
Abstract
Graph-based entropy, an index of the diversity of events in their distribution to parts of a co-occurrence graph, is proposed for detecting signs of structural changes in the data that are informative in explaining latent dynamics of consumers’ behavior. For obtaining graph-based entropy, connected sub-graphs are first obtained from the graph of co-occurrences of items in the data. Then, the distribution of items occurring in events in the data to these sub-graphs is reflected on the value of graph-based entropy. For the data on the position of sale, a change in this value is regarded as a sign of the appearance, the separation, the disappearance, or the uniting of consumers’ interests. These phenomena are regarded as the signs of dynamic changes in consumers’ behavior that may be the effects of external events and information. Experiments show that graph-based entropy outperforms baseline methods that can be used for change detection, in explaining substantial changes and their signs in consumers’ preference of items in supermarket stores.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Statistics and machine learning have been adopted to forecasting demands in markets [1, 2]. However, changes in the market due to the effects of external events are hard to explain by learning causalities from data, because external causal events are out of data by definition. Here, we define explanation as to relate a change in the observation with causes that may not be events in the data. Let us assume that we have data on the position of sale (POS) in a supermarket as D in Eq. (1), that is the target data dealt with in this paper, where \(B_{t}\) stands for a basket, i.e., a set of items (members of I, the set of all items in the supermarket) purchased at time t by some consumer and T is the length of the period of time in the data:
Here, suppose that the sales’ volume of coffee increases for a week beyond prediction on the POS data. The cause of this increase may be a TV program broadcasted a few days ago, about the positive effect of coffee on human’s health. Such a causality of change may be explained if a marketer focuses attention on the period of time when the external cause, i.e., the TV program about healthcare that is not in set I, occurred and if additional data about past TV programs are given. Then, the marketer can create a strategy to promote the sales of coffee by publishing a book relevant to the content of the TV program.
Change points have been detected on the changes in parameters and/in models of time series in the approach of machine learning. In Principal Component Analysis (PCA), projecting data to principal components do not only reduce computational cost, but also sharpen the sensitivity of change detection. Here, the change in the correlation, the variance, and the mean of components is detected from before to after a change [3]. Methods for detecting changes in parameters in the model capturing the structure of latent causality have been developed for both discrete [4,5,6] and continuous [7] changes, and the method for the latter is turning out to work for the former as well. The changes in the values of the parameter set \(\varTheta\), from time \(t - \delta t\) to t, are learned as \(\varTheta [t - \Delta t,t] - \varTheta [t - \delta t - \Delta t,t - \delta t]\), where \(\Delta t\) is the width of the training time window of the data to learn \(\varTheta [t - \Delta t,t]\) and \(\varTheta [t - \delta t - \Delta t,t - \delta t]\) from, and \(\delta t\) is the time step of the change. \(\varTheta\) is learned to minimize the error of prediction from the reality of observable events. The precision of change detection is expected to be the better for the larger \(\Delta t\) that can be regarded be a part of tolerant delay, i.e., the length of time the analysis should wait for detecting a change. However, a large \(\Delta t\) is not reasonable from the viewpoint to explain the change quickly. For example, to highlight the causality above from the transient TV program to the coffee sales, \(\Delta t\) is better to be set to 1 month than to 1 year, so that the TV program can outstand as an essential cause in the period of length \(\Delta t\).
From to the viewpoint not only to detect, but also to explain a change with linking to external knowledge, i.e., knowledge about events not included in data, there are methods to learn latent topics of interest in a sequence of words or actions without known labels corresponding to the topics. For example, consecutive time segments, each of which is relevant to a vector in the space of a limited number of latent topics that are not labeled by known labels, are obtained by the dynamic topic model (DTM [8]). By applying DTM to POS data, the changes in consumers’ interests can be detected as the boundaries between the obtained time segments corresponding to the changes in the topic vector. Topic-tracking model (TTM) has been also presented to consider the evolution of each consumer if the behavior of each consumer c is reflected on D in the form of Bt,c instead of Bt in Eq. (1) regarding each consumer as a generator of topic vectors [9]. Topic models have a potential not only to learn topics behind observed events, but also to explain changes. In contrast, the aim of this paper can be positioned as to cope with changes, where such a transient topic, as the healthy coffee above, causes influence on the market and may disappear or get united with other topics.
Furthermore, to explain a change as an effect of an external cause, it is essential to detect a precursor that may be an evidence of the causality. In the example above, the precursor of the increase in the sales of coffee may be a novel co-occurrence of coffee with some healthy food in consumers’ purchase, because people interested in health care may be the leading users of coffee. Such a precursor should appear in a short period that is before a larger number of people start to buy coffee but is after the TV program. Thus, this paper is addressed to the problem to detect a sign of change, i.e., any evidence of the change or the precursor of the change, on the data of a short \(\Delta t\) and also to explain the sign with linking to external events.
Precursors to changes have been really explored in various domains, such as epileptic seizure [10], natural phenomenon [11], aviation [12], etc. These studies aim at alerting to a predefined influential event early enough for prevision, treatment, or management of consequences. Because of the requirement to explain what is coming after the precursor and what human(s) should do, these approaches directly or indirectly use knowledge and models of the dynamics of events in the target domain. For example, the state transition in disease progress [10] has been modeled for detecting precursory symptoms, and physical models have been used for monitoring events relevant to future earthquakes [11]. Methods for precursor detection have been developed also in aviation, to enable human–machine interaction for managing anomalous events [12, 13]. The strength of thus linking external knowledge, out of the data in the target of analysis, is twofold: the potential to explain causalities and the reinforcement of sensitivity to precursors. The idea to use external information for detecting and explaining precursors is also found in extracting associative relations between drugs and symptoms from the text in online medical forums that appear before the changes in label drugs by the Food and Drugs Associations [14].
In this paper, we first set a rough model of consumers’ preference transition in the market, which may be caused by external events, i.e., events out of data in Sect. 2. This transition occurs from seeking diversity to focusing on preferred items, and vice versa, during which new interests of consumers may emerge, possibly due to influential external events. In Sect. 3, we define graph-based entropy (GBE in short) as an index for detecting structural changes of events’ occurrence, modeled as the changes of sub-graphs that are graph-based clusters. Such structural changes are regarded as a computational model of the transitions of consumers’ preference that is redefined as a context in Sect. 2. For each learning period (\(\Delta t\) above, e.g., 4 weeks corresponding to a business period of the supermarket) in available POS data, the value of GBE is computed. The method is evaluated in experiments of Sects. 4 and 5, relating the change in GBE to the interpretable visualizations to explain latent changes in consumers’ interest, and comparing with baseline methods.
2 Explanatory Signs of Changes in Consumers’ Behaviors
2.1 Four-Step Model of Variety Seeking and Focus Making
A consumer explores various products [15], by such an act as browsing the real space of supermarkets or online shop stores. Then, one may look at the details of an interesting item, until finally deciding to buy it after comparison with other items. By the time of the decision to buy, the consumer may be influenced by peripheral information such as the name of a famous person who used the item [16] or externalizes topics of one’s own latent interest via communication with others [17]. All in all, events and information that cannot be included in data may affect consumers’ behaviors via providing new contexts of consumption. A context here means a latent condition of any behaviors of the consumers that does not appear in the data.
The outline of the process toward the emergence of contexts is illustrated in Fig. 1. Here, note that Fig. 1 illustrates the outline conceptually, for imaginary (not real) POS data as in Eq. (1). Here, each node represents a purchased item and the closeness of two nodes their tendency to co-occur in baskets. A node colored the more densely shows an item purchased by the higher frequency. Each sub-graph in which nodes are connected via solid lines, shown in an ellipse of a dotted line, is a cluster. A cluster is a set of items that tend to be purchased in the same baskets, as will be defined more specifically in 3.1 for experimental implementation. Referring to Fig. 1, a rough qualitative model of dynamics in the market is summarized as Phase 1 through 4 below. This process borrows its basis from theories of consumers’ behaviors including variety seeking [15] and decision making in a dynamic market with uncertain events [18].

Transition of consumers’ preference foci. The more densely colored clusters include items by the higher frequency. The separation, movement, and the uniting of clusters correspond to diversity seeking exploration, shifts of interest, and the emergence of new contexts (behind clusters) to fuse consumers’ interests
-
(Phase 1)
Consumers are interested in some part of the market, i.e., as in the large cluster of items (i.e., products) in Fig. 1a
-
(Phase 2)
The interests of various consumers diverge to create a number of clusters, due to their awareness of new contexts, where various items can be used or consumed, via their interaction with various information in exploratory activities, as in Fig. 1b
-
(Phase 3)
After exploring clusters, consumers as a group may come to highlight selected clusters as in Fig. 1c, corresponding to a new context in the market that biases consumer’s actions to purchase
-
(Phase 4)
The clusters may get united, because each consumer having been interested in some specific clusters of items, changes to buy items from multiple clusters in which other consumers were interested, via communications in the context that emerged in Phase 3. Thus, the united clusters form a new large cluster
2.2 Detecting Explanatory Signs of Changes
Based on the rough model of the consumers’ contextual preference transition above, we aim at enabling to explain changes in the market. Here, the explanation of a change in the market means to relate an event, that occurs in the transition from a phase to the next, to previous or forthcoming phases via an admissible (coinciding with other marketers’) hypothetical causality. On this explanation, a plan of business can be presented. To explain a change in this sense, it is desired to execute the following steps.
-
Step 1.
Detect an event in which the dynamics of the market can be explained, e.g., a sign (precursor or an observable evidence) of a change in the market.
-
Step 2.
Explain the cause and the effect of the change above.
-
Step 3.
Propose a plan of actions to suppress or enhance the change, expecting any benefit in business, on the explained causality in Step 2.
The event in Step 1, that initiates these three steps, is called an explanatory sign here. I should be noted that explanatory that means a different concept from explainable that is recently studied in machine learning [19]. When one says that X is explainable, it means that X can be explained (usually to humans). On the other hand, when one says that X is explanatory, it means that X is useful information for explaining something, as in the usage “explanatory hypothesis” [20]. In the sense that this event has an influence on Step 3 where a plan of actions is proposed to/by a decision maker(s), an explanatory sign is a type of a “chance” in chance discovery [18]. In addition, for enabling Steps 2 and 3, we visualize a sequence of graphs for periods close to the time an explanatory sign. By visualizing the co-occurrences of items in the data here, the user can relate the latent context (cause) of the consumption represented by each cluster of items (effect). Therefore, the information about an explanatory sign, to be detected in Step 1, should be related to the graphs used in Step 2, so that the sign can be related to latent causes via clusters in the graph. Thus, we developed a method to highlight events appearing when the structure of the graph changes significantly that corresponds to the timing of a change between phrases in the process above. By regarding such an event, as an explanatory sign of change, the user can explain the essential change in the market, e.g., “the interest of consumers has been expanding to various liquors (Phase 2) but is now focusing on a cold beer or on cold wine (Phase 3) because they drink out-doors under the hot sun,” or “each customer recently buys various cold drinks (Phase 4)” that leads to the action to sell drinks and foods for reducing the sensible temperature.
The definition above of explanatory signs of changes is beyond a mathematical specification in the form of optimizing an object function computable on given data, because explanatory signs of changes mentioned above are linked to the interpretation of the visualized graphs with relating to causal events not included in data. Therefore, we focus on quantifying the likeliness of an event to be an explanatory sign using the graph-based entropy (GBE) below in the next section, based on the co-occurrence graphs (Step 1). In addition, then, we evaluate the performance of GBE in detecting explanatory signs by comparing with changes in the sales of items in the target category. Then, let us show examples of explanations by real marketers in a supermarket (Steps 2 and 3 above), that will go more to details in the future work.
3 Graph-Based Entropy
Kahn suggested using entropy as a measure of variety seeking tendency of consumers [15]. Entropy has also been used in political and marketing sciences to analyze uncertainty and variety in the behaviors of societies and organizations [21,22,23]. The entropy of each part of an image and its variation has been used for detecting contours and changes in the image [24], exemplified for detecting the precursors of weather change. Furthermore, the entropies of traffics and of events in computer networks turned out to provide a scalable technique to detect unexpected behaviors and abrupt changes [25, 26]. In this paper, graph-based entropy, a quantitative index for evaluating structural changes, is proposed based on clusters obtained as connected sub-graphs in the co-occurrence graph of items in the POS data. Below, let us model the process above, i.e., the transition of consumer behaviors from/to variety seeking to/from focusing interest towards decision making, as the decrease/increase in graph-based entropy. Because a basket of items in POS data as in Eq. (1) is in a similar position to a sentence of words in a document [27], a group of active faults quaking in a consecutive set of earthquakes in a certain period [18], or to a set of stocks whose prices increase in the same week [28], the author expects the presented method can be extended to explaining changes in various application domains.
3.1 Graph-Based Entropy as an Index of Explanatory Diversity
Graph-based entropy (GBE) is defined as in Eq. (2).
where \(p\left( {{\text{cluster}}_{j} } \right) = \frac{{{\text{freq}}\left( {{\text{cluster}}_{j} } \right)}}{{\sum\nolimits_{j} {{\text{freq}}\left( {{\text{cluster}}_{j} } \right)} }}.\)
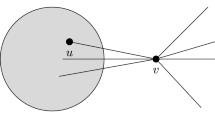
Here, freq(clusterj) denotes the frequency of events in POS data, to which cluster j is the closest among all clusters. An event here means the event that some consumer purchased a set of items in a basket [Bt in Eq. (1)], so a basket corresponds to an event. In defining the closest cluster to a certain basket, the measure of closeness is defined by the cosine of two binary vectors, i.e., \(\overrightarrow {u } \left( {u_{1} ,u_{2} , \ldots u_{m} } \right)\) for basket u and \(\overrightarrow {v } \left( {v_{1} ,v_{2} , \ldots v_{m} } \right)\) for cluster u. In \(u_{i}\) and \(v_{i}\), the presence of the ith among m items in the market is represented by 1 (the absence by 0). A cluster here means a group of items, connecting the top \({{\rho N\left( {N + 1} \right)} \mathord{\left/ {\vphantom {{\rho N\left( {N + 1} \right)} 2}} \right. \kern-0pt} 2}\) pairs of the N nodes via edges, corresponding to the N items in the data. The top pairs here mean pairs of the highest co-occurrence, where a co-occurrence is given by the pointwise mutual information, i.e., p(x and y)/p(x)p(y) for a pair of items x and y. Here, p(x) is the proportion of baskets including item-set x, \(\rho\) is the given (as in 3.2) density of the co-occurrence graph to obtain, from which clusters above are taken as connected sub-graphs. In each panel of Fig. 1, a cluster is shown by the set of nodes in a dotted ellipse.
In obtaining clusters, we do not employ projection to the distance space of topics or distributed representation of items, because the aim of this paper to enable explanation defined in Sect. 2 is realized by visualizing item graphs in this paper. In addition, there is a reason why we should take this graph-based clustering rather than the distance-based. If we apply the distance-based method for convex clustering such as k-means, the three clusters in Fig. 1 (c) will not be united into one even after they get bridged as in (d) as far as k is held to 3, because the centers of the original three clusters still have stronger gravity than bridges such as node A. In addition, there is no obvious logic to reduce k. Hence, a tendency of distance-based clustering method to cut such a bridge as node A and disable to organize the large cluster as in (d). Although we may avoid detecting undesired convex clusters by such methods as spectral clustering [29], its computational complexity is O(n3).
Because such a bridge may play an important role in forecasting or creating new trends in societies and markets [18, 26], we choose to obtain clusters by connecting nodes via edges representing co-occurrence. Thus, we call Hg in Eq. (2) a graph-based entropy (distinguished from entropy-based clustering [30], where entropy is minimized for clustering). When time t is considered, Hg(t) is computed by obtaining clusters and frequencies as in Eq. (2) for the data in the time range of \([t - \Delta t,t]\). \({\text{cps}}_{\text{GBE}} (t)\) in Eq (3) represents the time derivative of Hg(t), for periods when the derivative takes a positive value:
Here, \({\text{cps}}_{\text{GBE}} \left( t \right)\) means that the decrease in Hg(t) from the average value in the recent period of length \(\Delta t\). \({\text{cps}}_{\text{GBE}} \left( t \right)\) takes the larger value if consumers’ interest had ranged across various clusters of items in the market at time \(t - {\text{d}}t\), followed by focusing on restricted clusters of items at time t. Thus, a larger positive value of \({\text{cps}}_{\text{GBE}} \left( t \right)\) means the combination or focusing of consumers’ interest in fewer clusters. Here, in this paper, the value of \({\text{cps}}_{\text{GBE}} \left( t \right)\) is regarded as the change-point score obtained by GBE, for time t. That is, \({\text{cps}}_{\text{GBE}} \left( t \right)\) is an index of the structural change of consumers’ interest is large, from the exploration of various items to the choice of focused items, that corresponds to Phases (c) and (d) in Fig. 1. Let us hereafter focus on these two phases that are more noteworthy in detecting decision making of consumers than Phase (a) or (b).
The direct reflection of changes in the graph structure is a feature of GBE that differentiates it from the previous methods for change detection. Among them, Local Linear Regression (LLR [7]) is taken as a baseline in the experimental comparison in Sects. 4 and 5. On the other hand, in comparison with the dynamic topic models (e.g., DTM [8]) to be also compared experimentally, GBE is free from the constraint of DTM that each of the K topics should succeed one of the topics in the previous periods, because clusters in GBE can be separated/united to lose/form topics fitting the contexts in the external world.
These differences of GBE from existing approaches mentioned above are illustrated in Fig. 2. The transition of Hg(t), in the right of Fig. 2, differs from that of topic distributions in dynamic topic models in that the contexts (corresponding to topics in topic models) in GBE are born or lost via their separations or uniting of graph-based clusters, adapting sensitively to the dynamic interests of consumers due to the emergence of new context formed via such a bridge as node A in Fig. 1. Experimental comparison with change-point scores obtained by other methods will be shown experimentally in Sects. 4 and 5.

Three methods compared: graph-based entropy in the right of this figure differs from the other methods in the sense that the appearance, the separation, the disappearance, and the uniting of contexts, underlying clusters, are reflected on the reformation of graph-based clusters (illustrated by black spots) of items
3.2 The Algorithm to Compute GBE and Its Time Derivative
Based on the definition of GBE and cpsGBE above, Algorithm 1 for detecting a change in the structure of the co-occurrence graph is shown below. The main function calls function Hg(t) corresponding to the computation in Eq. (2). The top \(\theta_{r}\) times, i.e., the times of the \(\theta_{r}\) largest \({\text{cps}}_{\text{GBE}} \left( t \right)\) in Eq. (3), are taken as times when signs of structural changes are detected.
The data given is represented by D, where T is the length of the time series, in which each time t includes Bt that is a set of baskets at t that is really a period such as a week. A basket is a set of items, and each item starts from being one cluster including only itself, in initializing clusters. Clusters are obtained by connecting items co-occurring frequently with each other, where the co-occurrence of two items itema and itemb in set B of baskets is computed as the pointwise mutual information [31] as in Eq. (4):
In Eq. (4), \(p_{B} \left( {{\text{item}}_{a} } \right)\) represents the probability of the occurrence of itema, computed as the number of baskets including itema divided by the number of baskets in B. In Algorithm 1, \({\text{cooc}}_{{B\left( {t - \Delta t} \right):B\left( t \right)}} \cdot {\text{rank}}\left( {{\text{item}}_{i} , {\text{item}}_{j} } \right)\) in line 11 means the rank of pair \(\left\{ {{\text{item}}_{i} , {\text{item}}_{j} } \right\}\), ranked on the co-occurrence in the basket sets from time \(t - \Delta t\) through time t. Here, \(\Delta t\) should be set to a period of the periodical behavior of the market, e.g., a month that is a unit of business period for the supermarket. The highest \(\rho \left| I \right|^{2} /2\) pairs of items, in the ranking of co-occurrence, are connected by edges to form a cluster, so that the density of the graph, represented by \(\rho\) as stated in 3.1, is set constant. The value of \(\rho\) is set to 0.06 here, by which the number of clusters came to be between 10 and 20 for all the given categories, that makes the graph easy to overview and interpret for marketers when visualized as in Sect. 5.
Two items of high co-occurrence take the same clusterID and combined to form one cluster, i.e., a connected sub-graph, as in line 12. Each cluster is reflected on Hg(t) in line 15. Then, \({\text{cps}}_{\text{GBE}} \left( t \right)\), the time derivative of Hg(t) in Eq. (3) is obtained

4 Experiments
Here, let us show results of comparison executed between (1: rank change) that is weekly change in the ranking of items in their purchase frequency (2: LLR) the Local Linear Regression for the detection of changes, (3: DTM), and (4: the time derivative of GBE) \({\text{cps}}_{\text{GBE}} \left( t \right)\), for each category of items.
Let D be the data on purchases of items (item classes precisely, as mentioned just later) in a given target category of items in the market, including a sequence of Bt meaning a purchased set of baskets each time t, that really means 4 weeks ending with the tth week in the data, as in Eq. (5), where Lt is the number of included baskets. For example, let us define liquor as the target category. Then, items are really item classes, for example, wine of 720 ml bottle, beer of 350 ml, etc. Here, the author does not deal with each product item given as Casillero del Diablo 720 ml bottle, Kirin draft beer of 350 ml, etc:
POS data for 1 year for four retail stores have been provided by Kasumi Co. Ltd, a supermarket chain. Here, I deal with ten categories of items that are dry food, stationary, liquor, ice cream, bread, spice, sauce, vegetable, processed food, and processed meat. The POS data from each store dealt with here had 35,995 baskets (seven the ten categories above), 49,853 baskets (8 categories), 22,299 baskets (nine categories), and 17,607 baskets (six categories), on the completeness of the data. That is, stores lacking in items of some subcategories of a category are excluded from the target data, to assure the unique assignment of subcategories to the same items. We divided all baskets in the year in each store into weeks, so T was 52 weeks.
In computing Hg(t) and cpsGBE(t) in Eqs. (2), (3), \(\Delta t\) is set to 4 weeks, for aiding marketers in a supermarket to explain the signs of changes, because 1 month is a unit of business time and weeks are regarded as units of consumers’ life. As mentioned in Sect. 5, \(\Delta t\) is partially set to 2 weeks just for experiment.
(Baseline 0: Regarded as Correct Changes) Weekly Changes in the Rank of the Frequency of Items.
The rank change computed here is regarded as the real change, because this directly reflects consumers’ preference change. For Bt, the R top items of sales volume, i.e., the number of baskets including each item, are sorted as in Eq. (6). Here, rankedi(t) is the (i + 1)th most frequent item in basked set Bt, i.e., at time t:
Here, rankedi(t) represents the ith most frequently purchased item at time (week) t, and topR(t) the set of rankedi(t) for all i in [1, R]. Then, t is regarded as a time of rank change that means a substantial weekly change or a precursor of change, iff alertreal(t) is Truth as in line 2. That is, a rank change is detected at time t, iff the total weekly change of ranks of items, i.e., cpsreal (t) obtained in line 13, becomes larger than its average of 3 weeks before t as in line 1. In addition, as in line 1, an event at or before a rank change by within 2 weeks is regarded as a candidate of the precursor.

Intuitively, the weekly change at t represented by cpsreal(t) in line 13 means the extent to which topR(t) differs from topR(t-1), putting weights on items of higher rank at time t (by the factor \(R - i\) to the ith highest). For example, if top3(t-1) was {apple, banana, orange} and top3(t) is {tomato, apple, orange}, the distance of movement of apple from time t-1 to time t is counted to be 1 that is the absolute value of 1 (= i) minus 0 (= j) in the RHS of line 9. On the other hand, the movement distance of tomato as ranked0(t) (the first in time t) is 3 that is factor R in line 10, because it did not appear in top3(t-1). As a result, the appearance of a new item causes a greater influence on cpsreal(t) than the movement of items that existed since the previous time. Furthermore, the factor \(R - i\) in the RHS of lines 9 and 10 is used to highlight the movement of an item of the higher rank at time t.
We take the total rank change cpsreal(t) in line 13 as the real change of week t, reflecting the requirements of marketers of supermarket chain Kasumi Co. Ltd. that noteworthy changes are the shifts of ranks, especially of higher ranked items.
(Baseline 1) Local Linear Regression.
Whereas the previous studies on change detection often assumed that changes occur abruptly [5, 6], changes came to be assumed to really take place continuously in Local Linear Regression (LLR [7]). In the market, consumers may seem to change suddenly if affected by external events or information such as TV programs, news, or opinions in SNS. However, the information really makes an influence, continuously taking time, on the process of consumers’ decision making rather than to their actions directly and suddenly. By detecting times of high values of the original change-point score, specifically defined for LLR, changes are detected with high accuracy at an early moment after the starting of the real change, i.e., within a short tolerant delay. LLR has been experimentally shown to be effective for real-life data on the events in servers, industrial machines, etc. In this paper, the same 1-year data, as given to other methods, has been given to LLR, in the form below for all the T weeks. In Eq. (7), pitemi (t) represents the proportion (in the range of [0, 1]) of baskets in which item i was bought in the tth week:
In LLR, the change-point score is computed, setting extinction coefficient r. For example, if r is 0.7, i.e., the influence of weak t-1 is reflected on the learning of the parameter \(\varTheta \left( t \right)\) weakened by the factor of 1 − r as 0.3, so that we regard 4 weeks ago as ignorable due to the factor of 0.01. Thus, this condition enables a fair comparison with GBE, if \(\Delta t\) for GBE [the time window of data for computing Hg(t)] is set to 4 weeks. Thus, r has been set to 0.7 in the t test in Sect. 5. To compare with other methods, let us refer to the change-point score of LLR at time t as cpsLLR(t).
(Baseline 2) Dynamic Topic Model (DTM).
DTM introduced in the introduction has been here applied to the POS data assuming that the purchase of each item is caused by consumers’ interest in a given number of topics. By DTM, we can model the transition of topic distribution of each item as time passes by reflecting the time-to-time continuity. In this experiment, DTM has been employed as a tool for detecting changing points of consumers’ behaviors with a dynamic model of latent structural causality. The number of topics has been set to the range of [3, 10] and parameter \(\alpha\) to 0.1, where the number of peaks for the tested 1 year came to be comparable to compared methods. Here, Eq. (8) has been taken as the change-point score:
where \(\theta \left( t \right)\) is the topic vector of the tth week, counting each unique item in one basket purchased as each unique word in one document in DTM [8]. The topic-tracking model (TTM [9]) has also been compared, but we choose only DTM to show experimentally in this paper, because our POS data did not include customers ID for all purchases that is a part of input data for TTM. In general, a supermarket tends to have a lot of customers having no customer IDs. DTM has not such condition and can be tested free from the package provided in https://github.com/magsilva/dtm/tree/master/bin.
For the 1-year sequence of events, the data of 4 weeks (as \(\Delta t\)) are used for evaluating cpsGBE for each week. These data are used for obtaining cpsGBE(t) on the time derivative as far as Hg(t–dt) could be obtained for dt in range of [1, 4] as in Algorithm 1. We can point out the convenience of GBE in that it runs for smaller data (as well as large data) than LLR or DTM using full data for evaluating the change-point scores of each week.
5 Results and Discussion
Based on the experimental results, let us here present the features of GBE from three aspects: in 5.1, we choose two stores of the supermarket chain and the visible correspondence of the curves of change-point scores to the real rank change. In 5.2, the curves are related to co-occurrence graphs of items, for explaining causalities including events out of POS data. In 5.3, statistic comparison with baselines for all the four stores.
5.1 The Correspondence of Change-Point Scores with the Real Rank Change
The three change-point scores, i.e., cpsGBE(t), the cpsLLR(t), and cpsDTM(t), were compared here with the real rank change cpsreal(t). In Fig. 3, the curve for the category of “cooking spice” in store 1 is shown as an example. In (a), the comparison is made for all weeks in the target year. In (b), the period from the 7th until 12th weeks is extracted from (a).

Real rank change (dotted line) in the category of “cooking spice” for store no. 1 and the change-point scores on GBE, DTM, and LLR (solid lines: cpsGBE, cpsDTM, cpsLLR), for the 4th–50th weeks (a), and the extracted 7th to the 12th week (b)
In Fig. 3, the three methods cpsGBE, cpsDTM, and cpsLLR have peaks from the 28th until 31st weeks in category “cooking spices” of store 1, where cpsreal increases with some turbulence. The peak of cpsreal in the 10th week fits the peak of cpsGBE. cpsGBE, cpsDTM, and cpsLLR is rising from the 46th week that is the peak of the real change and find peaks in the 47th week. Thus, the peaks of the three functions tend to synchronize with the curve of cpsreal that is here regarded as the real change of consumers’ preference. In Fig. 4, the curve for the category of “bread” in store 2 is shown. The peaks of cpsGBE, cpsGBE, and cpsDTM do not coincide in this case as well as in (a), so let us expand a part of the 30th through the 46th week as in (b). Here, the peak of cpsreal in the 39th week is preceded by the peak of cpsGBE in the 37th week. In addition, the increase in cpsreal after the 42nd week is preceded by the peak of cpsGBE. Neither of these peaks coincides or is preceded by the peaks of cpsDTM or cpsLLR.

Real rank change in the category of “bread” of store no. 2 and the change-point scores on GBE, DTM, and LLR (solid lines: cpsGBE, cpsDTM, cpsLLR), for the 4th–50th weeks (a), and the extracted 30th–46th weeks (b)
In summary, some visible correspondence of the change-point scores with the real rank change is found and cpsGBE shows relative strength in detecting changes and their precursors. Although obvious superiorities of cpsGBE are not always found by just looking at the curves, cpsGBE precedes cpsreal in some cases. Let us evaluate the feature of GBE integrating a user-oriented viewpoint below.
5.2 Relating the Curve and Co-occurrence Graphs of Items for Explaining Causalities, Considering External Events
Here, let us exemplify the proposed general method in Sect. 2.2, to relate the time series curve of change-point score and the co-occurrence graphs, so that a marketer can explain the latent causality of changes. That is, the user who is supposed to be a marketer first detects the periods of high change-point score, for which the relations of events are selected and visualized. As a result, a sign of a change in the market may be detected (Step 1). Then, he/she explains the causes and the effects of the change (Step 2), to propose a plan of actions to suppress or enhance the change, expecting benefits in business (Step 3).
Corresponding to (b) in Fig. 3, the transition of the co-occurrence graph of items is shown in Fig. 5 for the same data. Here, the nodes represent 20 item classes in the category. In addition, \(\rho \left| I \right|^{2} /2\) pairs (in Algorithm 1), pairs of nodes, are connected via edges. The dotted lines show singly connected lines and the solid multi-connected. That is, if any edge of the dotted line is cut, the graph gets separated into connected sub-graphs, i.e., clusters. A sub-graph connected by either solid or dotted lines forms a cluster.

Variation of the graph corresponding to the 6th through the 11th week for rathe category “cooking spices” in store 1. In the 9th and 10th weeks corresponding to the changes of GBE in Fig. 3, the structure of the graph changes
In the sequence of graphs in Fig. 5 for category “cooking spices”, we find the structure of the graph starts to change from the 9th week, by changing the links of the cluster in the lower part and involving “cream stew” into it. In addition, the cluster gets separated into two clusters in the 10th week. Then, the cluster in the lower half of the graph is reinforced in the 11th week, as shown by the generated cluster. These times of structural changes, i.e., the 9th and 10th weeks, coincide more obviously with peaks of cpsGBE(t), as shown in Fig. 3, than with cpsLLR(t) or cpsDTM(t). “Cream stew” is found to stay in the finally reinforced (multi-connected) cluster in graphs from the 8th until 11th weeks, and other spices in this cluster are also used in cooking stew. Using Google Trends (https://trends.google.co.jp/trends/) for the Japanese query “shichu” that means “stew”, as in Fig. 6, we find that the interest of people in eating stew gets highlighted from the latter half of August every year that nearly coincides with the 9th week when “cream stew” joined the lower cluster. On this finding, the marketers of the supermarket found new actionable plan to promote foods and drinks relevant to stew that are not only spices but also side foods (e.g., bread, pickles, and cabbage), and food to put in stew (potato, onion, mushrooms, and meat), and also such tools as stewpans for cooking stew. This result means that if the marketer first uses a curve in Fig. 3 to choose the period in Fig. 5 (Step 1), to explain the causality of the change (Step 2), and to propose actions of business (Step 3), cpsGBE(t) works in aiding his/her process better than the compared methods.

Changes in the popularity of stew according to Google Trends search
In addition, in the case of “bread” corresponding to Fig. 4, for the period from the 34th until the 44th weeks, corresponding to the changes in the last part of Fig. 4 (b), the transition of the graph is shown in Fig. 7. Here, the nodes represent the 20 items in the category. In the sequence of graphs here, we find that the structure of the graph starts to change substantially from the 37th week and the cluster of “Chinese” bread (mantou with meat inside that is classified in the category of bread in this supermarket) is suppressed. Then, from the 42nd week, the new small cluster including “croissant” appeared and stayed in the graph. These structural changes in the 37th and 42nd weeks coincide with the peaks of only cpsGBE(t), among the three in Fig. 6. The finally created cluster shows breads and bans used in parties with friends and families that are popular in this season (the end of March) in the Japanese culture, because cherries blossom and attract people to do parties under cherry trees, and the new year of schools and firms starts from April. Such a culture had been known to the marketers of the supermarket who provided the POS data, but the importance of the new cluster has not been recognized so far. The combination of detecting changes with GBE and the visualization of graphs thus aids marketers’ insights. The marketers of the supermarket found a new actionable plan to promote sales of bread and other foods and drinks (e.g., cakes and wines) with advertisements to relate those items with parties of young people.

Graphs for the 34th through the 44th weeks for the category “breads” in store 2. In the 37th corresponding to a peak of cpsGBE(t) in Fig. 4, the structure changed
5.3 Statistic Comparison with Baselines
The performance of detecting the signs of change, i.e., of changes or of their precursors, has been evaluated by a statistic comparison. Here, the correspondence of the times of the top values of cpsGBE, cpsLLR, cpsDTM, and cpsreal has been evaluated. The timing of the rank change is given by the times when alertreal is True in Algorithm 2. The top values of cpsGBE are defined by such times when alertGBE is Truth in Algorithm 1. In addition, the times of the same number (\(\theta_{r}\) in Algorithm 1) of the highest values for cpsLLR and cpsDTM. In the evaluation below, the precision of method M is computed as the proportion of t, where alertreal is True, among all t of the top values of cpsM. The recall of method M is the proportion of times of the top values of cpsM, among all t, where alertreal is True.
As a result, the precision of GBE is significantly larger than LLR and DTM as in Tables 1 and 2a. In Table 2, r of LLR has been set to 0.7 in the t test, as mentioned in Sect. 2.2. LLR and DTM have no significant difference, implying that the previous methods did not show such a significant improvement in the detection of precursors as GBE shows. The recall of GBE is also higher than LLR and DTM as in Table 1, although the superiority against DTM is not as significant as of precision according to Table 2b.
An observed phenomenon of DTM in this experiment was that the evaluated recall, precision, and F1 are not monotonically larger for the larger number of topics. In more detailed observation of the analysis by DTM, beyond the results in Tables 1 and 2, items in small (low probability) topics sometimes switch with other small topics, for 1–3 weeks around the top values of change-point score. As a result, the changing moment was not obtained stably. Such a tendency may not be found in evaluating DTM on such standard criteria as perplexity because switching of all words in a topic with another topic does not affect perplexity substantially. In summary of the results, we can say GBE is showing a breakthrough in finding high precision signs of changes, which are sometimes precursors of changes in consumers’ purchase priority.
6 Conclusions
GBE is presented here, based on a model of consumer’s preference shift, that go via preference diversity to focusing. The experiments first show the high correspondence of the change-point scores, obtained on GBE, to the correct real changes in the market. Furthermore, the result supports the proposed method to detect the peaks of change-point score on GBE and take the co-occurrence graphs corresponding to the times of those peaks, to aid a marketer in explaining the latent dynamics and causalities of changes in the market.
The simplicity of the computing algorithm and its linkage to the structure of items’ co-occurrence graph enables a user, who is supposed to be marketers in this paper, to explain the dynamic changes in the contexts behind data on consumers’ buying for living. Thus, we can validate the importance of each change both quantitatively (evaluation of the change-point score), qualitatively (explaining the meaning of changes on the graphs), and quickly (detecting signs some of are found to be precursors). The method is currently being introduced to the supermarket having provided the data to the author, for understanding consumers and improving marketing strategies.
References
Ferreira, K. J., Lee, B. H. A., & Simchi-Levi, D. (2015). Analytics for an online retailer: Demand forecasting and price optimization. Manufacturing and Service Operations Management, 18(1), 69–88.
Efendigil, T., Onut, S., & Kahraman, C. (2009). A decision support system for demand forecasting with artificial neural networks and neuro-fuzzy models: A comparative analysis. Expert Systems with Applications, 36(3), 6697–6707.
Abdulhakim, Q., Alharbi, B., Wang, S., and Zhang, X. (2015) A PCA-based change detection framework for multidimensional data streams: change detection in multidimensional data streams. Proc. 21st ACM SIGKDD Int’l Conf. on Knowledge Discovery and Data Mining, pp. 935–944
Kleinberg, J. (2003). Bursty and hierarchical structure in streams. Data Mining and Knowledge Discovery, 7(4), 373–397.
Fearnhead, P., & Liu, Z. (2007). Online Inference for Multiple Changepoint Problems. Journal of Royal Statistical Society: Series B, 69(4), 589–605.
Hayashi, Y., & Yamanishi, K. (2015). Sequential network change detection with its applications to ad impact relation analysis. Data Mining and Knowledge Discovery, 29, 137–167.
Miyaguchi, K., & Yamanishi, K. (2017). Online detection of continuous changes in stochastic processes. International Journal of Data Science and Analytics, 3(3), 213–229.
Blei, D., and Lafferty, J.D. (2006) Dynamic topic models. Proceedings of International Conference on Machine Learning 23,113–120
Iwata, T., Watanabe, S., Yamada, T., Ueda, N (2009) Topic tracking model for analyzing consumer purchase behavior. 21st International Joint Conference on Artificial Intelligence, 1427–1432
Nesaei, S., & Sharafat, A. R. (2014). Real-time detection of precursors to epileptic seizures: Non-linear analysis of system dynamics. Journal of Medical Signals and Sensors, 4(2), 103–112.
Chmyrev, V., Smith, A., Kataria, D., Nesterov, B., Owen, C., Sammonds, P., et al. (2013). Detection and monitoring of earthquake precursors: TwinSat, a Russia–UK satellite project. Advances in Space Research, 52, 1135–1145.
Melnyk, I., Yadav, P., Steinbach, M., Srivastava, J., Kumar, V., and Banerjee, A. (2013) Detection of precursors to aviation safety incidents due to human factors. Proceedings IEEE 13th International Conference on Data Mining Workshops, 407–412
Matthews, B., Das, S., Bhaduri, K., Das, K., Martin, R., Oza, N., et al. (2013). Discovering anomalous aviation safety events using scalable data mining algorithms. Journal of Aerospace Information Systems, 10(10), 467–475.
Feldman, R., Netzer, O., Peretz, A., Rosenfeld, B. (2015) Utilizing text mining on online medical forums to predict label change due to adverse drug reactions. Proceedings 21st ACM SIGKDD Int’l Conference on Knowledge Discovery and Data Mining, 1779–1788
Kahn, B. K. (1995). Consumer variety seeking among goods and service. Journal of Retailing and Consumer Services, 2, 139–148.
Petty, R. E., Cacioppo, J. T., & Schumann, D. (1983). Central and peripheral routes to advertising effectiveness: The moderating role of involvement. Journal of Consumer Research, 10, 135–145.
Ohsawa, Y., Matsumura, N., & Takahashi, N. (2006). Resonance without response: TShe way of topic growth in communication. Studies in Computational Intelligence (SCI), 30, 155–165.
Ohsawa, Y., & McBurney, P. (2003). Chance Discovery. Heidelberg: Springer.
IJCAI 2017 Workshop on Explainable Artificial Intelligence (2017). http://home.earthlink.net/~dwaha/research/meetings/ijcai17-xai/. Accessed 27 July 2018.
Thagard, P. (1989). Explanatory coherence. Behavioral and Brain Sciences, 12(3), 435–467.
Saviotti, P. P. (1988). Information, variety and entropy in technoeconomic development. Research Policy, 17(2), 89–103.
Alexander, P. J. (1997). Product variety and market structure: A new measure and a simple test. Journal of Economic Behavior and Organization, 32(2), 207–214.
Grigoriev, A. V. (2012). The evaluation of variety of market structure using the entropy indicator. Journal of Siberian Federal University Humanities and Social Sciences, 4, 521–527.
Fuchs, M., Homann, R., & Schwonke, F. (2008). Change detection with GRASS GIS –comparison of images taken by different sensors. Geinformatics FCE CTU, 3, 28.
Nychis, G., Sekar, V., Andersen, D.G., Kim, H., Zhang, H. (2008) An empirical evaluation of entropy-based traffic anomaly detection. Proceedings of the 8th ACM SIGCOMM Conference on Internet Measurement, 151–156, New York, NY, USA
Winter, P., Lampesberger, H., Zeilinger, M., & Hermann, E. (2011). On detecting abrupt changes in network entropy time series. On Communications and Multimedia Security: IFIP Int’l Conf (pp. 194–205). Heidelberg: Springer.
Ohsawa, Y., Soma, H., Matsuo, Y., Usui, M., and Matsumura, N. (2002) Featuring web communities based on word co-occurrence structure of communications. Proceedings of the ACM Eleventh Conf. World Wide Web, 736–742
Ohsawa, Y. (2015) Tangled string diverted for evaluating stock risks: A by product of innovators marketplace on data jackets. IEEE International Conference on Data Mining Workshops, 734–741, Atlantic City, NJ
Nie, F., Zeng, Z., Tsang, I. W., Xu, D., & Zhang, C. (2011). Spectral embedded clustering: A framework for in-sample and out-of-sample spectral clustering. IEEE Transactions on Neural Networks, 22(11), 1796–1808.
Li, T., Ma, S., Ogihara, M. (2004) Entropy-based criterion in categorical clustering, in Proceedings 21st International Conference on Machine Learning, 68–75
Church, K. W., & Hanks, P. (1990). Word association norms, mutual information, and lexicography. Computational Linguistics, 16(1), 22–29.
Acknowledgements
This study was funded by JST-CREST Grant Number JPMJCR1304, and JSPS KAKENHI Grant Numbers JP16H01836 and JP16K12428, Kasumi Co. Ltd., and Kozo Keikaku Engineering Inc.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Ohsawa, Y. Graph-Based Entropy for Detecting Explanatory Signs of Changes in Market. Rev Socionetwork Strat 12, 183–203 (2018). https://doi.org/10.1007/s12626-018-0023-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12626-018-0023-8