
Abstract
The objective of this paper is to quantify the use of past seismicity to forecast the locations of future large earthquakes and introduce optimization methods for the model parameters. To achieve this the binary forecast approach is used where the surface of the Earth is divided into l° × l° cells. The cumulative Benioff strain of m ≥ m c earthquakes that occurred during the training period, ΔT tr, is used to retrospectively forecast the locations of large target earthquakes with magnitudes ≥m T during the forecast period, ΔT for. The success of a forecast is measured in terms of hit rates (fraction of earthquakes forecast) and false alarm rates (fraction of alarms that do not forecast earthquakes). This binary forecast approach is quantified using a receiver operating characteristic diagram and an error diagram. An optimal forecast can be obtained by taking the maximum value of Pierce’s skill score.
Similar content being viewed by others


1 Introduction
Forecasts of the locations of future major earthquakes play an important role in earthquake preparedness and determining earthquake insurance costs. Many such forecasts have been carried out, one example is the National Seismic Hazard Map for the United States (Frankel et al., 1996). This is a probabilistic estimate of the ground-shaking risk. A major input into this assessment is the observed rate of occurrence of past earthquakes. Kossobokov et al. (2000) utilized the rates of occurrence of m ≥ 4.0 earthquakes globally to forecast the expected rates of occurrence of larger earthquakes. Recently, the Regional Earthquake Likelihood Models (RELM) forecasts were published (Field, 2007). This represents the first-generation of forecasts based on a variety of approaches and methods. It also introduces a testing methodology to verify and compare these forecasts (Schorlemmer et al., 2007).
In this paper we have presented a method to construct a binary forecast of where future large earthquakes are likely to occur globally. We divide the Earth’s surface into l° × l° cells in order to construct the forecast and evaluate its success. The input for our forecast is a relative intensity (RI) map of m ≥ m c earthquakes that occur in the cells during a specified training period, ΔT tr. As a measure of RI we have utilized the cumulative Benioff strain in each cell during that period. The cumulative Benioff strain has been computed using the data from the CMT (Harvard) catalog (http://www.globalcmt.org). This catalog is complete from 1/1/1976 to 1/1/2008 to magnitude m c = 5.5. The RI map is then converted to a binary forecast by introducing a threshold cumulative Benioff strain. Cells with Benioff strains greater than this threshold constitute alarm cells where future earthquakes are forecast to occur. A high threshold reduces the forecast areas but leads to more events that are not predicted. A low threshold reduces the failures to predict but increases the false alarms. We have introduced a standard optimization procedure for binary forecasts in order to select the optimal threshold.
In order to test our method we have performed a retrospective analysis. To define training and forecasting time periods we subdivide the catalog using a base year T b , a forecasting year T f , and an end year T e . We have utilized seismicity during the training period from T b = 1/1/1976 to T f = 1/1/2004 (ΔT tr ≡ T f − T b = 28 years) to make a forecast for the locations of future target earthquakes of a specified magnitude, m T ≥ 7.2. The locations of earthquakes during the forecasting period T f = 1/1/2004 to T e = 1/1/2008 (ΔT for ≡ T e − T f = 4 years) are then used to test the validity of the method. The success of the binary forecast has been evaluated using techniques developed in the atmospheric sciences (Mason, 2003). The evaluation is in terms of a hit rate (fraction of events that are successfully forecast) versus a false alarm rate (the fraction of forecast cells in which earthquakes do not occur). Both hit rate and false alarm rate are functions of the tuning parameter (in our case the threshold Benioff strain). Their parametric plot produces a receiver operating characteristic (ROC) diagram. This approach has been used by Holliday et al. (2005) to test the success of forecasting algorithms in California. Similar analysis was also applied to the verification of the intermediate-term earthquake prediction algorithm M 8 by Minster and Williams (1999).
We have also quantified our approach using the variation of the error diagram introduced by Molchan (1991), Molchan and Keilis-Borok (2008). The comparison of the error diagram approach and the maximum likelihood method for evaluation of earthquake forecasting methods was given by Kagan (2007). The connection between the entropy score and log-likelihood estimates with applications to several seismicity models is given in Harte and Vere-Jones (2005). The analysis of the error diagram approach applied to California seismicity was performed by Zechar and Jordan (2008). Kossobokov and Shebalin (2003) and Zaliapin et al. (2003) have applied the error diagram to test a number of earthquake predictions algorithms.
2 Relative Intensity of Global Seismicity
The proposed analysis is based on the RI of past seismicity where large target earthquakes with magnitudes greater than m T ≥ 7.2 are forecasted. The moment magnitude m of earthquakes has been calculated from the scalar moment according to the formula \(m={\frac{2}{3}}\hbox{log}_{10}(M_0)-10.7,\) where M 0 is a scalar moment reported in the CMT catalog. The grid size plays an important role in this analysis. In this study the Earth’s surface has been subdivided into 2° × 2° cells
As a measure of the RI the cumulative Benioff strain has been computed in each cell for a specified training time period ΔT tr. The cumulative Benioff strain B up to time t is defined as
where E (i) xy is the seismic energy release in the ith earthquake and N xy (t) is the number of earthquakes considered up to time t, and (xy) is the coordinates of a given cell. The seismic energy E is related to the seismic moment M 0 as E ∼ M 0.
The normalized RI in a cell is given by B xy /B max where B xy is the cumulative Benioff strain in the active cell under consideration and B max is the Benioff strain for the most active cell. The cumulative Benioff strain is also normalized by the actual area of the corresponding cell measured in square kilometers.
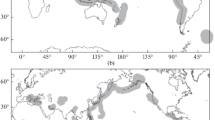
In order to construct a binary map a decision threshold of RI is applied. All cells with intensities greater than the specified threshold are alarm cells and constitute the binary forecast. To illustrate our approach we consider a specific example. The analysis is based on the seismicity during a training period from T b = 1/1/1976 to T f = 1/1/2004 (ΔT tr = 28 years). The threshold for the normalized Benioff strain B/B max = 0.0417 is used. The reason for selecting this particular threshold will be discussed in the next section. The alarm cells in which earthquakes are forecast to occur are illustrated in Fig. 1. During the entire time period (T b = 1/1/1976 to T e = 1/1/2008) there were 1,503 active cells (cells with at least one earthquake with magnitudes m ≥ 5.5) out of total of 16,200 cells. Note that the area of the active cells depends on the chosen cell size and their geographic location. Also shown in Fig. 1 are the 34 earthquakes with m T ≥ 7.2 that occurred during the forecast period T f = 1/1/2004 to T e = 1/1/2008 (ΔT for = 4 years). The next step is to quantify the success of our binary forecast of the locations of these earthquakes.

Spatial distribution of 2° × 2° alarm cells. Earthquakes with magnitudes greater than m ≥ 5.5 are considered during the time period 1/1/1976 until 1/1/2004 (ΔT tr = 28 years). Also shown as squares are the locations of earthquakes with m T ≥ 7.2 that occurred during the forecast period T f = 1/1/2004 to T e = 1/1/2008 (ΔT for = 4 years). The threshold value corresponds to the maximum Pierce’s skill score given in Fig. 3a
3 Forecast Verification
The success of a forecast is based on maximizing the fraction of the earthquakes that occur in alarm cells and minimizing the fraction of the alarm cells in which no earthquake occurs. This analysis is carried out by utilizing a contingency table approach. Each cell in which an earthquake is forecast to occur constitutes an alarm cell. Earthquakes occur in some of these alarm cells but also in cells where alarms have not been issued. As a result of this test each cell falls in one of four categories: a, alarm and earthquake (successful forecast); b, alarm but not earthquake (false alarm); c, no alarm but an earthquake (failure to predict); d, no alarm and no earthquake (successful forecast of non-occurrence). In addition a is the number of target earthquakes that occurred in alarm cells, b is the number of alarm cells with no earthquakes in them, c is the number of target earthquakes that occurred outside alarm cells, and d is the number of cells with no target earthquakes and which are not alarm cells.
As a specific example we consider the forecast given in Fig. 1. We retrospectively test this forecast in terms of the locations of m T ≥ 7.2 target earthquakes that occurred during the forecast period T f = 1/1/2004 to T e = 1/1/2008. The total number of 2° × 2° cells in which a m ≥ 5.5 occurred during the entire time period (active cells) was 1,503. During the forecast period a + c = 34 earthquakes with m T ≥ 7.2 occurred. Of these a = 23 occurred in alarm cells (were forecast) and c = 11 occurred in the other cells (were not forecast).
The success of a forecast can be quantified using a hit rate, H, and a false alarm rate, F:
The hit rate H is the fraction of earthquakes that are successfully forecast. For this example we have H = 23/34 = 0.676. The false alarm rate F is the fraction of cells with no earthquake for which an alarm was issued. The hit rate H and the false alarm rate F define conditional probabilities H = P(A|E) and F = P(A|not E) respectively, where A denotes an event of having an alarm in given cells and E denotes an event of having a target earthquake in a given cell. For this example we have F = 371/1469 = 0.253. The result of a forecast is given in a contingency table (Table 1).
The above example has given the values of H and F for the specific value of the tuning parameter B/B max = 0.0417. The plot of H and F for a range of B/B max values is known as a ROC diagram. An ROC diagram for our forecast is shown in Fig. 2a. Results are given for large earthquakes with magnitudes m T ≥ 7.2. The diagonal line from (0.0) to (1.1) would be the long-run expectation for alarms that are declared randomly. A perfect forecast would have F = 0 (no false alarms) and H = 1 (all earthquakes are forecast).

a The ROC diagram for our forecast of global seismicity. b The error diagram for our forecast. Also included the results of 150,300 Monte-Carlo simulations (shaded area) in which alarm cells have been redistributed randomly and the corresponding confidence intervals
The choice of the optimal forecast (preferred value of B/B max) is the subject of extensive discussions in the atmospheric science literature (Mason, 2003). Several quantitative measures find wide use. One of these is Pierce’s skill score:
which is the difference between the observed hit rate H and the value on the diagonal line corresponding to the random forecast. This score is also known as Hansen-Kuiper’s score or Kuiper’s performance index (Mason, 2003; Harte and Vere-Jones, 2005). The history and applications of this score along with its properties can be found in Mason (2003). A perfect forecast would be PSSROC = 1.0. The values of PSSROC corresponding to the results in Fig. 2a are given in Fig. 3a. They are plotted as a function of the tuning parameter values B/B max (Fig. 2a).

a Pierce’s skill scores PSSROC from the ROC diagram given in Fig. 2a as a function of the threshold values of the normalized cumulative Benioff strain B/Bmax. The maximum value of the Pierce’s skill score is \(\hbox{PSS}_{\rm ROC}^{\rm max}=0.424\) corresponding to the threshold value B/Bmax = 0.042. b Dependence of the area under ROC diagram on different cell sizes
The maximum value of \(\hbox{PSS}_{\rm ROC}^{\rm max}=\hbox{PSS}_{\rm ROC}\) from an ROC diagram can be used to find an optimizing value of the tuning parameter. For large earthquakes m T ≥ 7.2 the maximum value of Pierce’s skill score is \(\hbox{PSS}_{\rm ROC}^{\rm max}=0.424\) corresponding to the threshold value B/B max = 0.0417. This corresponds to H = 0.676 and F = 0.253 and was the basis for selecting this threshold value for the example given in Fig. 1. The value of the hit rate H = 0.676 (67.6%) gives the probability of having a large earthquake in the alarm cells during the forecast period. The threshold values obtained from retrospective forecasts can be applied a priori in subsequent prospective forecasts. This can be done by analyzing a particular region of study where the magnitude of completeness of a catalog is obtained and the optimal threshold and cell size values were determined from the retrospective analysis.
Another method of measuring the success of a forecast is the error or Molchan’s diagram approach (Molchan, 1991; Molchan and Kagan, 1992; Molchan and Keilis-Borok, 2008). In order to construct the error diagram the miss and alarm rates
are introduced. The sum of the hit rate and miss rate is unity, i.e. H + ν = 1. The alarm rate τ is the fraction of all cells that are alarm cells and defines the probability of a forecast of occurrence in weather forecast verification (Mason, 2003). The parametric plot of ν and τ for a range of threshold parameters B/B max is known as an error diagram. The error diagram for the above example is given in Fig. 2b. An analog of the Pierce’s skill score for the error diagram is
From the analysis of the error diagram curve the maximum value of this skill score is \(\hbox{SS}_{\rm ED}^{\rm max}=1-0.324-0.262=0.414\) corresponding to the threshold value B/B max = 0.0417. It is worthwhile to note that the threshold values corresponding to the maximum values of the skill scores for both ROC and error diagrams are the same. This is due to the fact that the values of F and τ are very close to each other for corresponding threshold values as they are both dominated by large b + d values compared to small a + c. As a result the error diagram curve is almost a mirror image of the ROC curve due to the fact that ν = 1 − H. In general this is not always the case.
In the above analysis we have used a uniform prior distribution for the seismically active cells and assumed a null hypothesis where alarm cells are redistributed randomly. To reject this null hypothesis in favor of the method presented here we have also included in Fig. 2a and b the results of 150,300 Monte-Carlo simulations in which alarm cells have been redistributed randomly and the same target earthquakes were used to construct ROC and error diagrams. The confidence intervals were evaluated using the exact analytical result for the binomial distribution given in Zechar and Jordan (2008).
4 Discussion
The primary purpose of this paper is to quantify the extent to which locations of past smaller earthquakes can be used to forecast the locations of future large earthquakes. Our study has been carried out globally. The surface of the Earth has been divided into a grid of l° × l° cells with l = 2°. The objective is to forecast the locations of future large target earthquakes with magnitudes greater than m T based on the past seismicity. Another important aspect of this work is to introduce different optimization procedures to find the best forecast and optimal values for model parameters. It is also important to note that in the presented analysis the measure of seismicity based on cumulative Benioff strain does not perform better than the predictor based on a long-run rate of occurrence of earthquakes.
The sensitivity of the method to the model parameters is an important issue. The cell size l = 2° has been chosen based on the analysis of the areas under the ROC curves constructed for different cell sizes and different forecasting magnitudes. The analysis shows that the areas tend to increase (better forecast) with increasing cell sizes (Fig. 3b). Bigger cell sizes cover a larger Earth’s surface and increase the total success rate. However, bigger cell sizes are less practical in forecasting as they include larger geographical regions and decrease the value of the forecast. In this analysis we assume all earthquakes are point events. Cell size can be an important factor if forecast earthquakes are defined through their rupture areas which can span several cell sizes.
Other important parameters are the durations of the training and forecasting intervals and the lower magnitude cutoff. The analysis of the areas under the ROC curves shows that increasing the training time interval (ΔT tr) usually improves the forecast. As to the forecasting time interval (ΔT for) changes in the duration of the interval result in different numbers for forecasting earthquakes which, as was shown by Zechar and Jordan (2008), affects the ROC and error diagrams. To investigate the performance of the method for different forecasting time intervals a contour plot of the values of the areas between the ROC curve and 95% confidence interval for different forecasting years, T f , and base years, T b , is given in Fig. 4. Darker areas indicate a better performance with respect to the 95% confidence interval of the random forecast. It shows a prominent increase in the values for intervals less than 4 years and another increase for 15-year interval. This was a reason to use a 4-year forecasting interval in our analysis.

A contour plot of the values of the areas between the ROC curve and the 95% confidence interval for the random forecast for different forecasting (T f ) and base (T b ) years
Finally, the dependence of the method on the lower magnitude cutoff, m c , shows a strong trend in the performance increase of the method with decreasing m c . However, the completeness of the catalog prevents the use of events smaller than m < 5.5. The full analysis of the dependence of the method on the above parameters will be presented elsewhere. By varying the threshold B/B max the method generates a spectrum of forecasts. The use of the Pierce’s skill score is probably the most accepted optimization tool, but several others have been proposed (Mason, 2003; Harte and Vere-Jones, 2005). An actual optimization should also be based on other factors such as available resources, population densities, quality of construction, and other risk factors.
References
Field, E.H. (2007), Overview of the working group for the development of Regional Earthquake Likelihood Models (RELM), Seismol. Res. Lett. 78, 7–16.
Frankel, A., Mueller, C., Barnhard, T., Perkins, D., Leyendecker, E., Dickman, N., Hanson, S., and Hopper, M. (1996), National seismic-hazard maps, Tech. Rep. Open-File Report 96–532, USGS.
Harte, D. and Vere-Jones, D. (2005), The entropy score and its uses in earthquake forecasting, Pure Appl. Geophys. 162, 1229–1253.
Holliday, J.R., Nanjo, K.Z., Tiampo, K.F., Rundle, J.B., and Turcotte, D.L. (2005), Earthquake forecasting and its verification, Nonlinear Proc. Geophys. 12, 965–977.
Kagan, Y.Y. (2007), On earthquake predictability measurement: Information score and error diagram, Pure Appl. Geophys. 164, 1947–1962.
Kossobokov, V.G., Keilis-Borok, V.I., Turcotte, D.L., and Malamud, B.D. (2000), Implications of a statistical physics approach for earthquake hazard assessment and forecasting, Pure Appl. Geophys. 157, 2323–2349.
Kossobokov, V.G. and Shebalin, P., Earthquake prediction. In Nonlinear Dynamics of the Lithosphere and Earthquake Prediction (eds. Keilis-Borok, V.I., and Soloviev, A.A.) (Springer-Verlag, Berlin 2003), pp. 141–207.
Mason, I.B., Binary events. In Forecast Verification (eds. Jolliffe, I.T. and Stephenson, D.B.) (Wiley, Chichester 2003), pp. 37–76.
Minster, J.-B. and Williams, N., Systematic global testing of intermediate-term earthquake prediction algorithm. In 1-st ACES Workshop Proceedings (ed. Mora, P.) (GOPRINT, Brisbane 1999).
Molchan, G. and Keilis-Borok, V. (2008), Earthquake prediction: Probabilistic aspect, Geophys. J. Int. 173, 1012–1017.
Molchan, G.M. (1991), Structure of optimal strategies in earthquake prediction, Tectonophysics 193, 267–276.
Molchan, G.M. and Kagan, Y.Y. (1992), Earthquake prediction and its optimization, J. Geophys. Res. 97, 4823–4838.
Schorlemmer, D., Gerstenberger, M.C., Wiemer, S., Jackson, D.D., and Rhoades, D.A. (2007), Earthquake likelihood model testing, Seismol. Res. Lett. 78, 17–29.
Zaliapin, I., Keilis-Borok, V., and Ghil, M. (2003), A Boolean delay equation model of colliding cascades. Part II: Prediction of critical transitions, J. Stat. Phys. 111, 839–861.
Zechar, J.D. and Jordan, T.H. (2008), Testing alarm-based earthquake predictions, Geophys. J. Int. 172, 715–724.
Acknowledgments
This work has been supported by NSERC Discovery grant (RS), by NSF grant ATM-0327558 (DLT), by NASA grant NGT5 (JRH), by a US Department of Energy grant to UC Davis DEFG03-14499 (JRH, JBR), and by the NSERC and Benfield/ICLR Chair in Earthquake Hazard Assessment (KFT).
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License (https://creativecommons.org/licenses/by-nc/2.0), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Shcherbakov, R., Turcotte, D.L., Rundle, J.B. et al. Forecasting the Locations of Future Large Earthquakes: An Analysis and Verification. Pure Appl. Geophys. 167, 743–749 (2010). https://doi.org/10.1007/s00024-010-0069-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00024-010-0069-1