
Abstract
Covolutional neural networks extract deep features from input image. The features are invariant to small distortions in the input, but are sensitive to rotations, which makes them inefficient to classify rotated images. We propose an architecture that requires training with images having digits at one orientation, but is able to classify rotated digits oriented at any angle. Our network is built such that it uses any simple unit of CNN by training it with single orientation images and uses it multiple times in testing to accomplish rotation invariant classification. By using CNNs trained with prominent features of images, we create a stacked architecture which gives adequately satisfactory classification accuracy. We demonstrate the architecture on handwritten digit classification and on the benchmark mnist-rot-12k. The introduced method is capable of roughly identifying the orientation of digit in an image.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


1 Introduction
Feature extraction and classification have become much more simpler and efficient with the aid of convolutional neural networks(CNN). They use a series of convolution, non-linear activation, sub-sampling and fully connected layers to extract deep hierarchical features from the input image. CNNs have extensively been applied for computer vision and classification tasks such as texture classification [1], image super resolution [2], medical image segmentation [3], etc.
CNN features are highly distinguishable and invariant to scale changes and distortions in the input. But they are sensitive to rotations in the image. Thus a CNN trained with images having digits at one orientation may fail to classify images with rotated digits. Nonetheless, attempts have been made to achieve rotation independent classification by rotating the training dataset at various angles and using large rotated dataset for training. This technique is called data augmentation and has been used in many works including [4, 5]. But large training data requires larger training time. Also, augmented data contains rotated form of same image, thus it might have redundant features. Another approach for rotation invariant classification is Spatial Transformer Networks [6] in which they introduce a STN module which has a localisation sub-network that learns the parameters of transformation from the input image and transforms the feature maps across a sampling grid using those parameters such that the overall cost function is minimized. But inserting a STN module in a network makes the training more complicated.
We introduce an architecture that is trained with images having digits at single orientation (say 0\(^{\circ }\)) and is able to classify the digits rotated at any angle. We introduce multiple instance testing to accomplish the task, which uses a trained CNN architecture various times in testing and decides the final label based on the activations obtained from multiple CNNs. CNN has the ability to include different features in terms of maps to arrive at better classification or recognition and we have utilized this fact to improve the proposed basic architecture to achieve even better classification by replicating it with datasets derived from enhanced features such as edges, morphological operations, etc. The introduced architecture is also capable of estimating the approximate orientation of digit in the input image without any additional computations.
2 Proposed Architecture: RIMCNN
In various classification tasks such as digit classification, object classification, etc., the orientation of digit/object in an image is very crucial. An ideal classifier should be able to classify all digits irrespective of persons handwriting which can be erect or slanted. Also, it might benefit automated readability of scanned documents, as documents scanned in any direction can be correctly read.
We design an architecture that can identify rotated digits at all angles without any complexity in training. It can achieve rotation invariant digit classification using multiple instances in training. We will use the abbreviated form of the architecture ‘RIMCNN’ throughout the paper. The architecture has two stages: (a) Training (b) Testing
2.1 Training
As mentioned above, the proposed architecture requires simple training, as is done for any CNN. We construct or choose an existing CNN architecture which is efficient enough to classify test data having images with digits without rotations, and train it with available data. We do not introduce any rotation or modification in the network during training. The selected CNN is trained with stochastic gradient descent (SGD) approach. This trained network is then used in testing.
2.2 Testing
This is the essential phase of our architecture that differs from other methods which merely evaluate the trained network with test dataset. It is quiet obvious and proven that the network trained with images having non-oriented digits is able to classify the non-oriented test images successfully. But when tested with rotated images, the network becomes inefficient. We build a rotation invariant CNN architecture by using a basic CNN unit multiple times in testing.
The CNN trained in the training phase is used in parallel for N times. The inputs to CNNs are N rotated versions of original image i.e. original image rotated at N angles (L\(_{1}\),L\(_{2}\),...,L\(_{N}\)). Thus each test image is rotated N times and each rotated version is fed to a parallel instance of trained CNN. The motivation behind the selected approach is that the CNN unit which gets that rotated version of test image that has orientation closer to that of training data, will always produce correct label. Also, it is observed that the activation produced by that CNN for correct label will always be higher than the activations produced by all other CNNs for all labels. Thus by selecting the label corresponding to maximum response is decided as the final label. Thus if we have C classes, then each CNN will generate C \(\times \) 1 output. Now if we use N rotations in testing, then we get N \(\times \) C responses at the output of RIMCNN. Now final label is the one which generates the maximum response among N \(\times \) C outputs.
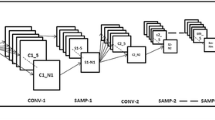
For handwritten digit classification, LeNet-5 architecture introduced in [7] is a very efficient architecture. Thus we use the same for evaluating our results. The RIMCNN test architecture with LeNet is shown in Fig. 1.

RIMCNN test phase
Number of CNN Units and Rotation Angles. The number of CNN units(N) and rotation angles(L\(_{1}\),L\(_{2}\),...,L\(_{N}\)) depend on the application. The rotation angles should be selected such that they span the entire range of rotation in the test data, say (L\(_{min}\),L\(_{max}\)). If rotations in test data are not known in prior, the angles can be uniformly spaced between 0\(^{\circ }\) to 360\(^{\circ }\). Higher is the number of CNN units selected(N), higher is the accuracy for all rotations, but more is the testing time. so there is always a trade-off between N and classification error.
Orientation of Digit in Test Image. The highest response is obtained from the angle (say L\(_{k}\)) that brings the digit closer to the orientation that was included in the training dataset, thus negative of the angle L\(_{k}\) gives the approximate orientation of the digit in the test image. Now if we wish to get more accurate orientation, then we can use another stage of RIMCNN that has rotation angles sampled around L\(_{k}\). Thus, without any additional complexity, we can obtain the rough estimation of digit-orientation.
3 Modified-RIMCNN
The basic RIMCNN discussed above is a simple approach with fair results, but selecting the final label is merely based on the maximum activation, which might not be always reliable. To further improve the accuracy in classification, we apply RIMCNN for some of the enhanced features of the original images, such as edges, morphological features, etc. However, these features independently do not improve classification. But when stacked together, they boost up the performance of RIMCNN. We extract edges from the original MNIST dataset to obtain edge dataset. Also, we dilate the original dataset to obtain dilated dataset. Now we train two different LeNet architectures with edge and dilated datasets respectively. RIMCNN is applied using three LeNets trained individually with original, edges and dilated images. Now instead of selecting the class corresponding to maximum activation as the final class, we select the class based on the outputs of all three LeNets. We find the vector sum of output activations from three LeNets, for each rotation, and decide the final label as the class which gives the maximum sum. The modified architecture is shown in Fig. 2.

Modified RIMCNN with edges and dilation. Lenet-Org, LeNet-Edge and LeNet-Dil are the LeNet-5 architectures trained on Original, Edges and Dilated datasets respectively
4 Simulation Results
We applied our architecture for handwritten digit classification using LeNet-5 as the basic CNN unit and observe that it performs better than LeNet for rotated test data. All simulations have been performed using a high-level neural networks library Keras(1.0.5) running on top of Theano(0.8.2). Intel(R) Xeon(R) X5675 computer with 24 GB RAM and NVIDIA Quadro 6000 graphics card is used. We evaluated our architecture on two datasets:
4.1 Performance Evaluation on MNIST Dataset
MNIST dataset consists of 60000 handwritten digits images divided into 50000 images for training and 10000 images for testing. We rotate the test dataset at different angles to analyse rotation independent abilities of our network. To account for the boundary distortions caused on rotating an image, we center the original 28 \(\times \) 28 image in larger image(52 \(\times \) 52). Also, on rotation between 0\(^{\circ }\) to 360\(^{\circ }\), the class-9 and 6 images may look similar, so we discard all images belonging to class 9 to avoid any ambiguity in classification. Thus the resultant 9-class dataset contains 54000 images for training and 9000 test images rotated across center, at steps of 10\(^{\circ }\) between 0\(^{\circ }\) to 360\(^{\circ }\) for testing. We train the LeNet-5 architecture with 54000 images and use it in RIMCNN for testing with 36 rotated versions of 9000 test images. The results obtained from RIMCNN and Modified-RIMCNN with N = 12 on modified MNIST dataset and its comparison with LeNet is shown in Fig. 3.

Comparison of classification error (Y-axis) between RIMCNN and LeNet for MNIST test data rotated at various angles (X-axis)
4.2 Performance Evaluation on Mnist-rot-12k Dataset
The dataset mnist-rot-12k [9] is derived by rotating the images of MNIST dataset at random angles between 0\(^{\circ }\) to 360\(^{\circ }\). It has 12000 training images and 50000 test images containing rotated digits. As our architecture has an advantage that it doesn’t require rotations for training, thus we can use the already existing model trained with MNIST dataset for testing rotated dataset as well. On using the same model, as was used in Sect. 2 on MNIST dataset, in RIMCNN with N = 13 and rotations uniformly sampled between 0\(^{\circ }\) to 360\(^{\circ }\), we achieve the classification accuracy of 86.73% on test images. RIMCNN takes 649.65 s for testing the given set of images. On applying modified RIMCNN introduced in Sect. 3 on the same dataset, accuracy is further improved to 89.36%. We demonstrate test error for different configurations of RIMCNN in Table 1.
[10] compare their results with other architectures for mnist-rot dataset created by them. The approach they use to create their dataset is similar to that used for mnist-rot-12k, thus both datasets, more or less, are comparable. Almost all state-of-the-art architectures use rotated data for training. Since our architecture is not trained with rotated samples, whereas all other methods use rotated samples in some form, our results on classification accuracy cannot be directly compared with those obtained using state-of-the art methods. For fair comparison of our approach with state of the art methods, we include their results when they are trained on the original training set (without rotation) and tested with rotated images. ORN [10] achieves the lowest error of 16.21% against 55.59% error by STN [6], when trained without rotations and tested with rotated images. We manage to achieve the lowest possible error rates of 13.27% and 10.64% using RIMCNN and Modified RIMCNN respectively.
From the training time comparison made in [10], we can observe that their baseline CNN takes the minimum time of 16.4 s per epoch, let us denote this time by T, then ORN ([10]) and STN [6] take 1.09\(\times \)T and 1.14 \(\times \) T s respectively, whereas TI-Pooling [11] takes the maximum time i.e. 7.73 \(\times \) T for one epoch. If our method is compared with them, it uses only a baseline CNN (LeNet), thus will take the minimum time for training among all networks.
5 Conclusion and Future Work
The introduced architecture is able to classify handwritten digits even at higher degree of rotation. It requires minimal training and shows better performance than LeNet architecture. It has an additional advantage of using pre-trained deep networks without any fine-tuning.
Its ability to identify rotated digits makes it applicable for rotated CAPTCHA recognition. It can further be applied to various tasks which demand rotation invariant classification such as texture classification, object recognition, etc. It can estimate the orientation of objects in the image, thus can be used in robotics, object tracking, etc.
References
Gonzalez, D.M., Volpi, M., Tuia, D.: Learning rotation invariant convolutional filters for texture classification. CoRR, abs/1604.06720 (2016)
Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 38(2), 295–307 (2016)
Kayalibay, B., Jensen, G., van der Smagt, P.: CNN-based segmentation of medical imaging data. CoRR, abs/1701.03056 (2017)
Dieleman, S., Willett, K.W., Dambre, J.: Rotation-invariant convolutional neural networks for galaxy morphology prediction. Monthly Not. R. Astron. Soc. 450(2), 1441–1459 (2015)
Tivive, F.H.C., Bouzerdoum, A.: Rotation invariant face detection using convolutional neural networks. In: King, I., Wang, J., Chan, L.-W., Wang, D.L. (eds.) ICONIP 2006. LNCS, vol. 4233, pp. 260–269. Springer, Heidelberg (2006). doi:10.1007/11893257_29
Jaderberg, M., Simonyan, K., Zisserman, A., Kavukcuoglu, K.: Spatial transformer networks. CoRR, abs/1506.02025 (2015)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998)
LeCun, Y., Cortes, C.: MNIST handwritten digit database. AT&T Labs (2010). http://yann.lecun.com/exdb/mnist
Larochelle, H., Erhan, D., Courville, A., Bergstra, J., Bengio, Y.: An empirical evaluation of deep architectures on problems with many factors of variation. In: Proceedings of the 24th International Conference on Machine Learning, ICML 2007, pp. 473–480, New York, NY, USA. ACM (2007)
Zhou, Y., Ye, Q., Qiu, Q., Jiao, J.: Oriented response networks. CoRR, abs/1701.01833 (2017)
Laptev, D., Savinov, N., Buhmann, J.M., Pollefeys, M.: TI-POOLING: transformation-invariant pooling for feature learning in convolutional neural networks. CoRR, abs/1604.06318 (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper

Cite this paper
Jain, A., Sai Subrahmanyam, G.R.K., Mishra, D. (2017). Stacked Features Based CNN for Rotation Invariant Digit Classification. In: Shankar, B., Ghosh, K., Mandal, D., Ray, S., Zhang, D., Pal, S. (eds) Pattern Recognition and Machine Intelligence. PReMI 2017. Lecture Notes in Computer Science(), vol 10597. Springer, Cham. https://doi.org/10.1007/978-3-319-69900-4_67
Download citation
DOI: https://doi.org/10.1007/978-3-319-69900-4_67
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-69899-1
Online ISBN: 978-3-319-69900-4
eBook Packages: Computer ScienceComputer Science (R0)
