
Abstract
The main purpose of this paper is to develop a fast numerical method for solving the first kind boundary integral equation, arising from the two-dimensional interior Dirichlet boundary value problem for the Helmholtz equation with a smooth boundary. This method leads to a fully discrete linear system with a sparse coefficient matrix. We observe that it requires a nearly linear computational cost to produce and then solve this system, and the corresponding approximate solution obtained by this proposed method preserves the optimal convergence order. One numerical example demonstrates the efficiency and accuracy of the proposed method.
Similar content being viewed by others

1 Introduction
In this paper, we establish a fast numerical solution for the first kind boundary integral equation, induced from a single layer approach for solving the interior Dirichlet problem for the Helmholtz equation
satisfying the boundary condition
where D is a bounded, simply connected open region in ℝ2 with a smooth boundary S. We seek a solution \(U\in C^{2}(D)\cap C(\bar{D})\) for the boundary value problem (1.1)–(1.2). κ in (1.1) is a given positive constant, and the function h in (1.2) is assumed to be given and continuous on the boundary S. As shown in [1, 2, 5, 20, 21], if the transfinite diameter C S of the boundary S is not equal to 1, then −κ 2 is not the eigenvalue of the Laplace operator, and then the boundary value problem (1.1)–(1.2) has a unique solution, otherwise, this boundary value problem can be rescaled to another Dirichlet problem for the Helmholtz equation, with the curve whose transfinite diameter is not 1. Hence, in this paper, without loss of generality, we assume that the boundary value problem (1.1)–(1.2) has a unique solution.
Among all methods for solving the two-dimensional Dirichlet boundary value problem for the Helmholtz equation with a smooth boundary, the boundary integral equation method is one of the most fundamental treatments. As shown in [17], the single layer method to the solution of the Dirichlet problem for the Helmholtz equation leads to a first kind boundary integral equation. This integral equation can be split into three parts. The first part in the kernel is a logarithmic term with a constant coefficient, and the second smooth part are familiar with the integral equation arising from the single layer approach to the Dirichlet problem for the Laplace equation, and the third part in the kernel function is a product of a logarithmic singular function and a smooth function, which requires our special attention.
For this arising boundary integral equation, various numerical methods have been developed in the literature. In [17], a fully discrete Fourier-Galerkin method is proposed. In [1, 5, 20, 21], the quadrature method and the modified quadrature method are considered. In [22, 23], the qualocation method has been developed as a new approximation, which tries to combine the advantage of the Galerkin method and the collocation method into a new scheme.
All these numerical methods enjoy nice convergence properties but at the same time suffer from having large computational costs due to the density of the coefficient matrix of the discrete linear system. To overcome this shortcoming, in [6], a fast truncated Fourier-Galerkin method is presented for solving the singular boundary integral equations, which are induced from the two-dimensional interior Dirichlet and Neumann boundary value problem for Laplace equation with a smooth boundary. This fast truncated Fourier-Galerkin method preserves the optimal order of the approximate solution, and leads to a semi-discrete linear system with a sparse coefficient matrix. In [14], they continue the theme of [6] and obtain a fast fully discrete Fourier-Galerkin method. This method generates a fully discrete sparse linear system with a nearly linear computational complexity, and preserves the optimal order of the approximate solution. In [24], following the ideas coming from [6, 14], a fast fully discrete Fourier-Galerkin method is used for solving first-kind logarithmic-kernel integral equation, induced from the two-dimensional Dirichlet problem for the Laplace equation on open arcs. In this paper, we shall continue the work of [6, 14, 24] and develop a fast numerical solution for the first kind boundary integral equation, arising from the interior Dirichlet problem for Helmholtz equation.
We organize this paper as follows. In Sect. 2, we introduce some notations and review the boundary integral equation method for solving (1.1)–(1.2). For the linear system produced by the Fourier-Galerkin method, we propose the matrix truncation strategy in Sect. 3.6. This truncation strategy leads to a semi-discrete linear system with a sparse coefficient matrix. Moreover, we give a few necessary technical results so as to analyze this truncation algorithm. In Sect. 4, we construct an efficient numerical integration scheme to compute all nonzero entries in the semi-discrete sparse linear system produced in last section. This scheme combining the matrix truncation strategy leads to a fully discrete sparse linear system. We prove that it requires a nearly linear computational cost to generate this fully discrete sparse linear system. In Sect. 5, the stability of this linear system and the convergence of this approximate solution are considered. We establish that this fully discrete linear system has a unique solution, and the approximate solution produced by this proposed method remains the optimal convergence order. Moreover, a precondition for the compressed coefficient matrix is proposed to obtain a preconditioned matrix having a uniformly bounded spectral condition number. In Sect. 6, the numerical example is presented to show the efficiency and accuracy of this method. In Sect. 7, we give a conclusion.
2 The Fourier-Galerkin method for solving singular boundary integral equations
In this section, as shown in [17], we first review the boundary integral equation reformulation of the boundary value problem (1.1)–(1.2) by a single-layer approach, and then describe the Fourier-Galerkin method for solving this arising boundary integral equation.
Let ℤ:={…,−1,0,1,…}, ℕ:={1,2,…,},ℕ0:=ℕ∪{0}, \(\mathbb{Z}_{n}^{+}:=\{1,2,\ldots,n\}\) and \(\mathbb{Z}_{n}:=\mathbb{Z}_{n}^{+}\cup\{0\}\) for each n∈ℕ. We introduce the Bessel function J 0(z), the Neumann function N 0(z) and the Hankel function \(H_{0}^{(1)}(z)\) as follows
and
and
in which c Euler:=0.57721… and i is the imaginary unit.
Let
be the fundamental solution to the Helmholtz equation (1.1). Using a single-layer potential method, the solution U of the boundary value problem (1.1)–(1.2) is expressed in the form
where ds Q denotes the differential of the line element along S with respect to Q.
In (2.1), letting P tend to a point on the boundary S, and using the boundary condition (1.2), we obtain a first kind boundary integral equation
If the function ϕ on the boundary S is the solution for the first kind boundary integral equation (2.2), then the single-layer representation (2.1) gives the solution U of the boundary value problem (1.1)–(1.2).
In order to give the operator form of (2.2), we let I:=[0,2π] and introduce a parameterization
for the boundary S. We assume that each component of x is in \(C_{2\pi}^{\infty}(I)\), the space of 2π-periodic functions in C ∞(I). Choosing P:=x(t) and Q:=x(s), then (2.2) becomes
where u(s):=ϕ(x(s))|x′(s)| and f(t):=h(x(t)).
Let r(s,t):=|x(s)−x(t)|, and we have that
Likewise, in [17], we decompose the kernel function \(\frac{i}{4}H_{0}^{(1)}(\kappa r(s,t))\) into three parts. For this we let
and
and

with
If the curve S and its parameterization x(t),t∈I are smooth, so is the function c
∗ in (2.5). Now we define three integral operators  ,
,  and
and  defined by the following equations
defined by the following equations

Using these notations, we rewrite (2.3) in the operator form

In order to study (2.6), we need an appropriate space of functions. For ψ∈L 2(I), we denote its l-th Fourier coefficient by

where
Following [1, 16, 17], we denote by H p(I)(p≥0) the Sobolev space of functions ψ∈L 2(I) with the property

The inner product of space H p(I)(p≥0) is defined by

and the corresponding norm is given by \(\|\psi\|_{p}:=(\psi,\psi)_{p}^{\frac{1}{2}}\).
For any ψ∈H 0(I) having the following expression

applying the result (7.2.24) in [1] we have

which implies that operator  is a bijective mapping from H
0(I) onto H
1(I).
is a bijective mapping from H
0(I) onto H
1(I).
By the smoothness of the boundary S, it follows from Theorem 3.1 in [17] that  and
and  are two compact integral operators from H
0(I) to H
1(I) and
are two compact integral operators from H
0(I) to H
1(I) and  is an isomorphism.
is an isomorphism.
Next we describe the Fourier-Galerkin method for solving (2.6). For each n∈ℕ we define a finite-dimensional subspace sequence
Let  be the orthogonal projection operator from space H
0(I) to X
n
. By Theorem 8.2 in [16], for all ω∈H
μ+ν(I) with μ,ν≥0, we have
be the orthogonal projection operator from space H
0(I) to X
n
. By Theorem 8.2 in [16], for all ω∈H
μ+ν(I) with μ,ν≥0, we have

The Fourier-Galerkin method for solving (2.6) is to seek a solution
satisfying

By (2.7), the operator  has the Fourier basis functions as its eigenfunctions, which implies
has the Fourier basis functions as its eigenfunctions, which implies  . Hence, (2.10) has the form
. Hence, (2.10) has the form

Letting  and
and  , (2.11) is rewritten as
, (2.11) is rewritten as

The related stability and convergence results regarding the Fourier-Galerkin method can be obtained by the result in Chap. 7.3.3 in [1].
Theorem 2.1
Suppose that (2.6) has a unique solution u, then there exist a positive integer n 0 and a positive constant ς such that for n≥n 0 and for any w∈X n ,

and

Moreover, if the solution u to (2.6) belongs to space H q(I) with q>0, then we have
At the end of this section, we present the matrix form of (2.12). For this purpose we use the notation \(\mathbf {v}:=[v_{k}, v_{-k}, k\in\mathbb{Z}_{n}^{+}]^{T}\in\mathbb{C}^{2n}\) to denote the vector [v 1,v −1,…,v n ,v −n ]T and v:=[v k ,v −k ,k∈ℤ n ]T∈ℂ2n+1 by [v 0,v 1,v −1,…,v n ,v −n ]T. For m 1,m 2∈ℤ, we let

and then set

For k,l∈ℕ, set

and we define matrix A ∗ of order 2n
Using these matrix notations, we denote matrix A by
Clearly, the formula (2.7) produces that
Likewise, for m 1,m 2∈ℤ, setting

and

we can define matrix B and matrix C and their corresponding blocks. We let

and then denote the coefficient vector in the approximate solution (2.9) by
Using these matrix and vector notations, (2.10) has the matrix form
The Fourier-Galerkin numerical method for solving (2.6) is equivalent to solve the linear system (2.16). Due to the density of matrix B and matrix C, we observe that storing this linear system requires  of computational complexity, and then generating its fully discrete form needs
of computational complexity, and then generating its fully discrete form needs  number of multiplications by the fast Fourier transform, and at last, solving the fully discrete linear system of (2.16) requires
number of multiplications by the fast Fourier transform, and at last, solving the fully discrete linear system of (2.16) requires  number of multiplications. Moreover, the spectral condition number of the coefficient matrix A+B+C is
number of multiplications. Moreover, the spectral condition number of the coefficient matrix A+B+C is  . When the order n is large, the computational cost for solving (2.16) is huge at the sane time the linear system (2.16) is extremely ill-posed. Hence, it is of great importance to develop a fast and stable algorithm for solving (2.16).
. When the order n is large, the computational cost for solving (2.16) is huge at the sane time the linear system (2.16) is extremely ill-posed. Hence, it is of great importance to develop a fast and stable algorithm for solving (2.16).
The issues about the fast and stable algorithm includes: (1) Can the dense coefficient matrix A+B+C be replaced by a sparse one so as to yield a semi-discrete sparse linear system? (2) Can the semi-discrete sparse linear system be fully discretized with a quasi-linear computational cost? (3) Can the fully discrete sparse linear system be solved efficiently and steadily while the approximate solution remains the optimal convergence order? We are going to answer these three questions in the next three sections, respectively.
3 The matrix truncation strategy and its analysis
In this section, we first compress these two full matrices B and C into two sparse ones by using two different matrix truncation strategies, and then analyze these two truncation strategies.
For the dense matrix B, since the kernel function b is smooth, we use the hyperbolic cross approximate method in [6, 14, 15, 19] to compress matrix B into a sparse matrix \(\tilde{\mathbf{B}}\) without loss of critical information encoded in the matrix. Specifically, we introduce an index set \(\mathbb{L}_{n}^{\mathbf{B}}:=[(m_{1},m_{2})\in{\mathbb{Z}_{n}^{*}}^{2}:|m_{1}m_{2}|\leq n]\), where \({\mathbb{Z}_{n}^{*}}^{2}:=[(k_{1},k_{2}):|k_{1}|,|k_{2}|\in\mathbb{Z}_{n}]\), and then define matrix \(\tilde{\mathbf{B}}\) by preserving the entry  in B for \((m_{1},m_{2})\in\mathbb {L}_{n}^{\mathbf{B}}\) and replacing others by zeros.
in B for \((m_{1},m_{2})\in\mathbb {L}_{n}^{\mathbf{B}}\) and replacing others by zeros.
If we use the symbol  to denote the number of the nonzero entries for any matrix G, then Theorem 3.1 in [6] shows that
to denote the number of the nonzero entries for any matrix G, then Theorem 3.1 in [6] shows that  is
is  .
.
For the matrix C, since the kernel function c is not smooth, we are going to develop another matrix truncation strategy different form that of matrix B. Similarly, we first introduce an index collection \({\mathbb{L}_{n}^{\mathbf{C}}}\) given by
and then define matrix \(\tilde{\mathbf{C}}\) by preserving the entry  in matrix C for \((m_{1},m_{2})\in{\mathbb{L}_{n}^{\mathbf{C}}}\) and replacing others by zeros.
in matrix C for \((m_{1},m_{2})\in{\mathbb{L}_{n}^{\mathbf{C}}}\) and replacing others by zeros.
In the next theorem we show that the matrix \(\tilde{\mathbf{C}}\) is a sparse matrix. To this end, we denote by  the cardinality for any set S.
the cardinality for any set S.
Theorem 3.1
For each
n∈ℕ, we have that
 is
is
 .
.
Proof
Noting the fact that  , as a result, we only need to estimate the latter. Let
, as a result, we only need to estimate the latter. Let

Clearly,
which implies that

A direct estimation produces that

On the other hand, we have that

which combining the fact that  yields that
yields that

A direct combination of (3.1)–(3.3) leads to the desired result. □
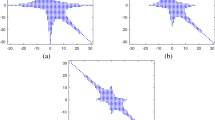
Figure 1 shows the sparsity of matrix \(\tilde{\mathbf{B}}\) and matrix \(\tilde{\mathbf{C}}\).

(a) The sparse matrix \(\tilde{\mathbf{B}}\) of order 1025 and (b) The sparse matrix \(\tilde{\mathbf{C}}\) of order 1025
Let  and
and  be the linear operators such that their matrix representations under the Fourier basis X
n
are \({\tilde{\mathbf{B}}}\) and \(\tilde{\mathbf{C}}\), respectively. Below we give the estimations of
be the linear operators such that their matrix representations under the Fourier basis X
n
are \({\tilde{\mathbf{B}}}\) and \(\tilde{\mathbf{C}}\), respectively. Below we give the estimations of  and
and  . To this end, we let H
μ,ν(I
2),μ,ν≥0 denote the Sobolev space of functions ψ∈L
2(I
2) with the norm
. To this end, we let H
μ,ν(I
2),μ,ν≥0 denote the Sobolev space of functions ψ∈L
2(I
2) with the norm

The next result concerns the difference  .
.
Lemma 3.1
Suppose that the kernel function b∈H q+1,q+1(I 2), then there holds

for w∈H ν(I) with ν:=0 or q.
Proof
By Lemma 4.4 in [6], we obtain that

which and the fact that ∥w∥0≤∥w∥ q lead to the desired conclusion. □
Next we consider the difference between  and
and  . For this purpose, let
. For this purpose, let
and we present a few technical results.
Lemma 3.2
Assume that the function
c
∗∈L
2(I
2), then every entry
 in (2.15) can be rewritten as
in (2.15) can be rewritten as

Proof
Since c ∗∈L 2(I 2), then its Fourier expansion has the following form

Substituting the right hand side of the equation above into (2.15) with \(\bar{e}_{m_{1}}e_{j_{1}}=\frac{1}{\sqrt{2\pi}}\bar{e}_{m_{1}-j_{1}}\) and \(\bar{e}_{m_{2}}e_{j_{2}}=\frac{1}{\sqrt{2\pi}}\bar{e}_{m_{2}-j_{2}}\) yields

Again substituting the result (3.12) in [17],
into the right hand side of (3.7) confirms (3.6). □
Remark 3.1
By changing the variable of integration in (3.7),  can also be expressed as
can also be expressed as

The next lemma gives three fundamental inequalities.
Lemma 3.3
For k,l∈ℤ, there holds


A combination of (3.5) and (3.9) yields that
Proof
The equalities (3.9), (3.10) hold and the equality (3.11) holds for the case |k+l|≤1, obviously. Hence, it only requires us to prove (3.11) for the case |k+l|≥2. In fact, by the definition (3.5), we have that

which combining (3.9) and the next inequality for |k+l|≥2
produces that
This completes the proof of this Lemma. □
For a vector v:=[v k ,v −k :k∈ℤ n ]T, we use the notation ∥v∥ to denote its spectral norm and then use \(\mathbf{v}_{\mu}:=[(1+k^{2})^{\frac{\mu}{2}}v_{k}, (1+k^{2})^{\frac{\mu}{2}}v_{-k}:k\in\mathbb{Z}_{n}]^{T}\) to denote a weighted vector for a nonnegative constant μ.
Lemma 3.4
Suppose that there exist a sequence \(\beta_{m_{1},m_{2},j}\) and a positive constant θ independent of m 1∈ℤ such that for some nonnegative constant μ,
then there holds for any two vectors v,w∈ℂ2n+1 and for ν:=0 or μ,

Proof
Associated with the sequence \(\beta_{m_{1},m_{2},j}\), we let
and associated with the vectors v and w, we define
We denote by  the left hand side of (3.13), that is,
the left hand side of (3.13), that is,

Using the Cauchy-Schwarz inequality to the right hand side of the above equation yields

On one hand, employing the inequality
with the hypothesis (3.12) produces that
On the other hand, using (3.9) with k:=m 2−m 1 and l:=j yields
which combining \((m_{1},m_{2})\in{\mathbb{Z}_{n}^{*}}^{2}\backslash{\mathbb{L}_{n}^{\mathbf{C}}}\) obtains that
Using (3.10) with k:=m 2−m 1 and l:=j yields that
Employing (3.11) with k:=m 1 and l:=j produces that
A combination of (3.18) and (3.19) obtains that
Hence, a direct consequence of (3.17) and (3.20) concludes that
which and (3.14), (3.16) yield the desired conclusion (3.13). □
The following result concerns the difference between two matrices C and \(\tilde{\mathbf{C}}\).
Lemma 3.5
Assume that there exist a positive constant σ and some nonnegative constant μ,

then for any two arbitrary vectors v,w∈ℂ2n+1 and for ν:=0 or μ, there holds
Proof
We first observe that

which combining (3.6) yields that

Hence, using the condition (3.21) and the estimation (3.13) with  confirms that
confirms that
This with \(\frac{\sqrt{8}}{2\pi}<1\) yields the desired conclusion. □
Now we give the difference between  and
and  .
.
Lemma 3.6
Suppose that the function c ∗∈H q+1,q+1(I 2), then for each w∈H ν(I) with ν:=0 or q, there holds

Proof
By the definition of norm, we have that

For v∈H 1(I) and w∈H 0(I), we express their orthogonal projections onto X n as

Two coefficient vectors in (3.24) are denoted by v:=[v k ,v −k :k∈ℤ n ]T and w:=[w k ,w −k :k∈ℤ n ]T, respectively. Obviously,
From (3.24) and the definition of the operators  and
and  , we obtain that
, we obtain that

A combination of (3.22) and (3.25) with σ:=∥c ∗∥ q+1,q+1, μ:=q leads to the desired estimation (3.23). □
Replacing B and C in (2.16) by \(\tilde{\mathbf{B}}\) and \(\tilde{\mathbf{C}}\), respectively leads to a truncated linear system
with the unknown solution vector \(\tilde{\mathbf{u}}:=[\tilde {a}_{l},\tilde{a}_{-l}: l\in\mathbb{Z}_{n}]^{T}\). Because the coefficient matrix \(\mathbf{A}+\tilde{\mathbf{B}}+\tilde{\mathbf{C}}\) has  number of nonzero entries, solving (3.26) is a fast semi-discrete algorithm.
number of nonzero entries, solving (3.26) is a fast semi-discrete algorithm.
4 The numerical integration scheme and its analysis
The numerical implementation of the fast method (3.26) requires an efficient computation of the nonzero elements in this linear system. We observe that  ,
,  and
and  are oscillatory integrals. To treat these oscillatory integrals, we adopt the product integration method so the integrals of the oscillatory factors are evaluated exactly. For recent development of numerical integration of oscillatory integrals, see [10–13, 18, 20]. With the product integration method, we can obtain sufficient precision to ensure that the approximate solution has the optimal convergence order. Specifically, we are going to use three appropriate functions to replace b, c
∗ and f, respectively, so that it requires a quasi-linear computational cost to generate the fully discrete forms of \(\tilde{\mathbf{B}}\), \(\tilde{\mathbf{C}}\) and f and the approximate solution preserves the optimal order.
are oscillatory integrals. To treat these oscillatory integrals, we adopt the product integration method so the integrals of the oscillatory factors are evaluated exactly. For recent development of numerical integration of oscillatory integrals, see [10–13, 18, 20]. With the product integration method, we can obtain sufficient precision to ensure that the approximate solution has the optimal convergence order. Specifically, we are going to use three appropriate functions to replace b, c
∗ and f, respectively, so that it requires a quasi-linear computational cost to generate the fully discrete forms of \(\tilde{\mathbf{B}}\), \(\tilde{\mathbf{C}}\) and f and the approximate solution preserves the optimal order.
In the next three subsections we are going to present and analyze the efficient numerical integration algorithm for computing all nonzero entries in \(\tilde{\mathbf{B}}\), \(\tilde{\mathbf{C}}\) and f, respectively. Accordingly, we use the notation ⌊x⌋ to denote the largest integer not more than x.
4.1 The numerical integration scheme for matrix \(\tilde{\mathbf{B}}\)
In this section, we first present the Boolean approximate function of the function b. This idea comes from [3, 4, 8]. To this end, for any two-dimensional continuous function g∈C(I 2) and for M k ∈ℕ and \(|j_{k}|\in\mathbb{Z}_{M_{k}}\), k=1,2, we set

and then let

As shown in [4], let r:=⌊log2 n⌋+1, and we define the two-dimensional Boolean approximate function of b by

A direct computation for  yields that
yields that

where \(\delta_{l_{1},l_{2}}\) is defined by
We let \(\hat{\mathbf{B}}\) denote the matrix \(\tilde{\mathbf{B}}\) with  being replaced by
being replaced by  for \((m_{1},m_{2})\in\mathbb{L}_{n}^{\mathbf{B}}\). Now we describe the algorithm for generating the fully discrete matrix \(\hat{\mathbf{B}}\).
for \((m_{1},m_{2})\in\mathbb{L}_{n}^{\mathbf{B}}\). Now we describe the algorithm for generating the fully discrete matrix \(\hat{\mathbf{B}}\).
Algorithm 4.1
Choosing r:=⌊log2 n⌋+1 for n∈ℕ.
- Step 1::
-
Computing \(b(\frac{2\pi j_{1}}{2^{j+1}}, \frac{2\pi j_{2}}{2^{r+2-j}})\) for \(j_{1}\in\mathbb{Z}_{2^{j+1}-1},j_{2}\in\mathbb{Z}_{2^{r+2-j}-1}\), \(j\in\mathbb{Z}_{r}^{+}\).
- Step 2::
-
Computing \(b(\frac{2\pi j_{1}}{2^{j+1}}, \frac{2\pi j_{2}}{2^{r+1-j}})\) for \(j_{1}\in\mathbb{Z}_{2^{j+1}-1},j_{2}\in\mathbb{Z}_{2^{r+1-j}-1}\), \(j\in\mathbb{Z}_{r-1}^{+}\).
- Step 3::
-
For \(j\in\mathbb{Z}_{r}^{+}\), computing
 for \(j_{1}\in\mathbb{Z}_{2^{j+1}-1}, j_{2}\in\mathbb{Z}_{2^{r+2-j}-1}\) by the two-dimensional fast Fourier transform.
for \(j_{1}\in\mathbb{Z}_{2^{j+1}-1}, j_{2}\in\mathbb{Z}_{2^{r+2-j}-1}\) by the two-dimensional fast Fourier transform. - Step 4::
-
For \(j\in\mathbb{Z}_{r-1}^{+}\), computing
 for \(j_{1}\in\mathbb{Z}_{2^{j+1}-1}, j_{2}\in\mathbb{Z}_{2^{r+1-j}-1}\) by the two-dimensional fast Fourier transform.
for \(j_{1}\in\mathbb{Z}_{2^{j+1}-1}, j_{2}\in\mathbb{Z}_{2^{r+1-j}-1}\) by the two-dimensional fast Fourier transform. - Step 5::
-
Computing
 for all \((m_{1},m_{2})\in\mathbb{L}_{n}^{\mathbf{B}}\), according to the formula (4.2).
for all \((m_{1},m_{2})\in\mathbb{L}_{n}^{\mathbf{B}}\), according to the formula (4.2).
 for
for  for
for  for all
for all The next theorem concerns on the computational cost used in generating \(\hat{\mathbf{B}}\).
Theorem 4.1
For (s,t)∈I
2, if the number of multiplications used in computing
b(s,t) is
 , then the number of multiplications for computing all nonzero entry in
\(\tilde{\mathbf{B}}\)
is
, then the number of multiplications for computing all nonzero entry in
\(\tilde{\mathbf{B}}\)
is
 .
.
Proof
The number of multiplications used in Step 1 and Step 2 is  . Step 3 and Step 4, by FFT method, require
. Step 3 and Step 4, by FFT method, require  number of multiplications. In Step 5, a direct observation infers that the number of multiplications is
number of multiplications. In Step 5, a direct observation infers that the number of multiplications is  . In view of the total number of multiplications used in Algorithm 4.1 equaling to the sum of that used in each step, we obtain the desired result. □
. In view of the total number of multiplications used in Algorithm 4.1 equaling to the sum of that used in each step, we obtain the desired result. □
Let  be the linear operator such that its matrix representation under the Fourier basis X
n
is \({\hat{\mathbf{B}}}\). The next step is to give a few technical results so as to show the difference between
be the linear operator such that its matrix representation under the Fourier basis X
n
is \({\hat{\mathbf{B}}}\). The next step is to give a few technical results so as to show the difference between  and
and  .
.
Lemma 4.1
Suppose that the kernel function \(b\in{H}^{q_{1}, q_{1}}(I^{2})\) such that q 1>q+3/2, then there exists a positive integer n 0 such that when n≥n 0 and for any two arbitrary vectors v,w∈ℂ2n+1,
Proof
A direct expansion of \(\mathbf{v}_{2}^{T}(\tilde{\mathbf{B}}-\hat{\mathbf{B}})\mathbf{w}\) yields that

Employing Cauchy-Schwartz inequality to the right hand side of the above equation, we have

Applying Theorem 8 in [4], there exists a positive constant ς 1 such that for \(b\in H^{q_{1},q_{1}}(I^{2})\),

which yields that

Together with (4.6) and the inequality \(1+m_{1}^{2}\leq2 n^{2}\) for |m 1|∈ℤ n , the inequality (4.4) infers that
Since

there exists a positive constant ς 2 such that

Because −q 1+q+3/2<0, we obtain that \(n^{-q_{1}+q+3/2}\log_{2}^{3/2}n\rightarrow0\) as n→∞, and then there exists a positive constant n 0 such that n≥n 0, the value \(\varsigma_{2} n^{-q_{1}+q+3/2}\log_{2}^{3/2}n\) is bounded by 1. Substituting the above estimate into the right hand side of (4.7) leads to (4.3). □
Similar to the proof of Lemma 3.6, using Lemma 4.1 leads to
Lemma 4.2
Suppose that the function \(b\in{H}^{q_{1},q_{1}}(I^{2})\), then there exists a positive integer n 0 such that when n≥n 0 and for any w∈H 0(I),

4.2 The numerical integration scheme for matrix \(\tilde{\mathbf{C}}\)
Similar as in Sect. 4.1, using  to denote the Boolean approximate function of c
∗, we let
to denote the Boolean approximate function of c
∗, we let

and then set
A simple computation for  by (3.5) yields that
by (3.5) yields that

where
We let \(\hat{\mathbf{C}}\) denote the matrix \(\tilde{\mathbf{C}}\) with  being replaced by
being replaced by  for \((m_{1},m_{2})\in{\mathbb{L}_{n}^{\mathbf{C}}}\). Now we describe the algorithm for computing all nonzero entries in matrix \(\tilde{\mathbf{C}}\).
for \((m_{1},m_{2})\in{\mathbb{L}_{n}^{\mathbf{C}}}\). Now we describe the algorithm for computing all nonzero entries in matrix \(\tilde{\mathbf{C}}\).
Algorithm 4.2
Choosing r:=⌊log2 n⌋+1 for n∈ℕ.
- Step 1::
-
For \((m_{1},m_{2})\in\mathbb{L}_{n}^{\mathbf{B}}\), computing
 by Algorithm 4.1.
by Algorithm 4.1. - Step 2::
-
Computing
 for all \((m_{1},m_{2})\in{\mathbb{L}_{n}^{\mathbf{C}}}\), according to the formula (4.11).
for all \((m_{1},m_{2})\in{\mathbb{L}_{n}^{\mathbf{C}}}\), according to the formula (4.11).
 by Algorithm 4.1.
by Algorithm 4.1. for all
for all The next result considers the computational cost for generating \(\hat{\mathbf{C}}\).
Theorem 4.2
For (s,t)∈I
2, if the number of multiplications used in computing
c
∗(s,t) is
 , then the number of multiplications for computing all nonzero entries in
\(\tilde{\mathbf{C}}\)
is
, then the number of multiplications for computing all nonzero entries in
\(\tilde{\mathbf{C}}\)
is
 .
.
Proof
Noting that the computational cost of Step 1 is  by Theorem 4.1, it only requires to estimate the cost of Step 2 in Algorithm 4.2. Consequently, let p:=m
1−m
2, and we define an index set \(\mathbb{M}_{p,n}\) as
by Theorem 4.1, it only requires to estimate the cost of Step 2 in Algorithm 4.2. Consequently, let p:=m
1−m
2, and we define an index set \(\mathbb{M}_{p,n}\) as
where
and
Thus we write  of (4.11) as
of (4.11) as

where
Clearly,  for p
2−4n≤0, otherwise,
for p
2−4n≤0, otherwise,  . Let
. Let

and we infer that the number of multiplications finishing Step 2 by the FFT method is not more than

which yields the desired conclusion. □
Next we concern on the estimation  . For this we set
. For this we set

By Theorem 1 in [15], there exists a positive constant τ 1 such that for \(c^{*}\in H^{q_{1}, q_{1}}(I^{2})\),
Again using Theorem 8 in [4], combining (4.9) and (4.12) with (4.5) yields that there exists a positive constant τ 2 such that

A combination of (4.13) and (4.14) yields that
Lemma 4.3
Suppose that the function \(c^{*}\in{H}^{q_{1}, q_{1}}(I^{2})\), then there exists a positive constant τ such that

Proof
By the definition, the difference between  and
and  is written as
is written as

Using Cauchy-Schwartz inequality to the right hand side of the equation above with letting
produces that

Clearly, τ 3<+∞. Substituting the estimate (4.15) into the right hand side of the equation above with τ:=(τ 1+τ 2)τ 3 leads to the desired conclusion. □
We denote by  the linear operator such that its matrix representation under the Fourier basis X
n
is \({\hat{\mathbf {C}}}\) and then estimate the difference between
the linear operator such that its matrix representation under the Fourier basis X
n
is \({\hat{\mathbf {C}}}\) and then estimate the difference between  and
and  .
.
Lemma 4.4
Suppose that the function \(c^{*}\in{H}^{q_{1},q_{1}}(I^{2})\), then there exists a positive integer n 0 such that when n≥n 0, for any two arbitrary vectors v,w∈ℂ2n+1,
Hence, we also have that for w∈H 0(I),

Proof
Combining Lemma 4.3, a similar proof of Lemmas 4.1 and 4.2 yields the desired conclusion. □
4.3 The numerical integration scheme for vector f
We first consider the right hand side vector f in (3.26). For |m 1|∈ℤ n , we define \(\tilde{f}_{m_{1}}\) by,
and then let
Clearly, we have that for |m
1|∈ℤ
n
,  . Now we use \(\hat{f}_{m_{1}}\) to approximate \({f}_{m_{1}}\) and let
. Now we use \(\hat{f}_{m_{1}}\) to approximate \({f}_{m_{1}}\) and let
A standard argument in [1, 9] shows that obtaining \(\hat{\mathbf{f}}\) requires  number of computational cost by the fast Fourier transform method and there exists a positive constant ε such that for f∈H
q+1(I) with q>0,
number of computational cost by the fast Fourier transform method and there exists a positive constant ε such that for f∈H
q+1(I) with q>0,
By replacing the matrices \(\tilde{\mathbf{B}}, \tilde{\mathbf{C}}\) and f in (3.26) by the fully discrete matrices \(\hat{\mathbf{B}}, \hat{\mathbf{C}}\) and \(\hat{\mathbf{f}}\), a fully discrete truncated linear system is obtained
with the unknown solution vector \(\hat{\mathbf{u}}:=[\hat{a}_{l},\hat {a}_{-l}: l\in\mathbb{Z}_{n}]^{T}\).
From the analysis above we observe that generating the linear system (4.19) requires the number of  of multiplications. Moreover, solving this linear system requires
of multiplications. Moreover, solving this linear system requires  number of multiplications by the multilevel augmentation method proposed in [7]. Hence, it is a fast fully discrete algorithm.
number of multiplications by the multilevel augmentation method proposed in [7]. Hence, it is a fast fully discrete algorithm.
5 The analysis of the proposed fast method
In this section, we first present the stability of the approximate operator  .
.
Lemma 5.1
Suppose that the kernel function \(b\in{H}^{q_{1},q_{1}}(I^{2})\), then there exists a positive integer n 0 such that for n≥n 0 and for any w∈H 0(I),

Proof
Using the triangle inequality we have that

which combining (2.3) and (4.8) with \(H^{q_{1},q_{1}}(I^{2}) \subseteq H^{q+1,q+1}(I^{2}) \) yields the desired conclusion. □
Lemma 5.2
Suppose that the function \(c^{*}\in{H}^{q_{1},q_{1}}(I^{2})\), then there exist a positive integer n 0 and a positive constant γ such that when n≥n 0 and for w∈H ν(I) with ν:=0 or q,

Proof
This result is a consequence of Lemma 3.6 and Lemma 4.4. □
Theorem 5.1
Suppose that the functions \(b,c^{*}\in{H}^{q_{1}, q_{1}}(I^{2})\), then there exists a positive integer n 0 such that n≥n 0 and for any w∈X n

where ς is given in (2.13).
Proof
By the hypothesis on the function b, using (5.1) and the fact that lim n→∞ n −q=0, we conclude that there exists a positive integer n 1 such that for all n≥n 1 and for all w∈X n ,

As mentioned in the above, a consequence of (5.2) leads to the fact that there exists a positive integer n 2 such that when n≥n 2 and for w∈X n ,

When n≥n 0:=max{n 1,n 2}, these two estimates (5.4) and (5.5) combining with (2.13) yield that

proving the desired conclusion. □
This theorem shows that when n≥n 0, (4.19) has a unique solution. Clearly, the linear system (4.19) is equivalent to the operator form:

where
Next we establish the convergence order of the approximate solution \(\hat{u}_{n}\).
Theorem 5.2
Suppose the conditions in Theorem 5.1 hold, f∈H q+1(I), then there exist a positive constant η and a positive integer n 0 such that for n≥n 0,
Proof
By the triangle inequality we have that

Using (2.8) with ω:=u,μ:=q,ν:=0 obtains that the first term on the right hand side of (5.7) is bounded by ∥u∥ q n −q. Therefore, it requires us to give an estimate of the second term on the right hand side of (5.7). Using Theorem 5.1 there exists a positive integer n 0 such that n≥n 0,

On the other hand, employing operator  to both sides of (2.6) and using \({f}_{n}:=\hat{f}_{n}+{f}_{n}-\hat{f}_{n}\) yield that
to both sides of (2.6) and using \({f}_{n}:=\hat{f}_{n}+{f}_{n}-\hat{f}_{n}\) yield that

Combining (5.9) and (4.19) shows that

A direct computation using (5.10) confirms the equation

Together with (2.8), (4.18), (4.8), (4.17) and (5.3) using the triangle inequality for the equation above shows that there exist a positive constant η 1 and a positive integer n 0 such that when n≥n 0,

Hence, there exists a positive constant η such that
which and (5.11) lead to the desired conclusion. □
Theorem 5.2 illustrates that the proposed method preserves the optimal order of convergence.
In the remainder of this section, we consider a precondition of the coefficient matrix of the linear system (4.19) so that the resulting matrix has a uniformly bounded spectral condition number. For this purpose, we introduce a lemma.
Lemma 5.3
Suppose that the conditions in Theorem 5.1 hold, then there exist two positive constants θ 1 and θ 2 and a positive integer n 0 such that when n≥n 0 and for w∈X n ,

Proof
By Theorem 5.1 we observe that the left hand side of the inequality (5.12) holds with θ 1:=ς/2. The left issue is to prove the right hand side of this inequality. By using the triangle inequality, there holds

Noting that  is bounded. With the definition of operators
is bounded. With the definition of operators  and
and  , there exist a positive constant ξ and a positive integer n
1 such that for n≥n
1 and w∈X
n
,
, there exist a positive constant ξ and a positive integer n
1 such that for n≥n
1 and w∈X
n
,

Again by (5.1) and (5.2) there exists a positive integer n 2 such that n≥n 2,

Substituting these two estimates (5.14) and (5.15) into the right hand side of (5.13) leads to the desired result (5.12) with θ 2:=ξ+1 and n≥n 0:=max{n 1,n 2}. □
Now we define a diagonal matrix D by
which will be used as a preconditioner for the coefficient matrix \((\mathbf{A}+\hat{\mathbf{B}}+\hat{\mathbf{C}})\). To this end, we let
Clearly, (4.19) is rewritten as
Below we prove that matrix E enjoys a uniformly bounded spectral condition number. For this purpose, we use the symbol \(\operatorname{cond}(\bf G)\) to denote the spectral condition number for any inverse square matrix G.
Theorem 5.3
Suppose that the conditions in Theorem 5.2 hold, then there exists a positive integer n 0 such that when n≥n 0, the spectral condition number of matrix E is uniformly bounded, that is
Proof
This proof is similar to that of Theorem 4.2 in [13]. For any w:=[w l ,w −l :l∈ℤ n ]T, we let

Clearly, v∈X
n
. Let  , and we have that
, and we have that
that is,
which yields

A combination of (5.12) and (5.17) with the fact ∥w∥0=∥w∥ leads to the estimate (5.16). □
6 Numerical examples
In this section, we shall adopt the conventional method and the proposed method respectively to compute one numerical example and then show that our proposed method is better than the conventional method.
In the conventional method, the fully discrete form of B is obtained by using the two-dimensional fast Fourier transform algorithm. For the matrix C, we first use the two-dimensional fast Fourier transform algorithm to compute  for \((m_{1},m_{2})\in{\mathbb{Z}_{n}^{*}}^{2}\), and then obtain the fully discrete form of matrix C by using (3.8) and the fast Fourier transform method. In our proposed method, we obtain the matrix \(\hat{\mathbf{B}}\) and matrix \(\hat{\mathbf{C}}\) by Algorithm 4.1 and Algorithm 4.2 respectively.
for \((m_{1},m_{2})\in{\mathbb{Z}_{n}^{*}}^{2}\), and then obtain the fully discrete form of matrix C by using (3.8) and the fast Fourier transform method. In our proposed method, we obtain the matrix \(\hat{\mathbf{B}}\) and matrix \(\hat{\mathbf{C}}\) by Algorithm 4.1 and Algorithm 4.2 respectively.
All computer programs are compiled by Matlab language and run on a personal computer with a 2.01 GHz celeron CPU and 1 G memory. We solve the fully discrete linear system by the multilevel augmentation method. We use the notations CT1 and CT2 to denote the computing time (measured in seconds), spent in generating the fully discrete form of matrix B and C in the conventional method and that of \(\tilde{\mathbf{B}}\) and \(\tilde{\mathbf{C}}\) in the proposed method, respectively. We use CT3 to denote the time (measured in seconds) spent in solving the linear system (2.16) and (4.19), respectively.
Example
Consider solving the boundary value problem (1.1)–(1.2). Assume the boundary S has a parametrization x(t):=(2cost,sint), t∈I. We choose the boundary function h in (1.2) so that the exact solution for the boundary value problem (1.1)–(1.2) is U(P):=N 0(2|P−P 0|), P∈D, where P 0:=(4,0). Let \(\hat{u}_{n}\) be the solution by solving (5.6), and we define the corresponding approximate solution \(\hat{U}_{n}\) for the boundary value problem (1.1)–(1.2) by
We define the error function δ(x,y) as follows
The numerical results for this example obtained by using the conventional method and the proposed method are given in Tables 1 and 2, respectively, where δ k :=δ(P k ) at the points \(P_{k}:=p_{k}(\cos\frac{\pi}{4}, \sin\frac{\pi}{4}), k=1,2,3\), where p 1:=0,p 2:=0.25 and p 3:=0.5 and the values of \(\hat{U}_{k}\) at points P k are computed by the trapezoid quadrature formula. Figure 2 illustrates that our proposed method is more efficient than the conventional method.

Computation times CT of conventional and proposed methods
7 Conclusion
The proposed method is superior to the conventional numerical method for solving the first kind boundary integral equation, reformulations of boundary value problems of the two-dimensional Helmholtz equation with a smooth boundary. Moreover, this method may be used to solve other boundary value problems.
References
Atkinson, K.E.: The Numerical Solution of Integral Equations of the Second Kind. Cambridge University Press, Cambridge (1997)
Atkinson, K.E., Sloan, I.H.: The numerical solution of the first kind logarithmic-kernel integral equations on smooth open arcs. Math. Comput. 56, 119–139 (1991)
Baszenski, G., Delvos, F.J.: A discrete Fourier transform scheme for Boolean sums of trigonometric operators. In: Chui, C.K., Schempp, W., Zeller, K. (eds.) Multivariate Approximation Theory IV, ISNM 90, pp. 15–24. Birkhäuser, Basel (1989)
Barthelmann, V., Novak, E., Ritter, K.: High dimensional polynomial interpolation on sparse grids. Adv. Comput. Math. 12, 273–288 (2000)
Burn, B.J., Sloan, I.H.: An unconventional quadrature method for logarithmic-kernel integral equations on closed curves. J. Integral Equ. Appl. 4, 117–151 (1992)
Cai, H., Xu, Y.: A fast Fourier-Galerkin method for solving singular boundary integral equations. SIAM J. Numer. Anal. 48, 1965–1984 (2008)
Chen, Z., Wu, B., Xu, Y.: Multilevel augmentation methods for solving operator equations. Numer. Math. J. Chin. Univ. 14, 244–251 (2005)
Delvos, F.J.: Boolean methods for double integration. Math. Comput. 55, 683–692 (1990)
Gasquet, C., Witomski, P.: Fourier Analysis and Applications. Springer, New York (2002)
Iserles, A.: On the numerical quadrature of highly-oscillating integrals I: Fourier transforms. IMA J. Numer. Anal. 24, 365–391 (2004)
Iserles, A.: On the numerical quadrature of highly-oscillating integrals II: Irregular oscillators. IMA J. Numer. Anal. 25, 25–44 (2005)
Iserles, A., Nørsett, S.P.: On quadrature methods for highly oscillatory integrals and their implementation. BIT Numer. Math. 44, 755–772 (2004)
Jiang, Y., Xu, Y.: Fast discrete algorithms for sparse Fourier expansions of high dimensional functions. J. Complex. 26, 21–51 (2010)
Jiang, Y., Xu, Y.: Fast Fourier-Galerkin methods for solving singular boundary integral equations: numerical integration and precondition. J. Comput. Appl. Math. 234, 2792–2807 (2010)
Knapek, S.: Hyperbolic cross approximation of integral operators with smooth kernel. Technical Report 665, SFB 256, Univ. Bonn (2000)
Kress, R.: Linear Integral Equations. Springer, New York (1989)
Kress, R., Sloan, I.H.: On the numerical solution of a logarithmic integral equation of the first kind for the Helmholtz equation. Numer. Math. 66, 199–214 (1995)
Levin, D.: Procedures for computing one-and-two dimensional integrals of functions with rapid irregular oscillations. Math. Comput. 38, 531–538 (1982)
Pereverzev, S.V.: Hyperbolic cross and the complexity of the approximate solution of Fredholm integral equations of the second kind with differentiable kernels. Sib. Math. J. 32, 85–92 (1991)
Saranen, J.: The modified quadrature method for logarithmic-kernel integral equations on closed curves. J. Integral Equ. Appl. 3, 575–600 (1991)
Saranen, J., Sloan, I.H.: Quadrature methods for logarithmic-kernel integral equations on closed curves. IMA J. Numer. Anal. 12, 167–187 (1991)
Sloan, I.H.: A quadrature-based approach to improving the collocation method. Numer. Math. 54, 41–56 (1988)
Sloan, I.H.: Error analysis of boundary integral methods. Acta Numer. 1, 287–339 (1991)
Wang, B., Wang, R., Xu, Y.: Fast Fourier-Galerkin methods for first-kind logarithmic-kernel integral equations on open arcs. Sci. China Ser. A 53, 1–22 (2010)
Acknowledgements
The author thanks the referees for very helpful suggestions, which help me improve this paper.
Open Access
This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Jan Hesthaven.
Supported by National Science Foundation of China 10901093, 11061008 and the National Science Foundation of ShanDong Province ZR2010AQ001, ZR2010AQ012.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Cai, H. A fast numerical solution for the first kind boundary integral equation for the Helmholtz equation. Bit Numer Math 52, 851–875 (2012). https://doi.org/10.1007/s10543-012-0380-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10543-012-0380-6
Keywords
- Boundary integral equation method
- Fast numerical solution
- Matrix truncation strategy
- Numerical integration scheme