
Abstract
This work provides an unsupervised learning approach based on a single-valued performance indicator to monitor the global behavior of critical components in a viaduct, such as bearings. We propose an outlier detection method for longitudinal displacements to assess the behavior of a singular asymmetric prestressed concrete structure with a 120 m high central pier acting as a fixed point. We first show that the available long-term horizontal displacement measurements recorded during the undamaged state exhibit strong correlations at the different locations of the bearings. Thus, we combine measurements from four sensors to design a robust performance indicator that is only weakly affected by temperature variations after the application of principal component analysis. We validate the method and show its efficiency against false positives and negatives using several metrics: accuracy, precision, recall, and F1 score. Due to its unsupervised learning scope, the proposed technique is intended to serve as a real-time supervision tool that complements maintenance inspections. It aims to provide support for the prioritization and postponement of maintenance actions in bridge management.
Similar content being viewed by others


1 Introduction
Over the last decades, monitoring systems have gained importance in our society [1, 2]. Their main objective is to provide quantitative information on the performance of structures under service conditions to optimize the maintenance programs and avoid severe failures [3].
In the management of civil engineering structures, there are some elements whose correct behavior is critical in the planning of repair and substitution actions due to the high technical and economic costs. Some of these crucial components are bearings, particularly when they employ newly developed technologies or are installed in bridges with unconventional designs. The correct performance of these elements becomes even more important as the management of infrastructures evolves towards predictive maintenance strategies at the network level [4]. In this context, owners have the responsibility to adequately prioritize actions on multiple different bridges based on their real condition [5,6,7,8,9].
There is a great interest on developing improved structural health monitoring (SHM) alternatives to support traditional visual inspections [10, 11]. We can broadly classify these improved SHM methods into model based and data based [11].
Model-based techniques have been traditionally applied in the field of civil engineering [12,13,14,15,16,17,18]. They employ computational models that incorporate the physics of the system, including geometry, material properties, and boundary conditions. They solve an inverse problem by building a physics-based model and then updating its parameters until the response of the model matches that which is measured in the real structure. Although this approach is currently under exhaustive research [19,20,21,22,23,24,25], it still presents some drawbacks in the assessment of real systems. Such drawbacks include the need for high-quality data and the impossibility to provide real-time insight due to the computational effort required to solve the updating problem [26].
Data-based techniques rely exclusively on experimental data acquired during monitoring campaigns and do not require a physics-based model [11]. Instead, they build statistical models and extract higher value information from instrumentation systems with multiple sensing devices [27, 28]. Once trained, they can work autonomously and provide real-time assessment [29,30,31]. We classify data-based algorithms as supervised learning (where training data contain information about the damage of the structure), and unsupervised learning (for which the status of the structure and possible damage scenarios are unknown) [32,33,34].
Machine learning techniques can identify damage due to their ability to learn complex input–output relations present in the systems under study [28, 35]. Some recently applied algorithms include artificial neural networks (ANNs) [36, 37], support vector machines [38, 39], or k-nearest neighbor [40]. There are also several works that employ unsupervised machine learning approaches to civil engineering applications [41,42,43,44,45], but these are more powerful in supervised learning contexts, where there is full knowledge about the outcome of each training sample [11].
When working with civil engineering structures under service, we often employ unsupervised learning techniques due to the lack of damaged data [11, 43]. This situation leads to the implementation of novelty detection algorithms, which detect deviations from what it is considered the reference behavior but are unable to characterize the type and extent of the damage [46].
The simplest unsupervised learning approach for novelty detection is control charts, which monitor some features extracted from measurements and find departures from their expected values [30, 47, 48]. SHM has adopted this technique from the industrial machinery field, where a much more controlled environment holds [11, 30]. Unfortunately, in the case of bridge structures, greater manufacturing inaccuracies occur, and also environmental and operational effects strongly affect measurements [29]. Statistical pattern recognition (SPR) methods represent a more robust novelty detection technique that deals with this variability [11, 28, 41, 49,50,51]. SPR algorithms employ monitoring data to create statistical models that represent the undamaged or reference condition of a system [27]. When the probability of a new measurement is below a predefined threshold value, it corresponds to an outlier [29, 30, 52].
Statistical methods become more feasible when there exists long-term monitoring data to obtain reference patterns of a system. Yet, we find very few works in the literature that employ long-term monitoring data from real civil engineering structures. In [53], authors investigate the applicability of an autoregression SPR algorithm to dynamic field data using information from the Z24 bridge in Switzerland. This bridge contains measurements under progressive damage scenarios acquired during its controlled demolition. In [54], authors use a strain regression model to calculate a health indicator based on the statistical process control theory to detect behavior changes during the 14-year monitoring period in the presence of opening cracks.
In [55] and [56], authors focus on temperature–displacement correlation analysis and regression models to remove environmental effects and normalize displacements. The recent work [57] investigates the longitudinal behavior of a jointless railway bridge and defines regression models to remove the temperature-induced displacements and implement a robust early warning system.
In this work, we propose a data-based SHM approach to assess the global behavior of Beltran bridge, a singular asymmetric prestressed concrete viaduct in Mexico. The objective is to provide reliable information on the longitudinal response of the bridge against horizontal loads. We assess the global behavior of the sliding bearings that limit the lateral loads transmitted to the substructure. To do so, we employ long-term monitoring data from four fiber optic sensors that measure the relative displacement at each bearing location. Changes in temperature during the monitoring period induce a significant variability in the measurements [33]. However, since this phenomenon affects the structure globally, there exists a high correlation between displacements from the different sensors [58], as demonstrated later in the present work.
The presence of damage at the sliding surface of the bearing increases its friction coefficient and reduces the allowable displacement for a particular load [59,60,61]. Thus, a malfunction at any of the support devices will restrict the sliding of the deck over the corresponding pier. This situation will substantially affect the correlation condition that holds during normal operation (without damage) [58]. As a consequence of the malfunction, the affected pier cap will suffer larger displacements, leading to the appearance of cracks that may compromise the structural integrity of the bridge [59].
In this work, we first apply principal component analysis (PCA) based on the presence of sensor correlation to deal with environmental variability instead of using complex thermal sensor arrays and regression models [31]. Hence, the temperature is not required as an additional variable. We calculate a single-value performance indicator from the results of PCA that has low environmental sensitivity [62]. Next, we generate a statistical model for this indicator to represent the undamaged condition of the structure [63]. To do so, we employ a kernel density function [11, 57]. We then calculate a threshold value over the model that sets the limit for outlier detection based on a confidence level. A malfunction of a bearing will result in a reduction of the existing correlation between measurements at the four locations, and, therefore, in an outlier.
Finally, to prove the efficiency of the algorithm, we submit it to a validation phase using the test dataset. To account for the presence of damage at one of the bearings, we apply a reduction of the corresponding relative displacement (50% loss of its sliding capability).
The proposed method offers a SHM tool for early warning on the real condition of bridges, which can assist managers in the scheduling of maintenance actions at the network level. The methodology also helps to complement visual inspections for individual elements with more quantitative insight regarding the global behavior of the structure. We envision the present work as a complementary tool that should work together with other SHM assessment practices, including deterministic approaches to locate and quantify the damage.
2 Methodology
2.1 Data acquisition and pre-processing
Monitoring large civil engineering structures mainly consists of acquiring long-term measurements of the structural response under ambient excitation that results mainly from environmental and operational loads (e.g. temperature, wind, traffic).
When implementing data-driven algorithms, we split the available information into a training and a testing subset. We use the training subset for optimization and the testing one is kept for validation. We denote the training dataset by \(\hat{\user2{X}} \in R^{m \times d}\). It is a multivariate dataset that contains \(m\) measurement samples from \(d\) sensors in the undamaged state of the structure. Thus, each sensor has an associated measurement vector \(\hat{\user2{x}} \in R^{m}\).
2.2 Principal component analysis
Principal component analysis is a data analysis technique that re-expresses the original data in a new basis where the information is arranged in terms of maximal variance and minimal redundancy [64, 65]. In the field of SHM and novelty detection, it is important to characterize those changes occurring under normal operation, as they may compromise the efficiency of the assessment method [43, 51]. Further details of this procedure are available in [66,67,68], where authors present various applications for SHM. In here, we briefly describe the main steps involved in the procedure, namely (i) to rescale data, (ii) to calculate the covariance matrix, (iii) to extract principal components and (iv) to compute a single-value performance indicator.
2.3 Data rescaling
Rescaling variables is a key step [66]. This step becomes critical when sensors of different types are involved [66]. Herein, we define a rescaling function \(R_{i}\) for each sensor with \(i = 1,2, \ldots , d\)
where \(\mu_{i}\) and \(\sigma_{i}\) are the mean and standard deviation of measurement vector of the \(i\)th sensor, respectively. For each sensor dataset \(\hat{\user2{x}}_{i}\), we obtain the rescaled measurement vector \({\varvec{x}}_{i} = R_{i} \left( {\hat{\user2{x}}_{i} } \right)\). We denote to the rescaled training dataset by \({\varvec{X}} \in R^{m \times d}\).
2.4 Covariance matrix calculation
The covariance matrix measures the presence of relationships in the data and demonstrates the existence of correlations [64]. For any pair of measurement vectors corresponding to two different sensors \(\left( {{\varvec{x}}_{i} , {\varvec{x}}_{j} } \right) \in R^{m}\), the covariance is:
where \(\mu_{i}\) and \(\mu_{j}\) are the mean values of the \(i\)th and \(j\)th variables, respectively. The covariance matrix \(C\) is symmetric and contains the covariance values of the \(d\) variables.
2.5 Extraction of principal components
Principal components represent the directions of the data space that contain most of the original information in terms of variability [68]. We calculate them as the eigenvectors of the covariance matrix, and its weight in the analysis depends on the amount of the original variability they contain, which is directly related to the magnitude of the corresponding eigenvalue [65, 66, 68]. Since principal components indicate the directions of maximum variability in the measurements, we can isolate environmental effects by creating two different subspaces [69].
The first subspace contains most of the variability, and it is represented by the most important eigenvectors (i.e., those with larger eigenvalues) [70]. The second subspace is formed by the remaining principal components, which are associated to the lowest eigenvalues [70]. Since the second subspace has very little variability, this allows for the calculation of a robust performance indicator.
Hence, we must decide the number of components that are sufficient to account for the environmental variability and form the first subspace. We can justify this decision on the cumulative percentage of variance \({\text{CPV}}\) [68], which measures the amount of variance captured by the first \(k\) components, such that
where \(\lambda_{j}\) represents the \(j\)th eigenvalue. An acceptable level of variance for the first subspace is typically around 90–95% [64, 71].
Let \({\varvec{P}} \in R^{d \times d}\) be a square matrix containing the principal components of the training dataset \({\varvec{X}}\). We divide \({\varvec{P}}\) into two submatrices, \({\varvec{P}}_{s1} \in R^{d \times k}\) and \({\varvec{P}}_{s2} \in R^{{d \times \left( {d - k} \right)}}\), associated with the first and second subspaces, respectively.
2.6 Single-value performance indicator
In this step, we calculate the distance of the original data in the training set to the two previously defined subspaces, \({\varvec{P}}_{s1}\) and \({\varvec{P}}_{s2}\). The Hotelling’s or \(T^{2}\)statistic measures the distance from the first subspace \({\varvec{P}}_{s1}\) [65, 72]. For each measurement example \({\varvec{x}}\left( j \right) = \left( {x_{1} ,x_{2} , \ldots , x_{d} } \right)\) in the training set with \(j = 1,2, \ldots ,m\), we compute the performance indicator as
where matrix \(\Lambda \in R^{k \times k}\) is a diagonal matrix containing the first \(k\) eigenvalues. Complementarily, \(Q\) statistic, also referred to as squared prediction error, quantifies the distance from the second subspace [42]:
Here \(\Lambda_{2} \in R^{{\left( {d - k} \right) \times \left( {d - k} \right)}}\) is the diagonal matrix that contains the less meaningful eigenvalues. During normal operation, the \(Q\) statistic takes small values due to its low variability content. This enables to find a statistical representative model for the outlier detection algorithm.
2.7 Baseline model generation
The baseline model stems from the statistical characterization of the \(Q\) statistic sample in the undamaged state. For that purpose, we employ Kernel density estimation [73, 74]. This technique provides a continuous function that accurately fits the distribution of the reference performance indicator sample and constitutes the baseline pattern for damage detection [57, 75].
2.8 Threshold value calculation
The assessment methodology for outlier detection developed in this work belongs to the unsupervised learning domain. This is the most common situation in SHM strategies to in-service structures since data from possible damage states are rarely available [11, 56, 76]. The main goal of this approach is to detect deviations from what is considered to be the reference state, which is statistically defined as the baseline model.
In the baseline model, we select an uncertainty level over which we assume the structure may have some unknown damage. In our case, we select a 5% uncertainty level (95% confidence level) to achieve a strong enough SHM assessment tool [11]. The limit value is directly obtained by calculating the 95 percentile of the corresponding kernel density function [73, 77, 78].
2.9 Validation
Once we have constructed the baseline model and set the threshold value to detect outliers, we validate the algorithm using the test dataset. Let \({\varvec{X}}_{test} \in R^{n \times d}\) be the test matrix that contains \(n\) new examples unseen by the algorithm. We evaluate the performance of the algorithm based on the main machine learning metrics, i.e. accuracy, precision, recall, and F1 score [79].
3 Case study
In this work, we employ a data-driven SHM approach for bearing behavior assessment. This technique provides a “single-value” tool for decision-making and bearing damage assessment in structural management.
3.1 Bridge description
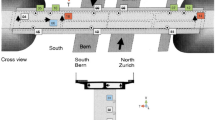
This study considers the Beltran bridge, located in kilometer point (KP) 119.5 of the Guadalajara–Colima highway in Mexico. Its design incorporates one pier of considerable height and only two expansion joints in the deck, located over the abutments. This structural profile is typically employed to cross abrupt areas, such as valleys [80]. A representative view is shown in Fig. 1.

Structural profile of the singular Beltran bridge. Detail of the fixed point
Its continuous superstructure is 297.49 m long and it is distributed in four spans (73.60 + 12.40 + 134.90 + 76.59 m). The prestressed concrete deck is a single box girder with variable depth from 4.40 m in the mid-section of the main span to 7.50 m in support sections. The top and bottom slabs are 0.50 m and 0.75 m thick, respectively. Figure 2 shows the section specifications.

Bridge section details
Pier 4 is rigidly connected to the deck and it represents the theoretical fixed point in the structure for longitudinal loads. This pier is 120.45 m height. Its width varies linearly (1:60) from 6.00 m at the foundation to 4.00 m at the cap. The thickness of the walls is 0.80 m.
Piers 2 and 3 are made of concrete and they have box sections of 0.40 m thickness. They have a height of 24.25 m. The deck-pier contact is established with pot bearings allowing for sliding in the longitudinal direction. This kind of sliding bearing carries vertical loads by compression on an elastomeric element confined within the machined pot plate that works under a triaxial pressure. It offers low resistance to deformation but high vertical stiffness [61, 81]. These elements limit the horizontal force transmitted to the piers by allowing certain translation to accommodate longitudinal displacements [61].
The structural scheme of the bridge must withstand horizontal loads that are likely to occur during the bridge lifetime as a result of temperature variations, wind, small seismic-induced motions, or strong braking forces from vehicles, among others [82]. Sliding bearings limit the horizontal force that reaches the pier and causes displacements at the pier cap [82]. We can model these devices as a friction element whose behavior is governed by a parameter \(\mu\) that represents its sliding capabilities. A degradation on the sliding surface of the bearing will reduce the required relative displacement between the deck and the piers [57, 60, 82].
Figure 3 illustrates the pier-deck structural system, where \(u_{a} ,u_{p}\) and \(u_{b}\) stand for the longitudinal displacement of the deck, the pier, and the bearing, respectively. \(M_{d}\) and \(M_{p}\) represent the mass of the deck and the pier, \(\mu\) is the friction coefficient of the bearing and \(K_{p}\) is the longitudinal stiffness of the pier. We express the displacement at the pier cap as

Simplified approximation of the structural system deck-bearing pier
Based on this model, pot bearings can operate in two different regions, as shown in Fig. 4 [59, 61, 83]. When the external loads are below the friction force, there is no displacement of the bearing (static friction) [84]. On the other hand, when exceeding the limit friction force, the energy transmitted to the pier is limited due to a displacement of the bearing [61].

Operating schemes for an undamaged and a damaged pot bearing
For an undamaged bearing, the friction coefficient is very low (\(\mu \varepsilon \left[ {0.02 - 0.05} \right]\)), and except for very small loads, it will work in the sliding region [59]. In this situation, the transmitted load is the critical friction force that will be small enough to ensure the correct longitudinal behavior [61, 84]. The presence of damage at the sliding surfaces of the bearing causes a reduction of its allowable displacement for a certain load [59,60,61]. We can mathematically model this situation as an increase in the friction coefficient [59].
Figure 4 compares the behavior diagram of an undamaged and a damaged bearing, where \(\mu^{u}\) and \(\mu^{d}\) represent the friction coefficient in the undamaged and the damaged state, respectively [59, 85].
For the same external load, a damaged bearing will transmit higher loads to the pier cap and cause cracks that may compromise the structural integrity. Hence, assessing the performance of these devices in the long term is key to ensure a correct structural response against horizontal loads.
3.2 The monitoring system
Given the structural particularities of Beltran bridge, a long-term monitoring system was installed in 2012. The bridge was equipped exclusively with fiber optic sensors [86,87,88]. In this work, we had access to the four fiber optic displacement sensors that record the longitudinal displacements of the deck over the substructure of the bridge. Figure 5 describes their location. These measurements correspond to the relative displacement of the sliding bearings, \(u_{b}\).

Locations of the displacement sensors
Pier 4 represents the fixed point of the structure for longitudinal forces. Although no relative displacement exists there, it is subjected to absolute displacements. Displacement sensors are located at the top of piers 1, 2, 3 and 5, where pot bearings connect the piers with the deck to allow for sliding in the longitudinal direction. Bearings are critical elements to ensure the structural integrity of this bridge.
3.3 Data acquisition
The monitoring system was activated in August 2012 and worked continuously until July 2013. Due to some temporary outages, the total recording period lasted approximately 9 months.
The data acquisition process was carried out at a sampling frequency of 200 Hz. The transmission of the data was done monthly and contained the mean values of the displacements measured every ten minutes for each sensor. This subsampling suffices to analyze the long-term variations of longitudinal displacements at the bearing locations (\(u_{b}\)) and reduces the storage space to 40.5 MB for the whole dataset. After training statistical the model, it is possible to transmit the data daily for real-time damage assessment. With the previous specifications, we obtained a total of 38,592 measurements for each displacement sensor during the monitoring period. After removing zero values, the final number of measurements per sensor is 37,692. Finally, we split the data into training and test subspaces. We select the first 80% of samples to train the algorithm, resulting in a training dataset \({\varvec{X}} \in R^{30154 \times 4}\). We employ the final 20% to evaluate the performance of the algorithm against unseen data during the validation phase.
3.4 Data pre-processing
Temperature changes affect the structure globally. Accordingly, there must exist a correlation between measurements at different locationsFootnote 1 [55, 58, 62]. Following [62], the use of linear PCA is justified since there exists a linear correlation between variables, i.e. relative displacements at the four bearing locations. In [62], where the analysis variables are dynamic features of the structure, it was also proven that linear PCA works even in slightly nonlinear cases. Figure 6 shows the presence of these correlations through the scatterplot of each pair of variables together with the value of the Pearson’s coefficient of correlation, verifying that the monitoring period corresponds to the undamaged or reference condition of the support devices. Figure 6 also includes the histogram for the training dataset of each sensor (\(THL1\) to \(THL4\)).

Correlation summary of the four displacement sensors
3.5 Data processing
In long-term monitoring, environmental changes (i.e. temperature) strongly affect longitudinal displacements during normal operation. For this reason, these measurements are inadequate for outlier detection since they exhibit a large variability even under normal operation. Given the existing correlation between sensor measurements at the different locations (as shown in Fig. 6), we look for a damage indicator that is robust to these phenomena. We use principal component analysis (PCA) to find and isolate any variance induced by temperature in the training dataset. We emphasize that temperature is unmeasured, and the force–displacement response of isolate bearings is untreated. Instead, we focus on the existing correlations in the displacement measurements of the bearings at different locations.
We firstly rescale the training dataset by applying the corresponding function \(R^{i}\) to each sensor dataset with \(i = \left( {1,2,3,4} \right)\).
The covariance matrix \(C\) for the four standardized displacement sensors is
According to the theory of PCA, we obtain the principal components as the eigenvectors of matrix \(C\). Table 1 shows the four principal components.
The analysis requires an exhaustive evaluation of the principal components to understand how powerful PCA is to manage multivariate data [67, 68]. Table 2 summarizes the most relevant information.
An acceptable level of variance for the first subspace is typically around 90–95% of the total variance [64, 71]. In this case, we only need two components to reach almost 91% of the total variance, so we define the first subspace with half of the total components and leave the other two components for the second subspace. Since principal components indicate the directions of maximum variability in the measurements, the first subspace contains most of the variation present in the data, and the second subspace contains the remaining noise. Here, the main source of variability comes from environmental effects, i.e., temperature variations. Thus, the first subspace contains environmental variability. The matrices representing both subspaces are, respectively.
Next, we calculate both statistics for the training set and obtain the corresponding samples \({\varvec{T}}^{2} \in R^{m}\) and \({\varvec{Q}} \in R^{m}\) that are representative of the undamaged condition of the structure. The temporary representation (see Fig. 7) of both statistics for the training set provides an insightful interpretation on the distribution of the existing variability. On the one hand, \({\varvec{T}}^{2}\) statistic contains most of the variability, in this case induced by seasonal temperature changes. On the other hand, \({\varvec{Q}}\) statistic shows a much lower fluctuation, indicating that its value is poorly affected by the inherent environmental trends.

Representation of \(T^{2}\) and \(Q\) statistics for the training set
Table 3 gathers the statistical properties of both indicators, including the mean value and the standard deviation. This information supports the decision of employing \(Q\) statistic as the damage sensitive feature for outlier detection.
We first generate the statistical baseline model for the \(Q\) statistic vector calculated for the training dataset using the kernel density estimation approach. Onto this baseline model, we select an uncertainty level over which we will assume the bridge may have some unknown damage. We consider that those indicators exceeding the threshold value are more likely to belong to the unknown damage state. In our case, we select a 5% uncertainty level (95% confidence level) to achieve a strong enough SHM assessment tool towards false negatives (undetected damage), as they are of great importance in the civil engineering field [74].
The limit value is directly obtained by calculating the 95 percentile over the corresponding kernel model [73, 77, 78], being \(Q_{{{\text{limit}}}} = 0.9845\).
Figure 8 shows graphically the limit between the two possible states. The green-shadowed region, which includes 95% of the sample data, represents the undamaged state, while the red-shadowed region stands for the unknown state of the structure. Hence, we identify the abnormal behavior or damaged state as any departure from the previously calculated threshold value in the \(Q\) statistic indicator with 95% certainty.

Classification threshold over the reference model with a 5% uncertainty
4 Validation results
In this section, we use the test dataset, which contains the final 20% of the available measurements, i.e. \(X_{{{\text{test}}}} \in R^{7538 \times 4}\). Since the whole monitoring period belongs to the undamaged condition of the structure, this dataset only tests the algorithm against false positives. We additionally account for the presence of damage at one of the bearings, assuming that it results in a reduction of the measured displacement, indicating a loss of its sliding properties. We apply this reduction to the measurements of the sensor associated to the bearing at pier 2. We assume the following relations between displacements in the undamaged state:
where \(\alpha\) expresses the distribution of the absolute displacement (\(u_{a,u}\)) between the pier and the bearing. In the undamaged state, we set a value of \(\alpha = 0.9\) since the bearing absorbs most of the absolute displacement. Then, we represent the damaged scenario through a reduction in \(\alpha\), as:
where \(\alpha ^{\prime}\) measures the new fraction of absolute displacement that goes to the bearing in the damaged condition and \(x\) indicates the corresponding reduction with respect to the undamaged state. These bearings must always allow sliding at operational loads. Despite bridges are generally calculated assuming a total blockage of the supports, this is a critical situation. In here, we apply a reduction factor of \(x = 0.45\), meaning a 50% loss of the sliding capabilities of a bearing. This scenario is sufficiently far from the limit situation but reasonably indicates the need of an intervention. We reach the following relation between damaged and undamaged bearing displacements:
Hence, the final test dataset contains two parts: the original test dataset and the damaged test dataset, resulting in a total of \(2 \cdot n = 15076\) testing examples. Figure 9 shows the results delivered by the algorithm after calculating the \(Q\) indicators, where the first half of the test corresponds to undamaged bearings and the last half represents the damaged bearing situation. In addition, Table 4 gathers the main metrics that evaluate the algorithm performance.

Performance indicator in the test dataset
These results prove the ability of the algorithm to detect novel measurements and also its low sensitivity to environmental variability. When new long-term monitoring measurements are registered, we can recalibrate the algorithm. However, to prove the ability of the algorithm to detect damage would require the occurrence of the damage while the monitoring system is activated.
5 Conclusions
This work addresses the problem of structural performance assessment with a data-based approach as opposed to more traditional model-based methods. The main advantage of this data-driven scope lies in its expected flexibility to fit any type of system or structure where correlations are detected in the response measurements from various sensors.
Due to the characteristics of this bridge, any repair or substitution work is complicated and requires expensive interventions according to its complexity. Therefore, any action should be justified towards an efficient budget allocation.
With the use of the proposed method, we evaluate quantitatively the behavior of the structure, where we can detect anomalies by comparing a single damage indicator with a threshold value, isolating the effects from changing environmental conditions and providing a robust performance statistic.
The damage indicator \(Q\) shows to be a powerful measure of the correlation found between displacements at different locations. It gathers the information from all of the considered displacement sensors and provides a global vision for decision-making in the management of the bridge. In addition, this statistic is isolated from the variability induced by environmental and operational phenomena during normal service, giving robustness to the methodology.
With the temporary representation of the new damage indicators registered during a monitoring period in an unknown state, we detect departures from the normal condition and identify trends in the evolution of the statistic. In addition, once an alert is raised, the location of the damaged bearing can be identified just by looking at the current displacement data and finding the abnormal sensor measurement that is causing the loss of correlation at that moment.
The tool configuration is useful for the scheduling of periodic inspections as a supplement to traditional bridge inspections, providing a more objective approach to complete the information and help managers in decision-making.
In conclusion, this study demonstrates the utility of exploiting and managing the available historical data stemming from periodical monitoring processes to control and predict the evolution of the behavior of certain critical elements in structures, helping managers to prioritize maintenance actions and take decisions at the network level.
Future work includes the application of this method to different bridges to further prove the validity of the approach. We also envision to replace the PCA method by a residual deep neural network that exploits also nonlinear correlations between the different sensors.
Notes
We also observed a correlation between approximated ambient temperatures in the area and the recorded measurements at different locations; however, we lack exact temperature data on the bridge.
References
Chen HP (2018) Structural health monitoring of large civil engineering structures. Wiley Black. DOI: 10.1002/ejoc.201200111
Cawley P (2018) Structural health monitoring: closing the gap between research and industrial deployment. Struct Health Monit 17(5):1225–1244. https://doi.org/10.1177/1475921717750047
Baxter R, Hastings N, Law A, Glass EJ (2008) Maintenance, monitoring, safety, risk and resilience of bridges and bridge networks, vol 39. CRC Press. https://doi.org/10.1201/9781315207681 (ISBN 9781138028517)
Vagnoli M, Remenyte-Prescott R, Andrews J (2018) Railway bridge structural health monitoring and fault detection: state-of-the-art methods and future challenges. Struct Health Monit 17(4):971–1007. https://doi.org/10.1177/1475921717721137
Sakib N, Wuest T (2018) Challenges and opportunities of condition-based predictive maintenance: a review. Procedia CIRP 78(November):267–272. https://doi.org/10.1016/j.procir.2018.08.318
Jong-Ho S, Hong-Bae J (2015) On condition based maintenance policy. J Comput Design Eng 2(2):119–127. https://doi.org/10.1016/j.jcde.2014.12.006
Figueiredo E, Moldovan I, Barata Marques M (2013) Condition assessment of bridges : past , present and future a complementary approach
Oke SA (2012) Condition Based Maintenance: Status and Future Directions. S Afr J Ind Eng. https://doi.org/10.7166/15-2-203
Thöns S (2017) On the value of monitoring information for the structural integrity and risk management. Doi: 10.1111/mice.12332
Brownjohn JMW, de Stefano A, Xu YL, Wenzel H, Aktan AE (2011) Vibration-based monitoring of civil infrastructure: challenges and successes. J Civil Struct Health Monit 1(3–4):79–95. https://doi.org/10.1007/s13349-011-0009-5
Worden K, Farrar CR (2013) Structural health monitoring: a machine learning perspective. Doi: 10.1177/1475921708090560
Teughels A, De Roeck G (2004) Structural damage identification of the highway bridge Z24 by FE model updating. J Sound Vib 278(3):589–610. https://doi.org/10.1016/j.jsv.2003.10.041
Ettefagh MM, Akbari H, Asadi K, Abbasi F (2015) New structural damage-identification method using modal updating and model reduction. Proc Inst Mech Eng Part C J Mech Eng Sci 229(6):1041–1059. https://doi.org/10.1177/0954406214542966
Jung DS, Kim CY (2013) Finite element model updating on small-scale bridge model using the hybrid genetic algorithm. Struct Infrastruct Eng 9(5):481–495. https://doi.org/10.1080/15732479.2011.564635
Tran-Ngoc H, Khatir S, De Roeck G, Bui-Tien T, Nguyen-Ngoc L, Abdel WM (2018) Model updating for Nam O bridge using particle swarm optimization algorithm and genetic algorithm. Sensors 18(12):4131. https://doi.org/10.3390/s18124131
Samir K, Brahim B, Capozucca R, Abdel WM (2017) Damage detection in CFRP composite beams based on vibration analysis using proper orthogonal decomposition method with radial basis functions and cuckoo search algorithm. Compos Struct 2018(187):344–353. https://doi.org/10.1016/j.compstruct.2017.12.058
Khatir S, Belaidi I, Khatir T, Hamrani A, Zhou YL, Wahab MA (2017) Multiple damage detection in unidirectional graphite-epoxy composite beams using particle swarm optimization and genetic algorithm. Mechanika 23(4):514–521. https://doi.org/10.5755/j01.mech.23.4.15254
Khatir S, Belaidi I, Serra R, Wahab MA, Khatir T (2015) Damage detection and localization in composite beam structures based on vibration analysis. Mechanika 21(6):472–479. https://doi.org/10.5755/j01.mech.21.6.12526
Khatir S, Dekemele K, Loccufier M, Khatir T, Abdel WM (2018) Crack identification method in beam-like structures using changes in experimentally measured frequencies and particle swarm optimization. CR Mec 346(2):110–120. https://doi.org/10.1016/j.crme.2017.11.008
Tiachacht S, Bouazzouni A, Khatir S, Abdel Wahab M, Behtani A, Capozucca R (2018) Damage assessment in structures using combination of a modified Cornwell indicator and genetic algorithm. Eng Struct 177(May):421–430. https://doi.org/10.1016/j.engstruct.2018.09.070
Khatir S, Abdel WM (2018) Fast simulations for solving fracture mechanics inverse problems using POD-RBF XIGA and Jaya algorithm. Eng Fract Mech 2019(205):285–300. https://doi.org/10.1016/j.engfracmech.2018.09.032
Khatir S, Abdel Wahab M (2019) A computational approach for crack identification in plate structures using XFEM XIGA PSO and Jaya algorithm. Theor Appl Fract Mech. https://doi.org/10.1016/j.tafmec.2019.102240
Gillich GR, Furdui H, Abdel Wahab M, Korka ZI (2019) A robust damage detection method based on multi-modal analysis in variable temperature conditions. Mech Syst Signal Process 115:361–379. https://doi.org/10.1016/j.ymssp.2018.05.037
Asadollahi P, Huang Y, Li J (2018) Bayesian finite element model updating and assessment of cable-stayed bridges using wireless sensor data. Sensors 18(9):3057. https://doi.org/10.3390/s18093057
Khatir S, Abdel Wahab M, Boutchicha D, Khatir T (2019) Structural health monitoring using modal strain energy damage indicator coupled with teaching-learning-based optimization algorithm and isogoemetric analysis. J Sound Vib 448:230–246. https://doi.org/10.1016/j.jsv.2019.02.017
Friswell MI (2008) Inverse problems in structural dynamics. In: Second international conference on multidisciplinary design optimization and applications 2008 (September), pp 1–12. DOI: 10.1002/nme.1620170306.
Sawo F, Kempkens E (2017) Model-based and Statistical Approaches for sensor data monitoring for smart bridges. In: IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems 2017, pp 347–352. DOI: 10.1109/MFI.2016.7849512.
Salehi H, Burgueño R (2018) Emerging artificial intelligence methods in structural engineering. Eng Struct 171(April):170–189. https://doi.org/10.1016/j.engstruct.2018.05.084
Gul M, Necati CF (2009) Statistical pattern recognition for structural health monitoring using time series modeling: theory and experimental verifications. Mech Syst Signal Process 23(7):2192–2204. https://doi.org/10.1016/j.ymssp.2009.02.013
Sohn H, Czarnecki JA, Farrar CR (2006) Structural health monitoring using statistical process control. J Struct Eng 126(11):1356–1363. https://doi.org/10.1061/(asce)0733-9445(2000)126:11(1356)
Bakdi A, Kouadri A, Mekhilef S (2018) A data-driven algorithm for online detection of component and system faults in modern wind turbines at different operating zones. Renew Sustain Energy Rev 2019(103):546–555. https://doi.org/10.1016/j.rser.2019.01.013
Hayton P, Utete S, King D, King S, Anuzis P, Tarassenko L (1851) Static and dynamic novelty detection methods for jet engine health monitoring. Philos Trans R Soc A: Math Phys Eng Sci 2007(365):493–514. https://doi.org/10.1098/rsta.2006.1931
Sohn H (1851) Effects of environmental and operational variability on structural health monitoring. Philos Trans R Soc A: Math Phys Eng Sci 2007(365):539–560. https://doi.org/10.1098/rsta.2006.1935
Shyu ML, Chen SC, Sarinnapakorn K, Chang L (2003) A novel anomaly detection scheme based on principal component classifier. In: 3rd IEEE international conference on data mining 2003, pp 353–365. DOI: 10.1007/11539827–18.
Neves C (2017) Structural health monitoring of bridges: model-free damage detection method using machine learning, Licentiate Dissertation. KTH Royal Institute of Technology, TRITA-BKN. Bulletin, ISSN 1103-4270; 149, ISBN: 978-91-7729-345-3
Mehrjoo M, Khaji N, Moharrami H, Bahreininejad A (2008) Damage detection of truss bridge joints using artificial neural networks. Expert Syst Appl 35(3):1122–1131. https://doi.org/10.1016/j.eswa.2007.08.008
Vagnoli M, Remenyte-Prescott R, Andrews J (2018) Railway bridge structural health monitoring and fault detection: state-of-the-art methods and future challenges. Struct Health Monit 17(4):971–1007. https://doi.org/10.1177/1475921717721137
HoThu H, Mita A (2013) Damage detection method using support vector machine and first three natural frequencies for shear structures. Open J Civil Eng 03(02):104–112. https://doi.org/10.4236/ojce.2013.32012
Gui G, Pan H, Lin Z, Li Y, Yuan Z (2017) Data-driven support vector machine with optimization techniques for structural health monitoring and damage detection. KSCE J Civil Eng 21(2):523–534. https://doi.org/10.1007/s12205-017-1518-5
Salehi H, Das S, Chakrabartty S, Biswas S, Burgueño R (2017) A machine-learning approach for damage detection in aircraft structures using self-powered sensor data. In: Sensors and smart structures technologies for civil, mechanical, and aerospace systems 2017, vol. 10168, SPIE; 2017. DOI: 10.1117/12.2260118.
Chalouhi EK, Gonzalez I, Gentile C, Karoumi R (2017) Damage detection in railway bridges using machine learning: application to a historic structure. Procedia Eng 199:1931–1936. https://doi.org/10.1016/j.proeng.2017.09.287
Cha YJ, Wang Z (2018) Automated damage-sensitive feature extraction using unsupervised convolutional neural networks. SPIE Intl Soc Optical Eng. https://doi.org/10.1117/122295966
Dervilis N, Antoniadou I, Barthorpe RJ, Cross EJ, Worden K (2015) Robust methods for outlier detection and regression for SHM applications. Int J Sustain Mater Struct Syst 2(1/2):3. https://doi.org/10.1504/ijsmss.2015.078354
Chen K, Yadav A, Khan A, Meng Y, Zhu K (2019) Improved crack detection and recognition based on convolutional neural. Network. https://doi.org/10.1155/2019/8796743
Santos A, Figueiredo E, Silva MFM, Sales CS, Costa JCWA (2016) Machine learning algorithms for damage detection: Kernel-based approaches. J Sound Vib 363:584–599. https://doi.org/10.1016/j.jsv.2015.11.008
Rytter A (1993) Vibrational based inspection of civil engineering structures. Fracture and dynamics, No. 44, vol R9314. PhD Thesis, Dept. of Building Technology and Structural Engineering, Aalborg University
Hu X, Subbu R, Bonissone P, Qiu H, Iyer N (2008) Multivariate anomaly detection in real-world industrial systems. In: Proceedings of the international joint conference on neural networks 2008 (June), pp 2766–2771. DOI: 10.1109/IJCNN.2008.4634187.
Cunha A, Caetano E, Magalh F (2012) Vibration based structural health monitoring of an arch bridge: from automated OMA to damage detection. Mech Syst Signal Process 28:212–228. https://doi.org/10.1016/j.ymssp.2011.06.011
Sohn H, Farrar CR, Hunter NF, Worden K (2001) Structural health monitoring using statistical pattern recognition techniques. J Dyn Syst Meas Contr 123(4):706. https://doi.org/10.1115/1.1410933
Surace C, Worden K (2010) Novelty detection in a changing environment: a negative selection approach. Mech Syst Signal Process 24(4):1114–1128. https://doi.org/10.1016/j.ymssp.2009.09.009
Cross EJ, Worden K, Koo KY, Brownjohn JMW (2012) Filtering environmental load effects to enhance novelty detection on cable-supported bridge performance. In: Bridge maintenance, safety, management, resilience and sustainability—proceedings of the sixth international conference on bridge maintenance, safety and management 2012 (June), pp 745–752. DOI: 10.1201/b12352–101.
Haritos N, Owen JS (2004) The use of vibration data for damage detection in bridges: a comparison of system identification and pattern recognition approaches. Struct Health Monit 3(2):141–163. https://doi.org/10.1177/1475921704042698
Cheung A, Cabrera C, Sarabandi P, Nair KK, Kiremidjian A, Wenzel H (2008) The application of statistical pattern recognition methods for damage detection to field data. Smart Mater Struct. https://doi.org/10.1088/0964-1726/17/6/065023
Hu WH, Said S, Rohrmann RG, Teng J (2018) Continuous dynamic monitoring of a prestressed concrete bridge based on strain, inclination and crack measurements over a 14-year span. Struct Health Monit 17(5):1073–1094. https://doi.org/10.1177/1475921717735505
Ding Y, Li A (2011) Assessment of bridge expansion joints using long-term displacement measurement under changing environmental conditions. Front Archit Civil Eng China 5(3):374–380. https://doi.org/10.1007/s11709-011-0122-x
Farreras-Alcover I, Chryssanthopoulos MK, Andersen JE (2015) Regression models for structural health monitoring of welded bridge joints based on temperature, traffic and strain measurements. Struct Health Monit 14(6):648–662. https://doi.org/10.1177/1475921715609801
Zhao H, Ding Y, Nagarajaiah S, Li A (2019) Longitudinal displacement behavior and girder end reliability of a jointless steel-truss arch railway bridge during operation. Appl Sci (Switzerland). https://doi.org/10.3390/app9112222
Jianting Z, Jianxi Y, Diankun W (2009) A method for analysis linear correlation for multi-sensor of bridge monitoring system. ACM Int Conf Proc Ser 403:1126–1129. https://doi.org/10.1145/1655925.1656130
Kim SH, Mha HS, Lee SW (2006) Effects of bearing damage upon seismic behaviors of a multi-span girder bridge. Eng Struct 28(7):1071–1080. https://doi.org/10.1016/j.engstruct.2005.11.015
Oladimeji Fasheyi A (2012) Bridge bearings: merits, demerits. M.Sc. Thesis, Royal Institute of Technology (KTH), Stockholm, Sweden. KTH, School of Architecture and the Built Environment (ABE), Civil and Architectural Engineering, Structural Engineering and Bridges
Spanish Ministry of Public Works (1995) Nota técnica sobre aparatos de apoyo para puentes de carretera (Serie normativas). M.O.P: Ministerio de Obras Públicas, Transportes y Medio Ambiente. ISBN: 84-498-1980-6
Yan AM, Kerschen G, De Boe P, Golinval JC (2005) Structural damage diagnosis under varying environmental conditions—Part I: a linear analysis. Mech Syst Signal Process 19(4):847–864. https://doi.org/10.1016/j.ymssp.2004.12.002
Markou M, Singh S (2003) Novelty detection: a review—part 1: statistical approaches. Signal Process 83(12):2481–2497. https://doi.org/10.1016/j.sigpro.2003.07.018
Tharwat A (2016) Principal component analysis—a tutorial. Int J Appl Pattern Recogn 3(3):197. https://doi.org/10.1504/ijapr.2016.079733
Mujica LE, Rodellar J, Fernández A, Güemes A (2011) Q-statistic and t2-statistic pca-based measures for damage assessment in structures. Struct Health Monit 10(5):539–553. https://doi.org/10.1177/1475921710388972
Pozo F, Arruga I, Mujica LE, Ruiz M, Podivilova E (2016) Detection of structural changes through principal component analysis and multivariate statistical inference. Struct Health Monit 15(2):127–142. https://doi.org/10.1177/1475921715624504
Tibaduiza DA, Mujica LE, Rodellar J, Güemes A (2016) Structural damage detection using principal component analysis and damage indices. J Intell Mater Syst Struct 27(2):233–248. https://doi.org/10.1177/1045389X14566520
De Ketelaere B, Hubert M, Schmitt E (2015) Overview of PCA-based statistical process-monitoring methods for time-dependent, high-dimensional data. J Qual Technol 47(4):318–335. https://doi.org/10.1080/00224065.2015.11918137
Park S, Lee JJ, Yun CB, Inman DJ (2008) Electro-mechanical impedance-based wireless structural health monitoring using PCA-data compression and k-means clustering algorithms. J Intell Mater Syst Struct 19(4):509–520. https://doi.org/10.1177/1045389X07077400
Kullaa J (2014) Statistical analysis of the damage detection performance under environmental or operational influences. In: Proceedings of the International Conference on Structural Dynamic , EURODYN 2014; 2014 (July), pp 2303–2310
Lazzarotto E, Gramani LM, Neto AC, Teixeira Junior LA (2016) Principal components in multivariate control charts applied to data instrumentation of dams. Indep J Manag Prod 7(1):17–37. https://doi.org/10.14807/ijmp.v7i1.369
Nguyen VH, Mahowald J, Golinval JC, Maas S (2014) Damage detection in civil engineering structure considering temperature effect. In: Conference Proceedings of the Society for Experimental Mechanics Series 2014; 4: 187–196. DOI: 10.1007/978-3-319-04546-7_22
Ahsan M, Mashuri M, Kuswanto H, Prastyo DD, Khusna H (2018) Multivariate control chart based on PCA mix for variable and attribute quality characteristics. Prod Manuf Res 6(1):364–384. https://doi.org/10.1080/21693277.2018.1517055
Farrar CR (2013) Structural health monitoring: a machine learning perspective
Chou YM, Mason RL, Young JC (2001) The control chart for individual observations from a multivariate non-normal distribution. Commun Stat Theory Methods 30(8–9):1937–1949. https://doi.org/10.1081/STA-100105706
Worden K, Manson G, Fieller NRJ (2000) Damage detection using outlier analysis. J Sound Vib 229(3):647–667. https://doi.org/10.1006/jsvi.1999.2514
Kwitt R, Hofmann U (2006) Robust methods for unsupervised PCA-based anomaly detection. Online
Peeters B, De Roeck G (2001) One-year monitoring of the Z24-bridge: environmental effectsversus damage events. Earthq Eng Struct Dyn 30(2):149–171. https://doi.org/10.1002/1096-9845(200102)30:2<149:AID-EQE1>3.0.CO;2-Z
Sokolova M, Lapalme G (2009) A systematic analysis of performance measures for classification tasks. Inf Process Manag 45(4):427–437. https://doi.org/10.1016/j.ipm.2009.03.002
Xu XL, Xu X, Li XH, Li ZJ, Wang KR, Zhou D (2012) Study on seismic constraint system of high-pier continuous bridges. In: 15th World Conference on Earthquake Engineering, Lisbon, Portugal, 24–28 September 2012, vol 27, pp 21926–21936
FHWA (2015) Steel bridge design handbook. U.S. Department of Transportation Federal Highway Administration, Publication No. FHWA-HIF-16-002, vol 20
Lin W, Yoda T (2017) Bridge engineering: classifications, design loading, and analysis Methods. Elsevier Inc., pp 1–292. https://doi.org/10.1061/9780784481240.068
Lu CH, Liu KY, Chang KC (2011) Seismic performance of bridges with rubber bearings: Lessons learnt from the 1999 Chi-Chi Taiwan earthquake. J Chin Inst Eng Trans Chin Inst Eng, Ser A/Chung-Kuo Kung Ch’eng Hsuch K’an 34(7):889–904. https://doi.org/10.1080/02533839.2011.591920
Revell J (2013) Quasi-isolated highway bridges: influence of bearing anchorage strength on seismic performance. M.S. Thesis, Univ. of Illinois at Urbana-Champaign, Champaign, IL
Rahman Bhuiyan A, Alam MS (2013) Seismic performance assessment of highway bridges equipped with superelastic shape memory alloy-based laminated rubber isolation bearing. Eng Struct 49:396–407. https://doi.org/10.1016/j.engstruct.2012.11.022
Inaudi D (2010) Overview of 40 Bridge structural health monitoring projects. In: International Bridge Conference, IBC 09-45
Inaudi D, Posenato D, Glisic B (2005) Combined static and dynamic monitoring of civil structures with long-gauge fiber optic sensors. In: Proceedings of IMAC XXIII conference and exposition on structural dynamics
Huston D, Fuhr P, Beliveau J (1992) Bridge monitoring with fiber optic sensors. In: US–Japan Bridge Engineering Symposium 1992, pp 475–482
Acknowledgements
Authors would like to acknowledge the discussions with Marcos Pantaleón from APIA XXI, Ambher Monitoring Systems and Banobras S.N.C.
This work has received funding from the European’s Union Horizon 2020 research and innovation program under the grant agreement No 690660 (RAGTIME Project) and No 769373 (FORESEE Project). This paper reflects only the author’s views. The European Commission and INEA are not responsible for any use that may be made of the information contained therein.
David Pardo has received funding from the European Union's Horizon 2020 research and innovation program under the Marie Sklodowska-Curie grant agreement No 777778 (MATHROCKS), the European POCTEFA 2014-2020 Project PIXIL (EFA362/19) by the European Regional Development Fund (ERDF) through the Interreg V-A Spain-France-Andorra program, the Project of the Spanish Ministry of Science and Innovation with reference PID2019-108111RB-I00 (FEDER/AEI), the BCAM “Severo Ochoa” accreditation of excellence (SEV-2017-0718), and the Basque Government through the BERC 2018-2021 program, the two Elkartek projects 3KIA (KK-2020/00049) and MATHEO (KK-2019-00085), the grant "Artificial Intelligence in BCAM number EXP. 2019/00432", and the Consolidated Research Group MATHMODE (IT1294-19) given by the Department of Education.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Garcia-Sanchez, D., Fernandez-Navamuel, A., Sánchez, D.Z. et al. Bearing assessment tool for longitudinal bridge performance. J Civil Struct Health Monit 10, 1023–1036 (2020). https://doi.org/10.1007/s13349-020-00432-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13349-020-00432-1