
Abstract
Discovery of frequent subgraphs of an input network is one of the most important facilities for mining and analyzing complex networks. The most accurate solution to frequent subgraph discovery is to enumerate all subgraphs of size k and then count the frequency of each isomorphic class. However, the process is much time consuming because the number of subgraphs grows exponentially with the growth of the input network, or by increasing the size of the subgraphs. Also, there is no known polynomial-time algorithm for subgraph isomorphism detection, and this issue makes the problem harder. Hence, the available solutions can just mine small input networks and small subgraph sizes. A parallel and load-balanced solution named Subdigger is proposed which is faster and more efficient compared to available solutions. Subdigger efficiently executes on current multicore and multiprocessor machines, and incorporates a fast heuristic with a high-performance concurrent data structure which significantly accelerates detection and counting of isomorphic subgraphs. Subdigger can also handle large networks and subgraph sizes using external memory and external sorting. We performed several experiments using real-world input networks. Compared to the available solutions, Subdigger can extract frequent subgraphs much faster and the performance scales almost linearly using additional processor cores. The experimental results show that Subdigger can be more than 100 times faster than other solutions on a 4-core Intel i7 machine. Besides performance, Subdigger can process larger subgraphs using external memory while other tools crash due to memory limitation.





Similar content being viewed by others


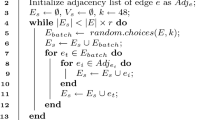
References
Milo R, Shen-Orr S, Itzkovitz S, Kashtan N, Chklovskii D, Alon U (2002) Network motifs: simple building blocks of complex networks. Science 298(5594):824–827
Ribeiro P, Silva F (2010) g-Tries: an efficient data structure for discovering network motifs. In: Proceedings of the ACM symposium on applied computing, pp 1559–1566
Kashani ZRM, Ahrabian H, Elahi E, Nowzari-Dalini A, Ansari E, Asadi S, Mohammadi S, Schreiber F, Masoudi-Nejad A (2009) Kavosh: a new algorithm for finding network motifs. BMC Bioinform 10(1):318
Wernicke S, Rasche F (2006) FANMOD: a tool for fast network motif detection. Bioinformatics 22(9):1152–1153
Grochow J, Kellis M (2007) Network motif discovery using subgraph enumeration and symmetry-breaking. In: Speed T, Huang H (eds) Research in computational molecular biology, vol 4453. Springer, Berlin, Heidelberg, pp 92–106
Harary F, Palmer E (1967) The enumeration methods of Redfield. Am J Math 89(2):373–384
Johnson DS (2005) The NP-completeness column. ACM Trans Algorithms 1(1):160–176
Wernicke S (2006) Efficient detection of network motifs. IEEE/ACM Trans Comput Biol Bioinform 3(4):347–359
Leskovec J, Faloutsos C (2006) Sampling from large graphs. In: Proceedings of the 12th ACM SIGKDD international conference on knowledge discovery and data mining, pp 631–636
Kashtan N, Itzkovitz S, Milo R, Alon U (2004) Efficient sampling algorithm for estimating subgraph concentrations and detecting network motifs. Bioinformatics 20(11):1746–1758
Gjoka M, Kurant M, Butts CT, Markopoulou A (2010) Walking in facebook: a case study of unbiased sampling of osns. In: INFOCOM Proceedings IEEE, pp 1–9
Lee C-H, Xu X, Eun DY (2012) Beyond random walk and metropolis-hastings samplers: why you should not backtrack for unbiased graph sampling. ACM SIGMETRICS Perform Eval Rev 40(1):319–330
Schreiber F, Schwbbermeyer H (2004) Towards motif detection in networks: frequency concepts and flexible search. In: Proceedings of the international workshop on network tools and applications in biology, pp 91–102
Rudi AG, Shahrivari S, Jalili S, Kashani ZRM (2013) RANGI: a fast list-colored graph motif finding algorithm. IEEE/ACM Trans Comput Biol Bioinform 10(2):504–513
McKay BD (1981) Practical graph isomorphism. Department of Computer Science, Vanderbilt University
Pietro Cordella L, Foggia P, Sansone C, Vento M (2001) An improved algorithm for matching large graphs. In: 3rd IAPR-TC15 workshop on graph-based representations in pattern recognition, pp 149–159
Junttila T, Kaski P (2007) Engineering an efficient canonical labeling tool for large and sparse graphs. In: Proceedings of the ninth workshop on algorithm engineering and experiments and the fourth workshop on analytic algorithms and combinatorics, pp 135–149
Khakabimamaghani S, Sharafuddin I, Dichter N, Koch I, Masoudi-Nejad A (2013) QuateXelero: an accelerated exact network motif detection algorithm. PloS one 8(7):e68073
Ribeiro P, Silva F, Lopes L (2012) Parallel discovery of network motifs. J Parallel Distrib Comput 72(2):144–154
Wang T, Touchman JW, Zhang W, Suh EB, Xue G (2005) A parallel algorithm for extracting transcriptional regulatory network motifs. In: Fifth IEEE symposium on bioinformatics and bioengineering, pp 193–200
Li X, Stones DS, Wang H, Deng H, Liu X, Wang G (2012) NetMODE: network motif detection without Nauty. PloS one 7(12):e50093
Schatz M, Cooper-Balis E, Bazinet A (2008) Parallel network motif finding. Technical report, University of Maryland, Institute for Advanced Computer Studies
Zhao Z, Khan M, Kumar VSA, Marathe M (2010) Subgraph enumeration in large social contact networks using parallel color coding and streaming. In: 39th international conference on parallel processing, vol 10, pp 594–603
Ribeiro P, Silva F, Lopes L (2010) Efficient parallel subgraph counting using g-tries. In: IEEE international conference on cluster computing (CLUSTER), pp 217–226
Dean J, Ghemawat S (2010) MapReduce: a flexible data processing tool. Commun ACM 53(1):72–77
Zhao Z, Wang G, Butt AR, Khan M, Kumar VS, Marathe MV (2012) Sahad: subgraph analysis in massive networks using hadoop. In: Proceedings of IEEE international parallel and distributed processing symposium (IPDPS), pp 390–401
Zhao Z (2012) Subgraph querying in relational networks: a MapReduce approach. In: IEEE international parallel and distributed processing symposium workshops (IPDPSW), pp 2502–2505
Cohen J (2009) Graph twiddling in a MapReduce world. Comput Sci Eng 11:29–41
Wu B, Bai Y (2010) An efficient distributed subgraph mining algorithm in extreme large graphs. In: Artificial intelligence and computational intelligence, Springer, pp 107–115
Afrati FN, Fotakis D, Ullman JD (2013) Enumerating subgraph instances using map-reduce. In: Proceedings of IEEE 29th international conference on data engineering (ICDE), pp 62–73
Babai L, Luks EM (1983) Canonical labeling of graphs. In: Proceedings of the fifteenth annual ACM symposium on Theory of computing, pp 171–183
Katebi H, Sakallah K, Markov I (2012) Conflict anticipation in the search for graph automorphisms. In: Bjørner N, Voronkov A (eds) Logic for programming, artificial intelligence, and reasoning, vol 7180. Springer, Berlin, Heidelberg, pp 243–257
Ying L, Ding D (2012) Topology structure and centrality in a java source code. In: International conference on granular computing (GrC), pp 787–789
Shen-Orr SS, Milo R, Mangan S, Alon U (2002) Network motifs in the transcriptional regulation network of Escherichia coli. Nat Genet 31(1):64–68
Pablo MG, Danon L (2003) Community structure in jazz. Adv Complex Syst 6(04):565–573
Guimerà R, Danon L, D’iaz-Guilera A, Giralt F, Arenas A (2003) Self-similar community structure in a network of human interactions. Phys Rev E 68(6):65103
Leskovec J, Kleinberg J, Faloutsos C (2007) Graph evolution: densification and shrinking diameters. ACM Trans Knowl Discov Data 1(1):1–41
Zaharia M, Chowdhury M, Franklin MJ, Shenker S, Stoica I (2010) Spark: cluster computing with working sets. In: Proceedings of the 2nd USENIX conference on hot topics in cloud computing
Shahrivari S (2014) Beyond batch processing: towards real-time and streaming big data. Computers 3(4):117–129
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Shahrivari, S., Jalili, S. High-performance parallel frequent subgraph discovery. J Supercomput 71, 2412–2432 (2015). https://doi.org/10.1007/s11227-015-1391-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-015-1391-2