
Abstract
The OSU/PNNL Superfund Research Program (SRP) represents a longstanding collaboration to quantify Polycyclic Aromatic Hydrocarbons (PAHs) at various superfund sites in the Pacific Northwest and assess their potential impact on human health. To link the chemical measurements to biological activity, we describe the use of the zebrafish as a high-throughput developmental toxicity model that provides quantitative measurements of the exposure to chemicals. Toward this end, we have linked over 150 PAHs found at Superfund sites to the effect of these same chemicals in zebrafish, creating a rich dataset that links environmental exposure to biological response. To quantify this response, we have implemented a dose-response modelling pipeline to calculate benchmark dose parameters which enable potency comparison across over 500 chemicals and 12 of the phenotypes measured in zebrafish. We provide a rich dataset for download and analysis as well as a web portal that provides public access to this dataset via an interactive web site designed to support exploration and re-use of these data by the scientific community at http://srp.pnnl.gov.
Similar content being viewed by others
Background & Summary
The Comprehensive Environmental Response, Compensation, and Liability Act (CERCLA), also known as the Superfund, has been credited with cleaning up over 800 toxic waste sites across the United States since it was enacted in 19801. Despite the aggressive clean-up activity, polycyclic aromatic hydrocarbons (PAHs) continue to raise concern and serve as the risk driver for remediation at 20% of all Superfund sediment sites2. While it has been established PAH contamination still exists at these sites and can affect human health in nearby communities, the specific impact that results from exposure to various PAH contaminants is not well characterized. Toward this end, we introduce the SRP Analytics Compendium, an online resource that captures chemical measurements from Superfund site samples and links them to their potential biological impact in humans using model organism data, available at http://srp.pnnl.gov for interactive browsing and https://data.pnnl.gov/group/nodes/dataset/13337 for download and analysis.
The scientific community has identified more than 100 parent PAH compounds and numerous substituted and degradation products of PAHs. While parent compounds arise from industrial processes and extraction and burning of fossil fuels in industrial countries3, lower-temperature combustion activities, such as smoking tobacco or burning wood, generate lower-molecular-weight PAHs. Conversely, higher-temperature industrial processes and wildfires typically generate higher-molecular-weight PAHs4. Substantially higher concentrations of PAHs exist in the soil, water, and outdoor air in Asia, Africa, and Latin America than in Europe, Australia, the U.S., and Canada3, but as we and others have demonstrated, PAHs travel long distances to impact human exposures5,6,7,8. Most importantly, PAHs typically exist in complex environmental mixtures4,9. PAHs have been shown to cause cancer10, impede normal development11,12, suppress the immune system13,14, and target the neurological systems15. Furthermore, there is a strong association between maternal exposure to PAHs and paediatric neuro-behavioural problems: early-life PAH exposures have been shown to have an effect on childhood cognition and attention deficit disorders16,17,18,19, as well as obesity and asthma20.
The Oregon State University Superfund Research Program focuses on the identification of PAHs in the environment and characterizing their toxicity. We have pioneered the development of passive sampling devices to measure chemical mixtures at various Superfund sites around the Pacific Northwest21,22,23,24,25. We have also demonstrated the utility of the embryonic zebrafish model system for high throughput screening of chemicals for hazard assessment26,27,28. By collecting real-world chemical mixtures at Superfund sites and evaluating their toxicity in the zebrafish model, we supply regulatory agencies with actionable information and tools to prioritize sites for remediation and evaluate the effectiveness of remediation strategies.
To facilitate the sharing of data we have collected on PAHs in the environment, we introduce the Superfund Research Program Analytics compendium, a harmonized, open data resource that enables members of the larger research community to browse environmental samples from diverse Superfund sites, and to identify their chemical composition as well as observe their impact on zebrafish using 18 different morphological and behavioural endpoints. Of the these 18 endpoints, 12 are displayed on the web portal. The 12 endpoints include the most commonly measured endpoints and 6 summary endpoints to allow for ease of comparing chemical bioactivity. We also provide summaries of the transcriptome data describing the effect of these chemicals on human cell lines from the Carcinogenome Project29 as well as links out to the Carcinogenome Project web application. In addition to sharing the processed data files30, we also have provided a browsable interface by which scientists can query and interact with the data31. Our system is built using a containerized data processing pipeline so that additional data types can be added to our repository for future release.
Methods
Our approach integrates data from environmental sample measurements together with data from zebrafish activity using a containerized workflow to create reproducible results across years of sample collection and experimental measurement, depicted in Fig. 1.

Overview of data collection and analysis pipeline to generate SRP Analytics Compendium.
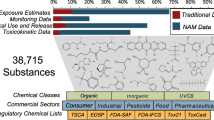
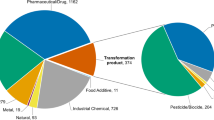
In short, environmental sample extracts were collected via low-density polyethylene (LDPE) passive sampling devices (PSDs) from diverse Superfund sites in the United States. The composition of these environmental sample extracts was measured (top left) by deploying low-density polyethylene (LDPE) passive sampling devices (PSDs), and quantifying the samples on a gas chromatograph (GC) for 62 PAHs which were then evaluated in zebrafish to ascertain any morphological defects caused by the PAHs27,32. We then expanded the chemical measurements in zebrafish to over 400 other chemicals summarized in Table 1. Chemicals were classified into one of ten classes (or left unclassified): anilines, dioxins and furans, halo ethers, oxygenated polycyclic aromatic hydrocarbons (OPAH), organophosphorus flame retardants (OPFR), polycyclic aromatic hydrocarbons (PAH), polybrominated biphenyls (PBB), polybrominated diphenyl ethers (PBDE), polychlorinated biphenyls (PCB), and phenols. Those that have not been annotated yet, or do not fall into one of the 10 classes, were labelled as ‘Unclassified’. The data from the environmental sample extracts as well as the individual chemicals were then processed via an analytical pipeline described below to a shared database, which is then showcased in the SRP Analytics Portal and shared on DataHub.
The result, depicted in Table 1, is a collection of chemicals, environmental samples (extracts), and the number of endpoint measurements calculated to indicate the resulting impact each chemical had on the developing zebrafish.
Passive sampling of superfund research sites
We used previously developed low-density polyethylene (LDPE) passive sampling devices (PSDs) to measure PAHs at Superfund research sites33, summarized in Fig. 2. For these data, LPDE PSDs were prepared as described previously21, using 2.5 cm wide × 70 µm thick LDPE tubing (Brentwood Plastics, St Louis, MO). Briefly, prior to construction, PSDs were cut to length, loosely rolled, placed in glass jars, immersed in Optima grade hexanes (Fisher, Fairlawn, NJ), and placed on a low-speed orbital shaker for 48 h with two changes of solvent. After the solvent was decanted, clean PSDs were dried under vacuum at room temperature until the residual solvent is removed. PSDs were then heat-sealed on each end with a small loop at the midpoint. Finished PSDs measured 100 cm in length.

Overall schema for environmental sample extraction and quantification.
Samplers were deployed by passing a steel ring through the centre loop on the PSD and suspending a “jellyfish” of 40 strips at the desired depth in the water column using weights and a buoy system. In many studies, co-deployed PSDs with performance reference compounds (PRCs) were used to calculate local free-water concentrations (Cfree). Because of the presence of PRCs, these samples were not appropriate for toxicological studies.
After deployment, PSDs were recovered, rinsed in the field to remove any biofouling, and returned to a metal canister for transportation to the lab and stored at −20 °C. LDPE strips were initially cleaned in the laboratory by light scrubbing and sequential washing in 1 N HCl and 18 MΩ-cm water, followed by two rinses with isopropanol, then dried and stored at −20 °C in batches of five strips per amber glass jar until extraction.
For extraction, the PSDs were dialyzed twice at room temperature with n‐hexane. Surrogate standards were added pre-extraction to quality control and performance reference compound‐containing samples, before the first addition of n‐hexane. No surrogate standards were added to samples intended for zebrafish analysis.
Extraction volume was quantitatively reduced to 1 mL using Turbo Vap closed-cell concentrators (Biotage) and small volume blow-down under a gentle stream of nitrogen. Concentrated extracts were transferred to amber glass vials, combining extracts from the same sampling site such that 8 mL represent 40 LDPE strips, hereby referred to as an environmental sample. Samples were stored at –20 °C. Prior to zebrafish exposure, environmental samples and fractions of those samples were evaporated to dryness under a gentle nitrogen stream and reconstituted in an equal volume of DMSO.
Zebrafish biological measurements
The zebrafish model has become a common animal model for developmental toxicity studies as it is highly amenable to high-throughput animal screening27,34,35 due to the high degree of genetic and physiological similarity between zebrafish and other vertebrates. Because the embryos develop externally and are optically clear, we can carry out detailed morphological studies in our screens.
The developmental toxicity experimental design used to generate the data in the SRP analytics compendium is described in Geier et al.27 and illustrated in Fig. 3. Briefly, Tropical 5D wildtype adult zebrafish were housed at a density of 1,000 fish in 100-gallon tanks kept on a 14-h light/10-h dark photoperiod. Embryos were collected and staged prior to dechorionation at 4 hours post-fertilization (hpf). At 4 hpf, the chorions were enzymatically removed and placed into individual wells of a round-bottom 96-well plate filled with 100 µL of embryo media. Endpoints were then mapped to existing ontologies36 or merged to form summary endpoints, described in Supplemental Table 1. Of the individual and summary endpoints, we selected 12 to display in the SRP Analytics portal, depicted in Table 2.

Depiction of zebrafish bioactivity screen.
The samples used in these studies were provided in 100% Dimethyl Sulfoxide (DMSO), a solvent that induced no adverse effects on developing zebrafish up to 1% vol/vol. The chemicals were verified to be soluble in DMSO and then added by using a Hewlett Packard D300e and normalized to 1% DMSO (vol/vol). For the individual chemicals, stocks were provided at 20 mM, and the maximum test concentration was 50 µM, while the environmental samples were assessed at a maximum of 1% of the sample. Adverse morphological defects were assessed at two-time points: 24 and 120 hpf. At 24 hpf, mortality, developmental progression, spontaneous movement, and notochord distortion was assessed in each embryo. At 120 hpf, additional morphological endpoints were measured, including mortality, yolk, and pericardial edema, bent or curved bent body axis, abnormal eye, snout, jaw or brain, truncated body, response to touch, and failure of swim bladder to inflate (Supplemental Table 1). The data is recorded in a custom zebrafish laboratory information management system as binary incidence. Larval behaviour was assessed in the embryos using a photomotor response assay (LPR) at 120 hpf. The larvae are free-swimming and the total movement (swim distance) under multiple light- > dark transitions. The larvae in 96-well plates were tracked for 24-minutes in a Viewpoint Zebrabox (Montreal, CA). The light cycle consists of 3 minutes visible light and 3 minutes I.R. (dark), with movement being classified using two metrics – AUC and MOV – as described previously37.
To facilitate interpretability of the data and comparison with the Carcinogenome project, we chose 12 endpoints to visualize in the portal, depicted in Table 2. For example, the Muscle (MUSC) endpoint was not displayed but is incorporated in the ‘Any effect except mortality’ (ANY_MORT) endpoint. Furthermore, we compressed some of the mortality endpoints that made it difficult to compare across other datasets. However, all endpoints in Supplemental Table 1 are released in our data package, regardless of whether they are shown on the portal.
Analyte processing and dose-response curve fitting
Determination of summary statistics in dose-response data is complex, with many competing algorithms and tools available. To rectify this, we have built a comprehensive workflow to assess the impact of the chemicals and environmental samples on the zebrafish37. This workflow was updated and standardized for release as part of the superfund research analytics portal at http://github.com/pnnl-compbio/srpAnalytics and is described in Fig. 4. The processing is broken down into three steps: data pre-processing (Fig. 4A), dose-response quality check (Fig. 4B) and dose-response curve-selection (Fig. 4C). The end goal is a quality control (QC) score of the data as well as benchmark dose (BMD) statistics if the QC score was deemed Moderate or Good as described below.

Data analysis pipeline described in three steps with depiction of quality control badge applied on the SRP data portal. (A) Data is pre-processed to ensure that there are appropriate negative controls. (B) Data is then evaluated to ensure there are at least 3 data points and that the curve goes in a stable direction. (C) Many models are attempted, if at least one model is identified the data receives a green check mark.
In the data pre-processing step (Fig. 4A), the binary morphological response data for individual zebrafish at each endpoint (0: no response observed, 1: response observed) is transformed to a standard dose-response data format by aggregating all wells (typically 32 wells) for each unique condition (e.g. pair of chemical ID and end-point). To increase the statistical power for separating the background effects from chemical effects, plates with more than 50% of the total embryos in negative control wells (vehicle only) that have observed responses are removed from the analysis. The combined counts from wells in the remaining plates are then used to obtain a fractional response for each concentration by dividing the number of wells with responding embryos (each well has one embryo) by the total number of wells with living embryos per each condition.
The dose-response data quality check (QC) removes data that are not appropriate to fit a curve model. First, it removes pairs of chemical ID and endpoint that have less than three concentration groups. Second, it assesses the curve quality (e.g. whether the response to each dose positively correlates with the concentration itself) and if the Spearman correlation between dose and response is below a threshold of 0.2 a curve is not fit. In both cases, a QC score of Poor is assigned, and no model is fit (Fig. 4B).
The curve-selection step is applied to all dose-response data with a QC score that is not Poor as depicted in Fig. 4C. The data is fit to eight standard dose-response models for dichotomous data using loglikelihood optimization of model parameters: logistic, gamma, Weibull, probit, log-logistic, log-probit, multistage, and quantal linear. For each successfully converged optimization of model parameters, the fit quality is assessed by computing a chi-squared value and the associated p-value, the Akaike Information Criterion (AIC) value, and the scaled residuals. If a single model proves to be optimal, the curve fit is scored as Good. If there are multiple to choose from, the curve fit is scored as Moderate and the model with the lowest AIC is selected. A benchmark dose (BMD), is calculated from the curve to represent a dose or concentration that produces a predetermined change in the response rate of an adverse effect38, which is currently the US EPA-preferred dose-response assessment method. We calculate the concentration at which a 10% change in the incidence of the zebrafish phenotype is observed with chemical exposure relative to the control group (BMD10), as a point of departure to guide chemical risk assessment37. Furthermore, a benchmark dose lower bound (BMDL), which is the corresponding lower limit of a one-sided 95% confidence interval on the BMD, is also calculated by optimizing the profile likelihood for the BMD10 value for each model. Following the EPA guidance document39, the best model is selected based on the fit-quality metrics.
Data Records
This resource compiles three different types of data into two distinct resources: the SRP analytics portal31 and a downloadable data package30 that contains eight distinct data files and one data dictionary (v1Schema.xlsx): extract composition and environmental measurements distinct scientific measurements (chemicalsByExtractSample.csv) measurements of the chemicals and environmental sample mixtures on zebrafish (chemdoseResponseVals.csv, chemSummaryStats.csv,chemXYcoords.csv, envSampleResponseVals.csv, envSampleSummarystats.csv, envSampleXYcoords.csv), and statistics describing number of genes differentially expressed upon treatment by chemicals on human cell lines (sigGeneStats.csv) as mined from the Xposome portal at https://montilab.bu.edu/Xposome/. The data files are shared on the PNNL DataHub30, with the schema for each file documented on our GitHub site https://github.com/PNNL-CompBio/srpAnalytics.
Technical Validation
Here we describe the validation of data quality for the environmental sample chemical measurements and the zebrafish data.
Measuring technical quality of passive samples
We quantified 62 PAHs on a modified Agilent 7890 gas chromatograph (GC) coupled to an Agilent 7000 triple quadrupole mass spectrometer (MS/MS)40. The internal standard, perylene-d12, was added to each sample or parallel aliquots of bioassay samples immediately prior to analyses. Additionally, samples were screened for 1397 compounds with methods adapted from Bergmann et al. and Allan et al.41,42.
For the 62 PAH method, labelled internal surrogate standards of known concentration are used to quantify PAHs with similar physiochemical characteristics. Response ratios of surrogates to individual analytes were established using a nine-point calibration curve using standards ranging 10 to 1000 ng/mL. During analysis, continuing calibration verification (CV) samples of known concentration are typically run before and after every analytical batch and after every fifteen samples within large batches. Flanking C.V.s must meet data quality objectives (DQOs) for the analytical run to be considered valid. PAH method DQOs are defined as 80% of analytes being within 30% of the known value.
The Multi Analyte Screen Version 1530 (MASV15)43 analyte screening method uses deconvolution reporting software (DRS) coupled to a standard GC-MS method locked to the retention time of chlorpyrifos and an automated M.S. deconvolution and Identification system (AMDIS). As above, during analysis, DRS continuing calibration verification (CV) samples of known concentration are typically run before and after every analytical batch and after every fifteen samples within large sets. Flanking CVs must meet data quality objectives (DQOs) for the analytical run to be considered valid. DRS Method DQO’s are defined as retention time within 19.10 and 19.36 min, and positive detections between 80% and 120%. Each analyte detected by AMDIS is confirmed by the chemist using AMDIS peak selection and retention time match. At least one of the qualifier ion ratios is within the ratio established during analyte addition. Analytes measured are listed on the portal, but if there are no valid measurements they are not shown in the graph.
Zebrafish measurements
Embryos are assessed at 24 and 120 hpf for mortality or malformations. Data is collected for each animal and a summary of affected and normal for each concentration per chemical is recorded. The experimental design includes a minimum of 24 animals being exposed per concentration. The average incidence rate per day (across all experimental plates) is ~12% (both morbidity and mortality). A minimum of 6 plates is conducted in a day to compute a daily global control incidence rate in addition to a chemical control incidence rate. In addition to the negative control, a daily positive control plate (ethyl parathion) is run per experimental day with an estimated effective concentration that induces 50% adverse effects (EC50) within 1 standard deviation. Therefore, to determine whether a chemical/sample causes developmental toxicity, both the global negative control and chemical negative control must have a lower than 20% morbidity rate. The positive control must induce the expected EC50 concentration. In the cases that the negative or positive quality control metrics are not met, the experiment is re-run.
Zebrafish dose-response values
Determining the quality of dose-response measurements in high throughput quantitative data is still an open challenge. Toward this end, we provide objective and reproducible criteria as recommended by the United States Environmental Protection Agency39, described below.
Our workflow, available at http://github.com/PNNL-CompBio/srpAnalytics, evaluates quality control at various steps of the technical platform. Ultimately, data set quality control categorization consists of three distinct classes (Fig. 4).
Descriptions of each of the QC score classes are in Table 3. A QC score of’Poor’ is assigned when there are less than 3 dose groups, as there are not enough points to fit a curve, or when there are at least 3 doses, but no trend is detected in dose-response data, i.e. when experimental data shows a decreasing trend or flat response along with chemical concentration increase. Among the 6885 unique conditions (e.g. chemical ID-chemical concentration-endpoint combination), less than half (2781) had this designation.
For those data for which we were able to calculate a concentration-response curve, we used a t-test to measure the significance of the mean first-order response differences. If the p-value equals or is less than 0.32 (a value determined via hundreds of trials), then we gave the fit a QC score of “Good”. If the p-value is greater than 0.32, but still BMD is calculable, then ‘Moderate’ QC score is given, as the fractional responses systematically cancel each other.
In summary, our program is reproducible with transparent criteria and a fully automated method. Specifically, it processes various ranges of numerical values of dose-response groups (Fig. 4) and determines the quality of the data, and benchmark dose statistics when the quality is sufficient.
Usage Notes
To facilitate interaction with the data described in this resource, we built a public-facing website that summarized the data and allows scientists to query specific compounds or sites of interest at http://srp.pnnl.gov.
This website allows is comprised of three types of pages: a chemical summary page (Fig. 5A) that summarizes the chemicals samples and their representation in the data resource, a sample summary page (Fig. 5B) that summarizes the data for all environmental samples, and a details page that describes information about a specific chemical (Fig. 5C) or environmental sample.

Images of SRP Analytics Portal public facing web site. The site can be entered by browsing chemicals or samples. (A) depicts the chemical summary page describing the total number of chemicals measured by class (upper left hand side), a table of all chemicals together with their CAS Id, and a summary of the end points. The table can be searched to filter by chemical class. (B) depicts the summary of environmental sample extracts, with a map of where they were collected, a list of their descriptions and the endpoints that were measured. (C) depicts the chemical page that describes a single chemical selected from panel (A). This includes its concentration across samples (top) and its effect in Zebrafish (bottom). A user can click on the sample name in the barplots to access sample information (or navigate from (B). Clicking on various endpoints changes the dose response curve values.
The detail pages display the summary endpoints and concentration-response curves for each summary endpoint for which a curve could be calculated. The benchmark dose (BMD10, BMD50), and area under the curve (AUC) are depicted for each summary end point. They also show the chemical composition of samples when measured, and links out to Human gene expression data.
All data is freely available for download from PNNL’s DataHub resource30.
Code availability
All code required to analyse the data and format it for the package and web site are incorporated in a software container available at http://github.com/PNNL-CompBio/srpAnalytics or at Docker hub. To create a new data package with additional code, we can run the docker image with additional files in the prescribed data format. Command-line arguments to the docker will format the data to the schema on our github site so that it can be added to the repository.
References
Sarno, D. J. Making cleanup decisions at hazardous waste sites: the clean sites approach. J Air Waste Manage Assoc 41, 1172–1175, https://doi.org/10.1080/10473289.1991.10466911 (1991).
Agency for Toxic Substances and Disease Registry (ATSDR). 1995. Toxicological profile for polycyclic aromatic hydrocarbons. Atlanta, GA: U.S. Department of Health and Human Services, Public Health Service.
Ramesh, A., Archibong, A., Hood, D. B., Guo, Z. & Loganathan, B. G. Global Environmental Distribution and Human Health Effects of Polycyclic Aromatic Hydrocarbons. in book: Global Contamination Trends of Persistent Organic Chemicals. (eds B. G., Loganathan & P. K.-S., Lam) First Ed, Chapter 5: 97–126 (CRC Press, 2011).
Tobiszewski, M. & Namiesnik, J. PAH diagnostic ratios for the identification of pollution emission sources. Environ Pollut 162, 110–119, https://doi.org/10.1016/j.envpol.2011.10.025 (2012).
Shrivastava, M. et al. Global long-range transport and lung cancer risk from polycyclic aromatic hydrocarbons shielded by coatings of organic aerosol. Proc Natl Acad Sci USA 114, 1246–1251, https://doi.org/10.1073/pnas.1618475114 (2017).
Lafontaine, S. et al. Relative Influence of Trans-Pacific and Regional Atmospheric Transport of PAHs in the Pacific Northwest, U.S. Environ Sci Technol 49, 13807–13816, https://doi.org/10.1021/acs.est.5b00800 (2015).
Lang, C., Tao, S., Liu, W., Zhang, Y. & Simonich, S. Atmospheric transport and outflow of polycyclic aromatic hydrocarbons from China. Environ Sci Technol 42, 5196–5201, https://doi.org/10.1021/es800453n (2008).
Primbs, T., Wilson, G., Schmedding, D., Higginbotham, C. & Simonich, S. M. Influence of Asian and Western United states agricultural areas and fires on the atmospheric transport of pesticides in the Western United States. Environ Sci Technol 42, 6519–6525, https://doi.org/10.1021/es800511x (2008).
Ravindra, K., Sokhi, R. & Van Grieken, R. Atmospheric polycyclic aromatic hydrocarbons: Source attribution, emission factors and regulation. Atmospheric Environment 42, 2895–2921, https://doi.org/10.1016/j.atmosenv.2007.12.010 (2008).
Bostrom, C. E. et al. Cancer risk assessment, indicators, and guidelines for polycyclic aromatic hydrocarbons in the ambient air. Environ Health Persp 110, 451–488, https://doi.org/10.1289/ehp.110-1241197 (2002).
Wassenberg, D. M. & Di Giulio, R. T. Synergistic embryotoxicity of polycyclic aromatic hydrocarbon aryl hydrocarbon receptor agonists with cytochrome P4501A inhibitors in Fundulus heteroclitus. Environ Health Perspect 112, 1658–1664, https://doi.org/10.1289/ehp.7168 (2004).
Kristensen, P. et al. Fertility in mice after prenatal exposure to benzo[a]pyrene and inorganic lead. Environ Health Perspect 103, 588–590, https://doi.org/10.1289/ehp.95103588 (1995).
Environmental Health Criteria 202, International Programme on Chemical Safety. Polycyclic aromatic hydrocarbons, selected non-heterocyclic, https://inchem.org/documents/ehc/ehc/ehc202.htm (2010).
Burchiel, S. W. & Luster, M. I. Signaling by environmental polycyclic aromatic hydrocarbons in human lymphocytes. Clin Immunol 98, 2–10, https://doi.org/10.1006/clim.2000.4934 (2001).
Jedrychowski, W. A. et al. Prenatal exposure to polycyclic aromatic hydrocarbons and cognitive dysfunction in children. Environ Sci Pollut Res Int 22, 3631–3639, https://doi.org/10.1007/s11356-014-3627-8 (2015).
Perera, F. P. et al. Early-life exposure to polycyclic aromatic hydrocarbons and ADHD behavior problems. PLoS One 9, e111670, https://doi.org/10.1371/journal.pone.0111670 (2014).
Perera, F. P. et al. Prenatal airborne polycyclic aromatic hydrocarbon exposure and child IQ at age 5 years. Pediatrics 124, e195–e202, https://doi.org/10.1542/peds.2008-3506 (2009).
Perera, F. P. et al. Effect of prenatal exposure to airborne polycyclic aromatic hydrocarbons on neurodevelopment in the first 3 years of life among inner-city children. Environ Health Persp 114, 1287–1292, https://doi.org/10.1289/ehp.9084 (2006).
Perera, F. P. et al. Prenatal polycyclic aromatic hydrocarbon (PAH) exposure and child behavior at age 6-7 years. Environ Health Persp 120, 921–926, https://doi.org/10.1289/ehp.1104315 (2012).
Miller, R. L. et al. Polycyclic aromatic hydrocarbon metabolite levels and pediatric allergy and asthma in an inner-city cohort. Pediatr Allergy Immunol 21, 260–267, https://doi.org/10.1111/j.1399-3038.2009.00980.x (2010).
Anderson, K. A., Sethajintanin, D., Sower, G. & Quarles, L. Field trial and modeling of uptake rates of in situ lipid free polyethylene membrane passive sampler. Environmental Science and Technology 42, 4486–4493, https://doi.org/10.1021/es702657n (2008).
Hillwalker, W. E., Allan, S. E., Tanguay, R. L. & Anderson, K. A. Exploiting lipid-free tubing passive samplers and embryonic zebrafish to link site specific contaminant mixtures to biological responses. Chemosphere 79, 1–7, https://doi.org/10.1016/j.chemosphere.2010.02.001 (2010).
Allan, S. E., Sower, G. J. & Anderson, K. A. Estimating risk at a Superfund site using passive sampling devices as biological surrogates in human health risk models. Chemosphere 85, 920–927, https://doi.org/10.1016/j.chemosphere.2011.06.051 (2011).
Matzke, M. M., Allan, S. E., Anderson, K. A. & Waters, K. M. An approach for calculating a confidence interval from a single aquatic sample for monitoring hydrophobic organic contaminants. Environ Toxicol Chem 31, 2888–2892, https://doi.org/10.1002/etc.2014 (2012).
Forsberg, N. D., Smith, B. W., Sower, G. J. & Anderson, K. A. Predicting polycyclic aromatic hydrocarbon concentrations in resident aquatic organisms using passive samplers and partial least-squares calibration. Environ Sci Technol 48, 6291–6299, https://doi.org/10.1021/es5000534 (2014).
Truong, L. et al. Multidimensional in vivo hazard assessment using zebrafish. Toxicol Sci 137, 212–233, https://doi.org/10.1093/toxsci/kft235 (2014).
Geier, M. C. et al. Comparative developmental toxicity of a comprehensive suite of polycyclic aromatic hydrocarbons. Arch Toxicol 92, 571–586, https://doi.org/10.1007/s00204-017-2068-9 (2018).
Geier, M. C. et al. Systematic developmental neurotoxicity assessment of a representative PAH Superfund mixture using zebrafish. Toxicol Appl Pharmacol 354, 115–125, https://doi.org/10.1016/j.taap.2018.03.029 (2018).
Li, A. et al. The Carcinogenome Project: In Vitro Gene Expression Profiling of Chemical Perturbations to Predict Long-Term Carcinogenicity. Environ Health Perspect 127, 47002, https://doi.org/10.1289/EHP3986 (2019).
Gosline, S. K. et al. Superfund Analytics Compendium. Pacific Northwest National Laboratory (PNNL) https://doi.org/10.25584/1923005 (2023).
Gosline, S. K. et al. The Superfund Analytics Portal http://srp.pnnl.gov (2023).
Knecht, A. L. et al. Comparative developmental toxicity of environmentally relevant oxygenated PAHs. Toxicol Appl Pharmacol 271, 266–275, https://doi.org/10.1016/j.taap.2013.05.006 (2013).
Adams, R. G., Lohmann, R., Fernandez, L. A. & MacFarlane, J. K. Polyethylene Devices: Passive Samplers for Measuring Dissolved Hydrophobic Organic Compounds in Aquatic Environments. Environmental Science & Technology 41, 1317–1323, https://doi.org/10.1021/es0621593 (2007).
Hagstrom, D., Truong, L., Zhang, S., Tanguay, R. & Collins, E. S. Comparative Analysis of Zebrafish and Planarian Model Systems for Developmental Neurotoxicity Screens Using an 87-Compound Library. Toxicol Sci 167, 15–25, https://doi.org/10.1093/toxsci/kfy180 (2019).
Truong, L. et al. The multi-dimensional embryonic zebrafish platform predicts flame retardant bioactivity. Reprod Toxicol https://doi.org/10.1016/j.reprotox.2020.08.007 (2020).
Van Slyke, C. E., Bradford, Y. M., Westerfield, M. & Haendel, M. A. The zebrafish anatomy and stage ontologies: representing the anatomy and development of Danio rerio. J Biomed Semantics 5, 12, https://doi.org/10.1186/2041-1480-5-12 (2014).
Thomas, D. G., Shankaran, H., Truong, L., Tanguay, R. L. & Waters, K. M. Time-dependent behavioral data from zebrafish reveals novel signatures of chemical toxicity using point of departure analysis. Comput Toxicol 9, 50–60, https://doi.org/10.1016/j.comtox.2018.11.001 (2019).
Davis, J. A., Gift, J. S. & Zhao, Q. J. Introduction to benchmark dose methods and U.S. EPA’s benchmark dose software (BMDS) version 2.1.1. Toxicol Appl Pharmacol 254, 181–191, https://doi.org/10.1016/j.taap.2010.10.016 (2011).
Forum, R. A. (ed Environmental Protection Agency) (https://www.epa.gov/sites/production/files/2015-01/documents/benchmark_dose_guidance.pdf 2015).
Anderson, K. A., Szelewski, M. J., Wilson, G., Quimby, B. D. & Hoffman, P. D. Modified ion source triple quadrupole mass spectrometer gas chromatograph for polycyclic aromatic hydrocarbon analyses. J Chromatogr A 1419, 89–98, https://doi.org/10.1016/j.chroma.2015.09.054 (2015).
Bergmann, A. J., Points, G. L., Scott, R. P., Wilson, G. & Anderson, K. A. Development of quantitative screen for 1550 chemicals with GC-MS. Anal Bioanal Chem 410, 3101–3110, https://doi.org/10.1007/s00216-018-0997-7 (2018).
Allan, S. E., Smith, B. W., Tanguay, R. L. & Anderson, K. A. Bridging environmental mixtures and toxic effects. Environ Toxicol Chem 31, 2877–2887, https://doi.org/10.1002/etc.2018 (2012).
Oregon State University. Multi Analyte Screen Version 1530 (MASV15) - Analyte List, https://fses.oregonstate.edu/1530 (2022).
Acknowledgements
This work was funded by NIEHS grants P42 ES016465 and P30 ES030287. Pacific Northwest National Laboratory is operated by Battelle Memorial Institute for the U.S. Department of Energy under Contract No. DE-AC05-76RL01830.
Author information
Authors and Affiliations
Contributions
Sara J.C. Gosline organized the data and wrote the manuscript. Doo Nam Kim, Paritosh Pande, Dennis Thomas, Sara Gosline, and David Degnan wrote the analytics pipeline. Lisa Truong collected and curated the zebrafish data. Peter Hoffman, Michael Barton collected and curated the environmental sample data. Joseph Loftus, Addy Moran, Shawn Hampton, Scott Dowson, Lyndsey Franklin designed and implemented the web portal. Lindsey Anderson collected the data resources to be shared. Anne Thessen defined the zebrafish endpoints. Kim A. Anderson, Robyn L. Tanguay, and Katrina M Waters designed the study and coordinated the project.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gosline, S.J.C., Kim, D.N., Pande, P. et al. The Superfund Research Program Analytics Portal: linking environmental chemical exposure to biological phenotypes. Sci Data 10, 151 (2023). https://doi.org/10.1038/s41597-023-02021-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-02021-5
