
Abstract
A new framework is presented for evaluating the performance of self-consistent field methods in Kohn–Sham density functional theory (DFT). The aims of this work are two-fold. First, we explore the properties of Kohn–Sham DFT as it pertains to the convergence of self-consistent field iterations. Sources of inefficiencies and instabilities are identified, and methods to mitigate these difficulties are discussed. Second, we introduce a framework to assess the relative utility of algorithms in the present context, comprising a representative benchmark suite of over fifty Kohn–Sham simulation inputs, the scf-xn suite. This provides a new tool to develop, evaluate and compare new algorithms in a fair, well-defined and transparent manner.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Preface
Compute power, which refers here to both the performance and accessibility of computer hardware, has grown significantly over the past half-century. This increase has led to the rise of computational science as a discipline. In the present context, we are concerned with the hierarchy of methods that has emerged for calculating the properties of molecular and solid state systems by approximating the Schrödinger equation [1–3]. In particular, the most prominent method from this hierarchy over the past few decades has proven to be density functional theory (DFT) within the Kohn–Sham framework [4, 5]. For a variety of reasons, practitioners in both the physics and chemistry communities have deemed this level of theory appropriate to tackle a range of problems at an acceptable computational cost [6–8]. It is, therefore, of paramount importance that implementations of Kohn–Sham DFT optimally utilise the available computational resources.
Many distinct implementations to Kohn–Sham theory exist, differing according to the choice of basis set, whether to use a density matrix or explicit wavefunction formulation etc, each with advantages and disadvantages in the computational domain [2, 9–18]. When one has decided on such an approach, its effectiveness is limited by the efficiency and reliability of the available numerical algorithms. This work reviews an aspect of Kohn–Sham theory that is more-or-less universal across many of these approaches; that is, how one iterates a density towards so-called self-consistency. This is conventionally referred to as the self-consistent field procedure, and is the most common source of numerical divergence when solving the equations of Kohn–Sham theory in silico [19]. This work examines the effectiveness of the methods and algorithms used in the self-consistent field procedure, reviewing a wide range of available methods drawn from the literature, studying the causes of divergences and inefficiencies and exploring how the available algorithms mitigate these potential issues. In order to assess the performance of the algorithms, a test suite is presented comprising a wide range of representative simulations. This test suite allows the algorithms to be judged according to both their robustness (ability to find a solution to the Kohn–Sham equations) and efficiency (speed with which a given solution is found) in a transparent and unbiased manner. The test suite and the associated workflow constitute a powerful new framework for the development, testing and assessment of new methods and algorithms. Throughout this work care has been taken to present the wide range of different methods in a consistent way, such that the similarities and differences of the methods are readily apparent.
2. Introduction
2.1. Background
The concept of self-consistency has been prevalent across many domains of physics, typically as a characteristic requirement when one invokes a mean-field approximation. For example, Hartree theory replaces the two-body Coulomb interaction between electrically-charged quantum particles with a mean-field, the Hartree potential, generated by the distribution of the electric charge in the system. Each particle is influenced by the Hartree potential, which in turn alters the distribution of charge in the system. This charge distribution can then be used to construct a new Hartree potential. The Hartree potential is self-consistent when these two fields are the same, i.e. the potential leads to a charge distribution which gives rise to the same potential. In fact, this was the context in which self-consistency was first introduced,
'If the final field is the same as the initial field, the field will be called 'self-consistent', and the determination of self-consistent fields for various atoms is the main object of this paper'.
–D.R. Hartree (1927) [20].
Later refined by Fock [21] and Slater [22], Hartree–Fock theory became widely adopted in computational quantum chemistry to compute ground state properties of molecules [3]. Whilst Hartree and Hartree–Fock theory are mean-field approximations, Hohenberg et al [5, 23] showed that a mean-field exists which reproduces the ground-state energy and particle density exactly. This 'density functional theory' allows, in principle, the computation of the exact electronic structure of any quantum system; however the exact density functional is not known, and must be approximated in any practical application of DFT. For a more detailed examination of the origins and physical foundations of Kohn–Sham theory, the reader is directed to the following resources [1, 4, 24], and references therein.
This work concerns the need to achieve self-consistency in the context of DFT simulations of atoms, molecules and materials. Namely, we focus on computing the particle density  for a set of atomic species and positions within the framework of Kohn–Sham DFT. Each of the N particles in the system are influenced by an external potential
for a set of atomic species and positions within the framework of Kohn–Sham DFT. Each of the N particles in the system are influenced by an external potential  which is uniquely defined by the species and positions of the atoms, the level of approximation employed, and more. For the purposes of this article, finding the ground state energy E in Kohn–Sham theory is viewed as a constrained minimisation problem,
which is uniquely defined by the species and positions of the atoms, the level of approximation employed, and more. For the purposes of this article, finding the ground state energy E in Kohn–Sham theory is viewed as a constrained minimisation problem,


where atomic units are used, and, for now, spin degrees of freedom are omitted. The particle density,  , is defined in terms of the single-particle orbitals,
, is defined in terms of the single-particle orbitals,  , via
, via

That is, one must minimise the Kohn–Sham objective functional equation (1) over a set of N orthogonal, normalisable functions  whose first derivative is also normalisable, i.e. they exist in the Sobolev space
whose first derivative is also normalisable, i.e. they exist in the Sobolev space  . The exchange-correlation functional
. The exchange-correlation functional  is a yet undetermined functional of the density designed to capture the effects of exchange and correlation missing from the remainder of the functional. In principle, the Hohenberg–Kohn theorems guarantee that the Kohn–Sham objective functional is a functional of the density alone [23]. However, in the case of Kohn–Sham theory, recourse to an orbital-dependent functional is necessitated by the definition of the single-particle kinetic energy.
is a yet undetermined functional of the density designed to capture the effects of exchange and correlation missing from the remainder of the functional. In principle, the Hohenberg–Kohn theorems guarantee that the Kohn–Sham objective functional is a functional of the density alone [23]. However, in the case of Kohn–Sham theory, recourse to an orbital-dependent functional is necessitated by the definition of the single-particle kinetic energy.
Explicit constrained variation of the orbitals allows one to approach the optimisation problem in equation (1) directly. This can be done, for example, with a series of line searches in the direction of steepest descent of  with respect to the orbitals [25, 26]. Alternatively, assuming differentiability [27], the associated Lagrangian problem can be formulated, and the functional derivative of the Lagrangian set to zero. This yields the Euler–Lagrange equations for the problem, the solution of which is a stationary point of the functional. In the present context, the Euler–Lagrange equations constitute a nonlinear eigenvalue problem,
with respect to the orbitals [25, 26]. Alternatively, assuming differentiability [27], the associated Lagrangian problem can be formulated, and the functional derivative of the Lagrangian set to zero. This yields the Euler–Lagrange equations for the problem, the solution of which is a stationary point of the functional. In the present context, the Euler–Lagrange equations constitute a nonlinear eigenvalue problem,

where the Hamiltonian operator  depends on its eigenvectors via
depends on its eigenvectors via



These are the Kohn–Sham equations. The eigenvalues (quasi-particle energies)  are the Lagrange multipliers associated with the orbital orthonormality constraint. Solving the Kohn–Sham equations to find a stationary point of the Kohn–Sham functional is a necessary but not sufficient condition for (local) optimality. A sufficient condition would require the second derivative (curvature) about the stationary point to be everywhere positive. Furthermore, in general, the Kohn–Sham functional for some approximate
are the Lagrange multipliers associated with the orbital orthonormality constraint. Solving the Kohn–Sham equations to find a stationary point of the Kohn–Sham functional is a necessary but not sufficient condition for (local) optimality. A sufficient condition would require the second derivative (curvature) about the stationary point to be everywhere positive. Furthermore, in general, the Kohn–Sham functional for some approximate  is not a convex functional of the orbitals, meaning that verifying global optimality is a difficult task. In practice, solving the Kohn–Sham equations with certain methods of biasing the solution toward a (possibly local) minimum are often chosen rather than direct minimisation methods [28]. The advantages and drawbacks of each approach will be examined in section 4.
is not a convex functional of the orbitals, meaning that verifying global optimality is a difficult task. In practice, solving the Kohn–Sham equations with certain methods of biasing the solution toward a (possibly local) minimum are often chosen rather than direct minimisation methods [28]. The advantages and drawbacks of each approach will be examined in section 4.
It is now possible to formally define what is meant by self-consistency. In order to construct the Kohn–Sham Hamiltonian, one requires a density as input  to compute the Hartree and exchange-correlation potentials. An output density
to compute the Hartree and exchange-correlation potentials. An output density  is then calculated (non-linearly) from the eigenfunctions of the Kohn–Sham Hamiltonian
is then calculated (non-linearly) from the eigenfunctions of the Kohn–Sham Hamiltonian


In general, the input density is not equal to the output density. For a given external potential and exchange-correlation functional, the density  is self-consistent when
is self-consistent when  , and hence the non-linear eigenvalue problem of equations (8) and (9) is solved. The non-linearity in equation (9) necessitates an iterative procedure that takes an initial estimate of the density as input and iterates this density toward a self-consistent solution of the Kohn–Sham equations: the self-consistent field procedure, figure 1. As one might expect, an infinity of self-consistent densities exist for a given external potential and exchange-correlation functional [29]. However, we are interested primarily in the subset of these densities that are local minima of the Kohn–Sham objective functional.
, and hence the non-linear eigenvalue problem of equations (8) and (9) is solved. The non-linearity in equation (9) necessitates an iterative procedure that takes an initial estimate of the density as input and iterates this density toward a self-consistent solution of the Kohn–Sham equations: the self-consistent field procedure, figure 1. As one might expect, an infinity of self-consistent densities exist for a given external potential and exchange-correlation functional [29]. However, we are interested primarily in the subset of these densities that are local minima of the Kohn–Sham objective functional.

Figure 1. An iterative algorithm generates a series of perturbations to the density  in order to converge the initial guess density (top) to the fixed-point density
in order to converge the initial guess density (top) to the fixed-point density  (bottom). Example for an fcc four atom aluminium unit cell.
(bottom). Example for an fcc four atom aluminium unit cell.
Download figure:
Standard image High-resolution imageModern computational implementations of Kohn–Sham theory can vary significantly due to various factors. The key distinguishing factor is the choice of basis set, which leads to the related problem of whether one treats all the electrons in the computation explicitly, or treats core electrons with a pseudopotential [30]. Despite these differences, perhaps with the exception of linear scaling methods [14], the self-consistent field techniques to be discussed here are adaptable to most implementations. Indeed, some of the most popular software, such as vasp [15, 31], abinit [10, 32], quantum espresso [33], and castep [34], use similar default methods to achieve self-consistency: preconditioned multisecant methods, which are discussed in section 4.
2.2. Review purpose and structure
The overarching goal of this work is to quantify the utility of a given algorithm for reaching self-consistency in Kohn–Sham theory. In turn, this allows us to compare and analyse the performance of a sample of existing algorithms from the literature. Assessing these algorithms requires the creation of a test suite of Kohn–Sham inputs, representative of a range of numerical issues. This test suite generates a standard which can be used to test, improve, and present new algorithms designed by method developers. Furthermore, the test suite allows DFT developers to more effectively assess which algorithms they wish to implement. With these aims in mind, this article is structured in two partitions, as follows.
The first part constitutes a review of self-consistency in Kohn–Sham theory. As such, the relevant sections are ideal for an interested party who is not actively involved in development to gain a more in-depth understanding of self-consistency from an algorithmic perspective. In particular, this review collates decades of past literature on self-consistency in Kohn–Sham theory, thus elucidating conclusions that have become conventional wisdom. Section 3 examines the Kohn–Sham framework abstractly from a mathematical and computational perspective in order to study where and why algorithms encounter difficulties. This involves, for example, a discussion on the nature of so-called 'charge-sloshing', the initial guess density, sources of ill-conditioning, and more. Section 4 then examines and categorises the range of available algorithms in present literature. A focus will be placed on detailing the algorithms which have proven to be particularly successful.
The second part then utilises the analysis presented in the prior sections to perform a study akin to recent benchmarking efforts such as GW100 [35] and the  -project [36] for assessing reproducibility in GW and DFT codes respectively. Whilst the study presented here will take on a similar structure to these examples, it differs in the following way. The aim of the
-project [36] for assessing reproducibility in GW and DFT codes respectively. Whilst the study presented here will take on a similar structure to these examples, it differs in the following way. The aim of the  -project is to assess an 'error' for each DFT software in a given computable property compared to a reference software over a set of test systems. Here, we instead aim to assess the utility of an algorithm, rather than an error, which we do with two competing measures: efficiency and robustness, defined in section 5. A test suite of Kohn–Sham inputs is then constructed to target weaknesses in contemporary algorithms and exploit the difficulties discussed in section 3. This test suite is designed to be representative of the range of systems practitioners may encounter and with which they may have difficulties reaching convergence. Each algorithm is then assigned a robustness and efficiency score when tested over the full suite. The methods of Pareto analysis then provide a prescription for the definition of optimal when there exist two or more competing measures of utility. Section 6 demonstrates these concepts by using this workflow on a selection of algorithms described in section 4, implemented in the plane-wave, pseudopotential software castep. This study allows conclusions to be drawn about the current state of self-consistency algorithms in Kohn–Sham codes. Finally, we discuss how one might utilise the test suite and workflow demonstrated here to present and assess future methods and algorithms.
-project is to assess an 'error' for each DFT software in a given computable property compared to a reference software over a set of test systems. Here, we instead aim to assess the utility of an algorithm, rather than an error, which we do with two competing measures: efficiency and robustness, defined in section 5. A test suite of Kohn–Sham inputs is then constructed to target weaknesses in contemporary algorithms and exploit the difficulties discussed in section 3. This test suite is designed to be representative of the range of systems practitioners may encounter and with which they may have difficulties reaching convergence. Each algorithm is then assigned a robustness and efficiency score when tested over the full suite. The methods of Pareto analysis then provide a prescription for the definition of optimal when there exist two or more competing measures of utility. Section 6 demonstrates these concepts by using this workflow on a selection of algorithms described in section 4, implemented in the plane-wave, pseudopotential software castep. This study allows conclusions to be drawn about the current state of self-consistency algorithms in Kohn–Sham codes. Finally, we discuss how one might utilise the test suite and workflow demonstrated here to present and assess future methods and algorithms.
3. Self-consistency in Kohn–Sham theory
In computational implementations of Kohn–Sham theory, when a user has supplied the external potential (e.g. atomic species and positions) and exchange-correlation approximation, the Kohn–Sham energy functional is completely specified. The remaining parameters that are not related to self-consistency, such as Brillouin-zone sampling ('k-point sampling'), symmetry tolerances, and so on, tune either the accuracy or efficiency of the calculation. In the context of self-consistency, the user has control over a variety of parameters that can alter the convergence properties of the calculation. Hence, if a calculation is diverging due to the self-consistent field iterations (or converging inefficiently), the user has two options: adjust the parameters of the self-consistency method, or switch to a more reliable fall-back method. This section elucidates the self-consistent field iterations so one can more transparently see why one's iterations may be divergent or inefficient. No claim is made for providing a strictly detailed and rigorous treatment of the mathematical problem at hand. Instead, literature is cited throughout such that the interested reader can venture further in detail than this article provides.
3.1. Computational implementation
The central approximation involved in converting the framework of Kohn–Sham theory into a form suitable for computation is called the finite-basis approximation, or the Galerkin approximation [28]. The orbitals  are continuous functions of a continuous three dimensional variable, x. These functions are equivalent to vectors existing in an infinite dimensional vector space, spanned by a complete basis
are continuous functions of a continuous three dimensional variable, x. These functions are equivalent to vectors existing in an infinite dimensional vector space, spanned by a complete basis  . Provided this basis does indeed span the space, the orbitals can be expressed exactly as
. Provided this basis does indeed span the space, the orbitals can be expressed exactly as

Note that the basis set is required to be complete, but not necessarily orthogonal,

If the basis is non-orthogonal, the finite-basis Kohn–Sham equations generalise to include the overlap matrix,  , see [28] for more details. This distinction does not affect the ensuing analysis, and so the basis set is hereafter taken to be orthogonal for clarity. Once the basis is specified, the equations can be rearranged and solved for the infinity of coefficients to the basis
, see [28] for more details. This distinction does not affect the ensuing analysis, and so the basis set is hereafter taken to be orthogonal for clarity. Once the basis is specified, the equations can be rearranged and solved for the infinity of coefficients to the basis  . In practice, one must truncate the basis such that it is no longer complete and instead captures only the most relevant regions of the formally infinite Hilbert space,
. In practice, one must truncate the basis such that it is no longer complete and instead captures only the most relevant regions of the formally infinite Hilbert space,

The characteristic size of the basis Nb will depend primarily on the choice of basis functions. Within the finite-basis approximation, the Kohn–Sham Hamiltonian becomes an  matrix, of which a subset of the eigenvalues and eigenvectors is required to progress toward a solution of the non-linear eigenvalue problem, equations (8) and (9). Basis functions which are localised about the atomic cores [37] are a popular choice. These tend to be particularly accurate per basis function, meaning Nb is typically the same order of magnitude as the number of electrons, N. Methods utilising local basis functions are often able to form and diagonalise the Kohn–Sham Hamiltonian matrix explicitly. In such implementations, the Kohn–Sham energy functional can be expressed in terms of the density matrix,
matrix, of which a subset of the eigenvalues and eigenvectors is required to progress toward a solution of the non-linear eigenvalue problem, equations (8) and (9). Basis functions which are localised about the atomic cores [37] are a popular choice. These tend to be particularly accurate per basis function, meaning Nb is typically the same order of magnitude as the number of electrons, N. Methods utilising local basis functions are often able to form and diagonalise the Kohn–Sham Hamiltonian matrix explicitly. In such implementations, the Kohn–Sham energy functional can be expressed in terms of the density matrix,


rather than the orbitals, where the density matrix is also of dimension  . The Kohn–Sham energy functional has a closed-form expression in terms of the density matrix (see [28] and section 4.2), and therefore the constrained optimisation in equation (1) becomes an optimisation over allowed variations in the density matrix. From the point of view of the work to follow, the ability to construct, store, and optimise the density matrix directly is the distinguishing characteristic of localised basis sets with respect to the basis set considered in the following work: namely, the set of Nb plane-waves,
. The Kohn–Sham energy functional has a closed-form expression in terms of the density matrix (see [28] and section 4.2), and therefore the constrained optimisation in equation (1) becomes an optimisation over allowed variations in the density matrix. From the point of view of the work to follow, the ability to construct, store, and optimise the density matrix directly is the distinguishing characteristic of localised basis sets with respect to the basis set considered in the following work: namely, the set of Nb plane-waves,

with the same periodicity as the unit cell [15, 31], labelled by the frequency of the plane-wave G. This basis set is delocalised, meaning the functions  are non-zero across the whole unit cell. The introduction of a delocalised basis results in a reduction in accuracy per basis function, which in turn necessitates a much larger value of Nb to reproduce the same accuracy as a computation using localised basis sets. The advantage of a plane-wave, or similar, basis set lies elsewhere [15, 31]. This will become relevant in section 4, as certain algorithms exploit the ability to construct
are non-zero across the whole unit cell. The introduction of a delocalised basis results in a reduction in accuracy per basis function, which in turn necessitates a much larger value of Nb to reproduce the same accuracy as a computation using localised basis sets. The advantage of a plane-wave, or similar, basis set lies elsewhere [15, 31]. This will become relevant in section 4, as certain algorithms exploit the ability to construct  explicitly. Nevertheless, much of the analysis to follow in this section will remain largely independent of basis set. The discussion will, however, be framed in the language of an entirely plane-wave basis set.
explicitly. Nevertheless, much of the analysis to follow in this section will remain largely independent of basis set. The discussion will, however, be framed in the language of an entirely plane-wave basis set.
3.2. The Kohn–Sham map
As already stated, Kohn–Sham theory is a constrained optimisation problem, equation (1). The associated Euler–Lagrange equations provide a method for transforming the optimisation problem into a fixed-point problem: the Kohn–Sham equations. That is, we seek the density  such that it is a fixed-point of the discretised Kohn–Sham map,
such that it is a fixed-point of the discretised Kohn–Sham map,


In general, ![$K[\rho^{{\rm in}}] = \rho^{{\rm out}}$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn029.gif) , where K is defined using equations (8) and (9). That is, K takes an input density which is used to construct the Hartree and exchange-correlation potentials, then the associated Kohn–Sham Hamiltonian is diagonalised, and an output density is constructed as the sum of the square of N eigenfunctions. Formally, the Kohn–Sham map is a map from the set of non-interacting
, where K is defined using equations (8) and (9). That is, K takes an input density which is used to construct the Hartree and exchange-correlation potentials, then the associated Kohn–Sham Hamiltonian is diagonalised, and an output density is constructed as the sum of the square of N eigenfunctions. Formally, the Kohn–Sham map is a map from the set of non-interacting  -representable densities onto itself. Here, a non-interacting
-representable densities onto itself. Here, a non-interacting  -representable density is a density that can be constructed via equation (9) for a given Kohn–Sham Hamiltonian. The 'size' of this set, as a subset of
-representable density is a density that can be constructed via equation (9) for a given Kohn–Sham Hamiltonian. The 'size' of this set, as a subset of  , is an open problem [27]. Hence, it is entirely possible that algorithms generate input densities that are not non-interacting
, is an open problem [27]. Hence, it is entirely possible that algorithms generate input densities that are not non-interacting  -representable; however this appears to not be an issue in practice4. The aim now is to generate a converging sequence of densities
-representable; however this appears to not be an issue in practice4. The aim now is to generate a converging sequence of densities  starting from an initial guess density
starting from an initial guess density  , where
, where  to within some desired tolerance. The ease with which this sequence can be generated in practice depends on the functional properties of K, which are examined later in this section.
to within some desired tolerance. The ease with which this sequence can be generated in practice depends on the functional properties of K, which are examined later in this section.
3.3. Defining convergence
The Kohn–Sham map K, can be used to define a new map R, the residual

which transforms the fixed-point problem into a root-finding problem. An absolute scalar measure of convergence is thus provided by the norm of the residual ![$||R[\rho^{{\rm in}}]||_2$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn037.gif) , where ||.||2 is used to denote the vector L2-norm. However, ||R||2 is a quantity which lacks transparent physical interpretation, making it difficult to assess just how converged a calculation is by consideration of ||R||2 alone. Hence, convergence is conventionally defined in terms of fluctuations in the total energy, a more tractable measure. When fluctuations in the total energy are sufficiently low to satisfy the accuracy requirements of the users' calculation, the iterations are terminated and the calculation is converged. In practice, the total energy is often not calculated by evaluating the Kohn–Sham energy functional
, where ||.||2 is used to denote the vector L2-norm. However, ||R||2 is a quantity which lacks transparent physical interpretation, making it difficult to assess just how converged a calculation is by consideration of ||R||2 alone. Hence, convergence is conventionally defined in terms of fluctuations in the total energy, a more tractable measure. When fluctuations in the total energy are sufficiently low to satisfy the accuracy requirements of the users' calculation, the iterations are terminated and the calculation is converged. In practice, the total energy is often not calculated by evaluating the Kohn–Sham energy functional ![$E_{\tiny{\rm KS}}[\rho_n^{{\rm in}}]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn038.gif) . Instead, the Harris-Foulkes functional
. Instead, the Harris-Foulkes functional  is defined [38],
is defined [38],

which can be shown to give the exact ground state energy correct to quadratic order in the density error about the fixed-point density  —i.e. it is correct to
—i.e. it is correct to  . Note that it is not the Harris-Foulkes functional that is minimised during the computation, as it possesses incorrect behaviour away from
. Note that it is not the Harris-Foulkes functional that is minimised during the computation, as it possesses incorrect behaviour away from  [39, 40]. However, evaluating the energy using this functional when near
[39, 40]. However, evaluating the energy using this functional when near  allows one to terminate the iterations at a desired accuracy earlier than if one evaluates the energy using the Kohn–Sham functional, which is correct to linear order in the density. Finally, recall that
allows one to terminate the iterations at a desired accuracy earlier than if one evaluates the energy using the Kohn–Sham functional, which is correct to linear order in the density. Finally, recall that  is the criterion for solving the Kohn–Sham equations, not for finding a minimum of the Kohn–Sham functional. Indeed, to verify that a local minimiser of the Kohn–Sham functional is obtained, one would need to ensure all eigenvalues of the Hessian were positive. Such a procedure is not practical in plane-wave codes, and hence the exit criterion for algorithms in section 4 is based solely on fluctuations in the total energy.
is the criterion for solving the Kohn–Sham equations, not for finding a minimum of the Kohn–Sham functional. Indeed, to verify that a local minimiser of the Kohn–Sham functional is obtained, one would need to ensure all eigenvalues of the Hessian were positive. Such a procedure is not practical in plane-wave codes, and hence the exit criterion for algorithms in section 4 is based solely on fluctuations in the total energy.
3.4. Some unique properties of K
Identifying properties unique to K can help guide and narrow the choice of algorithms in section 4. Firstly, we note that it is computationally expensive to 'query the oracle', meaning evaluate K for a given input density to generate the pair  on the ith iteration. This is because, when one has specified
on the ith iteration. This is because, when one has specified  , finding the corresponding
, finding the corresponding  requires one to construct and diagonalise the Kohn–Sham Hamiltonian. In plane-wave codes, this diagonalisation is done iteratively, and only the relevant N eigenfunctions and eigenvalues are computed. This procedure scales as approximately
requires one to construct and diagonalise the Kohn–Sham Hamiltonian. In plane-wave codes, this diagonalisation is done iteratively, and only the relevant N eigenfunctions and eigenvalues are computed. This procedure scales as approximately  , and is (in a sense) the bottleneck of the computation [15]. Hence, an algorithm that uses all past iterative data optimally so as to reduce evaluations of K is desirable. Here, the past iterative data constitutes the set of n iterative density pairs
, and is (in a sense) the bottleneck of the computation [15]. Hence, an algorithm that uses all past iterative data optimally so as to reduce evaluations of K is desirable. Here, the past iterative data constitutes the set of n iterative density pairs ![$\{(\rho^{{\rm in}}_i, \rho^{{\rm out}}_i) \ | \ i \in [0,n] \}$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn049.gif) . In order to utilise this set to generate the subsequent density
. In order to utilise this set to generate the subsequent density  from some algorithm, one is required to store the history of iterative densities in memory. Each density is represented by an array that scales with Nb5, meaning as the iteration number n grows large, so does the memory requirement of storing the entire history. Therefore, a limited memory algorithm is also desirable here, meaning no more than m of the most recent density pairs are stored. The final feature of computational Kohn–Sham theory that we will mention here is the accuracy of the initial guess,
from some algorithm, one is required to store the history of iterative densities in memory. Each density is represented by an array that scales with Nb5, meaning as the iteration number n grows large, so does the memory requirement of storing the entire history. Therefore, a limited memory algorithm is also desirable here, meaning no more than m of the most recent density pairs are stored. The final feature of computational Kohn–Sham theory that we will mention here is the accuracy of the initial guess,  . A discussion on the generation of the initial guess is left to later in this section, but it suffices to note that the initial guess is typically 'close' to the converged density
. A discussion on the generation of the initial guess is left to later in this section, but it suffices to note that the initial guess is typically 'close' to the converged density  . By 'close' we mean that a linear response approximation can be employed effectively, see section 4. As perhaps would be expected when this is the case, some of the most successful algorithms are able to utilise the past iterations cleverly with limited memory requirements, and employ some form of linearising approximation.
. By 'close' we mean that a linear response approximation can be employed effectively, see section 4. As perhaps would be expected when this is the case, some of the most successful algorithms are able to utilise the past iterations cleverly with limited memory requirements, and employ some form of linearising approximation.
3.5. Fixed-point and damped iterations
As mentioned previously, convergence of the self-consistent field iterations depends on the functional properties K, where we recall that each K is specified by the framework of Kohn–Sham theory plus an exchange-correlation approximation and external potential. Despite little being known about the precise functional properties of K [41–43], empirical wisdom allows us to make certain broad statements about it. For the sake of analysis, we now introduce the fixed-point iteration,

This is perhaps the most simple iterative scheme one could envisage, yet it remains profoundly important from the point of view of functional analysis [44]. An example algorithm that makes use of the fixed-point iteration scheme is given in figure 2. This algorithm, on iteration n, constructs and diagonalises the Kohn–Sham Hamiltonian for a given  , and computes the output density
, and computes the output density  from the N eigenvectors corresponding to the lowest N eigenvalues, otherwise known as the aufbau principle. The fixed-point iteration is then used as one sets
from the N eigenvectors corresponding to the lowest N eigenvalues, otherwise known as the aufbau principle. The fixed-point iteration is then used as one sets  , and the procedure is repeated. For the algorithm in figure 2 to converge, K must be so-called locally k-contractive in the region of the initial guess. For the Kohn–Sham map to be k-contractive under the L2-norm, it must satisfy
, and the procedure is repeated. For the algorithm in figure 2 to converge, K must be so-called locally k-contractive in the region of the initial guess. For the Kohn–Sham map to be k-contractive under the L2-norm, it must satisfy

for some real number 0 < k < 1. The intuition here is that, for any two points in the 'contractive region', the map K brings these points closer in the L2-norm. A contractive region is simply defined as a domain in density space where equation (21) is true for all densities within this domain. Successive application of K—the fixed-point iteration scheme—thus continues to bring these points closer toward a locally unique fixed-point,  . (See the Banach fixed-point theorem [45] or its generalisations [46] for k-contractive maps). Unfortunately, as section 6 shows, the Kohn–Sham map is not locally k-contractive for the vast majority of Kohn–Sham inputs. However, perhaps surprisingly, certain calculations do lead to a k-contractive Kohn–Sham map, such as spin-independent fcc aluminium at the PBE [47] level of theory, figure 3. In these cases, sophisticated acceleration algorithms tend to do little-to-nothing to assist convergence. The fixed-point iteration is also referred to as the Roothaan iteration in the physics and quantum chemistry communities [48]. It has been demonstrated that, in the context of Hartree–Fock theory, the Roothaan algorithm either converges linearly toward a solution or oscillates between two densities about the solution [49]. It is expected that this behaviour will carry over to Kohn–Sham theory [50].
. (See the Banach fixed-point theorem [45] or its generalisations [46] for k-contractive maps). Unfortunately, as section 6 shows, the Kohn–Sham map is not locally k-contractive for the vast majority of Kohn–Sham inputs. However, perhaps surprisingly, certain calculations do lead to a k-contractive Kohn–Sham map, such as spin-independent fcc aluminium at the PBE [47] level of theory, figure 3. In these cases, sophisticated acceleration algorithms tend to do little-to-nothing to assist convergence. The fixed-point iteration is also referred to as the Roothaan iteration in the physics and quantum chemistry communities [48]. It has been demonstrated that, in the context of Hartree–Fock theory, the Roothaan algorithm either converges linearly toward a solution or oscillates between two densities about the solution [49]. It is expected that this behaviour will carry over to Kohn–Sham theory [50].
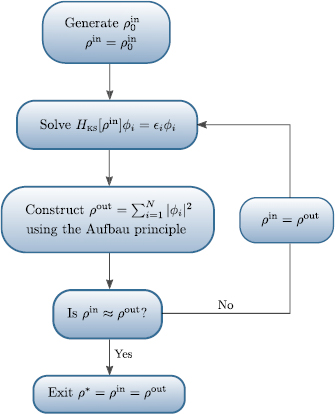
Figure 2. A flowchart detailing an example algorithm for achieving self-consistency using fixed-point (or Roothaan) iterations.
Download figure:
Standard image High-resolution image
Figure 3. Iterative convergence in the residual L2-norm ||R||2 toward a fixed-point using fixed-point iterations. Simulation of a four atom fcc aluminium unit cell, with k-point spacing of 
 using the PBE functional.
using the PBE functional.
Download figure:
Standard image High-resolution imageWe now define a new iterative scheme, the damped iteration (or one of its many other aliases, such as Krasnosel'skii–Mann or averaged iteration [51, 52]) such that

Hereafter, we refer to a scheme utilising the damped iteration as linear mixing. This scheme constitutes a series of steps in the residual L2-norm steepest descent direction R weighted by the parameter  . It can be shown that provided K is non-expansive, there always exists some
. It can be shown that provided K is non-expansive, there always exists some  such that the damped iteration converges [53–55]. Here, non-expansive refers to an instance whereby k = 1 in equation (21), i.e. densities do not get further apart upon successive application of K. This property is typically assumed, just as we also assume differentiability of
such that the damped iteration converges [53–55]. Here, non-expansive refers to an instance whereby k = 1 in equation (21), i.e. densities do not get further apart upon successive application of K. This property is typically assumed, just as we also assume differentiability of  , in theorems relating to convergence features of algorithms discussed in section 4 (e.g. [56]). Indeed, the past few decades of computation using Kohn–Sham theory has lead to the wisdom that one can always find some
, in theorems relating to convergence features of algorithms discussed in section 4 (e.g. [56]). Indeed, the past few decades of computation using Kohn–Sham theory has lead to the wisdom that one can always find some  such that one's calculation converges [50], albeit often impractically slowly. Fortunately, rather large damping parameters of
such that one's calculation converges [50], albeit often impractically slowly. Fortunately, rather large damping parameters of  are sometimes able to significantly improve convergence, as demonstrated in figure 4 [57]. In this sense, the Kohn–Sham map is relatively well-behaved, although many problems of physical interest are not so well-behaved. In these cases, sophisticated algorithms are required in order to accelerate and stabilise convergence. However, as section 6 demonstrates, even when recourse to a sophisticated algorithm is required, most inputs excluding those belonging to certain problematic classes are able to converge effectively. This is a testament to the Kohn–Sham map often being dominated by its linear response within some relatively large region about the current iterate, a property which is examined further in section 3.7.
are sometimes able to significantly improve convergence, as demonstrated in figure 4 [57]. In this sense, the Kohn–Sham map is relatively well-behaved, although many problems of physical interest are not so well-behaved. In these cases, sophisticated algorithms are required in order to accelerate and stabilise convergence. However, as section 6 demonstrates, even when recourse to a sophisticated algorithm is required, most inputs excluding those belonging to certain problematic classes are able to converge effectively. This is a testament to the Kohn–Sham map often being dominated by its linear response within some relatively large region about the current iterate, a property which is examined further in section 3.7.

Figure 4. Iterative convergence in the residual L2-norm ||R||2 using damped iterations with  , and undamped iterations
, and undamped iterations  . Simulation of a four atom fcc silicon unit cell, with k-point spacing of
. Simulation of a four atom fcc silicon unit cell, with k-point spacing of 
 using the PBE functional.
using the PBE functional.
Download figure:
Standard image High-resolution imageThe behaviour of K discussed here could be interpreted as arising due to the lack of convexity of the underlying functional  used to generate it. Convexity is defined formally in section 4, but for now it suffices to note that it can be taken to mean
used to generate it. Convexity is defined formally in section 4, but for now it suffices to note that it can be taken to mean  has a unique minimum, which is the unique fixed-point of K, and moreover this minimum is global [58]. In other words, solving the Euler–Lagrange equations is a necessary and sufficient condition to verify global optimality. While this is clearly an attractive quality for an energy functional, not least because only the global minimum has direct physical meaning in Kohn–Sham theory, it is not the case here (in general). The lack of convexity of
has a unique minimum, which is the unique fixed-point of K, and moreover this minimum is global [58]. In other words, solving the Euler–Lagrange equations is a necessary and sufficient condition to verify global optimality. While this is clearly an attractive quality for an energy functional, not least because only the global minimum has direct physical meaning in Kohn–Sham theory, it is not the case here (in general). The lack of convexity of  is particularly pronounced in spin-dependent Kohn–Sham theory, where it is not uncommon for many minima to exist, which are interpreted as representing different meta-stable spin states of the system [59]. In this case, one could, for example, employ some form of global optimisation in an attempt to explore the landscape of local minima with hopes of finding the global minimum.
is particularly pronounced in spin-dependent Kohn–Sham theory, where it is not uncommon for many minima to exist, which are interpreted as representing different meta-stable spin states of the system [59]. In this case, one could, for example, employ some form of global optimisation in an attempt to explore the landscape of local minima with hopes of finding the global minimum.
In summary, while a large class of Kohn–Sham inputs are well-behaved and convergent for relatively high values of the damping parameter, many inputs, especially the increasingly complex ones involved in modern technologies, are not. The remainder of this section explores the precise characteristics of K that lead to ill-behaved convergence.
3.6. The Aufbau principle and fractional occupancy
The question remains of how one might go about choosing which N eigenfunctions of the Kohn–Sham Hamiltonian are used to iteratively construct the output densities toward convergence. For Nb ≫ N, there is of course a large number of permutations of N eigenfunctions from which to choose. While it is perhaps taken for granted, [29] demonstrates that, in the case of Hartree–Fock theory, the lowest energy solution to the Hartree–Fock equations will necessarily be one which corresponds to the N eigenvectors with the lowest eigenvalues of  . This is otherwise known as the aufbau principle, and appears in the algorithm presented in figure 2. These eigenfunctions
. This is otherwise known as the aufbau principle, and appears in the algorithm presented in figure 2. These eigenfunctions  are termed 'occupied' orbitals, with associated quasi-particle energies
are termed 'occupied' orbitals, with associated quasi-particle energies  . However, just because the exact ground state solution satisfies the aufbau principle does not guarantee that doing so at each iteration is optimal [43, 49, 60]. Furthermore, iteratively satisfying the aufbau principle does not guarantee a global, or even local, minimum of
. However, just because the exact ground state solution satisfies the aufbau principle does not guarantee that doing so at each iteration is optimal [43, 49, 60]. Furthermore, iteratively satisfying the aufbau principle does not guarantee a global, or even local, minimum of  will be obtained as a solution to the Kohn–Sham equations [28]. Nevertheless, iteratively satisfying the aufbau pricinple has proven a successful heuristic for finding minima of
will be obtained as a solution to the Kohn–Sham equations [28]. Nevertheless, iteratively satisfying the aufbau pricinple has proven a successful heuristic for finding minima of  via the Kohn–Sham equations. Here, the aufbau principle serves to bias our solution of the Kohn–Sham equations toward a minimum of
via the Kohn–Sham equations. Here, the aufbau principle serves to bias our solution of the Kohn–Sham equations toward a minimum of  , rather than an inflection point or maximum.
, rather than an inflection point or maximum.
Iterative procedures utilising the aufbau principle are well-defined and work best primarily when the input possesses a Kohn–Sham gap, i.e. when it is not a (Kohn–Sham) metal. The Kohn–Sham gap is defined in the limit of large system size as

otherwise known as the HOMO-LUMO gap—the difference in energy between the highest energy occupied and lowest energy unoccupied (molecular) orbitals. When this gap disappears, meaning there exists a non-zero density of states at the Fermi energy, convergence becomes increasingly difficult [25, 26]. Here, the Fermi energy  is defined as the energy of the highest occupied orbital, which is the Lagrange multiplier corresponding to the constraint that the particle number N remain fixed in the minimisation of the Kohn–Sham energy functional. Such cases are prone to the phenomenon of occupancy sloshing: iterations become hindered by a continual iterative switching of binary occupation of orbitals whose energies are close to the Fermi energy. In some circumstances, an aufbau solution to the Kohn–Sham equations does not exist for binary occupation of orbitals [27, 61–63]. For example, [61] demonstrates that, in the case of the C2 molecule, the Kohn–Sham solution possesses a 'hole' below the highest occupied orbital. In the context of self-consistent field iterations, this would mean any algorithm would continue to switch orbital occupancies at each iteration ad infinitum. This occurrence is a consequence of degeneracy in the highest occupied Kohn–Sham orbitals, which can occur even in the absence of symmetry and degeneracy in the exact many-body system. Here, and in other cases like this, the density should be constructed from a density matrix
is defined as the energy of the highest occupied orbital, which is the Lagrange multiplier corresponding to the constraint that the particle number N remain fixed in the minimisation of the Kohn–Sham energy functional. Such cases are prone to the phenomenon of occupancy sloshing: iterations become hindered by a continual iterative switching of binary occupation of orbitals whose energies are close to the Fermi energy. In some circumstances, an aufbau solution to the Kohn–Sham equations does not exist for binary occupation of orbitals [27, 61–63]. For example, [61] demonstrates that, in the case of the C2 molecule, the Kohn–Sham solution possesses a 'hole' below the highest occupied orbital. In the context of self-consistent field iterations, this would mean any algorithm would continue to switch orbital occupancies at each iteration ad infinitum. This occurrence is a consequence of degeneracy in the highest occupied Kohn–Sham orbitals, which can occur even in the absence of symmetry and degeneracy in the exact many-body system. Here, and in other cases like this, the density should be constructed from a density matrix

via

The wavefunctions  are Slater determinants of Kohn–Sham orbitals corresponding to each degenerate solution within some q-fold degenerate subspace. After rearrangement, we find that the density can now be written as
are Slater determinants of Kohn–Sham orbitals corresponding to each degenerate solution within some q-fold degenerate subspace. After rearrangement, we find that the density can now be written as

where the fractional occupancies fi are determined as some combination of the weights  in equation (24). This form of the density allows one to see more transparently that we have now introduced fractional occupancy of the orbitals whose energy is degenerate at the Fermi energy. In the example of C2 in [61], the degenerate subspace is first identified, and then the occupancies f i are varied smoothly until the energies of the identified orbitals are equal. This procedure, termed evaporation of the hole, yielded accurate energy predictions when compared to configuration interaction calculations. In this case, the Kohn–Sham degeneracy is interpreted as being due to the presence of strong electron correlation. These degeneracies lead to densities that are so-called ensemble non-interacting v-representable. That is, the exact Kohn–Sham density can no longer be constructed from a pure state via the sum of the square of orbitals as in equation (3), but instead must be constructed from some ensemble of states via equations (24) and (25). The extension of Kohn–Sham theory to include fractional occupancy is described well in [64, 65].
in equation (24). This form of the density allows one to see more transparently that we have now introduced fractional occupancy of the orbitals whose energy is degenerate at the Fermi energy. In the example of C2 in [61], the degenerate subspace is first identified, and then the occupancies f i are varied smoothly until the energies of the identified orbitals are equal. This procedure, termed evaporation of the hole, yielded accurate energy predictions when compared to configuration interaction calculations. In this case, the Kohn–Sham degeneracy is interpreted as being due to the presence of strong electron correlation. These degeneracies lead to densities that are so-called ensemble non-interacting v-representable. That is, the exact Kohn–Sham density can no longer be constructed from a pure state via the sum of the square of orbitals as in equation (3), but instead must be constructed from some ensemble of states via equations (24) and (25). The extension of Kohn–Sham theory to include fractional occupancy is described well in [64, 65].
This so-called ensemble extension to Kohn–Sham theory is also utilised when constructing a non-interacting theory of Mermin's finite temperature formulation of DFT [66]. It is this version of Kohn–Sham theory that is usually used in modern Kohn–Sham codes that include fractional occupancy. As we are interested primarily in how this extension mitigates convergence issues, the reader interested in an in-depth discussion of finite temperature Kohn–Sham theory is referred to [25, 64], and references therein. Here, it suffices to observe that we now seek to minimise the following free energy functional

where the entropy functional and density are defined respectively as


The real-valued fractional occupancies ![$f_i \in [0,1]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn080.gif) now constitute additional variational parameters alongside the orbitals. Minimisation of the finite temperature Kohn–Sham functional can be tackled directly as in [26], which is discussed in section 4 and tested in section 6. Alternatively, the associated fixed-point problem can be formulated, whereby the occupancies are given a fixed functional form dependent on both T and the Kohn–Sham Hamiltonian eigenenergies
now constitute additional variational parameters alongside the orbitals. Minimisation of the finite temperature Kohn–Sham functional can be tackled directly as in [26], which is discussed in section 4 and tested in section 6. Alternatively, the associated fixed-point problem can be formulated, whereby the occupancies are given a fixed functional form dependent on both T and the Kohn–Sham Hamiltonian eigenenergies  . This is otherwise known as the smearing scheme, an example of which is the Fermi–Dirac function,
. This is otherwise known as the smearing scheme, an example of which is the Fermi–Dirac function,

The electronic temperature T is now an input parameter which determines the degree of broadening of occupancies about the Fermi energy, figure 5. At each iteration, the occupancies are updated with new values of  , and this process is continued toward convergence. This procedure demonstrably mitigates occupancy sloshing for Kohn–Sham metals with large density of states at the Fermi energy [67, 68]6. Furthermore, introducing finite temperature also assists with sampling of the Brillouin zone in periodic Kohn–Sham codes. That is, interpolation techniques for evaluating integrals across the Brillouin zone are inaccurate when many band crossings (discontinuous changes of occupancy) exist, i.e. in Kohn–Sham metals. This necessitates a fine sampling of k-space in order to accurately evaluate the integrals. As discussed, fractional occupancies negate these discontinuities, allowing for a coarser sampling of the Brillouin zone, meaning interpolation techniques become increasingly accurate—see [67, 69] for more details. In any case, finite electronic temperatures are a valuable numerical tool to assist convergence of the self-consistent field iterations in the event of inputs with large density of states at the Fermi energy. Hence, the test suite in section 5 includes many such systems, and in particular a variety of electronic temperatures are considered.
, and this process is continued toward convergence. This procedure demonstrably mitigates occupancy sloshing for Kohn–Sham metals with large density of states at the Fermi energy [67, 68]6. Furthermore, introducing finite temperature also assists with sampling of the Brillouin zone in periodic Kohn–Sham codes. That is, interpolation techniques for evaluating integrals across the Brillouin zone are inaccurate when many band crossings (discontinuous changes of occupancy) exist, i.e. in Kohn–Sham metals. This necessitates a fine sampling of k-space in order to accurately evaluate the integrals. As discussed, fractional occupancies negate these discontinuities, allowing for a coarser sampling of the Brillouin zone, meaning interpolation techniques become increasingly accurate—see [67, 69] for more details. In any case, finite electronic temperatures are a valuable numerical tool to assist convergence of the self-consistent field iterations in the event of inputs with large density of states at the Fermi energy. Hence, the test suite in section 5 includes many such systems, and in particular a variety of electronic temperatures are considered.

Figure 5. Functional dependence of the occupancy f of a given eigenenergy  for various temperatures using the Fermi–Dirac smearing scheme.
for various temperatures using the Fermi–Dirac smearing scheme.
Download figure:
Standard image High-resolution image3.7. The initial guess
As one might expect, a more accurate initial guess of the variable to be optimised leads monotonically to more efficient and stable convergence rates [70]. In the case of self-consistent field methodology, and for plane-wave and similar codes, the initial guess charge density is often computed as a sum of pseudoatomic densities [15, 31]. That is, once the exchange-correlation and pseudopotential for the atomic species in the computation has been specified, the charge density for these atoms in vacuum is calculated. Then, each individual density is overlaid at positions centered on the atomic cores in order to construct the initial guess density, figure 6. This figure demonstrates visually the accuracy of this prescription for generating initial guess charge densities. Note that different considerations are required in order to generate an initial guess for the density matrix or orbitals. The accuracy of the initial guess is, in part, responsible for the relative success of methods that employ linearising approximations, such as quasi-Newton methods, see section 4. Notable cases in which the initial guess density is relatively poor include polar materials such as magnesium oxide. The initial guess is charge neutral by construction, meaning the charge is required to shift onto the electro-negative species for convergence. Furthermore, inputs whereby the atomic species are subject to large inter-atomic forces can also lead to inaccurate initial guesses. This is partly due to the fact that the initial guess becomes exact in the limit of large atomic separation, and since large inter-atomic forces imply low inter-atomic separation, this can result in potentially inaccurate initial guess densities. Such inputs are generated routinely during structure searching applications [71]. The test suite includes various examples of these 'far-from-equilibrium' systems.
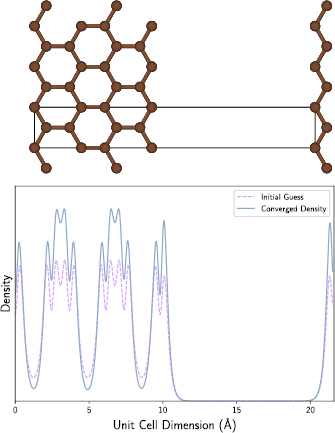
Figure 6. The difference between the initial guess density, constructed from a sum of isolated pseudoatomic densities, and the converged density, for a graphene nanoribbon along one dimension (above). The density is plotted along a one-dimensional slice across the axis shown in the above image.
Download figure:
Standard image High-resolution imageSpin polarised Kohn–Sham theory presents more serious issues: there is no widely successful method for generating initial guess spin densities. In the spin polarised or 'unrestricted' formalism, the following spin densities are introduced (see [2]),


generated from spin up and down particles occupying separate spin orbitals  . This leads now to two coupled non-linear eigenvalue problems, one for each spin. A method for generating the initial guess spin densities is thus required, rather than just the initial guess charge density. As one, in general, has no knowledge of the spin state a priori, this initial guess can be relatively far away from the ground state. In practice, one conventionally deals with charge and spin densities, rather than spin up and spin down densities,
. This leads now to two coupled non-linear eigenvalue problems, one for each spin. A method for generating the initial guess spin densities is thus required, rather than just the initial guess charge density. As one, in general, has no knowledge of the spin state a priori, this initial guess can be relatively far away from the ground state. In practice, one conventionally deals with charge and spin densities, rather than spin up and spin down densities,


The charge density can be initialised similarly to the spin-independent case, with a sum of independent pseudoatomic charge densities. The spin density can be initialised to zero, or be scaled by specifying some magnetic character on the atoms, e.g. ferromagnetic. Such a prescription typically leads to initial guess densities that are further away in the residual L2-norm than spin-independent initial guess charge densities. This observation at least partially accounts for the reason that spin polarised systems tend to be much harder to converge than spin unpolarised systems. For this reason, and others cited in the following section, many spin polarised inputs are included in the test suite. Recently, various schemes have been proposed that aim to better predict self-consistent densities to use as the initial guess [70, 72]. In particular, [70] considers a data-derived approach to predicting and assessing uncertainty in a guess density away from the ground state.
3.8. Ill-conditioning and charge sloshing
The condition of a problem, loosely speaking, can be taken as characteristic of the difficulty a black-box algorithm will have in solving the problem. Due to the complexity of the Kohn–Sham map, evaluating its condition number directly is impossible in practice. However, within the context of linear response theory, it is possible to explore certain causes of ill-conditioning generic to either all, or certain broad classes, of inputs. Hence, we begin by linearising the map K about a fixed-point7,

This is the definition of linearisation in the present context, i.e. a small change in the input density yields a change in the output density proportional to the initial change, where the constant of proportionality is shown by the components of the Jacobian of the map K,

Within the language of linear response theory, the Jacobian can be identified with the non-interacting charge dielectric via

which is the linear response function of the residual map, rather than the Kohn–Sham map. The dielectric can be expanded as such

where  , which are the only two potentials which have a dependence on the density. Hence, the dielectric is given is terms of the non-interacting susceptibility
, which are the only two potentials which have a dependence on the density. Hence, the dielectric is given is terms of the non-interacting susceptibility  as
as

where  and
and  are the kernels of the Hartree (Coulomb) and exchange-correlation integrals. Therefore, the linear response of a system to a density perturbation is given by the interplay between the exchange-correlation and Coulomb kernels, and the susceptibility
are the kernels of the Hartree (Coulomb) and exchange-correlation integrals. Therefore, the linear response of a system to a density perturbation is given by the interplay between the exchange-correlation and Coulomb kernels, and the susceptibility

which is highly system dependent [57, 73]. As the non-interacting susceptibility plays a central role in the description of many physical phenomena, such as absorption spectra, it is a relatively well-studied object [74, 75]. The remainder of this section classifies certain generic behaviours of  so that causes of divergence in the self-consistency iterations can be studied. First, in order to see why the linear response function is important for self-consistency iterations, note that one may consider each iteration as a perturbation in the density about the current iterate. Knowledge of the exact response function
so that causes of divergence in the self-consistency iterations can be studied. First, in order to see why the linear response function is important for self-consistency iterations, note that one may consider each iteration as a perturbation in the density about the current iterate. Knowledge of the exact response function  , and subsequently
, and subsequently  , would thus allow one to take a controlled step toward the fixed-point density, depending on how well-behaved8 the map is about the current iterate. An iterative scheme utilising the exact response function is given by
, would thus allow one to take a controlled step toward the fixed-point density, depending on how well-behaved8 the map is about the current iterate. An iterative scheme utilising the exact response function is given by

which one may recognise as Newton's method. While Newton's method is not global, it has many attractive features, see section 4.1. However, one is rarely privileged with knowledge of the exact dielectric as it is vastly expensive to compute and store [78–81]. In practice, one is left to estimate, or iteratively build, this response function. Cases in which the input is very sensitive to density perturbations, characterised by large eigenvalues of the discretised  , tend to amplify errors in iterates, and thus potentially move one away from the fixed-point.
, tend to amplify errors in iterates, and thus potentially move one away from the fixed-point.
Consider now completely neglecting higher order terms in the Taylor expansion of the Kohn–Sham map, and let us examine the map as if it were linear. This allows us to borrow results from numerical analysis of linear systems, and apply these results as well-motivated heuristics to convergence in the non-linear case. In particular, assuming linearity, absolute convergence can be identified as

using equation (35), meaning  for all i, where
for all i, where  are the eigenvalues of the inverse dielectic matrix, which have been shown to be real and positive for some appropriate
are the eigenvalues of the inverse dielectic matrix, which have been shown to be real and positive for some appropriate  [57]. Hence, simply multiplying the dielectric by a scalar
[57]. Hence, simply multiplying the dielectric by a scalar  such that
such that  is below unity can ensure convergence. This comes at the cost of reducing the efficiency of convergence for components of the density corresponding to low eigenvalues of the dielectric matrix. Defining the condition number of the dielectric as
is below unity can ensure convergence. This comes at the cost of reducing the efficiency of convergence for components of the density corresponding to low eigenvalues of the dielectric matrix. Defining the condition number of the dielectric as

it can be seen that the efficiency of the linear mixing procedure is limited by how close this ratio is to unity. One ansatz for the scalar premultiplying the dielectric is

which ensures, as much as the linear approximation is valid, that components of the density corresponding to the maximal and minimal eigenvalues of  converge at the same rate [57, 73, 82]. However, this form of
converge at the same rate [57, 73, 82]. However, this form of  ignores the distribution (e.g. clustering) of eigenvalues [83], and is not commonly used in conjunction with more sophisticated schemes such as those in section 4. An additional strategy to improve convergence would be to construct a matrix, the preconditioner, such that when the preconditioner is applied to
ignores the distribution (e.g. clustering) of eigenvalues [83], and is not commonly used in conjunction with more sophisticated schemes such as those in section 4. An additional strategy to improve convergence would be to construct a matrix, the preconditioner, such that when the preconditioner is applied to  , the eigenspectrum of the product is compressed toward unity. This is done in practice, see [15] for example, and is the core idea behind the Kerker preconditioner [84, 85], as discussed shortly.
, the eigenspectrum of the product is compressed toward unity. This is done in practice, see [15] for example, and is the core idea behind the Kerker preconditioner [84, 85], as discussed shortly.
It is clear from equation (43) that the convergence depends critically on the spectrum of the inverse dielectric matrix. The minimum eigenvalue is unity, and the large eigenvalues are dominated by the contributions from the Coulomb kernel, rather than the exchange-correlation kernel [73, 78, 86]. To see why this is, it is first asserted that the discretised Coulomb kernel possesses large (divergent) eigenvalues due to its  dependence, which will be demonstrated in the work to follow shortly. These large eigenvalues act as a generic amplification factor when multiplied by the eigenvalues of
dependence, which will be demonstrated in the work to follow shortly. These large eigenvalues act as a generic amplification factor when multiplied by the eigenvalues of  in equation (39), thus resulting in large (divergent) eigenvalues in the dielectric. Conversely, the exchange-correlation kernel does not generically possess such large eigenvalues. In semi-local Kohn–Sham theory, the exchange-correlation kernel is a polynomial of the density and potentially its higher order derivatives. Crucially, it has a simple, local (explicit) dependence on position given by
in equation (39), thus resulting in large (divergent) eigenvalues in the dielectric. Conversely, the exchange-correlation kernel does not generically possess such large eigenvalues. In semi-local Kohn–Sham theory, the exchange-correlation kernel is a polynomial of the density and potentially its higher order derivatives. Crucially, it has a simple, local (explicit) dependence on position given by  ,
,

that cannot, by definition, introduce x-dependent ill-conditioning. As such, no generic amplification of the eigenvalues of  occurs, and hence the exchange-correlation kernel can be ignored relative to the Coulomb kernel from the perspective of ill-conditioning. In other words, the following analysis utilises in the random phase approximation (RPA) by setting
occurs, and hence the exchange-correlation kernel can be ignored relative to the Coulomb kernel from the perspective of ill-conditioning. In other words, the following analysis utilises in the random phase approximation (RPA) by setting  in equation (39). As [78] notes, even in situations whereby the density vanishes in some region, meaning that negative powers of the density are divergent, the linear response function tempers this divergence, and the exchange-correlation contribution remains well-conditioned.
in equation (39). As [78] notes, even in situations whereby the density vanishes in some region, meaning that negative powers of the density are divergent, the linear response function tempers this divergence, and the exchange-correlation contribution remains well-conditioned.
The principle categorisation one can make when analysing generic behaviour of the response function is the distinction between Kohn–Sham metals and insulators. Consider a homogeneous and isotropic system, i.e. the homogeneous electron gas, such that  , which satisfies
, which satisfies

This is a convolution in real space, and hence a product in reciprocal space

where we label the Fourier components G by convention. This susceptibility is local and homogeneous in reciprocal space, and relates perturbations in the input density to a response by the output density (within the RPA) via

The susceptibility of the homogeneous electron gas, which constitutes a simple metal in the present context, is derived from Thomas–Fermi theory as the Thomas–Fermi wavevector  , which is constant9 [87]. It can therefore be seen that if there is any error in a trial input density, generated by an iterative algorithm, away from the optimal update, then this error is amplified by a factor of |G|−2 for
, which is constant9 [87]. It can therefore be seen that if there is any error in a trial input density, generated by an iterative algorithm, away from the optimal update, then this error is amplified by a factor of |G|−2 for  , where
, where  does not contribute. This sensitivity to error in iterates is identified as the source of charge sloshing, and is a somewhat generic feature of Kohn–Sham metals. Whilst the above derivation utilises Thomas–Fermi theory of the homogeneous electron gas to demonstrate constant susceptibility, it can be shown that all Kohn–Sham metals display this behaviour in the small
does not contribute. This sensitivity to error in iterates is identified as the source of charge sloshing, and is a somewhat generic feature of Kohn–Sham metals. Whilst the above derivation utilises Thomas–Fermi theory of the homogeneous electron gas to demonstrate constant susceptibility, it can be shown that all Kohn–Sham metals display this behaviour in the small  limit [75, 88]. A demonstration of charge sloshing is illustrated in figure 7, whereby a linear mixing algorithm purposefully takes slightly too large steps in the density. This leads to vast over-corrections in each iteration, giving the appearance that charge is 'sloshing' about the unit cell. This is not the only source of large eigenvalues of the dielectric in Kohn–Sham metals, as the susceptibility possesses inherently divergent eigenvalues independent from the amplification by the Coulomb kernel. To see this, consider the Adler–Wiser equation which is defined as
limit [75, 88]. A demonstration of charge sloshing is illustrated in figure 7, whereby a linear mixing algorithm purposefully takes slightly too large steps in the density. This leads to vast over-corrections in each iteration, giving the appearance that charge is 'sloshing' about the unit cell. This is not the only source of large eigenvalues of the dielectric in Kohn–Sham metals, as the susceptibility possesses inherently divergent eigenvalues independent from the amplification by the Coulomb kernel. To see this, consider the Adler–Wiser equation which is defined as

which is an expression from perturbation theory for the exact Kohn–Sham susceptibility [74, 75]. As [82] originally noted, the denominator  approaches zero when the input is gapless, i.e. it has a large density of states about the Fermi energy. If left untreated, this observation, in conjunction with the amplifying factor from the low
approaches zero when the input is gapless, i.e. it has a large density of states about the Fermi energy. If left untreated, this observation, in conjunction with the amplifying factor from the low  components of the Coulomb kernel, lead to significant ill-conditioning. The largest condition numbers arise when
components of the Coulomb kernel, lead to significant ill-conditioning. The largest condition numbers arise when  is extremely small; since G is a reciprocal lattice vector, this will occur for unit cells that are large in any (or all) of the three real-space dimensions. Whilst the dependence of the eigenvalues of the dielectric on unit cell size is in practice complicated [73], it suffices to note that increased unit cell size is a significant source of ill-conditioning. As compute power continues to grow, larger and larger systems are being tackled using Kohn–Sham theory, and the increase in required number of self-consistency iterations as a result of this instability poses serious issues for Kohn–Sham calculations. Inefficiencies of this kind are best dealt with using preconditioners, as section 4 demonstrates. On the other hand, insulators possess no such divergences in the eigenvalues of the dielectric matrix. It can be shown that in the low
is extremely small; since G is a reciprocal lattice vector, this will occur for unit cells that are large in any (or all) of the three real-space dimensions. Whilst the dependence of the eigenvalues of the dielectric on unit cell size is in practice complicated [73], it suffices to note that increased unit cell size is a significant source of ill-conditioning. As compute power continues to grow, larger and larger systems are being tackled using Kohn–Sham theory, and the increase in required number of self-consistency iterations as a result of this instability poses serious issues for Kohn–Sham calculations. Inefficiencies of this kind are best dealt with using preconditioners, as section 4 demonstrates. On the other hand, insulators possess no such divergences in the eigenvalues of the dielectric matrix. It can be shown that in the low  limit the behaviour of the susceptibility for gapped materials is [75, 88]
limit the behaviour of the susceptibility for gapped materials is [75, 88]


Figure 7. An illustration of charge sloshing for a graphene nanoribbon unit cell (top right). The linear mixing algorithm is applied with damping parameter  ; this leads to an overcorrection in the density at each iteration, resulting in complete divergence.
; this leads to an overcorrection in the density at each iteration, resulting in complete divergence.
Download figure:
Standard image High-resolution imageThis functional dependence cancels the |G|−2 dependence from the Coulomb kernel, and thus the eigenvalues of the dielectric become constant for all G. This constant is unknown in general, and guaranteed convergence for simple insulators amounts to finding the damping parameter  such that this constant is below unity. This is in line with the empirical wisdom that insulators are much easier to converge than metals, provided that the insulator does not artificially assume a metallic character during the self-consistency iterations.
such that this constant is below unity. This is in line with the empirical wisdom that insulators are much easier to converge than metals, provided that the insulator does not artificially assume a metallic character during the self-consistency iterations.
In this vein, inputs that are increasingly complex, i.e. deviating from simple metals or insulators, are likely to exhibit problematic behaviour. As discussed in section 4, preconditioners are able to alleviate charge sloshing in simple metals. However, when a metal-insulator interface is used as input, there are regions with starkly different behaviour in the response function, which is difficult to capture analytically. Hence, preconditioning techniques may fail to assist, and even hinder, iterations in calculations on interfaces of this kind [73]. Furthermore, it is possible that artificial phase transitions between gapped and gapless phases occur during the self-consistency iterations. Many algorithms function by building up an approximation to the dielectric using past iterates. The discontinuous change in behaviour of the dielectric in differing phases causes parts of the iterative history to actively interfere in correctly modelling the dielectric. Hence, iterations become hindered or divergent. An artificial phase change of this kind is demonstrated to occur in [89] for an isolated iron atom. Various examples of the aforementioned problematic classes of inputs are included in the test suite.
Finally, a brief comment is provided on how the above analysis translates to spin-dependent Kohn–Sham theory. As discussed, in the spin-dependent case one solves two non-linear eigenvalue problems that independently look very similar to equations (8) and (9), but crucially are coupled through the Hartree and exchange-correlation potential. That is, an algorithm that perturbs the spin up (spin down) density will lead to a response by the spin up (spin down) density given by the prior analysis. However, one must now also consider how a perturbation in the spin up density affects the spin down density, and vice versa, which is again through the Coulomb and exchange-correlation kernels. Hence, all of the above sources of ill-conditioning translate directly to the spin-dependent case, with the added difficulty that the number of optimisation parameters has doubled, and these parameters are coupled in such a way that potentially introduces further ill-conditioning. In other words, the response function now contains four components,

where the diagonal elements describe the response of the spin up (spin down) density to perturbations in the spin up (spin down) density, and the off-diagonal elements describe the response of the spin up (spin down) density to perturbations in the spin down (spin up) density. Implementations of spin-dependent Kohn–Sham theory often utilise the charge and spin densities, defined in equations (33) and (34), rather than the spin up and spin down densities. In this representation, the behaviour of the off-diagonal (coupling) elements is determined via the exchange-correlation potential, as the Hartree contribution cancels, see [2, 57]. To the authors' knowledge, there is less literature on the manifestation of this coupling in the self-consistency iterations than on the spin-independent counterpart. Dederichs and Zeller [57] uses self-consistency in the Stoner model to demonstrate that the condition of the system is indeed worsened in the presence of magnetism due to the coupling. However, it is noted that the charge and spin densities decouple near self-consistency. In any case, for these reasons, and perhaps for reasons yet unexplored, empiricism demonstrates that spin polarised calculations are, in general, more difficult to converge than spin unpolarised calculations. Analysing this coupling in terms of self-consistency and ill-conditioning is an avenue for further research, which could be used to assist self-consistency iterations through the use of improved preconditioners, see section 4.3.
4. Methods and algorithms
Having established a variety of sources of ill-conditioning in the non-linear Kohn–Sham map, we now examine methodology used to find self-consistent densities that are fixed-points of this map. Of course, over the past few decades, a number of differing approaches to the self-consistency problem in Kohn–Sham and Hartree–Fock theory have been reviewed, analysed, and advanced; see, for example, [19, 28, 49, 73, 89–92] and references therein. The aim of this section is to collate conclusions from these studies, and many others, in order to provide a contemporary survey of self-consistency methodology in a pedagogical manner. This survey includes methodology suitable for software utilising either a localised or delocalised basis set. However, only the subset of algorithms suitable for a delocalised basis set are implemented in castep for the benchmarking effort in section 6.
Consider the general iteration for solving the Kohn–Sham equations,

where n is the current iteration number, ![$i \in [1,n]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn118.gif) , and we seek a prescription for generating the update f n as a function of all past data in the history of iterates. The underlying black-box methodology one uses to generate f n can be regarded as separate to how one alters f n by preconditioning. Hence, we first review the black-box methodology, and then review preconditioning strategies in section 4.3. Elementary algorithms for generating f n were first considered in section 3.5: the fixed-point and linear mixing algorithms,
, and we seek a prescription for generating the update f n as a function of all past data in the history of iterates. The underlying black-box methodology one uses to generate f n can be regarded as separate to how one alters f n by preconditioning. Hence, we first review the black-box methodology, and then review preconditioning strategies in section 4.3. Elementary algorithms for generating f n were first considered in section 3.5: the fixed-point and linear mixing algorithms,


respectively. As stated, the linear mixing algorithm is a weighted step in the direction of the error and is identically zero at convergence. Hence, assuming K is continuous (in some sense) and non-expansive, this algorithm converges for sufficiently low fixed values of  [57]. It can be shown that this algorithm converges q-linearly toward the fixed-point density
[57]. It can be shown that this algorithm converges q-linearly toward the fixed-point density  [93]; where q-linear convergence is defined as
[93]; where q-linear convergence is defined as

That is, the error decreases linearly iteration by iteration, and the gradient of this linear decrease is given by the factor  , which is determined by the initial guess and the fixed parameter
, which is determined by the initial guess and the fixed parameter  . Assuming one chooses an appropriate value for
. Assuming one chooses an appropriate value for  , the linear mixing algorithm is global, meaning it converges from any initial guess in the
, the linear mixing algorithm is global, meaning it converges from any initial guess in the  limit. The price one often pays for global convergence here is an impractically slow convergence rate, or q factor, for the problematic classes of inputs defined in the prior section. The remainder of this section considers methods for accelerating the linear mixing iterations, conventionally referred to as acceleration algorithms. In particular, these algorithms exhibit q-superlinear convergence,
limit. The price one often pays for global convergence here is an impractically slow convergence rate, or q factor, for the problematic classes of inputs defined in the prior section. The remainder of this section considers methods for accelerating the linear mixing iterations, conventionally referred to as acceleration algorithms. In particular, these algorithms exhibit q-superlinear convergence,

for some positive real number  , where q > 1 and q = 2 defines quadratic convergence. These algorithms tend to sacrifice guaranteed global convergence, but can vastly improve the rate of convergence, as demonstrated in section 6.
, where q > 1 and q = 2 defines quadratic convergence. These algorithms tend to sacrifice guaranteed global convergence, but can vastly improve the rate of convergence, as demonstrated in section 6.
Before introducing the various acceleration strategies, we remark that the difficulty in solving a constrained functional optimisation problem, or equally the associated Lagrangian fixed-point problem, is not primarily determined based on the linearity of a problem, or lack thereof. Rather, as [58] asserts and demonstrates, the characteristic difficulty of an optimisation problem depends on whether or not the underlying functional is convex,

Here, F is a convex functional, x and y are two elements in the domain of the functional, and  and
and  are two real numbers. Convex functionals have a unique minimum, and minimiser, which can be found, in some sense, in a controlled and efficient manner, see [53, 58, 93] for more information on convex optimisation. The Kohn–Sham functional is demonstrably not convex in the general case. However, many of the algorithms to follow operate by solving an associated convex problem in order to compute the update f n. This is typically a quadratic programming problem, which is subsequently used to solve the non-convex Kohn–Sham problem. The most popular and successful class of updates in the present context are quasi-Newton updates. As we will see, these updates differ chiefly based on the underlying quadratic programming problem one solves to compute f n.
are two real numbers. Convex functionals have a unique minimum, and minimiser, which can be found, in some sense, in a controlled and efficient manner, see [53, 58, 93] for more information on convex optimisation. The Kohn–Sham functional is demonstrably not convex in the general case. However, many of the algorithms to follow operate by solving an associated convex problem in order to compute the update f n. This is typically a quadratic programming problem, which is subsequently used to solve the non-convex Kohn–Sham problem. The most popular and successful class of updates in the present context are quasi-Newton updates. As we will see, these updates differ chiefly based on the underlying quadratic programming problem one solves to compute f n.
4.1. The quasi-Newton update
First, we make some general comments about the Newton update. The Newton update is the optimal first order update in the density at the current iteration. In other words, if the current iterate is within the linear response radius of the root, then the exact Newton update would lead to convergence in one iteration by definition. That is, we seek the update  such that
such that

where J: = JR is the Jacobian of the residual, defined similarly to equation (36), evaluated at the current iterate. Rearranging for  , the update is given as
, the update is given as

Assuming the Jacobian exists and is Lipschitz continuous10, this update is shown to have quadratic convergence in some region about the root [83]. The Jacobian must be computed numerically, which can be done with either the Adler–Wiser equation equation (49) [74, 75], or with finite-difference numerical differentiation [94]. As section 4.3 will explore in more depth, in the absence of further approximation, both of these techniques are inadequate for modern calculations due to the computational complexity and the size of the basis set. The former strategy is an  process that requires the computation and storage of all eigenvectors of the Kohn–Sham Hamiltonian [78, 79]. The latter strategy requires excessively many evaluations of K [95]. We now examine the class of methods that can be cast as a Newton step with some iteratively updated approximation to the Jacobian: quasi-Newton methods.
process that requires the computation and storage of all eigenvectors of the Kohn–Sham Hamiltonian [78, 79]. The latter strategy requires excessively many evaluations of K [95]. We now examine the class of methods that can be cast as a Newton step with some iteratively updated approximation to the Jacobian: quasi-Newton methods.
4.1.1. Broyden's methods.
Consider having knowledge of an approximate Jacobian at the previous iteration, Jn−1. We seek a prescription for generating an approximate Jacobian at the current iteration, Jn, such that the following quasi-Newton update can be performed,

where ![$R_n := R[\rho^{{\rm in}}_n]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn132.gif) . First, note that all methods of this kind must begin from some initial estimate of the Jacobian, J0. For lack of a better option, this can be taken as a scaled identity,
. First, note that all methods of this kind must begin from some initial estimate of the Jacobian, J0. For lack of a better option, this can be taken as a scaled identity,  . Although, in the present context, the Kerker matrix is used, which is defined in section 4.3. We begin with a description of Broyden's two methods [96]. These methods, as they are about to be presented, are not commonly used in modern Kohn–Sham software. However, the conceptual foundation of Broyden's methods, that is, low rank updates to a Jacobian that satisfies secant conditions, remain foundational to contemporary methodology. First, the meaning of a secant condition is defined. For illustrative purposes, a finite-difference approximation for the derivative of a one-dimensional function f at the current iterate xn is given by
. Although, in the present context, the Kerker matrix is used, which is defined in section 4.3. We begin with a description of Broyden's two methods [96]. These methods, as they are about to be presented, are not commonly used in modern Kohn–Sham software. However, the conceptual foundation of Broyden's methods, that is, low rank updates to a Jacobian that satisfies secant conditions, remain foundational to contemporary methodology. First, the meaning of a secant condition is defined. For illustrative purposes, a finite-difference approximation for the derivative of a one-dimensional function f at the current iterate xn is given by

which is increasingly accurate as the iterates become closer. Since the Jacobian is the derivative of the residual map, the Nb-dimensional equivalent of this finite-difference equation is

where hereafter we define  and
and  . If the nth Jacobian satisfies equation (62), it is said to satisfy the secant condition of the current iteration, and thus belongs to Broyden's family of methods. Since Jn is an
. If the nth Jacobian satisfies equation (62), it is said to satisfy the secant condition of the current iteration, and thus belongs to Broyden's family of methods. Since Jn is an  matrix, and the secant condition only specifies how Jn acts on the vector
matrix, and the secant condition only specifies how Jn acts on the vector  , there are a remaining
, there are a remaining  components of the Jacobian that are yet unspecified. Broyden fixes these remaining components by requiring Jn acts on all vectors orthogonal to
components of the Jacobian that are yet unspecified. Broyden fixes these remaining components by requiring Jn acts on all vectors orthogonal to  similarly to Jn−1. This is equivalent to requiring that the Jacobian of the current iteration solves the following constrained quadratic programming problem,
similarly to Jn−1. This is equivalent to requiring that the Jacobian of the current iteration solves the following constrained quadratic programming problem,


as demonstrated by [97, 98], which defines Broyden's first method. The Frobenius norm ||.||f of a square matrix A is defined as

In other words, the current Jacobian Jn is required to satisfy the current secant condition, and otherwise minimise the difference between itself and the previous Jacobian Jn−1 in the sense of the Frobenius norm. Note that the nth Jacobian satisfies all of the previous n secant equations provided the past iterates are mutually orthogonal,  for
for  . However, the space of past iterates is often linearly independent, but not mutually orthogonal. Therefore, if one requires Jn to satisfy only the most recent secant equation, one loses information about past secant equations, i.e. Jn no longer satisfies the past secant equations. Schemes that ensure Jn satisfies multiple previous secant equations are studied in the next section.
. However, the space of past iterates is often linearly independent, but not mutually orthogonal. Therefore, if one requires Jn to satisfy only the most recent secant equation, one loses information about past secant equations, i.e. Jn no longer satisfies the past secant equations. Schemes that ensure Jn satisfies multiple previous secant equations are studied in the next section.
The constrained optimsiation problem of equation (63) has a unique analytic solution, which is obtained in [97, 98] by means of unconstrained optimisation using the method of Lagrange multipliers,

The notation  defines the outer product of the vectors
defines the outer product of the vectors  . One can now observe from equation (66) that this prescription has lead transparently to a rank-one update of the Jacobian at each iteration. The full quasi-Newton update for Broyden's first method involves subsequently inverting equation (66), applying it to residual vector, and performing the quasi-Newton step equation (60). The apparent excessive cost of inverting equation (66) is negated as the inverse of a rank-one matrix can be computed analytically using the Sherman–Morrison–Woodbury formula [99]. Furthermore, as matrix-vector multiplication is associative, one can compute the vector
. One can now observe from equation (66) that this prescription has lead transparently to a rank-one update of the Jacobian at each iteration. The full quasi-Newton update for Broyden's first method involves subsequently inverting equation (66), applying it to residual vector, and performing the quasi-Newton step equation (60). The apparent excessive cost of inverting equation (66) is negated as the inverse of a rank-one matrix can be computed analytically using the Sherman–Morrison–Woodbury formula [99]. Furthermore, as matrix-vector multiplication is associative, one can compute the vector  without constructing or storing Jn explicitly, and instead using a series of vector–vector products. This was originally demonstrated in [100], so that at a given instance Broyden's first method only requires the storage of two Nb-length vectors, and the computation of a few vector–vector products. Broyden's second method optimises the components of the matrix
without constructing or storing Jn explicitly, and instead using a series of vector–vector products. This was originally demonstrated in [100], so that at a given instance Broyden's first method only requires the storage of two Nb-length vectors, and the computation of a few vector–vector products. Broyden's second method optimises the components of the matrix  directly via
directly via


instead of optimising the Jacobian, then subsequently inverting. Hereafter, methods that optimise the Jacobian are referred to as 'type-I' methods, and methods that optimise the inverse Jacobian are referred to as 'type-II' methods, see [91]. Note that the constraint in equation (68) is simply the inverse secant condition. Similarly to Broyden's first method, this has the analytic solution,

which can be substituted directly into the quasi-Newton step11. The conventional wisdom has emerged that Broyden's second method tends to provide more robust and efficient convergence than Broyden's first method. However, both methods are shown to be q − superlinearly convergent [83, 97] in the sense that

which is a necessary condition for some q > 1 in equation (56). Broyden's second method is implemented and tested in section 6.
4.1.2. Multisecant Broyden's methods.
A natural extension to Broyden's methods is to consider all prior secant conditions at each iteration, rather than just the most recent secant condition. This leads to a so-called generalised or multisecant version of Broyden's methods, which are examined extensively in both optimisation and electronic structure literature [83, 91, 100, 102]. The ensuing summary follows a similar structure to that of [91]. A multisecant method is defined as a method that generates an iterative Jacobian Jn such that this Jacobian satisfies the most recent m secant conditions. That is, the following  matrices are defined
matrices are defined


such that a Jacobian satisfying the previous m secant conditions must satisfy the matrix equation

The parameter m introduced here defines the history length, i.e. the number of iterates that are stored and used for secant conditions. If m is less than the full history size n then the method takes on its modified limited memory form. If m = n, then the method satisfies all prior secant conditions. The generalisation of Broyden's two methods is now readily established: alter the constraints in the optimisation problems equations (63) and (67) to reflect the multisecant condition equation (73). The multisecant version of Broyden's first and second method respectively are


which are of type-I and type-II respectively. These both have a unique analytic solution in the form of a rank-m update,

which are found by solving the associated Lagrangian problems. The former Jacobian update can be inverted similarly to Broyden's first method with the Sherman–Morrison–Woodbury formula. As [89, 92] conclude, and section 6 also examines, the type-II variant tends to outperform the type-I variant in the context of multisecant Broyden's methods, in line with the conventional wisdom from Broyden's original methods. As stated previously, if the space of past iterates is mutually orthogonal, this method is equivalent to Broyden's original methods.
Finally, we remark on the connection between the above methods and the method examined by Eyert, Vanderbilt & Louie and Johnson in [101–103]. First, the following unconstrained minimisation problem for variations in Hn is defined,

where we choose to update the inverse Jacobian Hn−1, although a similar method can be formulated in terms of Jacobian updates. The weights  are introduced as free parameters that act as penalty coefficients. That is, the weights are chosen to signify how 'important' it is to satisfy the corresponding constraint. In this sense, inspection of equation (76) shows that w0 controls the degree to which the inverse Jacobian can change iteration-to-iteration, and wi controls the degree to which the ith secant equation should be satisfied by Hn. Therefore, this method also constitutes a multisecant method, but the multisecant conditions are allowed to be weighted according to relative importance. Various common fixed-point methods can be recovered as special cases of these weights. Notably, as [15, 31] demonstrate, the choice wi = 0 for i < n, and
are introduced as free parameters that act as penalty coefficients. That is, the weights are chosen to signify how 'important' it is to satisfy the corresponding constraint. In this sense, inspection of equation (76) shows that w0 controls the degree to which the inverse Jacobian can change iteration-to-iteration, and wi controls the degree to which the ith secant equation should be satisfied by Hn. Therefore, this method also constitutes a multisecant method, but the multisecant conditions are allowed to be weighted according to relative importance. Various common fixed-point methods can be recovered as special cases of these weights. Notably, as [15, 31] demonstrate, the choice wi = 0 for i < n, and  , leads to Broyden's second method. This can be intuited from equation (76): the weights wi now favour exclusively the most recent secant condition, and in directions orthogonal to that secant condition, the minimum norm condition on Hn is applied. In the original work of [102, 103], the weights
, leads to Broyden's second method. This can be intuited from equation (76): the weights wi now favour exclusively the most recent secant condition, and in directions orthogonal to that secant condition, the minimum norm condition on Hn is applied. In the original work of [102, 103], the weights  are considered, which favour secant conditions closer to convergence. This was used in the context of electronic structure calculations with success in [101–103]. However, as [101] demonstrates, the optimal set of weights require
are considered, which favour secant conditions closer to convergence. This was used in the context of electronic structure calculations with success in [101–103]. However, as [101] demonstrates, the optimal set of weights require  , and if {wi} are to be non-zero, these weights in fact cancel in the update formula. Hence, wi = 1 can be set without loss of generality, and the method can be identified with a standard multisecant method; see [101] for additional detail. An interesting aspect of the multisecant methods discussed here are their relationship Pulay's or Anderson's method—a ubiquitous method in electronic structure theory software—which is now examined.
, and if {wi} are to be non-zero, these weights in fact cancel in the update formula. Hence, wi = 1 can be set without loss of generality, and the method can be identified with a standard multisecant method; see [101] for additional detail. An interesting aspect of the multisecant methods discussed here are their relationship Pulay's or Anderson's method—a ubiquitous method in electronic structure theory software—which is now examined.
4.1.3. Pulay's method.
Pulay's method [104, 105], or the discrete inversion in the iterative subspace (DIIS), as it is known in electronic structure literature, or Anderson's method, as it is known in optimisation literature [106], has proven extremely effective at converging Kohn–Sham calculations. The simplicity of its formulation combined with its impressive efficiency and robustness has lead to Pulay's method becoming the default algorithm in a range of Kohn–Sham codes [10, 15, 33, 34, 107, 108]. The past few decades of wisdom suggest that Pulay's method systematically outperforms the unmodified Broyden's methods in both the single and multisecant formulation. This conclusion will be tested in section 6. First, a brief review of Pulay's method as it was originally formulated is given.
Consider constructing a so-called 'optimum' residual—a residual whose argument is an optimum density—as a linear combination of past residuals in the m-dimensional iterative subspace,

Here, optimum is defined by the method one chooses to fix the coefficients ci. In Pulay's method, these coefficients are fixed by requiring that the L2-norm of the residual is minimal, i.e. solve

where the constraint that the coefficients must sum to unity is an exact requirement at convergence. Substitution of equations (77) into (78), and use of Lagrange multipliers, allows the optimisation problem to be cast as an  -dimensional linear system,
-dimensional linear system,

for  , which is readily generalised for n > m. Assuming the space of past iterates is of full rank (comprised of linearly independent vectors), solution of this linear system provides the set of coefficients ci. Given these coefficients, the density update remains to be defined. Following [56, 90, 91, 101, 109], the optimum residual can be first be expanded as such,
, which is readily generalised for n > m. Assuming the space of past iterates is of full rank (comprised of linearly independent vectors), solution of this linear system provides the set of coefficients ci. Given these coefficients, the density update remains to be defined. Following [56, 90, 91, 101, 109], the optimum residual can be first be expanded as such,

If K is assumed to be linear, the rightmost term in equation (79) can be interpreted as the optimal input density,

Hence, the optimal update can take the standard undamped form


This update is favoured over  so that the algorithm does not stagnate in the subspace of past input densities. Alternatively, as originally studied in [106], a damped step can be taken,
so that the algorithm does not stagnate in the subspace of past input densities. Alternatively, as originally studied in [106], a damped step can be taken,

for  . An example algorithm that implements this formulation of Pulay's method is given in algorithm 1.
. An example algorithm that implements this formulation of Pulay's method is given in algorithm 1.
Algorithm 1. Pulay's algorithm.
1: Input: tol,  |
2: for  ,... ,... |
3: Compute ![$R[\rho^{{\rm in}}_n]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn157.gif) and store the pair and store the pair ![$\{\rho^{{\rm in}}_n, R[\rho^{{\rm in}}_n] \}$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn158.gif) |
| 4: Solve equation (78) for {ci} |
5: if  |
6: Set ![$\rho^{{\rm in}}_{n+1} = \sum_{i=1}^n c_i (\rho^{{\rm in}}_i + \alpha R[\rho^{{\rm in}}_i])$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn160.gif) |
| 7: else |
8: Set ![$\rho^{{\rm in}}_{n+1} = \sum_{i=n-m+1}^n c_i (\rho^{{\rm in}}_i + \alpha R[\rho^{{\rm in}}_i])$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn161.gif) |
9: if ![$||R[\rho^{{\rm in}}_n]||_2 < $](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn162.gif) tol, exit tol, exit |
At a first glance, Pulay’s method bears little resemblance to the secant-based methods discussed in the previous section. However, as described in [56, 91, 109], a rearrangement of the optimisation problem in equation (78) reveals a close relationship between Pulay’s method and type-II multisecant methods. A more detailed treatment of this correspondence is found in [56, 91, 109]; here, we simply state that the following unconstrained optimisation problem

for variations in  is equivalent to Pulay's optimisation problem equation (78). The new coefficients
is equivalent to Pulay's optimisation problem equation (78). The new coefficients  are related to the old coefficients {ci} such that the update in equation (83) now takes the form
are related to the old coefficients {ci} such that the update in equation (83) now takes the form

where  on iteration n is solved by
on iteration n is solved by

The parallel between Pulay's method and multisecant methods becomes apparent when these equations are combined to give the final update,


By comparison with the updated inverse Jacobian in equation (75), we can observe that Pulay's method is a type-II quasi-Newton step where the iterative inverse Jacobian is updated according to

In other words, this optimisation problem minimises the difference between the components of the inverse Jacobian Hn and the initial guess inverse Jacobian H0, while also requiring the previous m secant conditions to be fulfilled. Note that  is required in order to recover the update in equation (88). This reformulation not only connects Pulay's method to the type-II variant of multisecant Broyden's method, but also uncovers another flavour of Pulay's method,
is required in order to recover the update in equation (88). This reformulation not only connects Pulay's method to the type-II variant of multisecant Broyden's method, but also uncovers another flavour of Pulay's method,

which is of type-I, i.e. the Jacobian is optimised, rather than the inverse Jacobian. This form of Pulay's method, as originally described in [91], has seen comparatively less application and testing in the context of Kohn–Sham codes [56]. These methods differ from multisecant Broyden methods precisely when m > n, in which case the multisecant Broyden methods retain information from all prior secant equations implicitly, whereas Pulay's method(s) ignore completely secant equations not in the (size m) history.
A few modifications to Pulay's method are now examined; although we note that these modifications are adaptable to all the secant-based methods discussed previously. First, the work in [110], based on [111], suggests that alternating between Pulay and linear mixing steps can improve the robustnesss of the iterations over standard Pulay—the 'Periodic Pulay' method. Each new Pulay step utilises the history from the linear mixing and past Pulay steps to solve the optimisation subproblem equation (78). This is demonstrated to have a stabilising effect as the linear mixing history data is used well by the Pulay extrapolation. In [110], an input parameter k determines the number of linear mixing steps performed between each Pulay step, i.e. k linear steps per Pulay step. As suggested in the original work, the values k = 2 are tested in section 6 with a damping parameter of  for both the Pulay and linear mixing steps.
for both the Pulay and linear mixing steps.
Second, [112] considers occasionally flushing the history every time a certain criterion is met, rather than iteratively overriding the history—'Restarted Pulay'. This criterion is chosen to be whenever the current iteration number is an integer multiple of the maximum history size, i.e. n = am for some  . For inputs with a considerable degree of non-linearity, either due to a poor initial guess, or inherent to the Kohn–Sham map, the history can actively interfere with modelling an accurate iterative Jacobian at the current iteration. Restarted Pulay thus represents a strategy for dealing with this issue by periodically removing the history.
. For inputs with a considerable degree of non-linearity, either due to a poor initial guess, or inherent to the Kohn–Sham map, the history can actively interfere with modelling an accurate iterative Jacobian at the current iteration. Restarted Pulay thus represents a strategy for dealing with this issue by periodically removing the history.
The final technique we discuss here is the 'Guaranteed Reduction Pulay' algorithm of [113]. The approach of Guaranteed Reduction Pulay involves ensuring that the Pulay predicted optimal residual  decreases each iteration. This is achieved by rearranging the stored history of residuals {Ri} such that, at a given iteration, the Pulay predicted optimal residual is added to the history, rather than the residual obtained from evaluating the Kohn–Sham map. The subsequent iteration then involves a linear mixing step, which generates a new exact residual that is added to the history. The coefficients {ci} of the now current iteration are determined by solving Pulay's optimisation problem equation (78). However, note that the previous Pulay predicted optimal residual is an element of the set of residuals that are used to determine {ci}. Hence, the addition of the residual from the linear mixing step can only lower the Pulay predicted optimal residual, or at worst leave it the same. This new reduced Pulay predicted optimal residual replaces the exact linear mixing residual in the history, and the process repeats. As expected, this method performs best when the predicted optimal residual accurately models what the residual would have been were the optimal density evaluated with the Kohn–Sham map. Pulay's method predicts the residual increasingly well the closer it is to the linear response regime from the root. Therefore, when the behaviour of Kohn–Sham map is highly non-linear, the guaranteed reductions in the predicted residual tend to stagnate, while the exact residual does not decrease. All three of these techniques are benchmarked in section 6.
decreases each iteration. This is achieved by rearranging the stored history of residuals {Ri} such that, at a given iteration, the Pulay predicted optimal residual is added to the history, rather than the residual obtained from evaluating the Kohn–Sham map. The subsequent iteration then involves a linear mixing step, which generates a new exact residual that is added to the history. The coefficients {ci} of the now current iteration are determined by solving Pulay's optimisation problem equation (78). However, note that the previous Pulay predicted optimal residual is an element of the set of residuals that are used to determine {ci}. Hence, the addition of the residual from the linear mixing step can only lower the Pulay predicted optimal residual, or at worst leave it the same. This new reduced Pulay predicted optimal residual replaces the exact linear mixing residual in the history, and the process repeats. As expected, this method performs best when the predicted optimal residual accurately models what the residual would have been were the optimal density evaluated with the Kohn–Sham map. Pulay's method predicts the residual increasingly well the closer it is to the linear response regime from the root. Therefore, when the behaviour of Kohn–Sham map is highly non-linear, the guaranteed reductions in the predicted residual tend to stagnate, while the exact residual does not decrease. All three of these techniques are benchmarked in section 6.
4.1.4. Modern multisecant-based algorithms.
Here, we highlight one modern use of multisecant methods in particular, the methods outlined in [89, 92], which are now default self-consistency methods in wien2k [114]. These algorithms can be considered a sophisticated modern variant of the standard multisecant already methods discussed. Furthermore, they are designed with the aim of converging Kohn–Sham calculations. The range of strategies utilised make [89, 92] an interesting case to isolate and examine here. The most recent published form of these algorithms is that given in [89] titled 'multisecant rank one' (MSR1). However, this algorithm is designed to converge both the atomic (geometry optimisation) and electronic degrees of freedom. Hence, we focus on the techniques that are relevant to the self-consistent field iterations, and the reader is referred to [89, 92] for a more in-depth treatment.
First, the updates considered in [89, 92] are defined in equations (90) and (89), which are of the form

The initial guess inverse Jacobian is  , and
, and  ,
,  define a type-I and type-II update respectively. It is demonstrated in [92], and further verified in section 6, that type-II methods are superior for the self-consistency problem than type-I methods. However, if atomic degrees of freedom are included, it is advantageous to consider a linear combination of updates,
define a type-I and type-II update respectively. It is demonstrated in [92], and further verified in section 6, that type-II methods are superior for the self-consistency problem than type-I methods. However, if atomic degrees of freedom are included, it is advantageous to consider a linear combination of updates,

for  . The parameter
. The parameter  controls the degree to which the method takes a type-II step,
controls the degree to which the method takes a type-II step,  , or a type-I step,
, or a type-I step,  . As noted in [89], this is similar to a technique used in [115] whereby a criterion is defined to assess whether a type-I or type-II step will be optimal, and then the corresponding step is taken. In MSR1, the parameter
. As noted in [89], this is similar to a technique used in [115] whereby a criterion is defined to assess whether a type-I or type-II step will be optimal, and then the corresponding step is taken. In MSR1, the parameter  is determined based on an ansatz that seeks to ensure the eigenvalues of the Jacobian are positive, as they should be in the case that the fixed-point corresponds to a variational minimum. However, as stated, in the context of density mixing type-II methods consistently outperform type-I methods, meaning we hereafter consider
is determined based on an ansatz that seeks to ensure the eigenvalues of the Jacobian are positive, as they should be in the case that the fixed-point corresponds to a variational minimum. However, as stated, in the context of density mixing type-II methods consistently outperform type-I methods, meaning we hereafter consider  .
.
Second, a core feature of the methods in [89, 92] involve partitioning of the full update into a predicted and unpredicted component, which are now defined. Consider the update generated from equation (91),

which is now split in two,

Since we are now considering the type-II variant,  , the unpredicted component of the update,
, the unpredicted component of the update,  , is defined as the orthogonal projection of the current residual Rn onto the past residual differences,
, is defined as the orthogonal projection of the current residual Rn onto the past residual differences,

In other words, the unpredicted vector is the part of the full update that is not described within the iterative subspace of residuals. In this sense, the remaining update can be considered to be the part of the update that the iterative subspace does describe. Equation (95) is shown in [92] to have the solution,

The update now takes the rearranged form


This partitioning is used to introduce the concept of algorithmic greed, which is quantified with an iterative damping parameter  that multiplies the unpredicted update, rather than the full update,
that multiplies the unpredicted update, rather than the full update,

In the implementation tested in section 6, the unpredicted direction is also Kerker preconditioned (see section 4.3). References [89, 92] refer to the updating of the parameter  as an implicit trust region. That is,
as an implicit trust region. That is,  is allowed to increase, within some bounds, provided the algorithm is performing well, by some definition of 'well' which defines the greed controls. If the algorithm is performing poorly, the damping parameter is decreased accordingly, thus reducing the need for user intervention. The precise greed controls for MSR1 are found in [89]; the controls used for section 6 are slightly modified for performance in the plane-wave pseudopotential setting. Furthermore, the matrix inverse in equation (91) is Tikhonov regularised [116] to prevent spurious behaviour due to rank-deficiencies, and the matrices involved are scaled appropriately. The method that has been described thus far is similar to 'multisecant Broyden 2' (MSB2) of [92]. The type-I variant, MSB1, can be derived in a similar fashion, and both are tested in section 6.
is allowed to increase, within some bounds, provided the algorithm is performing well, by some definition of 'well' which defines the greed controls. If the algorithm is performing poorly, the damping parameter is decreased accordingly, thus reducing the need for user intervention. The precise greed controls for MSR1 are found in [89]; the controls used for section 6 are slightly modified for performance in the plane-wave pseudopotential setting. Furthermore, the matrix inverse in equation (91) is Tikhonov regularised [116] to prevent spurious behaviour due to rank-deficiencies, and the matrices involved are scaled appropriately. The method that has been described thus far is similar to 'multisecant Broyden 2' (MSB2) of [92]. The type-I variant, MSB1, can be derived in a similar fashion, and both are tested in section 6.
Both of these methods remain prone to charge sloshing due to the primary form of step length control being an implicit trust region, the greed controls. Hence, particularly ill-conditioned simulations can still lead to divergence of the self-consistency iterations. In this context, a further stabilising measure is taken in the form of an explicit trust region. Given Rn as a descent direction on iteration n, the trust region subproblem can take a standard form


for variations in X with some trust region radius  . The variable X is the new trial step generated from the trust-region subproblem, and the scalar ||X||2 is the trail total step length, where the exact step length is
. The variable X is the new trial step generated from the trust-region subproblem, and the scalar ||X||2 is the trail total step length, where the exact step length is  . If the exact step length exceeds the trust region radius
. If the exact step length exceeds the trust region radius  , then the trust region problem is required to be solved to generate this new step. Details on how the trust-region subproblem is solved are given in [83, 89]. As [89] also states, the trust region problem does not need to be defined in terms of the full update,
, then the trust region problem is required to be solved to generate this new step. Details on how the trust-region subproblem is solved are given in [83, 89]. As [89] also states, the trust region problem does not need to be defined in terms of the full update,  . Instead, the trust region problem can be solved for the predicted component of the update,
. Instead, the trust region problem can be solved for the predicted component of the update,  . This is motivated by the fact that the size of the step in the unpredicted direction is already restricted by the greed controls. Note that
. This is motivated by the fact that the size of the step in the unpredicted direction is already restricted by the greed controls. Note that  is also iteratively updated based on algorithmic progress. The inclusion of an explicit trust region for the predicted update, in conjunction with the strategies described earlier, are able to significantly stabalise the self-consistency iterations [89, 92].
is also iteratively updated based on algorithmic progress. The inclusion of an explicit trust region for the predicted update, in conjunction with the strategies described earlier, are able to significantly stabalise the self-consistency iterations [89, 92].
A second method we highlight is a global variant of the type-I Pulay update [56], which has not yet been tested in the context of self-consistency iterations. (However, note that this method utilises a selection of the techniques from section 4.1.3 that do perform well for self-consistency iterations). First, similarly to the previous method, the Jacobian is required to be non-singular, which is achieved here through a form of Powell regularisation [117]. The regularisation parameter that is introduced, in some sense, scales the update between an unregularised Pulay step, and a fixed-point step, and thus must be chosen appropriately as not to negatively impact the efficiency of the method. The remaining modifications are aimed at stabilising the iterations and preventing stagnation in the reduction of the residual norm. Type-I methods, more so than type-II methods, tend to suffer from stagnation due to rank-deficiency in the iterative subspace of density differences  , see [56]. Rank-deficiency is avoided using a technique derived from the Restarted Pulay method [112] in the previous section, i.e. occasionally restart the history of stored iterates. Here, the restart condition can be triggered based on two separate criteria, the first of which is whenever the number of iterates stored reaches a maximum value m, similarly to [112]. The second of the restart criteria is based on ensuring the iterative subspace remains approximately of full rank. This is done by first using Gram–Schmit orthonormalisation on set of vectors used to construct
, see [56]. Rank-deficiency is avoided using a technique derived from the Restarted Pulay method [112] in the previous section, i.e. occasionally restart the history of stored iterates. Here, the restart condition can be triggered based on two separate criteria, the first of which is whenever the number of iterates stored reaches a maximum value m, similarly to [112]. The second of the restart criteria is based on ensuring the iterative subspace remains approximately of full rank. This is done by first using Gram–Schmit orthonormalisation on set of vectors used to construct  in order to generate a new set of vectors with the same span,
in order to generate a new set of vectors with the same span,  . Elements of this new set of vectors are identically zero if the original set had linear dependencies. The condition
. Elements of this new set of vectors are identically zero if the original set had linear dependencies. The condition

is therefore used to quantify the degree of linear independence we require from the iterative subspace, parametised by  . If this condition is triggered, for some sensible value of
. If this condition is triggered, for some sensible value of  , the iterative history is deemed too linearly dependent, and the history is reset.
, the iterative history is deemed too linearly dependent, and the history is reset.
Given that update Jacobian is now bounded, and the iterative history is linearly independent, global convergence is further guaranteed by using techniques similar to the Periodic Pulay method [110, 118, 119]. That is, linear mixing steps are included in between Pulay steps, and added to the history. However, instead of performing the linear mixing steps with a fixed period, the linear mixing steps are performed based on a criterion that ensures progress is made. Namely, the following inequality is defined

for parameters D and  , where
, where  is the number of Pulay steps performed so far in the simulation. If the inequality is not satisfied, linear mixing steps are performed until the inequality is satisfied again, and then Pulay steps are resumed. In other words, if the Pulay steps are not making sufficient progress, then linear steps are performed until a certain amount of progress, defined by D and
is the number of Pulay steps performed so far in the simulation. If the inequality is not satisfied, linear mixing steps are performed until the inequality is satisfied again, and then Pulay steps are resumed. In other words, if the Pulay steps are not making sufficient progress, then linear steps are performed until a certain amount of progress, defined by D and  , has been made, and then Pulay steps are continued. The proof of global convergence for this algorithm is given in [56].
, has been made, and then Pulay steps are continued. The proof of global convergence for this algorithm is given in [56].
4.2. Density matrix optimisation
The methods introduced previously define density mixing schemes, by which we mean the one-particle density is iteratively updated in order to find a fixed-point of the Kohn–Sham equations. Density mixing is common in implementations that utilise some form of delocalised basis set. In these implementations, both the Kohn–Sham Hamiltonian and the density matrix can be prohibitive to compute and store due to the size of the basis Nb. However, in the context of localised basis sets, it is common to formulate Kohn–Sham theory so that the density matrix equation (13) is the optimised variable, rather than the density12. The Kohn–Sham energy functional has a closed-form expression in terms of the density matrix,

which is now minimised over allowed variations in D,



for binary occupancy of the Kohn–Sham orbitals. These conditions define the set of density matrices  which form the domain of
which form the domain of ![$E_{\tiny{\rm KS}}[D]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn199.gif) , i.e. the set of density matrices for which the Kohn–Sham functional is defined. These are necessary but not sufficient conditions for a density matrix to be so-called N-representable, meaning it can be constructed from an antisymmetric wavefunction [120]. The first condition forces the density matrix to correspond to an N-particle system. The second condition forces the density matrix to be Hermition, which is true by construction. The third condition is called idempotency, which leads to the requirement that the eigenvalues of discretised density matrix, the orbital occupancies, are f i = {0,1} [28]. The Kohn–Sham Hamiltonan, sometimes referred to as the Fock matrix, can also be constructed and used to solve the Kohn–Sham equations for a self-consistent density matrix. As expected, a variety of self-consistent field techniques exist that are well suited to the this formulation, such as leveling shifting and its modern variants [121–124], methods that minimise a local model energy functional [122, 125–127], and more [19, 60, 128–131]. As many of these methods are not readily adaptable to the plane-wave setting, we keep the discussion here brief, and instead refer readers to the following review articles [19, 130, 132, 133] and references therein. In fact, we highlight one class of methods in particular, the relaxed constraints algorithms given in [49, 60, 129, 131, 134]. A member of this class, 'Energy DIIS', is now the default self-consistency method in gaussian09 [18].
, i.e. the set of density matrices for which the Kohn–Sham functional is defined. These are necessary but not sufficient conditions for a density matrix to be so-called N-representable, meaning it can be constructed from an antisymmetric wavefunction [120]. The first condition forces the density matrix to correspond to an N-particle system. The second condition forces the density matrix to be Hermition, which is true by construction. The third condition is called idempotency, which leads to the requirement that the eigenvalues of discretised density matrix, the orbital occupancies, are f i = {0,1} [28]. The Kohn–Sham Hamiltonan, sometimes referred to as the Fock matrix, can also be constructed and used to solve the Kohn–Sham equations for a self-consistent density matrix. As expected, a variety of self-consistent field techniques exist that are well suited to the this formulation, such as leveling shifting and its modern variants [121–124], methods that minimise a local model energy functional [122, 125–127], and more [19, 60, 128–131]. As many of these methods are not readily adaptable to the plane-wave setting, we keep the discussion here brief, and instead refer readers to the following review articles [19, 130, 132, 133] and references therein. In fact, we highlight one class of methods in particular, the relaxed constraints algorithms given in [49, 60, 129, 131, 134]. A member of this class, 'Energy DIIS', is now the default self-consistency method in gaussian09 [18].
Relaxed constraints algorithms are introduced in the context of Hartree–Fock theory, where, unlike in extended Kohn–Sham theory discussed in section 3.6, the notion of fractional occupancy is not a part of the framework. Relaxed constraints algorithms operate by permitting fractional occupation of the Hartree–Fock orbitals as a tool to reach convergence. The binary occupation fixed-point solution is recovered at the end of the calculation. First, consider the set of allowed discretised density matrices,

It is now apparent that the idempotency condition equation (107) requires that the eigenvalues of the density matrix, the orbital occupancies, are binary,  . The extension to fractional occupancy, as described in section 3.6, thus alters the set of allowed density matrices,
. The extension to fractional occupancy, as described in section 3.6, thus alters the set of allowed density matrices,

i.e. the eigenvalues of the density matrix must now satisfy  , which is the case for
, which is the case for  . Relaxed constraint algorithms are now founded based on two theorems, the proofs of which are given in [135]. The first theorem states that the Hartree–Fock functional varied over
. Relaxed constraint algorithms are now founded based on two theorems, the proofs of which are given in [135]. The first theorem states that the Hartree–Fock functional varied over  has the same stationary points as the Hartree–Fock functional varied over
has the same stationary points as the Hartree–Fock functional varied over  . In other words, minimising the Hartree–Fock functional over
. In other words, minimising the Hartree–Fock functional over  will always lead to physical (binary occupation) solutions. The second theorem states that the set
will always lead to physical (binary occupation) solutions. The second theorem states that the set  is convex. This means that, given a convex combination of density matrices
is convex. This means that, given a convex combination of density matrices  ,
,

for ![$\gamma \in [0,1]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn208.gif) , then
, then  . This is not the case for elements of
. This is not the case for elements of  . Algorithms that utilise these theorems in conjunction with the set
. Algorithms that utilise these theorems in conjunction with the set  belong to the class of relaxed constraints algorithms.
belong to the class of relaxed constraints algorithms.
The question remains of how these theorems translate to the Kohn–Sham functional equation (104). In fact, the former theorem no longer holds [134], meaning that the functional varied over  does lead to different stationary points than in the case of binary occupation. This is expected, as these solutions correspond to solutions of the extended Kohn–Sham theory developed in section 3.6. Therefore, the absence of the former theorem does not pose a problem, as solutions that are obtained that are members of
does lead to different stationary points than in the case of binary occupation. This is expected, as these solutions correspond to solutions of the extended Kohn–Sham theory developed in section 3.6. Therefore, the absence of the former theorem does not pose a problem, as solutions that are obtained that are members of  retain meaning within extended Kohn–Sham theory. Furthermore, the set
retain meaning within extended Kohn–Sham theory. Furthermore, the set  remains convex. The optimal damping algorithm was the first of the relaxed constraints algorithms, as examined in [60]. This algorithm seeks, at each iteration, to find an 'optimal' damping parameter
remains convex. The optimal damping algorithm was the first of the relaxed constraints algorithms, as examined in [60]. This algorithm seeks, at each iteration, to find an 'optimal' damping parameter  in the linear mixing scheme equation (22). Consider the pair
in the linear mixing scheme equation (22). Consider the pair  on iteration n. A trail density matrix is now constructed as a convex combination of this pair,
on iteration n. A trail density matrix is now constructed as a convex combination of this pair,

for ![$\alpha \in [0,1]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn217.gif) , where we note that
, where we note that  is a descent direction. The Kohn–Sham energy functional
is a descent direction. The Kohn–Sham energy functional ![$E_{{\rm ks}}[D^{{\rm trial}}]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn219.gif) is then minimised along this line-segment by varying
is then minimised along this line-segment by varying  . The value of the damping parameter that leads to the minimum energy is the so-called optimal damping value
. The value of the damping parameter that leads to the minimum energy is the so-called optimal damping value  . The subsequent input density matrix is thus
. The subsequent input density matrix is thus

Note that this method works precisely because the elements along the line-segment equation (111) remain in the domain of  . Furthermore, it is much cheaper to evaluate the energy for a given density matrix, rather than construct and diagonalise the Fock matrix for a new output density matrix.
. Furthermore, it is much cheaper to evaluate the energy for a given density matrix, rather than construct and diagonalise the Fock matrix for a new output density matrix.
This method is improved by instead considering an (at most) m-dimensional iterative subspace of past density matrices, rather than just the most recent pair. In other words, similar to Pulay's method, a trail density matrix is constructed

for some unknown coefficients ci. These coefficients are then fixed as the coefficients that minimise ![$E_{\tiny{\rm KS}}[D^{{\rm trial}}]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn223.gif) . An algorithm to accomplish this is provided in [131]. However, note that only convex combinations of past density matrices are permissible, otherwise the resulting density matrix may not be a valid according to the conditions imposed in
. An algorithm to accomplish this is provided in [131]. However, note that only convex combinations of past density matrices are permissible, otherwise the resulting density matrix may not be a valid according to the conditions imposed in  . This observation necessitates the restriction
. This observation necessitates the restriction  , which leads to the following constrained minimisation problem,
, which leads to the following constrained minimisation problem,


The coefficients that solve this problem form the optimal density matrix that is set equal to the subsequent input density matrix  . This method is titled 'Energy DIIS' (EDIIS) and has been demonstrated to perform well in a variety of cases [130, 131]. Furthermore, this method is global, as the energy functional is required to be minimised at each iteration in equation (114). The minimisation of the energy functional is an interpolation step in the space of past density matrices due to the constraint on the coefficients, and can be slow when the iterates are near convergence [131]. For this reason, EDIIS is commonly augmented with Pulay iterations (DIIS) when close to convergence, which demonstrably improves efficiency [130]. These methods, and similar methods, can be impractical in plane-wave codes as one is required to construct and store the density matrix.
. This method is titled 'Energy DIIS' (EDIIS) and has been demonstrated to perform well in a variety of cases [130, 131]. Furthermore, this method is global, as the energy functional is required to be minimised at each iteration in equation (114). The minimisation of the energy functional is an interpolation step in the space of past density matrices due to the constraint on the coefficients, and can be slow when the iterates are near convergence [131]. For this reason, EDIIS is commonly augmented with Pulay iterations (DIIS) when close to convergence, which demonstrably improves efficiency [130]. These methods, and similar methods, can be impractical in plane-wave codes as one is required to construct and store the density matrix.
4.3. Preconditioning
Preconditioning refers to the modification of an optimisation problem such that the condition number of the problem is improved. Crucially, the modified problem is required to have the same minimum, and minimiser, as the original problem. Algorithms applied to the modified problem thus have more stable and accelerated convergence. A preconditioner is most transparently defined for linear systems as being the matrix P such that

where the P−1A has a lower condition number equation (43) than A. In the case P = A the linear system is solved, and P is the exact preconditioner. The definition of a preconditioner for non-linear systems is less transparent. Consider the optimisation of the Kohn–Sham residual L2-norm, which now takes the preconditioned form

The preconditioned residual  is required to have the same solution as R, but has, in some sense, improved convergence properties. The perfect preconditioner here would modify R such that only one step of appropriate size in the steepest descent direction is required for convergence. A successfully preconditioned problem therefore represents a problem whose landscape is easier to traverse toward a minimum using, for example, Newton's algorithm. It is known that the Jacobian (Hessian) eigenvalue spectrum of the objective function determines the rate of convergence of Newton, and quasi-Newton, methods [58, 83, 97]. Therefore, a preconditioner should accomplish one or more of the following: reduce the number of eigenvalue clusters; reduce the width of the eignevalue clusters; or compress the spectrum as a whole. A discussion on the importance of the clustering of the eigenvalues, rather than just the condition number, can be found in [83, 89, 136]. To simplify matters, we consider P to be a matrix constant with respect to the optimised variable, the density, such that
is required to have the same solution as R, but has, in some sense, improved convergence properties. The perfect preconditioner here would modify R such that only one step of appropriate size in the steepest descent direction is required for convergence. A successfully preconditioned problem therefore represents a problem whose landscape is easier to traverse toward a minimum using, for example, Newton's algorithm. It is known that the Jacobian (Hessian) eigenvalue spectrum of the objective function determines the rate of convergence of Newton, and quasi-Newton, methods [58, 83, 97]. Therefore, a preconditioner should accomplish one or more of the following: reduce the number of eigenvalue clusters; reduce the width of the eignevalue clusters; or compress the spectrum as a whole. A discussion on the importance of the clustering of the eigenvalues, rather than just the condition number, can be found in [83, 89, 136]. To simplify matters, we consider P to be a matrix constant with respect to the optimised variable, the density, such that  . Hence, in the present context, preconditioning amounts to finding the matrix P such that the spectrum of the dielectric is more suitable for quasi-Newton algorithms. Note that the preconditioning matrix is permitted to change iteration-to-iteration. The strategy used in practice is to identify the source of divergent eigenvalues of the dielectric, as examined in section 3, and temper this divergence in such a fashion that is generally applicable to all, or large classes, of Kohn–Sham inputs. Depending on the implementation, the preconditioning approach can differ. For example, in augmented plane-wave implementations [114], the unit cell is partitioned into the regions surrounding atomic cores, represented by local basis functions, and an interstitial region, represented by plane-waves. Naturally, due to the differing number of basis functions involved in each region, among other properties, the preconditioning for each region is separate [89, 92]. The following work assumes an entirely plane-wave basis set, although the preconditioners can be adapted for a variety of implementations.
. Hence, in the present context, preconditioning amounts to finding the matrix P such that the spectrum of the dielectric is more suitable for quasi-Newton algorithms. Note that the preconditioning matrix is permitted to change iteration-to-iteration. The strategy used in practice is to identify the source of divergent eigenvalues of the dielectric, as examined in section 3, and temper this divergence in such a fashion that is generally applicable to all, or large classes, of Kohn–Sham inputs. Depending on the implementation, the preconditioning approach can differ. For example, in augmented plane-wave implementations [114], the unit cell is partitioned into the regions surrounding atomic cores, represented by local basis functions, and an interstitial region, represented by plane-waves. Naturally, due to the differing number of basis functions involved in each region, among other properties, the preconditioning for each region is separate [89, 92]. The following work assumes an entirely plane-wave basis set, although the preconditioners can be adapted for a variety of implementations.
Recall from section 3.8 that the Coulomb kernel, in combination with the susceptibility, is principally responsible for the large eigenvalues of the Kohn–Sham residual linear response function. As discussed, in the general case, the susceptibility is a complicated object about which it is difficult to make sweeping statements. However, when the system is homogeneous and isotropic, the dielectric eigenvalues of gapped and gapless phases are approximately determined by


for some a priori unknown system-dependent constant  . In the case of the homogeneous electron gas, this constant in equation (118) is identified with the square of the Thomas–Fermi screening wavevector
. In the case of the homogeneous electron gas, this constant in equation (118) is identified with the square of the Thomas–Fermi screening wavevector  . Modest departures from homogeneity and isotropy remain accurately modelled by equations (118) and (119), particularly in the low
. Modest departures from homogeneity and isotropy remain accurately modelled by equations (118) and (119), particularly in the low  limit [75, 88]. Therefore, these model dielectrics can be used to improve the condition of the residual map by allowing
limit [75, 88]. Therefore, these model dielectrics can be used to improve the condition of the residual map by allowing  for either equation (118) or (119) depending on whether one suspects the input to be metallic or insulating. Collecting and relabelling the unknown constants, the preconditioner becomes
for either equation (118) or (119) depending on whether one suspects the input to be metallic or insulating. Collecting and relabelling the unknown constants, the preconditioner becomes

where |G0| and  are parameters that are determined by the linear response of the input system; e.g. |G0| = 0 for Kohn–Sham insulators, and |G0| is related to the Wigner–Seitz radius for the homogeneous electron gas. The values of |G0| and
are parameters that are determined by the linear response of the input system; e.g. |G0| = 0 for Kohn–Sham insulators, and |G0| is related to the Wigner–Seitz radius for the homogeneous electron gas. The values of |G0| and  naturally differ depending on the input, although fixing |G0| = 1.5
naturally differ depending on the input, although fixing |G0| = 1.5  and
and  [15, 31] demonstrably improves convergence, see section 6. The modified Kohn–Sham problem is now solved
[15, 31] demonstrably improves convergence, see section 6. The modified Kohn–Sham problem is now solved

which is referred to as Kerker preconditioned equation (120) [84, 85]. The Kerker preconditioner suppresses charge sloshing, as defined in section 3.8, by damping eigenvalues of the dielectric corresponding to low  components of the density, see figure 8. It is these components that have a generically amplified response due to the Coulomb kernel. Note that the optimal damping algorithm detailed in section 4.2 can be regarded as a preconditioner that updates the value of
components of the density, see figure 8. It is these components that have a generically amplified response due to the Coulomb kernel. Note that the optimal damping algorithm detailed in section 4.2 can be regarded as a preconditioner that updates the value of  at each iteration. The adaptation of the Kerker preconditioner to real space implementations of Kohn–Sham theory more difficult. The dielectric response function of the homogeneous electron gas is non-local in real space, meaning the integral in equation (39) leads to a dense
at each iteration. The adaptation of the Kerker preconditioner to real space implementations of Kohn–Sham theory more difficult. The dielectric response function of the homogeneous electron gas is non-local in real space, meaning the integral in equation (39) leads to a dense  matrix that must be computed and stored. The susceptibility takes the Yukawa screening form in real space [76]. An efficient real space implementation of the Kerker preconditioner is given in [137].
matrix that must be computed and stored. The susceptibility takes the Yukawa screening form in real space [76]. An efficient real space implementation of the Kerker preconditioner is given in [137].

Figure 8. The Kerker preconditioner for various values of  .
.
Download figure:
Standard image High-resolution imageOne aspect of the preconditioning presented here is that, for increasingly homogeneous and isotropic inputs, the dependence of the dielectric condition number on unit cell dimension  cancels [73]. This is by construction, and is identified by examining the eigenvalues of the Kerker preconditioned dielectric. For inputs that are not so accommodating, while the Kerker preconditioner does help, the scaling of iterations with unit cell dimension persists [73, 138]. Removing this scaling can be considered one of the primary goals of preconditioners in Kohn–Sham theory as large simulation cells are required for many modern applications. Moderate extensions to the Kerker preconditioner have been proposed [139], which involve more accurately modelling the dielectric response, e.g. [140]. However, in these examples, the main drawback of the Kerker preconditioner remains: there is no scope for systematically including anisotropy and inhomogeneity. Furthermore, the exchange-correlation kernel is ignored. This is a reasonable practice in non spin polarised systems, but in spin polarised systems, the spin density interacts entirely through the exchange-correlation kernel, and is thus not preconditioned.
cancels [73]. This is by construction, and is identified by examining the eigenvalues of the Kerker preconditioned dielectric. For inputs that are not so accommodating, while the Kerker preconditioner does help, the scaling of iterations with unit cell dimension persists [73, 138]. Removing this scaling can be considered one of the primary goals of preconditioners in Kohn–Sham theory as large simulation cells are required for many modern applications. Moderate extensions to the Kerker preconditioner have been proposed [139], which involve more accurately modelling the dielectric response, e.g. [140]. However, in these examples, the main drawback of the Kerker preconditioner remains: there is no scope for systematically including anisotropy and inhomogeneity. Furthermore, the exchange-correlation kernel is ignored. This is a reasonable practice in non spin polarised systems, but in spin polarised systems, the spin density interacts entirely through the exchange-correlation kernel, and is thus not preconditioned.
There have been various efforts to construct a preconditioner that provides an improved description of inhomogeneous and anisotropic inputs. In the most extreme examples, computation of the exact linear response function is considered [78–81, 86, 141]. As discussed, the exact linear response function does not represent a preconditioning scheme, rather it is the exact Newton method. A density-dependent preconditioner necessarily alters the Jacobian, equation (117), in a non-trivial manner. Hence, it is not obvious the extent to which the condition of the modified problem will improve. Nevertheless, even approximate attempts at computing the exact response function, when treated as a Newton step, are able to improve the iterations over accelerated fixed-point algorithms such as Pulay's method [78, 141]. The central difficulty in computing the exact susceptability, and subsequently the exact dielectric, is that it requires a summation over all unoccupied-occupied eigenfunction pairs equation (49). In plane-wave codes, both the computation and storage of all eigenfunctions of the Kohn–Sham Hamiltonian is infeasible.
Past attempts [79, 80] are able to implement and examine computation of the exact susceptibility with success, albeit with a basis set size now unsuited to modern computation. The problem of having to compute the full set of eigenfunctions, and having too large a basis, can be remedied with a few differing approaches. First, the size of the effective basis can be reduced by recalling that the low  components of the density are those responsible for divergent eigenvalues of the dielectirc. Therefore, the susceptibility need only be computed for a reduced set of plane-waves—those with low frequency G. Working in this reduced space for the purposes of density mixing leads to a significant reduction in compute and memory overhead13 [15, 31, 78]. Second, we highlight two strategies to remove the infinite summation over unoccupied eigenfunctions in the Adler–Wiser equation equation (49). The first strategy utilises density functional pertubation theory, and in particular the Sternheimer equation [142]. Solution of the Sternheimer equation allows one to obtain the first-order response in a perturbed quantity—here, the density in the direction of the residual—without requiring the full eigendecomposition of the Kohn–Sham Hamiltonian. This is utilised in, for example, the implementation of the GW approximation [143], and hence is available functionality within many Kohn–Sham codes. The density functional pertubation theory approach is used to construct a Newton step in [141] and is shown to significantly reduce the number of iterations taken to converge when compared to Pulay's method. The second strategy involves exploiting the completeness of eigenfunctions,
components of the density are those responsible for divergent eigenvalues of the dielectirc. Therefore, the susceptibility need only be computed for a reduced set of plane-waves—those with low frequency G. Working in this reduced space for the purposes of density mixing leads to a significant reduction in compute and memory overhead13 [15, 31, 78]. Second, we highlight two strategies to remove the infinite summation over unoccupied eigenfunctions in the Adler–Wiser equation equation (49). The first strategy utilises density functional pertubation theory, and in particular the Sternheimer equation [142]. Solution of the Sternheimer equation allows one to obtain the first-order response in a perturbed quantity—here, the density in the direction of the residual—without requiring the full eigendecomposition of the Kohn–Sham Hamiltonian. This is utilised in, for example, the implementation of the GW approximation [143], and hence is available functionality within many Kohn–Sham codes. The density functional pertubation theory approach is used to construct a Newton step in [141] and is shown to significantly reduce the number of iterations taken to converge when compared to Pulay's method. The second strategy involves exploiting the completeness of eigenfunctions,

This identity cannot be applied to the Adler–Wiser equation equation (49) without further approximation due to the denominator depending on the j th eigenenergy,  . However, these eigenenergies can be replaced with some approximate constant value
. However, these eigenenergies can be replaced with some approximate constant value  above a certain cut-off number of eigenfunctions
above a certain cut-off number of eigenfunctions  . This allows equation (122) to transform the Adler–Wiser equation into a sum over
. This allows equation (122) to transform the Adler–Wiser equation into a sum over  eigenfunctions, which is used [78, 81] to successfully reduce the number of iterations taken to converge. However, note that these methods retain a poor scaling with the number of electrons;
eigenfunctions, which is used [78, 81] to successfully reduce the number of iterations taken to converge. However, note that these methods retain a poor scaling with the number of electrons;  in the most recent examples. Whilst the prefactor of the scaling is much reduced compared to earlier efforts [79], such methods, without further approximation or development, are precluded for larger system sizes. A major advantage of the methods discussed here though is the ability to take into account the spin linear response function. To the authors knoweldge, no other methods based around model dielectrics attempt to include the spin response function, and thus the spin density is often not preconditioned.
in the most recent examples. Whilst the prefactor of the scaling is much reduced compared to earlier efforts [79], such methods, without further approximation or development, are precluded for larger system sizes. A major advantage of the methods discussed here though is the ability to take into account the spin linear response function. To the authors knoweldge, no other methods based around model dielectrics attempt to include the spin response function, and thus the spin density is often not preconditioned.
Finally, methods are examined that attempt to include inhomogeneity and anisotropy through model response functions, rather than with the exact methods discussed prior. An extension to the Kerker preconditioner, which is based on Thomas–Fermi theory of the homogeneous electron gas, is considered [144]. Here, Thomas–Fermi–Von Weizäcker14 theory is used, in combination with Pulay's method, to generate the subsequent density. Crucially, this work does not restrict to the case of the homogeneous electron gas, and instead numerically minimises the relevant functional. That is, the modified orbital-free functional

is minimised with respect to variations in  , where
, where  , the effective potential used to solve the Kohn–Sham equations. The details of the modification term
, the effective potential used to solve the Kohn–Sham equations. The details of the modification term ![$\delta E[\rho^{{\rm in}}_n,\rho]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn250.gif) are given in [144], and is derived such that the minimiser of equation (123) can be used as the subsequent input density. Namely, the method calculates the repsonse that is required to bring the current input density to self-consistency within the framework of Thomas–Fermi–Von Weizäcker theory, and uses this as a model of the exact Kohn–Sham response. Minimisation of the Thomas–Fermi–Von Weizäcker functional, which is done using the conjugate gradient method [144], is vastly more efficient than minimisation of the Kohn–Sham functional due to that fact it is orbital-free. In certain test cases this method is demonstrated to reduce the time taken to converge by up to a factor of three, and is implemented in the software package abinit [10, 32].
are given in [144], and is derived such that the minimiser of equation (123) can be used as the subsequent input density. Namely, the method calculates the repsonse that is required to bring the current input density to self-consistency within the framework of Thomas–Fermi–Von Weizäcker theory, and uses this as a model of the exact Kohn–Sham response. Minimisation of the Thomas–Fermi–Von Weizäcker functional, which is done using the conjugate gradient method [144], is vastly more efficient than minimisation of the Kohn–Sham functional due to that fact it is orbital-free. In certain test cases this method is demonstrated to reduce the time taken to converge by up to a factor of three, and is implemented in the software package abinit [10, 32].
Alternatively, given an input that can be transparently partitioned into metallic and insulating regions, such as an interface, inhomogeneity can be included explicitly by varying |G0| in each region. That is, set |G0| = 0 for the insulating region, and have finite |G0| in the metallic region, which is considered in [73, 145]. This is non-trivial as the dielectric equation (39) becomes non-diagonal in both Fourier and real space, and hence becomes unfavourable to construct and store. However, note that one requires the dielectric applied to the residual vector Rn, rather than the dielectric itself. Therefore, inhomogeneity can be included using an algorithm that successively switches between Fourier and real space as to avoid constructing the non-diagonal dielectric; see [145]. Furthermore, if the potential is treated as the optimisation variable rather than the density, a modified Poission equation can be solved for the updated potential residual, see [73]. Here, the inhomogeneity is specified a priori with two functions that are now inputs to the calculation. These methods thus have the drawback that they are not black-box, as one is required to specify the inhomogeneity using prior knowledge of ones input system. Nonetheless, for specific systems, these frameworks provide an expert user with an additional degree of freedom for optimising convergence.
4.4. Direct minimisation
Whilst self-consistent field methods are widespread, alternative techniques are available based on direct minimisation of the energy functional. These methods exploit the variational principle, and are thus global, varying  to minimise
to minimise ![$E_{\tiny{\rm KS}}[\{\phi_i \} ]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn252.gif) . The density in these schemes is a dependent quantity, always derived directly from
. The density in these schemes is a dependent quantity, always derived directly from  with no history of previous densities. From an initial guess set of orbitals,
with no history of previous densities. From an initial guess set of orbitals,  , a density
, a density

is constructed, and the energy ![$E_{\tiny{\rm KS}}[\{\phi^{(0)}_i \} ]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn255.gif) and Kohn–Sham eigenvalue estimates
and Kohn–Sham eigenvalue estimates  are evaluated, along with the energy gradient with respect to changes in
are evaluated, along with the energy gradient with respect to changes in  ,
,

Since the energy gradients are the steepest ascent directions, the steepest descent direction is the negative of this. This steepest descent direction may be interpreted as a force acting on the degrees of freedom of the trial states  . If masses are assigned to these degrees of freedom, then the states may be evolved forward in time according to a suitable equation of motion, and this forms the foundation of the Car–Parrinello method [17, 146]. By damping the motion appropriately, the system evolves towards the ground state.
. If masses are assigned to these degrees of freedom, then the states may be evolved forward in time according to a suitable equation of motion, and this forms the foundation of the Car–Parrinello method [17, 146]. By damping the motion appropriately, the system evolves towards the ground state.
An alternative approach is to consider the search for the ground state as a minimisation problem. A candidate search direction  may be constructed to minimise the energy as,
may be constructed to minimise the energy as,

i.e. the steepest descent direction. In practice more sophisticated methods are used to construct a search direction, usually based on preconditioned quasi-Newton methods such as conjugate gradients.
Once a search direction has been obtained, an improved set of trial orbitals are constructed, e.g.

where  is a scalar parameter, chosen to minimise
is a scalar parameter, chosen to minimise ![$E_{\tiny{\rm KS}}[\{\phi^{(1)}_i \} ]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn261.gif) . Note that, in general,
. Note that, in general,  will not be orthonormal and must be orthonormalised explicitly first. The search for an optimal value of
will not be orthonormal and must be orthonormalised explicitly first. The search for an optimal value of  is known as the line-minimisation step. It is also important to note that, in the evaluation of
is known as the line-minimisation step. It is also important to note that, in the evaluation of ![$E_{\tiny{\rm KS}}[\{\phi^{(1)}_i \} ]$](https://content.cld.iop.org/journals/0953-8984/31/45/453001/revision2/cmab31c0ieqn264.gif) ,
,  and
and  are always constructed from the density
are always constructed from the density

This is the critical difference between the self-consistent field methods and the direct energy minimisation methods. In self-consistent field methods the corresponding optimisation of the orbitals is carried out using the original  and
and  . Figure 9 shows a direct comparison between these two approaches for a simulation of silicon, using an 8-atom conventional unit cell. The effect of updating the Kohn–Sham potential at each step along the line minimisation is to increase the curvature of the energy with respect to the step-length
. Figure 9 shows a direct comparison between these two approaches for a simulation of silicon, using an 8-atom conventional unit cell. The effect of updating the Kohn–Sham potential at each step along the line minimisation is to increase the curvature of the energy with respect to the step-length  leading to higher energies and an energy minimum at a smaller value of
leading to higher energies and an energy minimum at a smaller value of  . In contrast, the over-estimation of
. In contrast, the over-estimation of  when the energy curve along the steepest descent direction is computed with the fixed initial potential (from
when the energy curve along the steepest descent direction is computed with the fixed initial potential (from  ) can be considered one of the root causes of charge-sloshing instabilities in self-consistent field methods, see section 3.8.
) can be considered one of the root causes of charge-sloshing instabilities in self-consistent field methods, see section 3.8.

Figure 9. Comparison of the energy for a line-minimisation in the steepest descent direction with respect to the orbitals as a function of step-length  . The energy function is specified with fixed initial potentials (solid line) or with continually updated potentials along the line-minimisation (dashed line). The data is from the first step of a simulation of a conventional 8-atom fcc silicon cell, using the local density approximation.
. The energy function is specified with fixed initial potentials (solid line) or with continually updated potentials along the line-minimisation (dashed line). The data is from the first step of a simulation of a conventional 8-atom fcc silicon cell, using the local density approximation.
Download figure:
Standard image High-resolution imageThe direct energy minimisation method discussed thus far is suitable for simulations with a band-gap. For metals and finite temperature insulators, however, it is not sufficient to consider only the lowest N eigenstates as occupied and there is an additional dependence on the partial occupancies f i. The ground state must now be found by searching over both the Kohn–Sham states and their occupancies. One of the most robust methods of this form is the ensemble density functional theory (EDFT) method of Marzari et al [26]. In EDFT every update of the trial states  is followed by a direct energy-minimisation over the density matrix in the basis of the trial states occupancies, {f ij}. This density matrix is nothing more than a generalisation of the occupancies to the case when the trial states
is followed by a direct energy-minimisation over the density matrix in the basis of the trial states occupancies, {f ij}. This density matrix is nothing more than a generalisation of the occupancies to the case when the trial states  do not diagonalise the subspace Hamiltonian h directly, where
do not diagonalise the subspace Hamiltonian h directly, where

5. Test suite
The test suite [147] presented here differs from available test suites (e.g. [35, 36]) as it is required to sample the range of sources of ill-conditioning discussed in section 3. Therefore, it is the aim of this test suite that standard algorithms, such as Broyden's methods, should fail to converge for approximately thirty to forty percent of cases. Furthermore, the standard algorithms should be inefficient, as defined in section 6, for the majority of the remainder of the systems. The test suite is designed to consume only moderate computational resources. Some of the most taxing inputs, such as large clusters with vacuum, require approximately sixty cores and a few hours. In its current version, which is subject to change, the test suite contains 56 systems. The geometries and relevant input parameters are given in [147] in the form of castep input files, but are readily converted using, for example, [148].
The content of the test suite is compiled from a range of sources, for example, self-consistency articles (e.g. [73, 89, 92, 122, 123, 131, 144]), collaboration, and online databases. This content is now briefly motivated in terms of the theory in section 3. First, we recall that within semi-local Kohn–Sham theory, the exchange-correlation approximation can be largely ignored from the point of view of ill-conditioning. Hence, the exchange-correlation approximation is not varied across the test suite, and the PBE [47] level of theory is applied throughout. A primary source of numerical difficulty, particularly relevant to future applications, was identified as ill-conditioning arising from large unit cell dimensions. As such, a range of inputs with varying dimensionality is included. For example, we include a relatively large rubidium cluster, a rare earth silicide in the form of a long thin pillar, a slab of gold with a large vacuum, and so on. These additions should allow the test suite to be used to evaluate different preconditioners effectively, rather than just black-box methodology. When necessary, calculations are performed with spin polarisation, where any symmetry is broken by specifying some prior spin state. This initial spin polarisation is applied following Hund's rules in order to ensure the algorithms converge to the same fixed-point. Approximately fifty percent of the test suite is spin polarised. Moreover, a particular emphases is placed on including inputs that are aligned with contemporary research. For example, superconductivity candidates, perovskites, and phases of matter that are far from their atomic equilibrium such as those generated by structure searching algorithms. The latter in particular can tend to introduce a very high density of states about the Fermi energy, and hence a variety of electronic temperatures is in the test suite for one such out of equilibrium system. Furthermore, isolated atoms in vacuum are conventionally difficult to converge, and in certain cases have been demonstrated to display artificial phase changes during the self-consistency iterations [89]. The test suite includes examples of isolated systems with varying atomic configurations, such as oxygen, nitrogen, iron, titanium, and vanadium. Finally, further to these classes of inputs, we also include examples of interfaces, highly inhomogeneous systems, electronegative systems, supercells of conventional metals, and poorly constructed problems (e.g. undersampling k-space).
6. Results and discussion
The aim of this section is to combine to the analysis of section 3, a sample of the methods presented in section 4, and the test suite of section 5, in order to arrive at a workflow that can provide insight on the strengths and weaknesses of contemporary self-consistency algorithms. Hence, the following work constitutes a benchmarking effort. However, the conclusions of this benchmark are not intended to be the focus of this section. The reasons for this are two-fold. First, the benchmark is not universal. That is, the benchmark omits a variety of successful methods simply because these methods are unsuitable for the underlying DFT software used, for example, EDIIS [131]. Second, the utility measures are necessarily imperfect as a degree of detail is lost when condensing all convergence data to two scalar measures for each method. We elaborate on this comment after defining the utility measures. This section is instead primarily intended to demonstrate a workflow that can be imitated by both methods developers and DFT software developers. That is, method developers are able to utilise the test suite, and similar measures of efficiency and robustness, to present and analyse new methodology in a more transparent and systematic fashion. Additionally, DFT software developers are able to do the same in order to assess whether they wish to replace old methodology with confidence. Nonetheless, despite the caveats discussed with regards to the benchmark itself, the conclusions of the benchmark remain indicators of the kinds of techniques and principles that are proving successful, and can assist in guiding future method development.
As discussed previously, one must quantify utility precisely in order to compare and contrast differing algorithms. Here, this is done by introducing two separate measures, robustness and efficiency. Robustness is defined as the percentage of the test suite for which a given algorithm converges in less than a certain cut-off, which depends on how the efficiency measure is defined. Iterations are chosen as the efficiency measure, as discussed shortly, in which case we define two thousand iterations as the cut-off number of iterations after which an algorithm is said to have diverged—this choice depends on the content of the test suite. A robustness measure of r = 0.6, for example, would indicate an algorithm converges 60% of the test suite in under two thousand iterations. Efficiency, in general, is a more complex quantity to measure. Many of the algorithms presented in section 4 require a negligible amount of time to compute the update in a given iteration, and hence number of iterations becomes an effective measure of efficiency. However, there exist many methods that require a significant amount of time per iteration to compute the update. Therefore, these methods demand another measure of efficiency, such as wall-clock time. The use of wall-clock time as a measure of efficiency has transferability issues as it depends heavily on the computer architecture used, number of cores, efficiency and parallel scaling of the implementation, and so on. If one is required to use a measure such as wall-clock time, one must be very careful in assuring all potential sources of interfering causal influence, like changing computer architecture, are held constant. All but one of the methods to be tested here require negligible compute time per iteration, and hence we measure efficiency by number of iterations. For the remaining method that cannot be assessed using number of iterations, namely, ensemble DFT [26], we use wall-clock time to provide an estimated number of iterations, while ensuring all the aforementioned variables are held constant.
The quantity that defines the efficiency of a given algorithm in the present context is given as

where  is the number of inputs for which the algorithm converged, and ni is the iterations taken to converge for the ith member of the test suite. The inverse is included such that
is the number of inputs for which the algorithm converged, and ni is the iterations taken to converge for the ith member of the test suite. The inverse is included such that  is larger for a more efficient method. The normalisation factor
is larger for a more efficient method. The normalisation factor  is included in order to separate the measures of efficiency and robustness as much as possible. If this normalisation were not included, algorithms that converge a significantly higher percentage of the test suite would spuriously appear more inefficient than they actually are—this effect is still present, but diminished. A further complication is the following. Inputs which generically take a larger number of iterations to converge (e.g. large systems) will have a much higher method-to-method variance in iteration number than inputs which generically take significantly less iterations to converge. The inputs which lead to a large variance in iteration number can act to drown out the contribution to the total efficiency of the inputs with less absolute variance (but equally high relative variance). For example, a method that performs well on one large system and poor on many small systems may lead to a improved efficiency
is included in order to separate the measures of efficiency and robustness as much as possible. If this normalisation were not included, algorithms that converge a significantly higher percentage of the test suite would spuriously appear more inefficient than they actually are—this effect is still present, but diminished. A further complication is the following. Inputs which generically take a larger number of iterations to converge (e.g. large systems) will have a much higher method-to-method variance in iteration number than inputs which generically take significantly less iterations to converge. The inputs which lead to a large variance in iteration number can act to drown out the contribution to the total efficiency of the inputs with less absolute variance (but equally high relative variance). For example, a method that performs well on one large system and poor on many small systems may lead to a improved efficiency  when compared to a method which performs well on many small systems and poor on one large system. This issue is not particularly pronounced here because iteration count as a measure of efficiency suffers far less from this pathology than, for example, wall-clock time. Furthermore, one can recover the detail lost due to this issue by comparing any two methods individually, a workflow for which is provided later in this section. Therefore, the efficiency and robustness measures outlined here are able to provide an approximate guide toward methodology that performs well. Further inspection of the convergence data can then allow one to make more to make more concrete conclusions.
when compared to a method which performs well on many small systems and poor on one large system. This issue is not particularly pronounced here because iteration count as a measure of efficiency suffers far less from this pathology than, for example, wall-clock time. Furthermore, one can recover the detail lost due to this issue by comparing any two methods individually, a workflow for which is provided later in this section. Therefore, the efficiency and robustness measures outlined here are able to provide an approximate guide toward methodology that performs well. Further inspection of the convergence data can then allow one to make more to make more concrete conclusions.
As there exist two separate measures of utility, we must determine a prescription for how optimal can be defined here. This is done using the concept of Pareto optimality. Consider an algorithm X with associated efficiency and robustness scores,  . If X is Pareto optimal, then there exists no algorithm
. If X is Pareto optimal, then there exists no algorithm  such that
such that  and
and  . In other words, there is no algorithm that is both more efficient and more robust than X, and hence X has utility. Any algorithm that is not Pareto optimal, or nearly Pareto optimal, has no utility as there exists another algorithm with significantly higher individual utility scores. The set of all Pareto optimal algorithms, which includes differing parameter sets of the same underlying method, define the Pareto frontier. Algorithms that lie on, or lie close to, the Pareto frontier can be utilised in the sense that it is up to the developer to make a trade-off between robustness and efficiency. A developer might choose, for example, a particularly robust yet inefficient algorithm as a fall-back, and a slightly less robust yet more efficient algorithm as default, both of which should lie on the Pareto frontier.
. In other words, there is no algorithm that is both more efficient and more robust than X, and hence X has utility. Any algorithm that is not Pareto optimal, or nearly Pareto optimal, has no utility as there exists another algorithm with significantly higher individual utility scores. The set of all Pareto optimal algorithms, which includes differing parameter sets of the same underlying method, define the Pareto frontier. Algorithms that lie on, or lie close to, the Pareto frontier can be utilised in the sense that it is up to the developer to make a trade-off between robustness and efficiency. A developer might choose, for example, a particularly robust yet inefficient algorithm as a fall-back, and a slightly less robust yet more efficient algorithm as default, both of which should lie on the Pareto frontier.
As discussed previously, all possible parameters that could influence the convergence behaviour of the algorithm, that are not directly related to the algorithm, must be held constant. In the benchmark presented here, this includes (unless stated otherwise): PBE exchange-correlation functional, Gaussian smearing scheme, electronic temperature T = 300 K, history length m = 20, k-point spacing 
 , and parallelised over sixty four cores using Intel Xeon Gold 6142 processors at 2.6 GHz. Note that the energy tolerance required for convergence, the cut-off energy, and the pseudopotential are varied across the members of the test suite, but not across the algorithms. Ultrasoft pseudopotentials are generated following the prescriptions of castep's on-the-fly pseudopotential generator. A summary of these input parameters for each member of the test suite is given in [147].
, and parallelised over sixty four cores using Intel Xeon Gold 6142 processors at 2.6 GHz. Note that the energy tolerance required for convergence, the cut-off energy, and the pseudopotential are varied across the members of the test suite, but not across the algorithms. Ultrasoft pseudopotentials are generated following the prescriptions of castep's on-the-fly pseudopotential generator. A summary of these input parameters for each member of the test suite is given in [147].
The results of the benchmark are given in table 1, and illustrated in figure 10. The first observation of note is that Pulay's algorithm, Kerker preconditioned using the default parameter set [15, 31], is Pareto optimal. In particular, Pulay's method significantly outperforms Broyden's methods in both the singlesecant and multisecant form. Despite Pulay's method being Pareto optimal, there exist multiple algorithms that are more stable than Pulay's method while sacrificing little efficiency. The relationship between efficiency and robustness is generally non-linear, meaning it is worth sacrificing more than 10% efficiency for a method that is 10% more robust. Hence, algorithms more robust than Pulay's method, that only incur a relatively small drop in efficiency, can be considered potential upgrades over Pulay's method. From the algorithms tested here, these potential upgrades include certain parameterisations of Restarted Pulay [112], Periodic Pulay [110], and Marks & Lukes' MSB2 [92]. The parameters used for these methods, as detailed in table 1, are not necessarily optimal; by this we mean the parameters have not been tailored for performance over the test suite. Rather, these parameter sets are sensible choices that demonstrate improved convergence properties. It is feasible that parameter adjustments could lead to even more stable and efficient convergence. To this end, we provide a modest demonstration of how the representativeness of how the test suite can be used to determine optimal parameter sets. Figure 11 illustrates the results of calculations using eight different Kerker parameter sets for Pulay's method over the test suite. As expected, removing the Kerker preconditioner markedly reduces both the efficiency and robustness, as does setting the Kerker parameter |G0| too high, or too low. In fact, the default parameters |G0| = 1.5  and
and  suggested in [15, 31] are found to be approximately optimal. Reducing the history size to m = 10 rather than m = 20 had a slight stabilising effect.
suggested in [15, 31] are found to be approximately optimal. Reducing the history size to m = 10 rather than m = 20 had a slight stabilising effect.

Figure 10. Results of the benchmark tests of the algorithms in table 1. Each node corresponds to a separate algorithm placed corresponding to its robustness and efficiency across the test suite, with those that are on or close to the Pareto frontier explicitly labelled.
Download figure:
Standard image High-resolution image
Figure 11. Results of the tests for differing Kerker parameter sets using Kerker preconditioned Pulay's method. Each node corresponds to a separate parameter set placed corresponding to its robustness and efficiency across the test suite.
Download figure:
Standard image High-resolution imageTable 1. A table consisting of each algorithm tested and its corresponding parameter set, efficiency score, and robustness score.
| Method | Parameters | Robustness | Efficiency |
|---|---|---|---|
| Pulay II (2) |  , |G0| = 1.5 , |G0| = 1.5 |
0.775 | 0.0118 |
| Pulay II |  , |G0| = 0.0 , |G0| = 0.0 |
0.637 | 0.0085 |
| Pulay II |  , |G0| = 1.5 , |G0| = 1.5 |
0.689 | 0.0088 |
| Pulay II |  , |G0| = 1.0 , |G0| = 1.0 |
0.741 | 0.0094 |
| Pulay II (3) |  , |G0| = 1.5 , |G0| = 1.5 |
0.741 | 0.0161 |
| Pulay II |  , |G0| = 1.5, m = 10 , |G0| = 1.5, m = 10 |
0.827 | 0.0063 |
| Pulay II |  , |G0| = 2.5 , |G0| = 2.5 |
0.775 | 0.0097 |
| Pulay II |  , |G0| = 1.5 , |G0| = 1.5 |
0.637 | 0.0046 |
| Broyden II |  , |G0| = 1.5 , |G0| = 1.5 |
0.706 | 0.0118 |
| Broyden II |  , |G0| = 1.5 , |G0| = 1.5 |
0.672 | 0.0090 |
| Multisecant Broyden I |  , |G0| = 1.5 , |G0| = 1.5 |
0.620 | 0.0056 |
| Multisecant Broyden II |  , |G0| = 1.5 , |G0| = 1.5 |
0.706 | 0.0179 |
| MSB1 | Greed controlled, |G0| = 1.5 | 0.689 | 0.0098 |
| MSB2 | Greed controlled, |G0| = 1.5 | 0.793 | 0.0097 |
| Two-Step Steepest Descent |
N/A | 0.689 | 0.0070 |
| Guar. Red. Pulay |  |
0.448 | 0.0103 |
| Restarted Pulay |  , |G0| = 1.54, m = 10 , |G0| = 1.54, m = 10 |
0.819 | 0.0088 |
| Linear |  |
0.328 | 0.0154 |
| Linear |  |
0.534 | 0.0033 |
| Kerker |  , |G0| = 1.5 , |G0| = 1.5 |
0.500 | 0.0025 |
| Fixed-Point | N/A | 0.054 | 0.0344 |
| Periodic Pulay (1) |  , |G0| = 1.5, k = 2 , |G0| = 1.5, k = 2 |
0.828 | 0.0063 |
| Periodic Pulay |
 , |G0| = 1.5, k = 2 , |G0| = 1.5, k = 2 |
0.705 | 0.0062 |
| EDFT |  , |G0| = 1.5 , |G0| = 1.5 |
0.948 | 0.000 03 |
aAs proposed in [149]. bPerformed with k Pulay steps in between each linear step.
As expected, EDFT [25] is able to converge the vast majority of the test suite—it is global by design. Note that the method is not 100% robust as two methods took over the maximum allowed time to converge. The cost of global convergence here is apparent: the efficiency is drastically reduced. Ensemble DFT should be used if and only if one expects divergent iterations with self-consistent field methods. An interesting area of future work is to examine the extent to which self-consistent field methods can match the robustness of EDFT whilst approximately maintaining the efficiency of self-consistent field methods. Recent sophisticated algorithms attempt this [56, 92, 131], see section 4.1.4, using some form of step-length control, i.e. line-searches or trust-regions. Incorporating some of the techniques that demonstrably stabalise iterations, such as adding linear mixing steps to the history or occasionally restarting the history, could be advantageous here. To conclude, this workflow, namely, assessing an algorithm utilising the test suite and similar measures of performance, can be used to confidently highlight the improvements possible with, for example, global self-consistent field methods. Note that a one-to-one comparison of algorithms can also be illustrated, figure 12. Here, we compare the efficiency of Pulay's method versus Broyden's second method, which brings to light the classes of systems for which one method outperforms the other. In this example, Pulay's method is demonstrated to uniformly outperform Broyden's second method over the test suite. In the case only two methods are being tested, presenting the results in this form is preferable to figure 10, as it removes the aforementioned pathologies related to comparing only the efficiency and robustness scores. For example, we are able to observe that Pulay's method does indeed uniformly outperform Broyden's second method, as one might expect from a method with a significantly higher efficiency and robustness score.

Figure 12. A direct comparison of the efficiency measure of two algorithms. The plot is restricted to the range of 1–70 iterations for illustrative purposes.
Download figure:
Standard image High-resolution image7. Conclusion
Modern research utilising Kohn–Sham theory is progressively demanding self-consistent solutions from inputs that lead to significant ill-conditioning. This ill-conditioning can be a result of increased unit cell sizes, and/or related to the atomic species and positions involved. The core aim of this article is to elucidate these issues and provide a clearer path forward for algorithm development. We began in section 3 by examining a variety of properties of the Kohn–Sham map, whose fixed-points define self-consistent densities. The topics covered in this section ranged from, for example, the definition of convergence, generation of the initial guess density, and sources of ill-conditioning within the linear response approximation. Following this, an overview of both standard and contemporary methodology was provided. This overview was intended to be fairly brief, and aimed at providing a broad yet digestible introduction for interested practitioners and DFT software developers not actively involved in the development of self-consistency methodology.
The analysis of section 3 revealed certain classes of inputs that induce difficulty in the self-consistency iterations. These classes include far-from-equilibrium systems, large units cells, highly degenerate systems, complex interfaces with differing electronic behaviour, and others. The insight gained from this analysis led to the creation of a test suite, the scf-xn suite, containing over fifty ill-conditioned inputs from a variety of sources. A selection of algorithms suitable to be implemented in castep were then benchmarked using this test suite, and their utility was quantified. The results of this benchmark led to a several observations of note. First, from the standard methods, which include unmodified versions of Pulay and generalised Broyden, the best performing was indeed Pulay's original method. That being said, relatively simple modifications to these methods were able to demonstrate improved robustness. These modifications involved interweaving linear mixing steps in-between Pulay steps [110, 118, 119], and flushing the stored history of iterates after a given number of iterations [112]. Furthermore, considerable promise is shown by more sophisticated methods such as those in [56, 89, 92, 131]. These methods aim to converge the majority of cases with minimal user intervention. This will become increasingly important in the future as significant adjustments to default parameters may be required to force convergence in difficult cases due to increased ill-conditioning. Finally, the parameter space of Kerker preconditioned Pulay's method was sampled using the test suite. This confirmed that the default parameters suggested by Kresse [15, 31] are indeed optimal. In particular, lowering the damping parameter too much can negatively impact robustness as well as efficiency, due to the complexities inherent within the Kohn–Sham functional landscape. The damping parameter in Pulay's method should be kept as close to unity as possible, and reduced if and only if the iterations are divergent.
To conclude, we emphasise that the benchmark itself, while able to reveal certain well-performing methods and parameter sets, is not intended to be the focus of the latter part of this article. Rather, the workflow used in section 6 to generate this benchmark is the central development. That is, we present a workflow that comprises a test suite of difficult to converge inputs that are used to compare methodologies with some appropriate measure of efficiency and robustness. Indeed, if one were to replicate this workflow, the test suite need not be exactly the same as the version of scf-xn used here. Instead, one can augment the suite with any selection of systems, as long as due care is taken to ensure that the range of sources of ill-conditioning already included here is at least retained. It is hoped that the workflow presented enables and assists the development of self-consistency algorithms that are able to meet the needs of practitioners in modern applications.
Acknowledgments
The authors would like to thank D Bowler, M J Smith, M Hutcheon, A Wade, C J Pickard, and L D Marks for many helpful discussions. NDW is supported by the EPSRC Centre for Doctoral Training in Computational Methods for Materials Science for funding under Grant No. EP/L015552/1. PJH is supported by an EPSRC RSE Fellowship, funded by EPSRC Grant ref EP/R025770/1. MCP acknowledges funding from EPSRC Grant EP/P034616/1.
Footnotes
- 4
This observation is based on the fact that, in general, one can always find an algorithm that converges to a fixed-point density.
- 5
For example, in plane-wave codes, the density is represented by an array of size 8Nb, see [2] for more details.
- 6
Note that is it possible to approximately recover the zero-temperature solution [65].
- 7
Note that one can linearise about any density, not necessarily a fixed-point density. We have chosen the density about which we linearise to be the fixed-point density for the sake of analysis and due to the accuracy of the initial guess.
- 8
By 'well-behaved' here, we mean that the higher order than linear terms can be ignored without much detriment.
- 9
A detailed treatment of
 for inhomogeneous inputs is given within the framework of Lindhard theory [76].
for inhomogeneous inputs is given within the framework of Lindhard theory [76]. - 10
Lipschitz continuity refers to all real
in equation (21). - 11
- 12
Note that denisty mixing schemes are usually translated to density matrix mixing schemes relatively straightforwardly, e.g. [28].
- 13
- 14
The Von Weizäcker kinetic energy extension to Thomas–Fermi theory serves to better model inhomogeneities in the density [87].


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}