
Abstract
In songbirds of the temperate zone, often only males sing and their songs serve to attract females and to deter territorial rivals. In many species, males vary certain aspects of their singing behavior when engaged in territorial interactions. Such variation may be an honest signal of the traits of the signaler, such as fighting strength, condition, or aggressive motivation, and may be used by receivers in decisions on whether to retreat or to escalate a fight. This has been studied intensively in species that sing discontinuously, in which songs are alternating with silent pauses. We studied contextual variation in the song of skylarks (Alauda arvensis), a songbird with a large vocal repertoire and a continuous and versatile singing style. We exposed subjects to simulated territorial intrusions by broadcasting conspecific song and recorded their vocal responses. We found that males sing differently if they are singing spontaneously with no other conspecific around than if they are territorially challenged. In this last case, males produced lower-frequency syllables. Furthermore, they increased the sound density of their song: they increased the proportion of sound within song. They seem to do so by singing different elements of their repertoire when singing reactively. Furthermore, they increased the consistency of mean peak frequency: they repeated syllable types with less variability when singing reactively. Such contextual variation suggests that skylarks might use low frequencies, sound density, and song consistency to indicate their competitive potential, and thus, those song features might be important for mutual assessment of competitive abilities.
Similar content being viewed by others
Introduction
Acoustic communication helps to resolve conflicts over limited resources such as mates or breeding sites in diverse animal taxa such as mammals, birds, frogs, and insects whereby birdsong is probably the most intensively studied example (Bradbury and Vehrencamp 1998; Van Staaden et al. 2011). In many songbirds that breed in the temperate zone, only males sing and the songs serve to attract females and to repel territorial rivals (Catchpole and Slater 2008). It has been shown in many species that the song may vary with the territorial context: a male may sing differently if he is just singing spontaneously with no other conspecific around than if he is actually engaged in a territorial vocal interaction with a male competitor (reviewed in Vehrencamp 2000; Searcy and Beecher 2009) and often males increase the intensity of their songs when interacting with a rival by singing, for example, at higher rate (Benedict et al. 2012) or at higher amplitude (Brumm and Todt 2004).
During a territorial conflict, birds vocally communicate their competitive potential, providing the possibility of mutual assessment; this helps them in resolving a conflict without necessarily engaging in costly physical fights (reviewed in Todt and Naguib 2000; ten Cate et al. 2002). Furthermore, females might base their reproductive decisions on information gained through eavesdropping on such vocal interactions (e.g., Mennill et al. 2002). Vocal signals used in territorial interactions may provide information about the physical qualities of the sender such as body size. Correlations between song parameters and body size may only become apparent when birds are advertising such as in purple-crowned fairy-wrens (Malurus coronatus coronatus, as a songbird example; Hall et al. 2013) or when they are territorially challenged such as in African black coucals (Centropus grillii, as a non-songbird example; Geberzahn et al. 2009; see also the review of Cardoso 2012). Likewise, vocal signals may provide information about an individual’s current aggressive intent, which may also crucially influence the outcome of a conflict. For instance, birds may use specific categories of songs to indicate their aggressiveness (e.g., Järvi et al. 1980; Catchpole 1983; Nelson and Croner 1991; Staicer 1996; Trillo and Vehrencamp 2005; Anderson et al. 2008). Furthermore, temporal or pattern-specific adjustment to an opponent’s singing has been interpreted as a signal for aggressive intent (reviewed in Todt and Naguib 2000; Searcy and Beecher 2009). A male may provide such information by adjusting the timing of his own singing relative to the song of a rival (Naguib and Mennill 2010, but see critique in Searcy and Beecher 2009, 2011). Another example is vocal matching, i.e., pattern-specific adjustment: a male replies to a rival with the same song pattern that the rival has just sung (e.g., Stoddard et al. 1992; Beecher et al. 2000; Rogers et al. 2006; Vehrencamp et al. 2007; Price and Yuan 2011). A prerequisite for temporal and pattern-specific adjustment is a discontinuous singing style such as in nightingales (Luscinia megarhynchos; Todt and Naguib 2000) or in song sparrows (Melospiza melodia; Beecher and Brenowitz 2005). In these species, songs are alternated with silent inter-song pauses, allowing males to avoid complete mutual acoustic overlap during vocal interactions, for instance, by inserting their own songs in the silent pauses of the territorial rival (e.g., Geberzahn et al. 2013). Previous studies on context-specific variation focused on birds with the more common, discontinuous singing style. Thus, it remains an open question how songbirds with a continuous singing style (syllables are produced continuously with only short silent intervals between them) signal competitive ability during territorial interactions. As a first step to address this question, we here identify song features that vary with the context in such a songbird species, the skylark (Alauda arvensis).
The skylark is a territorial songbird that breeds in the temperate zone and usually only males sing. As a species of the open country, the skylark is one of the few species of songbirds that perform aerial song displays: they sing at the same time as they fly. They have a large repertoire of different syllable types (>300; Briefer et al. 2008) and they perform their syllables in a continuous fashion with short intersyllable intervals (Fig. 1) during a song flight that can last up to 1 h (NG, personal observation). Two males singing simultaneously largely mask each other’s songs. Accordingly, temporal or pattern-specific adjustment of song seems not to be the predominant way to vocally interact, although in rare instances, we observed syllable type matching in naturally occurring interactions (NG, personal observation).

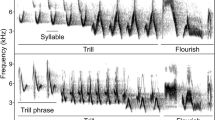
Oscillograms (top) and spectrographic illustrations (bottom) of skylark song. a Spontaneous song: singing spontaneously with no other conspecific around. b Reactive song: song in response to a territorial playback by the same bird as shown in a. Syllables of the same type are labeled with the same number, syllables found only in either spontaneous or reactive song (unshared syllables) are labeled with italic numbers, and syllables found in both contexts are labeled with bold numbers (note that some of those shared syllables are not displayed in both excerpts). Syllable duration is indicated above the oscillograms
In the current study, we, therefore, examined other song parameters that may provide information on the competitive potential of a male. We focused on spectrotemporal parameters and repertoire parameters such as number of syllables produced per time unit (syllable rate) and number of syllable types produced per time unit (indicating song versatility). In discontinuous singers, the rate of vocalizations can be assessed both as syllable rate and song rate. Swamp sparrows (Melospiza georgiana; DuBois et al. 2011) increase syllable rate and banded wrens (Thryophilus pleurostictus; Vehrencamp et al. 2013) increase trill syllable rate when challenged by a territorial playback. An increase of song rate has, for instance, been described in song sparrows (Kramer et al. 1985) and canyon wrens (Catherpes mexicanus; Benedict et al. 2012) that were singing in response to a playback, whereas western meadowlarks, Sturnella neglecta, increased versatility when territorially challenged (Falls and d’Agincourt 1982). We also assessed the sound density, calculated here as the sum of all syllable durations divided by the overall duration of a given song sample. This parameter may change concordantly with syllable rate, if syllables with constant durations are produced at higher rates. However, if syllable duration and gap duration both vary independently, then sound density may quantify a different facet of signal intensity than syllable rate. Measures related to sound density have been shown to be intersexually selected (e.g., in zebra finches, Taeniopygia guttata; Holveck and Riebel 2007) and tended to covary with body condition of male dark-eyed juncos (Junco hyemalis; Cardoso et al. 2012). Furthermore, a similar song measure termed “duty cycle” has been suggested to convey information about the motivational state of a signaler in an alarm context (black-capped chickadees, Poecile atricapillus; Wilson and Mennill 2011). Thus, sound density could also carry such information in a territorial context.
Finally, we assessed vocal consistency, a song feature that has recently received attention as a possible signal for competitive potential. Vocal consistency refers to the ability to faithfully replicate the acoustic features of a song from one rendition to the next (reviewed in Sakata and Vehrencamp 2012). This feature correlates with reproductive success (in chestnut-sided warblers, Dendroica pensylvanica; Byers 2007) and increases with age and/or dominance in house wrens (Troglodytes aedon; Cramer 2013a), tropical mockingbirds (Mimus gilvus; Botero et al. 2009), banded wrens (de Kort et al. 2009), and great tits (Parus major; Rivera-Gutierrez et al. 2010). In a recent playback experiment, great tits reacted more aggressively to song stimuli with a higher consistency, suggesting that this feature provides information on competitive abilities (Rivera-Gutierrez et al. 2011). Studies on zebra finches (Sossinka and Böhner 1980) and Bengalese finches (Lonchura striata var. domestica; Sakata et al. 2008) revealed that song consistency varies with the context: males sing more consistently when directing their song to females than when singing an undirected song. Thus, this trait can vary intraindividually, and this opens the possibility that it may also be modulated by male skylarks reacting to a territorial challenge.
We recorded songs of male skylarks in two different contexts: when they were singing spontaneously, i.e., without any indication of an interaction with a conspecific, and when they were singing in response to a playback of conspecific song simulating a territorial intrusion. We examined whether song parameters changed when males responded to the playback in comparison to when they were singing spontaneously. Our prediction was that, if males use such song parameters to communicate their competitive ability, then they should modify song parameters in a context-specific manner.
Methods
Study site, subjects, and songs
The study was conducted on 16 male skylarks at 9 different locations in the agricultural fields surrounding the University of Paris 11, Orsay, France, during the 2011 (N = 9 subjects, 9 May to 1 July) and 2012 (N = 7 subjects, 3 May to 20 June) breeding seasons. Skylarks are extremely hard to catch during the breeding season. After a short unsuccessful trial to catch and ring them in April 2011, we decided to work with unmarked individuals. However, we are confident that we were able to identify individual subjects by carefully observing position and behavior, especially the conspicuous flight song, repeatedly displayed at a given location. Furthermore, site fidelity is very strong in breeding skylarks (Delius 1965) and boundaries between adjoining territories are stable once territories are established (Aubin 1981). Skylarks migrate during winter and return to the breeding grounds around February when they settle in adjacent territories until the end of July (Delius 1963). Their flight song and, thus, the song lasts, on average, for 261 s (Hedenström 1995) but can take up to 1 h (NG, personal observation). A song flight consists of three characteristic phases: the ascending flight; the level flight, which makes up the majority of the time spent in the air; and the descending flight (Hedenström 1995; Linossier et al. 2013). Skylarks have, on average, 341 ± 21 different syllable types (Briefer et al. 2008). Following Briefer et al. (2008), we define a syllable as a continuous trace on the sound spectrogram (syllable 1 or 2 in Fig. 1a) or a group of continuous traces spaced out by <25 ms (syllable 3 or 7 in Fig. 1a). Syllables can be part of a stereotyped sequence of syllables that recurs in the song (sequence 26–27–28–29–26–30–30–31–32–26–33 in Fig. 1b). Syllables are either sung with “immediate variety”: males switch to a new syllable type with each syllable produced or a given syllable type is repeated several times (“eventual variety,” syllable 10 in Fig. 1a).
Recording methods for spontaneous singing
Recordings were made at a sample rate of 44.1 kHz using a Sennheiser ME62/K6 omnidirectional microphone (frequency response of 20 Hz to 20 kHz, ±1 dB) mounted on a Telinga Universal parabola (diameter, 50 cm) and connected to a Marantz PMD 670 solid-state recorder. We recorded songs between 0800 and 1300 hours. We observed the behavior of the subjects and checked whether a male was interacting with a conspecific (e.g., chasing a conspecific). Spontaneous singing was defined as singing without any indication of such interactions.
Playback experiments and recording methods during playback
We conducted playback experiments to elicit a territorial response and recorded the song produced by the tested subject during the playback and in the 10 min after the end of the presentation of the playback stimulus. Skylarks show a very clear territorial behavior with stereotyped patterns (Delius 1963). A male usually reacts by flying towards a loudspeaker simulating an intruder, landing in its vicinity or flying over it at low height. We considered a male as responding to a playback if he clearly approached, that is, flew towards the loudspeaker and sang. Recordings of such reactive song were made using the same equipment as described previously for spontaneous song.
In the playback experiments, we broadcast each of two different stimuli subsequently with a silent pause of 5 min between stimulus presentations. We broadcast two stimuli to increase the likelihood of eliciting a vocal response and we broadcast two different stimuli to avoid habituation (Aubin 1982). Stimuli consisted of conspecific song recorded in our study population in the same breeding season. For each playback experiment, we used a unique set of stimuli recorded from a unique source male to avoid pseudoreplication (except for one set of stimuli that was used twice). Stimulus duration was 85.6 ± 5.1 s (mean ± SD) and stimuli were broadcast at an amplitude of 85.8 ± 8.2 dB (mean ± SD) (re. 20 μPa, measured as peak amplitude from 30 stimuli at 1 m from the loudspeaker with a Brüel & Kjaer 2235 sound level meter, linear setting).
In 2011, we broadcast stimuli using a Marantz PMD 670 solid-state recorder connected via a 20-m cable to a 10-W MegaVox Pro MEGA-6000 loudspeaker (frequency response of 400 Hz to10 kHz, ±3 dB). In 2012, we broadcast stimuli with a Foxpro Fury GX7 remote-controlled autonomous amplifier, connected to a Hortus CT30 loudspeaker (frequency response of 65 Hz to 21 kHz, ±6 dB). We positioned the loudspeaker on the ground at approximately 5–10 m into the subject’s territory. The experimenter stood 20–30 m from the loudspeaker, recorded the reactive song, and quietly narrated observed behavior into the silent pauses between the vocalizations.
We recorded spontaneous song before conducting the playback experiment to avoid potential long-term effects of the playback on the song (cf. Schmidt et al. 2007). Furthermore, we recorded reactive song as promptly as possible after spontaneous song in order to minimize potential seasonal effects. Thus, reactive song was recorded after spontaneous song, either on the same day (N = 8), the following day (N = 4), or on 4, 10, or 14 days (N = 1, each) thereafter. In one subject, we had to record spontaneous song after recording reactive song and to minimize a potential effect of the playback experiment, we waited for 7 days before recording spontaneous song.
Song analysis
We used Avisoft SASLAB Pro for song analysis. For each context and each subject, we selected one song recording with the highest signal-to-noise ratio (in most cases, this song was recorded after the end of the playback, as song overlapping with the playback was usually masked by the playback). The overall duration of those songs was 175 ± 134 s (mean ± SD). In order to compare songs from the same flight phase, we confined our analysis to the first 40 s of the song corresponding approximately to the ascending phase of the flight. To remove unwanted noise, we then high-pass filtered the songs (cutoff frequency of 1.4 kHz) and labeled syllables according to their syllable types (Fig. 1). Classification of a total of 6,890 syllables into syllable types was based on visual comparison of overall frequency modulation shapes in spectrograms by one observer (NG) who is very experienced with this task. In order to verify that this approach did not produce idiosyncratic results (Jones et al. 2001), a second highly experienced observer (TA) who was blind to the context of the recording controlled the classification of a subset of syllables (947 syllables produced by 2 subjects, corresponding to 14 % of the total dataset) and agreed in 894 cases (94 % agreement).
We measured temporal parameters by manually delineating onsets and offsets of syllables in the oscillograms and created spectrograms to measure mean peak frequency (MPF) (FFT length, 1,024; frame, 100 %; overlap, 75 %; Hamming window) using the “automatic parameter measurements setup” with interactive element separation from section labels, that is, based on the manual delineation in oscillograms. Temporal parameters were measured with a resolution of 2.9 ms, and MPF was measured with a frequency resolution of 43 Hz. We measured and calculated the average of the following parameters: syllable duration, gap duration (the interval between syllables), and MPF (see description in Table 1). Furthermore, we assessed the lowest MPF. From those parameters, we calculated sound density for the overall song sample (overall sound density; Table 1). To calculate sound density for subsets of syllables, we divided the sum of all syllable durations of the relevant syllable types by the sum of the same syllable durations plus the subsequent gap durations. We chose the subsequent rather than the preceding gap duration as only subsequent gap duration correlates with syllable duration, suggesting a link between these two parameters (Csicsaky 1978). From the list of labeled syllables, we also calculated the number of syllables (syllable rate) and the number of syllable types (our measure of versatility; see Table 1).
Furthermore, we calculated the coefficient of variation (CV) for all spectrotemporal parameters (see description in Table 1). To this end, we selected the three syllable types for each subject that were produced the most often both in spontaneous and reactive singing to calculate the CV based on their renditions in the 40-s song sample (one subject repeated only one syllable type several times in both contexts and we, thus, selected only this one syllable type). Those syllables were produced equally often in both contexts (spontaneous song sample, 6.4 ± 2.6 [mean ± SD] times; reactive song sample, 5.6 ± 2.4 [mean ± SD] times; paired t test: t = −1.55, df = 15, p = 0.14). Cramer (2013b) suggested using a combined approach when measuring consistency of song: next to calculating the CVs of specific acoustic features, she suggested to use spectrogram cross-correlation as these two approaches seem to complement each other. Therefore, on the same dataset of the three most frequent syllable types, we estimated rendition-to-rendition consistency of overall syllable shape by means of spectral cross-correlation. To this end, we used the spectrogram cross-correlation function (CCF) within the classification option of Avisoft and calculated the averages of all pairwise comparisons of syllable renditions (see Table 1).
To rule out that our findings were influenced by seasonal or daytime effects, we tested whether those parameters for which we found context-specific modulation (lowest MPF, song density, and CV of MPF) changed with the time of the day (measured as minutes after sunrise) and the season (measured as number of days after the start of the experiment). All but 1 of the 12 correlations (3 parameters in each of 2 contexts) were nonsignificant (mean p = 0.51; range, 0.09–0.90). However, the CV of MPF was negatively correlated with the number of days after the start of the experiment (Pearson’s product–moment correlation t = −2.4, df = 14, p = 0.03). For this parameter, we, therefore, included the number of days after the start of the experiment as a predictor variable in a generalized linear mixed model (GLMM) (see the “Statistical analysis” section). Furthermore, we retested lowest MPF, song density, and CV of MPF using only the subsample of 12 subjects for which reactive singing was recorded on the same or the following day as spontaneous singing so that seasonal effects can be assumed to be negligible.
Additionally, in the case of modulations of the overall sound density with the context, we were interested in understanding how subjects would change this parameter. Therefore, we calculated the sound density for the following subsets of data (see Table 1): the most frequent syllable type produced in both contexts, the shared types (syllable types sung in both contexts), and the unshared syllable types (syllable types sung only in one context). To calculate sound density for shared and unshared syllable types, we considered only the first rendition of each syllable type as a given syllable may be sung more or less frequent in each context and we wanted to rule out this to affect our measure of sound density. If sound density was modulated by changing syllable and gap duration of a given syllable type relative to each other (for instance, by decreasing gap duration while keeping syllable duration constant), we expected that the sound density of the most frequent syllable type and the sound density of shared syllable types would be different between spontaneous and reactive song. If, however, birds changed sound density by switching to another subset of syllables, we expected that sound density of unshared syllables would differ.
Finally, in the case of modulations of the lowest MPF with the context, we explored modulation in this parameter in the subset of the most frequent syllable type as well as the unshared and shared syllables in order to test whether this parameter is changed by modifying given syllables or by switching to other syllables.
Statistical analysis
Statistical analyses were conducted using R2.13.0 (http://www.r-project.org/). We tested for normality using Shapiro–Wilk tests. In cases of normal distributions, we used a paired t test to compare song parameters in spontaneous and reactive singing and Pearson’s product–moment correlation to test for correlations with daytime and season. Where distributions were not normally distributed, we used paired samples Wilcoxon tests or Spearman’s rank correlation. When entering several measures per subject into the analysis, we used generalized linear mixed models (GLMMs) implemented in R2.13.0 and the add-on package nlme (Pinheiro et al. 2009). The dependent variable was the relevant response measure (CCF, CV of syllable duration, gap duration, sound density, and MPF); the independent variable was the context (spontaneous or reactive singing). Subject identity was a random factor. For one parameter that changed with season in reactive singing (CV of MPF), we further included the number of days after the start of the experiment as predictor. In the full model for this parameter, the number of days after the start of the experiment was not significant (p = 0.08) and was, therefore, removed from the final model. All tests were two-tailed. To control for multiple testing when comparing the sound density in several different subsets of data, we applied the Benjamini–Hochberg false discovery rate procedure and provide adjusted p values in addition to the uncorrected p values (Benjamini and Hochberg 1995).
Results
Spectrotemporal parameters
Skylarks increased the overall sound density in the first 40 s of their flight song when singing in response to the territorial playback. Changes were small in each subject, but all males (except two) sang with higher overall sound density in reactive than in spontaneous song, and this difference was highly significant (Table 2; Fig. 2). Mean values for syllable duration were slightly larger and mean values for gap duration were slightly smaller in reactive than in spontaneous song, but these differences were not significant when looking at the whole song sample (Table 2). Taken together, these small effects might nevertheless have contributed to the increase in sound density. Likewise, skylarks modulated the lowest MPF with the context: when singing reactively, the lowest value of MPF was significantly lower than when singing spontaneously (Table 2; Fig. 3).

Overall sound density increased in response to territorial threats. Overall sound density (in percent) in spontaneous and reactive singing skylarks. For statistics, see Table 2

Lowest MPF decreased in response to territorial threats. Lowest MPF in spontaneous and reactive singing skylarks. For statistics, see Table 2
Repertoire parameters
Skylarks did not sing more syllables in the first 40 s of their flight song when singing in response to the territorial playback than when singing spontaneously. However, the number of different syllable types produced during reactive songs tended to be higher than in spontaneous songs (Table 2); thus, their songs tended to be more versatile when singing in response to the simulated territorial intrusion.
Consistency of singing
As a measure for rendition-to-rendition consistency, we calculated the CV of spectrotemporal parameters in the three syllables which were produced most often by a given subject in both contexts. We found that the CV was significantly lower in reactive compared to spontaneous song for MPF (Table 3; Fig. 4). For the parameters syllable duration, gap duration, and sound density, we did not detect a significant difference in the CV between spontaneous and reactive singing (Table 3). When applying spectral cross-correlation as an additional approach to assess consistency of overall syllable shape, we did not detect a significant difference between spontaneous and reactive singing (Table 3).

Variability of MPF decreased in response to territorial threats. CV for the parameter MPF in spontaneous and reactive singing skylarks. For statistics, see Table 3
Sound density and lowest MPF of most frequent, shared, and unshared syllables
When comparing the syllable types used both during spontaneous and reactive singing (shared syllable types), we found that subjects used between 7 and 102 syllable types (mean ± SD = 41 ± 24; cf. syllables labeled with bold numbers in Fig. 1) in both contexts. Other syllable types could be identified only in one of the two contexts (unshared syllable types: spontaneous singing mean ± SD = 69 ± 16, reactive singing mean ± SD = 83 ± 32; cf. syllables labeled with italic numbers in Fig. 1). To disentangle how skylarks arrive at lower MPF in reactive songs, we examined contextual variation in the lowest MPF for different subsets of syllables. However, neither did we detect a significant difference between spontaneous and reactive song for the most frequently performed syllable type (paired t test, t = 0.94, df = 15, p = 0.36), nor in the subsets of shared and unshared syllable types (shared: paired t test, t = −0.61, df = 15, p = 0.55; unshared: paired t test, t = −0.79, df = 15, p = 0.44).
To understand how skylarks increased the overall sound density, we examined contextual variation in the sound density for different subsets of syllables. First, we compared the one shared syllable type produced most often by a given subject in both contexts. Sound density for the most frequently performed syllable type did not differ between spontaneous and reactive song (Table 4). Furthermore, sound density did not vary with the context when considering the subset of syllables that were used both in spontaneous and reactive song (shared syllable types; Table 4). In contrast, syllables only used in reactive song had a significantly higher sound density than those syllables only produced in spontaneous song (unshared syllable types; Table 4). To further elucidate this last finding, we compared syllable and gap duration for the same subset of unshared syllable types, as those two parameters should determine the sound density. Syllable types produced uniquely in reactive singing were indeed followed by smaller intersyllable gaps than those produced uniquely in spontaneous singing (spontaneous singing mean ± SD = 47.67 ± 5.04 ms, reactive singing mean ± SD = 44.49 ± 4.19 ms, paired t test: t = −2.43, df = 15, p = 0.03; cf. Fig. 1). In contrast, the duration of such syllables did not differ between the two contexts (spontaneous singing mean ± SD = 151.16 ± 19.19 ms, reactive singing mean ± SD = 151.32 ± 13.75 ms, paired t test: t = 0.04, df = 15, p = 0.97).
Discussion
Skylarks increased the overall sound density in the ascending phase of their flight song when singing in response to a territorial challenge: they produced a higher proportion of sound. We did not find an increase in the sound density of the one syllable that they produced most often in both contexts, nor did they seem to change the sound density in those syllables that they used in both contexts (shared syllables). However, sound density was higher in syllables uniquely produced during reactive singing compared to those uniquely produced in spontaneous singing (unshared syllables), and this was due to the former syllables being followed by shorter intersyllable gaps. Furthermore, skylarks decreased the lowest MPF when singing reactively while all other spectrotemporal parameters did not vary significantly with the context. We could not detect a change in the syllable rate when birds were singing reactively. However, the number of different syllable types that they produced tended to be higher; thus, their song tended to be more versatile when singing in response to the territorial playback. Finally, males produced their three most frequent syllables with lower rendition-to-rendition variability corresponding to higher consistency in terms of repeating more faithfully the MPF of these syllables when singing reactively. Such consistency in song structure was restricted to the MPF: we could not detect differences in the rendition-to-rendition variability of the syllable duration, the gap duration, the sound density, and in syllable shape consistency (the latter being assessed by spectral cross-correlation).
Searcy and Beecher (2009) postulated three criteria that should be met to establish that a given singing behavior is an aggressive signal. Signal value should increase in aggressive contexts (context criterion). The signal should predict aggressive escalation by the signaler (predictive criterion). Differential signal values should elicit differential responses (response criterion), and in fact, most playbacks exposing subjects to such different signal values elicited differential responses of receivers (reviewed in Searcy and Beecher 2009, but see DuBois et al. 2010, 2011; Cramer 2013c). In the current study, we showed that sound density, vocal consistency, and the lowest MPF each meet the context criterion and are, therefore, likely candidates to serve as signals for the competitive potential of the signaler. In future studies, we will examine whether such variation is meaningful to skylarks; that is, whether receivers respond differently when exposed to playback stimuli that vary accordingly. Furthermore, it would be interesting to correlate data on male quality such as morphometric and/or fitness data with those candidate song traits and their variability in order to establish that they serve as indicators for male quality.
Mean peak frequency
The lowest MPF that skylarks produced varied with the context: when singing in response to a territorial playback, the lowest MPF was smaller than when singing spontaneously. However, we have to acknowledge that this effect was not very strong and that we could not confirm this finding when retesting the subset of 12 subjects for which spontaneous and reactive song were recorded within a short period of time. We also did not detect differences of the lowest MPF in the subset of the most frequently performed syllable type and the subset of the shared syllable types. Thus, skylarks seem not to modify given syllables to lower the frequency when singing reactively. Also, they do not seem to switch to particular low-frequency syllables when singing reactively as we could also not detect differences of the lowest MPF in the subset of unshared syllables. Thus, our data do not allow disentangling how exactly skylarks modulate the lowest MPF.
Several previous studies have reported that birds decrease the frequency parameters of their vocalizations in a territorial interaction (black-capped chickadees, P. atricapillus; Hill and Lein 1987; Otter et al. 2002; Montezuma Oropendolas, Psarocolius montezuma, Price et al. 2006; scops owls, Otus scops, Hardouin et al. 2007; African black coucals, C. grillii, Geberzahn et al. 2009, 2010). Such context-specific variation has usually been interpreted as providing information on the competitive potential in the framework of a size–frequency allometry: only large individuals having a large vocal organ and a large vocal tract may be able to produce low-frequency vocalizations. Whereas such a size–frequency allometry is well established for non-songbirds, its existence in oscine songbirds is a matter of debate (Patel et al. 2010; Cardoso 2012; Hall et al. 2013). Our results for skylarks provide some evidence in support of size–frequency allometry in songbirds, but do not allow drawing very firm conclusions.
Vocal consistency of mean peak frequency
Male skylarks produced their most frequent syllables with higher consistency in terms of repeating more faithfully the MPF when singing reactively. Song consistency increased with age in tropical mockingbirds and males producing more consistent songs tended to have higher dominance status and reproductive success (Botero et al. 2009). The authors concluded that consistency may indicate the integrity of brain function in birds. Singing consistent songs requires not only consistent vocal motor commands generated by the nervous system but, furthermore, the coordination of syringeal and respiratory muscle activities and muscular resistance to motor fatigue (Lambrechts and Dhondt 1988; Suthers and Zollinger 2008). Accordingly, vocal consistency could be a signal for male quality, as only males in which all those requirements are met should be able to produce highly consistent song (cf. Podos et al. 2009; Sakata and Vehrencamp 2012). Findings in great tits support such reasoning as males reacted more aggressively to playback song stimuli with high versus low consistency, suggesting that this feature indeed provides information on competitive abilities (Rivera-Gutierrez et al. 2011).
Context-dependent variation in vocal consistency has been described in intersexual communication in estrildid finches and has become a prominent model to study neuronal mechanisms controlling song plasticity (Kao et al. 2005; Ölveczky et al. 2005; Kao and Brainard 2006; Teramitsu and White 2006; Sakata et al. 2008; Leblois et al. 2010). Those studies suggest that variability in adult song enables birds to refine and maintain consistent vocal performance by means of auditory feedback and reinforcement mechanisms (Sakata and Vehrencamp 2012) and such variable song, thus, corresponds to a form of “motor exploration” (e.g., Tumer and Brainard 2007; Sakata et al. 2008; Woolley and Doupe 2008). In contrast, song produced with high consistency reflects a “performance state” and is subject to intersexual selection: female zebra finches prefer the highly consistent female-directed song over the more variable undirected song (Woolley and Doupe 2008). Likewise, the higher vocal plasticity in the song of spontaneously singing skylarks could reflect a form of “motor exploration” and could allow the birds to adjust and refine their song, whereas they would switch to the “performance state” during a territorial intrusion, in which MPF is performed more consistently, which in turn might be the more effective territorial signal.
Sound density
Almost all subjects increased the overall sound density in a context-specific manner, revealing a highly significant difference. By doing so, they increased the intensity of their territorial signal. Males of different songbird species have been shown to increase the intensity of their songs when interacting with a rival, for instance, by increasing the song rate (Benedict et al. 2012) or amplitude (Brumm and Todt 2004). Such an increase in song intensity has been shown to play a role not only in territorial aggression (e.g., Brumm and Ritschard 2011) but also in female song preferences (Holveck and Riebel 2007; Ritschard et al. 2010). Signalers from a wide range of species have been shown to encode motivational information by increasing the sound density (Owings and Morton 1998). For instance, Wilson and Mennill (2011) showed that black-capped chickadees responded more strongly to calls with a higher sound density in an alarm context and suggested that variation in sound density provided information about the motivational state of the signaler. Thus, skylarks might be more motivated to defend their territory when they are in danger of losing it and express this heightened motivation by increasing the sound density of their song.
Alternatively, the sound density could convey information about the physical quality of a male. Increasing the proportion of time when sound is produced necessarily reduces the proportion of time when no sound is produced. Such silent periods usually correspond to inspiration (Franz and Goller 2002). Especially during the ascending phase of the flight song, it could, therefore, be difficult to increase the sound density, and perhaps, only males of high physical quality are able to do so.
Furthermore, increasing the sound density could increase the masking effect on the song of the rival: producing more sound per unit of time should increase the proportion of syllables that are not overlapped by syllables of the rival (assuming a static sound density for the rival), whereas it should increase the proportion of syllables of the rival being masked. This idea concerns, however, only reactive song actually overlapping with the song of an intruder, in our case simulated by the playback song. We mostly got around such overlapping signaling in the current study by selecting songs for analysis with the highest signal-to-noise ratio corresponding to nonoverlapping song. The fact that sound density increased in our sample, thus, suggests that this increase cannot only be explained by such a mechanism of masking avoidance alone.
A closer look at different subsets of syllables revealed that the sound density was mainly increased for those syllable types that were uniquely detected in reactive singing. Thus, skylarks seem to selectively perform syllable types with high sound density in their song rather than modifying syllable and gap duration within a given syllable type. The question that remains is how the sound density can vary for different syllable types. Perhaps skylarks can decrease intersyllable gaps (and thereby increase sound density) during reactive singing by choosing syllable sequences in which the differences of frequency between the end of a given syllable and the start of the subsequent syllable is minimized (cf. Podos et al. 2009): if syllables end and begin at approximately the same frequency, the vocal apparatus should already be in an appropriate configuration for the production of the subsequent syllable which should allow for a short gap duration (cf. Fig. 1 in Podos et al. 2009).
Syllable rate and versatility
In discontinuous singers, the rate of vocalizations is usually assessed as the number of either syllables or songs per unit of time and both have been shown to increase in a territorial context (reviewed in Vehrencamp 2000; Searcy and Beecher 2009). In a continuous singer, this rate is measured as syllable rate and skylarks kept this measure at the same level when singing in response to the territorial playback. This is in contrast to findings on discontinuous singers. Syllable rate might be a less flexible trait in skylarks because of their continuous singing style. In particular, it could be difficult for the birds to increase the syllable rate and the sound density at the same time as this would only be possible by decreasing dramatically the silent gaps between syllables corresponding to inspiration. In contrast, we detected a tendency to increase song versatility: skylarks tended to sing more different syllable types when singing reactively, which could be a means of displaying a closer approximation of the singer’s full repertoire size. This could in turn be a signal of male quality (Spencer et al. 2004; Reid et al. 2005). Indeed, larger repertoires have been shown to be more efficient territorial signals in great tits (Krebs et al. 1978). In skylarks, it is obvious that males change the composition of syllables produced in a territorial context (see the previous section); whether the increase in versatility is a signal in itself or might be a by-product of producing selectively certain syllables to increase the sound density remains an open question.
Conclusions
Modulation in the song in response to a territorial challenge has been studied intensively in songbird species with a discontinuous singing style. Such modulation allows birds to vocally exchange information about their competitive potentials and thereby resolve territorial conflicts vocally. For instance, birds may adjust the timing of their song or the song pattern to an opponent’s singing, allowing them to signal their aggressive intent. This communication strategy is, however, only amenable to discontinuous singing. Here, we reported on context-specific variation in the song of skylarks, a songbird with a continuous singing style. We described three parameters in the song of this species: lowest MPF, vocal consistency, and sound density that changed in a context-specific manner. This raises the possibility that skylarks might use modulation in those parameters to signal their competitive potential in a territorial interaction.
References
Anderson RC, Searcy WA, Peters S, Nowicki S (2008) Soft song in song sparrows: acoustic structure and implications for signal function. Ethology 114:662–676
Aubin T (1981) Etude expérimentale du chant territorial de l’alouette des champs (Alauda arvensis L.). Caractéristiques physiques, valeur sémantique et spécificité. Dissertation, University of Besançon, Nancy 1, Strasbourg
Aubin T (1982) Habituation au chant territorial chez l’alouette des champs (Alauda arvensis L.); rôle de la diversité et de la monotonie. Biol Behav 7:353–362
Beecher MD, Brenowitz EA (2005) Functional aspects of song learning in songbirds. Trends Ecol Evol 20:143–149
Beecher M, Campbell S, Burt J, Hill C, Nordby J (2000) Song-type matching between neighbouring song sparrows. Anim Behav 59:21–27
Benedict L, Rose A, Warning N (2012) Canyon wrens alter their songs in response to territorial challenges. Anim Behav 84:1463–1467
Benjamini Y, Hochberg Y (1995) Controlling the false discovery rate—a practical and powerful approach to multiple testing. J Roy Stat Soc B Met 57:289–300
Botero CA, Rossman RJ, Caro LM, Stenzler LM, Lovette IJ, de Kort SR, Vehrencamp SL (2009) Syllable type consistency is related to age, social status, and reproductive success in the tropical mockingbird. Anim Behav 77:701–706
Bradbury JW, Vehrencamp SL (1998) Principles of animal communication. Sinauer Associates, Sunderland
Briefer E, Aubin T, Lehongre K, Rybak F (2008) How to identify dear enemies: the group signature in the complex song of the skylark Alauda arvensis. J Exp Biol 211:317–326
Brumm H, Todt D (2004) Male–male vocal interactions and the adjustment of song amplitude in a territorial bird. Anim Behav 67:281–286
Brumm H, Ritschard M (2011) Song amplitude affects territorial aggression of male receivers in chaffinches. Behav Ecol 22:310–316
Byers BE (2007) Extrapair paternity in chestnut-sided warblers is correlated with consistent vocal performance. Behav Ecol 18:130–136
Cardoso GC, Atwell JW, Hu Y, Ketterson ED, Price TD (2012) No correlation between three selected trade-offs in birdsong performance and male quality for a species with song repertoires. Ethology 118:584–593
Cardoso GC (2012) Paradoxical calls: the opposite signaling role of sound frequency across bird species. Behav Ecol 23:237–241
Catchpole CK (1983) Variation in the song of the great reed warbler Acrocephalus arundinaceus in relation to mate attraction and territorial defense. Anim Behav 31:1217–1225
Catchpole CK, Slater PJB (2008) Bird song: biological themes and variations. Cambridge University Press, Cambridge
ten Cate C, Slabbekoorn H, Ballintijn MR (2002) Birdsong and male–male competition: causes and consequences of vocal variability in the collared dove (Streptopelia decaocto). Adv Stud Behav 31:31–75
Cramer ERA (2013a) Physically challenging song traits, male quality, and reproductive success in house wrens. PLoS ONE 8:e59208
Cramer ERA (2013b) Measuring consistency: spectrogram cross-correlation versus targeted acoustic parameters. Bioacoustics. doi:10.1080/09524622.2013.793616
Cramer ERA (2013c) Vocal deviation and trill consistency do not affect male response to playback in house wrens. Behav Ecol 24:412–420
Csicsáky M (1978) Über den Gesang der Feldlerche (Alauda arvensis) und seine Beziehung zur Atmung. J Ornithol 119:249–264
de Kort SR, Eldermire ERB, Valderrama S, Botero CA, Vehrencamp SL (2009) Trill consistency is an age-related assessment signal in banded wrens. Proc R Soc Lond B 276:2315–2321
Delius JD (1963) Das Verhalten der Feldlerche. Z Tierpsychol 20:297–348
Delius J (1965) A population study of skylarks Alauda arvensis. Ibis 107:466–492
DuBois AL, Nowicki S, Searcy WA (2010) Discrimination of vocal performance by male swamp sparrows. Behav Ecol Sociobiol 65:717–726
DuBois AL, Nowicki S, Searcy WA (2011) Swamp sparrows modulate vocal performance in an aggressive context. Biol Lett 5:163–165
Falls JB, D’Agincourt LG (1982) Why do meadowlarks switch song types. Can J Zool 60:3400–3408
Franz M, Goller F (2002) Respiratory units of motor production and song imitation in the zebra finch. J Neurobiol 51:129–141
Geberzahn N, Goymann W, ten Cate C (2010) Threat signaling in female song-evidence from playbacks in a sex-role reversed bird species. Behav Ecol 21:1147–1155
Geberzahn N, Goymann W, Muck C, ten Cate C (2009) Females alter their song when challenged in a sex-role reversed bird species. Behav Ecol Sociobiol 64:193–204
Geberzahn N, Hultsch H, Todt D (2013) Memory-dependent adjustment of vocal response latencies in a territorial songbird. J Physiol (Paris) 107:203–209
Hall ML, Kingma SA, Peters A (2013) Male songbird indicates body size with low-pitched advertising songs. PLoS ONE 8:e56717
Hardouin LA, Reby D, Bavoux C, Burneleau G, Bretagnolle V (2007) Communication of male quality in owl hoots. Am Nat 169:552–562
Hedenström A (1995) Song flight performance in the skylark Alauda arvensis. J Avian Biol 26:337–342
Hill B, Lein M (1987) Function of frequency-shifted songs of black-capped chickadees. Condor 89:914–915
Holveck MJ, Riebel K (2007) Preferred songs predict preferred males: consistency and repeatability of zebra finch females across three test contexts. Anim Behav 74:297–309
Järvi T, Radesater T, Jacobsson S (1980) The song of the willow warbler Phylloscopus trochilus with special reference to singing behavior in agonistic situations. Ornis Scand 11:236–242
Jones AE, ten Cate C, Bijleveld CJH (2001) The interobserver reliability of scoring sonagrams by eye: a study on methods, illustrated on zebra finch songs. Anim Behav 62:791–801
Kao MH, Brainard MS (2006) Lesions of an avian basal ganglia circuit prevent unshared changes to song variability. J Neurophysiol 96:1441–1455
Kao MH, Doupe AJ, Brainard MS (2005) Contributions of an avian basal ganglia–forebrain circuit to real-time modulation of song. Nature 433:638–643
Kramer HG, Lemon RE, Morris MJ (1985) Song switching and agonistic stimulation in the song sparrow (Melospiza melodia)—5 tests. Anim Behav 33:135–149
Krebs J, Ashcroft R, Weber M (1978) Song repertoires and territory defence in the great tit. Nature 271:539–542
Lambrechts M, Dhondt AA (1988) The anti-exhaustion hypothesis: a new hypothesis to explain song performance and song switching in the great tit. Anim Behav 36:327–334
Leblois A, Wendel BJ, Perkel DJ (2010) Striatal dopamine modulates basal ganglia output and regulates social context-dependent behavioral variability through D1 receptors. J Neurosci 30:5730–5743
Linossier J, Rybak F, Aubin T, Geberzahn N (2013) Flight phases in the song of skylarks: impact on acoustic parameters and coding strategy. PLoS ONE: e72768. doi:10.1371/journal.pone.0072768
Mennill DJ, Ratcliffe LM, Boag PT (2002) Female eavesdropping on male song contests in songbirds. Science 296:873
Naguib M, Mennill DJ (2010) The signal value of birdsong: empirical evidence suggests song overlapping is a signal. Anim Behav 80:e11–e15
Nelson DA, Croner LJ (1991) Song categories and their functions in the field sparrow (Spizella pusilla). Auk 108:42–52
Ölveczky BP, Andalman AS, Fee MS (2005) Vocal experimentation in the juvenile songbird requires a basal ganglia circuit. PLoS Biol 3:e153
Otter KA, Ratcli L, Njegovan M, Fotheringham J (2002) Importance of frequency and temporal song matching in black-capped chickadees: evidence from interactive playback. Ethology 108:181–191
Owings DH, Morton ES (1998) Animal vocal communication: a new approach. Cambridge University Press, Cambridge
Patel R, Mulder RA, Cardoso GC (2010) What makes vocalisation frequency an unreliable signal of body size in birds? A study on black swans. Ethology 116:554–563
Podos J, Lahti D, Moseley D (2009) Vocal performance and sensorimotor learning in songbirds. Adv Stud Behav 40:159–195
Pinheiro J, Bates D, DebRoy S, Sarkar D, R Core Team (2009) nlme: linear and nonlinear mixed effects models. R package version 3.1-96. Available at http://cran.r-project.org/web/packages/nlme/
Price JJ, Earnshaw SM, Webster MS (2006) Montezuma oropendolas modify a component of song constrained by body size during vocal contests. Anim Behav 71:799–807
Price JJ, Yuan D (2011) Song-type sharing and matching in a bird with very large song repertoires, the tropical mockingbird. Behaviour 148:673–689
Reid J, Arcese P, Cassidy AEV, Marr A, Smith JM, Keller L (2005) Hamilton and Zuk meet heterozygosity? Song repertoire size indicates inbreeding and immunity in song sparrows (Melospiza melodia). Proc R Soc Lond B 272:481–487
Ritschard M, Riebel K, Brumm H (2010) Female zebra finches prefer high-amplitude song. Anim Behav 79:877–883
Rivera-Gutierrez HF, Pinxten R, Eens M (2010) Multiple signals for multiple messages: great tit, Parus major, song signals age and survival. Anim Behav 80:451–459
Rivera-Gutierrez HF, Pinxten R, Eens M (2011) Songs differing in consistency elicit differential aggressive response in territorial birds. Bio Lett 7:339–342
Rogers AC, Mulder RA, Langmore NE (2006) Duet duels: sex differences in song matching in duetting eastern whipbirds. Anim Behav 72:53–61
Sakata JT, Hampton CM, Brainard MS (2008) Social modulation of sequence and syllable variability in adult birdsong. J Neurophysiol 99:1700–1711
Sakata JT, Vehrencamp SL (2012) Integrating perspectives on vocal performance and consistency. J Exp Biol 215:201–209
Searcy WA, Beecher MD (2009) Song as an aggressive signal in songbirds. Anim Behav 78:1281–1292
Searcy WA, Beecher MD (2011) Continued scepticism that song overlapping is a signal. Anim Behav 81:e1–e4
Schmidt R, Amrhein V, Kunc HP, Naguib M (2007) The day after: effects of vocal interactions on territory defence in nightingales. J Anim Ecol 76:168–173
Sossinka R, Böhner J (1980) Song types in the zebra finch Poephila futtata castanotis. Z Tierpsychol 53:123–132
Spencer KA, Buchanan KL, Goldsmith AR, Catchpole CK (2004) Developmental stress, social rank and song complexity in the European starling (Sturnus vulgaris). Proc R Soc Lond B 271:S121–S123
Staicer CA (1996) Acoustic features of song categories of the Adelaide’s warbler (Dendroica adelaidae). Auk 113:771–783
Stoddard PS, Beecher M, Campbell SE, Horning CL (1992) Song-type matching in the song sparrow. Can J Zool 70:1440–1444
Suthers RA, Zollinger SA (2008) From brain to song: the vocal organ and vocal tract. In: Zeigler HP, Marler P (eds) Neuroscience of birdsong. Cambridge University Press, Cambridge, pp 78–98
Teramitsu I, White SA (2006) FoxP2 regulation during undirected singing in adult songbirds. J Neurosci 26:7390–7394
Todt D, Naguib M (2000) Vocal interactions in birds: the use of song as a model in communication. Adv Stud Behav 29:247–296
Trillo PA, Vehrencamp SL (2005) Song types and their structural features are associated with specific contexts in the banded wren. Anim Behav 70:921–935
Tumer EC, Brainard MS (2007) Performance variability enables adaptive plasticity of “crystallized” adult birdsong. Nature 450:1240–1244
Van Staaden MJ, Searcy WA, Hanlon RT (2011) Signaling aggression. In: Huber R, Bannasch DL, Brennan P (eds) Advances in genetics, 1st edn. Elsevier Inc., Burlington, pp 23–49
Vehrencamp SL (2000) Handicap, index, and conventional signal elements of bird song. In: Espmark Y, Amundsen T, Rosenqvist G (eds) Animal signals: signaling and signal design in animal communication. Tapir Acad, Trondheim, pp 277–300
Vehrencamp SL, Hall ML, Bohman ER, Depeine CD, Dalziell AH (2007) Song matching, overlapping, and switching in the banded wren: the sender’s perspective. Behav Ecol 18:849–859
Vehrencamp SL, Yantachka J, Hall ML, de Kort SR (2013) Trill performance components vary with age, season, and motivation in the banded wren. Behav Ecol Sociobiol 67:409–419
Wilson DR, Mennill DJ (2011) Duty cycle, not signal structure, explains conspecific and heterospecific responses to the calls of black-capped chickadees (Poecile atricapillus). Behav Ecol 22:784–790
Woolley SC, Doupe AJ (2008) Social context-induced song variation affects female behavior and gene expression. PLoS Biol 6:e62
Acknowledgements
Many thanks to Juliette Linossier for help with the fieldwork and to the farmers for allowing us to work on their land. François Chiron, Fabien Martayan, and Dieter Schmidl kindly helped us in trying to catch the skylarks. We thank Hélène Courvoisier and Fanny Rybak for discussions. Hélène Courvoisier, Henrik Brumm, and two anonymous reviewers deserve thanks for constructive comments on an earlier version of this paper. This work was supported by a grant of the European Research Network in Neurosciences of the National Centre for Scientific Research (CNRS), France and the Max Planck Society (MPG), Germany (GDRE CNRS-MPG Neuroscience grant) to NG.
Ethical standards
All work conforms to the ABS/ASAB guidelines for the treatment of animals in behavioral research and teaching, and the experiments comply with the current laws of the country in which they were performed.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by H. Brumm
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Geberzahn, N., Aubin, T. How a songbird with a continuous singing style modulates its song when territorially challenged. Behav Ecol Sociobiol 68, 1–12 (2014). https://doi.org/10.1007/s00265-013-1616-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00265-013-1616-4