
Abstract
Decision-making for pest management in agriculture can be assisted by sampling plans that guide users in determining the need for an intervention. The tomato leafminer, Tuta absoluta, is easily recognizable by most tomato growers and several sampling plans have been developed. Yet, the adoption of decision-making systems for this pest is still incipient. Market uncertainty and farmers’ risk aversion are two potential obstacles that could be tackled by sampling plans that allow for the scheduling of interventions according to rough estimates of economic thresholds and to farmers’ intuition and experience. In this study, we used computer simulations and greenhouse trials to compare the efficiencies of four sampling plans both to estimate the mean number of larvae per plant and to classify pest populations according to a predefined economic threshold. We also analyzed the time spent and the number of plants examined by volunteers when applying each plan on a leafminer-infested tomato crop slightly over a predefined economic threshold. We show here that sampling plans giving the most precise classifications are not necessarily those yielding accurate pest density estimations. While computer simulations showed that the best plans for classification are those for estimation, results with humans evidenced the opposite. However, the average number of samples required by sampling plans does not reflect the time spent by humans sampling real plants. Our results show, for the first time, that sampling plans based on counts rather than on binary data can provide reliable information on the current level of a T. absoluta infestation relative to a decision threshold. We suggest that sampling plans promoting the creation of farmers’ memory, such as those based on counts, may be more suitable both to reduce risk aversion and to increase adaptability to market uncertainty.
Similar content being viewed by others

1 Introduction
The ongoing digital agricultural revolution aims to tackle unsustainable agriculture through the use of biopesticides and biofertilizers, ecosystem services, and the use of information (Fraser and Campbell 2019). While the use of bioproducts helps to replace chemical inputs, and ecosystem services help reduce the need for corrective treatments, information plays a key role in decision-making (Barzman et al. 2015). Market prices, changing customer demands, and policies are ever-looming risks which farmers face. These risks reduce the willingness of farmers to assume other risks, such as insect pests, which they can control using unsustainable (though immediately effective) practices. As such, effective procedures that help farmers make informed decisions on pest management are fundamentally linked to the adoption of integrated pest management (IPM) programs, and favor intrinsic system controls over corrective interventions, which in turn reduces costs and detriments to the environment and public health (Peterson et al. 2018).
Conventionally, sequential sampling plans have been the most widely used in pest management and are often developed for either estimation or classification. Sequential sampling for estimation has been used mainly for research purposes because it aims to deliver population density estimations at predefined (fixed) precision levels, at the cost of being labor intensive. On the other hand, sequential sampling for classification has been used more widely in decision-making since it requires fewer samples and delivers a categorical recommendation (intervene or not) based in predefined thresholds. Both estimation and classification sampling may be based on binomial assessments or on discrete counts. The former is clearly faster and easier to carry out but lacks the precision of the latter. Sequential binomial sampling plans, based on the sequential probability ratio tests (SPRT) framework (Wald 1945), became popular for decision-making in pest management because they require relatively low number of samples, and data collection is usually feasible (at least for low tally thresholds) (Binns et al. 2000). Variable-intensity sampling (VIS) plans were originally proposed in the early 1980s as an alternative to SPRT plans to both facilitate decisions when pest populations are close to the threshold, and to allow for (and encourage) a thorough inspection of the entire field (Hoy et al. 1983). However, despite the sound justification and background that support VIS plans, they have been barely applied, presumably because of the complicated calculations required for their implementation.
Pest population classification by sampling based on fixed economic thresholds is often unrealistic, given the significant uncertainty about produce prices and control costs (Rincon et al. 2019; Plant 1986). There is also the potential of continuously making biased decisions if the pest or damage chosen as a sampling unit is too obvious, because users might systematically select positives (or negatives). Moreover, depending on the sampling unit and method, requiring a low number of samples might not necessarily lead to a substantially lower sampling effort and farmers may be open to dedicating more time to examining a reasonable number of samples and gathering more information as long as they can ensure sound management decisions.
The tomato leafminer (TLM), Tuta absoluta (Meyrick) (Lepidoptera: Gelechiidae), is one of the most limiting pests of greenhouse and open field tomatoes in most producing regions of the world. Larvae usually mine leaves but may occasionally cause direct damage to fruits (Fig. 1). The reason why some larvae prefer to feed on fruits over leaves is unknown, but there are some reports claiming that such preference is density-dependent (Cassino et al. 1995; Cocco et al. 2015). Since larvae damaging fruit cause most of the economic losses, economic thresholds for this pest are based on estimations of larval or mine density as a proxy for proportion of infested fruits (e.g., Cocco et al. 2015). Although the economic effect of moderate densities of the TLM is probably negligible [up to 73% of fully formed leaves with > 0 larvae are required to cause economic damage (Cocco et al. 2015)], farmers tend to have a zero tolerance for this pest. In South America, reports indicate that farmers use up to 36 applications of broad-spectrum chemical insecticides in a single crop cycle to prevent damage from the TLM, most of which are probably unnecessary (Donado et al. 2017). This overuse of insecticides has resulted in the development of resistance to most registered products (Haddi et al. 2012; Silva et al. 2011).

Participatory sampling of Tuta absoluta larvae in greenhouses of Boyacá, Colombia. Volunteers were instructed to carry out the sampling plans (a) by inspecting leaves (b) and fruits (c) for damage or insects. Arrows show T. absoluta larvae on leaves and fruits. Photographs taken by the authors
Even though the TLM is easily recognizable by most tomato growers and that some sampling plans have been developed, adoption of decision-making systems for this pest is still incipient, particularly in developing countries (Parsa et al. 2014). Two potential reasons are (1) the high start-up investment (greenhouse facilities and elevated production costs) that makes tomato farmers particularly risk-averse and (2) the difficulty to estimate reliable economic thresholds, given the uncertainty in tomato market price (which is often outside of their control). Both market uncertainty and risk aversion could be dealt with by providing farmers with means to carry out, learn and adapt from small, informed (calculated) experiments (Feola and Binder 2010). In fact, human decision-making is known to rely mostly on intuition and on feelings of “what seems to be correct,” rather than on complicated calculations or normative rules, especially under risky conditions (Tversky and Kahneman 1981; Barberis 2013). For example, sampling plans that provide reliable indications of pest population sizes and how close they are from reaching the economic injury level (EIL) could allow farmers to make their own predictions about the need for applying control measures and make calculated bets accordingly. In the long-run, it is expected that both reliable information provided by sampling plans and farmers’ intuition and experience on reducing economic risks associated with produce prices, will increase adaptation to uncertainty.
In this study, we aim to assess the ability of different sampling plans to provide information that promotes memory and willingness of farmers to assume calculated risks under economic uncertainty. We evaluated two SPRT and two VIS plans for classification using computer simulations and a greenhouse trial. We decided to exclude sampling plans for estimation from our study, since our focus is sampling based on predefined thresholds for decision-making. We also excluded plans based on abundance classes (e.g., Bout et al. 2010), because TLM larvae rarely occur in large numbers in leaves or plants. However, our conclusions may apply for most sampling plans for classification, regardless the technique used for data collection. We compared the efficiency and the ability of each plan to both estimate the actual mean number of larvae per plant and to classify pest populations according to a predefined economic threshold. We also analyzed the time spent and number of plants examined by human subjects while applying each plan on a tomato crop with a TLM infestation slightly over a predefined economic threshold.
2 Materials and methods
2.1 Greenhouse data collection
Eight tomato greenhouses of approx. 3000 m2 from two neighboring municipalities, Santa Sofía and Sáchica (Boyacá, Colombia), were sampled five times each between November 2017 and July 2018 to obtain 40 datasets. Each dataset consists of approx. 100 samples, which were collected from sampling units that were distributed along a Cartesian grid designed to cover the complete area of each greenhouse. In order to ensure moderate natural TLM infestations in the selected greenhouses, formal agreements with farmers were made, in which an economic compensation was offered in exchange for delaying or suppressing insecticide applications that may hamper pest occurrence or natural spatial distribution within the greenhouse. To homogenize sampling size across sampling events, sampling units were defined based on crop age as follows: 1–50 days after planting (dap), 3 plants; 51–90 dap, 2 plants; and 90–130 dap, 1 plant. Variances were modeled as a function of means using least squares and the linearized version of Taylor’s power law (TPL), which is defined as:
where σ2 is the sample variance associated with the mean, μ, number of larvae per sample unit, and a and b are parameters.
2.2 Construction of sampling plans
We selected two modalities of sampling plans, the SPRT (Wald 1945) and VIS (Hoy et al. 1983; Hoy 1991), and two different strategies for data collection, by counts, and by presence/absence in sampling units (binomial). Briefly, SPRT plans rely on sequential likelihood ratio tests made each time a sample is collected until there is enough evidence to decide on a classification with a predefined probability of misclassification. In practice, users operate SPRT plans with the aid of plots with the number of examined samples in the x-axis and the cumulative counts in the y-axis, and two parallel stop lines. The user points the cumulative counts as the number of samples examined advances, and the sampling continues until the cumulative counting falls outside the area between the parallel stop lines. If the sampling stops with the counting in the upper region, action should be performed because there is enough evidence to classify the pest population above the predefined threshold. Otherwise, no action is required. VIS plans, in turn, require an extensive examination of the entire field, since a predefined number of transects are distributed systematically throughout the field. The idea is to examine all the transects with a varying level of intensity (number of subsamples), which is calculated by a normal approximation of the fixed-sample size for a predefined confidence level (usually 95%) and a precision (length of the confidence interval) given by sequential estimations of pest population density. When the estimated density is within the predefined decision threshold interval, the maximum sample size (which is set arbitrarily) is recommended. When the estimated density is outside the threshold interval, the sample size is calculated to achieve the precision required for confidence intervals that are set depending on the location of the density estimate relative to the threshold. If the estimated density is below the interval, the upper bound of the confidence interval is placed at the midpoint of the threshold interval. When the estimate is above, the threshold midpoint is the lower bound of the confidence interval. In practice, VIS plans require either a complicated table or a programmed calculator to estimate the sample size for the subsequent transect as the sampling is performed. The first transect is usually designated in one of the crop corners (where all the subsamples are examined), and the remaining transects are sampled in a predefined order (e.g., by rows) so as to reduce transit among them. The decision is made based on a simple comparison between the estimated mean, after sampling all the transects, and the predefined threshold. All the sampling plans were developed based on the TLP parameters (a and b, Eq. 1) estimated from the 40 datasets that were collected in the study area (see “Section 2.1”). Equations and procedures to derive stop lines (SPRT plans) and adjusted sampling intensities (VIS plans) were extracted from Binns et al. (2000), including the empirical model used to predict the proportion of infested plants (with > 0 larvae), PT, as a function of the mean number of larvae per plant, μ:
where c and d are parameters, which were estimated from data by least squares using the linear version of Eq. 2a:
2.3 Evaluation of sampling plans through simulation
Sampling plans were evaluated using a conventional approach by simulating sampling events with computer-generated data. The negative binomial distribution was used to model the distribution of larval counts. The aggregation parameter, k, used for simulations was calculated as a function of the mean number of larvae per plant, μ:
where z is a random normal variate with zero mean and standard deviation, σε, which equals the mean squared error of the regression model used to fit Eq. 1. Each time the counts of a TLM population are generated with a predefined mean (μ), k is assigned with a different value according to the uncertainty about a and b (Binns et al. 2000).
Count datasets were generated using an algorithm that produces 6000 counts (to obtain datasets similar in size to the average number of plants/greenhouse in the study area) based on a given μ. The algorithm consisted of a random number generator with a negative binomial distribution and Eq. 3 to assign values for the aggregation parameter, k, each simulation run, based on μ (R script provided in Code 1, https://doi.org/10.5281/zenodo.4432813). Validation was performed by comparing generated datasets with observed counts, which came from the 40 datasets that were collected from the eight greenhouses in the study area (see “Section 2.1”). One thousand simulated datasets (6000 counts/dataset) were generated for each of the 40 observed means, and the mean probability distribution of each was compared with the corresponding observed frequency distribution by a chi-squared goodness of fit test (40 tests total, with as many classes as different simulated and observed counts). The precision level was calculated as the proportion of observed probability distributions not significantly different from the simulated distributions over the 40 datasets.
Using simulations (in silico), both the operating characteristic (OC) and average sample number (ASN) curves were constructed for each sampling plan. In addition, accuracy curves were derived by estimating the normalized root mean squared error (NRMSE) associated to estimates of a range of larval densities. This association allows the evaluation of sampling plans for their ability to estimate pest densities as they approach a predefined threshold. This measure is useful in deciding which sampling plan is best in situations when there is uncertainty about the predefined threshold, since accurate estimations of pest population sizes allow users to make educated guesses based on experience. The NRMSE is given by:
where μo represents the means (larvae/plant) obtained through the sampling plans, μe the real means, and N the number of simulations. Lower NRMSE values denote higher accuracy. All three, OC, ASN, and NRMSE curves, were constructed with 1000 simulations for each pest density in a range of 0–20 larvae per plant. For SPRT plans, each simulation consisted of a sequential selection of single counts, whose cumulative sum is registered and compared each time with the corresponding upper and lower thresholds defined by the stop lines. To simulate VIS plans, 24 and 16 transects of 15 and 5 plants each were distributed throughout the sample universes (datasets), for the binomial and count plans, respectively. The mean number of larvae (for counts) or the number of subsamples with > 0 larvae (for binomial) was registered and used to calculate the number of subsamples to examine in the next transect (R script provided in Code 2, https://doi.org/10.5281/zenodo.4432813).
2.4 Evaluation of sampling plans through human sampling
In addition to the simulations, a greenhouse trial (in situ) was carried out by eight volunteers in order to evaluate the sampling plans in a real tomato crop. A greenhouse tomato crop (Solanum lycopersicum L. var. Libertador) of approx. 320 m2 and 760 plants was planted using conventional procedures similar to those used by growers in the study area. Plants were distributed in eight rows of 95 plants each, with 1.2 m between rows and 30 cm between plants within the same row. We infested the greenhouse twice with 450 TLM adults, one at 73 dap and the other at 80 dap (900 adults total). In order to establish a gold standard to compare with the results delivered by the evaluated sampling plans, an intensive sampling event was carried out in which 101 plants (~12 per row) homogeneously distributed in space were examined and the number of larvae in each was registered. Once the gold standard was estimated, the predefined threshold was set slightly below it, in such a way that the threshold upper limit equals the gold standard 95% confidence interval lower limit. This threshold was used for both the in silico and in situ experiments and does not necessarily reflect a real economic threshold, since it was set solely for evaluation purposes.
Each one of the eight volunteers carried out each sampling plan. For SPRT plans, volunteers were provided with pamphlets containing plots with the number of examined samples in the x-axis and the cumulative counts in the y-axis, and the two parallel stop lines for either count or binomial plans. They were asked to start and proceed with the sampling at random but using their own ideas to do so (e.g., random number generators in cell phones, ballots, intuition, etc.). For VIS plans, participants were provided with a web-based R script through RStudio Cloud® (https://rstudio.cloud/) that they were able to run from their cell phones. The R script was designed to store counts, calculate the number of subsamples to examine in subsequent transects, and deliver sampling results (R script provided in Code 3, https://doi.org/10.5281/zenodo.4432813). Subjects were asked to start the sampling whichever corner they decided, but to proceed in order, following predefined transects aligned with crop rows: 24 and 16 transects of 15 and 5 plants each, for the binomial and count plans, respectively. For each sampling plan, participants reported the final decision (intervene or not), the number of samples and time required to make that decision, and the estimated mean number of larvae at the end the procedure. For binomial plans, Eq. 2a was used to derive the estimated mean number of larvae, based on the estimated proportion of infested plants. Z-tests were used to compare the mean number of larvae reported by the volunteers for each plan with the gold standard. The mean time spent and mean number of samples required were compared among sampling plans by ANOVA followed by Tukey’s HSD test, assuming gamma and normal distribution for the error terms, respectively. All analyses were carried out using software R (version 3.5.1) (R Core Team 2018).
3 Results and discussion
3.1 Greenhouse data
The means observed in the 40 datasets collected in grower greenhouses ranged between 0.009 and 33.287 larvae per sampling unit, while the observed variance varied between 0.009 and 192.337. The TPL described the variance-mean relationship of larval counts well (P < 0.001, n = 40, F = 1249, R2 = 0.970) (Fig. 2a). Parameter estimate for a was 1.830 ± 0.051 (estimate ± standard error) and 1.218 ± 0.034 for b. We also found good fit between Eq. 2a and the proportion of infested plants explained as a function of the mean number of larvae per plant (P < 0.001, n = 40, F = 1102.9, R2 = 0.967) (Fig. 2b). The parameter estimate for c was −0.384 ± 0.036 and 0.844 ± 0.025 for d. Altogether, the algorithm developed to simulate TLM larvae counts showed that 92% of the observed probability distributions were not significantly different from simulated distributions with corresponding means (chi-squared test at P = 0.1 level). According to the criteria established by Rykiel (1996) for dynamic models (>75% of the times within the expected confidence interval), such precision level could be considered adequate for the purpose of this study.

Aggregation pattern of Tuta absoluta larvae found in greenhouse tomato crops (N = 40). a Variance-mean relationship. b Proportion of infested plants, PT, as a function of mean number of larvae per plant, μ
3.2 Establishing the gold standard and reference threshold
Through the intensive sampling of our experimental greenhouse crop, the estimated 95% confidence interval of mean number of larvae per plant was [10.647, 14.878] (mean = 12.762), which was used as gold standard for comparing sampling plans. Thus, we set the decision threshold interval (i.e., [μ0, μ1]) at [8, 10] larvae per plant (mean = 9), which is equivalent to ~ 98–99% of plants infested (with > 0 larvae), according to Eq. 2a. We think that such a threshold, although apparently high (relative to that established by farmers), is realistic and would still not cause economic losses, based on ongoing field studies that show that both fruit size and number are not affected by TLM feeding on leaves, even with infestations of more than 30 larvae per plant (Rincon et al., unpublished results). Moreover, Cocco et al. (2015) estimated that between 47 and 73% of sampled leaves infested are required to cause 3% of damaged fruits, which might be close to our designated threshold (98–99% of infested sampling units), considering the plant-scale false negatives in the method of Cocco et al. (2015) caused by the within-plant aggregated nature of TLM larvae (Torres et al. 2001). In reality, the decision threshold for the TLM could be even higher, if the effect of the presence of TLM natural enemies is taken into account (Zhang and Swinton 2009).
3.3 Evaluation of sampling plans through simulation
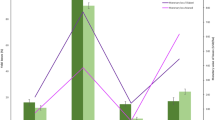
According to the simulations, in general, SPRT plans required fewer samples than VIS plans. This is not surprising since VIS plans, in contrast to SPRT plans, require the user to examine a predefined number of transects irrespective of how far or how close the estimated pest density is from the threshold. By far, the VIS binomial plan required the greater number of samples, especially when pest population is above the designated threshold (Fig. 3a). This effect might be a consequence of repeated sequential estimations of proportions that are very close to the threshold, which cause the maximum sampling intensity to be required in most transects. Again, binomial plans (SPRT and VIS) showed a distinct pattern, since the required sample size does not decrease even when pest population is far above the threshold. Presumably, the proportion of infested plants is so similar at high population densities (approaching 1) that binomial classifications tend to demand a maximum number of samples to distinguish between populations that are above or below the threshold.

Evaluation of sampling plans (sequential probability ratio test [SPRT] by counts [black] and binomial [red], and variable-intensity sampling [VIS] by counts [blue] and binomial [green]), using computer simulations. Plot a shows the average number of samples required as a function of mean larvae per plant, for each sampling plan. Plot b shows the comparison between operating characteristic curves. Plot c shows the comparison in accuracy to estimate the population density of Tuta absoluta, using the normalized root mean squared error (NRMSE) as a function of mean larvae per plant. The vertical line in the three plots represents the predefined decision threshold, 9 larvae/plant
Simulations revealed that sampling plans differed considerably in their ability to deliver accurate recommendations (Fig. 3b). According to the OC curves, the sampling plans based on counts produce fewer incorrect decisions than those based on presence/absence (binomial). In general, all four plans are conservative, since most mistakes are made in the area of applying an intervention when it was not really needed (Fig. 3b). However, binomial sampling plans tend to deliver incorrect recommendations almost exclusively when pest population is under the decision threshold, while plans based on counts showed a more balanced trend. Such unbalanced misclassification trend showed by binomial plans could be a consequence of the relationship between mean number of larvae and proportion of plants infested, which is relatively insensitive when the means fall above ~ 6 (Fig. 2b). So, when populations are high, the proportion of plants infested does not seem to change enough to allow binomial samplings to distinguish populations that are below the threshold.
Among the four sampling plans, according to the simulations, the VIS plans produced lower NRMSE than SPRT plans, and VIS by counts evidenced the lowest NRMSE (Fig. 3c). In general, those plans based on counts were more accurate to estimate TLM population density than those based on binary data. This is not surprising since accuracy reflected the sample size required by each sampling plan. It is interesting that, according to our simulations, plans that excel in pest classification accuracy are not necessarily those that perform poorly in estimation and vice versa.
3.4 Evaluation of sampling plans through human sampling
The greenhouse evaluations carried out by volunteers showed similar results. Sampling plans based on counts were more accurate to estimate TLM population density than those based on binary data. Neither the estimated means from VIS by counts nor those from SPRT by counts were significantly different from the gold standard (VIS counts: Z = −0.734, P = 0.462; SPRT counts: Z = 0.622, P = 0.533) (Fig. 4a). Contrarily, the estimated means of both VIS binomial and SPRT binomial were significantly different from the gold standard (VIS binomial: Z = −11.068, P < 0.001; SPRT binomial: Z = −10.983, P < 0.001) (Fig. 4a). Also, similar to what we observed in simulations, the SPRT binomial was the most inaccurate plan for estimation purposes (highest NRMSE). However, among plans based on counts, the VIS had slightly higher NRMSE than the SPRT (Fig. 4a–b), which contrasts with what was found with simulations (Fig. 3c). This apparent contradiction could be due to the high variability in estimation of means for VIS plans, relative to the variability observed for the SPRT plan (Fig. 4a). This difference in variability was not observed in simulations, probably because count data generation in simulations was not spatially explicit and VIS plans, in contrast to SPRT plans, are highly sensitive to the place chosen to collect the first sample. Thus, the number of samples required by and accuracy of VIS plans varied in the greenhouse trial as a result of differences in partial estimations after the first few samples were collected (participants were allowed to select the location of the first sample freely). Such variation is reduced in simulations since each time a sampling was simulated, a new dataset was generated, without considering spatial variations explicitly.

Evaluation of sampling plans in a greenhouse trial with human volunteers. Each point type in a, c, and d represents a different individual. Plot a shows the comparison in precision and accuracy of sampling plans estimating Tuta absoluta population density (the horizontal, dashed lines represent the gold standard 95% confidence interval). Plot b shows the comparison among sampling plans in pest density estimation accuracy using the normalized root mean squared error (NRMSE). Plots c and d show the comparison in number of samples and time (in minutes) required, respectively. In a, c, and d, bars represent 95% confidence intervals, and different letters denote significant differences between sampling plans (P < 0.05)
Similarly, although the sampling plans based on counts (both SPRT and VIS) were more accurate at estimating pest population sizes (see above), they tended to deliver imprecise and inaccurate management recommendations. While the correct decision in the greenhouse trial should have been to intervene, volunteers decided correctly only 50% and 37.5% of the times when they performed SPRT and VIS sampling based on counts, respectively. This is low, considering that simulations with pest density of 12 larvae/plant (density estimated in the intensive sampling = 12.762 larvae/plant) delivered correct decisions 99.9% and 99.6% of the times for SPRT and VIS based on counts, respectively. Interestingly, all volunteers reported a “no intervene” decision when they performed the VIS binomial plan, even though the resulting estimation of the population density was even better than that delivered by the SPRT binomial, which correctly suggested an intervention 100% of the times. Correct decisions (i.e., “intervene”) for binomial plans in simulations with pest density of 12 larvae/plant were above 90% for both SPRT and VIS.
The mean number of samples required by humans to make a decision differed among sampling plans (F = 17.45, P < 0.001) and followed a similar trend in comparison with what was observed in simulations, where VIS binomial demanded the highest number of samples and SPRT by counts the least (Fig. 4c). In fact, except for the VIS binomial, the required mean number of samples for each sampling plan was similar in the greenhouse trial and in the simulations performed for pest densities of 12 larvae/plant (~pest density found in the intensive sampling in the greenhouse), which were 6.87 ± 0.81 larvae/plant and 10.96 ± 0.22 for SPRT counts, 30.3 ± 8.98 and 27.55 ± 0.50 for VIS counts, 47.87 ± 5.95 and 300.57 ± 2.45 for VIS binomial, and 27.66 ± 2.81 and 30 ± 0 for SPRT binomial, for observed and simulated data, respectively. It is likely that the unusually high mean number of samples found in simulations for the VIS binomial plan is the result of an artifact produced by the lack of spatial structure in the procedure for count data generation in the simulation algorithm. In greenhouses, TLM (and many other insects) tend to aggregate in certain locations, such as borders and along, not across, rows (Martins et al. 2018). In simulations, the probability of obtaining a given mean across transects is constant but, in the greenhouse, there is an increased probability of obtaining repeatedly low or high counts depending on the location of the plants being sampled. Those repeated low or high counts may trigger a decision by locating the real mean far from the decision threshold.
Despite the robust trend found in the mean number of samples required by each sampling plan, such differences among plans were not reflected in the time human subjects spent performing them. Although the plan performed significantly affected the time that participants spent sampling the experimental crop (X2 = 17.593, P < 0.001), all plans seemed to require roughly the same amount of time (Fig. 4d). The single exception was the VIS by counts, which required significantly more time in average than both SPRT binomial and SPRT by counts (Fig. 4d). However, the variability in time required to complete sampling plans was notably higher for VIS plans than for SPRT plans. In particular, the significantly longer average time spent registered for VIS by counts was probably heavily affected by the report of two individuals (both > 45 min) (Fig. 4d). It is likely that people’s low familiarity with VIS plans (compared to SPRT plans) increases the sampling time of some practitioners. If that is the case, the average time required to perform VIS plans (and associated variability) is expected to decrease as practitioners gain experience.
3.5 Implementation and outlook
We show that the evaluated sampling plans differ in their ability to both estimate pest population size and deliver accurate management recommendations. According to our results, binomial sampling plans perform best when the purpose is to deliver a recommendation based on a fixed control threshold (i.e., classification). However, binomial sampling plans lose accuracy in estimation when populations are high, whereas sampling methods using counts remain robust independent of the population density (Fig. 3c). In fact, we argue that, in practice, binomial methods, particularly SPRT, may be overestimating populations when populations are low since real randomization of observations is rare, due to subconscious human bias towards highly conspicuous damage (as was our case), an effect that we cannot observe in simulations. One way to increase classification precision of binomial plans is to choose tally numbers, T, greater than zero, which may also reduce the average sample size, especially when the decision threshold is high (Binns et al. 2000). However, binomial plans with high values of T are, in practice, similar to counting and blur the inherent practical benefits of binomial plans. Furthermore, the benefits of increasing T in estimation precision are subtle, since reductions of sample size generally result in higher bias, and means are ultimately calculated from adjusted versions of Eq. 2a (with a more gradual increase of PT across μ, as T increases). In fact, we observed in simulations that increasing T (in both VIS and SPRT) only slightly reduces the sample size and moves the maximum NRMSE towards higher means with only marginal reductions in the overall area under the curve compared to T = 0 (data not shown).
Methods based on counts, on the other hand, may be limited by the amount of time (labor) needed in cases when pests may be too numerous or difficult to count (such as whiteflies or mites). While this may be true, we do not see a significant decrease in the time spent between plans using counts and those based on binary data, although this is likely to change among systems and crops of different areas. Similarly, VIS plans performed better at estimating TLM population size than did SPRT plans (except for counts in our experimental greenhouse trial, see discussion above), but the accuracy of the final recommendation did not change with the type of the plan. SPRT plans required a smaller number of samples to reach a decision than VIS plans, which was not surprising given that SPRT were originally developed for quality control applications (Wald 1945), while VIS was designed for pest management (Hoy et al. 1983). VIS plans have the advantage of requiring that growers walk through the entire crop which allows them to simultaneously observe the plants for other problems and obtain empirical information that can be used to focus pesticide applications only where it is required. A potential limitation of VIS plans is that they require a constant recalculation of subsequent sample size, which is hardly realistic since farmers could not be expected to run these calculations as part of their daily routine. However, with the computing power that we all carry in pockets nowadays, apps that carry out these calculations may facilitate the uptake and implementation of VIS as a strategy. As a matter of fact, the participants who evaluated the sampling plans in the greenhouse trial used a simple R script on their phones to implement both VIS plans (counts and binomial) (R script provided in Code 3, https://doi.org/10.5281/zenodo.4432813).
To a large extent, the whole idea behind developing and implementing sampling plans based on EILs is to favor the adoption of IPM programs and hence the reduction of the dependence on chemical inputs. However, technologies that objectively guide the need of insecticide applications are not widely adopted by farmers, especially in the developing world (Parsa et al. 2014; Morse 2008). We identify two general obstacles for this lack of adoption. The first is the uncertainty about the establishment of decision thresholds, which comes mainly from produce market volatility, and variations in the cost of control measures (Naranjo et al. 1996; Plant 1986). The relative impact of each depends on the system, but the globalization of markets has particularly increased the risk associated with the income farmers can obtain from their crops, which is often more volatile than the reported produce market price. Although control thresholds were originally designed to limit pesticide use while assuring farmers’ income, even rough estimates of fixed (nominal) economic thresholds assuming unstable markets seem to be unrealistic. However, many farmers have acquired the skills to make good guesses on the prices they can expect at a given time, based on weather, experience, or the behavior of competitors (Stonehouse 1995). In fact, Stonehouse (1995) suggests that, in the developing world context (i.e., small farms and ecogeographical heterogeneity), experience associated with local production systems might be more important than advice from extension services when establishing decision criteria for pest problems. As we previously suggested (Rincon et al. 2019), the promotion of marketing information systems that allow farmers to adapt to market uncertainty might be one way to reduce vulnerability due to market uncertainty and increase their tolerance to pest populations accordingly.
A second obstacle we see is the inherent risk aversion of farmers, and the myriad ways they can alter their behavior in response to additional information. In general, one should expect that the more information about the risks, the higher the rationality associated with the decision-making process, as judgment is refined based on better calculation of true outcome probabilities (Pratt et al. 1995). This should be especially true under conditions of heightened uncertainty, which is when people often have more difficulty making decisions. However, this is not always the case in human behavior. When the risk estimated from outsiders (e.g., decision-support systems, neighbors, extensionist, pesticide salesmen, etc.) is divergent, farmers may respond by asymmetrically weighing information sources, increasing the influence of sources which predict higher risk. For example, Lybbert et al. (2016) found an overall negative environmental impact of a disease forecast system made to assist wine grape farmers’ management decisions. Apparently, rather than adjusting their reaction proportionally to the estimated risk, farmers responded by applying asymmetrically more aggressive control treatments as the estimated risk from the forecast system increased. When people are exposed to multiple and conflicting risk estimations, they tend to disproportionately weight sources that indicate the highest risk. This effect is referred to as the “alarmist decision” and results in both an excessive consideration of worst-case scenarios in decision-making processes and increased risk aversion in learning. Unfortunately, this distortion in judgment is observed regardless of the level of credibility of the information source, and it is the mere divergence in risk estimations from different sources that triggers it (Viscusi 1997). In other words, decision-making in pest management seems to be stuck in risk aversive behavior as long as farmers are subjected to divergent risk estimations (which is the most common scenario). However, according to recent theoretical developments, one way to overcome this apparent trap is to focus on farmer experimentation as the foundation of the decision-making process. Keller et al. (2019) show that even the most risk-averse individuals might make risky decisions when risky situations produce information that can be used to reduce risk in the future. We advocate that sampling plans for decision-making in pest management should offer a focus on experimentation, in such a way that farmers are provided with tools to make calculated bets (experiments) on the establishment of action thresholds. For example, sampling plans, such as VIS and SPRT by counts—as shown in this study, can provide reliable information on the status of a tomato crop in relationship with a rough estimate of a predefined threshold. Considering the uncertainty associated with the management decision, farmers may use the estimation of how close the pest population is from the estimated threshold to take calculated risks and collect valuable information, initiating an experience-based learning process, which can be used to make better decisions during future crop cycles at the cost of an investment in sampling time.
Our results show that sampling plan modalities that are already developed could be used to reduce vulnerability of production systems and potentially increase adoption rate of decision-making systems by including the opportunity to learn as part of the output. This is especially important for systems like the TLM in greenhouse tomato crops, where current risk perception is considerably high relative to the real effect of moderate infestations on yield. Such aversion can be dealt with by providing the appropriate tools to allow farmers to make rough, but sound estimates of economic thresholds, taking into account predictions of produce prices and costs of control measures. Once the threshold is estimated, the selection of the sampling plan should be based on obtaining information about the infestation status relative to the estimated threshold, and not solely on reducing the effort required. We propose that VIS plans, especially by counts, are the best suitable for this purpose, at least for TLM management in greenhouse tomato crops. VIS plans delivered the most precise estimations, while requiring a reasonable time and effort. Such estimations are to be used as a guide to allow farmers to decide which action is most appropriate for the given context (tomato price volatility, time to harvest, pest population size, etc.) rather than as a management recommendation. Even though SPRT may deliver similar pest estimations, VIS plans make farmers sample across their entire field, which provides them with additional information, such as spatial distributions and other potential problems. Of course, implementation of adaptive sampling plans, such as those suggested in this study, requires simultaneous technological developments to make real-time calculations and deliver the information in an appropriate format.
Smartphone-based apps offer a solution for the uptake of VIS sampling plans in decision-making. We envision an app that will carry out the necessary calculations for VIS sampling. This app will also allow farmers to input their perceived risk and have a threshold calculated for them to trigger their decisions. We further propose that, integrated with machine learning, such an app could include user feedback to adjust these thresholds based on their own assessment of the decisions they made in the past. Even though most apps used in agriculture nowadays are designed for individual growers (Eichler Inwood and Dale 2019), such an app could also be used collectively by growers in such a way that information about produce price, pest incidence in an area, or other risk conditions is used to better learn and calculate thresholds in real time based on collective and historical data supplied by farmers’ own experiences. By analyzing all the information gathered from various growers mathematically by the app, rather than subjectively by growers or external sources, alarm behavior could be avoided and could increase the uptake of IPM at regional scales. Although the use of apps in agriculture is incipient, a recent study by Bonke et al. (2018) shows that in Germany, 93% of farmers who participated in the study are using agricultural apps, and 82% are willing to pay for apps which will help them better manage their crops. These results show that farmers are willing to use technology to help them in their decision-making process. Even though there is no information on the uptake of apps in Latin American agriculture, it is safe to assume that it will increase in the coming years, particularly if farmers are involved in their development firsthand.
4 Conclusion
Sustainability requires farmers to shift from strongly preventive agriculture, based on low pest tolerance and overuse of inputs, to one that is corrective, based on objective information. The main difficulty in achieving this change is that farmers have an aversion to risk since their livelihood depends on the quality of their harvest. Even though oftentimes quality or quantity will not be affected by low pest populations, perceived risk outweighs optimal decision-making, decision-making, leading farmers to incur in additional costs through the preventive or unnecessary use of pesticides. However, risk aversion may best be dealt with through experience. As such, sampling plans should not be based on a static threshold for decision-making which farmers had no hand in developing and may not apply to their current conditions, but rather, on dynamic thresholds based on the risk farmers estimate themselves. We show through both computer simulations and human sampling that VIS sampling plans, and particularly those based on counts, give the most accurate estimation of pest densities and that even though they may be more labor intensive than traditional SPRT sampling methods, they offer additional benefits to farmers such as providing spatial information. Since we now have the capacity to carry out the calculations required by VIS sampling easily in the field, the accuracy obtained from it will allow farmers to determine how close, or far, they are from a threshold which may vary according to their perceived risk. We propose that allowing farmers to experiment with using control measures in a more informed way will change their own perception of risk and reduce pesticide applications. If farmers experiment in low-risk situations (moments with low market price or low pest populations) and begin to see for themselves that they may reduce pesticide applications without affecting their harvest, they will become more prone to taking risks under higher-risk situations. Once farmers realize that zero tolerance policies, such as that established for TLM in greenhouse tomato crops, are actually harming their income through the unnecessary use of agricultural inputs, we will be able to move towards a future of sustainable food production.
Availability of data and material
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Code availability
The computer code generated during the current study is available in the Zenodo repository, https://doi.org/10.5281/zenodo.4432813.
References
Barberis NC (2013) Thirty years of prospect theory in economics: a review and assessment. J Econ Perspect 27(1):173–196. https://doi.org/10.1257/jep.27.1.173
Barzman M, Bàrberi P, Birch ANE, Boonekamp P, Dachbrodt-Saaydeh S, Graf B, Hommel B, Jensen JE, Kiss J, Kudsk P, Lamichhane JR, Messéan A, Moonen A-C, Ratnadass A, Ricci P, Sarah J-L, Sattin M (2015) Eight principles of integrated pest management. Agron Sustain Dev 35(4):1199–1215. https://doi.org/10.1007/s13593-015-0327-9
Binns MR, Nyrop JP, Werf W (2000) Sampling and monitoring in crop protection: the theoretical basis for developing practical decision guides. CABI Pub., Wallingford; New York
Bonke V, Fecke W, Michels M, Musshoff O (2018) Willingness to pay for smartphone apps facilitating sustainable crop protection. Agron Sustain Dev 38(5):51. https://doi.org/10.1007/s13593-018-0532-4
Bout A, Boll R, Mailleret L, Poncet C (2010) Realistic global scouting for pests and diseases on cut rose crops. J Econ Entomol 103(6):2242–2248. https://doi.org/10.1603/ec10115
Cassino P, Perusso J, Rego L, Sampaio HN (1995) Proposta metodológica de monitoramento de pragas emtomateiro estaqueado. An Soc Entomol Bras 24:279–285
Cocco A, Serra G, Lentini A, Deliperi S, Delrio G (2015) Spatial distribution and sequential sampling plans for Tuta absoluta (Lepidoptera: Gelechiidae) in greenhouse tomato crops. Pest Manag Sci 71(9):1311–1323. https://doi.org/10.1002/ps.3931
Donado MdP, Soto M, Camelo M, Rincon DF, Espitia E (2017) Riesgos determinados sobre los principales contaminantes químicos y microbiológicos en tomate cultivado bajo condiciones protegidas en los departamentos de Cundinamarca, Boyacá y Antioquia. Informe final de meta: Levantamiento de información primaria para construcción de línea base. Corporación Colombiana de investigación agropecuaria (AGROSAVIA), Mosquera (Cundinamarca)
Eichler Inwood SE, Dale VH (2019) State of apps targeting management for sustainability of agricultural landscapes. A review. Agron Sustain Dev 39(1):8. https://doi.org/10.1007/s13593-018-0549-8
Feola G, Binder CR (2010) Identifying and investigating pesticide application types to promote a more sustainable pesticide use. The case of smallholders in Boyacá, Colombia. Crop Prot 29(6):612–622. https://doi.org/10.1016/j.cropro.2010.01.008
Fraser EDG, Campbell M (2019) Agriculture 5.0: reconciling production with planetary health. One Earth 1(3):278–280. https://doi.org/10.1016/j.oneear.2019.10.022
Haddi K, Berger M, Bielza P, Cifuentes D, Field LM, Gorman K, Rapisarda C, Williamson MS, Bass C (2012) Identification of mutations associated with pyrethroid resistance in the voltage-gated sodium channel of the tomato leaf miner (Tuta absoluta). Insect Biochem Mol Biol 42(7):506–513. https://doi.org/10.1016/j.ibmb.2012.03.008
Hoy CW (1991) Variable-intensity sampling for proportion of plants infested with pests. J Econ Entomol 84(1):148–157. https://doi.org/10.1093/jee/84.1.148
Hoy CW, Jennison C, Shelton AM, Andaloro JT (1983) Variable-intensity sampling - a new technique for decision-making in cabbage pest-management. J Econ Entomol 76(1):139–143
Keller G, Novák V, Willems T (2019) A note on optimal experimentation under risk aversion. J Econ Theory 179:476–487. https://doi.org/10.1016/j.jet.2018.11.006
Lybbert TJ, Magnan N, Gubler WD (2016) Multidimensional responses to disease information: how do winegrape growers react to powdery mildew forecasts and to what environmental effect? Am J Agric Econ 98(2):383–405. https://doi.org/10.1093/ajae/aav097
Martins JC, Picanço MC, Silva RS, Gonring AH, Galdino TV, Guedes RN (2018) Assessing the spatial distribution of Tuta absoluta (Lepidoptera: Gelechiidae) eggs in open-field tomato cultivation through geostatistical analysis. Pest Manag Sci 74(1):30–36. https://doi.org/10.1002/ps.4664
Morse S (2008) IPM: ideals and realities in developing countries. In: Radcliffe EB, Cancelado RE, Hutchison WD (eds) Integrated pest management: concepts, tactics, strategies and case studies. Cambridge University Press, Cambridge, pp 458–470. https://doi.org/10.1017/CBO9780511626463.016
Naranjo SE, Chu CC, Henneberry TJ (1996) Economic injury levels for Bemisia tabaci (Homoptera: Aleyrodidae) in cotton: impact of crop price, control costs, and efficacy of control. Crop Prot 15(8):779–788
Parsa S, Morse S, Bonifacio A, Chancellor TCB, Condori B, Crespo-Pérez V, Hobbs SLA, Kroschel J, Ba MN, Rebaudo F, Sherwood SG, Vanek SJ, Faye E, Herrera MA, Dangles O (2014) Obstacles to integrated pest management adoption in developing countries. Proc Natl Acad Sci U S A 111(10):3889–3894. https://doi.org/10.1073/pnas.1312693111
Peterson RKD, Higley LG, Pedigo LP (2018) Whatever happened to IPM? Am Entomol 64(3):146–150. https://doi.org/10.1093/ae/tmy049
Plant RE (1986) Uncertainty and the economic threshold. J Econ Entomol 79(1):1–6. https://doi.org/10.1093/jee/79.1.1
Pratt JW, Raiffa H, Schlaifer R (1995) Introduction to statistical decision theory. MIT Press, Cambridge Massachusetts, USA
R Core Team (2018) R: a language and environment for statistical computing. Version 3.5.1. "Feather Spray" edn. R Foundation for Statistical Computing, Vienna, Austria
Rincon DF, Vasquez DF, Rivera-Trujillo HF, Beltrán C, Borrero-Echeverry F (2019) Economic injury levels for the potato yellow vein disease and its vector, Trialeurodes vaporariorum (Hemiptera: Aleyrodidae), affecting potato crops in the Andes. Crop Prot 119:52–58. https://doi.org/10.1016/j.cropro.2019.01.002
Rykiel EJ (1996) Testing ecological models: the meaning of validation. Ecol Model 90(3):229–244. https://doi.org/10.1016/0304-3800(95)00152-2
Silva GA, Picanço MC, Bacci L, Crespo ALB, Rosado JF, Guedes RNC (2011) Control failure likelihood and spatial dependence of insecticide resistance in the tomato pinworm, Tuta absoluta. Pest Manag Sci 67(8):913–920. https://doi.org/10.1002/ps.2131
Stonehouse JM (1995) Pesticides, thresholds and the smallscale tropical farmer. Int J Trop Insect Sci 16(3):259–262. https://doi.org/10.1017/s1742758400017264
Torres JB, Faria CA, Evangelista WS, Pratissoli D (2001) Within-plant distribution of the leaf miner Tuta absoluta (Meyrick) immatures in processing tomatoes, with notes on plant phenology. Int J Pest Manag 47(3):173–178. https://doi.org/10.1080/02670870010011091
Tversky A, Kahneman D (1981) The framing of decisions and the psychology of choice. Science 211(4481):453–458. https://doi.org/10.1126/science.7455683
Viscusi WK (1997) Alarmist decisions with divergent risk information. EJ 107(445):1657–1670
Wald A (1945) Sequential tests of statistical hypotheses. Ann Math Stat 16(2):117–186. https://doi.org/10.2307/2235829
Zhang W, Swinton SM (2009) Incorporating natural enemies in an economic threshold for dynamically optimal pest management. Ecol Model 220(9-10):1315–1324. https://doi.org/10.1016/j.ecolmodel.2009.01.027
Acknowledgements
We are grateful to Diego Fernando Sanchez, Marcela Preciado, Diego Avendaño, Lorena Carmona, Nadia Yurany Luque, and Victor Pulido (AGROSAVIA) who provided valuable support collecting the data and to Patricia Corredor, Edison Corredor, Atalivar Ramirez, Ernesto Cubides, Jesus Heredia, and Maria H. Pardo who allowed us to work in their greenhouses to carry out part of this study.
Funding
This study was funded by the Ministerio de Agricultura y Desarrollo Rural de Colombia with government funds allocated to the Corporación Colombiana de Investigación Agropecuaria—AGROSAVIA (Grant No. 1000347 to DFR). Research support was provided by government funds assigned to AGROSAVIA. The authors assume full responsibility for the interpretation of results and ideas presented in this manuscript, which do not necessarily reflect the official opinions of these organizations.
Author information
Authors and Affiliations
Contributions
Conceptualization, DFR; methodology, DFR, FB-E, HFR-T; software, DFR; formal analysis, DFR; investigation, DFR, FB-E, HFR-T, LM-R; validation, HFR-T, LM-R; writing—original draft preparation, DFR, FB-E; writing—review and editing, DFR, FB-E, HFR-T, LM-R; visualization, DFR, FB-E, HFT-T; supervision, DFR.
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Consent to participate
Informed consent was obtained from all individual participants included in the study.
Consent for publication
Informed consent for publication of data was obtained from all individual participants. Verbal consent was provided by individuals appearing in image of Fig. 1a.
Conflicts of interest
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
About this article

Cite this article
Rincon, D.F., Rivera-Trujillo, H.F., Mojica-Ramos, L. et al. Sampling plans promoting farmers’ memory provide decision support in Tuta absoluta management. Agron. Sustain. Dev. 41, 33 (2021). https://doi.org/10.1007/s13593-021-00693-0
Accepted:
Published:
DOI: https://doi.org/10.1007/s13593-021-00693-0