
Abstract
Purpose
Pancreatic duct dilation is associated with an increased risk of pancreatic cancer, the most lethal malignancy with the lowest 5-year relative survival rate. Automatic segmentation of the dilated pancreatic duct from contrast-enhanced CT scans would facilitate early diagnosis. However, pancreatic duct segmentation poses challenges due to its small anatomical structure and poor contrast in abdominal CT. In this work, we investigate an anatomical attention strategy to address this issue.
Methods
Our proposed anatomical attention strategy consists of two steps: pancreas localization and pancreatic duct segmentation. The coarse pancreatic mask segmentation is used to guide the fully convolutional networks (FCNs) to concentrate on the pancreas’ anatomy and disregard unnecessary features. We further apply a multi-scale aggregation scheme to leverage the information from different scales. Moreover, we integrate the tubular structure enhancement as an additional input channel of FCN.
Results
We performed extensive experiments on 30 cases of contrast-enhanced abdominal CT volumes. To evaluate the pancreatic duct segmentation performance, we employed four measurements, including the Dice similarity coefficient (DSC), sensitivity, normalized surface distance, and 95 percentile Hausdorff distance. The average DSC achieves 55.7%, surpassing other pancreatic duct segmentation methods on single-phase CT scans only.
Conclusions
We proposed an anatomical attention-based strategy for the dilated pancreatic duct segmentation. Our proposed strategy significantly outperforms earlier approaches. The attention mechanism helps to focus on the pancreas region, while the enhancement of the tubular structure enables FCNs to capture the vessel-like structure. The proposed technique might be applied to other tube-like structure segmentation tasks within targeted anatomies.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction

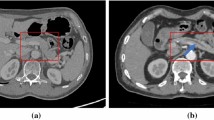
Visual examples of axial CT slices of a normal pancreas and b pancreas with dilated pancreatic duct. The pancreas region is surrounded by the orange contour, and the pancreatic duct is indicated by blue
Pancreatic cancer is one of the most deadly malignancies, killing hundreds of thousands of people every year around the world. Compared to other malignancies, it exhibits the lowest 5-year survival rate, which is approximately 10% in the USA [1]. Due to the mild symptoms, pancreatic cancer is difficult to detect until it has reached an advanced stage. Pancreatic ductal adenocarcinoma (PDAC), which develops in the main duct, accounts for more than 90% of pancreatic cancer [2]. Several clinical studies suggest that dilatation of the main pancreatic duct indicates an increased risk of pancreatic cancer [3, 4]. Therefore, the appearance of pancreatic duct dilatation may serve as a useful entry point for diagnosing pancreatic cancer. However, the main duct of a healthy pancreas is not apparent on the CT scans, as seen in Fig. 1a. On the other hand, if the main pancreatic duct is dilated, a dark line structure can be observed inside the pancreas region as shown in Fig. 1b. Due to this fact, we expect that the automated segmentation of dilated pancreatic ducts from CT volumes could aid in the early detection of pancreatic cancer.
In the past few years, several articles have been devoted to the study of PDAC segmentation [5,6,7,8,9] and its surrounding anatomy such as blood vessels potentially useful for evaluation of treatment response [9], but excluded the automated segmentation of the pancreatic duct itself. However, only a few consider the pancreatic duct region a discrete segmentation target [6, 7]. Both Zhou et al. [6] and Xia et al. [7] investigated pancreatic duct segmentation methods on a large number of precisely annotated venous and arterial phase CT volumes, which are extremely difficult to obtain. All CT volumes are from patients who have already been diagnosed with PDAC. Only a few attempts have so far been made on pancreatic duct segmentation in persons without any type of pre-existing pancreatic cancer. Shen et al. [10] presented a cascade framework for dilated pancreatic duct segmentation using single-phase CT volumes. The region of the pancreas was cut off, according to the segmentation of the pancreas, and only the pancreas regions were utilized as inputs for the pancreatic duct segmentation.
The pancreatic duct segmentation from patients who have not yet developed PDAC is difficult. The primary challenge in dilated pancreatic duct segmentation is the tiny size of the pancreatic duct region in comparison with the whole abdominal CT volume. After developing PDAC, the duct regions would be significantly thicker than that of a healthy person. Fully convolutional networks (FCNs) are the principal method for semantic segmentation, which effectively reduces the complexity of this task. However, some limitations result in the segmentation performance being unacceptable when dealing with small targets. The significant bias between the number of foreground and background voxels will affect the segmentation performance when utilizing FCNs. To overcome this issue, we propose a framework for dilated pancreatic duct segmentation based on anatomical attention. In deep learning-based methods, the attention mechanism is typically used to boost the influence of pertinent information and reduce irrelevant context. In medical image analysis, numerous attention strategies are applied and successfully improve FCN performance [11,12,13]. We assume that allowing the FCN to concentrate on the pancreas region during training will be beneficial for the segmentation of the dilated pancreatic duct. To achieve this, we propose a pancreatic anatomical attention-based method inspired by the Attention U-Net architecture [12]. To fully utilize the information produced at different scales, we employ the multi-scale aggregation before the final prediction. Considering that the anatomical structure of the pancreatic duct is similar to blood vessels, incorporating the tubular features during training may further help the FCN understand the duct’s connection component. We incorporated the feature information gained from the tubular structure enhancement filter [14] as an additional input of our FCN.
This work is an extension of our earlier report [15] at a scientific conference, which was included in the conference proceedings published 10th Workshop, CLIP 2021 of MICCAI 2021. We improved the following four aspects in this journal: (1) enhanced the FCNs for coarse pancreatic segmentation to fully raise network performance with limited computer power; (2) introduced tubular structure enhancement as an extra FCN input for better learning anatomical features; (3) greatly improved segmentation accuracy on dilated pancreatic duct; (4) more metrics were employed to evaluate the efficacy of our proposed strategy.
Methods
Overview
The framework we propose consists of two main steps. Firstly, we develop a straightforward but efficient pancreatic mask segmentation model using the publicly available pancreas dataset [16]. This model can be used to produce the coarse pancreas mask for the dilated pancreatic duct dataset. Then, we crop the pancreas ROIs based on the masks and only use the ROIs for pancreatic duct segmentation. The pancreas mask obtained from the first step can further utilized to guide the FCN for anatomical attention. Additionally, we incorporate a tubular structure enhancement as an additional input channel for FCN.
Coarse pancreatic mask segmentation
Since the pancreatic duct only takes up a small portion of the abdominal CT volume, it is particularly challenging to segment the target directly. Our preceding study suggests that using the pancreas ROIs in FCN during the dilated pancreatic duct segmentation will help train the FCN to concentrate on the pancreatic region [10]. In this study, we develop a straightforward yet effective pancreatic mask segmentation model using the publicly accessible dataset [17] for coarse pancreas mask segmentation. U-Net [18] is a ready-to-use FCN that has proven to be useful in the field of medical image segmentation. 3D U-Net [19] and V-Net [20] are well-known 3D extensions for U-Net, which show considerable power in handling 3D volumes instead of 2D images. As shown in Table 1, the standard V-Net can hold larger input volume sizes with less memory usage than the standard 3D U-Net. Due to this fact, we use V-Net as our baseline for the coarse pancreatic mask segmentation.
Scaling up the networks in depth, width, and resolution aspects has been shown to be beneficial in boosting segmentation performance [21]. When it comes to the V-Net, increasing the number of resolution levels of the network helps it to capture more specific information from the input volumes. Extending the input size of FCNs can also benefit the network by allowing it to handle larger volumes and more detailed contexts. However, simply scaling up a neural network is not always the best approach because larger networks are more computationally expensive to train and may be more prone to overfitting. Model complexity must be carefully balanced with computational efficiency and generalization performance. We scale up the standard V-Net to discover the most efficient type for coarse pancreas segmentation and then utilize it as a baseline for pancreatic duct segmentation in this work. We further introduced different types of normalization techniques, including batch normalization (BN) and instance normalization (IN).
Anatomical attention-based duct segmentation
Network architecture
For the dilated pancreatic duct segmentation, we proposed an anatomical attention-based FCN as shown in Fig. 2. The FCN structure consists of an encoder part and a decoder part with resolution levels of four. A training set \(\textbf{S}=\{\textbf{I}_n,\textbf{L}_n,\textbf{M}_n,\textbf{P}_n, n=1,\ldots ,N\}\) is prepared, where \(\textbf{I}_n\in \mathcal {R}^{W\times H\times D}\) indicates the n-th CT volume from the total N training sets. The volume size in width, height, and depth of the n-th training set is \(W\times H\times D\). \(\textbf{L}_n\) represents the corresponding ground-truth volume of the pancreatic duct region, and \(\textbf{M}_n\) represents the mask of the pancreas region, which is from the segmentation result in “Coarse pancreatic mask segmentation” section. \(\textbf{P}_n\) is the features generated from the tubular structure enhancement filter. The input of our FCN is a two-channel union of CT volume \(\textbf{I}_n\) and the corresponding pancreatic duct enhancement \(\textbf{P}_n\). The coarse pancreas prediction mask \(\textbf{M}_n\) is employed to guide the anatomical attention on each level for the decoder. In multi-level FCNs, the high-resolution features are typically more focused on spatial information, whereas low-resolution features usually concentrate on the semantic information from the input. Combining features from multiple scales enables the learning of additional complementary information, which helps boost and refine the final prediction [13, 22]. Therefore, we aggregate the feature maps from each level to produce the final segmentation similar to the deep supervision [23].

The proposed anatomical attention FCN architecture. The channel numbers are listed above the boxes in blue. The convolution blocks are shown by the blue boxes, and the feature map sizes are indicated next to the boxes
Anatomical attention
Our anatomical attention is inspired by the attention mechanism proposed for 3D U-Net, which was investigated to capture beneficial information and ignore the irrelevant context in FCNs [12]. Since the dilated pancreatic duct only makes up a small fraction of the entire pancreas, we prefer to focus on the whole pancreas rather than just the target. An attention coefficient \(\mathcal {A}_j^l\in [0,1]\) can be computed for each level l of the FCN based on the grid attention [11], where j is the j-th voxel of the input image. The coarse pancreas segmentation is used as a mask for the attention gate to provide spatial information. The detailed procedure of calculating the attention coefficient vector \({\varvec{\mathcal {A}}}^l\) on the l-th level is shown in Fig. 3. The pancreas masks \(\textbf{M}_n\) are downsampled using an adaptive averaging pooling to match the size of the bottleneck layer and are followed by a \(1\times 1\times 1\) convolution to learn the pixel-wise focus regions \(\textbf{g}_n\). For the input feature map, apply a \(2\times 2\times 2\) convolution with stride 2. Then sum up the output with the focus region \(\textbf{g}_n\) over the channel dimension. An attention vector \({\varvec{\mathcal {A}}}^l\) with values between 0 and 1 is produced by the sigmoid activation function. Furthermore, upsample operations are necessary to make the attention vector’s size suitable for each level’s feature map. The output of anatomical attention is obtained by multiplying the input feature map \(\textbf{x}^l\) and attention vector elementally, as

The process of computing the anatomical attention coefficient on l-th level of FCN. The colored boxes are denoting the feature maps, and the feature map sizes are indicated under the boxes
The tubular structure enhancement channel
To fully capture the tubular structure of the pancreatic duct, we introduce an additional channel as input to our FCN. In vessel segmentation, vessel enhancement algorithms are often incorporated to increase the robustness of segmentation performance [24]. Most of these algorithms try to depict the curvature of the vessel-like structure with the second derivatives of the volume intensities. In the medical image analysis field, the Frangi filter is commonly used as the vessels enhancement filter to identify tubular structures and suppress other image features such as noise and non-vessel structures [14]. It is a Hessian-based method proposed to strengthen the differences in intensity in medical volumes with eigenvalues \(|\lambda _{1}| \le |\lambda _{2}| \le |\lambda _{3}|\), where \(\lambda _{1}, \lambda _{2}, \lambda _{3}\) are derived from the Hessian matrix to indicate the principal curvatures of the intensity profile at each voxel. An ideal tubular structure in 3D voxel has \(|\lambda _1|\approx 0,|\lambda _1|\ll |\lambda _2|,\lambda _2\approx \lambda _3\). The Frangi filter is formulated as:
where \(\alpha =0.5\) and \(\beta =0.5\) are fixed by experience to control the sensitivity of the filter, and \(\gamma \) uses half of the maximum Hessian norm of the intensity range [14, 25]. \(R_a\) is used to distinguish the tubular-like and the plate-like structure, \(R_b\) to measure the blob-like structure, and S indicates the low-contrast backgrounds. These patterns can be formulated as:
For post-processing, we utilize pancreatic mask segmentation to eliminate the values outside the pancreas areas. Additionally, to better adapt to the deep neural network, we apply min–max normalization to convert the remaining filter output into the range of 0 to 1.
Experiments and results
Experiment details
We used the publicly accessible TCIA pancreas annotation dataset [16] to develop the coarse pancreatic mask segmentation model. The dataset contains 82 contrast-enhanced portal venous phase abdomen 3D CT volumes, with \(512\times 512\) pixels for each CT slice. Each CT volume has 181 to 466 slices, with slice resolution between 0.5 mm and 1.0 mm. The dataset was randomly divided into 48 training, 16 validation, and 18 testing samples. The dataset was resampled into \(1\times 1\) mm isotropic resolution for the pancreatic mask segmentation. We generated the pancreas ROIs based on the segmentation results, followed by [10]. For the dilated pancreatic duct segmentation, we utilized 30 contrast-enhanced portal venous phase 3D CT volumes from persons who had the symptom of pancreatic duct dilation. We must point out that none of them have been diagnosed with PDAC. This dataset is a private dataset, with all the CT volumes taken at Chiba Kensei Hospital in Japan. The duct regions were annotated by an experienced PhD student who is knowledgeable about the pancreas and pancreatic duct dilation and its appearance in abdominal CT images. All images were manually refined slice by slice using Pluto [26]. The details of pancreatic duct annotation operations are described in [10]. Each CT slice size is \(512\times 512\) pixels, and the slice numbers range from 192 to 887. The resolution of each axis is 0.59\(-\)0.75 mm, 0.59\(-\)0.75 mm, and 0.3\(-\)1.0 mm, respectively. The dilated pancreatic duct dataset was resampled into an isotropic resolution of \(0.5\times 0.5\times 0.5\) mm. To accommodate a higher resolution, the coarse pancreatic mask was scaled up before being used in the pancreatic duct segmentation. For a fair comparison among different methods, we exclusively used cropped ROIs of the pancreas regions as input in this task. The input size of FCNs in pancreatic duct segmentation is fixed at \(160\times 160\times 160\) voxels. We performed the four fold cross-validation on the pancreatic duct segmentation to ensure the reliability of the experimental results.
Our experiments are implemented on PyTorch 1.7.1, and NVIDIA Tesla V100 with 32 GB of memory is used for all experiments. For all CT volumes, we only kept the intensity within the range of [\(-\) 200, 200] H.U. and then rescaled the intensity values into the range of [0, 1] with min–max normalization to better illustrate the pancreas regions. During training, we use Adam optimization with a learning rate of \(10^{-4}\) to minimize the Dice loss function.
Results
Table 2 shows the quantitative evaluation result of the coarse pancreatic mask segmentation. We used V-Net as the baseline and scaled up the network in depth, width, and resolution, which correspond to the level number, filter number, and input size. Scaling up the V-Net positively influences pancreas segmentation. In this experiment, both BN and IN were used, with IN being more beneficial for pancreas segmentation.
Table 3 shows an ablation study of our proposed FCNs on the dilated pancreatic duct segmentation. Four metrics including Dice similarity score (DSC), sensitivity, NSD, and 95% Hausdorff Distance (HD95) are employed. We compared the standard Attention U-Net [11] with our proposed pancreatic anatomical attention network (PANet), as well as PANet with multi-scale aggregation (PAMNet) and further evaluated PAMNet with non-normalized (MCPAMNet) and normalized (NMCPAMNet) tubular structure enhancement. In the context of pancreatic duct segmentation, our baseline model is the Attention U-Net, with 3D U-Net serving as the backbone FCN. Recognizing V-Net’s strong performance in pancreas segmentation, we conducted additional experiments using V-Net as the backbone. Furthermore, we conducted evaluations of different FCNs with both IN and BN to identify the optimal combination The best results are obtained by NMCPAMNet using the V-Net as FCN backbone and IN as the normalization operation. Figure 4 shows segmentation examples of coronal slice and 3D rendering in each method with U-Net and BN as backbone. In Fig. 5, we present a segmentation comparison using NMCPAMNet with four different backbone combinations: U-Net+BN, U-Net+IN, V-Net+BN, and V-Net+IN. Figure 6 shows a comparison of the heatmap depiction of attention coefficients using Attention U-Net and our proposed anatomical attention.
Table 4 provides additional comparisons between the method we proposed and other reported pancreatic duct segmentation strategies. We must point out that [6] was carried out on PDAC patients, whose pancreatic ducts are substantially larger than normal cases. These studies used a dataset of 239 cases, which was much greater than the 30 examples we used. Our dataset was the same as in [10] and [15]. Although it is difficult to directly compare studies using different datasets, the approach we propose yields the highest DSC on pancreatic duct segmentation on single-phase CT volume.

Comparison of a ground truth and pancreatic duct segmentation result using b Attention U-Net [11] c PANet, d PAMNet, e MCPAMNet, f NMCPAMNet. All the approaches here are using U-Net and BN as backbone. The segmentation failure is indicated by a blue arrow

Comparison of pancreatic duct segmentation result using NMCPAMNet architecture with four different backbone settings: a U-Net+BN b U-Net+IN c V-Net+BN, and d V-Net+IN. The segmentation failure is indicated by a blue arrow. The ground truth of this case is shown in Fig. 4a

Heatmap visualization of attention coefficients on a CT using b Attention U-Net [11] and our proposed c Anatomical attention. The pancreatic duct is indicated by the red arrow inside the pancreas
Discussion
For the pancreatic mask segmentation, increasing the input size and number of levels of the V-Net is both beneficial and efficient. On the other hand, increasing the initial filter number helps in some situations, but significantly raises the parameter numbers of FCN. Thus, it is necessary to strike a balance between segmentation performance and model complexity. For normalization, IN is better suited for pancreatic segmentation using V-Net than BN. When applying IN on V-Net, the DSC for pancreatic segmentation increased considerably at each network scale. Because BN performance is heavily dependent on batch size, which is limited by computer power.
For pancreatic duct segmentation, focusing on the entire pancreas anatomy improves the segmentation compared to the original Attention U-Net [11]. In medical image analysis, it is not always optimal to focus on a particular target. Narrowing the FCN focus would result in a lower fault tolerance during training when the target region is quite small. This hypothesis was further affirmed by the visualization of attention coefficients in Fig. 6. Some pancreatic duct parts are outside of the focus in standard attention U-Net. The segmentation performance is also enhanced by multiscale aggregation of FCN, which makes full use of the knowledge acquired at each level. The DSC on pancreatic duct segmentation was significantly enhanced by introducing the normalized tubular structure enhancement as a second input channel. The additional channel helps FCN in understanding the duct’s tubular structure better. Our proposed NMCPAMNet with V-Net baseline and IN demonstrates the most favorable performance across all four metrics. It achieves the highest scores in DSC and lowest in HD95. While it may not have the highest accuracy in terms of sensitivity and NSD, its performance remains comparable to other methods. Segmentation examples of 3D rendering and coronal slice segmentation are shown in Fig. 4 and Fig. 5. The tubular structure enhancement can improve the connection of the pancreatic duct segmentation. The pancreatic duct segmented by NMCPAMNet using V-Net+IN as the backbone exhibits smoother duct segmentation with less exceeding segmentations.
We also compared our proposed method to existing pancreatic duct segmentation strategies that are published in Table 4. When compared to other reported results of pancreatic duct segmentation using single-phase CT volumes only, our method outperforms all existing strategies, despite the fact that we employed only 30 cases instead of the larger dataset’s 239 cases.
Conclusions
We investigated an anatomical attention-based strategy for the segmentation of the dilated pancreatic duct from CT volumes. Our strategy was motivated by a usual clinical experience. When radiologists look for the pancreatic duct from the CT volumes, they first try to locate the pancreas area. We proposed an attention mechanism that enables to focus on the entire pancreas anatomy rather than just the target. To fully capture the vessel-like structure of the pancreatic duct, we employed a tubular structure enhancement as an additional input channel for our FCN. We evaluated our proposed FCNs using four different assessment measures, which demonstrated the effectiveness of our proposed method. Upon comparing our results with other reported results for pancreatic duct segmentation, our method exhibits significant superiority over other strategies that rely on single-phase CT volumes. Our technique might be applied to other tube-like structure segmentation tasks for other anatomies in the future. Nevertheless, the duct component still has some exceeding and improper segmentation. For the use of PDAC diagnosis in real-world settings, the overall accuracy still needs to be increased to capture the full anatomy of the duct. This remains as future work.
References
Mizrahi JD, Surana R, Valle JW, Shroff RT (2020) Pancreatic cancer. Lancet 395(10242):2008–2020
Orth M, Metzger P, Gerum S, Mayerle J, Schneider G, Belka C, Schnurr M, Lauber K (2019) Pancreatic ductal adenocarcinoma: biological hallmarks, current status, and future perspectives of combined modality treatment approaches. Radiat Oncol 14(1):1–20
Edge MD, Hoteit M, Patel AP, Wang X, Baumgarten DA, Cai Q (2007) Clinical significance of main pancreatic duct dilation on computed tomography: single and double duct dilation. World J Gastroenterol 13(11):1701
Tanaka S, Nakao M, Ioka T, Takakura R, Takano Y, Tsukuma H, Uehara H, Suzuki R, Fukuda J (2010) Slight dilatation of the main pancreatic duct and presence of pancreatic cysts as predictive signs of pancreatic cancer: a prospective study. Radiology 254(3):965–972
Zhu Z, Xia Y, Xie L, Fishman EK, Yuille AL (2019) Multi-scale coarse-to-fine segmentation for screening pancreatic ductal adenocarcinoma. In: Medical image computing and computer assisted intervention—MICCAI 2019, Springer, Cham, pp 3–12
Zhou Y, Li Y, Zhang Z, Wang Y, Wang A, Fishman EK, Yuille AL, Park S (2019) Hyper-Pairing network for multi-phase pancreatic Ductal adenocarcinoma segmentation. In: Medical image computing and computer assisted intervention—MICCAI2019. Springer, vol 11765, pp 155–163
Xia Y, Yu Q, Shen W, Zhou Y, Fishman EK, Yuille AL (2020) Detecting pancreatic ductal adenocarcinoma in multi-phase CT scans via alignment ensemble. In: Medical image computing and computer assisted intervention—MICCAI2020. Springer, vol 12263, pp 285–295
Wang Y, Tang P, Zhou Y, Shen W, Fishman EK, Yuille AL (2021) Learning inductive attention guidance for partially supervised pancreatic ductal adenocarcinoma prediction. IEEE Trans Med Imaging 40(10):2723–2735
Mahmoudi T, Kouzahkanan ZM, Radmard AR, Kafieh R, Salehnia A, Davarpanah AH, Arabalibeik H, Ahmadian A (2022) Segmentation of pancreatic ductal adenocarcinoma (PDAC) and surrounding vessels in CT images using deep convolutional neural networks and texture descriptors. Sci Rep 12(1):3092
Shen C, Roth HR, Hayashi Y, Oda M, Miyamoto T, Sato G, Mori K (2022) A cascaded fully convolutional network framework for dilated pancreatic duct segmentation. Int J Comput Assist Radiol Surg 17(2):343–354
Oktay Ozan, Schlemper J, Folgoc LL, Lee M, Heinrich M, Misawa K, Mori K, McDonagh S, Hammerla NY, Kainz B, Glocker B, Rueckert D (2018) Attention U-Net: learning where to look for the pancreas. In: Medical imaging with deep learning
Schlemper Jo, Oktay O, Schaap M, Heinrich MP, Kainz B, Glocker B, Rueckert D (2018) Attention gated networks: learning to leverage salient regions in medical images. Med Image Anal 53:197–207
Sinha A, Dolz J (2021) Multi-scale self-guided attention for medical image segmentation. IEEE J Biomed Health Inform 25(1):121–130. https://doi.org/10.1109/JBHI.2020.2986926
Frangi AF, Niessen WJ, Vincken KL, Viergever MA (1998) Multiscale vessel enhancement filtering. In: International conference on medical image computing and computer-assisted intervention. Springer, pp 130–137
Shen C, Roth HR, Hayashi Y, Oda M, Miyamoto T, Sato G, Mori K (2021) Attention-guided pancreatic duct segmentation from abdominal CT volumes. In: Clinical image-based procedures, distributed and collaborative learning, artificial intelligence for combating COVID-19 and secure and privacy-preserving machine learning. Lecture Notes in Computer Science. Springer, vol 12969, pp 46–55. https://doi.org/10.1007/978-3-030-90874-4_5
Roth HR, Farag A, Turkbey EB, Lu L, Liu J, Summers RM (2016). Data from pancreas-CT. https://doi.org/10.7937/K9/TCIA.2016.tNB1kqBU
Clark K, Vendt B, Smith K, Freymann J, Kirby J, Koppel P, Moore S, Phillips S, Maffitt D, Pringle M, Tarbox L, Prior F (2013) The cancer imaging archive (TCIA): maintaining and operating a public information repository. J Digit Imaging 26(6):1045–1057
Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: International conference on medical image computing and computer-assisted intervention. Springer, pp 234–241
Çiçek Ö, Abdulkadir A, Lienkamp SS, Brox T, Ronneberger O (2016) 3D U-Net: learning dense volumetric segmentation from sparse annotation. In: International conference on medical image computing and computer-assisted intervention. Springer, pp 424–432
Milletari F, Navab N, Ahmadi S-A (2016) V-Net: Fully convolutional neural networks for volumetric medical image segmentation. In: 2016 fourth international conference on 3D vision (3DV). IEEE, pp 565–571
Tan M, Le Q (2019) EfficientNet: Rethinking model scaling for convolutional neural networks. In: Proceedings of the 36th international conference on machine learning. Proceedings of machine learning research. PMLR, vol 97, pp 6105–6114
Roth HR, Shen C, Oda H, Sugino T, Oda M, Hayashi Y, Misawa K, Mori K (2018) A multi-scale pyramid of 3D fully convolutional networks for abdominal multi-organ segmentation. In: Frangi AF, Schnabel JA, Davatzikos C, Alberola-López C, Fichtinger G (eds) Medical image computing and computer assisted intervention—MICCAI 2018. Springer, Cham, pp 417–425
Lee C-Y, Xie S, Gallagher P, Zhang Z, Tu Z (2015) Deeply-supervised nets. In: Lebanon G, Vishwanathan SVN (eds) Proceedings of the eighteenth international conference on artificial intelligence and statistics. Proceedings of machine learning research. PMLR, San Diego, vol 38, pp 562–570
Lamy J, Merveille O, Kerautret B, Passat N, Vacavant A (2021) Vesselness filters: A survey with benchmarks applied to liver imaging. In: 2020 25th international conference on pattern recognition (ICPR), pp 3528–3535
Jimenez-Carretero D, Santos A, Kerkstra S, Rudyanto RD, Ledesma-Carbayo MJ (2013) 3d frangi-based lung vessel enhancement filter penalizing airways. In: 2013 IEEE 10th international symposium on biomedical imaging, pp 926–929
Yukitaka N, Deguchi D, Kitasaka T, Mori K, Suenaga Y (2008) Pluto: a common platform for computer-aided diagnosis. Med Imaging Technol 26(3):187
Acknowledgements
Part of this work was supported by JST CREST (JPMJCR20D5), JST Moonshot (JPMJMS2214 and JPMJMS2033), JSPS KAKENHI (894030,21K19898).
Funding
Open Access funding provided by Nagoya University.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This study was approved by the institutional review board of the Chiba Kensei Hospital.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shen, C., Roth, H.R., Hayashi, Y. et al. Anatomical attention can help to segment the dilated pancreatic duct in abdominal CT. Int J CARS 19, 655–664 (2024). https://doi.org/10.1007/s11548-023-03049-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11548-023-03049-z