
Abstract
In this paper we propose a scale invariant search strategy for hadronic top or bottom plus missing energy final states. We present a method which shows flat efficiencies and background rejection factors over broad ranges of parameters and masses. The resulting search can easily be recast into a limit on alternative models. We show the strength of the method in a natural SUSY setup where stop and sbottom squarks are pair produced and decay into hadronically decaying top quarks or bottom quarks and higgsinos.
Similar content being viewed by others
1 Introduction
Supersymmetric models predict the existence of scalar partners (squarks and sleptons) to the fermions of the Standard Model. In particular, stops and left-handed sbottom squarks need to be light in order to solve the hierarchy problem of the Higgs boson mass. Consequently, searches for stops and sbottoms are at the core of the ongoing LHC program. However, despite intense efforts, see e.g. [1–39], they remain elusive, resulting in stringent limits by dedicated searches performed by both ATLAS [40–47] and CMS [48–55].
The interpretation of a new physics search requires a model hypothesis against which a measurement can be tensioned. Lacking evidence for superpartners and clear guidance from theory, apart from naturalness considerations, it makes sense to employ search strategies that make as few assumptions on the model as possible. For most reconstruction strategies a trade-off has to be made between achieving a good statistical significance in separating signal from backgrounds and the applicability to large regions in the model’s parameter space. Hence, experimental searches are in general tailored to achieving the best sensitivity possible for a specific particle or decay, leaving other degrees of freedom of interest unconsidered. This approach can lead to poor performance for complex models with many physical states and couplings, e.g. the MSSM and its extensions. Hence, a reconstruction that retains sensitivity over wide regions of the phase space, thereby allowing to probe large parameter regions of complex UV models, is crucial during the current and upcoming LHC runs. However, since the number of possible realizations of high-scale models exceeds the number of analyses available at the LHC, tools like ATOM [56–58], CheckMate [59], MadAnalysis [60] or FastLim [58] and SModels [61] have been developed in recent years to recast existing limits on searches for new physics. A method that shows a flat reconstruction efficiency despite kinematic edges and population of exclusive phase space regions would be particularly powerful to set limits on complex models allowing for broad parameter scans.
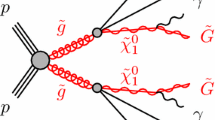
In this paper we develop a reconstruction strategy for third-generation squarks that accumulates sensitivity from a wide range of different phase space regions and for a variety of signal processes.Footnote 1 The proposed reconstruction is therefore a first step toward an general interpretation of data, i.e. recasting. As a proof of concept, we study stop and sbottom pair production, followed by a direct decay into a hadronically decaying top or a bottom and a neutralino or chargino; see Fig. 1. In our analysis we use simplified topologies, including only sbottom and stops as intermediate SUSY particles and we focus on jets and missing energy as final state signal. While this example might be oversimplifying, e.g. it might not capture long decay chains that arise if the mass spectrum is more elaborate, this setup is motivated by naturalness [64–66], i.e. it resembles minimal, natural spectra with light stops, higgsinos, and gluinos where all other SUSY particles are decoupled [67].

Generic Feynman diagram for stop production and decay. The initially produced squarks in our setup can be any of the two stops or the lighter sbottom. They decay subsequently into a top or a bottom and a higgsino, such that the electric charge is conserved
To be more specific, within this simplified setup the shape of the event depends strongly on the mass difference between the initially produced squarks and the nearly mass degenerate higgsinos in comparison to the top quark mass \(\mathcal {Q}=(m_{\tilde{q}}-m_{\tilde{h}})/m_t\). We can identify three regions in the physical parameter space leading to distinctly different topologies.
-
1.
\(\mathcal {Q}<1\): The only accessible two-body decay of the produced squark is the decay into a bottom quark and a charged higgsino. Possible three-body decays contribute only in small areas of the parameter space.
-
2.
\(\mathcal {Q}\gtrsim 1\): The decay into a top quark and a higgsino can become the main decay channel for the produced squark, depending on the squark and the parameter point. The top quark of this decay will get none or only a small boost from the decay and thus its decay products might not be captured by a single fat jet. However, the intermediate W boson can lead to a two-prong fat jet that can be identified by the BDRSTagger [68].
-
3.
\(\mathcal {Q}\gg 1\): If the squark decays into a top quark the latter will be very boosted and its decay products can no longer be resolved by ordinary jets. Yet they can be captured by one fat jet and subsequently identified as a decaying top by the HEPTopTagger [69, 70]. The HEPTopTagger was designed to reconstruct mildly to highly boosted top quarks in final states with many jets, as anticipated in the processes at hand. However, other taggers with good reconstruction efficiencies and low fake rates in the kinematic region of \(\mathcal {Q} \gg 1\) (see e.g. [71–73] and references therein) can give similar results.
Because the value of \(\mathcal {Q}\) is unknown and the event topology crucially depends on it, a generic reconstruction algorithm that is insensitive to details of the model needs to be scale invariant, i.e. independent of \(\mathcal {Q}\). Hence, it needs to be able to reconstruct individual particles from the unboosted to the very boosted regime.
Apart from scanning a large region of the parameter space, such an analysis has the advantage that it captures the final state particles from the three possible intermediate squark states \(\tilde{t}_{1,2}\) and \(\tilde{b}_1\), even if they have different masses. Therefore the effective signal cross section is increased compared to a search strategy which is only sensitive to specific processes and within a narrow mass range. In order to preserve this advantage we furthermore apply only cuts on variables that are independent of \(\mathcal {Q}\) or the mass of one of the involved particles.
The remainder of this paper is organized as follows. In Sect. 2 we give details of the parameter space that we target and the signal and background event generation. Section 3 contains a thorough description of the reconstruction of the top quark candidates and the proposed cuts as well as the results of the analysis. We conclude in Sect. 4.
2 Event generation
2.1 Signal sample and parameter space
As explained in the previous section, not only \(\tilde{t}_1\) but also \(\tilde{t}_2\) and \(\tilde{b}_1\) production contributes to the signal. For all these three production channels we consider the decay into a higgsino \(\widetilde{\chi }_1^\pm \), \(\widetilde{\chi }_{1,2}^0\), and a top or bottom quark. Since in our simplified topology setup we assume the higgsinos to be mass degenerate, we generate only the decay in the lightest neutralino \(\tilde{q}\rightarrow q+\widetilde{\chi }_1^0\) and the chargino \(\tilde{q} \rightarrow q' + \widetilde{\chi }_1^\pm \), where q, \(q'\) stand for t or b. The decay of the second lightest neutralino \(\widetilde{\chi }_2^0\rightarrow \widetilde{\chi }_1^{0,\pm } + X\) and of the chargino to one of the neutralinos \(\widetilde{\chi }_1^\pm \rightarrow \widetilde{\chi }_{1,2}^0+X\) does not leave any trace in the detector since the emitted particles X will be extremely soft. Thus, the event topologies for \(\tilde{t}_{1} \rightarrow t+\widetilde{\chi }_{1,2}^{0}\) will be the same and the different cross section for this topology can be obtained by rescaling with appropriate branching ratios.
We consider the following points in the MSSM parameter space. At fixed \(A_t=200\,\,\text {GeV}\) and \(\tan \beta =10\) we scan in steps of \(50~\,\text {GeV}\) over a grid defined by \(\mu \le m_{Q_3}, m_{u_3} \le 1\,400~\,\text {GeV}\) for the two values of \(\mu =150, 300\,\,\text {GeV}\). The gaugino masses as well as the other squark mass parameters are set to \(5\,\,\text {TeV}\) while the remaining trilinear couplings are set to zero. For each grid point we calculate the spectrum and the branching ratios with SUSY-HIT [74]. Despite the specific choices for the parameters our results will be very generic. An increased \(A_t\) would enhance the mixing between the left- and right-handed stops and thus render the branching ratios of the physical states into top and bottom quarks more equal. However, since the reconstruction efficiencies for both decay channels are similar, the final results would hardly change. The change due to a different mass of the physical states can be estimated from our final results. Similarly, a different choice for \(\mu \) only shifts the allowed region in the parameter space and the area where the decay into a top quark opens up but does not affect the efficiencies.
Since the squark production cross section only depends on the squark mass and the known branching ratios we can now determine which event topologies are the most dominant. In the left column of Fig. 2 we show for \(\mu =300\,\,\text {GeV}\) the relative contribution to the total SUSY cross section, defined as the sum of the squark pair production cross sections \(\sigma _ SUSY \equiv \sum _{S=\tilde{t}_1, \tilde{t}_2, \tilde{b}_1}\sigma _{S\bar{S}}\). In the right panels we show in color code the coverage defined as the sum of these relative contributions. The larger the coverage the more of the signal cross section can be captured by looking into these channels. Clearly considering only the decay of both squarks to top quarks and higgsinos is not enough as the parameter space with \(\mathcal {Q}<0\) is kinematically not accessible. Moreover, in the \(m_{Q_3}>m_{u_3}\) half of the space this final state misses large parts of the signal since the lighter stop decays dominantly into bottom quarks and charginos.
In the case where all three final states are taken into account, the coverage is nearly 100 % throughout the parameter space, except along the line \(m_{\tilde{t}_1}\approx m_t+m_{\tilde{h}}\) where the top decay channel opens up. There it drops to 70–80 %, because in this narrow region also the direct decay to a W boson \(\tilde{t}_1\rightarrow W+b+\widetilde{\chi }^0\) has a significant branching ratio.

Left panels The relative contribution of the different processes to the \(\sigma _ SUSY \), i.e. in red \(100\cdot \sigma _{T_1q_1q_2}/\sigma _{\mathrm{SUSY}}\) as a function of \(m_{Q_3}\) and \(m_{u_3}\), where \(T_1 q_1 q_2\) refers to \(\tilde{t}_1\) pair production followed by a decay into a higgsino plus \(q_1\) and \(q_2\), respectively. Right panels Coverage, i.e. sum of the relative contributions of the considered processes to \(\sigma _ SUSY \). From top to bottom the considered channels are missing energy plus only tt final states, tt and bt final states, and tt, bt, and bb final states. Note the different color scale of the lower right plot. The areas enclosed by the gray dashed lines show the points that are already excluded, determined by fastlim. Red dashed lines indicate the mass of the lightest stop in \(\,\text {GeV}\)
For all parameter points we generate events for each of the up to nine signal processes using MadGraph5_aMC@NLO, version 2.1.1 [75] at a center of mass energy \(\sqrt{s}=13\,\,\text {TeV}\). No cuts are applied at the generator level. The matching up to two jets is done with the MLM method in the shower-\(k_T\) scheme [76, 77] with PYTHIA version 6.426 [78]. We set the matching and the matrix element cutoff scale to the same value of \(m_{S}/6\) where \(m_S\) is the mass of the produced squark. We checked and found that the differential jet distributions [79] are smooth with this scale choice. The cross section for the signal processes is eventually rescaled by the NLO QCD and NLL K-factors obtained from NLL-fast, version 3.0 [80–82].
2.2 Background sample
In our analysis we use top tagging methods based on jet substructure techniques. We therefore focus on the decay of the squarks into a neutralino and a bottom quark or a hadronically decaying top quark. The latter will generate between one to three distinct jets and the former will generate missing energy. Our final state therefore consists of missing energy and up to six jets. As background we thus consider the following four processes, all generated with MadGraph5_aMC@NLO version 2.1.1 [75] and showered with PYTHIA version 6.426 [78].
-
\(\varvec{Wj}\) : \(p p \rightarrow W_\ell + (2+X) jets \), where we merge up to four jets in the five flavor scheme and require that the W decays into leptons (including taus), such that the neutrino accounts for the missing energy.
-
\(\varvec{Zj}\) : \(p p \rightarrow Z_\nu + (2+X) jets \), where we merge up to four jets in the five flavor scheme and the Z decays into two neutrinos and hence generates missing energy. In both channels Wj and Zj we require missing transverse energy of at least \(70\,\,\text {GeV}\) at the generator level.
-
\(\varvec{Zt\bar{t}}\) : \(p p \rightarrow Z_\nu + t + \bar{t}\), where both top quarks decay hadronically, faking the top quarks from the squark decay and the Z decays again into two neutrinos to generate missing energy. This cross section is known at NLO QCD [83] and rescaled by the corresponding K-factor.
-
\(\varvec{t\bar{t}}\) : \(p p \rightarrow t\bar{t} + jets \), where one top decays hadronically and the other one leptonically to emit a neutrino, which accounts for missing energy. The NNLO+NNLL QCD K-factor is obtained from Top++ version 2.0 [84] and multiplied with the cross section.
3 Analysis
3.1 Reconstruction
For the reconstruction of the events we use ATOM [56], based on Rivet [85]. Electrons and muons are reconstructed if their transverse momentum is greater than \(10\,\,\text {GeV}\) and their pseudo-rapidity is within \(\left| \eta \right| <2.47\) for electrons and \(\left| \eta \right| <2.4\) for muons. Jets for the basic reconstruction are clustered with FastJet version 3.1.0 [86] with the anti-\(k_t\) algorithm [87] and a jet radius of 0.4 . Only jets with \(p_T>20\,\,\text {GeV}\) and with \(\left| \eta \right| <2.5\) are kept. For the overlap removal we first reject jets that are within \(\Delta R=0.2\) of a reconstructed electron and then all leptons that are within \(\Delta R=0.4\) of one of the remaining jets. All constituents of the clustered jets are used as input for the following re-clustering as described below.
The underlying idea behind the reconstruction described in the following is to cover a large range of possible boosts of the top quark. We therefore gradually increase the cluster radius and employ successively both the HEPTop- and the BDRSTagger. This allows us to reduce background significantly while maintaining a high signal efficiency.
A flowchart for the reconstruction of the top candidates with the HEPTopTagger is shown in Fig. 3. First the cluster radius is set to \(R=0.5\) and the constituents of the initial anti-\(k_t\) jets are re-clustered with the Cambridge–Aachen (C/A) algorithm [88, 89]. Then for each of the jets obtained we check if its transverse momentum is greater than \(200\,\,\text {GeV}\) and if the HEPTopTagger tags it as a top. In this case we save it as candidate for a signal final state and remove its constituents from the event before moving on to the next jet. Once all jets are analyzed as described above we increase the cluster radius by 0.1 and start over again with re-clustering the remaining constituents of the event. This loop continues until we exceed the maximal clustering radius of \(R_ max =1.5\).

Flowchart of the top reconstruction with the HEPTopTagger
After the reconstruction with the HEPTopTagger is finished we continue the reconstruction of the top candidates with the BDRSTagger as sketched in Fig. 4. We choose our initial cluster radius \(R=0.6\) and cluster the remaining constituents of the event with the Cambridge–Aachen algorithm. Since we now only expect to find W candidates with the BDRSTagger and need to combine them with a b-jet to form top candidates, the order in which we analyze the jets is no longer arbitrary. Starting with the hardest C/A jet we check if its transverse momentum exceeds \(200\,\,\text {GeV}\), its invariant mass is within \(10\,\,\text {GeV}\) of the W mass, and the BDRSTagger recognizes a mass drop. In the case that one of the above requirements fails we proceed with the next hardest C/A jet until either one jet fulfills them or we find all jets to fail them. In the latter case we increase the cluster radius by 0.1 and repeat the C/A clustering and analyzing of jets until the radius gets greater than \(R_ max =1.5\). Once a jet fulfills all the previous criteria we need to find a b-jet to create a top candidate. To do this we recluster the constituents of the event that are not part of the given jet with the anti-\(k_T\) algorithm and a cone radius of 0.4 and pass them on to the b-tagger.Footnote 2 Starting with the hardest b-jet we check if the combined invariant mass of the W candidate and the b-jet is within \(25\,\,\text {GeV}\) of the top quark mass. If such a combination is found it is saved as a candidate and its constituents are removed from the event. The remaining constituents of the event are reclustered with the C/A algorithm and the procedure repeats. Alternatively, if all b-jets fail to produce a suitable top candidate the next C/A jet is analyzed. Once the C/A cluster radius exceeds \(R_ max \) the remaining constituents of the event are clustered with the anti-\(k_T\) algorithm with radius 0.4 and passed on to the b-tagger. Those that get b-tagged are saved as candidates of the signal final state as well.

Flowchart of the top reconstruction with the BDRSTagger
3.2 Analysis cuts
After having reconstructed the candidates for the hadronic final states of the signal—top candidates and b-tagged anti-\(k_T\) jets—we proceed with the analysis cuts. As our premise is to make a scale invariant analysis, we must avoid to introduce scales through the cuts. We propose the following ones and show the respective distribution before each cut in Fig. 5.
-
1.
Zero leptons: The leptons or other particles that are emitted by the decaying chargino or second lightest neutralino are too soft to be seen by the detector. Moreover, since we focus on the hadronic decay modes, no leptons should be present in the signal events. In the background, however, they are produced in the leptonic decays which are necessary to generate missing energy. We therefore require zero reconstructed electrons or muons.
-
2.
Exactly two candidates: The visible part of the signal process consists of two hadronic final states as defined above. In the rare case that an event contains more but in particular in the cases where an event contains less than these two candidates it is rejected. This means that no b-jets beyond possible b candidates are allowed.
-
3.
 : Since we cannot determine the two neutralino momenta individually, it is impossible to reconstruct the momenta of the initial squarks. Yet, we can make use of the total event shape. In the signal, the transverse missing energy is the combination of the two neutrino momenta and therefore balances the transverse momenta of the two candidates. Consequently the vectorial sum of the candidate’s transverse momenta \({\vec {p}}_{T,c_i}\) has to point in the opposite direction of the missing energy.
: Since we cannot determine the two neutralino momenta individually, it is impossible to reconstruct the momenta of the initial squarks. Yet, we can make use of the total event shape. In the signal, the transverse missing energy is the combination of the two neutrino momenta and therefore balances the transverse momenta of the two candidates. Consequently the vectorial sum of the candidate’s transverse momenta \({\vec {p}}_{T,c_i}\) has to point in the opposite direction of the missing energy. -
4.
 : This cut is based on the same reasoning as the previous one. The absolute value of the summed candidate’s transverse momenta and the missing transverse energy needs to be small. In order to maintain scale invariance we normalize the result by
: This cut is based on the same reasoning as the previous one. The absolute value of the summed candidate’s transverse momenta and the missing transverse energy needs to be small. In order to maintain scale invariance we normalize the result by  .
. -
5.
 : By this cut we require that the missing transverse energy and the transverse momentum of the harder of the two candidates are not back-to-back. Since the two produced squarks are of the same type and the higgsinos are mass degenerate, the recoil of the top or bottom quarks against the respective higgsino will be the same in the squark rest frame. Therefore, the two neutralinos should contribute about equally to the missing energy and spoil the back-to-back orientation that is present for each top neutralino pair individually. We therefore reject events where one top candidate recoils against an invisible particle and the second candidate does not. Moreover, we can thus reject events where the missing energy comes from a mismeasurement of the jet momentum.
: By this cut we require that the missing transverse energy and the transverse momentum of the harder of the two candidates are not back-to-back. Since the two produced squarks are of the same type and the higgsinos are mass degenerate, the recoil of the top or bottom quarks against the respective higgsino will be the same in the squark rest frame. Therefore, the two neutralinos should contribute about equally to the missing energy and spoil the back-to-back orientation that is present for each top neutralino pair individually. We therefore reject events where one top candidate recoils against an invisible particle and the second candidate does not. Moreover, we can thus reject events where the missing energy comes from a mismeasurement of the jet momentum. -
6.
 : This cut exploits the same reasoning as the previous one.
: This cut exploits the same reasoning as the previous one.
 : Since we cannot determine the two neutralino momenta individually, it is impossible to reconstruct the momenta of the initial squarks. Yet, we can make use of the total event shape. In the signal, the transverse missing energy is the combination of the two neutrino momenta and therefore balances the transverse momenta of the two candidates. Consequently the vectorial sum of the candidate’s transverse momenta
: Since we cannot determine the two neutralino momenta individually, it is impossible to reconstruct the momenta of the initial squarks. Yet, we can make use of the total event shape. In the signal, the transverse missing energy is the combination of the two neutrino momenta and therefore balances the transverse momenta of the two candidates. Consequently the vectorial sum of the candidate’s transverse momenta  : This cut is based on the same reasoning as the previous one. The absolute value of the summed candidate’s transverse momenta and the missing transverse energy needs to be small. In order to maintain scale invariance we normalize the result by
: This cut is based on the same reasoning as the previous one. The absolute value of the summed candidate’s transverse momenta and the missing transverse energy needs to be small. In order to maintain scale invariance we normalize the result by  .
. : By this cut we require that the missing transverse energy and the transverse momentum of the harder of the two candidates are not back-to-back. Since the two produced squarks are of the same type and the higgsinos are mass degenerate, the recoil of the top or bottom quarks against the respective higgsino will be the same in the squark rest frame. Therefore, the two neutralinos should contribute about equally to the missing energy and spoil the back-to-back orientation that is present for each top neutralino pair individually. We therefore reject events where one top candidate recoils against an invisible particle and the second candidate does not. Moreover, we can thus reject events where the missing energy comes from a mismeasurement of the jet momentum.
: By this cut we require that the missing transverse energy and the transverse momentum of the harder of the two candidates are not back-to-back. Since the two produced squarks are of the same type and the higgsinos are mass degenerate, the recoil of the top or bottom quarks against the respective higgsino will be the same in the squark rest frame. Therefore, the two neutralinos should contribute about equally to the missing energy and spoil the back-to-back orientation that is present for each top neutralino pair individually. We therefore reject events where one top candidate recoils against an invisible particle and the second candidate does not. Moreover, we can thus reject events where the missing energy comes from a mismeasurement of the jet momentum. : This cut exploits the same reasoning as the previous one.
: This cut exploits the same reasoning as the previous one.
Normalized distributions of the background and signal processes before the cut on the respective observable. The numbers in the brackets stand for the soft mass parameters \(m_{Q_3}\) and \(m_{u_3}\) in GeV and the sums in c and d are understood to be vectorial. In all plotted samples \(\mu =300\,\,\text {GeV}\)

Normalized distribution of the type of tags of the candidates and of \(m_{T2}\) after the last cut

Efficiency of the cuts as a function of the squark mass for all samples with \(\mu =300\,\,\text {GeV}\)

Total efficiency of all cuts combined in the \(m_{Q_3}\)–\(m_{u_3}\) plane. The red dashed lines show the mass of the lighter stop in GeV

Stacked distribution of \(m_{T2}\) after all cuts. The plots are based on the samples with \(\mu =300\,\,\text {GeV}\) and the numbers in the brackets refer to the soft mass parameters \(m_{Q_3}\) and \(m_{u_3}\) in GeV

Exclusion limits in the \(m_{Q_3}\)–\(m_{u_3}\)-plane. A Monte Carlo error and a systematic error of 15 % on the background normalization is assumed. In all three plots \(\mu =150\,\,\text {GeV}\), which corresponds roughly to the mass of the higgsinos

Exclusion limits in the \(m_{Q_3}\)–\(m_{u_3}\)-plane. A Monte Carlo error and a systematic error of 15 % on the background normalization is assumed as detailed in the main text. In all three plots \(\mu =300\,\,\text {GeV}\), which corresponds roughly to the mass of the higgsinos
In the left plot in Fig. 6 we show the relative contribution of the types of the two final state candidates after all cuts. In the samples with heavy stops and sbottoms the HEPTopTagger contributes between 30–40 % of the candidates. In the samples with lighter squarks and thus less boosted objects the HEPTopTagger finds less candidates and the BDRSTagger contributes up to about 15 % of the top quark candidates. However, most candidates besides the ones from the HEPTopTagger are b-jets.
In Fig. 7 we show the efficiency of each cut for the three possible final states as a function of the squark mass. As anticipated they show only a mild mass dependence. This is also reflected in the total efficiency which is very flat over the whole parameter space as can be seen in Fig. 8.
The cut flows for background and signal together with the signal over background ratios S / B are given in Tables 1 and 2, respectively. The values for S / B range from about 0.3 in the samples where the stops have a mass of only about \(350~\,\text {GeV}\) to \(10^{-3}\) in the sample with heavy stops of about 1 400 GeV.
3.3 Results
To continue further, we consider the \(m_{T2}\) [90, 91] distribution that is shown in the right plot of Fig. 6 (normalized) and in Fig. 9 (stacked). \(m_{T2}\) is designed to reconstruct the mass of the decaying particle and gives a lower bound on it. This is reflected in the plotted distribution, where the upper edge of the signal distribution is just at the actual squark mass. For the calculation of \(m_{T2}\) we assume zero neutralino mass and use a code described in [92] and provided by the authors of this reference.
Instead of imposing an explicit cut on \(m_{T2}\) to improve S / B, mainly to the benefit of the processes involving heavy squarks, we rather evaluate the statistical significance applying a binned likelihood analysis using the \(CL_s\) technique described in [93, 94]. For the calculation we employ the code MCLimit [95]. We assume an uncertainty of 15 % on the background cross section and also include an error stemming from the finite size of the Monte Carlo sample. For the latter we need to combine the pure statistical uncertainty with the knowledge of a steeply falling background distribution. To do this we determine for each background process and each bin the statistical uncertainty \(\omega \sqrt{N}\), where \(\omega \) is the weight of one event and N is the number of events in the given bin. Conservatively, we assign \(N=1\) for those bins which do not contain any events of the given process. In the high \(m_{T2}\) region where no background events appear this method clearly overestimates the error on the background which is steeply falling. In addition we therefore fit the slopes of the \(m_{T2}\) distributions with an exponential function and use this function to extrapolate the background distribution to the high-\(m_{T2}\) region. As uncertainty on the shape for a given background process we now take in each bin the minimum of \(\omega \sqrt{N}\) and three times the fitted function. This way the error in the low \(m_{T2}\) range is determined by the statistical uncertainty while the one in the high \(m_{T2}\) range from the extrapolation. The combined error on the background in each bin is then obtained by summing the squared errors of each process and taking the square root.
The results are shown in Fig. 10 (Fig. 11) for \(\mu =150\, (300) \,\,\text {GeV}\) and integrated luminosities of 100, 300, and \(1\,000\,\text {fb}^{-1}\). In Fig. 12 we show for \((m_{Q_3},m_{u_3})=(1500,1500)\) the \(CL_s\) exclusion limit as a function of the integrated luminosity. Even for this parameter point, close to the predicted sensitivity reach of the LHC, using our approach, we find a \(95~\%\) CL exclusion with \(600~\mathrm {fb}^{-1}\).

p values as a function of integrated luminosity for the parameter point with \((m_{Q_3},m_{u_3})=(1500\,\,\text {GeV},1500\,\,\text {GeV})\) and \(\mu =300\,\,\text {GeV}\)
4 Final remarks
The main idea behind this analysis was to obtain a scale invariant setup. In the first step we achieved this by employing the HEPTop- and BDRSTaggers together with varying radii. Thereby we managed to pick the minimal content of a hadronically decaying top quark for a large range of top momenta. In the second step we avoided introducing scales in the cuts and only exploited the event properties that are independent of the mass spectrum. After this proof of concept it will now be interesting to apply this principle to other searches where top quarks with various boosts appear in the final state as for example in little Higgs models with T-parity [96–98].
Notes
We significantly expand on the proposals of [62, 63]. In [62] a flat reconstruction efficiency was achieved over a wide range of the phase space for, however, only one process, \(pp \rightarrow HH \rightarrow 4b\), and only a one-step resonance decay, i.e. \(H\rightarrow \bar{b}b\). The authors of [63] showed that in scenarios with fermionic top partners fairly complex decay chains can be reconstructed including boosted and unboosted top quarks and electroweak gauge bosons. While several production modes were studied that can lead to the same final state, only one final state configuration was reconstructed. Focusing on a supersymmetric cascade decay, we will show that a flat reconstruction efficiency can be achieved over a wider region of the phase space, for a variety of production mechanisms and final state configurations.
For the b-tagger we mimic a tagger with efficiency 0.7 and rejection 50. We check if a given jet contains a bottom quark in its history and tag it as b-jet with a probability of 70 % if this is the case and with a probability of 2 % otherwise. Since the same jet may be sent to the b-tagger at different stages of the reconstruction process we keep the results of the b-tagger in the memory and reuse them each time it gets a previously analyzed jet. This way we avoid assigning different tagging results to the same jet.
References
P. Meade, M. Reece, Top partners at the LHC: spin and mass measurement. Phys. Rev. D 74, 015010 (2006). arXiv:hep-ph/0601124 [hep-ph]
T. Han, R. Mahbubani, D.G.E. Walker, L.-T. Wang, Top quark pair plus large missing energy at the LHC. JHEP 05, 117 (2009). arXiv:0803.3820 [hep-ph]
M. Perelstein, A. Weiler, Polarized tops from stop decays at the LHC. JHEP 03, 141 (2009). arXiv:0811.1024 [hep-ph]
T. Plehn, M. Spannowsky, M. Takeuchi, Boosted semileptonic tops in stop decays. JHEP 1105, 135 (2011). arXiv:1102.0557 [hep-ph]
J. Fan, M. Reece, J.T. Ruderman, A stealth supersymmetry sampler. JHEP 07, 196 (2012). arXiv:1201.4875 [hep-ph]
T. Plehn, M. Spannowsky, M. Takeuchi, Stop searches in 2012. JHEP 1208, 091 (2012). arXiv:1205.2696 [hep-ph]
D.S.M. Alves, M.R. Buckley, P.J. Fox, J.D. Lykken, C.-T. Yu, Stops and \(\lnot E_T\): the shape of things to come. Phys. Rev. D 87(3), 035016 (2013). arXiv:1205.5805 [hep-ph]
D.E. Kaplan, K. Rehermann, D. Stolarski, Searching for direct stop production in hadronic top data at the LHC. JHEP 1207, 119 (2012). arXiv:1205.5816 [hep-ph]
Z. Han, A. Katz, M. Son, B. Tweedie, Boosting searches for natural supersymmetry with R-parity violation via gluino cascades. Phys. Rev. D 87(7), 075003 (2013). arXiv:1211.4025 [hep-ph]
B. Bhattacherjee, S.K. Mandal, M. Nojiri, Top polarization and stop mixing from boosted jet substructure. JHEP 03, 105 (2013). arXiv:1211.7261 [hep-ph]
M.L. Graesser, J. Shelton, Hunting mixed top squark decays. Phys. Rev. Lett. 111(12), 121802 (2013). arXiv:1212.4495 [hep-ph]
A. Chakraborty, D.K. Ghosh, D. Ghosh, D. Sengupta, Stop and sbottom search using dileptonic \(M_{T2}\) variable and boosted top technique at the LHC. JHEP 10, 122 (2013). arXiv:1303.5776 [hep-ph]
G.D. Kribs, A. Martin, A. Menon, Natural supersymmetry and implications for Higgs physics. Phys. Rev. D 88, 035025 (2013). arXiv:1305.1313 [hep-ph]
Y. Bai, A. Katz, B. Tweedie, Pulling out all the stops: searching for RPV SUSY with stop-jets. JHEP 01, 040 (2014). arXiv:1309.6631 [hep-ph]
M. Czakon, A. Mitov, M. Papucci, J.T. Ruderman, A. Weiler, Closing the stop gap. Phys. Rev. Lett. 113(20), 201803 (2014). arXiv:1407.1043 [hep-ph]
G. Ferretti, R. Franceschini, C. Petersson, R. Torre, Spot the stop with a b-tag. Phys. Rev. Lett. 114, 201801 (2015). arXiv:1502.01721 [hep-ph]
G. Ferretti, R. Franceschini, C. Petersson, R. Torre, Light stop squarks and b-tagging. PoS CORFU2014, 076 (2015). arXiv:1506.00604 [hep-ph]]
J. Fan, R. Krall, D. Pinner, M. Reece, J.T. Ruderman, Stealth supersymmetry simplified. JHEP 07, 016 (2016). doi:10.1007/JHEP07(2016)016. arXiv:1512.05781 [hep-ph]
M. Drees, J.S. Kim, Minimal natural supersymmetry after the LHC8. Phys. Rev. D 93, 095005 (2016). doi:10.1103/PhysRevD.93.095005. arXiv:1511.04461 [hep-ph]
A. Kobakhidze, N. Liu, L. Wu, J.M. Yang, M. Zhang, Closing up a light stop window in natural SUSY at LHC. Phys. Lett. B 755, 76–81 (2016). arXiv:1511.02371 [hep-ph]
B. Kaufman, P. Nath, B.D. Nelson, A.B. Spisak, Light stops and observation of supersymmetry at LHC RUN-II. Phys. Rev. D 92, 095021 (2015). arXiv:1509.02530 [hep-ph]
H. An, L.-T. Wang, Opening up the compressed region of top squark searches at 13 TeV LHC. Phys. Rev. Lett. 115, 181602 (2015). arXiv:1506.00653 [hep-ph]
K.-I. Hikasa, J. Li, L. Wu, J.M. Yang, Single top squark production as a probe of natural supersymmetry at the LHC. Phys. Rev. D 93(3), 035003 (2016). arXiv:1505.06006 [hep-ph]
K. Rolbiecki, J. Tattersall, Refining light stop exclusion limits with \(W^+W^-\) cross sections. Phys. Lett. B 750, 247–251 (2015). arXiv:1505.05523 [hep-ph]
J. Beuria, A. Chatterjee, A. Datta, S.K. Rai, Two light stops in the NMSSM and the LHC. JHEP 09, 073 (2015). arXiv:1505.00604 [hep-ph]
B. Batell, S. Jung, Probing light stops with stoponium. JHEP 07, 061 (2015). arXiv:1504.01740 [hep-ph]
D. Barducci, A. Belyaev, A.K.M. Bharucha, W. Porod, V. Sanz, Uncovering natural supersymmetry via the interplay between the LHC and direct dark matter detection. JHEP 07, 066 (2015). arXiv:1504.02472 [hep-ph]
A. Crivellin, M. Hoferichter, M. Procura, L.C. Tunstall, Light stops, blind spots, and isospin violation in the MSSM. JHEP 07, 129 (2015). arXiv:1503.03478 [hep-ph]
T. Cohen, J. Kearney, M. Luty, Natural supersymmetry without light Higgsinos. Phys. Rev. D 91, 075004 (2015). arXiv:1501.01962 [hep-ph]
J. Eckel, S. Su, H. Zhang, Complex decay chains of top and bottom squarks. JHEP 07, 075 (2015). arXiv:1411.1061 [hep-ph]
J.A. Casas, J.M. Moreno, S. Robles, K. Rolbiecki, B. Zaldívar, What is a natural SUSY scenario? JHEP 06, 070 (2015). arXiv:1407.6966 [hep-ph]
D.A. Demir, C.S. Ün, Stop on top: SUSY parameter regions, fine-tuning constraints. Phys. Rev. D 90, 095015 (2014). arXiv:1407.1481 [hep-ph]
T. Cohen, R.T. D’Agnolo, M. Hance, H.K. Lou, J.G. Wacker, Boosting stop searches with a 100 TeV proton collider. JHEP 11, 021 (2014). arXiv:1406.4512 [hep-ph]
A. Katz, M. Reece, A. Sajjad, Naturalness, \(b \rightarrow s \gamma \), and SUSY heavy Higgses. JHEP 10, 102 (2014). arXiv:1406.1172 [hep-ph]
A. Mustafayev, X. Tata, Supersymmetry, naturalness, and light Higgsinos. Indian J. Phys. 88, 991–1004 (2014). arXiv:1404.1386 [hep-ph]
F. Brümmer, S. Kraml, S. Kulkarni, C. Smith, The flavour of natural SUSY. Eur. Phys. J. C 74(9), 3059 (2014). arXiv:1402.4024 [hep-ph]
C. Kim, A. Idilbi, T. Mehen, Y.W. Yoon, Production of stoponium at the LHC. Phys. Rev. D 89(7), 075010 (2014). arXiv:1401.1284 [hep-ph]
F. Brümmer, M. McGarrie, A. Weiler, Light third-generation squarks from flavour gauge messengers. JHEP 04, 078 (2014). arXiv:1312.0935 [hep-ph]
J.A. Evans, Y. Kats, D. Shih, M.J. Strassler, Toward full LHC coverage of natural supersymmetry. JHEP 07, 101 (2014). arXiv:1310.5758 [hep-ph]
ATLAS Collaboration, G. Aad et al., Search for a supersymmetric partner to the top quark in final states with jets and missing transverse momentum at \(\sqrt{s}=7\) TeV with the ATLAS detector. Phys. Rev. Lett. 109, 211802 (2012). arXiv:1208.1447 [hep-ex]
ATLAS Collaboration, G. Aad et al., Search for direct top squark pair production in final states with one isolated lepton, jets, and missing transverse momentum in \(\sqrt{s}=7\) TeV \(pp\) collisions using 4.7 \(fb^{-1}\) of ATLAS data. Phys. Rev. Lett. 109, 211803 (2012). arXiv:1208.2590 [hep-ex]
ATLAS Collaboration, G. Aad et al., Search for a heavy top-quark partner in final states with two leptons with the ATLAS detector at the LHC. JHEP 1211, 094 (2012). arXiv:1209.4186 [hep-ex]
ATLAS Collaboration, G. Aad et al., Search for top squark pair production in final states with one isolated lepton, jets, and missing transverse momentum in \(\sqrt{s} =8\) TeV \(pp\) collisions with the ATLAS detector. JHEP 1411, 118 (2014). arXiv:1407.0583 [hep-ex]
ATLAS Collaboration, G. Aad et al., Search for direct pair production of the top squark in all-hadronic final states in proton–proton collisions at \(\sqrt{s}=8\) TeV with the ATLAS detector. JHEP 1409, 015 (2014). arXiv:1406.1122 [hep-ex]
ATLAS Collaboration, G. Aad et al., Search for direct top-squark pair production in final states with two leptons in pp collisions at \(\sqrt{s} =8\) TeV with the ATLAS detector. JHEP 1406, 124 (2014). arXiv:1403.4853 [hep-ex]
ATLAS Collaboration, G. Aad et al., Measurement of spin correlation in top–antitop quark events and search for top squark pair production in pp collisions at \(\sqrt{s}=8\) TeV using the ATLAS detector. Phys. Rev. Lett. 114, 142001 (2015). doi:10.1103/PhysRevLett.114.142001. arXiv:1412.4742 [hep-ex]
ATLAS Collaboration, G. Aad et al., Search for pair-produced third-generation squarks decaying via charm quarks or in compressed supersymmetric scenarios in \(pp\) collisions at \(\sqrt{s}=8\) TeV with the ATLAS detector. Phys. Rev. D 90(5), 052008 (2014). arXiv:1407.0608 [hep-ex]
CMS Collaboration, V. Khachatryan et al., Search for top-squark pairs decaying into Higgs or Z bosons in pp collisions at \(\sqrt{s}=8\) TeV. Phys. Lett. B 736, 371–397 (2014). arXiv:1405.3886 [hep-ex]
CMS Collaboration, Search for top squarks decaying to a charm quark and a neutralino in events with a jet and missing transverse momentum. Technical Report. CMS-PAS-SUS-13-009, CERN, Geneva (2014)
CMS Collaboration, S. Chatrchyan et al., Search for top-squark pair production in the single-lepton final state in pp collisions at \(\sqrt{s} = 8\) TeV. Eur. Phys. J. C 73(12), 2677 (2013). arXiv:1308.1586 [hep-ex]
CMS Collaboration, Search for top squarks in multijet events with large missing momentum in proton–proton collisions at 8 TeV. Technical Report. CMS-PAS-SUS-13-015, CERN, Geneva (2013)
CMS Collaboration, Exclusion limits on gluino and top-squark pair production in natural SUSY scenarios with inclusive razor and exclusive single-lepton searches at 8 TeV. Technical Report. CMS-PAS-SUS-14-011, CERN, Geneva (2014)
CMS Collaboration, S. Chatrchyan et al., Search for anomalous production of events with three or more leptons in \(pp\) collisions at \(\sqrt{(s)} =8\) TeV. Phys. Rev. D 90(3), 032006 (2014). arXiv:1404.5801 [hep-ex]
CMS Collaboration, Search for supersymmetry in pp collisions at sqrt(s) = 8 TeV in events with three leptons and at least one b-tagged jet. Technical Report. CMS-PAS-SUS-13-008, CERN, Geneva (2013)
CMS Collaboration, S. Chatrchyan et al., Search for new physics in events with same-sign dileptons and jets in pp collisions at \(\sqrt{s}=8\) TeV. JHEP 1401, 163 (2014). arXiv:1311.6736
I.-W. Kim, M. Papucci, K. Sakurai, A. Weiler, ATOM: automated testing of models (in preparation)
R. Mahbubani, M. Papucci, G. Perez, J.T. Ruderman, A. Weiler, Light nondegenerate squarks at the LHC. Phys. Rev. Lett. 110(15), 151804 (2013). arXiv:1212.3328 [hep-ph]
M. Papucci, K. Sakurai, A. Weiler, L. Zeune, Fastlim: a fast LHC limit calculator. Eur. Phys. J. C 74(11), 3163 (2014). arXiv:1402.0492 [hep-ph]
M. Drees, H. Dreiner, D. Schmeier, J. Tattersall, J.S. Kim, CheckMATE: confronting your favourite new physics model with LHC data. Comput. Phys. Commun. 187, 227–265 (2014). arXiv:1312.2591 [hep-ph]
B. Dumont, B. Fuks, S. Kraml, S. Bein, G. Chalons, E. Conte, S. Kulkarni, D. Sengupta, C. Wymant, Toward a public analysis database for LHC new physics searches using MADANALYSIS 5. Eur. Phys. J. C 75(2), 56 (2015). arXiv:1407.3278 [hep-ph]
S. Kraml, S. Kulkarni, U. Laa, A. Lessa, W. Magerl, D. Proschofsky-Spindler, W. Waltenberger, SModelS: a tool for interpreting simplified-model results from the LHC and its application to supersymmetry. Eur. Phys. J. C 74, 2868 (2014). arXiv:1312.4175 [hep-ph]
M. Gouzevitch, A. Oliveira, J. Rojo, R. Rosenfeld, G.P. Salam, V. Sanz, Scale-invariant resonance tagging in multijet events and new physics in Higgs pair production. JHEP 07, 148 (2013). arXiv:1303.6636 [hep-ph]
A. Azatov, M. Salvarezza, M. Son, M. Spannowsky, Boosting top partner searches in composite Higgs models. Phys. Rev. D 89(7), 075001 (2014). arXiv:1308.6601 [hep-ph]
R. Barbieri, G.F. Giudice, Upper bounds on supersymmetric particle masses. Nucl. Phys. B 306, 63 (1988)
B. de Carlos, J.A. Casas, One loop analysis of the electroweak breaking in supersymmetric models and the fine tuning problem. Phys. Lett. B 309 (1993) 320–328. arXiv:hep-ph/9303291 [hep-ph]
G.W. Anderson, D.J. Castano, Measures of fine tuning. Phys. Lett. B 347, 300–308 (1995). arXiv:hep-ph/9409419 [hep-ph]
M. Papucci, J.T. Ruderman, A. Weiler, Natural SUSY endures. JHEP 1209, 035 (2012). arXiv:1110.6926 [hep-ph]
J.M. Butterworth, A.R. Davison, M. Rubin, G.P. Salam, Jet substructure as a new Higgs search channel at the LHC. Phys. Rev. Lett. 100, 242001 (2008). arXiv:0802.2470 [hep-ph]
T. Plehn, G.P. Salam, M. Spannowsky, Fat jets for a light Higgs. Phys. Rev. Lett. 104, 111801 (2010). arXiv:0910.5472 [hep-ph]
T. Plehn, M. Spannowsky, M. Takeuchi, D. Zerwas, Stop reconstruction with tagged tops. JHEP 1010, 078 (2010). arXiv:1006.2833 [hep-ph]
A. Abdesselam et al., Boosted objects: a probe of beyond the standard model physics. Eur. Phys. J. C 71, 1661 (2011). arXiv:1012.5412 [hep-ph]
T. Plehn, M. Spannowsky, Top tagging. J. Phys. G 39, 083001 (2012). arXiv:1112.4441 [hep-ph]
A. Altheimer et al., Jet substructure at the Tevatron and LHC: new results, new tools, new benchmarks. J. Phys. G 39, 063001 (2012). arXiv:1201.0008 [hep-ph]
A. Djouadi, M. Muhlleitner, M. Spira, Decays of supersymmetric particles: the program SUSY-HIT (SUspect-SdecaY-Hdecay-InTerface). Acta Phys. Polon. B 38, 635–644 (2007). arXiv:hep-ph/0609292 [hep-ph]
J. Alwall, R. Frederix, S. Frixione, V. Hirschi, F. Maltoni et al., The automated computation of tree-level and next-to-leading order differential cross sections, and their matching to parton shower simulations. JHEP 07, 079 (2014). doi:10.1007/JHEP07(2014)079. arXiv:1405.0301 [hep-ph]
M.L. Mangano, M. Moretti, R. Pittau, Multijet matrix elements and shower evolution in hadronic collisions: \(W b \bar{b}\) + \(n\) jets as a case study. Nucl. Phys. B 632, 343–362 (2002). arXiv:hep-ph/0108069 [hep-ph]
S. Hoeche, F. Krauss, N. Lavesson, L. Lonnblad, M. Mangano et al., Matching parton showers and matrix elements, in HERA and the LHC: A Workshop on the implications of HERA for LHC physics: Proceedings Part A (2006). arXiv:hep-ph/0602031 [hep-ph]. https://inspirehep.net/record/709818/files/arXiv:hep-ph_0602031.pdf
T. Sjostrand, S. Mrenna, P.Z. Skands, PYTHIA 6.4 physics and manual. JHEP 0605, 026 (2006). arXiv:hep-ph/0603175 [hep-ph]
P. Lenzi, J. Butterworth, A study on matrix element corrections in inclusive Z/gamma* production at LHC as implemented in PYTHIA, HERWIG, ALPGEN and SHERPA. arXiv:0903.3918 [hep-ph]
W. Beenakker, M. Kramer, T. Plehn, M. Spira, P. Zerwas, Stop production at hadron colliders. Nucl. Phys. B 515, 3–14 (1998). arXiv:hep-ph/9710451 [hep-ph]
W. Beenakker, S. Brensing, M. Kramer, A. Kulesza, E. Laenen et al., Supersymmetric top and bottom squark production at hadron colliders. JHEP 1008, 098 (2010). arXiv:1006.4771 [hep-ph]
W. Beenakker, S. Brensing, M. Kramer, A. Kulesza, E. Laenen et al., Squark and gluino hadroproduction. Int. J. Mod. Phys. A 26, 2637–2664 (2011). arXiv:1105.1110 [hep-ph]
A. Kardos, Z. Trocsanyi, C. Papadopoulos, Top quark pair production in association with a Z-boson at NLO accuracy. Phys. Rev. D 85, 054015 (2012). arXiv:1111.0610 [hep-ph]
M. Czakon, P. Fiedler, A. Mitov, Total top-quark pair-production cross section at hadron colliders through \(O(\alpha ^4_S)\). Phys. Rev. Lett. 110, 252004 (2013). arXiv:1303.6254 [hep-ph]
A. Buckley, J. Butterworth, L. Lonnblad, D. Grellscheid, H. Hoeth et al., Rivet user manual. Comput. Phys. Commun. 184, 2803–2819 (2013). arXiv:1003.0694 [hep-ph]
M. Cacciari, G.P. Salam, G. Soyez, FastJet user manual. Eur. Phys. J. C 72, 1896 (2012). arXiv:1111.6097 [hep-ph]
M. Cacciari, G.P. Salam, G. Soyez, The anti-\(k_t\) jet clustering algorithm. JHEP 0804, 063 (2008). arXiv:0802.1189 [hep-ph]
Y.L. Dokshitzer, G. Leder, S. Moretti, B. Webber, Better jet clustering algorithms. JHEP 9708, 001 (1997). arXiv:hep-ph/9707323 [hep-ph]
M. Wobisch, T. Wengler, Hadronization corrections to jet cross-sections in deep inelastic scattering in Monte Carlo generators for HERA physics. Proceedings, Workshop, Hamburg, Germany, 1998–1999 (1998), pp. 270–279. arXiv:hep-ph/9907280 [hep-ph]. https://inspirehep.net/record/484872/files/arXiv:hep-ph_9907280.pdf
C. Lester, D. Summers, Measuring masses of semiinvisibly decaying particles pair produced at hadron colliders. Phys. Lett. B 463, 99–103 (1999). arXiv:hep-ph/9906349 [hep-ph]
A. Barr, C. Lester, P. Stephens, m(T2): the truth behind the glamour. J. Phys. G 29, 2343–2363 (2003). arXiv:hep-ph/0304226 [hep-ph]
H.-C. Cheng, Z. Han, Minimal kinematic constraints and m(T2). JHEP 0812, 063 (2008). arXiv:0810.5178 [hep-ph]
T. Junk, Confidence level computation for combining searches with small statistics. Nucl. Instrum. Methods A 434, 435–443 (1999). arXiv:hep-ex/9902006 [hep-ex]
A.L. Read, Presentation of search results: the CL(s) technique. J. Phys. G 28, 2693–2704 (2002)
T. Junk, Sensitivity, exclusion and discovery with small signals, large backgrounds, and large systematic uncertainties (2007). https://plone4.fnal.gov:4430/P0/phystat/packages/0711001
H.-C. Cheng, I. Low, TeV symmetry and the little hierarchy problem. JHEP 0309, 051 (2003). arXiv:hep-ph/0308199 [hep-ph]
H.-C. Cheng, I. Low, Little hierarchy, little Higgses, and a little symmetry. JHEP 0408, 061 (2004). arXiv:hep-ph/0405243 [hep-ph]
H.-C. Cheng, I. Low, L.-T. Wang, Top partners in little Higgs theories with T-parity. Phys. Rev. D 74, 055001 (2006). arXiv:hep-ph/0510225 [hep-ph]
Acknowledgments
We are grateful to Rakhi Mahbubani and Minho Son for helpful discussions and support in the initial phase of this project. AW and MSc thank the CERN TH division for hospitality and computing resources and MSc thanks the Joachim Herz Stiftung for funding his work.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funded by SCOAP3.
About this article

Cite this article
Schlaffer, M., Spannowsky, M. & Weiler, A. Searching for supersymmetry scalelessly. Eur. Phys. J. C 76, 457 (2016). https://doi.org/10.1140/epjc/s10052-016-4299-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-016-4299-y