk from allergic mothers with children who did not develop an allergy. Further investigation of all identified Ig proteins showed that the mean abundance of these proteins is generally lower in the groups where mother, child or both are allergic, when compared to the non-allergic group (Figure 4). This effect is clearest in the comparison of the group where only the child developed an allergy with the group where both mother and child are nonallergic. Out of 83 Ig proteins, 77 have a mean abundance that is higher in the group where the child developed an allergy.
Corrections have been made to Results, Non-human proteins, paragraph one. This sentence previously stated:
In the current study, several non-human proteins were identified (n = 9), including albumin from dog, horse, and cat, as well as bovine αs1-casein and BLG (Table 2).
TABLE 2
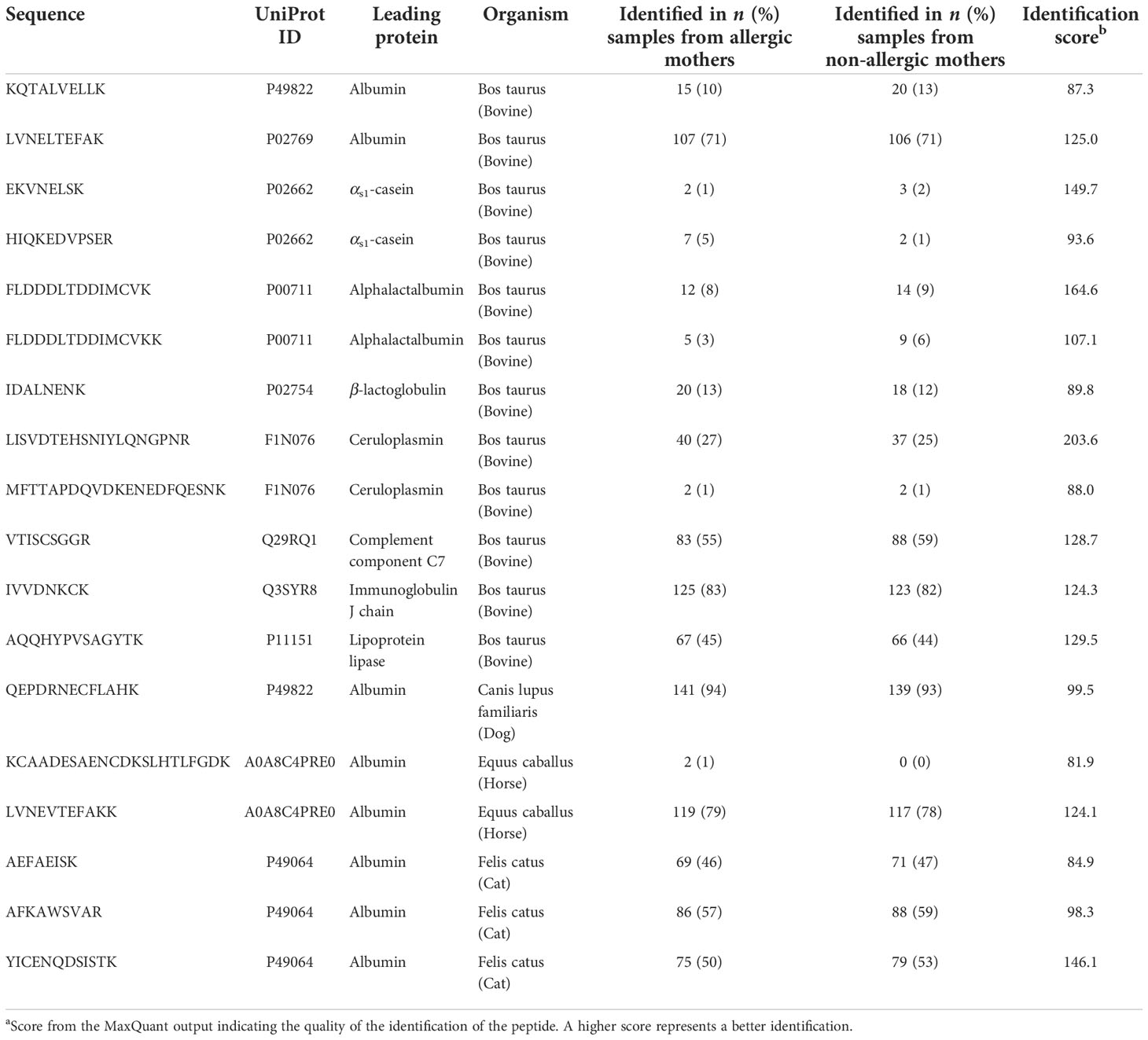
Table 2 Identified non-human tryptic peptides in human milk samples from the CHILD Cohort Study (n = 150 allergic mothers and 150 non-allergic mothers).
The corrected sentence appears below:
In the current study, several non-human proteins were identified (n = 11), including albumin from dog, horse, and cat, as well as bovine αs1-casein and BLG (Table 2).
Corrections have been made to Results, Network analysis, Network inference, paragraph 2. This paragraph previously stated:
To investigate this pattern further, proteins with differential connectivity > 50 were selected for further investigation (Supplementary Table 1). These proteins had the largest differences in connectivity among the four different groups and were selected for further functional analysis, to determine possible functional consequences of the differences between the networks. The selection resulted in 173, 171, and 153 proteins for the comparison of the group with non-allergic mother and child with respectively (i) allergic mother and non-allergic child, (ii) non-allergic mother and allergic child, and (iii) allergic mother and child groups. From these proteins, 95 proteins occurred in all three selections, showing a similarity in differential connectivity. Interestingly, GO overrepresentation analysis of these proteins showed a significant overrepresentation of proteins involved in translation initiation (p = 1.08×10−15). This overrepresentation is due to 24 ribosomal proteins and translation initiation factors (EIF3A, EIF4A1, EIF5A).
The corrected paragraph appears below:
To investigate this pattern further, proteins with differential connectivity > 50 were selected for further investigation (Supplementary Table 1). These proteins had the largest differences in connectivity among the four different groups and were selected for further functional analysis, to determine possible functional consequences of the differences between the networks. The selection resulted in 160, 168, and 144 proteins for the comparison of the group with non-allergic mother and child with respectively (i) allergic mother and non-allergic child, (ii) non-allergic mother and allergic child, and (iii) allergic mother and child groups. From these proteins, 79 proteins occurred in all three selections, showing a similarity in differential connectivity. Interestingly, GO overrepresentation analysis of these proteins showed a significant overrepresentation of proteins involved in translation (p = 9.13×10−9). This overrepresentation is due to 23 ribosomal proteins and translation elongation factor EEF1A1P5.
Corrections have been made to Results, Network analysis, Network modeling, paragraph 3. This paragraph previously stated:
The loadings for component 1 (see Figure 8) are overrepresented by proteins involved in gluconeogenesis (p = 0.0003), the synthesis of glucose. This component accounts for separation between the non-allergic group and the other three groups. The second component, which drives the separation of the groups on allergy status of the child, shows a significant overrepresentation of proteins involved in the positive regulation of DNA biosynthetic processes (p = 0.0013). This overrepresentation is mainly due to 5 members of the tailless complex polypeptide 1 ring complex (TRiC or CCT). In addition, several proteins involved in translation processes show differences in correlation patterns on this component.
The corrected paragraph appears below:
The loadings for component 1 (see Figure 8) are overrepresented by proteins involved in gluconeogenesis (p = 0.003), the synthesis of glucose. This component accounts for separation between the non-allergic group and the other three groups. The second component, which drives the separation of the groups on allergy status of the child, does not show a significant overrepresentation of gene ontology terms. However, among these proteins are 11 proteins involved in translation as well as 3 members of the tailless complex polypeptide 1 ring complex (TRiC or CCT).
Corrections have been made to Discussion, Differences in immunoglobulin abundances between groups with different allergy statuses, paragraph 6. This sentence previously stated:
Notably, soluble CD14, a protein in human milk that may be protective against the development of food allergies (56, 57), was not different between the allergy groups in our study (uncorrected p = 0.53).
The corrected sentence appears below:
Notably, soluble CD14, a protein in human milk that may be protective against the development of food allergies (56, 57), was not different between the allergy groups in our study (uncorrected p = 0.43).
Error in Figure/Table
For the same reason as explained above, corrections have been made to Tables 1–3, and Figures 3–8.
FIGURE 5
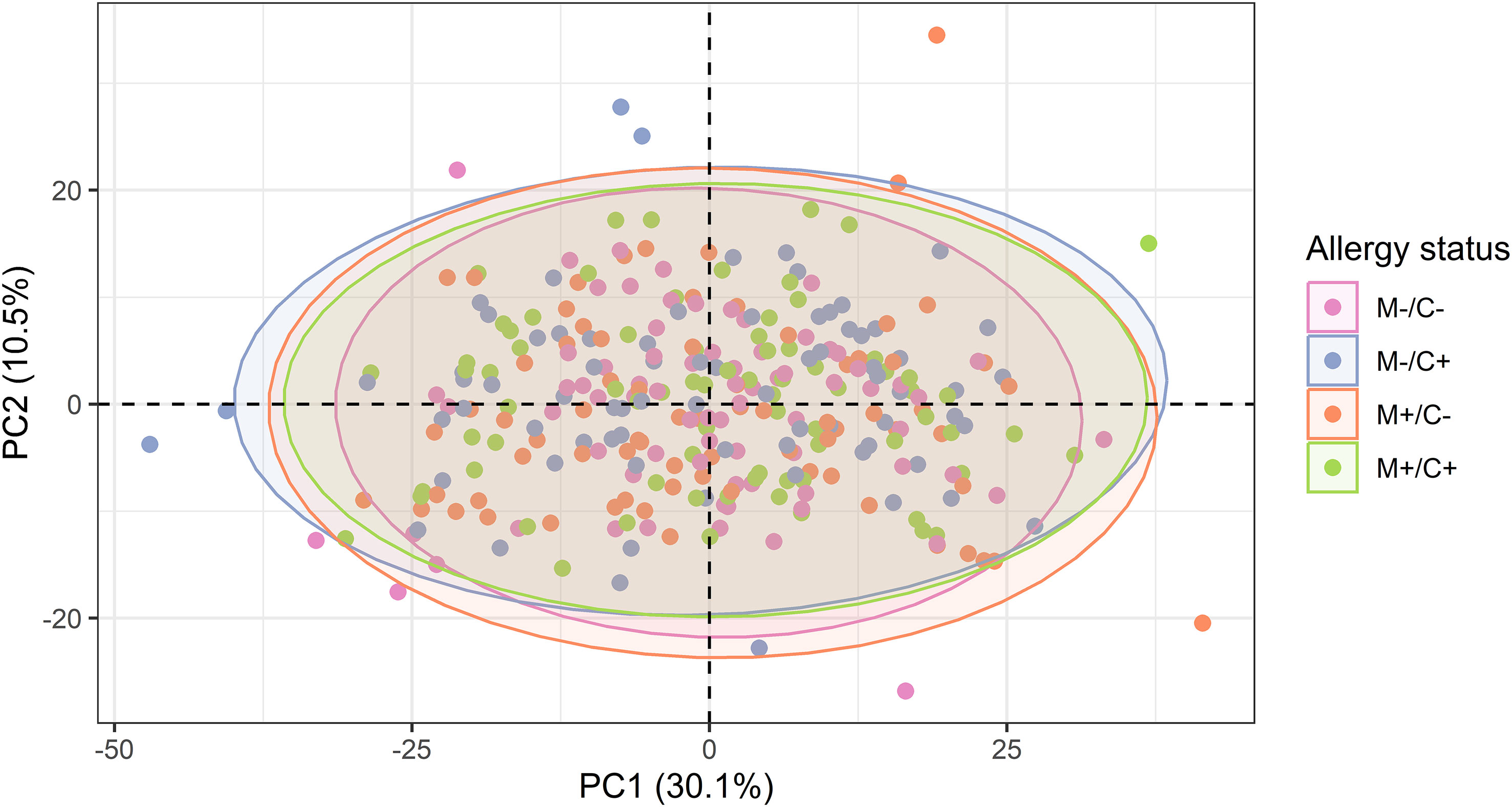
Figure 5 Scatter plot of principal component analysis (PCA) representing the human milk protein profile of mother-child dyads from the CHILD Cohort Study. Each point represents one dyad. No obvious differences can be observed among protein profiles of different mother-child allergy groups using this method.
FIGURE 6
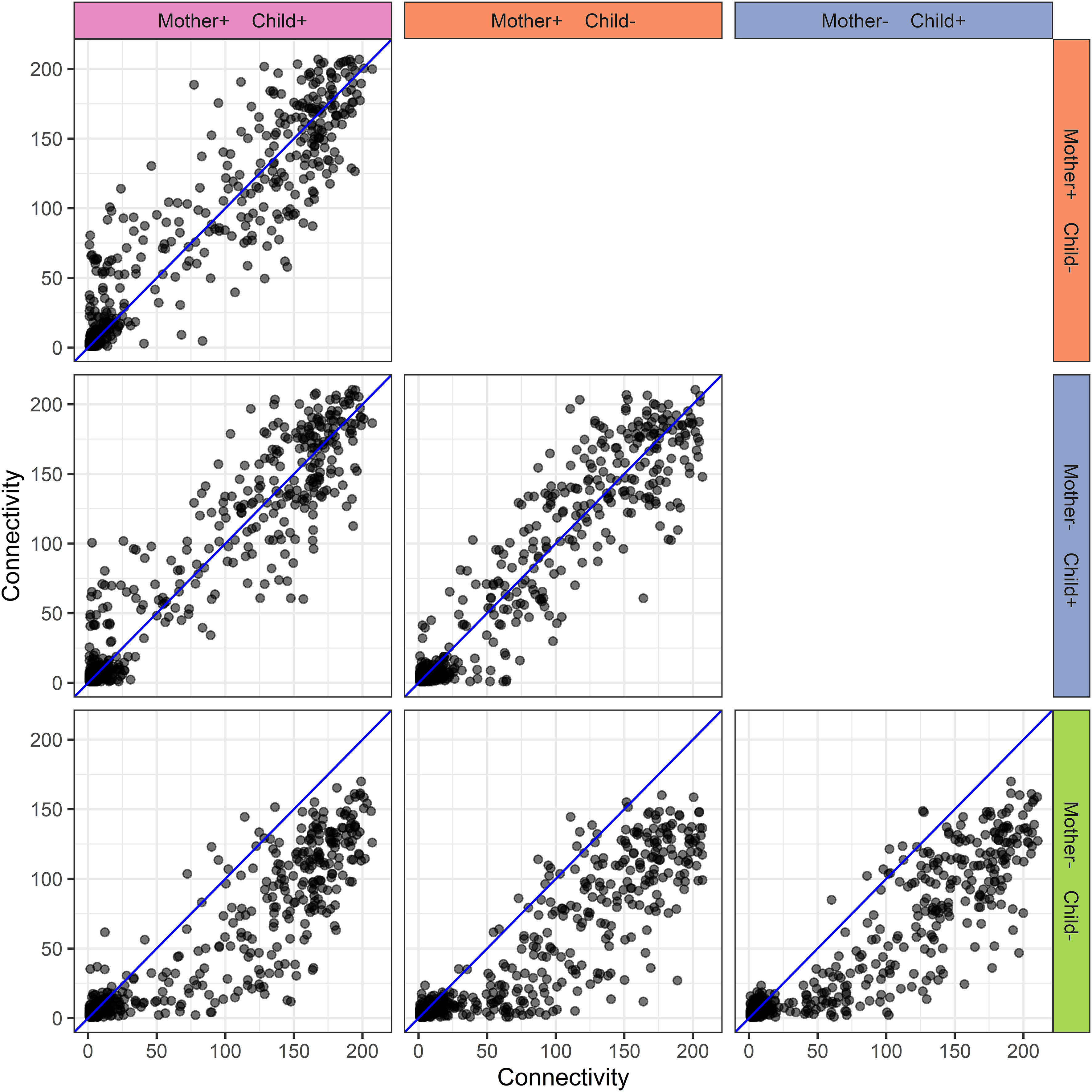
Figure 6 Human milk protein connectivity in the different mother-child allergy groups from the CHILD Cohort Study. Each subplot represents a pairwise comparison of protein connectivity in two mother-child allergy groups and each dot represents a single protein. Protein connectivity is obtained from the adjacency matrices build with the PCLRC algorithm and all groups are compared with one another in each subplot. In the labeling of the groups, + indicates allergy and - indicates no allergy. The group in which both mother and child are non-allergic shows a distinct connectivity pattern with an overall lower connectivity of the proteins.
FIGURE 7
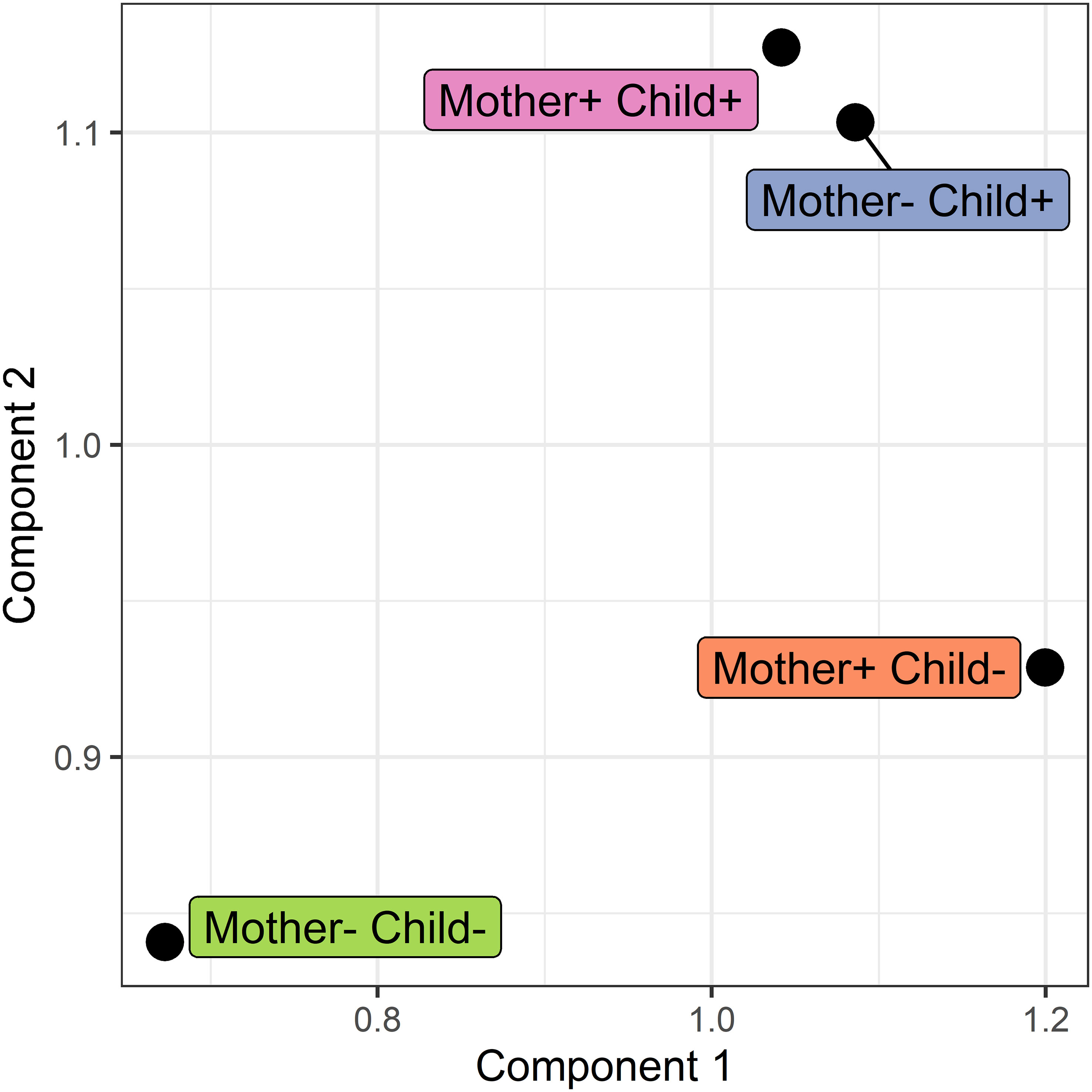
Figure 7 Score plot of the COVSCA model for the protein correlation network obtained using PCLRC of different groups based on maternal and child allergy status in the CHILD Cohort Study. Each point represents a protein-protein association network of one mother-child allergy group (+ indicates allergy, and- indicates no allergy). Protein importance for each component is shown in Figure 8. The groups with children who ultimately developed an allergy show similarities, whereas all the other groups show dissimilarities in correlation patterns.
FIGURE 8
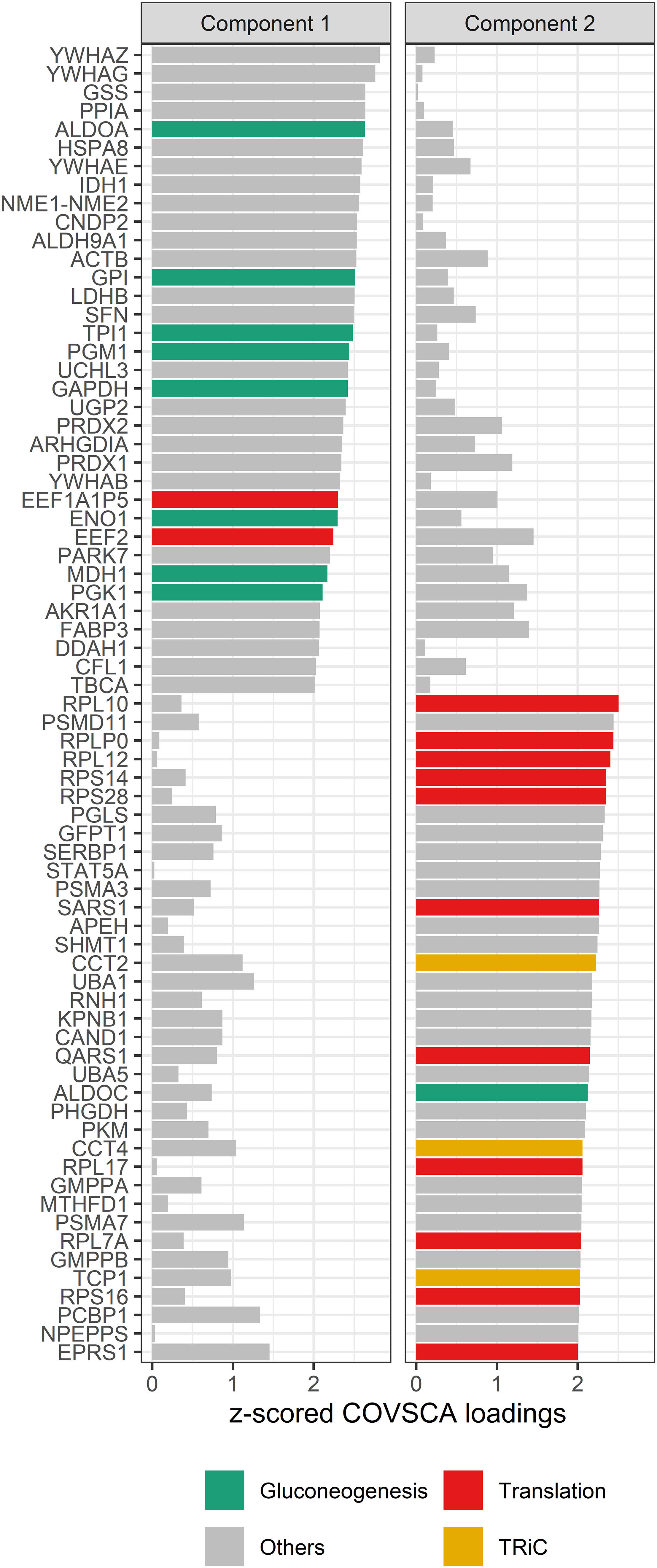
Figure 8 COVSCA loadings of the COVSCA model of different groups based on maternal and child allergy status in the CHILD Cohort Study. Loadings indicate the importance of each protein for the differences or similarities in correlation patterns observed in the COVSCA score plot (Figure 7). Proteins are labeled with gene IDs along the y-axis, and colors indicate shared gene ontology annotations. Among the proteins important for explaining the variability between the networks are proteins involved in gluconeogenesis, translation, and the tailless complex polypeptide 1 ring complex (TRiC).
TABLE 3
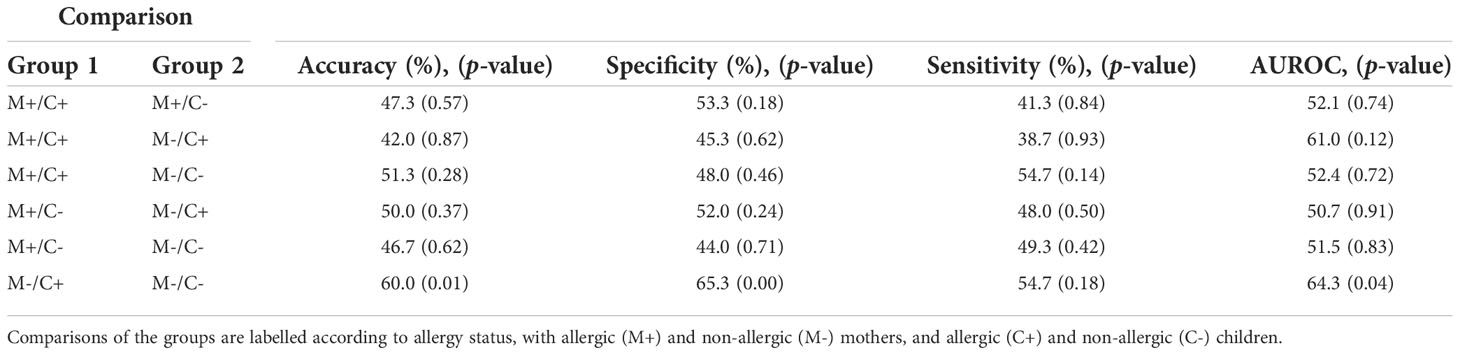
Table 3 Outcome of Random Forest models on human milk proteins for the discrimination of groups with different allergy statuses from the CHILD Cohort Study.
The corrected Tables and Figures appear below.
Incorrect Supplementary Material
For the same reason as explained above, corrections have been made to Supplementary Figure 1 and Table 1.
The correct Supplementary Material has been added to the original article.
The authors apologize for these errors and state that this does not change the scientific conclusions of the article in any way.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Keywords: breastmilk, milk proteome, allergic disease, allergy development, immunology of human milk, differential network analysis, allergen, immunomodulatory
Citation: Dekker PM, Azad MB, Boeren S, Mandhane PJ, Moraes TJ, Simons E, Subbarao P, Turvey SE, Saccenti E and Hettinga KA (2023) Corrigendum: The human milk proteome and allergy of mother and child: exploring associations with protein abundances and protein network connectivity. Front. Immunol. 14:1276180. doi: 10.3389/fimmu.2023.1276180
Received: 11 August 2023; Accepted: 22 August 2023;
Published: 18 September 2023.
Edited and Reviewed by:
Julio Villena, CONICET Centro de Referencia para Lactobacilos (CERELA), ArgentinaCopyright © 2023 Dekker, Azad, Boeren, Mandhane, Moraes, Simons, Subbarao, Turvey, Saccenti and Hettinga. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Kasper A. Hettinga, kasper.hettinga@wur.nl