
Abstract
This paper first introduces á trous wavelet correlogram feature descriptor for image representation. By further extension in this descriptor, á trous gradient structure descriptor (AGSD) is proposed for content-based image retrieval. AGSD facilitates the feature calculation with the help of á trous wavelet’s orientation information in local manner. The local information of the image is extracted through microstructure descriptor (MSD); it finds the relations between neighborhood pixels. Finally, relation among á trous quantized image and MSD image is used for final feature extraction. The experiments are performed on Corel 1000, Corel 2450, and MIRFLICKR 25000 databases. Average precision, weighted precision, standard deviation of weighted precision, average recall, standard deviation of recall, and rank, etc., of proposed methods are compared with optimal quantized wavelet correlogram, Gabor wavelet correlogram, and combination of standard wavelet filter and rotated wavelet filter correlogram. It is concluded that the proposed methods have improved the retrieval performance significantly.
Similar content being viewed by others


1 Introduction
1.1 Motivation
Nowadays digital media is increasing in various applications, e.g. satellite, scientific, industrial, medical, environmental, educational, entertainment, and general photographs database. For machine-based browsing of images according to user’s interest from these large image databases it is required to have efficient algorithm. To solve this problem content-based image retrieval (CBIR) came into picture [1]. CBIR uses the visual contents of an image such as color, shape, texture, and spatial layout to represent and index the image. There exist multiple representations for every content in the image, which characterize visual features from different visual perspectives. So, contents of the images in the database are extracted in the form of features and described as feature vectors. The feature vectors of the database images form a feature database. Similarity comparison is the next step after feature database creation. It finds similarities/distances between the feature vectors of the query image and database images and then retrieves relevant images in conjunction with an indexing scheme [2].
In an image, color is one of the most widely used spatial visual content for image retrieval. Swain et al. [3] proposed the idea of color histogram in 1990. Pass et al. [4] introduced color coherence vector (CCV) by splitting each histogram bin into two parts, i.e., coherent and incoherent. Huang et al. [5] designed a color feature called color correlogram (CC). It characterizes not only the color distributions of pixels, but also the spatial correlation between pairs of colors. Texture is another salient feature for CBIR. It contains important information about the structural arrangement of surfaces and their relationship to the surrounding environment. Smith et al. [6] calculated mean and variance of the wavelet coefficients for CBIR. Moghaddam et al. [7] introduced an algorithm called wavelet correlogram (WC) by combining the concept of color (color correlogram) and texture (wavelet transform) properties. Manjunath et al. [8] used Gabor wavelet transform (GWT) for texture image retrieval. Murala et al. [9] proposed the combination of color histogram and GWT for CBIR. Agarwal et al. [10] proposed the histogram of oriented gradients (HOG) local feature descriptor for CBIR. Agarwal et al. [11] found the application of log Gabor wavelet transform for image retrieval. Agarwal et al. [12] proposed binary wavelet transform-based histogram (BWTH) to retrieve images from natural image databases. BWTH exhibits the advantages of binary wavelet transform and histogram.
1.2 Related work
Moghaddam et al. [13] proposed the Gabor wavelet correlogram (GWC) for CBIR. Saadatmand et al. [14] has improved the performance of WC by optimizing the wavelet coefficients. Gonde et al. [15] proposed the texton co-occurrence matrix for image retrieval. Subrahmanyam et al. [16] proposed combination of standard wavelet filters (SWFs) and rotated wavelet filters (RWFs) to collect the four directional \((0^{\circ }, +45^{\circ }, 90^{\circ }, -45^{\circ })\) information of the image and further used for correlogram feature calculation. Liu et al. [17] proposed microstructure descriptor (MSD) for CBIR. The microstructures are defined by computing edge orientation similarity and the underlying colors, which can effectively represent image local features. Liu et al. [18] gave feature representation method, called multi-texton histogram (MTH) for image retrieval. MTH integrates the advantages of co-occurrence matrix and histogram by representing the attribute of co-occurrence matrix using histogram. Á trous wavelet transform [19] is a type of multiresolution analysis with non-orthogonal and shift-invariant properties.
The paper is organized as follows: Sect. 1 consists of overview of CBIR and related works. In Sect. 2, á trous wavelet correlogram (AWC) is proposed. Section 3 introduces á trous gradient structure descriptor (AGSD). Section 4 describes experimental results and comparative analysis of proposed methods. Finally, in Sect. 5 conclusions are derived.
2 Á trous wavelet correlogram (AWC)
In this paper AWC is proposed for CBIR application. For the AWC calculations in the primitive step á trous wavelet transform is required and is explained in the following section.

Quantization threshold for á trous wavelet decomposition scales

Schematic diagram for proposed features
2.1 Á trous wavelet transform
The multiresolution analysis can be performed in two manners, pyramid structure, and á trous structure. In pyramidal structure images at each scale are down sampled by a factor of 2. It causes reduction in subband sizes at each scale. But in case of á trous structure down sampling is not performed. This causes number of approximation coefficients always equal to number of image pixels. So, analysis of subbands among different scales is possible. By avoiding the down sampling translation invariant property is also achieved. In contrast to pyramid structural wavelet transform no classification among horizontal, vertical, and diagonal subbands are present in á trous structure [19]. These properties of á trous wavelet transform are utilized in the proposed features extraction. Given an image \(I\) of size \(X\times Y\) and resolution \(2^j,\) on each scale of á trous wavelet calculation the approximation of image \(I \) with coarser spatial resolution is obtained. Likewise, by dyadic decomposition approach at the \(N\)th scale the resolution of the approximation image is \(2^{j-N}\). The size of each approximation image is always same as the image \(I\). The scaling function used for calculating approximation image is \(B_{3}\) cubic spline and is given by low-pass filter shown by Eq. 1:
The approximation image at first scale is given by Eq. 2:
To obtain coarser approximations of the original image, the above filter must be filled with zeros, to match the resolution of desired scale. The detailed information lost between the \(2^{j}\) and \(2^{j-1}\) images are collected in one wavelet coefficient image \(W_{2}^{j-1},\) by subtracting corresponding approximation coefficients at consecutive decomposition scales. This wavelet plane represents the horizontal, vertical, and diagonal spatial detail between \(2^{j}\) and \(2^{j-1}\) resolution as given by Eq. 3.
The original image \(I_{2}^{j}\) can be reconstructed exactly by adding approximation image \(I_{2}^{j-N}\) to the wavelet plane \(W_{2}^{j-N }\) at \(N\)th scale like in Eq. 4.
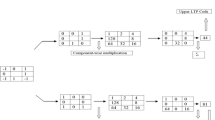
Á trous coefficients have wide dynamic range of real numbers, so directly it is not suitable for correlogram calculation. Á trous wavelet coefficients are calculated up to three scales and each scale is quantized into 16 levels using the quantization threshold given in Eq. 5 to avoid the problem of large dynamic range. \(L1, L2 {\ldots } L15\) defines the quantization thresholds. Figure 1 shows quantization thresholds and levels for á trous wavelet coefficients for different scales.

Schematic diagram for micro structure descriptor (MSD)
The authors have proposed á trous wavelet correlogram (AWC) by utilization of correlation among á trous wavelet coefficients. After quantization of á trous wavelet coefficients, for AWC (proposed method 1) extraction auto correlogram is calculated on quantized á trous wavelet coefficients in four directions. In Fig. 2 the area without dotted line covers the schematic diagram for proposed method 1 (PM1) and algorithm for PM1 is given as follows:
Algorithm 1:
Input: RGB images
Output: PM1 Feature vector for input image
-
1.
Take RGB image and convert it into gray image.
-
2.
Calculate á trous wavelet transform up-to three scales using Eq. 3.
-
3.
Quantize á trous wavelet coefficients at each scale as given by Eq. 5.
-
4.
On quantized á trous wavelet transformed image \(I\) at each scale s, auto correlogram is calculated in four directions by using Eq. 6.
$$\begin{aligned}&F_{{i,j}^{( k)}} {_{s}} =\mathop {Pr}\limits _{p_1 \in I_{c(i)} ,p_2 \in I} \left[{p_2 \in I^s_{c(j)} \left|\!{\left| {p_1 -p_2 } \right|=k} \right.} \right] \nonumber \\ & i=j\,\mathrm{ for\,autocorrelogram},\,k=1 \end{aligned}$$(6)\({I_{c( i)}}^s\) represents the set of pixels whose values are \(c(i), s\) represent the scale of á trous wavelet transformed image, and \(| {p_1 -p_2 }|\) is the distance between \(p_{1}\) and \(p_{2}\).
-
5.
For each scale \(F_{{i,j}^{(k)}} {_{s}}\) is calculated and combined for the construction of PM1 feature vector.
3 Á trous gradient structure descriptor (AGSD)
By further work in this direction á trous gradient structure descriptor (AGSD) is introduced as proposed method 2 (PM2). In the calculation of AGSD the first step is to obtain á trous wavelet transform image. From á trous wavelet transformed images orientation information are extracted. Through each á trous scaled image and its orientation information, MSD image is obtained. In the final step of calculation autocorrelogram is calculated from MSD images. The following sections illustrate all the processing steps.
3.1 Orientation angle calculation
In order to calculate PM2 from á trous transformed images, orientation information is extracted. If \(L(x, y)\) is the value of pixel at coordinate \((x, y)\), then orientation values can be calculated using Eq. 7.
It gives the orientation values ranging from \(-90^{\circ }\) to \(+90^{\circ }\). These orientation values are quantized into 17 levels.
3.2 Microstructure descriptor (MSD)
Textures are formed by simple primitive texture elements. A typical example is Julesz’s texton theory [20], but it emphasizes on regular texture images. To avoid this problem, the microstructures are used in this paper for image retrieval. Contents of natural images can be considered as constructed by many microstructures [17]. The microstructures compute the similarity of orientation in the neighborhood. The quantized orientation image is having values ranging from 1 to 17. For implementation of MSD the quantized orientation image is divided into \(3\times 3\) regions, called blocks. Flow diagram for MSD calculation is shown in Fig. 3 and algorithm for MSD calculation is as follows:

Figure 2 shows the PM2 (AGSD) framework for image feature extraction where the area without dotted line covers PM1. Implementation algorithm of the PM2 is given below.
Algorithm 3:
Input: RGB image
Output: PM2 Feature vector for input image
-
1.
Convert input RGB image into gray image \((I)\)
-
2.
Find the á trous wavelet transform of \(I\) up to three scales using Eq. 3
-
3.
From each scale of á trous wavelet transformed image extract the orientation information using Eq. 7
-
4.
Quantize the orientation image into 17 levels
-
5.
Calculate the MSD image from each scale of quantized á trous wavelet transformed image and orientation image (Algorithm 2)
-
6.
From each MSD image \(M\), calculate the auto correlogram for four directions by using Eq. 8.
$$\begin{aligned} {F_{i,j}}^{(k)} {_{s}}&= \mathop {Pr}\limits _{p_1 \in I_{c(i)} ,p_2 \in I} \left[{p_2 \in {M_{c(j)}} ^s\left|\!{\left| {p_1 -p_2 } \right|=k} \right.} \right]\nonumber \\ &i=j\,\mathrm{ for\,autocorrelogram},\,k=1 \end{aligned}$$(8)\({M_{c( i)}} ^s\) represents the set of pixels whose values are \(c(i), s\) represent the scale of á trous wavelet transformed image, and \(| {p_1 -p_2 }|\) is the distance between \(p_{1}\) and \(p_{2}\).
-
7.
For each scale \({F_{i,j}} ^{( k)} {_s} \) is calculated and combined for the construction of PM2 feature vector.
3.3 Similarity measurement
To find similarity among query and database images (query image is any image selected by user from the image database) first, query image and database images are processed to compute features. Distance measure \(d_{1}\) given by Eq. 9 is used to compute the difference between query image and database image features.
where \(Q_i \) is feature vector of query image,\(T_i \) is feature vector of database images, and \(\Gamma \) is the feature vector length. Database image having small \(D (Q, T)\) value is considered as more relevant to query image.
4 Experimental results
All experiments are performed on the Corel 1000 (DB1), Corel 2450 (DB2) natural image databases [21], and MIRFLICKR 25000 (DB3). Due to variety in contents these databases are being used by researchers in various scientific articles of CBIR. Various performance measures like precision, recall, and rank, etc., are calculated to compare the performance of proposed methods with some of already published papers [13, 14, 16] (see Appendix).
Precision is defined in terms of number of relevant images retrieved out of total number of retrieved images considered. Precision tends to decrease as the total number of retrieved images increases. In case of recall number of retrieved images is always considered as maximum number of relevant images in database. It is typical to have a high numeric value for both precision and recall. In ideal case both precision and recall should achieve 100%. It can be obtained when all the retrieved images belong to the query image group only, i.e. all retrieved images should be relevant. The retrieval result is not a single image but it is a list of images depending upon relevancy. \(T\) gives the total number of retrieved images considered (e.g. \(10,20,\ldots ,100\)). Value of \(T\) is selected by user. All images of the database are considered as query image to evaluate average performance on the database. These performance measures are provided in the following section.
Precision of any query image \(I_{q}\) can be obtained by Eq. 10
The weight precision of query image \(I_{q}\) is obtained by assigning weight to each relevant image retrieved and is given by Eq. 11.
Average precision for each group or database is given by Eq. 12
Similarly, average weight precision for each group or database is given by Eq. 13:
\(\Gamma \) is number of images; in case of group precision it is total number of images in particular group, whereas in case of average precision of database it is the total number of images in the database. Similarly, same parameters are calculated for recall using Eqs. 14 and 15.
Weighted recall and average weight recall can be calculated in a manner similar to Eqs. 11 and 13.
Total average retrieval rate is given by Eq. 16
where DB is total number of images in the database.
Rank of query image \(I_{q}\) is given by Eq. 17
\(\delta ( x)\) is the category of \(x\)th image. \(\mathrm{ Rank}( {I_i ,I_q })\) returns the rank of image \(I_{i }\)(for the query image \(I_{q})\) among all images of DB. Average rank \(C_\mathrm{ avg}\) can be calculated in a manner similar to Eq. 15.
Standard deviation of precision for each group or total database is another performance parameter obtained by Eq. 18.
Standard deviation of recall for each group or total database is obtained by Eq. 19
Similarly, standard deviation of weighted precision and standard deviation of average rank can be calculated. Average values of precision, weighted precision, and average value of recall should achieve higher values and average values of rank; standard deviation of all evaluation measures should achieve lower values to have good performance of retrieval system.
4.1 Database DB1 (Corel 1000)
Database DB1 [21] consists of total 1,000 natural images containing 10 groups and each group contains 100 images of the similar type. DB1 database consists images of two different sizes (either \(256\times 384\) or \(384\times 256)\). All images are in jpg format. Experiments are performed to calculate parameters given by Eqs. 10–19. The authors have first applied PM1 for CBIR application and analyzed its performance with respect to published literature. It is observed that PM1 results are better than [13, 14] and [16]. Tables 1, 2, 4 and 5 shows parameter \({P}_\mathrm{ wt}, {P}_\mathrm{ wt\_std}, {P}_\mathrm{ avg}, {P}_\mathrm{ std},\) \({R}_\mathrm{ avg}, {R}_\mathrm{ std}, {C}_\mathrm{ avg }\) and \({C}_\mathrm{ std}\) values for OQWC [14], Subrahmanyam et al. [16], PM1 and PM2, respectively. Table 3 gives \({P}_\mathrm{ avg}, {R}_\mathrm{ avg}\) and \({C}_\mathrm{ avg}\) results for GWC [13]. From the Table 4 it is clear that PM1 result is better than OQWC [14], Subrahmanyam et al. [16] and GWC [13]. But, again with Table 5, it is verified that the PM2 has improved the retrieval performance than PM1 too. As observed from Tables 1, 2, 3, 4, and 5 the performance of PM2 is better than that of other methods ([13, 14] and [16]). In Fig. 4 average retrieval rate (ARR%) comparison of PM2 is performed with OQWC [14], Subrahmanyam et al. [16] and GWC [13].

Average retrieval rate of PM2 according to number of image retrieved for DB1 database
It is clear from Fig. 4 that ARR (%) for PM2 is always higher than OQWC [14], Subrahmanyam et al. [16] and GWC [13] for different number of retrieved images. For 10 and 100 retrieved images, PM2 ARR (%) is 7.054, 46.12 while in the case of OQWC its 6.293, 37.278, for Subrahmanyam et al. [16] its 6.627, 41.281 and GWC [13] has 6.372, 39.873, respectively. Fig. 5 shows the retrieval results using the PM2. In the Fig. 5 first image is query image. It is clear from Fig. 5 that retrieved images are relevant to the query image.

Retrieval result of PM2 for query image a 333, b 427, c 613, d 789

Average precision of PM2 for DB2 database according to number of image retrieved
4.2 Database DB2 (Corel 2450)
Database DB2 [21] contains a total of 2,450 images. DB2 database consists of images with two different sizes (either \(256\times 384\) or \(384\times 256)\). All images are in jpg format. These images are pre-categorized into 19 groups. Each category contains 50–600 images. Average precision is calculated on database DB2 using the Eq. 12. In Fig. 6 nature of average precision according to number of retrieved images is shown. It is observed that compared with OQWC [14] and Subrahmanyam et al. [16] the performance of PM2 is better in all instances.
4.3 Database DB3 (MIRFLICKR 25000)
Database DB3 [22] consists of 25,000 images with tags. All images are in jpg format. DB3 is publically available on internet dedicated to research community [22]. This collection is prepared from the Flickr website. Various images in this collection comprise more than one tag. The most useful tags are assigned to image that can clearly describe the visual contents of image; likewise, few images are being repeated in groups. Total images are categorized into 19 groups; each group contains approximately 260–2,100 numbers of images. DB3 database comprises images with various sizes, so to maintain homogeneity in feature calculation all the images are resized to \(384\times 256\). Average precision is calculated on database DB3 using the Eq. 12. It is observed from Fig. 7 that compared with OQWC [14] and Subrahmanyam et al. [16]the performance of PM2 is better for various numbers of retrieved images.

Average precision of PM2 for DB3 database according to number of image retrieved
5 Conclusion
This paper proposes two methods, namely AWC (PM1) and AGSD (PM2) for CBIR application, where PM2 is the extended version of PM1. PM1 finds the correlation among á trous wavelet coefficients, while in the primitive step of PM2 á trous wavelet coefficients are extracted and further spatial relationship among orientation of á trous wavelet coefficients are utilized. Experiments are performed on databases DB1, DB2 and DB3 especially. The results of proposed method are compared with OQWC [14], combination of SWF and RWF correlogram [16] and GWC [13] with respect to various parameters. It is concluded that the results with proposed method are significantly better, irrespective of database.
Further, the performance of proposed methods can be improved by optimization of the quantization of á trous wavelet coefficients using any optimization algorithms like genetic algorithm, particle swarm optimization, etc.
References
Rui Y, Huang TS, Chang SF (1999) Image retrieval: current techniques, promising directions and open issues. Elsevier J Vis Commun Image Represent 10(1):39–62
Datta R, Joshi D, Li J, Wang JZ (2008) Image retrieval: ideas, influences, and trends of the new age. ACM Comput Surv 40(2):1–60
Swain MJ, Ballard DH (1990) Indexing via color histograms. In: Proceedings of the IEEE 3rd international conference on computer vision, Osaka, pp 390–393
Pass G, Zabih R, Miller J (1996) Comparing images using color coherence vectors. In: Proceedings of the 4th ACM multimedia conference, Boston, pp 65–73
Huang J, Kumar SR, Mitra M, Zhu W-J, Zabih R (1997) Image indexing using color correlograms. In: Proceedings of the IEEE computer vision and pattern recognition, San Juan, pp 762–768
Smith JR, Chang S-F (1996) Automated binary texture feature sets for image retrieval. In: Proceedings of the IEEE international conference on acoustics, speech and signal processing, vol 4, Atlanta, pp 2239–2242
Moghaddam HA, Khajoie TT, Rouhi AH (2003) A new algorithm for image indexing and retrieval using wavelet correlogram. In: Proceedings of the IEEE international conference image processing, vol 3, Barcelona, pp 497–500
Manjunath BS, Ma WY (1996) Texture features for browsing and retrieval of image data. IEEE Trans Pattern Anal Mach Intell 18(8):837–842
Murala S, Gonde AB, Maheshwari RP (2009) Color and texture features for image indexing and retrieval. In: Proceedings of the IEEE international advance computing conference, Patiala, pp 1411–1416
Agarwal M, Maheshwari RP (2010) HOG feature and vocabulary tree for content-based image retrieval. Int J Signal Imaging Syst Eng 3(4):246–254
Agarwal M, Maheshwari RP (2011) Content based image retrieval based on log Gabor wavelet transform. J Adv Mater Res 403–408:871–878
Agarwal M, Maheshwari RP (2011) Binary wavelet transform based histogram feature for content based image retrieval. Int J Electron Signals Syst 1(1):68–75
Moghaddam HA, Tarzjan MS (2006) Gabor wavelet correlogram algorithm for image indexing and retrieval. In: Proceedings of the 18th international conference on pattern recognition, Hong Kong, pp 925–928
Saadatmand M, Moghaddam HA (2007) A novel evolutionary approach for optimizing content based image retrieval. IEEE Trans Syst Man Cybern 37(1):139–153
Gonde AB, Maheshwari RP, Balasubramanian R (2010) Texton co-occurrence matrix: a new feature for image retrieval. In: Proceedings of the IEEE India conference, Kolkata, pp 1–5
Subrahmanyam M, Maheshwari RP (2011) A correlogram algorithm for image indexing and retrieval using wavelet and rotated wavelet filters. Int J Signal Imaging Syst Eng 4:27–34
Liu G-H, Li Z-Y, Zhang L (2011) Image retrieval based on micro-structure descriptor. Elsevier J Pattern Recognit 44(9):2123–2133
Liu G, Zhang L, Hou Y, Li Z, Yang J (2010) Image retrieval based on multi-texton histogram. Elsevier J Pattern Recognit 43:2380–2389
Audicana MG, Otazu X, Fors O, Seco A (2005) Comparison between Mallat’s and the ‘á trous’ discrete wavelet transform based algorithms for the fusion of multispectral and panchromatic images. Taylor Francis Int J Remote Sens 26:1–19
Julesz B (1986) Texton gradients: the texton theory revisited. Biol Cybern 54:245–251
Corel 1000 and Corel 10000 image database (2011). http://wang.ist.psu.edu/docs/related/
Huiskes MJ, Lew MS (2008) The MIR Flickr retrieval evaluation. In: Proceedings of the ACM international conference on multimedia information retrieval, Vancouver, pp 39–43
Acknowledgments
This work was funded by the Ministry of Human Resource and Development India under grant MHR-02-23-200 (429). The authors would like to thank anonymous reviewers for giving technical comments to improve the quality of work. The authors also thank A. B. Gonde, S. Murala, and K. Saini (research scholars), Department of Electrical Engineering, Indian Institute of Technology Roorkee, for moral support and suggestions throughout this work.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1. Optimized quantized threshold wavelet correlogram (OQWC)
Moghaddam et al. [7] introduced WC by combining the concept of color correlogram and wavelet transform properties. WC first computes the wavelet coefficients then autocorrelation of the quantized coefficients is computed along the direction of wavelet transform. Saadatmand et al. [14] has proposed OQWC by improving the performance of WC with optimizing wavelet coefficients. They used evolutionary group algorithm (EGA) to optimize the quantization thresholds of the wavelet-correlogram algorithm for CBIR. Further details can be found in Ref. [14].
2. Gabor wavelet correlogram (GWC)
Moghaddam et al. [13] has replaced the wavelet transform with Gabor transform and introduced the concept of GWC for CBIR. GWC handles the problem of rotation variant using Gabor wavelets and presents some ideas to handle redundancy problem due to non-orthogonal decomposition of Gabor wavelets. GWC first computes the wavelet coefficients using Gabor wavelets. The coefficients are discretized using the quantization thresholds obtained experimentally for good performance. Finally, the autocorrelogram of the quantized coefficients is computed along the direction normal to Gabor wavelet orientation
3. SWF and RWF correlogram
Subrahmanyam et al. [16] proposed combination of SWFs and RWFs to collect the four directional \((0^{\circ },+45^{\circ }, 90^{\circ }, -45^{\circ })\) information of the image and further used for correlogram feature calculation. The \(0^{\circ }\) and \(90^{\circ }\) information (sub-band) of image collected from SWF and \(+45^{\circ }\) and \(-45^{\circ }\) are collected from RWF and applied for correlogram feature calculation. Further details can be found in Ref. [16].
Rights and permissions
About this article
Cite this article
Agarwal, M., Maheshwari, R.P. Á trous gradient structure descriptor for content based image retrieval. Int J Multimed Info Retr 1, 129–138 (2012). https://doi.org/10.1007/s13735-012-0005-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13735-012-0005-5