
Abstract
We introduce a global analysis of collinearly factorized nuclear parton distribution functions (PDFs) including, for the first time, data constraints from LHC proton–lead collisions. In comparison to our previous analysis, EPS09, where data only from charged-lepton–nucleus deep inelastic scattering (DIS), Drell–Yan (DY) dilepton production in proton–nucleus collisions and inclusive pion production in deuteron–nucleus collisions were the input, we now increase the variety of data constraints to cover also neutrino–nucleus DIS and low-mass DY production in pion–nucleus collisions. The new LHC data significantly extend the kinematic reach of the data constraints. We now allow much more freedom for the flavor dependence of nuclear effects than in other currently available analyses. As a result, especially the uncertainty estimates are more objective flavor by flavor. The neutrino DIS plays a pivotal role in obtaining a mutually consistent behavior for both up and down valence quarks, and the LHC dijet data clearly constrain gluons at large momentum fraction. Mainly for insufficient statistics, the pion–nucleus DY and heavy-gauge-boson production in proton–lead collisions impose less visible constraints. The outcome – a new set of next-to-leading order nuclear PDFs called EPPS16 – is made available for applications in high-energy nuclear collisions.
Similar content being viewed by others


1 Introduction
Proton–lead (pPb) and lead–lead (PbPb) collisions at the Large Hadron Collider (LHC) have brought heavy-ion physics to the high-energy realm [1,2,3,4]. A more than tenfold increase in the center-of-mass energy with respect to the deuteron–gold (DAu) collisions at the Relativistic Heavy-Ion Collider (RHIC) has made it possible to study novel hard-process observables in a heavy-ion environment. For example, production cross sections of heavy-gauge bosons (Z and W\(^\pm \)) and jets have been measured. Because of the new experimental information from the LHC it is now also timely to update the pre-LHC global analyses of collinearly factorized nuclear parton distribution functions (PDFs) – for reviews, see e.g. Refs. [5, 6].
The original idea of having nuclear effects in PDFs was data-driven as the early deep inelastic scattering (DIS) experiments unexpectedly revealed significant nuclear effects in the cross sections [7, 8]. It was then demonstrated [9, 10] that such effects in DIS and fixed nuclear-target Drell–Yan (DY) cross sections can be consistently described by modifying the free nucleon PDFs at low \(Q^2\) and letting the Dokshitzer–Gribov–Lipatov–Altarelli–Parisi (DGLAP) evolution [11,12,13,14,15,16,17] take care of the \(Q^2\) dependence. In other words, the data were in line with a concept that the measured nuclear effects are of non-perturbative origin but at sufficiently high \(Q^2\) there is no fundamental difference in the scattering off a nucleon or off a nucleus. These ideas eventually led to the first global fit and the EKS98 set of leading-order nuclear PDFs [18, 19]. Since then, several parametrizations based on the DIS and DY data have been released at leading order (EKPS [20], HKM [21], HKN04 [22]), next-to-leading order (nDS [23], HKN07 [24], nCTEQ [25], AT12 [26]), and next-to-next-to-leading order (KA15 [27]) perturbative QCD.Footnote 1 For the rather limited kinematic coverage of the fixed-target data and the fact that only two types of data were used in these fits, significant simplifying assumptions had to be made e.g. with respect to the flavor dependence of the nuclear effects. The constraints on the gluon distribution are also weak in these analyses, and it is only along with the RHIC pion data [31] that an observable carrying direct information on the nuclear gluons has been added to the global fits – first in EPS08 [32] and EPS09 [33], later in DSSZ [34] and nCTEQ15 [35]. The interpretation of the RHIC pion production data is not, however, entirely unambiguous as the parton-to-pion fragmentation functions (FFs) may as well undergo a nuclear modification [36]. This approach was adopted in the DSSZ fit, and consequently their gluons show clearly weaker nuclear effects than in EPS09 (and nCTEQ15) where the FFs were considered to be free from nuclear modifications. To break the tie, more data and new observables were called for. To this end, the recent LHC dijet measurements [37] from pPb collisions have been most essential as a consistent description of these data is obtained with EPS09 and nCTEQ15 but not with DSSZ [38, 39].
Another observable that has caused some controversy and debate during the past years is the neutrino–nucleus DIS. It has been claimed [40] (see also Ref. [41]) that the nuclear PDFs required to correctly describe neutrino data are different from those optimal for the charged-lepton induced DIS measurements. However, it has been demonstrated [42, 43] that problems appear only in the case of one single data set and, furthermore, that it seems to be largely a normalization issue (which could e.g. be related to the incident neutrino flux which is model-dependent). The neutrino data were also used in the DSSZ fit without visible difficulties.
New data from the LHC 2013 p-Pb run have gradually become available and their impact on the nuclear PDFs has been studied [39, 44] in the context of PDF reweighting [45]. Apart from the aforementioned dijet data [37] which will e.g. require a complete renovation of the DSSZ approach, the available W [46, 47] and Z [48, 49] data were found to have only a rather mild effect mainly for the limited statistical precision of the data. However, the analysis of Ref. [39] used only nuclear PDFs (EPS09, DSSZ) in which flavor-independent valence and light sea-quark distributions were assumed at the parametrization scale. Thus, it could not reveal the possible constraints that these electroweak observables could have for a particular quark flavor. On the other hand, the analysis of Ref. [44] involves some flavor dependence but the usage of absolute cross sections which are sensitive to the free-proton baseline PDFs complicates the interpretation of the results.
In the present paper, we update the EPS09 analysis by adding a wealth of new data from neutrino DIS [50], pion–nucleus DY process [51,52,53], and especially LHC pPb dijet [37], Z [48, 49] and W [46] production. Thus, we take the global nuclear PDF fits onto a completely new level in the variety of data types. In addition, in comparison to EPS09, a large part of the whole framework is upgraded: we switch to a general-mass formalism for the heavy quarks, relax the assumption of the flavor independent nuclear modifications for quarks at the parametrization scale, undo the isospin corrections that some experiments had applied on their data, and also importantly, we now assign no extra weights to any of the data sets. In this updated analysis, we find no significant tension between the data sets considered, which lends support to the assumption of process-independent nuclear PDFs in the studied kinematical region. The result of the analysis presented in this paper is also published as a new set of next-to-leading order (NLO) nuclear PDFs, which we call EPPS16 and which supersedes our earlier set EPS09. The new EPPS16 set will be available at [54].
2 Parametrization of nuclear PDFs
Similarly to our earlier work, the bound proton PDF \(f_i^{\mathrm{p}/A}(x,Q^2)\) for mass number A and parton species i is defined relative to the free-proton PDF \(f_i^\mathrm{p}(x,Q^2)\) as
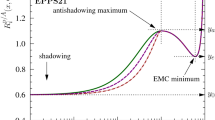
where \(R_i^A(x,Q^2)\) is the scale-dependent nuclear modification. Our free-proton baseline is CT14NLO [55]. Consistently with this choice, our analysis here uses the SACOT (simplified Aivazis–Collins–Olness–Tung) general-mass variable flavor number scheme [56,57,58] for the DIS cross sections. The fit function for the nuclear modifications \(R_i^A(x,Q^2_0)\) at the parametrization scale \(Q^2_0\), illustrated in Fig. 1, is also largely inherited from our earlier analyses [18, 20, 32, 33],

Illustration of the EPPS16 fit function \(R_i^A(x,Q^2_0)\)
where \(\alpha =10x_a\) and the i and A dependencies of the parameters on the r.h.s. are left implicit.Footnote 2 The purpose of the exponent \(\alpha \) is to avoid the “plateau” that would otherwise (that is, if \(\alpha =1\)) develop if \(x_a<0.1\). The coefficients \(a_i,b_i,c_i\) are fully determined by the asymptotic small-x limit \(y_0=R_i^A(x\rightarrow 0,Q^2_0)\), the antishadowing maximum \(y_a=R_i^A(x_a,Q^2_0)\) and the EMC minimum \(y_e=R_i^A(x_e,Q^2_0)\), as well as requiring continuity and vanishing first derivatives at the matching points \(x_a\) and \(x_e\). The A dependencies of \(y_0\), \(y_a\), \(y_e\) are parametrized as
where \(\gamma _i \ge 0\) and \(A_\mathrm{ref} = 12\). By construction, the nuclear effects (deviations from unity) are now larger for heavier nuclei. Without the factor \(y_i(A_\mathrm{ref})-1\) in the exponent one can more easily fall into a peculiar situation in which e.g. \(y_i(A_\mathrm{ref})<1\), but \(y_i(A\gg A_\mathrm{ref})>1\), which seems physically unlikely. For the valence quarks and gluons the values of \(y_0\) are determined by requiring the sum rules
separately for each nucleus and thus the A dependence of these \(y_0\) is not parametrized. All other parameters than \(y_0\), \(y_a\), \(y_e\) are A-independent. In our present framework we consider the deuteron (\(A=2\)) to be free from nuclear effects though few-percent effects at high x are found e.g. in Ref. [60]. The bound neutron PDFs \(f_i^{\mathrm{n}/A}(x,Q^2)\) are obtained from the bound proton PDFs by assuming isospin symmetry,
Above the parametrization scale \(Q^2>Q^2_0\) the nuclear PDFs are obtained by solving the DGLAP evolution equations with two-loop splitting functions [61, 62]. We use our own DGLAP evolution code which is based on the solution method described in Ref. [63] and also explained and benchmarked in Ref. [64]. Our parametrization scale \(Q^2_0\) is fixed to the charm pole mass \(Q^2_0 = m_c^2\) where \(m_c= 1.3\,\mathrm{GeV}\). The bottom quark mass is \(m_b= 4.75\,\mathrm{GeV}\) and the value of the strong coupling constant is set by \(\alpha _\mathrm{s}(M_\mathrm{Z}) = 0.118\), where \(M_\mathrm{Z}\) is the mass of the Z boson.
As is well known, at NLO and beyond the PDFs do not need to be positive definite and we do not impose such a restriction either. In fact, doing so would be artificial since the parametrization scale is, in principle, arbitrary, and positive definite PDFs, say, at \(Q^2_0=m_c^2\) may easily correspond to negative small-x PDFs at a scale just slightly below \(Q^2_0\). As we could have equally well parametrized the PDFs at such a lower value of \(Q^2_0\), we see that restricting the PDFs to be always positive would be an unphysical requirement.
3 Experimental data
All the \(\ell ^- A\) DIS, pA DY and RHIC DAu pion data sets we use in the present analysis are the same as in the EPS09 fit. The only modification on this part is that we now remove the isoscalar corrections of the EMC, NMC and SLAC data (see the next subsection), which is important as we have freed the flavor dependence of the quark nuclear modifications. The \(\ell ^- A\) DIS data (cross sections or structure functions \(F_2\)) are always normalized by the \(\ell ^-\)D measurements and, as in EPS09, the only kinematic cut on these data is \(Q^2>m_\mathrm{c}^2\). This is somewhat lower than in typical free-proton fits and the implicit assumption is (also in not setting a cut in the mass of the hadronic final state) that the possible higher-twist effects will cancel in ratios of structure functions/cross sections. While potential signs of \(1/Q^2\) effects have been seen in the HERA data [65] already around \(Q^2=10 \, \mathrm{GeV}^2\), these effects occur at significantly smaller x than what is the reach of the \(\ell ^- A\) DIS data.
From the older measurements, also pion–nucleus DY data from the NA3 [51], NA10 [52], and E615 [53] collaborations are now included. These data have been shown [66, 67] to carry some sensitivity to the flavor-dependent EMC effect. However, more stringent flavor-dependence constraints at large x are provided by the CHORUS (anti)neutrino–Pb DIS data [50], whose treatment in the fit is detailedly explained in Sect. 3.2.
The present analysis is the first one to directly include LHC data. To this end, we use the currently published pPb data for heavy-gauge boson [46, 48, 49] and dijet production [37]. These observables have already been discussed in the literature [39, 44, 68,69,70,71] in the context of nuclear PDFs. Importantly, we include the LHC pPb data always as forward-to-backward ratios in which the cross sections at positive (pseudo)rapidities \(\eta >0\) are divided by the ones at negative rapidities \(\eta <0\). This is to reduce the sensitivity to the chosen free-proton baseline PDFs as well as to cancel the experimental luminosity uncertainty. However, upon taking the ratio part of the information is also lost as, for example, the points near \(\eta =0\) are, by construction, always close to unity and carry essentially no information. In addition, since the correlations on the systematic errors are not available, all the experimental uncertainties are added in quadrature when forming these ratios (except for the CMS W measurement [46] which is taken directly from the publication) which partly undermines the constraining power of these data. The baseline pp measurements performed at the same \(\sqrt{s}\) as the pPb runs may, in the future, also facilitate a direct usage of the nuclear modification factors d\(\sigma ^\mathrm{pPb}/\mathrm{d}\sigma ^\mathrm{pp}\). The technicalities of how the LHC data are included in our analysis are discussed in Sect. 3.3.
In Fig. 2 we illustrate the predominant x and \(Q^2\) regions probed by the data. Clearly, the LHC data probe the nuclear PDFs at much higher in \(Q^2\) than the earlier DIS and DY data. For the wide rapidity coverage of the LHC detectors the new measurements also reach lower values of x than the old data, but for the limited statistical precision the constraints for the small-x end still remain rather weak. All the exploited data sets including the number of data points, their \(\chi ^2\) contribution and references are listed in Table 1. We note that approximately half of the data are now for the \(^{208}\)Pb nucleus while in the EPS09 analysis only 15 Pb data points (NMC 96) were included. Most of this change is caused by the inclusion of the CHORUS neutrino data.

The approximate regions in the \((x,Q^2)\) plane at which different data in the EPPS16 fit probe the nuclear PDFs
3.1 Isoscalar corrections
Part of the charged-lepton DIS data that have been used in the earlier global nPDF fits had been “corrected”, in the original publications, for the isospin effects. That is, the experimental collaborations had tried to eliminate the effects emerging from the unequal number of protons and neutrons when making the comparison with the deuteron data. In this way the ratios \(F_2^A/F_2^\mathrm{D}\) could be directly interpreted in terms of nuclear effects in the PDFs. However, this is clearly an unnecessary operation from the viewpoint of global fits, which has previously caused some confusion regarding the nuclear valence-quark modifications: the particularly mild effects found in the nDS [23] and DSSZ [34] analyses (see Fig. 27) most likely originate from neglecting such a correction.
The structure function of a nucleus A with Z protons and N neutrons can be written as
where \(F_2^{\mathrm{p},A}\) and \(F_2^{\mathrm{n},A}\) are the structure functions of the bound protons and neutrons. The corresponding isoscalar structure function is defined as the one containing an equal number of protons and neutrons,
Using Eq. (10), the isoscalar structure function reads
where
Usually, it has been assumed that the ratio \({F_2^{\mathrm{n},A}}/{F_2^{\mathrm{p},A}}\) is free from nuclear effects,
and parametrized according to the DIS data from proton and deuteron targets. Different experiments have used different versions:
-
EMC parametrization [78]:
$$\begin{aligned} \frac{F_2^{\mathrm{n}}}{F_2^{\mathrm{p}}} = 0.92-0.86x, \end{aligned}$$ -
SLAC parametrization [72]:
$$\begin{aligned} \frac{F_2^{\mathrm{n}}}{F_2^{\mathrm{p}}} = 1-0.8x, \end{aligned}$$ -
NMC parametrization [80]:
$$\begin{aligned} \frac{F_2^{\mathrm{n}}}{F_2^{\mathrm{p}}}= & {} A(x) \left( \frac{Q^2}{20} \right) ^{B(x)} \left( 1 + \frac{x^2}{Q^2} \right) \nonumber \\ A(x)= & {} 0.979 - 1.692x + 2.797x^2 - 4.313x^3 + 3.075x^4 \nonumber \\ B(x)= & {} -0.171x^2 + 0.244x^3. \nonumber \end{aligned}$$
Using these functions we calculate the correction factors \(\beta \) thereby obtaining the ratios \(F_2^A/F_2^\mathrm{D}\), to be used in the fit, from the isoscalar versions \(\hat{F}_2^A/F_2^\mathrm{D}\) reported by the experiments.
As discussed in Ref. [67], also the \(\pi ^- A\) DY data from the NA10 collaboration [52] have been balanced for the neutron excess. The correction was done by utilizing the leading-order DY cross section. Here, we account for this with the isospin correction factor given in Eq. (8) of Ref. [67].
3.2 Treatment of neutrino DIS data
In the present work we make use of the CHORUS neutrino and antineutrino DIS data [50]. Similar measurements are available also from the CDHSW [81] and NuTeV [82] collaborations, but only for the CHORUS data the correlations of the systematic uncertainties are directly available in the form we need.Footnote 3 Moreover, the \(^{208}\)Pb target has a larger neutron excess than the iron targets of CDHSW and NuTeV, thereby carrying more information on the flavor separation. The data are reported as double differential cross sections \(d\sigma _{i, \mathrm{exp}}^{\nu , \overline{\nu }}/\mathrm{d}x\mathrm{d}y\) in the standard DIS variables and, guided by our free-proton baseline fit CT14NLO [55], the kinematic cuts we set on these data are \(Q^2>4 \, \mathrm{GeV}^2\) and \(W^2>12.25 \, \mathrm{GeV}^2\).Footnote 4 In the computation of these NLO neutrino DIS cross sections, we apply the dominant electroweak [83] and target-mass [84] corrections as in Refs. [42, 43], together with the SACOT quark-mass scheme.
In order to suppress the theoretical uncertainties related to the free-proton PDFs, as well as experimental systematic uncertainties, we treat the data following the normalization prescription laid out in Ref. [43]. For each (anti)neutrino beam energy E, we compute the total cross section as
where \(E_i\) is the beam energy corresponding to the ith data point. By \(\Delta _i^{xy}\) we mean the size of the (x, y) bin (rectangles) to which the ith data point belongs. The original data are then normalized by the estimated total cross sections of Eq. (15) as
As discussed e.g. in [45, 85], the \(\chi ^2\) contribution of data with correlated uncertainties is obtained in terms of the covariance matrix C as
where now the theory values \({\mathrm{d}\tilde{\sigma }_{j, \mathrm{th}}^{\nu , \overline{\nu }}}/{\mathrm{d}x\mathrm{d}y}\) are the computed differential cross sections normalized by the corresponding integrated cross section (similarly to Eq. (16)). The elements of the covariance matrix are in our case defined as
where the statistical uncertainty \(\tilde{\delta }_i^\mathrm{stat}\) on \({\mathrm{d}\tilde{\sigma }_{i, \mathrm{exp}}^{\nu , \overline{\nu }}}/{\mathrm{d}x\mathrm{d}y}\) is computed from the original statistical uncertainties \(\delta _i^\mathrm{stat}\) by
Here we neglect the statistical uncertainty of \(\sigma ^{\nu , \overline{\nu }}(E)\) as for this integrated quantity it is always clearly smaller than that of the individual data points. The point-to-point correlated systematic uncertainties \(\tilde{\beta }_i^k\) for the normalized data points we form as
where
Above, the index k labels the parameters controlling the experimental systematic uncertainties and \(\beta _i^k\) are the cross-section shifts corresponding to a one standard deviation change in the kth parameter. We note that \(\tilde{\beta }_i^k\) in Eq. (20) for the relative cross sections in Eq. (16) are constructed such that if the \(\beta _i^k\) correspond only to the same relative normalization shift for all points, then \(\tilde{\beta }_i^k\) are just zero. We also note that in Eq. (18) we have assumed that the response of \({\mathrm{d}\tilde{\sigma }_{i, \mathrm{exp}}^{\nu , \overline{\nu }}}/{\mathrm{d}x\mathrm{d}y}\) to the systematic uncertainty parameters is linear.
As shown in e.g. Ref. [42], the \(Q^2\) dependence of nuclear effects in neutrino DIS data is weak. Hence, for a concise graphical presentation of the data as a function of x, we integrate over the y variable by
where \(\Delta _j^{y}\) is the size of the y bin to which the jth data point belongs, and \(x_j\) the corresponding value of the x variable. The overall statistical uncertainty to the relative cross section in Eq. (22) is computed as
and the total systematic uncertainty is given by
where
In the plots for \({\mathrm{d}\tilde{\sigma }_{\mathrm{exp}}^{\nu , \overline{\nu }}} / {\mathrm{d}x}\) presented in Sect. 5 (Figs. 20, 21), the statistical and total systematic uncertainties have been added in quadrature. We also divide by the theory values obtained by using the CT14NLO free-proton PDFs (but still with the correct amount of protons and neutrons). We stress that Eqs. (22)–(25) are used only for a simple graphical presentation of the data but not for the actual fit.
3.3 Look-up tables for LHC observables and others
In order to efficiently include the LHC observables in our fit at the NLO level, a fast method to evaluate the cross sections is essential. We have adopted the following pragmatic approach: For a given observable, a hard-process cross section \(\sigma ^\mathrm{pPb}\) in pPb collisions, we set up a grid in the x variable of the Pb nucleus, \(x_0,\ldots ,x_N=1\), and evaluate, for each x bin k and parton flavor j
where \(\hat{\sigma }_{ij}\) are the coefficient functions appropriate for a given process and \(f_{j,k}^\mathrm{Pb}\) involve only proton PDFs with no nuclear modifications,
Thus, the functions \(f_{j,k}^\mathrm{Pb}\) pick up the partonic weight of the nuclear modification \(R_j^\mathrm{Pb}\) in a given interval \(x_{k-1}< x < x_{k}\). Since the nuclear modification factors \(R_i^A\) are relatively slowly varying functions in x (e.g. in comparison to the absolute PDFs), the observable \(\sigma ^\mathrm{pPb}\) can be computed as a sum of \(\sigma _{j,k}^\mathrm{pPb}\) weighted by the appropriate nuclear modification,
As an illustration, in Fig. 3, we show the histograms of \(\sigma _{j,k}^\mathrm{pPb}\) corresponding to W\(^+\) production measured by CMS in the bin \(1< \eta _\mathrm{lab} < 1.5\). For the electroweak LHC observables we have used the MCFM code [86] to compute the grids, and for dijet production the modified EKS code [87,88,89].
We set up similar grids also for inclusive pion production in DAu collisions at RHIC using the INCNLO [90] code with KKP FFs [91], and for the DY process in \(\pi A\) collisions using MCFM with the GRV pion PDFs [92]. In all cases, we have checked that the grids reproduce a direct evaluation of the observables within 1% accuracy in the case of EPS09 nuclear PDFs.

An example of the \(\sigma _{j,k}^\mathrm{pPb}\) histograms used in evaluating the LHC pPb cross sections in Eq. (28). The cross section \(\sigma ^\mathrm{pPb}\) is computed as a sum of all the bins weighted by the appropriate nuclear modification factors. The sum of all the bins gives the cross section with no nuclear modifications (\(R_i^\mathrm{Pb}=1\))
4 Analysis procedure
The standard statistical procedure for comparing experimental data to theory is to inspect the behavior of the overall \(\chi ^2\) function, defined as
where \(\mathbf {a}\) is a set of theory parameters and \(\chi ^2_k \left( \mathbf {a} \right) \) denotes the contribution of each independent data set k,
Here, \(T_i\left( \mathbf {a} \right) \) denote the theoretical values of the observables in the data set k, \(D_i\) are the corresponding experimental values, and \(C_{ij}\) is the covariance matrix. In most cases, only the total uncertainty is known, and in this case \(C_{ij} = (\delta ^\mathrm{uncorr.}_i)^2\delta _{ij}\), where \(\delta ^\mathrm{uncorr.}_i\) is the point-to-point uncorrelated data uncertainty. In the case that the only correlated uncertainty is the overall normalization \(\delta ^\mathrm{norm.}\), we can also write
which is to be minimized with respect to \(f_N\). All the uncertainties are considered additive (e.g. the possible D’Agostini bias [93] or equivalent is neglected). The central fit is then defined to correspond to the minimum value of the global \(\chi ^2\) obtainable with a given set of free parameters,
In practice, we minimize the \( \chi ^2\) function using the Levenberg–Marquardt method [94,95,96].
In our previous EPS09 analysis, additional weight factors were included in Eq. (29) to increase the importance of some hand-picked data sets. We emphasize that in the present EPPS16 study we have abandoned this practice due to the subjectiveness it entails. In the EPS09 analysis the use of such data weights was also partially related to technical difficulties in finding a stable minimum of \(\chi ^2 \left( \mathbf {a} \right) \) when using the MINUIT [97] library. In the EPS09 analysis an additional penalty term was also introduced to the \(\chi ^2 \left( \mathbf {a} \right) \) function to avoid unphysical A dependence at small x (i.e. to have larger nuclear effects for larger nuclei). Here, such a term is not required because of the improved functional form discussed in Sect. 2.
As the nuclear PDFs are here allowed to go negative it is also possible to drift to a situation in which the longitudinal structure function \(F_\mathrm{L}^A\) becomes negative. To avoid this, we include penalty terms in \(\chi ^2 \left( \mathbf {a} \right) \) at small x that grow quickly if \(F_\mathrm{L}^A < 0\). We observe, however, that the final results in EPPS16 are not sensitive to such a positiveness requirement.
4.1 Uncertainty analysis
As in our earlier analysis EPS09, we use the Hessian-matrix-based approach to estimate the PDF uncertainties [98]. The dominant behavior of the global \(\chi ^2\) about the fitted minimum can be written as
where \(\delta a_j \equiv a_j-a_j^0\) are differences from the best-fit values and \(\chi ^2_0 \equiv \chi ^2(\mathbf {a}^0)\) is the lowest attainable \(\chi ^2\) of Eq. (32). The Hessian matrix \(H_{ij}\) can be diagonalized by defining a new set of parameters by
with
where \(\epsilon _k\) are the eigenvalues and \(v_j^{(k)}\) are the components of the corresponding orthonormal eigenvectors of the Hessian matrix,
In these new coordinates,
In comparison to Eq. (33), here in Eq. (38) all the correlations among the original parameters \(a_i\) are hidden in the definition Eq. (34), which facilitates a very simple error propagation [98]. Indeed, since the directions \(z_i\) are uncorrelated, the upward/downward-symmetric uncertainty for any PDF-dependent quantity \(\mathcal {O}\) can be written as
with an uncertainty interval \(\Delta z_i = (t_i^+ + t_i^-)/2\) where \(t_i^\pm \) are \(z_i\)-interval limits which depend on the chosen tolerance criterion. The partial derivatives in Eq. (39) are evaluated with the aid of PDF error sets \(S^\pm _i\) defined in the space of \(z_i\) coordinates in terms of \(t_i^\pm \) as
where N is the number of the original parameters \(a_i\). It then follows that
Although simple on paper, in practice it is a non-trivial task to obtain a sufficiently accurate Hessian matrix in a multivariate fit such that Eq. (38) would be accurate. One possibility, used e.g. in Ref. [99], is to use the linearized Hessian matrix obtained from Eq. (30)
where the partial derivatives are evaluated by finite differences. The advantage is that by this definition, the Hessian matrix is always positive definite and thereby has automatically positive eigenvalues and e.g. Eq. (34) is always well defined.
Another possibility, which is the option chosen in the present study, is to scan the neighborhood of the minimum \(\chi ^2\) and fit it with an ansatz
whose parameters \(h_{ij}\) then correspond to the components of the Hessian matrix. While this gives more accurate results than the linearized method (where some information is thrown away), the eigenvalues of the Hessian become easily negative for the presence of third- and higher-order components in the true \(\chi ^2\) profile. Hence, to arrive at positive-definite eigenvalues, some manual labour is typically required e.g. in tuning the parameter intervals used when scanning the global \(\chi ^2\). Yet, the resulting uncertainties always depend somewhat on the chosen parameter intervals, especially when the uncertainties are large. To improve the precision, we have adopted an iterative procedure similar to the one in Ref. [100]: After having obtained the first estimate for the Hessian matrix and the z coordinates, we recompute the Hessian matrix in the z space by re-scanning the vicinity of \(\mathbf {z} = 0\) and fitting it with a polynomial
where \(\hat{h}_{ij}\) is an estimate for the Hessian matrix in the z space. We then re-define the z coordinates by
where
and \(\hat{\epsilon }_k\) and \(\hat{\mathbf {v}}^{(k)}\) are now the eigenvalues and eigenvectors of the matrix \(\hat{h}_{ij}\). Then we repeat the iteration a few times, using the \(\hat{D}_{ij}\) of the previous round as \(D_{ij}\) in Eq. (46). Ideally, one should find that the eigenvalues \(\hat{\epsilon }_k\) converge to unity during the iteration but in practice, some deviations will always persist for the presence of non-quadratic components in the true \(\chi ^2\) profile. We have also noticed that, despite the iteration, the resulting uncertainty bands still depend somewhat on the finite step sizes and grids used in the \(\chi ^2\)-profile scanning especially in the regions where the uncertainties are large. In such regions the Hessian method starts to be unreliable and the uncertainties found represent only the lower limits for the true uncertainties.

The \(\chi ^2\) profiles (black curves) as a function of final eigenvector directions \(z_i\) compared to ideal behavior \(\chi ^2_0 + z_i^2\) (thicker colored curves)
The global \(\chi ^2\) profiles as a function of the final eigenvector directions, which we arrive at in the present EPPS16 analysis, are shown in Fig. 4. In obtaining these, during the iteration, the finite step sizes (\(z_i\) in Eq. (44)) along each provisional eigenvector direction were adjusted such that the total \(\chi ^2\) increased by 5 units from the minimum. As seen in the figure, in most cases, the quadratic approximation gives a very good description of the true behavior of \(\chi ^2\), but in some cases higher-order (e.g. cubic and quartic) components are evidently present. The effects of higher-order components can be partly compensated by using larger step sizes during the iteration such that the quadratic polynomial approximates the true \(\chi ^2\) better up to larger deviations from the minimum (but is less accurate near the minimum). However, we have noticed that with increasing step sizes the resulting PDF uncertainties get eventually smaller, which indicates that some corners of the parameter space are not covered as completely as with the now considered 5-unit increase in \(\chi ^2\).
The basic idea in the determination of the PDF uncertainty sets in the present work is similar to that in the EPS09 analysis. As in EPS09, for each data set k with \(N_k\) data points we determine a 90% confidence limit \(\chi ^2_{k,\mathrm{max}}\) by solving
where
and in which \(\chi ^2_{k,0}\) is the value of \(\chi ^2\) for kth data set at the global minimum. The integrand in Eq. (47) is the usual \(\chi ^2\) distribution – the probability density to obtain a given value of \(\chi ^2\) when the data are distributed in a Gaussian way around the known truth. The effect of Eq. (48) is, as sketched in Fig. 5, to scale the \(\chi ^2\) distribution such that its maximum occurs at the central value of the fit \(\chi ^2_{0,k}\), against which the confidence limit is defined. In other words, we assume that if the experiment would be repeated several times the outcome would follow the scaled distribution (the blue curve in Fig. 5) and not the ideal one (the green curve in Fig. 5). This procedure allows one to define confidence limits also for data sets which happen to give very large \(\chi ^2_k/N_k\) for e.g. underestimated uncertainties or particularly large fluctuations [101].

Determination of 90% confidence limit for an individual data set with \(N_k=50\) data points and for which the global minimum corresponds to \(\chi ^2_{k,0}=80\)

Determination of the confidence limits for the eigendirections 1 to 12. The bars show the limits \(z_{i,\mathrm{min}}^k\), \(z_{i,\mathrm{max}}^k\) for each individual (or grouped) data set k and the marker in between indicates where the minimum \(\chi ^2_{k,0}\) of that data set is reached. The set “all” refers to all data combined. An arrow signifies that the confidence limit has not yet been reached in the scanned interval. The gray bands are the intersection intervals \(\left[ z_{i,\mathrm{min}},z_{i,\mathrm{max}}\right] \) explained in the text

As Fig. 6 but for eigendirections 13 to 20
For each eigenvector direction \(z_i\) and data set k we find the interval \([z_{i,\mathrm{min}}^k,z_{i,\mathrm{max}}^k]\) for which \(\chi ^2_k < \chi ^2_{k,\mathrm{max}}\). Looping over all the data sets k we then find the intersection of the intervals \([z_{i,\mathrm{min}}^k,z_{i,\mathrm{max}}^k]\) for each i. In other words, we require all the individual data sets to remain within the defined 90% limit,
The outcome of this process is shown in Figs. 6 and 7 for all eigendirections. The individual limits \([z_{i,\mathrm{min}}^k,z_{i,\mathrm{max}}^k]\) are shown as solid lines (with bars or arrows) and the intersection \([z_{i,\mathrm{min}},z_{i,\mathrm{max}}]\) as a gray band. This procedure is repeated for all eigendirections i. We note that we have here grouped together all the data (summing the \(\chi ^2\) contributions) from a given experiment and thus, in Figs. 6 and 7 there are less labels than individual contributions in Table 1. Motivation for such a grouping is that even if an experiment gives data for various nuclei (e.g. SLAC E139) these are not unrelated e.g. for the baseline measurement and detector systematics. Furthermore, it may also happen (e.g. direction 8, lower limit; in Fig. 6) that none of the individual experiments (with grouped data) places stringent uncertainty limits, i.e. the intervals \([z_{i,\mathrm{min}},z_{i,\mathrm{max}}]\) become rather wide and the total \(\chi ^2\)grows substantially above \(\chi ^2_0\). In such a case, the data from various experiments together may provide a better constraint than an individual experiment. To take this into account, we treat the aggregate of all the data as a single additional “experiment” (the first rows in the panels of Figs. 6 and 7.
We study two options to define the PDF uncertainty sets \(S_i^\pm \). In the first one, we set \(t_i^+ = z_{i,\mathrm{max}}\) and \(t_i^- = -z_{i,\mathrm{min}}\) in Eq. (40), i.e.,
where the numbers \(z_{i,\mathrm{min/max}}\) are obtained as described above. This is sometimes referred to as dynamic tolerance determination [99]. For the second option, we specify an average tolerance \(\Delta \chi ^2\) as
where \(\chi ^2(S_{i}^\pm [\mathrm{dyn}])\) are the values of \(\chi ^2\) that correspond to the error sets \(S_i^\pm \left[ \mathrm{dyn}\right] \) defined above. For the present fit with all the data, we find \(\Delta \chi ^2 \approx 52\). This averaging process is illustrated in Fig. 8 which shows the individual differences \(\chi ^2(S_{i}^-[\mathrm{dyn}])-\chi ^2_0\) and \(\chi ^2(S_{i}^+[\mathrm{dyn}])-\chi ^2_0\) as bars together with the found average. In this case the PDF uncertainty sets \(S_i^\pm \left[ \Delta \chi ^2\right] \) are defined by imposing a fixed global tolerance \(\Delta \chi ^2=52\),
where the numbers \(\delta z_i^\pm \) are the deviations in positive and negative direction chosen such that the \(\chi ^2\) grows by 52. The obtained values for \(\delta z_i^\pm \) are listed in Table 2.

The individual values of \(\chi ^2(S_k^\pm )-\chi ^2_0\) compared with the average \(\Delta \chi ^2 = 52\)
As expected, Fig. 8 shows rather significant variations in \(\chi ^2(S_{i}^\pm [\mathrm{dyn}])-\chi ^2_0\) depending on which eigendirection one looks at. However, the corresponding variations in \(z_{i,\mathrm{min/max}}\sim \sqrt{\chi ^2(S_{i}^\pm [\mathrm{dyn}])-\chi ^2_0}\) which determine the error sets are much milder. Hence, it can be expected that the two error-set options, \(S_{i}^\pm [\mathrm{dyn}]\) and \(S_i^\pm [ \Delta \chi ^2]\), will eventually lead to rather similar uncertainty estimates. In the following (see Fig. 11), we will verify that this indeed is the case. Hence, and also to enable PDF reweighting [45], we choose the \(S_i^\pm [ \Delta \chi ^2]\) with the single global tolerance \(\Delta \chi ^2\) as the final EPPS16 error sets.
As in EPS09, the propagation of PDF uncertainties into an observable \(\mathcal {O}\) will be here computed separately for the upward and downward directions,
where \(\mathcal {O}\left( S_0\right) \) denotes the prediction with the central set and \(\mathcal {O}\left( S_i^\pm \right) \) are the values computed with the error sets [102].

The EPPS16 nuclear modifications for carbon (leftmost columns) and lead (rightmost columns) at the parametrization scale \(Q^2=1.69\,\mathrm{GeV}^2\) and at \(Q^2=10\,\mathrm{GeV}^2\). The thick black curves correspond to the central fit \(S_0\) and the dotted curves to the individual error sets \(S_i^\pm \left[ \Delta \chi ^2\right] \) of Eq. (52). The total uncertainties are shown as blue bands
5 Results
5.1 Parametrization and its uncertainties
The parameter values that define the fit functions, the nuclear modifications \(R_i^A\) in Eq. (2) at the initial scale \(Q^2_0\) are listed in Table 3 where we also indicate the parameters that were fixed to those of other parton species or assumed to have some particular value. The fixed value of \(\beta =1.3\) for all flavors as well as setting \(\gamma _{y_a}=0\) for sea quarks are motivated by the EPS09 analysis. Freeing the latter easily leads to an unphysical case (\(\gamma _{y_a}<0\)) and thus we have decided to keep it fixed at this stage.
The \(R_i^A\) functions themselves with error sets of Eq. (52) and uncertainty bands of Eq. (53) are plotted in Fig. 9 for carbon and lead nuclei at \(Q^2=Q_0^2\) and \(Q^2=10 \, \mathrm{GeV}^2\). Regarding these results, we make the following observations:
First, the obtained valence modifications \(R_{u_\mathrm{V}}^A\) and \(R_{d_\mathrm{V}}^A\) are very similar in the central set \(S_0\), and strongly anticorrelated: as the average valence modification is fairly well constrained (see Fig. 27) an error set whose, say, \(R_{u_\mathrm{V}}^A\) is clearly below the central value has to have an \(R_{d_\mathrm{V}^A}\) which is correspondingly above the central value, and vice versa. This is further demonstrated in Fig. 10 where only the errors sets \(S^\pm _1\) are shown for valence. The large error bands for \(R_{u_\mathrm{V}}^A\) and \(R_{d_\mathrm{V}}^A\) at small x in Fig. 9 reflect the fact that the flavor separation is not stringently constrained in the antishadowing region: the finite uncertainties there induce (via the sum rules) larger uncertainties in the shadowing region; see Fig. 10.

The EPPS16 nuclear modifications for valence and sea u & d quarks for lead at the parametrization scale \(Q^2=1.69\,\mathrm{GeV}^2\). The solid black curves correspond to the central result and the dotted/dashed curves to the specific error sets as indicated. The total uncertainties are shown as blue bands

The error bands of nuclear modifications at \(Q^2=10 \, \mathrm{GeV}^2\) from the global tolerance \(\Delta \chi ^2=52\) used in the final EPPS16 fit (black central line and light-blue bands) compared to the error bands from the dynamical tolerance determination (hatching) explained in Sect. 4.1
Second, interestingly also the u and d sea-quark modifications are very similar in the central set \(S_0\), and anticorrelated (except in the large-x region where they were assumed to be the same at \(Q^2_0\)), though not as strongly as the valence quarks because also the strange-quark distribution plays some role. An example is shown in Fig. 10 where the errors sets \(S^\pm _{10}\) and \(S^\pm _{16}\) have been plotted. In contrast to the valence quarks, individual sets are not always anticorrelated throughout all the x values, but sets that are anticorrelated e.g. near \(x_a\) can be very similar toward \(x \rightarrow 0\).
Third, the central value of the strange-quark nuclear modification indicates stronger nuclear effects than for the other light sea quarks. On the other hand, the uncertainty is also significant and even a large enhancement at small x appears possible. While such an effect is theoretically unlikely (we would expect shadowing), it is consistent with the utilized data whose uncertainties our uncertainty bands represent. It should also be borne in mind that the determination of the strange quark in CT14 (our baseline PDF) may suffer from uncertainties (e.g. related to treatment of dimuon process in neutrino–nucleus DIS) and can, to some extent, affect the nuclear modifications we obtain. Thus, building a “hard wall” e.g. prohibiting an enhancement at small x is not justified either. Nevertheless, the found central values of the strange-quark nuclear modifications are clearly in a sensible ballpark.


Ratios of structure functions for various nuclei as measured by the NMC [73, 74] and EMC [78] collaborations, compared with the EPPS16 fit. In the rightmost panel the labels “addendum” and “chariot” refer to the two different experimental setups in Ref. [78]. For a better visibility, some data sets have been offset by a factor of 0.92 as indicated

The \(Q^2\) dependence of the ratio \(F_2^\mathrm{Sn}/F_2^\mathrm{C}\) for various values of x as measured by NMC [79], compared with EPPS16

The SLAC [72] and NMC [75] data for DIS cross-section and structure-function ratios compared with the EPPS16 fit. For a better visibility, the SLAC data have been multiplied by 1.2, 1.1, 1.0, 0.9 for \(Q^2=2\,\mathrm{GeV}^2\), \(Q^2=5\,\mathrm{GeV}^2\), \(Q^2=10\,\mathrm{GeV}^2\), \(Q^2=15\,\mathrm{GeV}^2\), and the largest-x set by 0.8

Ratios of Drell–Yan dilepton cross sections \(d\sigma ^{\mathrm{p}A} / d\sigma ^\mathrm{pBe}\) as a function of \(x_1\) at various values of fixed M as measured by E866 [77], compared with EPPS16

Ratios of Drell–Yan cross sections measured by E772 as a function of \(x_2\) at fixed values of M, compared with the EPPS16 fit


The LHC pPb data from CMS [37, 46, 48] and ATLAS [49] for Z (upper panels) \(\mathrm{W}^\pm \) (middle panels), and dijet production (lower left panel) compared with the EPPS16 fit. The dashed lines indicate the results with no nuclear modifications in the PDFs. The PHENIX DAu data [31] for inclusive pion production (lower right panel) are shown as well and have been multiplied by the optimal normalization factor \(f_N=1.03\) computed by Eq. (31)


As Fig. 20 but for antineutrino beam
Fourth, for gluon distributions the uncertainties are large at small x at \(Q_0^2\) but quickly diminish as the scale is increased. The gluon distributions in some error sets also go negative at small x at low \(Q^2\) but since \(F_\mathrm{L}\) remains positive, this is allowed.
Fifth, on average, the nuclear effects of lead tend to be stronger than those of carbon and also the uncertainties on lead are larger than those on carbon. Given that most of the data are for heavier nuclei than carbon, especially the smaller errors for carbon may appear a bit puzzling. The reason is in the new way of parametrizing the A dependence of the nuclear effects, see Eq. (3), that favours larger nuclei to exhibit larger nuclear effects.
Sixth, the parametrization bias that our fit function entails is particularly well visible in the valence-quark panels where a narrow “throat” at \(x\approx 0.02\) can be seen. This is an artifact of not allowing for more freedom at small x while requiring the sum rules in Eq. (4) and Eq. (5): to satisfy the sum rule, an enhancement around \(x=0.1\) must be accompanied by a depletion at small x (or vice versa), and since \(x_a\) for valence is fairly well determined the fit function always crosses unity near \(x\approx 0.02\).
In Sect. 4.1 we mentioned that the two error-determination options, the dynamical tolerance and fixed global tolerance, lead to similar uncertainty estimates. To demonstrate this, we plot in Fig. 11 the error bands of the nuclear effects \(R_i^\mathrm{Pb}\) at \(Q^2=10\) GeV\(^2\) obtained correspondingly from the error sets \(S_{i}^\pm [\mathrm{dyn}]\) and \(S_i^\pm [ \Delta \chi ^2]\). Indeed, we find no significant differences between the two options.
5.2 Comparison with data
Figures 12, 13, 14, 15, 16, 17, 18, 19, 20 and 21 present a comparison of the EPPS16 fit with the experimental data of Table 1, computing the PDF error propagation according to Eq. (53). The error bars shown on the experimental data correspond to the statistical and systematic errors added in quadrature. The charged-lepton DIS data are shown in Figs. 12, 13, 14 and 15. We note that, for undoing the isoscalar corrections as explained in Sect. 3.1, the data appear somewhat different from those e.g. in the EPS09 paper. On average, the data are well reproduced by the fit. In some cases the uncertainty bands are rather asymmetric (see e.g. the NMC data panel in Fig. 15) which was the case in the EPS09 fit as well. This is likely to come from the fact that the A dependence is parametrized only at few values of x (small-x limit, \(x_a\), \(x_e\)) and in between these points the A dependence appears to be somewhat lopsided in some cases. The \(Q^2\) dependence of the data visible in Figs. 12 and 14 is also nicely consistent with EPPS16.
The pA vs. pD Drell–Yan data are shown in Figs. 16 and 17. In the calculation of the corresponding differential NLO cross sections \(\mathrm{d}\sigma ^\mathrm{DY}/\mathrm{d}x\mathrm{d}M\) we define \(x_{1,2}\equiv (M/\sqrt{s})e^{\pm y}\) where M is the invariant mass and y the rapidity of the dilepton. The scale choice in the PDFs is \(Q=M\). While these data are well reproduced, the scatter of the data from one nucleus to another is the main reason we are unable to pin down any systematic A dependence for the sea quarks at \(x_a\) (some A dependence develops via DGLAP evolution, however). For example, as is well visible in Fig. 17, it is not clear from the data whether there is a suppression or an enhancement for \(x\gtrsim 0.1\).
The pion–A DY data are presented in Fig. 18. As is evident from the figure, these data set into the EPPS16 fit without causing a significant tension. Overall, however, the statistical weight of these data is not enough to set stringent additional constraints to nuclear PDFs. Similarly to the findings of Ref. [67], the optimal data normalization of the lower-energy NA10 data (the lower right panel) is rather large (\(f_N=1.121\)), but the \(x_2\) dependence of the data is well in line with the fit.
The collider data, i.e. new LHC pPb data as well as the PHENIX DAu data, are shown in Fig. 19. To ease the interpretation of the LHC data (forward-to-backward ratios), the baseline with no nuclear effects in PDFs is always indicated as well. The baseline deviates from unity for isospin effects (unequal amount of protons and neutrons in Pb) as well as for experimental acceptances. For the electroweak observables, the nuclear effects cause suppression in the computed forward-to-backward ratios (with respect to the baseline with no nuclear effects) as one is predominantly probing the region below \(x\sim 0.1\) where the net nuclear effect of sea quarks has a downward slope toward small x. Very roughly, the probed nuclear x-regions can be estimated by \(x \approx (M_\mathrm{W,Z}/\sqrt{s})e^{-y}\) and thus, toward more forward rapidities (\(y>0\)) one probes smaller x than in the backward direction (\(y<0\)). The suppression comes about as smaller-x quark distributions are divided by larger-x (less-shadowed or antishadowed) quarks. In the case of dijets, the nuclear PDFs are sampled at higher x and, in contrast to the electroweak bosons, an enhancement is observed. In our calculations, this follows essentially from antishadowed gluons becoming divided by EMC-suppressed gluon distributions; see Ref. [70] for more detailed discussions. The PHENIX pion data [31] is also well consistent with EPPS16, though, for the more precise CMS dijet data, its role is no longer as essential as in the EPS09 analysis.
Finally, comparisons with the CHORUS neutrino and antineutrino data are shown in Figs. 20 and 21. The data exhibit a rather typical pattern of antishadowing followed by an EMC effect at large x. The incident beam energies are not high enough to reach the small-x region where a shadowing effect would be expected. Toward small x, however, the data do appear to show a slight downward bend, a possible onset of shadowing.
5.3 Comparison with baseline

The nuclear modifications at \(Q^2=10 \, \mathrm{GeV}^2\) from the EPPS16 fit (black central line and light-blue bands) compared with the baseline fit (green curves with hatching) which uses only the data included in the EPS09 fit

The contribution of the CHORUS data [50] to the total \(\chi ^2\) as a function of \(y_a^{u_\mathrm{V}}-y_a^{d_\mathrm{V}}\) (left) and the contribution of the CMS dijet data [37] to the total \(\chi ^2\) as a function of \(y_a^{g}-y_e^{g}\) (right). The green squares correspond to the EPPS16 error sets and the red circles to the error sets from the baseline fit. The arrow indicates the direction of change induced by inclusion of these data into the analysis

The values of \(\chi ^2/N_\mathrm{data}\) from the baseline fit (red bars) and EPPS16 (green bars) for data in Table 1

Comparison of the EPPS16 nuclear modifications (black central curve with shaded uncertainty bands) with those from the nCTEC15 analysis [35] (red curves with hatching) at \(Q^2=10\,\mathrm{GeV}^2\)
To appreciate the effects induced by the new data (pion–A DY, neutrino DIS and LHC data) in the EPPS16 fit, we have performed another fit excluding these data sets but still correcting the DIS data for the isospin effects. This fit is referred to as “baseline” in the following. The resulting nuclear modifications for Pb at \(Q^2= 10 \, \mathrm{GeV}^2\) with a comparison to the EPPS16 results are shown in Fig. 22. For the baseline fit here, the global tolerance is \(\Delta \chi ^2_\mathrm{baseline}=35\). As seen in the figure, it is not always the case that the uncertainties of EPPS16 would be smaller than those of the baseline. This originates from the mutually different global tolerances of the two fits and from the differences of the \(\chi ^2\) behavior around the minima. In any case, the uncertainty bands always overlap and both of these enclose the central values both from the baseline fit and the full analysis. Thus, the two are consistent. Qualitatively, the most notable changes are that, in comparison to the baseline, the EPPS16 central values of both valence-quark flavors as well as that of gluons exhibit a very similar antishadowing effect followed by an EMC pit. We have observed that this difference is mostly caused by the addition of neutrino DIS data (valence quarks) and the CMS dijet data (gluons). This is also illustrated in Fig. 23 where the left-hand panel shows the \(\chi ^2\) contribution of the CHORUS data as a function of \(y_a^{u_\mathrm{V}}-y_a^{d_\mathrm{V}}\) (the antishadowing peak heights for \(A_\mathrm{ref}\) as in Table 3) and the right-hand panel the \(\chi ^2\) contribution of the CMS dijet data as a function of \(y_a^{g}-y_e^{g}\). The individual points correspond to the EPPS16 and baseline-fit error sets. From these panels we learn that in order to optimally reproduce the CHORUS data we need \(y_a^{u_\mathrm{V}} \sim y_a^{d_\mathrm{V}}\), and agreement with the CMS dijet data requires \(y_a^\mathrm{g} > y_e^\mathrm{g}\) (EMC effect). The other new data (pion–A DY, LHC electroweak data) do not generate such a strong pull away from the central set of the baseline fit. Also the PHENIX data prefers a solution with a gluon EMC effect, but the contribution of these data in the total \(\chi ^2\) budget is so small that such a tendency is practically lost in the noise (in the EPS09 analysis this was compensated by giving these data an additional weight). The inclusion of the dijet data has also decreased the gluon uncertainties at large x, excluding the solutions with no antishadowing. In the case of u and d sea quarks there are no significant differences between the baseline fit and EPPS16. It appears that the s-quark uncertainty at small x has somewhat reduced by the inclusion of the new data, but the uncertainty is in any case large.

The values of \(\chi ^2/N_\mathrm{data}\) for individual data sets are shown in Fig. 24. For the CMS dijet data the baseline fit gives a very large value but this disagreement disappears when these data are included in the fit. However, upon including the new data no obvious conflicts with the other data sets show up and thus the new data appear consistent with the old. While it is true that on average \(\chi ^2/N_\mathrm{data}\) for the old data grows when including the new data (and this is mathematically inevitable) no disagreement (\(\chi ^2/N_\mathrm{data} \gg 1\)) occurs. For the NMC Ca/D data \(\chi ^2/N_\mathrm{data}\) is somewhat large but, as can be clearly seen from Fig. 13, there appears to be large fluctuations in the data (see the two data points below the EPPS16 error band). While the improvement in \(\chi ^2/N_\mathrm{data}\) for the CHORUS data looks smallish in Fig. 24, for the large amount of data points (824) the absolute decrease in \(\chi ^2\) amounts to 106 units and is therefore significant.

Comparison of the EPPS16 nuclear modifications (black central curve with light-blue uncertainty bands) to those from the EPS09 analysis (purple curves with hatching) and DSSZ [34] (gray bands) at \(Q^2=10\,\mathrm{GeV}^2\). The upper panels correspond to the average valence and sea-quark modifications of Eqs. (54) and (55), the bottom panel is for gluons
5.4 Comparison with other nuclear PDFs
In Fig. 25 we compare our EPPS16 results at the scale \(Q^2=10\,\mathrm{GeV}^2\) with those of the nCTEQ15 analysis [35]. The nCTEQ15 uncertainties are defined by a fixed tolerance \(\Delta \chi ^2 = 35\), which is similar to our average value \(\Delta \chi ^2 = 52\) and in this sense one would expect uncertainty bands of comparable size. The quark PDFs were allowed to be partly flavor dependent in the nCTEQ15 analysis (although to a much lesser extent than in EPPS16), hence we show the comparison for all parametrized parton species. The two fits (as well as nCTEQ15 and our baseline fit in Fig. 22) can be considered compatible since the uncertainty bands always overlap. For all the sea quarks the nCTEQ15 uncertainties appear clearly smaller than those of EPPS16 though less data was used in nCTEQ15. This follows from the more restrictive assumptions made in the nCTEQ15 analysis regarding the sea-quark fit functions: nCTEQ15 has only 2 free parameters for all sea quarks together, while EPSS16 has 9. Specifically, the nCTEQ15 analysis constrains only the sum of nuclear \(\bar{u} + \bar{d}\) with an assumption that the nuclear s quarks are obtained from \(\bar{u} + \bar{d}\) in a fixed way. In contrast, EPPS16 has freedom for all sea-quark flavors separately, and hence also larger, but less biased, error bars. For the valence quarks, the nCTEQ15 uncertainties are somewhat larger than the EPPS16 errors around the x-region of the EMC effect which is most likely related to the extra constraints the EPPS16 analysis has obtained from the neutrino DIS data. Especially the central value for \(d_\mathrm{V}\) is rather different from that of EPPS16. The very small nCTEQ15 uncertainty at \(x \sim 0.1\) is presumably a similar fit-function artifact as what we have for EPPS16 at slightly smaller x. Such a small uncertainty is supposedly also the reason why nCTEQ15 arrives at smaller uncertainties in the shadowing region than EPPS16. For the gluons the nCTEQ15 uncertainties are clearly larger than those of EPPS16, except in the small-x region. While, in part, the larger uncertainties are related to the LHC dijet data that are included in EPPS16 but not in nCTEQ15, this is not the complete explanation as around \(x \sim 0.1\) the nCTEQ15 uncertainties also largely exceed the uncertainties from our baseline fit (see Fig. 22). Since the data constraints for gluons in both analyses are essentially the same, the reason must lie in the more stringent \(Q^2\) cut (\(Q^2 > 4 \, \mathrm{GeV}^2\)) used in the nCTEQ15 analysis, which cuts out low-\(Q^2\) data points where the indirect effects of gluon distributions via parton evolution are the strongest. The inclusion of the dijet data into the nCTEQ15 analysis would clearly have a dramatic impact. This can be understood from Fig. 26 where we compare the CMS dijet data also with the nCTEQ15 prediction (here, we have formed the nCTEQ15 nuclear modifications from their absolute distributions and used the same dijet grid as in the EPPS16 analysis).
A comparison of EPPS16 with EPS09 [33] and DSSZ [34] is presented in Fig. 27. In the EPS09 and DSSZ analyses the nuclear modifications of valence and sea quarks were flavor independent at the parametrization scale and, to make a fair comparison we plot, in addition to the gluons, the average nuclear modifications for the valence quarks and light sea quarks,
instead of individual flavors. For the valence sector, all parametrizations give very similar results except DSSZ in the EMC-effect region. As noted earlier in Sect. 3.1 and in Ref. [6] this is likely to originate from ignoring the isospin corrections in the DSSZ fit. The sea-quark modifications look also mutually rather alike, the EPPS16 uncertainties being somewhat larger than the others as, being flavor dependent, the sea quarks in EPPS16 have more degrees of freedom. As has been understood already some while ago [5, 6], the DSSZ parametrization has almost no nuclear effects in gluons as nuclear effects were included in the FFs [36] when computing inclusive pion production at RHIC. As a result, DSSZ does not reproduce the new CMS dijet measurements as shown here in Fig. 26. Between EPS09 and EPPS16, the gluon uncertainties are larger in EPPS16. While EPPS16 includes more constraints for the gluons (especially the CMS dijet data), in EPS09 the PHENIX data was assigned an additional weight factor of 20. This in effect increased the importance of these data, making the uncertainties smaller than what they would have been without such a weight (the baseline-fit gluons in Fig. 22 serve as a representative of an unweighted case). In addition, in EPPS16 one more gluon parameter is left free (\(x_a\)) which also increases the uncertainties in comparison to EPS09.

The CMS W charge-asymmetry measurement [46] compared with the predictions using EPPS16 nuclear modifications and CT14NLO proton PDFs. In both panels the blue bands correspond to the combined EPPS16\(+\)CT14 uncertainty and in the lower panel the green band to the combined EPS09\(+\)CT14 uncertainty
6 Application: W charge asymmetry
The W charge-asymmetry measurement by CMS in pPb collisions [46] revealed some deviations from the NLO calculations in the backward direction and it was suggested that this difference could be due to flavor-dependent PDF nuclear modifications. While it was shown in Ref. [103] that such a difference does not appear in the ATLAS PbPb data [104] at the same probed values of x, the situation still remains unclear. To see how large variations the new EPPS16 can accommodate, we compare in Fig. 28 the CMS data with the EPPS16 and EPS09 predictions using the CT14NLO proton PDFs. As discussed in the original EPS09 paper [33], the total uncertainty should be computed by adding in quadrature the uncertainties stemming separately from EPPS16 and from the free-proton baseline PDFs,
where \(\delta \mathcal {O}_\mathrm{EPPS16}\) is evaluated by Eq. (53) using the uncertainty sets of EPPS16 with the central set of free-proton PDFs, and \(\delta \mathcal {O}_\mathrm{baseline}\) by the same equation but using the free-proton error sets with the central set of EPPS16. The same has been done in the case of EPS09 results. While the differences between the central predictions of EPPS16 and EPS09 are tiny, it can be seen that the uncertainty bands of EPPS16 are clearly wider and, within the uncertainties, the data and EPPS16 are in a fair agreement. As this observable is mostly sensitive to the free-proton baseline (to first approximation the nuclear effects in PDFs cancel) we do not use these asymmetry data as a constraint in the actual fit in which we aim to expose the nuclear effects in PDFs.
7 Summary and outlook
We have introduced a significantly updated global analysis of NLO nuclear PDFs – EPPS16 – with less biased, flavor-dependent fit functions and a larger variety of data constraints than in other concurrent analyses. In particular, new LHC data from the 2013 pPb run are for the first time directly included. Another important addition here is the neutrino–nucleus DIS data. Also the older pion–nucleus DY data are now for the first time part of the analysis. From the new data, the most significant role is played by the neutrino DIS data and the LHC dijet measurements whose addition leads to a consistent picture of qualitatively similar nuclear modifications for all partonic species. Remarkably, the addition of new data types into the global fit does not generate notable tensions with the previously considered data sets. This lends support to the validity of collinear factorization and process-independent nuclear PDFs in the kinematical \(x,Q^2\) region we have considered.
However, the uncertainties are still significant for all components and, clearly, more data is therefore required. In this respect, the prospects for rapid developments of nuclear PDFs are very good: It can be expected that new data from the LHC will be available soon. For example, from the 2013 pPb data taking, a more differential dijet analysis by the CMS collaboration [105] as well as W data by ATLAS [106] are still being prepared. In November–December 2016, the LHC has recorded pPb collisions at the highest energy ever, \(\sqrt{s}=8.16\) TeV, with more than six times more statistics than that from the 2013 pPb run at \(\sqrt{s}=5.02\) TeV.Footnote 5 The new data from this run will provide further constraints to the nuclear PDFs in the near future. As in the case of free-proton PDFs [107, 108] heavy-flavor production at forward direction [109] may offer novel small-x input. An interesting opportunity is also the possibility of the LHCb experiment to operate in a fixed-target mode and measure e.g. pNe (and other noble gases) collisions [110]. From other experiments, new fixed-target proton-induced Drell–Yan data from the Fermilab E-906/SeaQuest experiment [115] should also provide better constraints e.g. for the A dependence of the sea-quark nuclear modifications.
Further in the future, the planned Electron–Ion Collider [111] (and LHeC [112] if materialized) will provide high-precision DIS constraints for all nuclear parton flavors. In addition, the possible realization of a new forward calorimeter (FOCAL) at the ALICE experiment [113] would, in turn, give a possibility to measure isolated photons in the region sensitive to low x gluons [114].
On the theoretical side, there is ample room for improvements as well. For example, similarly to the free-proton fits, an upgrade to next-to-NLO or inclusion of photon distributions and mixed QCD–QED parton evolution are obvious further developments. In a longer run, to avoid biases due to specific baseline proton PDFs, especially regarding the s quark sector, fitting the proton PDFs and nuclear PDFs in one single analysis is ultimately needed.
Notes
See Ref. [59] for a study experimenting with a more flexible fit function at small x.
The cuts are more stringent here than for other DIS data as only absolute cross sections are available (instead of those relative to a lighter nucleus).
References
C.A. Salgado et al., J. Phys. G 39, 015010 (2012). doi:10.1088/0954-3899/39/1/015010. arXiv:1105.3919 [hep-ph]
C.A. Salgado, J.P. Wessels, Ann. Rev. Nucl. Part. Sci. 66, 449 (2016)
N. Armesto, E. Scomparin, Eur. Phys. J. Plus 131(3), 52 (2016). doi:10.1140/epjp/i2016-16052-4. arXiv:1511.02151 [nucl-ex]
P. Foka, M.A. Janik, Rev. Phys. 1, 172 (2016). doi:10.1016/j.revip.2016.11.001
K.J. Eskola, Nucl. Phys. A 910–911, 163 (2013). doi:10.1016/j.nuclphysa.2012.12.029. arXiv:1209.1546 [hep-ph]
H. Paukkunen, Nucl. Phys. A 926, 24 (2014). doi:10.1016/j.nuclphysa.2014.04.001. arXiv:1401.2345 [hep-ph]
J.J. Aubert et al., European Muon Collaboration. Phys. Lett. B 123, 275 (1983). doi:10.1016/0370-2693(83)90437-9
M. Arneodo, Phys. Rep. 240, 301 (1994). doi:10.1016/0370-1573(94)90048-5
L.L. Frankfurt, M.I. Strikman, S. Liuti, Phys. Rev. Lett. 65, 1725 (1990). doi:10.1103/PhysRevLett.65.1725
K.J. Eskola, Nucl. Phys. B 400, 240 (1993). doi:10.1016/0550-3213(93)90406-F
Y.L. Dokshitzer, Sov. Phys. JETP 46, 641 (1977)
Y.L. Dokshitzer, Zh. Eksp. Teor. Fiz. 73, 1216 (1977)
V.N. Gribov, L.N. Lipatov, Sov. J. Nucl. Phys. 15, 438 (1972)
V.N. Gribov, L.N. Lipatov, Yad. Fiz. 15, 781 (1972)
V.N. Gribov, L.N. Lipatov, Sov. J. Nucl. Phys. 15, 675 (1972)
V.N. Gribov, L.N. Lipatov, Yad. Fiz. 15, 1218 (1972)
G. Altarelli, G. Parisi, Nucl. Phys. B 126, 298 (1977). doi:10.1016/0550-3213(77)90384-4
K.J. Eskola, V.J. Kolhinen, P.V. Ruuskanen, Nucl. Phys. B 535, 351 (1998). doi:10.1016/S0550-3213(98)00589-6. arXiv:hep-ph/9802350
K.J. Eskola, V.J. Kolhinen, C.A. Salgado, Eur. Phys. J. C 9, 61 (1999). doi:10.1007/s100520050513, 10.1007/s100529900005. arXiv:hep-ph/9807297
K.J. Eskola, V.J. Kolhinen, H. Paukkunen, C.A. Salgado, JHEP 0705, 002 (2007). doi:10.1088/1126-6708/2007/05/002. arXiv:hep-ph/0703104
M. Hirai, S. Kumano, M. Miyama, Phys. Rev. D 64, 034003 (2001). doi:10.1103/PhysRevD.64.034003. arXiv:hep-ph/0103208
M. Hirai, S. Kumano, T.-H. Nagai, Phys. Rev. C 70, 044905 (2004). doi:10.1103/PhysRevC.70.044905. arXiv:hep-ph/0404093
D. de Florian, R. Sassot, Phys. Rev. D 69, 074028 (2004). doi:10.1103/PhysRevD.69.074028. arXiv:hep-ph/0311227
M. Hirai, S. Kumano, T.-H. Nagai, Phys. Rev. C 76, 065207 (2007). doi:10.1103/PhysRevC.76.065207. arXiv:0709.3038 [hep-ph]
I. Schienbein, J.Y. Yu, K. Kovarik, C. Keppel, J.G. Morfin, F. Olness, J.F. Owens, Phys. Rev. D 80, 094004 (2009). doi:10.1103/PhysRevD.80.094004. arXiv:0907.2357 [hep-ph]
S. Atashbar, Tehrani. Phys. Rev. C 86, 064301 (2012). doi:10.1103/PhysRevC.86.064301
H. Khanpour, S. Atashbar Tehrani, Phys. Rev. D 93(1), 014026 (2016). doi:10.1103/PhysRevD.93.014026. arXiv:1601.00939 [hep-ph]
L. Frankfurt, V. Guzey, M. Strikman, Phys. Rep. 512, 255 (2012). doi:10.1016/j.physrep.2011.12.002. arXiv:1106.2091 [hep-ph]
N. Armesto, J. Phys. G 32, R367 (2006). doi:10.1088/0954-3899/32/11/R01. arXiv:hep-ph/0604108
S.A. Kulagin, R. Petti, Nucl. Phys. A 765, 126 (2006). doi:10.1016/j.nuclphysa.2005.10.011. arXiv:hep-ph/0412425
S.S. Adler et al., PHENIX Collaboration, Phys. Rev. Lett. 98, 172302 (2007). doi:10.1103/PhysRevLett.98.172302. arXiv:nucl-ex/0610036
K.J. Eskola, H. Paukkunen, C.A. Salgado, JHEP 0807, 102 (2008). doi:10.1088/1126-6708/2008/07/102. arXiv:0802.0139 [hep-ph]
K.J. Eskola, H. Paukkunen, C.A. Salgado, JHEP 0904, 065 (2009). doi:10.1088/1126-6708/2009/04/065. arXiv:0902.4154 [hep-ph]
D. de Florian, R. Sassot, P. Zurita, M. Stratmann, Phys. Rev. D 85, 074028 (2012). doi:10.1103/PhysRevD.85.074028. arXiv:1112.6324 [hep-ph]
K. Kovarik et al., Phys. Rev. D 93(8), 085037 (2016). doi:10.1103/PhysRevD.93.085037. arXiv:1509.00792 [hep-ph]
R. Sassot, M. Stratmann, P. Zurita, Phys. Rev. D 81, 054001 (2010). doi:10.1103/PhysRevD.81.054001. arXiv:0912.1311 [hep-ph]
S. Chatrchyan et al. [CMS Collaboration], Eur. Phys. J. C 74(7), 2951 (2014). doi:10.1140/epjc/s10052-014-2951-y. arXiv:1401.4433 [nucl-ex]
H. Paukkunen, K.J. Eskola, C. Salgado, Nucl. Phys. A 931, 331 (2014). doi:10.1016/j.nuclphysa.2014.07.012. arXiv:1408.4563 [hep-ph]
N. Armesto, H. Paukkunen, J.M. Penín, C.A. Salgado, P. Zurita, Eur. Phys. J. C 76(4), 218 (2016). doi:10.1140/epjc/s10052-016-4078-9. arXiv:1512.01528 [hep-ph]
K. Kovarik, I. Schienbein, F.I. Olness, J.Y. Yu, C. Keppel, J.G. Morfin, J.F. Owens, T. Stavreva, Phys. Rev. Lett. 106, 122301 (2011). doi:10.1103/PhysRevLett.106.122301. arXiv:1012.0286 [hep-ph]
M. Hirai, arXiv:1603.07854 [hep-ph]
H. Paukkunen, C.A. Salgado, JHEP 1007, 032 (2010). doi:10.1007/JHEP07(2010)032. arXiv:1004.3140 [hep-ph]
H. Paukkunen, C.A. Salgado, Phys. Rev. Lett. 110(21), 212301 (2013). doi:10.1103/PhysRevLett.110.212301. arXiv:1302.2001 [hep-ph]
A. Kusina et al., arXiv:1610.02925 [nucl-th]
H. Paukkunen, P. Zurita, JHEP 1412, 100 (2014). doi:10.1007/JHEP12(2014)100. arXiv:1402.6623 [hep-ph]
V. Khachatryan et al., CMS Collaboration, Phys. Lett. B 750, 565 (2015). doi:10.1016/j.physletb.2015.09.057. arXiv:1503.05825 [nucl-ex]
J. Adam et al. [ALICE Collaboration], arXiv:1611.03002 [nucl-ex]
V. Khachatryan et al., CMS Collaboration, Phys. Lett. B 759, 36 (2016). doi:10.1016/j.physletb.2016.05.044. arXiv:1512.06461 [hep-ex]
G. Aad et al. [ATLAS Collaboration], Phys. Rev. C 92(4), 044915 (2015). doi:10.1103/PhysRevC.92.044915. arXiv:1507.06232 [hep-ex]
G. Onengut et al., CHORUS Collaboration, Phys. Lett. B 632, 65 (2006). doi:10.1016/j.physletb.2005.10.062
J. Badier et al., NA3 Collaboration, Phys. Lett. B 104, 335 (1981). doi:10.1016/0370-2693(81)90137-4
P. Bordalo et al., NA10 Collaboration, Phys. Lett. B 193, 368 (1987). doi:10.1016/0370-2693(87)91253-6
J.G. Heinrich et al., Phys. Rev. Lett. 63, 356 (1989). doi:10.1103/PhysRevLett.63.356
https://www.jyu.fi/fysiikka/en/research/highenergy/urhic/nPDFs
S. Dulat et al., Phys. Rev. D 93(3), 033006 (2016). doi:10.1103/PhysRevD.93.033006. arXiv:1506.07443 [hep-ph]
M. Kramer, F.I. Olness, D.E. Soper, Phys. Rev. D 62, 096007 (2000). doi:10.1103/PhysRevD.62.096007. arXiv:hep-ph/0003035
J.C. Collins, Phys. Rev. D 58, 094002 (1998). doi:10.1103/PhysRevD.58.094002. arXiv:hep-ph/9806259
R.S. Thorne, W.K. Tung, arXiv:0809.0714 [hep-ph]
I. Helenius, H. Paukkunen, N. Armesto, arXiv:1606.09003 [hep-ph]
A.D. Martin, A.J.T.M. Mathijssen, W.J. Stirling, R.S. Thorne, B.J.A. Watt, G. Watt, Eur. Phys. J. C 73(2), 2318 (2013). doi:10.1140/epjc/s10052-013-2318-9. arXiv:1211.1215 [hep-ph]
W. Furmanski, R. Petronzio, Phys. Lett. B 97, 437 (1980). doi:10.1016/0370-2693(80)90636-X
G. Curci, W. Furmanski, R. Petronzio, Nucl. Phys. B 175, 27 (1980). doi:10.1016/0550-3213(80)90003-6
P. Santorelli, E. Scrimieri, Phys. Lett. B 459, 599 (1999). doi:10.1016/S0370-2693(99)00698-X. arXiv:hep-ph/9807572
P. Santorelli, E. Scrimieri, Phys. Lett. B 459, 599 (1999). doi:10.1016/S0370-2693(99)00698-X. arXiv:hep-ph/9807572
I. Abt, A.M. Cooper-Sarkar, B. Foster, V. Myronenko, K. Wichmann, M. Wing, arXiv:1604.02299 [hep-ph]
D. Dutta, J.C. Peng, I.C. Cloet, D. Gaskell, Phys. Rev. C 83, 042201 (2011). doi:10.1103/PhysRevC.83.042201. arXiv:1007.3916 [nucl-ex]
P. Paakkinen, K.J. Eskola, H. Paukkunen, Phys.Lett. B 768, 7–11 (2017). doi:10.1016/j.physletb.2017.02.009
H. Paukkunen, C.A. Salgado, JHEP 1103, 071 (2011). doi:10.1007/JHEP03(2011)071. arXiv:1010.5392 [hep-ph]
P. Ru, B.W. Zhang, L. Cheng, E. Wang, W.N. Zhang, J. Phys. G 42(8), 085104 (2015). doi:10.1088/0954-3899/42/8/085104. arXiv:1412.2930 [nucl-th]
K.J. Eskola, H. Paukkunen, C. A. Salgado, JHEP 1310, 213 (2013). doi:10.1007/JHEP10(2013)213. arXiv:1308.6733 [hep-ph]
P. Ru, S.A. Kulagin, R. Petti, B.W. Zhang, arXiv:1608.06835 [nucl-th]
J. Gomez et al., Phys. Rev. D 49, 4348 (1994)
P. Amaudruz et al., New Muon Collaboration, Nucl. Phys. B 441, 3 (1995). doi:10.1016/0550-3213(94)00023-9. arXiv:hep-ph/9503291
M. Arneodo et al., New Muon Collaboration, Nucl. Phys. B 441, 12 (1995). doi:10.1016/0550-3213(95)00023-2. arXiv:hep-ex/9504002
M. Arneodo et al., New Muon Collaboration, Nucl. Phys. B 481, 3 (1996). doi:10.1016/S0550-3213(96)90117-0
D.M. Alde et al., Phys. Rev. Lett. 64, 2479 (1990). doi:10.1103/PhysRevLett.64.2479
M.A. Vasilev et al., NuSea Collaboration. Phys. Rev. Lett. 83, 2304 (1999). doi:10.1103/PhysRevLett.83.2304. arXiv:hep-ex/9906010
J. Ashman et al., European Muon Collaboration, Z. Phys. C 57, 211 (1993)
M. Arneodo et al., New Muon Collaboration, Nucl. Phys. B 481, 23 (1996). doi:10.1016/S0550-3213(96)90119-4
P. Amaudruz et al., New Muon Collaboration, Nucl. Phys. B 371, 3 (1992)
J.P. Berge et al., Z. Phys. C 49, 187 (1991). doi:10.1007/BF01555493
M. Tzanov et al., NuTeV Collaboration, Phys. Rev. D 74, 012008 (2006). doi:10.1103/PhysRevD.74.012008, arXiv:hep-ex/0509010
A.B. Arbuzov, D.Y. Bardin, L.V. Kalinovskaya, JHEP 0506, 078 (2005). doi:10.1088/1126-6708/2005/06/078, arXiv:hep-ph/0407203
A. Accardi, J.W. Qiu, JHEP 0807, 090 (2008). doi:10.1088/1126-6708/2008/07/090. arXiv:0805.1496 [hep-ph]
J. Gao et al., Phys. Rev. D 89(3), 033009 (2014). doi:10.1103/PhysRevD.89.033009. arXiv:1302.6246 [hep-ph]
J.M. Campbell, R.K. Ellis, W.T. Giele, Eur. Phys. J. C 75(6), 246 (2015). doi:10.1140/epjc/s10052-015-3461-2. arXiv:1503.06182 [physics.comp-ph]
J. Gao, Z. Liang, D.E. Soper, H.L. Lai, P.M. Nadolsky, C.-P. Yuan, Comput. Phys. Commun. 184, 1626 (2013). doi:10.1016/j.cpc.2013.01.022. arXiv:1207.0513 [hep-ph]
Z. Kunszt, D.E. Soper, Phys. Rev. D 46, 192 (1992). doi:10.1103/PhysRevD.46.192
S.D. Ellis, Z. Kunszt, D.E. Soper, Phys. Rev. Lett. 69, 1496 (1992). doi:10.1103/PhysRevLett.69.1496
F. Aversa, P. Chiappetta, M. Greco, J.P. Guillet, Nucl. Phys. B 327, 105 (1989). doi:10.1016/0550-3213(89)90288-5
B.A. Kniehl, G. Kramer, B. Potter, Nucl. Phys. B 582, 514 (2000). doi:10.1016/S0550-3213(00)00303-5. arXiv:hep-ph/0010289
M. Gluck, E. Reya, A. Vogt, Z. Phys. C 53, 651 (1992). doi:10.1007/BF01559743
G. D’Agostini, Nucl. Instrum. Methods A 346, 306 (1994). doi:10.1016/0168-9002(94)90719-6
K. Levenberg, Q. Appl. Math. 2, 164 (1944)
D.W. Marquardt, J. Soc. Ind. Appl. Math. 11(2), 431 (1963)
W.H. Press, S.A. Teukolsky, W.T. Vetterling, B.P. Flannery, Numerical Recipes in FORTRAN: The Art of Scientific Computing (ISBN-9780521430647)
F. James, CERN-D-506, CERN-D506
J. Pumplin, D. Stump, R. Brock, D. Casey, J. Huston, J. Kalk, H.L. Lai, W.K. Tung, Phys. Rev. D 65, 014013 (2001). doi:10.1103/PhysRevD.65.014013. arXiv:hep-ph/0101032
A.D. Martin, W.J. Stirling, R.S. Thorne, G. Watt, Eur. Phys. J. C 63, 189 (2009). doi:10.1140/epjc/s10052-009-1072-5. arXiv:0901.0002 [hep-ph]
J. Pumplin, D.R. Stump, W.K. Tung, Phys. Rev. D 65, 014011 (2001). doi:10.1103/PhysRevD.65.014011. arXiv:hep-ph/0008191
J. Pumplin, D.R. Stump, J. Huston, H.L. Lai, P.M. Nadolsky, W.K. Tung, JHEP 0207, 012 (2002). doi:10.1088/1126-6708/2002/07/012. arXiv:hep-ph/0201195
P.M. Nadolsky, Z. Sullivan, eConf C 010630, P510 (2001). arXiv:hep-ph/0110378
F. Arleo, E. Chapon, H. Paukkunen, Eur. Phys. J. C 76(4), 214 (2016). doi:10.1140/epjc/s10052-016-4049-1. arXiv:1509.03993 [hep-ph]
G. Aad et al. [ATLAS Collaboration], Eur. Phys. J. C 75(1), 23 (2015). doi:10.1140/epjc/s10052-014-3231-6. arXiv:1408.4674 [hep-ex]
CMS Collaboration [CMS Collaboration], CMS-PAS-HIN-16-003
The ATLAS collaboration, ATLAS-CONF-2015-056
O. Zenaiev et al. [PROSA Collaboration], Eur. Phys. J. C 75(8), 396 (2015). doi:10.1140/epjc/s10052-015-3618-z. arXiv:1503.04581 [hep-ph]
R. Gauld, J. Rojo, arXiv:1610.09373 [hep-ph]
The LHCb Collaboration [LHCb Collaboration], LHCb-CONF-2016-003, CERN-LHCb-CONF-2016-003
Y. Zhang [LHCb Collaboration], arXiv:1605.07509 [hep-ex]
A. Accardi et al., Eur. Phys. J. A 52(9), 268 (2016). doi:10.1140/epja/i2016-16268-9. arXiv:1212.1701 [nucl-ex]
J.L. Abelleira Fernandez et al., LHeC Study Group Collaboration, J. Phys. G 39, 075001 (2012). doi:10.1088/0954-3899/39/7/075001. arXiv:1206.2913 [physics.acc-ph]
T. Peitzmann [ALICE FoCal Collaboration], PoS DIS 2016, 273 (2016). arXiv:1607.01673 [hep-ex]
I. Helenius, K.J. Eskola, H. Paukkunen, JHEP 1409, 138 (2014). doi:10.1007/JHEP09(2014)138. arXiv:1406.1689 [hep-ph]
B.P. Dannowitz, FERMILAB-THESIS-2016-13
Acknowledgements
This research was supported by the Academy of Finland, Project 297058 of K.J.E.; by the European Research Council Grant HotLHC ERC-2011-StG-279579; by Ministerio de Ciencia e Innovación of Spain under project FPA2014-58293-C2-1-P; and by Xunta de Galicia (Conselleria de Educacion) – H.P. and C.A.S. are part of the Strategic Unit AGRUP2015/11. P.P. acknowledges the financial support from the Magnus Ehrnrooth Foundation. Part of the computing has been done in T. Lappi’s project at CSC, the IT Center for Science in Espoo, Finland.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funded by SCOAP3
About this article

Cite this article
Eskola, K.J., Paakkinen, P., Paukkunen, H. et al. EPPS16: nuclear parton distributions with LHC data. Eur. Phys. J. C 77, 163 (2017). https://doi.org/10.1140/epjc/s10052-017-4725-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-017-4725-9