
Abstract
The identification of vital nodes that maintain the network connectivity is a long-standing challenge in network science. In this paper, we propose a so-called reverse greedy method where the least important nodes are preferentially chosen to make the size of the largest component in the corresponding induced subgraph as small as possible. Accordingly, the nodes being chosen later are more important in maintaining the connectivity. Empirical analyses on eighteen real networks show that the reverse greedy method performs remarkably better than well-known state-of-the-art methods.
Similar content being viewed by others


Introduction
Network science is playing an increasingly significant role in many domains including physics, sociology, engineering, biology, management, and so on1. Because of the heterogeneous nature of real networks2, the overall connectivity of networks may depend on a small set of nodes, usually named as hub nodes. Taking the Internet as an example, several vital nodes attacked deliberately may lead to the collapse of the whole network3. Therefore, an efficient algorithm to identify vital nodes that have critical impacts on the network connectivity can help to better prevent catastrophic outages in power grids or the Internet3,4,5,6, maintain the connectivity or design efficient attacking strategies for communication networks7, improve urban transportation capacity with low cost8, enhance robustness of financial networks9, and so on.
Till far, to identify vital nodes for network connectivity, the majority of known methods only make use of the structural information10. Typical representatives include degree centrality (DC)11, H-index12, k-shell index (KS)13, PageRank (PR)14, LeaderRank15, closeness centrality (CC)16, betweenness centrality (BC)17, and so on. Recently, Morone and Makse18 proposed a novel index called collective influence (CI), which is based on the site percolation theory and can find out the minimal set of nodes that are crucial for the global connectivity. CI performs remarkably better than some known methods in identifying the nodes’ importance for network connectivity18,19. Furthermore, some sophisticated methods with even better performance have been reported, such as the belief propagation-guided decimation method20,21 (BPD), the two-core based algorithm22 (CoreHD) and the explosive immunization method23 (EI).
This paper proposes a novel method named reverse greedy (RG) method. The first word stands for the process that we add nodes one by one to an empty network, which is inverse to the usual process that removes nodes from the original network. The second word emphasizes that we choose the nodes added by minimizing the size of the largest component. Empirical analyses on eighteen real networks show that RG performs remarkably better than well-known state-of-the-art methods.
Algorithms
The core of the RG algorithm is the reverse process, which adds nodes one by one to an empty network while minimizes the cost function until all nodes in the considered network are added. Then, nodes are ranked inverse to the order of additions, that is to say, the later added nodes are more important in maintaining the network connectivity. Denote \(G(V,E)\) the original network under consideration, where \(V\) and \(E\) are the sets of nodes and edges, respectively. This paper focuses on simple networks, where the weights and directions of edges are ignored, and the self loops are not allowed. The reverse process starts from an empty network \({G}_{0}({V}_{0},{E}_{0})\), where \({V}_{0}=\varnothing \) and \({E}_{0}=\varnothing \). At the \((n+1)\)th time step, one node from the remaining set \(V-{V}_{n}\) is selected to add into the current network \({G}_{n}({V}_{n},{E}_{n})\) to form a new network of \((n+1)\) nodes, say \({G}_{n+1}({V}_{n+1},{E}_{n+1})\). Note that, all progressive networks \({G}_{n}\) (\(n=0,1,2,\cdots \ ,N\), with \(N\) being the size of the original network \(G\)) in the process are induced subgraphs of \(G\). For example, \({G}_{n}\) is consisted of all edges in \(G\) with both two ends belonging to \({V}_{n}\). According to the greedy strategy, the selected node \(i\) should minimize the size of the largest component in \({G}_{n+1}\). If there are multiple nodes satisfying this condition, we will choose the one with the help of another structural feature of the node \(i\) in \(G\) (e.g., degree, betweenness, and so on). Therefore, the cost function can be defined as
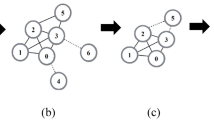
where \({G}_{n+1}^{\max }(i)\) is the size of the largest component after adding node \(i\) into \({G}_{n}\), \(f(i)\) is a certain structural feature of node \(i\) in \(G\), and \(\epsilon \) is a very small positive parameter and has no effect on the results of RG as long as \(\epsilon \ast maxf(i) < 1\) is guaranteed. The parameter \(\epsilon \) works only when \({G}_{n+1}^{\max }(\bullet )\) are indistinguishable for multiple nodes. At each time step, we add the node minimizing the cost function into the network, and if there are still multiple nodes with the minimum cost, we will select one of them randomly. This process stops after \(N\) time steps, namely all nodes are added with \({G}_{N}\equiv G\). An illustration of such process in a small network is shown in Fig. 1.

The process of RG in a network with six nodes. Here we use degree as the feature \(f\) and for convenience in the later description we set \(\epsilon =0.01\) (note that, \(\epsilon \) should be positive yet small enough and it is set to be \(1{0}^{-7}\) in the later experiments). Initially, the network is empty. At the first time step, \({G}_{1}^{\max }({v}_{1})={G}_{1}^{\max }({v}_{2})={G}_{1}^{\max }({v}_{3})={G}_{1}^{\max }({v}_{4})={G}_{1}^{\max }({v}_{5})={G}_{1}^{\max }({v}_{6})\ =\ 1\), and \(cost({v}_{1},1)=1.04\), \(cost({v}_{2},1)=1.03\), \(cost({v}_{3},1)=1.03\), \(cost({v}_{4},1)=1.03\), \(cost({v}_{5},1)=1.03\), \(cost({v}_{6},1)=1.02\). Therefore, we add node \({v}_{6}\) into the network because \(cost({v}_{6},1)\) is the smallest. In the second time step, \({G}_{2}^{\max }({v}_{1})={G}_{2}^{\max }({v}_{2})={G}_{2}^{\max }({v}_{3})=1\), and \({G}_{2}^{\max }({v}_{4})={G}_{2}^{\max }({v}_{5})=2\), so we only compare three candidates \({v}_{1}\), \({v}_{2}\) and \({v}_{3}\). Since \(cost({v}_{1},1)=1.04\), \(cost({v}_{2},1)=1.03\) and \(cost({v}_{3},1)=1.03\), we randomly select a node from \(\{{v}_{2},{v}_{3}\}\). Here we choose \({v}_{2}\) for example. Repeat this process until all nodes are added into the network. Finally, we get the ranking of nodes as \(\{{v}_{4},{v}_{5},{v}_{1},{v}_{3},{v}_{2},{v}_{6}\}\), in an inverse order of the additions. The symbol \(n\) in the bottom of each plot stands for the corresponding time step.
Data
In this paper, eighteen real networks from disparate fields are used to test the performance of RG, including four collaboration networks (Jazz, NS, Ca-AstroPh and Ca-CondMat), two communication networks (Email-Univ and Email-EuAll), four social networks (PB, Sex, Facebook and Loc-Gowalla), one transportation network (USAir), one infrastructure network (Power), one citation network (Cit-HepPh), one road network (RoadNet-TX), one web graph (Web-Google) and three autonomous systems graphs (Router, AS-733 and AS-Skitter). Jazz24 is a collaboration network of jazz musicians. NS25 is a co-authorship network of scientists working on network science. Ca-AstroPh26 is a collaboration network of Arxiv Astro Physics category. Ca-CondMat26 is a collaboration network of Arxiv Condensed Matter category. Email-Univ27 describes email interchanges between users including faculty, researchers, technicians, managers, administrators, and graduate students of the Rovira i Virgili University. Email-EuAll26 is an email network of a large European Research Institution. PB28 is a network of US political blogs. Sex29 is a bipartite network in which nodes are females (sex sellers) and males (sex buyers) and edges between them are established when males write posts indicating sexual encounters with females. Facebook30 is a sample of the friendship network of Facebook users. Loc-Gowalla31 describes the friendships of Gowalla users. USAir32 is the US air transportation network. Power33 is a power grid of the western United States. Cit-HepPh34 is a citation network of high energy physics phenomenology. RoadNet-TX35 is a road network of Texas. Web-Google35 is a web graph of the Google programming contest in 2002. Router36 is a symmetrized snapshot of the structure of the Internet at the level of autonomous systems. AS-73337 contains the daily instances of autonomous systems from November 8 1997 to January 2 2000. AS-Skitter37 describes the autonomous systems from traceroutes run daily in 2005 by Skitter. These networks’ topological features (including the number of nodes, the number of edges, the average degree, the clustering coefficient33, the assortative coefficient38 and the degree heterogeneity39) are shown in Table 1.
Besides real-world networks, we also work on ErdŐs-Rényi (ER) random networks40 with different densities. We generate four ER random networks with \(N=100000\) and \(\langle k\rangle =6,9,12,15\), named as ER-6, ER-9, ER-12, ER-15, respectively.
Results
We apply two widely used metrics to evaluate algorithms’ performance. One is called robustness \(R\)41. Given a network, we remove one node at each time step and calculate the size of the largest component of the remaining network until the remaining network is empty. The robustness\(R\) is defined as41
where \(S(Q)\) is the number of nodes in the largest component divided by \(N\) after removing \(Q\) nodes. The normalization factor 1/\(N\) ensures that the values of \(R\) of networks with different sizes can be compared. Obviously, a smaller \(R\) means a quicker collapse and thus a better performance. Another metric is the number of nodes to be removed to make the size of the largest component in the remaining network being no more than \(0.01N\), denoted by, \({\rho }_{min}\). Obviously, a smaller \({\rho }_{min}\) means a better performance.
Here we use BC, CC, DC, H-index, KS, PR, CI, CI with reinsertion (short for CI+), BPD, CoreHD and EI as the benchmark algorithms (see details about these benchmark algorithms in Methods). Tables 2 and 3 compare \(R\) and \({\rho }_{min}\) of RG and other benchmarks algorithms, respectively. Notice that, we use the random removal (Random) as the background benchmark in order to show the improvement by each method. Both BPD and CoreHD need a refinement process to insert back some removed nodes. In each step, it calculates the increase of the component size after the insertion of a node and select the node that gives the smallest increase. Such process stops when the largest component reaches \(0.01N\). These two methods do not provide a ranking of all nodes, and thus we cannot obtain \(R\) for them. For EI, according to23, we set \(K=6\) and the number of candidates being equal to 2000. So the networks with sizes smaller than 2000 fail to apply EI (those cases are marked by N/A in Tables 2–4). Each result of EI is obtained by averaging over 20 independent realizations. The radii of CI and CI+ are set to be 3 only except for AS-Skitter (its radius is set to be 2) because its size is too large and thus \(radius=3\) will leads to too much computation.
As shown in Table 2, subject to \(R\), CI, CI+, EI and RG perform better than the classical centralities (e.g., BC, CC, DC, H-index, KS and PR) in almost all networks, and RG is overall the best method subject to \(R\) for real networks. Figure 2 shows the collapsing processes of four representative networks, resulted from the node removal by RG and other benchmark algorithms. Obviously, RG can lead to faster collapse than all other algorithms, and CI+ is the second best algorithm. As shown in Table 3, subject to \({\rho }_{min}\), BPD, CoreHD, EI and RG perform better than the classical centralities and CI/CI+ in almost all networks. For real networks, RG and BPD perform remarkably better than other methods. For random networks, RG is among the best and much better than the classical centralities. However, RG is slightly worse than CI+ subject to \(R\) and BPD subject to \({\rho }_{min}\). In random networks, the topological difference among different nodes is relatively small, and thus RG may mistakenly select some influential nodes as unimportant nodes at the early stage, leading to unsatisfactory results. Table 4 compares the CPU times of the 12 methods under consideration, from which one can see that RG is slower than DC, H-index, KS, PR and CoreHD, similar to CC and BPD and faster than BC, CI/CI+ and EI. Generally speaking, RG is an efficient method.

Comparing the performance of the background benchmark (random removal, denoted by blue circles), RG (red stars) and the other benchmark algorithms (black symbols). The \(x\)-axis is the fraction of nodes being removed (i.e., \(Q\)/\(N\)), and the \(Y\)-axis denotes the number of nodes in the largest component divided by \(N\) (i.e., \(S(Q)\)). The four selected networks are (a) AS-733, (b) Sex, (c) Facebook, and (d) Cit-HepPh, respectively. Other networks exhibit similar results.
Discussion
To our knowledge, most previous methods directly identify the critical nodes by looking at the effects due to their removal10. In contrast, our method tries to firstly find out the least important nodes, so that the remaining ones are those critical nodes. To our surprise, such a simple idea eventually results in an efficient algorithm that outperforms many well-known benchmark algorithms. Beyond the percolation process considered in this paper, the reverse method provides a novel angle of view that may find successful applications in some other network-based optimization problems related to certain rankings of nodes or edges.
The performance of RG can be further improved by introducing some sophisticated skills. For example, instead of degree, \(f(i)\) can be different for different networks or set in a more complicated way to improve the algorithm’s performance. In addition, the simple adoption of the greedy strategy may bring us to some local optimums. Such shortage can be to some extent overcame by applying the beam search42, which searches for the best set of \(m\) nodes adding to the network that optimizes the cost function. The present algorithm is the special case for \(m=1\). Although beam search is still a kind of greedy strategy, it usually performs much better when \(m\) is larger. At the same time, the beam search with large \(m\) costs a lot on time and space. Therefore, how to find a good tradeoff is also an open challenge in real practice.
Methods
Benchmark centralities
DC11 of node \(i\) is defined as
where \(A=\{{a}_{ij}\}\) is the adjacency matrix, that is, \({a}_{ij}\) = 1 if \(i\) and \(j\) are directly connected and 0 otherwise.
H-index12 of node \(i\), denoted by \(H(i)\), is defined as the maximal integer satisfying that there are at least \(H(i)\) neighbors of node \(i\) whose degrees are all no less than \(H(i)\). Such index is an extension of the famous H-index in scientific evaluation43 to network analysis.
KS13 is implemented by the following steps: Firstly, remove all nodes with degree one, and keep deleting the existing nodes until all nodes’ degrees are larger than one. All of these removed nodes are assigned 1-shell. Then recursively remove the nodes with degree no larger than two and set them to 2-shell. This procedure continues until all higher-layer shells have been identified and all network nodes have been removed.
PR14 of node \(i\) is defined as the solution of the equations
where \({k}_{j}\) is the degree of node \(j\) and \(s\) is a free parameter controlling the probability of a random jump. In this paper, \(s\) is set to \(0.85\).
CC15 of node \(i\) is defined as
where \({d}_{ij}\) is the shortest distance between nodes \(i\) and \(j\).
BC16 of node \(i\) is defined as
where \({g}_{st}\) is the number of shortest paths between nodes \(s\) and \(t\), and \({g}_{st}(i)\) is the number of shortest paths between nodes \(s\) and \(t\) that pass through node \(i\).
CI18 of node \(i\) is defined as
where \(ball(i,\ell )\) is the set of nodes inside a ball of radius \(\ell \), consisted of all nodes with distances no more than \(\ell \) from node \(i\), and \(\partial ball(i,\ell )\) is the frontier of this ball. CI+ is the version of CI with reinsertion.
BPD21 is rooted in the spin glass model for the feedback vertex set problem44. At time \(t\) of the iteration process, the algorithm estimates the probability \({q}_{i}^{0}(t)\) that every node \(i\) of the remaining network \(G(t)\) is suitable to be deleted. The explicit formula for this probability is
where \(x\) is an adjustable reweighting parameter, and \(\partial i(t)\) denotes node \(i\)’s set of neighbors at time \(t\). The quantity \({q}_{i\to j}^{0}(t)\) is the probability that the neighboring node \(j\) is suitable to be deleted if node \(i\) is absent from the network \(G(t)\), while \({q}_{i\to j}^{j}(t)\) is the probability that this node \(j\) is suitable to be the root node of a tree component in the absence of node \(i\). The node with the highest probability of being suitable for deletion is deleted from network \(G(t)\) along with all its associated edges. This node deletion process stops after all the loops in the network have been destroyed. Then check the size of each tree component in the remaining network. If a tree component is too large (which occurs only rarely), an appropriately chosen node from this tree to achieve a maximal decrease in the tree size is deleted. Repeat this node deletion process until all the tree components are sufficiently small.
CoreHD22 simply removes highest-degrees nodes from the 2-core in an adaptive way (updating node degree as the 2-core shrinks), until the remaining network becomes a forest. Furthermore, CoreHD breaks the trees into small components. In case the original network has many small loops, a refined dismantling set is obtained after a reinsertion of nodes that do not increase (much) the size of the largest component.
EI23 selects \(m\) candidate nodes from the set of absent nodes at each step and calculate the score \({\sigma }_{i}\) of each of them using the following kernel
where \({N}_{i}\) represents the set of all connected components linked to node \(i\), each of which has a size \({C}_{j}\), and \({k}_{i}^{(eff)}\) is an effective degree attributed to each node (please see23 for the details). Then the nodes with the lowest scores are added to the network. This procedure is continued until the size of the giant connected component exceeds a predefined threshold. The minus one term in Eq. (9) is used to exclude any leaves connected to node \(i\), since they do not contribute to the formation of the giant connected component and should be ignored.
Data availability
All relevant data are available at https://github.com/ChinaYiqun/network-data.
Change history
15 June 2020
Due to a typesetting error, in the original version of this Article the character ü was replaced by the character �. This has now been fixed in the Article.
References
Newman, M. E. J. Networks. (Oxford University Press, Oxford, 2018).
Caldarelli, G. Scale-Free Networks: Complex Webs in Nature and Technology. (Oxford University Press, Oxford, 2007).
Cohen, R., Erez, K., Ben-Avraham, D. & Havlin, S. Breakdown of the internet under intentional attack. Phys. Rev. Lett. 86, 3682–3685 (2001).
Motter, A. E. & Lai, Y. C. Cascade-based attacks on complex networks. Phys. Rev. E 66, 065102 (2002).
Motter, A. E. Cascade control and defense in complex networks. Phys. Rev. Lett. 93, 098701 (2004).
Albert, R., Albert, I. & Nakarado, G. L. Structural vulnerability of the North American power grid. Phys. Rev. E 69, 025103 (2004).
Albert, R., Jeong, H. & Barabási, A. L. Error and attack tolerance of complex networks. Nature 406, 378–382 (2000).
Li, D. et al. Percolation transition in dynamical traffic network with evolving critical bottlenecks. Proc. Natl. Acad. Sci. USA 112, 669–672 (2015).
Haldane, A. G. & May, R. M. Systemic risk in banking ecosystems. Nature 469, 351–355 (2011).
Lü, L. et al. Vital nodes identification in complex networks. Phys. Rep. 650, 1–63 (2016).
Bonacich, P. Factoring and weighting approaches to status scores and clique identification. Math. Sociol. 2, 113–120 (1972).
Lü, L., Zhou, T., Zhang, Q. M. & Stanley, H. E. The H-index of a network node and its relation to degree and coreness. Nat. Commun. 7, 10168 (2016).
Kitsak, M. et al. Identification of influential spreaders in complex networks. Nat. Phys. 6, 888–893 (2010).
Brin, S. & Page, L. The anatomy of a large-scale hypertextual web search engine. Comput. Netw. ISDN Syst. 30, 107–117 (1998).
Lü, L., Zhang, Y.-C., Yeung, C.-H. & Zhou, T. Leaders in social networks, the delicious case. PLoS One 6, e21202 (2011).
Freeman, L. C. Centrality in social networks conceptual clarification. Soc. Networks 1, 215–239 (1979).
Freeman, L. C. A set of measures of centrality based on betweenness. Sociometry 40, 35–41 (1977).
Morone, F. & Makse, H. A. Influence maximization in complex networks through optimal percolation. Nature 524, 65–68 (2015).
Morone, F., Min, B., Bo, L., Mari, R. & Makse, H. A. Collective influence algorithm to find influencers via optimal percolation in massively large social media. Sci. Rep. 6, 30062 (2016).
Zhou, H. J. Spin glass approach to the feedback vertex set problem. Eur. Phys. J. B 86, 1–9 (2013).
Mugisha, S. & Zhou, H. J. Identifying optimal targets of network attack by belief propagation. Phys. Rev. E 94, 012305 (2016).
Zdeborová, L., Zhang, P. & Zhou, H. J. Fast and simple decycling and dismantling of networks. Sci. Rep. 6, 37954 (2016).
Clusella, P., Grassberger, P., Pérez-Reche, F. J. & Politi, A. Immunization and targeted destruction of networks using explosive percolation. Phys. Rev. Lett. 117, 208301 (2016).
Gleiser, P. & Danon, L. Community structure in Jazz. Adv. Complex Syst. 6, 565 (2003).
Newman, M. E. J. Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E 74, 036104 (2006).
Leskovec, J., Kleinberg, J. & Faloutsos, C. Graph Evolution: Densification and Shrinking Diameters. ACM Trans. Knowl. Disc. Data 1, 2 (2007).
Guimera, R., Danon, L., Díaz-Guilera, A., Giralt, F. & Arenas, A. Self-similar community structure in a network of human interactions. Phys. Rev. E 68, 065103 (2003).
Adamic, L. A. & Glance, N. The political blogosphere and the 2004 U.S. election: divided they blog. In Proceedings of the 3rd International Workshop on Link Discovery pp. 36–43 (ACM Press, 2005).
Rocha, L. E., Liljeros, F. & Holme, P. Simulated epidemics in an empirical spatiotemporal network of 50,185 sexual contacts. PLoS Comput. Biol. 7, e1001109 (2011).
Viswanath, B., Mislove, A., Cha, M. & Gummadi, K. P. On the Evolution of User Interaction in Facebook. In Proceedings of the 2nd ACM Workshop on Online Social Networks pp. 37–42 (ACM Press, 2009).
Cho, E., Myers, S. A. & Leskovec, J. Friendship and Mobility: Friendship and Mobility: User Movement in Location-Based Social Networks. In ACM SIGKDD International Conference on Knowledge Discovery and Data Mining pp. 1082–1090 (ACM Press, 2011).
Batageli, V. & Mrvar, A. Pajek Datasets. Available at, http://vlado.fmf.uni-lj.si/pub/networks/data/ (2007).
Watts, D. J. & Strogatz, S. H. Collective dynamics of ‘small-world’ networks. Nature 393, 440–442 (1998).
Gehrke, J., Ginsparg, P. & Kleinberg, J. Overview of the 2003 KDD Cup. SIGKDD Explorations 5, 149–151 (2003).
Leskovec, J., Lang, K., Dasgupta, A. & Mahoney, M. Community Structure in Large Networks: Natural Cluster Sizes and the Absence of Large Well-Defined Clusters. Internet Mathematics 6, 29–123 (2009).
Spring, N., Mahajan, R., Wetherall, D. & Anderson, T. Measuring ISP topologies with rocketfuel. IEEE/ACM Trans. Networking 12, 2–16 (2004).
Leskovec, J., Kleinberg, J. & Faloutsos, C. Graphs over Time: Densification Laws, Shrinking Diameters and Possible Explanations. In ACM SIGKDD International Conference on Knowledge Discovery and Data Mining pp. 177–187 (ACM Press, 2005).
Newman, M. E. J. Assortative mixing in networks. Phys. Rev. Lett. 89, 208701 (2002).
Hu, H. B. & Wang, X. F. Unified index to quantifying heterogeneity of complex networks. Physica A 387, 3769–3780 (2008).
Erdős, P. & Rényi, A. On the evolution of random graphs. Publ. Math. Inst. Hung. Acad. Sci. 5, 17–60 (1960).
Schneider, C. M., Moreira, A. A., Andrade, J. S., Havlin, S. & Herrmann, H. J. Mitigation of malicious attacks on networks. Proc. Natl. Acad. Sci. USA 108, 3838–3841 (2011).
Zhou, R. & Hansen, E. A. Beam-stack search: Integrating backtracking with beam search. In Proceedings of the 15th International Conference on Automated Planning and Scheduling pp. 90–98 (AAAI Press, 2005).
Hirsch, J. E. An index to quantify an individual’s scientific research output. Proc. Natl. Acad. Sci. USA 102, 16569–16572 (2005).
Karp, R. M., Miller, R. E. & Thatcher, J. W. Reducibility among combinatorial problems. Journal of Symbolic Logic 40, 618–619 (1975).
Acknowledgements
The authors acknowledge DataCastle to hold the related world-wide competition and to share the data. This work is partially supported by National Natural Science Foundation of China (61473073, 61104074, 61433014), Fundamental Research Funds for the Central Universities (N161702001, N171706003, N181706001, N182608003).
Author information
Authors and Affiliations
Contributions
T.R., Y.Q., Z.L. and T.Z. devised the research project. Y.Q., Y.X.Z. and S.M.L. performed the research. T.R., Z.L., Y.Q., Y.X.Z., S.M.L. and T.Z. analyzed the data. T.R., Z.L., Y.X.Z., S.M.L., Y.J.X. and T.Z. wrote the paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ren, T., Li, Z., Qi, Y. et al. Identifying vital nodes based on reverse greedy method. Sci Rep 10, 4826 (2020). https://doi.org/10.1038/s41598-020-61722-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-020-61722-8
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
