
Abstract
We present a general-purpose solver for convex quadratic programs based on the alternating direction method of multipliers, employing a novel operator splitting technique that requires the solution of a quasi-definite linear system with the same coefficient matrix at almost every iteration. Our algorithm is very robust, placing no requirements on the problem data such as positive definiteness of the objective function or linear independence of the constraint functions. It can be configured to be division-free once an initial matrix factorization is carried out, making it suitable for real-time applications in embedded systems. In addition, our technique is the first operator splitting method for quadratic programs able to reliably detect primal and dual infeasible problems from the algorithm iterates. The method also supports factorization caching and warm starting, making it particularly efficient when solving parametrized problems arising in finance, control, and machine learning. Our open-source C implementation OSQP has a small footprint, is library-free, and has been extensively tested on many problem instances from a wide variety of application areas. It is typically ten times faster than competing interior-point methods, and sometimes much more when factorization caching or warm start is used. OSQP has already shown a large impact with tens of thousands of users both in academia and in large corporations.





Similar content being viewed by others
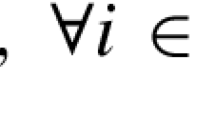

References
Agrawal, A., Verschueren, R., Diamond, S., Boyd, S.: A rewriting system for convex optimization problems. J. Control Decis. 5(1), 42–60 (2018). https://doi.org/10.1080/23307706.2017.1397554
Allgöwer, F., Badgwell, T.A., Qin, J.S., Rawlings, J.B., Wright, S.J.: Nonlinear Predictive Control and Moving Horizon Estimation–An Introductory Overview, pp. 391–449. Springer, London (1999)
Amestoy, P.R., Davis, T.A., Duff, I.S.: Algorithm 837: AMD, an approximate minimum degree ordering algorithm. ACM Trans. Math. Softw. 30(3), 381–388 (2004)
Balakrishnan, H., Hwang, I., Tomlin, C.J.: Polynomial approximation algorithms for belief matrix maintenance in identity management. In: IEEE Conference on Decision and Control (CDC), pp. 4874–4879 (2004)
Banjac, G., Goulart, P.: Tight global linear convergence rate bounds for operator splitting methods. IEEE Trans. Autom. Control 63(12), 4126–4139 (2018). https://doi.org/10.1109/TAC.2018.2808442
Banjac, G., Goulart, P., Stellato, B., Boyd, S.: Infeasibility detection in the alternating direction method of multipliers for convex optimization. J. Optim. Theory Appl. 183(2), 490–519 (2019). https://doi.org/10.1007/s10957-019-01575-y
Banjac, G., Stellato, B., Moehle, N., Goulart, P., Bemporad, A., Boyd, S.: Embedded code generation using the OSQP solver. In: IEEE Conference on Decision and Control (CDC) (2017)
Bauschke, H.H., Borwein, J.M.: On projection algorithms for solving convex feasibility problems. SIAM Rev. 38(3), 367–426 (1996)
Bauschke, H.H., Combettes, P.L.: Convex Analysis and Monotone Operator Theory in Hilbert Spaces, 1st edn. Springer, Berlin (2011)
Belotti, P., Kirches, C., Leyffer, S., Linderoth, J., Luedtke, J., Mahajan, A.: Mixed-integer nonlinear optimization. Acta Numer. 22, 1–131 (2013)
Benzi, M.: Preconditioning techniques for large linear systems: a survey. J. Comput. Phys. 182(2), 418–477 (2002)
Borrelli, F., Bemporad, A., Morari, M.: Predictive Control for Linear and Hybrid Systems. Cambridge University Press, Cambridge (2017)
Boyd, S., Busseti, E., Diamond, S., Kahn, R.N., Koh, K., Nystrup, P., Speth, J.: Multi-period trading via convex optimization. Found. Trends Optim. 3(1), 1–76 (2017). https://doi.org/10.1561/2400000023
Boyd, S., El Ghaoui, L., Feron, E., Balakrishnan, V.: Linear Matrix Inequalities in System and Control Theory. Society for Industrial and Applied Mathematics, Philadelphia (1994)
Boyd, S., Mueller, M.T., O’Donoghue, B., Wang, Y.: Performance bounds and suboptimal policies for multi-period investment. Found. Trends Optim. 1(1), 1–72 (2014)
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 3(1), 1–122 (2011)
Boyd, S., Vandenberghe, L.: Convex Optimization. Cambridge University Press, Cambridge (2004)
Bradley, A.: Algorithms for the equilibration of matrices and their application to limited-memory quasi-Newton methods. Ph.D. thesis, Stanford University (2010)
Candés, E.J., Wakin, M.B., Boyd, S.: Enhancing sparsity by reweighted \(\ell _1\) minimization. J. Fourier Anal. Appl. 14(5), 877–905 (2008)
Cornuejols, G., Tütüncü, R.: Optimization Methods in Finance. Finance and Risk. Cambridge University Press, Cambridge (2006)
Cortes, C., Vapnik, V.: Support-vector networks. Mach. Learn. 20(3), 273–297 (1995)
Dantzig, G.B.: Linear Programming and Extensions. Princeton University Press, Princeton (1963)
Davis, T.A.: Algorithm 849: a concise sparse Cholesky factorization package. ACM Trans. Math. Softw. 31(4), 587–591 (2005)
Davis, T.A.: Direct Methods for Sparse Linear Systems. Society for Industrial and Applied Mathematics, Philadelphia (2006)
Davis, T.A., Hu, Y.: The University of Florida sparse matrix collection. ACM Trans. Math. Softw. 38(1), 1:1–1:25 (2011). https://doi.org/10.1145/2049662.2049663
Diamond, S., Boyd, S.: CVXPY: a python-embedded modeling language for convex optimization. J. Mach. Learn. Res. 17(83), 1–5 (2016)
Diamond, S., Boyd, S.: Stochastic matrix-free equilibration. J. Optim. Theory Appl. 172(2), 436–454 (2017)
Diehl, M., Ferreau, H.J., Haverbeke, N.: Efficient Numerical Methods for Nonlinear MPC and Moving Horizon Estimation, pp. 391–417. Springer, Berlin (2009)
Dolan, E.D., Moré, J.J.: Benchmarking optimization software with performance profiles. Math. Program. 91(2), 201–213 (2002)
Domahidi, A., Chu, E., Boyd, S.: ECOS: an SOCP solver for embedded systems. In: European Control Conference (ECC), pp. 3071–3076 (2013)
Douglas, J., Rachford, H.H.: On the numerical solution of heat conduction problems in two and three space variables. Trans. Am. Math. Soc. 82(2), 421–439 (1956)
Duff, I.S., Erisman, A.M., Reid, J.K.: Direct Methods for Sparse Matrices. Oxford University Press, London (1989)
Dunning, I., Huchette, J., Lubin, M.: JuMP: a modeling language for mathematical optimization. SIAM Rev. 59(2), 295–320 (2017)
Eckstein, J.: Parallel alternating direction multiplier decomposition of convex programs. J. Optim. Theory Appl. 80(1), 39–62 (1994)
Eckstein, J., Ferris, M.C.: Operator-splitting methods for monotone affine variational inequalities, with a parallel application to optimal control. INFORMS J. Comput. 10(2), 218–235 (1998)
Ferreau, H.J., Kirches, C., Potschka, A., Bock, H.G., Diehl, M.: qpOASES: a parametric active-set algorithm for quadratic programming. Math. Program. Comput. 6(4), 327–363 (2014)
Fletcher, R., Leyffer, S.: Numerical experience with lower bounds for MIQP branch-and-bound. SIAM J. Optim. 8(2), 604–616 (1998)
Fougner, C., Boyd, S.: Parameter Selection and Preconditioning for a Graph Form Solver, pp. 41–61. Springer, Berlin (2018). https://doi.org/10.1007/978-3-319-67068-3_4
Frank, M., Wolfe, P.: An algorithm for quadratic programming. Naval Res. Log. Q. 3(1–2), 95–110 (1956)
Gabay, D.: Chapter IX applications of the method of multipliers to variational inequalities. Stud. Math. Appl. 15, 299–331 (1983)
Gabay, D., Mercier, B.: A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Comput. Math. Appl. 2(1), 17–40 (1976)
García, C.E., Prett, D.M., Morari, M.: Model predictive control: theory and practice—a survey. Automatica 25(3), 335–348 (1989)
Gertz, E.M., Wright, S.J.: Object-oriented software for quadratic programming. ACM Trans. Math. Softw. 29(1), 58–81 (2003)
Ghadimi, E., Teixeira, A., Shames, I., Johansson, M.: Optimal parameter selection for the alternating direction method of multipliers (ADMM): quadratic problems. IEEE Trans. Autom. Control 60(3), 644–658 (2015)
Gill, P.E., Murray, W., Saunders, M.A., Tomlin, J.A., Wright, M.H.: On projected Newton barrier methods for linear programming and an equivalence to Karmarkar’s projective method. Math. Program. 36(2), 183–209 (1986)
Giselsson, P., Boyd, S.: Metric selection in fast dual forward–backward splitting. Automatica 62, 1–10 (2015)
Giselsson, P., Boyd, S.: Linear convergence and metric selection for Douglas–Rachford splitting and ADMM. IEEE Trans. Autom. Control 62(2), 532–544 (2017)
Glowinski, R., Marroco, A.: Sur l’approximation, par éléments finis d’ordre un, et la résolution, par pénalisation-dualité d’une classe de problèmes de dirichlet non linéaires. ESAIM: Mathematical Modelling and Numerical Analysis - Modélisation Mathématique et Analyse Numérique 9(R2), 41–76 (1975)
Golub, G.H., Van Loan, C.F.: Matrix Computations, 3rd edn. Johns Hopkins University Press, Baltimore (1996)
Goulart, P., Stellato, B., Banjac, G.: QDLDL (2018). https://github.com/oxfordcontrol/qdldl. Accessed 6 Feb 2020
Gould, N., Scott, J.: A note on performance profiles for benchmarking software. ACM Trans. Math. Softw. 43(2), 15:1–15:5 (2016). https://doi.org/10.1145/2950048
Greenbaum, A.: Iterative Methods for Solving Linear Systems. Society for Industrial and Applied Mathematics, Philadelphia (1997)
Gurobi Optimization Inc.: Gurobi optimizer reference manual (2016). http://www.gurobi.com. Accessed 6 Feb 2020
He, B.S., Yang, H., Wang, S.L.: Alternating direction method with self-adaptive penalty parameters for monotone variational inequalities. J. Optim. Theory Appl. 106(2), 337–356 (2000)
Huber, P.J.: Robust estimation of a location parameter. Ann. Math. Stat. 35(1), 73–101 (1964)
Huber, P.J.: Robust Statistics. Wiley, New York (1981)
Intel Corporation: Intel Math Kernel Library. User’s Guide (2017)
Jerez, J.L., Goulart, P.J., Richter, S., Constantinides, G.A., Kerrigan, E.C., Morari, M.: Embedded online optimization for model predictive control at megahertz rates. IEEE Trans. Autom. Control 59(12), 3238–3251 (2014)
Kantorovich, L.: Mathematical methods of organizing and planning production. Manag. Sci. 6(4), 366–422 (1960). English translation
Karmarkar, N.: A new polynomial-time algorithm for linear programming. Combinatorica 4(4), 373–395 (1984)
Kelley, C.: Iterative Methods for Linear and Nonlinear Equations. Society for Industrial and Applied Mathematics, Philadelphia (1995)
Klee, V., Minty, G.: How good is the simplex algorithm. Department of Mathematics, University of Washington, Technical report (1970)
Knight, P.A., Ruiz, D., Uçar, B.: A symmetry preserving algorithm for matrix scaling. SIAM J. Matrix Anal. Appl. 35(3), 931–955 (2014)
Lions, P.L., Mercier, B.: Splitting algorithms for the sum of two nonlinear operators. SIAM J. Numer. Anal. 16(6), 964–979 (1979)
Löfberg, J.: YALMIP: a toolbox for modeling and optimization in MATLAB. In: IEEE International Conference on Robotics and Automation, pp. 284–289 (2004). https://doi.org/10.1109/CACSD.2004.1393890
Mangasarian, O.L., Musicant, D.R.: Robust linear and support vector regression. IEEE Trans. Pattern Anal. Mach. Intell. 22(9), 950–955 (2000). https://doi.org/10.1109/34.877518
Markowitz, H.: Portfolio selection. J. Finance 7(1), 77–91 (1952)
Maros, I., Mészáros, C.: A repository of convex quadratic programming problems. Optim. Methods Softw. 11(1–4), 671–681 (1999)
Mattingley, J., Boyd, S.: Real-time convex optimization in signal processing. IEEE Signal Process. Mag. 27(3), 50–61 (2010)
Mattingley, J., Boyd, S.: CVXGEN: a code generator for embedded convex optimization. Optim. Eng. 13(1), 1–27 (2012)
Mehrotra, S.: On the implementation of a primal–dual interior point method. SIAM J. Optim. 2(4), 575–601 (1992)
Mittelmann, H.: Benchmarks for optimization software. http://plato.asu.edu/bench.html. Accessed 08 Nov 2019
MOSEK ApS: The MOSEK optimization toolbox for MATLAB manual. Version 8.0 (Revision 57) (2017). http://docs.mosek.com/8.0/toolbox/index.html. Accessed 6 Feb 2020
Nesterov, Y., Nemirovskii, A.: Interior-Point Polynomial Algorithms in Convex Programming. Society for Industrial and Applied Mathematics, Philadelphia (1994)
Nishihara, R., Lessard, L., Recht, B., Packard, A., Jordan, M.I.: A general analysis of the convergence of ADMM. In: International Conference on Machine Learning (ICML), pp. 343–352 (2015)
Nocedal, J., Wright, S.J.: Numerical Optimization. Springer Series in Operations Research and Financial Engineering. Springer, Berlin (2006)
O’Donoghue, B., Chu, E., Parikh, N., Boyd, S.: Conic optimization via operator splitting and homogeneous self-dual embedding. J. Optim. Theory Appl. 169(3), 1042–1068 (2016)
O’Donoghue, B., Stathopoulos, G., Boyd, S.: A splitting method for optimal control. IEEE Trans. Control Syst. Technol. 21(6), 2432–2442 (2013)
Pock, T., Chambolle, A.: Diagonal preconditioning for first order primal–dual algorithms in convex optimization. In: 2011 International Conference on Computer Vision, pp. 1762–1769 (2011)
Raghunathan, A.U., Di Cairano, S.: ADMM for convex quadratic programs: Q-linear convergence and infeasibility detection (2014). arXiv:1411.7288
Raghunathan, A.U., Di Cairano, S.: Infeasibility detection in alternating direction method of multipliers for convex quadratic programs. In: IEEE Conference on Decision and Control (CDC), pp. 5819–5824 (2014). https://doi.org/10.1109/CDC.2014.7040300
Rawlings, J.B., Mayne, D.Q.: Model Predictive Control: Theory and Design. Nob Hill Publishing, San Francisco (2009)
Reuther, A., Kepner, J., Byun, C., Samsi, S., Arcand, W., Bestor, D., Bergeron, B., Gadepally, V., Houle, M., Hubbell, M., Jones, M., Klein, A., Milechin, L., Mullen, J., Prout, A., Rosa, A., Yee, C., Michaleas, P.: Interactive supercomputing on 40,000 cores for machine learning and data analysis. In: 2018 IEEE High Performance extreme Computing Conference (HPEC), pp. 1–6 (2018). https://doi.org/10.1109/HPEC.2018.8547629
Rockafellar, R.T., Wets, R.J.B.: Variational Analysis. Grundlehren der mathematischen Wissenschaften. Springer, Berlin (1998)
Ruiz, D.: A scaling algorithm to equilibrate both rows and columns norms in matrices. Technical Report RAL-TR-2001-034, Rutherford Appleton Laboratory, Oxon, UL (2001)
Sinkhorn, R., Knopp, P.: Concerning nonnegative matrices and doubly stochastic matrices. Pac. J. Math. 21(2), 343–348 (1967)
Stathopoulos, G., Shukla, H., Szucs, A., Pu, Y., Jones, C.N.: Operator splitting methods in control. Found. Trends Syst. Control 3(3), 249–362 (2016)
Stellato, B., Banjac, G.: Benchmark examples for the OSQP solver (2019). https://github.com/oxfordcontrol/osqp_benchmarks. Accessed 6 Feb 2020
Takapoui, R., Javadi, H.: Preconditioning via diagonal scaling (2014). https://web.stanford.edu/~hrhakim/projects/EE364B.pdf. Accessed 6 Feb 2020
Tibshirani, R.: Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 58(1), 267–288 (1996)
Vanderbei, R.: Symmetric quasi-definite matrices. SIAM J. Optim. 5(1), 100–113 (1995)
Wilkinson, J.H.: Rounding Errors in Algebraic Processes. Prentice Hall, Englewood Cliffs (1963)
Wohlberg, B.: ADMM penalty parameter selection by residual balancing (2017). arXiv:1704.06209v1
Wolfe, P.: The simplex method for quadratic programming. Econometrica 27(3), 382–398 (1959)
Wright, S.: Primal–Dual Interior-Point Methods. Society for Industrial and Applied Mathematics, Philadelphia (1997)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was supported by the People Programme (Marie Curie Actions) of the European Union Seventh Framework Programme (FP7/2007–2013) under REA Grant agreement No. 607957 (TEMPO).
Problem classes
Problem classes
In this section we describe the random problem classes used in the benchmarks and derive formulations with explicit linear equalities and inequalities that can be directly written in the form \(Ax \in {\mathcal {C}}\) with \({\mathcal {C}} = [l, u]\).
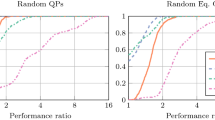
1.1 Random QP
Consider the following QP
Problem instances The number of variables and constraints in our problem instances are n and \(m=10n\). We generated random matrix \(P= M M^T+ \alpha I\) where \(M\in {\mathbf{R}}^{n \times n}\) and \(15 \%\) nonzero elements \(M_{ij}\sim {\mathcal {N}}(0,1)\). We add the regularization \(\alpha I\) with \(\alpha = 10^{-2}\) to ensure that the problem is not unbounded. We set the elements of \(A\in {\mathbf{R}}^{m \times n}\) as \(A_{ij} \sim {\mathcal {N}}(0,1)\) with only \(15 \%\) being nonzero. The linear part of the cost is normally distributed, i.e., \(q_i \sim {\mathcal {N}}(0,1)\). We generated the constraint bounds as \(u_i \sim {\mathcal {U}}(0,1)\), \(l_i \sim -{\mathcal {U}}(0,1)\).
1.2 Equality constrained QP
Consider the following equality constrained QP
This problem can be rewritten as (1) by setting \(l = u = b\).
Problem instances The number of variables and constraints in our problem instances are n and \(m=\lfloor n/2\rfloor \).
We generated random matrix \(P= M M^T+ \alpha I\) where \(M\in {\mathbf{R}}^{n \times n}\) and \(15 \%\) nonzero elements \(M_{ij}\sim {\mathcal {N}}(0,1)\). We add the regularization \(\alpha I\) with \(\alpha = 10^{-2}\) to ensure that the problem is not unbounded. We set the elements of \(A\in {\mathbf{R}}^{m \times n}\) as \(A_{ij} \sim {\mathcal {N}}(0,1)\) with only \(15 \%\) being nonzero. The vectors are all normally distributed, i.e., \(q_i, b_i \sim {\mathcal {N}}(0,1)\).
Iterative refinement interpretation Solution of the above problem can be found directly by solving the following linear system
If we apply the ADMM iterations (15)–(19) for solving the above problem, and by setting \(\alpha =1\) and \(y^0=b\), the algorithm boils down to the following iteration
which is equivalent to (31) with \(g = (-q, b)\) and \({\hat{t}}^k = (x^k,\nu ^k)\). This means that Algorithm 1 applied to solve an equality constrained QP is equivalent to applying iterative refinement [32, 92] to solve the KKT system (35). Note that the perturbation matrix in this case is
which justifies using a low value of \(\sigma \) and a high value of \(\rho \) for equality constraints.
1.3 Optimal control
We consider the problem of controlling a constrained linear time-invariant dynamical system. To achieve this, we formulate the following optimization problem [12]
The states \(x_t\in {\mathbf{R}}^{n_x}\) and the inputs \(u_k\in {\mathbf{R}}^{n_u}\) are subject to polyhedral constraints defined by the sets \({\mathcal {X}}\) and \({\mathcal {U}}\). The horizon length is T and the initial state is \(x_{\mathrm{init}}\in {\mathbf{R}}^{n_x}\). Matrices \(Q\in {\mathbf{S}}^{n_x}_+\) and \(R\in {\mathbf{S}}^{n_u}_{++}\) define the state and input costs at each stage of the horizon, and \(Q_T\in {\mathbf{S}}^{n_x}_+\) defines the final stage cost.
By defining the new variable \(z = (x_0, \ldots , x_{T}, u_0, \ldots , u_{T-1})\), problem (36) can be written as a sparse QP of the form (2) with a total of \(n_x(T+1) + n_u T\) variables.
Problem instances We defined the linear systems with \(n = n_x\) states and \(n_u = 0.5n_x\) inputs. We set the horizon length to \(T=10\). We generated the dynamics as \(A = I + \varDelta \) with \(\varDelta _{ij} \sim {\mathcal {N}}(0, 0.01)\). We chose only stable dynamics by enforcing the norm of the eigenvalues of A to be less than 1. The input action is modeled as B with \(B_{ij} \sim {\mathcal {N}}(0, 1)\).
The state cost is defined as \(Q = {\mathbf{diag}}(q)\) where \(q_i \sim {\mathcal {U}}(0, 10)\) and \(70\%\) nonzero elements in q. We chose the input cost as \(R = 0.1I\). The terminal cost \(Q_T\) is chosen as the optimal cost for the linear quadratic regulator (LQR) applied to A, B, Q, R by solving a discrete algebraic Riccati equation (DARE) [12]. We generated input and state constraints as
where \({\overline{x}}_i\sim {\mathcal {U}}(1, 2)\) and \({\overline{u}}_i \sim {\mathcal {U}}(0, 0.1)\). The initial state is uniformly distributed with \(x_{\mathrm{init}} \sim {\mathcal {U}}(-0.5{\overline{x}}, 0.5{\overline{x}})\).
1.4 Portfolio optimization
Portfolio optimization is a problem arising in finance that seeks to allocate assets in a way that maximizes the risk adjusted return [13, 15, 67, 17, §4.4.1],
where the variable \(x \in {\mathbf{R}}^{n}\) represents the portfolio, \(\mu \in {\mathbf{R}}^{n}\) the vector of expected returns, \(\gamma > 0\) the risk aversion parameter, and \(\varSigma \in {\mathbf{S}}_+^n\) the risk model covariance matrix. The risk model is usually assumed to be the sum of a diagonal and a rank \(k < n\) matrix
where \(F\in {\mathbf{R}}^{n\times k}\) is the factor loading matrix and \(D\in {\mathbf{R}}^{n\times n}\) is a diagonal matrix describing the asset-specific risk.
We introduce a new variable \(y=F^Tx\) and solve the resulting problem in variables x and y
Note that the Hessian of the objective in (37) is a diagonal matrix. Also, observe that \(FF^T\) does not appear in problem (37).
Problem instances We generated portfolio problems for increasing number of factors k and number of assets \(n=100k\). The elements of matrix F were chosen as \(F_{ij} \sim {\mathcal {N}}(0,1)\) with \(50 \%\) nonzero elements. The diagonal matrix D is chosen as \(D_{ii} \sim {\mathcal {U}}[0, \sqrt{k}]\). The mean return was generated as \(\mu _i \sim {\mathcal {N}}(0,1)\). We set \(\gamma = 1\).
1.5 Lasso
The least absolute shrinkage and selection operator (Lasso) is a well known linear regression technique obtained by adding an \(\ell _1\) regularization term in the objective [19, 90]. It can be formulated as
where \(x\in {\mathbf{R}}^{n}\) is the vector of parameters and \(A\in {\mathbf{R}}^{m \times n}\) is the data matrix and \(\lambda \) is the weighting parameter.
We convert this problem to the following QP
where \(y\in {\mathbf{R}}^{m}\) and \(t\in {\mathbf{R}}^{n}\) are two newly introduced variables.
Problem instances The elements of matrix A are generated as \(A_{ij} \sim {\mathcal {N}}(0,1)\) with \(15 \%\) nonzero elements. To construct the vector b, we generated the true sparse vector \(v\in {\mathbf{R}}^{n}\) to be learned
Then we let \(b=Av + \varepsilon \) where \(\varepsilon \) is the noise generated as \(\varepsilon _i \sim {\mathcal {N}}(0, 1)\). We generated the instances with varying n features and \(m = 100n\) data points. The parameter \(\lambda \) is chosen as \((1/5)\Vert A^Tb\Vert _{\infty }\) since \(\Vert A^Tb\Vert _{\infty }\) is the critical value above which the solution of the problem is \(x=0\).
1.6 Huber fitting
Huber fitting or the robust least-squares problem performs linear regression under the assumption that there are outliers in the data [55, 56]. The fitting problem is written as
with the Huber penalty function \(\phi _{\mathrm{hub}}:{\mathbf{R}}\rightarrow {\mathbf{R}}\) defined as
Problem (38) is equivalent to the following QP [66, Eq. (24)]
Problem instances We generate the elements of A as \(A_{ij} \sim {\mathcal {N}}(0,1)\) with \(15 \%\) nonzero elements. To construct \(b\in {\mathbf{R}}^m\) we first generate a vector \(v\in {\mathbf{R}}^n\) as \(v_i \sim {\mathcal {N}}(0,1/n)\) and a noise vector \(\varepsilon \in {\mathbf{R}}^m\) with elements
We then set \(b = Av + \varepsilon \). For each instance we choose \(m=100n\) and \(M=1\).
1.7 Support vector machine
Support vector machine problem seeks an affine function that approximately classifies the two sets of points [21]. The problem can be stated as
where \(b_i \in \{ -1, +1 \}\) is a set label, and \(a_i\) is a vector of features for the ith point. The problem can be equivalently represented as the following QP
where \({\mathbf{diag}}(b)\) denotes the diagonal matrix with elements of b on its diagonal.
Problem instances We choose the vector b so that
and the elements of A as
with \(15\%\) nonzeros per case.
Rights and permissions
About this article

Cite this article
Stellato, B., Banjac, G., Goulart, P. et al. OSQP: an operator splitting solver for quadratic programs. Math. Prog. Comp. 12, 637–672 (2020). https://doi.org/10.1007/s12532-020-00179-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12532-020-00179-2