Prediction of Ovarian Cancer-Related Metabolites Based on Graph Neural Network
 Jingjing Chen1†
Jingjing Chen1†  Yingying Chen1† Kefeng Sun1† Yu Wang1 Hui He1 Lin Sun2 Sifu Ha2 Xiaoxiao Li3 Yifei Ou3 Xue Zhang4*
Yingying Chen1† Kefeng Sun1† Yu Wang1 Hui He1 Lin Sun2 Sifu Ha2 Xiaoxiao Li3 Yifei Ou3 Xue Zhang4*  Yanli Bi5*
Yanli Bi5*- 1Department of Obstetrics and Gynecology, First Affiliated Hospital, Heilongjiang University of Chinese Medicine, Harbin, China
- 2Department of Reproductive Medicine, Dalian Maternal and Children’s Centre, Dalian, China
- 3Graduate School of Heilongjiang University of Chinese Medicine, Harbin, China
- 4Department of General Practice, Beijing Friendship Hospital, Capital Medical University, Beijing, China
- 5Department of Reproductive Medicine, The First Affiliated Hospital, Henan University of Chinese Medicine, Zhengzhou, China
Ovarian cancer is one of the three most malignant tumors of the female reproductive system. At present, researchers do not know its pathogenesis, which makes the treatment effect unsatisfactory. Metabolomics is closely related to drug efficacy, safety evaluation, mechanism of action, and rational drug use. Therefore, identifying ovarian cancer-related metabolites could greatly help researchers understand the pathogenesis and develop treatment plans. However, the measurement of metabolites is inaccurate and greatly affects the environment, and biological experiment is time-consuming and costly. Therefore, researchers tend to use computational methods to identify disease-related metabolites in large scale. Since the hypothesis that similar diseases are related to similar metabolites is widely accepted, in this paper, we built both disease similarity network and metabolite similarity network and used graph convolutional network (GCN) to encode these networks. Then, support vector machine (SVM) was used to identify whether a metabolite is related to ovarian cancer. The experiment results show that the AUC and AUPR of our method are 0.92 and 0.81, respectively. Finally, we proposed an effective method to prioritize ovarian cancer-related metabolites in large scale.
Introduction
Ovarian cancer is a common gynecological malignancy and one of the deadliest female diseases. Because the underlying symptoms are not obvious, about 70% of ovarian cancer patients are already at an advanced stage when they are diagnosed (Liu et al., 2020). The survival rates of patients with ovarian cancer at different stages are very different, and the mortality rate of patients with advanced stages exceeds 75% (Hussain, 2020). Therefore, there is an urgent need to find metabolites related to ovarian cancer to improve the prognosis of ovarian cancer and improve the efficiency of individualized treatment of patients (Perrone et al., 2020). Many life activities in cells occur at the metabolite level, so metabolomics has become one of the current research hotspots in the field of omics (Blimkie et al., 2020). The research of metabolomics in the early diagnosis of malignant tumors has shown its advantages (Agakidou et al., 2020). Ovarian cancer is a disease with a very high mortality rate of gynecological malignancies. There is an urgent need for a method to diagnose the disease early. The application of metabolomics in ovarian cancer can provide ideas for the diagnosis and prevention of ovarian cancer.
The analysis of the metabolites caused by the disease will help us to more comprehensively grasp the process of disease changes and the metabolic pathway of substances in the body, so as to make the clinical diagnosis more accurate. Zhou et al. (2010) collected 44 serous papillary ovarian cancer (stage I–IV) and 50 healthy women and found that histamine, purine nucleotide, glycine, serine, and sarcosine were the differential metabolites, and alanine, serine, cysteine, threonine, and glycine were overexpressed. Fong et al. (2011) found that there are 364 kinds of biochemical substances in human ovarian metabolic tissue by gas chromatography–mass spectrometry and liquid chromatography tandem mass spectrometry. Ovarian transformation can cause changes in energy utilization, resulting in glycolysis and fatty acids (such as carnitine, acetylcarnitine, and butyrylcarnitine) β-oxidation changes. Based on the non-targeted metabonomics method of LC/MS, Chen et al. (2011) analyzed the serum samples of 27 healthy women, 28 cases of benign ovarian tumor, and 29 cases of epithelial ovarian cancer. β-Cholestane-3,7,12,24,25, pentose glucoside, phenylalanine, glycine cholic acid, and propionyl carnitine are potential biomarkers for epithelial ovarian cancer.
Garcia et al. (2011) used the 1H NMR method to analyze the concentration of alanine, valine, phospholipid choline, etc., from the serum of 170 healthy women of appropriate age and 182 ovarian cancer stage I/II patients, while β-hydroxybutyrate, acetone, and acetoacetic acid have higher concentrations. These can be qualitatively compared with the changes in the concentration distribution of serum samples of cancer patients studied by other NMR-based metabolomics. This proves that early diagnosis of ovarian cancer can significantly affect the clinical outcome of patients with ovarian cancer. Chen et al. (2011) analyzed the serum samples of 27 healthy women, 28 cases of benign ovarian tumors, and 29 cases of epithelial ovarian cancer using LC/MS combined analysis, liquid chromatography selective ion monitoring mass spectrometry technology combined with PCR, and other pattern recognition techniques. The study found that 27-nor-5β-cholestane-3,7,12,24,25 pentanol glucuronide can be used in the early diagnosis of epithelial ovarian cancer. It is elevated in the serum of early epithelial ovarian cancer (stage I). Gaul et al. (2015) used ultra-high performance liquid chromatography and high-resolution mass spectrometry from 46 early (I/II) serous epithelial ovarian cancer (EOC) patients and 49 age-matched normal healthy female controls. UPLC-MS and tandem mass spectrometry (MS/MS) methods found that 16 metabolites in lipids and fatty acids have 100% accuracy in the diagnosis of early-stage ovarian cancer patients. Woo et al. (2009) tested the metabolites in urine of 10 breast cancer patients, 9 ovarian cancer patients, 12 cervical cancer patients, and 22 normal controls. They found that 1-Methyladenosine is a powerful biomarker for diagnosing ovarian cancer. Zhang et al. (2012) found that 2-Piperidinone could be used to distinguish epithelial ovarian cancer (EOC) and benign ovarian tumor (BOT).
Although multiple metabolites have been found to be related to ovarian cancer, the time and money cost of this discovery is huge. With the development of computational method, increasing number of researchers try to use machine learning or deep learning methods to solve biological problems (Chen et al., 2019, 2020; Zhao et al., 2020b). Disease-related genes (Peng and Zhao, 2020; Zhao et al., 2021), RNAs (Gebauer et al., 2021), proteins (Zhao et al., 2020c), and drugs (Tianyi et al., 2020) have all been identified by computational methods in large scale, which significantly increases the speed of discovering knowledge. Predicting disease-related metabolites by computational methods has become a hot issue in recent years. Hu et al. (2018) used random walk to identify disease-related metabolites by similarity network in 2018. Following this research, Wang et al. (2019) fused text mining technology with random walk to further infer relationship between metabolites and diseases. Then, Peng and Zhao (2020) developed “MDBIRW,” which is an improved random walk method to identify disease-related metabolites. However, these methods all traverse network by random walk, which did not fully extract the topological relationship of similarity network. In 2020, Zhao et al. (2020a) proposed “Deep-DRM,” which used Graph convolutional network (GCN) to encode similarity network and achieved high accuracy. In this paper, we followed this research and focused on ovarian cancer to provide support for the treatment and diagnosis of ovarian cancer by prioritizing metabolites.
Materials and Methods
Deep-DRM is a method that fuses GCN, principal component analysis (PCA), and deep neural network (DNN). Considering we only focus on ovarian cancer, the sample set would be much smaller. Therefore, we used support vector machine (SVM) to replace DNN to build a model with a small sample. The workflow of our method is shown in Figure 1.
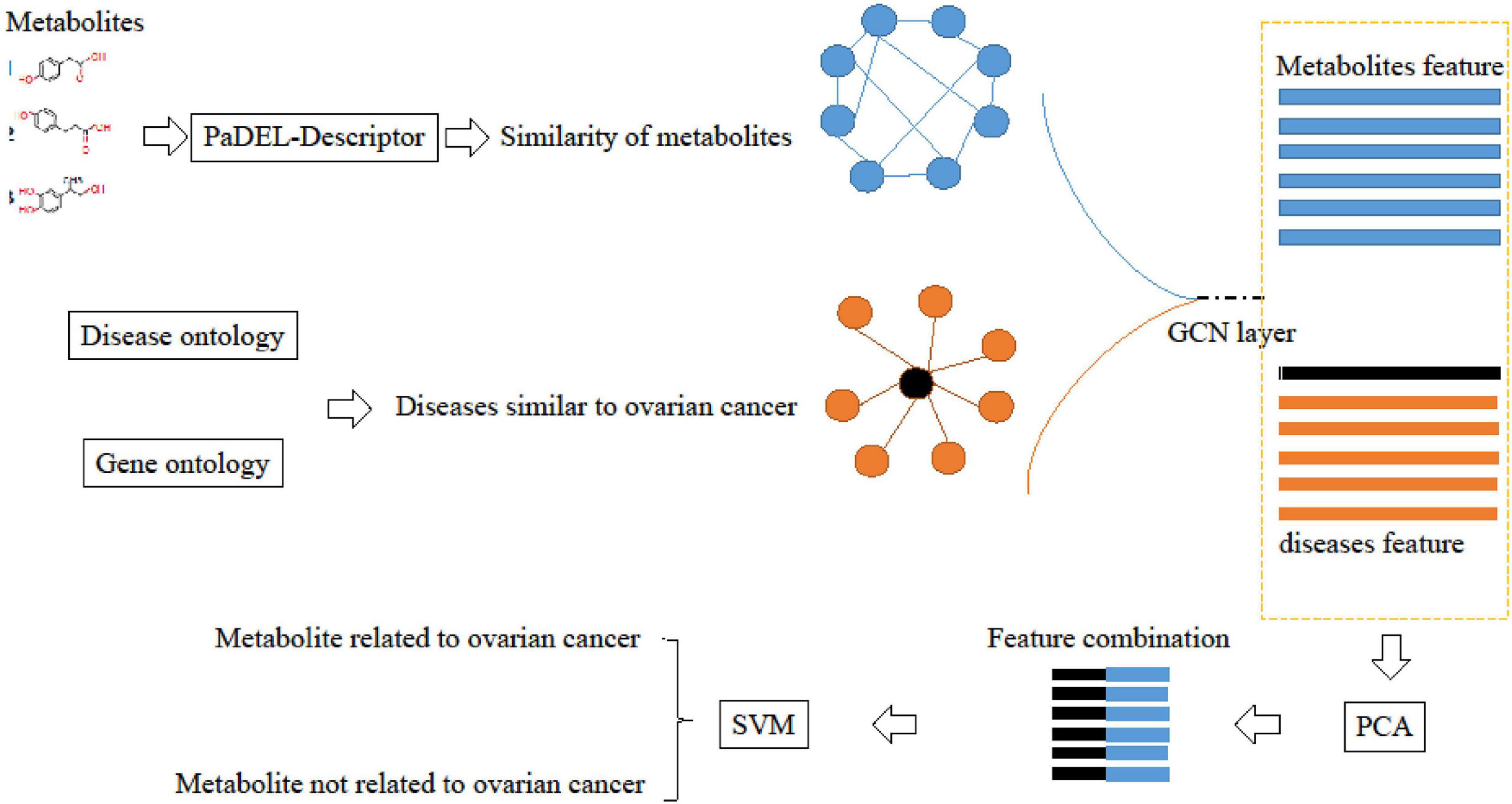
Figure 1. Workflow of GPS-OCM (the fusion of GCN, PCA, and SVM to identify ovarian cancer-related metabolites).
Metabolite and Disease Similarity Network
We used “PaDEL-Descriptor” (Yap, 2011) to estimate the chemical property of metabolites by their chemical structure. The output of this tool includes 1D and 2D descriptors and fingerprints. Each metabolite could be represented as a vector of 2,325 dimension in this way.
The similarity of each of the two metabolites could be calculated by vector cosine.
Using the similarities of metabolites, we could build a metabolite similarity network. In the network, each node is a metabolite and each edge is the similarity between the two metabolites.
Cheng et al. (2014) proposed SemFunsim to calculate disease similarity. We used their results to build an ovarian cancer similarity network. All the nodes in this network are diseases similar to ovarian cancer. The edges are the similarities between ovarian cancer and other diseases.
Feature Encoding by Graph Convolutional Network
Graph convolutional network was implemented on both metabolite and disease similarity networks, respectively. The GCN-based network feature extraction method can convert the network structure into a vector output through a non-linear function:
H(0) = X which is the initial feature of each node.
First, we need to perform Laplacian changes on the network, and the corresponding Laplacian matrix calculation formula is as follows:
Among them, D is the degree matrix of the graph, which can be solved by formula 5. A is the adjacency matrix.
Since D is a diagonal matrix, only its diagonal elements need to be solved, and the remaining elements are all 0.
Then, we need to normalize the Laplacian matrix:
The final formula of GCN would be:
σ() is the activation function, W(l) the parameter to be trained.
Finally, we obtained the encoded feature of metabolites and ovarian cancer.
Feature Dimensionality Reduction
Since the dimension of metabolites and ovarian cancer features are large, we used PCA to reduce the dimension.
Principal component analysis reduces the n-dimensional input data to r-dimensional, where r < n. PCA is essentially a basis transformation, so that the transformed data have the largest variance, that is, by rotating the coordinate axis and translating the origin of the coordinate, the variance between one of the axes (main axis) and the data point is minimized. After the coordinate conversion, the orthogonal axis with high variance is removed, and the dimensionality reduction data set is obtained.
The SVD method is used to perform PCA dimensionality reduction. Assuming that there are p × n-dimensional data samples X, there are p samples in total, and each row is n-dimensional. The p × n real matrix can be decomposed into:
Here, the dimension of the orthogonal matrix U is p × n, the dimension of the orthogonal matrix V is n × n (orthogonal matrix satisfies: UUT = VVT = 1), and Σ is a diagonal matrix of n × n. Next, divide Σ into r columns, denoted as Σr; use U and V to get the dimensionality reduction data point Yr:
After PCA, 99% of the feature information are preserved for both metabolites and ovarian cancer.
Identify Ovarian Cancer-Related Metabolites
After extracting and reducing the features of metabolites and ovarian cancer, we need to combine features of metabolites and ovarian cancer to make ovarian cancer–metabolite pairs. If the metabolite has relationship with ovarian cancer, the label of this pair would be 1; otherwise, the label is 0.
There are five steps to build the SVM model. The process is shown in Figure 2.
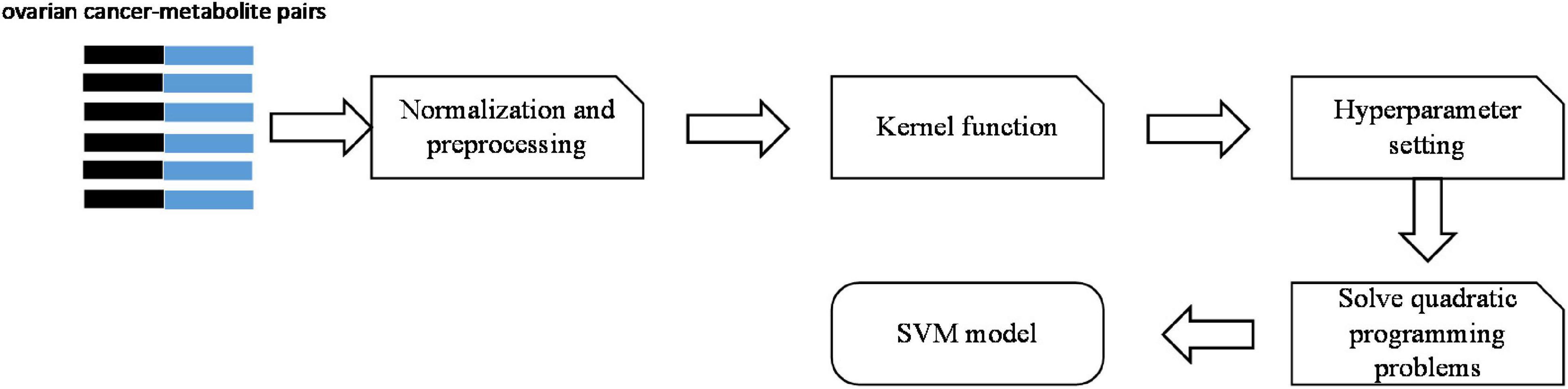
Figure 2. Process of building the SVM model.
Experiment Results
Since we only focus on ovarian cancer, we divided our experiments into two classes. One is to identify ovarian cancer-related metabolites from known disease-related metabolites, which is named as “SP.” The other one is to identify ovarian cancer-related metabolites from metabolites associated with no disease, which is names as “SM”.
We did 10-cross validation on both “SP” and “SM” experiments. The AUC and AUPR of these experiments are shown in Figure 3.
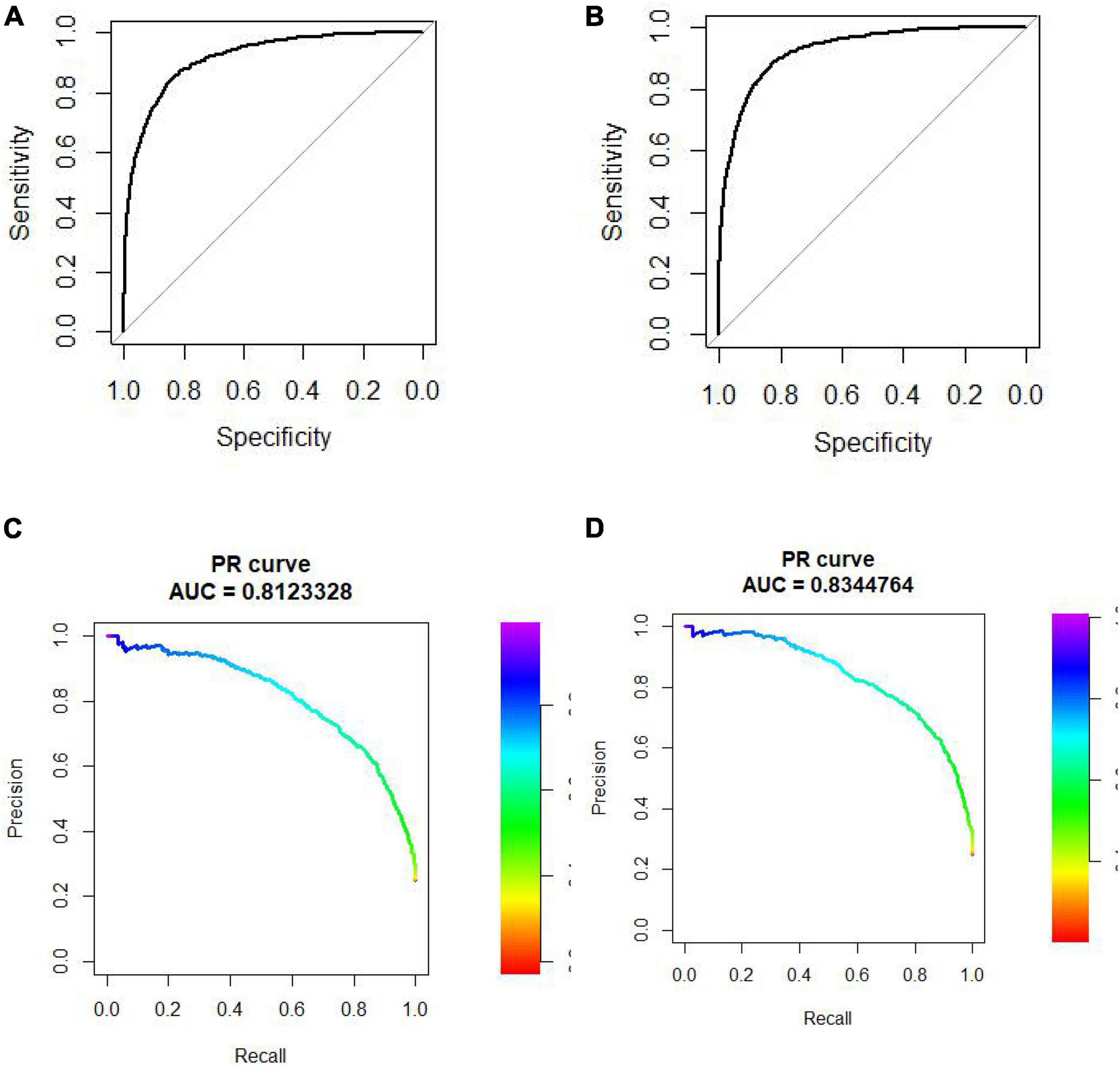
Figure 3. (A) ROC curve of “SP.” Experiment. (B) ROC curve of “SM” experiment. (C) PR curve of “SP” experiment. (D) PR curve of “SM” experiment.
The AUC of “SP” and “SM” experiments is 0.9168 and 0.9282, respectively. The AUPR of “SP” and “SM” experiments is 0.81 and 0.83, respectively.
To show the superiority of GPS-OCM, we compared GPS-OCM with RWPS-OCM, GPR-OCM, and GPD-OCM. We replaced GCN by Random Walk (RW) to construct RWPS-OCM. GPR-OCM is the fusion of GCN, PCR, and Random Forest (RF). GPD-OCM is to replace SVM by deep neural network (DNN). The results are shown in Table 1. GPS-OCM performed best among these methods.
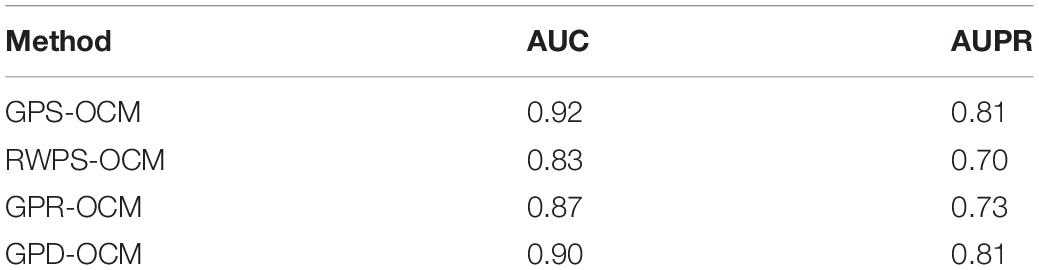
Table 1. Comparison experiment of GPS-OCM and other methods on the “SP” test.
After verifying the effectiveness of our method, we used all known ovarian cancer-related metabolites as positive samples and randomly selected equal number of other metabolites as negative samples to build a final GPS-OCM model. We totally identified 257 more metabolites that are associated with ovarian cancer. To verify whether these metabolites are associated with ovarian cancer, we chose the top five of these metabolites and did case studies.
Three of the top five metabolites have been reported to be related to ovarian cancers. Niemi et al. (2017) used morning urine samples from 23 women with benign ovarian tumors and 37 women with malignant ovarian tumors and found that N1, N12-Diacetylspermine showed significant statistical differences, and found that it can help distinguish benign and malignant ovarian tumors as well as early and advanced stage, and low malignant potential and high-grade ovarian cancers from each other, respectively. Fahrmann et al. (2021) found that 3-acetamidopropyl can significantly increase the sensitivity of ovarian cancer diagnosis by 116 ovarian cancer patients and 143 controls. Dessources et al. (2017) collected samples from 16 patients with benign ovarian pathology and 21 patients with malignant pathology and found that multiple metabolites are significantly associated with ovarian cancer including N-acetylation, acyl carnitines, and tryptophan.
Conclusion
Identifying ovarian cancer-related metabolites can help better understand pathogenic mechanism and disease process. In addition, metabolites in blood and urine have shown strong power in diagnosing cancer in early stage as biomarkers. However, few metabolites associated with ovarian cancer have been found at present. In order to speed up the study of metabolites related to ovarian cancer, we proposed a calculation method “GPS-OCM” based on similarity of metabolites and diseases. This method is fusion of GCN, PCA, and SVM. GCN was used to extract network topology features and PCA was implemented to reduce the dimension of disease and metabolite features. SVM was applied to do classification. The experiments show the high accuracy of our method with high AUC and AUPR. In addition, three of the top five metabolites that are identified as ovarian cancer-related metabolites by our method have been proven by previous studies, which proved the accuracy of our results.
Data Availability Statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found in the article/supplementary material.
Author Contributions
JC and YC wrote this manuscript. YW and HH did experiments. KS, SH, XL, and YO contributed to software analysis. LS provided important ideas. XZ and YB guided the whole work. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by Scientific Research Projects of National Clinical Research Base of Chinese Medicine of Health Commission of Henan Province 2021JDZY101 and Doctoral research fund of the First Affiliated Hospital of Henan University of Chinese Medicine 2021BSJJ003 to YB.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Agakidou, E., Agakidis, C., Gika, H., and Sarafidis, K. (2020). Emerging biomarkers for prediction and early diagnosis of necrotizing enterocolitis in the era of metabolomics and proteomics. Front. Pediatr. 8:838. doi: 10.3389/fped.2020.602255
Blimkie, T., Lee, A. H. Y., and Hancock, R. E. (2020). MetaBridge: an integrative multi-omics tool for metabolite−enzyme mapping. Curr. Protoc. Bioinformatics 70:e98. doi: 10.1002/cpbi.98
Chen, J., Zhang, X., Cao, R., Lu, X., Zhao, S., Fekete, A., et al. (2011). Serum 27-nor-5β-cholestane-3, 7, 12, 24, 25 pentol glucuronide discovered by metabolomics as potential diagnostic biomarker for epithelium ovarian cancer. J. Proteome Res. 10, 2625–2632. doi: 10.1021/pr200173q
Chen, S. C., Liu, Z. M., Li, M., Huang, Y. H., Wang, M., Wang, W., et al. (2020). Potential prognostic predictors and molecular targets for skin melanoma screened by weighted gene co-expression network analysis. Curr. Gene Ther. 20, 5–14. doi: 10.2174/1566523220666200516170832
Chen, X. G., Shi, W. W., and Deng, L. (2019). Prediction of disease comorbidity using hetesim scores based on multiple heterogeneous networks. Curr. Gene Ther. 19, 232–241. doi: 10.2174/1566523219666190917155959
Cheng, L., Li, J., Ju, P., Peng, J., and Wang, Y. (2014). SemFunSim: a new method for measuring disease similarity by integrating semantic and gene functional association. PLoS One 9:e99415. doi: 10.1371/journal.pone.0099415
Dessources, K., Cohen, J., Sen, K., Ramadoss, S., and Chaudhuri, G. (2017). N-acetylation and ovarian cancer: a study of the metabolomic profile of ovarian cancer compared to benign counterparts. Gynecol. Oncol. 147, 223–224. doi: 10.1016/j.ygyno.2017.07.089
Fahrmann, J. F., Irajizad, E., Kobayashi, M., Vykoukal, J., Dennison, J. B., Murage, E., et al. (2021). A MYC-driven plasma polyamine signature for early detection of ovarian cancer. Cancers 13:913. doi: 10.3390/cancers13040913
Fong, M. Y., McDunn, J., and Kakar, S. S. (2011). Identification of metabolites in the normal ovary and their transformation in primary and metastatic ovarian cancer. PLoS One 6:e19963. doi: 10.1371/journal.pone.0019963
Garcia, E., Andrews, C., Hua, J., Kim, H. L., Sukumaran, D. K., Szyperski, T., et al. (2011). Diagnosis of early stage ovarian cancer by 1H NMR metabonomics of serum explored by use of a microflow NMR probe. J. Proteome Res. 10, 1765–1771. doi: 10.1021/pr101050d
Gaul, D. A., Mezencev, R., Long, T. Q., Jones, C. M., Benigno, B. B., Gray, A., et al. (2015). Highly-accurate metabolomic detection of early-stage ovarian cancer. Scientific reports 5:16351. doi: 10.1038/srep16351
Gebauer, F., Schwarzl, T., Valcárcel, J., and Hentze, M. W. (2021). RNA-binding proteins in human genetic disease. Nat. Rev. Genet. 22, 185–198. doi: 10.1038/s41576-020-00302-y
Hu, Y., Zhao, T., Zhang, N., Zang, T., Zhang, J., and Cheng, L. (2018). Identifying diseases-related metabolites using random walk. BMC Bioinformatics 19:116. doi: 10.1186/s12859-018-2098-1
Hussain, S. M. A. (2020). Molecular-based screening and therapeutics of breast and ovarian cancer in low-and middle-income countries. Cancer Res. Stat. Treat. 3:81. doi: 10.4103/CRST.CRST_88_20
Liu, T., Wei, Q., Jin, J., Luo, Q., Liu, Y., Yang, Y., et al. (2020). The m6A reader YTHDF1 promotes ovarian cancer progression via augmenting EIF3C translation. Nucleic Acids Res. 48, 3816–3831. doi: 10.1093/nar/gkaa048
Niemi, R. J., Roine, A. N., Häkkinen, M. R., Kumpulainen, P. S., Keinänen, T. A., Vepsäläinen, J. J., et al. (2017). Urinary polyamines as biomarkers for ovarian cancer. Int. J. Gynecol. Cancer 27, 1360–1366. doi: 10.1097/IGC.0000000000001031
Peng, J., and Zhao, T. (2020). Reduction in TOM1 expression exacerbates Alzheimer’s disease. Proc. Natl. Acad. Sci. U.S.A. 117, 3915–3916. doi: 10.1073/pnas.1917589117
Perrone, E., Lopez, S., Zeybek, B., Bellone, S., Bonazzoli, E., Pelligra, S., et al. (2020). Preclinical activity of sacituzumab govitecan, an antibody-drug conjugate targeting trophoblast cell-surface antigen 2 (Trop-2) linked to the active metabolite of irinotecan (SN-38), in ovarian cancer. Front. Oncol. 10:118. doi: 10.3389/fonc.2020.00118
Tianyi, Z., Yang, H., Valsdottir, L. R., Tianyi, Z., and Jiajie, P. (2020). Identifying drug–target interactions based on graph convolutional network and deep neural network. Brief. Bioinform. 22:bbaa044. doi: 10.1093/bib/bbaa044
Wang, Y., Juan, L., Peng, J., Zang, T., and Wang, Y. (2019). Prioritizing candidate diseases-related metabolites based on literature and functional similarity. BMC Bioinformatics 20:574. doi: 10.1186/s12859-019-3127-4
Woo, H. M., Kim, K. M., Choi, M. H., Jung, B. H., Lee, J., Kong, G., et al. (2009). Mass spectrometry based metabolomic approaches in urinary biomarker study of women’s cancers. Clin. Chim. Acta 400, 63–69. doi: 10.1016/j.cca.2008.10.014
Yap, C. W. (2011). PaDEL−descriptor: an open source software to calculate molecular descriptors and fingerprints. J. Comput. Chem. 32, 1466–1474. doi: 10.1002/jcc.21707
Zhang, T., Wu, X., Yin, M., Fan, L., Zhang, H., Zhao, F., et al. (2012). Discrimination between malignant and benign ovarian tumors by plasma metabolomic profiling using ultra performance liquid chromatography/mass spectrometry. Clin. Chim. Acta 413, 861–868. doi: 10.1016/j.cca.2012.01.026
Zhao, T., Hu, Y., Peng, J., and Cheng, L. (2020b). DeepLGP: a novel deep learning method for prioritizing lncRNA target genes. Bioinformatics 36, 4466–4472. doi: 10.1093/bioinformatics/btaa428
Zhao, T., Hu, Y., Zang, T., and Wang, Y. (2020c). Identifying protein biomarkers in blood for Alzheimer’s disease. Front. Cell Dev. Biol. 8:472. doi: 10.3389/fcell.2020.00472
Zhao, T., Hu, Y., and Cheng, L. (2020a). Deep-DRM: a computational method for identifying disease-related metabolites based on graph deep learning approaches. Brief. Bioinform. 22:bbaa212. doi: 10.1093/bib/bbaa212
Zhao, T., Lyu, S., Lu, G., Juan, L., Zeng, X., Wei, Z., et al. (2021). SC2disease: a manually curated database of single-cell transcriptome for human diseases. Nucleic Acids Res. 49, D1413–D1419. doi: 10.1093/nar/gkaa838
Keywords: ovarian cancer, metabolite, Graph convolutional network, support vector machine, prediction
Citation: Chen J, Chen Y, Sun K, Wang Y, He H, Sun L, Ha S, Li X, Ou Y, Zhang X and Bi Y (2021) Prediction of Ovarian Cancer-Related Metabolites Based on Graph Neural Network. Front. Cell Dev. Biol. 9:753221. doi: 10.3389/fcell.2021.753221
Received: 04 August 2021; Accepted: 27 August 2021;
Published: 05 October 2021.
Edited by:
Lei Deng, Central South University, ChinaReviewed by:
Fei Shen, South China University of Technology, ChinaSheng Li, Wuhan University, China
Copyright © 2021 Chen, Chen, Sun, Wang, He, Sun, Ha, Li, Ou, Zhang and Bi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xue Zhang, Vowwzx@163.com; Yanli Bi, biyanli.mary@163.com
†These authors have contributed equally to this work