
Abstract
Parkinson’s disease (PD) is the second most common neurological disorder caused by damage to dopaminergic neurons. Therefore, it is important to develop systems for early and automatic diagnosis of PD. For this purpose, a study that will contribute to the development of systems for the automatic diagnosis of PD is presented. The Electroencephalography (EEG) signals were decomposed into sub-bands using adaptive decomposition methods, such as empirical mode decomposition, variational mode decomposition, and Vold-Kalman order filtering (VKF). Various features were extracted from the sub-band decomposed signals, and the significant ones were determined by Chi-squared test. These important features were applied as input to support vector machine (SVM), fitch neural network (FNN), k-nearest neighbours (KNN), and decision trees (DT), machine learning (ML) models and classification was performed. We analysed the performance of ML models by obtaining accuracy, sensitivity, specificity, positive predictive value, negative predictive values, F1-score, false-positive rate, kappa statistics, and area under the curve. The classification process was performed for two cases: PD ON-HC and PD OFF-HC groups. The most successful method in this study was the VKF method, which was applied for the first time in this field with the approach specified for both cases. In both instances, the SVM algorithm was employed as the ML model, with classifier performance criterion values close to 100%. The results obtained in this study seem to be successful compared to the results of recent research on the diagnosis of PD.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
1.1 Background
Parkinson’s disease (PD) is the second most common neurodegenerative disease globally, particularly affecting people over the age of 50 [1, 2]. Patients with PD usually have motor symptoms, such as mild tremors, slowing of movements, gait or posture disturbance. In addition to these symptoms, non-motor symptoms such as depression, loss of smell, constipation, or sleep problems are also observed [1, 3, 4]. Clinical evaluation of PD according to these symptoms can be difficult [5]. Different neuroimaging measurement techniques have been used by clinicians in the diagnosis of PD. Some of these techniques are based on physiological signals, such as EEG, and electromyography, while others are based on magnetic resonance imaging types or computed tomography. Measurement techniques using physiological signals are more advantageous in terms of time and cost [6]. Among these signals, EEG is the most frequently used measurement method in neurodegenerative diseases, such as PD [7].
EEG is a measurement method that records the electrical activity in the cerebral cortex with the help of multiple electrodes through the scalp and is widely used to diagnose whether there is any abnormality in the brain [7, 8]. This method helps expert clinicians to interpret a neurological disorder or analyse a medical condition [8]. However, traditional diagnostic methods sometimes encounter conditions that are invisible to clinicians and therefore difficult to classify [9]. For this reason, expert clinicians need faster and more reliable systems that can be used for early diagnosis of a neurological disorder such as PD [4]. The development of these systems will allow specialists to rapidly detect PD, enabling early initiation of treatment.
Machine learning methods are mostly applied to EEG signals in the development of automatic diagnosis systems [7, 9]. Because of the complex structure of non-stationary EEG signals, they can be difficult to analyse. To facilitate these analyses, PD-healthy control (HC) groups can be easily classified by applying features obtained by various nonlinear feature extraction methods [10]. In addition, detailed information can be obtained at different frequencies by decomposing EEG signals into sub-bands with various methods. In this way, success can be achieved in ML-based studies for the automatic diagnosis of neurological disorders. As a result of these studies, a more systematic decision-making process can be provided to clinicians [9]. In order to contribute to the automatic detection of PD, EEG signals were decomposed into sub-bands using signal processing techniques in this study. Various features are extracted from these sub-bands and applied as input to ML models and an EEG–ML model-based study is proposed. There are recent studies based on EEG signals and ML models for the diagnosis of PD. These studies are mentioned in the next sub-section.
1.2 Related works
It is seen that there are successful studies that have recently contributed to the literature based on EEG signals that have performed the classification of PD with ML algorithms. Recent studies on Parkinson’s disease diagnosis utilising EEG signals and machine learning algorithms have shown promising results.
Anjum et al. [11] developed the LEAPD model, achieving an 85.40% accuracy in distinguishing PD from the HC group using various EEG signal data. Murugappan et al. [12] utilized tunable Q wavelet transform and neural network methods, achieving an impressive 96.16% accuracy in PD detection. In another study, Aljalal et al. [13] achieved remarkable success in diagnosing PD and evaluating treatment efficacy through the analysis of multiple aspects from EEG data with ML algorithms. They obtained 99% success in non-drug usage and 95–98% success in drug use. Motin et al. [14] proposed an EEG-based automated PD monitoring technique, using the SVM classifier, which resulted in an accuracy of 87.10%, sensitivity of 93.33%, and specificity of 81.25%. Using an Artificial Neural Network model and selected features from EEG signals, Kamalakannan et al. [15] achieved a commendable accuracy rate of 93.3% in classifying PD. Karakaş and Latifoğlu introduced a new method for analysing EEG signals from PD patients. They used the grey-level co-occurrence matrix method and various ML algorithms, obtaining the best performance with the SVM classifier, which resulted in an accuracy rate of 92.4% [16]. Furthermore, Biswas et al. [17] proposed an “Ensembled Expert System” ensemble model for early diagnosis of PD, achieving an accuracy of 93.2% in predicting PD. These recent studies demonstrate the potential of EEG and ML techniques in aiding the accurate diagnosis of Parkinson’s disease, bringing valuable contributions to the field.
In addition to the studies on the diagnosis of PD listed above, other investigations using EEG signals, ML techniques, and deep learning techniques are reported in the literature [1, 4, 6, 18,19,20]. These studies and especially the ones conducted with the data set used in this study are mentioned in detail in the discussion section. Studies using DL models require larger datasets and can be difficult to implement because in most cases, codes are not publicly available to replicate the study [13]. Various studies have been carried out to help diagnose PD, but it is seen that there is a need for new studies in addition to these studies to support clinicians [9, 13]. For this reason, in this study, a new study that can help early diagnosis of PD using EEG signals and ML algorithms is proposed. This study incorporates an innovative approach that combines VKF and ML techniques for the diagnosis of PD. The fusion of VKF and ML, in a manner not previously attempted, offers a novel and distinct perspective in the diagnosis of Parkinson’s disease. The developed model utilises VKF and ML methodologies to provide high diagnostic accuracy and reliability, surpassing existing diagnostic methods for Parkinson’s disease. In addition to early diagnosis of PD, drug efficacy is also investigated and analysed in the proposed study. Our motivation for conducting the proposed study, the purpose of the study, and its contributions to the literature are explained below.
1.3 Our purpose, motivation, and contributions
EEG signals are nonlinear. For this reason, the analysis of EEG signals in the diagnosis of PD can be difficult and time-consuming. Using EEG signals and ML models, this study aims to contribute to the development of systems for the early and automatic diagnosis of PD. Detailed information can be obtained from EEG signals by decomposing them into sub-bands and obtaining features. For this reason, in this study, EEG signals were decomposed into sub-bands with three different methods, and various features were obtained. These features were analysed with four different ML models to classify PD ON (drug using)-HC and PD OFF (non-medicated)-HC groups.
We were motivated by the technical quality of the data set used in the study (32 channels and a sampling frequency capable of providing high-resolution data) and its novelty. Another motivator was the fact that the VKF approach used in this work has not been studied in studies involving EEG medication efficacy data.
We consider it a significant benefit to examine the drug effect in this study because the data set contains EEG signals in the form of PD ON and PD OFF. There are studies on the application of the VKF approach in several domains [20] when the studies are analysed. But using the methodology used in this study, research has been done for the first time on the identification of neurological illnesses using EEG data. The EMD and VMD methods, which are common for breaking down signals into sub-bands, are compared with the performance of the VKF approach in this study rather than being evaluated separately. We think that this work can add to the body of knowledge. In the discussion section, the study’s benefits and contributions are described in more detail.
2 Material and method
2.1 Dataset description
The EEG dataset (version 1.0.4) shared as open source on the Open Neuro website by Rochill et al. [21] was used to test the approaches suggested in this work. The University of California, San Diego captured EEG signals. With the help of 16 HCs (mean age: 63.5 9.6 years, gender: 9 females, 7 males) and 15 PDs (mean age: 63.2 8.2 years, gender: 8 females, 7 men) who had mild-to-severe Parkinson’s symptoms, EEG signals were recorded from the participants. Each participant used their right hand. Participants were instructed to sit comfortably and fix their attention on the cross on the screen during the recording. In this method, 32-channel BioSemi ActiveTwo systems were used to record resting EEG at a 512-Hz sampling rate. Figure 1 depicts the placements of the 32-channel EEG electrodes utilised in the research. The PD group’s EEG signals were divided into two groups: those who got therapy with an equivalent amount of the dopaminergic medication levodopa three times per day (PD ON) and those who did not (PD OFF). On several days, PD ON and PD OFF recordings were gathered [4, 11]. Reference [21, 22] provides comprehensive information about the dataset and the preprocessing techniques used on the dataset.

Layout of 32-channel EEG electrodes [13]
2.2 Proposed study
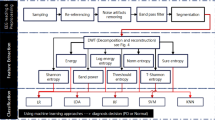
This study uses EEG data and ML models to categorise PD (ON–OFF)-HC groups. In the initial stage of the study, the noises in the EEG signals received from 32 channels were eliminated to achieve this. Using EMD, VMD, and VKF procedures, the denoised EEG signals were divided into eight subband components. Since all three approaches have a strong classification performance, eight sublevels were decided upon for the breakdown procedure. In this manner, more data was extracted from intricate EEG signals. These sub-bands were used to extract characteristics for Shannon entropy, Hjort parameters, Power Sum, Kolmogorov complexity, and Katz fractal dimension. The significant features were identified by applying the Chi-squared test to lessen the processing burden during the classification process and to enhance the functionality of the classifier models. Following the identification of the key features, the classification process was carried out for the PD OFF-HC and PD ON-HC groups using four ML models (FNN, SVM, KNN, and DT). As a result of the classification process, accuracy, sensitivity, specificity, positive predictive value, negative predictive value, F1-score, false-positive rate, kappa statistics, and area under the curve rates used to analyse the performance of ML models were obtained. The software programme MATLAB 2022a (MathWorks, Inc., Natick, MA, USA) was used to carry out every step of this work. Figure 2 provides a generic flow chart outlining the steps in the proposed investigation. Detailed information about the research steps explained in this section is explained in the following sections of the study.

Flowchart of the proposed work
2.3 EEG signals preprocessing
EEG signal data is multidimensional and contains noise. As a result, a preprocessing stage is required before feature extraction to remove noise from the data. Getting features and preprocessing them before the classification stage is a critical step in the creation of ML models. Blinking movements, electrical noise, and other sounds were eliminated from the EEG data used in this work before signal stage processing and feature extraction by using a 0.1–40 Hz finite impulse response (FIR) band-pass filter. Independent component analysis was also utilised to remove interference artefacts from the stream. The denoised EEG data were divided into sub-bands using EMD, VMD, and VKF signal processing techniques. Because the EEG signal encompasses a variety of oscillations, these sub-bands are referred to as intrinsic mode functions (IMF).
2.3.1 Empirical mode decomposition
To break down a signal into IMFs, Huang et al. [23] developed the EMD approach. EEG signals are hypothesised to exhibit many oscillations at the same time. The EMD approach is used in this situation to split the signals into stationary sub-bands. The difference between zero crossing and extremum numbers in the EMD approach should be smaller than one. Furthermore, the average value of the upper and lower envelopes created by local maxima and minima should be zero [24]. The EMD approach, which has been used for various physiological signals in research, both decomposes and removes noise [23, 25]. The EMD approach was used to split EEG signals into eight sub-bands in this investigation. Figure 3 depicts a sample of eight IMFs derived using EMD.

Eight IMF examples were obtained as a result of the application of the EMD method
2.3.2 Variational mode decomposition
The VMD method presented by Dragomiretskiy et al. is used as a time–frequency decomposition method [26]. With the VMD method, the signal complexity is reduced by capturing sudden power changes and the signals are adaptively decomposed against noise. In the VMD method, like EMD, signals are decomposed into IMFs. The VMD method overcomes the recursive approach that does not allow backward error correction and the inability to adequately handle noise, both of which are viewed as shortcomings in the EMD method [24]. The VMD method uses a simultaneous approach to extract the IMF from the signal. VMD is less sensitive to noise than EMD and leaves no residual noise [27]. As in the EMD method, EEG signals are decomposed into eight subband components in this study. A sample of eight IMFs obtained using VMD is shown in Fig. 4.

Example of eight sub-bands obtained as a result of applying the VMD method
2.3.3 Vold-Kalman order filtering
The VKF approach proposed by Hvard Vold and Jan Leuridan can use the frequency vector to separate the components of a non-stationary signal [28]. The VKF approach can effectively extract the desired sequence component and has been employed in studies in a variety of domains [29]. The VKF approach is capable of effectively decomposing the frequency components of complicated and multicomponent signals like EEG [29, 30]. This feature allows you to extract single-component signals from multicomponent signals. Signal components in the time domain can be retrieved directly using the VKF approach. In contrast to EMD and VMD signal decomposition and filtering approaches, the VKF method collects signal components directly from the time domain. In this manner, the phase variation produced by time–frequency conversion is avoided. In comparison to the EMD approach, the VKF method may change the centre frequency based on the instantaneous frequency and avoid the overlaps created by the EMD method [31]. The frequency vector was obtained in four Hz intervals from 4 to 32 Hz while dissecting the EEG data into subband components using the VKF method. Various frequency value ranges were attempted in the process of determining these frequency ranges. The best categorization performance was discovered in the frequency band of “4,8,…,28,32” Hz. As a result, EEG signals were divided into eight subband components in this investigation utilising Second Generation VKF (Fig. 5).

Example of eight sub-bands obtained as a result of applying the VKF method
2.4 Feature extraction and selection
Before developing ML models, the feature extraction and selection process is used to efficiently describe a dataset. These strategies can minimise the number of accessible features in a dataset, pick the most significant features, and improve the performance of ML models. Time–frequency domain and nonlinear studies were done on decomposed EEG signals to extract several properties (Shannon Entropy, Hjort parameters, Power Sum, Kolmogorov complexity, and Katz Fractal Dimension). These features were recovered from each subband of signals divided into eight sub-bands using the EMD, VMD, and VKF methods. A total of seven features reflecting time–frequency domain and nonlinear system properties were recovered during feature extraction (Table 1). The following are brief descriptions of the study’s features.
Shannon entropy is used to quantify how accurately signal information can be measured. It is a quantity that quantifies how much and in what proportion a signal generates information. It is an uncertainty metric that is frequently used to evaluate the degree of chaos in an EEG signal [32, 33]. Hjorth’s parameters (HP) are activity, mobility, and complexity, which he brought to the literature. Activity is defined as being aware of the signal strength. The average frequency is estimated using mobility. The complexity of the power spectrum is defined as its bandwidth, frequency variation, or standard deviation [34]. HPs are well-suited for non-stationary signals like EEG and are frequently employed in research [33, 34]. The power of the EEG signal was estimated by summing the power of each frequency after it was translated from the time domain to the frequency domain using the Fourier transform. Kolmogorov complexity is a technique for determining an object’s complexity, which is measured as the size of the shortest representation of information about an object [32, 35]. Another technique for calculating complexity is fractal dimension (FD), which uses the non-stationary features of EEG signals [36]. Higuchi and Katz FD are the most often utilised variants of FD for detecting rapid changes in EEG patterns and diagnosing various disorders. In this study, the Katz FD type was favoured.
The goal of this study was to estimate the upper limit of the performance of the preferred features. One of the automatic feature selection methods, the Chi-square-based feature selection approach, was used to limit the number of available features before the classification procedure. The Chi-square (X2) statistic is a traditional statistical test method for determining the relationship between actual data and the model. The independence of two variables is tested using this method. Furthermore, the Chi-square test explores if the distribution of one variable differs from that of another [33].
2.5 Classification
Classifier models use the classification process to predict the accurate labelling of the data supplied as input. In this study, a classification approach was used to separate PD patients (PD ON and PD OFF) from HC groups using variables derived from EEG data analysis. Classical ML methods such as FNN, SVM, KNN, and DT were employed in the classification process. The ten fold cross-validation (10-CV) and leave-one-subject-out-cross-validation (L-CV) approaches were utilised during the classification procedure. The following is a summary of the ML algorithms utilised in this study:
A feed-forward artificial neural network (ANN) model, commonly known as a multilayer neural network, is what Fitch Neural Network (FNN) is. It usually consists of three layers: the input layer, the output layer, and the hidden layer. Each layer of the neural network is linked to the layer before it [16, 37]. The model utilised in the study was constructed with the MATLAB software programme’s “fitcnet” function. An input layer, three hidden layers, and an output layer comprise the model.
Support Vector Machine (SVM) is a machine learning technique that decreases risk by utilising various solution approaches for linear or nonlinear problems. It is used to solve binary or multiple classification problems and is highly fast [16, 34].
The k-nearest neighbours (KNN) classifier is a supervised machine learning technique that leverages the nearest distance between data points to perform classification [16]. In general, the nearest neighbour is calculated by using distance calculations such as Euclid and Chebychev [34]. Finding the minimal values of these distances among all data sets yields classes [38].
The Decision Tree (DT) model compares numerical properties that consistently combine a set of tests. DT classifiers are recognised as one of the most powerful algorithms for data classification problems in a variety of domains [39].
2.6 Performance metrics
Performance evaluation based on classifier prediction is an important topic for classification procedures. Some factors govern the performance of any ML algorithm. True positive (tp), true negative (tn), false positive (fp), and false negative (fn) values are employed in the derivation of these criteria [40]. These values were used to calculate the accuracy (ACC), sensitivity (SENS), specificity (SPE), positive predictive value (PPV), negative predictive value (NPV), F1-score (F1), false-positive rate (FPR), and area under the curve (AUC) rates in this investigation. In order to measure the reliability between classifiers, kappa statistic (KPS) values were obtained using a probabilistic approach. The performances of ML models were compared based on the results.
TP: The classifier model correctly predicted the data labelled as PD.
TN: The classifier model correctly predicted the data labelled as HC.
FP: The classifier model incorrectly predicted the HC-labelled data and included it in the PD class.
FN: The classifier model incorrectly predicted data labelled PD and included it in the HC class.
The accuracy rate is defined as the percentage of correct predictions in a dataset.
The sensitivity rate refers to the ability of the classifier models to correctly identify positive examples (PD in this study). False negatives are important in disease detection. The sensitivity rate measures false negatives against true positives. It is also used as the Recall rate in studies.
The specificity is the percentage of negative samples (HC groups in this study) detected by the classifier models.
The PPV rate measures the proportion of true positive instances among all instances predicted as positive by the classifiers. It is also used as precision ratio in studies.
The NPV rate measures the proportion of true negative instances among all instances predicted as negative by the classifiers.
The F1-score combines the precision and recall values of the classifier model using their harmonic mean.
The FPR is the proportion of negative cases that are incorrectly identified as positive cases in the classification process.
The kappa statistic is a measure of the reliability of the classification process, which helps to evaluate the performance between classifiers in machine learning studies. As the kappa statistical value, which is measured based on probability, approaches + 1, the model performance is considered to be good.
The AUC rate is a performance measure of how well two classes can be distinguished according to the area under the receiver operating characteristics (ROC) curve. AUC value approaching 1 indicates that the performance of the classifier is perfect.
3 Experimental results
The goal of this study was to classify PD (ON–OFF) and HC groups using EEG signals. Three distinct signal processing approaches were used to extract various features from EEG signals for this purpose. These features were fed into four different ML algorithms to find the best successful signal processing method and ML algorithm.
Preprocessing was used to denoise EEG signals in the first step of this study. Three distinct signal processing algorithms (EMD, VMD, and VKF) were utilised to deconstruct the denoised EEG signals into sub-bands to retrieve characteristics from each component. The performances of the three approaches were so compared.
The second stage of the research identified seven features from each band of EEG signals, which were then divided into eight sub-bands using EMD, VMD, and VKF algorithms. The investigation yielded a total of 1792 features (32 channels, 8 sub-bands, and 7 features). The Chi-Squared test was used before the classification procedure since the number of extracted features is high in the number of data and may cause a processing load. Important features that will be used as input to ML algorithms and that are effective in classifying outcomes are determined in this manner. Classification results for 5–10–15–20 characteristics were obtained using the Chi-squared test. Experiments with varying numbers of features revealed that 5 features provided approximate classification performance when compared to other feature numbers. However, in this study, the classification results produced by analysing 5 features are provided to maintain a balance between the number of data utilised and the number of features used to interpret the classification results more accurately and to reduce the processing burden.
The final stage of the investigation involved classification based on CV-10 and L-CV instances. In the CV-10 process, k = 10 was selected and the data consisting of EEG recordings were randomly divided into parts. While 10% of this data was allocated for testing, 90% was allocated for training and this process was performed 10 times. In the L-CV process, the data obtained from one record was used as the test set and all other records in the data set were used as the training set. As a result, the performance criteria obtained at each stage were averaged and the final results were generated. In the classification procedure, four different ML algorithms (FNN, SVM, KNN, and DT) that are commonly utilised in biological investigations were chosen. The classification results were evaluated using the performance metrics ACC, SENS, SPE, PPV, NPV, FPR, F1, KPS, and AUC. The EMD, VMD, and VKF approaches were used to classify PD ON-HC and PD OFF-HC groups in three separate cases. In this approach, the performance of signal processing methods was analysed using four distinct ML algorithms, and the efficacy of dopaminergic drugs in Parkinson’s patients was evaluated.
Tables 2 and 3 show the outcomes of the classification processes done for the PD ON-HC and PD OFF-HC groups using the EMD approach. Tables 4 and 5 show the outcomes of the classification processes done for the PD ON-HC and PD OFF-HC groups using the VMD approach. Tables 6 and 7 present the results of the classification processes done for the PD ON-HC and PD OFF-HC groups using the VKF approach. In the tables, performance evaluation results are expressed as percentage (%).
When the results shown in Tables 2, 3, 4, 5, 6 and 7 are evaluated, it is clear that the VKF approach outperforms the VMD and EMD methods in all ML algorithms used in the study. In almost all ML algorithms, the VKF approach achieves a success rate of 100% or close to 100% in terms of classification performance criterion values. Based on the study’s findings, the SVM algorithm provided the most accurate classification results for the PD ON-HC group (10/L-CV). The FNN, KNN, and DT algorithms (10/L-CV) performed the best in the categorization of the PD OFF-HC group.
4 Discussions
Some issues can be detected in the early stages of PD until the disease reaches the medium level [22]. As a result, it is critical to develop automatic diagnostic methods that can provide early detection of PD to avoid disease development and assist experts. Several studies on the automatic diagnosis of PD have recently been completed, although it has been suggested that additional investigations are required to contribute to the development of systems [9, 13]. As a result, this study presents research that can contribute to the development of systems for the automatic diagnosis of PD utilising EEG data from the PD (OFF–ON) and HC groups. EEG signals were divided into sub-bands in this work using the EMD, VMD, and VKF signal processing methods, and characteristics were retrieved from these sub-bands. The Chi-squared test was used to find critical parameters influencing classification performance based on these features. The determined features were analysed using four different ML models, and the PD ON-HC and PD OFF-HC groups were classified. In this way, the performance of signal processing methods as well as the performance of ML models were assessed alongside the effects of drugs on PD. Multifaceted research has so been carried out in this way.
ML and DL approaches are commonly used with EEG signals in studies on the creation of automatic detection systems for PD and other neurological diseases [6, 7, 9, 10, 18, 41,42,43]. However, investigations employing DL models necessitate big data collection. Furthermore, investigations using DL models may necessitate a high computational load and may be time-consuming to implement [13]. As a result, investigations using ML models can assist specialists in making methodical decisions. Because EEG signals are non-stationary, they have a complicated structure. As a result, by splitting EEG signals into numerous sub-bands before undertaking EEG–ML model-based automatic disease detection studies, vital information can be collected, and the analysis of the EEG signal can be facilitated with various features [10, 42]
In this work, EEG data were divided into sub-bands using EMD, VMD, and VKF adaptive signal processing algorithms. Then, from these sub-bands, seven significant features [34, 35, 42] that are commonly used in EEG investigations were retrieved. Because EEG signals are difficult and time-consuming to analyse, it is critical to deconstruct them into sub-bands and extract features in order to obtain precise information. In PD studies, EMD and VMD approaches are recommended and compared [43, 44]. In research comparing EMD with VMD methodologies, VMD is consistently found to be superior [26, 45, 46]. When the results in Tables 2, 3, 4 and 5 of this study are analysed, it is clear that VMD results are successful in supporting the investigations.
To get comprehensive information from EEG data, these signals must be decomposed into several sub-bands [47]. Adaptive decomposition methods like VKF, VMD, and EMD are extremely powerful and effective in processing signals like EEG [30]. By recording immediate information from complicated signals, such as EEG, the VKF approach can successfully separate the frequency components of the signal. Because of this aspect, we believe that the VKF approach will be more successful than the EMD and VMD methods in investigations including EEG inputs.
When the studies are examined, it is clear that the VKF approach has been used in a variety of sectors [30, 31, 48]. There is a study that compares the advantages and disadvantages of the VKF approach to the EMD and VMD methods in detail [30]. When compared to EMD, the VKF approach is superior and yields successful results [31]. There has been no research comparing the VKF method to the VKF method. When the findings in Tables 2, 3, 4, 5, 6 and 7 are examined, it is clear that the VKF approach outperforms the EMD and VMD methods in all ML models. To the best of our knowledge, there is just one study in which the popular adaptive parsing algorithms VKF, VMD, and EMD are evaluated together and examples of their applicability in various domains are provided [30]. The VKF method has been used for the first time in the research of EEG signals and neurological diseases, such as the strategy used in this work. We believe that the study is unique and the first of its kind. We believe that comparing the performance of the applied methodologies, such as the one used in this study, can raise acceptance of the validity of the findings.
The Open Neuro [21] dataset, which is considered legitimate and technically important in recent studies [49], was used in this study. In addition to being new, it is critical that this dataset is available in a reliable international database, contains pharmacological activity, and has not been used sufficiently before this study. The strong features of the dataset are that it has a sampling frequency of 512 Hz and provides information from 32 channels, allowing detailed analysis of neural activity [49]. DL and ML models have been used in certain research with this dataset. There has been research that has yielded positive results for the automatic detection of PD utilising DL models [1, 4, 6, 20, 43]. Table 8 displays the findings from the studies that used ML models to evaluate the dataset in this study. Because ML models were employed in this study, papers using DL models were not included in the comparison table.
Table 8 lists recent studies [13,14,15, 47, 50] that have contributed to the development of automatic PD diagnosis methods. These research are all based on EEG readings and machine learning algorithms. This study analyses and compares the performance of ML models (SVM, KNN) that have been effectively utilised in the investigations listed in Table 8. In addition, the performance of FNN and DT models was examined in this work. As a result of the analysis, the features collected by the VKF approach, when combined with the FNN, SVM, and KNN models, outperformed or were comparable to the studies in Table 8. When the results of this study are evaluated in terms of the classifier measurement metrics given in Table 8, it is seen that ACC, AUC, F1, and KPS rates are 100%. It is seen that the FPR rate is 0%. In classification studies, FPR being 0 or close to 0 is a desirable rate for classifier performance. ACC, AUC, F1, and KPS rates close to 100 and 100 are considered to be desirable for classifier performance [51,52,53]. From this point of view, it is seen that the results obtained in the study are within the desired rates. In addition, it is seen that the results of the research are superior to the results of similar metric rates obtained in the studies given in Table 8.
To the best of our knowledge, this work is the first time the VKF approach has been used for EEG readings on neurological diseases. In this work, almost all of the ML algorithms that used the VKF technique characteristics as input in the classification of PD ON-HC and PD OFF-HC groups performed nearly perfectly. It can be shown that the results achieved in this study are more successful than those obtained in previous investigations [13, 14, 47, 50]. EEG data were split into sub-bands and various features were collected and assessed with ML models to classify PD (ON–OFF)-HC groups in the experiments presented in Ref [47, 50]. It was discovered in this investigation that the results achieved by using the VKF method were superior to the findings obtained in the studies cited in Ref [47, 50]. In this regard, we believe that our work will contribute to the literature and is significant. The study’s merits and shortcomings are discussed further below.
4.1 Advantages and limitations
According to the results obtained in this study, this research can contribute to the systems for automatic diagnosis of PD. The advantages of this study can be summarised as follows:
-
1.
In this work, a novel and underutilised technically powerful data set that is recognised as valid in research was employed to diagnose PD.
-
2.
The VKF approach was applied to EEG readings for the first time in a study to diagnose neurological diseases. Therefore, this study is unique research in this domain.
-
3.
The analysis revealed that the VKF method used in this study performed well in the ML models used in the study when compared to similar recent studies [47, 50].
-
4.
The accuracy, sensitivity, specificity, F1-score, AUC, PPV, FPR, kappa statistic, and NPV of ML models were evaluated in this study. The categorisation was carried out in four separate models using two different CV (10/L) methodologies. Furthermore, the processing load was lowered by selecting the important features using the feature selection method. As a result, we believe that the findings of this study are solid and dependable.
-
5.
The features extracted from the VKF-EMD-VMD adaptive subband decomposition methods were assessed with ML models in this work, and the three approaches’ performances were compared. In recent research for PD diagnosis, EMD and VMD approaches have been chosen [43, 44]. In addition to these methods, the VKF method was employed for the first time in a study for the diagnosis of PD. For the first time, the performance of EMD-VMD-VKF approaches was compared using the approach used in this work.
-
6.
This study also looked at two separate classification cases, PD ON-HC and PD OFF-HC. In this manner, the influence of a dopaminergic medication, which is significant for PD, was examined in terms of classifier performance measures.
Although the results obtained in this study are promising for the diagnosis of PD, the study has some limitations. These limitations can be summarised as follows:
-
1.
The dataset used in this work is technically advanced and novel [49]. However, the fact that there are so few open source datasets that are recognised as authentic, such as this one, limits the scope of our research. For the findings of this study to be recognised, we believe that the VKF approach should be used with similar data sets.
-
2.
The minimal number of participants in the study’s data set may be deemed insufficient for the construction of ML models. We intend to address this shortcoming in future studies by using the VKF approach and ML models for larger data sets.
-
3.
The results produced through the use of the VKF approach are promising for the diagnosis of PD. However, to improve the method’s applicability, it should be evaluated with different PD datasets or in research for the identification of various neurological diseases.
-
4.
This study can be considered as a preliminary study. In future studies, systems for early and automatic diagnosis of PD can be developed in collaboration with expert clinicians.
5 Conclusion
This research presents an ML-based study for the automatic diagnosis of PD by applying the VKF method to EEG signals. In the presented study, the VKF method is applied to the EEG signals of PD (ON–OFF)-HC groups and the signals are decomposed into sub-bands. Various features (SE, HPs, PS, KC, KFD) were extracted from these signals and the significant ones were determined by applying the Chi-squared test. The determined features were applied as input to four different ML algorithms to classify PD ON-HC and PD OFF-HC groups. The effect of dopaminergic drugs was also analysed by performing classification according to PD ON–OFF states. Four different ML models were analysed and their performances were compared. In addition, in this study, the VKF method was compared with EMD and VMD methods, which are widely used in research. According to the findings of the study, the VKF approach outperforms all ML algorithms when compared to other methods. We believe that the VKF approach results are promising for the development of systems for the automatic diagnosis of PD and can aid expert doctors in decision-making. The VKF approach has never been used to identify a neurological condition using EEG signals before. We believe that the VKF approach can produce positive results in research for the diagnosis of various neurological illnesses. In future studies, it is planned to carry out studies with more samples on the investigation of Parkinson’s disease and drug effects in cooperation with clinicians. As a result, we aim to support the findings of this study by using the VKF approach in different data sets in future studies to demonstrate the effectiveness of the VKF method.
Data availability
Datasets used are online available: San Diego dataset: https://openneuro.org/datasets/ds002778/versions/1.0.4. Additional data and information can be provided upon request.
References
Loh HW, Ooi CP, Palmer E, Barua PD, Dogan S, Tuncer T, Acharya UR (2021) GaborPDNet: gabor transformation and deep neural network for Parkinson’s disease detection using EEG signals. Electronics 10(14):1740
Tysnes OB, Storstein A (2017) Epidemiology of Parkinson’s disease. J Neural Transm 124(8):901–905. https://doi.org/10.1007/s00702-017-1686-y
Politis M, Wu K, Molloy S, Bain PG, Chaudhuri KR, Piccini P (2010) Parkinson’s disease symptoms: the patient’s perspective. Mov Disord 25(11):1646–1651
Shaban M, Amara AW (2022) Resting-state electroencephalography based deep-learning for the detection of Parkinson’s disease. PLoS ONE 17(2):e0263159
Perlmutter JS (2009) Assessment of Parkinson disease manifestations. Curr Protoc Neurosci 49(1):10–11
Khare SK, Bajaj V, Acharya UR (2021) PDCNNet: An automatic framework for the detection of Parkinson’s disease using EEG signals. IEEE Sens J 21(15):17017–17024
Yao S, Zhu J, Li S, Zhang R, Zhao J, Yang X, Wang Y (2022) Bibliometric analysis of quantitative electroencephalogram research in neuropsychiatric disorders from 2000 to 2021. Front Psych 13:830819
Dubey AK, Saraswat M, Kapoor R, Khanna S (2022) Improved method for analyzing electrical data obtained from EEG for better diagnosis of brain related disorders. Multimed Tools Appl 81(24):35223–35244
Mei J, Desrosiers C, Frasnelli J (2021) Machine learning for the diagnosis of Parkinson’s disease: a review of literature. Front Aging Neurosci 13:633752
Li K, Ao B, Wu X, Wen Q, Ul Haq E, Yin J (2023) Parkinson’s disease detection and classification using EEG based on deep CNN-LSTM model. Biotechnol Genetic Eng Rev
Anjum MF, Dasgupta S, Mudumbai R, Singh A, Cavanagh JF, Narayanan NS (2020) Linear predictive coding distinguishes spectral EEG features of Parkinson’s disease. Parkinsonism Relat Disord 79:79–85
Murugappan M, Alshuaib W, Bourisly AK, Khare SK, Sruthi S, Bajaj V (2020) Tunable Q wavelet transform based emotion classification in Parkinson’s disease using electroencephalography. PLoS ONE 15(11):e0242014
Aljalal M, Aldosari SA, AlSharabi K, Abdurraqeeb AM, Alturki FA (2022) Parkinson’s disease detection from resting-state EEG signals using common spatial pattern, entropy, and machine learning techniques. Diagnostics 12(5):1033
Motin MA, Mahmud M, Brown DJ (2022) Detecting Parkinson’s disease from electroencephalogram signals: an explainable machine learning approach. In: 2022 IEEE 16th ınternational conference on application of ınformation and communication technologies (AICT). IEEE, pp 1–6
Kamalakannan N, Balamurugan SPS, Shanmugam K (2021) A novel approach for the early detection of Parkinson’s disease using EEG signal. Technology (IJEET) 12(5):80–95
Karakaş MF, Latifoğlu F (2023) Distinguishing Parkinson’s disease with GLCM features from the hankelization of EEG signals. Diagnostics 13(10):1769
Biswas SK, Nath Boruah A, Saha R, Raj RS, Chakraborty M, Bordoloi M (2023) Early detection of Parkinson disease using stacking ensemble method. Comput Methods Biomech Biomed Engin 26(5):527–539
Sengur A, Akbulut Y, Guo Y, Bajaj V (2017) Classification of amyotrophic lateral sclerosis disease based on convolutional neural network and reinforcement sample learning algorithm. Health Inf Sci Syst 5(1):1–7. https://doi.org/10.1007/s13755-017-0029-6
Oh SL, Hagiwara Y, Raghavendra U, Yuvaraj R, Arunkumar N, Murugappan M, Acharya UR (2020) A deep learning approach for Parkinson’s disease diagnosis from EEG signals. Neural Comput Appl 32:10927–10933
Qiu L, Li J, Pan J (2022) Parkinson’s disease detection based on multi-pattern analysis and multi-scale convolutional neural networks. Front Neurosci 16:957181
Rockhill AP, Jackson N, George J, Aron A, Swann NC (2020) UC San Diego resting state EEG data from patients with Parkinson’s disease. Available https://openneuro.org/datasets/ds002778/versions/1.0.4
George JS, Strunk J, Mak-McCully R, Houser M, Poizner H, Aron AR (2013) Dopaminergic therapy in Parkinson’s disease decreases cortical beta band coherence in the resting state and increases cortical beta band power during executive control. NeuroImage: Clin 3:261–270
Huang NE, Shen Z, Long SR, Wu MC, Shih HH, Zheng Q, Liu HH (1998) The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. İn: proceedings of the Royal Society of London. Series A: mathematical, physical and engineering sciences, 454(1971), 903–995
Pandey P, Seeja KR (2022) Subject independent emotion recognition from EEG using VMD and deep learning. J King Saud Univ-Comput Inf Sci 34(5):1730–1738
Baydemir R, Latifoğlu F, Orhanbulucu F (2022) classification mental workload levels from EEG signals with 1D convolutional neural network. Eur J Res Dev 2(4):13–23
Dragomiretskiy K, Zosso D (2013) Variational mode decomposition. IEEE Trans Signal Process 62(3):531–544. https://doi.org/10.1109/TSP.2013.2288675
Jiang L, Zhou X, Che L, Rong S, Wen H (2019) Feature extraction and reconstruction by using 2D-VMD based on carrier-free UWB radar application in human motion recognition. Sensors 19(9):1962
Vold H, Leuridan J (1993) High resolution order tracking at extreme slew rates, using Kalman tracking filters (No. 931288). SAE Technical Paper
Yan Z, Wang L, Hu A Feature extraction by enhanced time-frequency representation based on Vold-Kalman filter. Liang and Hu, Aijun, Feature extraction by enhanced time-frequency representation based on Vold-Kalman filter
Liu T, Luo Z, Huang J, Yan S (2018) A comparative study of four kinds of adaptive decomposition algorithms and their applications. Sensors 18(7):2120
Li Y, Han Z, Wang Z (2020) Research on a signal separation method based on Vold-Kalman filter of improved adaptive instantaneous frequency estimation. IEEE Access 8:112170–112189
Henriques T, Ribeiro M, Teixeira A, Castro L, Antunes L, Costa-Santos C (2020) Nonlinear methods most applied to heart-rate time series: a review. Entropy 22(3):309
Li X, Song D, Zhang P, Zhang Y, Hou Y, Hu B (2018) Exploring EEG features in cross-subject emotion recognition. Front Neurosci 12:162
Işık Ü, Güven A, Batbat T (2023) Evaluation of emotions from brain signals on 3D VAD space via artificial intelligence techniques. Diagnostics 13(13):2141
Altıntop ÇG, Latifoğlu F, Akın AK, Bayram A, Çiftçi M (2022) Classification of depth of coma using complexity measures and nonlinear features of electroencephalogram signals. Int J Neural Syst 32(05):2250018
Chandrasekharan S, Jacob JE, Cherian A, Iype T (2023) Exploring recurrence quantification analysis and fractal dimension algorithms for diagnosis of encephalopathy. Cogn Neurodyn. 1–14
Krogh A (2008) What are artificial neural networks? Nat biotechnol 26(2):195–197
Istiadi I, Rahman AY, Wisnu ADR (2023) Identification of tempe fermentation maturity using principal component analysis and k-nearest neighbor. Sinkron: Jurnal dan Penelitian Teknik İnformatika 8(1):286–294
Charbuty B, Abdulazeez A (2021) Classification based on decision tree algorithm for machine learning. J Appl Sci Technol Trends 2(01):20–28
Phyu TZ, Oo NN (2016) Performance comparison of feature selection methods. In: MATEC web of conferences, vol 42. EDP Sciences, p 06002
Orhanbulucu F, Latifoğlu F, Baydemir R (2023) A new hybrid approach based on time frequency images and deep learning methods for diagnosis of migraine disease and investigation of stimulus effect. Diagnostics 13(11):1887
Barua PD, Dogan S, Tuncer T, Baygin M, Acharya UR (2021) Novel automated PD detection system using aspirin pattern with EEG signals. Comput Biol Med 137:104841
Rümeysa E, İleri R, Latifoğlu F (2021) A new approach to detection of Parkinson’s disease using variational mode decomposition method and deep neural networks. In: 2021 medical technologies congress (TIPTEKNO). IEEE, pp 1–4
Safi K, Aly WHF, AlAkkoumi M, Kanj H, Ghedira M, Hutin E (2022) EMD-based method for supervised classification of Parkinson’s disease patients using balance control data. Bioengineering 9(7):283
Latifoğlu F, Bulucu FO, Ileri R (2021) Detection of amyotrophic lateral sclerosis disease by variational modedecomposition and convolution neural network methods from event-relatedpotential signals. Turk J Electr Eng Comput Sci 29(8):2840–2854
Taran S, Bajaj V (2018) Clustering variational mode decomposition for identification of focal EEG signals. IEEE Sens Lett 2(4):1–4
Khare SK, Bajaj V, Acharya UR (2021) Detection of Parkinson’s disease using automated tunable Q wavelet transform technique with EEG signals. Biocybern Biomed Eng 41(2):679–689
Duan X, Feng Z (2023) Time-varying filtering for nonstationary signal analysis of rotating machinery: principle and applications. Mech Syst Signal Process 192:110204
Hamidi A, Yousefi M (2023) Classification of EEG signals to detect Parkinsons Disease using a computationally method. Preprint at arXiv:2305.02234
Aljalal M, Aldosari SA, Molinas M, AlSharabi K, Alturki FA (2022) Detection of Parkinson’s disease from EEG signals using discrete wavelet transform, different entropy measures, and machine learning techniques. Sci Rep 12(1):22547
Khan MS, Nath TD, Hossain MM, Mukherjee A, Hasnath HB, Meem TM, Khan U (2023) Comparison of multiclass classification techniques using dry bean dataset. Int J Cogn Comput Eng 4:6–20
Tharwat A (2020) Classification assessment methods. Appl Comput Inform 17(1):168–192
Saeedi S, Rezayi S, Keshavarz H, Niakan Kalhori SR (2023) MRI-based brain tumor detection using convolutional deep learning methods and chosen machine learning techniques. BMC Med Inform Decis Mak 23(1):16
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflicts of interest in this study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Latifoğlu, F., Penekli, S., Orhanbulucu, F. et al. A novel approach for Parkinson’s disease detection using Vold-Kalman order filtering and machine learning algorithms. Neural Comput & Applic 36, 9297–9311 (2024). https://doi.org/10.1007/s00521-024-09569-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-024-09569-2