
Abstract
A multimedia content is composed of several streams that carry information in audio, video or textual channels. Classification and clustering multimedia contents require extraction and combination of information from these streams. The streams constituting a multimedia content are naturally different in terms of scale, dynamics and temporal patterns. These differences make combining the information sources using classic combination techniques difficult. We propose an asynchronous feature level fusion approach that creates a unified hybrid feature space out of the individual signal measurements. The target space can be used for clustering or classification of the multimedia content. As a representative application, we used the proposed approach to recognize basic affective states from speech prosody and facial expressions. Experimental results over two audiovisual emotion databases with 42 and 12 subjects revealed that the performance of the proposed system is significantly higher than the unimodal face based and speech based systems, as well as synchronous feature level and decision level fusion approaches.








Similar content being viewed by others


Notes
The term facial feature may refer to a part of the face such as eye and mouth or a quantity acquired from the face such as the distance between the two eye centers. The distinction between these concepts should be clear from the context.
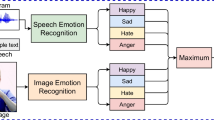
see Section 1.
Tarbiat Modares University Emotion Database.
References
Bassili JN (1979) Emotion recognition: the role of facial movement and the relative importance of upper and lower areas of the face. J Pers Soc Psychol 37(11):2049–2058
Black MJ, Yacoob Y (1997) Recognizing facial expressions in image sequences using local parameterized models of image motion. Int J Comput Vis 25:23–48
Boehner K, DePaula R, Dourish P, Sengers P (2007) How emotion is made and measured. Int J Human Comput Stud 65:275–291
Boersma P, Weenink D (2007) Praat: doing phonetics by computer (version 4.6.12) [computer program]
Busso C, Narayanan SS (2007) Interrelation between speech and facial gestures in emotional utterances: a single subject study. IEEE Trans Audio Speech Lang Process 15:2331–2347
Castellano G, Kessous L, Caridakis G (2008) Emotion recognition through multiple modalities: face, body gesture, speech. In: Beale R (ed) Affect and emotion in human-computer interaction, vol 4868. Springer, New York
Cowie R, Douglas-Cowie E, Tsapatsoulis N, Votsis G, Kollias S, Fellenz W, Taylor JG (2001) Emotion recognition in human-computer interaction. Signal Process Mag IEEE 18:32–80
De Silva LC, Pei Chi N (2000) Bimodal emotion recognition. In: Proceedings of the fourth IEEE international conference on automatic face and gesture recognition, vol 1, pp 332–335
Dupont S, Luettin J (2000) Audio-visual speech modeling for continuous speech recognition. IEEE Trans Multimedia 2(3):141–151
Ekman P (1993) Facial expression and emotion. Am Psychol 48:384–392
Ekman P, Friesen WV, Hager JC (2002) Facial Action Coding System (FACS), the manual: a human face
Fasel B, Luettin J (1999) Automatic facial expression analysis: a survey, vol 36
Fragopanagos N, Taylor JG (2005) Emotion recognition in human-computer interaction. Neural Netw 18:389–405
Gunes H, Piccardi M, Pantic M (2008) From the lab to the real world: affect recognition using multiple cues and modalities. In: Or J (ed) Affective computing: focus on emotion expression. InTech Education and Publishing, Vienna, pp 185–218
Hager GD, Belhumeur PN (1998) Efficient region tracking with parametric models of geometry and illumination. PAMI 20:1025–1039
Hall DL, Llians J (2001) Handbook of multisensor data fusion. CRC, Boca Raton
Jimenez LO, Morales-Morell A, Creus A (1999) Classification of hyperdimensional data based on feature and decision fusion approaches using projection pursuit, majority voting, and neural networks. IEEE Trans Geosci Remote Sens 37(3 Part 1):1360–1366
Liu H, Yu L (2005) Toward integrating feature selection algorithms for classification and clustering. IEEE Trans Knowl Data Eng 17(4):491–502
Mansoorizadeh M, Charkari NM (2008) Bimodal person-dependent emotion recognition: comparison of feature level and decision level information fusion. In: HCI/HRI workshop, PETRA’08
Mansoorizadeh M, Charkari NM (2009) Audiovisual emotion database in persian language (persian). In: CSI national conference, csicc 2009, CSI, Tehran
Martin O, Kotsia I, Macq B, Pitas I (2006) The enterface’05 audio-visual emotion database. In: Proc. 22nd intl. conf. on data engineering workshops (ICDEW’06)
Mehrabian A (1968) Communication without words. Psychol Today 2:53–56
Paleari M, Lisetti CL (2006) Toward multimodal fusion of affective cues. In: Proceedings of the 1st ACM international workshop on human-centered multimedia. ACM, New York, pp 99–108
Pantic M, Rothkrantz LJM (2000) Automatic analysis of facial expressions: the state of the art. PAMI 22:124–1445
Pierre-Yves O (2003) The production and recognition of emotions in speech: features and algorithms. Int J Human-Comput Stud 59(1–2):157–183
Ross A, Jain A (2003) Information fusion in biometrics. Pattern Recogn Lett 24(13):2115–2125
Sadlier DA, O’Connor NE (2005) Event detection in field sports video using audio-visual features and a support vector machine. IEEE Trans Circuits Syst Video Technol 15(10):1225–1233
Sobottka K, Pitas I (1998) A novel method for automatic face segmentation, facial feature extraction and tracking. Signal Process Image Commun 12:263–281
Song M, You M, Li N, Chen C (1920) A robust multimodal approach for emotion recognition. Neurocomputing 71:1913–2008
Webb A (ed) (2002) Statistical pattern recognition. Wiley, New York
Welch G, Bishop G (1995) An introduction to the Kalman filter, University of North Carolina at Chapel Hill, Chapel Hill
Wu Y, Chang EY, Chang KCC, Smith JR (2004) Optimal multimodal fusion for multimedia data analysis. In: Proceedings of the 12th annual ACM international conference on multimedia. ACM, New York, pp 572–579
Yang J, Yang J-y, Zhang D, Lu J-f (2003) Feature fusion: parallel strategy vs. serial strategy. Pattern Recogn 36(6):1369–1381
Zeng Z, Pantic M, Roisman GI, Huang TS (2009) A survey of affect recognition methods: audio, visual, and spontaneous expressions. PAMI 31:39–58
Zhou ZH, Geng X (2004) Projection functions for eye detection. Pattern Recogn 37:1049–1056
Acknowledgements
The authors would like to express their sincere thanks to professor Kabir, professor Khaki, Mr Massoud Kimyaei and Colleagues for their valuable help and suggestions.
Author information
Authors and Affiliations
Corresponding author
Additional information
This project has been supported in part by the Iran Telecommunication Research Center (ITRC) under grant no. T500/20592.
Rights and permissions
About this article
Cite this article
Mansoorizadeh, M., Moghaddam Charkari, N. Multimodal information fusion application to human emotion recognition from face and speech. Multimed Tools Appl 49, 277–297 (2010). https://doi.org/10.1007/s11042-009-0344-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-009-0344-2