1. Introduction
To comprehend a text, readers need to understand not only individual words, but also the connection between linguistic units, which often span clauses or sentences. One such connection is coreference, a mechanism in which a referring expression (e.g., a pronoun) and another element (e.g., an antecedent that is previously mentioned) refer to the same entity (Halliday & Hasan, Reference Halliday and Hasan1976). Establishing coreference is influenced by many factors, most notably, the antecedent's structural and linear position in the sentence, with the entity in the subject position or the first-mentioned entity being the preferred referent of a subsequent pronoun in certain discourse contexts (e.g., Ariel, Reference Ariel1990; Arnold, Reference Arnold1998; Crawley, Stevenson & Kleinman, Reference Crawley, Stevenson and Kleinman1990; Frederiksen, Reference Frederiksen1981; Givón, Reference Givón1992, Reference Givón1995; Grosz, Joshi & Weinstein, Reference Grosz, Joshi and Weinstein1995; Järvikivi, Van Gompel, Hyönä & Bertramet, Reference Järvikivi, Van Gompel, Hyönä and Bertram2005). In addition, verb meaning also affects coreference. For instance, when presented with a sentence fragment containing the verb fear, the connective because, and an ambiguous pronoun as in (1), people usually continue the sentence with the pronoun referring to the object Sara. By contrast, when the verb is changed to frighten as in (2), people tend to refer the pronoun to the subject Mary. This phenomenon is known as implicit causality (Garvey, Caramazza & Yates, Reference Garvey, Caramazza and Yates1976).
(1) Mary feared Sara because she . . .
(2) Mary frightened Sara because she . . .
The effect of verb meaning on coreference is modulated by discourse coherence relations (Kehler, Kertz, Rohde & Elman, Reference Kehler, Kertz, Rohde and Elman2008; Koornneef & Sanders, Reference Koornneef and Sanders2013; Stevenson, Knott, Oberlander & McDonald, Reference Stevenson, Knott, Oberlander and McDonald2000). When the connective in (1) and (2) is changed to so, thereby creating a different coherence relation, the biases of pronominal reference change accordingly: Mary in the case of fear and Sara in the case of frighten. This phenomenon is known as implicit consequentiality (IR hereafter with R standing for result) (Crinean & Garnham, Reference Crinean and Garnham2006; Stewart, Pickering & Sanford, Reference Stewart, Pickering, Sanford, Gernsbacher and Derry1998).
The interaction between these factors in interpreting coreference during comprehension has been recently described in a Bayesian framework (Kehler et al., Reference Kehler, Kertz, Rohde and Elman2008; Kehler & Rohde, Reference Kehler and Rhode2013). In this framework, as part of discourse processing, comprehenders make probabilistic predictions about which referent is likely to be re-mentioned in the following discourse on the basis of the semantic content of prior discourse. Upon encountering an anaphor, comprehenders then update their prediction of which is the referent by integrating their initial predictions (priors) with the referential bias (evidence) provided by the form of the anaphor: Pronouns indicate a strong subject/first-mention bias and fuller references signal biases towards non-subject antecedents. While this model has been shown to be useful in explaining many empirical findings concerning monolingual speakers, it has not been fully evaluated in the context of second language (L2) speakers’ resolution of coreference. This represents an important gap in the literature, because many recent theories of L2 processing (e.g., Grüter, Rohde & Schafer, Reference Grüter, Rohde, Schafer, Orman and Valleau2014, Reference Grüter, Rohde and Schafer2017; Kaan, Reference Kaan2014) have highlighted the role of prediction, which is an essential component of the Bayesian framework. In this paper, we aim to further our understanding of this issue by investigating advanced Chinese-speaking English learners’ coreference resolution in the contexts of implicit causality and consequentiality. In the remainder of the introduction, we first explain the phenomena of IC/IR and the Bayesian model of coreference resolution in more detail. We then review previous research on the establishment of coreference by non-native speakers in their L2.
1.1. Implicit causality and implicit consequentiality
IC and IR biases appear under different discourse coherence relations. In particular, IC biases are closely related to the ‘Explanation’ coherence relation (Kehler et al., Reference Kehler, Kertz, Rohde and Elman2008), in which the second clause provides an explanation for the event described in the first clause. IR biases arise in the ‘Result’ coherence relation (Kehler et al., Reference Kehler, Kertz, Rohde and Elman2008), in which the second clause is a consequence of the event described in the first clause.
Depending on the discourse coherence relation, some verbs – usually interpersonal verbs including psychological verbs as well as action verbs – show certain IC or IR biases. When the discourse coherence relation is Explanation, some verbs show an implicit direction of causality attributing the cause of the event described by the verb to one of its two arguments (e.g., Caramazza, Grober & Garvey, 1977; Koornneef & Van Berkum, Reference Koornneef and Van Berkum2006). As illustrated in (1) above, frighten attributes the cause to the first noun phrase (NP1) or the subject, whereas fear attributes the cause to the second noun phrase (NP2) or the object. When the discourse coherence relation is Result, some verbs show an implicit direction of consequentiality such that one of its arguments is usually considered as bearing the consequence of the event described by the verb (e.g., Au, Reference Au1986; Stewart et al., Reference Stewart, Pickering, Sanford, Gernsbacher and Derry1998). For instance, frighten has an IR bias towards NP2 while fear has an IR bias towards NP1. The contrast between frighten and fear demonstrates that different types of verbs have distinct IC or IR biases. Some argue that the difference is due to verbs’ semantic structures (e.g., Brown & Fish, Reference Brown and Fish1983; Crinean & Garnham, Reference Crinean and Garnham2006; Hartshorne & Snedeker, Reference Hartshorne and Snedeker2013), but others simply regard it as a reflection of world knowledge associated with different verbs (e.g., Pickering & Majid, Reference Pickering and Majid2007). Despite this controversy regarding the factors underlying these effects, it is uncontroversial that whether a verb has an NP1 or NP2 bias is dependent on its meaning.
IC biases are not only found in English but also in other languages, particularly for transitive psychological verbs (Hartshorne, Sudo & Uruwashi, Reference Hartshorne, Sudo and Uruwashi2013). Studies on Chinese also confirmed that IC biases are robust among many Chinese verbs (e.g., Cheng & Almor, Reference Cheng and Almor2015; Jiao & Zhang, Reference Jiao and Zhang2005; Miao, Reference Miao1996; Miao & Song, Reference Miao and Song1995; Sun, Shu, Zhou & Zheng, Reference Sun, Shu, Zhou and Zheng2001). In addition, robust IR biases were also found among Chinese verbs (Cheng & Almor, Reference Cheng and Almor2015). Thus, IC and IR biases are arguably universal biases.
1.2. A Bayesian approach to coreference resolution
IC and IR biases influence coreference resolution during comprehension. As shown in examples (1) and (2) above, the continuations people typically produce following an ambiguous pronoun that can potentially refer to either one of two arguments of a fragment with an IC or IR verb indicate that these biases affect their resolution of ambiguous pronouns (e.g., Ehrlich, Reference Ehrlich1980; Garvey & Caramazza, Reference Garvey and Caramazza1974; Hartshorne & Snedeker, Reference Hartshorne and Snedeker2013). In addition, these biases also exert an influence on re-mention biases in language production (e.g., Au, Reference Au1986; Kehler et al., Reference Kehler, Kertz, Rohde and Elman2008). For example, when presented with sentence fragments such as Mary feared Sara because, participants usually re-mention Sara, the referent consistent with the verb's IC bias, in their continuation to the sentence fragment.
In addition to semantic and discourse factors such as IC and IR biases, coreference production and comprehension are also affected by syntactic and linear order factors. Numerous studies have shown that the referent in the subject position or the first-mentioned referent of the previous clause is likely to be referred to by a reduced expression such as a pronoun rather than a fuller expression such as a name (e.g., Almor & Nair, Reference Almor and Nair2007; Ariel, Reference Ariel1990; Garrod & Sanford, Reference Garrod and Sanford1982; Givón, Reference Givón1987; Gordon, Grosz & Gilliom, Reference Gordon, Grosz and Gilliom1993; Gundel, Hedberg & Zacharski, Reference Gundel, Hedberg and Zacharski1993). Thus, the presence of a pronoun during comprehension as opposed to other fuller forms of reference provides a strong referential cue in favor of the subject/first-mention referent.
Kehler and colleagues (Kehler et al., Reference Kehler, Kertz, Rohde and Elman2008; Kehler & Rohde, Reference Kehler and Rhode2013) synthesized the above-mentioned factors that influence coreference resolution using Bayes rule as shown in (3).
(3)
 {\selectfont{$p(\,{\it referent} {|} {\it pronoun}) = \frac{{p( {\it referent} )\ \times \ p{\rm{(}}{\,\it pronoun}\ {\rm{|}}\ {\it referent}){\rm{\ }}}}{{p(\, {{\it pronoun}} )}}$}}
{\selectfont{$p(\,{\it referent} {|} {\it pronoun}) = \frac{{p( {\it referent} )\ \times \ p{\rm{(}}{\,\it pronoun}\ {\rm{|}}\ {\it referent}){\rm{\ }}}}{{p(\, {{\it pronoun}} )}}$}}

p(referent│pronoun) represents the probability that a pronoun just encountered by the comprehender is coreferential with a particular antecedent. According to the formula, it is determined by two factors. The first is p(referent), the prior probability the comprehender assigns to a referent to be re-mentioned in subsequent discourse just before encountering the pronoun. This represents a predictive process, in which language comprehenders use contextual cues to generate a prediction about the next-mentioned referent before encountering the pronoun. As the input unfolds, listeners and readers make a probabilistic evaluation of the coherence relation between clauses or sentences and then form a prediction about the next-mentioned referent consistent with the coherence relation. Since IC and IR biases are associated with the Explanation and Result coherence relations, respectively, it is in this process that comprehenders make predictions that prefer an IC or IR bias-consistent antecedent as the most probable entity to be re-mentioned.
The other factor that affects pronoun resolution in the Bayesian model is the likelihood p(pronoun│referent), which is the probability that a particular referent is referred to by a pronoun as opposed to other forms of reference. When comprehenders encounter a pronoun, their interpretation of the pronoun will reflect the product of the prior probability of each possible referent to be mentioned next and the relative probabilities that each of these referents will be referred to by a pronoun. Thus, the pronoun itself provides evidence that is integrated with the priors, resulting in the posterior probabilities of the different possible referents as antecedents of the pronoun. The referent chosen as the antecedent is the one with the highest posterior probability. Given that the referent in the subject position or the first-mentioned referent is usually referred to by a pronoun in the following clause instead of other referring expressions, pronouns typically contribute a strong subjecthood/first-mention cue (meaning that the probability that the antecedent is the subject or the first-mentioned entity of the previous clause is higher than with the priors alone).
To sum up, according to the Bayesian model, to successfully resolve an anaphoric expression amounts to calculating the posterior probabilities for all possible antecedents and picking the most probable one as the referent. This process relies on two sources of information in terms of Bayes formula: (1) p(referent), i.e., the priors, which are the probabilities that each referent will be re-mentioned and which are based on the comprehension of prior contextual semantic information such as IC and IR biases, as well as discourse coherence relations; (2) p(pronoun | referent), i.e., the likelihood that a given antecedent would be referred to by a pronoun as opposed to other forms of reference, which is based on prior knowledge about language, for example, that pronouns are typically used for subject or first-mentioned referents. Thus, in this view, pronoun resolution is a process that involves the integration of comprehenders’ prediction of likely referents based on context, as well as multiple sources of probabilistic information about the general circumstances in which pronouns are used in the language, and finally choosing the referent with the highest posterior probability as the pronoun's antecedent.
It is important to note that much of the work in this area is based on two related assumptions that are often left implicit. The first assumption is that constrained production tasks, in which participants produce continuations for previous contexts provided to them, can yield important information about their comprehension of the preceding context. Indeed, much of the scientific understanding of the effects of IC and IR on language comprehension comes from language production sentence continuation tasks. Although the reliance on production tasks for the understanding of comprehension processes may seem problematic, it is in fact a common practice in psycholinguistics, where various production tasks such as cross-modal naming have been frequently used as means to examine the comprehension of preceding material.
The second related assumption is that similar patterns occur in both language production and comprehension, albeit possibly for different underlying reasons. In particular, IC and IR biases are assumed to occur in both language production and language comprehension, although their origin may be different in the two modalities. For example, while the choice of reference form may reflect production constraints, such as using a minimal form for referring to the most salient entity so as to minimize interference (Almor & Nair, Reference Almor and Nair2007), comprehenders are sensitive to the patterns in language and can use the form of a referential expression as a source of information about the likely referent (e.g., MacDonald, Reference MacDonald2013). Most relevant here is that, under this assumption, participants’ choices in production (for example, whether they produce a continuation describing a specific referent) can be used as a measure of the probabilistic knowledge that guides their comprehension (for example, how they interpret a pronoun that was provided to them in the context fragment).
1.3. Establishing coreference in the L2
Compared to the large number of studies on L1 coreference resolution, only a few have looked at how L2 speakers establish coreference in discourse. Among these, to the best of our knowledge, only two studies (Cheng & Almor, Reference Cheng and Almor2017; Grüter et al., Reference Grüter, Rohde, Schafer, Orman and Valleau2014, Reference Grüter, Rohde and Schafer2017) have adopted the Bayesian approach of coreference resolution and investigated L2 speakers’ sensitivity to contextual information in resolving ambiguous reference (other studies have focused on other aspects such as native language influence (e.g., Roberts, Gullberg & Indefrey, Reference Roberts, Gullberg and Indefrey2008), the role of different anaphor types (e.g., Sorace & Filiaci, Reference Sorace and Filiaci2006), or the use of gender cues in online pronoun interpretation (e.g., Liu & Nicol, Reference Liu, Nicol, Prior and Watanabe Lee2010)).
In an offline sentence-completion study, Grüter et al. (Reference Grüter, Rohde, Schafer, Orman and Valleau2014, Reference Grüter, Rohde and Schafer2017) investigated L2 learners’ sensitivity to event structures in resolving ambiguous reference. They manipulated event structures by contrasting perfective and imperfective aspect marked on Source-Goal verbs (e.g., hand). The results showed that native English speakers continued the sentence with more references to the Source referent (e.g., John) following sentences in the imperfective aspect (e.g., John was handing a book to Bob) than following sentences in the perfective aspect (e.g., John handed a book to Bob). By contrast, despite having acquired the knowledge of English aspect as shown in an independent grammaticality test, Japanese and Korean-speaking learners of English showed a referential bias towards the Goal referent (i.e., Bob) following both structures. Interestingly, when presented with prompts that ended with a pronoun (e.g., John handed/was handing a book to Bob. He. . .), L2 speakers still did not show any difference between the aspect conditions, but, like native speakers, produced more continuations with references to the subject /first-mentioned antecedent than when no pronoun was present. Based on the Bayesian model of coreference resolution, these results indicate that although L2 speakers are sensitive to the subjecthood/first-mention cue in resolving pronouns, they are not sensitive to the aspect information in their prior prediction about which referent is likely to be re-mentioned.
On the basis of these findings, Grüter et al. (Reference Grüter, Rohde, Schafer, Orman and Valleau2014, Reference Grüter, Rohde and Schafer2017) proposed the RAGE hypothesis (Reduced Ability to Generate Expectations), arguing that L2 speakers are not able to engage in native-like predictions. This is a timely proposal that ties to recent trends in research on monolinguals, which has established that L1 processing is characterized by prediction (e.g., Kamide, Reference Kamide2008; Kuperberg & Jaeger, Reference Kuperberg and Jaeger2016). However, as argued by Kaan (Reference Kaan2014), there may be no qualitative difference between L1 and L2 speakers in terms of prediction and that any differences in performance may simply reflect external factors that influence predictive processing in general, related to L2 speakers’ native language influence and their proficiency in the L2. Therefore, it is not clear whether L2 participants’ failure to generate native-like anticipation about which referent to be re-mentioned in Grüter et al.’s study reflects a specific difficulty in generating predictions in L2.
Cheng and Almor (Reference Cheng and Almor2017) is another study that employed a Bayesian approach to examine L2 pronoun resolution. In two sentence-completion experiments, they investigated advanced Chinese-speaking L2 English learners’ sensitivity to IC and IR biases in resolving ambiguous pronouns. They used Experiencer-Stimulus (ES) verbs such as fear and Stimulus-Experiencer (SE) verbs such as frighten, two typical types of psychological verbs that have different IC or IR biases as introduced above. Participants wrote continuations to sentence fragments ending with a pronoun prompt such as Mary frightened/feared Sara because/so she _. The results showed that although L2 participants resolved the pronoun in accordance with different IC or IR biases between ES and SE verbs, they could not apply this type of information as robustly as native speakers. Specifically, when the discourse-biased referent was NP2, L2 participants produced significantly more references to NP1 than native speakers.
According to the Bayesian model of coreference resolution, there are three possible explanations for Cheng and Almor's (Reference Cheng and Almor2017) results. First, the difference between the native and the L2 speakers could be due to the latter's reduced ability to use IC and IR biases in their prediction about the referent to be re-mentioned, in line with the RAGE hypothesis (Grüter et al., Reference Grüter, Rohde, Schafer, Orman and Valleau2014, Reference Grüter, Rohde and Schafer2017). A second alternative is that the L2 speakers in Cheng and Almor's study may have encountered no specific difficulty in prediction, but had problems integrating these predictions that were based on the IC and IR biases with the strong subjecthood/first-mention cue provided by the pronoun. Since all the materials in Cheng and Almor included pronouns at the end of the prompt, these two explanations cannot be teased apart. Finally, a third alternative is that, in line with Kaan (Reference Kaan2014), Cheng and Almor's results could reflect differences between Chinese and English. By this explanation, the L2 speakers in their study behaved differently than native English speakers due to differences between Chinese and English. In particular, compared with English, which has a large number of SE verbs, Chinese has a limited set of SE verbs, as causation for SE predicates is mainly being expressed in periphrastic causatives in Chinese (Liu, Reference Liu2016; Zhang, Reference Zhang2003). Thus, it may be that the difference between L1 and L2 speakers found by Cheng and Almor resulted from L2 participants’ difficulty in understanding SE verbs, especially those without counterparts in their native language. Therefore, overall, it is unclear why L2 speakers cannot use IC and IR biases as robustly as native speakers when establishing coreference.
1.4. The present study
The current study aimed to address the open questions discussed above and thus further our understanding of the similarities and differences in establishing coreference between native and non-native speakers. To do so, we investigated advanced L1-Chinese L2-English speakers’ use of IC and IR biases in coreference resolution in two sentence-completion experiments, one on IC (Experiment 1) and the other on IR (Experiment 2). In both experiments, participants were instructed to write up natural continuations to sentence fragments that contained two same-gender names and either an NP1-biasing or NP2-biasing verb. Each fragment ended with either a free prompt or a pronoun prompt. Materials with free prompts were used in previous studies to probe comprehenders’ predictions of the next-mentioned referent (e.g., Kehler et al., Reference Kehler, Kertz, Rohde and Elman2008; Grüter et al., Reference Grüter, Rohde, Schafer, Orman and Valleau2014, Reference Grüter, Rohde and Schafer2017) and thus allowed us to test if L2 speakers are able to use IC and IR biases effectively to generate expectations about the next-mentioned referent. Comparing free prompt and pronoun prompt conditions enabled us to find out whether and, if so, to what extent, L2 speakers’ coreference is influenced by the subjecthood/first-mention cue provided by pronouns. While the task used here involved language production in that participants were required to generate continuations, the experimental manipulation concerns the context that they need to comprehend prior to producing the continuation. Thus, in line with most previous research in this area, we employed a task involving language production to study the comprehension that must have occurred before production was initiated.
The current study extends the Cheng and Almor (Reference Cheng and Almor2017) study in two important ways. First, unlike Cheng and Almor, which exclusively used pronoun prompts, we used materials that contained both pronoun and free prompts, allowing us to determine whether L2 speakers are able to use discourse information to engage in both native-like predictions about the referent to be re- mentioned and native-like integration of the evidence provided by a pronoun. The second difference is that, instead of using exclusively ES and SE verbs, we included in this study a wide variety of verbs that have equivalents and exhibit similar IC or IR biases in both Chinese and English. By using a set of diverse verbs that are equivalent in terms of biases in both languages, we could exclude as much as possible the potential cross-linguistic influence from learners’ native language lexicon. We next report the results from the two experiments.
2. Experiment 1
Experiment 1 aimed to compare native English speakers’ and Chinese-speaking English learners’ referent choices following English sentence fragments with NP1-biasing and NP2- biasing IC verbs that ended without or with a pronoun in a causal discourse context. All verbs had Chinese equivalents with similar biases, thus minimizing the concern that different performance of L2 speakers reflects influences of their L1. This allows us to focus in this experiment on testing the two alternative Bayesian hypotheses: If L2 learners have difficulty making predictions in English, their performance should diverge from that of native English speakers in all conditions. However, if their difficulty is related to the integration of the prior predictions with the evidence provided by the pronoun, their performance should diverge from native speakers’ performance only following the pronoun fragments but not following the fragments without the pronouns.
2.1. Method
Participants
Forty-three native English speakers (L1 group) were recruited from the University of South Carolina. One participant was eliminated from analysis because she had been raised in a bilingual family. The data from the remaining 42 native English participants (31 women, Mage = 19.6 years, age range: 18–39 years) were analyzed.
Forty-four Chinese-speaking English learners (L2 group) were recruited from the Guangdong University of Technology in China and received extra credit for participation. All were native speakers of Standard Mandarin, which is the lingua franca in China and the medium of instruction at all levels of schools. All participants were undergraduate students majoring in English in their sixth semester in a four-year BA program. Many of them lived in the Guangdong area and also spoke other dialects such as Cantonese, Teochew, Hakka, etc. L2 participants were required to finish two tasks: a sentence-completion task and a translation task (see details in Procedure). Only the data of those who finished both tasks were included in the analysis. In the end, 36 participants finished both tasks (28 women, Mage = 21.5 years, age range: 21–23 years). These participants started learning English as a foreign language in a school setting at an average age of 9.5 years (age range: 7–14 years) and had learned English for an average of 12 years (range: 9– 15 years). At the time of testing, two of them had visited English-speaking countries for a brief period of time (10 days and 2 months, respectively), and the others had never been to English-speaking countries. The English proficiency of the L2 participants were determined by their scores on the Test for English Majors (TEM) Band 4, which classified them as advanced English learners.Footnote 1 In order to better understand the individual differences in their English proficiency, a C-test adopted from Schulz (Reference Schulz2006) and composed of three short passages with 60 blanks was administered to L2 participants. The average C-test score was 35.05 out of 60 (SD = 6.46). The C-test score was used as a covariate in the analysis.
Materials and design
The experiment contained two types of verbs: 16 NP1-biasing IC verbs and 16 NP2-biasing IC verbs. To eliminate potential influence from learners’ native language lexicon as much as possible, the verbs were selected from Ferstl, Garnham, and Manouilidou's (Reference Ferstl, Garnham and Manouilidou2011) norming study of English verbs’ IC biases, using the following criteria: First, the English verbs must have lexical counterparts in Chinese. Second, each verb must have a strong IC bias in the same referential direction in both English and Chinese. To establish this, a norming study was conducted on Chinese verbs. The first author, an English–Chinese bilingual, translated the 300 verbs from Ferstl et al. into Chinese.Footnote 2 These verbs were then embedded in sentence fragments of the form NP1 verb NP2 yinwei “because”, with the two NPs being common Chinese names of different genders. The 300 items were randomly divided into five lists, each consisting of 60 verbs. To counterbalance the effect of gender, five more lists were prepared by reversing the order of the two names. The norming study was conducted via paper- and-pencil surveys divided into ten booklets. 174 undergraduate students from the Guangdong University of Technology in China (different from L2 participants) filled out the surveys during class in exchange for extra credit. All were native speakers of Mandarin Chinese (106 women, Mage = 19.3 years, age range: 18–21 years). They were divided into ten groups almost even in size, and each group filled out one of the ten versions of the survey. Participants’ continuations were coded as referring to either NP1 or NP2 by the first author and another trained native Chinese speaker. Coders were instructed to be conservative so that, as long as there was a possibility of ambiguity, the reference was coded as ‘unclear’. The coding agreement rate between the two raters was 93.1%. All disagreements were resolved through discussion between coders. Disagreements that could not be resolved were coded as ‘unclear’. Each verb's IC bias was determined by the percentage of NP1 references out of all NP1 and NP2 references. The Appendix shows the list of chosen verbs and their biases.
For the actual experiment, the English verbs chosen according to the above criteria were embedded in sentence fragments of the type NP1 verb-ed NP2 because. The two NPs were common English names of the same gender. To counterbalance the effect of gender, one half of the items had female names and the other half had male names. In the pronoun prompt condition, a pronoun of the same gender as the names in the first clause was placed after the connective because. In the free prompt condition, no pronoun was used. Each item appeared in both the pronoun prompt and free prompt conditions, but each participant saw each item only once in only one condition. Sample items are given in Table 1.
Table 1. Sample Items in Experiment 1.

The experiment had a 2×2 design with the independent variables being verb bias (NP1-biasing vs. NP2-biasing verbs) and prompt type (pronoun vs. free). The dependent variable was the continuation reference to either NP1 or NP2 in the first clause. The design was counterbalanced. Every participant saw half of the items in the free prompt condition and the other half in the pronoun prompt condition. Every item was presented in the pronoun prompt condition to half of the participants and in the free prompt condition to the other half. In the end, two lists were prepared. Each list contained 32 experimental stimuli as well as 48 fillers that had the same structure as the experimental stimuli but contained non-IC verbs and other types of connectives (e.g., and, but, etc.). All the stimuli within a list were pseudo-randomized, with at least one filler between experimental stimuli.
Following the sentence-completion task, L2 participants were also required to finish a translation task as a measurement of their semantic knowledge of the items used in the experiment. This was a necessary step because their responses would not be meaningful if they did not know what the verb meant. The translation task was composed of the same 32 items used in the sentence-completion experiment except that participants were only presented with the first clause of the items as an independent sentence (e.g., Mary called Sara).
Procedure
The study was conducted via an offline paper-and-pencil survey. L1 participants took the survey in small groups of 3–7 people in a lab. L2 participants took the survey in a class. Participants were randomly and evenly assigned to one of the two lists printed on a booklet. Before the experiment started, participants were given verbal instructions on how to complete the survey. Specifically, they were asked to write down natural continuations to the sentence fragments in an intuitive way and in the prescribed order. Following Goikoetxea, Pascual, and Acha (Reference Goikoetxea, Pascual and Acha2008), participants were instructed to go over all the stimuli from the beginning to the end after the continuation phase was complete. If there was a subject pronoun in the second clause, regardless of whether it was part of the stimuli or supplied by participants themselves, they were instructed to circle the name that they intended the pronoun to refer to. Examples were given to participants to demonstrate how to do this. This step was taken to improve coding accuracy, as explained below. Participants were not constrained by time to finish the survey.
Following the fragment completion task, L2 participants were administered a translation task and an English proficiency C-test in a separate booklet. In the translation task, they needed to write down the Chinese translations of the experimental stimuli in the sentence-completion experiment (excluding fillers). In the C-test, they were asked to fill in the blanks in three short passages. The translation task was administered after the sentence-completion task to avoid potential influences of the former on sentence-completion performance. Because participants were allowed to take as much time as they needed to finish the completion task and because participants were tested in class, which did have a finite duration, participants were allowed to finish the two additional tasks in their spare time after class and turn in the answer sheet in the next class meeting one week later. They were specifically told that they were not allowed to use dictionaries if they encountered unfamiliar words.
Coding
The data in the sentence-completion experiment were coded independently by the first author and another trained native English speaker naive to the purpose of the study. Coding was done according to the following procedure: Based on participants’ sentence continuations, the subject NP in the second clause was coded as referring to either the first antecedent (NP1) or the second antecedent (NP2) in the first clause. Coders were instructed to be conservative so that, as long as there was a possibility of ambiguity, the reference was coded as ‘unclear’. For continuations that included a subject pronoun, coders were instructed to rely on the marking made by the participant but verify whether the entity circled by the participant made sense given the rest of the continuation. If the circled entity did not make sense given the rest of the continuation, the response was to be marked ‘unclear’. Trials in which no continuation was given, or in which the continuation was nonsense, began with a plural reference or a reference to another entity, showed misunderstanding of the gender of the names, or in which the connective because was interpreted as part of because of, were also coded as ‘unclear’. Table 2 illustrates different types of coded continuations.
Table 2. Sample Coded Continuations in Experiment 1.

Note: Participants’ continuations were in italics.
The coding agreement rate between the two raters was 93.2%. All disagreements were resolved through discussion between the first author and a third independent native English- speaking coder. Disagreements which could not be resolved were coded as ‘unclear’. Overall, there were 3.9% unclear responses in the L1 group (n = 53) and 8.9% unclear responses in the L2 group (n = 103).
The first author who is a Chinese–English bilingual coded L2 participants’ translation data as either ‘correct’ or ‘incorrect’ by matching their translation with the intended meanings of the items. Items with missing translations were counted as ‘incorrect’ as well. Overall, there were 6.4% incorrect translations (n = 74, M = 2, SD = 1.61, range: 0–6).
2.2. Results
All data coded as ‘unclear’ were excluded from analysis. For the L2 group, the data whose counterparts in the translation task were coded as ‘incorrect’ were also excluded from analysis. This affected 3.9% of the dataset of the L1 group and 15% of the L2 group. Table 3 presents the mean proportions of NP1 references out of all NP1 and NP2 references from the remaining trials.
Table 3. Mean Proportions and Standard Deviations of NP1 References by Verb Bias and Prompt Type in L1 and L2 Groups in Experiment 1.

Note: Standard deviations are presented in parentheses.
We used logit mixed-effects regressions to analyze the data. Logit mixed-effects models are more suitable for analyzing categorical and unbalanced data than ANOVA (Jaeger, Reference Jaeger2008). All categorical factors were initially sum-coded to obtain main effects and interactions. Stepwise model comparison was used to estimate the significance of each term, starting with a maximal model containing all individual factors and their interactions. The interaction term was first eliminated. If the elimination did not lead to a significant loss of model fit, each of the individual factors was then removed (Baayen, Reference Baayen2008). If the interaction was significant, the interaction term and all embedded lower level interactions and main effects were kept in the model. Following Barr, Levy, Scheepers, and Tily (Reference Barr, Levy, Scheepers and Tily2013), all the models contained the random effects of participants and items as well as maximal slopes when appropriate and allowed by the data. The analysis was implemented in R 3.1.0 (R Core team, Reference Core Team2014) using the lme4 package 1.1-7 (Bates, Maechler, Bolker & Walker, Reference Bates, Maechler, Bolker and Walker2014), and an alpha level of .05 was used for all statistical tests. The R package lmerTest 2.0-25 (Kuznetsova, Brockhoff & Christensen, Reference Kuznetsova, Brockhoff and Christensen2017) was used to estimate coefficients’ p values using the Satterthwaite approximation. For pairwise comparisons, we used the R package LSmeans 2.18 (Lenth, Reference Lenth2016) which estimates p values of individual contrasts within the fitted model, using Bonferroni correction.
We performed an analysis on both the L1 and L2 data. A maximal model was fitted with group (L1 vs. L2), verb bias (NP1 vs. NP2-biasing verbs), and prompt type (free vs. pronoun), and all interactions between the three factors as the fixed effects, as well as participants and items as random effects with slopes of verb bias and prompt type for the former and slopes of prompt type and group for the latter. Removing the three-way interaction resulted in a significant loss of model fit, χ 2(1) = 8.28, p = .004. The parameter estimates of the full model are reported in Table 4.
Table 4. Summary of the Logistic Regression Analysis for Variables Predicting NP1 Reference in L1 and L2 Participants’ Continuations in Experiment 1.

Note: All factors were sum-coded to obtain main effects and interactions. The L1 group, NP1 verb, and free prompt were used as the reference levels (value = −1) for the factors of group, verb bias, and prompt type, respectively. Significant effects at a p ≤ .05 level are marked with a*.
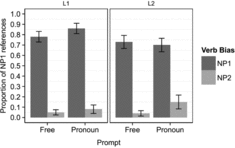
An examination of the model's parameters shows three important things: First, there was a main effect of prompt type with more NP1 references following the pronoun prompt than the free prompt, but no two-way interaction between group and prompt type, suggesting that L1 and L2 participants showed similar patterns of coreference in response to different types of prompts. Second, although there was a main effect of verb with more NP1 references following NP1-biasing verbs than NP2- biasing verbs, there was a two-way interaction between group and verb bias, demonstrating that L1 and L2 participants resolved reference differently in continuations following NP1 and NP2- biasing verbs. Third, there was a three-way interaction between group, verb bias, and prompt type, indicating that the effect of group on NP1 reference were modulated by the factors of verb bias and prompt type. These patterns are also illustrated in Figure 1.

Figure 1. Proportions of NP1 references in Experiment 1. Error bars represent 95% confidence intervals.
Because the presence of the three-way interaction can make the interpretation of the lower order coefficients in the model problematic, we conducted further analyses to better understand the three-way interaction using the simple slope method. To this end we refitted the full model with dummy coding using different reference levels for the factors of verb bias and prompt type. The results were adjusted using a Bonferroni p value correction. In the free prompt conditions, there was no two-way interaction between group and verb bias or an effect of group, demonstrating that L1 and L2 participants had similar re-mention biases in continuations following free prompts, that is, NP1 after NP1- biasing verbs and NP2 after NP2-biasing verbs. However, when the prompt was a pronoun, there was a two-way interaction between group and verb bias, B = −1.85, SE B = .56, z = −3.31, p = .002. Specifically, although L2 participants were able to distinguish IC biases of the two types of verbs, they produced fewer NP1 references than L1 participants in continuations following NP1 verbs, B = −.94, SE B = .35, z = −2.70, p = .01, but more NP1 references than L1 speakers in continuations following NP2 verbs, B = .91, SE B = .42, z = 2.16, p = .06. The latter difference also led to a two-way interaction between group and prompt type when the verbs were NP2-biasing verbs, B = −1.18, SE B = .53, z = −2.25, p = .05.
In order to determine whether the variance in L2 participants’ English proficiency had an effect on the results, we included their C-test scores (centered) in a maximal model regressed to the L2 data only. Model comparisons showed that the C-test score did not contribute significantly to model fit, indicating that the variance in L2 participants’ English proficiency did not influence their referential choice.
2.3. Discussion
This experiment investigated how L1 and L2 speakers establish coreference by using the IC information from the context. Results showed that L1 participants made reference choices following IC biases: NP1 after NP1-biasing verbs and NP2 after NP2-biasing verbs. However, the results were also affected by whether the pronoun was present or not. When L1 participants saw a pronoun prompt in the sentence fragment, they continued the sentence with significantly more references to NP1 than when they saw a free prompt. The findings are thus consistent with the Bayesian model (Kehler et al., Reference Kehler, Kertz, Rohde and Elman2008; Kehler & Rohde, Reference Kehler and Rhode2013) on the effect of IC bias on native pronoun resolution.
Like L1 speakers, L2 participants applied the differences in verbs’ IC biases to the choice of subsequent coreference. Overall, the prompt also influenced their coreference resolution with more NP1 references following the pronoun prompt than the free prompt, indicating that L2 participants were aware of the special relationship between pronouns and subject/first-mention antecedents.
Despite the general similarity in the performance of the two groups, we also observed a three-way interaction among group, prompt type, and verb bias, indicating that the extent to which L2 participants’ performance resembled native speakers’ performance depends on the types of prompt and verb. When there was a free prompt, L2 participants showed the same extent of re-mention biases as L1 participants, demonstrating that L2 participants had no problems using the IC information to predict the next-mentioned referent. However, when the prompt was a pronoun, L2 participants produced more NP1 references in continuations after NP2-biasing verbs than L1 participants. The discrepancy between the free and pronoun prompt conditions indicates that L2 participants resolved pronouns in different ways from L1 speakers. When the context had an NP2 IC bias, they were more likely to interpret the pronoun as referring to NP1 than L1 speakers. This ‘NP1 bias’ shown in the L2 data was also found in Cheng and Almor (Reference Cheng and Almor2017). Interestingly, such ‘NP1 bias’ was not observed following NP1-biasing verbs in the pronoun condition. Instead, L1 speakers produced significantly more NP1 references than L2 speakers. This contrast will be further explored in the General Discussion.
3. Experiment 2
Experiment 2 aimed to test the same hypotheses as in Experiment 1 using IR verbs embedded in resultative discourse contexts. Except for the differences in the items, the design and methods were the same as Experiment 1.
3.1. Method
Participants
New L1 and L2 participants were recruited from the same populations as in Experiment 1. Forty-nine native English speakers participated in the experiment for extra credit. Three participants were eliminated from analysis because one was an early bilingual, one had an old age (78 years), and the third one's responses were not relevant to the task. In the end, the data from 46 native English participants (38 women, M age = 20.3 years, age range: 18–48 years) were analyzed.
Forty-seven Chinese-speaking English learners took part in this experiment for extra credit. Only the data of those who finished both the sentence-completion and the translation tasks were included in the analysis. In the end, 35 participants finished both tasks (34 women, M age = 21.5 years, age range: 20–23 years). These participants started learning English as a foreign language in a school setting at an average age of 9.80 years (age range: 7– 14 years) and had learned English for an average of 11.68 years (range: 8–14 years). At the time of testing, none of them had visited English-speaking countries. All of them took the same C-test as in Experiment 1 with an average score of 33.74 (SD = 8.17). Independent samples t-Test showed that there was no significant difference in participants’ C-test scores between Experiments 1 and 2, suggesting that L2 participants in the two experiments were at comparable English proficiency levels.
Materials and design
The verbs used in Experiment 2 were IR verbs selected from a norming experiment on the 300 verbs tested in Ferstl et al.’s (Reference Ferstl, Garnham and Manouilidou2011) IC study. The verbs were embedded in sentence fragments of the form NP1 verb-ed NP2 and as a result with the two NPs being English names of different genders. The 300 items were randomly divided into three lists, each consisting of 100 items. To counterbalance the effect of gender, three more lists were prepared by reversing the order of the two names. Another group of native English speakers recruited from the same population (N = 115, 80 women, M age = 20.7 years, age range: 18–34) took part in the norming study on the survey website Qualtrics. They were randomly assigned to each of the six lists and typed continuations to the sentence fragments. Following the same procedure as in Experiment 1, participants’ continuations were coded as referring to either NP1 or NP2 by the first author and another trained native English speaker with an inter-rater agreement rate of 95.1%. In order to ensure that the verbs in the current experiment had similar IR biases in learners’ native language, a norming study on Chinese verbs was administered to 180 different native Chinese speakers (153 women, M age = 21.3 years, age range: 20–23) in the same way as the one conducted in Experiment 1 except that, in this study, verbs were embedded in sentence fragments of the form NP1 verb NP2 yinci “because of that”, eliciting a Result coherence relation. Following the same procedure as in Experiment 1, continuations were coded as referring to either NP1 or NP2 by the first author and another trained native Chinese speaker with an agreement rate of 93.6%. In the end, 16 NP1-biasing and 16 NP2-biasing verbs were selected following the same procedure and criteria as in Experiment 1 (see Appendix).
The stimuli were prepared in the same way as in Experiment 1 except that the verbs were embedded in sentence fragments of the type NP1 verb-ed NP2 and as a result. We did not use the connective so as in the Cheng and Almor (Reference Cheng and Almor2017) study because the connective so may denote other meanings than result (Stevenson, Crawley & Kleinman, Reference Stevenson, Crawley and Kleinman1994). The phrase as a result, by contrast, specifically indicates that the coherence relation is Result. The materials for the translation task were prepared in the same way following Experiment 1.
The design was identical to that of Experiment 1.
Procedure
The procedure was identical to that of Experiment 1.
Coding
The data were coded by the first author and another trained coder following the same procedure as in Experiment 1 with a coding agreement rate of 96.2%. Overall, there were 10% unclear responses in the L1 group (n = 143) and 17% unclear responses in the L2 group (n = 187). Furthermore, there were 6% incorrect translations in the L2 group (n = 58, M = 1.66, SD = 1.55, range: 0–6).
3.2. Results
The responses coded as ‘unclear’ were excluded from analysis. For the L2 group, the data whose counterparts in the translation task were coded as ‘incorrect’ were also excluded. Data trimming affected 10% of the dataset in the L1 group and 20% in the L2 group. Table 5 presents the mean proportions and standard deviations of NP1 references out of all NP1 and NP2 references.
Table 5. Mean Proportions and Standard Deviations of NP1 References by Verb Bias and Prompt Type in L1 and L2 Groups in Experiment 2.

Note: Standard deviations are presented in parentheses.
The data were analyzed in the same manner as in Experiment 1. A maximal model was fitted with group, verb bias, and prompt type, and all interactions between the three factors as the fixed effects, as well as participants and items as random effects with slopes of verb bias and prompt type for the former and slopes of prompt type and group for the latter. Removing the three-way interaction resulted in a significant loss of model fit, χ 2(1) = 6.13, p = .01. The parameter estimates of the full model are reported in Table 6. An examination of the model's parameters reveals that, in addition to the three-way interaction, there was a two-way interaction between group and prompt type. To better understand this two-way interaction, we conducted pairwise comparisons, using a Bonferroni p-value adjustment. For both L1 and L2 groups, there were significantly more NP1 references following the pronoun prompt than the free prompt: (L1) B = 1.29, SE B = .29, z = 4.63, p < .001; (L2) B = 2.83, SE B = .38, z = 7.54, p < .001. However, while there was no significant difference between the two groups in the free prompt condition, L2 participants produced more NP1 references than L1 participants in the pronoun prompt condition, B = 1.47, SE B = .41, z = 3.57, p = .002.
Table 6. Summary of the Logistic Regression Analysis for Variables Predicting NP1 Reference in L1 and L2 Participants’ Continuations in Experiment 2.

Note: All factors were sum-coded to obtain main effects and interactions. The L1 group, NP1 verb, and free prompt were used as the reference levels (value = −1) for the factors of group, verb bias, and prompt type, respectively. Significant effects at a p ≤ .05 level are marked with a*.
As in Experiment 1, we carried out additional simple slope analyses to better understand the three-way interaction as illustrated in Figure 2. Similar to Experiment 1, in the free prompt condition, there was no two-way interaction between group and verb bias, or an effect of group, demonstrating that L1 and L2 participants had similar re-mention biases in continuations following free prompts, that is, NP1 after NP1-biasing verbs and NP2 after NP2-biasing verbs. When the prompt was a pronoun, there was no two-way interaction between group and verb bias. There was no two-way interaction between group and prompt type in the condition of NP1-biasing verbs. However, there was a two-way interaction between group and prompt type when the verbs were NP2-biasing verbs, B = −2.44, SE B = .48, z = −5.10, p < .001. This interaction reflected that when verbs had an NP2 bias, L2 participants produced significantly more NP1 references than L1 participants in continuations following a pronoun prompt, B = 2.09, SE B = .44, z = 4.77, p < .001. In these conditions, while the L1 group showed a clear NP2 bias (NP1 percentage = 34%), the L2 group showed an opposite bias towards NP1 (NP1 percentage = 68%).
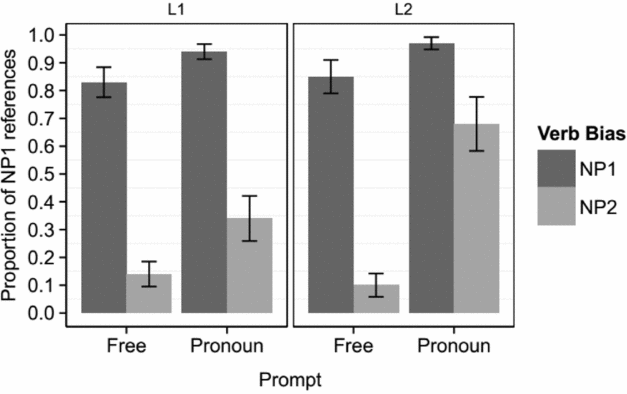
Figure 2. Proportions of NP1 references in Experiment 2. Error bars represent 95% confidence intervals.
Finally, we included L2 participants’ C-test scores (centered) in a maximal model regressed to the L2 data. Model comparisons showed that, as in Experiment 1, the C-test score did not contribute significantly to model fit, indicating that the variance in L2 participants’ English proficiency did not influence their coreference resolution in this experiment.
3.3. Discussion
Experiment 2 investigated the extent to which L2 speakers use the information of IR in coreference resolution. Consistent with previous IR studies (e.g., Au, 1987; Stevenson et al., Reference Stevenson, Crawley and Kleinman1994; Stewart et al., Reference Stewart, Pickering, Sanford, Gernsbacher and Derry1998), the results showed that L1 speakers followed IR biases to establish coreference. Like in Experiment 1, the strength of the bias was affected by the referring form with significantly more NP1 references in continuations following a pronoun prompt than a free prompt. The consistent findings of the two experiments indicate that the presence of pronouns has an independent effect on coreference regardless of contextual biases.
As far as the L2 group is concerned, the results showed that L2 participants also produced more continuations with NP1 references following a pronoun prompt than a free prompt. The findings are similar to those in Experiment 1, indicating that, in both the IC and IR contexts, the referring form affected L2 speakers’ establishment of coreference such that the presence of a pronoun increased the likelihood of NP1 reference.
As in Experiment 1, we once again observed a three-way interaction between group, verb bias, and prompt type in this experiment. In the free prompt condition, L2 participants showed the same extent of re-mention biases as native speakers, indicating that they were able to derive IR biases from the context and use them to predict which referent would be re-mentioned in the following discourse. However, when the pronoun was present, L2 participants were more likely than L1 participants to resolve the pronoun towards NP1, even though the context had an NP2 bias. Thus, as found in Experiment 1, L2 participants demonstrated a ‘NP1 bias’ for pronoun interpretation. The ‘NP1 bias’ in this experiment was strong enough to flip the reference bias choice in the L2 group to an NP1 bias even after contexts with NP2-biasing verbs. This finding is consistent with Cheng and Almor (Reference Cheng and Almor2017) and helps pinpoint the reason for differences in L2 reference resolution to the stage of the Bayesian integration of priors with the evidence provided by reference form rather than their ability to make predictions.
4. General discussion
This study investigated the extent to which advanced Chinese-speaking L2 English learners rely on IC and IR biases when establishing coreference. According to the Bayesian model (Kehler et al., Reference Kehler, Kertz, Rohde and Elman2008; Kehler & Rohde, Reference Kehler and Rhode2013), when establishing coreference between a pronoun and its antecedent, comprehenders rely on 1) contextual information such as IC and IR biases as well as discourse relations to predict which referent will be re-mentioned, and 2) integrating these prior predictions with the probabilistic information provided by the subjecthood/first-mention cue derived from the presence of a pronoun. We tested L2 speakers’ performance in these two aspects of processing by manipulating verb bias (NP1-biasing vs. NP2-biasing verbs) and prompt type (free prompt vs. pronoun prompt) in two sentence-completion experiments that focused on IC and IR, respectively. The experiments yielded converging results in line with the hypothesis that L2 speakers are able to form predictions from the context preceding a pronoun that are comparable to those of native speakers but then tend to behave differently when integrating the information provided by the pronoun with their prior predictions about which referent is most likely to be mentioned next.
With respect to forming predictions from the context preceding the pronoun, our experiments found that, in the free prompt conditions, there were no significant differences between the L1 and L2 groups. Like L1 participants, in both the IC (Experiment 1) and IR (Experiment 2) contexts, L2 participants produced more NP1 re-mentions following NP1-biasing verbs and more NP2 re-mentions following NP2-biasing verbs. The results, therefore, indicate that L2 speakers are able to derive IC and IR biases from the context and use them in a native-like way to generate predictions about the referent to be re-mentioned.
These results contradict those of Grüter et al. (Reference Grüter, Rohde, Schafer, Orman and Valleau2014, Reference Grüter, Rohde and Schafer2017) who found that advanced L1- Japanese and L1-Korean L2 English learners were not able to use discourse information to generate native-like re-mention biases. One possible reason for the difference between our study and theirs is related to the different linguistic phenomena tested in both studies. To create distinct kinds of discourse contexts, Grüter et al. manipulated verb aspect whereas we manipulated verb meaning. Aspect is a well-known area of difficulty for L2 learners (Bardovi-Harlig, Reference Bardovi-Harlig2000). It is also linguistically encoded in different ways in Grüter et al.’s L2 participants’ native languages (Korean and Japanese) and the target language of English (Shirai, Reference Shirai1998). By contrast, IC and IR biases are argued to be universal biases involving simple interpersonal verbs (Hartshorne et al., Reference Hartshorne, Sudo and Uruwashi2013), which may be comparatively easier to master, especially when learners’ L1 and L2 have equivalent lexical items, as was the case in our study. Therefore, it is likely that L2 speakers may find it more difficult to use aspect than IC and IR biases to establish coreference in discourse. Although factors related to participants’ L2 proficiency could also account for the different findings, the fact that, in both Grüter et al.’s and our studies, participants demonstrated native-like knowledge of the phenomena tested, speaks against such explanations.
Overall, the free prompt results in the present study provide important insights into the nature of predictive processing in L2. Specifically, L2 speakers’ native-like performance in the free prompt condition indicates that they are able to use verb-bias and discourse-coherence information to generate native-like coreference expectations. This is incompatible with the RAGE hypothesis (Grüter et al., Reference Grüter, Rohde, Schafer, Orman and Valleau2014, Reference Grüter, Rohde and Schafer2017), which assumes a general reduced ability for L2 speakers to generate expectations.
In the pronoun prompt condition, L2 participants patterned with L1 participants in producing more continuations with NP1 references than in the free prompt condition. This finding is consistent with Grüter et al.’s (Reference Grüter, Rohde, Schafer, Orman and Valleau2014, Reference Grüter, Rohde and Schafer2017) study, which also found that the presence of a pronoun increased L2 speakers’ references to NP1 despite their difficulty in using the information of aspect to establish coreference. Given that pronouns are the preferred referential form for subject/first-mention antecedents (e.g., Almor & Nair, Reference Almor and Nair2007; Ariel, Reference Ariel1990; Garrod & Sanford, Reference Garrod and Sanford1982; Givón, Reference Givón1987; Gordon et al., Reference Gordon, Grosz and Gilliom1993; Gundel et al., Reference Gundel, Hedberg and Zacharski1993), the current study provides further evidence that L2 speakers are sensitive to the subjecthood/first-mention cue provided by the presence of a pronoun.
However, when the context had an NP2 bias, L2 participants were more likely to interpret the pronoun as referring to NP1 than L1 participants. These findings replicate Cheng and Almor (Reference Cheng and Almor2017), who also observed an ‘NP1 bias’ in L2 speakers’ pronoun interpretation in IC and IR contexts. In that study, however, SE verbs were used, which might have posed a general problem for the L1-Chinese participants because SE verbs are rare in Chinese and difficult to acquire for Chinese-speaking English learners (Juffs, Reference Juffs1996; Zhang, Reference Zhang2003). In the present study, we used a more diverse set of verbs that are shared in both Chinese and English. The fact that we replicated what appears like an enhanced L2 ‘NP1 bias’ in this study indicates that it is not due to the specific verbs chosen, but rather reflects a general stronger-than-native tendency to resolve the pronoun to the subject or first-mentioned referent by L2 speakers in the NP2-biasing context.
The remaining questions are why there is a stronger ‘NP1 bias’ in L2 speakers’ pronoun interpretation following NP2-biasing verbs, and whether this bias can be explained in the Bayesian framework of Kehler et al. (Reference Kehler, Kertz, Rohde and Elman2008) and Kehler and Rohde (Reference Kehler and Rhode2013). As the results of our free prompt conditions show, L2 speakers understand IC and IR biases and apply them to the formation of re-mention predictions. Therefore, according to the Bayesian framework of coreference resolution, the source of L2 speakers’ ‘NP1 bias’ in the NP2-biasing verb conditions must reflect the Bayesian updating of context-dependent prior predictions about the next-mentioned referent with the evidence provided by the pronoun to derive the posterior probabilities for the potential antecedents to be the actual antecedent of the pronoun. L2 speakers’ stronger posterior preference for NP1 in the NP2-biasing context could, therefore, reflect (1) their assigning weaker prior context-based predictions to each of the antecedents than L1 speakers, or (2) their assigning a higher probability than L1 speakers to a pronoun to be used as the referential form for subject or first-mentioned antecedents. A third alternative is that the basic Bayesian framework cannot account for our results, perhaps because L2 speakers assign a greater weight to the subjecthood/first-mention cue provided by the pronoun than L1 speakers when integrating it with prior context-based expectations. While such weighing can be added to the Bayesian framework, it will require modifying this account. As each of these (not mutually exclusive) alternatives has important implications for theories of language processing in L2, we consider each of them in turn.
According to the first explanation, L2 speakers may form weaker prior probabilities for which referent will be re-mentioned, thus allowing the evidence provided by the pronoun to have a stronger effect on their posterior probabilities of which is the most likely antecedent. This explanation is not likely given the native-like performance of L2 speakers in the absence of a pronoun.
According to the second explanation, L2 speakers assign a stronger-than-native likelihood to pronouns to be used as the referential form for subject or first-mentioned antecedents following NP2-biasing verbs. Under the assumption that participants’ comprehension and production preferences resemble each other, this means that L2 participants may show a stronger production bias to use a pronoun (as opposed to other forms of reference) for subject or first-mentioned referents in the NP2-biasing contexts but not in the NP1-biasing contexts. To determine if this is the case, we examined participants’ choice of referring expressions in the free prompt condition, in which they were free to choose any form (e.g., pronoun, repeated name) to refer to a referent. We coded their binary choice between pronouns and names for the subject of the second clause referring to either NP1 or NP2 in the context clause and calculated the percentage of pronominalization with regard to verb bias and referent for both L1 and L2 participants. The results are presented in Table 7. Footnote 3
Table 7. Differences in Proportions of Subject Pronouns in Continuations in the Free Prompt Condition and Differences in Proportions of NP1 References in Experiments 1 and 2.

As noted above, we assume that the rate at which our participants produce pronouns is related to how they estimate someone else would use a pronoun. Under the Bayesian approach, this assumption entails that participants’ own pronoun production rates would be related to their pronoun interpretation performance in the pronoun prompt condition. To assess how strong a signal the pronoun prompt provides to our participants for deciding between the two possible referents, we focus on the differences between pronominalization rates of NP1 and NP2 references in each condition. For example, if participants pronominalize the same proportion of their NP1 and NP2 continuations, encountering a pronoun in comprehension would not be informative for choosing the referent, but if instead participants pronominalize 89% of their NP1 responses but only 39% of their NP2 responses, encountering a pronoun in comprehension should provide a strong cue in favor of NP1 being the antecedent. Table 7 shows these pronominalization-rate differences.
To establish whether these differences in pronoun production biases can account for our results, we also calculated the difference between the proportions of NP1 references in the pronoun and free prompt conditions for each verb bias and group combination in the two experiments. These differences, which are also shown in Table 7, reflect the impact of encountering a pronoun on participants’ choice of referent. Our aim is to compare L1 and L2 groups’ pronoun production biases and see if the conditions where one group exhibits a stronger bias for pronominalizing NP1 referents than the other group are the same conditions in which that group shows a bigger difference in the proportion of NP1 references between the free and pronoun prompt conditions. In other words, we now compare the patterns of Columns 6 and 9 in Table 7 to determine whether the two types of differences follow similar patterns in the two groups.
In Experiment 1, for NP1-biasing verbs, L1 speakers’ pronoun production patterns show that they had a stronger pronoun-NP1 connection in this condition than L2 speakers (.50 vs. .31). This is mirrored by the coreference patterns in how the two groups interpreted pronouns following these verbs (.08 vs. -.03). For the NP2-biasing verbs in Experiment 1, it is the L2 speakers’ production that shows a greater pronoun-NP1 connection than the L1 speakers’ production (.54 vs. .23). Here too, this is mirrored by the coreference patterns: The L2 group was more strongly affected by the pronoun cue than the L1 group (.11 vs. .03) in their interpretation of pronouns in the NP2-biasing context. Indeed, the three-way interaction reflects this: In the free prompt, there was no group-by-verb-bias interaction (meaning L1 and L2 speakers responded to verb bias similarly to generate their priors), but in the pronoun prompt, there were differences by group and verb bias.
In Experiment 2, for NP1-biasing verbs, similar to Experiment 1, L1 speakers’ pronoun production patterns show that they had a stronger pronoun-NP1 connection in this condition than L2 speakers (.70 vs. .47). However, in this case, this is not mirrored by the coreference patterns, which are comparable in the two groups (.11 vs. .12). Note, yet, that this likely reflects the fact that, in this condition, NP1 coreference choices are almost at ceiling for both groups in the pronoun prompt condition (.94 vs. .97), which could obscure any potential difference between the two groups. For NP2-biasing verbs, again, similar to Experiment 1, L1 speakers showed a weaker pronoun-NP1 connection than L2 speakers (.27 vs. 59). As in Experiment 1, the coreference patterns mirror this pattern in that L1 speakers were less affected by the pronoun cue than L2 speakers (.20 vs. .58). In this experiment too, the three-way interaction reflects this, although, in the pronoun prompt, the group differences only emerge for NP2-biasing verbs and not for NP1-biasing verbs (due to ceiling effects).
Thus, we can conclude that both L1 and L2 participants’ interpretations of pronouns, as reflected in their continuations following the pronoun prompt, conform to the Bayesian principles in that they follow the same patterns shown by pronoun productions following the free prompt. In this sense, our results are in line with the predictions of the Bayesian framework of Kehler et al. (Reference Kehler, Kertz, Rohde and Elman2008) and Kehler and Rohde (Reference Kehler and Rhode2013) and are consistent with the second explanation mentioned earlier.
As a final test of the Bayesian framework, we calculated for each experiment the posterior probabilities of NP1 references in the pronoun prompt condition (reflecting the final outcome of interpreting the pronouns). The proportion of NP1 references in the free prompt condition was used as an estimate of the prior p(referent=NP1), the pronominalization rate of NP1 responses in the free prompt condition was used as an estimate of p(pronoun | NP1), and the pronominalization rate in the free prompt condition for both NP1 and NP2 responses was used as an estimate of p(pronoun). Formula (4) shows the calculation, and the rightmost column in Table 7 shows the results of this estimation for each verb bias and group combination. Formula (5) illustrates the calculation for the first row in Table 7 (Experiment 1, NP1 biasing verbs, L1 speakers).
(4) p(NP1│Pronoun)
$ = \frac{{p( \text{\it NP1} )\ \times \ p{\rm{(}}pronoun\ {\rm{|}}\ \text{\it NP1}){\rm{\ }}}}{{p( {pronoun} )}}$(5) p(NP1│pronoun) =
$\frac{{.78\ \times \ .89}}{{( {216\ + \ 26} )/( {242\ + \ 67} )}}$ = .89
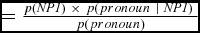
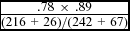
As can be seen in Table 7, the posterior probabilities estimated on the basis of the free prompt condition match quite well the actual proportion of NP1 references observed in the pronoun prompt condition. This reinforces the validity of the Bayesian framework to describe the performance of both our L1 and L2 participants, and furthermore allows us to attribute the differences in their pronoun interpretation performance to differences in their beliefs about pronoun use, as reflected in their own pronoun production data, rather than to the predictions they generate prior to encountering the pronoun, as reflected in their re-mention biases in the free prompt condition, or the integration of these predictions with the evidence provided by the pronouns.
Another issue concerning the stronger ‘NP1 bias’ in L2 speakers’ pronoun interpretation following NP2-biasing verbs is whether such bias reflects a subject preference or a first-mention preference for pronouns, given that, in our sentence fragments, the referents in the subject position were also the first-mentioned entities in the sentence. Although previous studies on L1 pronoun resolution have identified both grammatical role and order of mention as important factors in pronoun resolution (e.g., Järvikivi et al., Reference Järvikivi, Van Gompel, Hyönä and Bertram2005), the respective role of each factor is still a matter of debate. Some studies (e.g., Gordon & Hendrick, Reference Gordon and Hendrick1998; Gordon et al., Reference Gordon, Grosz and Gilliom1993; Gordon, Ledoux & Yang, Reference Gordon, Hendrick, Ledoux and Yang1999) claim that referents in the subject position are more accessible than referents in other syntactic positions and thus the preferred antecedents for subsequent pronouns. By contrast, others (e.g., Gernsbacher, Reference Gernsbacher1990; Gernsbacher & Hargreaves, Reference Gernsbacher and Hargreaves1988) hold that order of mention is more important than syntactic structure in coreference processing, arguing that first-mentioned referents are retrieved more easily than later-mentioned referents and are thus more likely to be interpreted as antecedents of subsequent pronouns. One problem in most of these studies is that, similar to our study, grammatical roles and order of mention are confounded, as the subject is usually the first-mentioned entity in English. A recent study in Finnish, a language that allows both SVO and OVS structures and therefore makes it possible to disentangle these two factors, showed an effect of first-mention but not of subjecthood on participants’ interpretation of pronouns in IC contexts (Järvikivi, Van Gompel & Hyönä, Reference Järvikivi, Van Gompel and Hyönä2017). However, another study in Chinese, a language that also allows a relatively free word order, found that order of mention had no effect on pronoun resolution in Chinese (Xu, Reference Xu2015). Given these contradictory findings in the L1 literature, and the fact that, in our study, grammatical subjects were also the first mentioned antecedents, we cannot say whether our L2 speakers’ ‘NP1 bias’ reflects a preference for the subject or the first-mention entity to be the referent of the pronoun. We thus leave the resolution of this issue for future research.
In summary, by investigating advanced Chinese-speaking English learners’ sensitivity to IC and IR biases in making re-mention decisions and resolving pronominal reference, this study furthers our understanding of how L2 speakers establish coreference in discourse. In both the IC and IR contexts, L2 participants showed native-like re-mention biases. This indicates that L2 speakers are able to generate native-like predictions about the next-mentioned referent based on discourse-level information. However, unlike native speakers, L2 participants exhibited an ‘NP1 bias’ in pronoun resolution by producing more NP1 references following the NP2-biasing context than native speakers. A close inspection of pronominalization rates in the free prompt conditions under the Bayesian framework suggests that this reflects differences between the groups in their beliefs about the likelihood of pronoun use in different conditions. Specifically, L2 participants show a weaker association between pronouns and NP1 referents than L1 speakers following NP1 biasing verbs, and a stronger association between pronouns and NP1 referents than L1 speakers following NP2 biasing verbs. Future research will have to explore the reasons for this difference and establish whether it may reflect influences of L1 or other factors. More generally, this work highlights the utility of using a Bayesian approach in L2 research as a means for capturing and explaining what might otherwise be complex findings. This is helpful for identifying specific factors that have a probabilistic effect on L2 processing.
Appendix. Mean Proportions of NP1 References for Verbs Used in Experiments 1&2