
Abstract
The soil nutrition is an important indicator of soil fertility. The method K-means and FCM are always used to evaluating the soil fertility, but the cluster number need to be set, and the outlier couldn’t be eliminated accurately, and there is the deviation between the real result and the soil fertility. So the paper applied the FUMF to analysis the soil nutrient data of Nong An county for eight years, 2005–2012. The result show that the low fertility soils gradually decreased from 2005 to 2012 by precision fertilization, and the moderate and high fertility soil was rising, the overall soil fertility of Nong An had improved significantly. The analysis result was consistent with the actual situation, The FUMF algorithm is proved that was an effective evaluate method of the soil fertility evaluation. It has the practical significance to analyze the large number of soil fertility of high complexity and interactive, it also provided the technical support for precision fertilization decision-making.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Soil nutrient content is an important symbol of fertility and productivity of arable land, also it is an important indicator of soil fertility evaluation. With the arrival of precision agriculture era, spatial variability and correlations of wide variety agricultural data which have complex links relationship are more significantly. The attendant massive, diverse and dynamic changes, incomplete, uncertain and a series of characteristics.
Since the 1990s, Data Mining and geographic information systems technology in the agricultural sector has been increasingly widely used. DM and GIS technology can effectively statistics and analysis of massive, complex data. DM Clustering algorithms can dig out the knowledge of soil fertility evaluation from soil nutrient data analysis. Li et al. put forward the application of clustering analysis which is in site classification and soil fertility evaluation [3]. Zheng et al. improved rough K- means algorithm, and put forward the rough K- means clustering algorithm based on density weighted [5]. Chen et al. put forward a weighted spaces fuzzy dynamic clustering algorithm, and proved the validity of method in evaluation of soil fertility [6]. But conventional K-means, FCM and other clustering algorithms have some limitations on soil fertility evaluation. Such as K- means is hard clustering algorithm that can only get a hard divide. Although FCM can get fuzzy clustering divide, both algorithms require artificially set the number of clusters. So it can not eliminate outlier accurately or solve the problem of soil fertility data including complex, dynamic, and interactive fuzzy. Whatever, the clustering results presence of a certain error with the real fertility. For this reason the paper use FUMF algorithm to analyze and evaluate soil fertility.
National measuring territories precise fertilizer projects in Jilin Province for over 10 years. During this period a large number of soil samples were collected and sample of soil nutrients were determined and analyzed. All of this could lay the foundation for soil fertility status by using DM and GIS technology. Thus, this paper use large amounts of data by successive years of soil testing precise fertilizer projects that from Nong An county in Jilin Province. Then, we use GIS and Matlab technical conducted a rapid unsupervised multiscale fuzzy clustering for soil nutrient data from 2005 to 2012. The results show that FUMF algorithm is an effective method for soil fertility evaluation and has practical significance when analyze large amounts of high complexity, strong interaction soil fertility factors. So, it is can provide a technical support for the precise fertilization decision.
2 Experiments and Methods
2.1 The Situation of Research Area
Nong’an is located in Songliao Plain, Changchun, Jilin. specific in northwest of Changchun city away from 60 km, north latitude 43° 54’–44° 56’, longitude 124° 32’–125° 45’; The zone is in the temperate semi-humid continental monsoon climate. So, monsoon features obviously, four distinct seasons, abundant sunshine, less rainfall and the annual average temperature of 4.6 °C, annual average sunshine hours 2590 h, the average annual rainfall 507 mm; On the one hand, there are diverse landforms such as high mesa, mesa, two terraces, a terrace, floodplain, sand dunes, depressions, gullies and so on. Thus, most soil is chernozem, meadow soil and black soil; On the other hand, they grow corn sorghum, wheat, millet and soybean and other crops production as the mainstay. It is arguably one of the country’s important commodity grain production bases and its total grain production ranked first in the major grain-producing counties.
2.2 Collection and Analysis of Sample Data
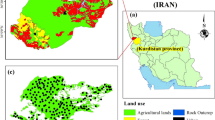
On the basis of field research, we are cooperation with cropland capacity survey quality evaluation office and considering soil types, land use, topography, cropping patterns, management measures and production level and other factors according second national soil survey. After that, we determine the sampling point through DGPS and RS systems. Then we can comprehensive analyze the survey plots of soil testing precision fertilizing work from 2005 to 2012. It collected 23,976 samples, sampling map of soil nutrients in Figs. 1 and 2.

Nong an soil fertility sampling map

Part of the grid sampling map from Nong an
Samples were collected depth from 0 to 20 cm. Random multi-point sampling within the same plots. Whatever, after mixing the soil by quartering, we take 1.5 or 2 kg bagging spare. Then, take it back to the laboratory for spare through dry naturally pulverized and sieving. Ultimately, index measuring soil nitrogen, phosphorus and potassium and other nutrients in which a total of 26 kinds of soil types. So, in this paper we analyze the collected 23976 data and calculate maximum, minimum, average value of nitrogen (N), phosphorus (P), potassium (K) according to the different soil types. The data of 2010 is shown in Table 1:
According to soil grading standards of second soil survey, soil nutrients are divided into six levels, such as shown in Table 2.
According to preliminary results of the analysis, we begin to accurate classification of soil fertility through data mining.
3 Results and Discussion
3.1 Fast Unsupervised Multiscale Fuzzy Clustering (FUMF) Algorithm
First of all, we clustering the N, P, K three indicators of 23976 data by FUMF algorithm, the purpose is to eliminate the isolated samples point of each index. Then these three indicators data were normalized. Finally, set the parameters of weighted dimensional data for clustering analysis by FUMF.
We can accelerate UMF algorithm through nearest neighbor criterion and get FUMF. Well, FUMF method is divided into two stages:
The first stage: re-expression data by using the nearest neighbor criterion, the data is divided into \( \bar{n} \) disjoint subsets \( S_{j} \), Each subset’s data represented by its representative point \( C_{j} \) which is as a whole.
The second stage, implementation of weighted UMF algorithm.
FUMF algorithm is as follows:
Step 1. The re-expression data, initialize the \( m - 1,\,c_{m} = \left\{ {x_{1} } \right\} \), \( i = 2 \) to \( N:d\left( {x_{i} ,\,c_{k} } \right) = \min_{1 \le j \le m} d\left( {x_{i} ,c_{j} } \right) \), If \( d\left( {x_{i} ,c_{k} } \right) >\Theta \) and \( m < q \) then \( m = m + 1\;c_{m} = \left\{ {x_{i} } \right\} \) Else \( c_{k} = c_{k} \cup \left\{ {x_{i} } \right\} \).
Step 2. Clustering UMF, set \( j = 1 \), set a threshold \( \varepsilon > 0 \) and \( v^{\left( 0 \right)} = c_{j} \), then using the updated formula 1:
Calculate convergence point of \( c_{j} \), denote as \( p_{j} \). If \( j < \bar{n} \), then \( j = 1 + j \), repeat step 2.
Step 3. If \( \left\| {p_{a} - p_{b} } \right\| \le \varepsilon \), The \( S_{a} \) and \( S_{b} \) of the data points into a class; otherwise, divided into different classes.
3.2 Soil Nutrient Content Analysis
Through statistical analyze 23,976 samples of soil nutrient content, we summarizes the changes of soil nutrients from early, metaphase and anaphase data. As shown in Table 3:
3.3 FUMF Analysis
Taking into account the soil sampling N, P, K three indicators’ observed values are different. Data will inevitably be contaminated during sampling that resulting in some isolated points Therefore before cluster analysis of soil nutrient, we need to pre-processing the data set. Pretreatment divided into the following steps:
-
(1)
Executing clustering algorithm for N, P, K three indicators respectively. If it contains a small number of data points when clustering, indicating this category may be constituted by isolated point. In the experiment, we analyze categories which data points lower than 20 and delete those isolated points which beyond the normal range of values.
-
(2)
Because of three indicators of N, P, K have differences in dimension as raw data. Therefore, each of these three indicators were normalized so that the mean of each index is 0 and variance is 1.
After process the raw data, each sample as a data point for clustering. Due to Evaluation of soil fertility mainly depends on the content of P indexes, and P indexes are generally lower than the value of N, K. Thus, we should weighted N, P, K as 1:10:1 before performing clustering algorithm.
-
(3)
Parameter settings: the convergence of the scale parameter is 0.15; convergence precision is \( 10^{ - 5} \); maximum number of iterations is 100; fuzzy factor is m = 2; data reduction parameters is 0.8; convergence scale parameter 0.14 multiplied mean value; After performing clustering algorithm to pretreatment and weighted data, using inverse transform to get clustering results.
3.3.1 The Initial Precision Fertilization Clustering Results
In this paper, we collected 2297 samples from 27 towns in 2005 to establish the experimental data set(remove isolated points of 38 when prepossessing), all of the data come from Bajilei, Bangchai, Binghe, Fuquanlong, Gaojiadian, Halahai and so on. Then we clustering by FUMF. The clustering results shown in Table 4 and Fig. 3(a 2005).

Soil nutrient spatial clustering map
3.3.2 The Middle Precision Fertilization Clustering Results
Experimental data sets with 5115 samples from 23 towns in 2009 (remove isolated points of 24 when prepossessing). The data come from Bajielei, Dehui, Gaojiadian, Halahai, Helong and so on. And clustering results Table 5 and Fig. 3(b 2009).
3.3.3 The Late Precise Fertilization Clustering Results
Experimental data sets with 6329 samples from 17 towns in 2012 (remove isolated points of 17 when prepossessing). All of the data come from Helong, Qiangang, Bajilei, Fuquanlong, Gaojiadian, Halahai, Huajia and so on. Then we clustering by FUMF. The clustering results shown in Table 6 and Fig. 3(c 2012).
3.4 Clustering Analysis
When compared the clustering results from 2005, 2009 to 2012, we can derive trend of soil fertility that soil fertility tend towards equilibrium and rise after precision fertilization.
4 Conclusions
Through the clustering results we analyzed, soil fertility tend towards equilibrium and rise after precision fertilization, so it can reflect the trend of soil fertility better. The results can be seen from Table 7:
-
(1)
We clustering according to the parameters which is set by clustering algorithm. The data is from 2005, 2009 and 2012 and the number of samples are 2259, 5091 and 6312. Then we can derived its cluster classification results are consistent with the actual high fertility, the fertility and low fertility referring soil grading standards. So, it could prove that FUMF algorithm is an effective method to soil fertility evaluation.
-
(2)
The data were compared from 2005, 2009 and 2012, the clustering results show that high fertility soils were increased from 8.16 % to 13.99 % and 15.30 %; The second soil fertility were increased from 53.64 % to 62.80 % and 65.80 %; low soil fertility dropped 22.60 % from 38.10 % to 18.93 % respectively. It is shown that from 2005 to 2012, the low soil fertility decreases and other soil fertility increase after precise fertilization. So, soil fertility has improved significantly.
-
(3)
The analysis results are consistent with the actual situation, it is not only shows FUMF algorithm is an effective method for soil fertility evaluation, but also proved that after precise fertilization soil fertility has improved significantly in general. Therefore, we believe that the method is meaningful by using data mining to analyze fertility factors of large the high complexity and, strong interaction data. So it can provide technical support for precision fertilization decisions.
References
Zeitouni, K.: A survey of spatial data mining methods databases and statistics point of views. In: Becker, S. (ed.) Data Warehousing and Web Engineering, pp. 229–242. IRM Press, London (2002)
Sharma, L.K., Vyas, O.P., Tiwary, U.S., Vyas, R.: A novel approach of multilevel positive and negative association rule mining for spatial databases. In: Perner, P., Imiya, A. (eds.) MLDM 2005. LNCS (LNAI), vol. 3587, pp. 620–629. Springer, Heidelberg (2005). doi:10.1007/11510888_61
Li, L., Li, L.: Application of clustering analysis in site classification and soil fertility evaluation. In: Proceedings of 2010 Third International Conference on Education Technology and Training (2010)
Guo, X., Liu, X., Li, X.: Improvement and analysis of hierarchical clustering algorithm. Comput. Appl. Softw. 25(6), 243–244 (2005)
Zheng, C., Miao, D., Wang, R.: Improved K-means clustering algorithm based on rough density weighted. Comput. Sci. (2009)
Cheng, G., Cao, L., Wang, G.: Application of weighted spatial fuzzy dynamic clustering algorithm in soil fertility evaluation of the black soil zone. Chin. Agric. Sci. 42(10), 3559–3563 (2009)
Zhang, J., Liu, X.: Research and application of K-means algorithm based on clustering Analysis. Appl. Comput. 24(5), 166–168 (2007)
Li, Y., Yin, P.: Speculative multithreading partitioning algorithm based on fuzzy clustering. J. Comput. 37(3), 580–592 (2014)
Yang, Y., Guo, S.: FCM image segmentation algorithm based on kernel function and spatial information. Jilin Univ. (Eng. Sci.) 41(2), 283–287 (2011)
Liu, F., Shi, X., Yu, D.: Research of mapping of soil properties in Taihu based on geostatistics and GIS–In total soil nitrogen in cartography example. J. Soil 41(1), 20–27 (2004)
Zhao, Y., Shi, X., Yu, D.: Discussion of mall-scale spatial variability of soil nutrients and its influencing factors– In urban areas in Wuxi city, Jiangsu province 37(2), 214–219 (2006)
Huang, S., Jin, J., Yang, L.: Research Grain Crop spatial variability of soil nutrients and the partition management technology in Region of County. J. Soil 40(1), 79–88 (2003)
Yang, Y., Shi, X., Yu, D.: Research of region scale soil nutrients spatial variability and influencing factors. Geogr. Sci. 28(6), 788–792 (2008)
Guo, X., Fu, B., Ma, K.: Research on spatial variability of soil fertility based on GIS and geostatistics—case by Hebei Zunhua. J. Appl. Ecol. 11(4), 557–563 (2000)
Sun, Y., Lu, Y.: High-dimensional data flow subspace clustering algorithm based on grid. Comput. Sci., 199–203 (2007)
Shan, S., Yan, Y., Zhang, X.: Clustering algorithm based on K most similar clustering subspace. Comput. Eng., 4–6 (2009)
Qiu, B., Zheng, Z.: Clustering algorithm based on the local density and dynamically generated mesh. Comput. Eng. 31(2), 385–387 (2010)
Acknowledgment
This work was supported by the National “863” High-tech Project (2006AA10A309), Jilin province science and technology development projects(key science and technology research project): “The development and demonstration of corn production’s monitoring and traceability system based on Internet of things technology” (20140204045NY), Jilin province agricultural committee projects: “The demonstration and generalization of Corn precision operation system based on Internet of things”.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 IFIP International Federation for Information Processing
About this paper
Cite this paper
Chen, H., Chen, G., Hu, Y., Cao, L., Cai, L., Yang, S. (2016). Analysis of Soil Fertility Based on FUMF Algorithm. In: Li, D., Li, Z. (eds) Computer and Computing Technologies in Agriculture IX. CCTA 2015. IFIP Advances in Information and Communication Technology, vol 478. Springer, Cham. https://doi.org/10.1007/978-3-319-48357-3_53
Download citation
DOI: https://doi.org/10.1007/978-3-319-48357-3_53
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-48356-6
Online ISBN: 978-3-319-48357-3
eBook Packages: Computer ScienceComputer Science (R0)