
Abstract
Existing deep learning technologies generally learn the features of chest X-ray data generated by Generative Adversarial Networks (GAN) to diagnose COVID-19 pneumonia. However, the above methods have a critical challenge: data privacy. GAN will leak the semantic information of the training data which can be used to reconstruct the training samples by attackers, thereby this method will leak the privacy of the patient. Furthermore, for this reason, that is the limitation of the training data sample, different hospitals jointly train the model through data sharing, which will also cause privacy leakage. To solve this problem, we adopt the Federated Learning (FL) framework, a new technique being used to protect data privacy. Under the FL framework and Differentially Private thinking, we propose a Federated Differentially Private Generative Adversarial Network (FedDPGAN) to detect COVID-19 pneumonia for sustainable smart cities. Specifically, we use DP-GAN to privately generate diverse patient data in which differential privacy technology is introduced to make sure the privacy protection of the semantic information of the training dataset. Furthermore, we leverage FL to allow hospitals to collaboratively train COVID-19 models without sharing the original data. Under Independent and Identically Distributed (IID) and non-IID settings, the evaluation of the proposed model is on three types of chest X-ray (CXR)images dataset (COVID-19, normal, and normal pneumonia). A large number of truthful reports make the verification of our model can effectively diagnose COVID-19 without compromising privacy.
Similar content being viewed by others


1 Introduction
COVID-19 is a highly contagious infectious disease which is caused by Severe Acute Respiratory Syndrome Coronavirus-2 (SARS-CoV-2) in which it and its variants are still spreading worldwide (Cao 2020; Tai et al. 2021). As COVID-19 is raging around the world, hospitals lack sufficient staff to diagnose suspected patients with COVID-19 disease. To improve the efficiency of diagnosing COVID-19, researchers generally develop deep learning systems to diagnose patients’ chest X-ray images (Liang et al. 2020; Ting et al. 2020; Chang 2018; Klinker et al. 2020; Abdel-Basset et al. 2020b). Dhiman et al. (2021) proposed the J48 decision three model in order to discover the COVID-19 samples and gained the conclusion that the method is useful. Although deep learning technologies have greatly improved the efficiency of diagnosis, these technologies base on a great amount of annotated instances and labeled data, which is hard for hospitals to find enough training samples (Wang et al. 2020; Abdel-Basset et al. 2020a, 2021a, 2021b; Ghahramani and Wang 2019). Furthermore, due to the privacy of medical image dataset, hospitals find it hard to gather enough samples. Therefore, the above data availability issues have brought many severe challenges to such a diagnostic method.
Inspired by the Generative Adversarial Networks (GANs) techniques (Goodfellow et al. 2014), researchers generally use GAN to generate diverse training data to solve the data availability issues. For example, Waheed et al. (2020) proposed a GAN model to generate CXR images by developing an ACGAN model. Bao et al. (2020) proposed a model named COVID-GAN to predict the impact of COVID-19 epidemic. However, the above-mentioned method using GAN as a generative model will leak the patient’s private information. Since the GAN-based model remembers the semantic information of the distribution of a big deal number of training samples, it is easy for a hacker to use reverse engineering to reconstruct the patient’s private data (Jordon et al. 2018; Liu et al. 2019; Xu et al. 2019; Chen et al. 2020a). For instance, Gu et al. (2020) used reverse engineering technique to obtain the hidden encoding of the real image combining the corresponding feature maps of the middle layer generated in the generator and then reconstructed picture similar to the real image. Therefore, we need to seek a way to design a data generative model that does not reveal privacy.
Furthermore, researchers also utilize data sharing strategies to solve data availability issues (Cosgriff et al. 2020). Moorthy et al. (2020) designed a data sharing strategy to enable the hospital to have enough labeled data to train deep learning models. Data sharing methods have been used by hospitals to expand the scale of training samples until the issuance of the General Data Protection Regulation (GDPR) (Voigt and Von dem Bussche 2017). The reason why we can no longer use data sharing methods is that the GDPR stipulates that organizations do not allow arbitrary sharing of user data, because this will leak user privacy. In particular, COVID-19 data is medical data, which is very sensitive to patients. Therefore, we need to seek novel learning methods to avoid data sharing that would leak privacy and violate the law.
First, since Differential Privacy (DP) technology is generally used in privacy protection, previous works (Xie et al. 2018; Liu et al. 2019; Xu et al. 2019; Jordon et al. 2018; Hitaj et al. 2017) focused on using DP technology to alleviate the problem of leaking privacy. Preuveneers et al. (2021) suggested to combine Federated learning with secure multi-party computation to process users behaviors data which made sure users participation privacy protection. Xie et al. (2018) and Liu et al. (2019) proposed Differentially Private GAN (DPGAN) to protect the user privacy by leveraging (ε,δ)-DP technique. However, such DPGAN-based models are only suitable for centralized learning rather than distributed learning. Second, due to GDPR’s restrictions on data sharing strategies, data exists between hospitals in the form of “islands” (Liu et al. 2020d; Li et al. 2020), which inspired researchers to develop a privacy-persevering distributed machine learning paradigm, i.e., Federated Learning, architecture to big data sources as well as to improve resource utilization and aggregate performance in shared environments (McMahan et al. 2017; Chiusano et al. 2021). In this context, applying privacy protection in distance learning systems was hot topic been discuss in Chiusano et al. (2021). Therefore, references (Li et al. 2019; Ge et al. 2020; Sheller et al. 2020; Sui et al. 2020) applied FL in medical fields to develop some privacy-persevering distance learning systems such as Medical Imaging (Li et al. 2019), Medical Relation Extraction (Sui et al. 2020), and Medical Named Entity Recognition (Ge et al. 2020).
We gain inspiration in these above methods and propose the Federated Differentially Private Generative Adversarial Network (FedDPGAN) model to detect COVID-19 pneumonia without compromising patient privacy. In this model, DPGAN is a key component of the proposed model and its function is by adding Gaussian noise in training gradient that protects the training samples’ privacy. In particular, we introduce a federated learning framework and developed a distributed DPGAN to enable different hospitals to train COVID-19 diagnostic models collaboratively without data sharing. Specifically, with the help of FL and its aggregation mechanism, FedDPGAN can aggregate model parameters from medical institutions in different geographical locations to construct a global GAN model with well-preserved privacy. A large number of truthful data studies that FedDPGAN model is better than the existing centralized learning and FL-based models. The research contents and contributions include as:
-
Unlike existing frameworks, we propose a Federated Differentially Private Generative Adversarial Network framework, which enables different hospitals can utilize the privacy-preserving data augmentation method, i.e., distributed DPGAN model to generated high-quality training samples which relieves the problem of lacking the training sample of COVID-19 then apply ResNet (He et al. 2016) model in FL to achieve high-precision COVID-19 detection.
-
To address the data availability issues in detecting COVID-19, we design a distributed DPGAN by leveraging FL framework. In particular, we find that distributed DPGAN can alleviate the Non-independent and identically distributed (non-IID) issue in FL. Specifically, with the help of FL and its aggregation mechanism, FedDPGAN can construct a global and local data augmentation model by aggregating model parameters from medical institutions in different geographical locations to do different medical task.
-
We conduct extensive case studies on different pneumonia CXR images demonstrate that the proposed model FedDPGAN is better than the existing centralized learning and FL-based models. Specifically, our model shows that the best centralized model by 1.52% and the FL model by 0.49% in IID distribution. In non-IID data distribution, our model performance is 3.00% higher than the best FL model.
The article organizational structure is as follows. Section 2 is literature review about differential Private Generative Adversarial Networks and Federated Learning. Sections 3 and 4 presents the FedDPGAN algorithm. In FedDPGAN, we applicate the FedAVG algorithm and differential private method makes introduction particularly. The final result compares between Sections 5 and 5.1.5. The Section 6 includes brief summary of the article.
2 Related Work
In this section, we summarize the advanced work in the Differentially Private Generative Adversarial Networks (DPGAN) and Federated Learning (FL) fields.
2.1 Differentially Private Generative Adversarial Networks
How to combine deep learning technology with privacy protection technology is an emerging research direction. For example, many researchers apply differential privacy (DP) technologies to training model that ensures models security. Abadi et al. (2016b) developed a privacy-preserving deep learning model training paradigm by adding well-designed differential privacy noise (i.e., Gaussian noise) when computing the model gradients. Voigt and Von dem Bussche (2017) proposed a DP-based deep learning models to achieve privacy-preserving disease classification application. In particular, Xie et al. (2018) suggested using DPGAN to protect the user privacy by leveraging (ε,δ) −DP techniques. Inspired by the above work, the current work focuses on using DPGAN to develop some medical-related applications (Choi et al. 2017; Xie et al. 2018; Chang et al. 2020). Chang et al. (2020) utilized DPGAN to develop a medical imaging application.
However, such DPGAN-based models are only suitable for centralized learning rather than distributed learning. As a result, although researchers have solved the above problems and proposed some privacy preserving methods to protect the local model training, distributed DPGAN has not been studied yet. We propose the distributed DPGAN that can be applied in distributed learning-based applications.
2.2 Federated Learning
Federated Learning (FL) (McMahan et al. 2017) will establish a data protection model, distributing dataset on each client machine, and aggregating locally-computed updates for a globally model which helps the participating clients to achieve experimental results similar to distributed data (Liu et al. 2020b, 2020b), while maintaining the privacy of the training data (Liu et al. 2020a). Therefore, as a promising distributed machine learning framework for privacy protection, FL has spawned many emerging applications such as Google Keyboard (Hard et al. 2018), traffic flow prediction (Liu et al. 2020c), anomaly detection (Liu et al. 2021; Wu et al. 2019), medical imaging (Sheller et al. 2020), etc. In particular, medical institutions turn their attention to FL to develop a collaborative learning paradigm for privacy protection, thereby avoiding legal problems caused by data sharing. For example, Ge et al. (2020) applied Medical Named Entity Recognition (NER) in FL by utilizing different hospitals data to promote the hospitals training models. Chen et al. (2020b) proposed FL-QSAR model contributing the performance in QSAR prediction by collaborating among pharmaceutical institutions in drug discovery. However, the non-IID problem in FL hinders the rapid development of FL in the medical field.
To address this problem, many novel optimization algorithms are designed to overcome the adverse effects of non-IID. Wang et al. (2020) designed a mechanism based on deep Q learning to maximize the reward for overcoming this problem by adopting the method of selecting a subset of devices during each round of communication. However, such optimization algorithms are suitable for mobile IoT and cannot be applied in the medical field. The reason is that this algorithm requires complex client selection and training complex deep Q-leaning models. In this paper, we find that GAN can address this problem by generating diverse training samples for FL training. In short, solving the non-IID problem in FL is the only way to apply FL in the medical field.
3 Preliminary
3.1 Differential Privacy
DP is widely used to maintain secure model and protects the training data, hence it is a privacy protection technology. The classic definition of DP provided below relies on the concept of so-called adjacent databases, that is, databases that differ in only one element (or sample, as it is the case in Machine Learning datasets). Therefore, the formal definition of DP is as follows:
Definition 1 ((ε,δ) − D P 2014)
Any two adjacent datasets b and \(b^{\prime }\) are input, with the random algorithm \(\mathcal {K}\) and the subset of outputs S hold that:
where 𝜖 is the privacy budget and δ is the failure probability. The smaller the δ, the closer the distribution of the data output by \(\mathcal {K}\) in b,b′ datasets.
According to Definition 1, we can use DP to ensure the privacy of the semantic information of training data. But DP can not be directly applied in deep learning because DP is applicable to query functions in the database. Therefore, researchers generally apply DP in deep learning by adding the well-designed Gaussian noise that is in keeping with the definition of the differential privacy. The formal definition of Gaussian noise mechanism is as follows:
Definition 2 (Gaussian Noise Mechanism)
Sf is a random function sensitivity for the two adjacent dataset \(b, b^{\prime }\), f(b) is the query function, and \({{S_{f}^{2}} \cdot {\sigma ^{2}}}\) is the variance of the Gaussian distribution. For each pair of adjacent inputs b and \(b^{\prime }\), the Gaussian noise mechanism can be expressed as follows:
where \(\mathcal {N}\left (0, {S_{f}^{2}} \cdot \sigma ^{2}\right )\) is the noise to disturb the distribution in 0 and standard deviation Sf ⋅ σ. Then we give the definition of the sensitivity Sf of the random function f as follows:
Definition 3 (Sensitivity (Mironov 2017))
The sensitivity of the random function f is as follows:
where prioritize the two adjacent datasets \(b, b^{\prime }\).
According to Definitions 2 and 3, it can be seen that the core meaning of the parameter of sensitivity indicating the magnitude of noise is to indicate the effect of deleting deleted records in the data set on the query result. That is to say, the noise scale change of the Gaussian noise mechanism is proportional to the sensitivity. In particular, when \(\delta \geqslant \frac {4}{5}\exp \left ({ - {{(\sigma \cdot \varepsilon )}^{2}}/2} \right )\) and ε < 1, the random function f satisfies the definition of (ε,δ)-DP after adding Gaussian noise.
3.2 Generative Adversarial Networks
Generative Adversarial Network (GAN) is an approach of the non-supervision model. GAN contains two parts: Generator N and Discriminator M. The generator randomly takes samples which is from potential space (latent space) and emulate the truthful traning data more and more. Input set of discriminator network is truthful output data, that distinguish training data from truthful samples as much as possible. Inspired by Game Theory, the generative model N make effort that capture distribution of the data, and the model to discrimate M tries to estimate the probability. They confront and constantly adjust the parameters during training. The ultimate goal of GAN is to make the discriminator unable to judge whether the output result of the generator is true or fake. We mentioned above that the GAN optimization problem is actually a game theory of N and M, that is, a minimal-maximization problem, so reference (Goodfellow et al. 2014) proposed an important approach is to solve this problem:
Definition 4 (Optimal Generator)
For generator, it learn a distribution Pg of dataset. The input data distribution Pz(z), the generator \(G\left (z ; \theta _{g}\right ): z \rightarrow x \), and the discriminator \(G\left (z ; \theta _{g}\right ): z \rightarrow x\). Therefore, the optimal generator of a function can be expressed as follows:
However, the above optimization model has the problems of vanishing gradient and samples diversity. Therefore, researchers put forward an optimized GAN, which solves the problem of gradient disappearance, which is defined as follows:
Definition 5 (Optimize GAN)
\(\prod \left (\mathrm {F}_{\gamma }, \mathrm {F}_{g}\right )\) is the set of joint distribution γ include Fγ and Fg all possible combinations. Fγ and Fg are the edge distribution.
3.3 Federated Learning
As a promising distributed machine learning framework for privacy protection, Federated Learning protects users’ privacy data by keeping their local data locally and only periodically exchanges updates with the server which reduces their communication costs. The classic algorithm for optimizing federated optimization problems is Federated Averaging (FedAvg) (McMahan et al. 2017).
In FL, we consider a server \(\mathcal {S}\) and a subset of the clients \(\mathcal {K}\) participating in the training of a shared global model F(⋅). We assume that each client holds an IID or non-IID datasets Dk. At the client side for data sample x, we let ℓ(ω;x) be the loss function, where \(\omega \in {\mathbb {R}^{d}}\) denotes the model’s trainable parameters. At the server side, we let \({\mathscr{L}}(\omega )=E_{x \sim \mathcal {D}}[\ell (\omega ; x)]\) be the loss function and let the server to optimize the following objective function:
where K represents the clients, \(({p_{k}},\sum \limits _{k} {{p_{k}}} = 1)\) indicates the relative influence of each client on the global model. In FL, the training is conducted between the server and clients side in a T-round communication rounds to minimize the above objective function following a three step protocol:
-
(Step 1, Initialization): The t-th round of training, the server selects a subset from clients \(\mathcal {K}\) to participate in training and broadcasts the initialized global model parameters ωt to each client.
-
(Step 2, Local Training): Each client individually executes the local training to obtain the model updates. Specifically, the client trains the received global model ωt on the dataset \(\mathcal {D}_{k}\) by using the local optimizer, e.g., Stochastic Gradient Descent (SGD) and then uploads all updates \({\Delta } {\omega _{k}^{t}}\) to the server.
-
(Step 3, Aggregation): After collecting all updates uploaded by \(\mathcal {K}_{t}\) clients, the central server uses the aggregation algorithm, i.e., FedAvg Algorithm to obtain the new global model which serves as an initial point for the next communication round by aggregate the model updates.
Repeat the above steps until the global model converges.
4 Proposed FedDPGAN Model
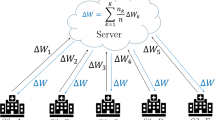
We start with an introduction of medical DPGAN model. Then we introduce the FedDPGAN to diagnosis COVID-19 CXR images from various medical platforms. Specifically, FedDPGAN is a client-server architecture in which server shares the global model and coordinates the client’s local privacy protection DPGAN model with SGD optimizer (Fig. 1).

Overview of federated differentially private generative adversarial network (FedDPGAN) framework
4.1 Architecture of FedDPGAN
In this subsection, we present the approaches to protect the users’ private data, including the basic DP noise mechanism and FedDPGAN algorithm. In our framework, there is a central server \(\mathcal {S}\) and a client set \(\mathcal {K}\) with their local dataset \(\mathcal {D}_{k}\). Next, we introduce in detail the functions of the components of the proposed model.
4.1.1 Distributed DPGAN
First, we present our distributed DPGAN mechanism. Since COVID-19 data is very private, we need to protect the privacy of patients when we use GAN to generate COVID-19 data. Therefore, following existing works (Liu et al. 2019; Xie et al. 2018), we adopt the method of adding Gaussian noise to the training gradient to ensure dataset security. Specifically, we adopt this way by adding random noise in discriminator which interferes with original data distribution, thereby protecting the privacy of the training data. Therefore, according to Definitions 1–3 we have:
where gσ is the noisy gradient, cg is the sensitivity of the gradient function and C is the clipping threshold. The gradient as a random variable approximately obeys Gaussian distribution, we have:
where μ is the mean of the random variable.
To make the above random function f satisfy the definition of differential privacy, we assume that \({\Delta } f = \mathop {{\max \limits } }\limits _{d,d^{\prime } \in \mathcal {D}}\) \({\left \| {f(x) - f(x^{\prime })} \right \|_{2}}\) is the L2-Sensitivity and ∀δ ∈ (0,1), we have:
When we add Gaussain noise \( \mathcal {N}\left (0, {\sigma _{n}^{2}} {c_{g}^{2}} I\right )\) to the gradient, If and only if
where sample rate is q. we can say that this function f satisfies the definition of DP. To prevent the gradient from exploding, we use gradient clipping technology to make the gradient in the range of (−c,c).
4.1.2 FedDPGAN Framework
Following the client-server architecture in FL, the central server \(\mathcal {S}\) selects a random fraction C of clients. Then the clients aggregate a model broadcasting the model to each client. After global model is initialized, the client uploads generator model’s parameter \(\theta _{t+1}^{k}\) to the aggregator. Then the aggregator accumulates \({\sum }_{k=1}^{k} \frac {N_{k}}{N} \theta _{t+1}^{k}\) getting the average value of 𝜃t+ 1 and updates to the global model.
The server coordinates multiple clients updating and shares a new global model into the clients. The specific steps between clients and server can be summarized in three steps:
-
(Step 1, FL Initialization): Firstly, central server picks the subset of the clients. Then it broadcasts the initialized generator parameter 𝜃t.
-
(Step 2, Distributed DPGAN Training): After the initialization, the selected clients K perform training iterations of SGD over their local data. We add Gaussian noise \(\mathcal {N}(0,{\sigma _{n}^{2}}{c_{g}^{2}}I)\) appropriately in a bounded range \(min(1,\frac {C}{\left \|g_{\sigma } \right \|})\) and then it will automatically clipping parameters to add noise when the next time update. The client updates the weight parameters ω and truncating in the range of (−c,c) after updating the weight parameters to optimize the discriminator.
-
(Step 3, FL Aggregation): The clients upload their model parameters \(\theta _{t+1}^{k}\) to the aggregator. The aggregator aggregates all model parameters getting the average value of \({\sum }_{k=1}^{k} \frac {N_{k}}{N} \theta _{t+1}^{k}\) and then updates to server to create a global model that is used as an initialization point for the next communication round.
4.2 FedDPGAN-based COVID-19 Diagnosis Model
We represent the COVID-19 dataset characteristics and the COVID-19 diagnpsis model. First, we use the publicly available COVID-19 dataset as a benchmark dataset for evaluating the performance of the proposed model. This dataset consists of chest X-ray images of patients. To this end, we need to apply advanced Convolutional Neural Network (CNN) structure suitable for vision tasks in FedDPGAN to achieve higher performance.

Therefore, in this paper, we use ResNet (He et al. 2016) model to diagnosis COVID-19 by classifying the chest X-ray images. Specifically, ResNet is a powerful emerging deep learning model that has attracted considerable attention in recent years. ResNet adds a direct connection channel to the network structure to quickly transfer the training gradient, which greatly improves the efficiency of model training. Specifically, we get the gradient after the lower layer network training the parameters, the gradient is direct to transmit to the upper layer network parameters, that is, the original input information is allowed to be directly transmitted to the upper layer. Also, the correlation of gradients decays with the increase of layers. It has been proved that RESNET can effectively reduce the attenuation of this correlation. This feature enables ResNet to build a deeper network structure, which is widely used in image classification and is suitable for our COVID-19 medical image classification task.
5 Experimental Results
We apply real-world CXR images that comprehensively evaluate the proposed model. First, we give details of the experimental environment, datasets, hyperparameters, and model details for this experiment. Second, we compare the other baseline model like advanced centralized learning model and electronic language-based model to determine the performance of our proposed model. Then, we compare the model performance with other benchmark models under simulated non-IID distributions. Finally, the influence of privacy parameters on model performance is discussed.
5.1 Experimental Setting
5.1.1 Datasets
We evaluate the FedDPGAN on different pneumonia images dataset published by Cohen et al. (2020a, 2020b), where the dataset consists of normal lung images, ordinary pneumonia images, and COVID-19 pneumonia images. Specifically, such a dataset contains 2,000 normal images, 1,250 normal pneumonia images and 350 COVID-19 pneumonia images. As mentioned above, we can find that this data has the problem of class imbalance, which is why we use the model DPGAN to generate diverse data. We generate fake chest X-ray images through DPGAN model and mix them into our dataset. More details can be seen in Fig. 2. In addition, we adjusted the image size about 28 × 28 pixels that speeds up the convergence of the model.

Overview of the generated dataset
5.1.2 Baseline Models and Aggregation Method
In this experiment, we use FedResNet, centralized ResNet (He et al. 2016), Convolutional Neural Network (CNN) (Tajbakhsh et al. 2016), Multilayer Perceptron (MLP) (Li et al. 2018), K Nearest Neighbors (KNN) (Park and Lee 2018), and Support Vector Machines (SVM) (Morra et al. 2009) as our baseline models that proves FedDPGAN performance. Note that we apply ResNet model in our FedDPGAN framework.
Second, we use the FedAvg aggregation algorithm as the updated aggregation algorithm in the proposed framework. The reason is that the training model under the classic FedAvg aggregation algorithm performs well in various tasks.
5.1.3 Non-IID Setting
In the medical field, since the data of different hospitals are collected by different types of collection equipment, the data between different hospitals is non-IID. In this paper, to achieve non-IID data distribution, we assign two types of data, i.e., normal chest images and general pneumonia images to most clients and we put COVID-19 images into only a few clients. More details can be seen in Fig. 3.

Overview of non-IID data allocation method
5.1.4 Hyperparameters
In this experiment, we set K = 100 clients and place the equal size dataset in each client. At each round of communication, we randomly select C = 10% of clients to participate in training and set the the local batch size B = 10, local epochs E = 5, the learning rate of α = 0.01, and Gaussian noise generator generates the noise which default σ = 0.0001.
5.1.5 Implementation and Setup
The implementation of the model is under the TensorFlow 2.0 (Abadi et al. 2016a), which is a powerful framework released by Google that can run on the GPU for acceleration. PyTorch (Paszke et al. 2019) is an open-source ML toolkit that hastens everything ranging from research prototyping to production deployment. All of the experiments are conducted using PyTorch and TensorFlow with Ubuntu 16.04. Experiments are conducted on a Linux Server with NVIDIA GeForce RTX 2080TI GPU and an i7 9900K CPU.
5.2 Model Performance
We compare the model performance of the proposed FedDPGAN-based ResNet model with that of FedResNet, DPGAN-based ResNet, ResNet, CNN, MLP, KNN, and SVM models with the same simulation configuration. Among these seven competing methods, DPGAN-based FedResNet and FedResNet are federated models and the rest are centralized models. ResNet (He et al. 2016) has a good performance on image classification tasks and become a widely used baseline model. The SVM, KNN, and MLP models are popular ML models for general classification applications (Hao et al. 2006).
Table 1 indicates the accuracy of model and the compared model in diagnosing COVID-19. From all of the results in the table, we can see that the proposed model can not only protect privacy but also use data augmentation method to improve performance. Figure 4a shows that the performance of DPGAN-based ResNet model is better than the best baseline method centralized ResNet by 0.84%, which is 4.36% higher than the worst centralized baseline method SVM and is better than the worst deep learning baseline method CNN which is 3.05% below. The reason is that: (1) The large amount of data generated enables ResNet models to learn more samples. (2) Model training with DPGAN makes ResNet more generalizable.

Comparison of COVID-19 diagnostic performance between the proposed model and the benchmark models
In federated learning, our model can achieve the best model performance which is 0.49% higher than the baseline method DPGAN-based ResNet model, as shown in Fig. 4b. In a word, FedDPGAN-based ResNet model can achieve accurate without compromising privacy.
5.3 Performance of Federated Learning with Data Augmentation under IID and non-IID Settings
In this part, we quest the influence of data augmentation methods in IID and non-IID settings. First, we compare the performance of the FedResNet model under IID and non-IID settings. Figure 5a shows that the prediction error of FedResNet model under the non-IID setting is 2.75% higher than under the IID setting. Experimental results show that non-IID distribution will affect the convergence performance of the model, resulting in the degradation of model. The reason is that the distribution of non-IID data will affect the convergence of the model, resulting in a decline in model performance.

(a) Performance comparison of FedResNet model under IID and non-IID settings; (b) Performance comparison between FedResNet model and FedDPGAN-based ResNet model under non-IID settings
Second, under non-IID settings, we make overall evaluation of FedResNet by using data augmentation method and the FedResNet model without this method. Figure 5b shows that the prediction error of FedDPGAN-based ResNet (using data augmentation method) model is 3.00% lower than FedResNet (without using data augmentation method) under non-IID setting. The reason is that data augmentation methods can alleviate non-IID problems by generating diverse data. Such a method can make the convergence of federated learning training more stable.
Third, we compare the performance of FedDPGAN-based ResNet model under non-IID setting and FedResNet model under IID setting. Figure 6a shows that the performance of the FedDPGAN-based ResNet model with non-IID setting is close to the FedResNet with IID setting. Furthermore, Fig. 6b shows the prediction error of the proposed models under IID and non-IID settings. In this case, our model is superior to the centralized ResNet which without privacy protection as shown in Fig. 7. In a word, our model is more suitable for real-world medical application scenarios.

(a) Performance comparison of FedResNet model under IID setting and FedDPGAN-based ResNet model under non-IID settings; (b) Performance comparison between FedDPGAN-based ResNet model under IID setting and under non-IID settings

Performance comparison between ResNet model and FedDPGAN-based ResNet model under non-IID settings
5.4 Performance Comparison of Different Privacy Budgets
In this part, we assess the performance of the proposed model by setting different privacy budgets. Since the privacy budget σ indicates the scale of Gaussian noise (Fredrikson et al. 2015), we need to explore the relationship between the scale of Gaussian noise and the performance of the proposed model. Specifically, we generate fake images of different quality by adjusting privacy budgets σ and then explore their performance. We enhance the privacy protection ability of datasets through improving σ. From Table 2, we can draw a conclusion that the smaller size of σ the higher model performance we will gain. The experimental results show that we can adjust the privacy budget σ to achieve a balance between performance and privacy protection.
6 Results and Discussion
We propose the FedDPGAN model can be used in diagnosing COVID-19 under using CXR images without compromising privacy. Such a model enables hospitals in different geographic locations to collaboratively train a COVID-19 diagnostic model without sharing data. Specifically, our method solves two serious challenges currently encountered in diagnosing COVID-19: data availability and data privacy. First, in this model, we design a distributed DPGAN model to address data availability issue by generating COVID-19 image data. In particular, we use (ε,δ)-DP noise to protect the privacy of GAN’ training gradient. Second, we introduce FL framework to protect patient’s privacy and apply the ResNet model to diagnostic COVID-19. In the experiment part, we test the performance of FedDPGAN model on COVID-19 chest X-ray image datasets and compare it with centralized ResNet, CNN, MLP, KNN, and SVM models. The results show that our method has the best model performance and privacy protection ability compared with competing methods. Furthermore, the experimental results indicate that the GAN component in the proposed model can alleviate the non-IID problem in FL, which opens a window for the use of data augmentation to solve the non-IID problem.
In the future, we will design a more realistic semi-supervised federated learning system (Liu et al. 2020a) to solve the lack of data labeling and data privacy issues in the medical field. Furthermore, we will explore how data augmentation methods can improve the non-IID problem in FL, which motivates us to design more efficient data augmentation methods to solve non-IID problem in the future.
References
Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., Devin, M., Ghemawat, S., Irving, G., Isard, M., & et al. (2016a). Tensorflow: a system for large-scale machine learning. In 12Th {USENIX} symposium on operating systems design and implementation ({OSDI}, (Vol. 16 pp. 265–283).
Abadi, M., Chu, A., Goodfellow, I., McMahan, H.B., Mironov, I., Talwar, K., & Zhang, L. (2016b). Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC conference on computer and communications security (pp. 308–318).
Abdel-Basset, M., Chang, V., & Mohamed, R. (2020a). Hsma_woa: a hybrid novel slime mould algorithm with whale optimization algorithm for tackling the image segmentation problem of chest x-ray images. Applied Soft Computing, 95, 106642.
Abdel-Basset, M., Hawash, H., Chang, V., Chakrabortty, R.K., & Ryan, M. (2020b). Deep learning for heterogeneous human activity recognition in complex iot applications. IEEE Internet of Things Journal, 1–1. https://doi.org/10.1109/JIOT.2020.3038416.
Abdel-Basset, M., Chang, V., Hawash, H., Chakrabortty, R.K., & Ryan, M. (2021a). Fss-2019-ncov: a deep learning architecture for semi-supervised few-shot segmentation of covid-19 infection. Knowledge-Based Systems, 212, 106647.
Abdel-Basset, M., Chang, V., & Nabeeh, N.A. (2021b). An intelligent framework using disruptive technologies for covid-19 analysis. Technological Forecasting and Social Change, 163, 120431.
Bao, H., Zhou, X., Zhang, Y., Li, Y., & Xie, Y. (2020). Covid-gan: Estimating human mobility responses to covid-19 pandemic through spatio-temporal conditional generative adversarial networks. In Proceedings of the 28th international conference on advances in geographic information systems (pp. 273–282).
Cao, X. (2020). Covid-19: immunopathology and its implications for therapy. Nature Reviews Immunology, 20(5), 269–270.
Chang, Q., Qu, H., Zhang, Y., Sabuncu, M., Chen, C., Zhang, T., & Metaxas, D.N. (2020). Synthetic learning: Learn from distributed asynchronized discriminator gan without sharing medical image data. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR).
Chang, V. (2018). Computational intelligence for medical imaging simulations. Journal of Medical Systems, 42(1), 1–12.
Chen, D., Yu, N., Zhang, Y., & Fritz, M. (2020a). Gan-leaks: A taxonomy of membership inference attacks against generative models. In Proceedings of the 2020 ACM SIGSAC conference on computer and communications security (pp. 343–362).
Chen, S., Xue, D., Chuai, G., Yang, Q., & Liu, Q. (2020b). Fl-qsar: a federated learning based qsar prototype for collaborative drug discovery. bioRxiv.
Chiusano, S., Cerquitelli, T., Wrembel, R., & Quercia, D. (2021). Breakthroughs on cross-cutting data management, data analytics, and applied data science. Information Systems Frontiers, 23(1), 1–7.
Choi, E., Biswal, S., Malin, B., Duke, J., Stewart, W.F., & Sun, J. (2017). Generating multi-label discrete patient records using generative adversarial networks. arXiv:170306490.
Cohen, J.P., Morrison, P., & Dao, L. (2020a). Covid-19 image data collection. arXiv:200311597https://github.com/ieee8023/covid-chestxray-dataset.
Cohen, J.P., Morrison, P., Dao, L., Roth, K., Duong, T.Q., & Ghassemi, M. (2020b). Covid-19 image data collection: Prospective predictions are the future. arXiv:200611988https://github.com/ieee8023/covid-chestxray-dataset.
Cosgriff, C.V., Ebner, D.K., & Celi, L.A. (2020). Data sharing in the era of covid-19. The Lancet Digital Health, 2(5), e224.
Dhiman, G., Chang, V., Kant Singh, K., & Shankar, A. (2021). Adopt: automatic deep learning and optimization-based approach for detection of novel coronavirus covid-19 disease using x-ray images. Journal of Biomolecular Structure and Dynamics, 1–13.
Dwork, C., Roth, A., & et al. (2014). The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science, 9(3-4), 211–407.
Fredrikson, M., Jha, S., & Ristenpart, T. (2015). Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC conference on computer and communications security (pp. 1322–1333).
Ge, S., Wu, F., Wu, C., Qi, T., Huang, Y., & Xie, X. (2020). Fedner: Medical named entity recognition with federated learning. arXiv:200309288.
Ghahramani, F., & Wang, J. (2019). Impact of smartphones on quality of life: a health information behavior perspective. Information Systems Frontiers, 1–16.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial nets. Advances in Neural Information Processing Systems, 27, 2672–2680.
Gu, J., Shen, Y., & Zhou, B. (2020). Image processing using multi-code gan prior. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 3012–3021).
Hao, Z., Berg, A.C., Maire, M., & Malik, J. (2006). Svm-knn: Discriminative nearest neighbor classification for visual category recognition. In 2006 IEEE computer society conference on computer vision and pattern recognition (CVPR’06). https://doi.org/10.1109/CVPR.2006.301, (Vol. 2 pp. 2126–2136).
Hard, A., Rao, K., Mathews, R., Ramaswamy, S., Beaufays, F., Augenstein, S., Eichner, H., Kiddon, C., & Ramage, D. (2018). Federated learning for mobile keyboard prediction. arXiv:181103604.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–778).
Hitaj, B., Ateniese, G., & Perez-Cruz, F. (2017). Deep models under the gan: information leakage from collaborative deep learning. In Proceedings of the 2017 ACM SIGSAC conference on computer and communications security (pp. 603–618).
Jordon, J., Yoon, J., & van der Schaar, M. (2018). Pate-gan: Generating synthetic data with differential privacy guarantees. In International conference on learning representations.
Klinker, K., Wiesche, M., & Krcmar, H. (2020). Digital transformation in health care: Augmented reality for hands-free service innovation. Information Systems Frontiers, 22(6), 1419–1431.
Li, T., Sahu, A.K., Talwalkar, A., & Smith, V. (2020). Federated learning: Challenges, methods, and future directions. IEEE Signal Processing Magazine, 37(3), 50–60.
Li, W., Milletarì, F., Xu, D., Rieke, N., Hancox, J., Zhu, W., Baust, M., Cheng, Y., Ourselin, S., Cardoso, M.J., & et al. (2019). Privacy-preserving federated brain tumour segmentation. In International workshop on machine learning in medical imaging (pp. 133–141): Springer.
Li, Y., Yang, H., Lei, B., Liu, J., & Wee, C.Y. (2018). Novel effective connectivity inference using ultra-group constrained orthogonal forward regression and elastic multilayer perceptron classifier for mci identification. IEEE Transactions on Medical Imaging, 38(5), 1227–1239.
Liang, W., Yao, J., Chen, A., Lv, Q., Zanin, M., Liu, J., Wong, S., Li, Y., Lu, J., Liang, H., & et al. (2020). Early triage of critically ill covid-19 patients using deep learning. Nature Communications, 11(1), 1–7.
Liu, Y., Peng, J., James, J., & Wu, Y. (2019). ppgan: Privacy-preserving generative adversarial network. In 2019 IEEE 25Th international conference on parallel and distributed systems (ICPADS) (pp. 985–989): IEEE.
Liu, Y., Nie, J., Li, X., Ahmed, S.H., Lim, W.Y.B., & Miao, C. (2020a). Federated learning in the sky: Aerial-ground air quality sensing framework with uav swarms. IEEE Internet of Things Journal, 1–1. https://doi.org/10.1109/JIOT.2020.3021006.
Liu, Y., Peng, J., Kang, J., Iliyasu, A.M., Niyato, D., & El-Latif, A.A.A. (2020b). A secure federated learning framework for 5g networks. IEEE Wireless Communications, 27(4), 24–31. https://doi.org/10.1109/MWC.01.1900525.
Liu, Y., Yu, J.J.Q., Kang, J., Niyato, D., & Zhang, S. (2020c). Privacy-preserving traffic flow prediction: a federated learning approach. IEEE Internet of Things Journal, 7(8), 7751–7763. https://doi.org/10.1109/JIOT.2020.2991401.
Liu, Y., Yuan, X., Xiong, Z., Kang, J., Wang, X., & Niyato, D. (2020d). Federated learning for 6g communications: Challenges, methods, and future directions. China Communications, 17(9), 105–118. https://doi.org/10.23919/JCC.2020.09.009.
Liu, Y., Yuan, X., Zhao, R., Zheng, Y., & Zheng, Y. (2020a). Rc-ssfl: Towards robust and communication-efficient semi-supervised federated learning system. arXiv:201204432.
Liu, Y., Zhao, R., Kang, J., Yassine, A., Niyato, D., & Peng, J. (2020b). Towards communication-efficient and attack-resistant federated edge learning for industrial internet of things. arXiv:201204436.
Liu, Y., Garg, S., Nie, J., Zhang, Y., Xiong, Z., Kang, J., & Hossain, M.S. (2021). Deep anomaly detection for time-series data in industrial iot: a communication-efficient on-device federated learning approach. IEEE Internet of Things Journal, 8(8), 6348–6358. https://doi.org/10.1109/JIOT.2020.3011726.
McMahan, B., Moore, E., Ramage, D., Hampson S., & y Arcas, B.A. (2017). Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, PMLR (pp. 1273–1282).
Mironov, I. (2017). Rényi differential privacy. In 2017 IEEE 30th computer security foundations symposium (CSF) (pp. 263–275): IEEE.
Moorthy, V., Restrepo, A.M.H., Preziosi, M.P., & Swaminathan, S. (2020). Data sharing for novel coronavirus (covid-19). Bulletin of the World Health Organization, 98(3), 150.
Morra, J.H., Tu, Z., Apostolova, L.G., Green, A.E., Toga, A.W., & Thompson, P.M. (2009). Comparison of adaboost and support vector machines for detecting alzheimer’s disease through automated hippocampal segmentation. IEEE Transactions on Medical Imaging, 29(1), 30–43.
Park, J., & Lee, D.H. (2018). Privacy preserving k-nearest neighbor for medical diagnosis in e-health cloud. Journal of Healthcare Engineering, 2018.
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., & et al. (2019). Pytorch: An imperative style, high-performance deep learning library. In Advances in neural information processing systems (pp. 8026–8037).
Preuveneers, D., Garofalo, G., & Joosen, W. (2021). Cloud and edge based data analytics for privacy-preserving multi-modal engagement monitoring in the classroom. Information Systems Frontiers, 23(1), 151–164.
Sheller, M.J., Edwards, B., Reina, G.A., Martin, J., Pati, S., Kotrotsou, A., Milchenko, M., Xu, W., Marcus, D., Colen, R.R., & et al. (2020). Federated learning in medicine: facilitating multi-institutional collaborations without sharing patient data. Scientific Reports, 10(1), 1–12.
Sui, D., Chen, Y., Zhao, J., Jia, Y., Xie, Y., & Sun, W. (2020). Feded: Federated learning via ensemble distillation for medical relation extraction. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) (pp. 2118–2128).
Tai, Y., Gao, B., Li, Q., Yu, Z., Zhu, C., & Chang, V. (2021). Trustworthy and intelligent covid-19 diagnostic iomt through xr and deep learning-based clinic data access. IEEE Internet of Things Journal, 1–1. https://doi.org/10.1109/JIOT.2021.3055804.
Tajbakhsh, N., Shin, J.Y., Gurudu, S.R., Hurst, R.T., Kendall, C.B., Gotway, M.B., & Liang, J. (2016). Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Transactions on Medical Imaging, 35(5), 1299–1312.
Ting, D.S.W., Carin, L., Dzau, V., & Wong, T.Y. (2020). Digital technology and covid-19. Nature Medicine, 26(4), 459–461.
Voigt, P., & Von dem Bussche, A. (2017). The eu general data protection regulation (gdpr). A Practical Guide, 1st edn. Cham: Springer International Publishing.
Waheed, A., Goyal, M., Gupta, D., Khanna, A., Al-Turjman, F., & Pinheiro, P.R. (2020). Covidgan: Data augmentation using auxiliary classifier gan for improved covid-19 detection. IEEE Access, 8, 91916–91923.
Wang, H., Kaplan, Z., Niu, D., & Li, B. (2020). Optimizing federated learning on non-iid data with reinforcement learning. In IEEE INFOCOM 2020 - IEEE conference on computer communications. https://doi.org/10.1109/INFOCOM41043.2020.9155494 (pp. 1698–1707).
Wang, L., Lin, Z.Q., & Wong, A. (2020). Covid-net: a tailored deep convolutional neural network design for detection of covid-19 cases from chest x-ray images. Scientific Reports, 10(1), 1–12.
Wu, Y., Liu, Y., Ahmed, S.H., Peng, J., & Abd El-Latif, A.A. (2019). Dominant data set selection algorithms for electricity consumption time-series data analysis based on affine transformation. IEEE Internet of Things Journal, 7(5), 4347–4360.
Xie, L., Lin, K., Wang, S., Wang, F., & Zhou, J. (2018). Differentially private generative adversarial network. arXiv:180206739.
Xu, C., Ren, J., Zhang, D., Zhang, Y., Qin, Z., & Ren, K. (2019). Ganobfuscator: Mitigating information leakage under gan via differential privacy. IEEE Transactions on Information Forensics and Security, 14(9), 2358–2371.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work is supported by Heilongjiang Provincial Natural Science Foundation of China (Grant No. LH2020F044) ,the 2019-“Chunhui Plan” Cooperative Scientific Research Project of Ministry of Education of China (Grant No. HLJ2019015), and the Fundamental Research Funds for Heilongjiang Universities, China (Grant No. 2020-KYYWF-1014).
Longling Zhang and Bochen Shen have equal contributions.
Rights and permissions
About this article

Cite this article
Zhang, L., Shen, B., Barnawi, A. et al. FedDPGAN: Federated Differentially Private Generative Adversarial Networks Framework for the Detection of COVID-19 Pneumonia. Inf Syst Front 23, 1403–1415 (2021). https://doi.org/10.1007/s10796-021-10144-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10796-021-10144-6