
Abstract
In this paper, we present the Lipschitz regularization theory and algorithms for a novel Loss-Sensitive Generative Adversarial Network (LS-GAN). Specifically, it trains a loss function to distinguish between real and fake samples by designated margins, while learning a generator alternately to produce realistic samples by minimizing their losses. The LS-GAN further regularizes its loss function with a Lipschitz regularity condition on the density of real data, yielding a regularized model that can better generalize to produce new data from a reasonable number of training examples than the classic GAN. We will further present a Generalized LS-GAN (GLS-GAN) and show it contains a large family of regularized GAN models, including both LS-GAN and Wasserstein GAN, as its special cases. Compared with the other GAN models, we will conduct experiments to show both LS-GAN and GLS-GAN exhibit competitive ability in generating new images in terms of the Minimum Reconstruction Error (MRE) assessed on a separate test set. We further extend the LS-GAN to a conditional form for supervised and semi-supervised learning problems, and demonstrate its outstanding performance on image classification tasks.











Similar content being viewed by others

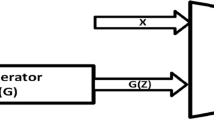
Notes
The minus sign exists as the U is maximized over \(f_w\) in the WGAN. On the contrary, in the GLS-GAN, \(S_C\) is minimized over \(L_\theta \).
References
Arjovsky, M., & Bottou, L. (2017). Towards principled methods for training generative adversarial networks. arXiv preprint arXiv:1701.04862
Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein GAN. arXiv preprint arXiv:1701.07875
Arora, S., Ge, R., Liang, Y., Ma, T., & Zhang, Y. (2017). Generalization and equilibrium in generative adversarial nets (GANs). arXiv preprint arXiv:1703.00573
Border, K. C. (1989). Fixed point theorems with applications to economics and game theory. Cambridge: Cambridge University Press.
Carando, D., Fraiman, R., & Groisman, P. (2009). Nonparametric likelihood based estimation for a multivariate lipschitz density. Journal of Multivariate Analysis, 100(5), 981–992.
Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., & Abbeel, P. (2016). Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Advances in neural information processing systems (pp. 2172–2180).
Coates, A., & Ng, A. Y. (2011). Selecting receptive fields in deep networks. In Advances in neural information processing systems (pp. 2528–2536).
Denton, E. L., Chintala, S., Fergus, R., et al. (2015). Deep generative image models using a laplacian pyramid of adversarial networks. In Advances in neural information processing systems (pp. 1486–1494).
Dosovitskiy, A., Fischer, P., Springenberg, J. T., Riedmiller, M., & Brox, T. (2015). Discriminative unsupervised feature learning with exemplar convolutional neural networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38, 1734–1747.
Dosovitskiy, A., Tobias Springenberg, J., & Brox, T. (2015). Learning to generate chairs with convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1538–1546).
Dumoulin, V., Belghazi, I., Poole, B., Lamb, A., Arjovsky, M., Mastropietro, O., & Courville, A. (2016). Adversarially learned inference. arXiv preprint arXiv:1606.00704
Edraki, M., Qi, & G. J. (2018). Generalized loss-sensitive adversarial learning with manifold margins. In Proceedings of the European conference on computer vision (ECCV) (pp. 87–102).
Gatys, L. A., Ecker, A. S., & Bethge, M. (2015). A neural algorithm of artistic style. arXiv preprint arXiv:1508.06576
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672–2680).
Gregor, K., Danihelka, I., Graves, A., Rezende, D. J., & Wierstra, D. (2015). Draw: A recurrent neural network for image generation. arXiv preprint arXiv:1502.04623
Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., & Courville, A. (2017). Improved training of wasserstein gans. arXiv preprint arXiv:1704.00028
Hui, K. Y. (2013). Direct modeling of complex invariances for visual object features. In International conference on machine learning (pp. 352–360).
Im, D. J., Kim, C. D., Jiang, H., & Memisevic, R. (2016). Generating images with recurrent adversarial networks. arXiv preprint arXiv:1602.05110
Kingma, D., & Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Kingma, D. P., Mohamed, S., Rezende, D. J., & Welling, M. (2014). Semi-supervised learning with deep generative models. In Advances in neural information processing systems (pp. 3581–3589).
Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114
Krizhevsky, A. (2009). Learning multiple layers of features from tiny images.
Laine, S., & Aila, T. (2016). Temporal ensembling for semi-supervised learning. arXiv preprint arXiv:1610.02242
Maaløe, L., Sønderby, C. K., Sønderby, S. K., & Winther, O. (2016). Auxiliary deep generative models. arXiv preprint arXiv:1602.05473
Mirza, M., & Osindero, S. (2014). Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784
Miyato, T., Maeda, S.i., Koyama, M., Nakae, K., & Ishii, S. (2015). Distributional smoothing by virtual adversarial examples. arXiv preprint arXiv:1507.00677
Nagarajan, V., & Kolter, J. Z. (2017). Gradient descent gan optimization is locally stable. In Advances in neural information processing systems (pp. 5585–5595).
Netzer, Y., Wang, T., Coates, A., Bissacco, A., Wu, B., & Ng, A. Y. (2011). Reading digits in natural images with unsupervised feature learning. In NIPS workshop on deep learning and unsupervised feature learning 2011. http://ufldl.stanford.edu/housenumbers/nips2011_housenumbers.pdf.
Nowozin, S., Cseke, B., & Tomioka, R. (2016). f-GAN: Training generative neural samplers using variational divergence minimization. arXiv preprint arXiv:1606.00709
Odena, A. (2016). Semi-supervised learning with generative adversarial networks. arXiv preprint arXiv:1606.01583
Qi, G. J., Zhang, L., Hu, H., Edraki, M., Wang, J., & Hua, X. S. (2018). Global versus localized generative adversarial nets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1517–1525).
Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434
Rasmus, A., Berglund, M., Honkala, M., Valpola, H., & Raiko, T. (2015). Semi-supervised learning with ladder networks. In Advances in Neural Information Processing Systems (pp. 3546–3554).
Sajjadi, M., Javanmardi, M., & Tasdizen, T. (2016). Regularization with stochastic transformations and perturbations for deep semi-supervised learning. In Advances in neural information processing systems (pp. 1163–1171).
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., & Radford, A. (2016). Chen, X.: Improved techniques for training GANs. In Advances in neural information processing systems (pp. 2226–2234).
Springenberg, J. T. (2015). Unsupervised and semi-supervised learning with categorical generative adversarial networks. arXiv preprint arXiv:1511.06390
Tarvainen, A., & Valpola, H. (2017). Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in neural information processing systems (pp. 1195–1204).
Valpola, H. (2015). From neural pca to deep unsupervised learning. In Advances in independent component analysis and learning machines (pp. 143–171). Academic Press.
Wolpert, D. H. (1996). The lack of a priori distinctions between learning algorithms. Neural Computation, 8(7), 1341–1390.
Yadav, A., Shah, S., Xu, Z., Jacobs, D., & Goldstein, T. (2017). Stabilizing adversarial nets with prediction methods. arXiv preprint arXiv:1705.07364
Zhao, J., Mathieu, M., Goroshin, R., & Lecun, Y. (2015). Stacked what-where auto-encoders. arXiv preprint arXiv:1506.02351
Zhao, J., Mathieu, M., & LeCun, Y. (2016). Energy-based generative adversarial network. arXiv preprint arXiv:1609.03126
Zhao, Y., Jin, Z., Qi, G. J., Lu, H., & Hua, X. S. (2018). An adversarial approach to hard triplet generation. In Proceedings of the European conference on computer vision (ECCV) (pp. 501–517).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Patrick Perez.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Proof of Lemma 1
To prove Lemma 1, we need the following lemma.
Lemma 5
For two probability densities \(p({\mathbf {x}})\) and \(q({\mathbf {x}})\), if \(p({\mathbf {x}})\ge \eta q({\mathbf {x}})\) almost everywhere, we have
for \(\eta \in (0,1]\).
Proof
We have the following equalities and inequalities:
This completes the proof. \(\square \)
Now we can prove Lemma 1.
Proof
Suppose \((\theta ^*,\phi ^*)\) is a Nash equilibrium for the problems (4) and (5).
Then, on one hand, we have
where the first inequality follows from \((a)_+\ge a\).
We also have \(T(\theta ^*,\phi ^*)\le T(\theta ^*,\phi )\) for any \(G_\phi \) as \(\phi ^*\) minimizes \(T(\theta ^*,\phi )\). In particular, we can replace \(P_G({\mathbf {x}})\) in \(T(\theta ^*,\phi )\) with \(P_{data}({\mathbf {x}})\), which yields
Applying this inequality into (17) leads to
where the last inequality follows as \(L_\theta ({\mathbf {x}})\) is nonnegative.
On the other hand, consider a particular loss function
When \(\alpha \) is a sufficiently small positive coefficient, \(L_{\theta _0}({\mathbf {x}})\) is a nonexpansive function (i.e., a function with Lipschitz constant no larger than 1.). This follows from the assumption that \(P_{data}\) and \(P_G\) are Lipschitz. In this case, we have
By placing this \(L_{\theta _0}({\mathbf {x}})\) into \(S(\theta ,\phi ^*)\), one can show that
where the first equality uses Eq. (20), and the second equality is obtained by substituting \(L_{\theta _0}({\mathbf {x}})\) in Eq. (19) into the equation.
Assuming that \((1+\lambda )P_{data}({\mathbf {x}})- \lambda P_{G^*}({\mathbf {x}})<0\) on a set of nonzero measure, the above equation would be strictly upper bounded by \(\lambda \mathop {\mathbb {E}}\limits _{\begin{array}{c} {\mathbf {x}}\sim P_{data}({\mathbf {x}}) \\ {\mathbf {z}}_G\sim P_{G^*}({\mathbf {z}}_G) \end{array}}\varDelta ({\mathbf {x}}, {\mathbf {z}}_G)\) and we have
This results in a contradiction with Eq. (18). Therefore, we must have
for almost everywhere. By Lemma 5, we have
Let \(\lambda \rightarrow +\infty \), this leads to
This proves that \(P_{G^*}({\mathbf {x}})\) converges to \(P_{data}({\mathbf {x}})\) as \(\lambda \rightarrow +\infty \). \(\square \)
Proof of Lemma 3
Proof
Suppose a pair of \((f_w^*, g_\phi ^*)\) jointly solve the WGAN problem.
Then, on one hand, we have
where the inequality follows from \(V(f_w^*,g_\phi ^*)\ge V(f_w^*,g_\phi )\) by replacing \(P_{g_\phi }({\mathbf {x}})\) with \(P_{data}({\mathbf {x}})\).
Consider a particular \(f_w({\mathbf {x}})\triangleq \alpha (P_{data}({\mathbf {x}})-P_{g_\phi ^*}({\mathbf {x}}))_+\). Since \(P_{data}({\mathbf {x}})\) and \(P_{g_\phi ^*}\) are Lipschitz by assumption, when \(\alpha \) is sufficiently small, it can be shown that \(f_w({\mathbf {x}})\in {\mathcal {L}}_1\).
Substituting this \(f_w\) into \(U(f_w, g_\phi ^*)\), we get
Let us assume \(P_{data}({\mathbf {x}}) > P_{g_\phi ^*}({\mathbf {x}})\) on a set of nonzero measure, we would have
This leads to a contradiction with (23), so we must have
almost everywhere.
Hence, by Lemma 5, we prove the conclusion that
\(\square \)
Proof of Theorem 2
For simplicity, throughout this section, we disregard the first loss minimization term in \(S(\theta ,\phi ^*)\) and \(S_m(\theta ,\phi ^*)\), since the role of the first term would vanish as \(\lambda \) goes to \(+\infty \). However, even if it is involved, the following proof still holds with only some minor changes.
To prove Theorem 2, we need the following lemma.
Lemma 6
For all loss functions \(L_\theta \), with at least the probability of \(1-\eta \), we have
when the number of samples
with a sufficiently large constant C.
The proof of this lemma needs to apply the McDiarmid’s inequality and the fact that \((\cdot )_+\) is an 1-Lipschitz to bound the difference \(|S_m(\theta ,\phi ^*)-S(\theta ,\phi ^*)|\) for a loss function. Then, to get the union bound over all loss functions, a standard \(\epsilon \)-net (Arora et al. 2017) will be constructed to yield finite points that are dense enough to cover the parameter space of the loss functions. The proof details are given below.
Proof
For a loss function \(L_\theta \), we compute \(S_m(\theta ,\phi ^*)\) over a set of m samples \(\{({\mathbf {x}}_i, {{\mathbf {z}}_G}_i)|1\le i\le m\}\) drawn from \(P_{data}\) and \(P_{G^*}\) respectively.
To apply the McDiarmid’s inequality, we need to bound the change of this function when a sample is changed. Denote by \(S^i_m(\theta ,\phi ^*)\) when the jth sample is replaced with \({\mathbf {x}}'_i\) and \({{\mathbf {z}}'_G}_i\). Then we have
where the first inequality uses the fact that \((\cdot )_+\) is 1-Lipschitz, the second inequality follows from that \(\varDelta ({\mathbf {x}}, {\mathbf {z}}_G)\) is bounded by \(B_\varDelta \) and \(L_\theta ({\mathbf {x}})\) is \(\kappa \)-Lipschitz in \({\mathbf {x}}\).
Now we can apply the McDiarmid’s inequality. Noting that
we have
The above bound applies to a single loss function \(L_\theta \). To get the union bound, we consider a \(\varepsilon /8\kappa _L\)-net \({\mathcal {N}}\), i.e., for any \(L_\theta \), there is a \(\theta '\in {\mathcal {N}}\) in this net so that \(\Vert \theta -\theta '\Vert \le \varepsilon /8\kappa _L\). This standard net can be constructed to contain finite loss functions such that \(|{\mathcal {N}}|\le O(N\log (\kappa _L N/\varepsilon ))\), where N is the number of parameters in a loss function. Note that we implicitly assume the parameter space of the loss function is bounded so we can construct such a net containing finite points here.
Therefore, we have the following union bound for all \(\theta \in {\mathcal {N}}\) that, with probability \(1-\eta \),
when \(m\ge \dfrac{C B_\varDelta ^2(\kappa +1)^2 \big (N \log (\kappa _L N/\varepsilon )+\log (1/\eta )\big )}{\varepsilon ^2}\).
The last step is to obtain the union bound for all loss functions beyond \({\mathcal {N}}\). To show that, we consider the following inequality
where the first inequality uses that fact that \((\cdot )_+\) is 1-Lipschitz again, and the second inequality follows from that \(L_\theta \) is \(\kappa _L\)-Lipschitz in \(\theta \). Similarly, we can also show that
Now we can derive the union bound over all loss functions. For any \(\theta \), by construction we can find a \(\theta '\in {\mathcal {N}}\) such that \(\Vert \theta -\theta '\Vert \le \varepsilon /8\kappa _L\). Then, with probability \(1-\eta \), we have
This proves the lemma. \(\square \)
Now we can prove Theorem 2.
Proof
First let us bound \(S_m-S\). Consider \(L_{\theta ^*}\) that minimizes \(S(\theta ,\phi ^*)\). Then with probability \(1-\eta \), when \(m\ge \dfrac{C N B_\varDelta ^2(\kappa +1)^2\log (\kappa _L N/\eta \varepsilon )}{\varepsilon ^2}\), we have
where the first inequality follows from the inequality \(S_m\le S_m(\theta ^*,\phi ^*)\) as \(\theta ^*\) may not minimize \(S_m\), and the second inequality is a direct application of the above lemma. Similarly, we can prove the other direction. With probability \(1-\eta \), we have
Finally, a more rigourous discussion about the generalizability should consider that \(G_{\phi ^*}\) is updated iteratively. Therefore we have a sequence of \(G_{\phi ^*}^{(t)}\) generated over T iterations for \(t=1,\ldots ,T\). Thus, a union bound over all generators should be considered in (24), and this makes the required number of training examples m become
However, the iteration number T is usually much smaller than the model size N (which is often hundreds of thousands), and thus this factor will not affect the above lower bound of m. \(\square \)
Proof of Theorem 4 and Corollary 2
We prove Theorem 4 as follows.
Proof
First, the existence of a minimizer follows from the fact that the functions in \({\mathcal {F}}_\kappa \) form a compact set, and the objective function is convex.
To prove the minimizer has the two forms in (10), for each \(L_\theta \in {\mathcal {F}}_\kappa \), let us consider
It is not hard to verify that \(\widehat{L}_\theta ({\mathbf {x}}^{(i)})=L_\theta ({\mathbf {x}}^{(i)})\) and \(\widetilde{L}_\theta ({\mathbf {x}}^{(i)})=L_\theta ({\mathbf {x}}^{(i)})\) for \(1\le i\le n+m\).
Indeed, by noting that \(L_{\theta }\) has its Lipschitz constant bounded by \(\kappa \), we have \(L_{\theta }({\mathbf {x}}^{(j)})-L_{\theta }({\mathbf {x}}^{(i)})\le \kappa \varDelta ({\mathbf {x}}^{(i)},{\mathbf {x}}^{(j)})\), and thus
Because \(L_{\theta }({\mathbf {x}}^{(i)})\ge 0\) by the assumption (i.e., it is lower bounded by zero), it can be shown that for all j
Hence, by the definition of \(\widehat{L}_{\theta }({\mathbf {x}})\) and taking the maximum over j on the left hand side, we have
On the other hand, we have
because \(\widehat{L}_{\theta }({\mathbf {x}}) \ge \big (L_\theta ({\mathbf {x}}^{(i)})-\kappa \varDelta ({\mathbf {x}},{\mathbf {x}}^{(i)})\big )_+\) for any \({\mathbf {x}}\), and it is true in particular for \({\mathbf {x}}={\mathbf {x}}^{(i)}\). This shows \(\widehat{L}_{\theta }({\mathbf {x}}^{(i)}) = L_{\theta }({\mathbf {x}}^{(i)})\).
Similarly, one can prove \(\widetilde{L}_\theta ({\mathbf {x}}^{(i)})=L_\theta ({\mathbf {x}}^{(i)})\). To show this, we have
by the Lipschitz continuity of \(L_\theta \). By taking the minimum over j, we have
On the other hand, we have \(\widetilde{L}_\theta ({\mathbf {x}}^{(i)})\le L_\theta ({\mathbf {x}}^{(i)})\) by the definition of \(\widetilde{L}_\theta ({\mathbf {x}}^{(i)})\). Combining these two inequalities shows that \(\widetilde{L}_\theta ({\mathbf {x}}^{(i)})=L_\theta ({\mathbf {x}}^{(i)})\).
Now we can prove for any function \(L_\theta \in {\mathcal {F}}_\kappa \), there exist \(\widehat{L}_\theta \) and \(\widetilde{L}_\theta \) both of which attain the same value of \(S_{n,m}\) as \(L_\theta \), since \(S_{n,m}\) only depends on the values of \(L_\theta \) on the data points \(\{{\mathbf {x}}^{(i)}\}\). In particular, this shows that any global minimum in \({\mathcal {F}}_\kappa \) of \(S_{n,m}\) can also be attained by the corresponding functions of the form (10). By setting \(l^*_i=\widehat{L}_{\theta ^*}({\mathbf {x}}^{(i)})=\widetilde{L}_{\theta ^*}({\mathbf {x}}^{(i)})\) for \(i=1,\ldots ,n+m\), this completes the proof. \(\square \)
Finally, we prove Corollary 2 that bounds \(L_\theta \) with \(\widehat{L}_\theta ({\mathbf {x}})\) and \(\widetilde{L}_\theta ({\mathbf {x}})\) constructed above.
Proof
By the Lipschitz continuity, we have
Since \(L_\theta ({\mathbf {x}})\ge 0\), it follows that
Taking the maximum over i on the left hand side, we obtain
This proves the lower bound.
Similarly, we have by Lipschitz continuity
which, by taking the minimum over i on the left hand side, leads to
This shows the upper bound. \(\square \)
Rights and permissions
About this article

Cite this article
Qi, GJ. Loss-Sensitive Generative Adversarial Networks on Lipschitz Densities. Int J Comput Vis 128, 1118–1140 (2020). https://doi.org/10.1007/s11263-019-01265-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-019-01265-2