
Abstract
This paper presents a fast and reliable method for moving object detection with moving cameras (including pan–tilt–zoom and hand-held cameras). Instead of building large panoramic background model as conventional approaches, we construct a small-size background model, whose size is the same as input frame, to decrease computation time and memory storage without loss of detection performance. The small-size background model is built by the proposed single spatio-temporal distributed Gaussian model and this can solve false detection results arising from registration error and background adaptation problem in moving background. More than the proposed background model based on spatial and temporal information, several pre- and post-processing methods are adopted and organized systematically to enhance the detection performances. We evaluate the proposed method with several video sequences under difficult conditions, such as illumination change, large zoom variation, and fast camera movement, and present outperforming detection results of our algorithm with fast computation time.
Similar content being viewed by others


1 Introduction
In these days, monitoring of public and private spaces is required because of the steady increase in crimes and safety issues [17]. As a result, large numbers of camera are deployed in various sites, such as airports, infrastructures, hospitals, and homes and trained people are watching real-time videos through closed-circuit TV (CCTV) system to find any interesting things. However, humans are not capable of watching many cameras simultaneously, and this results in ineffective/failed surveillance scenarios. For this reason, automated visual surveillance system is widely researched and actually implemented in various areas from the perspective that vision-based security systems are easy to set up, inexpensive, and non-obtrusive [20].
Automated visual surveillance system generally starts with detection of moving objects from the scene with the assumption that nothing might happen in areas without any motion. The detected moving objects might be turned over to the tracking process as initial positions [25] or used as regions to be classified in recognition. Moreover, moving object detection itself can alert interesting areas where it is required to be focused on (intrusion, line cross, etc.). Extraction of moving objects is an important and fundamental research topic of surveillance system in these senses [12].
Among traditionally proposed algorithms to extract moving objects, the background subtraction technique is one of the most successful approaches in this area [7, 11, 21–23, 27]. These methods build statistical background model and extract moving objects by finding regions which do not have similar characteristics to the background model. However, they have limitation that they are only applicable with the stationary cameras: the cameras should not move (even mechanical vibrations can make detection errors) and their fields of view are fixed, which lead to increasing number of required cameras to cover large areas. Detection of moving objects with moving cameras (including pan–tilt–zoom and hand-held cameras) has been researched to overcome this limitation of installment and inefficiency.
The most typical method for detecting moving objects with non-stationary cameras is the extension of background subtraction method [4, 6, 8–10, 14, 18, 19]. In these methods, panoramic background models are constructed by applying various image registration techniques [1–3, 13] to input frames and the position of current frame in panoramas is found by image matching algorithms. Then, moving objects are segmented in a similar way to the fixed camera case. Cucchiara et al. [6] and Robinault et al. [19] estimated camera motion matrix by comparing input frame to background mosaic and did foreground segmentation. They used different type of motion model, but both of them do not consider image registration error by parallax effect. Kang et al. [10] built background mosaic considering internal parameters of cameras. However, camera internal parameters are not always available and possible registration errors are still not considered in this method. To solve the problem of registration errors and segment moving object robustly, Bhat et al. [4] used cylindrical mosaics and Ren et al. [18] proposed spatial distribution of Gaussian. Hayman et al. [9] considered one pixel as spatial mixture of random processes, sum of signal and noise, to solve possible registration errors. Mittal [14] and Guillot et al. [8] improved adaptability of background mosaic by modifying background update and using key point matching method. These algorithms commonly require a panoramic background mosaic before extracting moving objects. However, mosaic-based approaches cannot avoid several limitations. The underlying assumptions for using panorama include sufficiently accurate motion model, accurately estimated parameters, and distortion-free lenses [18]. Moreover, they suffer from several difficulties including background adaptation, stitching error accumulation, slow initialization, and large computation memory and time problems. These problems are illustrated in Fig. 1.

Limitations of mosaic-based approaches. a Finding the accurate position of current frame in panorama. b Background adaptation. If camera stays long in red circled regions, then background model in blue circled regions is not updated frequently and brings weak performances, especially in illumination change. c Stitching errors. The edges in panorama image are vague by accumulated stitching errors (colour figure online)
The second method to detect moving objects with moving camera is optical flow [24, 28]. They assume that the motions of backgrounds and foreground objects are divided by different optical flows and reduce moving object detection to motion segmentation problem. This scheme has been adopted in the following approaches. Zhang et al. [28] used focus of expansion and its residual map to segment moving objects in the scene. Thakoor et al. [24] used dense optical flow and detected moving objects by comparing it to the estimated camera motion. However, in the perspective of detecting moving objects, dense optical flow requires heavy computation and camera motions should be relatively small.
In this paper, a robust and novel moving object detection algorithm is proposed to solve the existing problems in traditional approaches. The proposed method detects moving objects with a moving camera robustly without panoramic background model. This allows real-time and online computation, and problems of panoramic mosaic (stitching error accumulation and background model adaptation) can also be avoided. Background model is updated with spatial and temporal information, and several pre- and post-processing methods are effectively combined to improve the performance of the proposed algorithm.
2 Overall flow of algorithm
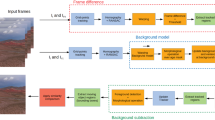
The framework of the proposed method is illustrated in Fig. 2. The highlight of this paper is the part of spatio-temporal Gaussian model update scheme for adaptation of non-stationary background due to moving camera. In addition, several techniques including a proportional-integral-derivative (PID) control are utilized systematically as shown in Fig. 2. Because camera induces its own motion, the estimation of camera motion, which is the same as background motion, is required to prevent background regions from falsely being detected as foregrounds. In the proposed method, Lucas Kanade Tracking method (LKT) [13] is adopted to estimate the camera motion between current frame and background model. After the motion of camera is estimated, difference of Gaussian filter (DoG) sharpens both current frame and background model, and the calculated camera motion warps the filtered background model to the filtered current frame. This warping divides the current input frame into two regions: overlapped region and newly covered region. Moving objects are extracted only in the overlapped region and newly covered regions are directly modeled as a part of background. The main difference between traditional panorama-based approaches and our algorithm is that those approaches actually stitch several frames to build large panoramic background, while we simply use image registration method to find overlapped region and newly covered region in the current frame. The extraction of moving objects is processed by background subtraction based on pixel-wise spatio-temporal distribution of Gaussian. In Fig. 2, temporary foreground mask map is illustrated under moving object detection (MOD) part. Here, white region is extracted foregrounds and black region is background part. The detection results shown here, however, still have silhouette distortion problem. This can be caused by two reasons: foreground colors similar to background regions and label (foreground or background) decision based on local neighborhoods. Hence, the foreground segmentation result is further refined by PID control-based smoothing/estimation process and probabilistic morphology and, finally, the regions labeled as background are used to update the current background model in the spatio-temporal sense. The details of the methods are explained in each section below.

System overview diagram of the proposed algorithm: each part is described detail in labeled sections
3 Preprocessing
In the proposed method, 2D DoG filter [26], a well-known image-sharpening algorithm is applied to captured frames before main processes. This filter strengthens edges on image and makes them more noticeable. The effect of this filter and its shape is shown in Fig. 3, and the general equation for 1D DoG filter is
where \(x\) is pixel’s intensity value. For each pixel, the difference of its values in two Gaussian distributions with different standard deviations increases the visibility of edges. Figure 3a shows a walking person in the field, but it is hard to recognize because of low-contrast video quality. However, in Fig. 3b, we can see that edges of person are strengthened after applying DoG filter. By building background model with filtered image, we get more discriminative background models even for the low-contrast video. Every step in the proposed method is processed with DoG filtered image except calculating motion of camera between current frame and background model in image registration part. Finding camera motion between consecutive frames is preferred to be done in gray channel by experiments.

DoG filter and its example. a Original image, b filtered image, c the shape of 1D DoG filter. 2D filter is applied in proposed algorithm. Edges are strengthened by DoG filter, and it makes the object more noticeable than it is in the low-contrast original image
Since DoG filter strengthens the edges on current input and background image, it makes detection of small moving foregrounds even in low-contrast scenes as the video seq. 4 and the video seq. 8 in Fig. 4 possible. However, it may cause false alarms near edges and misclassify background pixels as foreground ones as seen in Fig. 4, where a portion of background is labeled as foreground. The performance gain and loss by DoG filter on several test clips is given in Table 1. By comparing precision and recall values in Table 1, we can see that precision values is almost same in both cases because the number of true positive and false positive are decreased together by removing DoG filter in our process. However, the recall values are decreased significantly due to a large number of false-negative samples, arising from turning off the DoG filter. This high drop of recall values can be seen especially in videos with low-contrast/small objects. More than the precision and the recall values, the shapes of foregrounds are enhanced by DoG filter in many cases as shown in Fig. 4.

The effect of DoG filter. The first row original image, the second row the results with DoG filter, and the third row the results without DoG filter. DoG filter can detect small object even in low-contrast scene. However, it can bring small false alarms as the video seq. 1 (misclassified pixels near edges)
4 Warping and background modeling
4.1 Image warping
To detect moving objects with non-stationary camera, most approaches build panoramic background model, find areas where current frame is corresponding to, and, then, compare current frame to corresponding background model. However, there are several drawbacks in this type of approaches. Without information of intrinsic and extrinsic camera parameters, building large panorama suffers from accumulated stitching errors and it is hard to find the accurate position of current frame in the panorama. Moreover, some part of panorama is not updated frequently because of obsolete background information, which leads to incorrect moving objects detection. Finally, the system takes initialization time to build panorama by sweeping all possible ranges of camera motions, and the system itself is very heavy. To avoid these problems, the proposed method does not make large panoramic background model, but constructs only a small background model corresponding to the current frame in an on-line manner.
The first task for moving objects detection with the small size background model is to find overlapped regions between background model and current frame. The first task of conventional approaches was to find corresponding part to a current input image in the large panoramic background. In the proposed method, not all pixels are overlapped between background model and current frame after camera motion because background size is the same as camera input. For this reason, a task for dividing current frame into overlapped regions and newly covered region is required and separate procedures for the two different types of regions should be implemented. In our method, the overlapped region between current frame and background model is chosen by simple feature tracking method; extracting and tracking features by LKT [13]. If we define \(X_i\) as \(i\)th extracted feature on background model and \(X_{i}^{\prime }\) as \(i\)th corresponding tracked feature on current frame, then, we can solve the below equation for transform matrix \(H\) between background model and current frame as,
where \(x_i, y_i, x_i^{\prime }\), and \(y_i^{\prime }\) are actual positions of feature points. The transform matrix \(H\) is a \(3 \times 3\) matrix and it describes the relationship between background model and current frame in least square sense. By multiplying estimated transform model \(H\) on background model, we can warp background model with respect to current frame and find overlapped region between them as in Fig. 5. The remaining region defined as newly covered region of current frame (black area in Fig. 5) is firstly labeled as background regions.

LKT and image warping. Homographic relationship between background model and current frame is found via LKT, and image warping divides current frame into overlapped or newly covered regions
In the proposed method, the estimation of transform model \(H\) is processed globally; all feature points are used to estimate single \(H\) for the whole image plane. Conventional methods using global estimation method have suffered from estimation error and its accumulation. In most cases, the estimation error mainly arises from inexact matches of some pixels from least squares solution \(H\) and subpixel accuracy. However, in our method, this estimation error can be ignored because our method suppresses the influence of the inexact matches, which is usually within few pixels, by considering local neighborhood of pixels in background modeling and label decision of pixels. Moreover, the accumulation of error does not happen in our method that does not stitch images to build large panoramic background model, which is made by repeated multiplication of previous \(H\)s and comparison between transformed panoramic model and current frame.
4.2 Foreground/background decision
After image warping step, moving objects are extracted from the overlapped regions in current frame. For fixed camera case, this step is quite reliable even when using conventional approaches. However, extracting moving objects with moving camera has to deal with several problems. The first problem is image registration error. It is well known that zero registration error is not possible because of many factors, such as parallax effect and sub-pixel accuracy. This registration error leads to false labeling of motionless pixels as foregrounds. In the proposed method, these false alarms are removed by considering neighbor pixels in the decision of the labels (foreground or background) of a pixel as follows. For a pixel \(X_\mathrm{c}\) in current frame, candidate anchor point \(X_\mathrm{b}\) in background model is computed by
where \(H\) is the transform matrix between current frame and background model, calculated in the Sect. 4.1. Then, the label of the pixel \(X_\mathrm{c}\) is determined by comparing \(X_\mathrm{c}\) to the neighbor pixels of \(X_\mathrm{b},\,N(X_\mathrm{b})\), as
where \({\sigma }^2(\cdot )\) and \(\mu (\cdot )\) are the standard deviation and the mean value in background model, and \(I(\cdot )\) stands for the intensity value in current frame. \(\hat{X}_\mathrm{b}\), which is a point in background model, is actual corresponding pixel of \(X_\mathrm{c}\). Large difference between \(\hat{X}_\mathrm{b}\) and \(X_\mathrm{b}\) means that transform matrix \(H\) is not precise and registration error occurs in image warping step. \(T_{c}\) is a threshold to decide the labels of pixels and it is set to 2.5 for all experiments in the proposed method. The illustration of decision concept by considering neighbor pixels is shown in Fig. 6, and the difference between \(X_\mathrm{b}\) and \(\hat{X}_\mathrm{b}\) (black arrow in right-most image) occurred by registration error.

Decision by considering neighboring pixels. \(X_\mathrm{c}\) and \(X_\mathrm{b}\) is a feature point in current frame and an matched anchor point in background model, respectively. The pixels in shaded circle are neighbor pixels of \(X_\mathrm{b}\), and \(\hat{X}_\mathrm{b}\) is actual corresponding point
This soft comparison method deals with general registration errors and significantly reduces the number of false alarms. Figure 7 is the result of detecting moving objects with/without considering neighbor pixels. It is easy to see that the number of false alarms is crucially reduced by using neighbor pixels concept. However, considering pixels within local area has a drawback. The silhouettes of moving objects might be distorted and their size can be reduced when the detected moving objects have similar color to their neighbor background pixels or objects to detect are small. To handle this problem, we use PID control-based tracking and probabilistic morphology refinement step, which are described in Sect. 5.

The effect of considering neighbor pixels. left column original image, center column moving objects detection without considering neighbor pixels, right column moving object detection with considering neighbor pixels
The second problem is how to deal with newly covered regions. Because panoramic background model is not constructed in our approach, motions of camera cause newly covered region in current frame, which does not have corresponding background model to compare with. For this reason, the pixels in this region are labeled as background directly and are used to update background model. Although foreground objects located in this area might be modeled as background at their first appearances, we experimentally check that they are detected as foreground in a short time because of their different motions to the camera motion.
4.3 Spatio-temporal background modeling
As fixed camera case, the background update stage is required to build adaptive model for illumination changes and view-point changes in detection with moving camera. To represent background model, we modify single Gaussian model, which has one mean and one variance per pixel. Similar strategy to [22], online K-means approximation, is applied, but only background-labeled pixels are used to update background model. The conventional single Gaussian model, however, is not enough to solve accumulated error in image registration when camera itself has motions. To handle this problem, we propose spatio-temporal background modeling method in this paper. By adding spatial and temporal terms to mean and variance update equations, we improve flexibility of background model for registration error and adaptiveness for changing views of cameras. The key concept for temporal term is to use different learning rate depending the age of background. Newly presented background with small age is rapidly updated with large learning rate (the example of age is shown in Fig. 8). For a pixel \(X_\mathrm{c}\) in current frame and its corresponding pixel \(\hat{X}_\mathrm{b}\) in background model, background update equation is
where \({\mu }_{t}(\cdot )\) and \({\sigma }_{t}^2(\cdot )\) are mean and variance in warped background model at time \(t\) described in Sect. 4.1, respectively. The important notation to notice is that \(\hat{X}_\mathrm{b}\), rather than \(X_\mathrm{b}\), is used. This spatial soft decision decreases the number of falsely detected pixels, which are generally caused by registration errors in the range of few pixels. \(Age(X)\) in Eq. (10) is defined as how many frames we have information on certain pixel \(X\) and this is illustrated in Fig. 8. It works as the learning rate in general background modeling method. However, the learning rate in conventional approaches has limitation because it is usually constant for all pixels over entire time range. On the other hand, the proposed learning rate scheme (age) is varying over temporal and spatial domain.

The age values over frames. a The initial age value is set to 1. b After warping, the pixels in overlapped regions between the first and the second frame increases their age values to two. c After warping. The pixels in overlapped regions among first, second and third frame have age value 3. The other regions have corresponding age values according to the number of its matched pixels in temporal domain
In Fig. 8a we can see that the age values are initially set to 1 for entire images. When camera is moved to right direction in the second frame, the overlapped regions are located in the left parts of current frame and right parts are newly covered regions. Then, the age values in overlapped areas are increased and those in the newly covered region are set to one again. The numbers in Fig. 8 are changing age values in consecutive frames. Different ages in pixels adjust adaptiveness of background to current frame, and this makes newly covered region directly modeled as background (\(Age\) and \(\alpha \) are both 1 for newly covered region).
There are several advantages to the proposed spatio-temporal background modeling method. First, modeling itself considers spatial window and increases the effects of consideration of neighbor pixels in decision of the labels of pixels. The background model becomes less accurate without spatial background model update. Second, temporal information, depending on the age in background model, reduces false alarms and increases the adaptiveness of background model. Moreover, dynamic learning rate does not have delay in detecting moving objects, whereas a constant learning rate requires background setup time and causes slow system initialization.
5 Tracking and refinement
5.1 PID smoothing and tracking
As described before, objects detection by considering neighbor pixels might cause holes or distortions in detection masks. In this paper, this problem is solved with aid of object tracking methodology. We track extracted moving objects (maintain their labels) by matching detected blobs between consecutive frames through data association method. Detected blobs in the previous frame and those in the current frame are matched and share their labels considering their mask appearances, positions, and sizes. After labels of objects are decided, their positions and sizes are smoothed. The positions and the sizes of the detected blobs usually have noisy values from drastic changes of shape and size of detected object blobs. In order to visualize the smooth motion of the object and improve the matching performance, it is necessary to filter out noisy observations (positions and sizes) of the objects. In our paper, we propose a filtering scheme mimicking the discrete proportional-integral-derivative (PID) control method [15]. The proposed method is depicted as in Fig. 9 for the case of the center position of an object. The reference input of the control system is given by the current position of the detected blob, \(p_\mathrm{d}(t)\). This implies that the output \(p(t)\) of the PID control system tracks the observation \(p_\mathrm{d}(t)\) smoothly. The control input \(u(t)\) is given by PID control strategy with negative feedback as shown in Eq. (12). Then the smoothed output \(p(t)\) is obtained by

PID tracking control system. The position and size of a certain object is smoothed by PID control method [15]. With information from the detected blob, \(p_\mathrm{d}(t)\), and the previous result, \(p(t-1)\), the position of object \(p(t)\) is determined
where \(K_\mathrm{p}, K_\mathrm{i}\), and \(K_\mathrm{d}\) are PID coefficients, and \(t\) is the frame time index. By the above equations, \(e(t)\) is minimized smoothly over time and we can get smoothed position of the object by using \(p(t)\) instead of \(p_\mathrm{d}(t)\) for the object position at time \(t\). The same scheme is applied for the case of size (width and height) of each object.
After the label of an object is maintained and its expected position and size are determined by PID control method, holes or distortions in detection masks are removed with the following steps. If a detected blob maintains its label more than \(T_p\) number of frames with tracking method, then, the object can be regarded as a solid object, which is not generated by image registration error. In this case, the spatial soft decision is not required to be applied for the object’s expected region in the next frame because the spatial soft decision is designed to suppress image registration error. Without spatial soft decision on the region of the detected blob, the detected blob can have better silhouette (less holes and distortions). Consequently, possible distortions of object silhouette from excessive consideration of neighbor pixels can be reduced through the PID scheme and selective application of the spatial soft decision on the evidence of object labeling. The scheme is illustrated in Fig. 10, and, for the experiments, the PID coefficients \((K_\mathrm{p}, K_\mathrm{i},K_\mathrm{d})\) were set to (0.2, 0.003, 0.03), and the \(T_p\) was 15 in this paper.

PID smoothing and its usage. The spatial soft decision (Sect. 4.2) is not applied to the expected position of the object (red shaded regions in d) in the next frame if the label of the object is maintained for long (colour figure online)
5.2 Probabilistic mask refinement
More than PID tracking method, probabilistic morphology is additionally applied to the extracted moving objects for better silhouettes of objects. When the object has similar color to its background model, detection masks might have holes and it decreases the performance of tracking and recognition processes. For this reason, in conventional approaches, various morphological operations are applied to detected foreground regions. However, simple morphological operation does not recover whole objects, or, sometimes, falsely increases the size of masks and distorts the true shape of the original object. In our paper, we propose probabilistic morphological operation to build better silhouette of moving objects.
When moving objects are extracted as foreground pixels, we can define foreground labeled pixel set in current frame as
and its surrounding candidate set as
where \(L(x)\) is the label of pixel (foreground/background) and \(dist(x,y)\) is the Euclidean distance between pixel \(x\) and \(y\) in frame domain. In the proposed method, \(T_\mathrm{d}\) is set to 3 and not changed. In Fig. 11b, the pixels in the set \(S_\mathrm{FG}\) are white and the pixels in the set \(S_\mathrm{CA}\) are grey as they are defined by equation (14) and (15). The label of pixels in the set \(S_{CA}\) is currently background, but those pixels are candidates to be transformed as foreground-labeled. While conventional morphology uses detected mask information only, proposed morphology method uses colors for better refinement. In detail, the candidate pixels are transformed to foreground when they have similar color values to the currently detected foreground pixels in neighborhood more than to nearby background pixels. For each pixel \(x_i\) in the set \(S_\mathrm{CA}\), its label \(L(x_i)\) is transformed to foreground with following equation:
where \(I(\cdot )\) is the pixel value in current frame, and \(\mu (\cdot )\) is the mean value in background model. \(FG\) and \(BG\) stands for foreground and background respectively. The transformed pixels (from background to foreground) are grey pixels in Fig. 12c.

The probabilistic morphology: a original frame, b original detection masks (white) and candidate set for probabilistic morphology (grey), (c) final recovered detection result

The effect of probabilistic morphology. Top row shows detection result and bottom row is multiplication of mask to original image. a Results without morphology. b Results of conventional morphology. c Results of probabilistic morphology. Grey colored region is recovered by the proposed method
6 Experimental results
The proposed algorithm is tested on various sequences captured by hand-held, pan–tilt–zoom (PTZ), and unmanned aerial vehicle (UAV) cameras. Each sequence has different number of moving objects, illumination conditions, and heights of cameras. A Core i5 3.3 GHz PC is used to implement the proposed method and it runs 40\(+\) frames per second with \(320\times 240\) resolution images. To show effectiveness of our algorithm, our performance is compared with that of SGM-R (single Gaussian model for background subtraction [16] and image registration for moving camera) method. In SGM-R method, current frame and background model (single Gaussian model based) are registered and moving objects are detected without considering registration errors. Several pre- and post-processings, which are proposed in this paper, are not applied to show the effects of the proposed methods.
The detection performance of the proposed algorithm is measured by two standards, precision and recall. The precision and recall are calculated by
where TP, FP, FN are defined in Table 2. They are computed object-wise in each frame (TP value is increased when actual object is successfully detected in one frame.) and the frame which does not have actual object and detected object is skipped for accurate performance evaluation. “Successfully detected” means more than \(50~\%\) of objects are detected for accurate performance evaluations.
Unlike panoramic background-based methods, our algorithm does not have large background model and decreases computational loads. Moreover, all pixels in background model are updated immediately with current input frame, preventing large illumination gaps between background model and current frame. Spatio-temporal background modeling reduces the number of falsely detected objects significantly in various sequences, and PID control and probabilistic morphology improves the masks of detected objects, which is better for tracking and recognition performances.
6.1 Hand-held camera sequences
Hand-held camera is the most widely used equipment to capture various scenes these days; Camcorders and mobile phones are well-known hand-held cameras. The moving objects detection results from hand-held camera sequences are illustrated in Fig. 13. In these sequences, cameras are following walking persons and changing their views over time while the cameras themselves change their positions by motions of camera operators. They are also suffered from unstable camera motion because they are not hinged to fixed place as PTZ cameras. Moreover, as we can see in the \(\#67\) frame in the second sequence, some frames have color noises (green noise). Even though there are many lines from cars, trees, and textures of sidewalks which can be detected by small registration errors, our proposed method detects moving objects well without falsely detected objects. On the other hand, SGM-R brings many false alarms especially in highly textured areas (trees)and lines of cars as we can see in the middle rows of each sequences. The precision and recall values of proposed algorithm and SGM-R for these sequences are in the Table 3.

The moving objects detection results from hand-held camera sequences. For each sequence, top rows are original images, mid rows are SGM-R (defined in Sect. 6), bottom rows are detection results, and their corresponding frame numbers
6.2 PTZ camera sequences
While hand-held camera is mainly used by individuals, it is different in the case of surveillance systems. Because surveillance system requires to watch specific regions without any disturbance from outer forces, the mostly used camera type is PTZ-controlled cameras installed on fixed positions, i.e., building walls, poles. These cameras can provide large areas under surveillance system by pan and tilt motion and magnification by zoom motion. Moreover, they can reduce the number of cameras significantly than general fixed cameras. The detection results of PTZ camera sequences are shown in Fig. 14.

The moving objects detection results from PTZ camera sequences. For each sequence, top rows are original images, mid rows are SGM-R (defined in Sect. 6), bottom rows are detection results, and their corresponding frame numbers
The fourth sequence is captured in rural field. Target objects are very small and they are hardly recognized by low-contrast video condition. The camera has only panning motion in this sequence, but moves very fast. Rich textures also make it hard to detect moving objects well in this dataset. Detection results of this sequence, however, show that our algorithm works well in this sequence. Walking humans are extracted clearly without false alarms. As we can see in Fig. 14, SGM-R makes large number of false alarms and it does not detect walking humans because of their small sizes and low-contrast video quality. This results to low precision and low recall values as we can see in Table 4. The fifth video sequence is captured by camera installed on the top of ten-storey building. In this sequence, camera shows large zoom-variation motion and many cars in parking lot might cause false alarms. Under this difficult situation, however, our method detects moving cars and humans under different viewpoints. If we see frame \(\#1847\) and \(\#1869\), two cars waiting to turn left are not detected. This is because they are not moving since they have been captured by camera. Lastly, in the sixth sequence, the moving object, a motor cycle, is large and moves fast, which leads to large camera motion per frame. As a result, detection silhouette by proposed method is quite distorted, but it still shows better detection performance than SGM-R. The precision and recall values of proposed algorithm and SGM-R for these sequences are in the Table 4.
6.3 UAV camera sequences
The UAV is an aircraft which can be controlled by remote control without pilot on board and its usage is widely increasing for military applications. UAV camera sequences have characteristics that moving objects are small but they have advantages than other cameras in showing objects clearly with less occlusion among objects. Also, the camera motion per frame is generally slow because the height of camera is very high. The dataset used for experiments are from PETS 2005 dataset by [5]. The detection results from UAV camera sequences are shown in Fig. 15 and their precision and recall are shown in Table 5.

The moving objects detection results from UAV camera sequences. For each sequence, top rows are original images, mid rows are SGM-R (defined in Sect. 6), bottom rows are detection results, and their corresponding frame numbers
In the seventh and eighth sequences, several cars are moving in large area and their size is very small from high altitude of cameras. Here, the shadow-removal algorithm is not adopted in the proposed method, so the detected area sizes become larger than actual objects’ sizes. Because of large degree of freedom in UAV motions (especially motion in depth), registration errors are larger than general sequences. As it is shown in Fig. 15, SGM-R cannot handle registration errors, so it brings many false alarms. However, even with large variation of viewpoints as frame changes, our algorithm shows robust performance as we can see in Fig. 15. The last video captured the scene of moving cars in forests. As in other test videos, moving cars are extracted successfully and false alarms in moving objects detection by plentiful textures of trees is suppressed by the proposed algorithm.
7 Conclusions
In this paper, we present a novel detection algorithm to extract moving objects in the sequences from moving cameras. In the proposed algorithm, spatio-temporal background modeling method has been developed to detect moving objects without building large panoramic background model. In addition, several techniques and practical ideas have been appropriately combined to enhance the detection performance. This solves the limitations of traditional panorama-based approaches, such as error accumulation, background adaptation, slow initialization, and large computation problem. Robust detection performance of the proposed algorithm can improve subsequent parts in wide-area surveillance system, such as object tracking and object recognition. The experiments show the reliable performance of our algorithm in various sequences. The proposed algorithm has been commercialized successfully and systematical combination of multiple techniques in this paper provides a successful result in actual applications.
References
Azzari, P., Bevilacqua, A.: Joint spatial and tonal mosaic alignment for motion detection with ptz camera. In: Proceedings of ICIAR, pp. 764–775 (2006)
Azzari, P., Di Stefano, L., Bevilacqua, A.: An effective real-time mosaicing algorithm apt to detect motion through background subtraction using a ptz camera. In: Advanced Video and Signal Based Surveillance, 2005. AVSS 2005. IEEE Conference on. pp. 511–516 (2005)
Bay, H., Ess, A., Tuytelaars, T., Gool, L.V.: Surf: speeded up robust features. Comput. Vision Image Understand. 110(3), 346–359 (2008)
Bhat, K., Saptharishi, M., Khosla, P.: Motion detection and segmentation using image mosaics. In: Multimedia and Expo, 2000. ICME 2000. 2000 IEEE International Conference on, vol. 3, pp. 1577–1580 (2000)
Collins, R., Zhou, X., Teh, S.: An open source tracking testbed and evaluation web site. In: Proceedings of IEEE PETS Workshop (2005)
Cucchiara, R., Prati, A., Vezzani, R.: Advanced video surveillance with pan tilt zoom cameras. In: Proceedings of Workshop on Visual Surveillance (VS) at ECCV (2006)
Elgammal, A., Duraiswami, R., Harwood, D., Davis, L.: Background and foreground modeling using nonparametric kernel density estimation for visual surveillance. Proc. IEEE 90(7), 1151–1163 (2002)
Guillot, C., Taron, M., Sayd, P., Pham, Q.C., Tilmant, C., Lavest, J.M.: Background subtraction adapted to ptz cameras by keypoint density estimation. In: BMVC, vol. 34, pp. 1–10 (2010)
Hayman, E., Eklundh, J.O.: Statistical background subtraction for a mobile observer. In: Computer Vision, 2003. Proceedings. Ninth IEEE International Conference on, vol. 1. pp. 67–74 (2003)
Kang, S., Paik, J., Kosehan, A., Abidi, B., Abidi, M.A.: Real-time video tracking using ptz cameras. In: Proceedings of the SPIE 6th International conference on Quality Control by Artificial Vision 5132. pp. 103–111 (2003)
Ko, T., Soatto, S., Estrin, D.: Warping background subtraction. Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on pp. 1331–1338 (2010)
Li, R., Yu, S., Yang, X.: Efficient spatio-temporal segmentation for extracting moving objects in video sequences. IEEE Trans. Consumer Electron. 53(3), 1161–1167 (2007)
Lucas, B.D., Kanade, T.: An iterative image registration technique with an application to stereo vision. In: International Joint Conference on, Artificial Intelligence. pp. 674–679 (1981)
Mittal, A., Huttenlocher, D.: Scene modeling for wide area surveillance and image synthesis. In: Computer Vision and Pattern Recognition, 2000. Proceedings. IEEE Conference on, vol. 2, pp. 160–167 (2000)
Nise, N.: Control Systems Engineering. The Benjamin/Cummings Publishing Company Inc, Menlo Park (1995)
Olson, T., Brill, F.: Moving object detection and event recognition algorithms for smart cameras. In: Proceedings DARPA Image Understanding, Workshop, pp. 159–175 (1997)
Remagnino, P., Velastin, S., Foresti, G., Trivedi, M.: Novel concepts and challenges for the next generation of video surveillance systems. Machine Vision Appl. 18(3–4), 135–137 (2007)
Ren, Y., Chua, C.S., Ho, Y.K.: Motion detection with non-stationary background. In: Proceedings of 11th International Conference on Image Analysis and Processing, pp. 78–83 (2001)
Robinault, L., Bres, S., Miguet, S.: Real time foreground object detection using ptz camera. In: VISSAPP (1)’09, pp. 609–614 (2009)
See, J., Sze-Wei Lee, S.W.: An integrated vision-based architecture for home security system. IEEE Trans. Consumer Electron 53(2), 489–498 (2007)
Sheikh, Y., Shah, M.: Bayesian modeling of dynamic scenes for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 27(11), 1778–1792 (2005)
Stauffer, C., Grimson, W.: Adaptive background mixture models for real-time tracking. In: IEEE Computer Society Conference on Computer Vision and Pattern Recognition, vol. 2, pp. 246–252 (1999)
Tavakkoli, A., Nicolescu, M., Bebis, G., Nicolescu, M.: Non-parametric statistical background modeling for efficient foreground region detection. Mach Vision Appl. 20, 395–409 (2009)
Thakoor, N., Gao, J., Chen, H.: Automatic object detection in video sequences with camera in motion. In: Proceedings of Advanced Concepts for Intelligent Vision Systems (2004)
Wang, J., Bebis, G., Nicolescu, M., Nicolescu, M., Miller, R.: Improving target detection by coupling it with tracking. Mach. Vision Appl. 20, 205–223 (2009)
Wilson, H.R., Giese, S.C.: Threshold visibility of frequency gradient patterns. Vision Res. 17(10), 1177–1190 (1977)
Zhang, R., Zhang, S., Yu, S.: Moving objects detection method based on brightness distortion and chromaticity distortion. IEEE Trans. Consumer Electron. 53(3), 1177–1185 (2007)
Zhang, Y., Kiselewich, S., Bauson, W., Hammoud, R.: Robust moving object detection at distance in the visible spectrum and beyond using a moving camera. In: Conference on Computer Vision and Pattern Recognition Workshop, 2006. CVPRW ’06, pp. 131 (2006)
Acknowledgments
This research is sponsored by Samsung Techwin Co., Ltd. and SNU Brain Korea 21 Information Technology program.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Kim, S.W., Yun, K., Yi, K.M. et al. Detection of moving objects with a moving camera using non-panoramic background model. Machine Vision and Applications 24, 1015–1028 (2013). https://doi.org/10.1007/s00138-012-0448-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00138-012-0448-y