
Abstract
The paper documents a concept of ocean forecasting system for ocean surface currents based on self-organizing map (SOM) trained by high-resolution numerical weather prediction (NWP) model and high-frequency (HF) radar data. Wind and surface currents data from the northern Adriatic coastal area were used in a 6-month long training phase to obtain SOM patterns. Very high correlation between current and joined current and wind SOM patterns indicated the strong relationship between winds and currents and allowed for creation of a prediction system. Increasing SOM dimensions did not increase reliability of the forecasting system, being limited by the amount of the data used for training and achieving the lowest errors for 4 × 4 SOM matrix. As the HF radars and high-resolution NWP models are strongly expanding in coastal oceans, providing reliable and long-term datasets, the applicability of the proposed SOM-based forecasting system is expected to be high.
Similar content being viewed by others

1 Introduction
The knowledge of ocean surface currents is a prerequisite for efficient management of hazardous situations and accidents at sea. A significant decrease in the search and rescue time and area is reached for coastal areas with implemented operational ocean monitoring and forecasting systems [2, 19], which also allows for better forecasting of oil spills and pollution trajectories [1], and can provide invaluable benefits to shipping, fishing, the tourist industry, and the community in general. The analysis of such system’s various strengths and weaknesses was presented in [28], who concluded that no single model is adequate and that improved coordination and integral approach to observing and modeling products is essential to improve predictive capabilities of both natural and human-induced ocean hazards.
Operational forecasts of sea properties are normally carried out by ocean numerical models [6]. However, there are two main disadvantages to this approach: (1) Numerical models normally require large computational time [38] and (2) they are demanding to verify [30]. While the latter problem can be partially addressed by introducing high-frequency (HF) oceanographic radars, which are a useful tool in rapid assessment of real surface ocean currents [10, 12, 27], the first problem can only be solved by replacing (at least partially) the numerical model with a surrogate that will demand less computational time while preserving accuracy. One such surrogate model was proposed by van der Merwe et al. [33] in a form of a neural network.
A hybrid forecasting model combines several forecasting models to produce a forecast that compensates for weaknesses of each individual model [48]. In our case, a neural network model will be used to determine a relationship between the sea surface currents and wind, while the atmospheric forecasting model will be used to provide the atmospheric dynamics. This has a strong background in the literature, as it was already shown that ocean forecast improves if HF radar data are used in combination with wind data [46]. Moreover, hybrid forecast models based on neural network applications and numerical modeling have already been developed [8, 9, 48], and neural networks became a standard in different aspects of atmosphere–hydrosphere–ocean forecasting studies (e.g., [3, 17, 20, 31]).
Neural network models are data models that establish a relationship between the input and output data during training phase, and evaluate the relationship during testing phase. One particular type of a neural network—a self-organizing map (SOM)—has been found effective for feature extraction and classification in different fields of geosciences [24, 26] and has been recently used for classifying different oceanographic properties in the Adriatic Sea [32, 36, 44].
The main applications of the SOM are the visualization of complex data usually in a two-dimensional space, and the creation of abstractions like in many other clustering techniques. It is generally held that the SOM is formed as an unsupervised process, similar to classical clustering methods which are traditionally regarded as unsupervised classification [23]. However, part of the variables introduced to the SOM can be modeled as dependent, enabling their predictions in time and space. In this case, SOM is used to model the relationship within data and variables, and this type of SOM is known as supervised SOM [23, 47]. This is the approach that we will utilize in our experiments, i.e., we use the concatenated data (wind and currents) to train the network and obtain their classifications and relationship. During the testing phase, the wind data from weather forecast model are classified and the sea surface currents are estimated from the class representative, i.e., the SOMs codebook vector. This is somewhat different from the traditional approach usually utilized in time-series prediction (e.g., [7, 14, 16, 31]), where the value X t is estimated from its predecessors [X t−1…X t−n ], while here the prediction is obtained from wind–sea current relationship as derived during the training phase. The study will be applied to the northern Adriatic region, covered extensively by HF radar data in 2008. The data used in the study are described in Sect. 2, the architecture of the forecasting system is explained in Sect. 3, Sect. 4 provides the results, while the major conclusions are outlined in Sect. 5.
2 Data
The training and testing of the forecasting system were performed on the surface current fields measured by HF oceanographic radars and surface winds simulated by the high-resolution numerical weather prediction (NWP) model Aladin/HR.
HF radars measure the radial components of the surface current vector in the coastal ocean using Bragg scattering of the electromagnetic radiation over a rough sea [13]. Therefore, two or more HF radars are needed for a full representation of the surface current vector field over an area. Depending on the transmit frequency and power, and sea state, maximum HF radar coverage may span from a few km to about 200 km offshore [34].
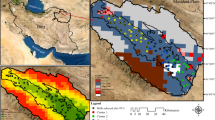
A network of high-frequency radars (Zub, Savudrija, Bibione, and Punta Sabbioni) was installed and operated in the northeastern Adriatic Sea in the period from September 2007 to October 2008 (Fig. 1). In this study, the data collected in the period February 1 to October 31, 2008, are used, having the largest spatial coverage and the best data quality. Hourly radial current vectors and maps were quality-controlled following Cosoli et al. [11] and transformed to Cartesian system onto a 2 km × 2 km regular grid (Fig. 1). The HF radar ocean currents have been processed using a low-pass Butterworth filter [42] with a cutoff period of 33 h, in order to remove high-frequency processes such as tides, seiches, inertial currents, or diurnal currents driven by sea breeze that may affect the SOM solutions [27].

Map of the northern Adriatic with HF radar sites (Bibione, Savudrija, Zub, Punta Sabbioni) operational between February 1 and October 31, 2008, together with 2 × 2 km grid mesh on which ocean surface current was measured. The square marks the area on which surface winds from Aladin/HR were extracted and used in the SOM-based forecasting model
NWP model Aladin/HR has been developed since the early 1990s [5]; it has been used for the operational forecast in the Meteorological and Hydrological Service of the Republic of Croatia since 2000 [21], with an aim of improving weather forecasts at a mesoscale level. The non-hydrostatic version of the model [43] has been used in this study, run in 2 km resolution on 37 levels in the vertical and using the full set of physics parameterizations, including prognostic turbulent kinetic energy (TKE), microphysics (cloud water and ice, rain, and snow), and prognostic convection scheme. The hindcast run was executed once a day, and hourly files between 6 and 30 h of the model run have been cumulatively stored and used for the analysis. The lowest model level is about 17 m above sea level, and thus the surface wind used in analyses is interpolated to the 10 m height using logarithmic profile [18].
The surface winds from Aladin/HR model have been processed in the same way as the surface ocean currents, by applying the low-pass Butterworth filter onto time series with a cutoff period of 33 h. The filtering removed some important atmospheric processes, such as sea–land breeze [35], having a potential to deviate SOM solutions and to lower the quality of a forecast.
3 The forecasting system
For the purpose of this research, the input data were divided into two parts, where the first part (February 1 to July 31, 2008) was used as a training set for self-organizing map (SOM), while the second part (August 1 to October 31, 2008) was used for evaluation of the forecasting system. The SOM is used to model the relationship between the data (sea surface currents) and the variables (wind), whereas the learning process can be interpreted as supervised process if variables are treated as (fuzzy) cluster information. In order to treat the wind data as additional information about clusters, we must assure that the SOM with and without this additional information does the clustering in a similar way. For this purpose, two separate SOMs were trained, one using the surface currents data (S) as input data and other using the surface currents data concatenated with forecasted wind data over the area of interest (WS).
Each dataset (at each grid point) has been normalized by the respective standard deviation before introducing it to the SOM. Since SOM is used for the classification of entries, each dataset will be abstracted to characteristic patterns represented by the best matching unit (BMU) from the neural network. Any SOM input data vector (S or WS) will be abstracted to the most representative pattern of the cluster—a characteristic pattern—that we will denote as C S or C WS. Thus, we can say that SOM does the mapping S i → C nS , or WS i → C nWS between ith input vector and nth characteristic pattern. This can be observed as a form of quantization, as part of information is omitted during this data abstraction. The omitted information is residual information due to the discrepancy between input vector and the characteristic patterns that is used by SOM to represent it. The measure of this omitted information will be referred to as the quantization error that we will define further on.
Let us notice that, if a correspondence between clusters of two SOMs, namely C nWS and C nS , can be established, we can easily link wind patterns to surface currents patterns in the following way:
where S q i denotes the quantized version of S i , due to the fact that residual information was lost once the data are abstracted to characteristic patterns. First data transformation (W i → C nWS ) does not pose a problem since sea surface currents are treated as missing data. Wind data from the meteorological model (W i ) are compared with the wind part of C nWS , and the best matching characteristic pattern is selected as representative for the sea current reconstruction. Furthermore, if the high correlation between C nWS and C nS can be established, we can justify the use of C nWS for sea surface currents reconstruction. In this way, sea surface currents can be reconstructed from forecast wind data since the extraction of quantized surface currents data S q i from characteristic patterns C nWS is trivial. Since the forecast wind data are always available from the meteorological model, the approach described by (1) can also be used to forecast sea surface currents from wind data in periods when current data are not available. Within this setup, forecast error can be defined as a root mean square error between the surface current values extracted from C nWS based on the correspondence between W i and C nWS and true values of the current data:
where it is important to notice that the difference is calculated between existing data points in S i and corresponding points in cluster C nWS , and N stands for the number of existing points.
The omitted information that we refer to as the quantization error will, at least partially, contribute to the forecast error. We define the quantization error as a root mean square error between the surface current values extracted from C nWS based on the correspondence between S i and C nWS . Therefore, the quantization error is calculated using Eq. 2, same as forecast error, with a significant difference that in this case the known sea surface currents measurements are utilized to find the estimate of the sea surface currents from the C nWS , i.e., we are linking:
In this context, several questions need to be considered: (1) Can we establish a one-to-one relationship between classes obtained from S data only (C nS ) and the classes obtained from the concatenated (WS) data (C nWS ), (2) What are the expected forecast and quantization errors that arise from representation of cluster by a codebook vector, and (3) How they relate to the number of neurons used by SOM. In order to answer these questions, multiple experiments have been conducted.
First, the correlation between surface currents data being part of the corresponding codebook vectors C nS and C nWS is calculated. High correlation would indicate high correspondence between cluster representatives, which in turn would indicate that using sea surface currents data only and joint data of sea surface currents and wind patterns classify to similar clusters. In this case, wind data can be interpreted as additional data that have the same class identity as the sea surface data, meaning that part of the data (in our case S data) can be modeled as dependent, for which predictions can be obtained. However, the correlation between cluster centers does not present the complete information about the similarity of clusters. To visualize the similarity of all clusters, we used the property of SOM to visualize multidimensional data in 2D space. Our approach follows the ideas of Tenenbaum et al. [41] and Roweis and Saul [37], where a nonlinear projection is done using the Isomap algorithm. In short, SOM nodes (which correspond to characteristic patterns) form a 2D lattice in a multidimensional space, and the algorithm projects the lattice to 2D plane preserving distances between nodes. After the projection is done, a Voronoi tessellation [45] is made to find border between clusters, based on the proximity of characteristic patterns visualized as points in 2D space [4, 15]. The Voronoi tessellation also provides a glimpse into the quantization error which is also one of our concerns and which is quantified during the skill estimation of the SOM-based prediction.
Second, the performance of the SOM-based reconstruction on the training period and forecast on the testing period is evaluated, and the results are discussed by comparing the forecast and quantization errors. Furthermore, as it is expected that the errors are related to the number of SOM neurons, multiple SOM lattices are evaluated to find the optimal number of SOM neurons for the forecast.
Thus, in the following section we will demonstrate the applicability of the method on the data from the northern Adriatic by (1) showing the relationship between corresponding codebook vectors obtained by two SOMs, (2) demonstrating temporal change in forecast error and showing how error relates to number of SOM neurons, and (3) discussing the quantization error and how it relates to overall forecast error.
4 Application to the northern Adriatic
In order to calculate the correlation coefficients between C nS and C nWS clusters, a corresponding pair of clusters ought to be found first. Each cluster is obtained from SOM with rectangular lattice initialized on the first two principal components. Batch algorithm with Epanechnikov neighborhood function was used for training. Pairs of clusters were obtained using greedy algorithm similar as in Kalinić et al. [22]. Complex correlation coefficient and veering angle [25, 39] for 3 × 4 SOM were calculated for each pair of corresponding clusters. The results presented in Table 1 show very high correlation and correspond well with earlier work of Mihanović et al. [32], which was done on more restricted dataset in space and time. While high correlation (0.91 on average) between sea surface currents and joint characteristic patterns is promising, it bears little information on how clusters represented by the characteristic patterns relate to one another. For this reason, a tessellation of the characteristic patterns nonlinearly projected to 2D space is done so that border between classes represented by each node can be visualized (Fig. 2). For easier comparison, both lattices are projected to the same underlying 2D space using Isomap algorithm. The correspondence between cluster pairs, as well as the overlap of their tessellation, can be easily established as nodes from each lattice kept their labels. Since data are normalized and nonlinearly projected to underlying 2D space, the axes in Fig. 2 are unitless. Nevertheless, we can conclude that there is a large overlap between clusters, so we can use SOM to reconstruct the quantized version of sea surface currents patterns from wind patterns. The amount of maximal quantization error can also be perceived from Fig. 2, as it will be related to the distance between node and Voronoi tessellation border.

Voronoi tessellation of SOM nodes projected to 2D space using Isomap algorithm. Since SOM variables are normalized, and Isomap is nonlinear mapping algorithm, the axis is unitless. The tessellation is used to visualize the cluster borders. Red indicates C nS and blue C nWS characteristic patterns. Each cell contains vector that have a particular reference vector as their closest neighbor. The reference vector is characteristic pattern projected to 2D plane. All nodes are plotted with their labels, so cluster pairs can be easily established (color figure online)
Figure 2 can also be used to visualize the prediction of sea surface currents (S i ) from wind (W i ): When only Wi is available, it classifies into one of the SOM classes (shown in blue in Fig. 2), and each class is represented by one SOM node which is concatenated surface wind and ocean current data; thus, surface current values (S q i ) can be reconstructed from it. This approach was used to reconstruct sea surface currents from wind forecast in the period from February 1, 2008, to July 31, 2008, and to forecast currents between August 1, 2008, and October 31, 2008.
Figure 3 shows spatial distribution of the forecast error and error is color coded at each grid point where blue indicates lowest and red indicates highest error. The quality of the surface currents reconstruction is found to be spatially variable, with larger forecast errors at the boundaries of the domain (Fig. 3). This is expected as the boundaries of the HF radar coverage contain less reliable data and often have more missing data, which was also the case for the data collected in the northern Adriatic. The lowest errors are reached in the center of the domain, where radials coming from different HF radars are quasi-perpendicular to each other. Therefore, posing a more restrictive elimination conditions to the quality of the data and omitting a borderline data from analyses will significantly lower the forecast error and make the forecast more reliable.

Spatial distribution of the forecast error. Every grid point is color coded showing the average error at specific location (color figure online)
In Figs. 4 and 5 direct comparisons between forecast (red vectors) and observed (blue vectors) surface currents for the worst-case (the highest forecast error) and the nearby good-case scenario (a low forecast error) are shown. A bad forecast characterized by high forecast error was found to be driven by several factors: (1) Quite strong currents were present over the domain, (2) the coverage of HF radar measurements was reduced, with some radars being not operative, influencing the estimation of surface current vectors, and (3) wind forcing was quite changeable over time. By contrast, lower forecast error has been reached when (1) currents were generally weaker, (2) coverage of the HF radar measurements was larger, and (3) the wind forcing was a persistent over a prolonged period of time.

Direct comparison between forecast and observed surface currents on September 14, 2008, at 20:00 (worst-case scenario)

Direct comparison between forecast and observed surface currents on October 12, 2008, at 6:00
To assess the overall quality of the reconstruction as a function of time, temporal changes in the forecast error for 3 × 4 SOM are estimated and shown in Fig. 6. The first part of the data was used for the training of the SOM, and the second part (August 1 to October 31, 2008) represented the testing dataset for which the forecast error is shown. The figure shows the hourly forecast quantization error normalized by the number of data (blue line), while associated 10-day running average is denoted by the red line. We can conclude that the error is larger on the testing set than on the training set, which is expected since the testing set contained values that were not present in the training set and thus were completely unknown to SOM. Average error for the training set is 6.7 cm/s, while on the testing set it equals 8.2 cm/s. The error also has large temporal variability, from 5 to more than 15 cm/s; the highest errors occurred for surface current distributions not properly represented by the SOM patterns, being a transition between mapped patterns and/or presumably occurring because of either unusual meteorological conditions or very bad data coverage. In our concept, these distributions have a potential to be classified as the bad forecast; however, proving of this statement falls beyond the scope of this study.

To calculate the forecast error, the equation equivalent to Eq. 2 was used, where chain given by Eq. 1 was used to obtain S q i values, i.e., the W i data were used to find representative SOM classes for each data record. However, when S i data are available, they can be used to obtain SOM classes, so that the S q i values reconstructed from the current part of the SOM classes contain only the quantization error, as no forecast is done. In this way, we could estimate how much of the forecast error can be attributed to the quantization properties of the SOM. We might also question how much of the forecasting error is dependent on the quantization introduced when SOM generalized the data and how this relates to the different number of nodes. For this reason, the average forecasting error and quantization error on training and testing sets are shown in Fig. 7. As quantization errors decline with the larger number of nodes, it can be suggested that increase in the number of nodes improves the prediction performance, as larger number of SOM nodes reduces the quantization error. However, the optimal number of SOM nodes is limited by the error coming from the testing dataset. We can notice that the forecasting error on the testing set is not monotonically decreasing as the number of nodes increases and that the error minimum may be found when applying SOM of size of 16 (4 × 4) nodes. This suggests that there is no significant improvement in the SOM-based forecasting skill if a larger number of nodes are used, at least for the dataset of this size and characteristics. Thus, in order to provide better accuracy, more SOM nodes and a larger dataset are required.

Average forecast error (solid lines) and quantization error (dashed lines) calculated on the training (black lines) and testing (red lines) dataset for different SOM sizes (color figure online)
5 Conclusions
We have shown that it is possible to associate the wind data from numerical weather forecast and sea surface currents from HF radars in a coastal shallow area of the northern Adriatic, where local wind has been found to strongly affect surface currents. However, for other coastal regions that may be subjected to strong offshore forcing (e.g., in the case of the Loop Current intrusion for the Gulf of Mexico coastal regions [28]), additional data (containing additional forcing) should be considered as the input to a SOM model. Thus, the drawback of the SOM (as any data model) prediction is that it can be only as good as the data provided to it.
The observed strong correlation between characteristic sea surface current of two different SOM models, as well as their Voronoi tessellation in the projected 2D space, fortified the use of SOM clusters for sea surface current forecast. The association of patterns and conclusively sea surface current prediction from wind data using SOM is efficient as it does not require large computational time. However, the limitation of the method is the quantization utilized by the data abstraction done by SOM. Overall, the results have shown larger forecast error on the testing set, where the majority of the error can be identified as a quantization error. From the results, it is clear that using more SOM nodes is of utter importance to further increase forecast accuracy. However, for the dataset of this size, much larger number of nodes than suggested in the paper could be counterproductive, as on the testing set it could produce larger error. Therefore, the quality of the SOM-based forecasting of surface currents from the NWP models is dependent on the size of the HF radar datasets; such datasets become more and more available for a number of coastal regions of the World Ocean, as HF radar technology becomes a standard in the monitoring of ocean currents in the last decade [34, 40], and they become an essential part of the coastal ocean observing systems [29].
References
Abascal AJ, Castanedo S, Medina R, Losada IJ, Alvarez-Fanjul E (2009) Application of HF radar currents to oil spill modeling. Mar Pollut Bull 58:238–248
Abascal AJ, Castanedo S, Fernandez V, Medina R (2012) Backtracking drifting objects using surface currents from high-frequency (HF) radar technology. Ocean Dyn 62:1073–1089
Abbot J, Marohasy J (2012) Application of artificial neural networks to rainfall forecasting in Queensland. Aust Adv Atmos Sci 29(4):717–730
Abdul-Rahman A, Pilouk M (2008) Spatial data modelling for 3D GIS. Springer, New York
Aladin International Team (1997) The ALADIN project: mesoscale modelling seen as a basic tool for weather forecasting and atmospheric research. WMO Bull 46:317–324
Allard R, Rogers E, Martin P, Jensen T, Chu P, Campbell T, Dykes J, Smith T, Choi J, Gravois U (2014) The US Navy coupled ocean-wave prediction system. Oceanography 27:92–103
Barreto GA (2007) Time series prediction with the self-organizing map: a review. Perspect Neural-Symb Integr 77:135–158
Corchado JM, Lees B (2001) A hybrid case-based model for forecasting. Appl Artif Intell 15:105–127
Corchado JM, Aiken J (2002) Hybrid artificial intelligence methods in oceanographic forecast models. IEEE Trans Syst Man Cybern C 32(4):307–313
Cosoli S, Mazzoldi A, Gačić M (2010) Validation of surface current measurements in the northern Adriatic Sea from high-frequency radars. J Atmos Ocean Technol 27:908–919
Cosoli S, Bolzon G, Mazzoldi A (2012) A real-time and offline quality control methodology for SeaSonde high-frequency radar currents. J Atmos Ocean Technol 29:1313–1328
Cosoli S, Licer M, Vodopivec M, Malačič V (2013) Surface circulation in the Gulf of Trieste (northern Adriatic Sea) from radar, model, and ADCP comparisons. J Geophys Res 118:6183–6200
Crombie DD (1955) Doppler spectrum of sea echo at 13.56 Mc/s. Nature 175:681–682
Dorffner G (1996) Neural networks for time series processing. Neural Netw World 6:447–468
Duda RO, Hart PE, Stork DG (2001) Pattern classification, 2nd edn. Wiley, New York
Faraway J, Chatfield C (1998) Time series forecasting with neural networks: a comparative study using the airline data. J R Stat Soc Ser C (Appl Stat) 47:231–250
Fdez-Riverola F, Corchado JM (2002) A hybrid CBR model for forecasting in complex domains. Adv Artif Intell 2527:101–110
Geleyn JF (1988) Interpolation of wind, temperature and humidity values from model levels to the height of measurement. Tellus 40A:347–351
Harlan J, Terrill E, Hazard L, Keen C, Barrick D, Whelan C, Howden S, Kohut J (2010) The integrated ocean observing system high-frequency radar network: status and local, regional, and national applications. Mar Technol Soc J 44:122–132
Hsieh WW, Tang B (1998) Applying neural network models to prediction and data analysis in meteorology and oceanography. Bull Am Meteorol Soc 79:1855–1870
Ivatek-Šahdan S, Tudor M (2004) Use of high-resolution dynamical adaptation in operational suite and research impact studies. Meteorol Z 13:99–108
Kalinić H, Mihanović H, Cosoli S, Vilibić I (2015) Sensitivity of self-organizing map surface current patterns to the use of radial versus Cartesian input vectors measured by high-frequency radars. Comput Geosci 84:29–36
Kohonen T (2001) Self-organizing maps, 3rd edn. Springer, New York
Krasnopolsky VM (2007) Neural network emulations for complex multidimensional geophysical mappings: applications of neural network techniques to atmospheric and oceanic satellite retrievals and numerical modeling. Rev Geophys 45:3009
Kundu PK (1976) Ekman veering observed near the ocean bottom. J Phys Oceanogr 6(2):238–242
Liu Y, Weisberg RH, He R (2006) Sea surface temperature patterns on the West Florida shelf using growing hierarchical self-organizing maps. J Atmos Ocean Technol 23:325–338
Liu Y, MacCready P, Hickey BM, Dever EP, Kosro PM, Banas NS (2009) Evaluation of a coastal ocean circulation model for the Columbia River plume in summer 2004. J Geophys Res 114:C00B04. doi:10.1029/2008JC004929
Liu Y, Weisberg RH, Hu C, Zheng L (2011) Tracking the deepwater horizon oil spill: a modeling perspective. EOS Trans AGU 92(6):45
Liu Y, Kerkering H, Weisberg R (2015) Coastal ocean observing systems, 1st edn. Academic Press, London
Lermusiaux PFJ (2006) Uncertainty estimation and prediction for interdisciplinary ocean dynamics. J Comput Phys 217:176–199
Martinetz TM, Berkovitsch SG, Schulten KJ (1993) ‘Neural-Gas’ network for vector quantization and its application to time-series prediction. IEEE Trans Neural Netw 4:558–569
Mihanović H, Cosoli S, Vilibić I, Ivanković D, Dadić V, Gačić M (2011) Surface current patterns in the northern Adriatic extracted from high-frequency radar data using self-organizing map analysis. J Geophys Res 116:C08033
van der Merwe R, Leen TK, Lu Z, Frolov S, Baptista AM (2007) Fast neural network surrogates for very high dimensional physics-based models in computational oceanography. Neural Netw 20:462–478
Paduan JD, Washburn L (2013) High-frequency radar observations of ocean surface currents. Annu Rev Mar Sci 5:115–136
Prtenjak MT, Grisogono B (2007) Sea/land breeze climatological characteristics along the northern Croatian Adriatic coast. Theor Appl Climatol 90:201–215
Rako N, Vilibić I, Mihanović H (2013) Mapping underwater sound noise and assessing its sources by using a self-organizing maps method. J Acoust Soc Am 133:1368–1376
Roweis ST, Saul LK (2000) Nonlinear dimensionality reduction by locally linear embedding. Science 290:2323–2326
Rozier D, Birol F, Cosme E, Brasseur R, Brankart JM, Verron J (2007) A reduced-order Kalman filter for data assimilation in physical oceanography. SIAM Rev 49:449–465
Saylor JH, Miller GS (1988) Observation of Ekman veering at the bottom of Lake Michigan. J Great Lakes Res 14(1):94–100
Stanev EV, Ziemer F, Schulz-Stellenfleth J, Seemann J, Staneva J, Gurgel K-W (2014) Blending surface currents from HF radar observations and numerical modeling: tidal hindcasts and forecasts. J Atmos Ocean Technol 32(2):256–281
Tenenbaum JB, De Silva V, Langford JC (2000) A global geometric framework for nonlinear dimensionality reduction. Science 290:2319–2323
Thomson RE, Emery WJ (2014) Data analysis methods in physical oceanography. Elsevier, Amsterdam
Tudor M, Ivatek-Šahdan S (2010) The case study of bura of 1st and 3rd February 2007. Meteorol Z 19:453–466
Vilibić I, Mihanović H, Šepić J, Matijević S (2011) Using Self-Organising Maps to investigate long-term changes in deep Adriatic water patterns. Cont Shelf Res 31:695–711
Voronoi G (1908) Nouvelles applications des paramètres continus à la théorie des formes quadratiques. Journal für die Reine und Angewandte Mathematik 133:97–178
Wahle K, Stanev EV (2011) Consistency and complementarity of different coastal ocean observations: a neural network-based analysis for the German Bight. Geophys Res Lett 38(10):1–4. doi:10.1029/2011GL047070
Wehrens E, Buydens LMC (2007) Self- and super-organizing maps in R: the Kohonen package. J Stat Softw 21:1–19
Zhang GP (2003) Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 50:159–175
Acknowledgments
The work on this paper was supported by the UKF project NEURAL (www.izor.hr/neural) and the IPA CBC project HAZADR (www.hazadr.eu). The SOM Toolbox version 2.0 for MATLAB was developed by E. Alhoniemi, J. Himberg, J. Parhankangas, and J. Vesanto at the Helsinki University of Technology, Finland, and is available at http://www.cis.hut.fi/projects/somtoolbox. Comments raised by anonymous reviewers are appreciated as greatly improving quality of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Kalinić, H., Mihanović, H., Cosoli, S. et al. Predicting ocean surface currents using numerical weather prediction model and Kohonen neural network: a northern Adriatic study. Neural Comput & Applic 28 (Suppl 1), 611–620 (2017). https://doi.org/10.1007/s00521-016-2395-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-016-2395-4